CUDA C编程权威指南:1.1-CUDA基础知识点梳理
主要整理了N多年前(2013年)学习CUDA的时候开始总结的知识点,好长时间不写CUDA代码了,现在LLM推理需要重新学习CUDA编程,看来出来混迟早要还的。
1.CUDA
解析:2007年,NVIDIA推出CUDA(Compute Unified Device Architecture,统一计算设备架构)这个编程模型,目的是为了在应用程序中充分利用CPU和GPU各自的优点,实现CPU/GPU联合执行。这种联合执行的需要已经在最新的集中编程模型(OpenCL,OpenACC,C++ AMP)中体现出来了。
2.并行编程语言和模型
解析:使用比较广泛的是为可扩展的集群计算设计的消息传递接口(Message Passing Interface,MPI)和为共享存储器的多处理器系统设计的OpenMP。目前,很多HPC(High-Performance Computing)集群采用的都是异构的CPU/GPU节点模型,也就是MPI和CUDA的混合编程,来实现多机多卡模型。目前,支持CUDA的编程语言有C,C++,Fortran,Python,Java [2]。CUDA采用的是SPMD(Single-Program Multiple-Data,单程序多数据)的并行编程风格。
3.数据并行性,任务并行性
解析:任务并行性通常对应用进行任务分解得到。例如,对一个需要做向量加法和矩阵-向量乘法的简单应用来说,每个操作可以看作一个任务。如果这两个任务可以独立地执行,那么就能得到任务并行性。
4.CUDA对C中函数声明的扩展
解析:
(1)__device__ float DeviceFunc():在设备上执行,并且只能从设备上调用。
(2)__global__ float KernelFunc():在设备上执行,并且只能从主机上调用。
(3)__host__ float HostFunc():在主机上执行,并且只能从主机上调用。
说明:如果在函数声明时没有指定CUDA扩展关键字,则默认的函数是主机函数。
5.thread,block,grid,warp,sp,sm
解析:
(1)grid、block、thread:在利用CUDA进行编程时,一个grid分为多个block,而一个block分为多个thread。
(2)sp:最基本的处理单元,最后具体的指令和任务都是在sp上处理的。
(3)sm:多个sp加上其它的一些资源(比如,存储资源、共享内存、寄储器等)组成一个sm。
(4)warp:GPU执行程序时的调度单位。目前CUDA的warp大小32,同在一个warp的线程,以不同数据资源执行相同指令。
6.CUDA核函数
解析:kernel函数完整的执行配置参数形式是<<<Dg, Db, Ns, S>>>,如下所示:
(1)参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block。
(2)参数Db用于定义一个block的维度和尺寸,即一个block有多少个thread。
(3)参数Ns是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。不需要动态分配时该值为0或省略不写。
(4)参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
7.CUDA存储系统
解析:每个线程拥有独立的寄存器(register)和局部存储器(local memory);每个线程块拥有独立的共享存储器(shared memory);所有线程都可以访问全局存储器(global memory),以及只读存储器常量存储器(constant memory)和纹理存储器(texture memory)。如下所示:
(1)寄存器(register)
(2)局部存储器(local memory)
(3)共享存储器(shared memory)
eg:__shared__ 数据类型 变量名;
(4)全局存储器(global memory)
(5)常量存储器(constant memory)
eg:__constant__ 数据类型 变量名;
(6)纹理存储器(texture memory)
8.CUDA线程组织
解析:CUDA通过内置变量threadIdx.x、threadIdx.y、threadIdx.z表示当前线程所处的线程块的位置,blockIdx.x、blockIdx.y、blockIdx.z表示当前线程所处的线程块在整个网格中所处的位置,blockDim.x、blockDim.y、blockDim.z表示块的维度,gridDim.x、gridDim.y、gridDim.z表示网格的维度。对网格中的任意点(i, j)表征CUDA代码中的一个线程,该线程对应的网格中的索引,如下所示:
i = threadIdx.x+blockIdx.x*blockDim.x
j = threadIdx.y+blockIdx.y*blockDim.y
9.变量类型
解析:
(1)__device__:GPU的global memory空间,grid中所有线程可访问。
(2)__constant__:GPU的constant memory空间,grid中所有线程可访问。
(3)__shared__:GPU上的thread block空间,block中所有线程可访问。
(4)local:位于SM内,仅本thread可访问。
10.CUDA函数库
解析:
(1)Thrust:一个C++ STL实现的函数库。
(2)NVPP:NVIDIA性能原语(和Intel的MKK类似)。
(3)CuBLAS:BLAS(基本线性代数)函数库的GPU版本。
(4)cuFFT:GPU加速的快速傅里叶变换函数库。
(5)cuSparse:稀疏矩阵数据的线性代数和矩阵操作。
(6)Magma:LAPACK和BLAS函数库。
(7)GPU AI:基于GPU的路径规划和碰撞避免。
(8)CUDA Math Lib:支持C99标准的数学函数。
(9)Jacket:对.m代码可选的、基于GPU的Matlab引擎。
(10)Array Fire:类似于IPP、MKL和Eigen的矩阵、信号和图像处理库。
(11)CULA工具:线性代数库。
(12)IMSL:Fortran IMSL数值函数库的实现。
(13)NPP(NVIDIA Performance Primitives):提供了一系列图像和通用信号处理的函数,并且支持所有的CUDA平台。
11.Ubuntu 14.04安装CUDA 7.5
解析:由于无论是CentOS还是Ubuntu都预装了开源的nouveau显卡驱动(SUSE没有这种问题),如果不禁用,则CUDA驱动可能不能正确安装。处理方法,如下所示:
sudo vim /etc/modprobe.d/blacklist.conf
blacklist nouveau # 增加一行
sudo apt-get --purge remove xserver-xorg-video-nouveau # 把官方驱动彻底卸载
sudo apt-get --purge remove nvidia-* # 清除之前安装的任何NVIDIA驱动
sudo service lightdm stop # 进命令行,关闭Xserver
sudo kill all Xorg # 杀死所有Xorg(Xorg软件包是包括显卡驱动、图形环境库等一系列软件包)
说明:gksudo nvidia-settings可以进行NVIDIA X Server Settings的设置。
(1)安装依赖类库
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install build-essential cmake g++ gfortran git pkg-config python-dev software-properties-common wget
sudo apt-get autoremove
sudo rm -rf /var/lib/apt/lists/*
(2)安装Nvidia驱动
lspci | grep -i nvidiasudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
sudo apt-get install nvidia-352sudo shutdown -r now
cat /proc/driver/nvidia/version
(3)安装CUDA
sudo dpkg -i cuda-repo-ubuntu1404*amd64.deb
# sudo apt-get update
sudo apt-get install cudaecho 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrcnvcc -V
sudo shutdown -r now
(4)安装CUDA例子和测试
/usr/local/cuda/bin/cuda-install-samples-7.5.sh ~/cuda-samples
cd ~/cuda-samples/NVIDIA*Samples
make -j $(($(nproc) + 1))bin/x86_64/linux/release/deviceQuery
说明:至此安装完毕,就可以使用Nsight Eclipse Edition愉快地进行CUDA异构计算开发了。
12.二维数组使用
#include <iostream>
#include<cstdlib>
using namespace std;static const int ROW = 10;
static const int COL = 5;int main() {int** array = (int**)malloc(ROW*sizeof(int*));int* data = (int*)malloc(ROW*COL*sizeof(int));// initialize the datafor (int i=0; i<ROW*COL; i++) {data[i] = i;}// initialize the arrayfor (int i=0; i<ROW; i++) {array[i] = data + i*COL;}// output the arrayfor (int i=0; i<ROW; i++) for (int j=0; j<COL; j++) {cout << array[i][j] << endl;}free(array);free(data);return 0;
}
13.查看GPU信息的代码
如果找不到#include <helper_cuda.h>,那么将$cuda-samples/NVIDIA_CUDA-7.5_Samples/common/inc添加到NVCC Compiler中的Includes中即可。
解析:
(1)#include
#include<cstdlib>提供数据类型:size_t,wchar_t,div_t,ldiv_t,lldiv_t;提供常量:NULL,EXIT_FAILURE,EXIT_SUCCESS,RAND_MAX,MB_CUR_MAX;提供函数:atof,atoi,atol, strtod, strtof, strtols, strtol, strtoll, strtoul, strtoull, rand, srand, calloc, free, malloc, realloc, abort, atexit, exit, getenv, system, bsearch, qsort, abs, div, labs, ldiv, llabs, tlldiv, mblen, mbtowc, wctomb, mbstowcs, wcstombs。
(2)CUDART_VERSION
CUDA Runtime API Version,在#include <cuda_runtime.h>中#define CUDART_VERSION 7050。
(3)stdin,stdout,stderr
进程将从标准输入文件中得到输入数据,将正常输出数据输出到标准输出文件,而将错误信息送到标准错误文件中。stdin的文件描述符为0,stdout的文件描述符为1,stderr的文件描述符为2。
(4)host cudaError_t cudaSetDevice ( int device )
设置device用于GPU扩展。
(5)cudaDeviceProp数据结构
cudaDeviceProp数据类型针对函式cudaGetDeviceProperties定义的,cudaGetDeviceProperties函数的功能是取得支持GPU计算装置的相关属性,比如支持CUDA版本号装置的名称、内存的大小、最大的thread数目、执行单元的频率等。如下所示:
struct cudaDeviceProp {char name[256]; // 识别设备的ASCII字符串(比如,"GeForce GTX 940M")size_t totalGlobalMem; // 全局内存大小size_t sharedMemPerBlock; // 每个block内共享内存的大小int regsPerBlock; // 每个block 32位寄存器的个数int warpSize; // warp大小size_t memPitch; // 内存中允许的最大间距字节数int maxThreadsPerBlock; // 每个Block中最大的线程数是多少int maxThreadsDim[3]; // 一个块中每个维度的最大线程数int maxGridSize[3]; // 一个网格的每个维度的块数量size_t totalConstMem; // 可用恒定内存量int major; // 该设备计算能力的主要修订版号int minor; // 设备计算能力的小修订版本号int clockRate; // 时钟速率size_t textureAlignment; // 该设备对纹理对齐的要求int deviceOverlap; // 一个布尔值,表示该装置是否能够同时进行cudamemcpy()和内核执行int multiProcessorCount; // 设备上的处理器的数量int kernelExecTimeoutEnabled; // 一个布尔值,该值表示在该设备上执行的内核是否有运行时的限制int integrated; // 返回一个布尔值,表示设备是否是一个集成的GPU(即部分的芯片组、没有独立显卡等)int canMapHostMemory; // 表示设备是否可以映射到CUDA设备主机内存地址空间的布尔值int computeMode; // 一个值,该值表示该设备的计算模式:默认值,专有的,或禁止的int maxTexture1D; // 一维纹理内存最大值int maxTexture2D[2]; // 二维纹理内存最大值int maxTexture3D[3]; // 三维纹理内存最大值int maxTexture2DArray[3]; // 二维纹理阵列支持的最大尺寸int concurrentKernels; // 一个布尔值,该值表示该设备是否支持在同一上下文中同时执行多个内核
}
(6)host cudaError_t cudaDriverGetVersion ( int* driverVersion )
返回CUDA驱动版本。
(7)host __device__ cudaError_t cudaRuntimeGetVersion ( int* runtimeVersion )
返回CUDA运行时版本。
说明:__host__和__device__同时使用时触发编译系统生成同一函数的两个不同的版本。它支持一种常见的应用,即只需要重编译同一函数的源代码就可以生成一个在设备上运行的版本。
(8)#if defined(WIN32) || defined(_WIN32) || defined(WIN64) || defined(_WIN64)
WIN32,_WIN32,WIN64,_WIN64是Windows操作系统预定义的宏。这句话的目的是C/C++编程通过宏定义来判断操作系统的类型。
14.#include<device_launch_parameters.h>
解析:#include<device_launch_parameters.h>头文件包含了内核函数的5个变量threadIdx、blockDim、blockIdx、gridDim和wrapSize。
15.事件管理
解析:常用函数,如下所示:
(1)cudaEventCreate():事件的创建。
(2)cudaEventDestroy():事件的销毁。
(3)cudaEventRecord():记录事件。
(4)cudaEventSynchronize():事件同步。
(5)cudaEventElapsedTime():计算两事件的时间差。
利用CUDA提供的事件管理API实现计时功能,如下所示:
float time;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
{
// 需要计时的代码
}
cudaEventRecord(stop,0);
cudaEventElapsedTime(&time, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
16.deviceQuery
解析:输出结果,如下所示:
root@ubuntu:~/cuda-samples/NVIDIA_CUDA-7.5_Samples/1_Utilities/deviceQuery# ./deviceQuery
./deviceQuery Starting...CUDA Device Query (Runtime API) version (CUDART static linking)Detected 1 CUDA Capable device(s)Device 0: "GeForce 940M"CUDA Driver Version / Runtime Version 7.5 / 7.5CUDA Capability Major/Minor version number: 5.0Total amount of global memory: 1024 MBytes (1073610752 bytes)( 3) Multiprocessors, (128) CUDA Cores/MP: 384 CUDA CoresGPU Max Clock rate: 980 MHz (0.98 GHz)Memory Clock rate: 1001 MhzMemory Bus Width: 64-bitL2 Cache Size: 1048576 bytesMaximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layersMaximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layersTotal amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Max dimension size of a thread block (x,y,z): (1024, 1024, 64)Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 1 copy engine(s)Run time limit on kernels: YesIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: DisabledDevice supports Unified Addressing (UVA): YesDevice PCI Domain ID / Bus ID / location ID: 0 / 4 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 7.5, CUDA Runtime Version = 7.5, NumDevs = 1, Device0 = GeForce 940M
Result = PASS
说明:3个SM,每个SM包含128个SP,总共384个SP。
17.矩阵分块乘法[15]
解析:

18.一维卷积
解析:卷积的物理意义就是加权叠加,常见的操作有一维卷积和二维卷积。需要说明的是,“幽灵元素"通常补0。因为全局存储器和常数存储器变量都是存储在DRAM中的,从DRAM中访问一个变量需要数百甚至数千个时钟周期,从DRAM访问变量的速度通常要比处理器完成算术操作的 速度慢很多。因此,DRAM的长延迟和有限带宽已经成为几乎所有现代处理器的性能瓶颈,通常被称为存储墙问题。为了缓解这个问题,现代处理器通常引进高速 缓存存储器(或多级高速缓存),以减少访问DRAM的次数。
(1)一维卷积
该算法的缺点是受限于访问输入数组d_N的DRAM带宽,掩码数组d_M已经放在L1高速缓存。
(2)分块一维卷积1
规定一个线程块处理的输出元素的集合成为"输出块”;计算不涉及幽灵元素的分块称为"中间块";输出数据最左边的分块称为左边界分块;输出数据最右边的分块称为右边界分块;涉及多个分块、被多个线程块加载的数据称为"光环元素"或者"边缘元素"。
该算法的优点是将输入数组d_N分块后放入共享存储器,减少了输入数组d_N的DRAM带宽,掩码数组d_M已经放在L1高速缓存。(分块一维卷积1对一维卷积的改进)
(3)分块一维卷积2
该算法的优点是充分利用了L2高速缓存,掩码数组d_M已经放在L1高速缓存。需要说明的是,最近的GPU(比如,Fermi)提供了通用L1和L2高速缓存,L1缓存是每个SM私有的,而L2缓存是所有SM共享的。这样的话,线程块中的光环元素可能存放在L2高速缓存中,我们直接利用光环元素即可,而不再需要将光环元素加载到线程块的共享存储器中。(分块一维卷积2对分块一维卷积1的改进)
19.cudaMemcpyToSymbol
解析:在device中,cudaMemcpyToSymbol进行赋值和读取(device,shared,constant),而在host中,cudaMemcpy进行赋值和读取。需要说明的是,在函数体外声明的变量默认为__device__类型,即全局变量类型。cudaMemcpyToSymbol(d_M, h_M, MaskLen*sizeof(float));和cudaMemcpyFromSymbol(h_M, d_M,MaskLen*sizeof(float));功能相反。常量存储器中的内容通常放在L1高速缓存中,因为常量存储器变量在kernel函数执行期间不会改变,刚好与GPU不提供缓存一致性相符合(主要是为了最大化利用硬件资源,提高处理器的算术运算吞吐率等)。需要说明的是,现代CPU通常都支持处理器核心之间的缓存一致性。
20.shared memory与bank conflict
解析:
(1)什么是bank conflict?
在实际中,shared memory被分割成32个等大小的存储体(比如,Maxwell架构),即bank(每个bank拥有每周期32bit=4byte=4char=1int=1float的宽度)。因为一个warp中有32个线程,相当于一个线程对应一个bank。(不同的设备,存储体的数目也不相同,比如设备Tesla架构为16个存储体,后面我们以32个存储体进行讲解)。
对于计算能力1.0设备,前个half-warp和后个half-warp不存在bank conflict;对于计算能力2.0设备,前个half-warp和后个half-warp可能存在bank conflict,因为shared memory可以同时让32个bank响应请求。
(2)bank conflict发生的原因?
理想情况下就是不同的线程访问不同的bank,可能是规则的访问,比如,线程0读写bank0,线程1读写bank1,也可能是不规则的,比如线程0读写bank1,线程1读写bank0。这种同一时刻每个bank只被最多1个线程访问的情况下不会出现bank conflict。特殊情况如果有多个线程同时访问同一个bank的同一个地址的时候也不会产生bank conflict,即broadcast。但当多个线程同时访问同一个bank不同的地址时,那么bank conflict就发生了。比如,线程0访问地址0,而线程1访问地址32(归一化后为0),由于它们在同一个bank中,所以就导致了冲突。因为bank conflict发生后,同一个bank的内存读写将被串行化,会导致程序性能大大降低。
(3)什么时候会发生bank conflict呢?
bank conflict主要出现在global memory与shared memory数据交换,及设备函数对shared memory操作中。
(4)如何避免bank conflict呢?
很多时候shared memory的bank conflict可以通过修改数据存储的方式来解决。
21.Thrust库
解析:Thrust是一款基于GPU CUDA的C++库,其中包含诸多并行算法和数据结构。Thrust主要通过管理系统底层的功能,比如memory access(内存获取)和memory allocation(内存分配)来实现加速,使得工程师们在GPU编程的环境下能更focus在算法的设计上。
(1)容器
host_vector:为主机提供的向量类,并且驻留在主机内存中;device_vector:为设备提供的向量类,并且驻留在设备全局内存中。
说明:fill(),copy(),sequence()。
(2)算法
转换(transformation);规约(reduction);前缀求和(prefix sum);再排序(reordering);排序(sorting)。
(3)迭代器
constant_iterator;counting_iterator;transform_iterator;permutation_iterator;zip_iterator。
22.事件,流,纹理内存
解析:
(1)事件:CUDA中的事件本质上是一个GPU时间戳,两个事件的时间差就是算法执行时间。
(2)流:CUDA流表示一个GPU操作队列,可以将一个流看做是GPU上的一个任务,不同任务可以并行执行。
(3)纹理内存:专门为那些在内存访问模式中存在大量空间局部性的图形应用程序而设计的只读内存。
参考文献:
[1] Java bindings for CUDA:http://jcuda.org/
[2] CNN之Caffe配置:http://www.cnblogs.com/alfredtofu/p/3577241.html
[3] Setting up a Deep Learning Machine from Scratch:https://github.com/saiprashanths/dl-setup
[4] CUDA初学大全:http://www.cnblogs.com/yangs/archive/2012/07/28/2613269.html
[5] 有哪些优秀的CUDA开源代码?:https://www.zhihu.com/question/29036289/answer/42971562
[6] CUDA一维矩阵的加法:http://tech.it168.com/a2009/1112/807/000000807771.shtml
[7] CUDA二维矩阵加法:http://www.cnblogs.com/jugg1024/p/4349243.html
[8] NVIDIA CUDA Runtime API:http://docs.nvidia.com/cuda/cuda-runtime-api/index.html#axzz4G8M3LWlq
[9] C/C++是如何通过宏定义来判断操作系统的:http://www.myexception.cn/operating-system/1981774.html
[10] CUDA编程其实写个矩阵相乘并不是那么难:http://www.cnblogs.com/yusenwu/p/5300956.html
[11] CUDA实例矩阵乘法:http://wenku.baidu.com/link?url=XCOgGQqpPUns-cifgGm1tbfqmY-5wWTwkXHh1_i_5ZZX6vFmbFu22r67fWMpcs-GxsH9thzOjVeNCpKIjGjdx2SYhq7bW4qfIquRTM0AAW_
[12] 华科并行计算上机作业:http://wenku.baidu.com/link?url=1tWvUvW0t7BnFChxetS_Mr5_pCF_LZHQGLWxN-ArVVPccOM_VmoTx9IUD76l_rVMP-iPKWI97vn7wa5ZChz59rr4wlur3rL6k3MGB15qF4W
[13] CUDA编程:http://www.cnblogs.com/stewart/archive/2013/01/05/2846860.html
[14] NVIDIA Docker:GPU Server Application Deployment Made Easy:https://devblogs.nvidia.com/parallelforall/nvidia-docker-gpu-server-application-deployment-made-easy/
[15] CUDA矩阵乘法——利用共享存储器:http://blog.csdn.net/augusdi/article/details/12614247
[16] 华科并行计算上机作业:http://wenku.baidu.com/link?url=1tWvUvW0t7BnFChxetS_Mr5_pCF_LZHQGLWxN-ArVVPccOM_VmoTx9IUD76l_rVMP-iPKWI97vn7wa5ZChz59rr4wlur3rL6k3MGB15qF4W
[17] GPUWattch Energy Model Manual:http://www.gpgpu-sim.org/gpuwattch/
[18] 图形学领域的关键算法及源码链接:http://blog.csdn.net/u013476464/article/details/40857873
[19] 拷贝global memory,cudaMemcpyToSymbol和cudaMemcpy函数是否有区别:http://blog.csdn.net/litdaguang/article/details/45047015
[20] CUDA GPU编程如何避免bank conflict:http://www.th7.cn/Program/c/201512/719448.shtml
[21] CUDA共享内存bank conflict:http://blog.csdn.net/endlch/article/details/47043069
[22] CUDA bank conflict in shared memory:http://bbs.csdn.net/topics/390836540
[23] CUDA Programming Guide之shared memory的Bank Confict:http://blog.csdn.net/o_oxo_o/article/details/4296281
[24]Parallel_programming_week3.md:https://github.com/mebusy/notes/blob/c278e037aa8a59aa139fc722d01ed41cf978921d/dev_notes/Parallel_programming_week3.md
[25] Thrust:http://docs.nvidia.com/cuda/thrust/index.html#axzz4H6gsFZs3
[26] Thrust File List:http://thrust.github.io/doc/files.html
相关文章:
CUDA C编程权威指南:1.1-CUDA基础知识点梳理
主要整理了N多年前(2013年)学习CUDA的时候开始总结的知识点,好长时间不写CUDA代码了,现在LLM推理需要重新学习CUDA编程,看来出来混迟早要还的。 1.CUDA 解析:2007年,NVIDIA推出CUDA(…...

讲讲项目里的仪表盘编辑器(四)分页卡和布局容器组件
讲讲两个经典布局组件的实现 ① 布局容器组件 配置面板是给用户配置布局容器背景颜色等属性。这里我们不需要关注 定义文件 规定了组件类的类型、标签、图标、默认布局属性、主文件等等。 // index.js import Container from ./container.vue; class ContainerControl extends…...

Qt模块、Qt开发应用程序类型、Qt未来主要市场、Qt6功能普及
Qt模块、Qt开发应用程序类型、Qt未来主要市场、Qt6功能普及 文章目录 1.Qt核心模块2.Qt的功能拓展3.Qt未来主要市场4.Qt6功能普及5.弃用的功能: Qt是一个跨平台的应用程序开发框架,提供了丰富的模块和工具来开发各种类型的应用程序。以下是Qt目前已有的…...

nodejs+vue高校校图书馆elementui
管理员输入书籍所在的书架位置,借阅提醒系统:可以查看个人借阅信息和图书到期提醒、挂失、检索、虚拟借书证不仅为群众提供了服务,而且也推广了自己,让更多的群众了解自己。 管理员页面: 第三章 系统分析 10 3.1需求分…...

CUDA C编程权威指南:1.2-CUDA基础知识点梳理
主要整理了N多年前(2013年)学习CUDA的时候开始总结的知识点,好长时间不写CUDA代码了,现在LLM推理需要重新学习CUDA编程,看来出来混迟早要还的。 1.闭扫描和开扫描 对于一个二元运算符 ⊕ \oplus ⊕和一个 n n n元…...

C语言—位运算符
目录 &(位与,AND): |(位或,OR): 位取反(~): 左移(<<): 右移(>>): &(位与,AND)&…...

怎么才能实现一个链接自动识别安卓.apk苹果.ipa手机和win电脑wac电脑
您想要实现的功能是通过检测用户代理(User Agent)来识别访问设备类型并根据设备类型展示相应的页面。您可以根据以下步骤进行实现: 选择后端语言和框架,例如:Node.js、Express。 创建一个新的Express项目。 编写一个…...
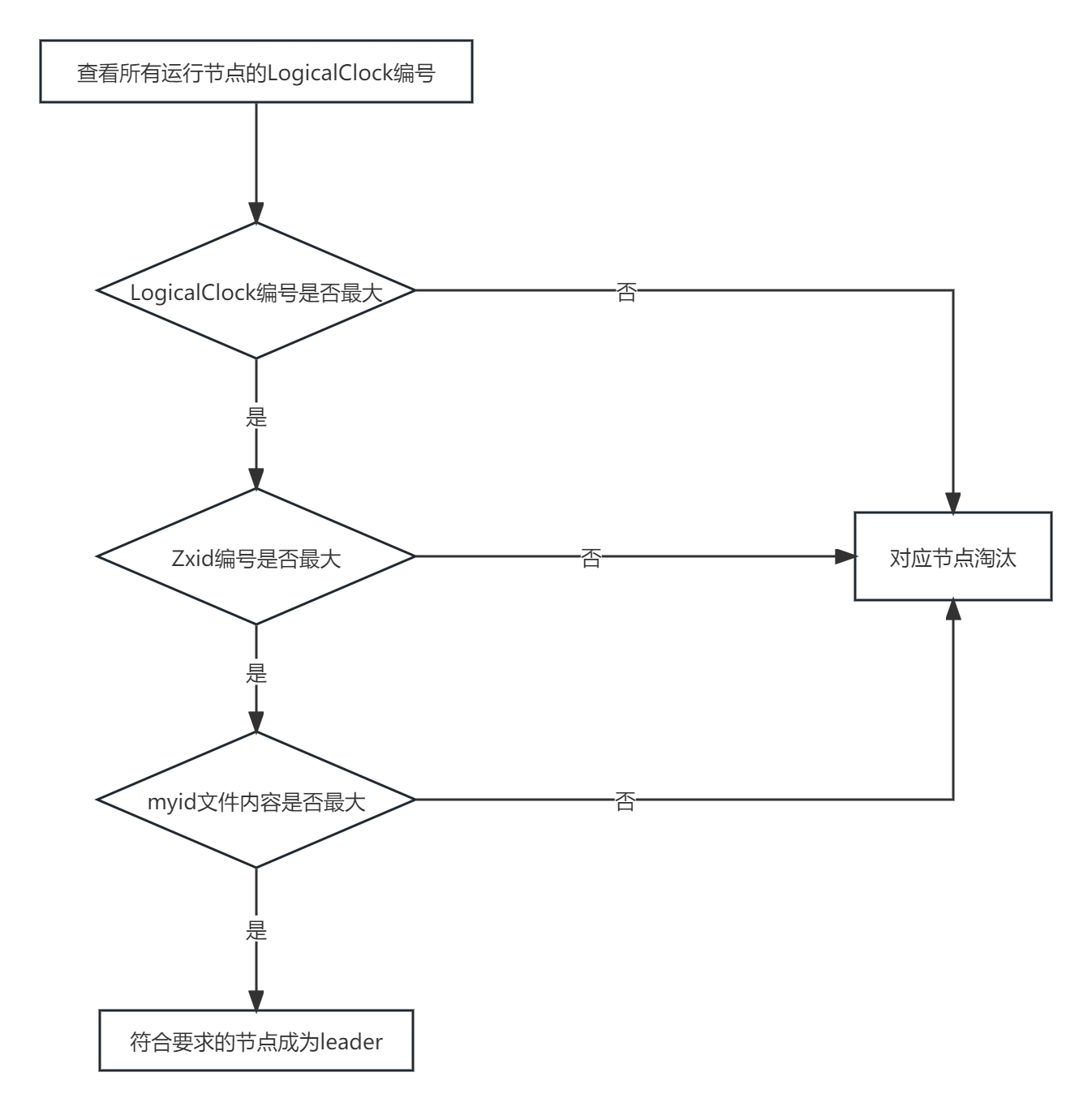
zookeeper选举机制
全新集群选举 zookeeper 全新集群选举机制网上资料很多说法很模糊,仔细思考了一下,应该是这样 得到票数最多的机器>机器总数半数 具体启动过程中的哪个节点成为 leader 与 zoo.cfg 中配置的节点数有关,下面以3个举例 选举过程如下 server…...

vcpkg切换 Visual Studio 版本
vcpkg切换 Visual Studio 版本 在使用vcpkg作为项目的包管理工具时,可能会遇到需要切换Visual Studio版本的情况。下面是一种简单的方法来实现这个目标,通过修改triplet文件来指定使用的Visual Studio版本。 步骤1: 创建或修改Triplet文件 首先&#…...
运算符重载
#include <iostream> using namespace std; class Num { private:int num1; //实部int num2; //虚部 public:Num(){}; //无参构造Num(int n1,int n2):num1(n1),num2(n2){}; //有参构造~Num(){}; //析构函数const Num operator(const Num &other)const //加号重载{Nu…...

Llama2-Chinese项目:7-外延能力LangChain集成
本文介绍了Llama2模型集成LangChain框架的具体实现,这样可更方便地基于Llama2开发文档检索、问答机器人和智能体应用等。 1.调用Llama2类 针对LangChain[1]框架封装的Llama2 LLM类见examples/llama2_for_langchain.py,调用代码如下所示:…...

ES6中数组的扩展
1. 扩展运算符 用三个点(...)表示,它如同rest参数的逆运算,将数组转为用逗号分隔的参数序列。扩展就是将一个集合分成一个个的。 console.log(...[1, 2, 3]); // 1, 2, 3可以用于函数调用 扩展运算符后还可以放置表达式 ...(x > 0 ? [a] : [])如…...
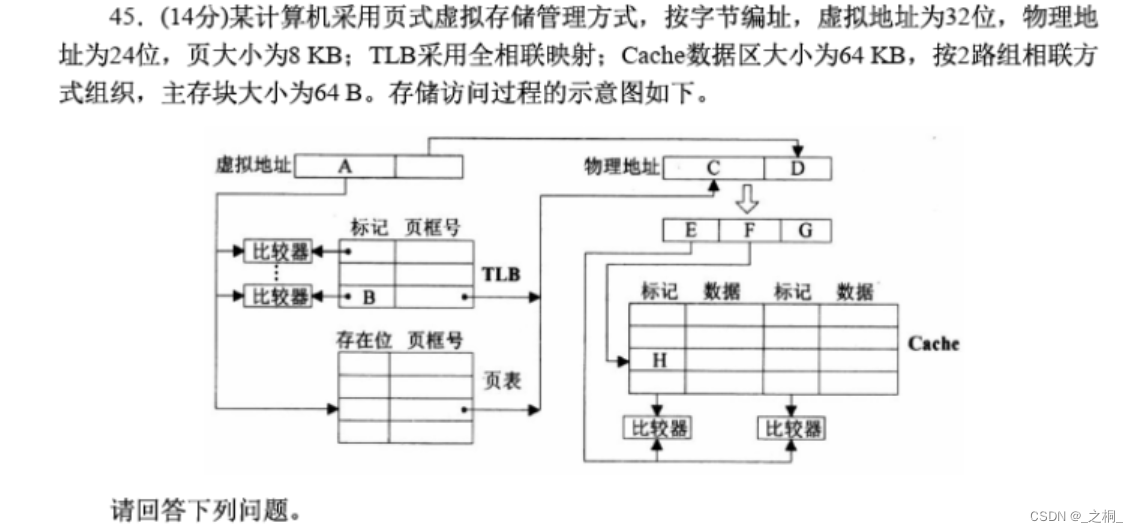
计算机考研 | 2016年 | 计算机组成原理真题
文章目录 【计算机组成原理2016年真题44题-9分】【第一步:信息提取】【第二步:具体解答】 【计算机组成原理2016年真题45题-14分】【第一步:信息提取】【第二步:具体解答】 【计算机组成原理2016年真题44题-9分】 假定CPU主频为5…...
Web版Photoshop来了,用到了哪些前端技术?
经过 Adobe 工程师多年来的努力,并与 Chrome 等浏览器供应商密切合作,通过 WebAssembly Emscripten、Web Components Lit、Service Workers Workbox 和新的 Web API 的支持,终于在近期推出了 Web 版 Photoshop(photoshop.adobe…...

FL Studio21.1.0水果中文官方网站
FL Studio 21.1.0官方中文版重磅发布纯正简体中文支持,更快捷的音频剪辑及素材管理器,多样主题随心换!Mac版新增对苹果M2/1家族芯片原生支持。DAW界萌神!极富二次元造型的水果娘FL chan通过FL插件Fruity Dance登场,为其…...
[BJDCTF2020]Mark loves cat
先用dirsearch扫一下,访问一下没有什么 需要设置线程 dirsearch -u http://8996e81f-a75c-4180-b0ad-226d97ba61b2.node4.buuoj.cn:81/ --timeout2 -t 1 -x 400,403,404,500,503,429使用githack python2 GitHack.py http://8996e81f-a75c-4180-b0ad-226d97ba61b2.…...
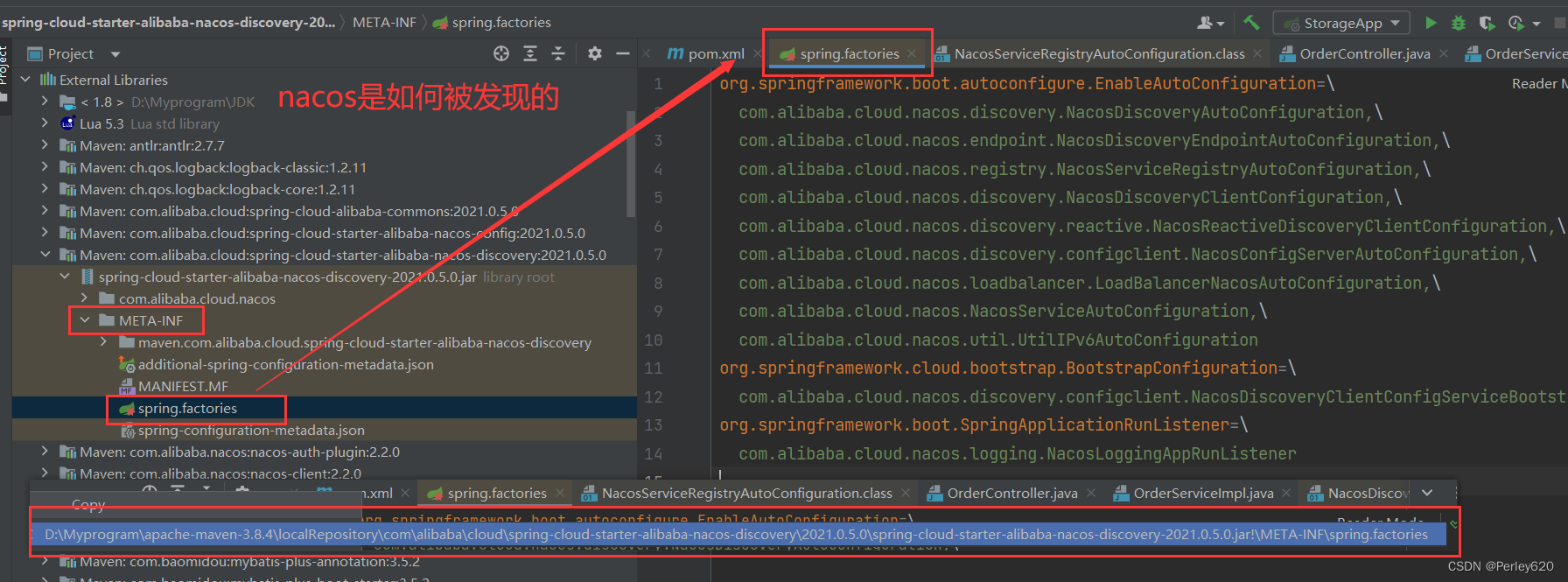
@SpringBootApplication注解的理解——如何排除自动装配 分布式情况下如何自动加载 nacos是怎么被发现的
前言 spring作为主流的 Java Web 开发的开源框架,是Java 世界最为成功的框架,持续不断深入认识spring框架是Java程序员不变的追求。 本篇博客介绍SpringBootApplicant注解的自动加载相关内容 其他相关的Spring博客文章列表如下: Spring基…...

HTTP的前世今生
史前时期 20 世纪 60 年代,美国国防部高等研究计划署(ARPA)建立了 ARPA 网,它有四个分布在各地的节点,被认为是如今互联网的“始祖”。 然后在 70 年代,基于对 ARPA 网的实践和思考,研究人员发…...

软件测试教程 自动化测试selenium篇(二)
掌握Selenium常用的API的使用 目录 一、webdriver API 1.1元素的定位 1.2 id定位 1.3name 定位 1.4tag name 定位和class name 定位 1.5CSS 定位 1.6XPath 定位 1.7link text定位 1.8Partial link text 定位 二、操作测试对象 2.1鼠标点击与键盘输入 2.2submit 提交…...
JavaSE入门--初始Java
文章目录 Java语言概述认识Java的main函数main函数示例运行Java程序认识注释认识标识符认识关键字 前言: 我从今天开始步入Java的学习,希望自己的博客可以带动小白学习,也能获得大佬的指点,日后能互相学习进步,都能如尝…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...