第81步 时间序列建模实战:Adaboost回归建模
基于WIN10的64位系统演示
一、写在前面
这一期,我们介绍AdaBoost回归。
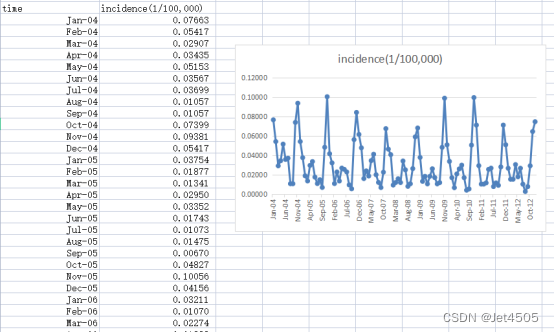
同样,这里使用这个数据:
《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndrome in Jiangsu Province, China》文章的公开数据做演示。数据为江苏省2004年1月至2012年12月肾综合症出血热月发病率。运用2004年1月至2011年12月的数据预测2012年12个月的发病率数据。
二、AdaBoost回归
(1)代码解读
sklearn.ensemble.AdaBoostRegressor(estimator=None, *, n_estimators=50, learning_rate=1.0, loss='linear', random_state=None, base_estimator='deprecated')咋一看,跟AdaBoostClassifier(用于分类,上传送门)参数也差不多,因此,我们列举出它们相同和不同的地方,便于对比记忆:
共同的参数:
base_estimator: 基估计器用于训练弱学习器。如果为 None,分类器默认使用决策树分类器,而回归器默认使用决策树回归器。
n_estimators: 最大的弱学习器数量。
learning_rate: 按指定的学习率缩小每个弱学习器的贡献。
random_state: 随机数生成器的种子或随机数生成器。
algorithm: 用于 AdaBoost 算法的执行版本。在分类器中是 {"SAMME", "SAMME.R"},在回归器中只有 "SAMME"。
差异:
AdaBoostClassifier 特有参数:
algorithm: 可选的执行算法可以是 "SAMME" 或 "SAMME.R"。默认为 "SAMME.R"。其中 "SAMME.R" 是 "SAMME" 的实值版本,它通常表现得更好,因为它依赖于类别概率,而不是类别预测。
AdaBoostRegressor 特有参数:
loss: 在增加新的弱学习器时用于更新权重的损失函数。可选的值包括 'linear', 'square', 和 'exponential'。
综上可见,虽然这两个类的大部分参数都很相似,但它们的主要区别在于分类器具有两种执行算法("SAMME" 和 "SAMME.R"),而回归器则添加了一个 loss 参数来定义更新权重时使用的损失函数。
(2)单步滚动预测
import pandas as pd
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.ensemble import AdaBoostRegressor
from sklearn.model_selection import GridSearchCVdata = pd.read_csv('data.csv')# 将时间列转换为日期格式
data['time'] = pd.to_datetime(data['time'], format='%b-%y')# 拆分输入和输出
lag_period = 6# 创建滞后期特征
for i in range(lag_period, 0, -1):data[f'lag_{i}'] = data['incidence'].shift(lag_period - i + 1)# 删除包含NaN的行
data = data.dropna().reset_index(drop=True)# 划分训练集和验证集
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
validation_data = data[(data['time'] >= '2012-01-01') & (data['time'] <= '2012-12-31')]# 定义特征和目标变量
X_train = train_data[['lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6']]
y_train = train_data['incidence']
X_validation = validation_data[['lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6']]
y_validation = validation_data['incidence']# 初始化AdaBoostRegressor模型
adaboost_model = AdaBoostRegressor()# 定义参数网格
param_grid = {'n_estimators': [50, 100, 150],'learning_rate': [0.01, 0.05, 0.1, 0.5, 1],'loss': ['linear', 'square', 'exponential']
}# 初始化网格搜索
grid_search = GridSearchCV(adaboost_model, param_grid, cv=5, scoring='neg_mean_squared_error')# 进行网格搜索
grid_search.fit(X_train, y_train)# 获取最佳参数
best_params = grid_search.best_params_# 使用最佳参数初始化AdaBoostRegressor模型
best_adaboost_model = AdaBoostRegressor(**best_params)# 在训练集上训练模型
best_adaboost_model.fit(X_train, y_train)# 对于验证集,我们需要迭代地预测每一个数据点
y_validation_pred = []for i in range(len(X_validation)):if i == 0:pred = best_adaboost_model.predict([X_validation.iloc[0]])else:new_features = list(X_validation.iloc[i, 1:]) + [pred[0]]pred = best_adaboost_model.predict([new_features])y_validation_pred.append(pred[0])y_validation_pred = np.array(y_validation_pred)# 计算验证集上的MAE, MAPE, MSE和RMSE
mae_validation = mean_absolute_error(y_validation, y_validation_pred)
mape_validation = np.mean(np.abs((y_validation - y_validation_pred) / y_validation))
mse_validation = mean_squared_error(y_validation, y_validation_pred)
rmse_validation = np.sqrt(mse_validation)# 计算训练集上的MAE, MAPE, MSE和RMSE
y_train_pred = best_adaboost_model.predict(X_train)
mae_train = mean_absolute_error(y_train, y_train_pred)
mape_train = np.mean(np.abs((y_train - y_train_pred) / y_train))
mse_train = mean_squared_error(y_train, y_train_pred)
rmse_train = np.sqrt(mse_train)print("Train Metrics:", mae_train, mape_train, mse_train, rmse_train)
print("Validation Metrics:", mae_validation, mape_validation, mse_validation, rmse_validation)看结果:

(3)多步滚动预测-vol. 1
AdaBoostRegressor预期的目标变量y应该是一维数组,所以你们懂的。
(4)多步滚动预测-vol. 2
同上。
(5)多步滚动预测-vol. 3
import pandas as pd
import numpy as np
from sklearn.ensemble import AdaBoostRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_absolute_error, mean_squared_error# 数据读取和预处理
data = pd.read_csv('data.csv')
data_y = pd.read_csv('data.csv')
data['time'] = pd.to_datetime(data['time'], format='%b-%y')
data_y['time'] = pd.to_datetime(data_y['time'], format='%b-%y')n = 6for i in range(n, 0, -1):data[f'lag_{i}'] = data['incidence'].shift(n - i + 1)data = data.dropna().reset_index(drop=True)
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
X_train = train_data[[f'lag_{i}' for i in range(1, n+1)]]
m = 3X_train_list = []
y_train_list = []for i in range(m):X_temp = X_trainy_temp = data_y['incidence'].iloc[n + i:len(data_y) - m + 1 + i]X_train_list.append(X_temp)y_train_list.append(y_temp)for i in range(m):X_train_list[i] = X_train_list[i].iloc[:-(m-1)]y_train_list[i] = y_train_list[i].iloc[:len(X_train_list[i])]# 模型训练
param_grid = {'n_estimators': [50, 100, 150],'learning_rate': [0.01, 0.05, 0.1, 0.5, 1],'loss': ['linear', 'square', 'exponential']
}best_ada_models = []for i in range(m):grid_search = GridSearchCV(AdaBoostRegressor(), param_grid, cv=5, scoring='neg_mean_squared_error')grid_search.fit(X_train_list[i], y_train_list[i])best_ada_model = AdaBoostRegressor(**grid_search.best_params_)best_ada_model.fit(X_train_list[i], y_train_list[i])best_ada_models.append(best_ada_model)validation_start_time = train_data['time'].iloc[-1] + pd.DateOffset(months=1)
validation_data = data[data['time'] >= validation_start_time]X_validation = validation_data[[f'lag_{i}' for i in range(1, n+1)]]
y_validation_pred_list = [model.predict(X_validation) for model in best_ada_models]
y_train_pred_list = [model.predict(X_train_list[i]) for i, model in enumerate(best_ada_models)]def concatenate_predictions(pred_list):concatenated = []for j in range(len(pred_list[0])):for i in range(m):concatenated.append(pred_list[i][j])return concatenatedy_validation_pred = np.array(concatenate_predictions(y_validation_pred_list))[:len(validation_data['incidence'])]
y_train_pred = np.array(concatenate_predictions(y_train_pred_list))[:len(train_data['incidence']) - m + 1]mae_validation = mean_absolute_error(validation_data['incidence'], y_validation_pred)
mape_validation = np.mean(np.abs((validation_data['incidence'] - y_validation_pred) / validation_data['incidence']))
mse_validation = mean_squared_error(validation_data['incidence'], y_validation_pred)
rmse_validation = np.sqrt(mse_validation)
print("验证集:", mae_validation, mape_validation, mse_validation, rmse_validation)mae_train = mean_absolute_error(train_data['incidence'][:-(m-1)], y_train_pred)
mape_train = np.mean(np.abs((train_data['incidence'][:-(m-1)] - y_train_pred) / train_data['incidence'][:-(m-1)]))
mse_train = mean_squared_error(train_data['incidence'][:-(m-1)], y_train_pred)
rmse_train = np.sqrt(mse_train)
print("训练集:", mae_train, mape_train, mse_train, rmse_train)结果:

三、数据
链接:https://pan.baidu.com/s/1EFaWfHoG14h15KCEhn1STg?pwd=q41n
提取码:q41n
相关文章:
第81步 时间序列建模实战:Adaboost回归建模
基于WIN10的64位系统演示 一、写在前面 这一期,我们介绍AdaBoost回归。 同样,这里使用这个数据: 《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndr…...

135.【JUC并发编程_01】
JUC 并发编程 (一)、基本概述1.概述 (二)、进程与线程1.进程与线程(1).进程_介绍(2).线程_介绍(3).进程与线程的区别 2.并行和并发(1).并发_介绍(2).并行_介绍(3).并行和并发的区别 3.应用(1).异步调用_较少等待时间(2).多线程_提高效率 (三)、Java 线程1.创建线程和运行线程(1…...
VC++创建windows服务程序
目录 1.关于windows标准可执行程序和服务程序 2.服务相关整理 2.1 VC编写服务 2.2 服务注册 2.3 服务卸载 2.4 启动服务 2.5 关闭服务 2.6 sc命令 2.7 查看服务 3.标准程序 3.1 后台方式运行标准程序 3.2 查找进程 3.3 终止进程 以前经常在Linux下编写服务器程序…...
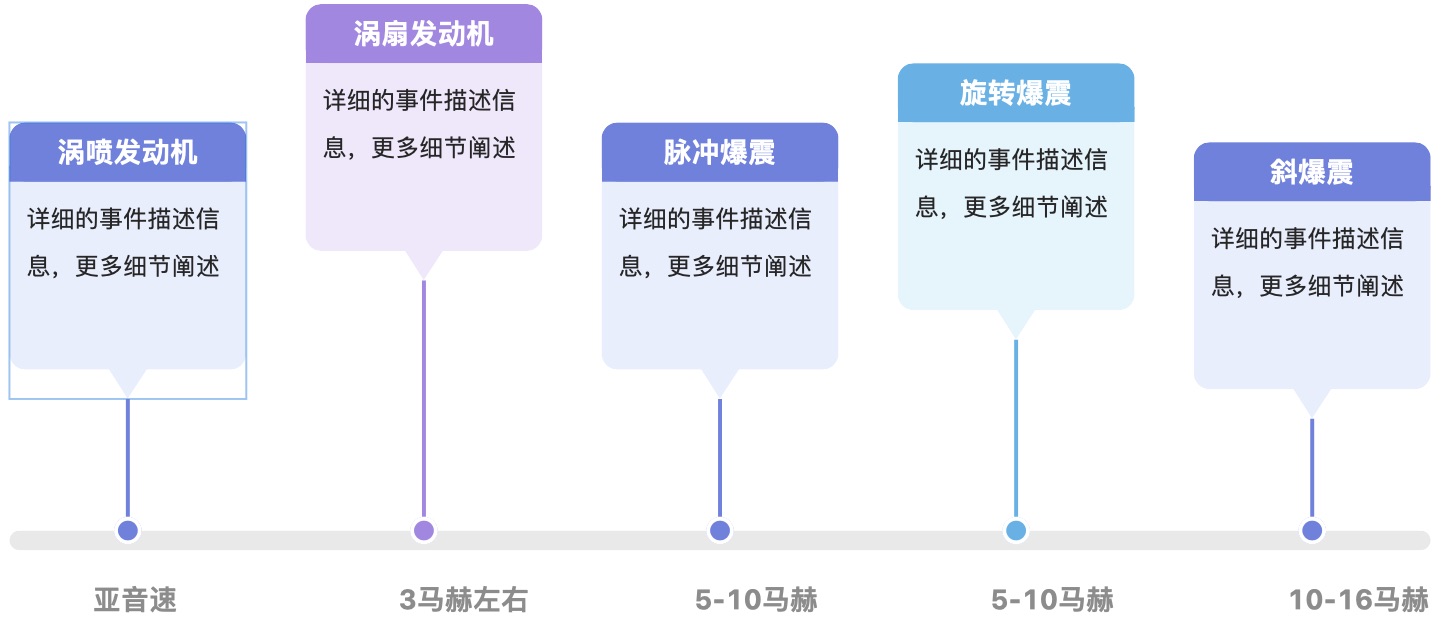
连续爆轰发动机
0.什么是爆轰 其反应区前沿为一激波。反应区连同前驱激波称为爆轰波。爆轰波扫过后,反应区介质成为高温高压的爆轰产物。能够发生爆轰的系统可以是气相、液相、固相或气-液、气-固和液-固等混合相组成的系统。通常把液、固相的爆轰系统称为炸药。 19世纪80年代初&a…...
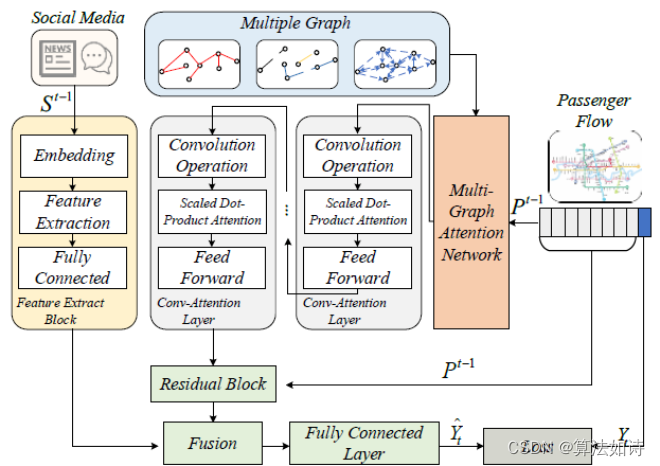
交通物流模型 | 基于时空注意力融合网络的城市轨道交通假期短时客流预测
短时轨道交通客流预测对于交通运营管理非常重要。新兴的深度学习模型有效提高了预测精度。然而,大部分现有模型主要针对常规工作日或周末客流进行预测。由于假期客流的突发性和无规律性,仅有一小部分研究专注于假期客流预测。为此,本文提出一个全新的时空注意力融合网络(ST…...

2.2.1 嵌入式工程师必备软件
1 文件比较工具 在开发过程中,不论是对代码的对比,还是对log的对比,都是必不可不少的,通过对比,我们可以迅速找到差异,定位问题。当前常用的对比工具有:WinMerge,Diffuse,Beyond Compare,Altova DiffDog,AptDiff,Code Compare等。这里推荐使用Beyond Compare,它不…...
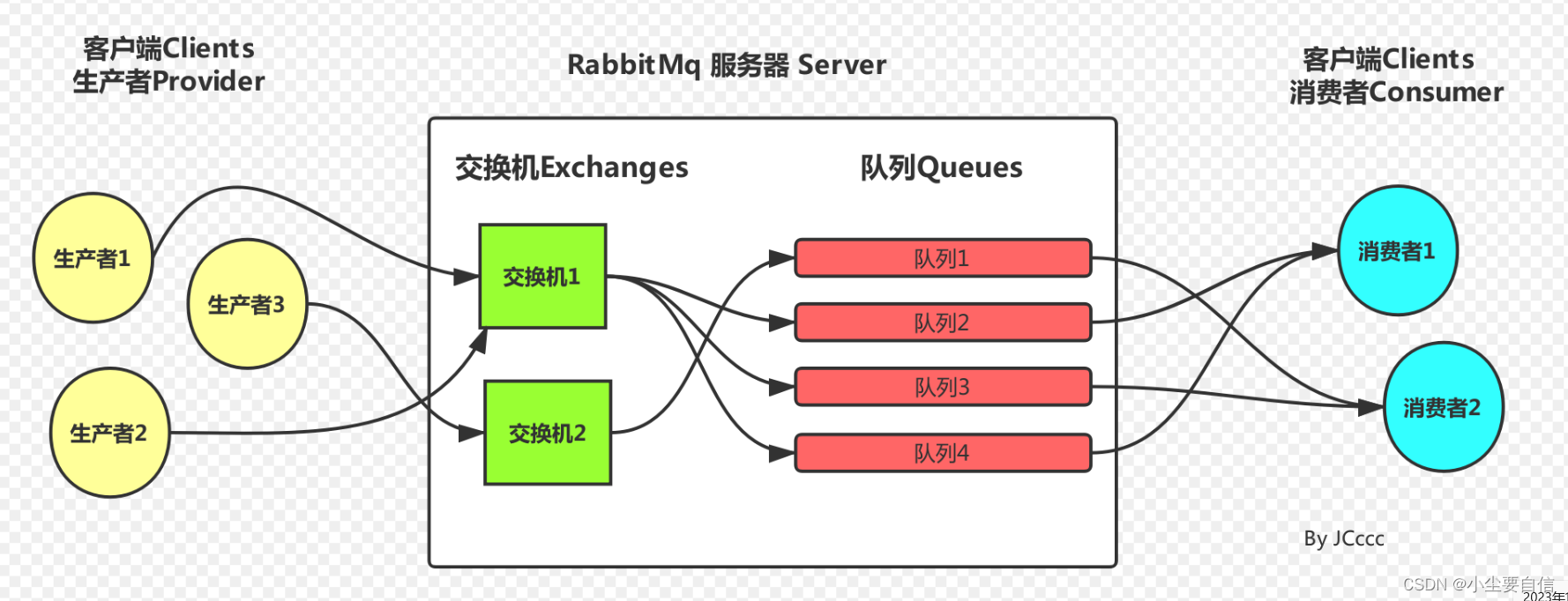
深入了解 RabbitMQ:高性能消息中间件
目录 引言:一、RabbitMQ 介绍二、核心概念三、工作原理四、应用场景五、案例实战 引言: 在现代分布式系统中,消息队列成为了实现系统间异步通信、削峰填谷以及解耦组件的重要工具。而RabbitMQ作为一个高效可靠的消息队列解决方案,…...

【数据库——MySQL】(14)过程式对象程序设计——游标、触发器
目录 1. 游标1.1 声明游标1.2 打开游标1.3 读取游标1.4 关闭游标1.5 游标示例 2. 触发器2.1 创建触发器2.2 修改触发器2.3 删除触发器2.4 触发器类型2.5 触发器示例 参考书籍 1. 游标 游标一般和存储过程一起配合使用。 1.1 声明游标 要使用游标,需要用到 DECLAR…...
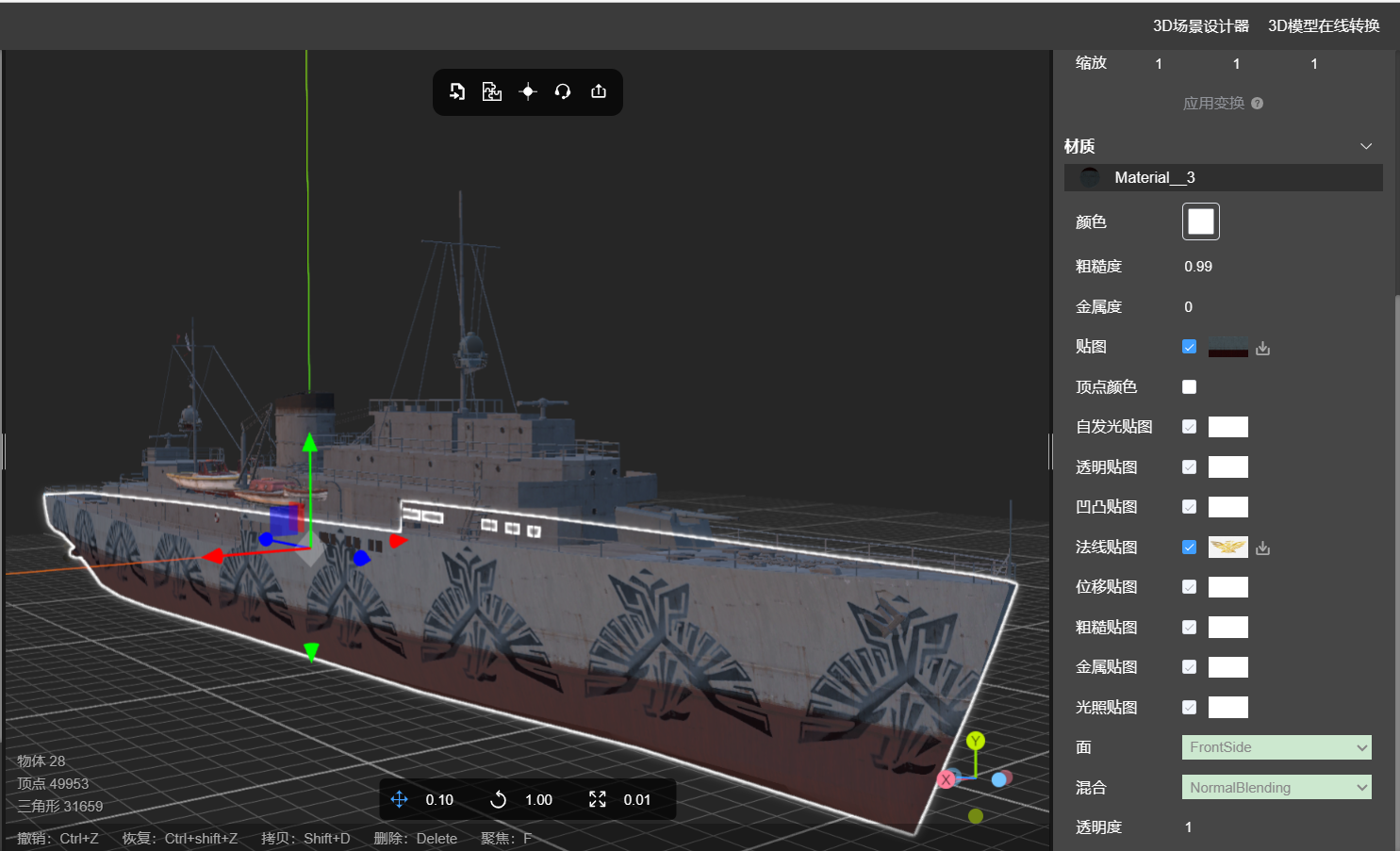
位移贴图和法线贴图的区别
位移贴图和法线贴图都是用于增强模型表面细节和真实感的纹理贴图技术,但是它们之间也存在着差异。 1、什么是位移贴图 位移贴图:位移贴图通过在模型顶点上定义位移值来改变模型表面的形状。该贴图包含了每个像素的高度值信息,使得模型的细节…...
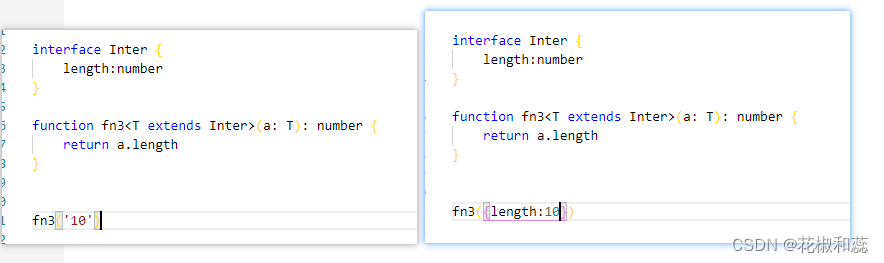
【typescript】面向对象(下篇),包含接口,属性的封装,泛型
假期第八篇,对于基础的知识点,我感觉自己还是很薄弱的。 趁着假期,再去复习一遍 面向对象:程序中所有的操作都需要通过对象来完成 计算机程序的本质就是对现实事物的抽象,抽象的反义词是具体。比如照片是对一个具体的…...
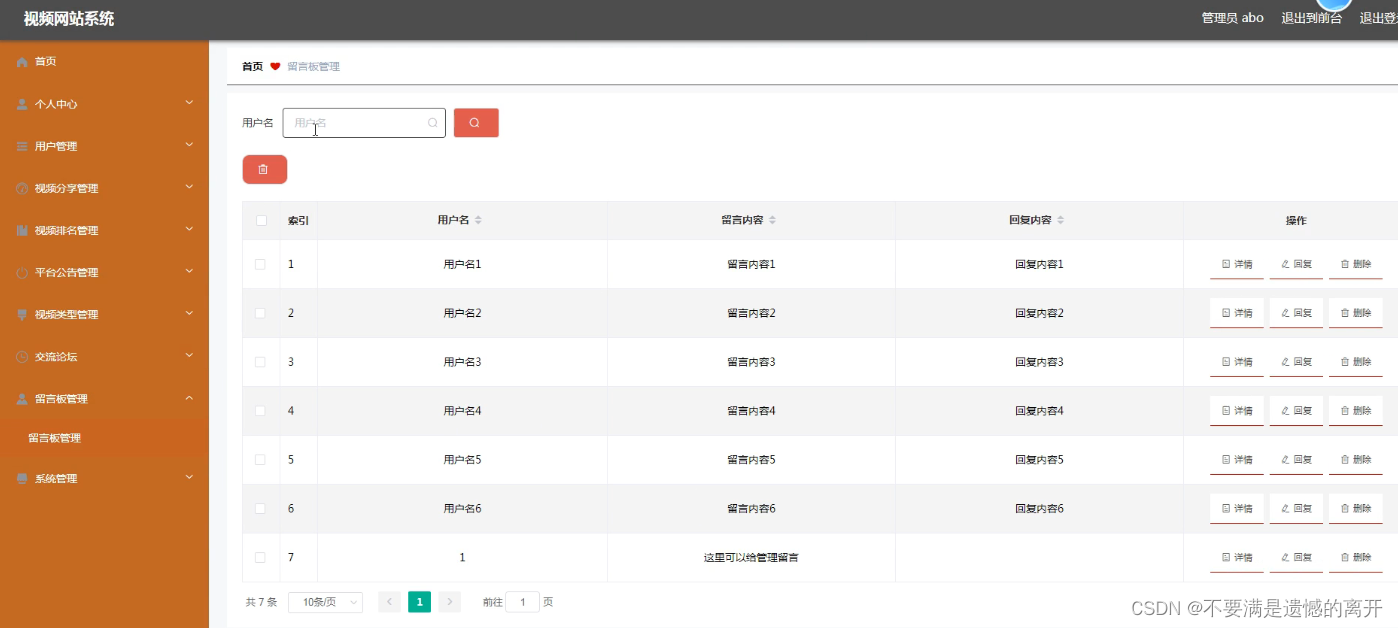
基于SpringBoot的视频网站系统
目录 前言 一、技术栈 二、系统功能介绍 用户信息管理 视频分享管理 视频排名管理 交流论坛管理 留言板管理 三、核心代码 1、登录模块 2、文件上传模块 3、代码封装 前言 使用旧方法对视频信息进行系统化管理已经不再让人们信赖了,把现在的网络信息技术运…...
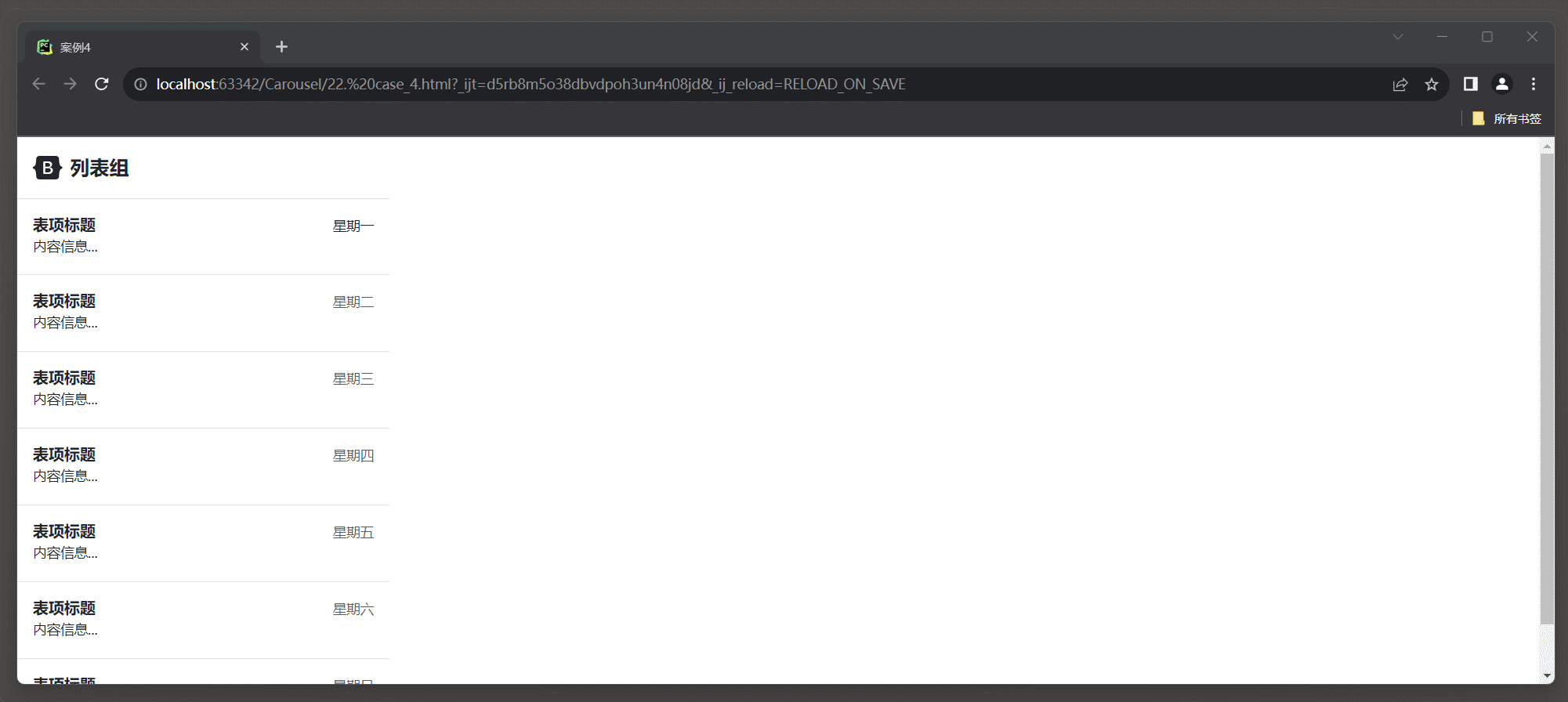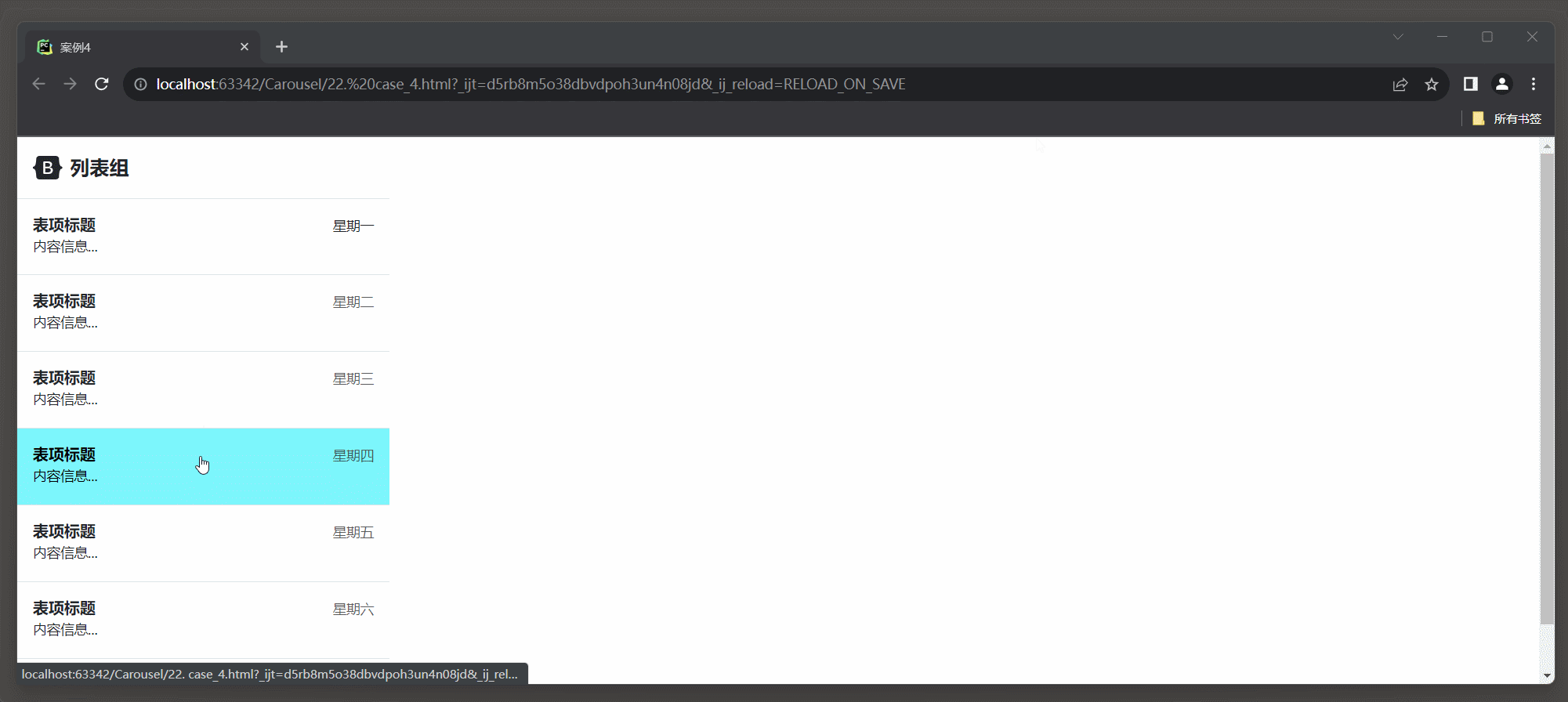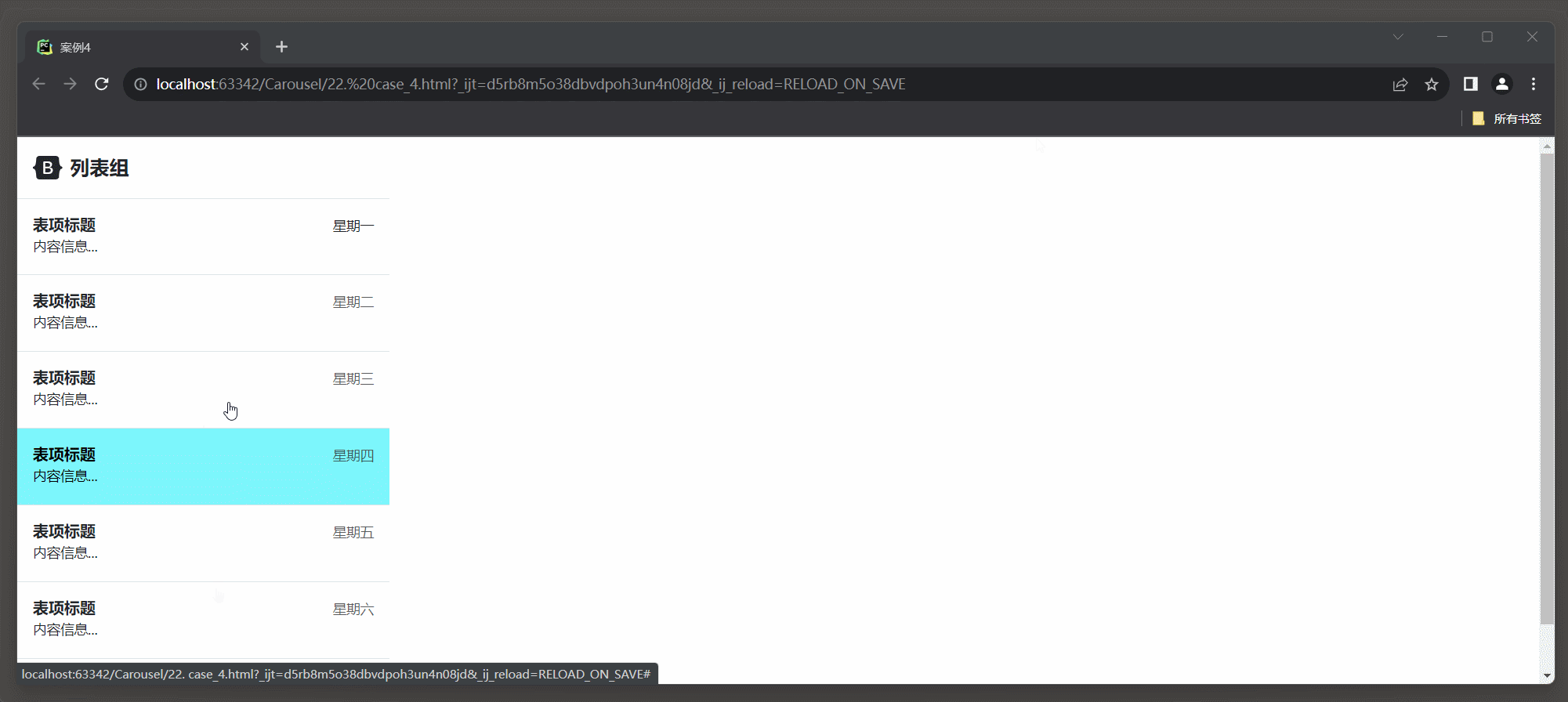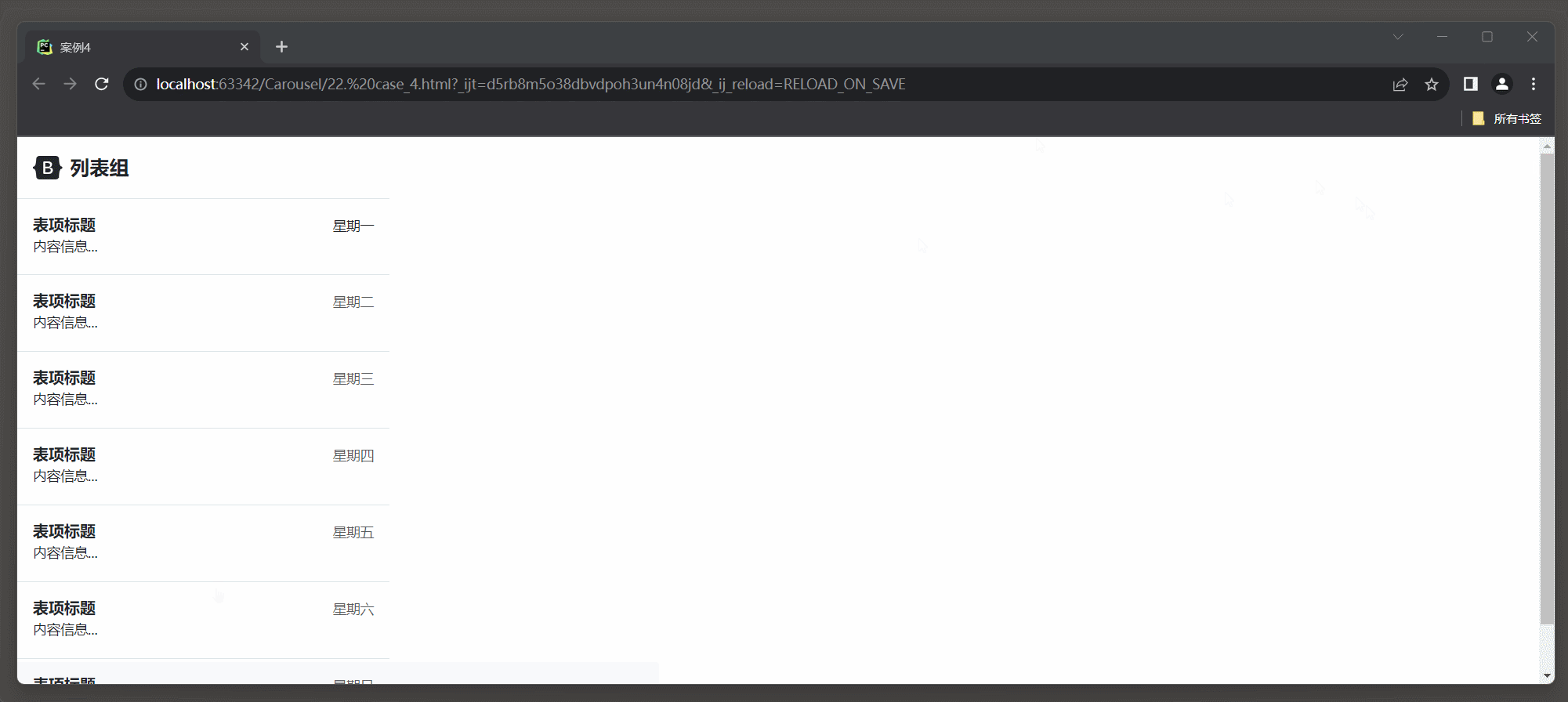
23.3 Bootstrap 框架4
1. 轮播 1.1 轮播样式 在Bootstrap 5中, 创建轮播(Carousel)的相关类名及其介绍: * 1. carousel: 轮播容器的类名, 用于标识一个轮播组件. * 2. slide: 切换图片的过渡和动画效果. * 3. carousel-inner: 轮播项容器的类名, 用于包含轮播项(轮播图底下椭圆点, 轮播的过程可以显…...

ESP32设备驱动-I2C-LCD1602显示屏驱动
I2C-LCD1602显示屏驱动 1、LCD1602介绍 LCD1602液晶显示器是广泛使用的一种字符型液晶显示模块。它是由字符型液晶显示屏(LCD)、控制驱动主电路HD44780及其扩展驱动电路HD44100,以及少量电阻、电容元件和结构件等装配在PCB板上而组成。 通过前面的实例我们知道,并口方式…...

vs工具箱在哪里找
VS工具箱在标题栏 视图->工具箱...

uniapp 事件委托失败 获取不到dataset
问题: v-for 多个span ,绑定点击事件 代码:view里包着一个span, <view class"status-list" tap"search"><span class"status-item" v-for"(key,index) in statusList" :key"index" :data-key"k…...
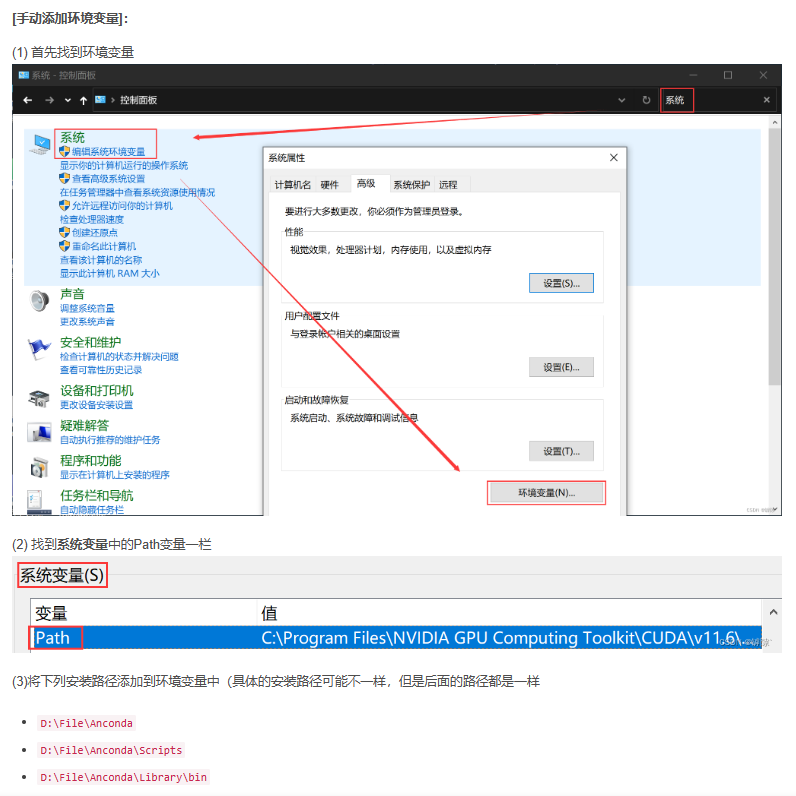
windows系统下pycharm配置anaconda
参考:超详细的PycharmAnconda安装配置教程_pycharm conda_罅隙的博客-CSDN博客 下载好anaconda安装后,比如我们安装在D盘anaconda文件夹下,在pycharm配置好环境激活时出现问题,可能是电脑没有配置环境变量 需要将一下4行添加到电…...

2023年CSP-J真题详解+分析数据
目录 亲身体验 江苏卷 选择题 阅读程序题 阅读程序(1) 判断题 单选题 阅读程序(2) 判断题 单选题 阅读程序(3) 判断题 单选题 完善程序题 完善程序(1) 完善程序(2) 2023CSP-J江苏卷详解 小结 亲身体验 2023年的CSP-J是在9月16日9:30--11:30进行…...
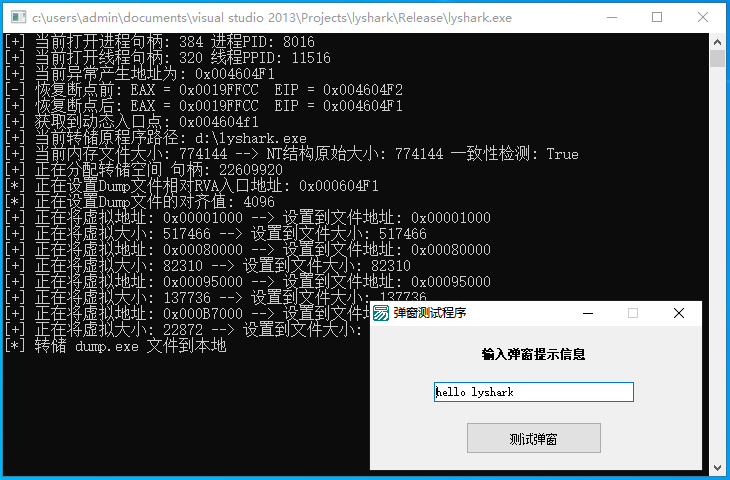
10.3 调试事件转存进程内存
我们继续延申调试事件的话题,实现进程转存功能,进程转储功能是指通过调试API使获得了目标进程控制权的进程,将目标进程的内存中的数据完整地转存到本地磁盘上,对于加壳软件,通常会通过加密、压缩等手段来保护其代码和数…...
深度学习实战基础案例——卷积神经网络(CNN)基于MobileNetV3的肺炎识别|第3例
文章目录 前言一、数据集介绍二、前期工作三、数据集读取四、构建CA注意力模块五、构建模型六、开始训练 前言 Google公司继MobileNetV2之后,在2019年发表了它的改进版本MobileNetV3。而MobileNetV3共有两个版本,分别是MobileNetV3-Large和MobileNetV2-…...
)
机器学习 面试/笔试题(更新中)
1. 生成模型 VS 判别模型 生成模型: 由数据学得联合概率分布函数 P ( X , Y ) P(X,Y) P(X,Y),求出条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)的预测模型。 朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...