2G大小的GPU对深度学习的加速效果如何?
训练数据情况
总共42776张224*224*3张图片
Found 42776 files belonging to 9 classes.
Using 12833 files for training.
模型参数情况
Total params: 10,917,385
Trainable params: 10,860,745
Non-trainable params: 56,640
batch-size:12
GPU信息
NVIDIA GeForce GT 730
驱动程序版本: 27.21.14.6133
驱动程序日期: 2021/1/19
DirectX 版本: 12 (FL 11.0)
物理位置: PCI 总线 1、设备 0、功能 0
利用率 11%
专用 GPU 内存 0.3/2.0 GB
共享 GPU 内存 0.0/31.9 GB
GPU 内存 0.4/33.9 GB
训练情况分析
完全使用CPU进行训练的时候,每次训练大约需要2750s。
Epoch 1/65
2496/2496 [==============================] - 2937s 1s/step - loss: 0.4254 - accuracy: 0.8403 - val_loss: 0.3192 - val_accuracy: 0.8867
Epoch 2/65
2496/2496 [==============================] - 2756s 1s/step - loss: 0.2890 - accuracy: 0.8973 - val_loss: 0.4358 - val_accuracy: 0.8520
Epoch 3/65
2496/2496 [==============================] - 2737s 1s/step - loss: 0.2464 - accuracy: 0.9102 - val_loss: 0.2689 - val_accuracy: 0.9020使用GPU加速进行训练的时候,每次训练的时间从2750s缩短到2100s左右,每次训练大约节省了650秒,效果也是比较明显的。
Epoch 1/65
2023-10-04 10:38:26.686146: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cudnn64_8.dll
2023-10-04 10:38:27.343524: I tensorflow/stream_executor/cuda/cuda_dnn.cc:359] Loaded cuDNN version 8101
2023-10-04 10:38:28.439803: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cublas64_11.dll
2023-10-04 10:38:29.088670: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cublasLt64_11.dll
2023-10-04 10:38:31.502277: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 606.50MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 10:38:31.805129: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.16GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 10:38:32.084683: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 599.75MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 10:38:32.129001: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 620.00MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 10:38:32.738828: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 620.00MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 10:38:32.801711: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 592.75MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 10:38:33.034554: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 592.19MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 10:38:33.056645: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 599.75MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 10:38:33.099135: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.14GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 10:38:33.124441: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.17GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
1070/1070 [==============================] - 2120s 2s/step - loss: 0.5235 - accuracy: 0.8034 - val_loss: 0.5122 - val_accuracy: 0.8171
Epoch 2/65
1070/1070 [==============================] - 2060s 2s/step - loss: 0.3620 - accuracy: 0.8668 - val_loss: 2.9616 - val_accuracy: 0.4629
Epoch 3/65124/1070 [==>...........................] - ETA: 18:02 - loss: 0.3194 - accuracy: 0.8844
Process finished with exit code -1
使用更小的数据集效果分析
数据集
10249
Found 10249 files belonging to 16 classes.
Using 3075 files for training.
参数
Total params: 6,143,760
Trainable params: 6,113,168
Non-trainable params: 30,592
只使用CPU
Epoch 1/65
684/684 [==============================] - 758s 1s/step - loss: 1.1408 - accuracy: 0.5963 - val_loss: 3.0769 - val_accuracy: 0.2738
Epoch 2/65
684/684 [==============================] - 744s 1s/step - loss: 0.7745 - accuracy: 0.7173 - val_loss: 1.0438 - val_accuracy: 0.6369
Epoch 3/65
684/684 [==============================] - 769s 1s/step - loss: 0.6504 - accuracy: 0.7602 - val_loss: 0.8624 - val_accuracy: 0.6964使用GPU
小数据集速度节省了接近50%
Epoch 1/65
2023-10-04 16:58:19.928226: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cudnn64_8.dll
2023-10-04 16:58:20.236817: I tensorflow/stream_executor/cuda/cuda_dnn.cc:359] Loaded cuDNN version 8101
2023-10-04 16:58:20.791072: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cublas64_11.dll
2023-10-04 16:58:21.096985: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cublasLt64_11.dll
2023-10-04 16:58:23.704576: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.16GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 16:58:24.962633: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.14GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 16:58:24.987354: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.17GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
256/257 [============================>.] - ETA: 0s - loss: 1.3775 - accuracy: 0.51432023-10-04 17:01:47.489983: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.15GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 17:01:48.530265: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.14GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 17:01:48.550469: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.15GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
257/257 [==============================] - ETA: 0s - loss: 1.3776 - accuracy: 0.51452023-10-04 17:04:21.899587: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 626.56MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 17:04:23.391704: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.15GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2023-10-04 17:04:23.801583: W tensorflow/core/common_runtime/bfc_allocator.cc:271] Allocator (GPU_0_bfc) ran out of memory trying to allocate 615.50MiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
257/257 [==============================] - 368s 1s/step - loss: 1.3776 - accuracy: 0.5145 - val_loss: 5.9301 - val_accuracy: 0.2432
Epoch 2/65
257/257 [==============================] - 376s 1s/step - loss: 1.0042 - accuracy: 0.6237 - val_loss: 1.0432 - val_accuracy: 0.6183
Epoch 3/65
相关文章:

2G大小的GPU对深度学习的加速效果如何?
训练数据情况 总共42776张224*224*3张图片 Found 42776 files belonging to 9 classes. Using 12833 files for training. 模型参数情况 Total params: 10,917,385 Trainable params: 10,860,745 Non-trainable params: 56,640 batch-size:12 GPU信息 NVIDIA GeForce GT 7…...

intel 一些偏门汇编指令总结
intel 汇编手册下载链接:https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html LDS指令: 手册中可以找到 位于 3-588 根据手册内容猜测:lds r16 m16:16 的作用,是把位于 [m16:16] 内存地址的数…...

python 多个proto文件import引用时出现ModuleNotFoundError错误
问题描述 my_proto文件夹里有两个proto文件,book.proto想要引用person.proto文件中的Person,如下 book.proto syntax "proto2";import "person.proto"; // 导入person.proto文件message Book {optional string name 1;optional …...
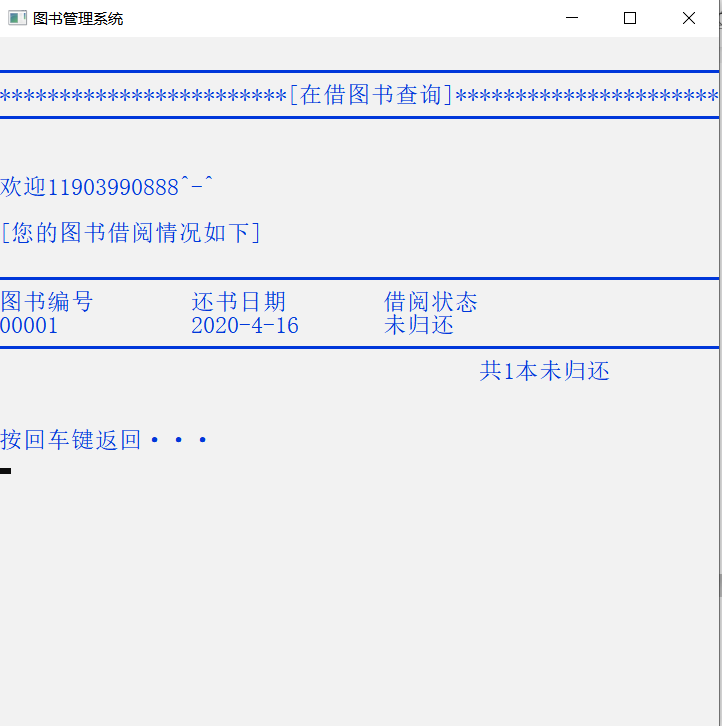
C语言图书管理系统
一、 系统概述 图书管理系统是一个用C语言编写的软件系统,旨在帮助图书馆或图书机构管理其图书馆藏书和读者信息。该系统提供了一套完整的功能,包括图书录入、借阅管理、归还管理、读者管理、图书查询、统计报表等。 二、 系统功能 2.1 图书录入 管理…...

归并排序及其非递归实现
个人主页:Lei宝啊 愿所有美好如期而遇 目录 归并排序递归实现 归并排序非递归实现 归并排序递归实现 图示: 代码: 先分再归并,像是后序一般。 //归并排序 void MergeSort(int* arr, int left, int right) {int* temp (int…...
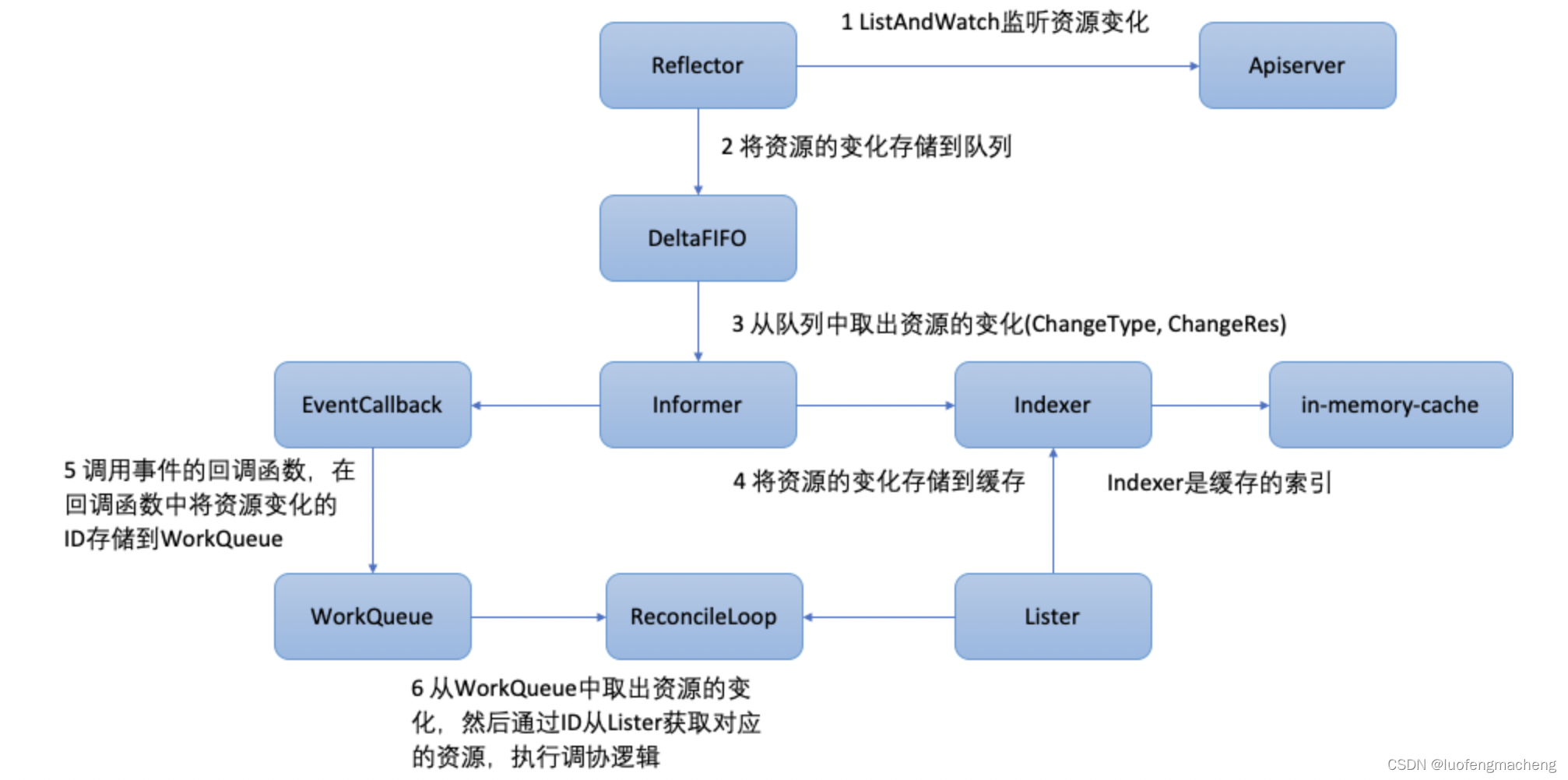
【kubernetes】kubernetes中的Controller
1 什么是Controller? kubernetes采用了声明式API,与声明式API相对应的是命令式API: 声明式API:用户只需要告诉期望达到的结果,系统自动去完成用户的期望命令式API:用户需要关注过程,通过命令一…...

RabbitMQ-死信队列
接上文 RabbitMQ-java使用消息队列 1 死信队列简介 死信队列模式实际上本质是一个死信交换机绑定的死信队列,当正常队列的消息被判定为死信时,会被发送到对应的死信交换机,然后再通过交换机发送到死信队列中,死信队列也有对应的消…...

ElasticSearch - 基于 DSL 、JavaRestClient 实现数据聚合
目录 一、数据聚合 1.1、基本概念 1.1.1、聚合分类 1.1.2、特点 1.2、DSL 实现 Bucket 聚合 1.2.1、Bucket 聚合基础语法 1.2.2、Bucket 聚合结果排序 1.2.3、Bucket 聚合限定范围 1.3、DSL 实现 Metrics 聚合 1.4、基于 JavaRestClient 实现聚合 1.4.1、组装请求 …...
什么是数学建模(mooc笔记)
什么是数学建模 前提:我们数学建模国赛计划选择C题,故希望老师的教学中侧重与C题相关性大的模型及其思想进行培训。之后的学习内容中希望涉及以下知识点: logistic回归相关知识点。如:用法、适用、限制范围等。精学数学建模中常…...
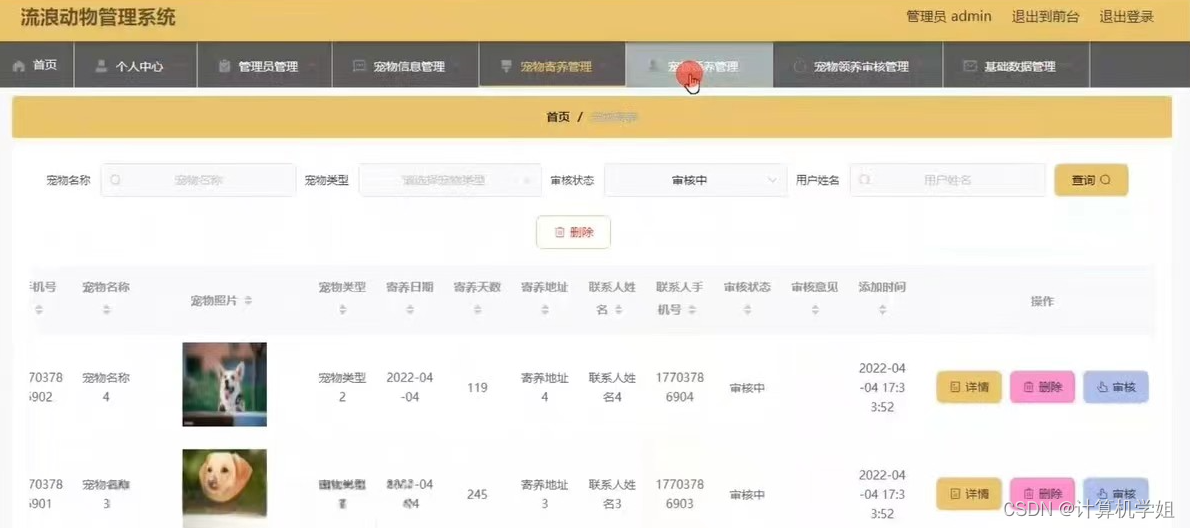
基于SpringBoot的流浪动物管理系
基于SpringBoot的流浪动物管理系的设计与实现,前后端分离 开发语言:Java数据库:MySQL技术:SpringBootMyBatisVue工具:IDEA/Ecilpse、Navicat、Maven 系统展示 首页 后台登陆界面 管理员界面 摘要 基于Spring Boot的…...
fcpx插件:82种复古电影胶卷框架和效果mFilm Matte
无论您是在制作音乐剪辑、私人假期视频还是大型广告活动,这个专业的插件都将帮助您为您的镜头赋予真正的电影角色。 复古效果在任何视频中都能立即识别出来,增添了感伤的复古氛围,并使镜头更具说服力。使用 mFilm Matte 轻松实现这些特征&…...
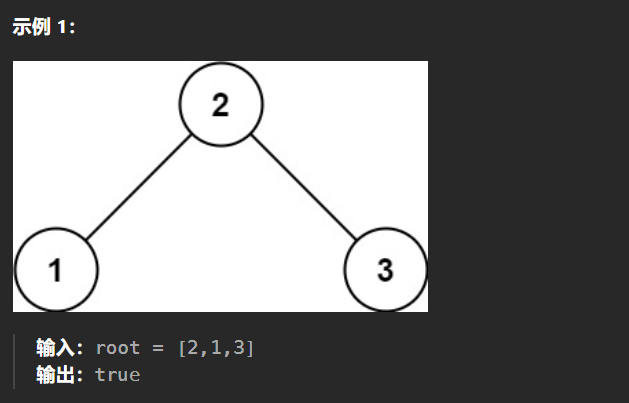
【LeetCode热题100】--98.验证二叉搜索树
98.验证二叉搜索树 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下: 节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。 由于二…...

wxpython:wx.grid 表格显示 Excel xlsx文件
pip install xlrd xlrd-1.2.0-py2.py3-none-any.whl (103 kB) 摘要: Library for developers to extract data from Microsoft Excel (tm) spreadsheet files pip install wxpython4.2 wxPython-4.2.0-cp37-cp37m-win_amd64.whl (18.0 MB) Successfully installed wxpython-4.…...

事件循环机制
eventLoop 事件循环(Event Loop)是用于管理和调度异步任务执行的一种机制,通常在浏览器中,也在其他 JavaScript 运行环境中存在。事件循环确保 JavaScript 单线程的执行模型下能够处理非阻塞的异步任务,以避免程序阻塞…...

苹果曾考虑基于定位控制AirPods Pro自适应音频
在一次最近的采访中,苹果公司的高管Ron Huang和Eric Treski透露,他们在开发AirPods Pro自适应音频功能时,曾考虑使用GPS信号来控制音频级别。这个有趣的细节打破了我们对AirPods Pro的固有认知,让我们对苹果的创新思维有了更深的…...

【代码阅读笔记】yolov5 rknn模型部署
一、main函数思路 二、值得学习的地方 1、关注yolov5检测流程 2、其中几个重要的结构体 typedef struct {int left;int right;int top;int bottom; } YOLOV5_BOX_RECT; // box坐标信息typedef struct {char name[YOLOV5_NAME_MAX_SIZE];int class_index;YOLOV5_BOX_RECT box…...
【多线程】进程与线程 并发编程 面试题总结
进程和线程 进程是程序执行时的一个实例,即它是程序已经执行到何种程度的数据结构的汇集。从内核的观点看,进程的目的就是担当分配系统资源(CPU时间、内存等)的基本单位。线程是进程的一个执行流,是CPU调度和分派的基…...

C++算法 —— 动态规划(10)二维费用背包
文章目录 1、动规思路简介2、一和零3、盈利计划 背包问题需要读者先明白动态规划是什么,理解动规的思路,并不能给刚接触动规的人学习。所以最好是看了之前的动规博客,以及两个背包博客,或者你本人就已经懂得动规了。 1、动规思路简…...

MySQL数据库正在耗用大量CPU的问题排查
这是一篇实战性的文章,如何处理正在发生的MYSQL服务器CPU飙升的问题,一般情况下,MySQL是不会耗用这么高的CPU的,要么是不走索引的查询,要么是同一时间出现了大量比较耗用资源的查询,不管出现的是哪一种情况…...

php替换字符串里的a变为b
$tempstrstr_replace("\\","/",$tempstr); //把$tempstr中的a替换成b $tempstrstr_replace("a","b",$tempstr);...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...

多元隐函数 偏导公式
我们来推导隐函数 z z ( x , y ) z z(x, y) zz(x,y) 的偏导公式,给定一个隐函数关系: F ( x , y , z ( x , y ) ) 0 F(x, y, z(x, y)) 0 F(x,y,z(x,y))0 🧠 目标: 求 ∂ z ∂ x \frac{\partial z}{\partial x} ∂x∂z、 …...