MySQL 多表关联查询优化实践和原理解析
目录
- 一、前言
- 二、表数据准备
- 三、表关联查询原理和两种算法
- 3.1、研究关联查询算法必备知识点
- 3.2、嵌套循环连接 Nested-Loop Join(NLJ) 算法
- 3.3、基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法
- 3.4、被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 Nested-Loop Join 呢?
- 四、多表关联查询优化实践
- 4.1、使用左连接查询 全部订单列表信息返回订单编号和客户昵称
- 4.2、使用内连接查询 全部订单列表信息返回订单编号和客户昵称
- 4.3、使用内连接查询 客户编号`C00000999`全部订单列表信息返回订单编号和客户昵称
- 五、总结
一、前言
索引是为了高效查询排好序的数据结构,当表数据量到达一个量级没有对应索引帮助查询耗时会很长,MySQL资源开销也会非常大,对于多表关联查询来说没有对应索引辅助查询资源开销是灾难级的,当然索引也不能随意创建,要做到尽量少的索引解决尽量多的问题,这里会对一些业务场景做索引优化演示,也会讲解多表关联查询的底层原理。
二、表数据准备
这里准备10w条订单数据和1000条用户数据,数据量越大能看到的效果越明显。
- 订单信息表和数据准备
# 创建订单信息表
DROP TABLE IF EXISTS `order_info`;
CREATE TABLE `order_info` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '订单ID',`order_no` varchar(100) NOT NULL COMMENT '订单编号',`customer_id` bigint(20) NOT NULL COMMENT '客户ID',`customer_no` varchar(100) NOT NULL COMMENT '客户编号',`goods_id` bigint(20) NOT NULL COMMENT '商品ID',`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='订单信息表';## 创建一个插入数据的存储过程
DROP PROCEDURE IF EXISTS insert_order_procedure;
delimiter;;
CREATE PROCEDURE insert_order_procedure()
BEGINDECLARE i INT DEFAULT 1;DECLARE customer_id BIGINT;DECLARE t_error INTEGER DEFAULT 0;DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET t_error=1;START TRANSACTION;WHILE ( i <= 100000 ) DOSET customer_id = CEIL(RAND() * 1000);INSERT INTO `order_info`(`order_no`,`customer_id`,`customer_no`, `goods_id`, `create_time`) VALUES (CONCAT('ON00000',i), customer_id, CONCAT('C00000',customer_id), CEIL(RAND() * 100), NOW());SET i = i + 1;END WHILE;IF t_error=1 THENROLLBACK;ELSECOMMIT;END IF;
END;;
delimiter;# 调用存储过程插入数据 我本地插入10w条数据耗时20s
CALL insert_order_procedure();
- 客户信息表和数据准备
# 创建客户信息表
DROP TABLE IF EXISTS `customer_info`;
CREATE TABLE `customer_info` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '客户ID',`customer_no` varchar(100) DEFAULT NULL COMMENT '客户编号',`nick_name` varchar(20) DEFAULT NULL COMMENT '昵称',`age` int(11) DEFAULT NULL COMMENT '年龄',`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='客户信息表';## 创建一个插入数据的存储过程
DROP PROCEDURE IF EXISTS insert_customer_procedure;
delimiter;;
CREATE PROCEDURE insert_customer_procedure()
BEGINDECLARE i INT DEFAULT 1;DECLARE t_error INTEGER DEFAULT 0;DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET t_error=1;START TRANSACTION;WHILE ( i <= 1000 ) DOINSERT INTO `customer_info`(`customer_no`,`nick_name`, `age`, `create_time`) VALUES (CONCAT('C00000',i),CONCAT('Kerwin',i), CEIL(RAND() * 100), NOW());SET i = i + 1;END WHILE;IF t_error=1 THENROLLBACK;ELSECOMMIT;END IF;
END;;
delimiter;# 调用存储过程插入数据
CALL insert_customer_procedure();
三、表关联查询原理和两种算法
在MySQL中表关联查询有两种算法,在关联字段有索引时使用的是 嵌套循环连接 Nested-Loop Join(NLJ) 算法,在没有索引时使用的是 基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法,下面会对两种算法做解释。
3.1、研究关联查询算法必备知识点
研究关联查询首先要知道什么是驱动表和什么是被驱动表,MySQL常用三种关联查询分别为左外连接(LEFT JOIN ON)、右外连接(RIGHT JOIN ON)、内连接(INNER JOIN ON),对于这三种关联查询驱动表和被驱动表也是不同的,下面举例说明。
- 左外连接(LEFT JOIN ON)
EXPLAIN SELECT * FROM order_info t1 LEFT JOIN customer_info t2 ON t1.customer_no=t2.customer_no;

执行计划中如果id相同那么执行顺序是由上到下,在执行计划里我们可以看到 t1(order_info)在上,t2(customer_info)在下,关联查询中谁在上那么谁就是驱动表,所以 t1(order_info)为驱动表,t2(customer_info)为被驱动表。
- 右外连接(RIGHT JOIN ON)
EXPLAIN SELECT * FROM order_info t1 RIGHT JOIN customer_info t2 ON t1.customer_no=t2.customer_no;

执行计划中如果id相同那么执行顺序是由上到下,在执行计划里我们可以看到t2(customer_info)在上, t1(order_info)在下,关联查询中谁在上那么谁就是驱动表,所以 t2(customer_info)为驱动表,t1(order_info)为被驱动表。
-
内连接(INNER JOIN ON)
- 查看执行计划SQL
EXPLAIN SELECT * FROM order_info t1 INNER JOIN customer_info t2 ON t1.customer_no=t2.customer_no;- 两张表的customer_no字段都没有索引

- 两张表的customer_no字段都有索引
# 添加索引 ALTER TABLE `customer_info` ADD INDEX `idx_customerNo`(`customer_no`); ALTER TABLE `order_info` ADD INDEX `idx_customerNo`(`customer_no`);
- customer_info表有customer_no字段索引order_info表没有
# 删除索引 ALTER TABLE `order_info` DROP INDEX `idx_customerNo`;
- order_info表有customer_no字段索引customer_info表没有
# 删除索引 ALTER TABLE `customer_info` DROP INDEX `idx_customerNo`; # 添加索引 ALTER TABLE `order_info` ADD INDEX `idx_customerNo`(`customer_no`);
-
总结
驱动表和被驱动表的辨认方式就在其执行顺序,在上的是驱动表,在下的是被驱动表,左连接查询那么左边的表一定是驱动表,右连接查询那么右边的表一定是驱动表,内连接会根据表的大小还有是否有索引来选择驱动表和被驱动表,因为customer_info只有1000条数据而order_info表有10w条数据在两张表都没有索引的情况下内连接选择了customer_info做驱动表,在两张表都有索引的情况下会内连接选择小表做驱动表,在一张表有索引一张表没有索引的情况下内连接会选择没有索引的表作为驱动表,原因会在下面说明。
3.2、嵌套循环连接 Nested-Loop Join(NLJ) 算法
嵌套循环连接算法一次一行循环地从第一张表(称为驱动表)中读取行,在这行数据中取到关联字段,根据关联字段在另一张表(被驱动表)里取出满足条件的行,然后取出两张表的结果合集,嵌套循环连接中被驱动表关联字段一定是有索引,如果没有索引那用的就是基于块的嵌套循环连接算法,下面演示一下。
- 因为嵌套循环连接需要索引,这里先对order_info表的customer_no创建一个普通索引:
# 如果没有删除customer_info表中的idx_customerNo索引需要先删除
ALTER TABLE `customer_info` DROP INDEX `idx_customerNo`;
# 添加order_info表索引
ALTER TABLE `order_info` ADD INDEX `idx_customerNo`(`customer_no`);
- 查看执行计划
EXPLAIN SELECT * FROM order_info t1 INNER JOIN customer_info t2 ON t1.customer_no=t2.customer_no;

这里可以看到内连接使用了customer_info作为驱动表,使用order_info作为被驱动表,还使用到了我们刚刚创建的idx_customerNo索引。
- 上面sql的大致流程如下:
- 1、从表 t2 中读取一行数据(如果t2表有查询过滤条件的,会从过滤结果里取出一行数据。
- 2、从第 1 步的数据中,取出关联字段 customer_no,到表 t1 中查找。
- 3、取出表 t1 中满足条件的行,跟 t2 中获取到的结果合并,作为结果返回给客户端。
- 4、 重复上面 3 步。
整个过程会读取 t2 表的所有数据(扫描1000行),然后遍历这每行数据中字段 customer_no 的值,根据 t2 表中 customer_no 的值索引扫描 t1 表中的对应行(扫描1000次 t1 表的索引,因为我们这里是一对多关系1次扫描可能最终扫描 t1 表对应多行完整数据,如果是一对一关系,也就是总共 t1 表也扫描了1000行),为了方便计算假设一个用户编号只能下一个订单因此整个过程扫描了 2000 行。
如果被驱动表的关联字段没索引,使用NLJ算法性能会比较低(下面有详细解释),MySQL会选择Block Nested-Loop Join算法。
3.3、基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法
基于块的嵌套循环连接算法和嵌套循环连接算法区别就在于被驱动表的关联字段没索引,基于块的嵌套循环连接算法会把驱动表的数据读入到 join_buffer 中,然后扫描被驱动表,把被驱动表每一行取出来跟 join_buffer 中的数据做对比。
- 先将表中的二级索引全删除
# 删除索引
ALTER TABLE `customer_info` DROP INDEX `idx_customerNo`;
ALTER TABLE `order_info` DROP INDEX `idx_customerNo`;
-
查看执行计划

这里可以看到内连接使用了customer_info作为驱动表,使用order_info作为被驱动表,而且在Extra中出现了Using join buffer (Block Nested Loop)说明该关联查询使用的是 BNL 算法。 -
上面sql的大致流程如下:
- 1、把 t2 的所有数据放入到 join_buffer 中
- 2、把表 t1 中每一行取出来,跟 join_buffer 中的数据做对比
- 3、返回满足 join 条件的数据
整个过程对表 t1 和 t2 都做了一次全表扫描,因此扫描的总行数为100000(表 t1 的数据总量) + 1000(表 t2 的数据总量) =101000。并且 join_buffer 里的数据是无序的,因此对表 t1 中的每一行,都要做 1000 次判断,所以内存中的判断次数是1000 * 100000= 1 亿次。
这个例子里表 t2 才 1000 行,要是表 t2 是一个大表,join_buffer 放不下怎么办呢?join_buffer 的大小是由参数 join_buffer_size 设定的,默认值是 256k。如果放不下表 t2 的所有数据话,策略很简单,就是分段放。
比如 t2 表有1000行记录, join_buffer 一次只能放800行数据,那么执行过程就是先往 join_buffer 里放800行记录,然后从 t1 表里取数据跟 join_buffer 中数据对比得到部分结果,然后清空 join_buffer ,再放入 t2 表剩余200行记录,再次从 t1 表里取数据跟 join_buffer 中数据对比。所以就多扫了一次 t1 表。
3.4、被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 Nested-Loop Join 呢?
如果上面第二条sql使用 Nested-Loop Join,那么扫描行数为 1000 * 100000 = 1亿次,这个是磁盘扫描。很显然,用BNL磁盘扫描次数少很多,相比于磁盘扫描,BNL的内存计算会快得多。
因此MySQL对于被驱动表的关联字段没索引的关联查询,一般都会使用 BNL 算法。如果有索引一般选择 NLJ 算法,有索引的情况下 NLJ 算法比 BNL算法性能更高。
四、多表关联查询优化实践
在前面说明了表关联查询原理和两种算法,其实基本优化思路就已经有了,那就是一定要小表驱动大表,给表关联字段加索引,下面会对一些情况做举例说明。
PS:这里例子使用的MySQL版本为5.7,MySQL8.0连接查询看着是没什么变化但是底层好像做了一些优化,我试了几个例子有索引反而会比没索引慢一点,
4.1、使用左连接查询 全部订单列表信息返回订单编号和客户昵称
# 删除索引
ALTER TABLE `customer_info` DROP INDEX `idx_customerNo`;
ALTER TABLE `order_info` DROP INDEX `idx_customerNo`;
SELECT t1.order_no,t2.nick_name FROM order_info t1 LEFT JOIN customer_info t2 ON t1.customer_no=t2.customer_no;
-
无索引情况查询测试


使用左连接查询无索引时耗时12.497s,因为使用了左连接所以会已左边的表为驱动表,右连接则会用右边表作为驱动表。 -
添加order_info表中的customer_no字段索引查询测试
# 添加索引 ALTER TABLE `order_info` ADD INDEX `idx_customerNo`(`customer_no`);

添加了order_info表的customer_no字段索引查询耗时和不添加基本一致,也没有使用到创建的索引。 -
添加customer_info表中的customer_no字段索引查询测试
ALTER TABLE `customer_info` ADD INDEX `idx_customerNo`(`customer_no`);

添加customer_info表中的customer_no字段索引查询耗时0.664s效率有大大提升,这里也看到了被驱动表有使用到索引会使用NLJ算法。
4.2、使用内连接查询 全部订单列表信息返回订单编号和客户昵称
# 删除索引
ALTER TABLE `customer_info` DROP INDEX `idx_customerNo`;
ALTER TABLE `order_info` DROP INDEX `idx_customerNo`;
SELECT t1.order_no,t2.nick_name FROM order_info t1 INNER JOIN customer_info t2 ON t1.customer_no=t2.customer_no;
-
无索引情况查询测试


MySQL选择了小表customer_info作为驱动表,在没有创建索引时查询耗时12.589s,执行计划中显示使用了BNL算法,下面我们加上索引试一下。 -
添加order_info表中的customer_no字段索引查询测试
# 添加索引 ALTER TABLE `order_info` ADD INDEX `idx_customerNo`(`customer_no`);

添加上索引后查询耗时0.306s性能有明显提升,MySQL还是选择了customer_info表做驱动表,这里使用了NLJ算法。 -
添加customer_info表中的customer_no字段索引查询测试
# 添加索引 ALTER TABLE `customer_info` ADD INDEX `idx_customerNo`(`customer_no`);

customer_info表中的customer_no字段索引查询耗时0.690s性能比不加索引高很多,比在order_info表中加索引性能又差一些,当只有小表有索引时,MySQL也会将小表作为被驱动表,这里大表驱动小表肯定会比上面小表驱动大表性能稍差一些。
4.3、使用内连接查询 客户编号C00000999全部订单列表信息返回订单编号和客户昵称
# 删除索引
ALTER TABLE `customer_info` DROP INDEX `idx_customerNo`;
ALTER TABLE `order_info` DROP INDEX `idx_customerNo`;
SELECT t1.order_no,t2.nick_name FROM order_info t1 LEFT JOIN customer_info t2 ON t1.customer_no=t2.customer_no WHERE t1.customer_no='C00000999';
-
无索引情况查询测试


查询耗时0.078s,在无索引时还是选择的t2表作为驱动表,但是查询时间确是快了很多。 -
添加order_info表中的customer_no字段索引查询测试
# 添加索引 ALTER TABLE `order_info` ADD INDEX `idx_customerNo`(`customer_no`);

这里查询耗时0.045s快了1倍,而且加上order_info表中的索引后MySQL选择了order_info作为驱动表,MySQL认为我们给了一个条件t1.customer_no=‘C00000999’,在order_info表中符合条件的数据会比较少,小于customer_info中的1000条数据,所以这里采用order_info作为驱动表,并且使用到了加的customer_no索引。 -
删除order_info表中索引添加customer_info表中的customer_no字段索引查询测试
# 删除索引 ALTER TABLE `order_info` ADD INDEX `idx_customerNo`(`customer_no`); # 添加索引 ALTER TABLE `customer_info` ADD INDEX `idx_customerNo`(`customer_no`);

耗时0.066s,比不加索引快一点,这里还是选择了customer_info作为驱动表。 -
给order_info表和customer_info表中的customer_no字段都添加索引查询测试
# 添加索引 ALTER TABLE `customer_info` ADD INDEX `idx_customerNo`(`customer_no`); # 添加索引 ALTER TABLE `order_info` ADD INDEX `idx_customerNo`(`customer_no`);

耗时0.032s效率又有提升,而且这里两个索引都使用到了,customer_info表因为索引后数据还是比order_info少所有MySQL还是选择了customer_info做驱动表。
五、总结
- 对于关联sql的优化
- 关联字段加索引
- 对于关联字段来说被驱动表最好加上索引,如果使用内连接不确定那张表是被驱动表时最好驱动表和被驱动表都加上。
- 小表驱动大表
- 在做左连接或右连接查询的时候如果业务允许一定要用小表驱动大表,或者使用内连接交给where条件去判断业务。
- where的条件也是要添加对应索引的
- 两张表关联查询不加条件t1 100w条数据,t2 1000条数据,内连接肯定选择t2做驱动表,但是如果有where条件并且有索引,t1表筛选后只剩10条,t2还是1000条,那么这个时候就会使用到t1做驱动表,查询效率会有所提升。
- 关于MySQL5.7和MySQL8.0连接查询效率问题
- 我本地跑了一些连接查询的例子MySQL8.0在有些情况比MySQL5.7的确要快而且是快很多,而且有些情况MySQL8.0没有索引时连接查询也很快,甚至比我加了索引走NLJ算法还快,看了执行计划和MySQL5.7是一样的,不知道是不是因为我本地部署两个版本配置是否有什么区别,MySQL8.0做了很多优化等以后研究明白再来详细说明。
- 关联字段加索引
相关文章:
MySQL 多表关联查询优化实践和原理解析
目录 一、前言二、表数据准备三、表关联查询原理和两种算法3.1、研究关联查询算法必备知识点3.2、嵌套循环连接 Nested-Loop Join(NLJ) 算法3.3、基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法3.4、被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 Nested…...
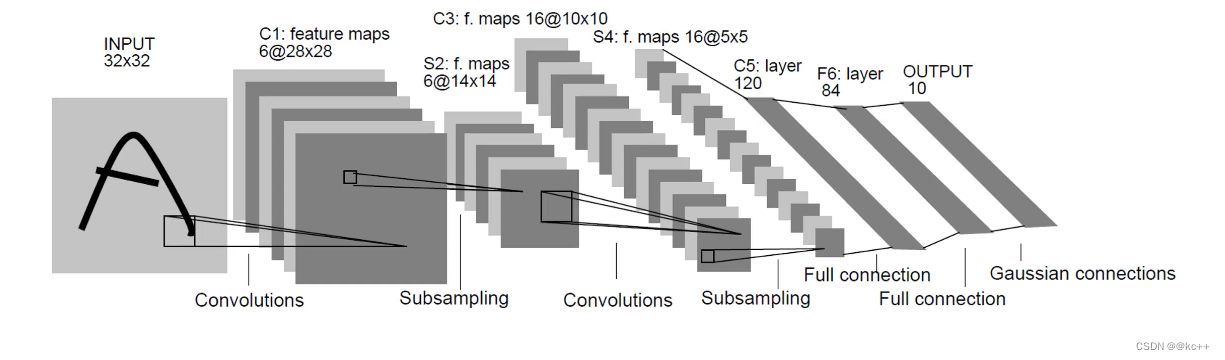
LeNet网络复现
文章目录 1. LeNet历史背景1.1 早期神经网络的挑战1.2 LeNet的诞生背景 2. LeNet详细结构2.1 总览2.2 卷积层与其特点2.3 子采样层(池化层)2.4 全连接层2.5 输出层及激活函数 3. LeNet实战复现3.1 模型搭建model.py3.2 训练模型train.py3.3 测试模型test…...

Oracle 慢查询排查步骤
目录 1. Oracle 慢查询排查步骤1.1. 前言1.2. 排查步骤1.2.1. 查询慢查询日志1.2.2. Oracle 查询 SQL 语句执行的耗时1.2.3. 定位系统里面哪些 SQL 脚本存在 TABLE ACCESS FULL (扫全表) 行为1.2.4. 查看索引情况1.2.5. 查看锁的竞争情况1.2.6. 其他锁语句 1.3. 慢查询优化1.3.…...

互联网Java工程师面试题·MyBatis 篇·第二弹
目录 16、Xml 映射文件中,除了常见的 select|insert|updae|delete标签之外,还有哪些标签? 17、Mybatis 的 Xml 映射文件中,不同的 Xml 映射文件,id 是否可以重复? 18、为什么说 Mybatis 是半自动 ORM 映射…...
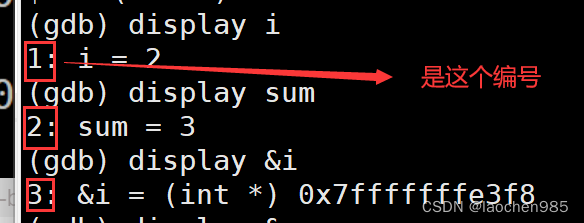
Linux 下如何调试代码
debug 和 release 在Linux下的默认模式是什么? 是release模式 那你怎么证明他就是release版本? 我们知道如果一个程序可以被调试,那么它一定是debug版本,如果它是release版本,它是没法被调试的,所以说我们可以来调试一…...
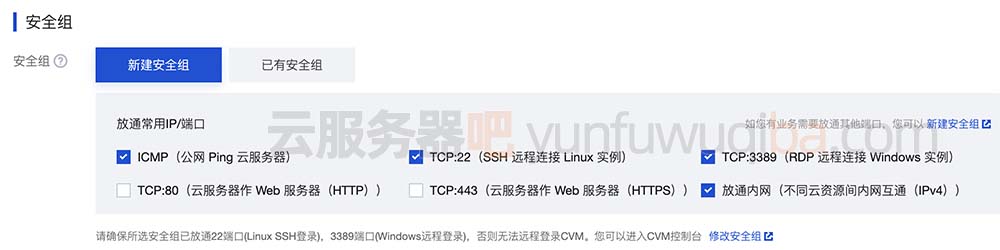
腾讯云服务器简介和使用流程
腾讯云服务器在云服务器CVM或轻量应用服务器页面自定义购买价格比较贵,但是自定义购买云服务器CPU内存带宽配置选择范围广,活动上购买只能选择固定的活动机,选择范围窄,但是云服务器价格便宜比较省钱。腾讯云服务器网来详细说下腾…...

python 二分查找
1.二分查找首先被查找的序列是一个有序的。 2.明确序列的左右边界 3.找出序列中间的元素,判断如果是要查找的元素,返回元素 4.如果中间元素,大于或者小于查找的元素,那么改变左右边间,直到中间的数等于查找的元素。…...

通过async方式在浏览器中调用web worker
通过async方式在浏览器中调用web worker 近年来,网络应用程序变得越来越复杂,增加了越来越多的功能。因此,性能和响应性已成为 Web 开发人员关注的重点。解决这个问题的一个办法是使用web worker。 web worker简介 web worker是一个 javas…...

FPGA project : TFT_LCD
实验目标: 驱动TFT_LCD显示十色彩条。 重点掌握的知识: 1,液晶显示器,简称LCD(Liquid Crystal Display),相对于上一代CRT显示器(阴极射线管显示器),LCD显示器具有功耗低、体积小、承载的信息量大及不伤眼…...
2023年-华为机试题库B卷(Python)【满分】
华为机试题库B卷 已于5月10号 更新为2023 B卷 (2023-10-04 更新本文) 华为机试有三道题目,前两道属于简单或中等题,分值为100分,第三道为中等或困难题,分值为200分。总分为 400 分,150分钟考试…...
创建GCP service账号并管理权限
列出当前GCP项目的所有service account 我们可以用gcloud 命令 gcloud iam service-accounts list gcloud iam service-accounts list DISPLAY NAME EMAIL DISABLED terraform …...

想要精通算法和SQL的成长之路 - 验证二叉树
想要精通算法和SQL的成长之路 - 验证二叉树 前言一. 验证二叉树1.1 并查集1.2 入度以及边数检查 前言 想要精通算法和SQL的成长之路 - 系列导航 并查集的运用 一. 验证二叉树 原题链接 思路如下: 对于一颗二叉树,我们需要做哪些校验? 首先…...
ERROR 6400 --- [ main] com.zaxxer.hikari.pool.HikariPool : root - Exception
在引用的日志中,报告了Hikari连接池初始化期间的异常。具体异常信息是"Exception during pool initialization"。这个异常可能是由于与MySQL数据库的通信链接失败导致的。在引用中也提到了与SSL连接相关的错误。 根据引用中提供的代码,可以看到…...

CART算法解密:从原理到Python实现
目录 一、简介CART算法的背景例子:医疗诊断 应用场景例子:金融风控 定义与组成例子:电子邮件分类 二、决策树基础什么是决策树例子:天气预测 如何构建简单的决策树例子:动物分类 决策树算法的类型例子:垃圾…...
C++项目:【高并发内存池】
文章目录 一、项目介绍 二、什么是内存池 1.池化技术 2.内存池 3.内存池主要解决的问题 4.malloc 三、定长的内存池 四、高并发内存池整体框架设计 1.高并发内存池--thread cache 1.1申请内存: 1.2释放内存: 1.3用TLS实现thread cache无锁访…...

[论文笔记]BitFit
引言 今天带来一篇参数高效微调的论文笔记,论文题目为 基于Transformer掩码语言模型简单高效的参数微调。 BitFit,一种稀疏的微调方法,仅修改模型的偏置项(或它们的子集)。对于小到中等规模数据,应用BitFit去微调预训练的BERT模型能达到(有时超过)微调整个模型。对于大规…...

浅谈yolov5中的anchor
默认锚框 YOLOv5的锚框设定是针对COCO数据集中大部分物体来拟定的,其中图像尺寸都是640640的情况。 anchors参数共3行: 第一行是在最大的特征图上的锚框 第二行是在中间的特征图上的锚框 第三行是在最小的特征图上的锚框 在目标检测中,一…...
RabbitMQ-工作队列
接上文 RabbitMQ-死信队列 1 工作队列模式 xx模式只是一种设计思路,并不是指具体的某种实现,可理解为实现XX模式需要怎么去写业务代码。 之前的是简单的一个消费者一个生产者模式,下边是一个生产者多个消费者的情况: 这里先定义两…...

网站安全防护措施
网络安全的重要性在网站和app的发展下已经被带到了全新的高度,已然成为各大运维人员工作里不可或缺的环节,重视网络安全能给我们的网站带来更好的口碑,也能为企业生产创造更稳定的环境。下面我们一起来看看有哪些是我们运维人员能够做的。 1、…...
C++的继承基础和虚继承原理
1.继承概念 “继承”是面向对象语言的三大特性之一(封装、继承、多态)。 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性基础上进行扩展,增加功能&…...

【深伪检测】论文整体调研与梳理方法
一、单篇论文精读:抓核心信息(先“拆”后“懂”) 每篇论文都要完成「标题→摘要→引言→方法→实验→相关工作」的递进式阅读,目的是精准捕捉“这篇论文在解决什么问题、用了什么方法、做出了什么贡献”。标题摘要(10分…...

RHCSA 认证必备:目录文件的管理
目录 一、创建目录 (1)格式 (2)参数 (3)示例 二、查看目录文件 1、查看目录文件 2、统计命令 3、编辑与删除 a.编辑目录文件 b.删除目录文件 一、创建目录 (1)格式 mkdi…...

2025届最火的十大降重复率助手实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 维普AIGC检测系统,是面向学术机构以及科研人员所推出的专业工具,其作…...

FastBle单元测试终极指南:Mockito在Android蓝牙BLE开发中的7个实战技巧
FastBle单元测试终极指南:Mockito在Android蓝牙BLE开发中的7个实战技巧 【免费下载链接】FastBle Android Bluetooth Low Energy (BLE) Fast Development Framework. It uses simple ways to filter, scan, connect, read ,write, notify, readRssi, setMTU, and mu…...

水泥路面裂缝分类数据集该数据集包含有图片40000张,类别是有裂缝和没有裂缝图像大小是227x227可直接进行使用
水泥路面裂缝分类数据集 该数据集包含有图片40000张,类别是有裂缝和没有裂缝 图像大小是227x227 可直接进行使用...

ollama部署本地大模型|embeddinggemma-300m跨境电商评论情感迁移学习实践
ollama部署本地大模型|embeddinggemma-300m跨境电商评论情感迁移学习实践 1. 环境准备与快速部署 想要在本地运行强大的文本嵌入模型吗?今天我来手把手教你用ollama部署embeddinggemma-300m,这是一个只有3亿参数但效果惊人的小模型…...

告别驱动臃肿:Radeon Software Slimmer轻量优化实现显卡性能释放
告别驱动臃肿:Radeon Software Slimmer轻量优化实现显卡性能释放 【免费下载链接】RadeonSoftwareSlimmer Radeon Software Slimmer is a utility to trim down the bloat with Radeon Software for AMD GPUs on Microsoft Windows. 项目地址: https://gitcode.co…...

3个步骤彻底释放惠普游戏本性能:OmenSuperHub终极指南
3个步骤彻底释放惠普游戏本性能:OmenSuperHub终极指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方Omen Gaming Hub的臃肿体积和…...
)
【西工大主办、连续多届稳定检索】第七届机械仪表与自动化国际学术会议(ICMIA 2026)
2026年第七届机械仪表与自动化国际学术会议(ICMIA 2026)定于2026年6月26-28日在中国成都隆重举行。随着科学技术的不断发展和工业化的加速,现代工业生产的自动化程度越来越高。而机械仪表自动化作为现代工业控制的重要组成部分,其…...

解锁Mac网络新姿势:HoRNDIS驱动让Android USB共享一键直达
解锁Mac网络新姿势:HoRNDIS驱动让Android USB共享一键直达 【免费下载链接】HoRNDIS Android USB tethering driver for Mac OS X 项目地址: https://gitcode.com/gh_mirrors/ho/HoRNDIS 还在为Mac无法直接使用Android手机的网络而烦恼吗?HoRNDIS…...