PyTorch应用实战二:实现卷积神经网络进行图像分类
文章目录
- 实验环境
- MNIST数据集
- 1.网络结构
- 2.程序实现
- 2.1 导入相关库
- 2.2 构建卷积神经网络模型
- 2.3 加载MNIST数据集
- 2.4 训练模型
- 附:系列文章
实验环境
python3.6 + pytorch1.8.0
import torch
print(torch.__version__)
1.8.0
MNIST数据集
MNIST数字数据集是一组手写数字图像的数据集,用于机器学习中的图像分类任务。
该数据集包含60,000张训练图像和10,000张测试图像,每张图像都是28x28像素大小的灰度图像。每张图像都被标记为0到9中的一个数字。
该数据集是由美国国家标准与技术研究所(NIST)收集和创建,因此得名为MNIST(Modified National Institute of Standards and Technology)。它已成为机器学习领域中广泛使用的基准数据集之一。
1.网络结构
网络层 参数 输出尺寸
Input N×1×28×28
Conv1 ksize=5, C_out=4, pad=0, stride=2 N×4×12×12
ReLU N×4×12×12
Conv2 ksize=3, C_out=8, pad=0, stride=2 N×8×5×5
ReLU N×8×5×5
Flatten N×200
Linear num_out=10 N×10
输出图像的维度计算方法:(图像大小 - 卷积核大小)÷步长+1
2.程序实现
2.1 导入相关库
import torch
from torch.nn import ReLU
from torch.nn.functional import conv2d, cross_entropy
from torchvision import datasets, transforms
2.2 构建卷积神经网络模型
定义ReLU激活函数
def relu(x):return torch.clamp(x, min=0)
torch.clamp函数是一个张量操作函数,在PyTorch中实现。该函数的作用是将输入的张量每个元素都限制在指定的区间内,返回一个新的张量。
可以通过指定min或max参数的值来实现对张量元素的限制,也可以同时指定同时限制上下限。若min和max均不指定,则默认为min=0,max=1。
定义线性函数
def linear(x, weight, bias):out = torch.matmul(x, weight) + bias.view(1, -1)return out
定义神经网络模型
conv2d的五大参数:x, w, b, stride, pad
def model(x, params):# 卷积层1# w=(4,1,5,5),输出通道为4,输入通道为1,卷积核为(5,5)x = conv2d(x, params[0], params[1], 2, 0)# (N×4×12×12)x = relu(x)# 卷积层2# w=(8,4,3,3),输出通道为8,输入通道为4,卷积核为(3,3)x = conv2d(x, params[2], params[3], 2, 0)x = relu(x)# (N×8×5×5)x = x.view(-1, 200)# 全连接层x = linear(x, params[4], params[5])return x
该程序定义了一个卷积神经网络模型,输入参数包括待处理的数据x和模型参数params。程序通过使用卷积层、ReLU激活函数和全连接层构建了一个简单的卷积神经网络模型。其中,程序使用了两个卷积层和一个全连接层。具体的模型参数包括两个卷积层的卷积核权重、偏置、以及一个全连接层的权重和偏置。程序返回模型的预测结果x。
初始化模型
init_std = 0.1
params = [torch.randn(4, 1, 5, 5) * init_std,torch.zeros(4),torch.randn(8, 4, 3, 3) * init_std,torch.zeros(8),torch.randn(200, 10) * init_std,torch.zeros(10)
]
for p in params:p.requires_grad=True #自动微分
params
[tensor([[[[ 0.1062, -0.0596, -0.0730, 0.0613, 0.1273],[ 0.0751, -0.0852, 0.0648, -0.0774, -0.0355],[ 0.1565, -0.0221, 0.0574, -0.1055, 0.0350],[-0.1299, 0.0169, 0.0297, 0.1494, -0.0993],[ 0.0464, 0.0628, -0.0133, -0.0545, 0.1265]]],[[[ 0.0291, 0.1538, -0.0692, -0.0637, 0.0829],[ 0.0735, -0.0594, -0.1185, -0.0026, -0.0351],[ 0.0697, 0.1032, -0.1001, -0.0212, -0.0946],[ 0.0311, 0.1461, 0.0641, -0.0407, 0.1615],[-0.0517, 0.0298, -0.0482, 0.0984, -0.0602]]],[[[ 0.0102, -0.1541, -0.1040, 0.0335, 0.0115],[-0.1167, 0.1155, 0.0832, 0.0561, 0.0435],[ 0.0429, -0.1574, 0.0323, -0.1353, -0.1211],[-0.2472, -0.2379, -0.0963, 0.0105, -0.0845],[ 0.0059, 0.0433, 0.0111, 0.0422, -0.0131]]],[[[-0.0741, 0.1411, 0.0006, 0.1485, 0.1257],[ 0.0446, 0.0822, -0.0458, 0.1525, 0.0695],[ 0.0616, 0.1892, 0.1525, -0.0594, 0.1515],[-0.0490, 0.1179, -0.1175, 0.1448, 0.0811],[-0.0641, -0.0494, -0.0980, -0.1119, 0.0599]]]], requires_grad=True),tensor([0., 0., 0., 0.], requires_grad=True),tensor([[[[-0.1564, 0.1481, 0.0995],[ 0.0157, 0.0025, -0.0513],[ 0.1011, -0.0417, -0.1049]],[[-0.2052, -0.0514, -0.0995],[ 0.1915, -0.0586, -0.0985],[-0.1371, -0.2874, -0.0977]],[[-0.0367, -0.2326, 0.0306],[ 0.0193, 0.0762, 0.0243],[-0.1507, -0.1265, -0.1493]],[[ 0.0769, -0.1014, 0.0888],[-0.0632, -0.0782, -0.1765],[ 0.0521, 0.2349, -0.0833]]],[[[ 0.0041, -0.0487, 0.1597],[-0.0210, -0.1051, 0.0374],[ 0.1981, 0.1395, 0.0108]],[[ 0.0418, 0.1592, 0.0219],[ 0.1168, 0.0305, -0.0702],[ 0.2217, -0.0670, -0.0037]],[[ 0.0501, -0.2496, 0.0381],[-0.1487, -0.0202, 0.0236],[-0.0738, 0.0733, -0.1244]],[[-0.0825, 0.0158, -0.0877],[ 0.0337, 0.2011, 0.1339],[-0.1452, -0.1665, 0.0141]]],[[[-0.0779, -0.1749, 0.0731],[-0.0936, 0.0519, 0.1093],[ 0.1049, 0.0406, -0.0594]],[[ 0.1012, 0.0804, -0.0153],[ 0.0899, -0.0954, -0.0520],[ 0.0724, -0.0487, -0.0048]],[[-0.0814, -0.0918, 0.0481],[-0.0482, 0.1069, -0.1442],[-0.0863, 0.0290, 0.0701]],[[ 0.1068, 0.1104, -0.0105],[ 0.1059, 0.0294, 0.2377],[ 0.0855, -0.0029, 0.0322]]],[[[ 0.0467, -0.1335, -0.0698],[-0.0683, 0.0323, -0.0197],[ 0.1748, 0.1601, 0.0385]],[[ 0.0100, -0.0644, 0.0374],[ 0.2065, -0.0637, -0.1515],[-0.1963, 0.0413, 0.0476]],[[ 0.0600, -0.0431, 0.0280],[ 0.0428, 0.0220, -0.0793],[-0.0876, 0.0013, -0.0618]],[[ 0.3182, 0.0358, 0.1933],[-0.0536, 0.1208, -0.0318],[ 0.0144, 0.0707, -0.0400]]],[[[ 0.1354, 0.0365, 0.0468],[-0.0399, 0.0050, 0.0589],[ 0.0335, 0.0415, -0.0896]],[[-0.2733, -0.0715, -0.0500],[-0.0501, -0.0715, -0.0644],[ 0.0130, 0.0041, -0.0051]],[[-0.0304, -0.0240, -0.0137],[ 0.0931, 0.0814, 0.0466],[ 0.1731, 0.0708, 0.1007]],[[-0.2261, 0.0397, -0.1092],[-0.0359, -0.1310, -0.0156],[ 0.1561, -0.0511, 0.0229]]],[[[ 0.1716, 0.1097, 0.0117],[-0.1617, 0.2321, 0.1619],[ 0.0721, 0.0619, 0.0418]],[[ 0.0714, -0.0578, -0.0358],[-0.0079, 0.0858, 0.1151],[ 0.0559, 0.1615, -0.1431]],[[ 0.0542, 0.0115, -0.0027],[-0.0479, -0.0977, -0.0463],[-0.0527, 0.1211, -0.3093]],[[-0.0261, -0.0288, -0.0048],[ 0.1089, 0.1711, 0.1310],[ 0.0552, -0.0664, -0.0463]]],[[[-0.0420, 0.1513, -0.1023],[-0.1159, -0.1849, -0.0109],[-0.1040, -0.0087, 0.0621]],[[ 0.0287, 0.1017, 0.0153],[-0.0875, -0.0534, -0.0378],[ 0.0076, -0.0756, -0.3164]],[[ 0.1255, 0.0647, -0.0439],[ 0.0973, -0.1135, -0.1946],[ 0.0965, 0.0432, 0.1767]],[[ 0.0021, 0.0215, 0.0423],[-0.0698, -0.0198, -0.0033],[-0.0363, -0.0935, 0.0433]]],[[[-0.0605, -0.0037, 0.0548],[ 0.0856, -0.0815, 0.0877],[ 0.0714, 0.1070, -0.1506]],[[ 0.1159, 0.0648, -0.0505],[-0.2376, 0.0337, 0.1003],[ 0.1495, 0.0696, 0.0500]],[[ 0.1888, 0.1441, 0.0078],[ 0.1022, -0.0609, -0.2317],[-0.0881, -0.0983, 0.1033]],[[ 0.0118, 0.0604, 0.0070],[ 0.0215, 0.0990, 0.1829],[-0.0226, 0.1505, 0.0927]]]], requires_grad=True),tensor([0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True),tensor([[ 0.1092, -0.0588, -0.0678, ..., -0.0369, 0.1425, -0.1710],[-0.2353, -0.1057, 0.0156, ..., 0.0120, 0.0512, 0.1080],[-0.0902, 0.1036, 0.1558, ..., -0.1726, 0.1594, -0.0046],...,[-0.1067, 0.1090, 0.0657, ..., 0.1041, -0.1314, 0.0274],[ 0.0735, -0.0332, 0.0949, ..., 0.0044, -0.1386, 0.0113],[ 0.0212, -0.0620, 0.1167, ..., 0.0424, 0.0393, -0.0940]],requires_grad=True),tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True)]
2.3 加载MNIST数据集
train_batch_size = 100 #一共60000个数据,100个数据一组,一共600组(N=100)
test_batch_size = 100 #一共10000个数据,100个数据一组,一共100组(N=100)
# 训练集
train_loader = torch.utils.data.DataLoader(datasets.MNIST('./data',train=True,download=True, transform=transforms.Compose([transforms.ToTensor(), #转为tensortransforms.Normalize((0.5),(0.5)) #正则化])),batch_size = train_batch_size, shuffle=True #打乱位置
)
# 测试集
test_loader = torch.utils.data.DataLoader(datasets.MNIST('./data',train=False,download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5),(0.5))])),batch_size = test_batch_size, shuffle=False
)
这段代码主要是用来读取MNIST数据集并进行数据预处理,将其转换为可以在神经网络中使用的格式。其中train_batch_size和test_batch_size分别为训练集和测试集每批处理的数据大小。通过torch.utils.data.DataLoader函数,将MNIST数据集读入,并通过transforms.Compose函数对数据进行预处理,包括将其转换为tensor以及进行正则化处理。在训练集和测试集中,还通过shuffle参数打乱数据集的顺序,以增加数据集的多样性。最终将处理好的数据通过train_loader和test_loader返回。
2.4 训练模型
alpha = 0.1 #学习率
epochs = 100 #训练次数
interval = 100 #打印间隔
for epoch in range(epochs):for i, (data, label) in enumerate(train_loader):output = model(data, params)loss = cross_entropy(output, label) #交叉熵函数for p in params: if p.grad is not None: #如果梯度不为零p.grad.zero_() #梯度置零loss.backward() #反向求导for p in params: #更新参数p.data = p.data - alpha * p.grad.dataif i % interval == 0:print("Epoch %03d [%03d/%03d]\tLoss:%.4f"%(epoch, i, len(train_loader), loss.item()))correct_num = 0total_num = 0with torch.no_grad():for data, label in test_loader:output = model(data, params)pred = output.max(1)[1]correct_num += (pred == label).sum().item()total_num += len(data)acc = correct_num / total_numprint('...Testing @ Epoch %03d\tAcc:%.4f'%(epoch, acc))
Epoch 000 [000/600] Loss:2.3276
Epoch 000 [100/600] Loss:0.4883
Epoch 000 [200/600] Loss:0.2200
Epoch 000 [300/600] Loss:0.1809
Epoch 000 [400/600] Loss:0.1448
Epoch 000 [500/600] Loss:0.2617
...Testing @ Epoch 000 Acc:0.9469
Epoch 001 [000/600] Loss:0.1120
Epoch 001 [100/600] Loss:0.1738
Epoch 001 [200/600] Loss:0.1212
Epoch 001 [300/600] Loss:0.1924
Epoch 001 [400/600] Loss:0.0743
Epoch 001 [500/600] Loss:0.3233
...Testing @ Epoch 001 Acc:0.9613
Epoch 002 [000/600] Loss:0.0553
Epoch 002 [100/600] Loss:0.2300
Epoch 002 [200/600] Loss:0.0489
Epoch 002 [300/600] Loss:0.0816
Epoch 002 [400/600] Loss:0.1188
Epoch 002 [500/600] Loss:0.1968
...Testing @ Epoch 002 Acc:0.9670
Epoch 003 [000/600] Loss:0.2476
Epoch 003 [100/600] Loss:0.1316
Epoch 003 [200/600] Loss:0.2912
Epoch 003 [300/600] Loss:0.0378
Epoch 003 [400/600] Loss:0.1028
Epoch 003 [500/600] Loss:0.1199
...Testing @ Epoch 003 Acc:0.9693
Epoch 004 [000/600] Loss:0.0853
Epoch 004 [100/600] Loss:0.1661
Epoch 004 [200/600] Loss:0.1067
Epoch 004 [300/600] Loss:0.0579
Epoch 004 [400/600] Loss:0.2422
Epoch 004 [500/600] Loss:0.0573
...Testing @ Epoch 004 Acc:0.9695
Epoch 005 [000/600] Loss:0.0816
Epoch 005 [100/600] Loss:0.0845
Epoch 005 [200/600] Loss:0.0607
Epoch 005 [300/600] Loss:0.0548
Epoch 005 [400/600] Loss:0.1351
Epoch 005 [500/600] Loss:0.0569
...Testing @ Epoch 005 Acc:0.9726
Epoch 006 [000/600] Loss:0.0441
Epoch 006 [100/600] Loss:0.0912
Epoch 006 [200/600] Loss:0.1213
Epoch 006 [300/600] Loss:0.0405
Epoch 006 [400/600] Loss:0.0311
Epoch 006 [500/600] Loss:0.0755
...Testing @ Epoch 006 Acc:0.9743
Epoch 007 [000/600] Loss:0.0342
Epoch 007 [100/600] Loss:0.0480
Epoch 007 [200/600] Loss:0.1276
Epoch 007 [300/600] Loss:0.1255
Epoch 007 [400/600] Loss:0.0572
Epoch 007 [500/600] Loss:0.0186
...Testing @ Epoch 007 Acc:0.9724
Epoch 008 [000/600] Loss:0.0515
Epoch 008 [100/600] Loss:0.0291
Epoch 008 [200/600] Loss:0.0362
Epoch 008 [300/600] Loss:0.0979
Epoch 008 [400/600] Loss:0.0950
Epoch 008 [500/600] Loss:0.0263
...Testing @ Epoch 008 Acc:0.9768
Epoch 009 [000/600] Loss:0.0766
Epoch 009 [100/600] Loss:0.1084
Epoch 009 [200/600] Loss:0.0495
Epoch 009 [300/600] Loss:0.0260
Epoch 009 [400/600] Loss:0.0708
Epoch 009 [500/600] Loss:0.0809
...Testing @ Epoch 009 Acc:0.9775
Epoch 010 [000/600] Loss:0.0179
Epoch 010 [100/600] Loss:0.0293
Epoch 010 [200/600] Loss:0.0534
Epoch 010 [300/600] Loss:0.0983
Epoch 010 [400/600] Loss:0.1292
Epoch 010 [500/600] Loss:0.0820
...Testing @ Epoch 010 Acc:0.9781
Epoch 011 [000/600] Loss:0.0542
Epoch 011 [100/600] Loss:0.0978
Epoch 011 [200/600] Loss:0.0596
Epoch 011 [300/600] Loss:0.0725
Epoch 011 [400/600] Loss:0.1350
Epoch 011 [500/600] Loss:0.0166
...Testing @ Epoch 011 Acc:0.9784
Epoch 012 [000/600] Loss:0.1395
Epoch 012 [100/600] Loss:0.0577
Epoch 012 [200/600] Loss:0.0437
Epoch 012 [300/600] Loss:0.1207
Epoch 012 [400/600] Loss:0.0795
Epoch 012 [500/600] Loss:0.0415
...Testing @ Epoch 012 Acc:0.9797
Epoch 013 [000/600] Loss:0.0897
Epoch 013 [100/600] Loss:0.0530
Epoch 013 [200/600] Loss:0.0421
Epoch 013 [300/600] Loss:0.0982
Epoch 013 [400/600] Loss:0.0646
Epoch 013 [500/600] Loss:0.0215
...Testing @ Epoch 013 Acc:0.9773
Epoch 014 [000/600] Loss:0.0544
Epoch 014 [100/600] Loss:0.0554
Epoch 014 [200/600] Loss:0.0236
Epoch 014 [300/600] Loss:0.0154
Epoch 014 [400/600] Loss:0.0262
Epoch 014 [500/600] Loss:0.1322
...Testing @ Epoch 014 Acc:0.9764
Epoch 015 [000/600] Loss:0.0204
Epoch 015 [100/600] Loss:0.0563
Epoch 015 [200/600] Loss:0.0309
Epoch 015 [300/600] Loss:0.0844
Epoch 015 [400/600] Loss:0.1167
Epoch 015 [500/600] Loss:0.0856
...Testing @ Epoch 015 Acc:0.9788
Epoch 016 [000/600] Loss:0.0052
Epoch 016 [100/600] Loss:0.1451
Epoch 016 [200/600] Loss:0.0279
Epoch 016 [300/600] Loss:0.0199
Epoch 016 [400/600] Loss:0.0765
Epoch 016 [500/600] Loss:0.1028
...Testing @ Epoch 016 Acc:0.9807
Epoch 017 [000/600] Loss:0.0149
Epoch 017 [100/600] Loss:0.0160
Epoch 017 [200/600] Loss:0.0454
Epoch 017 [300/600] Loss:0.1048
Epoch 017 [400/600] Loss:0.1013
Epoch 017 [500/600] Loss:0.0834
...Testing @ Epoch 017 Acc:0.9801
Epoch 018 [000/600] Loss:0.0062
Epoch 018 [100/600] Loss:0.0501
Epoch 018 [200/600] Loss:0.0478
Epoch 018 [300/600] Loss:0.0331
Epoch 018 [400/600] Loss:0.0333
Epoch 018 [500/600] Loss:0.0163
...Testing @ Epoch 018 Acc:0.9795
Epoch 019 [000/600] Loss:0.0331
Epoch 019 [100/600] Loss:0.0200
Epoch 019 [200/600] Loss:0.0242
Epoch 019 [300/600] Loss:0.0566
Epoch 019 [400/600] Loss:0.0917
这是一个简单的PyTorch训练循环,主要包括以下内容:
1.设置学习率(alpha)和迭代次数(epochs)
2.通过循环迭代训练数据集(train_loader),获得模型预测输出(output),并计算损失(loss)
3.将参数的梯度清零,进行反向传播求导(loss.backward())
4.使用梯度下降法更新参数的数值,即 p.data = p.data - alpha * p.grad.data
5.按照指定的间隔(interval)打印训练信息,包括训练次数(epoch),当前训练进度(i/len(train_loader))和当前损失(loss.item())
6.在测试数据集(test_loader)上对模型进行测试,获得预测结果(output),并计算准确率(acc)
7.打印测试结果,包括训练次数(epoch)和测试准确率(acc)
需要注意的是,这里采用的是交叉熵函数(cross_entropy),用于计算loss。同时也清空了参数梯度,防止梯度累加。
cross-entropy(交叉熵)是一种度量概率分布之间的差异性的方法,常用于机器学习中的分类问题。在分类问题中,预测结果通常表示为概率分布,而交叉熵则表示这个预测结果和实际类别分布之间的差异。交叉熵越小,则模型预测的概率分布越接近实际类别分布,模型的性能也越好。交叉熵公式如下:
H ( p , q ) = − ∑ i p ( i ) log q ( i ) H(p,q)=-\sum_{i}p(i)\log q(i) H(p,q)=−∑ip(i)logq(i)
其中, p p p 表示实际的类别分布, q q q 表示模型预测的概率分布。
附:系列文章
| 序号 | 文章目录 | 直达链接 |
|---|---|---|
| 1 | PyTorch应用实战一:实现卷积操作 | https://want595.blog.csdn.net/article/details/132575530 |
| 2 | PyTorch应用实战二:实现卷积神经网络进行图像分类 | https://want595.blog.csdn.net/article/details/132575702 |
| 3 | PyTorch应用实战三:构建神经网络 | https://want595.blog.csdn.net/article/details/132575758 |
| 4 | PyTorch应用实战四:基于PyTorch构建复杂应用 | https://want595.blog.csdn.net/article/details/132625270 |
| 5 | PyTorch应用实战五:实现二值化神经网络 | https://want595.blog.csdn.net/article/details/132625348 |
| 6 | PyTorch应用实战六:利用LSTM实现文本情感分类 | https://want595.blog.csdn.net/article/details/132625382 |
相关文章:

PyTorch应用实战二:实现卷积神经网络进行图像分类
文章目录 实验环境MNIST数据集1.网络结构2.程序实现2.1 导入相关库2.2 构建卷积神经网络模型2.3 加载MNIST数据集2.4 训练模型 附:系列文章 实验环境 python3.6 pytorch1.8.0 import torch print(torch.__version__)1.8.0MNIST数据集 MNIST数字数据集是一组手写…...
)
面试系列 - Java常见算法(二)
目录 一、排序算法 1、插入排序(Insertion Sort) 2、归并排序(Merge Sort) 二、图形算法 1、最短路径算法(Dijkstra算法、Floyd-Warshall算法) Dijkstra算法 Floyd-Warshall算法 2、最小生成树算法&…...
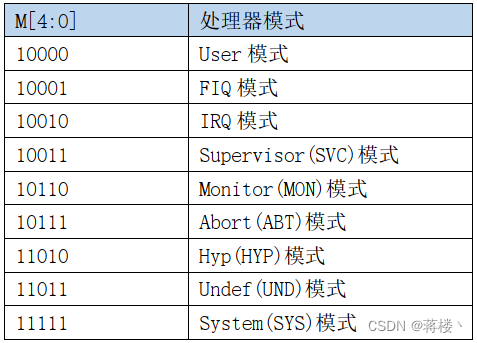
Cortex-A9 架构
一、Cortex-A 处理器运行模式 Cortex-A9处理器有 9中处理模式,如下表所示: 九种运行模式 在上表中,除了User(USR)用户模式以外,其它8种运行模式都是特权模式,在特权模式下,程序可以访问所有的系统资源。这…...
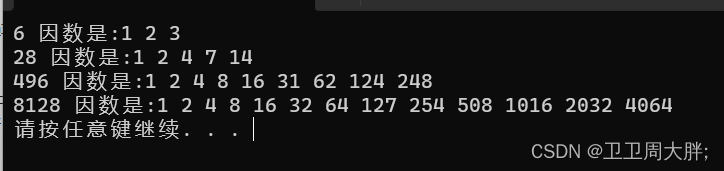
【C语言】循环结构程序设计(第二部分 -- 习题讲解)
前言:昨天我们学习了C语言中循环结构程序设计,并分析了循环结构的特点和实现方法,有了初步编写循环程序的能力,那么今天我们通过一些例子来进一步掌握循环程序的编写和应用。 💖 博主CSDN主页:卫卫卫的个人主页 💞 &am…...
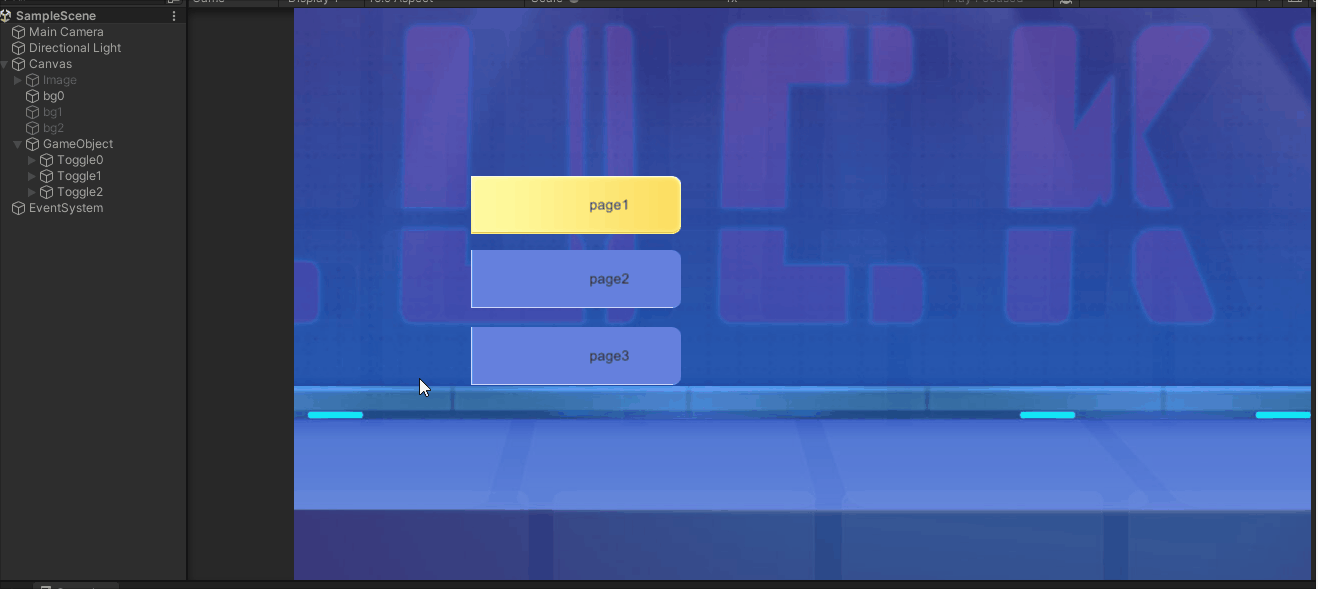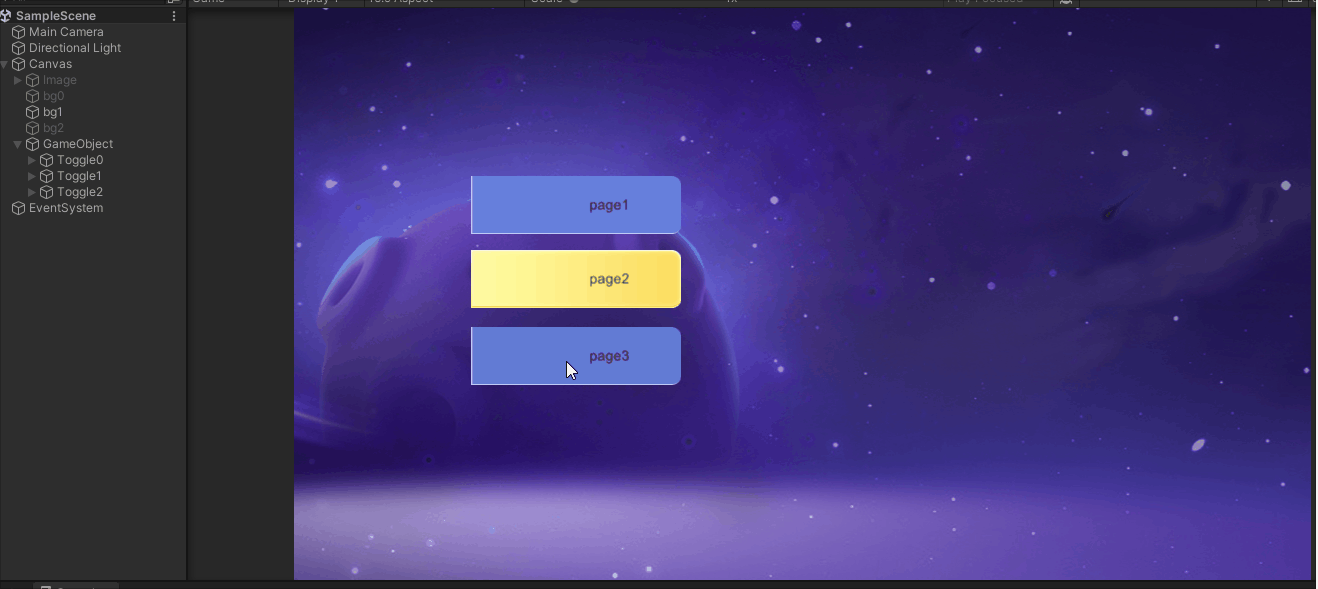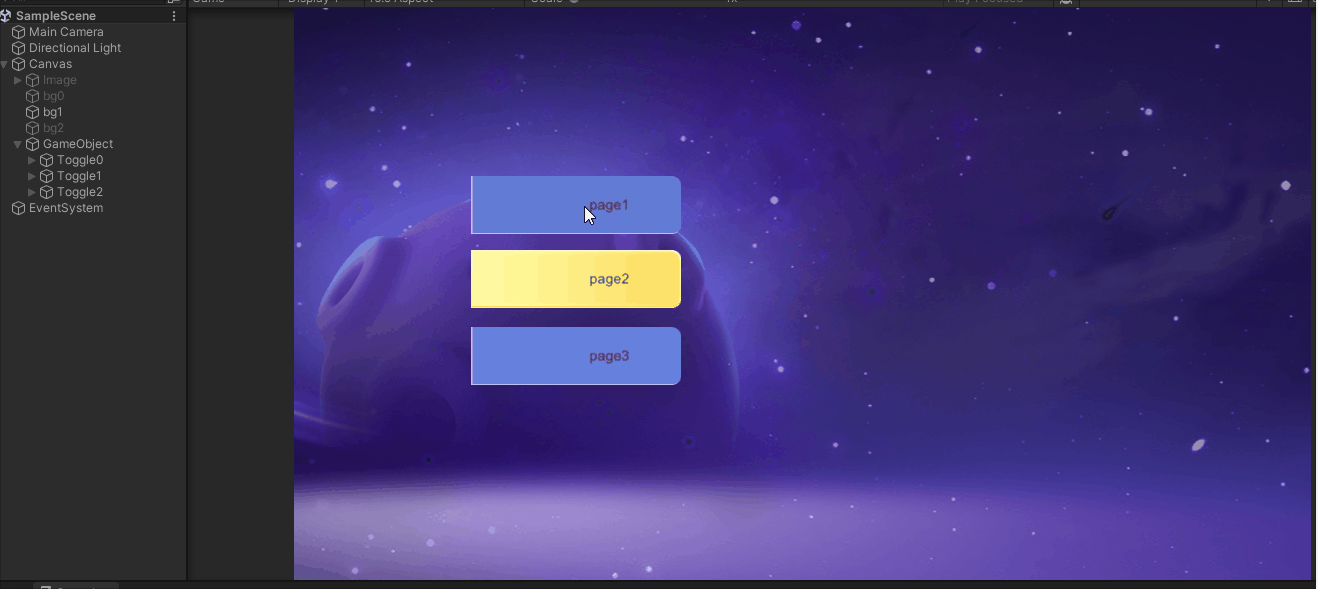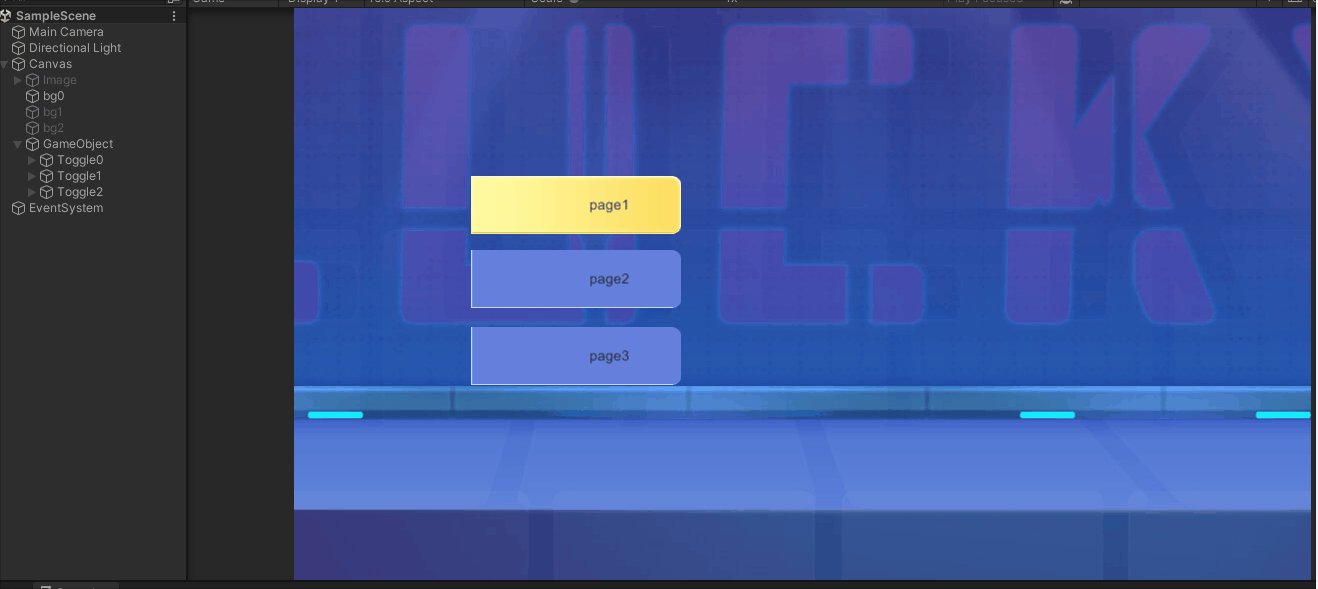
UGUI交互组件Toggle
一.Toggle对象的构造 Toggle和Button类似,是交互组件的一种 如果所示,通过菜单创建了两个Toggle,Toggle2中更换了背景和标记资源 对象说明Toggle含有Toggle组件的对象Background开关背景Checkmark开关选中标记Label名称文本 二.Toggle组件属…...

亲,您的假期余额已经严重不足了......
引言 大家好,我是亿元程序员,一位有着8年游戏行业经验的主程。 转眼八天长假已经接近尾声了,今天来总结一下大家的假期,聊一聊假期关于学习的看法,并预估一下大家节后大家上班时的样子。 1.放假前一天 即将迎来八天…...
【软件测试】自动化测试selenium(一)
文章目录 一. 什么是自动化测试二. Selenium的介绍1. Selenium是什么2. Selenium的特点3. Selenium的工作原理4. SeleniumJava的环境搭建 一. 什么是自动化测试 自动化测试是指使用软件工具或脚本来执行测试任务的过程,以替代人工进行重复性、繁琐或耗时的测试活动…...
Nginx实现动静分离
一、概述 1、什么是动静分离 动静分离是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路。 动静分离简单的概…...

【算法题】309. 买卖股票的最佳时机含冷冻期
题目: 给定一个整数数组prices,其中第 prices[i] 表示第 i 天的股票价格 。 设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票): 卖出股票后,你无法在…...

1951-2011年长序列高时空分辨率月尺度温度和降水数据集
简介 长序列高时空分辨率月尺度温度和降水数据集,基于中国及周边国家共1153个气温站点和1202个降水站点数据,利用ANUSPLIN软件插值,重建了1951−2011年中国月值气温和降水量的高空间分辨率0.025(~2.5km)格点数据集&am…...
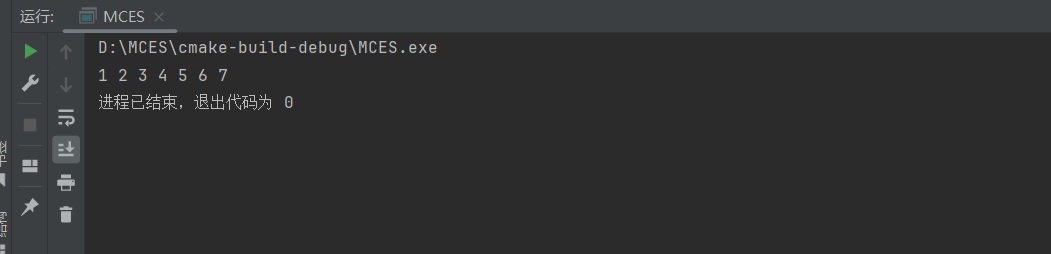
十天学完基础数据结构-第六天(树(Tree))
树的基本概念 树是一种层次性的数据结构,它由节点组成,这些节点按照层次关系相互连接。树具有以下基本概念: 根节点:树的顶部节点,没有父节点。 子节点:树中每个节点可以有零个或多个子节点。 叶节点&am…...
RobotFramework流程控制(最新版本)
文章目录 一 分支流程1. 关键字:Run Keyword If2. 关键字:IF/ELSE3. 嵌套IF/ELSE4. 关键字:Set Variable If 二 循环流程1. 普通FOR循环2. 嵌套FOR循环3. 退出循环4. 其它常用循环 一 分支流程 1. 关键字:Run Keyword If Run Key…...

win11 好用的 快捷方式 --chatGPT
gpt: Windows 11引入了许多新的功能和改进,同时也包括一些实用的快捷方式和功能。以下是一些Windows 11中的常用快捷方式: 1. **Win D**:最小化或还原所有打开的窗口,显示桌面。 2. **Win E**:打开文件资源管理器…...

在大数据相关技术中,HBase是个分布的、面向列的开源数据库,是一个适合于非结构化数据存储的数据库。
HDFS,适合运行在通用硬件上的分布式文件系统,是一个高度容错性的系统,适合部署在廉价的机器上。Hbase,是一个分布式的、面向列的开源数据库,适合于非结构化数据存储。MapReduce,一种编程模型,方…...
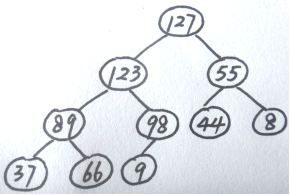
910数据结构(2020年真题)
算法设计题 问题1 现有两个单链表A和B,其中的元素递增有序,在不破坏原链表的情况下,请设计一个算法,求这两个链表的交集,并将结果存放在链表C中。 (1)描述算法的基本设计思想; (2)根据设计思想࿰…...
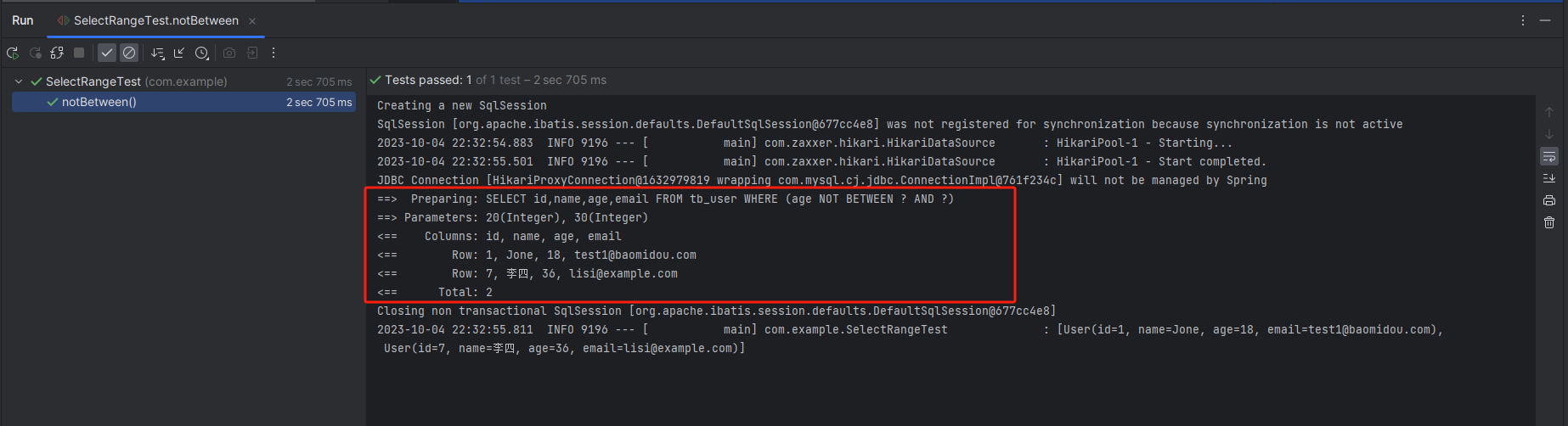
MyBatisPlus(八)范围查询
说明 范围查询,包括: 大于大于等于小于小于等于在范围内在范围外 大于:gt 代码 Testvoid gt() {LambdaQueryWrapper<User> wrapper new LambdaQueryWrapper<>();wrapper.gt(User::getAge, 20);List<User> users mapp…...

【day10.04】QT实现TCP服务器客户端搭建的代码
服务器: #include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this);//实例化一个服务器server new QTcpServer(this);//此时,服务器已经成功进入…...

milvus 结合Thowee 文本转向量 ,新建表,存储,搜索,删除
1.向量数据库科普 【上集】向量数据库技术鉴赏 【下集】向量数据库技术鉴赏 milvus连接 from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility connections.connect(host124.****, port19530)2.milvus Thowee 文本转向量 使用 …...
GEO生信数据挖掘(三)芯片探针ID与基因名映射处理
检索到目标数据集后,开始数据挖掘,本文以阿尔兹海默症数据集GSE1297为例 目录 处理一个探针对应多个基因 1.删除该行 2.保留分割符号前面的第一个基因 处理多个探针对应一个基因 详细代码案例一删除法 详细代码案例二 多个基因名时保留第一个基因名…...

力扣 -- 96. 不同的二叉搜索树
解题步骤: 参考代码: class Solution { public:int numTrees(int n) {vector<int> dp(n1);//初始化dp[0]1;//填表for(int i1;i<n;i){for(int j1;j<i;j){//状态转移方程dp[i](dp[j-1]*dp[i-j]);}}//返回值return dp[n];} }; 你学会了吗&…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...
自然语言处理——文本分类
文本分类 传统机器学习方法文本表示向量空间模型 特征选择文档频率互信息信息增益(IG) 分类器设计贝叶斯理论:线性判别函数 文本分类性能评估P-R曲线ROC曲线 将文本文档或句子分类为预定义的类或类别, 有单标签多类别文本分类和多…...
《信号与系统》第 6 章 信号与系统的时域和频域特性
目录 6.0 引言 6.1 傅里叶变换的模和相位表示 6.2 线性时不变系统频率响应的模和相位表示 6.2.1 线性与非线性相位 6.2.2 群时延 6.2.3 对数模和相位图 6.3 理想频率选择性滤波器的时域特性 6.4 非理想滤波器的时域和频域特性讨论 6.5 一阶与二阶连续时间系统 6.5.1 …...
)
2025.6.9总结(利与弊)
凡事都有两面性。在大厂上班也不例外。今天找开发定位问题,从一个接口人不断溯源到另一个 接口人。有时候,不知道是谁的责任填。将工作内容分的很细,每个人负责其中的一小块。我清楚的意识到,自己就是个可以随时替换的螺丝钉&…...

更新 Docker 容器中的某一个文件
🔄 如何更新 Docker 容器中的某一个文件 以下是几种在 Docker 中更新单个文件的常用方法,适用于不同场景。 ✅ 方法一:使用 docker cp 拷贝文件到容器中(最简单) 🧰 命令格式: docker cp <…...