深度学习实战基础案例——卷积神经网络(CNN)基于MobileNetV3的肺炎识别|第3例
文章目录
- 前言
- 一、数据集介绍
- 二、前期工作
- 三、数据集读取
- 四、构建CA注意力模块
- 五、构建模型
- 六、开始训练
前言
Google公司继MobileNetV2之后,在2019年发表了它的改进版本MobileNetV3。而MobileNetV3共有两个版本,分别是MobileNetV3-Large和MobileNetV2-Small。改进后的MobileNetV3,在ImageNet数据集的分类精度上,它的MobileNetV3-Large版本相较于MobileNetV2提升了大概3.2%的精度同时延迟减少了20%,而MobileNetV3-Small则提升了6.6%的精度,减少了大概23%的延迟。
今天,我们用MobileNetV3来进行肺炎的识别,同时我们用CA注意力机制替换了原模型中的SE注意力模块。
我的环境:
- 基础环境:python3.7
- 编译器:jupyter notebook
- 深度学习框架:pytorch
一、数据集介绍
ChestXRay2017数据集共包含5856张胸腔X射线透视图,诊断结果(即分类标签)主要分为正常和肺炎,其中肺炎又可以细分为:细菌性肺炎和病毒性肺炎。
胸腔X射线图像选自广州市妇幼保健中心的1至5岁儿科患者的回顾性研究。所有胸腔X射线成像都是患者常规临床护理的一部分。
为了分析胸腔X射线图像,首先对所有胸腔X光片进行了筛查,去除所有低质量或不可读的扫描,从而保证图片质量。然后由两名专业医师对图像的诊断进行分级,最后为降低图像诊断错误, 还由第三位专家检查了测试集。
主要分为train和test两大子文件夹,分别用于模型的训练和测试。在每个子文件内又分为了NORMAL(正常)和PNEUMONIA(肺炎)两大类。
在PNEUMONIA文件夹内含有细菌性和病毒性肺炎两类,可以通过图片的命名格式进行判别。

二、前期工作
from torch import nn
import torch.utils.data as Data
from torchvision.transforms import transforms
import torchvision
import torchsummary# 设置device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
三、数据集读取
data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}train_data=torchvision.datasets.ImageFolder(root=r"ChestXRay2017/chest_xray/train",transform=data_transform["train"])
train_dataloader=Data.DataLoader(train_data,batch_size=48,shuffle=True)test_data=torchvision.datasets.ImageFolder(root=r"ChestXRay2017/chest_xray/test",transform=data_transform["val"])
test_dataloader=Data.DataLoader(test_data,batch_size=48,shuffle=True)
四、构建CA注意力模块
我们都知道注意力机制在各种计算机视觉任务中都是有帮助,如图像分类和图像分割。其中最为经典和被熟知的便是SENet,它通过简单地squeeze每个2维特征图,进而有效地构建通道之间的相互依赖关系。
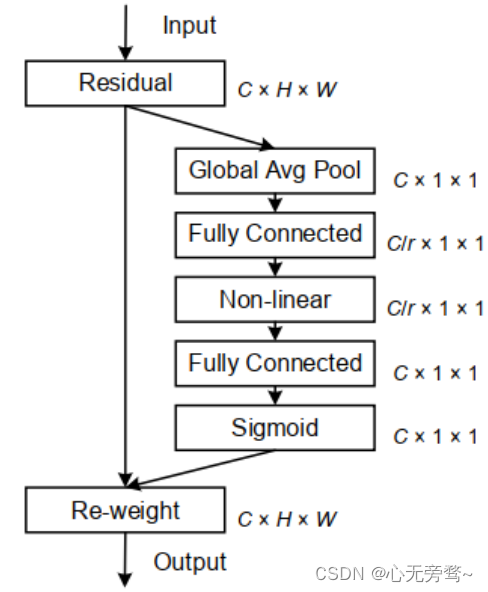
SE Block虽然近2年来被广泛使用;然而,它只考虑通过建立通道之间的关系来重新衡量每个通道的重要性,而忽略了位置信息,但是位置信息对于生成空间选择性attention maps是很重要的。因此就有人引入了一种新的注意块,它不仅仅考虑了通道间的关系还考虑了特征空间的位置信息,即CA(Coordinate Attention)注意力机制。
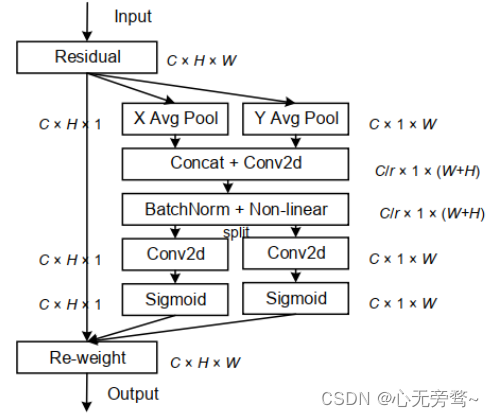
class h_swish(nn.Module):def __init__(self, inplace=True):super(h_swish, self).__init__()self.relu6 = nn.ReLU6()def forward(self, x):return x * self.relu6(x + 3) / 6class CoordAtt(nn.Module):def __init__(self, inp, oup, groups=32):super(CoordAtt, self).__init__()self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))mip = max(8, inp // groups)self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.conv2 = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.conv3 = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.relu = h_swish()def forward(self, x):identity = xn,c,h,w = x.size()x_h = self.pool_h(x)x_w = self.pool_w(x).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)y = self.conv1(y)y = self.bn1(y)y = self.relu(y)x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)x_h = self.conv2(x_h).sigmoid()x_w = self.conv3(x_w).sigmoid()x_h = x_h.expand(-1, -1, h, w)x_w = x_w.expand(-1, -1, h, w)y = identity * x_w * x_h# y=x_w * x_hreturn yclass CA_SA(nn.Module):def __init__(self,inchannel,outchannel):super(CA_SA, self).__init__()self.CA=CoordAtt(inchannel,outchannel)self.SA=Spatial_Attention_Module(7)def forward(self,x):y=self.CA(x)z=self.SA(x)return x*y*z五、构建模型
import torch.nn as nn
import torch
import torchsummarydevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 定义h-swith激活函数
class HardSwish(nn.Module):def __init__(self, inplace=True):super(HardSwish, self).__init__()self.relu6 = nn.ReLU6()def forward(self, x):return x * self.relu6(x + 3) / 6# DW卷积
def ConvBNActivation(in_channels, out_channels, kernel_size, stride, activate):# 通过设置padding达到当stride=2时,hw减半的效果。此时不与kernel_size有关,所实现的公式为: padding=(kernel_size-1)//2# 当kernel_size=3,padding=1时: stride=2 hw减半, stride=1 hw不变# 当kernel_size=5,padding=2时: stride=2 hw减半, stride=1 hw不变# 从而达到了使用 stride 来控制hw的效果, 不用去关心kernel_size的大小,控制单一变量return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,padding=(kernel_size - 1) // 2, groups=in_channels),nn.BatchNorm2d(out_channels),nn.ReLU6() if activate == 'relu' else HardSwish())class Inceptionnext(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride, activate):super(Inceptionnext, self).__init__()gc = int(in_channels * 1 / 4) # channel number of a convolution branch# self.dwconv_hw = nn.Conv2D(gc, gc, kernel_size,stride=stride,padding=(kernel_size-1)//2,groups=gc)self.dwconv_hw1 = nn.Conv2d(gc, gc, (1, kernel_size), stride=stride, padding=(0, (kernel_size - 1) // 2),groups=gc)self.dwconv_hw2 = nn.Conv2d(gc, gc, (kernel_size, 1), stride=stride, padding=((kernel_size - 1) // 2, 0),groups=gc)self.dwconv_hw = nn.Sequential(nn.Conv2d(gc, gc, (1, kernel_size), stride=stride, padding=(0, (kernel_size - 1) // 2), groups=gc),nn.Conv2d(gc, gc, (kernel_size, 1), stride=stride, padding=((kernel_size - 1) // 2, 0), groups=gc))# self.dwconv_hw = nn.Sequential(# nn.Conv2d(gc,gc//2,kernel_size=1,stride=1),# nn.Conv2d(gc//2, gc//2, (1, kernel_size), stride=stride, padding=(0, (kernel_size - 1) // 2), groups=gc//2),# nn.Conv2d(gc//2, gc//2, (kernel_size, 1), stride=stride, padding=((kernel_size - 1) // 2, 0), groups=gc//2)# )self.dwconv_w = nn.Conv2d(gc, gc, kernel_size=(1, 11), stride=stride, padding=(0, 11 // 2), groups=gc)self.dwconv_h = nn.Conv2d(gc, gc, kernel_size=(11, 1), stride=stride, padding=(11 // 2, 0), groups=gc)self.batch2d = nn.BatchNorm2d(out_channels)self.activate = nn.ReLU6() if activate == 'relu' else HardSwish()self.split_indexes = (gc, gc, gc, in_channels - 3 * gc)self.cheap=nn.Sequential(nn.Conv2d(gc // 2, gc // 2, (1, 3), stride=stride, padding=(0, (3 - 1) // 2),groups=gc//2),nn.Conv2d(gc // 2, gc // 2, (3, 1), stride=stride, padding=((3 - 1) // 2, 0), groups=gc//2))def forward(self, x):# B, C, H, W = x.shapex_hw, x_w, x_h, x_id = torch.split(x, self.split_indexes, dim=1)x = torch.cat((self.dwconv_hw(x_hw),self.dwconv_w(x_w),self.dwconv_h(x_h),x_id),dim=1)# x = torch.cat(# (torch.cat((self.dwconv_hw(x_hw),self.cheap(self.dwconv_hw(x_hw))),dim=1),# self.dwconv_w(x_w),# self.dwconv_h(x_h),# x_id),# dim=1)x = self.batch2d(x)x = self.activate(x)return x# PW卷积(接全连接层)
def Conv1x1BN(in_channels, out_channels):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),nn.BatchNorm2d(out_channels))class SqueezeAndExcite(nn.Module):def __init__(self, in_channels, out_channels, se_kernel_size, divide=4):super(SqueezeAndExcite, self).__init__()mid_channels = in_channels // divide # 维度变为原来的1/4# 将当前的channel平均池化成1self.pool = nn.AvgPool2d(kernel_size=se_kernel_size,stride=1)# 两个全连接层 最后输出每层channel的权值self.SEblock = nn.Sequential(nn.Linear(in_features=in_channels, out_features=mid_channels),nn.ReLU6(),nn.Linear(in_features=mid_channels, out_features=out_channels),HardSwish(),)def forward(self, x):a=x.shapeb, c, h, w = a[0],a[1],a[2],a[3]out = self.pool(x) # 不管当前的 h,w 为多少, 全部池化为1out = out.reshape([b, -1]) # 打平处理,与全连接层相连# 获取注意力机制后的权重out = self.SEblock(out)# out是每层channel的权重,需要扩维才能与原特征矩阵相乘out = out.reshape([b, c, 1, 1]) # 增维return out * x# # 普通的1x1卷积
# class Conv1x1BNActivation(nn.Module):
# def __init__(self,inchannel,outchannel,activate):
# super(Conv1x1BNActivation, self).__init__()
# self.first=nn.Sequential(
# nn.Conv2d(inchannel,outchannel//2,kernel_size=1,stride=1),
# nn.Conv2d(outchannel//2,outchannel//2,kernel_size=3,stride=1,padding=1,groups=outchannel//2)
# )
# self.second=nn.Conv2d(outchannel//2,outchannel//2,kernel_size=3,stride=1,padding=1,groups=outchannel//2)
# self.BN=nn.BatchNorm2d(outchannel)
# self.act=nn.ReLU6() if activate == 'relu' else HardSwish()
# def forward(self,x):
# x=self.first(x)
# y=torch.cat((x,self.second(x)),dim=1)
# y=self.BN(y)
# y=self.act(y)
# return y
def Conv1x1BNActivation(in_channels,out_channels,activate):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),nn.BatchNorm2d(out_channels),nn.ReLU6() if activate == 'relu' else HardSwish())class SEInvertedBottleneck(nn.Module):def __init__(self, in_channels, mid_channels, out_channels, kernel_size, stride, activate, use_se,se_kernel_size=1):super(SEInvertedBottleneck, self).__init__()self.stride = strideself.use_se = use_seself.in_channels = in_channelsself.out_channels = out_channels# mid_channels = (in_channels * expansion_factor)# 普通1x1卷积升维操作self.conv = Conv1x1BNActivation(in_channels, mid_channels, activate)# DW卷积 维度不变,但可通过stride改变尺寸 groups=in_channelsif stride == 1:self.depth_conv = Inceptionnext(mid_channels, mid_channels, kernel_size, stride, activate)else:self.depth_conv = ConvBNActivation(mid_channels, mid_channels, kernel_size, stride, activate)# self.depth_conv = ConvBNActivation(mid_channels, mid_channels, kernel_size,stride,activate)# 注意力机制的使用判断if self.use_se:# self.SEblock = SqueezeAndExcite(mid_channels, mid_channels, se_kernel_size)# self.SEblock = CBAM.CBAMBlock("FC", 5, channels=mid_channels, ratio=9)self.SEblock = CoordAtt(mid_channels,mid_channels)# self.SEblock = CAblock.CA_SA(mid_channels, mid_channels)# PW卷积 降维操作self.point_conv = Conv1x1BN(mid_channels, out_channels)# shortcut的使用判断if self.stride == 1:self.shortcut = Conv1x1BN(in_channels, out_channels)def forward(self, x):# DW卷积out = self.depth_conv(self.conv(x))# 当 use_se=True 时使用注意力机制if self.use_se:out = self.SEblock(out)# PW卷积out = self.point_conv(out)# 残差操作# 第一种: 只看步长,步长相同shape不一样的输入输出使用1x1卷积使其相加# out = (out + self.shortcut(x)) if self.stride == 1 else out# 第二种: 同时满足步长与输入输出的channel, 不使用1x1卷积强行升维out = (out + x) if self.stride == 1 and self.in_channels == self.out_channels else outreturn outclass MobileNetV3(nn.Module):def __init__(self, num_classes=8, type='large'):super(MobileNetV3, self).__init__()self.type = type# 224x224x3 conv2d 3 -> 16 SE=False HS s=2self.first_conv = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(16),HardSwish(),)# torch.Size([1, 16, 112, 112])# MobileNetV3_Large 网络结构if type == 'large':self.large_bottleneck = nn.Sequential(# torch.Size([1, 16, 112, 112]) 16 -> 16 -> 16 SE=False RE s=1SEInvertedBottleneck(in_channels=16, mid_channels=16, out_channels=16, kernel_size=3, stride=1,activate='relu', use_se=False),# torch.Size([1, 16, 112, 112]) 16 -> 64 -> 24 SE=False RE s=2SEInvertedBottleneck(in_channels=16, mid_channels=64, out_channels=24, kernel_size=3, stride=2,activate='relu', use_se=False),# torch.Size([1, 24, 56, 56]) 24 -> 72 -> 24 SE=False RE s=1SEInvertedBottleneck(in_channels=24, mid_channels=72, out_channels=24, kernel_size=3, stride=1,activate='relu', use_se=False),# torch.Size([1, 24, 56, 56]) 24 -> 72 -> 40 SE=True RE s=2SEInvertedBottleneck(in_channels=24, mid_channels=72, out_channels=40, kernel_size=5, stride=2,activate='relu', use_se=True, se_kernel_size=28),# torch.Size([1, 40, 28, 28]) 40 -> 120 -> 40 SE=True RE s=1SEInvertedBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1,activate='relu', use_se=True, se_kernel_size=28),# torch.Size([1, 40, 28, 28]) 40 -> 120 -> 40 SE=True RE s=1SEInvertedBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1,activate='relu', use_se=True, se_kernel_size=28),# torch.Size([1, 40, 28, 28]) 40 -> 240 -> 80 SE=False HS s=1SEInvertedBottleneck(in_channels=40, mid_channels=240, out_channels=80, kernel_size=3, stride=1,activate='hswish', use_se=False),# torch.Size([1, 80, 28, 28]) 80 -> 200 -> 80 SE=False HS s=1SEInvertedBottleneck(in_channels=80, mid_channels=200, out_channels=80, kernel_size=3, stride=1,activate='hswish', use_se=False),# torch.Size([1, 80, 28, 28]) 80 -> 184 -> 80 SE=False HS s=2SEInvertedBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=2,activate='hswish', use_se=False),# torch.Size([1, 80, 14, 14]) 80 -> 184 -> 80 SE=False HS s=1SEInvertedBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=1,activate='hswish', use_se=False),# torch.Size([1, 80, 14, 14]) 80 -> 480 -> 112 SE=True HS s=1SEInvertedBottleneck(in_channels=80, mid_channels=480, out_channels=112, kernel_size=3, stride=1,activate='hswish', use_se=True, se_kernel_size=14),# torch.Size([1, 112, 14, 14]) 112 -> 672 -> 112 SE=True HS s=1SEInvertedBottleneck(in_channels=112, mid_channels=672, out_channels=112, kernel_size=3, stride=1,activate='hswish', use_se=True, se_kernel_size=14),# torch.Size([1, 112, 14, 14]) 112 -> 672 -> 160 SE=True HS s=2SEInvertedBottleneck(in_channels=112, mid_channels=672, out_channels=160, kernel_size=5, stride=2,activate='hswish', use_se=True, se_kernel_size=7),# torch.Size([1, 160, 7, 7]) 160 -> 960 -> 160 SE=True HS s=1SEInvertedBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=7),# torch.Size([1, 160, 7, 7]) 160 -> 960 -> 160 SE=True HS s=1SEInvertedBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=7),)# torch.Size([1, 160, 7, 7])# 相比MobileNetV2,尾部结构改变,,变得更加的高效self.large_last_stage = nn.Sequential(nn.Conv2d(in_channels=160, out_channels=960, kernel_size=1, stride=1),nn.BatchNorm2d(960),HardSwish(),nn.AvgPool2d(kernel_size=7, stride=1),nn.Conv2d(in_channels=960, out_channels=1280, kernel_size=1, stride=1),HardSwish(),)# MobileNetV3_Small 网络结构if type == 'small':self.small_bottleneck = nn.Sequential(# torch.Size([1, 16, 112, 112]) 16 -> 16 -> 16 SE=False RE s=2SEInvertedBottleneck(in_channels=16, mid_channels=16, out_channels=16, kernel_size=3, stride=2,activate='relu', use_se=True, se_kernel_size=56),# torch.Size([1, 16, 56, 56]) 16 -> 72 -> 24 SE=False RE s=2SEInvertedBottleneck(in_channels=16, mid_channels=72//2, out_channels=24, kernel_size=3, stride=2,activate='relu', use_se=False),# torch.Size([1, 24, 28, 28]) 24 -> 88 -> 24 SE=False RE s=1SEInvertedBottleneck(in_channels=24, mid_channels=88//2, out_channels=24, kernel_size=3, stride=1,activate='relu', use_se=False),# torch.Size([1, 24, 28, 28]) 24 -> 96 -> 40 SE=True RE s=2SEInvertedBottleneck(in_channels=24, mid_channels=96//2, out_channels=40, kernel_size=5, stride=2,activate='hswish', use_se=True, se_kernel_size=14),# torch.Size([1, 40, 14, 14]) 40 -> 240 -> 40 SE=True RE s=1SEInvertedBottleneck(in_channels=40, mid_channels=240//2, out_channels=40, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),# torch.Size([1, 40, 14, 14]) 40 -> 240 -> 40 SE=True RE s=1SEInvertedBottleneck(in_channels=40, mid_channels=240//2, out_channels=40, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),# torch.Size([1, 40, 14, 14]) 40 -> 120 -> 48 SE=True RE s=1SEInvertedBottleneck(in_channels=40, mid_channels=120//2, out_channels=48, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),# torch.Size([1, 48, 14, 14]) 48 -> 144 -> 48 SE=True RE s=1SEInvertedBottleneck(in_channels=48, mid_channels=144//2, out_channels=48, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),# torch.Size([1, 48, 14, 14]) 48 -> 288 -> 96 SE=True RE s=2SEInvertedBottleneck(in_channels=48, mid_channels=288//2, out_channels=96, kernel_size=5, stride=2,activate='hswish', use_se=True, se_kernel_size=7),# torch.Size([1, 96, 7, 7]) 96 -> 576 -> 96 SE=True RE s=1SEInvertedBottleneck(in_channels=96, mid_channels=576//2, out_channels=96, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=7),# torch.Size([1, 96, 7, 7]) 96 -> 576 -> 96 SE=True RE s=1SEInvertedBottleneck(in_channels=96, mid_channels=576//2, out_channels=96, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=7),)# torch.Size([1, 96, 7, 7])# 相比MobileNetV2,尾部结构改变,,变得更加的高效self.small_last_stage = nn.Sequential(nn.Conv2d(in_channels=96, out_channels=576, kernel_size=1, stride=1),nn.BatchNorm2d(576),HardSwish(),nn.AvgPool2d(kernel_size=7, stride=1),nn.Conv2d(in_channels=576, out_channels=1280, kernel_size=1, stride=1),HardSwish(),)self.dorpout = nn.Dropout(0.5)self.classifier =nn.Linear(in_features=1280, out_features=num_classes)# self.init_params()def forward(self, x):x = self.first_conv(x) # torch.Size([1, 16, 112, 112])if self.type == 'large':x = self.large_bottleneck(x) # torch.Size([1, 160, 7, 7])x = self.large_last_stage(x) # torch.Size([1, 1280, 1, 1])if self.type == 'small':x = self.small_bottleneck(x) # torch.Size([1, 96, 7, 7])x = self.small_last_stage(x) # torch.Size([1, 1280, 1, 1])x = x.reshape((x.shape[0], -1)) # torch.Size([1, 1280])x = self.dorpout(x)x = self.classifier(x) # torch.Size([1, 5])return x
if __name__ == '__main__':models = MobileNetV3(8,type='large').to(device)input = torch.randn(size=[1, 3, 224, 224]).to(device)out = models(input)print(out.shape)torchsummary.summary(models,input_size=(3,224,224))
六、开始训练
import numpy
models = MobileNetV3(8,type='large').to('cuda')
# 设置优化器
optim = torch.optim.Adam(lr=0.001, params=models.parameters())
# 设置损失函数
loss_fn = torch.nn.CrossEntropyLoss().to('cuda')
bestacc=0
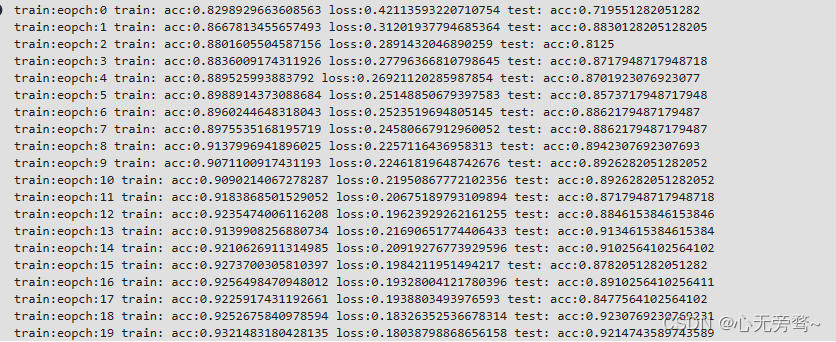
for epoch in range(20):train_data=0acc_data=0loss_data=0models.train()for batch_id, data in enumerate(train_dataloader):x_data,label=datapredicts=models(x_data.to('cuda'))loss=loss_fn(predicts, label.to('cuda'))acc=numpy.sum(numpy.argmax(predicts.cpu().detach().numpy(), axis=1)==label.numpy())train_data+=len(x_data)acc_data+=accloss_data+=loss# callbacks.step(loss)loss.backward()optim.step()optim.zero_grad()accuracy=acc_data/train_dataall_loss=loss_data/batch_idprint(f"train:eopch:{epoch} train: acc:{accuracy} loss:{all_loss.item()}",end=' ')if epoch+1:models.eval()test_data=0acc_data=0for batch_id, data in enumerate(test_dataloader):x_data,label=datapredicts=models(x_data.to('cuda'))acc=numpy.sum(numpy.argmax(predicts.cpu().detach().numpy(), axis=1)==label.numpy())test_data+=len(x_data)acc_data+=accaccuracy=acc_data/test_dataprint(f"test: acc:{accuracy}")if accuracy > bestacc:torch.save(models.state_dict(), "best.pth")bestacc = accuracyprint("Done")
相关文章:
深度学习实战基础案例——卷积神经网络(CNN)基于MobileNetV3的肺炎识别|第3例
文章目录 前言一、数据集介绍二、前期工作三、数据集读取四、构建CA注意力模块五、构建模型六、开始训练 前言 Google公司继MobileNetV2之后,在2019年发表了它的改进版本MobileNetV3。而MobileNetV3共有两个版本,分别是MobileNetV3-Large和MobileNetV2-…...
)
机器学习 面试/笔试题(更新中)
1. 生成模型 VS 判别模型 生成模型: 由数据学得联合概率分布函数 P ( X , Y ) P(X,Y) P(X,Y),求出条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)的预测模型。 朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机…...

【算法题】100019. 将数组分割成最多数目的子数组
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 题目: 给你一个只包含 非负 整数的数组 n…...

commons-io工具类常用方法
commons-io是Apache Commons项目的一个模块,提供了一系列处理I/O(输入/输出)操作的工具类和方法。它旨在简化Java I/O编程,并提供更多的功能和便利性。 读取文件内容为字符串 String path"C:\\Users\\zhang\\Desktop\\myyii\…...
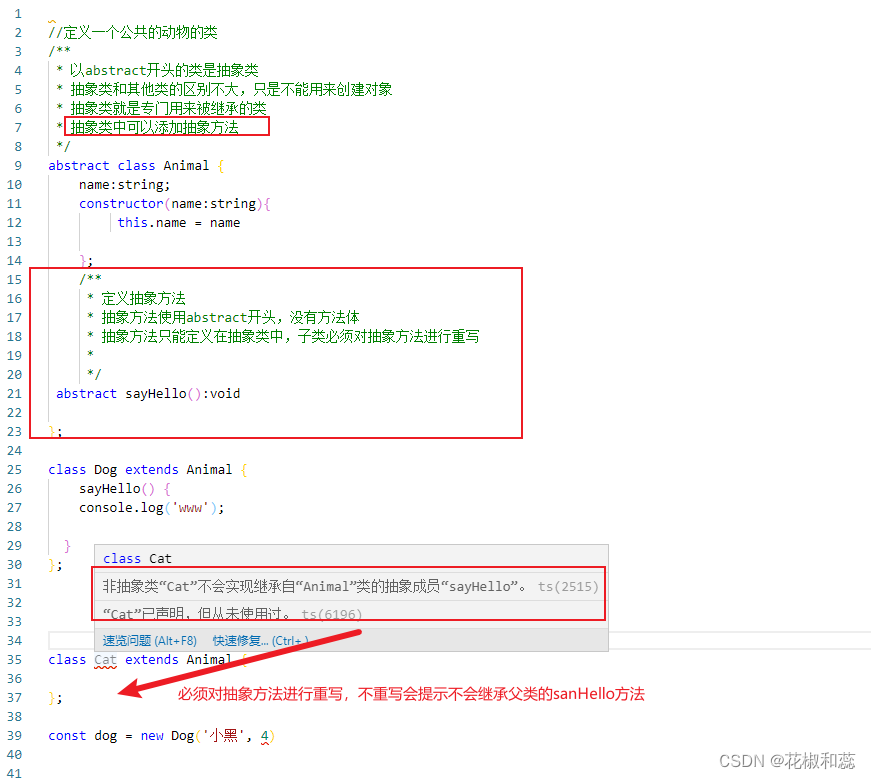
【Typescript】面向对象(上篇),包含类,构造函数,继承,super,抽象类
假期第七篇,对于基础的知识点,我感觉自己还是很薄弱的。 趁着假期,再去复习一遍 面向对象:程序中所有的操作都需要通过对象来完成 计算机程序的本质就是对现实事物的抽象,抽象的反义词是具体。比如照片是对一个具体的…...

【python】python中字典的用法记录
文章目录 序言1. 字典的创建和访问2. 字典如何添加元素3. 字典作为函数参数4. 字典排序 序言 总结字典的一些常见用法 1. 字典的创建和访问 字典是一种可变容器类型,可以存储任意类型对象 key : value,其中value可以是任何数据类型,key必须…...

基于Java的大学生心理咨询系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...
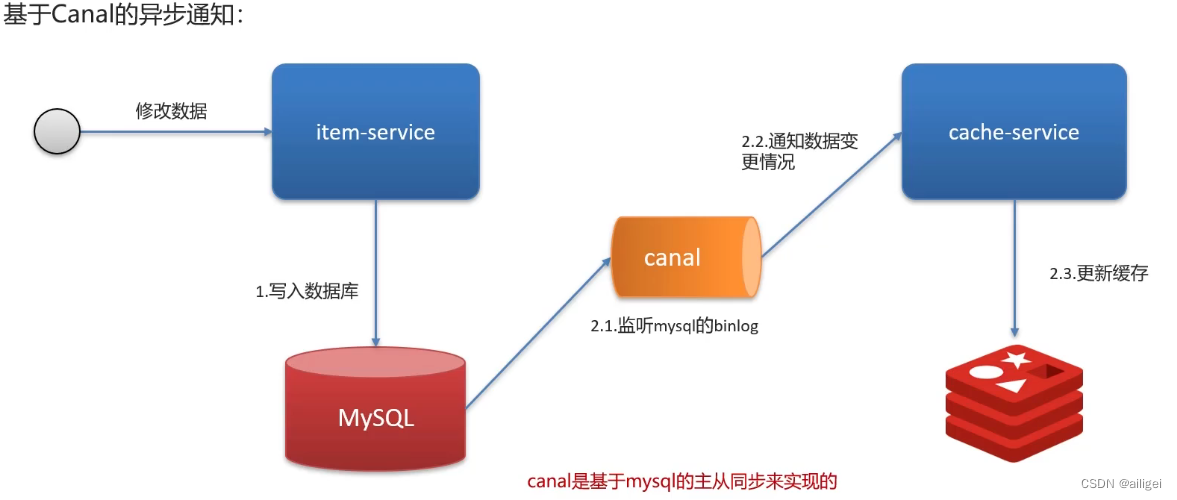
Redis-双写一致性
双写一致性 双写一致性解决方案延迟双删(有脏数据的风险)分布式锁(强一致性,性能比较低)异步通知(保证数据的最终一致性,高并发情况下会出现短暂的不一致情况) 双写一致性 当修改了数…...

CustomTkinter:创建现代、可定制的Python UI
文章目录 介绍安装设置外观与主题外观模式主题设置自定义主题颜色窗口缩放CTkFont字体设置CTkImage图片Widgets窗口部件CTk Windows窗口CTk窗口CTkInputDialog对话框CTkToplevel顶级窗口布局pack布局palce布局Grid 网格布局Frames 框架Frames滚动框架...

华为OD机试真题【不含 101 的数】
1、题目描述 【不含 101 的数】 【题目描述】 小明在学习二进制时,发现了一类不含 101的数,也就是: 将数字用二进制表示,不能出现 101 。 现在给定一个整数区间 [l,r] ,请问这个区间包含了多少个不含 101 的数&#…...

Spring IoC和DI详解
IOC思想 IoC( Inversion of Control,控制反转) 不是一门具体技术,而是一种设计思想, 是一种软件设计原则,它将应用程序的控制权(Bean的创建和依赖关系)从应用程序代码中解耦出来&am…...

mysql-binlog
1. 常用的binlog日志操作命令 1. 查看bin-log是否开启 show variables like log_%;2. 查看所有binlog日志列表 show master logs;3.查看master状态 show master status;4. 重置(清空)所有binlog日志 reset master;2. 查看binlog日志内容 1、使用mysqlb…...
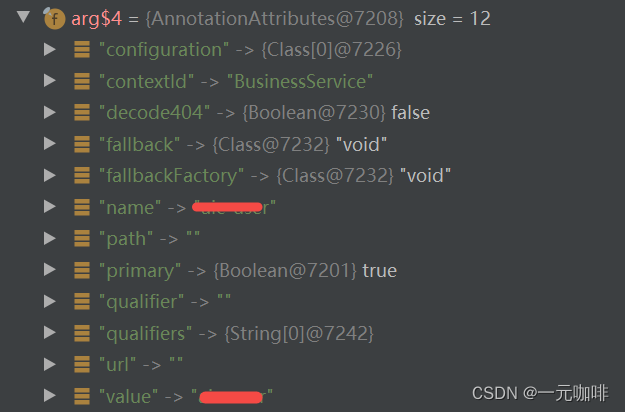
通过BeanFactotyPostProcessor动态修改@FeignClient的path
最近项目有个需求,要在启动后,动态修改FeignClient的请求路径,网上找到的基本都是在FeignClient里使用${…},通过配置文件来定义Feign的接口路径,这并不能满足我们的需求 由于某些特殊原因,我们的每个接口…...

数据结构与算法系列-二分查找
二分查找 什么是二分查找? 二分查找是一种针对有序集合,每次将要查找的区间缩小一半,直到找到查找元素,或区间被缩小为0。 如何实现二分查找? 实现有3个注意点: 终止条件是 low < high 2.求中点的算…...

CSS 毛玻璃特效运用目录
主要是记录毛玻璃相关的特效实践案例和实现思路。 章节名称完成度难度文章地址完整代码下载地址Glassmorphism 登录表单完成一般文章链接代码下载Glassmorphism 按钮悬停效果完成一般文章链接代码下载Glassmorphism 计算器完成一般文章链接代码下载Glassmorphism 卡片悬停效果…...
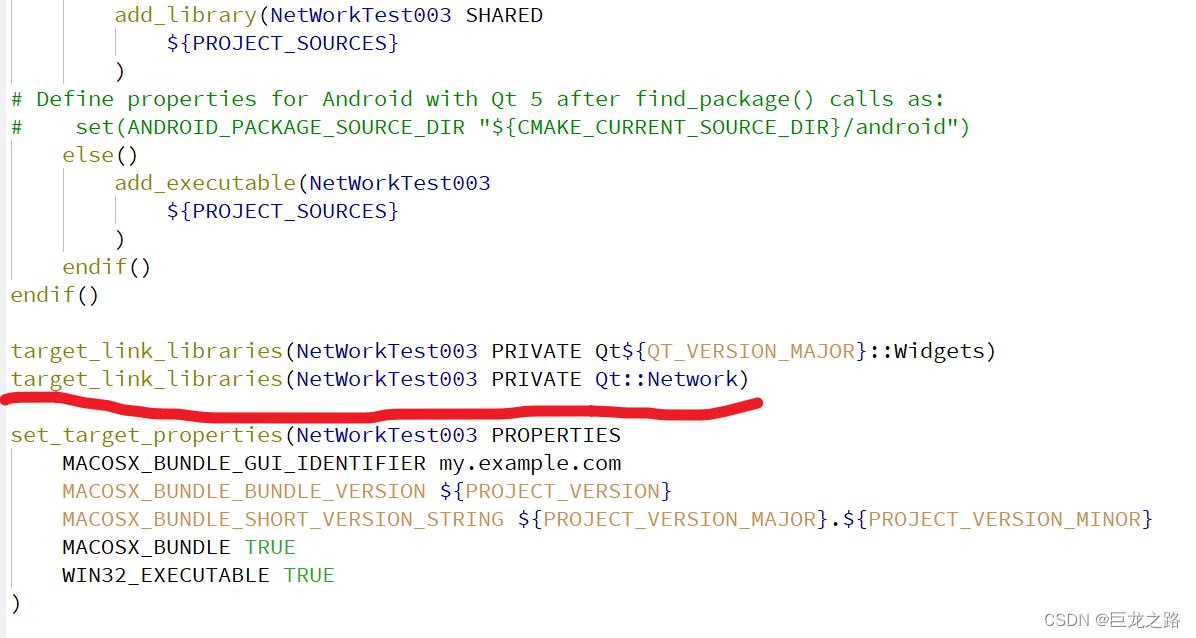
如何在Qt6中引入Network模块
2023年10月1日,周日凌晨 2023年10月2日,周一下午 第一次更新 目录 如果用的是CMakeQt Console ApplicationQt Widgets Application如果用的是qmake 如果用的是CMake find_package(Qt6 COMPONENTS Network REQUIRED) target_link_libraries(mytarget…...

2023/10/4 QT实现TCP服务器客户端搭建
服务器端: 头文件 #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTcpServer> #include <QTcpSocket> #include <QList> #include <QMessageBox> #include <QDebug>QT_BEGIN_NAMESPACE namespace Ui { cla…...
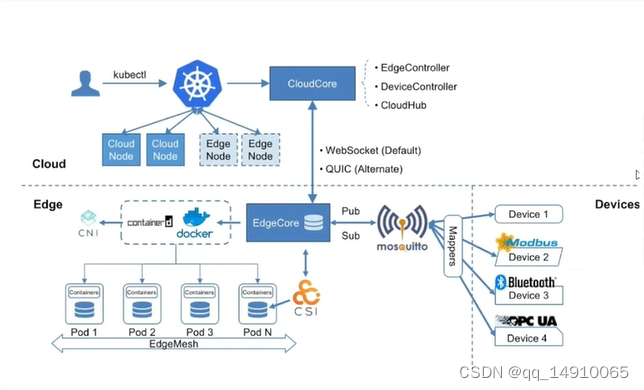
云原生边缘计算KubeEdge安装配置
1. K8S集群部署,可以参考如下博客 请安装k8s集群,centos安装k8s集群 请安装k8s集群,ubuntu安装k8s集群 2.安装kubEedge 2.1 编辑kube-proxy使用ipvs代理 kubectl edit configmaps kube-proxy -n kube-system #修改kube-proxy#大约在40多行…...
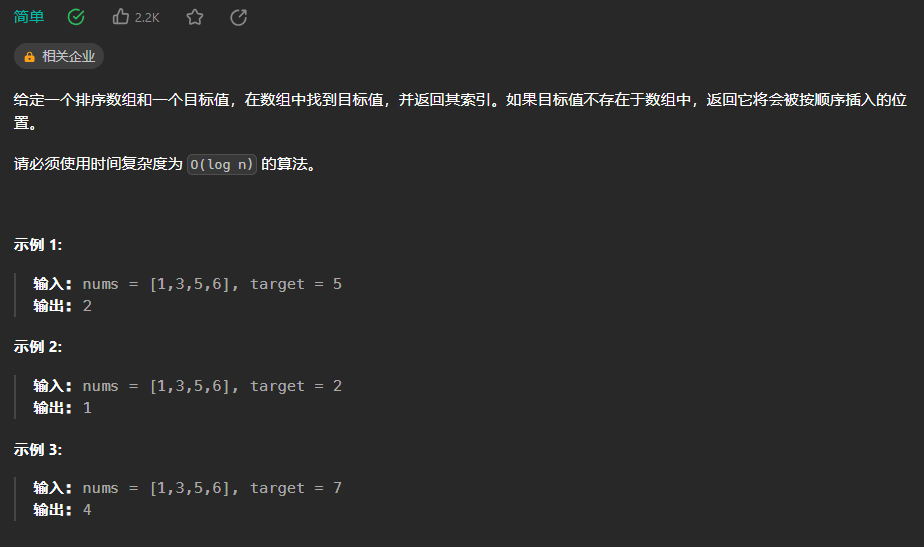
【LeetCode热题100】--35.搜索插入位置
35.搜索插入位置 使用二分查找: class Solution {public int searchInsert(int[] nums, int target) {int low 0,high nums.length -1;while(low < high){//注意每次循环完都要计算midint mid (low high)/2;if(nums[mid] target){return mid;}if(nums[mid]…...

mysql面试题13:MySQL中什么是异步复制?底层实现?
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:讲一讲mysql中什么是异步复制?底层实现? MySQL中的异步复制(Asynchronous Replication)是一种复制模式,主服务器将数据写入二进制日志后,无…...
【R语言工业AI部署白皮书】:从caret到tidymodels迁移实录,6类高发故障F1-score提升至0.92+
第一章:工业R语言设备故障预测概述在现代智能制造与工业物联网(IIoT)场景中,设备故障预测正从传统的定期维护转向基于数据驱动的主动预警模式。R语言凭借其强大的统计建模能力、丰富的机器学习生态(如caret、mlr3、sur…...

SenseVoice-Small模型部署避坑指南:解决403 Forbidden等常见网络与权限问题
SenseVoice-Small模型部署避坑指南:解决403 Forbidden等常见网络与权限问题 部署AI模型,尤其是从开源社区拉取模型时,最让人头疼的不是代码逻辑,而是那些看似玄学的环境问题。你照着教程一步步来,结果卡在了一个“403…...

Phi-3-Mini-128K企业级部署:支持Docker Compose编排+GPU资源隔离
Phi-3-Mini-128K企业级部署:支持Docker Compose编排GPU资源隔离 想体验微软最新的轻量级大模型Phi-3,但被复杂的部署流程和显存要求劝退?今天分享一个开箱即用的解决方案——一个基于Phi-3-mini-128k-instruct模型开发的本地对话工具。它不仅…...
 的读取大小限制)
channel.read(dest, channelPosition) 的读取大小限制
1.FileChannel.read(ByteBuffer, long) 一次**不一定**读完。 2.channel.read(dest, channelPosition) 并不是从 dest 的起始位置(索引 0)开始写入,而是从 dest 当前的 position() 开始写入,并随着写入自动推进 position。 ## 核…...

OpenClaw Docker 部署 · 完整速查手册
OpenClaw Docker 部署 完整速查手册 适用:Docker 安装、排错、命令解释 制作时间:2026.03.13一、基础 Docker 命令 删除旧容器(重新部署必用) docker rm -f openclaw 查看容器日志(看报错/运行状态) dock…...

个人项目复习-短链Day01
考点1:注册功能要求功能需求:使用手机号注册,且已经注册的手机号不能重复注册,密码不能使用简单的md5加密;用户上传头像需要用到文件存储。安全需求:高并发下账号的唯一性注册邮箱或手机号验证码不能被恶意…...

零基础入门Overleaf-Workshop:从安装到编译的简单步骤
零基础入门Overleaf-Workshop:从安装到编译的简单步骤 【免费下载链接】Overleaf-Workshop Open Overleaf/ShareLaTex projects in vscode, with full collaboration support. 项目地址: https://gitcode.com/gh_mirrors/ov/Overleaf-Workshop Overleaf-Work…...

ProcessHacker进程活动时间线:可视化展示进程的生命周期
ProcessHacker进程活动时间线:可视化展示进程的生命周期 【免费下载链接】systeminformer A free, powerful, multi-purpose tool that helps you monitor system resources, debug software and detect malware. Brought to you by Winsider Seminars & Soluti…...

医疗 Java 实战:HIS 系统多协议对接全解析
1. HIS系统:医疗信息化的“心脏”与“交通枢纽” 在医院这个庞大而精密的体系里,信息流就像人体的血液,必须时刻保持畅通、准确。而HIS系统,也就是医院信息系统,就是驱动这整个信息循环的“心脏”。它负责着患者从踏入…...
)
避坑指南:CentOS7.6离线升级GCC的那些‘坑’(含依赖包版本匹配与软连接修复)
从实战到精通:CentOS 7.6离线环境GCC升级的深度避坑与全流程解析 在离线或无外网的生产环境中,为CentOS 7.6升级GCC编译器,远不止是执行几条命令那么简单。这更像是一场对系统理解、依赖管理和故障排查能力的综合考验。许多运维工程师都曾在这…...