【Netty】ByteToMessageDecoder源码解析
目录
1.协议说明
2.类的实现
3.Decoder工作流程
4.源码解析
4.1 ByteToMessageDecoder#channelRead
4.2 累加器Cumulator
4.3 解码过程
4.4 Decoder实现举例
5. 如何开发自己的Decoder
1.协议说明
Netty框架是基于Java NIO框架,性能彪悍,支持的协议丰富,广受Java爱好者亲莱,支持如下协议
- TCP/UDP:Netty提供了基于NIO的TCP和UDP编程框架,可以用来构建高性能、高可用性的网络应用。
- HTTP/HTTPS:Netty提供了HTTP/HTTPS编程框架,可以用来开发Web服务器和客户端。
- WebSocket:Netty提供了WebSocket编程框架,可以用来实现双向通信应用程序,如聊天室等。
- SPDY/HTTP2:Netty提供了SPDY和HTTP2编程框架,可以用来实现高效的Web应用程序。
- MQTT/CoAP:Netty提供了MQTT和CoAP编程框架,可以用来构建IoT应用程序。
我们在基于Netty框架开发过程中往往需要自定义私有协议,如端到端的通信协议,端到平台数据通信协议,我们需要根据业务的特点自定义数据报文格式,举例如下:
| 帧头 | 版本 | 命令标识符 | 序列号 | 设备编码 | 帧长 | 正文 | 校验码 |
|---|---|---|---|---|---|---|---|
| 1byte | 1byte | 1byte | 2byte | 4byte | 4byte | N个byte | 2byte |
假如我们定义了上述私有协议的TCP报文,通过netty框架发送和解析
发送端:某类通信设备(client)
接收端:Java应用服务(Server)
本节我主要分析一下server端解析报文的一个过程,client当然也很重要,尤其在建立TCP连接和关闭连接需要严格控制,否则服务端会发现大量的CLOSE_WAIT(被动关闭连接),甚至大量TIME_WAIT(主动关闭连接),关于这个处理之前的文章有讲解。
本节Server端是基于Netty版本:netty-all-4.1.30.Final
本节源码分析需求就是要解析一个自定义TCP协议的数据报文进行解码,关于编码解码熟悉网络编程的同学都明白,不清楚的可以稍微查阅一下资料有助于学习为什么要解码以及如何解码。本节不会对具体报文的解析做具体讲解,只对Netty提供的解码器基类ByteToMessageDecoder做一下源码分解,以及如何使用ByteToMessageDecoder开发属于自己的Decoder,接下来我们看看ByteToMessageDecoder的定义。
#继承ChannelInboundHandlerAdapter
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
}2.类的实现
解码器的ByteToMessageDecoder ,该类继承了ChannelInboundHandlerAdapter ,ChannelInboundHandlerAdapter继承ChannelHandlerAdapter,
ChannelInboundHandlerAdapter实现ChannelInboundHandler接口,也就是说ChannelInboundHandler定义了解码器需要处理的工作(方法)
ChannelInboundHandlerAdapter是一个适配器模式,负责Decoder的扩展。它的实现有很多,简单列举一下:
-
HeartBeatHandler
-
MessageToMessageDecoder
-
SimpleChannelInboundHandler(抽象了方法channelRead0)
ByteToMessageDecoder。。。。。。
以上都是比较常用的Decoder或Handler,基于这些基类还定义了很多handler,有兴趣的同学可以跟代码查阅。
3.Decoder工作流程
每当数据到达Server端时,SocketServer通过Reactor模型分配具体的worker线程进行处理数据,处理数据就需要我们的事先定义好的Decoder以及handler,假如我们定义了以下两个对象:
- MyDecoder extends
ByteToMessageDecoder{} 作为解码器 MyHandler extendsSimpleChannelInboundHandler{} 作为解码后的业务处理器
worker线程——〉MyDecoder#channelRead实际就是调用ByteToMessageDecoder#channelRead——〉Cumulator累加器处理——〉
解码器decode处理(MyDecoder需要实现decode方法)——〉Myhandler#channelRead0处理具体的数据(msg)
4.源码解析
4.1 ByteToMessageDecoder#channelRead
@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {//如果是设置在ServerBootstrap的childHandler那么msg的对象类型就是ByteBuf,否则就执行elseif (msg instanceof ByteBuf) {//CodecOutputList对象可以查阅文档https://www.freesion.com/article/4800509769///这个out对象随着callDecode方法进行传递,解码后的数据保存在out中CodecOutputList out = CodecOutputList.newInstance();try {ByteBuf data = (ByteBuf) msg;//1.cumulation是累加器,处理tcp半包与粘包问题first = cumulation == null;if (first) {//2.第一次收到数据累加器为nullcumulation = data;} else {//3.第二次收到数据累加器需要评估ByteBuf的capacity,够用则追加到cumulation,capacity不够则进行扩容cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);}//4.调用callDecode进行解码//5.CodecOutputList out对象保存解码后的数据,它的实现是基于AbstractList,//重新定义了add(),set(),remove()等方法,其中add()方法实现对Array数组中//进行insert,没有直接拷贝而是通过对象引用,将对象指向数据索引的index,是性能的一个提升。callDecode(ctx, cumulation, out);} catch (DecoderException e) {throw e;} catch (Exception e) {throw new DecoderException(e);} finally {//6.如果累加器cumulation中的数据被解码器读完了,则可以完全释放累加器cumulationif (cumulation != null && !cumulation.isReadable()) {numReads = 0;cumulation.release();cumulation = null;} else if (++ numReads >= discardAfterReads) {// We did enough reads already try to discard some bytes so we not risk to see a OOME.// See https://github.com/netty/netty/issues/4275//7.释放累加器cumulation里面的已读数据,防止cumulation无限制增长numReads = 0;discardSomeReadBytes();}int size = out.size();decodeWasNull = !out.insertSinceRecycled();//8.解码完成后需要触发事先定义好的handler的channelRead()方法处理解码后的out数据fireChannelRead(ctx, out, size);//9.最终需要回收out对象out.recycle();}} else {//10.非ByteBuf直接向后触发传递ctx.fireChannelRead(msg);}}
4.2 累加器Cumulator
累加器的作用是解决tcp数据包中出现半包和粘包问题。
半包:接收到的byte字节不足一个完整的数据包,
半包处理办法:不足一个完整的数据包先放入累加器不做解码,等待续传的数据包;
粘包:接收到的byte字节数据包中包括其他数据包的数据(靠数据包协议中定义的帧头帧尾标识来识别,多于1个以上的帧头或帧尾数据包为粘包数据),
粘包处理办法:按照数据包帧结构定义去解析,需要结合累加器,解析完一个数据包交给handler去处理,剩下的不足一个数据包长度的字节保存在累加器等待续传的数据包收到之后继续解码。
ByteToMessageDecoder内部定义了Cumulator接口
/*** Cumulate {@link ByteBuf}s.*/public interface Cumulator {/*** Cumulate the given {@link ByteBuf}s and return the {@link ByteBuf} that holds the cumulated bytes.* The implementation is responsible to correctly handle the life-cycle of the given {@link ByteBuf}s and so* call {@link ByteBuf#release()} if a {@link ByteBuf} is fully consumed.*/ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in);}其中在类最开始的时候构建了两个对象,分别是MERGE_CUMULATOR,COMPOSITE_CUMULATOR,代码如下
/*** Cumulate {@link ByteBuf}s by merge them into one {@link ByteBuf}'s, using memory copies.*/public static final Cumulator MERGE_CUMULATOR = new Cumulator() {@Overridepublic ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {try {final ByteBuf buffer;//1.如果累加器ByteBuf 剩余可写的capacity不满足当前需要写入的ByteBuf(in)长度,则进行扩容累加器ByteBuf容量,执行expandCumulation方法if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()|| cumulation.refCnt() > 1 || cumulation.isReadOnly()) {buffer = expandCumulation(alloc, cumulation, in.readableBytes());} else {buffer = cumulation;}//2.写入累加器并返回更新后的cumulationbuffer.writeBytes(in);return buffer;} finally {// We must release in in all cases as otherwise it may produce a leak if writeBytes(...) throw// for whatever release (for example because of OutOfMemoryError)//3.由于是对in的拷贝,所以需要releasein.release();}}};//通过对CompositeByteBuf的累加器的实现,CompositeByteBuf内部使用ComponentList//实现对ByteBuf进行追加//ComponentList是ArrayList的实现,所以每次Add操作都是一次内存拷贝。public static final Cumulator COMPOSITE_CUMULATOR = new Cumulator() {@Overridepublic ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {ByteBuf buffer;try {if (cumulation.refCnt() > 1) {buffer = expandCumulation(alloc, cumulation, in.readableBytes());buffer.writeBytes(in);} else {CompositeByteBuf composite;if (cumulation instanceof CompositeByteBuf) {composite = (CompositeByteBuf) cumulation;} else {composite = alloc.compositeBuffer(Integer.MAX_VALUE);composite.addComponent(true, cumulation);}composite.addComponent(true, in);in = null;buffer = composite;}return buffer;} finally {if (in != null) {//因为是对ByteBuf in的拷贝,所以需要释放in.release();}}}};
4.3 解码过程
在ByteToMessageDecoder#channelRead看到了将累加器交给callDecoder方法
//这里ByteBuf in 就是累加器对象cumulaction
// List<Object> out解码后的对象
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {try {//1. 循环读取累加器对象的bytewhile (in.isReadable()) {int outSize = out.size();//2.如果解码后out对象中产生数据则触发后边的handler(MyHandler)处理数据if (outSize > 0) {fireChannelRead(ctx, out, outSize);out.clear();if (ctx.isRemoved()) {break;}outSize = 0;}//3.继续解析累加器传递过来的byteint oldInputLength = in.readableBytes();//4.注意out对象是从channelRead()方法传递过来,继续传递下去decodeRemovalReentryProtection(ctx, in, out);if (ctx.isRemoved()) {break;}//4.如果这次解码没有获得任何消息if (outSize == out.size()) {//5.如果解码器decode没有消费累加器 in 任何字节,结束循环 if (oldInputLength == in.readableBytes()) {break;//6.否则继续循环调用解码器decode} else {continue;}}//7.如果累加器ByteBuf in中可读字节数依然没有变化,说明实现的解码器decode()方法有问题,需要检查自身代码问题if (oldInputLength == in.readableBytes()) {throw new DecoderException(StringUtil.simpleClassName(getClass()) +".decode() did not read anything but decoded a message.");}//8.是否设定每次调用解码器一次,如果是,则结束本次解码if (isSingleDecode()) {break;} }} catch (DecoderException e) {} catch (Exception cause) {}}
继续查看ByteToMessageDecoder#decodeRemovalReentryProtection方法
//1.此方法不允许重写final void decodeRemovalReentryProtection(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)throws Exception {decodeState = STATE_CALLING_CHILD_DECODE;try {//2.核心方法decode,这是一个抽象方法,没有实现,需要在自定义的Decoder(Mydecoder)进行实现//3.自定义Decoder需要将解码后的数据放入到out对象中decode(ctx, in, out);} finally {boolean removePending = decodeState == STATE_HANDLER_REMOVED_PENDING;decodeState = STATE_INIT;if (removePending) {handlerRemoved(ctx);}}}//解码decode方法需要子类(自定义的实现类)去实现该方法,最终将解码后的数据放入List<Object> outprotected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception;4.4 Decoder实现举例
基于ByteToMessageDecoder的实现很多,简单列举一下
- JsonObjectDecoder
- RedisDecoder
- XmlDecoder
- MqttDecoder
- ReplayingDecoder
- SslDecoder
- DelimiterBasedFrameDecoder
- FixedLengthFrameDecoder
- LengthFieldBasedFrameDecoder
-
....
我们拿JsonObjectDecoder举例如下:
@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {// 省略代码。。。。。。int idx = this.idx;int wrtIdx = in.writerIndex();//省略代码。。。。。。。for (/* use current idx */; idx < wrtIdx; idx++) {byte c = in.getByte(idx);if (state == ST_DECODING_NORMAL) {decodeByte(c, in, idx);if (openBraces == 0) {ByteBuf json = extractObject(ctx, in, in.readerIndex(), idx + 1 - in.readerIndex());//1.解析后的对象加入out中if (json != null) {out.add(json);}in.readerIndex(idx + 1);reset();}} else if (state == ST_DECODING_ARRAY_STREAM) {//2.自身实现解析json格式的方法decodeByte(c, in, idx);if (!insideString && (openBraces == 1 && c == ',' || openBraces == 0 && c == ']')) {for (int i = in.readerIndex(); Character.isWhitespace(in.getByte(i)); i++) {in.skipBytes(1);}// skip trailing spaces.int idxNoSpaces = idx - 1;while (idxNoSpaces >= in.readerIndex() && Character.isWhitespace(in.getByte(idxNoSpaces))) {idxNoSpaces--;}ByteBuf json = extractObject(ctx, in, in.readerIndex(), idxNoSpaces + 1 - in.readerIndex());//3.解析后的对象加入out中if (json != null) {out.add(json);}in.readerIndex(idx + 1);if (c == ']') {reset();}}} //省略代码。。。。。。}if (in.readableBytes() == 0) {this.idx = 0;} else {this.idx = idx;}this.lastReaderIndex = in.readerIndex();}5. 如何开发自己的Decoder
读了ByteToMessageDecoder的部分源码,以及它的实现JsonObjectDecoder,那么如果我们自己实现一个Decoder该如何实现,这里提供三个思路给大家,有时间再补充代码。
- 基于ByteToMessageDecoder实现,MyDecoder extends ByteToMessageDecoder{实现decode()方法},可参考RedisDecoder、XmlDecoder等实现。
- 基于
ChannelInboundHandlerAdapter实现,这个时候需要自己负责解决TCP报文半包和粘包问题,重写其中的channelRead()方法。 直接使用已经实现ByteToMessageDecoder的解码器,如FixedLengthFrameDecoder、DelimiterBasedFrameDecoder、LengthFieldBasedFrameDecoder。
注意事项:
* Be aware that sub-classes of {@link ByteToMessageDecoder} <strong>MUST NOT</strong>
* annotated with {@link @Sharable}.
ByteToMessageDecoder的子类不能使用@Sharable注解修饰,因为解码器只能单独为一个Channel进行解码,也就是说每个worker线程需要独立的Decoder。
* <p>
* Some methods such as {@link ByteBuf#readBytes(int)} will cause a memory leak if the returned buffer
* is not released or added to the <tt>out</tt> {@link List}. Use derived buffers like {@link ByteBuf#readSlice(int)}
* to avoid leaking memory.如果基于
ChannelInboundHandlerAdapter自己实现Decoder#channelRead()方法时注意内存泄露问题,ByteBuf#readBytes(int)方法会产生一个新的ByteBuf,需要手动释放。或者
基于
ByteToMessageDecoder实现decode()方法时将解析后的对象放入out对象中(上面源码分析中有提示)
或者
使用派生的ByteBuf,如调用ByteBuf#readSlice(int)方法,返回的ByteBuf与原有ByteBuf共享内存,不会产生新的Reference count,可以避免内存泄露。
Netty Project官网也有说明:
Reference counted objects
ByteBuf.duplicate(), ByteBuf.slice() and ByteBuf.order(ByteOrder) create a derived buffer which shares the memory region of the parent buffer. A derived buffer does not have its own reference count, but shares the reference count of the parent buffer.
相关文章:

【Netty】ByteToMessageDecoder源码解析
目录 1.协议说明 2.类的实现 3.Decoder工作流程 4.源码解析 4.1 ByteToMessageDecoder#channelRead 4.2 累加器Cumulator 4.3 解码过程 4.4 Decoder实现举例 5. 如何开发自己的Decoder 1.协议说明 Netty框架是基于Java NIO框架,性能彪悍,支持的协…...
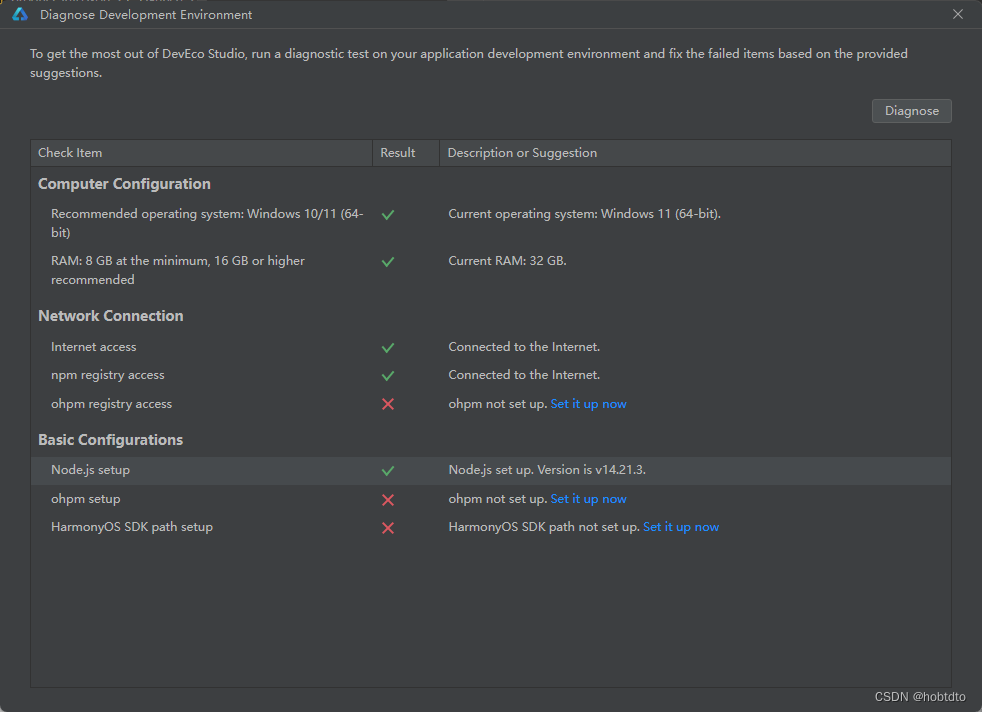
DevEco Studio设置Nodejs提示路径只能包含英文、数字、下划线等
安装DevEco Studio 3.1.1 Release 设置Nodejs路径使用nodejs默认安装路径 (C:\Program Files\nodejs) 提示只能包含英文、数字、下划线等 , 不想在安装nodejs请往下看 nodejs默认路径报错 修改配置文件 1、退出DevEco Studio 2、打开配置文件 cmd控制台…...
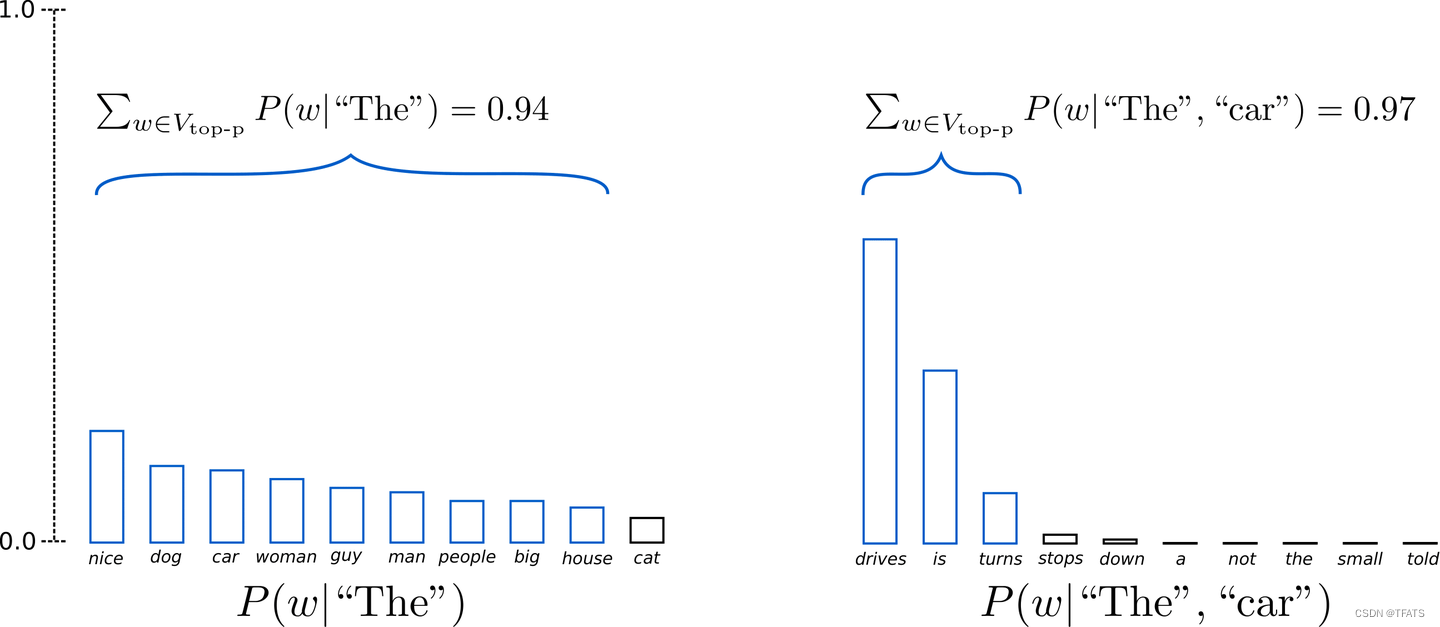
大模型 Decoder 的生成策略
本文将介绍以下内容: IntroductionGreedy Searchbeam searchSamplingTop-K SamplingTop-p (nucleus) sampling总结 一、Introduction 1、简介 近年来,由于在数百万个网页数据上训练的大型基于 Transformer 的语言模型的兴起,开放式语言生…...

队列和栈相互实现
相关题目 225. 用队列实现栈:弹出元素时,将对首的元素出列加到队尾,直到只剩下初始队列时队尾一个元素为止,然后弹出这个元素,即可实现LIFO 232. 用栈实现队列:用两个栈实现队列的功能,出栈时&a…...

Node.js 是如何处理请求的
前言:在服务器软件中,如何处理请求是非常核心的问题。不管是底层架构的设计、IO 模型的选择,还是上层的处理都会影响一个服务器的性能,本文介绍 Node.js 在这方面的内容。 TCP 协议的核心概念 要了解服务器的工作原理首先需要了…...
)
数据结构与算法之堆: Leetcode 215. 数组中的第K个最大元素 (Typescript版)
数组中的第K个最大元素 https://leetcode.cn/problems/kth-largest-element-in-an-array/ 描述 给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。…...
SpringBoot快速入门
搭建SpringBoot工程,定义hello方法,返回“Hello SpringBoot” ②导入springboot工程需要继承的父工程;以及web开发的起步依赖。 ③编写Controller ④引导类就是SpringBoot项目的一个入口。 写注解写main方法调用run方法 快速构建SpringBoo…...

深度学习笔记_4、CNN卷积神经网络+全连接神经网络解决MNIST数据
1、首先,导入所需的库和模块,包括NumPy、PyTorch、MNIST数据集、数据处理工具、模型层、优化器、损失函数、混淆矩阵、绘图工具以及数据处理工具。 import numpy as np import torch from torchvision.datasets import mnist import torchvision.transf…...

高效的开发流程搭建
目录 1. 搭建 AI codebase 环境kaggle的服务器1. 搭建 AI codebase 环境 python 、torch 以及 cuda版本,对AI的影响最大。不同的版本,可能最终计算出的结果会有区别。 硬盘:PCIE转SSD的卡槽,, GPU: 软件源: Anaconda: 一定要放到固态硬盘上。 VS code 的 debug功能…...
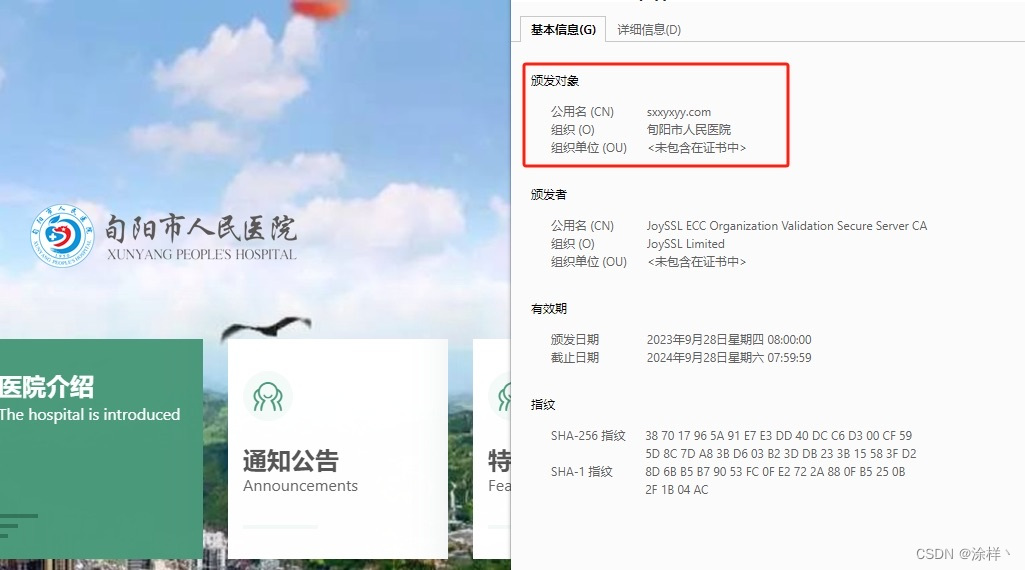
浅谈OV SSL 证书的优势
随着网络威胁日益增多,保护网站和用户安全已成为每个企业和组织的重要任务。在众多SSL证书类型中,OV(Organization Validation)证书以其独特的优势备受关注。让我们深入探究OV证书的优势所在,为网站安全搭建坚实的防线…...

一篇博客学会系列(3) —— 对动态内存管理的深度讲解以及经典笔试题的深度解析
目录 动态内存管理 1、为什么存在动态内存管理 2、动态内存函数的介绍 2.1、malloc和free 2.2、calloc 2.3、realloc 3、常见的动态内存错误 3.1、对NULL指针的解引用操作 3.2、对动态开辟空间的越界访问 3.3、对非动态开辟内存使用free释放 3.4、使用free释放一块动态…...

【C++ techniques】虚化构造函数、虚化非成员函数
constructor的虚化 virtual function:完成“因类型而异”的行为;constructor:明确类型时构造函数;virtual constructor:视其获得的输入,可产生不同的类型对象。 //假如写一个软件,用来处理时事…...
11.6-LE Audio 笔记之初识音频位置和通道分配)
蓝牙核心规范(V5.4)11.6-LE Audio 笔记之初识音频位置和通道分配
专栏汇总网址:蓝牙篇之蓝牙核心规范学习笔记(V5.4)汇总_蓝牙核心规范中文版_心跳包的博客-CSDN博客 爬虫网站无德,任何非CSDN看到的这篇文章都是盗版网站,你也看不全。认准原始网址。!!! 音频位置 在以前的每个蓝牙音频规范中,只有一个蓝牙LE音频源和一个蓝牙LE音频接…...
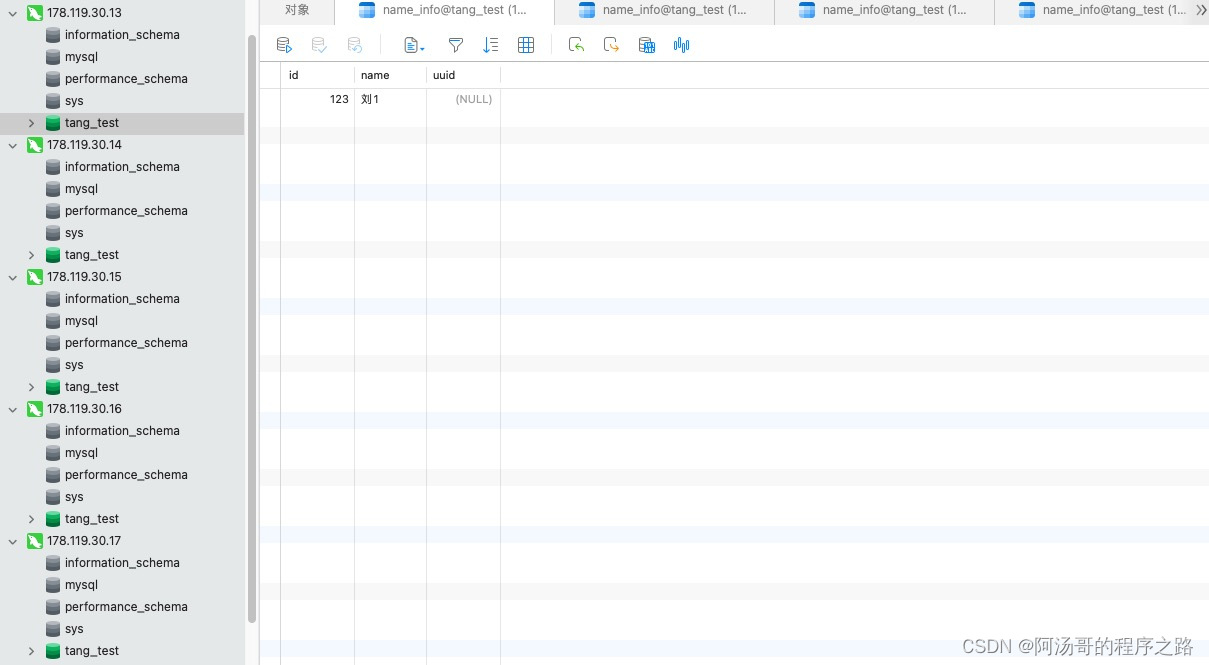
mysql双主+双从集群连接模式
架构图: 详细内容参考: 结果展示: 178.119.30.14(主) 178.119.30.15(主) 178.119.30.16(从) 178.119.30.17(从)...
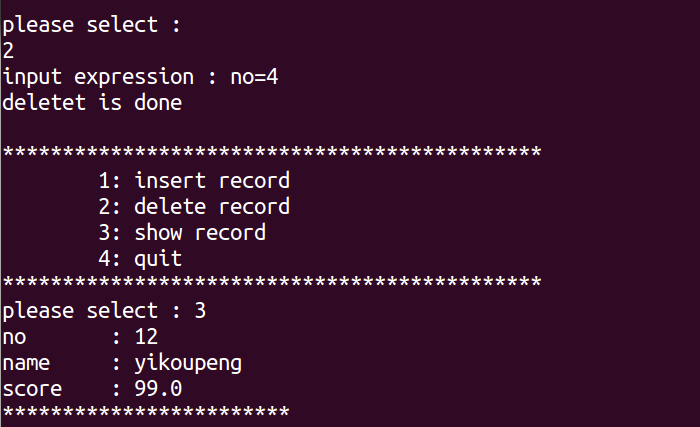
嵌入式中如何用C语言操作sqlite3(07)
sqlite3编程接口非常多,对于初学者来说,我们暂时只需要掌握常用的几个函数,其他函数自然就知道如何使用了。 数据库 本篇假设数据库为my.db,有数据表student。 nonamescore4嵌入式开发爱好者89.0 创建表格语句如下: CREATE T…...

RandomForestClassifier 与 GradientBoostingClassifier 的区别
RandomForestClassifier(随机森林分类器)和GradientBoostingClassifier(梯度提升分类器)是两种常用的集成学习方法,它们之间的区别分以下几点。 1、基础算法 RandomForestClassifier:随机森林分类器是基于…...
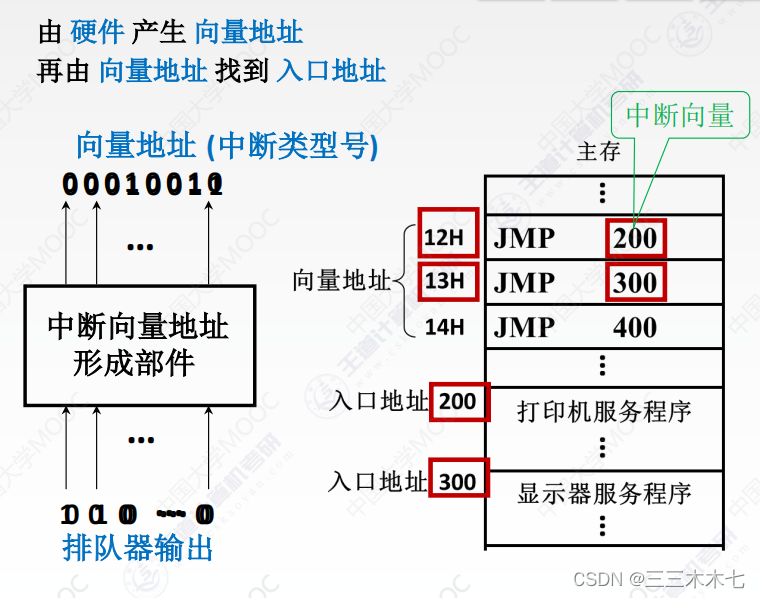
计组——I/O方式
一、程序查询方式 CPU不断轮询检查I/O控制器中“状态寄存器”,检测到状态为“已完成”之后,再从数据寄存器取出输入数据。 过程: 1.CPU执行初始化程序,并预置传送参数;设置计数器、设置数据首地址。 2. 向I/O接口发…...

jsbridge实战2:Swift和h5的jsbridge通信
[[toc]] demo1: 文本通信 h5 -> app 思路: h5 全局属性上挂一个变量app 接收这个变量的内容关键API: navigation代理 navigationAction.request.url?.absoluteString // 这个变量挂载在 request 的 url 上 ,在浏览器实际无法运行,因…...

集合原理简记
HashMap 无论在构造函数是否指定数组长度,进行的都是延迟初始化 构造函数作用: 阈值:threshold,每次<<1 ,数组长度 负载因子 无参构造:设置默认的负载因子 有参:可以指定初始容量或…...

机器学习的超参数 、训练集、归纳偏好
一、介绍 超参数(Hyperparameters)和验证集(Validation Set)是机器学习中重要的概念,用于调整模型和评估其性能。 超参数: 超参数是在机器学习模型训练过程中需要手动设置的参数,而不是从数据…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...
【LeetCode】算法详解#6 ---除自身以外数组的乘积
1.题目介绍 给定一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O…...