深度学习笔记_4、CNN卷积神经网络+全连接神经网络解决MNIST数据
1、首先,导入所需的库和模块,包括NumPy、PyTorch、MNIST数据集、数据处理工具、模型层、优化器、损失函数、混淆矩阵、绘图工具以及数据处理工具。
import numpy as np
import torch
from torchvision.datasets import mnist
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
import csv
import pandas as pd2、设置超参数,包括训练批次大小、测试批次大小、学习率和训练周期数。
# 设置超参数
train_batch_size = 64
test_batch_size = 64
learning_rate = 0.001
num_epochs = 103、创建数据转换管道,将图像数据转换为张量并进行标准化。
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5])
])4、下载和预处理MNIST数据集,分为训练集和测试集。
# 下载和预处理数据集
train_dataset = mnist.MNIST('data', train=True, transform=transform, download=True)
test_dataset = mnist.MNIST('data', train=False, transform=transform)5、创建用于训练和测试的数据加载器,以便有效地加载数据。
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)6、定义了一个简单的CNN模型,包括两个卷积层和两个全连接层。
# 定义CNN模型
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=5)self.conv2 = nn.Conv2d(32, 64, kernel_size=5)self.fc1 = nn.Linear(1024, 256)self.fc2 = nn.Linear(256, 10)def forward(self, x):x = F.relu(F.max_pool2d(self.conv1(x), 2))x = F.relu(F.max_pool2d(self.conv2(x), 2))x = x.view(x.size(0), -1)x = F.relu(self.fc1(x))x = self.fc2(x)return F.log_softmax(x, dim=1)7、初始化模型、优化器和损失函数。
# 初始化模型、优化器和损失函数
model = CNN()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()8、准备用于记录训练和测试过程中损失和准确率的列表。
# 记录训练和测试过程中的损失和准确率
train_losses = []
test_losses = []
train_accuracies = []
test_accuracies = []9、进入训练循环,遍历每个训练周期。在每个训练周期内,进入训练模式,遍历训练数据批次,计算损失、反向传播并更新模型参数,同时记录训练损失和准确率。
for epoch in range(num_epochs):model.train()train_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()train_loss += loss.item()# 计算训练准确率_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 计算平均训练损失和训练准确率train_loss /= len(train_loader)train_accuracy = 100. * correct / totaltrain_losses.append(train_loss)train_accuracies.append(train_accuracy) # 记录训练准确率# 测试模型model.eval()test_loss = 0.0correct = 0all_labels = []all_preds = []with torch.no_grad():for data, target in test_loader:output = model(data)test_loss += criterion(output, target).item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()all_labels.extend(target.numpy())all_preds.extend(pred.numpy())
10、在每个训练周期结束后,进入测试模式,遍历测试数据批次,计算测试损失和准确率,同时记录它们。打印每个周期的训练和测试损失以及准确率。
# 计算平均测试损失和测试准确率test_loss /= len(test_loader)test_accuracy = 100. * correct / len(test_loader.dataset)test_losses.append(test_loss)test_accuracies.append(test_accuracy)print(f'Epoch [{epoch + 1}/{num_epochs}] -> Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.2f}%, Test Loss: {test_loss:.4f}, Test Accuracy: {test_accuracy:.2f}%')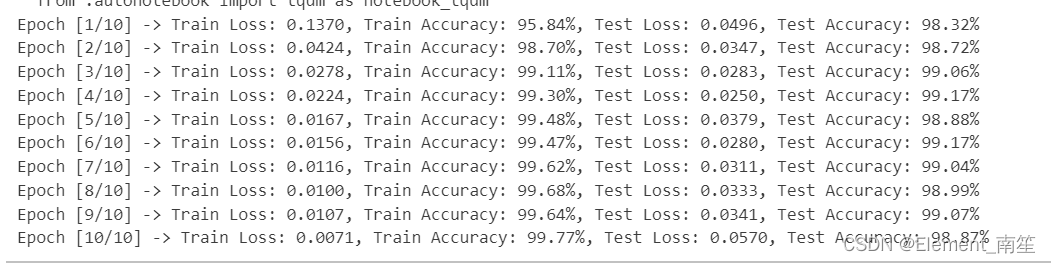 11、losses、acces、eval_losses、eval_acces保存到TXT文件
11、losses、acces、eval_losses、eval_acces保存到TXT文件
# 保存训练结果
data = np.column_stack((train_losses,test_losses,train_accuracies, test_accuracies))
np.savetxt("results.txt", data)12、绘制Loss、ACC图像
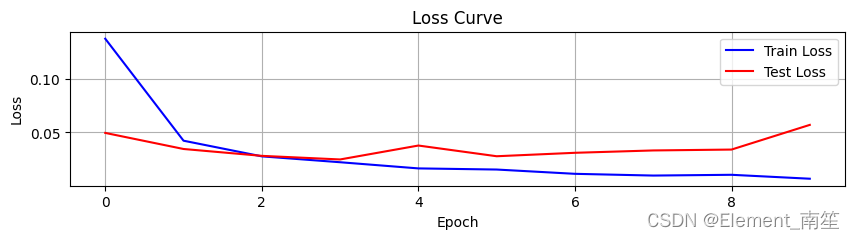
# 绘制Loss曲线图
plt.figure(figsize=(10, 2))
plt.plot(train_losses, label='Train Loss', color='blue')
plt.plot(test_losses, label='Test Loss', color='red')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Loss Curve')
plt.grid(True)
plt.savefig('loss_curve.png')
plt.show()# 绘制Accuracy曲线图
plt.figure(figsize=(10, 2))
plt.plot(train_accuracies, label='Train Accuracy', color='red') # 绘制训练准确率曲线
plt.plot(test_accuracies, label='Test Accuracy', color='green')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy Curve')
plt.grid(True)
plt.savefig('accuracy_curve.png')
plt.show() 
13、绘制混淆矩阵图像
# 计算混淆矩阵
confusion_mat = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mat, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix')
plt.savefig('confusion_matrix.png')
plt.show()

相关文章:
深度学习笔记_4、CNN卷积神经网络+全连接神经网络解决MNIST数据
1、首先,导入所需的库和模块,包括NumPy、PyTorch、MNIST数据集、数据处理工具、模型层、优化器、损失函数、混淆矩阵、绘图工具以及数据处理工具。 import numpy as np import torch from torchvision.datasets import mnist import torchvision.transf…...

高效的开发流程搭建
目录 1. 搭建 AI codebase 环境kaggle的服务器1. 搭建 AI codebase 环境 python 、torch 以及 cuda版本,对AI的影响最大。不同的版本,可能最终计算出的结果会有区别。 硬盘:PCIE转SSD的卡槽,, GPU: 软件源: Anaconda: 一定要放到固态硬盘上。 VS code 的 debug功能…...
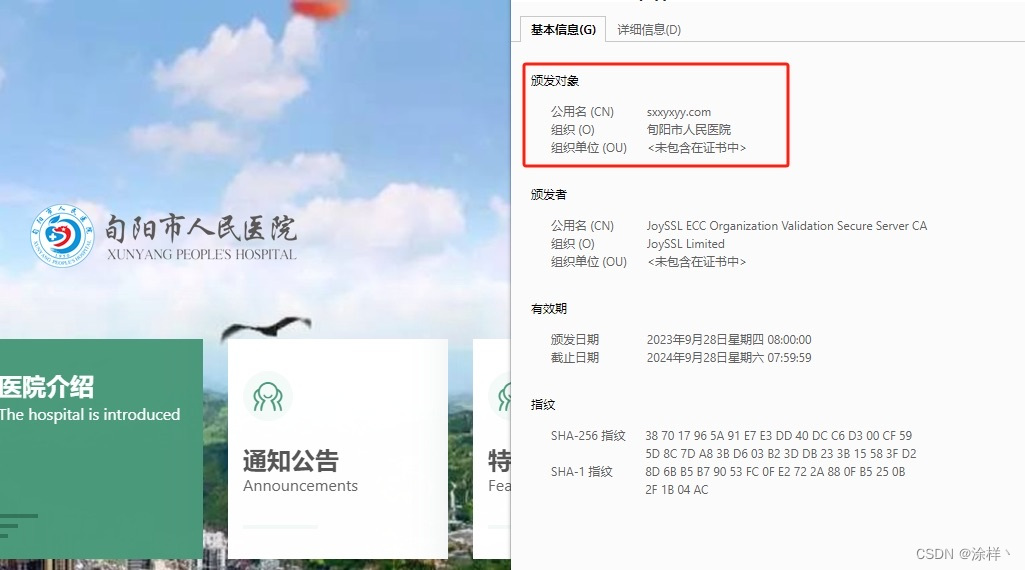
浅谈OV SSL 证书的优势
随着网络威胁日益增多,保护网站和用户安全已成为每个企业和组织的重要任务。在众多SSL证书类型中,OV(Organization Validation)证书以其独特的优势备受关注。让我们深入探究OV证书的优势所在,为网站安全搭建坚实的防线…...

一篇博客学会系列(3) —— 对动态内存管理的深度讲解以及经典笔试题的深度解析
目录 动态内存管理 1、为什么存在动态内存管理 2、动态内存函数的介绍 2.1、malloc和free 2.2、calloc 2.3、realloc 3、常见的动态内存错误 3.1、对NULL指针的解引用操作 3.2、对动态开辟空间的越界访问 3.3、对非动态开辟内存使用free释放 3.4、使用free释放一块动态…...

【C++ techniques】虚化构造函数、虚化非成员函数
constructor的虚化 virtual function:完成“因类型而异”的行为;constructor:明确类型时构造函数;virtual constructor:视其获得的输入,可产生不同的类型对象。 //假如写一个软件,用来处理时事…...
11.6-LE Audio 笔记之初识音频位置和通道分配)
蓝牙核心规范(V5.4)11.6-LE Audio 笔记之初识音频位置和通道分配
专栏汇总网址:蓝牙篇之蓝牙核心规范学习笔记(V5.4)汇总_蓝牙核心规范中文版_心跳包的博客-CSDN博客 爬虫网站无德,任何非CSDN看到的这篇文章都是盗版网站,你也看不全。认准原始网址。!!! 音频位置 在以前的每个蓝牙音频规范中,只有一个蓝牙LE音频源和一个蓝牙LE音频接…...
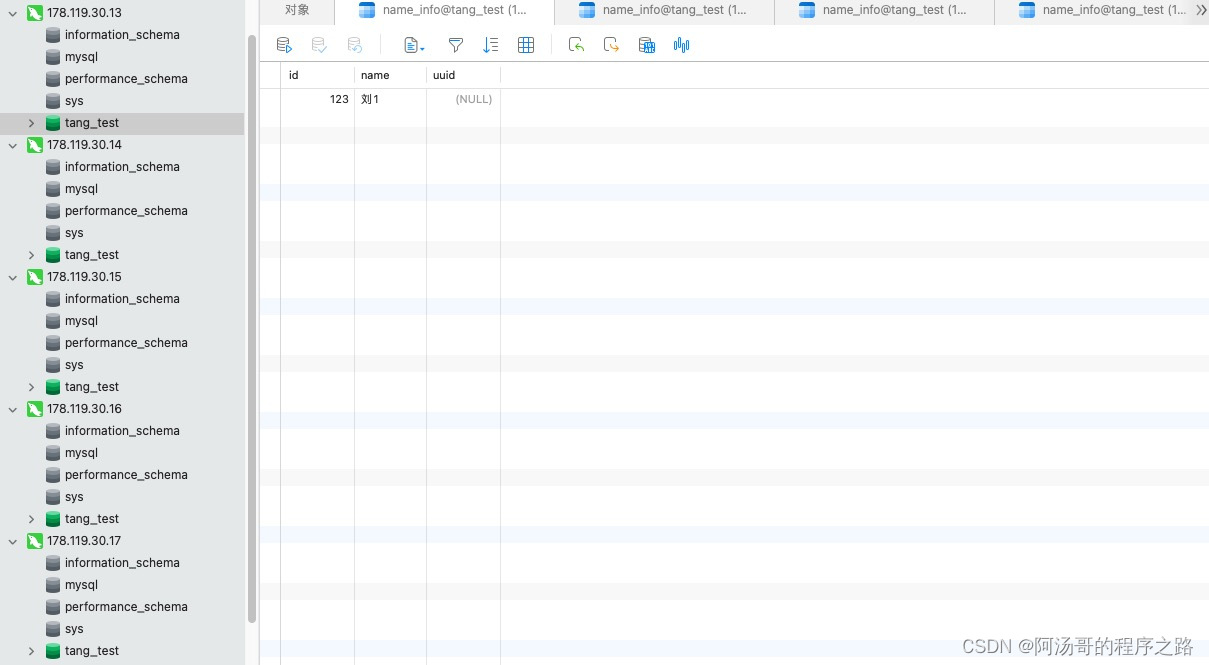
mysql双主+双从集群连接模式
架构图: 详细内容参考: 结果展示: 178.119.30.14(主) 178.119.30.15(主) 178.119.30.16(从) 178.119.30.17(从)...
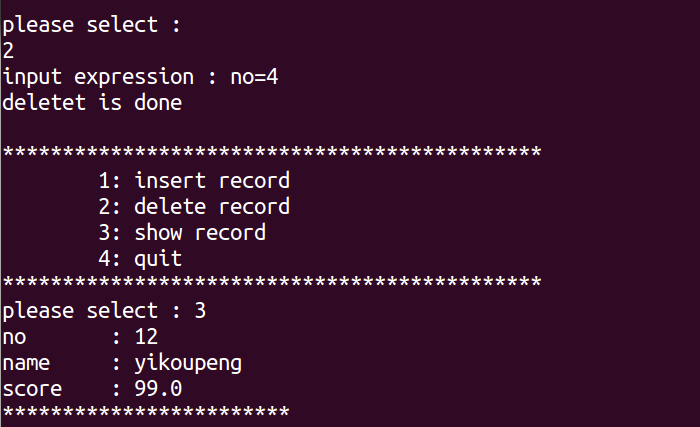
嵌入式中如何用C语言操作sqlite3(07)
sqlite3编程接口非常多,对于初学者来说,我们暂时只需要掌握常用的几个函数,其他函数自然就知道如何使用了。 数据库 本篇假设数据库为my.db,有数据表student。 nonamescore4嵌入式开发爱好者89.0 创建表格语句如下: CREATE T…...

RandomForestClassifier 与 GradientBoostingClassifier 的区别
RandomForestClassifier(随机森林分类器)和GradientBoostingClassifier(梯度提升分类器)是两种常用的集成学习方法,它们之间的区别分以下几点。 1、基础算法 RandomForestClassifier:随机森林分类器是基于…...
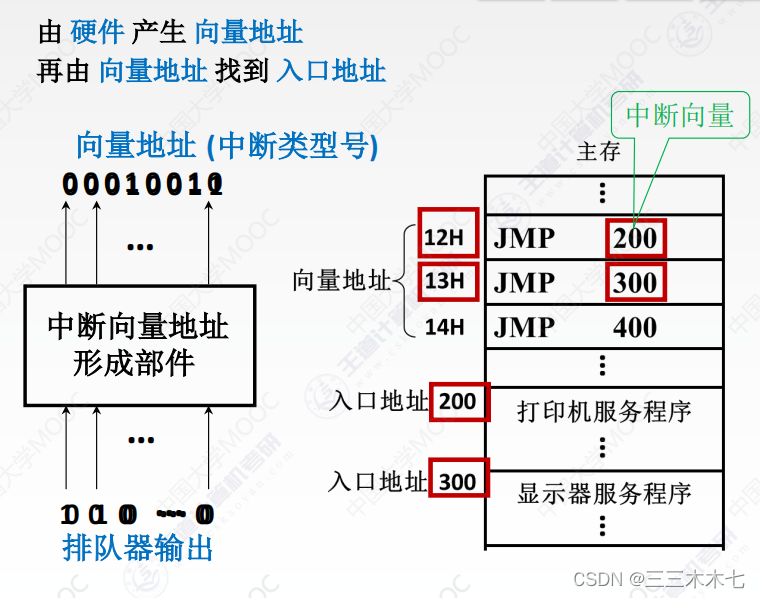
计组——I/O方式
一、程序查询方式 CPU不断轮询检查I/O控制器中“状态寄存器”,检测到状态为“已完成”之后,再从数据寄存器取出输入数据。 过程: 1.CPU执行初始化程序,并预置传送参数;设置计数器、设置数据首地址。 2. 向I/O接口发…...

jsbridge实战2:Swift和h5的jsbridge通信
[[toc]] demo1: 文本通信 h5 -> app 思路: h5 全局属性上挂一个变量app 接收这个变量的内容关键API: navigation代理 navigationAction.request.url?.absoluteString // 这个变量挂载在 request 的 url 上 ,在浏览器实际无法运行,因…...

集合原理简记
HashMap 无论在构造函数是否指定数组长度,进行的都是延迟初始化 构造函数作用: 阈值:threshold,每次<<1 ,数组长度 负载因子 无参构造:设置默认的负载因子 有参:可以指定初始容量或…...

机器学习的超参数 、训练集、归纳偏好
一、介绍 超参数(Hyperparameters)和验证集(Validation Set)是机器学习中重要的概念,用于调整模型和评估其性能。 超参数: 超参数是在机器学习模型训练过程中需要手动设置的参数,而不是从数据…...
Leetcode1071. 字符串的最大公因子(三种方法,带详细解析)
Leetcode1071. 字符串的最大公因子 对于字符串 s 和 t,只有在 s t … t(t 自身连接 1 次或多次)时,我们才认定 “t 能除尽 s”。 给定两个字符串 str1 和 str2 。返回 最长字符串 x,要求满足 x 能除尽 str1 且 x 能…...

如何像人类一样写HTML之图像标签,超链接标签与多媒体标签
文章目录 前言一、图像标签1.1 什么是图像标签?2.2 如何使用图像标签? 二、超链接标签2.1 什么是超链接标签?2.2 如何使用超链接标签? 三、多媒体标签3.1 什么是多媒体标签?3.2 如何使用多媒体audio标签?3.…...

1300*C. Rumor(并查集贪心)
解析: 并查集,求每个集合的最小费用。 每次合并集合的时候,根节点保存当前集合最小的费用。 #include<bits/stdc.h> using namespace std; #define int long long const int N1e55; int n,m,a[N],p[N],cnt[N]; int find(int x){retur…...
)
python实用小代码(数据分析向)
一、python实现31省市名称替换 首先定义了一个字典province_dict,其中包含每个省市的无缩写名称与其标准名称之间的映射。然后,我们使用map()函数将每个省市名称从无缩写名称转换为标准名称,并将结果存储在新列省市标准名称中。 province_di…...

【oncmdmsg 鼠标】2023/8/19 上午9:50:14
2023/8/19 上午9:50:14 oncmdmsg 鼠标 2023/8/19 上午9:50:22 抱歉,您提到的 “oncmdmsg” 和 “鼠标” 是什么?请提供更多上下文信息,我将尽力帮助您。 2023/8/19 上午9:51:43 OnCmdMsg 2023/8/19 上午9:52:21 “OnCmdMsg” 是一个在 MFC (Microsoft Foundation Cla…...

插入排序:简单而有效的排序方法
在计算机科学中,排序算法是一个重要且常见的主题,它们用于对数据进行有序排列。插入排序(Insertion Sort)是其中一个简单但有效的排序算法。本文将详细解释插入排序的原理和步骤,并提供Java语言的实现示例。 插入排序的…...

OpenGL之光照贴图
我们需要拓展之前的系统,引入漫反射和镜面光贴图(Map)。这允许我们对物体的漫反射分量和镜面光分量有着更精确的控制。 漫反射贴图 我们希望通过某种方式对物体的每个片段单独设置漫反射颜色。我们仅仅是对同样的原理使用了不同的名字:其实都是使用一张覆盖物体的图像,让我…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...