StarRocks数据导入
1、相关环境
Flink作为当前流行的流式计算框架,在对接StarRocks时,若直接使用JDBC的方式"流式"写入数据,对StarRocks是不友好的,StarRocks作为一款MVCC的数据库,其导入的核心思想还是"攒微批+降频率"。为此,StarRocks单独开发了flink-connector-starrocks,其内部实现仍是通过对数据缓存攒批后执行Stream Load导入。
1.1、StarRocks相关下载
https://www.mirrorship.cn/zh-CN/download/community
1.2、Flink CDC连接器
参考地址:
https://ververica.github.io/flink-cdc-connectors/release-2.0/content/about.html#supported-flink-versions
https://github.com/StarRocks/starrocks-connector-for-apache-flink
https://docs.starrocks.io/zh-cn/main/loading/Flink-connector-starrocks
1.3、搭建环境
- StarRocks
- Flink
- Kafka
- Zookeeper
- MySQL
2、Flink读取Kafka数据写入StarRocks
Routine Load是StarRocks自带的可以消费Kafka数据的导入方式,其特点是简单易用,不依赖外部组件,但若需要对Kafka中的数据进行复杂的ETL,Routine Load可能就不能胜任了,这时就可以考虑使用Flink去消费Kafka中的数据,进行清洗转换后,再sink至StarRocks。
常见的实时报表的例子,使用Flink对Kafka中追加写入的数据进行实时处理,然后将数据源源不断的同步入库StarRocks。
2.1、数据准备
2.1.1、在Kafka中创建主题behavior和province
kafka-topics.sh --zookeeper 192.168.110.101:2181 --create --replication-factor 1 --partitions 1 --topic behaviorkafka-topics.sh --zookeeper 192.168.110.101:2181 --create --replication-factor 1 --partitions 1 --topic province
2.1.2、向主题behavior生产数据
kafka-console-producer.sh --broker-list 192.168.110.101:9092 --topic behavior
2.1.3、生产数据
10001,zs,18,11,shopping
10002,ls,19, 11,add
10003,ww,19,61,star
2.1.4、向主题province生产数据
kafka-console-producer.sh --broker-list 192.168.110.101:9092 --topic province2.1.5、生产数据
11,北京
61,陕西
2.2、StarRocks准备
2.2.1、创建主键模型表s_province
create database starrocks;
use starrocks;
CREATE TABLE IF NOT EXISTS starrocks.`s_province` (`uid` int(10) NOT NULL COMMENT "",`p_id` int(2) NOT NULL COMMENT "",`p_name` varchar(30) NULL COMMENT ""
)
PRIMARY KEY(`uid`)
DISTRIBUTED BY HASH(`uid`) BUCKETS 1
PROPERTIES (
"replication_num" = "1",
-- 限主键模型
"enable_persistent_index" = "true"
);
2.3、Flink准备
2.3.1、启动Flink
./start-cluster.sh
2.3.2、启动sql-client
/sql-client.sh embedded
2.3.3、执行Flink SQL,创建上下游的映射表
1、Source部分,创建Flink向Kafka的映射表kafka_source_behavior
CREATE TABLE kafka_source_behavior (uuid int,name string,age int,province_id int,behavior string
) WITH ('connector' = 'kafka','topic' = 'behavior','properties.bootstrap.servers' = '192.168.110.101:9092','properties.group.id' = 'source_behavior','scan.startup.mode' = 'earliest-offset','format' = 'csv'
);
2、创建映射表kafka_source_province
CREATE TABLE kafka_source_province (pid int,p_name string
) WITH ('connector' = 'kafka','topic' = 'province','properties.bootstrap.servers' = '192.168.110.101:9092','properties.group.id' = 'source_province','scan.startup.mode' = 'earliest-offset','format' = 'csv'
);
3、Sink部分,创建Flink向StarRocks的映射表sink_province
CREATE TABLE sink_province (uid INT,p_id INT,p_name STRING,PRIMARY KEY (uid) NOT ENFORCED
)WITH ('connector' = 'starrocks','jdbc-url'='jdbc:mysql://192.168.110.101:9030','load-url'='192.168.110.101:8030','database-name' = 'starrocks','table-name' = 's_province','username' = 'root','password' = 'root','sink.buffer-flush.interval-ms' = '5000','sink.properties.column_separator' = '\x01','sink.properties.row_delimiter' = '\x02'
);
2.3.4、执行同步任务
执行Flink SQL,开始同步任务
insert into sink_province select b.uuid as uid, b.province_id as p_id, p.p_name from kafka_source_behavior b join kafka_source_province p on b.province_id = p.pid;
2.4、StarRocks查看数据
mysql -h192.168.110.101 -P9030 -uroot –prootuse starrocks;
select * from s_province;
3、Flink JDBC读取MySQL数据写入StarRocks
使用Flink JDBC方式读取MySQL数据的实时场景不多,因为JDBC下Flink只能获取执行命令时MySQL表的数据,所以更适合离线场景。假设有复杂的MySQL数据,就可以在Flink中跑定时任务,来获取清洗后的数据,完成后写入StarRocks。
3.1、MySQL准备
3.1.1、MySQL中创建表s_user
use ODS;
CREATE TABLE `s_user` (`id` INT(11) NOT NULL,`name` VARCHAR(32) DEFAULT NULL,`p_id` INT(2) DEFAULT NULL,PRIMARY KEY (`id`)
);
3.1.2、插入数据
insert into s_user values(10086,'lm',61),(10010, 'ls',11), (10000,'ll',61);
3.2、StarRocks准备
3.2.1、StarRocks创建表s_user
use starrocks;
CREATE TABLE IF NOT EXISTS starrocks.`s_user` (`id` int(10) NOT NULL COMMENT "",`name` varchar(20) NOT NULL COMMENT "",`p_id` INT(2) NULL COMMENT ""
)
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_num" = "1",
-- 限主键模型
"enable_persistent_index" = "true"
);
3.3、Flink创建映射表
3.3.1、启动Flink(服务未停止,可以跳过)
./start-cluster.sh
3.3.2、启动sql-client
./sql-client.sh embedded
3.3.3、Source部分,创建映射至MySQL的映射表source_mysql_suser
CREATE TABLE source_mysql_suser (id INT,name STRING,p_id INT,PRIMARY KEY (id) NOT ENFORCED
)WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://192.168.110.102:3306/ODS','table-name' = 's_user','username' = 'root','password' = 'root'
);
3.3.4、Sink部分,创建至StarRocks的映射表sink_starrocks_suser
CREATE TABLE sink_starrocks_suser (id INT,name STRING,p_id INT,PRIMARY KEY (id) NOT ENFORCED
)WITH ('connector' = 'starrocks','jdbc-url'='jdbc:mysql://192.168.110.101:9030','load-url'='192.168.110.101:8030','database-name' = 'starrocks','table-name' = 's_user','username' = 'root','password' = 'root','sink.buffer-flush.interval-ms' = '5000','sink.properties.column_separator' = '\x01','sink.properties.row_delimiter' = '\x02'
);
3.3.5、Flink清洗数据并写入StarRocks
只是简单做一个where筛选,实际业务可能是多表join的复杂场景
insert into sink_starrocks_suser select id,name,p_id from source_mysql_suser where p_id = 61;
数据写入StarRocks后,Flink任务完成并结束。此时若再对MySQL中s_user表的数据进行增删或修改操作,Flink亦不会感知。
4、Flink读取StarRocks数据写入MySQL
还使用MySQL 中的s_user表和StarRocks的s_user表,将业务流程反转一下,读取StarRocks中的数据写入其他业务库,例如MySQL。
4.1、Flink创建映射表
4.1.1、启动Flink(服务未停止,可以跳过)
./start-cluster.sh
4.1.2、启动sql-client
./sql-client.sh embedded
4.1.3、Source部分,创建StarRocks映射表source_starrocks_suser
CREATE TABLE source_starrocks_suser (id INT,name STRING,p_id INT
)WITH ('connector' = 'starrocks','scan-url'='192.168.110.101:8030','jdbc-url'='jdbc:mysql://192.168.110.101:9030','database-name' = 'starrocks','table-name' = 's_user','username' = 'root','password' = 'root'
);
4.1.4、Sink部分,创建向MySQL的映射表sink_mysql_suser
CREATE TABLE sink_mysql_suser (id INT,name STRING,p_id INT,PRIMARY KEY (id) NOT ENFORCED
)WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://192.168.110.102:3306/ODS','table-name' = 's_user','username' = 'root','password' = 'root'
);
4.2、MySQL准备
4.2.1、清空MySQL s_user表数据,为一会儿导入新数据做准备
use ODS;
truncate table s_user;
4.3、Flink执行导入任务
简单梳理操作,实际业务可能会对StarRocks中多个表的数据进行分组或者join等处理然后再导入。
insert into sink_mysql_suser select id,name,p_id from source_starrocks_suser;
4.4、查看MySQL数据
select * from s_user;
5、Flink CDC同步MySQL数据至StarRocks
- 使用FlinkJDBC来读取MySQL数据时,JDBC的方式是“一次性”的导入,若希望让Flink感知MySQL数据源的数据变化,并近实时的实现据 同步,就需要使用Flink CDC。
- CDC是变更数据捕获(Change Data Capture)技术的缩写,它可以将源数据库(Source)的数据变动记录,同步到一个或多个数据目的地中(Sink)。直观的说就是当数据源的数据变化时,通过CDC可以让目标库中的数据同步发生变化(仅限于DML操作)。
- 还使用前面MySQL的s_user表以及StarRocks的s_user表来演示。
5.1、MySQL准备
5.1.1、MySQL开启binlog(格式为ROW模式)
vi /etc/my.cnf
log-bin=mysql-bin # 开启binlog
binlog-format=ROW # 选择ROW模式
server_id=1 # 配置MySQL replaction
5.1.2、重启MySQL服务:
systemctl restart mysqld
5.2、StarRocks准备
5.2.1、StarRocks中清空s_user表中的数据
mysql -h192.168.110.101 -P9030 -uroot –prootuse starrocks;
truncate table s_user;
5.3、Flink准备
5.3.1、启动Flink(服务未停止,可以跳过)
./start-cluster.sh
5.3.2、启动sql-client
./sql-client.sh embedded
5.3.3、Source部分,创建MySQL映射表cdc_mysql_suser
CREATE TABLE cdc_mysql_suser (id INT,name STRING,p_id INT
) WITH ('connector' = 'mysql-cdc','hostname' = '192.168.110.102','port' = '3306','username' = 'root','password' = 'root','database-name' = 'ODS','scan.incremental.snapshot.enabled'='false','table-name' = 's_user'
);
5.3.4、Sink部分,创建向StarRocks的cdc_starrocks_suser
CREATE TABLE cdc_starrocks_suser (id INT,name STRING,p_id INT,PRIMARY KEY (id) NOT ENFORCED
)WITH ('connector' = 'starrocks','jdbc-url'='jdbc:mysql://192.168.110.101:9030','load-url'='192.168.110.101:8030','database-name' = 'starrocks','table-name' = 's_user','username' = 'root','password' = 'root','sink.buffer-flush.interval-ms' = '5000','sink.properties.column_separator' = '\x01','sink.properties.row_delimiter' = '\x02'
);
5.4、执行同步任务
insert into cdc_starrocks_suser select id,name,p_id from cdc_mysql_suser;
在CDC场景下,Flink SQL执行后同步任务将会持续进行,当MySQL中数据出现变化,Flink会快速感知,并将变化同步至StarRocks中。
5.5、数据观察
5.5.1、MySQL库中观察数据
mysql -uroot –prootuse ODS;
select * from s_user;
5.5.2、StarRocks库中观察数据
mysql -h192.168.110.101 -P9030 -uroot –prootuse starrocks;
select * from s_user;
5.5.3、MySQL中,对数据进行增删改操作
INSERT INTO s_user VALUES(12345,'SR',61);DELETE FROM s_user WHERE id = 10010;UPDATE s_user SET `name`='No.1' WHERE id = 10086;
5.5.4、查看StarRocks中表的数据
select * from s_user;
可以确认对MySQL源表数据的增加、修改和删除操作引起的数据变化,都能同步至StarRocks目标表中。
6、通过CDC+SMT实现MySQL多表数据的秒级同步
StarRocks Migration Tool:为了友好的解决多表同步时的问题,StarRocks发布了StarRocks-migrate-tools(简称smt)工具,来快捷生成StarRocks表结构和Flink-SQL映射表及同步语句。Smt目前可用于MySQL、PostgreSQL、Oracle和hive,后面三个数据库的同步还在公测中,先以MySQL来进行演示。
6.1 MySQL准备
已开启binlog的MySQL中创建数据库CDC,并在其中创建表departments和jobs,创建完成后再导入少量数据。
6.1.1、创建表departments
CREATE DATABASE CDC;
USE CDC;CREATE TABLE `departments` (`department_id` int(4) NOT NULL AUTO_INCREMENT,`department_name` varchar(3) DEFAULT NULL,`manager_id` int(6) DEFAULT NULL,`location_id` int(4) DEFAULT NULL,PRIMARY KEY (`department_id`)
);
6.1.2、为表departments插入数据
insert into `departments`(`department_id`,`department_name`,`manager_id`,`location_id`)
values (10,'Adm',200,1700),(20,'Mar',201,1800),(30,'Pur',114,1700),(40,'Hum',203,2400),(50,'Shi',121,1500),(60,'IT',103,1400),(70,'Pub',204,2700),(80,'Sal',145,2500),(90,'Exe',100,1700),(100,'Fin',108,1700),(110,'Acc',205,1700),(120,'Tre',NULL,1700),(130,'Cor',NULL,1700),(140,'Con',NULL,1700),(150,'Sha',NULL,1700),(160,'Ben',NULL,1700),(170,'Man',NULL,1700),(180,'Con',NULL,1700),(190,'Con',NULL,1700),(200,'Ope',NULL,1700),(210,'IT ',NULL,1700),(220,'NOC',NULL,1700),(230,'IT ',NULL,1700),(240,'Gov',NULL,1700),(250,'Ret',NULL,1700),(260,'Rec',NULL,1700),(270,'Pay',NULL,1700);
6.1.3、创建表jobs
CREATE TABLE `jobs` (`job_id` varchar(10) NOT NULL,`job_title` varchar(35) DEFAULT NULL,`min_salary` int(6) DEFAULT NULL,`max_salary` int(6) DEFAULT NULL,PRIMARY KEY (`job_id`)
);
6.1.4、为表jobs插入数据
insert into `jobs`(`job_id`,`job_title`,`min_salary`,`max_salary`)
values ('AC_ACCOUNT','Public Accountant',4200,9000),('AC_MGR','Accounting Manager',8200,16000),('AD_ASST','Administration Assistant',3000,6000),('AD_PRES','President',20000,40000),('AD_VP','Administration Vice President',15000,30000),('FI_ACCOUNT','Accountant',4200,9000),('FI_MGR','Finance Manager',8200,16000),('HR_REP','Human Resources Representative',4000,9000),('IT_PROG','Programmer',4000,10000),('MK_MAN','Marketing Manager',9000,15000),('MK_REP','Marketing Representative',4000,9000),('PR_REP','Public Relations Representative',4500,10500),('PU_CLERK','Purchasing Clerk',2500,5500),('PU_MAN','Purchasing Manager',8000,15000),('SA_MAN','Sales Manager',10000,20000),('SA_REP','Sales Representative',6000,12000),('SH_CLERK','Shipping Clerk',2500,5500),('ST_CLERK','Stock Clerk',2000,5000),('ST_MAN','Stock Manager',5500,8500);
6.2 配置SMT工具
6.2.1 下载smt工具,解压后修改配置文件
vi conf/config_prod.conf
1、配置MySQL部分
[db]host = 192.168.110.102 #MySQL所在服务器IP
port = 3306 #MySQL服务端口
user = root #用户名
password = root #密码
# currently available types: `mysql`, `pgsql`, `oracle`, `hive`
type = mysql #类型选择MySQL,目前PostgreSQL、Oracle和Hive正在公测中
# # only takes effect on `type == hive`.
# # Available values: kerberos, none, nosasl, kerberos_http, none_http, zk, ldap
# authentication = kerberos
[other]
# number of backends in StarRocks
be_num = 1 #配置StarRocks BE的节点数,以便生成更合理bucket数量的建表语句
# `decimal_v3` is supported since StarRocks-1.18.1
use_decimal_v3 = true #使用更高精度的Decimal类型,1.18后的版本都支持
# file to save the converted DDL SQL
output_dir = ./result #后续生成sql文件的保存目录
# !!!`database` `table` `schema` are case sensitive in `oracle`!!!
[table-rule.1]
# pattern to match databases for setting properties
# !!! database should be a `whole instance(or pdb) name` but not a regex when it comes with an `oracle db` !!!
database = CDC #配置需要同步的数据库,需使用正则表达式的写法
# pattern to match tables for setting properties
table = departments|jobs #配置需要同步的表,需使用正则表达式的写法
# `schema` only takes effect on `postgresql` and `oracle`
schema = ^public$ #同步MySQL时不需要管这个
2、配置StarRocks集群信息
############################################
### flink sink configurations #这部分与Flink Sink部分写法相似
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://192.168.110.101:9030
flink.starrocks.load-url=192.168.110.101:8030
flink.starrocks.username=root
flink.starrocks.password=root
flink.starrocks.sink.properties.format=json #以json格式攒批
flink.starrocks.sink.properties.strip_outer_array=true #展开为数组
flink.starrocks.sink.buffer-flush.interval-ms=10000 #攒批10秒导入一次
# # used to set the server-id for mysql-cdc jobs instead of using a random server-id
# flink.cdc.server-id = 5000
6.3 SMT工具使用
参考地址:
https://docs.starrocks.io/zh-cn/latest/loading/Flink_cdc_load#%E4%BB%8E-mysql-%E5%AE%9E%E6%97%B6%E5%90%8C%E6%AD%A5
6.3.1 执行smt工具
./starrocks-migrate-tool
6.3.2 在配置的./result路径下生成sql语句文件
flink-create.1.sql
flink-create.all.sql
starrocks-create.1.sql
starrocks-create.all.sql
starrocks-external-create.1.sql
starrocks-external-create.all.sql
6.4 生成Flink 任务
6.4.1 同步库表结构
如果数据需要经过 Flink 处理后写入目标表,目标表与源表的结构不一样,则您需要修改 SQL 文件 starrocks-create.all.sql 中的建表语句。
mysql -h192.168.110.101 -P9030 -uroot -proot < /opt/module/smt/result/starrocks-create.all.sql6.4.2、同步数据
进入 Flink 目录,执行如下命令
./bin/sql-client.sh -f /opt/module/smt/result/flink-create.all.sql
6.4.3、处理同步数据
在同步过程中,如果您需要对数据进行一定的处理,例如 GROUP BY、JOIN 等,则可以修改 SQL 文件 flink-create.all.sql。可以通过执行 count(*) 和 GROUP BY 计算。
INSERT INTO `default_catalog`.`demo`.`orders_sink` SELECT product_id,product_name, COUNT(*) AS cnt FROM `default_catalog`.`demo`.`orders_src` WHERE order_date >'2021-01-01 00:00:01' GROUP BY product_id,product_name;
执行同步数据命令(5.4.2),如果返回如下结果,则表示 Flink job 已经提交,开始同步全量和增量数据。
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 5ae005c4b3425d8bb13fe660260a35da
6.5 观察任务状况
./flink listWaiting for response...------------------ Running/Restarting Jobs -------------------19.01.2022 21:55:30 : 80c4e81de2d0d7e34c8f1aac1c22a8c4 : insert-into_default_catalog.CDC.departments_sink (RUNNING)19.01.2022 21:55:34 : b2b76afe7d33196a09a274142d9128cf : insert-into_default_catalog.CDC.jobs_sink (RUNNING)
6.6 数据观察
就不再演示改变数据了,与场景四中的情况相同,当数据源中的数据变化时,StarRocks中的数据也会同步变化,实现数据的近实时同步。
这个场景特别适合维度表的数据同步,因为当前StarRocks还不支持update语法,就可以将数据需要频繁更新的维度表放在MySQL中,使用Flink CDC+SMT实时的在StarRocks中同步数据,实现灵活的多表关联查询。
相关文章:
StarRocks数据导入
1、相关环境 Flink作为当前流行的流式计算框架,在对接StarRocks时,若直接使用JDBC的方式"流式"写入数据,对StarRocks是不友好的,StarRocks作为一款MVCC的数据库,其导入的核心思想还是"攒微批降频率&qu…...
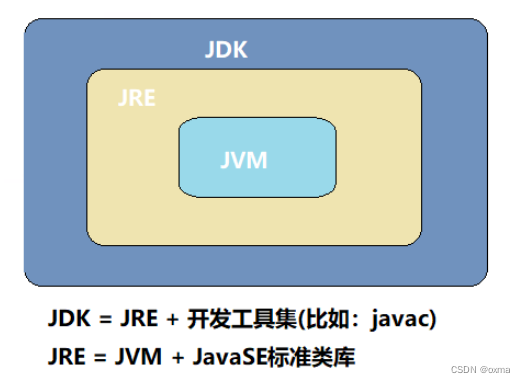
JavaSE | 初识Java(一) | JDK \ JRE \ JVM
Java初识 Java 是一门半编译型、半解释型语言。先通过 javac 编译程序把源文件进行编译,编译后生成的 .class 文件是由字节 码组成的平台无关、面向 JVM 的文件。最后启动 java 虚拟机 来运行 .class 文件,此时 JVM 会将字节码转换成平台能够理…...

6轮面试阿里Android开发offer,薪资却从21k降到17k,在逗我?
一小伙工作快3年了,拿到了阿里云Android开发岗位P6的offer,算HR面一起,加起来有6轮面试了,将近3个月的时间,1轮同级 1轮Android用人部门leader 1轮Android 组leader 1轮项目CTO 1轮HR 1轮HRBP。 一路上各种事件分…...

基于混合蛙跳优化的BP神经网络(分类应用) - 附代码
基于混合蛙跳优化的BP神经网络(分类应用) - 附代码 文章目录 基于混合蛙跳优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.混合蛙跳优化BP神经网络3.1 BP神经网络参数设置3.2 混合蛙跳算法应用 4.测试结果…...
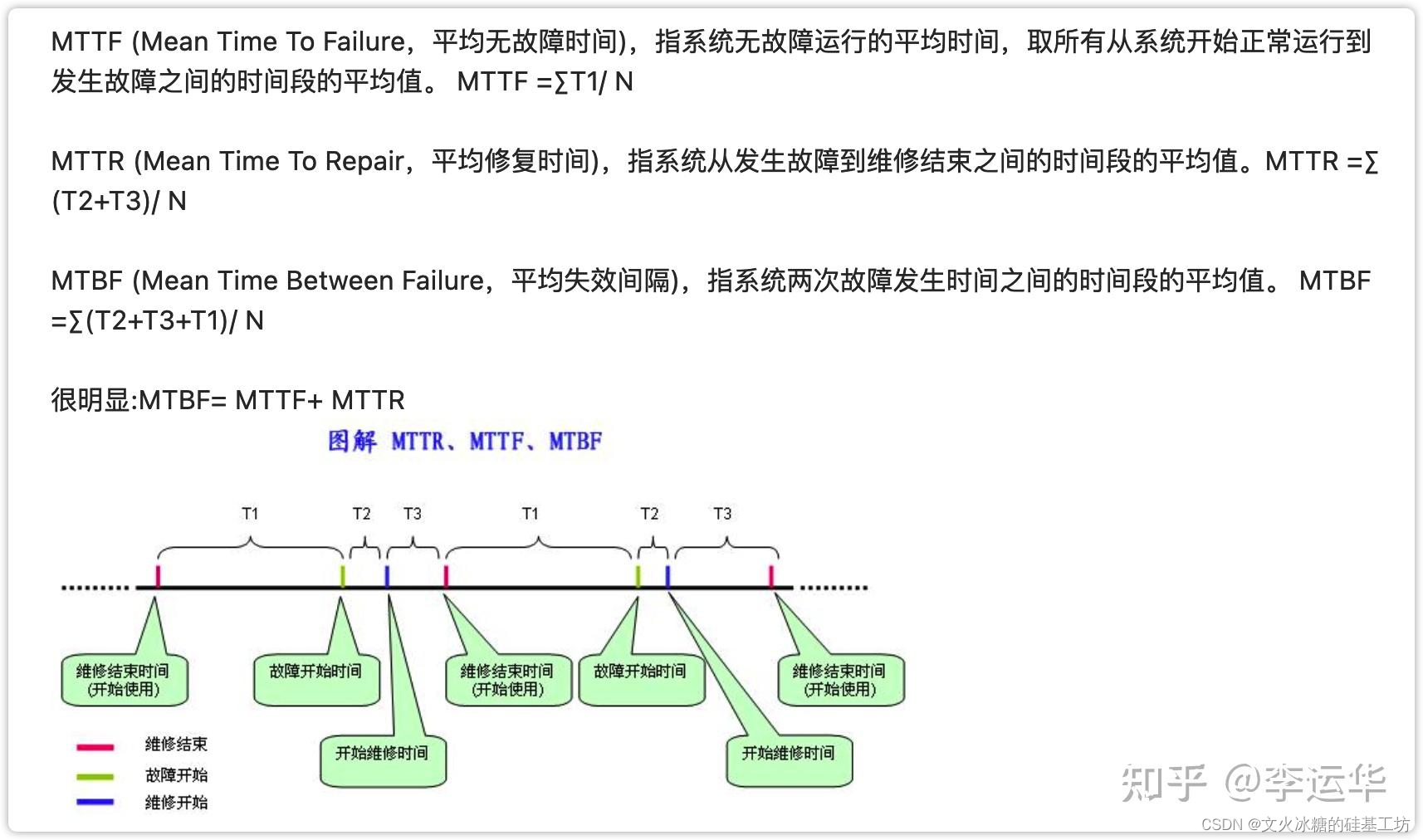
[架构之路-230]:计算机硬件与体系结构 - 可靠性、可用性、稳定性;MTTF、MTTR、MTBF
目录 一、软件质量属性 二、可靠性、可用性、稳定性区别 2.1 比较 2.2 公式比较 2.3 "正常工作时间"和"正常运行时间" 2.4 比较案例 2.5 可用性好但可靠性较差的示例 三、MTTF、MTTR、MTBF 3.1 图示 3.2 定义 (1)MTTF&am…...
selenium自动化测试环境安装教程
0X00前言: Selenium是一个广泛应用于Web应用程序测试的工具。它提供了一组功能强大的API,用于模拟用户与Web浏览器的交互。以下是对Selenium的简要介绍: 功能:Selenium能够自动化执行各种Web浏览器上的操作,如点击、输…...

如何修改springboot项目启动时的默认图标?
如下所示为springboot项目启动时的默认图标,我们可以把它换成我们自己喜欢的图片 方法如下: 第一步:我们需要将图片放置当前项目的resources目录下 如下所示为我自定义的一张照片 第二步: 方法1:在application.properties文件中…...

基于阴阳对优化的BP神经网络(分类应用) - 附代码
基于阴阳对优化的BP神经网络(分类应用) - 附代码 文章目录 基于阴阳对优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.阴阳对优化BP神经网络3.1 BP神经网络参数设置3.2 阴阳对算法应用 4.测试结果&#x…...

Spring bean定义Spring Bean 的作用域
Spring bean定义 目录 Spring bean定义 Spring配置元数据 Spring Bean 的作用域 singleton作用域: 原型作用域: 示例: 形成应用程序的骨干是由Spring IoC容器所管理的对象称为bean。bean被实例化,组装,并通过Sprin…...

代码随想录 动态规划 part16
583. 两个字符串的删除操作 给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个字符。 思路:dp[i][j]数组表示使得 word1[:i] 和 word2[:j] 相同所需的最小步数。当word1[i-1]word2[…...

非 Prop 的属性
概念 父组件传给子组件的属性,但该属性没有在子组件 props 属性里定义。 属性继承 非 Prop 的属性默认情况下会被子组件的根节点继承,非 prop 的属性会保存在子组件 $attrs 属性里。 举例 子组件 date-picker 如下 <!-- 我是子组件 date-picker --&…...

初识Java 12-3 流
目录 终结操作 将流转换为一个数组(toArray) 在每个流元素上应用某个终结操作(forEach) 收集操作(collect) 组合所有的流元素(reduce) 匹配(*Match) 选…...
、416. 分割等和子集)
代码随想录算法训练营第42天|动态规划:01背包理论基础、动态规划:01背包理论基础(滚动数组)、416. 分割等和子集
动态规划:01背包理论基础 动态规划:01背包理论基础(滚动数组) 以上两个问题的代码未本地化保存 416. 分割等和子集 https://leetcode.cn/problems/partition-equal-subset-sum/ 复杂的解法 class Solution { public:bool ca…...

(详解)Linux常见基本指令(1)
目录 目录: 1:有关路径文件下的操作(查看,进入) 1.1 ls 1.2 pwd 1.3 cd 2:创建文件或目录 2.1 touch 2.2 mkdir 3:删除文件或目录 3.1 rm与rmdir 4:复制剪切文件 4.1 cp 4.2 mv 1:有关路径的操作 1 ls 指令 语法:ls [选项] [目录或文…...

紫光同创FPGA图像视频采集系统,提供2套PDS工程源码和技术支持
目录 1、前言免责声明 2、紫光同创FPGA相关方案推荐3、设计思路框架视频源选择OV7725摄像头配置及采集OV5640摄像头配置及采集动态彩条HDMA图像缓存输入输出视频HDMA缓冲FIFOHDMA控制模块 HDMI输出 4、PDS工程1详解:OV7725输入5、PDS工程2详解:OV5640输入…...
第一章 函数 极限 连续(解题方法须背诵)
(一)求极限的常用方法 方法1 利用有理运算法则求极限 方法2 利用基本极限求极限 方法3 利用等价无穷小求极限 方法4 利用洛必达法则求极限 方法5 利用泰勒公式求极限 方法6 利用夹逼准则求极限 方法7 利用定积分的定义求极限 方法8 利用单调有界…...
selenium +IntelliJ+firefox/chrome 环境全套搭配
1第一步:下载IntelliJ idea 代码编辑器 2第二步:下载浏览器Chrome 3第三步:下载JDK 4第四步:配置环境变量(1JAVA_HOME 2 path) 5第五步:下载Maven 6第六步:配置环境变量&#x…...
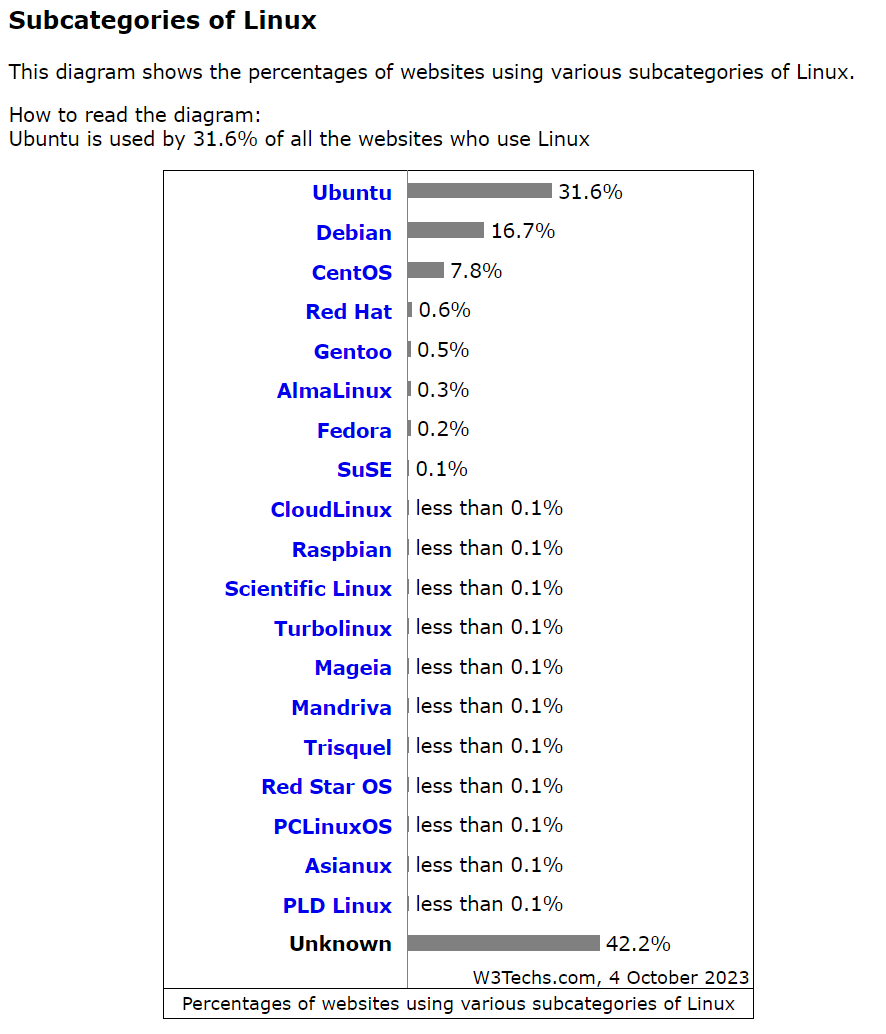
CentOS 7 停止维护后如何平替你的生产系统?
Author:rab 目录 前言一、Debian 家族1.1 Debian1.2 Ubuntu 二、RHEL 家族2.1 Red Hat Enterprise Linux2.2 Fedora2.3 CentOS2.4 Rocky Linux2.5 AlmaLinux 三、如何选择?思考? 前言 CentOS 8 系统 2021 年 12 月 31 日已停止维护服务&…...

第81步 时间序列建模实战:Adaboost回归建模
基于WIN10的64位系统演示 一、写在前面 这一期,我们介绍AdaBoost回归。 同样,这里使用这个数据: 《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndr…...

135.【JUC并发编程_01】
JUC 并发编程 (一)、基本概述1.概述 (二)、进程与线程1.进程与线程(1).进程_介绍(2).线程_介绍(3).进程与线程的区别 2.并行和并发(1).并发_介绍(2).并行_介绍(3).并行和并发的区别 3.应用(1).异步调用_较少等待时间(2).多线程_提高效率 (三)、Java 线程1.创建线程和运行线程(1…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

【DeepSeek事件驱动架构实战指南】:20年架构师亲授5大核心陷阱与避坑清单
更多请点击: https://kaifayun.com 第一章:DeepSeek事件驱动架构全景认知 DeepSeek事件驱动架构(Event-Driven Architecture, EDA)并非单一技术组件的堆叠,而是一种以事件为第一公民、强调松耦合与异步协作的系统设计…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...