Llama2-Chinese项目:4-量化模型
一.量化模型调用方式
下面是一个调用FlagAlpha/Llama2-Chinese-13b-Chat[1]的4bit压缩版本FlagAlpha/Llama2-Chinese-13b-Chat-4bit[2]的例子:
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized('FlagAlpha/Llama2-Chinese-13b-Chat-4bit', device="cuda:0")
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Llama2-Chinese-13b-Chat-4bit',use_fast=False)
input_ids = tokenizer(['<s>Human: 怎么登上火星\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {"input_ids":input_ids,"max_new_tokens":512,"do_sample":True,"top_k":50,"top_p":0.95,"temperature":0.3,"repetition_penalty":1.3,"eos_token_id":tokenizer.eos_token_id,"bos_token_id":tokenizer.bos_token_id,"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
这里面有个问题就是由Llama2-Chinese-13b-Chat如何得到Llama2-Chinese-13b-Chat-4bit?这涉及另外一个AutoGPTQ库(一个基于GPTQ算法,简单易用且拥有用户友好型接口的大语言模型量化工具包)[3]。先梳理下思路,由于meta-llama/Llama-2-13b-chat-hf对中文支持较差,所以采用中文指令集在此基础上进行LoRA微调得到了FlagAlpha/Llama2-Chinese-13b-Chat-LoRA,而FlagAlpha/Llama2-Chinese-13b-Chat=FlagAlpha/Llama2-Chinese-13b-Chat-LoRA+meta-llama/Llama-2-13b-chat-hf,即将两者参数合并后的版本。FlagAlpha/Llama2-Chinese-13b-Chat-4bit就是对FlagAlpha/Llama2-Chinese-13b-Chat进行4bit量化后的版本。总结起来就是如何合并,如何量化这2个问题。官方提供的一些合并参数后的模型[4],如下所示:

二.如何合并LoRA Model和Base Model
网上合并LoRA参数和原始模型的脚本很多,参考文献[6]亲测可用。合并后的模型格式包括pth和huggingface两种。如下所示:
1.LoRA Model文件列表
对于LLama2-7B-hf进行LoRA微调生成文件如下所示:
adapter_config.json
adapter_model.bin
optimizer.pt
README.md
rng_state.pth
scheduler.pt
special_tokens_map.json
tokenizer.json
tokenizer.model
tokenizer_config.json
trainer_state.json
training_args.bin
2.Base Model文件列表
LLama2-7B-hf文件列表,如下所示:
config.json
generation_config.json
gitattributes.txt
LICENSE.txt
model-00001-of-00002.safetensors
model-00002-of-00002.safetensors
model.safetensors.index.json
pytorch_model-00001-of-00002.bin
pytorch_model-00002-of-00002.bin
pytorch_model.bin.index.json
README.md
Responsible-Use-Guide.pdf
special_tokens_map.json
tokenizer.json
tokenizer.model
tokenizer_config.json
USE_POLICY.md
3.合并后huggingface文件列表
合并LoRA Model和Base Model后,生成huggingface格式文件列表,如下所示:
config.json
generation_config.json
pytorch_model-00001-of-00007.bin
pytorch_model-00002-of-00007.bin
pytorch_model-00003-of-00007.bin
pytorch_model-00004-of-00007.bin
pytorch_model-00005-of-00007.bin
pytorch_model-00006-of-00007.bin
pytorch_model-00007-of-00007.bin
pytorch_model.bin.index.json
special_tokens_map.json
tokenizer.model
tokenizer_config.json
4.合并后pth文件列表
合并LoRA Model和Base Model后,生成pth格式文件列表,如下所示:
consolidated.00.pth
params.json
special_tokens_map.json
tokenizer.model
tokenizer_config.json
5.合并脚本[6]思路
以合并后生成huggingface模型格式为例,介绍合并脚本的思路,如下所示:
# 步骤1:加载base model
base_model = LlamaForCausalLM.from_pretrained(base_model_path, # 基础模型路径load_in_8bit=False, # 加载8位torch_dtype=torch.float16, # float16device_map={"": "cpu"}, # cpu
)# 步骤2:遍历LoRA模型
for lora_index, lora_model_path in enumerate(lora_model_paths):# 步骤3:根据base model和lora model来初始化PEFT模型lora_model = PeftModel.from_pretrained(base_model, # 基础模型lora_model_path, # LoRA模型路径device_map={"": "cpu"}, # cputorch_dtype=torch.float16, # float16)# 步骤4:将lora model和base model合并为一个独立的model base_model = lora_model.merge_and_unload()......# 步骤5:保存tokenizer
tokenizer.save_pretrained(output_dir)# 步骤6:保存合并后的独立model
LlamaForCausalLM.save_pretrained(base_model, output_dir, save_function=torch.save, max_shard_size="2GB")
合并LoRA Model和Base Model过程中输出日志可参考huggingface[7]和pth[8]。
三.如何量化4bit模型
如果得到了一个训练好的模型,比如LLama2-7B,如何得到LLama2-7B-4bit呢?因为模型参数越来越多,多参数模型的量化还是会比少参数模型的非量化效果要好。量化的方案非常的多[9][12],比如AutoGPTQ、GPTQ-for-LLaMa、exllama、llama.cpp等。下面重点介绍下AutoGPTQ的基础实践过程[10],AutoGPTQ进阶教程参考文献[11]。
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig # 量化配置
from transformers import AutoTokenizer# 第1部分:量化一个预训练模型
pretrained_model_name = r"L:/20230713_HuggingFaceModel/20230903_Llama2/Llama-2-7b-hf" # 预训练模型路径
quantize_config = BaseQuantizeConfig(bits=4, group_size=128) # 量化配置,bits表示量化后的位数,group_size表示分组大小
model = AutoGPTQForCausalLM.from_pretrained(pretrained_model_name, quantize_config) # 加载预训练模型
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name) # 加载tokenizerexamples = [ # 量化样本tokenizer("auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm.")
]
# 翻译:准备examples(一个只有两个键'input_ids'和'attention_mask'的字典列表)来指导量化。这里只使用一个文本来简化代码,但是应该注意,使用的examples越多,量化后的模型就越好(很可能)。
model.quantize(examples) # 执行量化操作,examples提供量化过程所需的示例数据
quantized_model_dir = "./llama2_quantize_AutoGPTQ" # 保存量化后的模型
model.save_quantized(quantized_model_dir) # 保存量化后的模型# 第2部分:加载量化模型和推理
from transformers import TextGenerationPipeline # 生成文本device = "cuda:0"
model = AutoGPTQForCausalLM.from_quantized(quantized_model_dir, device=device) # 加载量化模型
pipeline = TextGenerationPipeline(model=model, tokenizer=tokenizer, device=device) # 得到pipeline管道
print(pipeline("auto-gptq is")[0]["generated_text"]) # 生成文本
参考文献:
[1]https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat
[2]https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat-4bit
[3]https://github.com/PanQiWei/AutoGPTQ/blob/main/README_zh.md
[4]https://github.com/FlagAlpha/Llama2-Chinese#基于Llama2的中文微调模型
[5]CPU中合并权重(合并思路仅供参考):https://github.com/yangjianxin1/Firefly/blob/master/script/merge_lora.py
[6]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/merge_llama_with_lora.py
[7]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/merge_llama_with_lora_log/merge_llama_with_lora_hf_log
[8]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/merge_llama_with_lora_log/merge_llama_with_lora_pt_log
[9]LLaMa量化部署:https://zhuanlan.zhihu.com/p/641641929
[10]AutoGPTQ基础教程:https://github.com/PanQiWei/AutoGPTQ/blob/main/docs/tutorial/01-Quick-Start.md
[11]AutoGPTQ进阶教程:https://github.com/PanQiWei/AutoGPTQ/blob/main/docs/tutorial/02-Advanced-Model-Loading-and-Best-Practice.md
[12]Inference Experiments with LLaMA v2 7b:https://github.com/djliden/inference-experiments/blob/main/llama2/README.md
[13]llama2_quantize_AutoGPTQ:https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/llama2_quantize_AutoGPTQ.py
相关文章:
Llama2-Chinese项目:4-量化模型
一.量化模型调用方式 下面是一个调用FlagAlpha/Llama2-Chinese-13b-Chat[1]的4bit压缩版本FlagAlpha/Llama2-Chinese-13b-Chat-4bit[2]的例子: from transformers import AutoTokenizer from auto_gptq import AutoGPTQForCausalLM model AutoGPTQForCausalLM…...
【深度学习实验】卷积神经网络(六):自定义卷积神经网络模型(VGG)实现图片多分类任务
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. 构建数据集(CIFAR10Dataset) a. read_csv_labels() b. CIFAR10Dataset 2. 构建模型(FeedForward&…...

Git/GitHub/Idea的搭配使用
目录 1. Git 下载安装1.1. 下载安装1.2. 配置 GitHub 秘钥 2. Idea 配置 Git3. Idea 配置 GitHub3.1. 获取 GitHub Token3.2. Idea 根据 Token 登录 GitHub3.3. Idea 提交代码到远程仓库3.3.1. 配置本地仓库3.3.2. GitHub 创建远程仓库1. 创建单层目录2. 创建多层目录3. 删除目…...
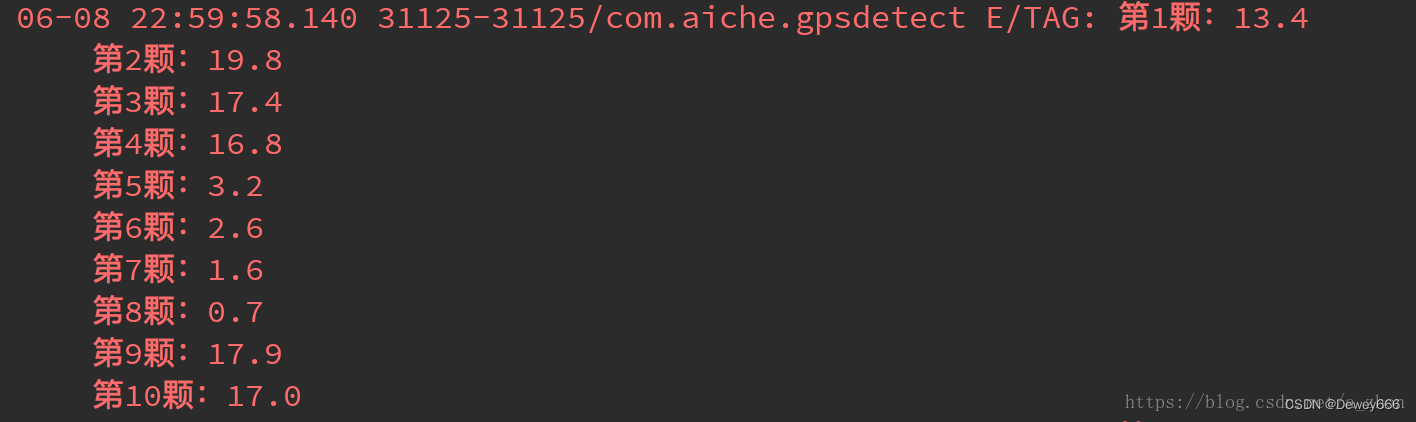
Android的GNSS功能,搜索卫星数量、并获取每颗卫星的信噪比
一、信噪比概念 信噪比,英文名称叫做SNR或S/N(SIGNAL-NOISE RATIO),又称为讯噪比。是指一个电子设备或者电子系统中信号与噪声的比例。 信噪比越大,此颗卫星越有效(也就是说可以定位)。也就是说࿰…...
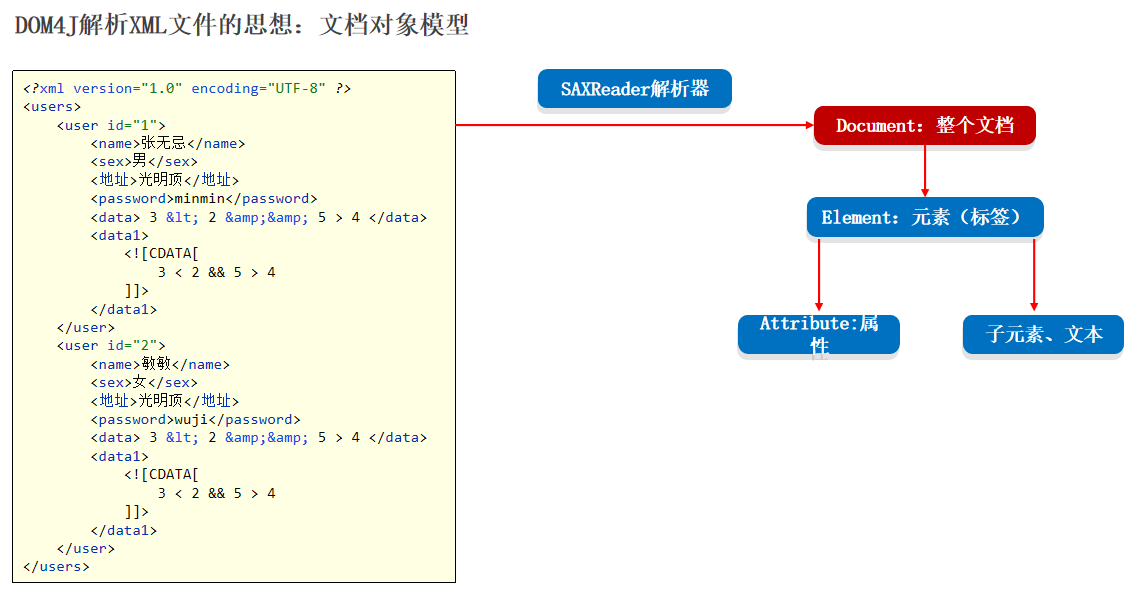
23-properties文件和xml文件以及dom4j的基本使用操作
特殊文件 我们利用这些特殊文件来存放我们 java 中的数据信息,当数据量比较大的时候,我们可以利用这个文件对数据进行快速的赋值 对于多个用户数据的存储的时候我们要用这个XML来进行存储 关于这些特殊文件,我们主要学什么 了解他们的特点&…...

新型信息基础设施IP追溯:保护隐私与网络安全的平衡
随着信息技术的飞速发展,新型信息基础设施在全球范围内日益普及,互联网已经成为我们社会和经济生活中不可或缺的一部分。然而,随着网络使用的增加,隐私和网络安全问题也引发了广泛关注。在这个背景下,IP(In…...

django 实现:闭包表—树状结构
闭包表—树状结构数据的数据库表设计 闭包表模型 闭包表(Closure Table)是一种通过空间换时间的模型,它是用一个专门的关系表(其实这也是我们推荐的归一化方式)来记录树上节点之间的层级关系以及距离。 场景 我们 …...

Redis与分布式-集群搭建
接上文 Redis与分布式-哨兵模式 1. 集群搭建 搭建简单的redis集群,创建6个配置,开启集群模式,将之前配置过的redis删除,重新复制6份 针对主节点redis 1,redis 2,redis 3都是以上修改内容,只是…...
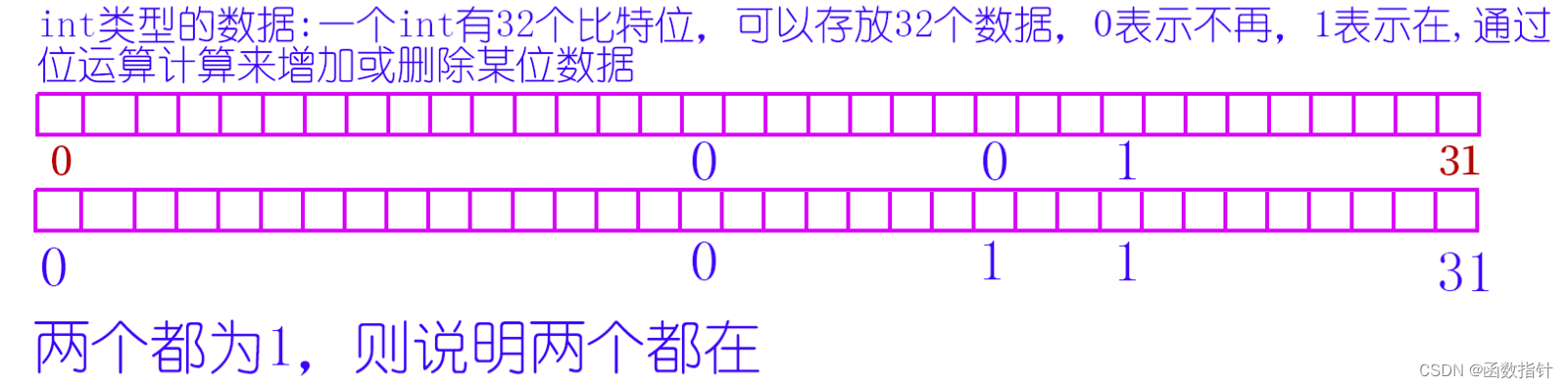
C++--位图和布隆过滤器
1.什么是位图 所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。比如int 有32位,就可以存放0到31这32个数字在不在某个文件中。当然,其他类型也可以。 2.位…...

linux常识
目录 i.mx6ull开发板配置ip 静态IP配置 命令行配置 配置文件配置 动态IP配置 命令行配置 配置文件配置 为什么编译驱动程序之前要先编译内核? init系统服务 systemv守护进程 systemd守护进程 i.mx6ull开发板配置ip i.mx6ull有两个网卡(eth0和…...

Codeforces Round 901 (Div. 1) B. Jellyfish and Math(思维题/bfs)
题目 t(t<1e5)组样例,每次给出a,b,c,d,m(0<a,b,c,d,m<2的30次方) 初始时,(x,y)(a,b),每次操作,你可以执行以下四种操作之一 ①xx&y,&为与 ②xx|y,|为或 ③yx^y,^为异或 …...
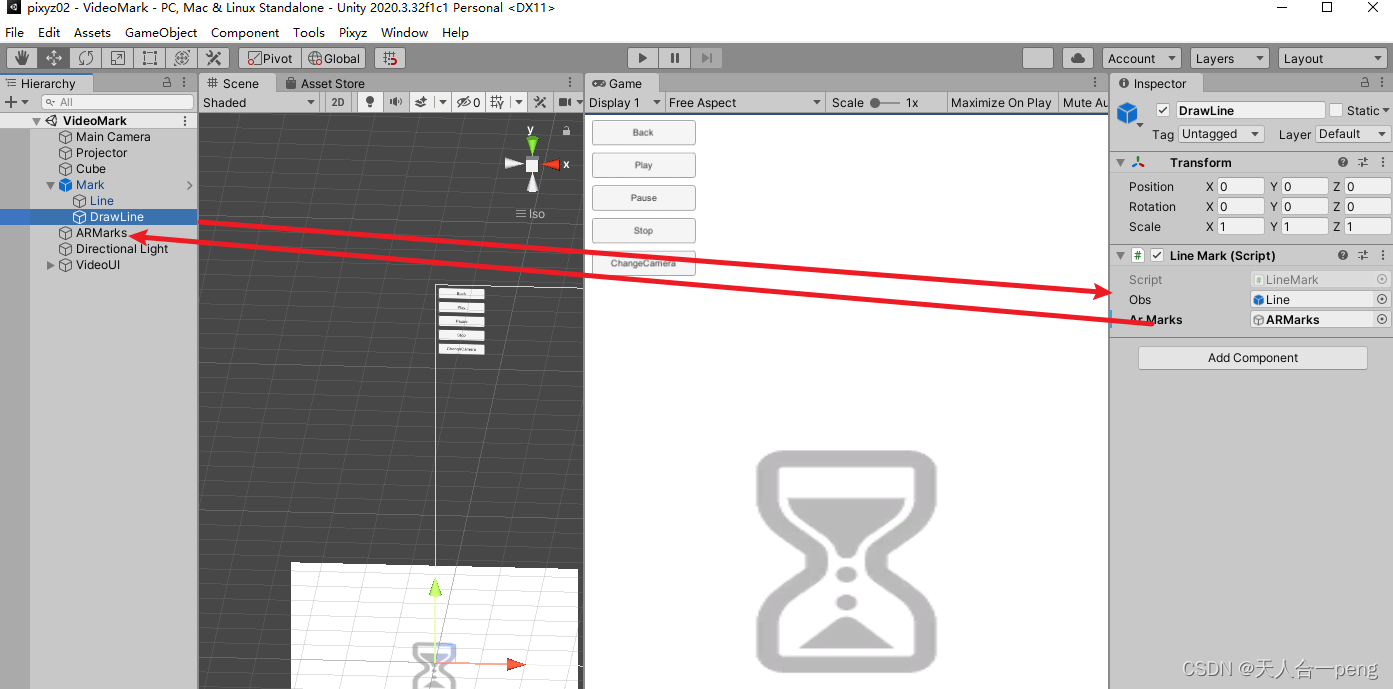
unity 鼠标标记 左键长按生成标记右键长按清除标记,对象转化为子物体
linerender的标记参考 unity linerenderer在Game窗口中任意画线_游戏内编辑linerender-CSDN博客 让生成的标记转化为ARMarks游戏对象的子物体 LineMark.cs using System.Collections; using System.Collections.Generic; using UnityEngine;public class LineMark : MonoBeh…...
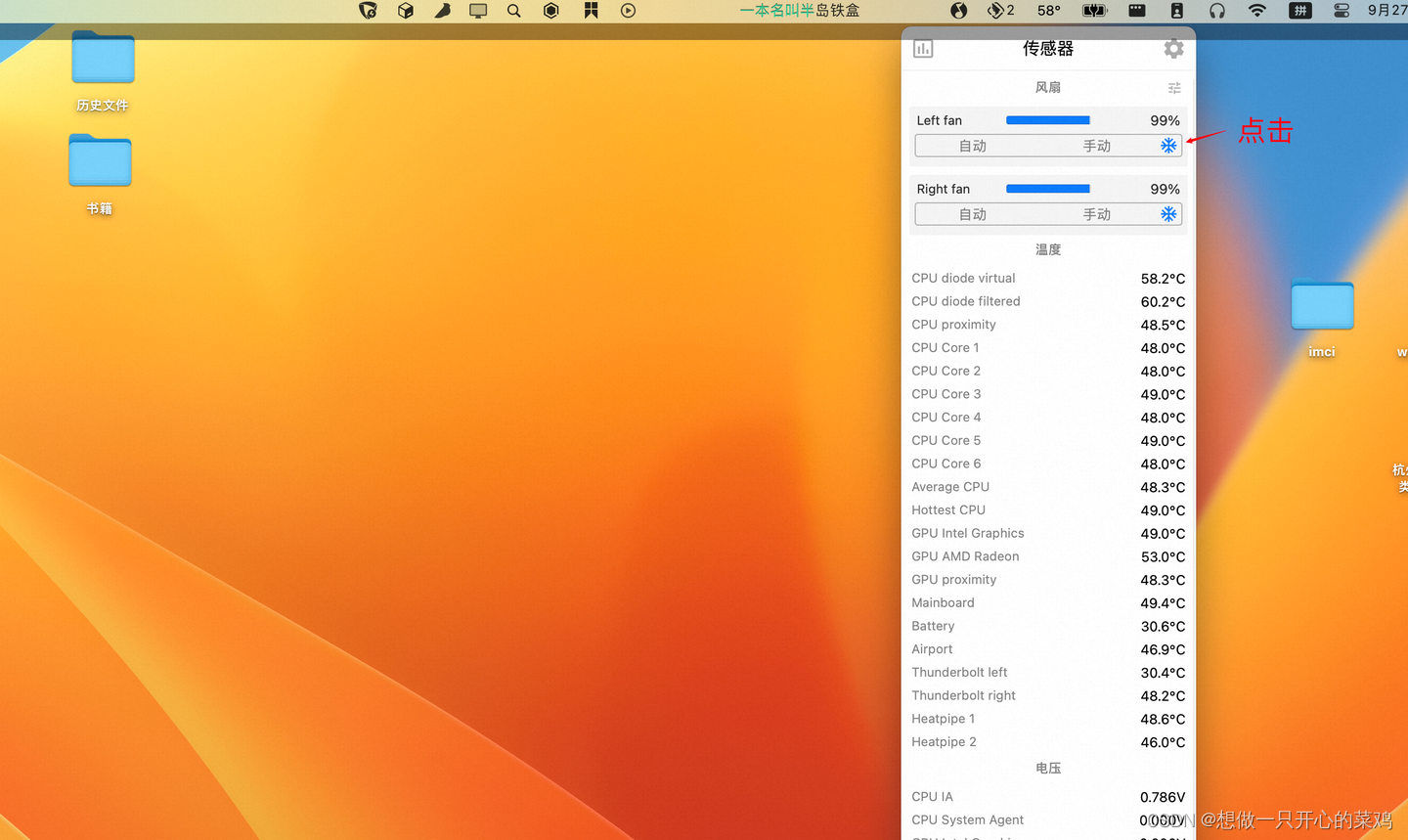
解决mac pro 连接4k显示器严重发烫、卡顿问题
介绍个不用花钱的方法。其实mac自带的风扇散热能力还可以的,但是默认比较懒散,可以用一个软件来控制下,激发下它的潜能。 可以下个stats软件 打开传感器开关,以及同步控制风扇开关 以及cpu显示温度 点击控制台上的温度图标&…...
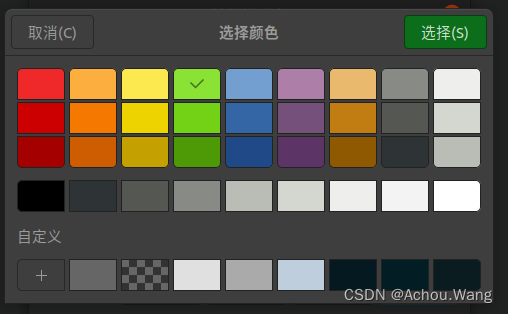
QT的ui设计中改变样式表的用法
在QT的ui设计中,我们右键会弹出一个改变样式表的选项,很多人不知道这个是干什么的。 首先我们来看下具体的界面 首先我们说一下这个功能具体是干嘛的, 我们在设置很多控件在界面上之后,常常都是使用系统默认的样式,但是当有些时候为了美化界面我们需要对一些控件进行美化…...
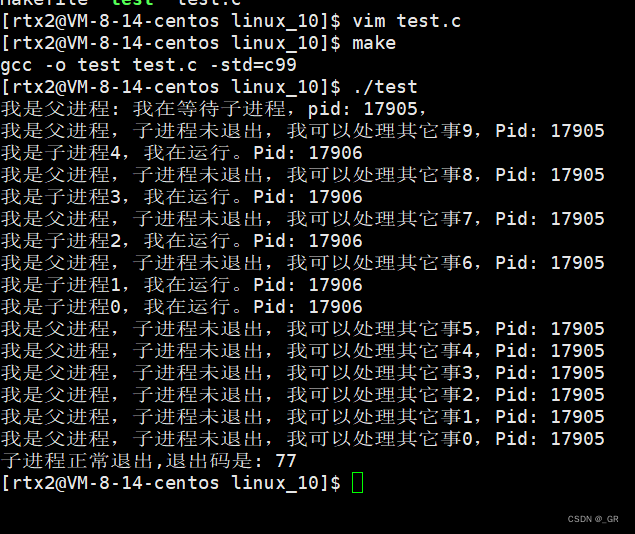
零基础Linux_10(进程)进程终止(main函数的返回值)+进程等待
目录 1. 进程终止 1.1 main函数的返回值 1.2 进程退出码和错误码 1.3 进程终止的常见方法 2. 进程等待 2.1 进程等待的原因 2.2 wait 函数 2.3 waitpid 函数 2.4 int* status参数 2.5 int options非阻塞等待 本篇完。 1. 进程终止 进程终止指的就是程序执行结束了&…...

【已解决】opencv 交叉编译 ffmpeg选项始终为NO
一、opencv 交叉编译没有 ffmpeg ,会导致视频打不开 在交叉编译时候,发现在 pc 端能用 opencv 打开的视频,但是在 rv1126 上打不开。在网上查了很久,原因可能是 交叉编译过程 ffmpeg 造成的。之前 ffmpeg 是直接用 apt 安装的&am…...

rust生命期
一、生命期是什么 生命期,又叫生存期,就是变量的有效期。 实例1 {let r;{let x 5;r &x;}println!("r: {}", r); }编译错误,原因是r所引用的值已经被释放。 上图中的绿色范围’a表示r的生命期,蓝色范围’b表示…...

实现将一张图片中的目标图片抠出来
要在python中实现将一张图片中的目标图片裁剪出来,需要用到图像处理及机器学习库,以下是一个常用的基本框架 加载图片并使用OpenCV库将其转换为灰度图像 import cv2img cv2.imread(screenshot.jpg) gray cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)准备模…...

Rust 使用Cargo
Rust 使用技巧 Rust 使用crates 假设你正在编写一个 Rust 程序,要使用一个名为 rand 的第三方库来生成随机数。首先,你需要在 Cargo.toml 文件中添加以下依赖项: toml [dependencies] rand "0.7.3" 然后运行 cargo build&…...

【k8s】集群搭建篇
文章目录 搭建kubernetes集群kubeadm初始化操作安装软件(master、所有node节点)Kubernetes Master初始化Kubernetes Node加入集群部署 CNI 网络插件测试 kubernetes 集群停止服务并删除原来的配置 二进制搭建(单master集群)初始化操作部署etcd集群安装Docker部署master节点解压…...
)
面试官:MySQL 唯一索引和主键索引的区别?(修订版)
在线 Java 面试刷题(持续更新):https://www.quanxiaoha.com/java-interview面试考察点索引类型理解:面试官不仅仅是想知道 "有什么区别",更是想考察你是否理解主键索引(聚簇索引)和唯…...

UnrealCLR异常处理与调试:为什么这是.NET开发者必须掌握的技能
UnrealCLR异常处理与调试:为什么这是.NET开发者必须掌握的技能 【免费下载链接】UnrealCLR Unreal Engine .NET 6 integration 项目地址: https://gitcode.com/gh_mirrors/un/UnrealCLR 在虚幻引擎中集成.NET开发时,UnrealCLR异常处理与调试是每个…...
5分钟部署数字人:lite-avatar形象库快速集成教程
5分钟部署数字人:lite-avatar形象库快速集成教程 1. 引言:为什么选择lite-avatar形象库? 数字人项目开发中最耗时的环节之一就是形象创建和训练。传统方式需要收集数据、训练模型、调试参数,整个过程可能需要数周时间。而lite-a…...

从官方Demo到项目集成:海康MV-EB435i RGBD相机C++采集与OpenCV图像处理实战
1. 环境准备与SDK安装 第一次接触海康MV-EB435i这款RGBD相机时,我花了两天时间才把开发环境搭好。现在回想起来,其实只要抓住几个关键点就能少走弯路。先说说硬件准备:这款相机支持USB3.0和千兆网口两种连接方式,实测USB连接更稳定…...

PyTorch 2.8镜像问题解决:常见CUDA内存不足、加载慢等故障排查指南
PyTorch 2.8镜像问题解决:常见CUDA内存不足、加载慢等故障排查指南 你是不是也遇到过这样的场景?在云端启动了一个全新的PyTorch 2.8镜像,准备大展身手训练模型,结果刚跑几行代码就弹出“CUDA out of memory”的红色警告。或者&a…...

工作流管理平台搭建指南:使用n8n-mcp-server构建企业级自动化流程
工作流管理平台搭建指南:使用n8n-mcp-server构建企业级自动化流程 【免费下载链接】n8n-mcp-server MCP server that provides tools and resources for interacting with n8n API 项目地址: https://gitcode.com/gh_mirrors/n8/n8n-mcp-server n8n-mcp-serv…...

深入解析Docker Bridge网络模式:从docker0到容器互联实战
1. Docker Bridge网络模式初探 刚接触Docker时,我发现每次启动容器都会自动分配一个IP地址,这些容器之间居然能直接互相访问。这背后的魔法就是Bridge网络模式——Docker的默认网络方案。想象一下docker0就像公司内部的交换机,所有工位&#…...

纯Verilog编程:万兆网以太网UDP协议的完整实现与产品化测试
纯verilog编写实现万兆网以太网完整UDP协议,并支持ARP和ping功能,在xilinx平台已产品化测试,稳定可靠搞过FPGA网络通信的都懂,万兆网协议栈这玩意儿就是个硬骨头。去年团队折腾的纯Verilog万兆网方案现在已经在Xilinx UltraScale板…...

1801181-54-3,Oregon Green Alkyne,在长时间光照下抗淬灭能力远优于传统荧光素
一.名称中文名称:俄勒冈绿 488 炔基英文名称:OG 488 Alkyne,OG 488 Alk,Oregon Green Alkyne,Oregon Green AlkCAS:1801181-54-3分子式:C24H13F2NO6分子量:449.37激发波长࿰…...

PX4飞控开发实战:如何调试mc_pos_control模块提升多旋翼飞行稳定性
PX4飞控开发实战:如何调试mc_pos_control模块提升多旋翼飞行稳定性 当多旋翼无人机在悬停时出现高频震荡,或是响应指令时显得迟缓笨重,背后往往隐藏着位置控制参数的配置问题。PX4飞控中的mc_pos_control模块作为多旋翼位置控制的核心&#x…...