C++ 并发编程实战 第八章 设计并发代码 二
目录
8.3 设计数据结构以提升多线程程序的性能
8.3.1 针对复杂操作的数据划分
8.3.2 其他数据结构的访问模式
8.4 设计并发代码时要额外考虑的因素
8.4.1 并行算法代码中的异常安全
8.4.2 可扩展性和Amdahl定律
8.4.3 利用多线程隐藏等待行为
8.4.4 借并发特性改进响应能力
8.5 并发代码的设计实践
参考:https://github.com/xiaoweiChen/CPP-Concurrency-In-Action-2ed-2019/blob/master/content/chapter8/8.2-chinese.md
8.3 设计数据结构以提升多线程程序的性能
8.1节了解了各种划分方法,8.2节中了解了影响性能的各种因素。如何在设计数据结构时,使用这些信息提高多线程代码的性能?与第6、7章中的问题不同,之前是关于如何设计安全、并发访问的数据结构。
当为多线程性能设计数据结构时,需要考虑竞争(contention),伪共享(false sharing)和邻近数据(data proximity),这三个对于性能都有着重大的影响的因素,改善数据布局,或者将数据进行修改。
8.3.1 针对复杂操作的数据划分
线程间划分工作的方式有很多,假设矩阵的行或列数量大于处理器的数量,可以让每个线程计算出结果矩阵列上的元素,或是行上的元素,亦或计算一个子矩阵。
回顾一下8.2.3和8.2.4节,对于数组来说访问连续元素是最好的方式,因为这会减少缓存的刷新,降低伪共享的概率。如果要让每个线程处理几行,线程需要读取第一个矩阵中的每一个元素,并且读取第二个矩阵上的相关数据,不过这里只需要对列进行写入。给定的两个矩阵是以行连续的方式存储,这就意味着当访问第一个矩阵的第一行的前N个元素,而后是第二行的前N个元素,以此类推(N是列的数量)。其他线程会访问每行的的其他元素,访问相邻的列,所以从行上读取的N个元素也是连续的,这将最大程度降低伪共享的几率。当然,如果N个元素已占有相应的空间,且N个元素也就是每个缓存行上具体的存储元素数量,就会让伪共享的情况消失,因为线程将会对独立缓存行上的数据进行操作。
另一方面,当每个线程处理一组行数据,就需要读取第二个矩阵上的数据,还要读取第一个矩阵中的相关行上的值,不过只需要对行上的值进行写入即可。因为矩阵是以行连续的方式存储,那么可以以N行的方式访问所有的元素。如果再次选择相邻行,这就意味着线程现在只能写入N行,就有不能被其他线程所访问的连续内存块。让线程对每组列进行处理就是一种改进,因为伪共享只可能有在一个内存块的最后几个元素和下一个元素的开始几个上发生,不过具体的时间还要根据目标架构来决定。
第三个选择——将矩阵分成小矩阵块?这可以看作先对列进行划分,再对行进行划分。因此,划分列的时候,同样有伪共享的问题存在。如果可以选择内存块所拥有行的数量,就可以有效的避免伪共享。将大矩阵划分为小块,对于读取来说是有好处的:就不再需要读取整个源矩阵了。只需要读取目标矩形里面相关行列的值就可以了。具体的来看,考虑1,000行和1,000列的两个矩阵相乘,就会有1百万个元素。如果有100个处理器,这样就可以每次处理10行的数据,也就是10,000个元素。不过,为了计算着10,000个元素,就需要对第二个矩阵中的全部内容进行访问(1百万个元素),再加上10,000个相关行(第一个矩阵)上的元素,大概就要访问1,010,000个元素。另外,硬件能处理100x100的数据块(总共10,000个元素),这就需要对第一个矩阵中的100行进行访问(100x1,000=100,000个元素),还有第二个矩阵中的100列(另外100,000个)。这才只有200,000个元素,就需要5轮读取才能完成。如果读取的元素少一些,缓存缺失的情况就会少一些。
因此,将矩阵分成小块或正方形的块,要比使用单线程来处理少量的列好的多。当然,可以根据源矩阵的大小和处理器的数量,在运行时对块的大小进行调整。性能是很重要的指标时,就需要对目标架构上的各项指标进行测量,并且查阅相关领域的文献——如果只是做矩阵乘法,我认为这并不是最好的选择。
同样的原理可以应用于任何情况,这种情况就是有很大的数据块需要在线程间进行划分。仔细观察所有数据访问的各个方面,以及确定性能问题产生的原因。各种领域中,出现问题的情况都很相似:改变划分方式就能够提高性能,不需要对基本算法进行任何修改。
OK,我们已经了解了访问数组是如何对性能产生影响的
8.3.2 其他数据结构的访问模式
同样的考虑适用于数据结构的数据访问模式,如同优化对数组的访问:
-
尝试调整数据在线程间的分布,让同一线程中的数据紧密联系在一起。
-
尝试减少线程上所需的数据量。
-
尝试让不同线程访问不同的存储位置,以避免伪共享。
和用互斥量来保护数据类似。假设有一个类,包含一些数据项和一个用于保护数据的互斥量(多线程环境下)。如果互斥量和数据项在内存中很接近,对于一个需要获取互斥量的线程来说是很理想的情况。因为在之前为了对互斥量进行修改,已经加载了需要的数据,所以需要的数据可能早已存入处理器的缓存中。不过,还有一个缺点:当其他线程尝试锁住互斥量时(第一个线程还没有是释放),线程就能对数据项进行访问。互斥锁是作为“读-改-写”原子操作实现的,对于相同位置的操作都需要先获取互斥量,如果互斥量已锁,就会调用系统内核。这种“读-改-写”操作可能会让数据存储在缓存中,让线程获取的互斥量变得毫无作用。从目前互斥量的发展来看,这并不是个问题,因为线程不会直到互斥量解锁才接触互斥量。不过,当互斥量共享同一缓存行时,其中存储的是线程已使用的数据,这时拥有互斥量的线程将会遭受到性能打击,因为其他线程也在尝试锁住互斥量。
一种测试伪共享问题的方法:填充大量的数据块,让不同线程并发访问。
struct protected_data
{std::mutex m;char padding[65536]; // 如果你的编译器不支持std::hardware_destructive_interference_size,可以使用类似65536字节,这个数字肯定超过一个缓存行my_data data_to_protect;
};用来测试互斥量竞争或
struct my_data
{data_item1 d1;data_item2 d2;char padding[65536];
};
my_data some_array[256];用来测试数组数据中的伪共享。
如果这样能够提高性能,就能知道伪共享在这里的确存在。
当然,设计并发的时候有更多的数据访问模式需要考虑。
8.4 设计并发代码时要额外考虑的因素
虽然,有很多设计并发代码的内容,但还需要考虑的更多,比如异常安全和可扩展性。随着核数的增加,性能越来越高(无论是在减少执行时间,还是增加吞吐率),这样的代码称为“可扩展”代码。理想状态下,性能随着核数的增加线性增长,也就是当系统有100个处理器时,其性能是系统只有1核时的100倍。
虽然,非扩展性代码依旧可以正常工作——单线程应用就无法扩展,例如:异常安全是一个正确性问题,如果代码不是异常安全的,最终会破坏不变量,或是造成条件竞争,亦或是操作抛出异常意外终止应用。我们就先来看一下异常安全的问题。
8.4.1 并行算法代码中的异常安全
代码8.2 std::accumulate的原始并行版本(源于代码2.8)
template<typename Iterator,typename T>
struct accumulate_block
{void operator()(Iterator first,Iterator last,T& result){result=std::accumulate(first,last,result); // 1}
};template<typename Iterator,typename T>
T parallel_accumulate(Iterator first,Iterator last,T init)
{unsigned long const length=std::distance(first,last); // 2if(!length)return init;unsigned long const min_per_thread=25;unsigned long const max_threads=(length+min_per_thread-1)/min_per_thread;unsigned long const hardware_threads=std::thread::hardware_concurrency();unsigned long const num_threads=std::min(hardware_threads!=0?hardware_threads:2,max_threads);unsigned long const block_size=length/num_threads;std::vector<T> results(num_threads); // 3std::vector<std::thread> threads(num_threads-1); // 4Iterator block_start=first; // 5for(unsigned long i=0;i<(num_threads-1);++i){Iterator block_end=block_start; // 6std::advance(block_end,block_size);threads[i]=std::thread( // 7accumulate_block<Iterator,T>(),block_start,block_end,std::ref(results[i]));block_start=block_end; // 8}accumulate_block()(block_start,last,results[num_threads-1]); // 9std::for_each(threads.begin(),threads.end(),std::mem_fn(&std::thread::join));return std::accumulate(results.begin(),results.end(),init); // 10
}代码8.3 使用std::packaged_task的并行std::accumulate
template<typename Iterator,typename T>
struct accumulate_block
{T operator()(Iterator first,Iterator last) // 1{return std::accumulate(first,last,T()); // 2}
};template<typename Iterator,typename T>
T parallel_accumulate(Iterator first,Iterator last,T init)
{unsigned long const length=std::distance(first,last);if(!length)return init;unsigned long const min_per_thread=25;unsigned long const max_threads=(length+min_per_thread-1)/min_per_thread;unsigned long const hardware_threads=std::thread::hardware_concurrency();unsigned long const num_threads=std::min(hardware_threads!=0?hardware_threads:2,max_threads);unsigned long const block_size=length/num_threads;std::vector<std::future<T> > futures(num_threads-1); // 3std::vector<std::thread> threads(num_threads-1);Iterator block_start=first;for(unsigned long i=0;i<(num_threads-1);++i){Iterator block_end=block_start;std::advance(block_end,block_size);std::packaged_task<T(Iterator,Iterator)> task( // 4accumulate_block<Iterator,T>());futures[i]=task.get_future(); // 5threads[i]=std::thread(std::move(task),block_start,block_end); // 6block_start=block_end;}T last_result=accumulate_block()(block_start,last); // 7std::for_each(threads.begin(),threads.end(),std::mem_fn(&std::thread::join));T result=init; // 8for(unsigned long i=0;i<(num_threads-1);++i){result+=futures[i].get(); // 9}result += last_result; // 10return result;
}这样问题就解决了:工作线程上抛出的异常,可以在主线程上抛出。如果不止一个工作线程抛出异常,那么只有一个异常能在主线程中抛出。如果这个问题很重要,可以使用类似std::nested_exception对所有抛出的异常进行捕捉。
剩下的问题:当第一个新线程和当所有线程都汇入主线程时抛出异常时,就会让线程产生泄露。最简单的方法就是捕获所有抛出的线程,汇入的线程依旧是joinable()的,并且会再次抛出异常:
代码8.4 异常安全版std::accumulate
template<typename Iterator,typename T>
T parallel_accumulate(Iterator first,Iterator last,T init)
{unsigned long const length=std::distance(first,last);if(!length)return init;unsigned long const min_per_thread=25;unsigned long const max_threads=(length+min_per_thread-1)/min_per_thread;unsigned long const hardware_threads=std::thread::hardware_concurrency();unsigned long const num_threads=std::min(hardware_threads!=0?hardware_threads:2,max_threads);unsigned long const block_size=length/num_threads;std::vector<std::future<T> > futures(num_threads-1);std::vector<std::thread> threads(num_threads-1);join_threads joiner(threads); // 1Iterator block_start=first;for(unsigned long i=0;i<(num_threads-1);++i){Iterator block_end=block_start;std::advance(block_end,block_size);std::packaged_task<T(Iterator,Iterator)> task(accumulate_block<Iterator,T>());futures[i]=task.get_future();threads[i]=std::thread(std::move(task),block_start,block_end);block_start=block_end;}T last_result=accumulate_block()(block_start,last);T result=init;for(unsigned long i=0;i<(num_threads-1);++i){result+=futures[i].get(); // 2}result += last_result;return result;
}std::async()的异常安全
当需要管理线程时,需要代码是异常安全的。那现在来看一下使用std::async()是怎样完成异常安全的。本例中标准库对线程进行了较好的管理,并且当future处以就绪状态时,就能生成新的线程。对于异常安全,还需要注意一件事,如果没有等待的情况下对future实例进行销毁,析构函数会等待对应线程执行完毕后才执行。这就能体现线程泄露的问题,因为线程还在执行,且持有数据引用。下面将展示使用std::async()完成异常安全的实现。
代码8.5 异常安全并行版std::accumulate——使用std::async()
template<typename Iterator,typename T>
T parallel_accumulate(Iterator first,Iterator last,T init)
{unsigned long const length=std::distance(first,last); // 1unsigned long const max_chunk_size=25;if(length<=max_chunk_size){return std::accumulate(first,last,init); // 2}else{Iterator mid_point=first;std::advance(mid_point,length/2); // 3std::future<T> first_half_result=std::async(parallel_accumulate<Iterator,T>, // 4first,mid_point,init);T second_half_result=parallel_accumulate(mid_point,last,T()); // 5return first_half_result.get()+second_half_result; // 6}
}这个版本是对数据进行递归划分,而非在预计算后对数据进行分块。因此,这个版本要比之前简单很多,并且这个版本也是异常安全的。和之前一样,要确定序列的长度①,如果其长度小于数据块包含数据的最大值,可以直接调用std::accumulate②。如果元素的数量超出了数据块包含数据的最大值,就需要找到数量中点③,将这个数据块分成两部分,然后再生成一个异步任务对另一半数据进行处理④。第二半的数据是通过直接的递归调用来处理的⑤,之后将两个块的结果加和到一起⑥。标准库能保证std::async的调用能够充分的利用硬件线程,并且不会产生线程的超额申请,一些“异步”调用在get()⑥后同步执行。
优雅的地方不仅在于利用硬件并发的优势,还能保证异常安全。如果有异常在递归⑤中抛出,通过std::async④所产生的future,将异常在传播时销毁。这就需要依次等待异步任务的完成,因此也能避免悬空线程的出现。另外,当异步任务抛出异常,且被future所捕获后,在对get()⑥调用的时候,future中存储的异常会再次抛出。
8.4.2 可扩展性和Amdahl定律
扩展性代表了应用利用系统中处理器执行任务的能力。一种极端的方式就是将应用写死为单线程运行,这种应用就是完全不可扩展的。即使添加了100个处理器到你的系统中,应用的性能都不会有任何改变。另一种就是像SETI@Home[3]项目一样,让应用使用系统中成千上万的处理器(以个人电脑的形式加入网络的用户)成为可能。
对于任意的多线程程序,运行时的工作线程数量会有所不同。应用初始阶段只有一个线程,之后会在这个线程上衍生出新的线程。理想状态:每个线程都做着有用的工作,不过这种情况几乎是不可能发生的。线程通常会花时间进行互相等待,或等待I/O操作的完成。
一种简化的方式就是就是将程序划分成“串行”和“并行”部分。串行部分:只能由单线程执行一些工作的地方。并行部分:可以让所有可用的处理器一起工作的部分。当在多处理系统上运行应用时,“并行”部分理论上会完成的相当快,因为其工作被划分为多份,放在不同的处理器上执行。“串行”部分则不同,只能一个处理器执行所有工作。这样的(简化)假设下,就可以随着处理数量的增加,估计一下性能的增益:当程序“串行”部分的时间用fs来表示,那么性能增益(P)就可以通过处理器数量(N)进行估计:
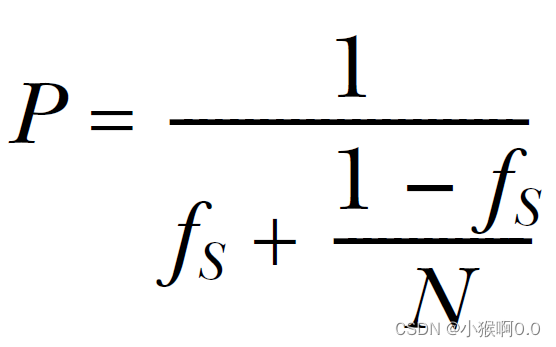
这就是Amdahl定律,讨论并发程序性能的时候都会引用到的公式。如果每行代码都能并行化,串行部分就为0,性能增益就为N。或者,当串行部分为1/3时,当处理器数量无限增长,都无法获得超过3的性能增益。
Amdahl定律明确了,对代码最大化并发可以保证所有处理器都能用来做有用的工作。如果将“串行”部分的减小,或者减少线程的等待,就可以在多处理器的系统中获取更多的性能收益。或者,当能提供更多的数据让系统进行处理,并且让并行部分做最重要的工作,就可以减少“串行”部分,以获取更高的性能增益。
扩展性:当有更多的处理器加入时,减少单个动作的执行时间,或在给定时间内做更多工作。有时这两个指标是等价的(如果处理器的速度相当快,就可以处理更多的数据)。选择线程间的工作划分的技术前,需要辨别哪些方面是能够扩展的。
8.4.3 利用多线程隐藏等待行为
8.4.4 借并发特性改进响应能力
代码8.6 将GUI线程和任务线程进行分离
std::thread task_thread;
std::atomic<bool> task_cancelled(false);void gui_thread()
{while(true){event_data event=get_event();if(event.type==quit)break;process(event);}
}void task()
{while(!task_complete() && !task_cancelled){do_next_operation();}if(task_cancelled){perform_cleanup();}else{post_gui_event(task_complete);}
}void process(event_data const& event)
{switch(event.type){case start_task:task_cancelled=false;task_thread=std::thread(task);break;case stop_task:task_cancelled=true;task_thread.join();break;case task_complete:task_thread.join();display_results();break;default://...}
}8.5 并发代码的设计实践
略
8.6 小结
本章我们讨论了很多东西。从划分线程间的工作开始(比如,数据提前划分或让线程形成流水线),以低层视角来看多线程下的性能问题,顺带了解了伪共享和数据通讯,了解访问数据的模式对性能的影响。再后,了解了异常安全和可扩展性是如何影响并发代码设计的。最后,用一些并行算法实现结束本章。
设计这些并行算法实现时碰到的问题,在设计其他并行代码的时候也会遇到。
本章关于线程池的部分移除了,线程池——一个预先设定的线程组,会将任务指定给池中的线程。很多不错的想法可以用来设计一个不错的线程池,所以我们将在下一章中来了解一些有关线程池的问题,以及线程的高级管理方式。
相关文章:
C++ 并发编程实战 第八章 设计并发代码 二
目录 8.3 设计数据结构以提升多线程程序的性能 8.3.1 针对复杂操作的数据划分 8.3.2 其他数据结构的访问模式 8.4 设计并发代码时要额外考虑的因素 8.4.1 并行算法代码中的异常安全 8.4.2 可扩展性和Amdahl定律 8.4.3 利用多线程隐藏等待行为 8.4.4 借并发特性改进响应…...

list(链表)
文章目录 功能迭代器的分类sort函数(排序)merage(归并)unique(去重)removesplice(转移) 功能 这里没有“[]"的实现;原因:实现较麻烦;这里使用迭代器来实…...

使用代理IP进行安全高效的竞争情报收集,为企业赢得竞争优势
在激烈的市场竞争中,知己知彼方能百战百胜。竞争对手的信息对于企业来说至关重要,它提供了洞察竞争环境和市场的窗口。在这个信息时代,代理IP是一种实用的工具,可以帮助企业收集竞争对手的产品信息和营销活动数据,为企…...

【数学知识】一些数学知识,以供学习
矩阵的特征值和特征向量 https://zhuanlan.zhihu.com/p/104980382 矩阵的逆 https://zhuanlan.zhihu.com/p/163748569 对数似然方程(log-likelihood equation),简称“似然方程”: https://baike.baidu.com/item/%E5%AF%B9%E6%95%B0%E4%BC%BC%E7%84%B6%E6%96%B9%E7…...

JKChangeCapture swift 版本的捕捉属性变化的工具
在OC的时代里,大家捕捉属性的变化通常是通过KVO机制来实现的,KVO把所有的属性变化都放在了一个方法进行相应处理,并不友好,之前基于KVO的机制实现了一套属性变化工具JKKVOHelper,这里不就在过多介绍这个了,在swift的时…...

RISC-V 指令
RISC-V指令都是32位长。 文章目录 R-Type指令格式:I-Type指令格式:S-Type指令格式:B-Type指令格式:U-Type指令格式:UJ-Type指令格式:J-Type指令格式:R4-Type指令格式:F-Type指令格式:vC-Type指令格式:CB-Type指令格式:CIW-Type指令格式:CL-Type指令格式:R-Type指…...
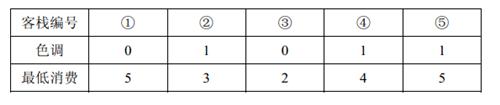
[NOIP2011 提高组] 选择客栈
[NOIP2011 提高组] 选择客栈 题目描述 丽江河边有 n n n 家很有特色的客栈,客栈按照其位置顺序从 1 1 1 到 n n n 编号。每家客栈都按照某一种色调进行装饰(总共 k k k 种,用整数 0 ∼ k − 1 0 \sim k-1 0∼k−1 表示)&am…...
桂院校园导航 静态项目 二次开发教程 1.2
Gitee代码仓库:桂院校园导航小程序 GitHub代码仓库:GLU-Campus-Guide 先 假装 大伙都成功安装了静态项目,并能在 微信开发者工具 和 手机 上正确运行。 接着就是 将项目 改成自己的学校。 代码里的注释我就不说明了,有提到 我…...

private static final long serialVersionUID = 1L的作用是什么?
1.作用是什么? 当一个类被序列化后,存储在文件或通过网络传输时,这些序列化数据会包含该类的结构信息。当反序列化操作发生时,Java虚拟机会根据序列化数据中的结构信息来还原对象。 但是,如果在序列化之后,…...

leetCode 122.买卖股票的最佳时机 II 贪心算法
122. 买卖股票的最佳时机 II - 力扣(LeetCode) 给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买&…...

阿里云ACP知识点(三)
1、弹性伸缩不仅提供了在业务需求高峰或低谷时自动调节ECS实例数量的能力,而且提供了ECS实例上自动部署应用的能力。弹性伸缩的伸缩配置支持多种特性,例如______,帮助您高效、灵活地自定义ECS实例配置,满足业务需求。 标签、密钥对、 实例RAM…...

nmap 扫描内网IP, 系统, 端口
nmap 扫描内网IP, 系统, 端口 扫描内网ip 对内网进行ARP扫描 .\nmap.exe -sn 192.168.110.0/24 # 全网段 .\nmap.exe -sn 192.168.110.100-200 # 100-200范围 扫描端口 .\nmap.exe -sT 192.168.110.130 # 三次握手连接 较慢, 但更有效 .\nmap.exe -sS 192.168.110.130 # 发…...

Llama2-Chinese项目:4-量化模型
一.量化模型调用方式 下面是一个调用FlagAlpha/Llama2-Chinese-13b-Chat[1]的4bit压缩版本FlagAlpha/Llama2-Chinese-13b-Chat-4bit[2]的例子: from transformers import AutoTokenizer from auto_gptq import AutoGPTQForCausalLM model AutoGPTQForCausalLM…...
【深度学习实验】卷积神经网络(六):自定义卷积神经网络模型(VGG)实现图片多分类任务
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. 构建数据集(CIFAR10Dataset) a. read_csv_labels() b. CIFAR10Dataset 2. 构建模型(FeedForward&…...

Git/GitHub/Idea的搭配使用
目录 1. Git 下载安装1.1. 下载安装1.2. 配置 GitHub 秘钥 2. Idea 配置 Git3. Idea 配置 GitHub3.1. 获取 GitHub Token3.2. Idea 根据 Token 登录 GitHub3.3. Idea 提交代码到远程仓库3.3.1. 配置本地仓库3.3.2. GitHub 创建远程仓库1. 创建单层目录2. 创建多层目录3. 删除目…...
Android的GNSS功能,搜索卫星数量、并获取每颗卫星的信噪比
一、信噪比概念 信噪比,英文名称叫做SNR或S/N(SIGNAL-NOISE RATIO),又称为讯噪比。是指一个电子设备或者电子系统中信号与噪声的比例。 信噪比越大,此颗卫星越有效(也就是说可以定位)。也就是说࿰…...
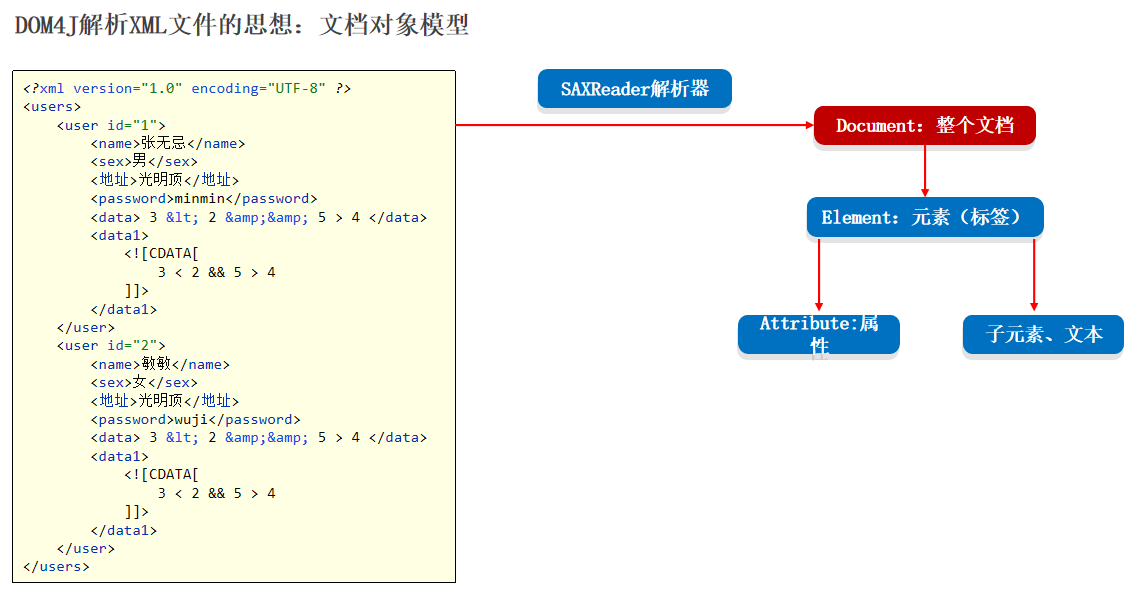
23-properties文件和xml文件以及dom4j的基本使用操作
特殊文件 我们利用这些特殊文件来存放我们 java 中的数据信息,当数据量比较大的时候,我们可以利用这个文件对数据进行快速的赋值 对于多个用户数据的存储的时候我们要用这个XML来进行存储 关于这些特殊文件,我们主要学什么 了解他们的特点&…...

新型信息基础设施IP追溯:保护隐私与网络安全的平衡
随着信息技术的飞速发展,新型信息基础设施在全球范围内日益普及,互联网已经成为我们社会和经济生活中不可或缺的一部分。然而,随着网络使用的增加,隐私和网络安全问题也引发了广泛关注。在这个背景下,IP(In…...

django 实现:闭包表—树状结构
闭包表—树状结构数据的数据库表设计 闭包表模型 闭包表(Closure Table)是一种通过空间换时间的模型,它是用一个专门的关系表(其实这也是我们推荐的归一化方式)来记录树上节点之间的层级关系以及距离。 场景 我们 …...

Redis与分布式-集群搭建
接上文 Redis与分布式-哨兵模式 1. 集群搭建 搭建简单的redis集群,创建6个配置,开启集群模式,将之前配置过的redis删除,重新复制6份 针对主节点redis 1,redis 2,redis 3都是以上修改内容,只是…...
)
告别 GCC 11 兼容性烦恼:在 Ubuntu 22.04 上为旧内核项目配置专用编译环境(gcc-9 实战)
在 Ubuntu 22.04 上构建多版本 GCC 编译环境的完整指南 当现代 Linux 发行版遇上历史悠久的开源项目,版本兼容性问题往往成为开发者最大的痛点。Ubuntu 22.04 默认搭载的 GCC 11 编译器虽然性能优异,但在编译某些旧版内核或系统级软件时,可能…...

CrewAI 任务优先级排序:智能体团队处理多任务的调度算法
CrewAI 任务优先级排序:智能体团队处理多任务的调度算法 一、引言 (Introduction) 1.1 钩子 (The Hook) 你有没有遇到过这样的场景?用 CrewAI 搭了一支由文案生成Agent、竞品调研Agent、代码审查Agent组成的“创业小团队”,为下季度的产品发布会赶进度: 市场经理(临时设…...

Cross Q: Enhancing Deep Reinforcement Learning with Batch Normalization and Wide Critic Networks for
1. 深度强化学习的样本效率困境 深度强化学习(Deep Reinforcement Learning, DRL)近年来在游戏AI、机器人控制等领域取得了显著进展,但样本效率(Sample Efficiency)问题始终是制约其实际应用的瓶颈。简单来说ÿ…...

FPGA JESD204B链路调试实战:从时钟配置到同步状态解析
1. JESD204B接口基础:关键参数解析 第一次接触JESD204B接口时,我被那一堆参数搞得晕头转向。M、N、N、F、K这些字母组合看起来像密码一样,但理解它们对后续调试至关重要。让我用最直白的语言帮你梳理清楚。 M代表转换器数量,这个最…...

保姆级避坑指南:在只有一台能上网的服务器上,搞定Proxmox VE 7.0三节点集群和Ceph存储
混合网络环境下Proxmox VE集群与Ceph存储的实战部署指南 在企业的IT基础设施部署中,网络环境往往存在各种限制。特别是在安全要求较高的场景下,服务器节点可能被划分为不同的网络区域,仅有少数节点能够直接访问互联网。这种混合网络环境给Pro…...

Kubernetes集群的自动化运维实践
Kubernetes集群的自动化运维实践 🔥 硬核开场 各位技术老铁,今天咱们聊聊Kubernetes集群的自动化运维实践。别跟我扯那些理论,直接上干货!在云原生时代,Kubernetes已经成为容器编排的事实标准,但随着集群规…...
)
Windows 10/11 上保姆级安装AdGuard Home,并配置为开机自启服务(附NSSM详细步骤)
Windows 系统深度集成 AdGuard Home:从零构建企业级 DNS 过滤服务 在数字生活高度渗透的今天,网络隐私保护已成为现代计算机用户的刚需。作为 Windows 平台用户,我们常常面临一个两难选择:要么忍受各类广告追踪和恶意域名的侵扰&…...

数据伦理革命:从泰坦尼克号数据集看公共数据的责任边界
数据伦理革命:从泰坦尼克号数据集看公共数据的责任边界 【免费下载链接】awesome-public-datasets A topic-centric list of HQ open datasets. 项目地址: https://gitcode.com/GitHub_Trending/aw/awesome-public-datasets 公共数据是数字时代的重要资源&am…...

yojimbo网络模拟器完全使用指南:在开发环境中测试真实网络条件
yojimbo网络模拟器完全使用指南:在开发环境中测试真实网络条件 【免费下载链接】yojimbo A network library for client/server games written in C 项目地址: https://gitcode.com/gh_mirrors/yo/yojimbo yojimbo是一款专为客户端/服务器游戏设计的C网络库&…...
)
Abaqus GUI界面中文乱码终极解决方案(含插件兼容指南)
1. Abaqus中文乱码问题全解析 第一次打开Abaqus发现菜单栏全是"口口口"的时候,我差点以为软件装坏了。这种中文乱码问题在工程仿真领域特别常见,尤其是使用中文操作系统的用户。经过多次实践,我发现根本原因是Abaqus默认的locale设…...