Java之SpringCloud Alibaba【六】【Alibaba微服务分布式事务组件—Seata】
一、事务简介
事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。
在关系数据库中,一个事务由一组SQL语句组成。
事务应该具有4个属性:
原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
原子性(atomicity) ∶个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
一致性(consistency) ∶事务必须是使数据库从一个一致性状态变到另一个一致性状态,事务的中间状态不能被观察到的。
隔离性((isolation):一个事务的执行不能被其他事务干扰。
即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
隔离性又分为四个级别:
读未提交(read uncommitted)、
读已提交(read committed,解决脏读)、
可重复读(repeatable read,解决虚读)、
串行化(serializable,解决幻读)。
持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
接下来的其他操作或故障不应该对其有任何影响。
任何事务机制在实现时,都应该考虑事务的ACID特性,包括:本地事务、分布式事务,及时不能都很好的满足,也要考虑支持到什么程度。
二、本地事务
@Transaction
大多数场景下,我们的应用都只需要操作单一的数据库,这种情况下的事务称之为本地事务(Local Transaction)。
本地事务的ACID特性是数据库直接提供支持。
本地事务应用架构如下所示:
在JDBC编程中,我们通过java.sql.Connection对象来开启、关闭或者提交事务。
代码如下所示:
Connection conn = .../获取数据库连接
conn.setAutoCommit(false);//开启事务
try{//...执行增删改查sqlconn.commit();//提交事务
}catch (Exception e){conn.rollback( );//事务回滚
}finally{conn.close();//关闭链接
}
三、分布式事务
1、分布式事务Seata使用
Seatas是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。
Seata将为用户提供了AT、TCC、SAGA和XA事务模式,为用户打造一站式的分布式解决方案。
AT模式是阿里首推的模式,阿里云上有商用版本的GTS (Global Transaction Service 全局事务服务)
官网: https://seata.io/zh-cn/index.html
源码: https://github.com//seata//seata
官方Demo: https://github.com/seata/seata-samples
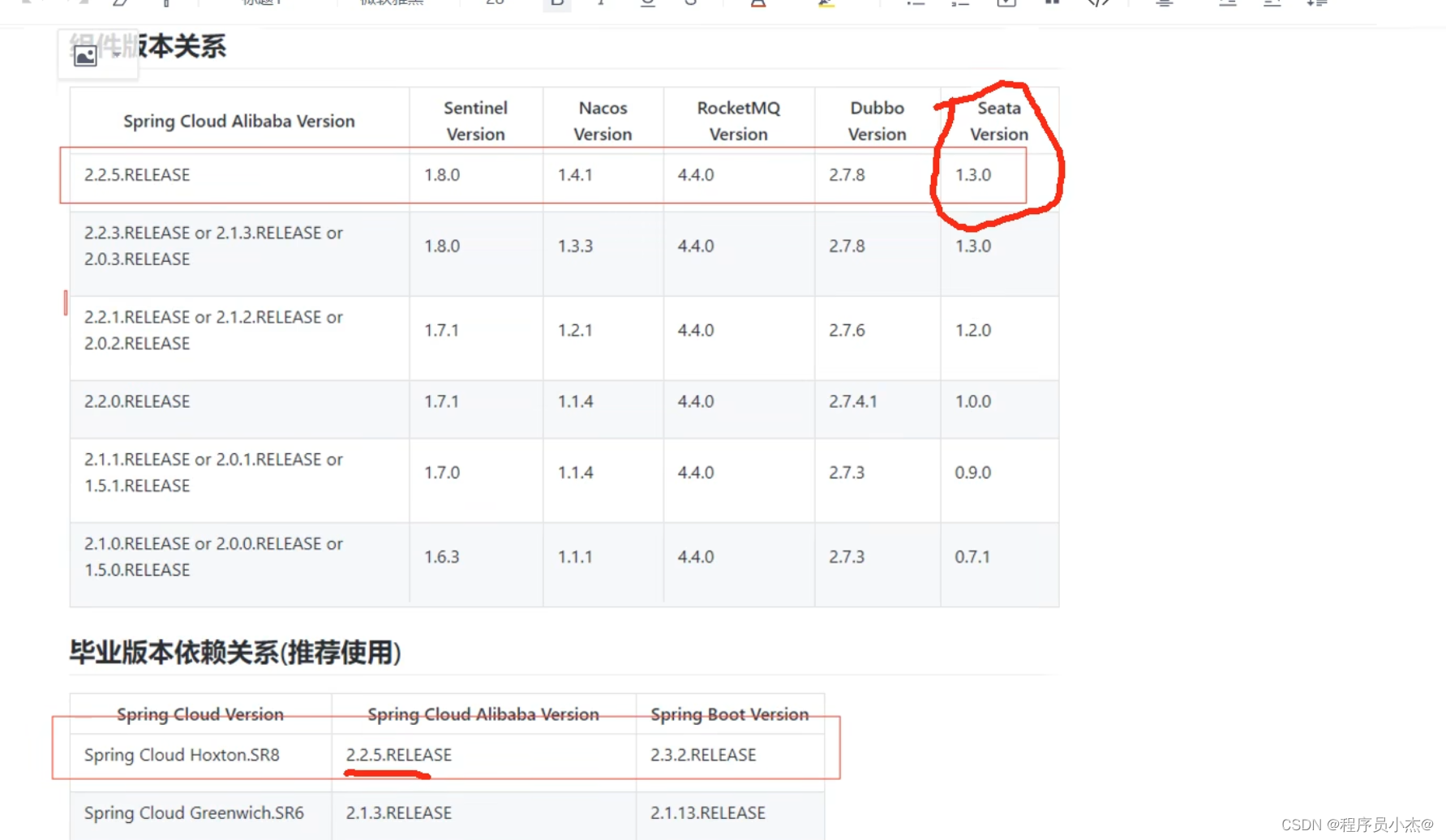
seata版本: v1.4.0
(1)Seata的三大角色
在Seata的架构中,一共有三个角色:
TC(Transaction Coordinator)-事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager)-事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM(Resource Manager)-资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC为单独部署的Server服务端,TM和RM为嵌入到应用中的 Client客户端。
在Seata 中,一个分布式事务的生命周期如下:
常见分布式事务解决方案
1、seata阿里分布式事务框架
2、消息队列
3、saga
4、XA
他们有一个共同点,都是"两阶段(2PC)。
"两阶段"是指完成整个分布式事务,划分成两个步骤完成。
实际上,这四种常见的分布式事务解决方案,分别对应着分布式事务的四种模式:
AT、TCC、Saga、XA;
四种分布式事务模式,都有各自的理论基础,分别在不同的时间被提出每种模式都有它的适用场景,同样每个模式也都诞生有各自的代表产品;
而这些代表产品,可能就是我们常见的(全局事务、基于可靠消息、最大努力通知、TCC)。
今天,我们会分别来看4种模式(AT、TCC、Saga、XA)的分布式事务实现。在看具体实现之前,先讲下分布式事务的理论基础。
分布式事务理论基础
解决分布式事务,也有相应的规范和协议。分布式事务相关的协议有2PC、3PC。
由于三阶段提交协议X3PC非常难实现,目前市面主流的分布式事务解决方案都是2PC协议。
这就是文章开始提及的常见分布式事务解决方案里面那些列举的都有一个共同点"两阶段"的内在原因。
有些文章分析2PC时,几乎都会用TCC两阶段的例子,第一阶段try,第二阶段完成confirm或cancel。其实2PC并不是专为实现TCC设计的,2PC具有普适性。
——协议一样的存在,目前绝大多数分布式解决方案都是以两阶段提交协议2PC为基础的。
TCC (Try-Confirm-Cancel)实际上是服务化的两阶段提交协议。
(2)Seata的三大角色2PC两阶段提交协议:
2PC(两阶段提交,Two-Phase Commit)
顾名思义,分为两个阶段:
Prepare和CommitPrepare:提交事务请求
基本流程如下图:
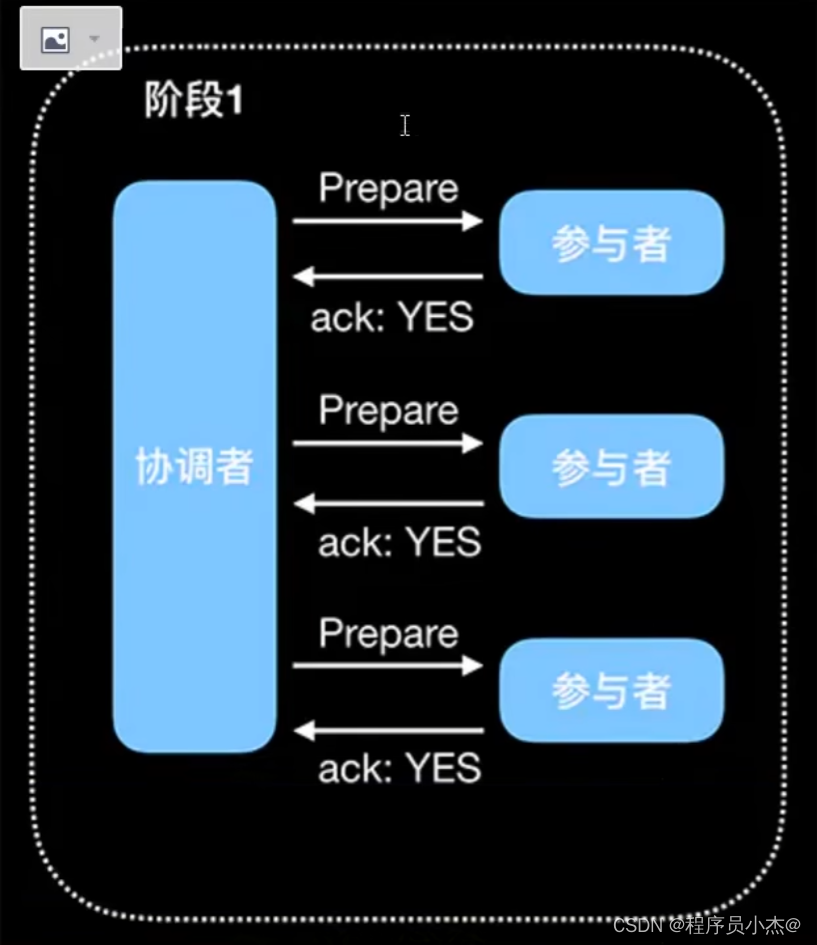
1.询问协调者向所有参与者发送事务请求,询问是否可执行事务操作,然后等待各个参与者的响应。
2.执行各个参与者接收到协调者事务请求后,执行事务操作(例如更新一个关系型数据库表中的记录),并将Undo和Redo 信息记录事务日志中。
3.响应如果参与者成功执行了事务并写入Undo和Redo信息,则向协调者返回YES响应,否则返回NO响应。当然,参与者也可能宕机,从而不会返回响应。
(3)中断事务
在执行Prepare步骤过程中,如果某些参与者执行事务失败、宕机或与协调者之间的网络中断,那么协调者就无法收到所有参与者的YES响应,或者某个参与者返回了No响应,此时,协调者就会进入回退流程,对事务进行回退。
流程如下图红色部分(将Commit请求替换为红色的Rollback请求):
2、2PC的问题
1.同步阻塞参与者在等待协调者的指令时,其实是在等待其他参与者的响应,在此过程中,参与者是无法进行其他操作的,也就是阻塞了其运行。
倘若参与者与协调者之间网络异常导致参与者一直收不到协调者信息,那么会导致参与者一直阻塞下去。
2.单点在2PC中,一切请求都来自协调者,所以协调者的地位是至关重要的,如果协调者宕机,那么就会使参与者一直阻塞并一直占用事务资源。
如果协调者也是分布式,使用选主方式提供服务,那么在一个协调者挂掉后,可以选取另一个协调者继续后续的服务,可以解决单点问题。
但是,新协调者无法知道上一个事务的全部状态信息(例如已等待Prepare响应的时长等),所以也无法顺利处理上一个事务。
3.数据不一致Commit事务过程中Comit请求Roltack请求可能因为协调者宕机或协调者与参与者网络问题丢失,那么就导致了部分参与者没有收到Conmit/Rollback请求,而其他参与者则正常收到执行了CommitRollback操作,没有收到请求的参与者则继续阻塞。
这时,参与者之间的数据就不再一致了。当参与者执行ComitRollack后会向协调者发送Ack,然而协调者不论是否收到所有的参与者的Ack,该事务也不会再有其他补救措施了,协调者能做的也就是等待超时后像事务发起者返回一个“我不确定该事务是否成功”。
4.环境可靠性依赖
协调者Prepare请求发出后,等待响应,然而如果有参与者宕机或与协调者之间的网络中断,都会导致协调者无法收到所有参与者的响应那么在2PC中,协调者会等待一定时间,然后超时后,会触发事务中断,在这个过程中协调者和所有其他参与者都是出于阻塞的。
这种机制对网络问题常见的现实环境来说太苛刻了。
下面我们分别来看4种模式(AT、TCC、Saga、XA)的分布式事务实现。
3、AT模式
AT模式是一种无侵入的分布式事务解决方案。
阿里Seata框架,实现了该模式。
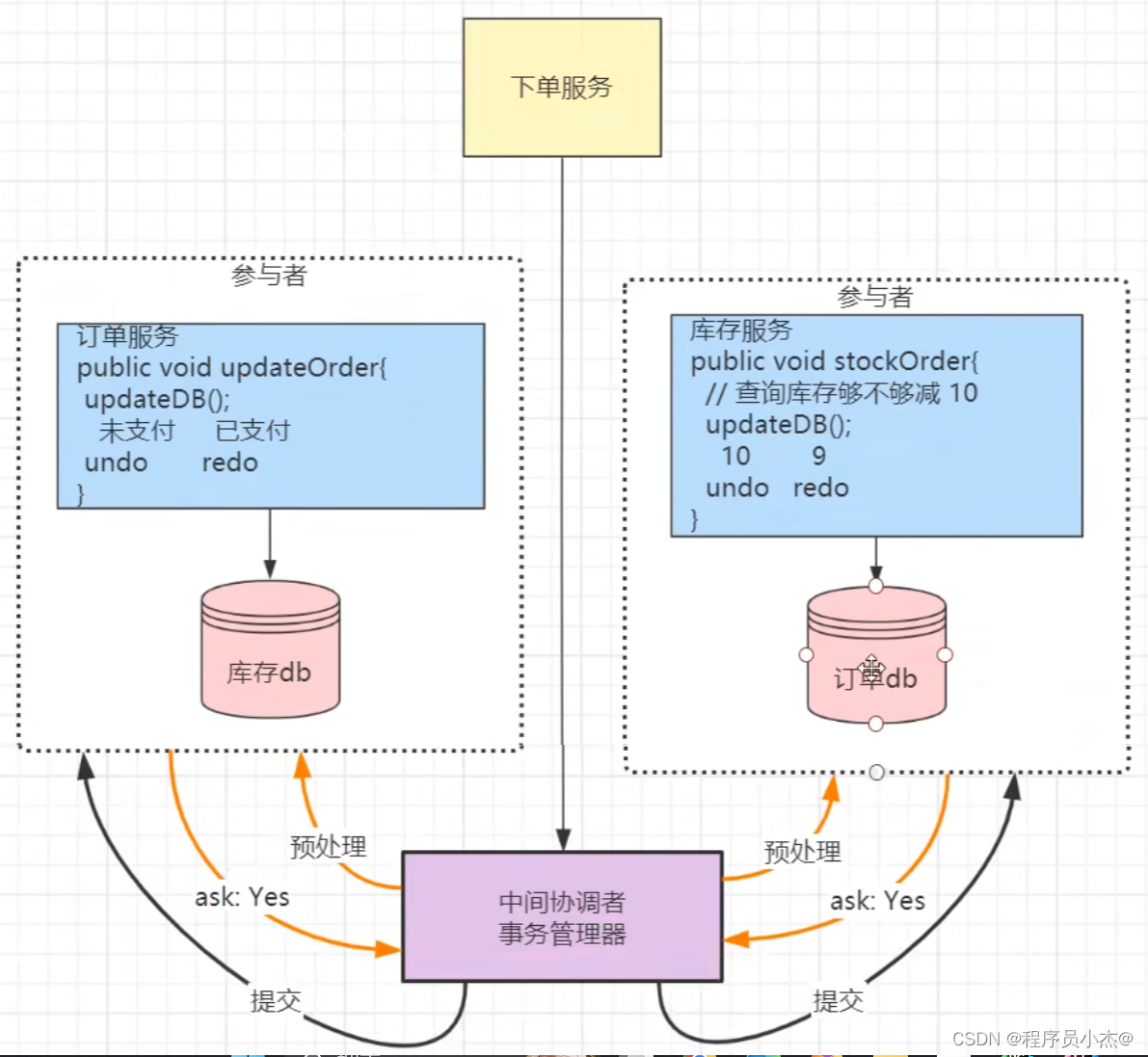
在AT模式下,用户只需关注自己的"业务SQL",用户的“业务SQL”作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
AT模式如何做到对业务的无侵入:
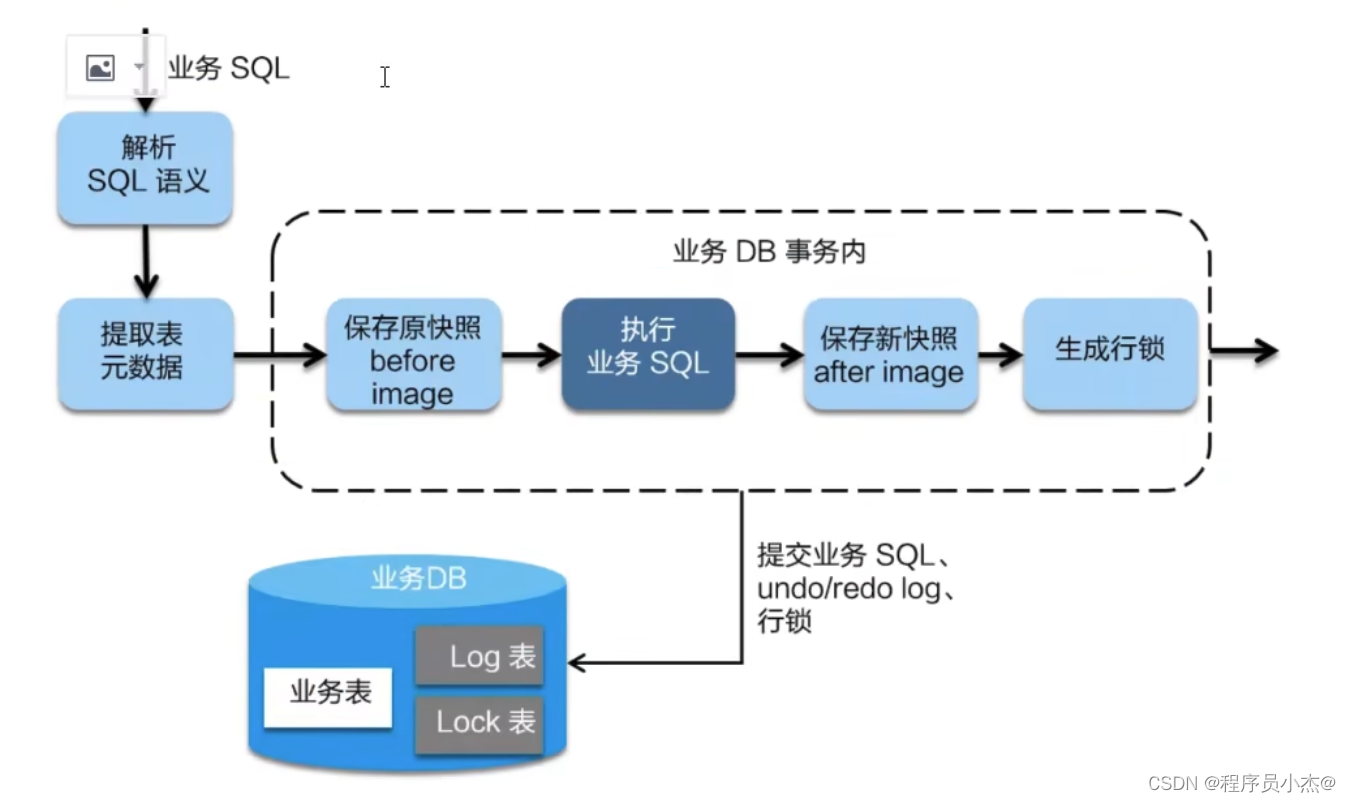
- 一阶段
在一阶段,Seata会拦截业务SQL",首先解析SQL语义,找到业务SQL要更新的业务数据,在业务数据被更新前,将其保存成"before image”,然后执行"业务SQL"更新业务数据,在业务数据更新之后,再将其保存成"after image”,最后生成行锁。
以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
- 二阶段提交:
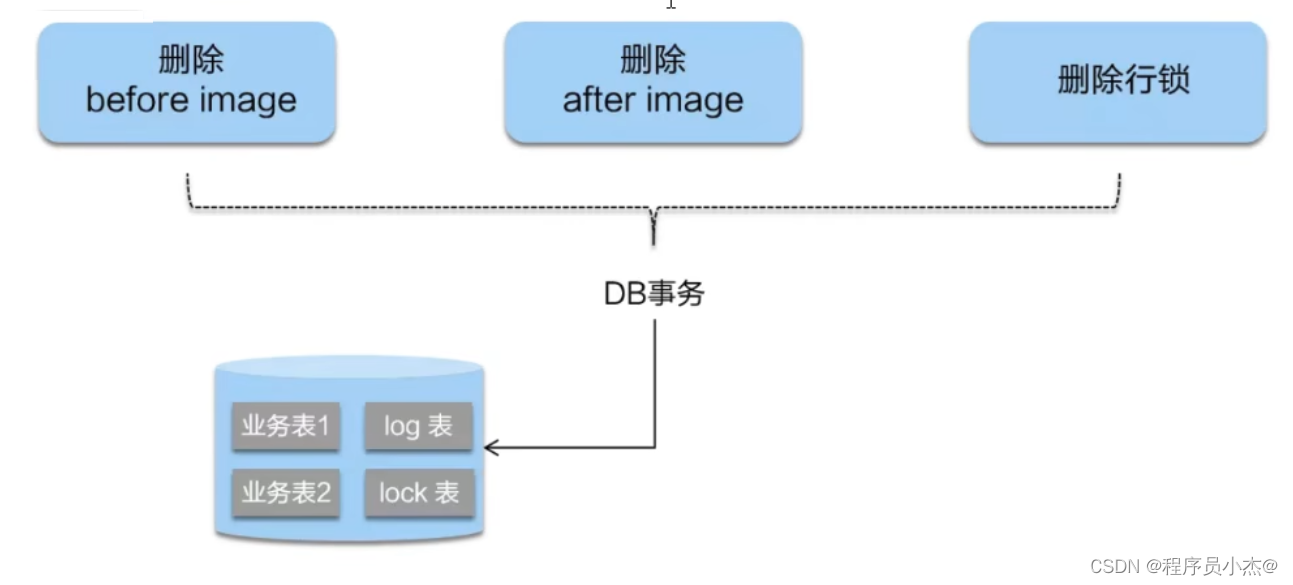
二阶段如果是提交的话,因为"业务SQL"在一阶段已经提交至数据库,
所以Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
- 二阶段回滚:
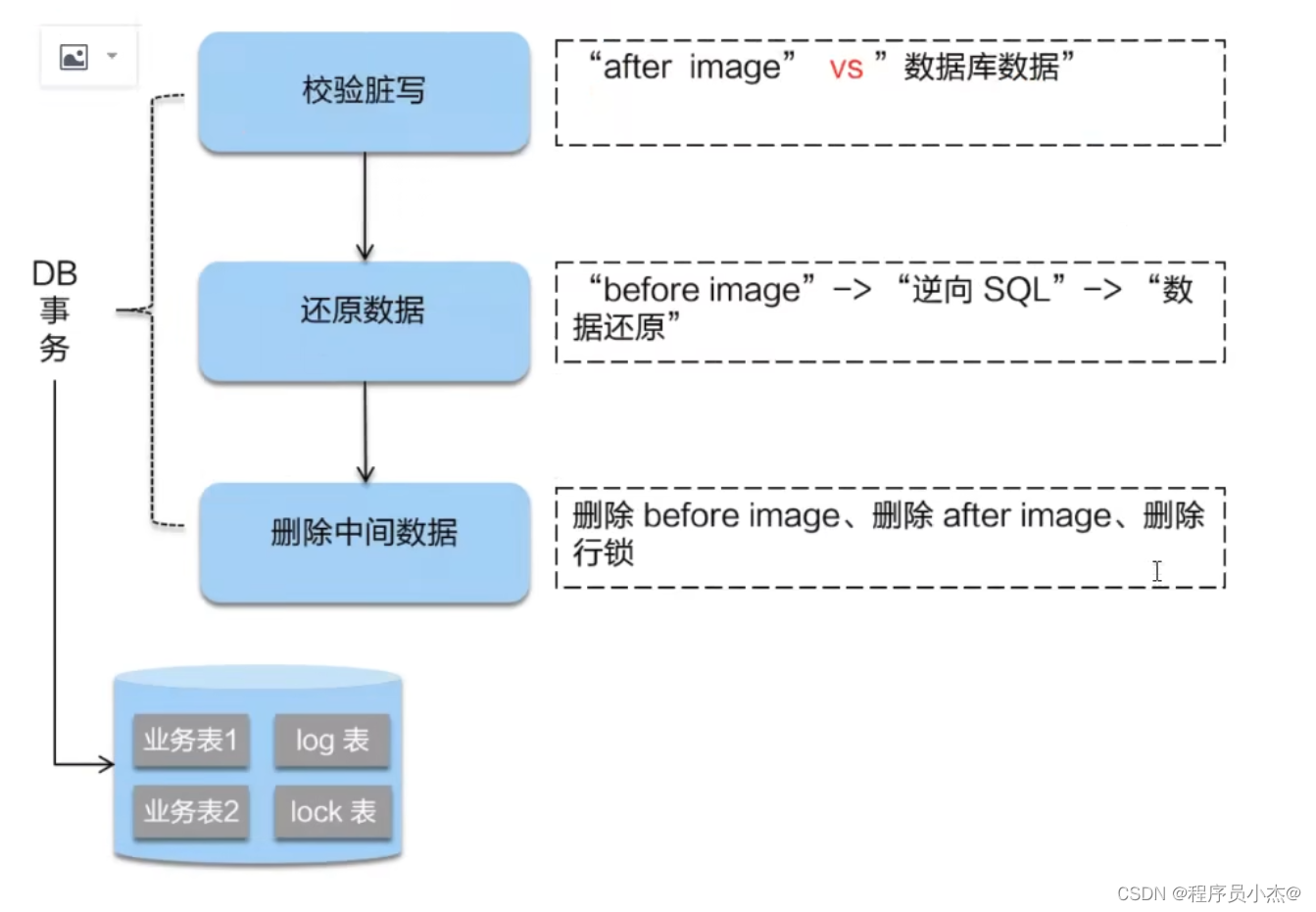
二阶段如果是回滚的话,Seata就需要回滚一阶段已经执行的业务SQL”,还原业务数据。
回滚方式便是用"before image"还原业务数据;但在还原前要首先要校验脏写,对比"数据库当前业务数据"和"after image",如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
 AT模式的一阶段、二阶段提交和回滚均由Seata框架自动生成,用户只需编写业务SQL”,便能轻松接入分布式事务,AT模式是一种对业务无任何侵入的分布式事务解决方案。
AT模式的一阶段、二阶段提交和回滚均由Seata框架自动生成,用户只需编写业务SQL”,便能轻松接入分布式事务,AT模式是一种对业务无任何侵入的分布式事务解决方案。
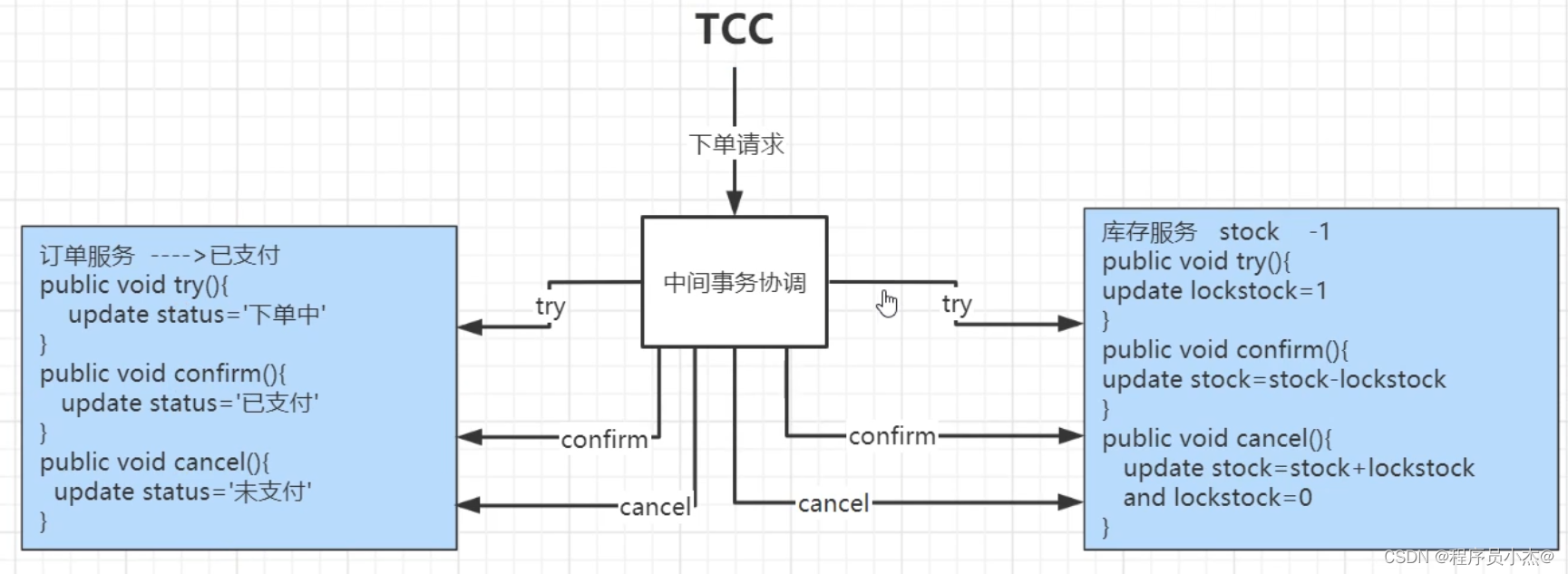
4、TCC模式
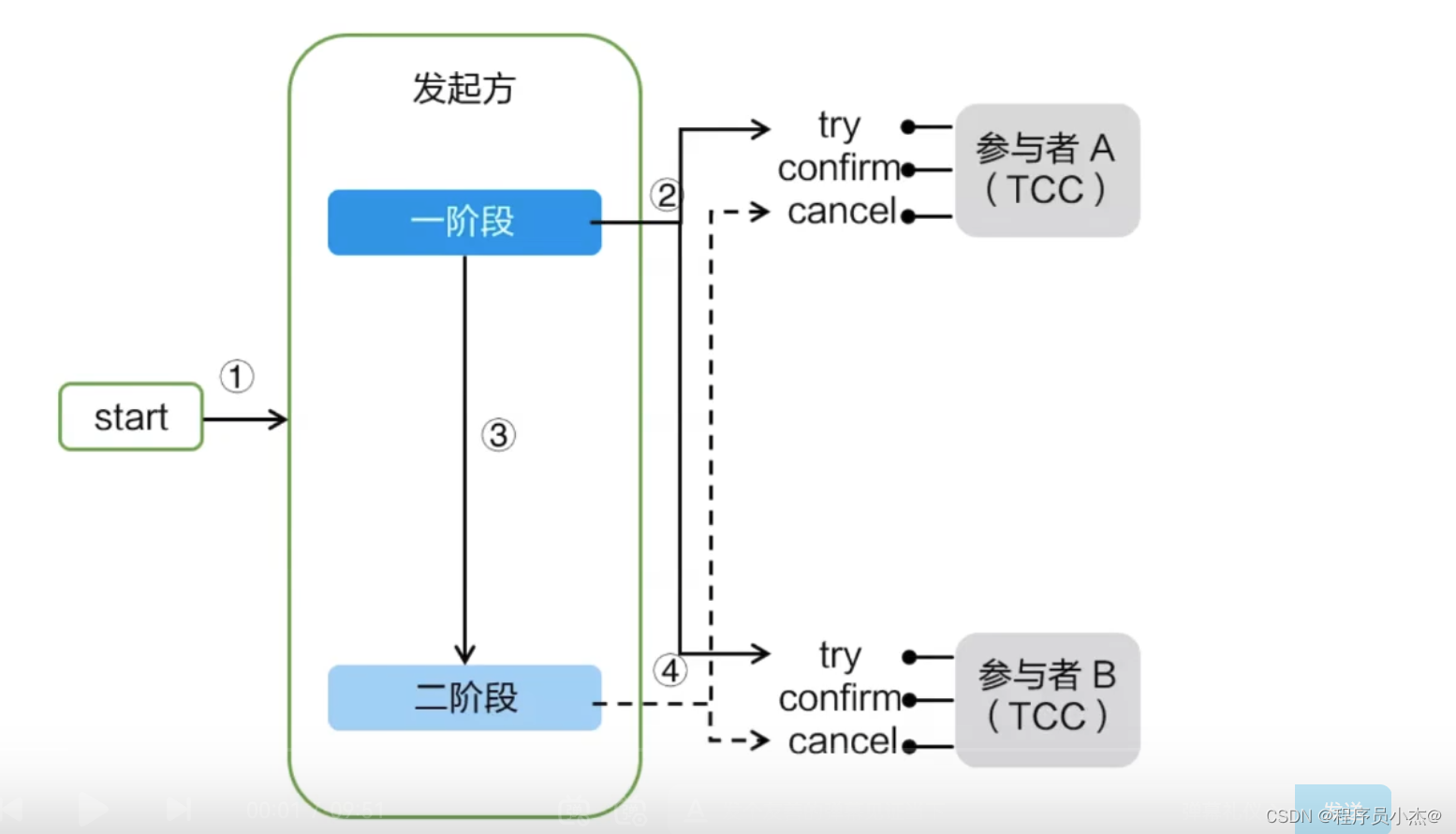
TCC模式需要用户根据自己的业务场景实现
Try、Confim和Cancel 三个操作;
事务发起方在一阶段执行Try方式,在二阶段提交执行Confim方法,二阶段回滚执行Cancel方法。
 缺点:侵入性比较强,并且得自己实现相关的事务控制逻辑。
缺点:侵入性比较强,并且得自己实现相关的事务控制逻辑。
优点:在整个过程当中,基本没有锁的概念,性能更加强大。
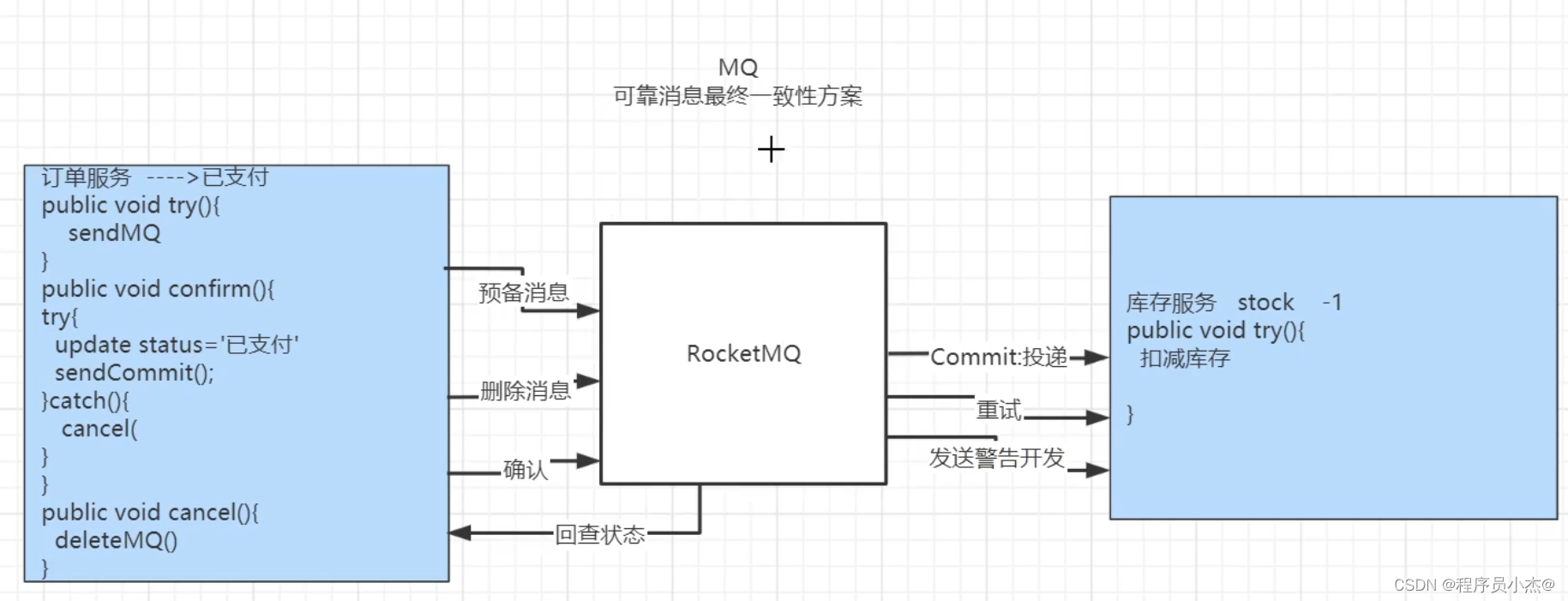
5、MQ【可靠消息最终一致性方案】
四、Seata的三大角色
1、在Seata的架构中,一共有三个角色:
TC (Transaction Coordinator)-事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager)-事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM(Resource Manager)-资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC为单独部署的Server服务端,TM和RM为嵌入到应用中的Client客户端。
在Seata 中,一个分布式事务的生命周期如下:
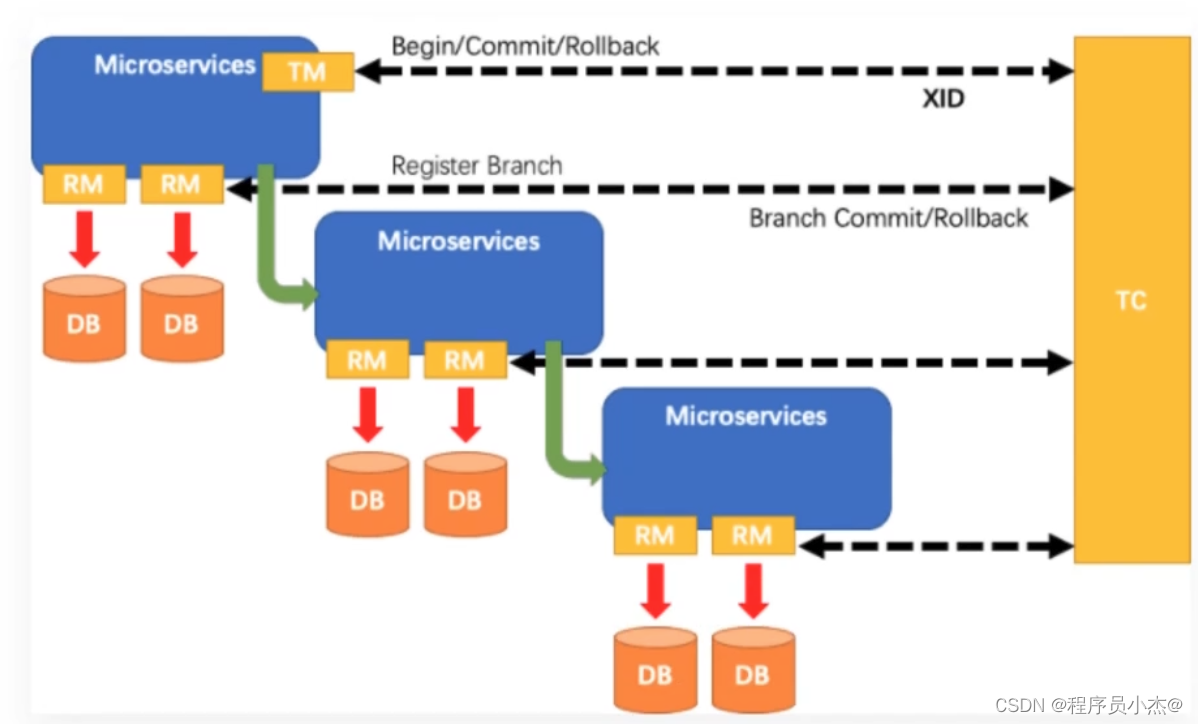
1.TM请求TC开启一个全局事务。
TC会生成一个XID作为该全局事务的编号。XID,会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起。
2.RM请求TC将本地事务注册为全局事务的分支事务,通过全局事务的XID进行关联。
3.TM请求TC告诉XID对应的全局事务是进行提交还是回滚。
4.TC驱动RM们将XID 对应的自己的本地事务进行提交还是回滚。
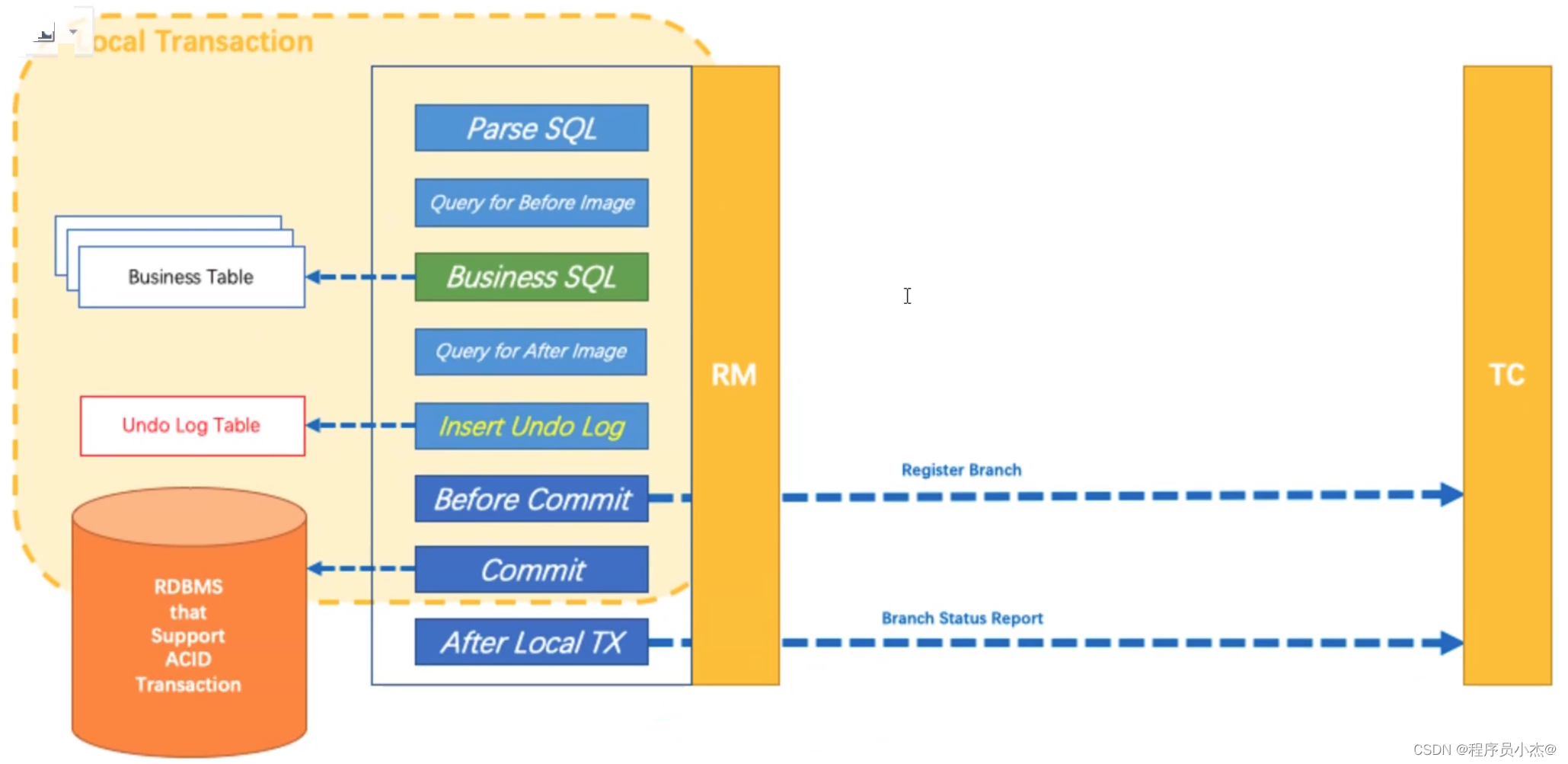
2、设计思路
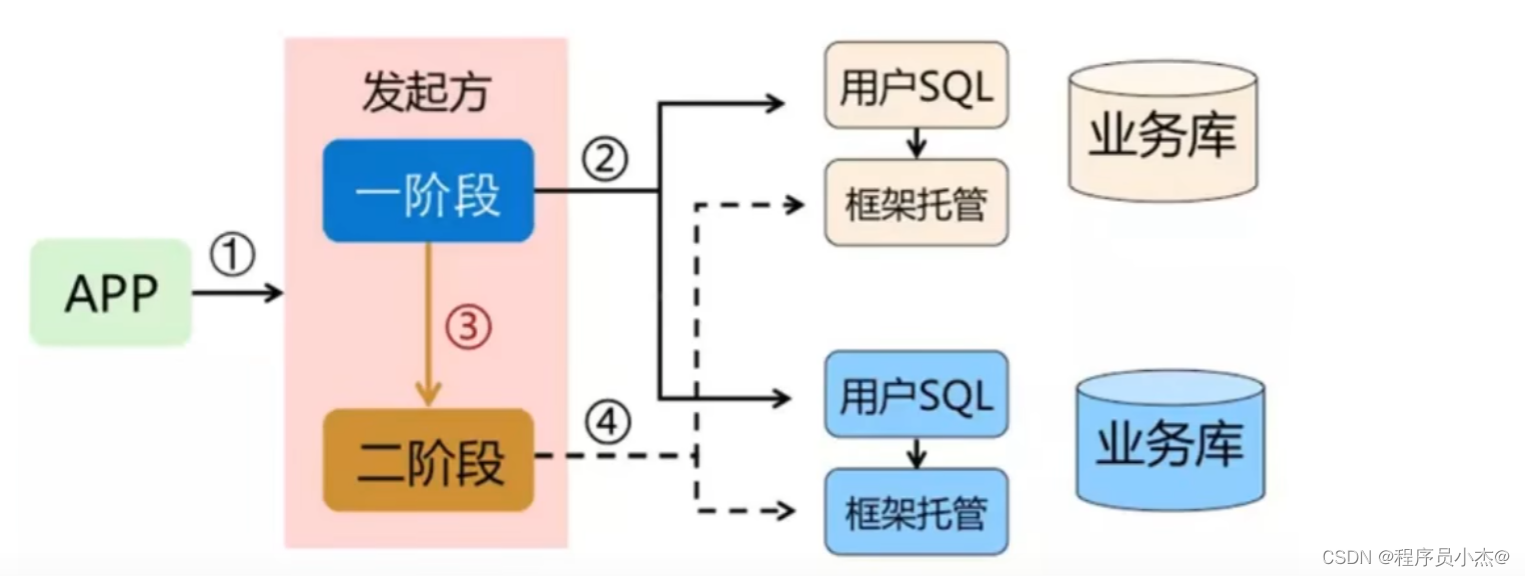
AT模式的核心是对业务无侵入,是一种改进后的两阶段提交,其设计思路如图
第一阶段
业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
核心在于对业务sql进行解析,转换成undolog,并同时入库,这是怎么做的呢?
先抛出一个概念DataSourceProxy代理数据源,通过名字大家大概也能基本猜到是什么个操作,后面做具体分析
参考官方文档:
https://seata.io/zh-cn/docs/dev/mode/at-mode.html
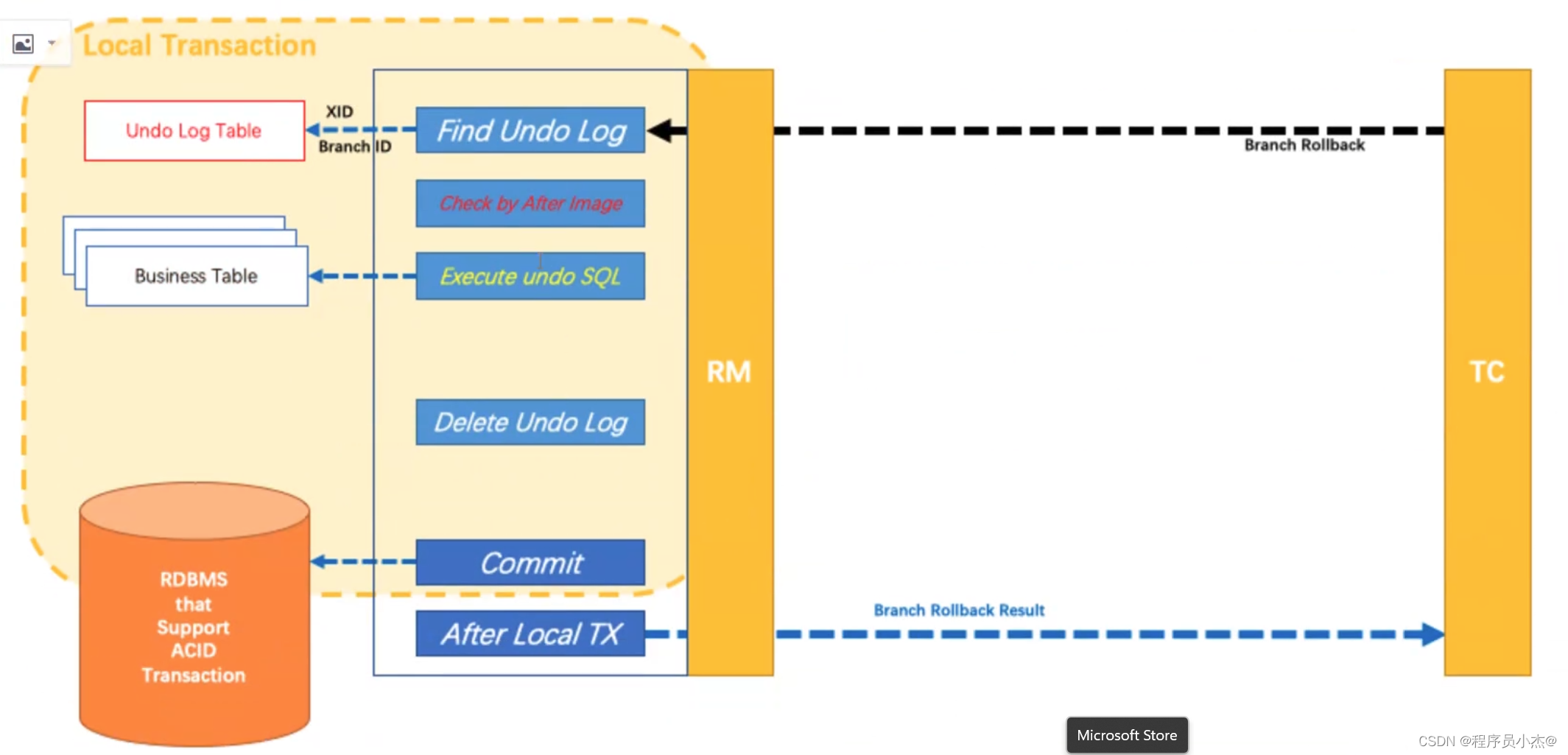
 分布式事务操作失败,TM向TC发送回滚请求,RIM收到协调器TC发来的回滚请求,通过XD和Branch lD找到相应的回滚日志记录,通过回滚记录生成反向的更新SQL并执行,以完成分支的回滚。
分布式事务操作失败,TM向TC发送回滚请求,RIM收到协调器TC发来的回滚请求,通过XD和Branch lD找到相应的回滚日志记录,通过回滚记录生成反向的更新SQL并执行,以完成分支的回滚。
 相比与其它分布式事务框架,Seata架构的亮点主要有几个:
相比与其它分布式事务框架,Seata架构的亮点主要有几个:
1.应用层基于SQL解析实现了自动补偿,从而最大程度的降低业务侵入性;
2.将分布式事务中TC(事务协调者)独立部署,负责事务的注册、回滚;
3.通过全局锁实现了写隔离与读隔离。
3、存在问题
性能损耗
一条Update的SQL,则需要全局事务xd获取(与TC通讯) 、before image(解析SQL,查询一次数据库) 、after image(查询一次数据库)、inser undo log(写一次数据库) 、before commit (与TC通讯,判断锁冲突),这些操作都需要一次远程通讯RPC,而且是同步的。
另外undo log写入时blob字段的插入性能也是不高的。
每条写SQL都会增加这么多开销,粗略估计会增加5倍响应时间。
性价比
为了进行自动补偿,需要对所有交易生成前后镜像并持久化,可是在实际业务场景下,这个是成功率有多高,或者说分布式事务失败需要回滚的有多少比率?
按照二八原则预估,为了20%的交易回滚,需要将80%的成功交易的响应时间增加5倍,这样的代价相比于让应用开发一个补偿交易是否是值得?
全局锁
热点数据
相比:(XA,Seata 虽然在一阶段成功后会释放数据库锁,但一阶段在comit前全局锁的判定也拉长了对数据锁的占有时间,这个开销比XA的prepare低多少需要根据实际业务场景进行测试。
全局锁的引入实现了隔离性,但带来的问题就是阻塞,降低并发性,尤其是热点数据,这个问题会更加严重。
回滚锁释放时间
五、Seata快速开始
1、Seata Server (TC)环境搭建
https://seata.io/zh-cn/docslops/deploy-guide-beginner.html
Server端存储模式(store.mode)支持三种:
- file:单机模式,全局事务会话信息内存中读写并持久化本地文件root.data,性能较高(默认)
- db:高可用模式,全局事务会话信息通过db共享,相应性能差些
- 打开config/file.conf
- 修改
mode="db" - 修改数据库链接信息(
URL\USERNAME\PASSWORD)
- redis: Seata-Server 1.3及以上版本支持,性能较高,存在事务信息丢失风险,请提前配置适合当前场景的redis持久化配置
资源目录: https://github.com/seata/seata/tree/1.3.0/script
- client
存放client端sql脚本,参数配置 - config-center
各个配置中心参数导入脚本,config.txt(包含server和client,原名nacos-config.txt)为通用参数文件 - server
server端数据库脚本及各个容器配置
db存储模式+Nacos(注册&配置中心)部署
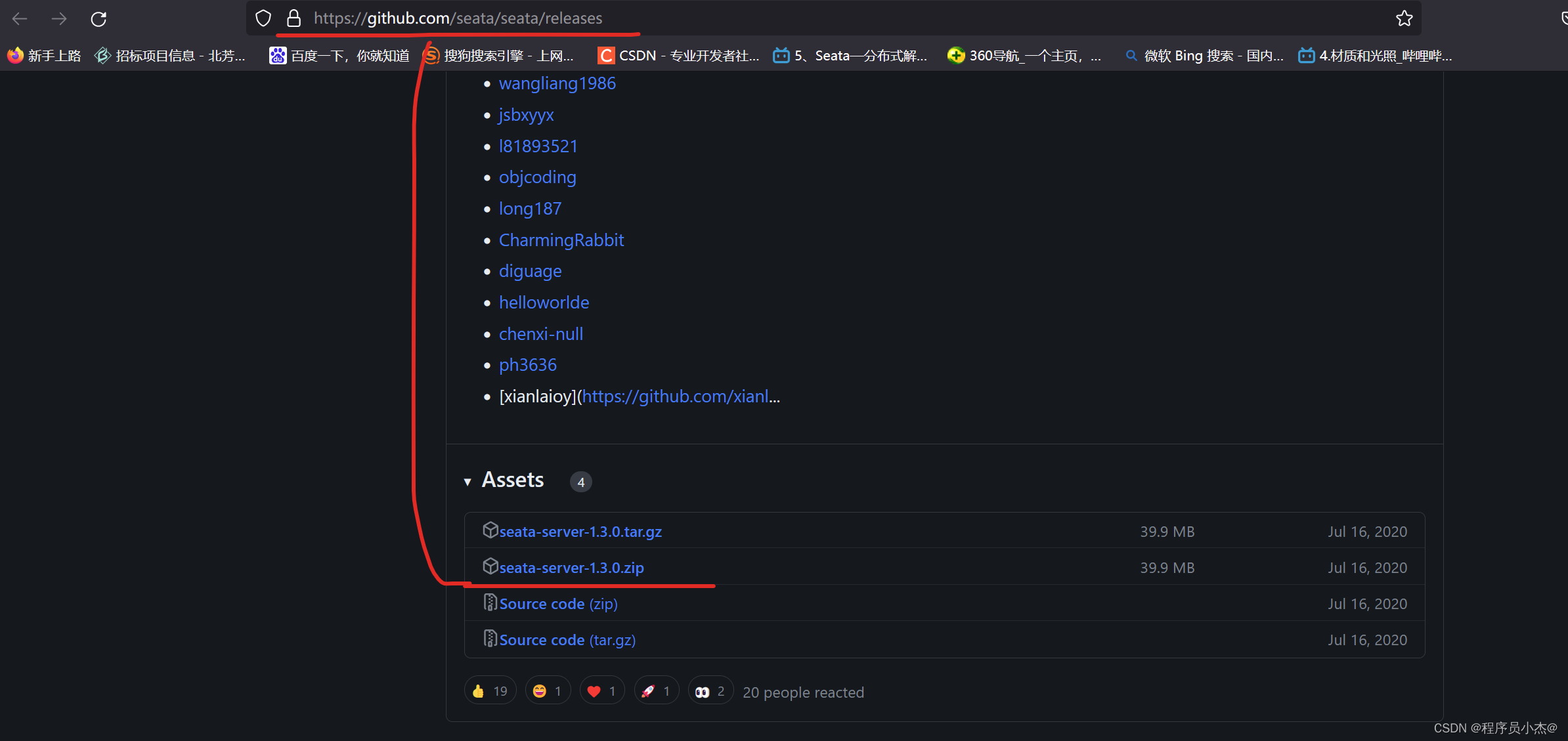
步骤一:下载安装包
https://github.com/seata/seata/releases
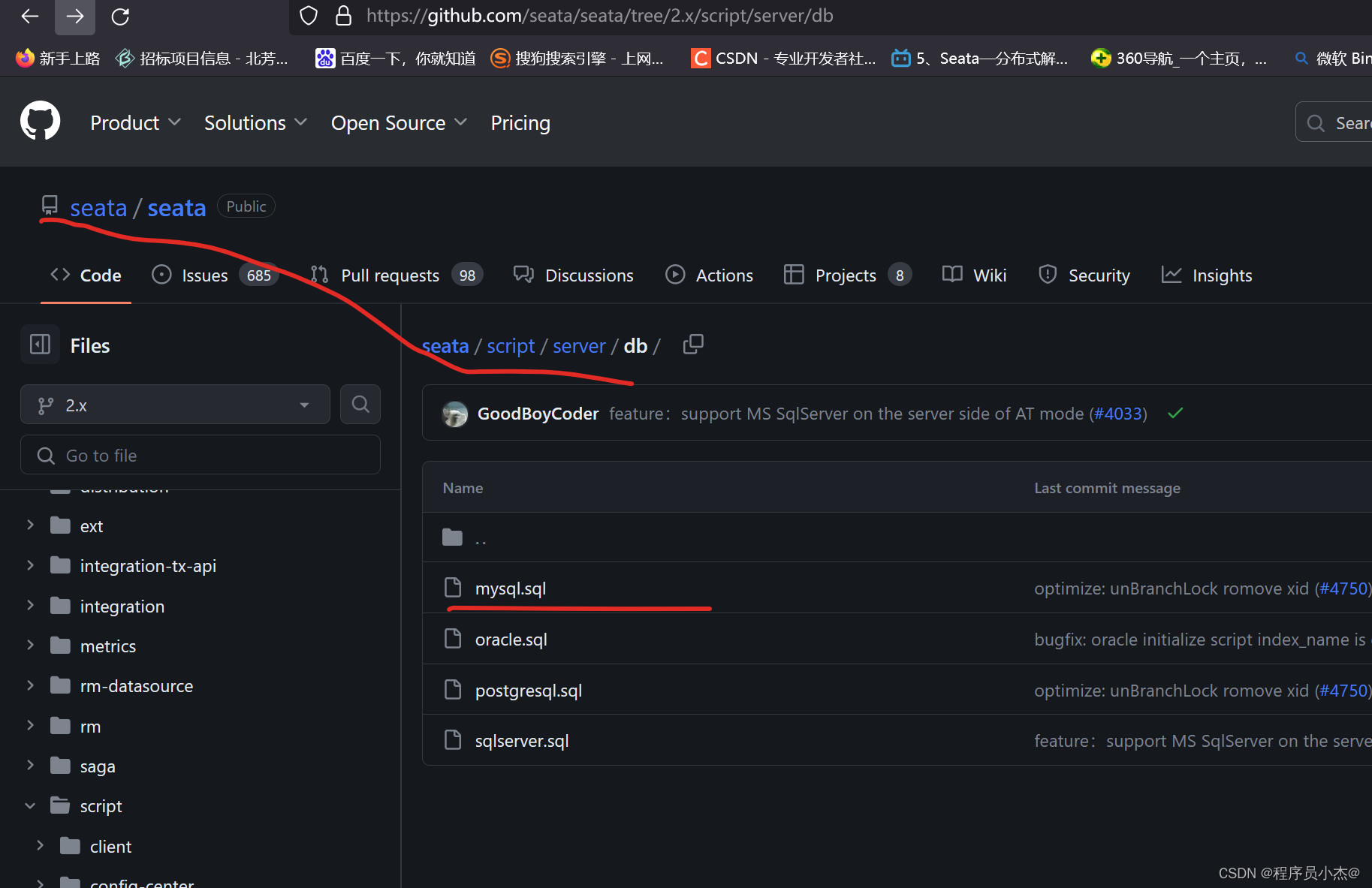
2、建表(仅db模式)
全局事务会话信息由3块内容构成,全局事务-->分支事务-->全局锁,对应表
global_table、branch_table、lock_table
创建数据库seata,执行sql脚本,文件在script/server/db/mysql.sql (seata源码)中
https://github.com/seata/seata/tree/2.x/script/server/db
-- -------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(`xid` VARCHAR(128) NOT NULL,`transaction_id` BIGINT,`status` TINYINT NOT NULL,`application_id` VARCHAR(32),`transaction_service_group` VARCHAR(32),`transaction_name` VARCHAR(128),`timeout` INT,`begin_time` BIGINT,`application_data` VARCHAR(2000),`gmt_create` DATETIME,`gmt_modified` DATETIME,PRIMARY KEY (`xid`),KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(`branch_id` BIGINT NOT NULL,`xid` VARCHAR(128) NOT NULL,`transaction_id` BIGINT,`resource_group_id` VARCHAR(32),`resource_id` VARCHAR(256),`branch_type` VARCHAR(8),`status` TINYINT,`client_id` VARCHAR(64),`application_data` VARCHAR(2000),`gmt_create` DATETIME(6),`gmt_modified` DATETIME(6),PRIMARY KEY (`branch_id`),KEY `idx_xid` (`xid`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(`row_key` VARCHAR(128) NOT NULL,`xid` VARCHAR(128),`transaction_id` BIGINT,`branch_id` BIGINT NOT NULL,`resource_id` VARCHAR(256),`table_name` VARCHAR(32),`pk` VARCHAR(36),`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',`gmt_create` DATETIME,`gmt_modified` DATETIME,PRIMARY KEY (`row_key`),KEY `idx_status` (`status`),KEY `idx_branch_id` (`branch_id`),KEY `idx_xid` (`xid`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;CREATE TABLE IF NOT EXISTS `distributed_lock`
(`lock_key` CHAR(20) NOT NULL,`lock_value` VARCHAR(20) NOT NULL,`expire` BIGINT,primary key (`lock_key`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);
导入数据库

注意:如果配置了seata sever使用nacos作为配置中心,
则配置信息会从nacos读取,file.conf可以不用配置。
客户端配置registy.conf使用nacos时也要注意group要和seata server中的group一致,
默认group是"DEFAULT_GROUP"获取/seata/script/config-center/config.txt,修改配置信息。
 将script目录下载下拉复制到应用的跟目录
将script目录下载下拉复制到应用的跟目录

4、seata设置集成nacos
下载好nacos之后本地启动nacos
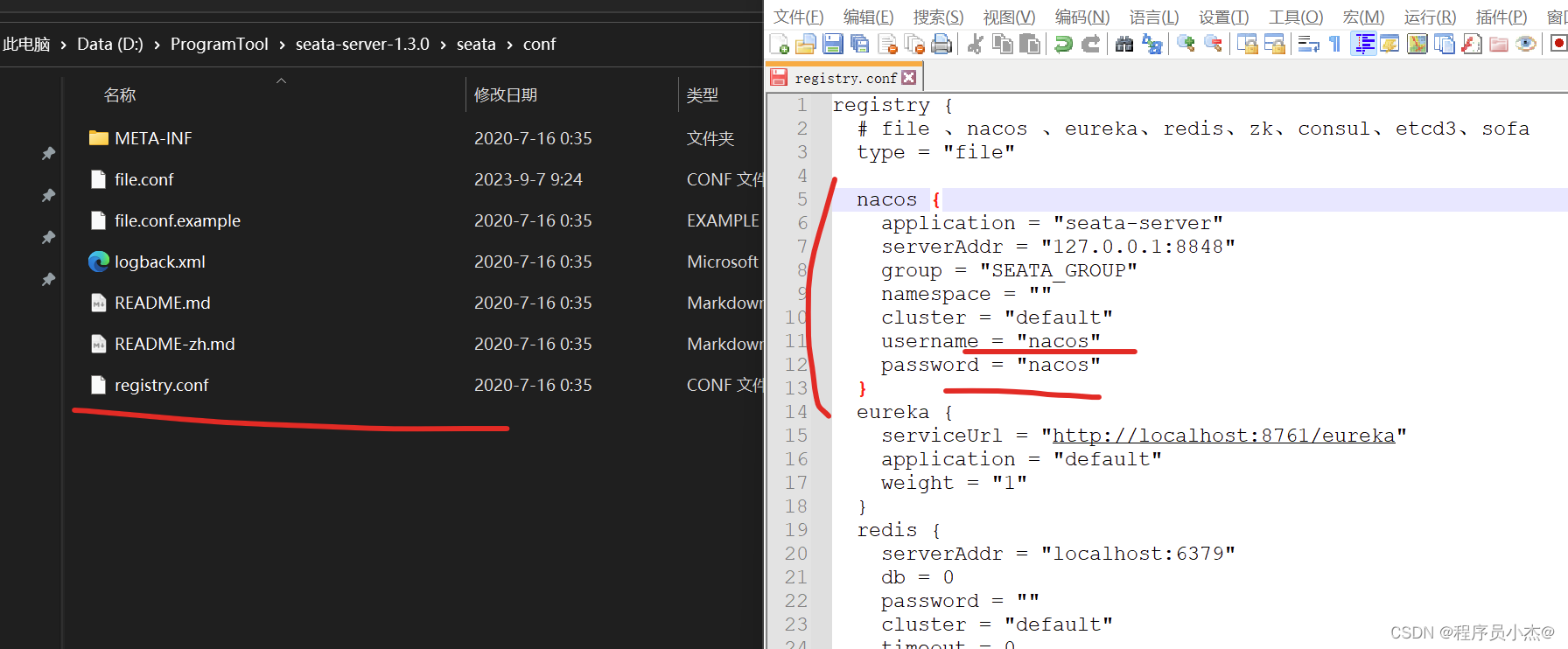
 配置
配置\seata\conf下的registry.conf设置对应的nacos的配置信息
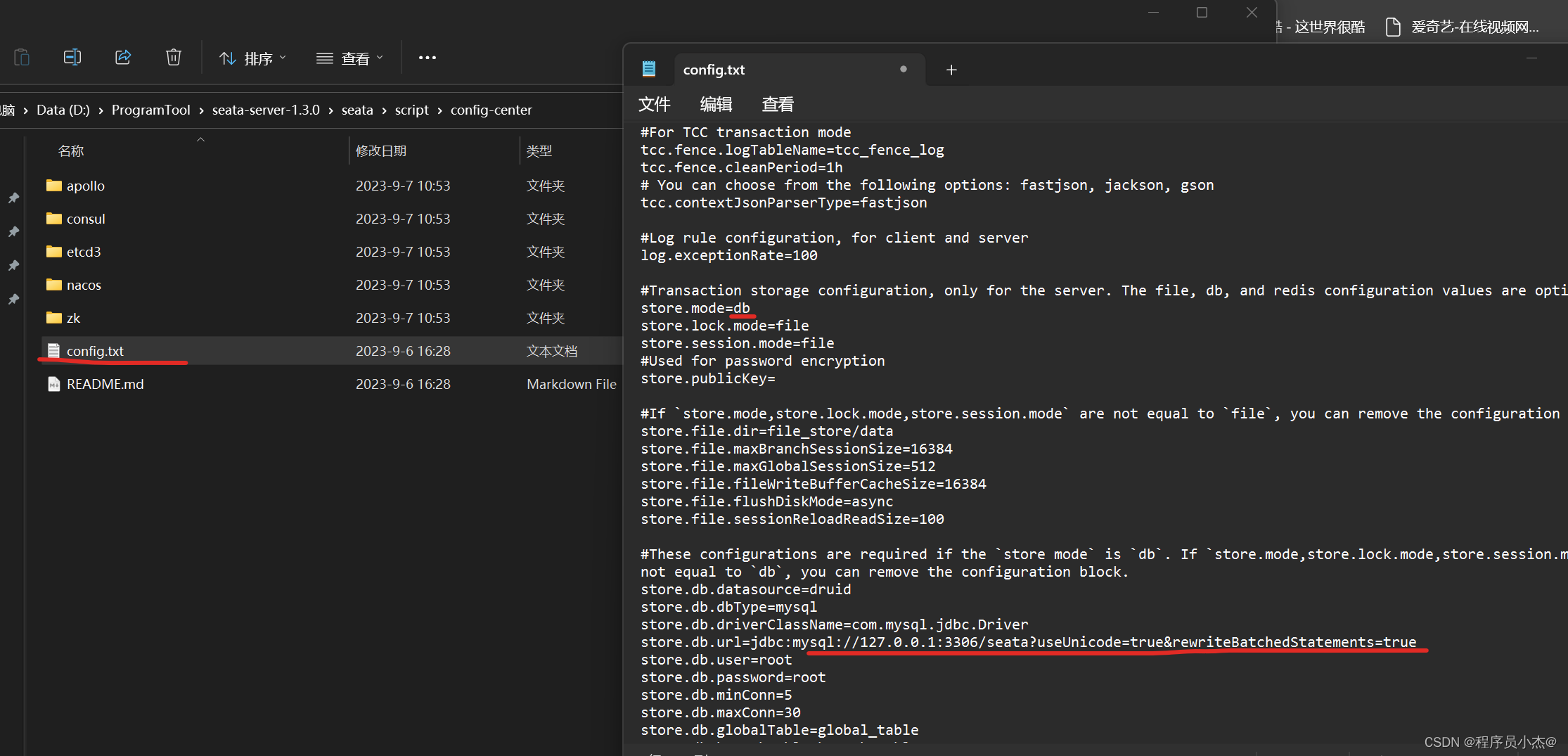 事务分组:异地机房停电容错机制
事务分组:异地机房停电容错机制
my_test_tx_group 可以自定义 比如:(guangzhou、shanghai),对应的client也要去设置
service.vgroupMapping.default_tx_group=default
default 必须要等于 registry.confi cluster = "default"
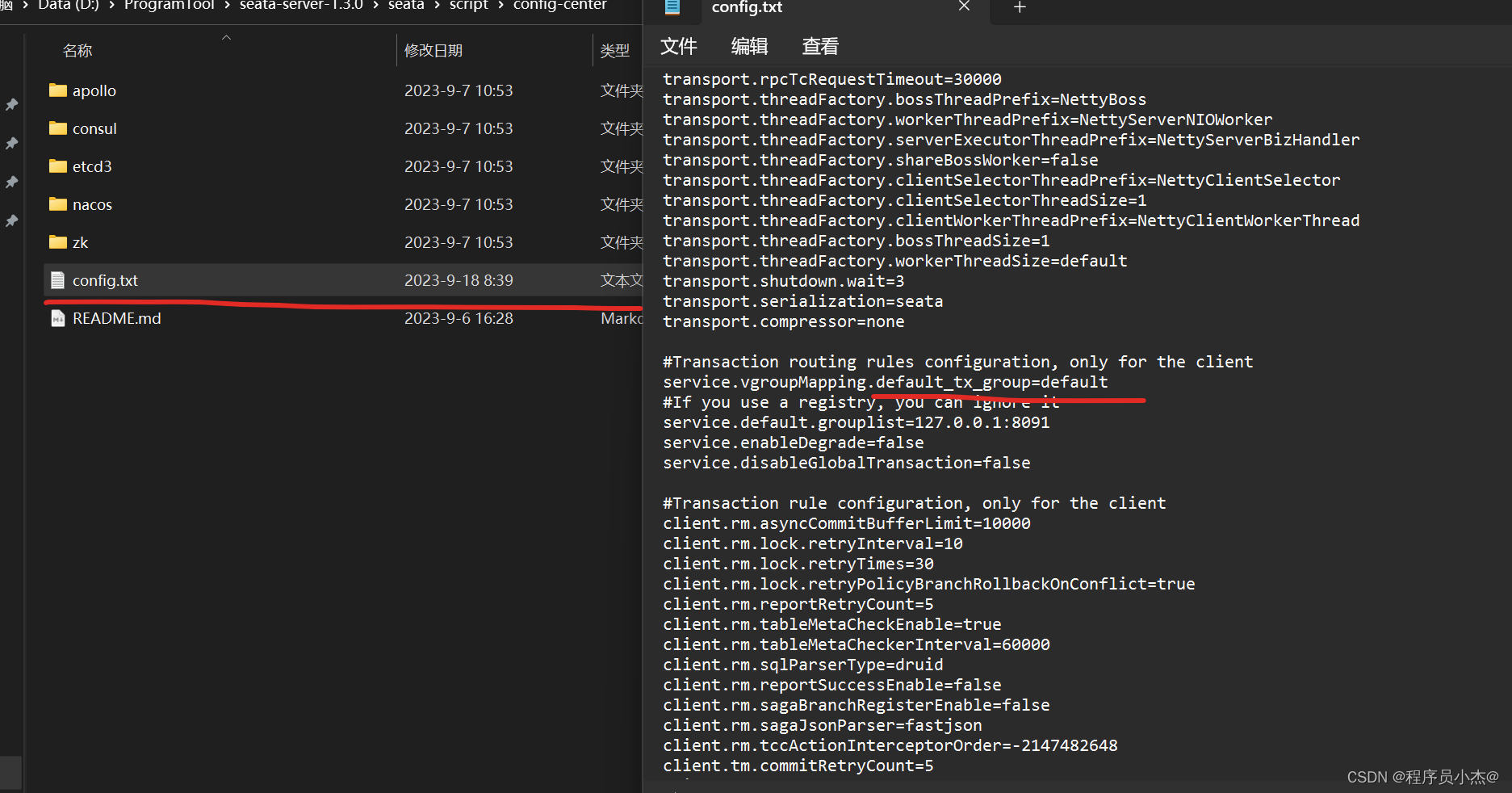 配置参数同步到
配置参数同步到Nacos
在nacos的安装目录下面

如果是自定义的nacos需要配置自定义启动参数
sh $(SEATAPATH)/script/config-center/nacos/nacos-config.sh -h localhost -p 8848 -g SEATA_GROUuP -t 5a3c7d6c-f497-4d68-a712-2e5e3340b3ca
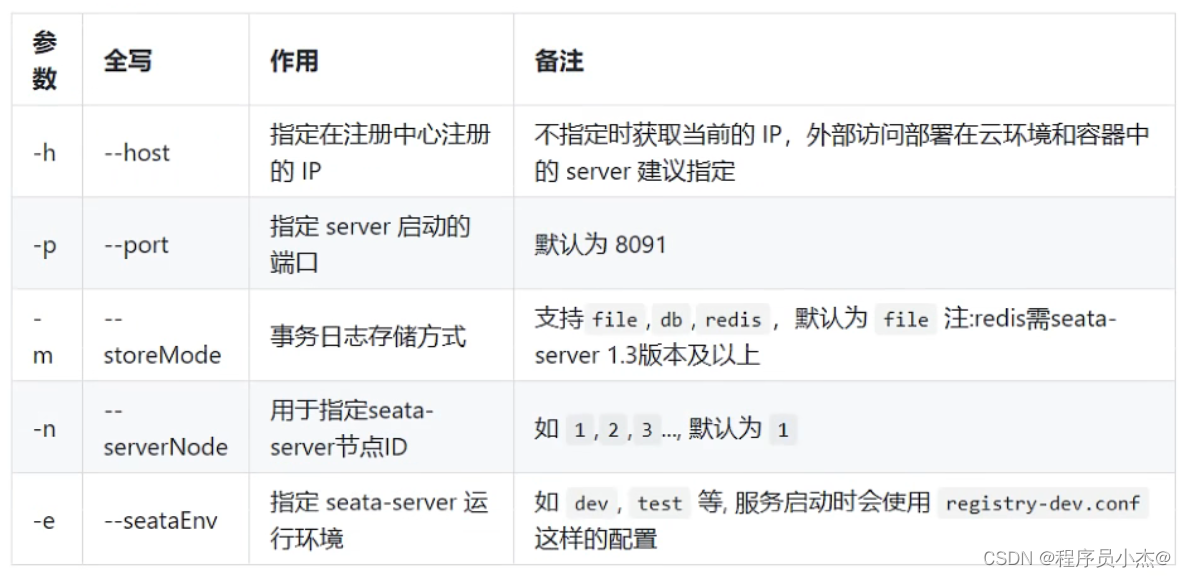
参数说明:
-h: host,默认值localhost
-p: port,默认值8848
-g:配置分组,默认值为’SEATA_GROUP’
-t:租户信息,对应 Nacos的命名空间ID字段,默认值为空"
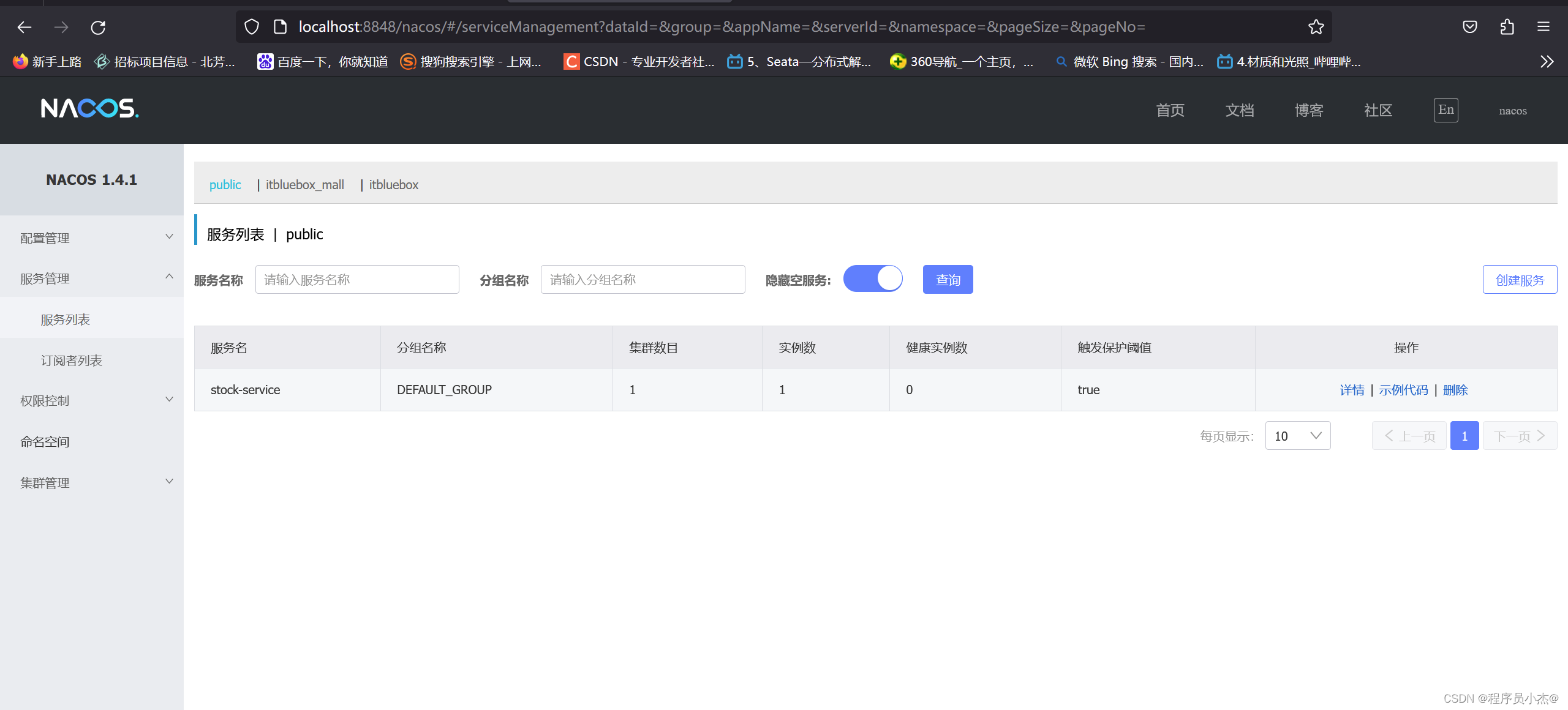
访问:http://localhost:8848/nacos/
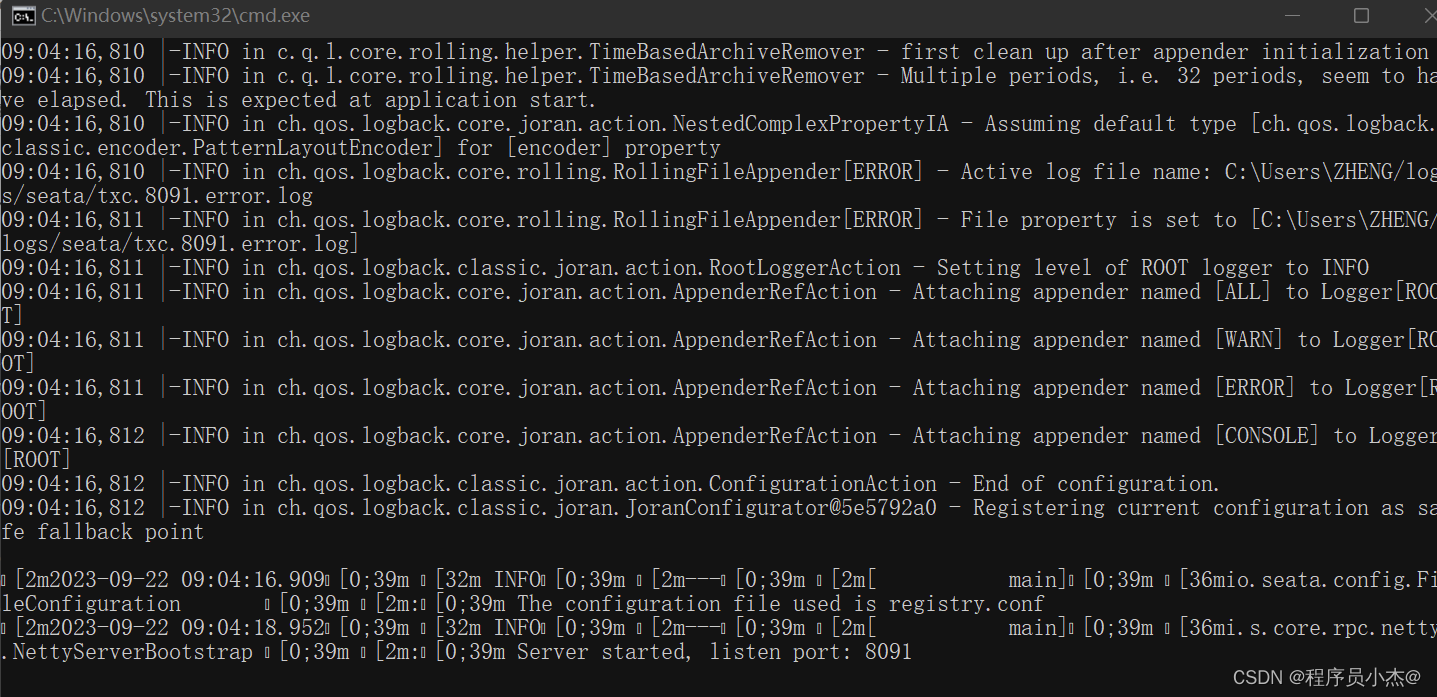
5、启动seata Server
- 源码启动:执行server模块下io.seata.server.Server.java的main方法
- 命令启动:
bin/seata-server.sh -h 127.0.0.1 -p 8091 -m db -n 1 -e test
支持的启动参数
启动Seata Server
bin/seata-server. sh -p 8092
双击
启动成功
六、Seata Client快速开始
声明式事务实现(@GlobalTransactional)
接入微服务应用
业务场景:
用户下单,整个业务逻辑由三个微服务构成:
- 订单服务:根据采购需求创建订单
- 库存服务:对给定的商品扣除库存数量。
1、项目搭建
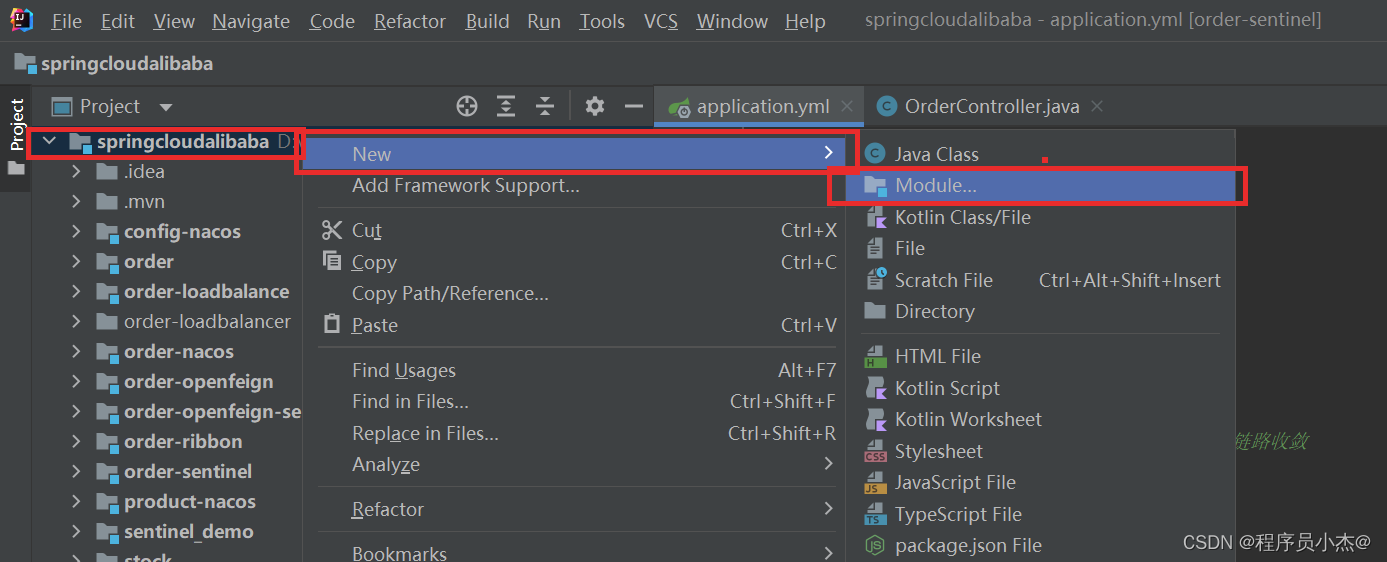
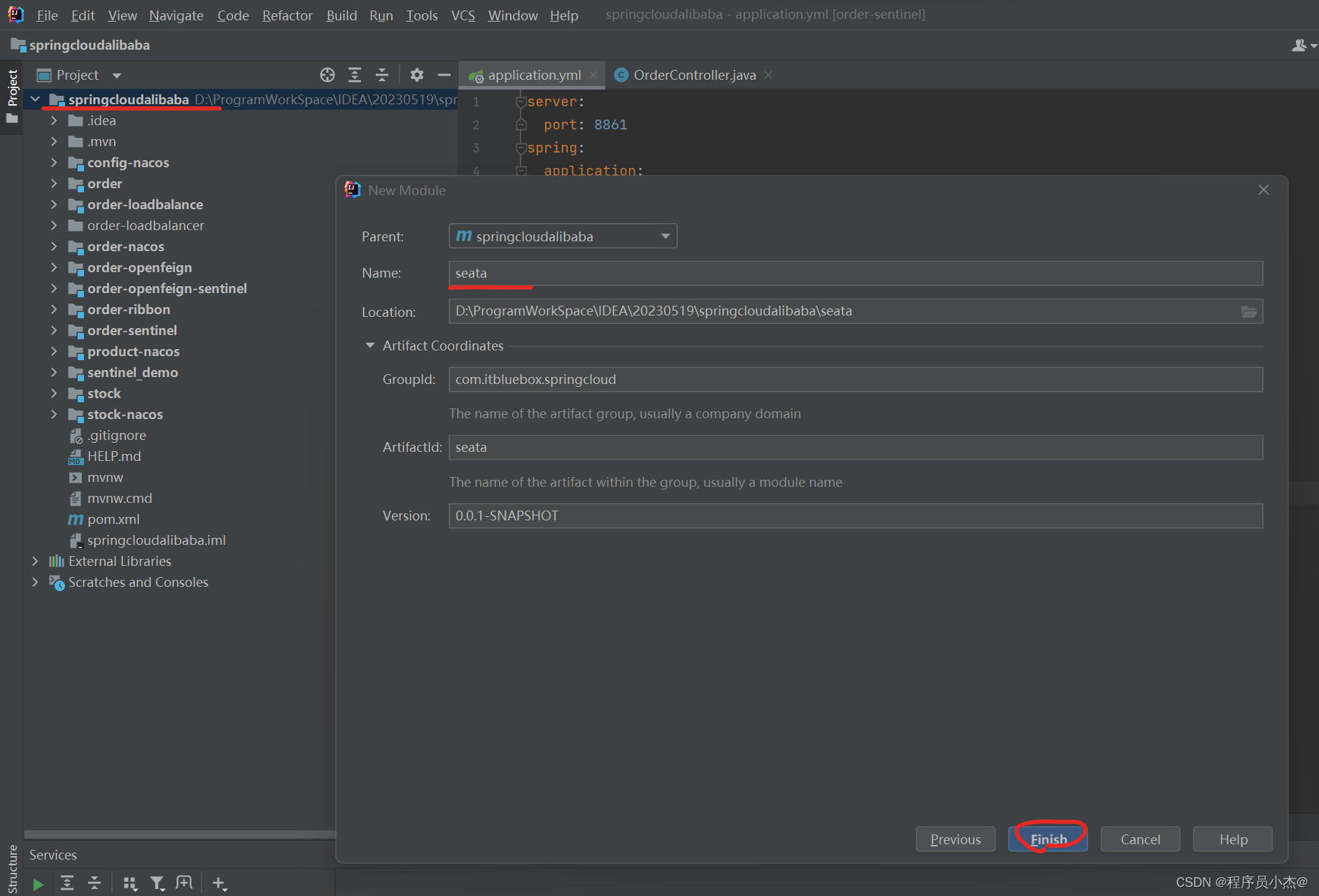

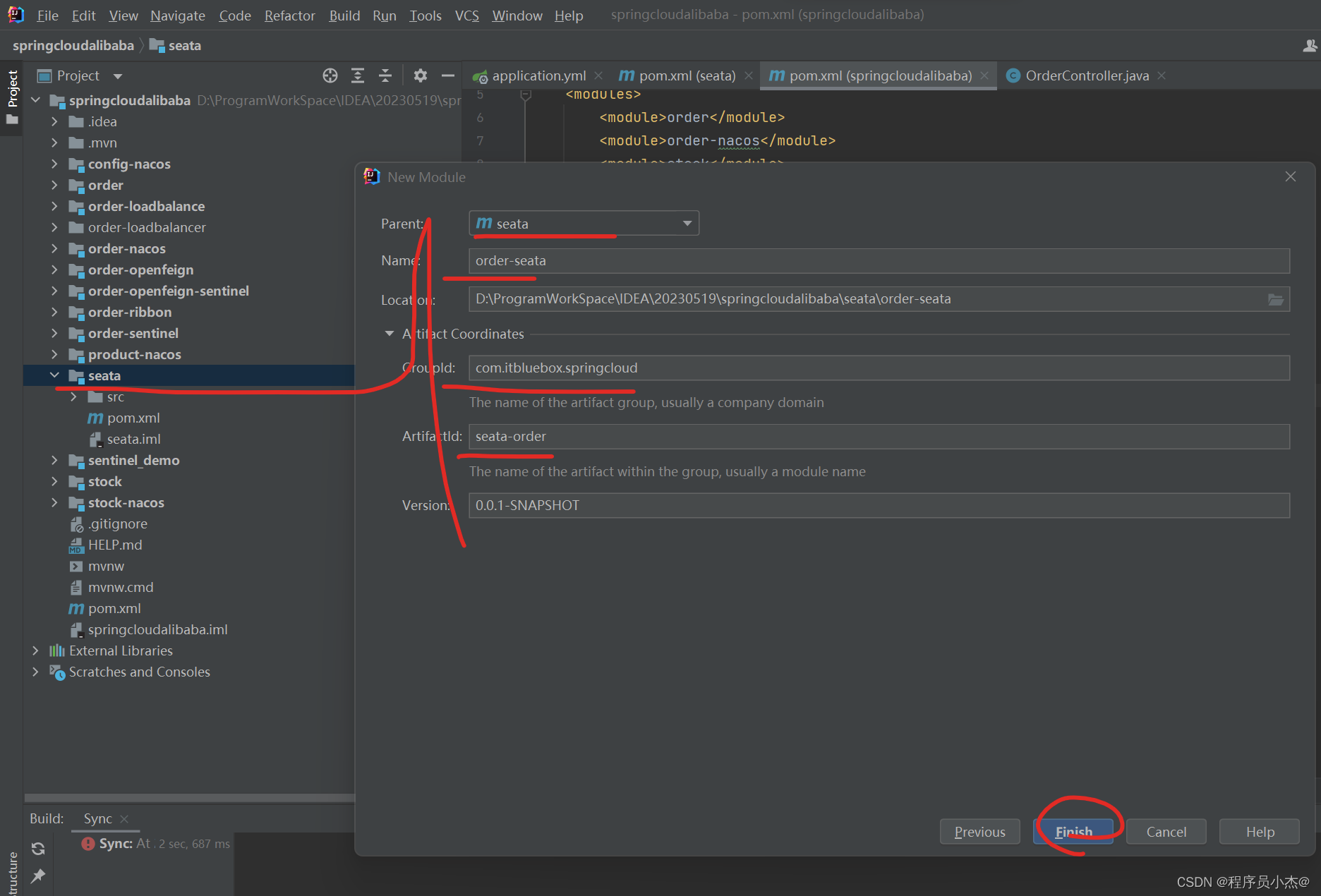
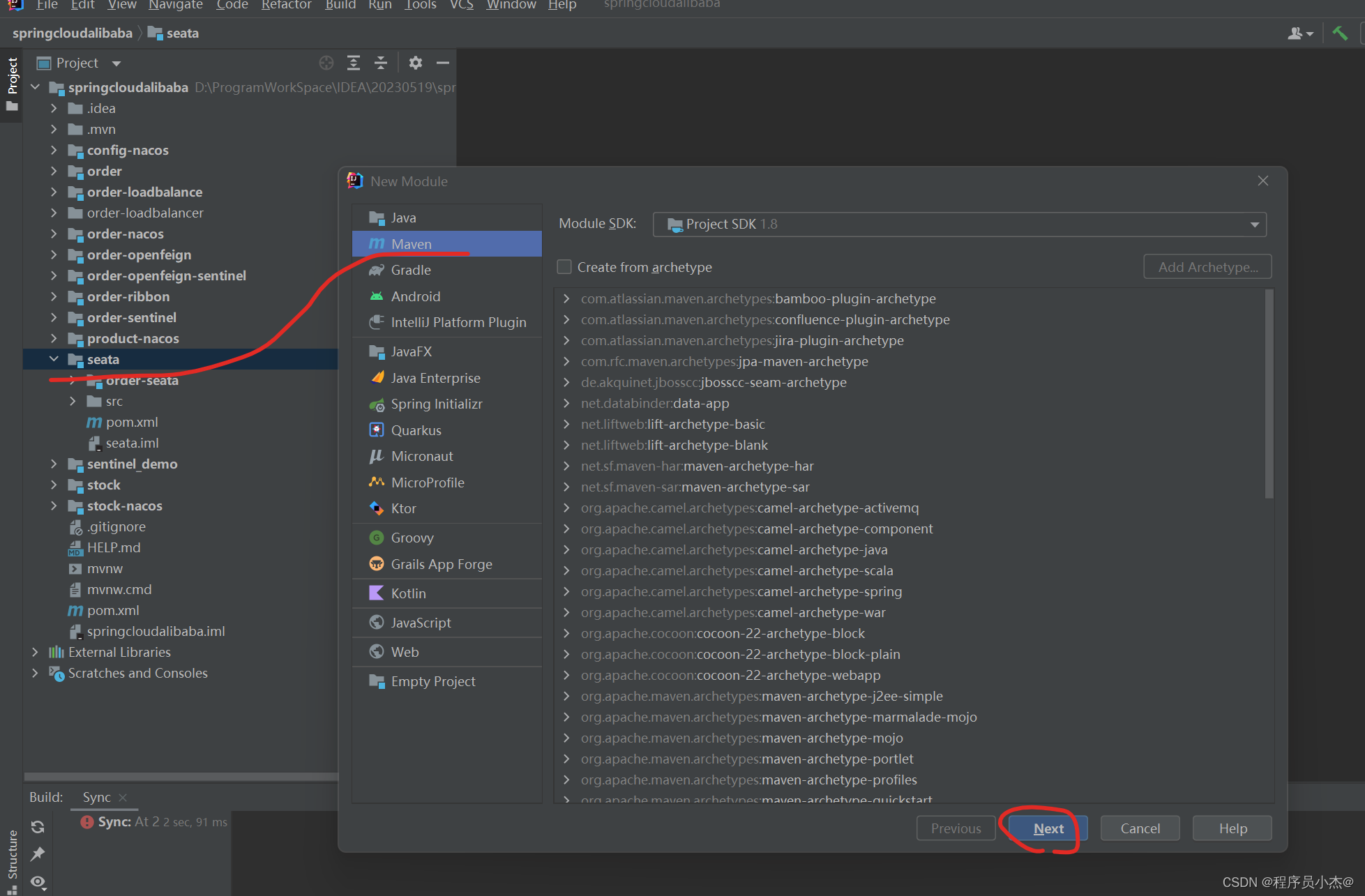
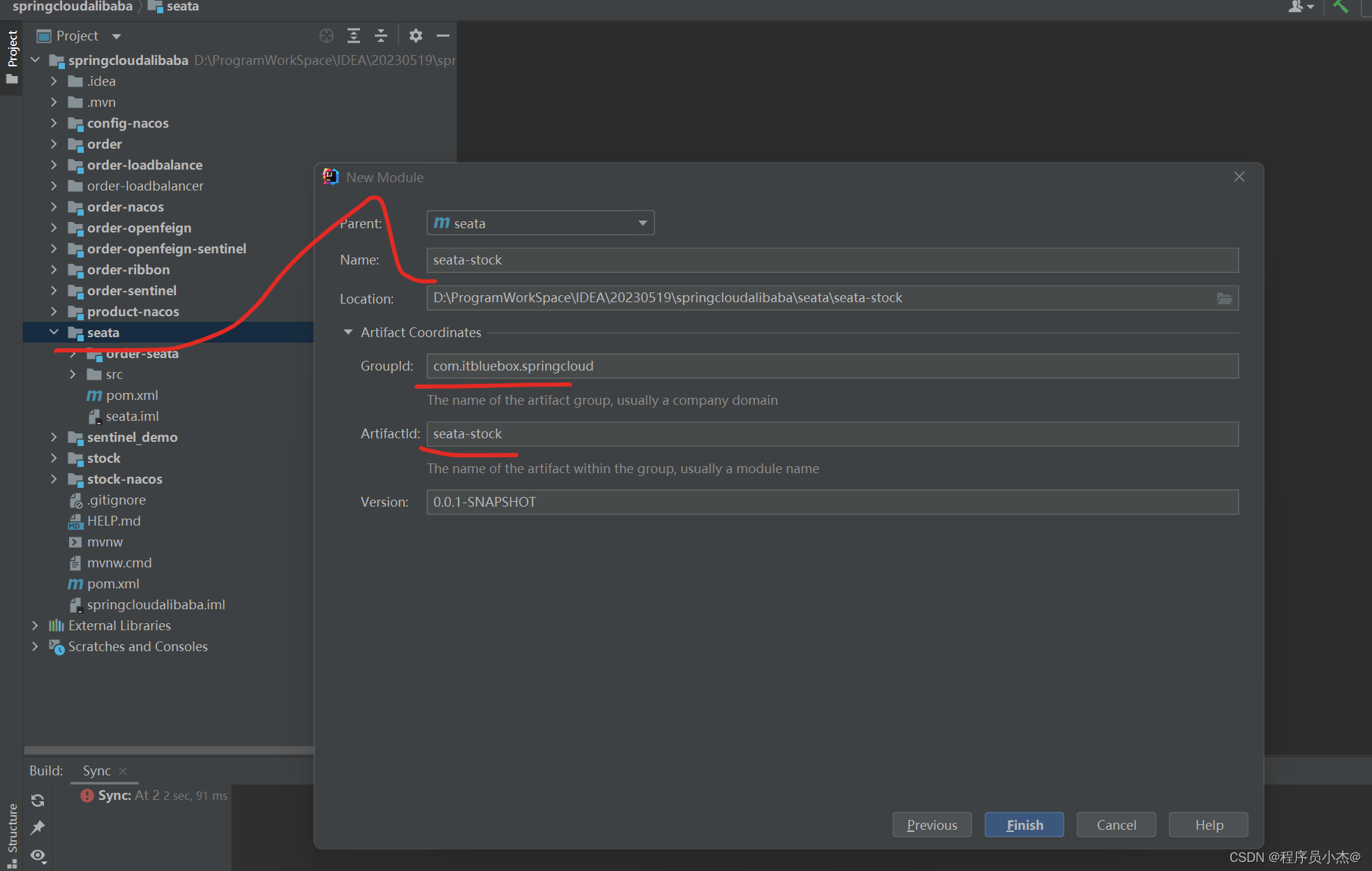
2、创建数据库
DROP TABLE IF EXISTS `order_tbl`;
CREATE TABLE `order_tbl` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',`product_id` int NULL DEFAULT NULL COMMENT '项目id',`total_amount` int NULL DEFAULT NULL COMMENT '数量',`status` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of order_tbl
-- ----------------------------SET FOREIGN_KEY_CHECKS = 1;
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for stock_tbl
-- ----------------------------
DROP TABLE IF EXISTS `stock_tbl`;
CREATE TABLE `stock_tbl` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',`product_id` int NULL DEFAULT NULL COMMENT '项目id',`count` int NULL DEFAULT NULL COMMENT '数量',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of stock_tbl
-- ----------------------------
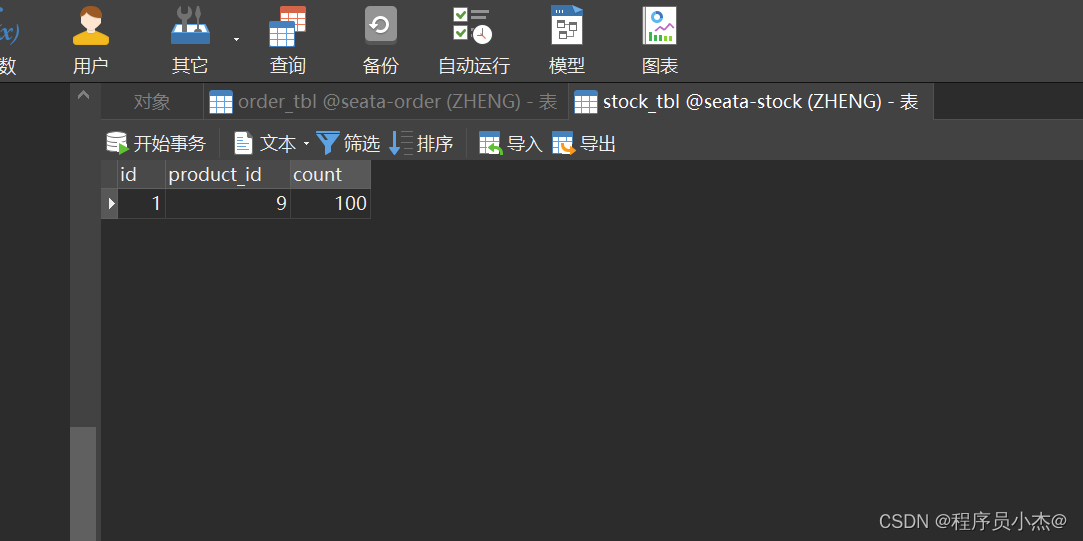
INSERT INTO `stock_tbl` VALUES (1, 9, 100);SET FOREIGN_KEY_CHECKS = 1;
3、完善上述两个代码
order-seata
seata-stock
分别启动两个项目
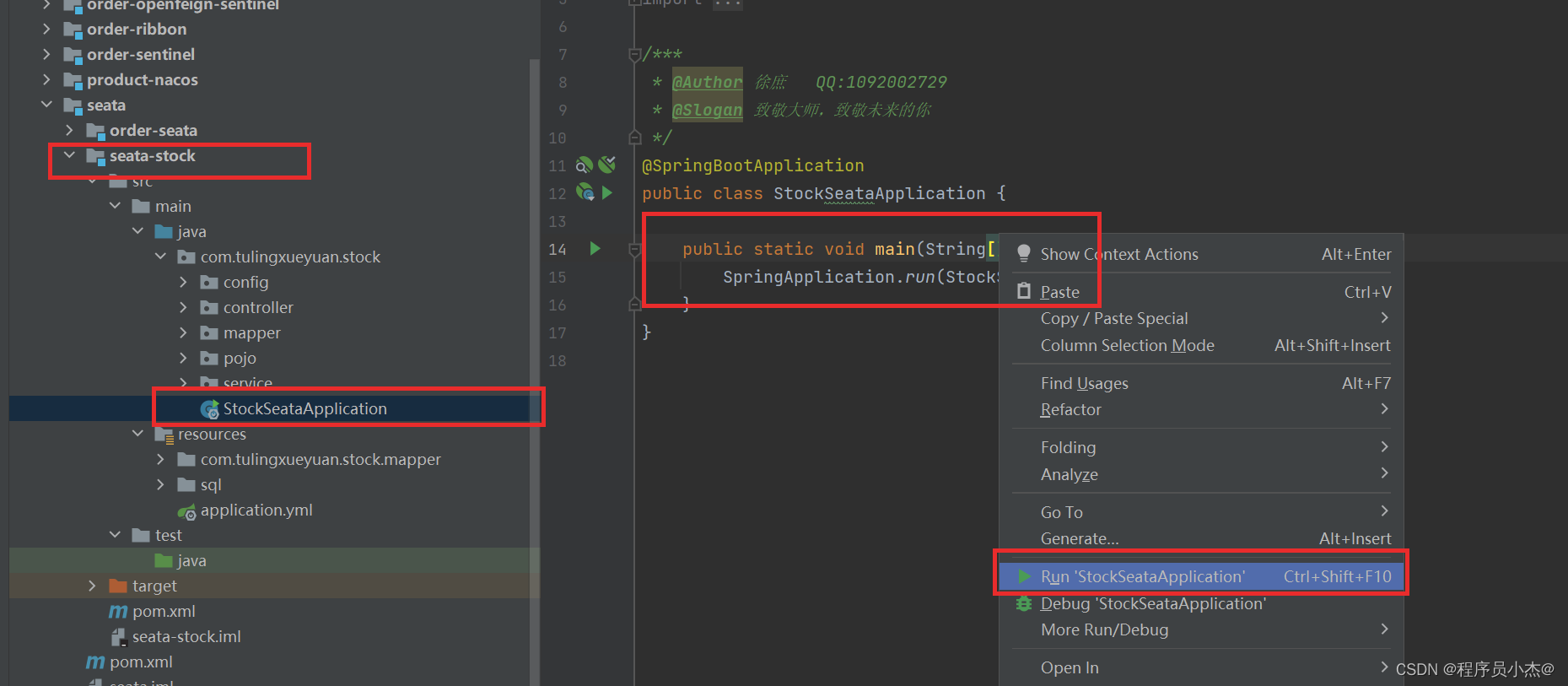
http://localhost:8070/order/add
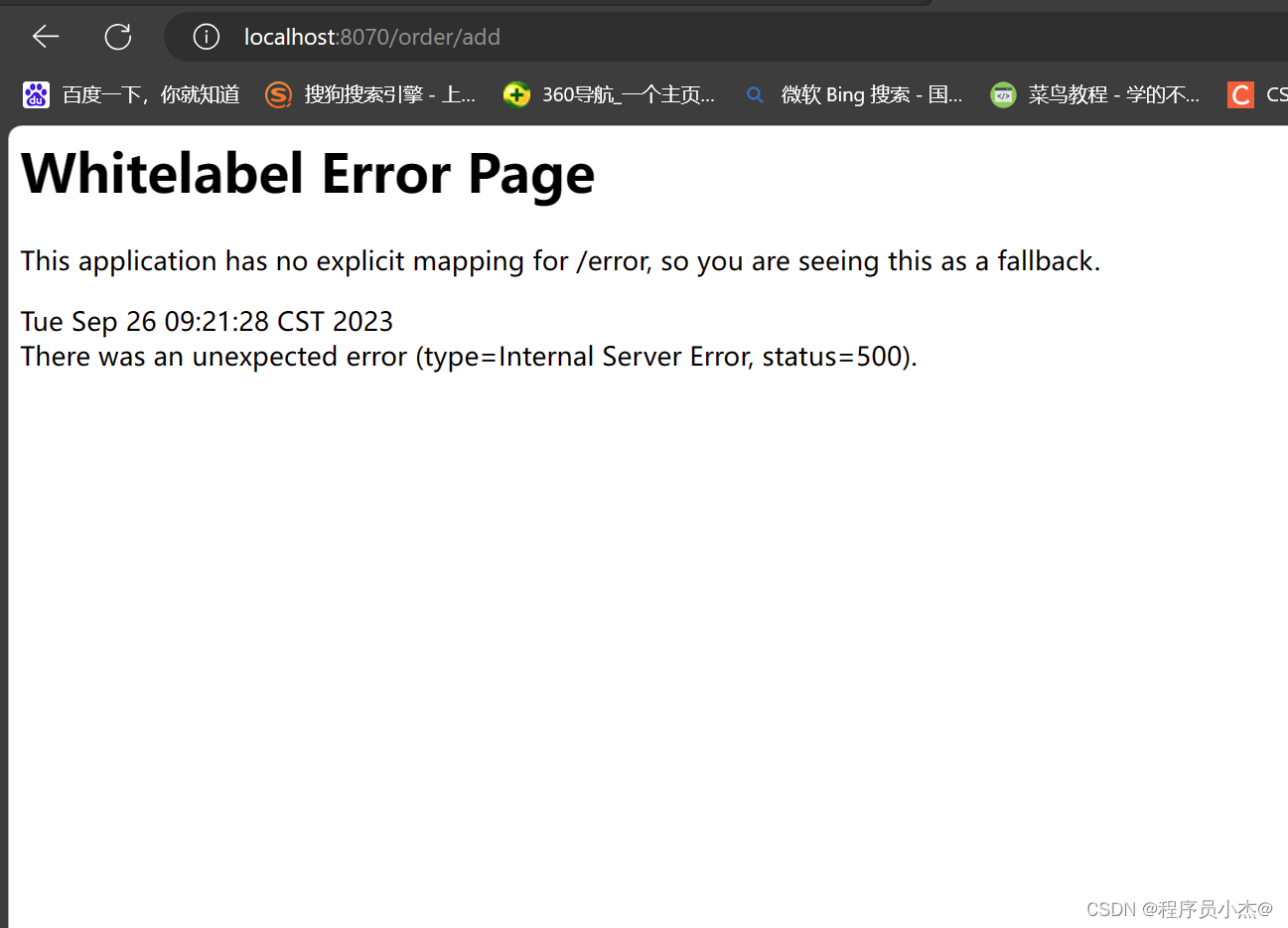
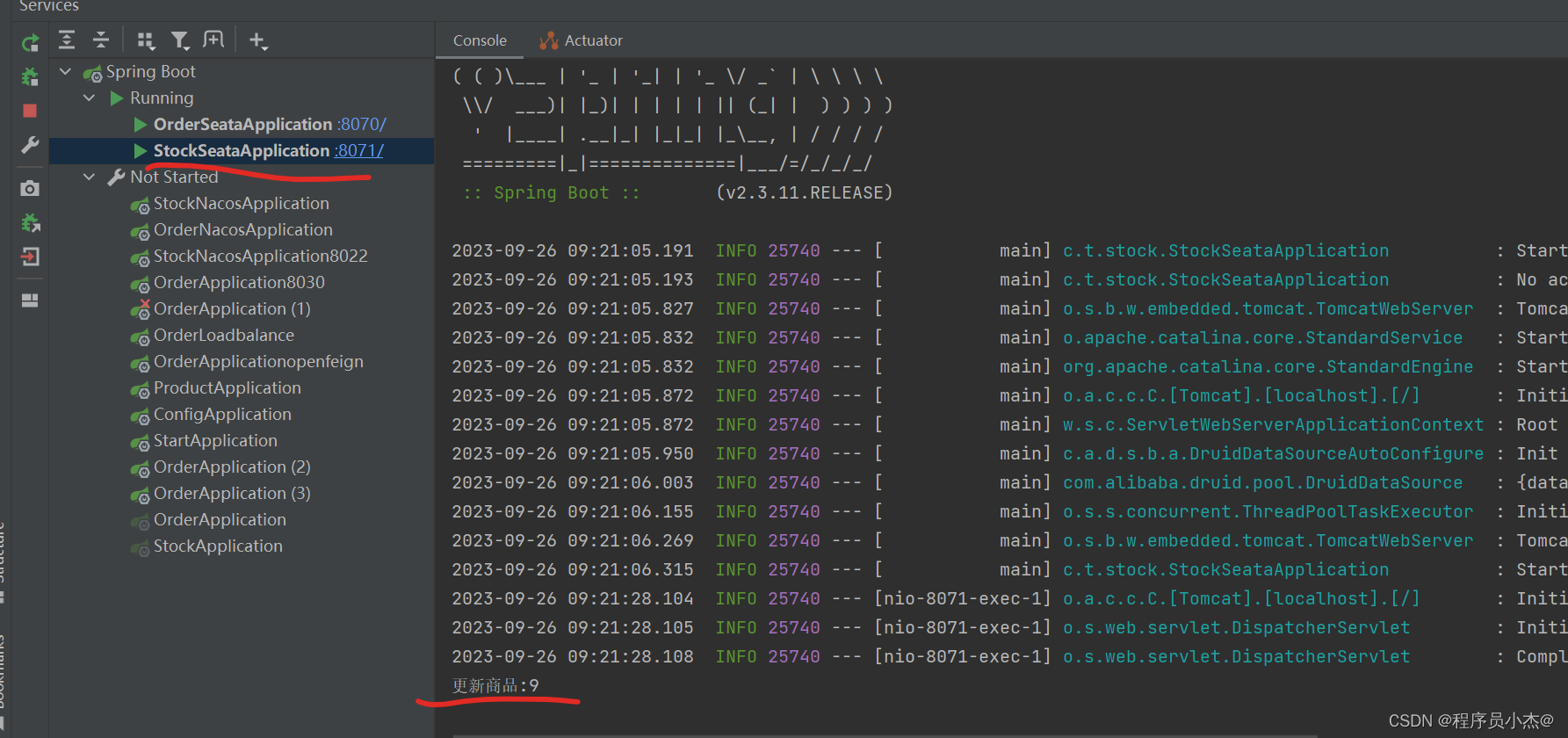
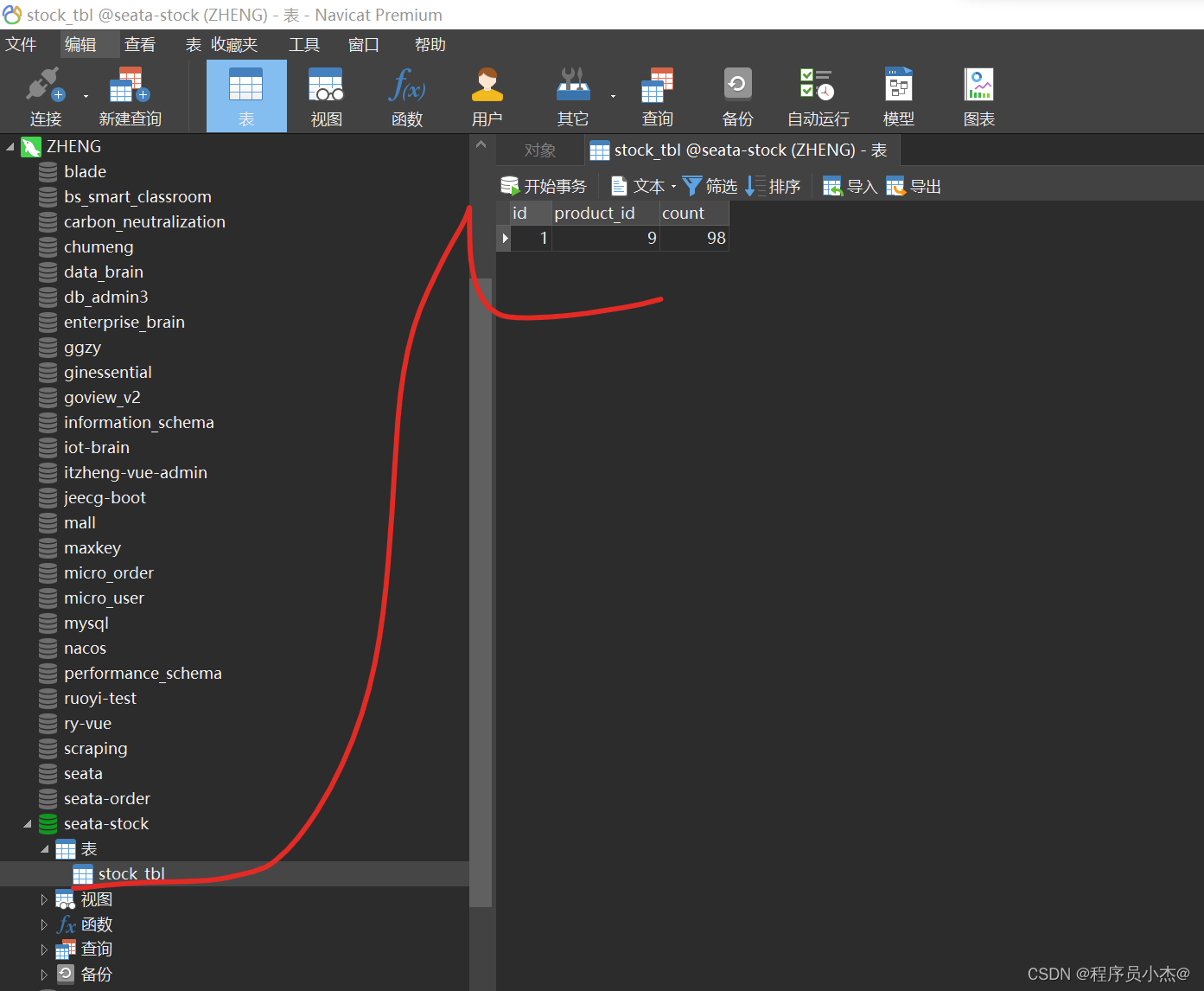
再次访问
http://localhost:8070/order/add
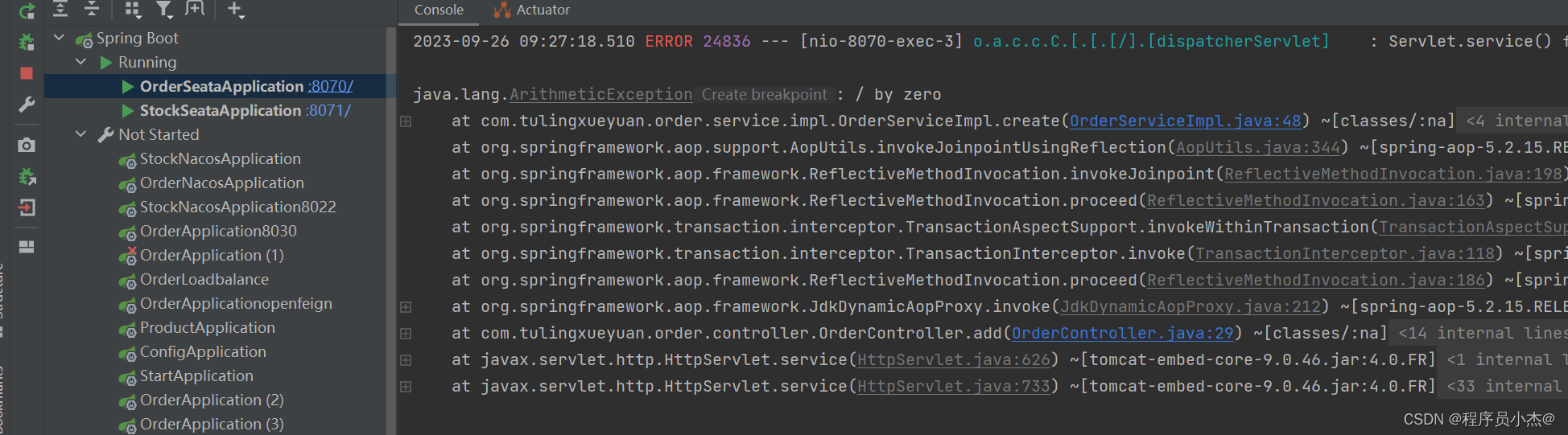
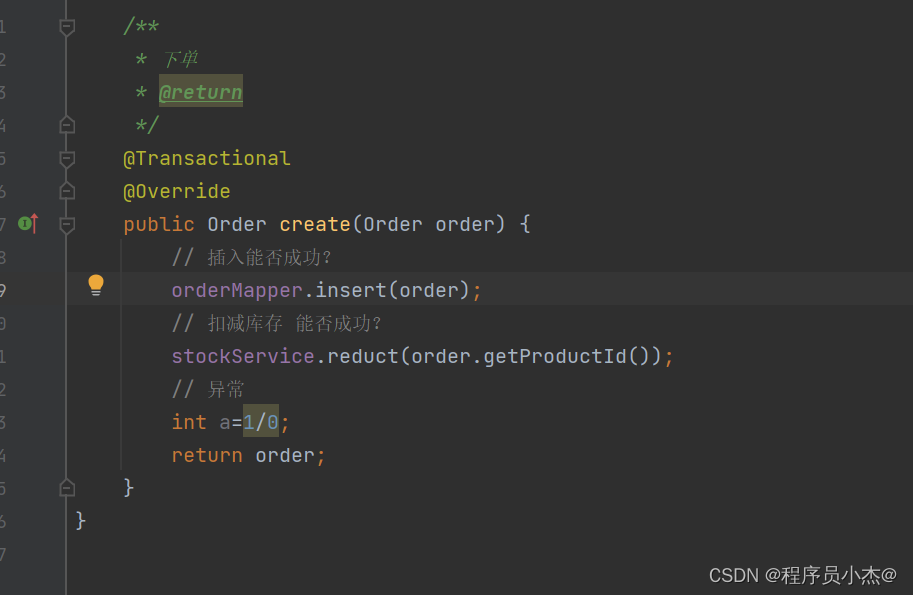
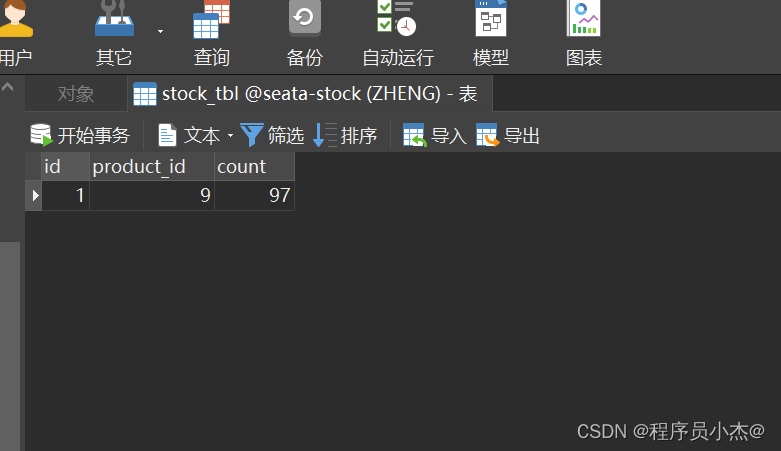 这里添加了事务
这里添加了事务

并且抛出了异常
但是数量依旧减掉了,因此在分布式事务场景下,这样添加事务是失效
4、在SpringCloud Alibaba事务情况,复制之前的工程创建新模块
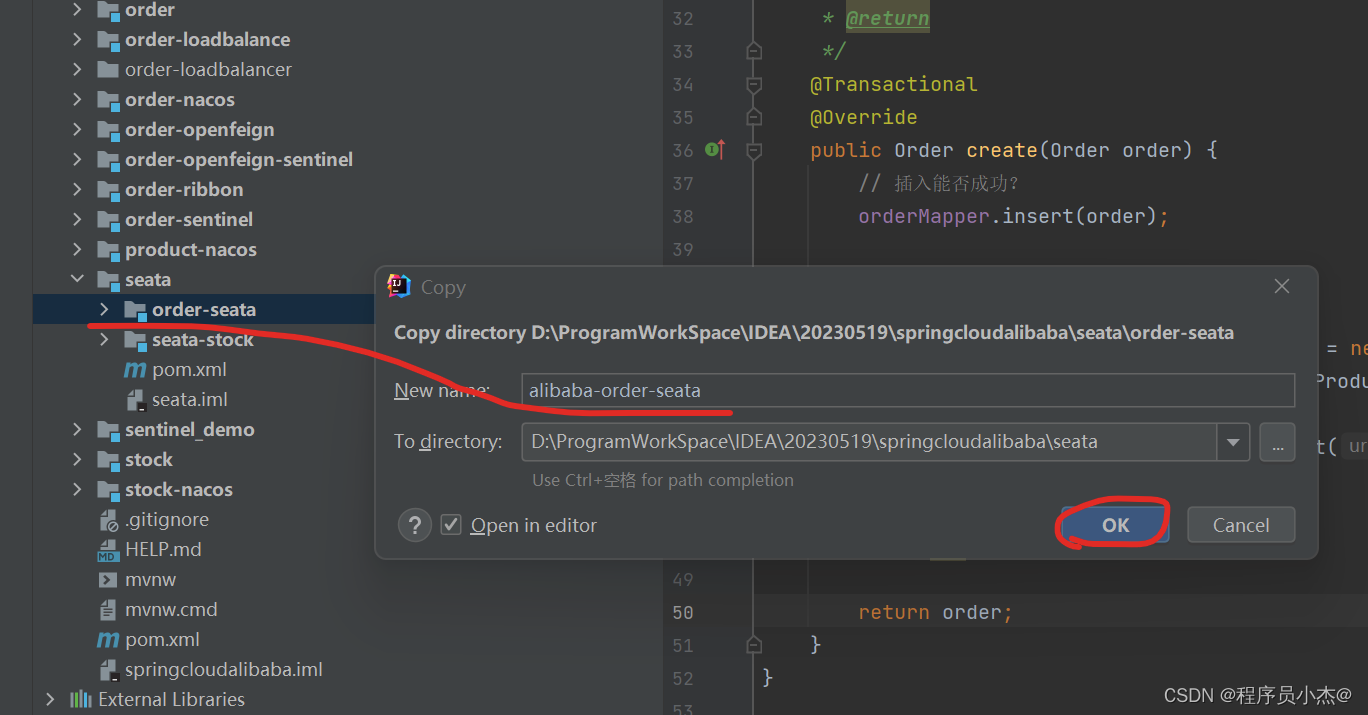
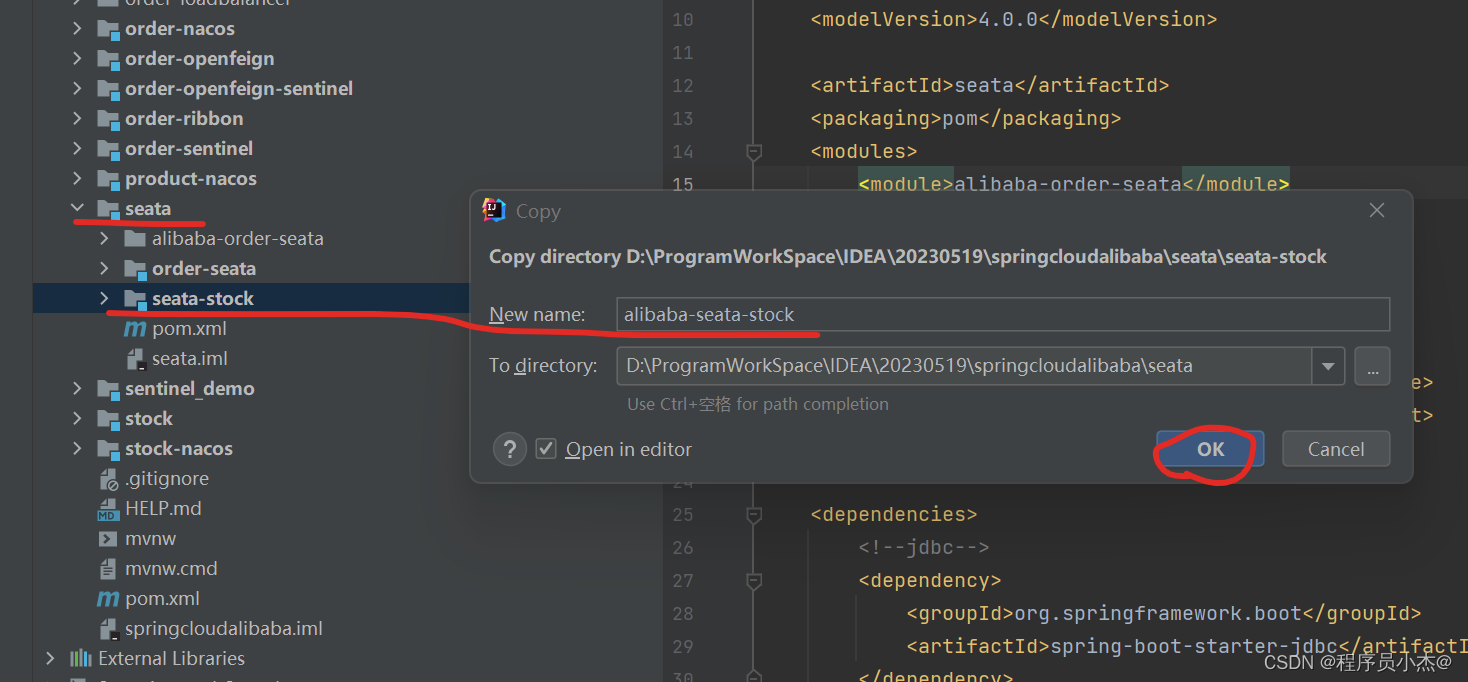
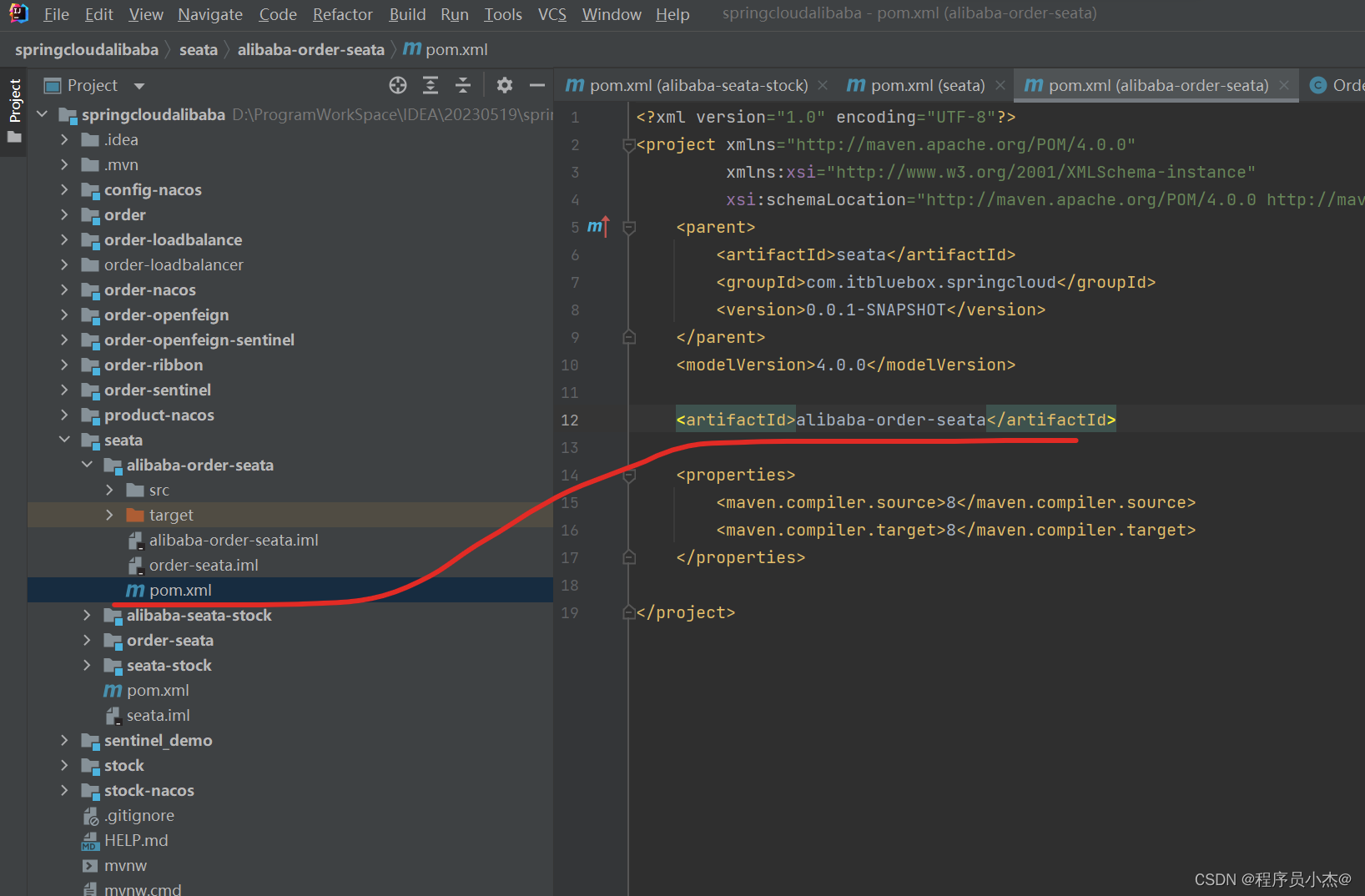
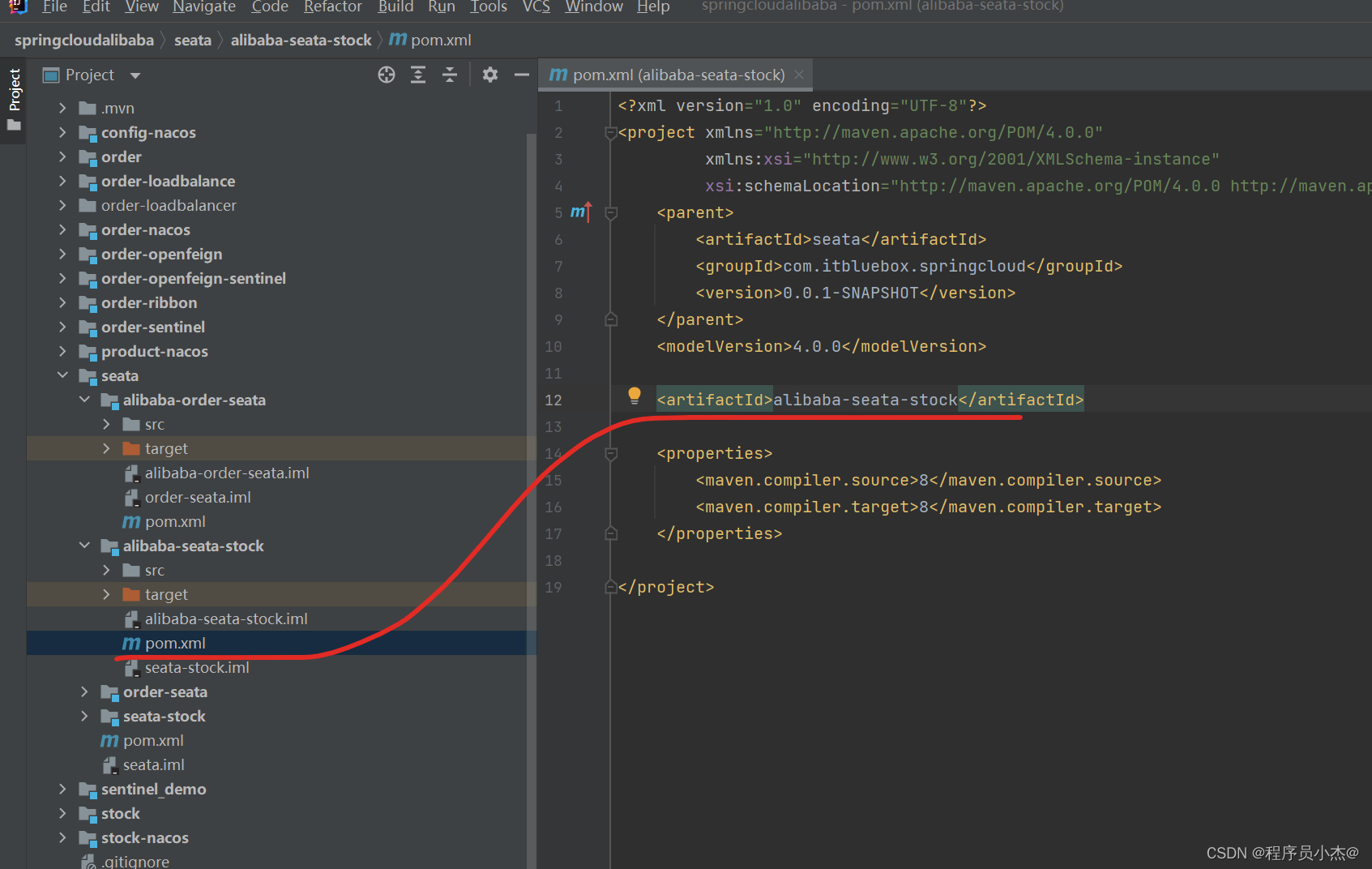
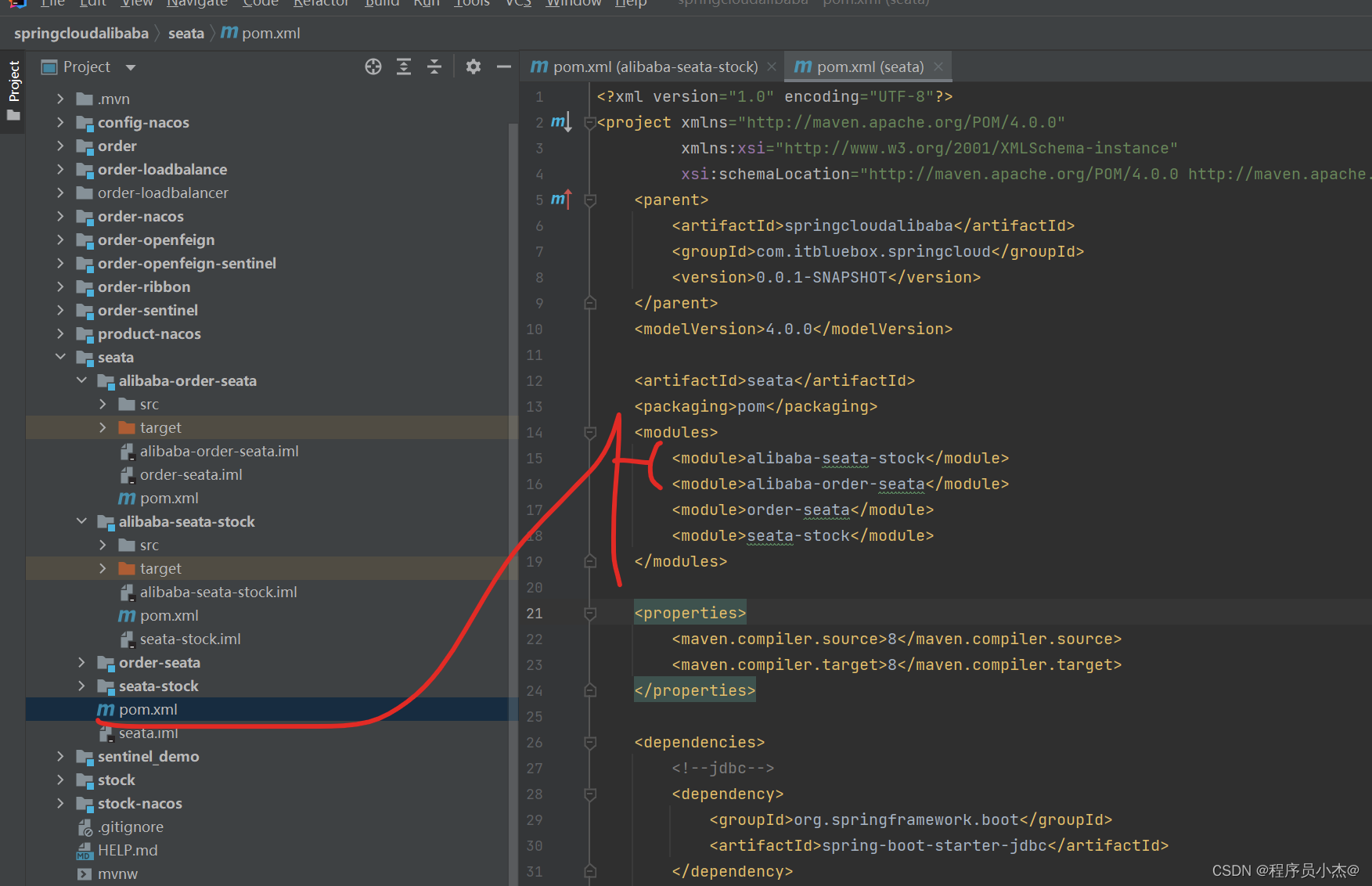
完善依赖
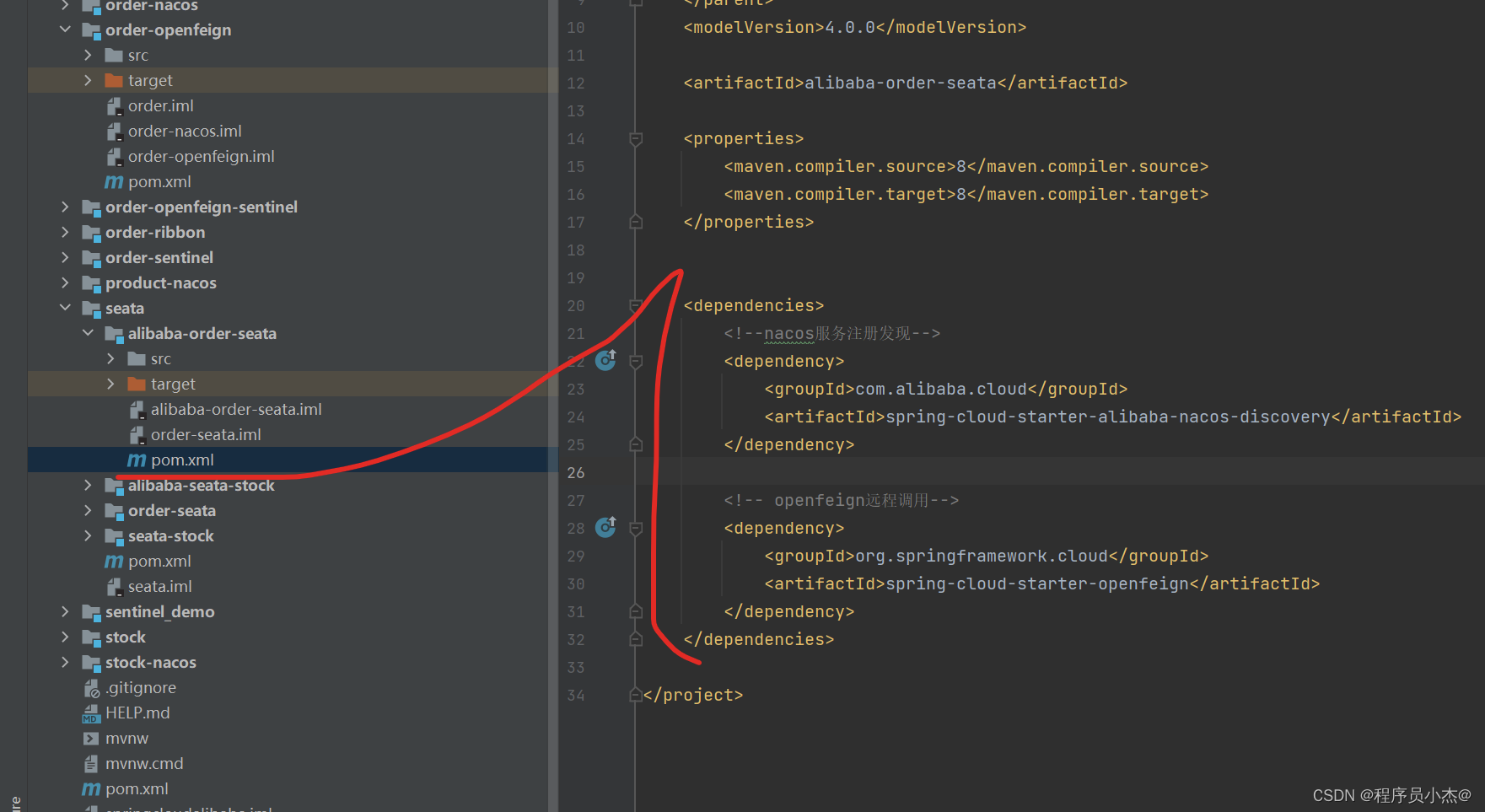
<dependencies><!--nacos服务注册发现--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!-- openfeign远程调用--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency></dependencies>
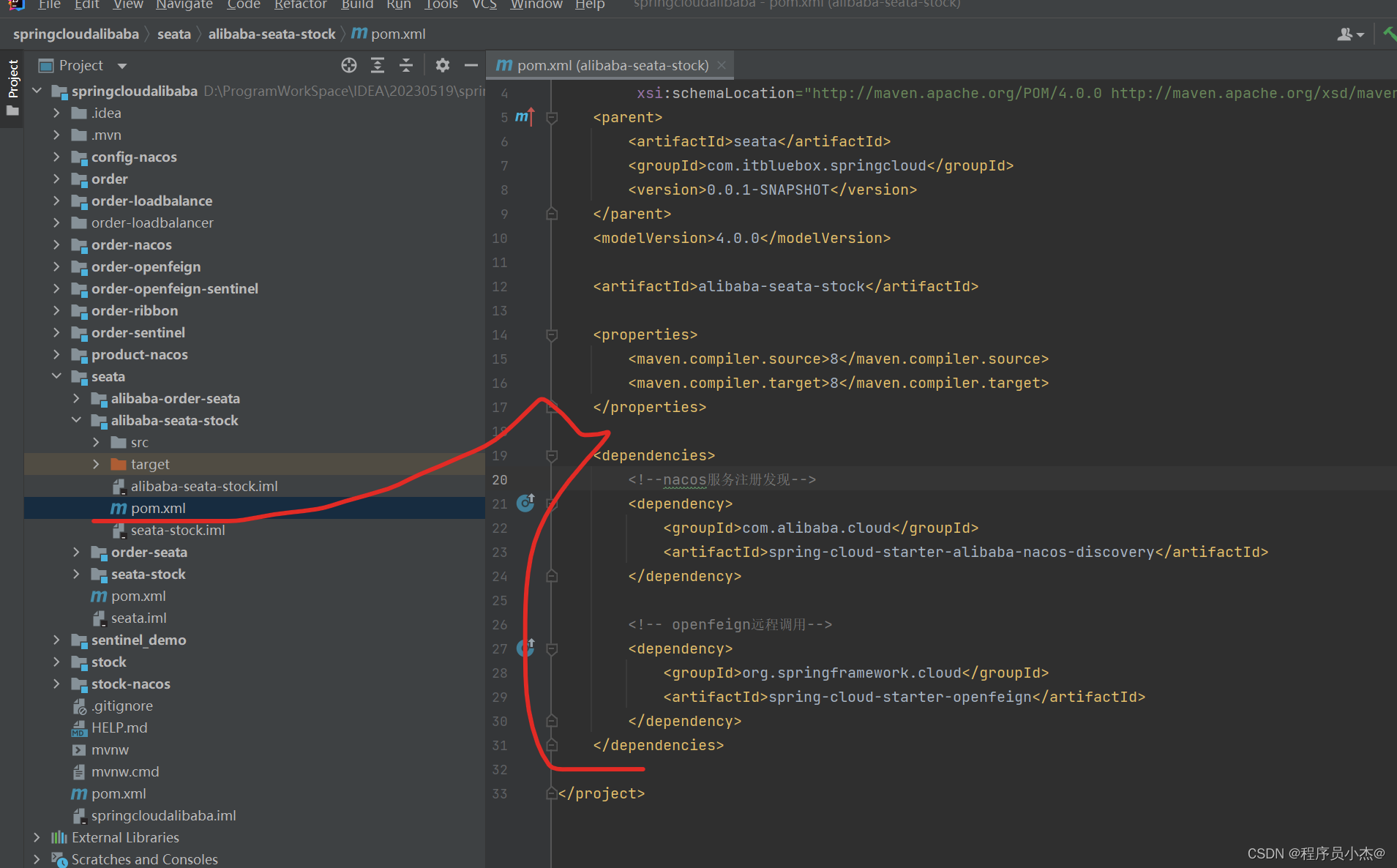
<dependencies><!--nacos服务注册发现--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!-- openfeign远程调用--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency></dependencies>
5、完善上述对应的yml
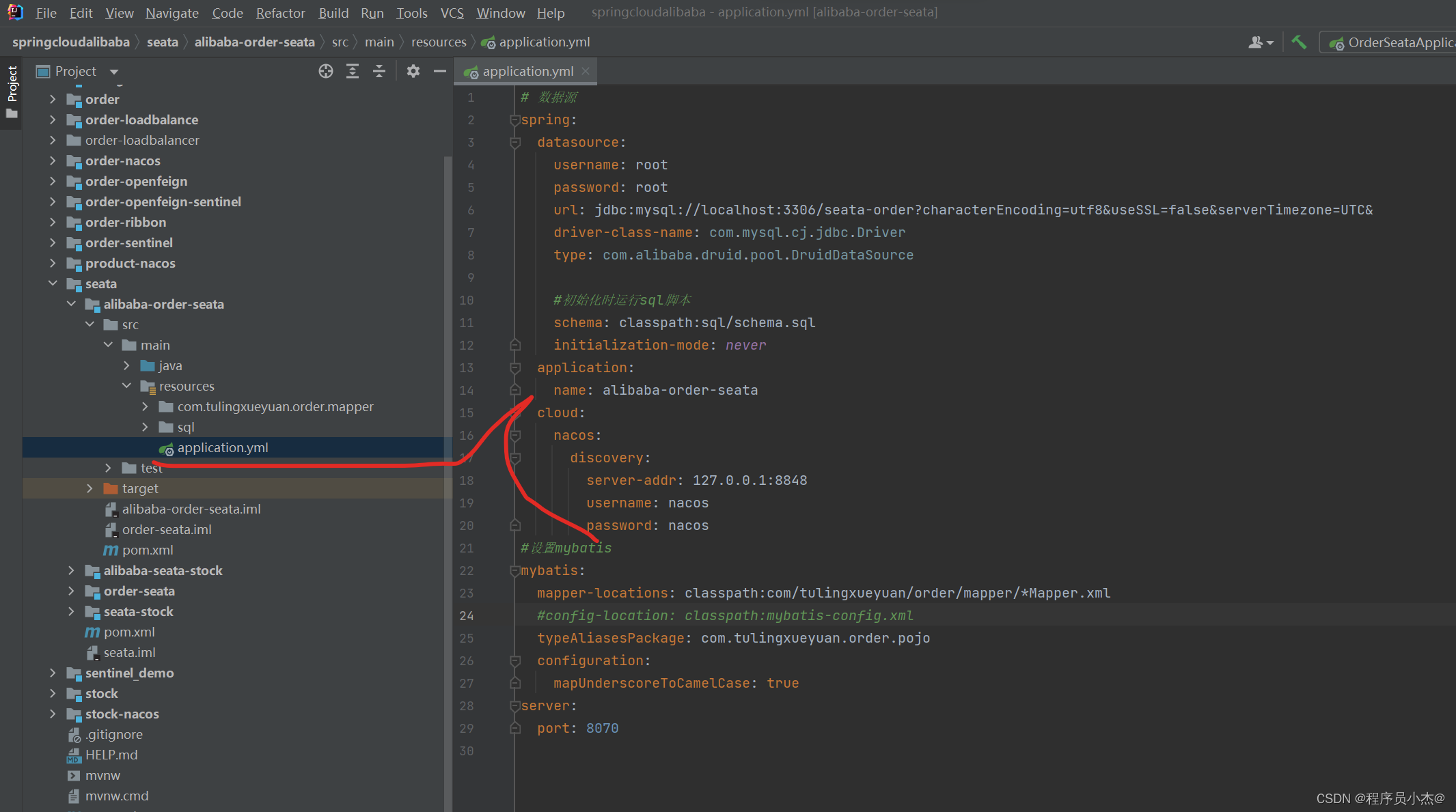
application:name: alibaba-order-seatacloud:nacos:discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacos
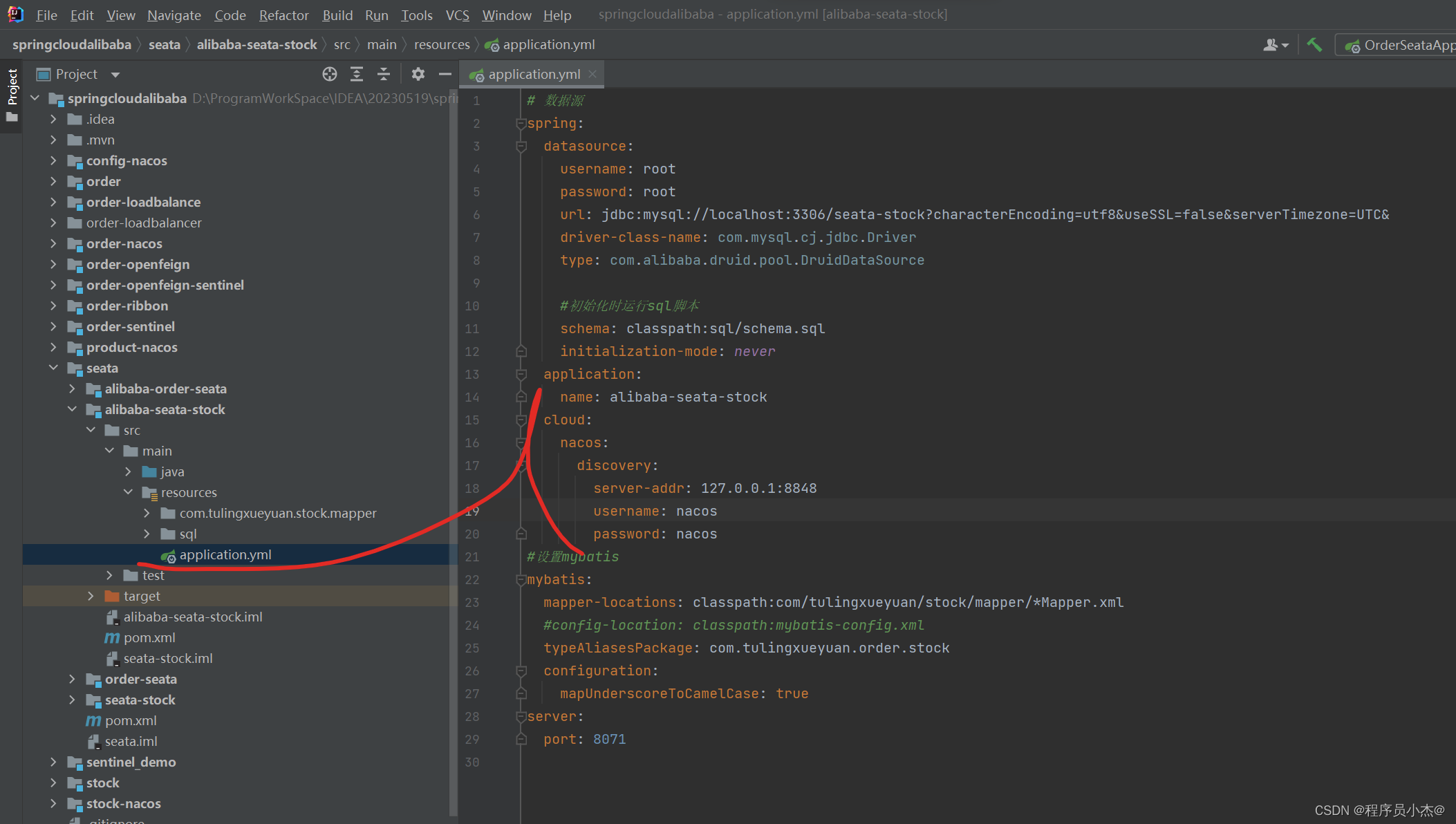
application:name: alibaba-seata-stockcloud:nacos:discovery:server-addr: 127.0.0.1:8848username: nacospassword: nacos
6、完善SpringCloud Alibaba相关代码
@EnableFeignClients
修改上述类名
对AlibabaStockSeataApplication 进行重新命名
7、启动两个项目
访问之前的库存
访问:http://localhost:8072/order/add
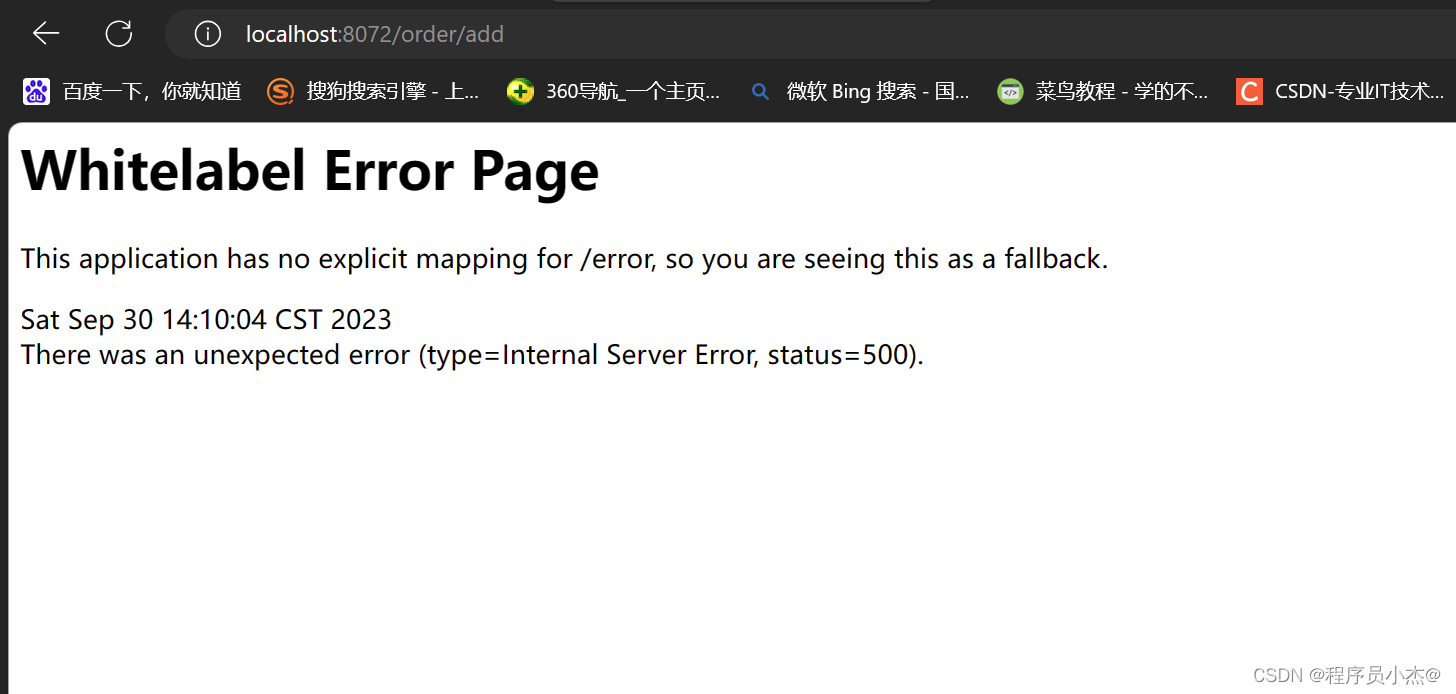
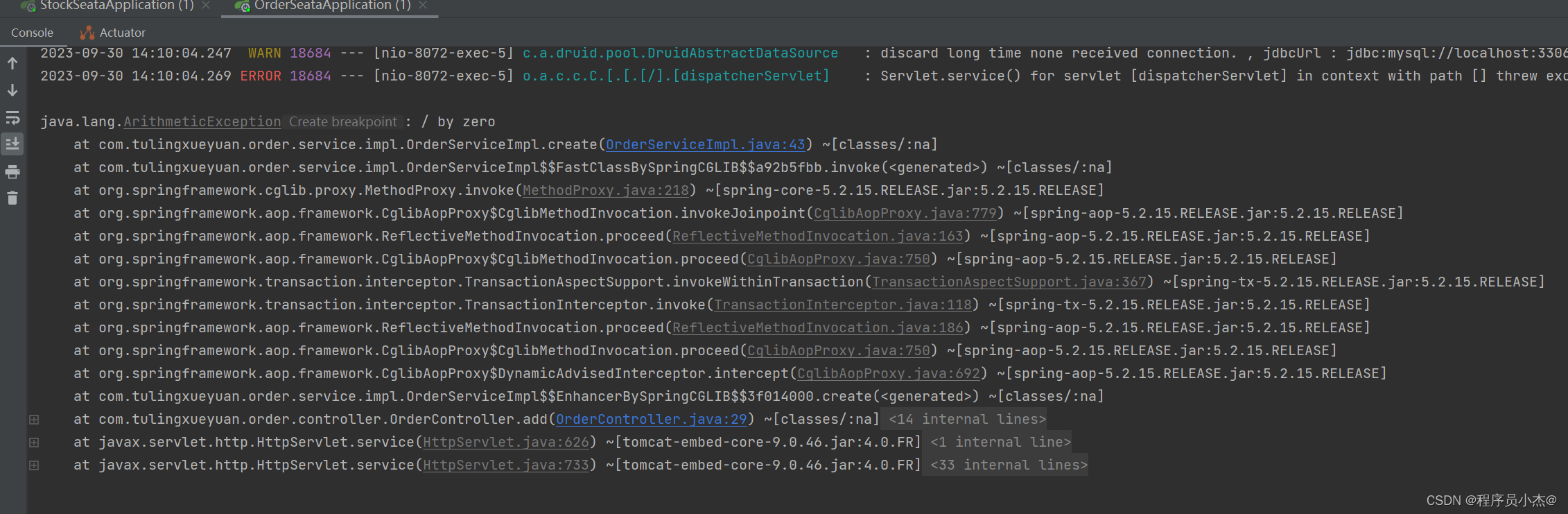
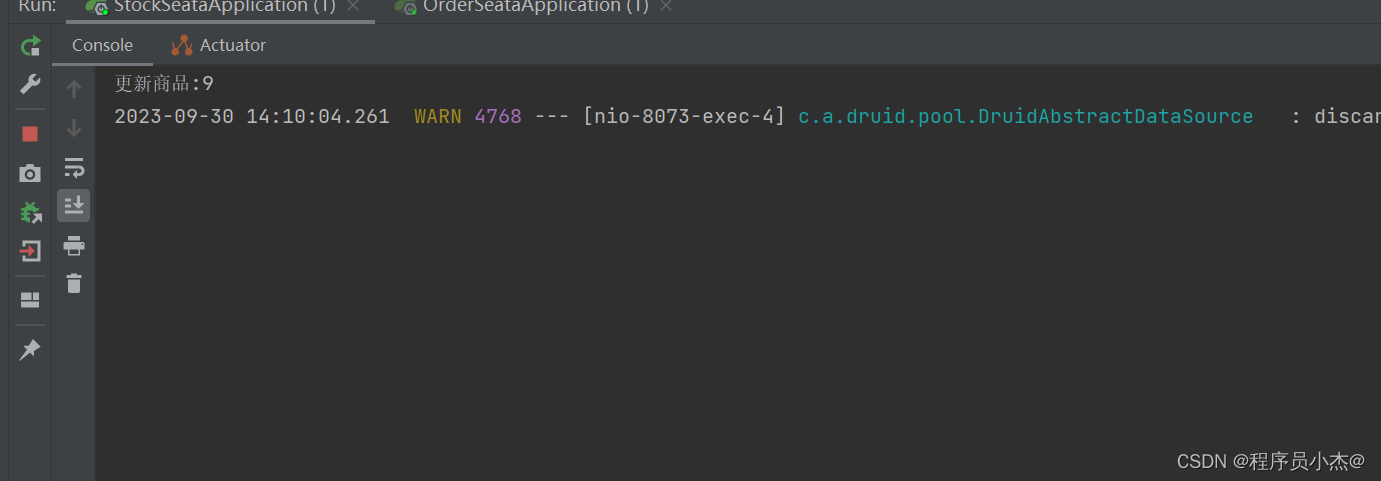
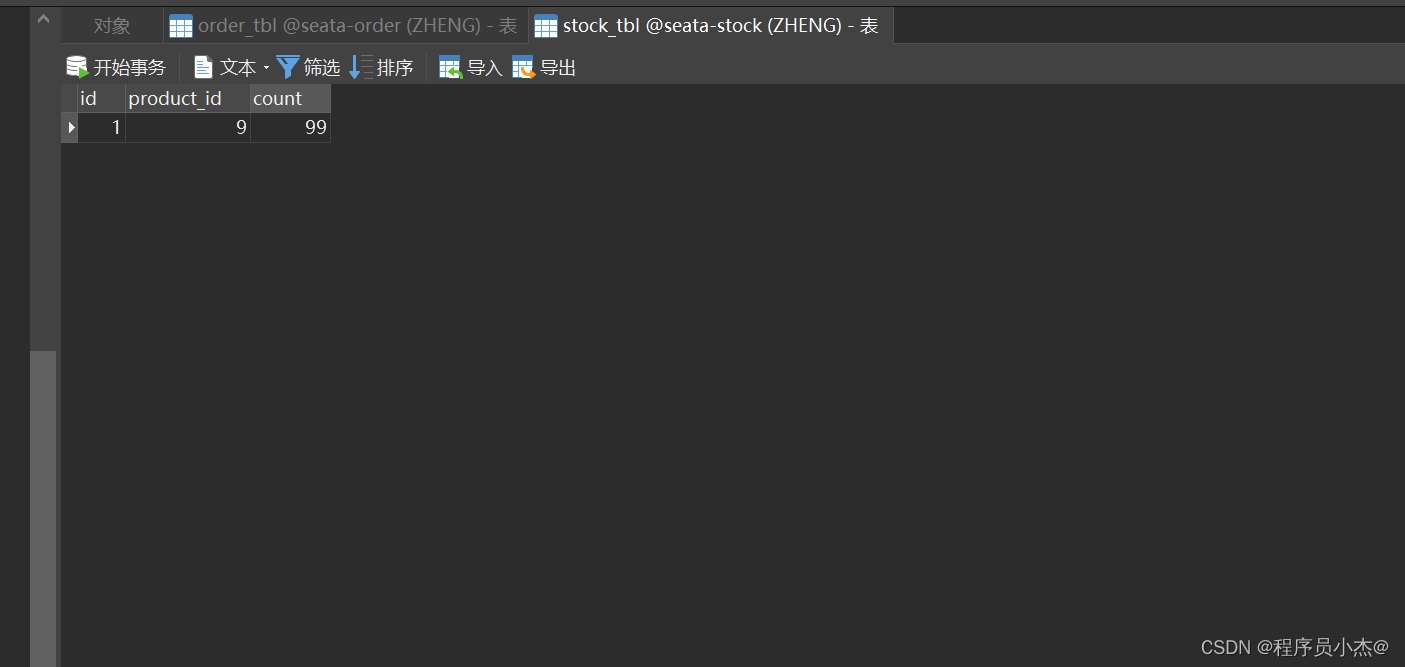 订单并没有添加
订单并没有添加
上述逻辑方法当中对应的内容一个成功了,一个没有成功
8、配置微服务整合seata
1)添加依赖
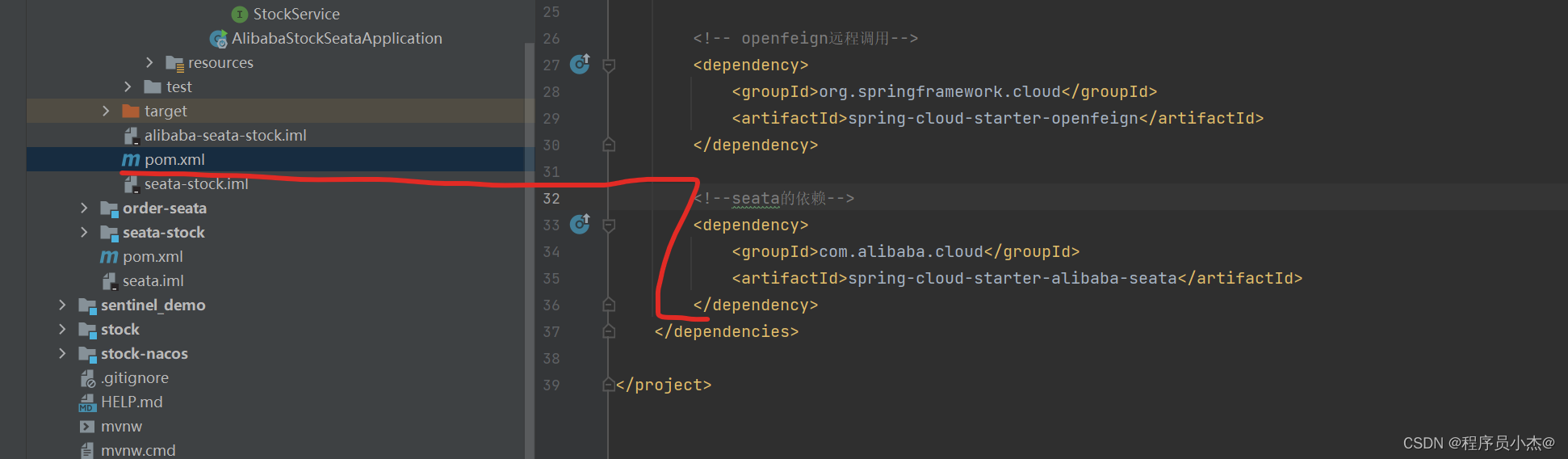
<!--seata的依赖--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId></dependency>
<!--seata的依赖--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId></dependency>
2)各微服务对应数据库中添加undo_log表
CREATE TABLE `undo_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`branch_id` bigint(20) NOT NULL,`xid` varchar(100) NOT NULL,`context` varchar(128) NOT NULL,`rollback_info` LONGBLOB NOT NULL,`log_status` int(11) NOT NULL,`log_created` datetime NOT NULL,`log_modified` datetime NOT NULL, PRIMARY KEY(`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE = Innodb AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8
在两个数据库当中都添加改表
9、配置微服务整合seata
相关文章:
Java之SpringCloud Alibaba【六】【Alibaba微服务分布式事务组件—Seata】
一、事务简介 事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。 在关系数据库中,一个事务由一组SQL语句组成。 事务应该具有4个属性: 原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。 原子性(atomicity) ∶个事务…...
Android逆向学习(五)app进行动态调试
Android逆向学习(五)app进行动态调试 一、写在前面 非常抱歉鸽了那么久,前一段时间一直在忙,现在终于结束了,可以继续更新android逆向系列的,这个系列我会尽力做下去,然后如果可以的话我看看能…...
音频编辑软件Steinberg SpectraLayers Pro mac中文软件介绍
Steinberg SpectraLayers Pro mac是一款专业的音频编辑软件,旨在帮助音频专业人士进行精细的音频编辑和声音处理。它提供了强大的频谱编辑功能,可以对音频文件进行深入的频谱分析和编辑。 Steinberg SpectraLayers Pro mac软件特点 1. 频谱编辑ÿ…...

基于.Net Core实现自定义皮肤WidForm窗口
前言 今天一起来实现基于.Net Core、Windows Form实现自定义窗口皮肤,并实现窗口移动功能。 素材 准备素材:边框、标题栏、关闭按钮图标。 窗体设计 1、创建Window窗体项目 2、窗体设计 拖拉4个Panel控件,分别用于:标题栏、关…...

【Rust】操作日期与时间
目录 介绍 一、计算耗时 二、时间加减法 三、时区转换 四、年月日时分秒 五、时间格式化 介绍 Rust的时间操作主要用到chrono库,接下来我将简单选一些常用的操作进行介绍,如果想了解更多细节,请查看官方文档。 官方文档:chr…...

blender快捷键
1, shift a 添加物体 2,ctrl alt q 切换四格视图 3, ~ 展示物体的各个视图按钮,(~ 就是tab键上面的键) 4,a 全选,全选后,点 ctrl 鼠标框选 减去已经选择的;…...
java Spring Boot 自动启动热部署 (别再改点东西就要重启啦)
上文 java Spring Boot 手动启动热部署 我们实现了一个手动热部署的代码 但其实很多人会觉得 这叫说明热开发呀 这么捞 写完还要手动去点一下 很不友好 其实我们开发人员肯定是希望重启这种事不需要自己手动去做 那么 当然可以 我们就让它自己去做 Build Project 这个操作 我们…...

TouchGFX之后端通信
在大多数应用中,UI需以某种方式连接到系统的其余部分,并发送和接收数据。 它可能会与硬件外设(传感器数据、模数转换和串行通信等)或其他软件模块进行交互通讯。 Model类 所有TouchGFX应用都有Model类,Model类除了存…...

cesium gltf控制
gltf格式详解 glTF格式本质上是一个JSON文件。这一文件描述了整个3D场景的内容。它包含了对场景结构进行描述的场景图。场景中的3D对象通过场景结点引用网格进行定义。材质定义了3D对象的外观,动画定义了3D对象的变换操作(比如选择、平移操作)。蒙皮定义了3D对象如何进行骨骼…...

Spring的依赖注入(DI)以及优缺点
Spring的依赖注入(DI):解释和优点 依赖注入(Dependency Injection,简称DI)是Spring框架的核心概念之一,也是现代Java应用程序开发的重要组成部分。本文将深入探讨DI是什么,以及它的…...

【强化学习】05 —— 基于无模型的强化学习(Prediction)
文章目录 简介蒙特卡洛算法时序差分方法Example1 MC和TD的对比偏差(Bias)/方差(Variance)的权衡Example2 Random WalkExample3 AB 反向传播(backup)Monte-Carlo BackupTemporal-Difference BackupDynamic Programming Backup Boot…...
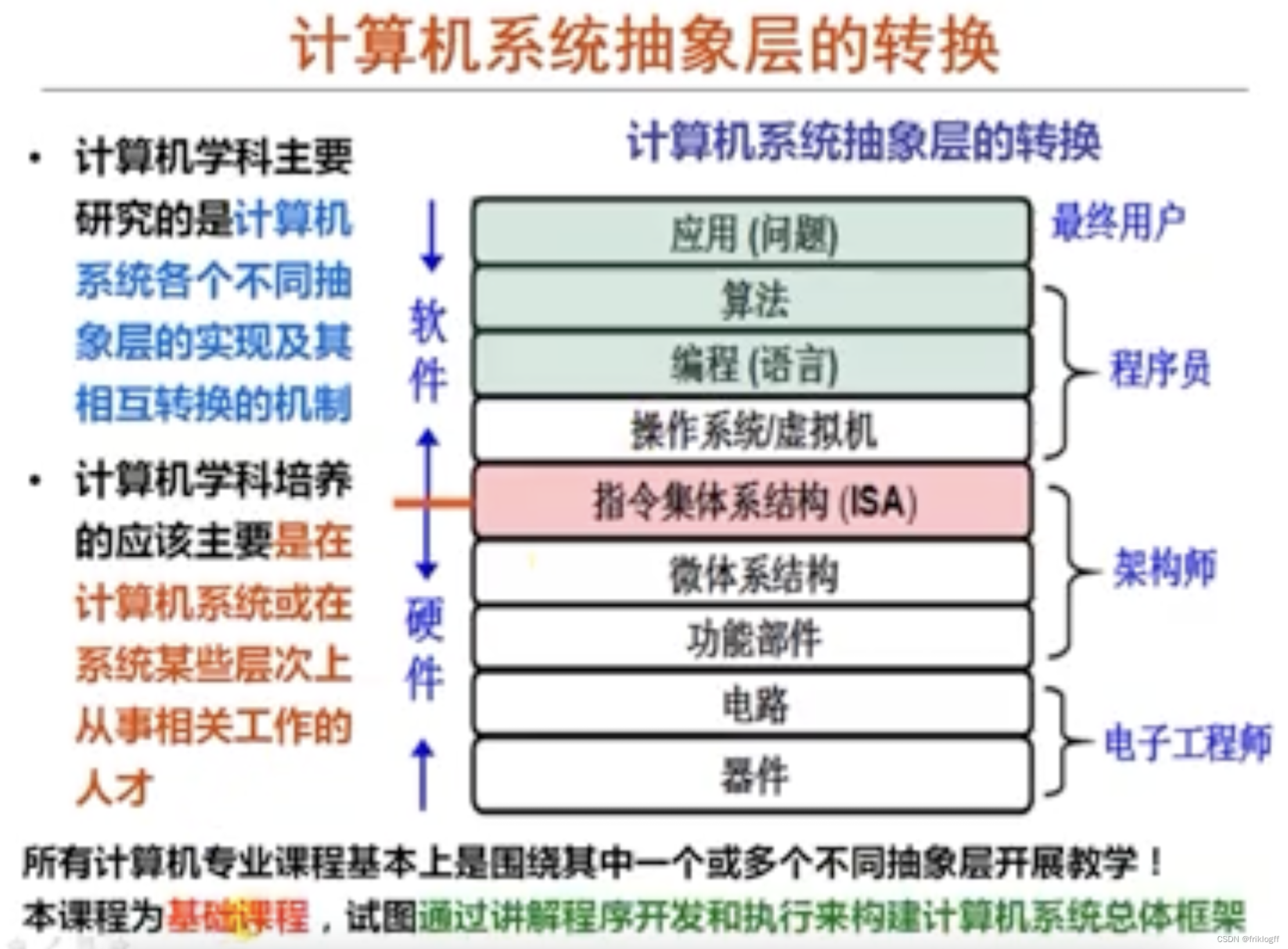
【计算机组成原理】考研真题攻克与重点知识点剖析 - 第 1 篇:计算机系统概述
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术有限ÿ…...

【Java-LangChain:面向开发者的提示工程-8】聊天机器人
第八章 聊天机器人 使用一个大型语言模型的一个令人兴奋的事情是,我们可以用它来构建一个定制的聊天机器人 (Chatbot) ,只需要很少的工作量。在这一节中,我们将探索如何利用聊天的方式,与个性化(或专门针对特定任务或…...

利用t.ppft.interval分别计算T分布置信区间[实例]
scipy.stats.t.interval用于计算t分布的置信区间,即给定置信水平时,计算对应的置信区间的下限和上限。 scipy.stats.t.ppf用于计算t分布的百分位点,即给定百分位数(概率)时,该函数返回给定百分位数对应的t…...
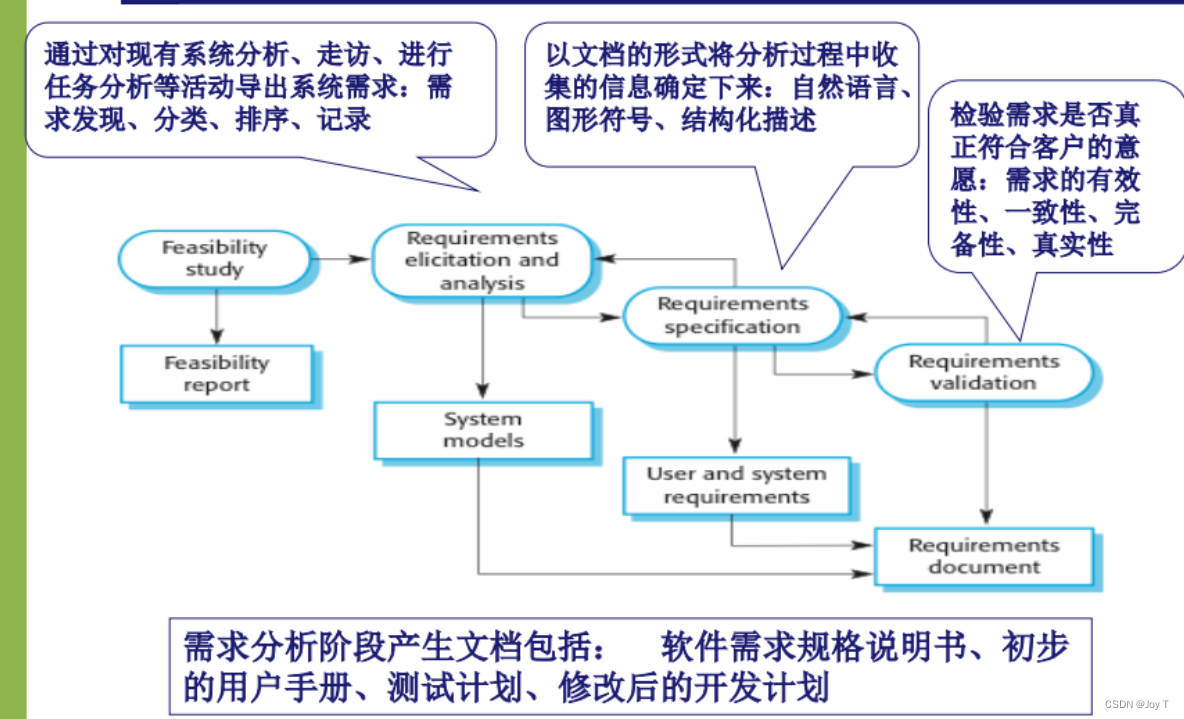
软件工程第三周
可行性研究 续 表达工作量的方式 LOC估算:Line of Code 估算公式S(Sopt4SmSpess)/6 FP:功能点 1. LOC (Line of Code) 估算 定义:LOC是指一个软件项目中的代码行数。 2. FP (Function Points) 估算 定义:FP是基于软件的功能性和…...
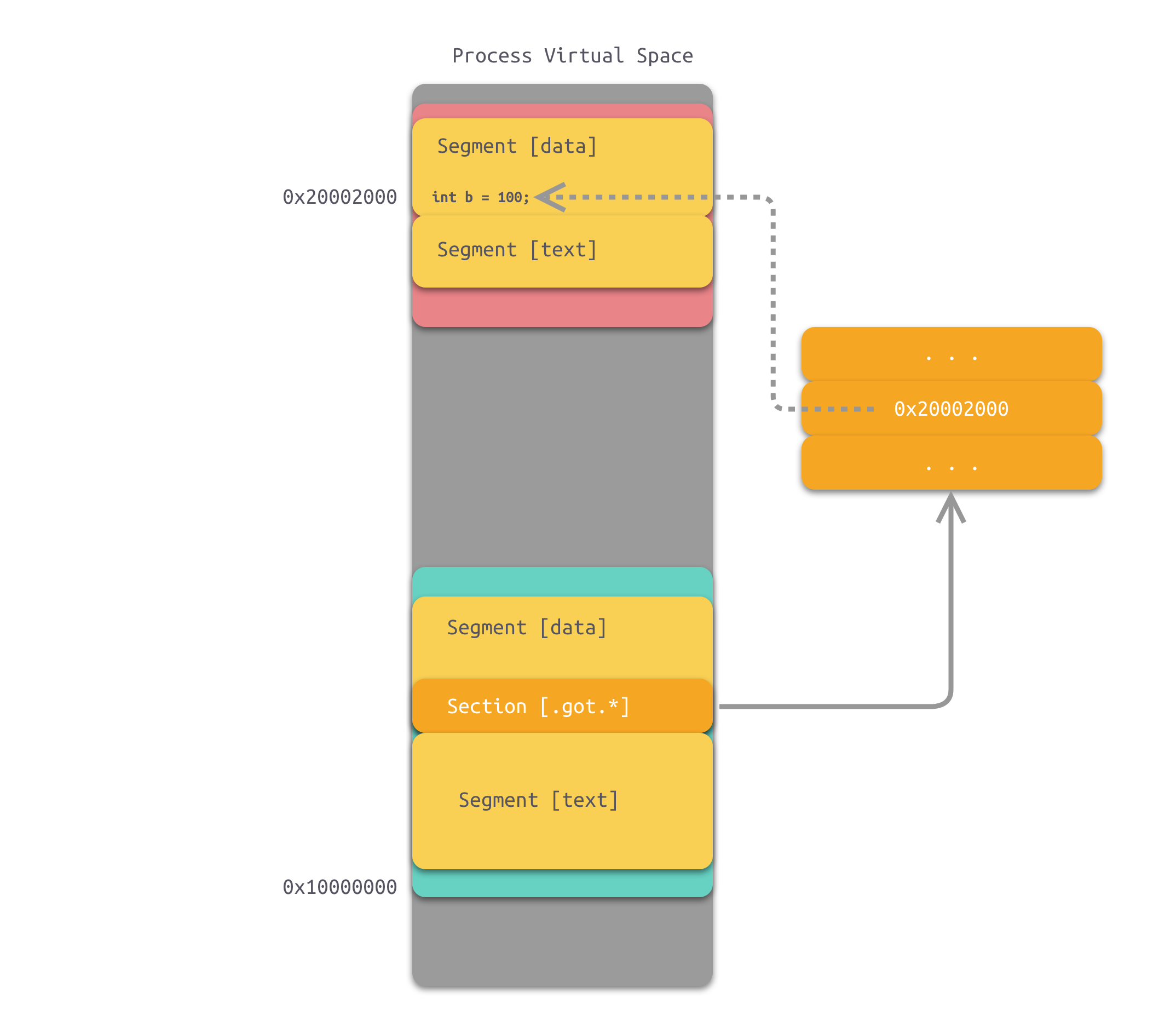
动态链接那些事
1、为什么要动态链接 1.1 空间浪费 对于静态链接来说,在程序运行之前,会将程序所需的所有模块编译、链接成一个可执行文件。这种情况下,如果 Program1 和 Program2 都需要用到 Lib.o 模块,那么,内存中和磁盘中实际上就…...

力扣:118. 杨辉三角(Python3)
题目: 给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 来源:力扣(LeetCode) 链接:力扣(LeetCode)官…...

QGIS文章二——DEM高程裁剪和3D地形图
经常看到别人基于高程文件制作出精美的3D地图,笔者按照互联网几种制作方式进行尝试后,写的DEM高程裁剪和3D地形图教程,或许其中有一些错误的,也请指出。 本文基于海南省的shp文件和海南省DEM高程文件,制作海口地区的3D…...

【kubernetes】kubernetes中的StatefulSet使用
TOC 1 为什么需要StatefulSet 常规的应用通常使用Deployment,如果需要在所有机器上部署则使用DaemonSet,但是有这样一类应用,它们在运行时需要存储一些数据,并且当Pod在其它节点上重建时也希望这些数据能够在重建后的Pod上获取&…...

创建文件夹
/storage/emulated/0/代码文件/ 没有就创建 文件名命名方法:编号. 库 时间戳 使用Python的os模块来检查目录是否存在,并在不存在时创建它。下面是一个示例代码,演示了如何检查指定路径下的目录是否存在,若不存在则创建…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...