网络爬虫指南
一、定义
网络爬虫,是按照一定规则,自动抓取网页信息。爬虫的本质是模拟浏览器打开网页,从网页中获取我们想要的那部分数据。
二、Python为什么适合爬虫
Python相比与其他编程语言,如java,c#,C++,python抓取网页的接口更简洁;并且有丰富的网络抓取模块。
三、爬虫库beautifulsoup
1、Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。
2、Beautiful Soup抓取数据后得到一个文档对象(beautifulsoup对象),其实也是一个复杂的树形结构文档,因此还需要解析器来解析这段文档。可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析(相对于其他几种来说要强大一些)。
说明:选择使用lxml解析器解析,需要安装lxml模块,但是使用时候无需import lxml
3、模块安装
pip install bs4
pip install lxml
4、模块导入
from bs4 import BeautifulSoup
5、BeautifulSoup方法
BeautifulSoup(markup, features)接受两个参数:第一个参数(markup):文件对象或字符串对象第二个参数(features):解析器,未指定则使用python自带的标准解析器(html.parser),但会产警告6、 Beautiful Soup对象
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: BeautifulSoup 、Tag 、NavigableString 、Comment 。

6.1 BeautifulSoup对象
BeautifulSoup对象对象表示的是一个文档的全部内容。
例如:
from bs4 import BeautifulSoup # 导入BeautifulSoup4库f1 = open(r'D:\Document\Workspace\pywokrspace\test1\urllib_test_runoob_search.html','r',encoding='utf-8')
soup1 = BeautifulSoup(f1,'lxml')#使用lxml解析器解析
print(soup1)
f1.close()
返回的内容为Beautiful Soup对象文档,其实和html页面很类似。
<!DOCTYPE html>
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<meta content="width=device-width, initial-scale=1.0" name="viewport"/>
<title>Python 教程 的搜索結果</title>
<meta content="noindex, follow, max-image-preview:large" name="robots"/>
<link href="https://static.runoob.com/images/icon/mobile-icon.png" rel="apple-touch-icon"/>
<meta content="菜鸟教程" name="apple-mobile-web-app-title"/>
</head>
<body>
<!-- 头部 -->
<div class="col search row-search-mobile">
<form action="index.php">
<input autocomplete="off" class="placeholder" name="s" placeholder="搜索……"/>
</form>
</div>
</body>
</html>
6.2 Tag对象
1、Tag即HTML或XML中的标签对:Tag对象与XML或HTML原生文档中的tag相同。
2、获取Tag对象
步骤一:从一个beautifulsoup对象中获取指定的Tag对象,可以使用:beautifulsoup对象.标签名,要获取哪个标签的Tag对象,就传入哪个标签的标签名,它返回的是一个标签。注:当存在多个标签名相同时,这种方法返回的Tag对象是所有内容中第一个符合要求的标签。
步骤二:获取tag对象的属性,返回属性内容字典
属性说明:
-
(1)、attrs属性:指的是一个标签的属性,一个标签的属性一般是由键值对组成,属性名=值
(2)、一个标签可能有很多个属性
(3)、获取一个Tag对象的attrs属性,可以使用:Tag对象.attrs
(4)、使用Tag对象的attrs属性可以把标签对的属性以字典形式返回Tag对象无属性时返回的是一个空字典
步骤三:获取到Tag对象属性后,可以继续使用使用字典方法获取标签对中的具体数据
举例说明:
from bs4 import BeautifulSoup # 导入bs4库html = """<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>"""
soup = BeautifulSoup(html, "lxml") # 指定解析器
a_tag = soup.a # 获取a标签
print("a标签的tag对象为:", a_tag)
a_tag_attrs = soup.a.attrs # 获取a标签的属性,也可先获取a标签,再获取a属性,分2步
print("a标签的tag对象的属性为:", a_tag_attrs)
a_tag_attrs_href_dict = a_tag_attrs["href"] # 使用字典的索引
print("通过字典索引获取到的tag对象的属性"+ a_tag_attrs_href_dict)
输出:
a标签的tag对象为: <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
a标签的tag对象的属性为: {'href': 'http://example.com/tillie', 'class': ['sister'], 'id': 'link3'}
通过字典索引获取到的tag对象的属性http://example.com/tillie
6.3、NavigableString对象
1、NavigableString对象:指的是标签对中的数据
2、获取一个Tag对象中的数据(NavigableString对象),可以使用:Tag对象.string
from bs4 import BeautifulSoup # 导入bs4库html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story A</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Tillie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3"><!-- Elsie --></a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""soup = BeautifulSoup(html, "lxml") # 指定解析器,创建beautifulsoup对象
head_string = soup.head.string
p_string = soup.p.string
a_tag = soup.a
a_tag_string = a_tag.string
print("header标签中的数据为:", head_string)
print("p标签中的数据为:", p_string)
print("a标签中的数据为:",a_tag_string)
6.4 Comment对象
Comment 对象是一个特殊类型的NavigableString对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦。
举例说明:
from bs4 import BeautifulSoup # 导入bs4库html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""soup = BeautifulSoup(html, "lxml") # 指定解析器,创建beautifulsoup对象
print("a标签的tag对象为:", soup.a)
print("a标签内的数据为:", soup.a.string) # a标签内的数据为一个注释
输出:
a标签的tag对象为: <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
a标签内的数据为: Elsie
6.5 补充
获取Tag对象,上面提到:使用beautifulsoup对象.标签名获取标签的Tag对象,当存在多个标签名相同时,它返回的是所有内容中第一个符合要求的标签。
获取某个指定的tag有两种情况:一种是获取指定的第一个标签(这种实际中用得很少),另一种是获取指定的全部标签对
场景一:获取指定的第一个标签
获取指定的第一个标签就是使用前面介绍的"soup对象.标签名"
这种方法总计如下:
1、获取某个标签对可以使用:soup对象.标签名
2、这种方法:只能获得整个文档中第一个符合要求的标签(存在多个一样的标签对时只会返回第一个)
3、如果想要的标签对中镶嵌了其他标签对,那么也会把里面镶嵌的标签对一起返回
4、这种方法在实际运用中发现:不能把标签名定义成变量,就是不能通过变量来批量获得一些标签对,所以这种方法有比较大的局限性
场景二:获取指定的全部标签对
1、要获取一个文档中某个指定的所有标签,就需要使用find_all()方法:BeautifulSoup对象或Tag对象都可以使用find_all()方法来找其下面的子标签
2、其参数可以是很多类型,最常用的是:传入需要获取的标签的标签名
3、find_all()方法返回的是一个由所有符合要求的标签组成的列表
举例如下:
from bs4 import BeautifulSouphtml = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""soup = BeautifulSoup(html, "lxml")tag_body = soup.find_all("p") # 获取所有p标签的tag对象
print("p标签对为:", tag_body)tag_a = soup.find_all("a") # 获取所有a标签的tag对象
print("a标签对为:", tag_a)
输出:
p标签对为: [<p class="title" name="dromouse"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <p class="story">...</p>]
a标签对为: [<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]4、上面是使用find_all()方法获取所有符合要求的tag对象组成的列表,然后可以遍历出每一个tag对象,最后获得每一个tag对象的name、attrs属性以及string
举例如下:
from bs4 import BeautifulSouphtml = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""soup = BeautifulSoup(html, "lxml")def parse_msg(tagName):tags = soup.find_all(tagName) # find_all()返回的是一个由tag对象组成的列表,因此需要遍历for tag in tags:print("标签的tag对象为为:", tag)print("标签的属性为:", tag.attrs)print("标签的数据为:", tag.string)parse_msg("a")
parse_msg("p")输出:
标签的tag对象为为: <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
标签的属性为: {'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
标签的数据为: Elsie
标签的tag对象为为: <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
标签的属性为: {'href': 'http://example.com/lacie', 'class': ['sister'], 'id': 'link2'}
标签的数据为: Lacie
标签的tag对象为为: <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
标签的属性为: {'href': 'http://example.com/tillie', 'class': ['sister'], 'id': 'link3'}
标签的数据为: Tillie标签的tag对象为为: <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
标签的属性为: {'class': ['story']}
标签的数据为: None
标签的tag对象为为: <p class="story">...</p>
标签的属性为: {'class': ['story']}
标签的数据为: ...
也可以看出:这种嵌套在里面的标签对,如果返回的是外层的tag对象,那也只能获得外层tag对象的name和attrs属性
NavigableString对象同理tag对象:
1、获取标签对中的NavigableString对象,可以使用:soup对象.标签名.string的方法来获取(跟前面name或attrs一样,只是说这里的字符串属于另一个对象)。且这种方法只会返回第一个符合要求的标签对中的字符串
2、也可以先试用find_all()的方法先找出全部符合要求的标签对,然后遍历得到每一个标签对内的字符串
另外还有
1、find()方法,find()与find_all() 用法一样,区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果(即找到了就不再找,只返第一个匹配的),find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None。
2、get_text()方法:只输出tag中的文本内容
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i>点我</a>'
soup = BeautifulSoup(markup, "lxml")
print(soup)
print(soup.get_text())
3、select()方法:可以按标签查找,用的多是按标签逐层查找筛选元素
Beautiful Soup支持大部分的CSS选择器,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数, 即可使用CSS选择器的语法找到tag。可以按标签逐层查找到我们需要的内容,这点特别方便,就是定位,避免了单一的标签无法定位到我们所需要的内容元素。
soup.select("html head title") #标签层级查找
soup.select("td div a") #标签路径 td-->div-->a
soup.select('td > div > a') #note:推荐使用这种记法
选择谷歌浏览器,右键copy --copy selector,可以得到对应的CSS选择器。如下:
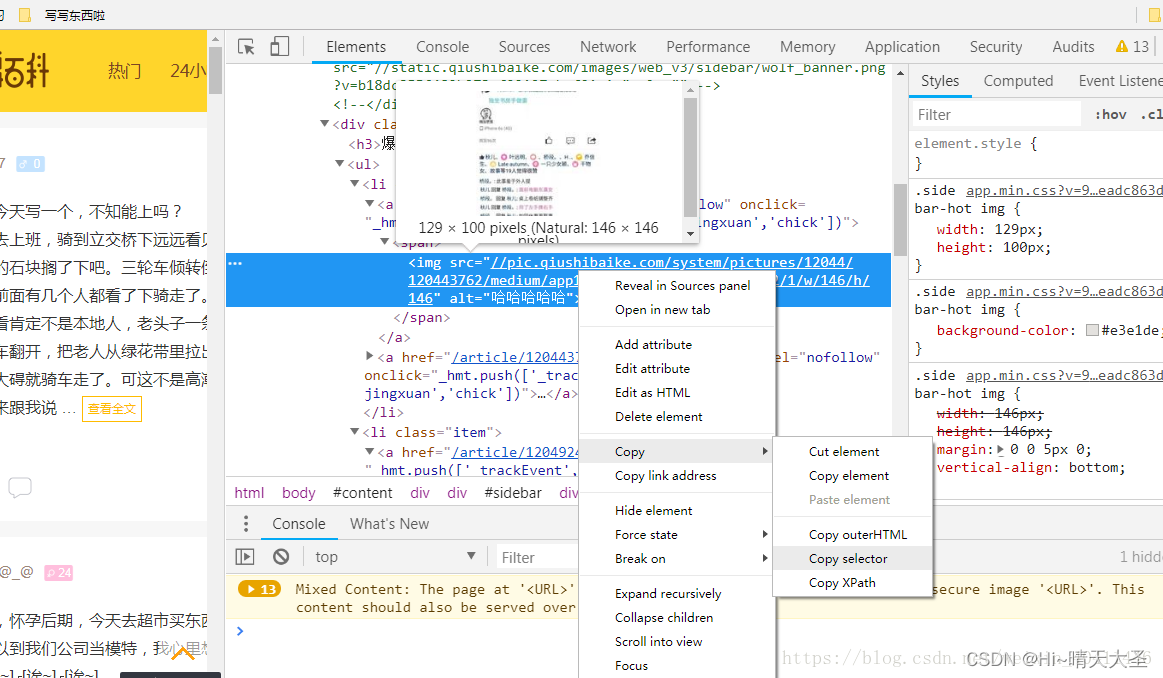
div > a > div > span (我运行的时候发现一个问题,> 前后一定要有空格,不然会报错的)
#coding=utf-8
from bs4 import BeautifulSoup
import requests#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面就是select()方法咯~
links = soup.select('div > a >div >span')
for link in links:print(link.get_text())
四、网络请求
在使用Python爬虫时,需要模拟发起网络请求访问html页面(上面案例为了方便查阅,直接赋值了一个页面),主要用到的库有requests库和python内置的urllib库,一般建议使用requests,它是对urllib的再次封装。
requests的优势:Python爬虫时,更建议用requests库。因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,一步到位,而urllib.request只能先构造get,post请求,再发起,需要分2步完成。
requests模块的使用方法见文档《Python requests模块》
五、RE模块(标准库)
在html文档中获取到的内容,可能还不够细致,比如,我们取到的是不是我们想要的链接、不是我们需要提取的邮箱数据等等,为了提取细精确的数据,需要使用正则表达式。
RE模块的使用方法见文档《Python 正则表达式》
六、案例实践
#coding=utf-8
from bs4 import BeautifulSoup
import requests#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面就是select()方法咯~
links = soup.select('div > a >div >span')
for link in links:print(link.get_text())
相关文章:
网络爬虫指南
一、定义 网络爬虫,是按照一定规则,自动抓取网页信息。爬虫的本质是模拟浏览器打开网页,从网页中获取我们想要的那部分数据。 二、Python为什么适合爬虫 Python相比与其他编程语言,如java,c#,Cÿ…...

9、媒体元素标签
9、媒体元素标签 一、视频元素 video标签 二、音频元素 audio标签 <!--音频和视频 video:视频标签 audio:音频标签 controls:控制选项,可以显示进度条 autoplay:自动播放 -->示例 <!DOCTYPE html> &…...
php单独使用think-rom数据库 | thinkphp手动关闭数据库连接
背景(think-orm2.0.61) 由于需要长时间运行一个php脚本,而运行过程并不是需要一直与数据库交互,但thinkphp主要是为web站点开发的框架,而站点一般都是数据获取完则进程结束,所以thinkphp没提供手动关闭数据…...

337. 打家劫舍 III
题目描述 小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。 除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两…...
tio-websocket-spring-boot-starter的最简单实例,看完你一定有所收获
前言 我最近一个月一直在寻找能够快速开发实时通讯的简单好用的模块,所以我就去寻找了一下相关的内容.在此之前我使用的是Spring原生的webSocket,她有个弊端就是设置组不容易设置,而且配置上也稍微复杂一点,需要配置拦截器和处理器,还需要把它放入到Springboot的启动容器里面,也…...

列出连通集
输入样例: 8 6 0 7 0 1 2 0 4 1 2 4 3 5 输出样例: { 0 1 4 2 7 } { 3 5 } { 6 } { 0 1 2 7 4 } { 3 5 } { 6 } solution #include <stdio.h> #include <string.h> int arcs[10][10]; int visited[10] {0}; void DFS(int n, int v); void BFS(int n , int i)…...

前端 富文本编辑器原理——从javascript、html、css开始入门
文章目录 ⭐前言⭐html的contenteditable属性💖 输入的光标位置(浏览器获取selection)⭐使用Selection.toString () 返回指定的文本⭐getRangeAt 获取指定索引范围 💖 修改光标位置💖 设置选取range ⭐总结⭐结束 ⭐前…...

堆--数据流中第K大元素
如果对于堆不是太认识,请点击:堆的初步认识-CSDN博客 数据流与上述堆--数组中第K大元素-CSDN博客的数组区别: 数据流的数据是动态变化的,数组是写死的 堆--数组中第K大元素-CSDN博客题的小顶堆加一个方法: class MinH…...
【算法|动态规划No.12】leetcode152. 乘积最大子数组
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【手撕算法系列专栏】【LeetCode】 🍔本专栏旨在提高自己算法能力的同时,记录一下自己的学习过程,希望…...
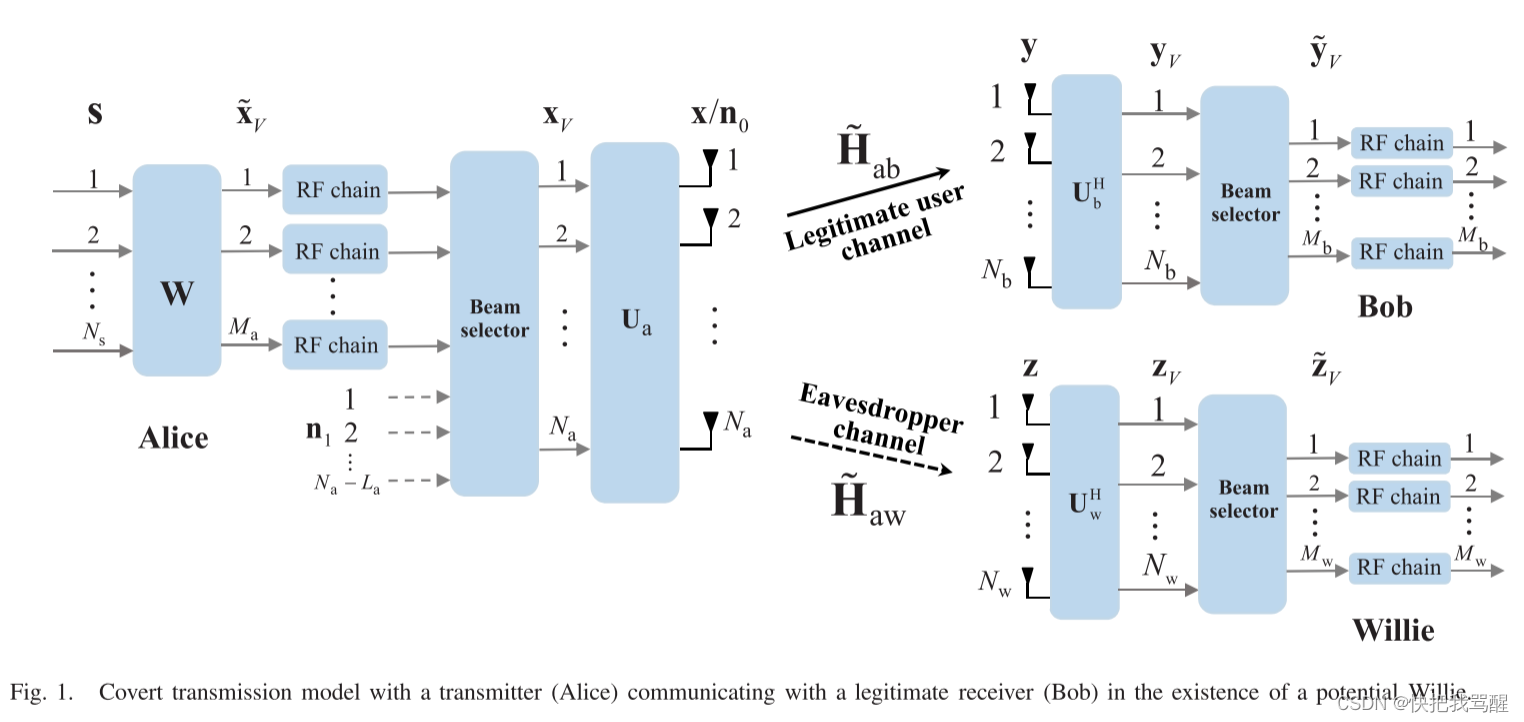
Covert Communication 与选择波束(毫米波,大规模MIMO,可重构全息表面)
Covert Communication for Spatially Sparse mmWave Massive MIMO Channels 2023 TOC abstract 隐蔽通信,也称为低检测概率通信,旨在为合法用户提供可靠的通信,并防止任何其他用户检测到合法通信的发生。出于下一代通信系统安全链路的强烈…...

计算机毕业设计 基于协调过滤算法的绿色食品推荐系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
华为云云耀云服务器L实例评测|部署在线影音媒体系统 Jellyfin
华为云云耀云服务器L实例评测|部署在线影音媒体系统 Jellyfin 一、云耀云服务器L实例介绍1.1 云服务器介绍1.2 产品规格1.3 应用场景1.4 支持镜像 二、云耀云服务器L实例配置2.1 重置密码2.2 服务器连接2.3 安全组配置 三、部署 Jellyfin3.1 Jellyfin 介绍3.2 Docke…...
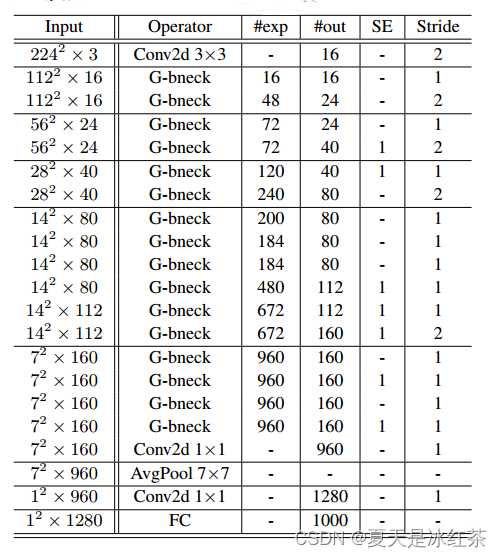
GhostNet原理解析及pytorch实现
论文:https://arxiv.org/abs/1911.11907 源码:https://github.com/huawei-noah/ghostnet 简要论述GhostNet的核心内容。 Ghost Net 1、Introduction 在训练良好的深度神经网络的特征图中,丰富甚至冗余的信息通常保证了对输入数据的全面理…...
视频二维码的制作方法,支持内容修改编辑
现在学生经常会需要使用音视频二维码,比如外出打开、才艺展示、课文背诵等等。那么如何制作一个可以长期使用的二维码呢?下面来给大家分享一个二维码制作(免费在线二维码生成器-二维码在线制作-音视频二维码在线生成工具-机智熊二维码&#x…...

清华GLM部署记录
环境部署 首先安装anaconda(建议包管理比较方便)windows用户需手动配置一下环境变量,下面默认是在ubuntu环境说明创建python环境,conda create -n your_env_name python3.10 (注:官方是提供是python3.8,但…...

贪心算法+练习
正值国庆之际,祝愿祖国繁荣昌盛,祝愿朋友一生平安!终身学习,奋斗不息! 目录 1.贪心算法简介 2.贪心算法的特点 3.如何学习贪心算法 题目练习(持续更新) 1.柠檬水找零(easy&…...
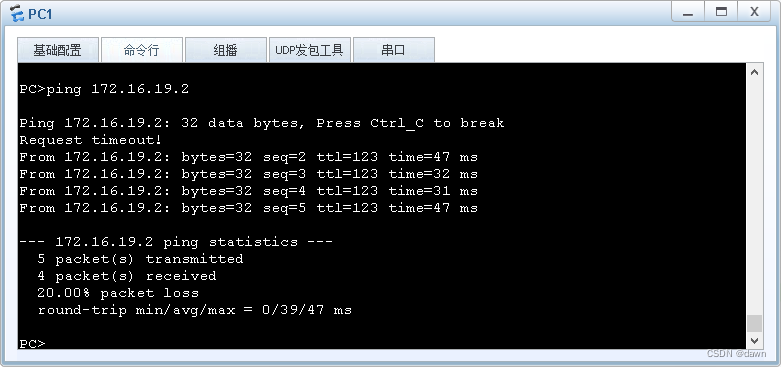
使用华为eNSP组网试验⑷-OSPF多区域组网
今天进行了OSPF的多区域组网试验,本来这是个很简单的操作,折腾了好长时间,根本原因只是看了别人写的配置代码,没有真正弄明白里面对应的规则。 一般情况下,很多单位都使用OSPF进行多区域的组网,大体分为1个…...

P1843 奶牛晒衣服 【贪心】
P1843 奶牛晒衣服 【贪心】 题目背景 熊大妈决定给每个牛宝宝都穿上可爱的婴儿装 。但是由于衣服很湿,为牛宝宝晒衣服就成了很不爽的事情。于是,熊大妈请你(奶牛)帮助她完成这个重任。 题目描述 一件衣服在自然条件下用一秒的时间…...
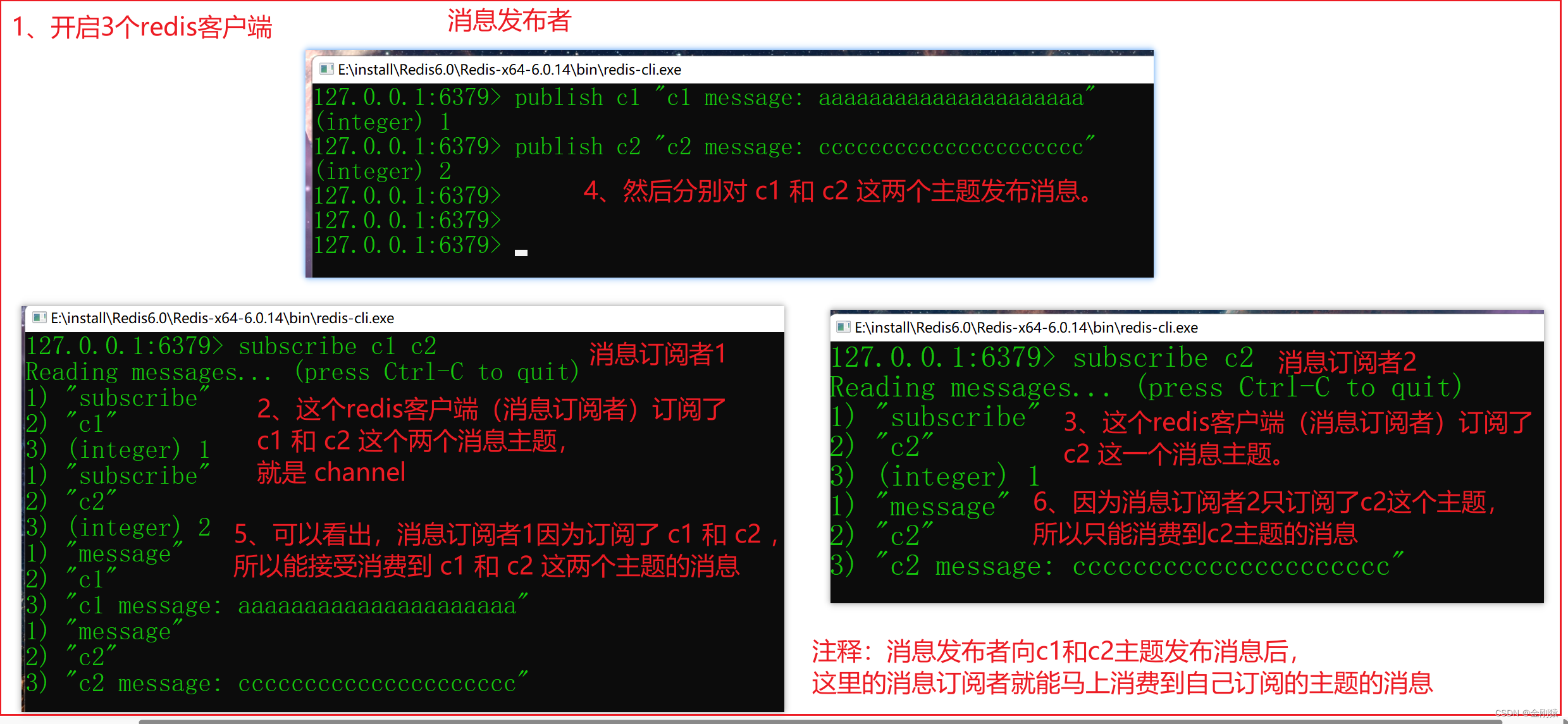
91、Redis - 事务 与 订阅-发布 相关的命令 及 演示
★ 事务相关的命令 Redis事务保证事务内的多条命令会按顺序作为整体执行,其他客户端发出的请求绝不可能被插入到事务处理的中间, 这样可以保证事务内所有命令作为一个隔离操作被执行。 Redis事务同样具有原子性,事务内所有命令要么全部被执…...
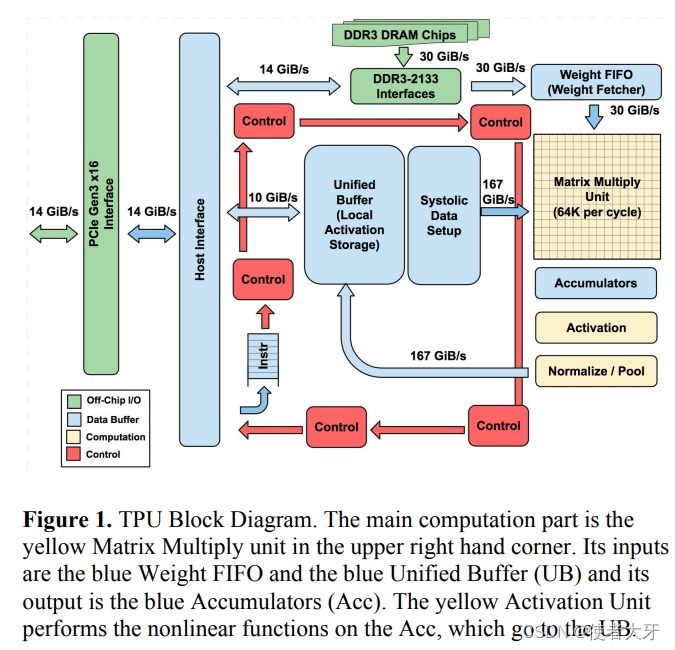
GPU如何成为AI的加速器
0. 前言 按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。 本文关键词:GPU、深度学习、GP…...

基于Spark+Hadoop+Hive 深度学习大数据的运河航运效率提升平台的设计与实现
前言随着全球贸易的不断发展,运河航运作为连接内陆与海洋的重要交通方式,其运输效率的提升对于促进经济发展、优化资源配置具有重要意义。基于大数据的运河航运效率提升平台的设计与实现,旨在通过收集、处理和分析大量的航运数据,…...
)
别再死磕公式了!用Python+SymPy从零推导6轴机械臂的DH参数与正逆解(附完整代码)
用PythonSymPy自动化推导6轴机械臂运动学:从DH参数到八组逆解实战 机械臂运动学分析是机器人开发中最烧脑的环节之一。传统手工推导DH参数矩阵不仅容易出错,验证过程更是令人崩溃——想象一下,当你花了两天时间推导出十几页公式,…...

Wan2.1 VAE与微信小程序开发结合:打造个人AI头像生成工具
Wan2.1 VAE与微信小程序开发结合:打造个人AI头像生成工具 你有没有想过,用一张自己的照片,就能快速生成几十种不同风格的艺术头像?无论是动漫风、油画感,还是赛博朋克,都能一键搞定。以前这可能需要专业的…...
数码管显示)
51单片机学习(五)数码管显示
如有大佬发现我文章里的错误,希望多多指出,或者有缺少的也欢迎告诉我,我会尽快补充上去的,感谢各位的支持,要互三的d我哦!一.数码管数码管显示屏和U4 74HC245U574H138译码器一位数码管引脚定义一个数码管由…...

ENet核心架构深度解析:从主机管理到对等通信
ENet核心架构深度解析:从主机管理到对等通信 【免费下载链接】enet ENet reliable UDP networking library 项目地址: https://gitcode.com/gh_mirrors/en/enet ENet是一款高性能的可靠UDP网络库,专为实时多人游戏和低延迟应用设计。它通过创新的…...

忍者绘卷Z-Image Turbo新手避坑:3个技巧搞定负向提示词
忍者绘卷Z-Image Turbo新手避坑:3个技巧搞定负向提示词 1. 负向提示词在忍者绘卷中的特殊价值 在忍者绘卷Z-Image Turbo这个专为二次元/火影忍者风格优化的AI绘画工具中,负向提示词扮演着"封印术"般的角色。它不仅仅是简单的排除列表&#x…...
 正确配置PCA9545 I2C Switch的DTS节点)
手把手教你为OpenBMC (AST2600平台) 正确配置PCA9545 I2C Switch的DTS节点
深入解析AST2600平台PCA9545 I2C Switch设备树配置实战指南 在嵌入式系统开发中,I2C总线扩展是连接多个外设的常见需求。NXP的PCA9545作为一款4通道I2C总线开关芯片,能够有效解决I2C地址冲突问题,但在实际应用中,设备树(DTS)配置…...

如何打破微信单设备限制:WeChatPad终极指南
如何打破微信单设备限制:WeChatPad终极指南 【免费下载链接】WeChatPad 强制使用微信平板模式 项目地址: https://gitcode.com/gh_mirrors/we/WeChatPad 你是不是也遇到过这样的尴尬时刻?在电脑上登录微信工作,手机上的微信就被迫下线…...
实战:从协议解析到车辆传感器校准)
UDS诊断服务-10例程控制服务(0x31)实战:从协议解析到车辆传感器校准
1. 从车辆抖动问题认识0x31服务的重要性 去年夏天,我遇到一辆行驶里程8万公里的SUV,车主反映急加速时发动机抖动明显。用诊断仪读取故障码显示"P0172 - 燃油修正系统过浓",但更换氧传感器和火花塞后问题依旧。这时候就需要请出我们…...

实时口罩检测系统性能优化:从算法到工程全链路调优
实时口罩检测系统性能优化:从算法到工程全链路调优 1. 引言 在公共场所疫情防控中,实时口罩检测系统发挥着重要作用。但在实际部署中,很多开发者会遇到性能瓶颈:检测速度跟不上视频流帧率、GPU资源占用过高、误报漏报频发等问题…...