大数据-玩转数据-Flink 海量数据实时去重
一、海量数据实时去重说明
借助redis的Set,需要频繁连接Redis,如果数据量过大, 对redis的内存也是一种压力;使用Flink的MapState,如果数据量过大, 状态后端最好选择 RocksDBStateBackend; 使用布隆过滤器,布隆过滤器可以大大减少存储的数据的数据量。
二、海里书实时去重为什么需要布隆过滤器
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。
但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为。
布隆过滤器即可以解决存储空间的问题, 又可以解决时间复杂度的问题.
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
三、布隆过滤基本概念
布隆过滤器(Bloom Filter,下文简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。它专门用来检测集合中是否存在特定的元素。
它实际上是一个很长的二进制向量和一系列随机映射函数。
实现原理
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
当要插入一个元素时,将其数据分别输入k个哈希函数,产生k个哈希值。以哈希值作为位数组中的下标,将所有k个对应的比特置为1。
当要查询(即判断是否存在)一个元素时,同样将其数据输入哈希函数,然后检查对应的k个比特。如果有任意一个比特为0,表明该元素一定不在集合中。如果所有比特均为1,表明该集合有(较大的)可能性在集合中。为什么不是一定在集合中呢?因为一个比特被置为1有可能会受到其他元素的影响(hash碰撞),这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
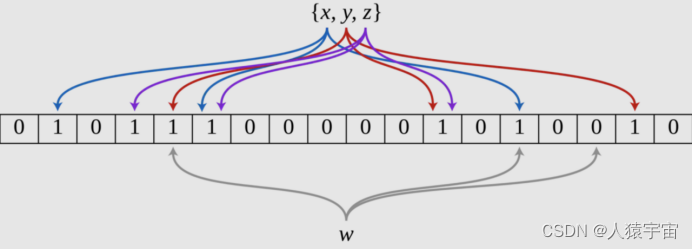
下图示出一个m=18, k=3的BF示例。集合中的x、y、z三个元素通过3个不同的哈希函数散列到位数组中。当查询元素w时,因为有一个比特为0,因此w不在该集合中。
优点
1.不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
2.时间效率也较高,插入和查询的时间复杂度均为, 所以他的时间复杂度实际是
3.哈希函数之间相互独立,可以在硬件指令层面并行计算。
缺点
1.存在假阳性的概率,不适用于任何要求100%准确率的情境;
2.只能插入和查询元素,不能删除元素,这与产生假阳性的原因是相同的。我们可以简单地想到通过计数(即将一个比特扩展为计数值)来记录元素数,但仍然无法保证删除的元素一定在集合中。
使用场景
所以,BF在对查准度要求没有那么苛刻,而对时间、空间效率要求较高的场合非常合适.
另外,由于它不存在假阴性问题,所以用作“不存在”逻辑的处理时有奇效,比如可以用来作为缓存系统(如Redis)的缓冲,防止缓存穿透。
假阳性概率的计算
假阳性的概率其实就是一个不在的元素,被k个函数函数散列到的k个位置全部都是1的概率。可以按照如下的步骤进行计算: p = f(m,n,k)
其中各个字母的含义:
1.n :放入BF中的元素的总个数;
2.m:BF的总长度,也就是bit数组的个数
3.k:哈希函数的个数;
4.p:表示BF将一个不在其中的元素错判为在其中的概率,也就是false positive的概率;
A.BF中的任何一个bit在第一个元素的第一个hash函数执行完之后为 0的概率是:
B.BF中的任何一个bit在第一个元素的k个hash函数执行完之后为 0的概率是:
C.BF中的任何一个bit在所有的n元素都添加完之后为 0的概率是:
D.BF中的任何一个bit在所有的n元素都添加完之后为 1的概率是:
E.一个不存在的元素被k个hash函数映射后k个bit都是1的概率是:
结论:在哈数函数个数k一定的情况下
1.比特数组m长度越大, p越小, 表示假阳性率越低
2.已插入的元素个数n越大, p越大, 表示假阳性率越大
经过各种数学推导:
对于给定的m和n,使得假阳性率(误判率)最小的k通过如下公式定义:
四、使用布隆过滤器实现去重
Flink已经内置了布隆过滤器的实现(使用的是google的Guava)
package com.lyh.flink12;import com.atguigu.flink.java.chapter_6.UserBehavior;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.shaded.guava18.com.google.common.hash.BloomFilter;
import org.apache.flink.shaded.guava18.com.google.common.hash.Funnels;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;public class Flink02_UV_BoomFilter {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 创建WatermarkStrategyWatermarkStrategy<UserBehavior> wms = WatermarkStrategy.<UserBehavior>forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner(new SerializableTimestampAssigner<UserBehavior>() {@Overridepublic long extractTimestamp(UserBehavior element, long recordTimestamp) {return element.getTimestamp() * 1000L;}});env.readTextFile("input/UserBehavior.csv").map(line -> { // 对数据切割, 然后封装到POJO中String[] split = line.split(",");return new UserBehavior(Long.valueOf(split[0]), Long.valueOf(split[1]), Integer.valueOf(split[2]), split[3], Long.valueOf(split[4]));}).filter(behavior -> "pv".equals(behavior.getBehavior())) //过滤出pv行为.assignTimestampsAndWatermarks(wms).keyBy(UserBehavior::getBehavior).window(TumblingEventTimeWindows.of(Time.minutes(60))).process(new ProcessWindowFunction<UserBehavior, String, String, TimeWindow>() {private ValueState<Long> countState;private ValueState<BloomFilter<Long>> bfState;@Overridepublic void open(Configuration parameters) throws Exception {countState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("countState", Long.class));bfState = getRuntimeContext().getState(new ValueStateDescriptor<BloomFilter<Long>>("bfState", TypeInformation.of(new TypeHint<BloomFilter<Long>>() {})));}@Overridepublic void process(String key,Context context,Iterable<UserBehavior> elements, Collector<String> out) throws Exception {countState.update(0L);// 在状态中初始化一个布隆过滤器// 参数1: 漏斗, 存储的类型// 参数2: 期望插入的元素总个数// 参数3: 期望的误判率(假阳性率)BloomFilter<Long> bf = BloomFilter.create(Funnels.longFunnel(), 1000000, 0.001);bfState.update(bf);for (UserBehavior behavior : elements) {// 查布隆if (!bfState.value().mightContain(behavior.getUserId())) {// 不存在 计数+1countState.update(countState.value() + 1L);// 记录这个用户di, 表示来过bfState.value().put(behavior.getUserId());}}out.collect("窗口: " + context.window() + " 的uv是: " + countState.value());}}).print();env.execute();}
}
相关文章:
大数据-玩转数据-Flink 海量数据实时去重
一、海量数据实时去重说明 借助redis的Set,需要频繁连接Redis,如果数据量过大, 对redis的内存也是一种压力;使用Flink的MapState,如果数据量过大, 状态后端最好选择 RocksDBStateBackend; 使用布隆过滤器,…...

1.在vsCode上创建Hello,World
(1).编译器的安装配置 使用vsCode进行编写c语言,首先需要安装gcc编译器,可以自己去寻找资料或者gcc官网进行下载. 下载好后,将文件夹放入到自己指定的目录后,配置系统环境变量,将path指向编译器的bin目录 进入bin目录打开cmd,输入gcc -v,然后就会成功输出信息. (2).vsCode配…...

XrayGLM - 医学大模型
文章目录 关于 XrayGLM研究背景VisualGLM-6B 关于 XrayGLM XrayGLM: 首个会看胸部X光片的中文多模态医学大模型 | The first Chinese Medical Multimodal Model that Chest Radiographs Summarization. 基于VisualGLM-6B 微调 github : https://github.com/WangRongsheng/Xra…...
)
Hive 常见数据倾斜场景及解决方案(Map\Join\Reduce端)
目录 MapReduce流程简述a) Map倾斜b) Join倾斜c) Reduce倾斜 首先回顾一下MapReduce的流程 MapReduce流程简述 输入分片: MapReduce 作业开始时,输入数据被分割成多个分片,每个分片大小一般在 16MB 到 128MB 之间。这些分片会被分配给不同的…...

C++中的四种强制类型转换符详解
前 言 C 既支持 C 风格的类型转换,又有自己风格的类型转换。C 风格的转换格式很简单,但是有不少缺点: 转换太过随意,可以在任意类型之间转换。你可以把一个指向 const 对象的指针转换成指向非 const 对象的指针,把一…...

Windows电脑多开器的优缺点对比
Windows电脑多开器是一种能够让用户同时运行多个应用程序、游戏或者网页的软件工具。它的作用在于让用户能够更加高效地工作、学习或者娱乐。但是,这种软件也存在一些优劣势的对比。 优点: 提升工作效率。多开器可以让用户同时打开多个应用程序或者网页…...
Java笔记六(面向对象:类与对象)
面向对象编程的本质:以类的方式组织代码,以对象的组织(封装)数据 抽象 三大特征:封装 继承 多态 从认识角度考虑是先有对象后有类。对象,是具体的事物。类,是抽象的,是对对象的抽…...
Git使用【中】
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析3 目录 👉🏻分支管理分支概念git branch(查看/删除分…...

Greenplum7一键安装
2023年9月底,Greenplum 发布了7.0.0版本,并于2023年10月03日开放了安装部署说明文档,现在快速尝鲜版的docker一键部署方式如下: mkdir /data/gpdb docker run -d --name greenplum -p 15432:5432 -v /data/gpdb:/data inrgihc/g…...
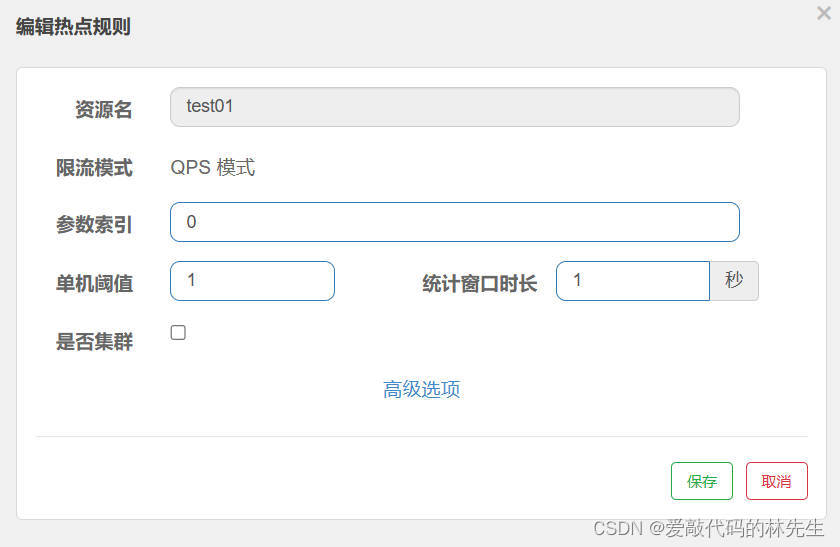
Springboo整合Sentinel
Springboo整合Sentinel 1.启动Sentinel java -jar sentinel-dashboard-1.8.6.jar2.访问localhost:8080到Sentinel管理界面(默认账号和密码都是sentinel) 3.引入依赖(注意版本对应) <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spr…...
python爬取csdn个人首页中的所有封面
#爬取csdn个人首页中的所有封面 import requests import json import reurlhttps://blog.csdn.net/community/home-api/v1/get-business-list? headers{User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safar…...

EasyHttp - 网络请求,如斯优雅
官网 项目地址:Github博客地址:网络请求,如斯优雅 OkHttp 另外对 OkHttp 原理感兴趣的同学推荐你看以下源码分析文章 OkHttp 精讲:拦截器执行原理OkHttp 精讲:RetryAndFollowUpInterceptorOkHttp 精讲:…...

【Java】Stream的基本使用
Stream特点 Stream的一系列操作组成了Stream的流水线, Stream流水线包含: 数据源: 这里的数据源可能是集合/数组, 可能是生成器, 甚至可能是IO通道(Files.lines)零个或多个中间操作: 中间操作会导致流之间的转化, 如filter(Predicate)一个终端操作: 终端操作会产生最终所需要的…...
idea Springboot 高校科研资源共享系统VS开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 springboot 高校科研资源共享系统是一套完善的信息系统,结合springboot框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用springboot框架(MVC模式开发), 系统具有完整的源代码和数据…...
机器学习算法基础--K-means应用实战--图像分割
目录 1.项目内容介绍 2.项目关键代码 3.项目效果展示 1.项目内容介绍 本项目是将一张图片进行k-means分类,根据色彩k进行分类,最后比较和原图的效果。 题目还是比较简单的,我们只要通过k-means聚类,一类就是一种色彩得出聚类之…...
CSS学习小结
css的两种使用方式: ①内嵌样式表 ②导入外部样式表(实际开发常用)<link href"...." rel"stylesheet"/> 选择器: ①标签选择器:通过标签种类决定 ②类选择器:class"..…...

数据挖掘实验(一)数据规范化【最小-最大规范化、零-均值规范化、小数定标规范化】
一、数据规范化的原理 数据规范化处理是数据挖掘的一项基础工作。不同的属性变量往往具有不同的取值范围,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果。为了消除指标之间由于取值范围带来的差异,需要进行标准化处理。将数据…...
C++17中std::filesystem::directory_entry的使用
C17引入了std::filesystem库(文件系统库, filesystem library)。这里整理下std::filesystem::directory_entry的使用。 std::filesystem::directory_entry,目录项,获取文件属性。此directory_entry类主要用法包括: (1).构造函数、…...
C/C++跨平台构建工具CMake入门
文章目录 1.概述2.环境准备2.1 安装编译工具2.2 安装CMake 3.编译一个示例程序总结 1.概述 本人一直对OpenGL的3d渲染很感兴趣,但是苦于自己一直是Android开发,没有机会接触这方面的知识。就在最近吗,机会来了,以前一个做3D渲染的…...
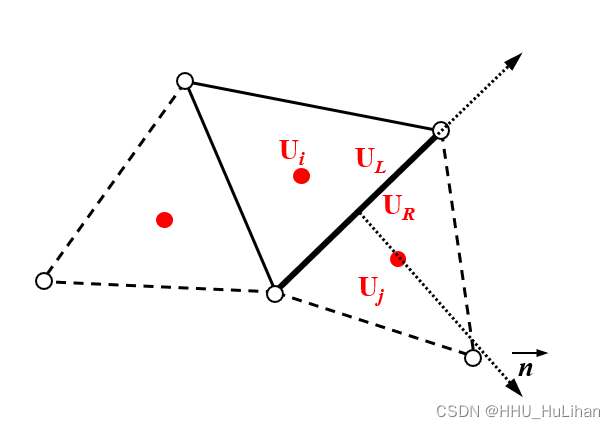
【CFD小工坊】浅水方程的离散及求解方法
【CFD小工坊】浅水方程的离散及求解方法 前言基于有限体积法的方程离散界面通量与源项计算干-湿网格的处理数值离散的稳定性条件参考文献 前言 我们模型的控制方程,即浅水方程组的表达式如下: ∂ U ∂ t ∂ E ( U ) ∂ x ∂ G ( U ) ∂ y S ( U ) U…...

Caffeine缓存库进阶指南:动态过期时间的3种实现方式对比
Caffeine缓存库进阶指南:动态过期时间的3种实现方式对比 在Java应用性能优化领域,缓存技术扮演着至关重要的角色。作为Guava Cache的现代替代品,Caffeine凭借其卓越的性能和灵活的API设计,已成为众多中高级Java开发者的首选缓存解…...

【技术解读】NeuroLM:当EEG成为LLM的“第二语言”,多任务脑电分析的统一范式
1. 当脑电波遇上大语言模型:NeuroLM的技术革命 想象一下,如果你的脑电波能像外语一样被AI翻译和理解,会是怎样的场景?这正是NeuroLM带来的颠覆性突破。这个将EEG(脑电图)信号视为"第二语言"的通用…...

倒立摆这玩意儿在控制领域算是个经典玩具,今天咱们用MATLAB整点有意思的——用LQR同时实现小车的平衡控制和外加摆杆起摆。先来点硬核的,直接上状态方程
MATLAB直线倒立摆一阶倒立摆LQR控制仿真,小车倒立摆起摆和平衡控制,附带参考文献% 系统参数(单位全部国际标准制) M 0.5; % 小车质量 m 0.2; % 摆杆质量 l 0.3; % 摆杆半长 g 9.81; % 重力加速度% 状态空间模型推导…...

计算机毕业设计springboot小区服务平台管理设计与开发 基于SpringBoot的智慧社区综合管理系统设计与实现 微服务架构下住宅小区数字化服务平台构建研究
计算机毕业设计springboot小区服务平台管理设计与开发jylcm9 (配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着城镇化进程的不断加快,城市住宅小区数量持续增长&am…...

【生产级部署】基于Docker Compose构建高可用StarRocks数据仓库集群
1. 为什么选择Docker Compose部署StarRocks 在数据仓库选型时,我们往往会面临一个经典问题:如何在保证性能的同时简化部署流程?StarRocks作为新一代MPP分析型数据库,凭借其优异的查询性能在实时分析场景中脱颖而出。但传统部署方…...

Outlookmail Plus
链接:https://pan.quark.cn/s/0d68dd538fae用于统一管理 Outlook / IMAP 邮箱账号、读取邮件、提取验证码,并支持邮箱池调度的 Web 项目(or 注册机...

《ShardingSphere解读》13 路由引擎:如何理解分片路由核心类 ShardingRouter 的运作机制?
前面我们对 ShardingSphere 中的 SQL 解析引擎做了介绍,我们明白 SQL 解析的作用就是根据输入的 SQL 语句生成一个 SQLStatement 对象。 从今天开始,我们将进入 ShardingSphere 的路由(Routing)引擎部分的源码解析。从流程上讲&am…...

Nanbeige 4.1-3B惊艳案例分享:学生用像素贤者终端完成编程作业与故事创作
Nanbeige 4.1-3B惊艳案例分享:学生用像素贤者终端完成编程作业与故事创作 1. 像素冒险终端的独特魅力 1.1 打破常规的交互体验 Nanbeige 4.1-3B像素冒险聊天终端彻底改变了传统AI对话界面的刻板印象。这款采用JRPG风格设计的终端,将枯燥的编程和写作任…...

用Human Resource Machine教孩子学编程:20个趣味关卡背后的计算机原理
用Human Resource Machine解锁孩子的计算思维:20个趣味关卡中的编程奥秘 当我的小侄女第一次在平板上玩《Human Resource Machine》时,她完全没意识到自己正在学习计算机科学中最核心的概念。这款看似简单的游戏,实际上是一套精心设计的可视化…...

如何快速掌握多光谱目标检测:跨模态融合技术的终极指南
如何快速掌握多光谱目标检测:跨模态融合技术的终极指南 【免费下载链接】multispectral-object-detection Multispectral Object Detection with Yolov5 and Transformer 项目地址: https://gitcode.com/gh_mirrors/mu/multispectral-object-detection 多光谱…...