Mysql分库分表
1.原理




2.Sharding JDBC
官网https://shardingsphere.apache.org/

2.1 水平拆分
创建一个新的springboot项目

导入依赖,直接将原本的dependencies给覆盖掉
<dependencies><!-- ShardingJDBC依赖 --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.1.0</version></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.31</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
</dependencies>


在本地和远端创建数据库
create database yyds;
use yyds;
create table test (`id` int primary key,`name` varchar(255) NULL,`passwd` varchar(255) NULL
);


配置两个数据源
spring:shardingsphere:datasource:# 有几个数据就配几个,这里是名称,按照下面的格式,名称+数字的形式names: db0,db1# 为每个数据源单独进行配置db0:# 数据源实现类,这里使用默认的HikariDataSourcetype: com.zaxxer.hikari.HikariDataSource# 数据库驱动driver-class-name: com.mysql.cj.jdbc.Driver# 不用我多说了吧jdbc-url: jdbc:mysql://192.168.0.8:3306/yydsusername: rootpassword: 123456db1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://192.168.0.13:3306/yydsusername: rootpassword: 123456


添加实体类和mapper


@Data
@AllArgsConstructor
public class User {int id;String name;String passwd;
}
@Mapper
public interface UserMapper {@Select("select * from test where id = #{id}")User getUserById(int id);@Insert("insert into test(id, name, passwd) values(#{id}, #{name}, #{passwd})")上述代码都是正常业务。现在需要编写配置文件,告诉ShardingJDBC要如何进行分片。首先明确:现在是两个数据库都有test表存放用户数据,目标是将用户信息分别存放到这两个数据库的表中。
进行配置
spring:shardingsphere:rules:sharding:tables:#这里填写表名称,程序中对这张表的所有操作,都会采用下面的路由方案#比如我们上面Mybatis就是对test表进行操作,所以会走下面的路由方案test:#这里填写实际的路由节点,比如现在我们要分两个库,那么就可以把两个库都写上,以及对应的表#也可以使用表达式,比如下面的可以简写为 db$->{0..1}.testactual-data-nodes: db0.test,db1.test#这里是分库策略配置database-strategy:#这里选择标准策略,也可以配置复杂策略,基于多个键进行分片standard:#参与分片运算的字段,下面的算法会根据这里提供的字段进行运算sharding-column: id#这里填写我们下面自定义的算法名称sharding-algorithm-name: my-algsharding-algorithms:#自定义一个新的算法,名称随意my-alg:#算法类型,官方内置了很多种,这里演示最简单的一种# 取模分片算法-根据sharding-column(id)的值对2取模,结果为0存第一个库,结果为1存第二个库type: MODprops:sharding-count: 2props:#开启日志,一会方便我们观察sql-show: true



编写测试类测试

@ResourceUserMapper mapper;@Testvoid contextLoads() {for (int i = 0; i < 10; i++) {//这里ID自动生成0-9,然后插入数据库mapper.addUser(new User(i, "xxx", "ccc")); }}
这里出现注入错误,需要在启动类上加上@MapperScan(“com.example.mapper”)注解。分析日志往往在最后一句,不需要将所有报错信息都进行查找。
运行测试类后结果



这样就实现了分库策略。
实现分表策略

以本地数据库为例,创建两张表
create table test_0 (`id` int primary key,`name` varchar(255) NULL,`passwd` varchar(255) NULL
);create table test_1 (`id` int primary key,`name` varchar(255) NULL,`passwd` varchar(255) NULL
);

在分库策略基础上只修改配置文件内容
rules:sharding:tables:test:#db0.test_$->{0..1}actual-data-nodes: db0.test_0,db0.test_1#现在我们来配置一下分表策略,注意这里是table-strategy上面是database-strategytable-strategy:#基本都跟之前是一样的standard:sharding-column: idsharding-algorithm-name: my-algsharding-algorithms:my-alg:#这里我们演示一下INLINE方式,我们可以自行编写表达式来决定type: INLINEprops:#比如我们还是希望进行模2计算得到数据该去的表#只需要给一个最终的表名称就行了test_,后面的数字是表达式取模算出的#实际上这样写和MOD模式一模一样algorithm-expression: test_$->{id % 2}#没错,查询也会根据分片策略来进行,但是如果我们使用的是范围查询,那么依然会进行全量查询#这个我们后面紧接着会讲,这里先写上吧,false代表不允许全量查询allow-range-query-with-inline-sharding: falseprops:#开启日志,一会方便我们观察sql-show: true

再次测试



测试查询
@Testvoid contextLoads() {System.out.println(mapper.getUserById(0));System.out.println(mapper.getUserById(1));}

测试范围查询
@Select("select * from test where id between #{start} and #{end}")
List<User> getUsersByIdRange(int start, int end);

将配置文件的允许范围查询改为allow-range-query-with-inline-sharding改为true

测试范围查询
@Testvoid contextLoads() {System.out.println(mapper.getUsersByIdRange(3, 5));}


最终得出来的sql语句是直接对两个表都进行查询,然后求出一个并集算出来作为最后的结果。
相关文章:
Mysql分库分表
1.原理 2.Sharding JDBC 官网https://shardingsphere.apache.org/ 2.1 水平拆分 创建一个新的springboot项目 导入依赖,直接将原本的dependencies给覆盖掉 <dependencies><!-- ShardingJDBC依赖 --><dependency><groupId>org.apache.shardings…...

【算法学习】-【双指针】-【复写零】
LeetCode原题链接:1089. 复写零 下面是题目描述: 给你一个长度固定的整数数组 arr ,请你将该数组中出现的每个零都复写一遍,并将其余的元素向右平移。 注意:请不要在超过该数组长度的位置写入元素。请对输入的数组 …...

【算法优选】双指针专题——叁
文章目录 😎前言🌳[两数之和](https://leetcode.cn/problems/he-wei-sde-liang-ge-shu-zi-lcof/)🚩题目描述:🚩算法思路:🚩算法流程:🚩代码实现 🎄[三数之和]…...

Java栈的压入、弹出序列(详解)
目录 1.题目描述 2.题解 方法1 方法2 1.题目描述 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序…...

RabbitMQ学习笔记(消息发布确认,死信队列,集群,交换机,持久化,生产者、消费者)
MQ(message queue):本质上是个队列,遵循FIFO原则,队列中存放的是message,是一种跨进程的通信机制,用于上下游传递消息。MQ提供“逻辑解耦物理解耦”的消息通信服务。使用了MQ之后消息发送上游只…...
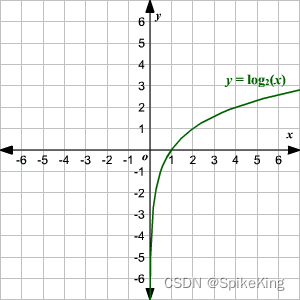
PyTorch - 模型训练损失 (Loss) NaN 问题的解决方案
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/133378367 在模型训练中,如果出现 NaN 的问题,严重影响 Loss 的反传过程,因此,需要加入一些微小值…...
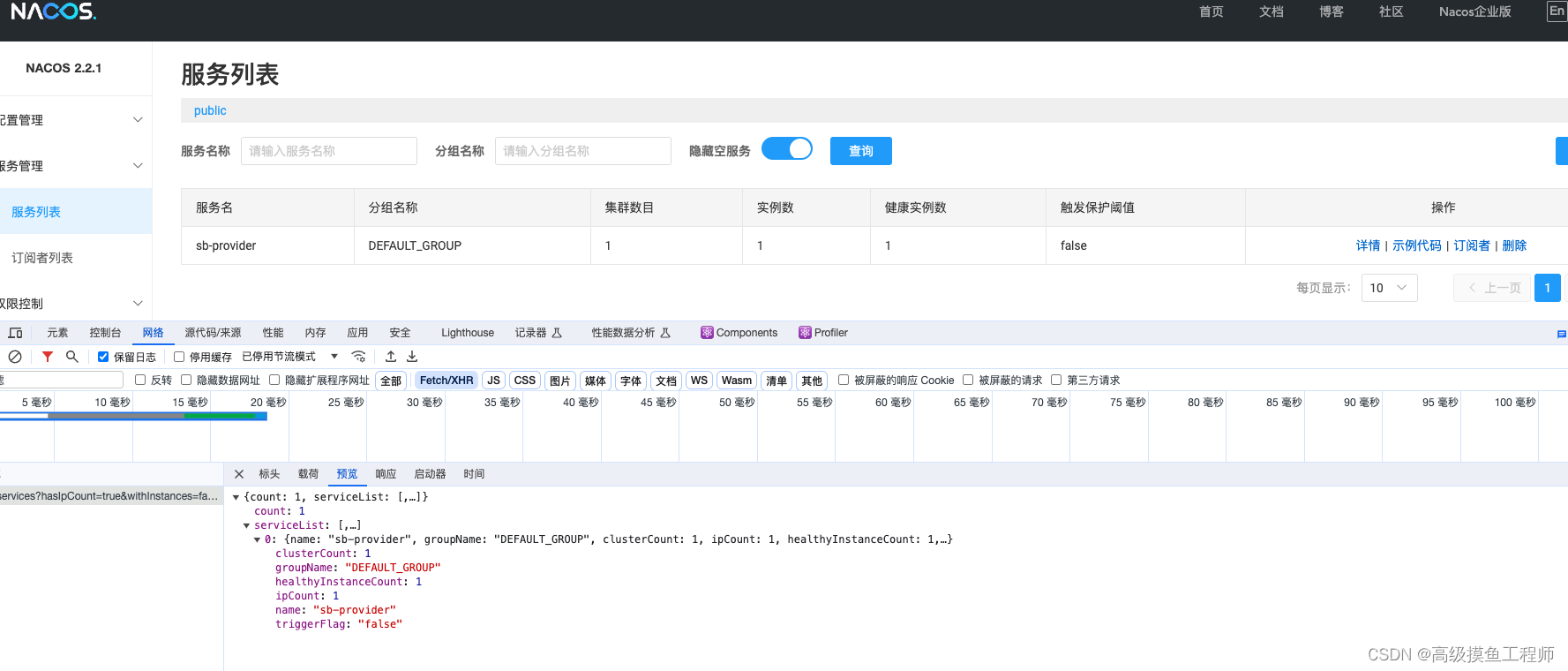
8、Nacos服务注册服务端源码分析(七)
本文收录于专栏 Nacos 中 。 文章目录 前言确定前端路由CatalogController.listDetail()ServiceManager总结 前言 前文我们分析了Nacos中客户端注册时数据分发的设计链路,本文根据Nacos前端页面请求,看下前端页面中的服务列表的数据源于哪里。 确定前端…...

MySQL使用Xtrabackup在线做主从
1、主库上操作 1.1前提 172.16.11.2(主库) 172.16.11.4(从库) 在执行备份之前,确保数据库没有锁定,以避免备份期间的任何写操作。 确保主库上的 MySQL 服务器正在运行,以便备份数据的一致性。…...
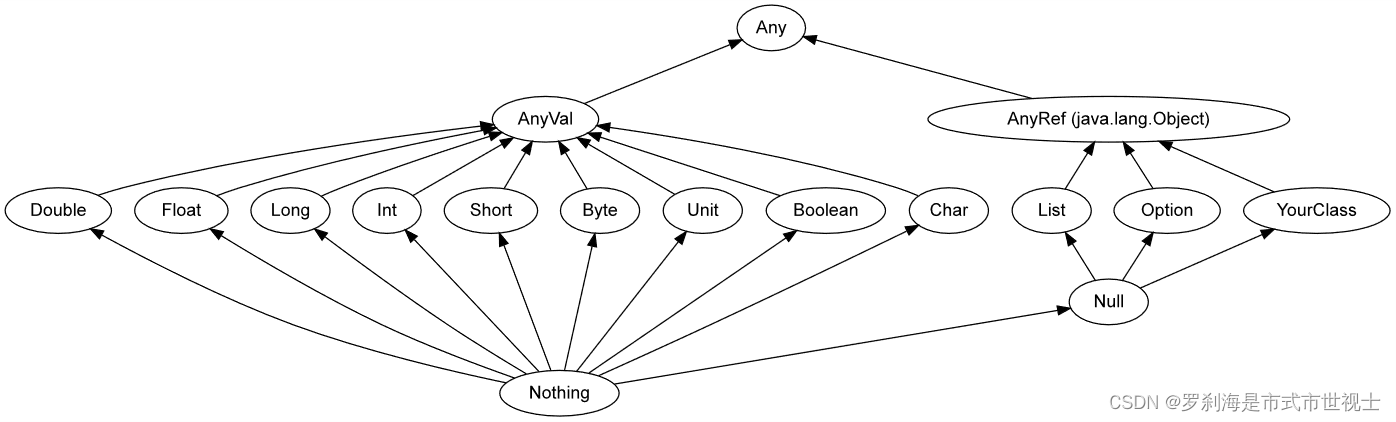
scala基础入门
一、Scala安装 下载网址:Install | The Scala Programming Language ideal安装 (1)下载安装Scala plugins (2)统一JDK环境,统一为8 (3)加载Scala (4)创建工…...

【Java-LangChain:面向开发者的提示工程-5】推断
第五章 推断 推断任务可以看作是模型接收文本作为输入,并执行某种分析的过程。其中涉及提取标签、提取实体、理解文本情感等等。如果你想要从一段文本中提取正面或负面情感,在传统的机器学习工作流程中,需要收集标签数据集、训练模型、确定如…...
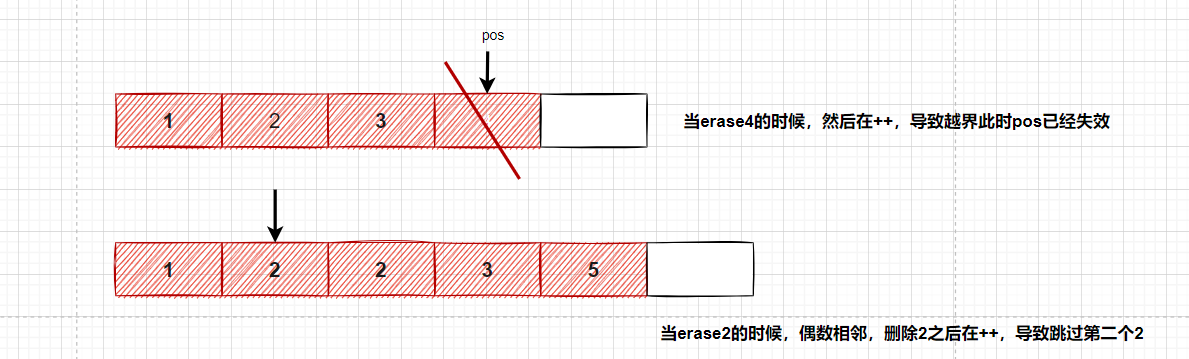
【C++】手撕vector(vector的模拟实现)
手撕vector目录: 一、基本实现思路方针 二、vector的构造函数剖析(构造歧义拷贝构造) 2.1构造函数使用的歧义问题 2.2 vector的拷贝构造和赋值重载(赋值重载不是构造哦,为了方便写在一起) 三、vector的…...

智能指针那些事
《Effective Modern C》学习笔记之条款二十一:优先选用std::make_unique和std::make_shared,而非直接new - 知乎...
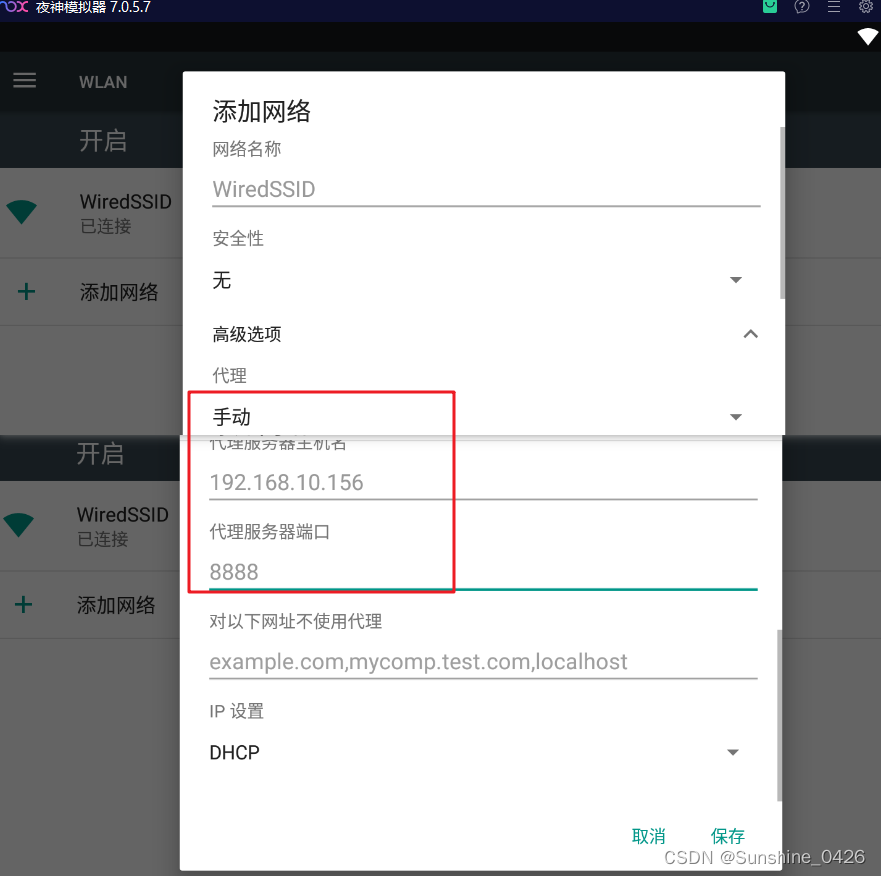
Fiddler抓取手机https包的步骤
做接口测试时,有时我们需要使用fiddler进行抓包分析,那么如何抓取https包。主要分为以下七步: 1.设置fiddler选项:Tools->Options,按如下图勾选 2.下载并安装Fiddler证书生成器 下载地址:http://www.telerik.com/…...
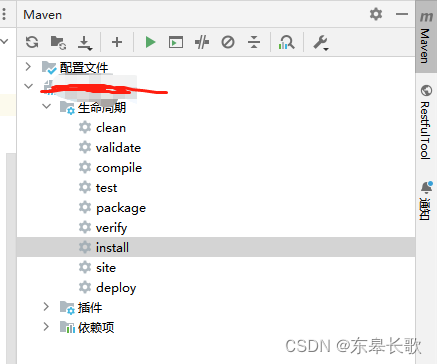
idea没有maven工具栏解决方法
背景:接手的一些旧项目,有pom文件,但是用idea打开的时候,没有认为是maven文件,所以没有maven工具栏,不能进行重新加载pom文件中的依赖。 解决方法:选中pom.xml文件,右键 选择添加为…...
levelDB引擎
一、背景 1.1、影响磁盘性能的因素: 主要受限于磁盘的寻道时间,优化磁盘数据访问的方法是尽量减少磁盘的IO次数。磁盘数据访问效率取决于磁盘IO次数,而磁盘IO次数又取决于数据在磁盘上的组织方式。磁盘数据存储大多采用B树类型数据结构&…...

IM同步服务
设计概述 后台同步方案的设计就是数据存储结构的设计,如何快速体现“信息变化”,如何快速计算出“变化信息”。后台数据存储结构是由同步协议中同步契约决定的。 设计方案 该方案的同步是按照业务粒度来划分,只需要同步sdk要求同步的数据。…...

MySQL 运维常用脚本
常用功能脚本 1.导出整个数据库 mysqldump -u 用户名 -p –default-character-setlatin1 数据库名 > 导出的文件名(数据库默认编码是latin1) mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql 2.导出一个表 mysqldump -u 用户名 -p 数据库名 表名> 导出的文件…...

ABC322刷题记
ABC322刷题记 T1.A A - First ABC 2。 妥妥的简单题…… 用find函数做就行。(如果不存在那个子串就返回-1,否则返回第一次出现位置) 注意题目中编号是从1开始的。 时间复杂度:O(log(n))。find函数有一定代价,我记…...
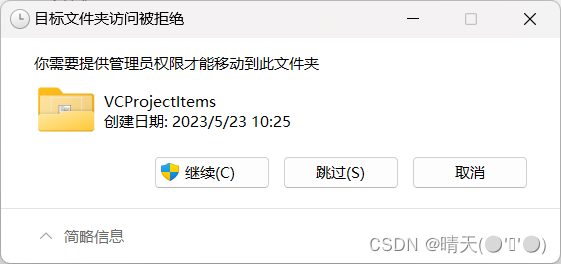
visual studio的安装及scanf报错的解决
visual studio是一款很不错的c语言编译器 下载地址:官网 点击后跳转到以下界面 下滑后点击下载Vasual Sutdio,选择社区版即可 选择位置存放下载文件后,即可开始安装 安装时会稍微等一小会儿。然后会弹出这个窗口,我们选择安装位…...

React生命周期
React的生命周期主要是指React组件从创建到销毁的过程,包括三个阶段:挂载期(实例化期)、更新期(存在期)、卸载期(销毁期) 挂载期: constructor(props&#…...

Fish Speech 1.5GPU部署案例:单节点支持50+并发TTS请求压测报告
Fish Speech 1.5 GPU部署案例:单节点支持50并发TTS请求压测报告 1. 测试背景与目标 最近我们在单台GPU服务器上部署了Fish Speech 1.5语音合成模型,这是一款基于VQ-GAN和Llama架构的先进TTS系统。你可能听说过这个模型在100万小时的多语言数据上训练过…...
)
DTIIA 9.1.1、角形传动滚筒头架(槽钢)
图示 【主视图】 【侧视图】 【俯视图】 【Tip】滚筒与支架连接的紧固件(螺栓)已包括在本部件内。 组成 见下面 标准图 “120JA1072Q” 参数 (结合下面3张表) 【Y】传动滚筒中心 到 中间架焊接角钢 (带面角度&#…...

保姆级教程:用FineBI 6.0连接本地MySQL 8.0数据库,手把手搞定数据可视化第一步
零基础实战:FineBI 6.0与MySQL 8.0的无缝对接指南 当你第一次打开FineBI 6.0,面对空白的画布和复杂的数据源选项,可能会感到无从下手。别担心,这篇文章将带你一步步完成从数据库连接到数据可视化的全过程。无论你是市场分析师、业…...

高质量就业分析网络安全就业现状:哪些岗位最缺人、薪资多少?
高质量就业分析|网络安全就业现状:哪些岗位最缺人、薪资多少? 打开招聘软件,你会发现一个极为矛盾的现象:一边是未散的传统互联网"裁员潮",求职竞争白热化;另一边是网络安全岗位持续"求贤若…...
)
CTF新手必看:用Stegsolve破解Misc图片隐写的完整流程(附盲水印解决方案)
CTF新手入门:Stegsolve图片隐写分析与盲水印实战指南 引言 第一次参加CTF比赛时,面对Misc类题目中的图片隐写,我完全摸不着头脑。直到一位资深选手向我推荐了Stegsolve这个神器,才真正打开了新世界的大门。如果你也正在为如何从一…...

SPIRAN ART SUMMONER实战:为你的游戏角色生成FFX风格原画
SPIRAN ART SUMMONER实战:为你的游戏角色生成FFX风格原画 1. 认识SPIRAN ART SUMMONER SPIRAN ART SUMMONER是一款专为《最终幻想10》(FFX)风格艺术创作设计的AI图像生成工具。它基于Flux.1-Dev模型,融合了定制LoRA权重,能够生成极具FFX特色…...

轻量模型InternLM2-Chat-1.8B在嵌入式领域的联想:STM32开发日志智能分析
轻量模型InternLM2-Chat-1.8B在嵌入式领域的联想:STM32开发日志智能分析 最近在折腾一个STM32的物联网项目,设备跑起来后,每天产生的日志数据量不小。看着那一行行的时间戳、状态码和调试信息,我就在想,有没有更聪明的…...

Redis 分布式锁的五大深坑与实战解法
在单体架构时代,遇到并发问题,我们直接上 synchronized 或者 ReentrantLock 就能轻松搞定。但一到微服务、分布式时代,这些本地锁就集体罢工了。这时候,我们通常会请出 Redis 来救场,实现分布式锁。很多人拍脑袋一想&a…...

别再死记硬背了!用这个‘快递分拣’比喻,5分钟彻底搞懂H3C交换机Hybrid口
快递分拣员视角:5分钟图解H3C交换机Hybrid口的标签魔术 每次路过物流仓库,总会被那些行云流水的分拣流程吸引——快递员们像变魔术般撕贴面单,包裹们精准飞向不同区域。这场景与网络设备中Hybrid端口处理VLAN数据包的过程惊人相似。今天我们就…...

大模型时代:掌握未来,从学习AI开始!揭秘大模型背后的技术秘密与商业价值
本文深入探讨了人工智能领域的大型预训练模型(大模型),解释了其定义、重要性及广泛应用场景。文章首先介绍了大模型的基本概念,随后阐述了学习大模型对于个人和职业发展的关键意义。接着,详细列举了大模型在自然语言处…...