GPU如何成为AI的加速器
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文关键词:GPU、深度学习、GPGPU、渲染、Brook语言、流计算、硬件T&L、CUDA、PyTorch、TOPS、TPU、NPU
深度学习理论的发展是一个渐进的过程,从1940年代人工神经元网络的提出到1970~1980年代的反向传播的提出及兴起,再到2006年后深度学习的崛起,这个过程经历了多个阶段。早期的深度学习理论受限于硬件性能,无法进行大规模的数据训练,网络也不能做的太深。近年来随着硬件性能的不断提升,尤其是图形处理器(GPU)的发展,深度学习理论乃至整个AI领域开始得以快速发展及广泛应用。
你在最初接触深度学习时是否有以下疑问:
- 显卡不是用来处理计算机图像的吗,怎么和深度学习扯上了关系?
- GPU为什么就比CPU处理深度学习训练过程更快?
- 为什么我的电脑明明有显卡,确不能使用显卡进行深度学习的训练加速?
以上疑问促使了本文的创作,但是经历大量资料查阅后,我发现要讲清楚这些问题涉及了很多领域的专业理论,而我本人也非这些方面的专家,所以只能以科普的方式带大家(以及我自己)一瞥这个深奥且广阔的领域。
1. 从显卡的诞生说起
1981年,在IBM推出的计算机IBM 5150中搭载了世界上的首个“独立显卡”——CGA(Color Graphics Adapter,彩色图形适配器)。CGA两种常用的图形显示模式:320×200分辨率4色和640×200分辨率2色,我们熟知的Pac-Man吃豆人游戏运行在CGA上的效果如下:

在80~90年代,IBM又相继推出了EGA (Enhanced Graphics Adapter)和VGA (Video Graphics Array),这些“显卡”可以支持更高的分辨率及更多的显示颜色。
但是无论CGA、EGA还是VGA这些“显卡”本身并不具有计算能力,仅仅是将CPU计算生成的图形翻译成显示设备能识别的信号来进行显示。“显卡”完全根据CPU的指令进行相应的操作,然后将结果返回给CPU,纯纯是CPU的打工仔。所以这个阶段的“显卡”严格意义上来说也不能叫“显卡”,叫“图形适配器”或者“图像加速卡”更合适。
2. GPU粉墨登场
随着对图像显示要求越来越高,尤其是3D图像显示越来越普及,仅靠CPU已经不能达到越来越复杂的图像处理要求,因此需要一块真正有算力的芯片——显卡来单独处理图像。显卡在90年代经历了混战的局面,当时几十家做显卡的公司各有个的开发标准,各家的兼容性也非常差。这段时期的显卡典型代表是3dfx公司的Voodoo显卡。
显示标准与硬件驱动兼容多么重要啊!还记得小时候下载完(盗版)游戏,眼巴巴等着下载完了,安装完了,但是不能玩!
真正具有划时代意义的产品是NVIDIA英伟达在1999年9月推出的GeForce 256被称为——世界上首个GPU,不仅搭载了硬件T&L引擎(Transforming&Lighting,T&L的最大功能是处理图形的整体角度旋转以及光源阴影等三维效果。)也支持微软的Direct 3D显示。从此NVIDIA也就开始了在GPU领域的领导之路。
NVIDIA这个名字起源于罗马神话的Invidia,在拉丁文中,Invidia有忌妒与目不转睛之意,和恶意及“邪恶之眼”有相对应的关系,所以英伟达的logo也就是一只眼睛。
但是由于INVIDIA这个名字已经被注册,英伟达选择了去掉最开始的“I”,注册了NVIDIA这个名字,但是在其中文名“英伟达”中保留了“I”的发音。

随着3D图像领域尤其是游戏领域的蓬勃发展,推动了各大厂商快速迭代GPU的性能,GPU从昔日CPU的打工仔,逐渐开始与CPU平起平坐。GPU在有了自己的算力后也承担越来越多的工作任务。
3. 渲染——让计算机图像更逼真
首先我们看一下2021年发布的《极限竞速:地平线5》游戏画质:

没错,上面这个图片并非实拍而是游戏中的画面,而游戏画面能从吃豆人进化到地平线5要归功于——渲染。而要达到计算机生成的图像能有以假乱真的效果,靠CPU是无法完成的(CPU硬件设计原理就不适合渲染计算,这个后面会讲),于是这个任务就由最初的完全由CPU负责,逐步完全转移给GPU。
渲染是一门庞杂的工程学科,本文也不可能逐个介绍渲染包含的各个算法(这也并非本文的重点),我们只需明白它的本质是将颜色分配到像素上的过程,它可以根据物体的形状、材质和光源等信息,计算出每个像素的颜色,渲染算法主要包含以下方面:
- 几何处理:将3D模型的几何信息转化为计算机能够处理的形式,包括点、线、面等基本几何元素的描述。
- 光线追踪:光线追踪是一种计算光线在场景中的路径的技术,它可以模拟光线在场景中的反射、折射和散射等现象,从而生成逼真的图像。
- 纹理映射:纹理映射是将纹理贴图应用到模型表面的技术,它可以模拟物体表面的纹理,例如木纹、石纹等。
- 透视投影:透视投影是将三维场景转换为二维图像的技术,它可以模拟人的视觉感知,从而生成逼真的图像。
下面我们仅以几何处理中最基本的点在三维坐标系的运动来举例:假设点在三维坐标系中分别绕x, y, z三个轴旋转
角度,并以位移
平移,得到运动后的点
为:
旋转矩阵为:
公式写到这里,如果你对神经元网络的数学模型比较熟悉是不是已经发现了什么?如果把旋转矩阵简写为:
这个矩阵的计算过程不正式神经元网络模型的正向传播过程吗!
那GPU能否也应用到神经元网络模型计算及其他主要用到矩阵运算的领域,让GPU不仅应用于图形计算而变得更“通用”?你不是第一个想到这个的人!
4. 从GPU到GPGPU
2004年Ian Buck等人在Brook for GPUs: Stream Computing on Graphics Hardware提出:随着可编程图形硬件的发展,这些处理器的功能指令已经非常通用,已经可以在渲染领域之外使用了!通用GPU——GPGPU(General Purpose Graphic Process Unit)的概念被提出。
这篇文章主要为GPU引入了流计算编程系统——Brook。最初对GPU的编程仅能使用汇编语言,在Brook之前虽然也有一些基于C语言的高级语言被提出来对GPU进行编程,但是这些语言仍然把GPU仅仅作为一个图像渲染器,而且限制很多,不能虚拟化底层硬件的限制,导致当时GPU的开发人员不仅要掌握最新的图像程序API,还必须了解所使用的GPU硬件的特征及限制,对编程人员提出了极高的要求。
而改进后的Brook语言可以反应不同硬件的的能力,并且在传统C语言上延展出了数据并行处理(Data Parallelism)架构,提升了硬件的算力密度(Arithmetic Intensity)。
这里说明下上面提到的流计算(Stream computing),包含3个主要概念:
- 流(Streams):流可以理解为要处理的原始数据,这些数据①是可以并行处理的,②是动态数据,③是可以即时处理的,而不用等数据完全收集完之后才开始处理;
- 核(Kernel):作用于流上的算法;
- Reduction:这是核的一个机制,即把多个流合并成一个流,或者把一个更大的流减少成更小的流,如果你了解卷积神经元网络(CNN),可以很容易理解核和Reduction;
流计算在我们现在的生活场景应用已经非常普遍了,例如:视频直播、实时监控、网络购物等等……
如果你不了解CNN,可以看一下我的往期博客:卷积神经元网络中常用卷积核理解及基于Pytorch的实例应用(附完整代码)_卷积神经网络卷积核选择-CSDN博客
文章介绍到这里,我们应该明白了为什么原本用于图像处理的GPU可以通用化跨界到其他领域,那为什么在深度学习中GPU可以取得比CPU更快的处理速度呢?
这是由硬件底层的架构决定的:CPU的设计目的是处理串行的复杂计算(例如排序算法),而GPU的设计目的是处理并行并行的简单运算(例如渲染算法、深度学习算法)。CPU和GPU的区别如下表:

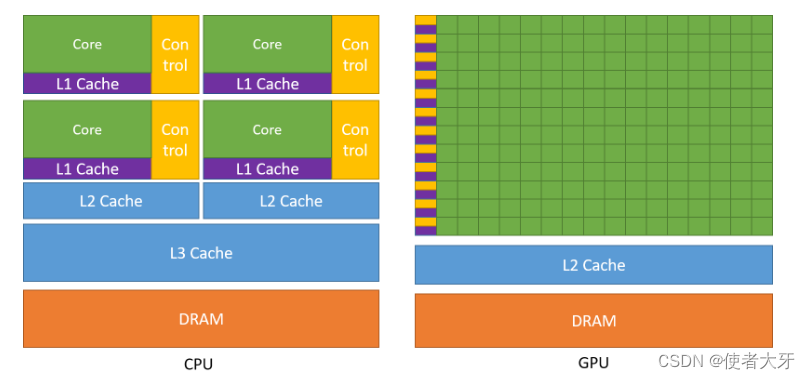
从处理器的核心数量上可以直观地看出差距,使用目前消费级CPU和GPU来对比:Intel 酷睿i9 13900K CPU:24核心,32线程;NVIDIA GeForce系列GPU核心数如下:

显然GPU成千上万的核心数更加适合深度学习数学模型的简单大量计算要求,这个视频就非常直观地阐释了多核GPU在并行计算上的优势:NVIDIA现场形象展示CPU和GPU工作原理上的区别_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1ry4y1y7KZ/?spm_id_from=autoNext&vd_source=b1f7ee1f8eac76793f6cadd56716bfbf
https://www.bilibili.com/video/BV1ry4y1y7KZ/?spm_id_from=autoNext&vd_source=b1f7ee1f8eac76793f6cadd56716bfbf
讲到这里,似乎会有种GPU比CPU性能更好的错觉,但是我们必须要意识到多核心的GPU仅能处理简单的运算,涉及到复杂的运算还是要靠CPU,两者各有所长,上面的视频仅是从GPU更擅长的工作角度展现的GPU的原理!
5. CUDA——奠定了NVIDIA成为寡头的基础
在2006年NVIDIA也在费尽心思地想如何打造完整的GPU生态,估计老黄也是看到了上面的论文,就把主要作者Ian Buck挖到了NVIDIA(Ian Buck现在已经是NVIDIA副总裁兼加速计算首席总监。),而后NVIDIA在2007年推出了改变游戏规则的、具有划时代意义的算力平台高级编程语言——CUDA(Compute Unified Device Architecture)。

CUDA的出现奠定了后日NVIDIA在GPU领域成为霸主的地位,甚至在最近衡量一个公司的算力水平就看这个公司购买了多少个NVIDIA的A100显卡。

CUDA我们可以简单理解为NVIDIA自己专用的Brook环境,CUDA支持多种高级编程语言,也内部封装了很多库文件,极大地便利了开发者的使用。

NVIDIA也不惜重金投入,改进自己的GPU硬件,让它们支持CUDA。

上面的Tesla不是马斯克的特斯拉……是英伟达自己的产品型号。
上面已经介绍过,对于深度学习这类大吞吐量的并行算法,GPU有着天然的优势,所以现在主流的第三方库都会兼容CUDA,例如PyTorch(其实PyTorch大部分就是由C++和CUDA编写的)

安装CUDA版PyTorch后,可以查看CUDA的可用性:
print(torch.cuda.is_available())如果为True则表示CUDA可用。
至此我们回到最上面的问题:为什么我的电脑明明有显卡,确不能使用显卡进行深度学习的训练加速?
因为必须使用支持CUDA的显卡=NVIDIA的显卡才能进行GPU加速啊!!!
而在近些年来,AI的爆火也推进了NVIDIA市值爆发式地增长,其他公司也翻过头来想推出类似CUDA的产品,无奈在2007年就起跑的NVIDIA已经“遥遥领先”。所以说CUDA奠定了今天NVIDIA成为寡头的基础一点也不为过,现在我们在NVIDIA的官网上看下它涉及的业务领域(甚至可以说NVIDIA已经成为这些领域绕不开的存在了),你如果不知道这个公司,能猜到它原本的主营业务是造显卡的吗?
这里也必须再说明下,从本文的介绍来看好像感觉一切的发展都是那么的合理,但是NVIDIA的成长绝非顺风顺水!!!
且不说早期弱小的NVIDIA在与微软、ATI、AMD、INTEL等巨头的纠纷中几经被推进ICU,就单论CUDA的投入几乎让NVIDIA濒临破产。老黄在后面的演讲中是这样形容的:
老黄的完整版演讲(需要FQ):https://m.youtube.com/watch?v=mkGy1by5vxw&t=0s而让NVIDIA的GPU都支持CUDA这也绝对是一个非常大胆的决定!我仍记得在上大学选择电脑时,当时的原则是必须要买A卡,因为N卡有发热大、开机没画面的风险,而这些都是因为老黄执着地改变GPU的设计,让GPU兼容CUDA的早期问题!
如果后期没有比特币的爆火、没有AI的爆火、没有元宇宙的爆火,估计可能NVIDIA未必能支撑到今天。(当然NVIDIA也反过来推进了这些领域的爆火)

6. 未来不只有GPU
GPU虽然相比于CPU在AI算法上更有优势,但是GPU的诞生原本并不是为了AI算法,只不过是因为它的通用性被人发掘而跨界应用到了AI领域。那么可否为AI相关领域的芯片进行“私人定制”呢?
答案是肯定的,现在已有多种专用集成电路(ASIC)被推出,这些ASIC相比GPU有着更低的功耗、更高的算力,下面仅简单介绍两种常见的ASIC——NPU和TPU。
NPU(Neural network Processing Unit,神经元网络处理器)
顾名思义NPU是专门用来处理神经元网络模型的处理器,其在电路架构上的设计思路是参考神经元的特性——计算和存储一体化,而通过上面CPU和GPU的原理图我们可以看到计算(core,其实就是ALU)和存储(cache)仍然是分离的。目前NPU已经有很广泛的应用了,例如下面苹果A15芯片的NEURAL ENGINE:

TPU(Tensor Processing Unit, 张量处理器)
TPU的诞生背景是2013年谷歌发现人们平均每天会有3min使用语音搜索功能,这对谷歌的数据中心的算力要求几乎翻倍,因此他们想设计一款比GPU起码多10倍算力的ASIC,于是TPU在2017年被提出。
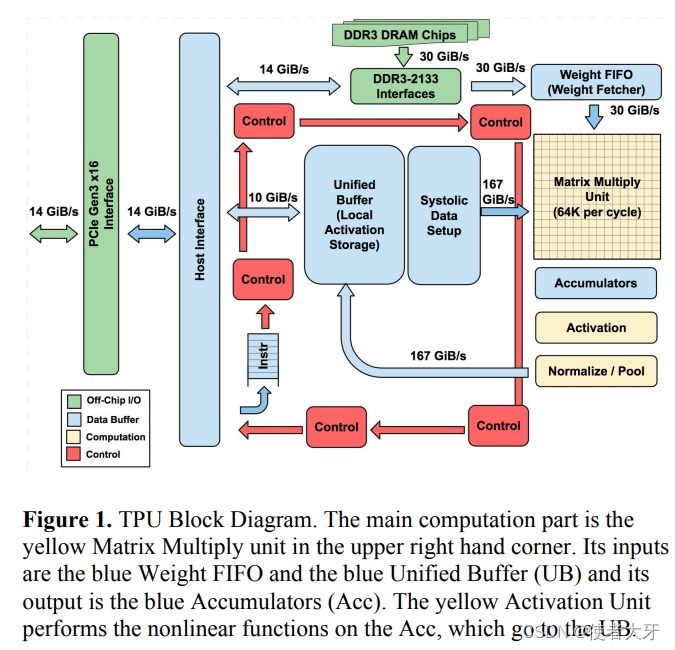
TPU的主要计算单元是256×256的矩阵乘法单元,TPU的设计思路就是让这个矩阵乘法单元一直不间断地运算。一个包含65,536个8位MAC(Multiply Accumulate,乘法累计运算)块的TPU可以达到92TOPS的算力,是当时GPU的15~30倍,而算力功耗比TOPS/W是当时GPU的30~80倍!
这里再科普两个单位:TOPS(Tera Operations Per Second)和TFLOPS(Tera Floating Point Operations Per Second)
TOPS是指每秒钟可执行的整数运算次数(Operations Per Second),主要应用在图像处理、语音识别等。
TFLOPS则是指每秒钟可执行的浮点运算次数(Floating Point Operations Per Second),主要应用在科学计算、人工智能训练等需要大量浮点运算的应用领域。
区分两者的主要差异在于计算的类型,两者没有固定的转换关系,但是由于浮点运算比整数运算更复杂,所以在相同的计算设备下,TFLOPS通常会比TOPS更低。
本文主要参考文献:
[1]英伟达官网:World Leader in Artificial Intelligence Computing | NVIDIA
[2]FletcherDunn,IanParberry,邓恩,等.3D数学基础:图形与游戏开发[M].清华大学出版社,2005.
[3]Buck I , Foley T , Horn D ,et al.Brook for GPUs: Stream computing on graphics hardware[J].ACM Transactions on Graphics, 2004, 23(3):777-786.DOI:10.1145/1186562.1015800.
[4]刘振林,黄永忠,王磊,等.基于Brook在GPU的应用[J].信息工程大学学报, 2008, 9(1):5.DOI:10.3969/j.issn.1671-0673.2008.01.022.
[5]Jouppi N P , Young C , Patil N ,et al.In-Datacenter Performance Analysis of a Tensor Processing Unit[J].Computer architecture news, 2017, 45(2):1-12.DOI:10.1145/3079856.3080246.
相关文章:
GPU如何成为AI的加速器
0. 前言 按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。 本文关键词:GPU、深度学习、GP…...

Map声明、元素访问及遍历、⼯⼚模式、实现 Set - GO语言从入门到实战
Map声明、元素访问及遍历 - GO语言从入门到实战 Map 声明的方式 m := map[string]int{"one": 1, "two": 2, "three": 3} //m初始化时就已经设置了3个键值对,所以它的初始长度len(m)是3。m1 := map[string]int{} //m1被初始化为一个空的m…...
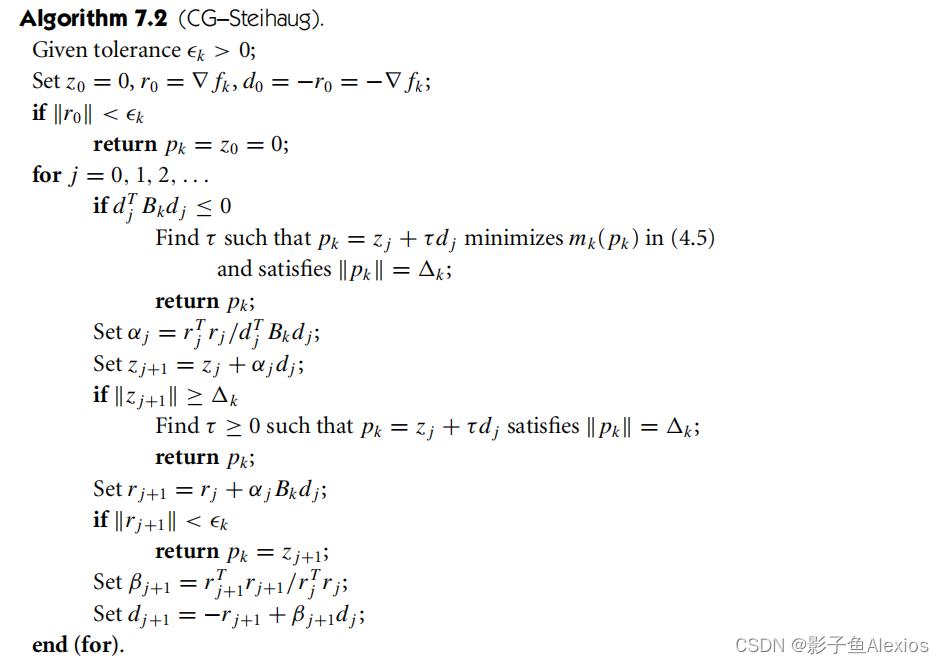
机器人中的数值优化|【七】线性搜索牛顿共轭梯度法、可信域牛顿共轭梯度法
机器人中的数值优化|【七】线性搜索牛顿共轭梯度法、可信域牛顿共轭梯度法 Line Search Newton-CG, Trust Region Newton-CG 往期回顾 机器人中的数值优化|【一】数值优化基础 机器人中的数值优化|【二】最速下降法,可行牛顿法的python实现,以Rosenbro…...

websocket实现go(server)与c#(client)通讯
go 服务端 使用到github.com/gorilla/websocket package mainimport ("fmt""github.com/gorilla/websocket""log""net/http" )func main() {var upgrader websocket.Upgrader{ReadBufferSize: 1024,WriteBufferSize: 1024,CheckOr…...

洛谷题目题解详细解答
洛谷是一个很不错的刷题软件,可是找不到合适的题解是个大麻烦,大家有啥可以私信问我,以下是我已经通过的题目。 你如果有哪一题不会(最好是我通过过的,我没过的也没关系),可以私信我࿰…...
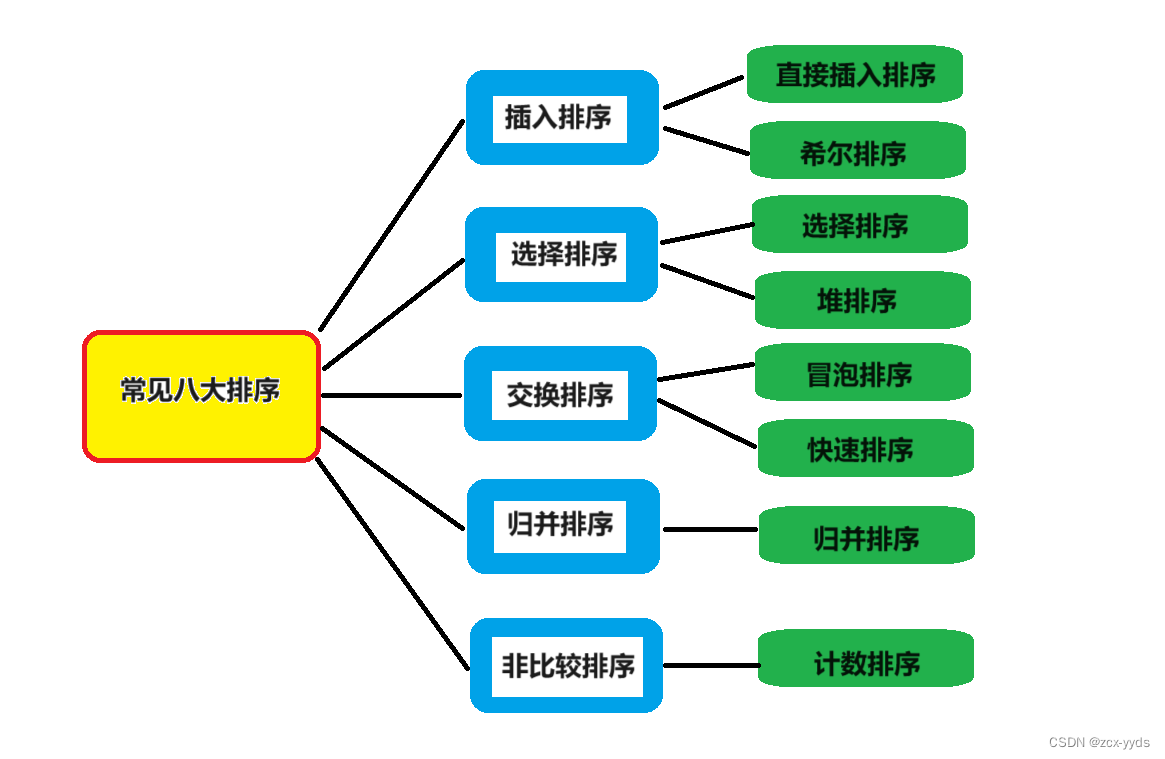
【C语言】八大排序算法
文章目录 一、冒泡排序1、定义2、思想及图解3、代码 二、快速排序1、hoare版本2、挖坑法3、前后指针法4、非递归快排5、快速排序优化1)三数取中选key值2)小区间优化 三、直接插入排序1、定义2、代码 四、希尔排序1、定义2、图解3、代码 五、选择排序1、排…...

2023年中国智能电视柜产量、需求量、市场规模及行业价格走势[图]
电视柜是随着电视机的发展和普及而演变出的家具种类,其主要作用是承载电视机,又称视听柜,随着生活水平的提高,与电视机相配套的电器设备也成为电视柜的收纳对象。 随着智能家具的发展,智能电视机柜的造型和风格都是有了…...

docker容器使用初体验
我们写程序时,都会搭建相关的环境,比如写了一个web,使用了tomcat、nginx等,现在想要把程序部署到云服务器或者在其他电脑上运行,就需要重新部署一遍环境,尤其是项目开源后,上手成本大。 docker…...

React Hooks ——性能优化Hooks
什么是Hooks Hooks从语法上来说是一些函数。这些函数可以用于在函数组件中引入状态管理和生命周期方法。 React Hooks的优点 简洁 从语法上来说,写的代码少了上手非常简单 基于函数式编程理念,只需要掌握一些JavaScript基础知识与生命周期相关的知识不…...
C#学习系列相关之多线程(一)----常用多线程方法总结
一、多线程的用途 在介绍多线程的方法之前首先应当知道什么是多线程, 在一个进程内部可以执行多个任务,而这每一个任务我们就可以看成是一个线程。是程序使用CPU的基本单位。进程是拥有资源的基本单位, 线程是CPU调度的基本单位。多线程的作用…...
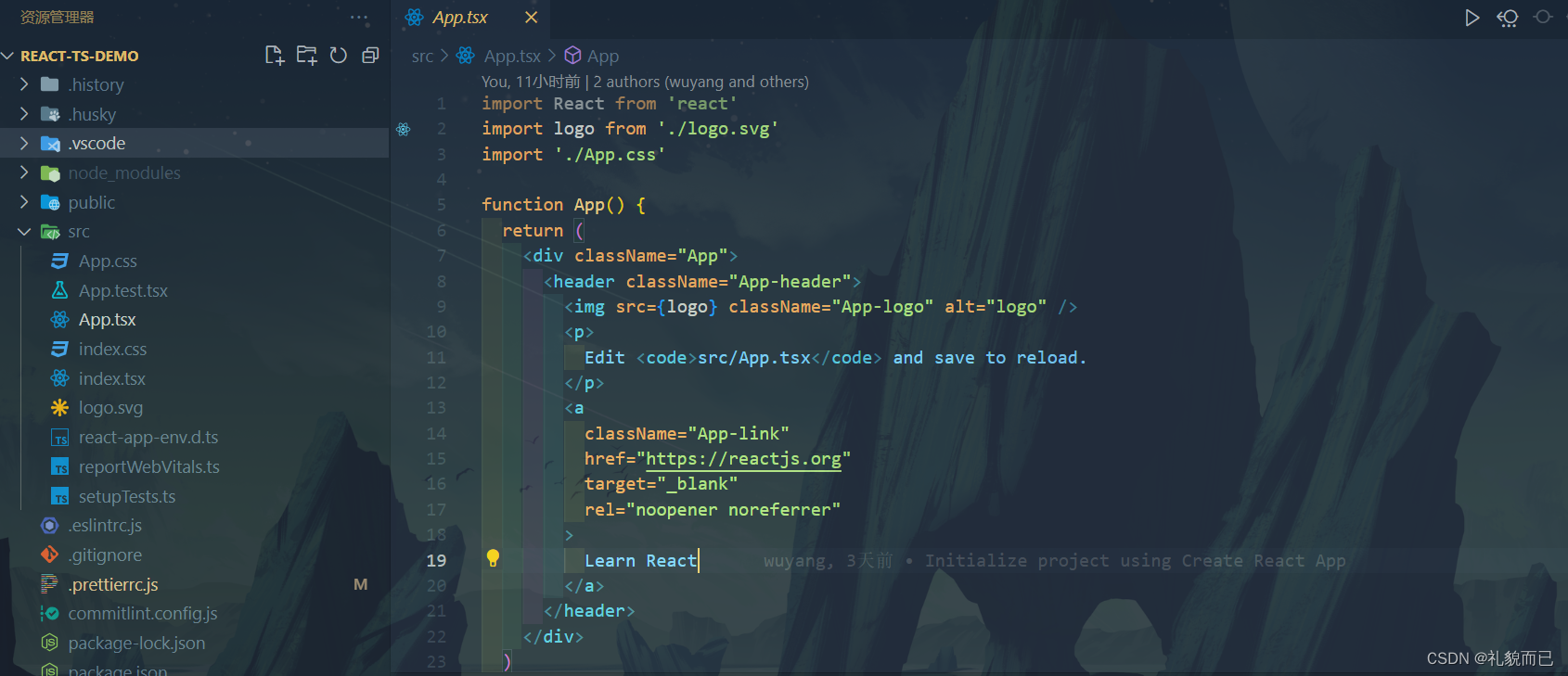
Vscode爆红Delete `␍`eslintprettier/prettier
一、先看报错 文件中爆红,提示 Delete ␍eslintprettier/prettier 二、解决方案 项目根目录下,.prettierrc.js 文件中: endOfLine: auto,三、重启VsCode 此时不在爆红,问题完美解决...

Mac安装Ecplise产品报错:dose not contain the JNI_CreateJavaVM symbol
1. 絮絮叨叨 工作中需要借助Ecplise Memory Analyzer (MAT)分析dump文件,直接下载、安装、运行MAT报错 询问同事后,同事说可以先安装Ecplise,再以插件的形式安装MAT下载、安装好Eclipse,点击运行仍然报错,且错误信息一…...

如何使用大语言模型来绘制图画
请创作一张科技感十足的图片,包含siri和iphone两个元素,请帮我挑选合适的style和background 好的,我会为你创作一张科技感十足的图片,包含siri和iphone两个元素。我会根据你的要求,选择一种适合的风格和背景。请稍等一…...

代码随想录算法训练营第23期day11 | 20. 有效的括号、1047. 删除字符串中的所有相邻重复项 、150. 逆波兰表达式求值
目录 一、(leetcode 20)有效的括号 二、(leetcode 1047)删除字符串中的所有相邻重复项 用栈存放 将字符串直接当成栈 三、(leetcode 150)逆波兰表达式求值 一、(leetcode 20)…...
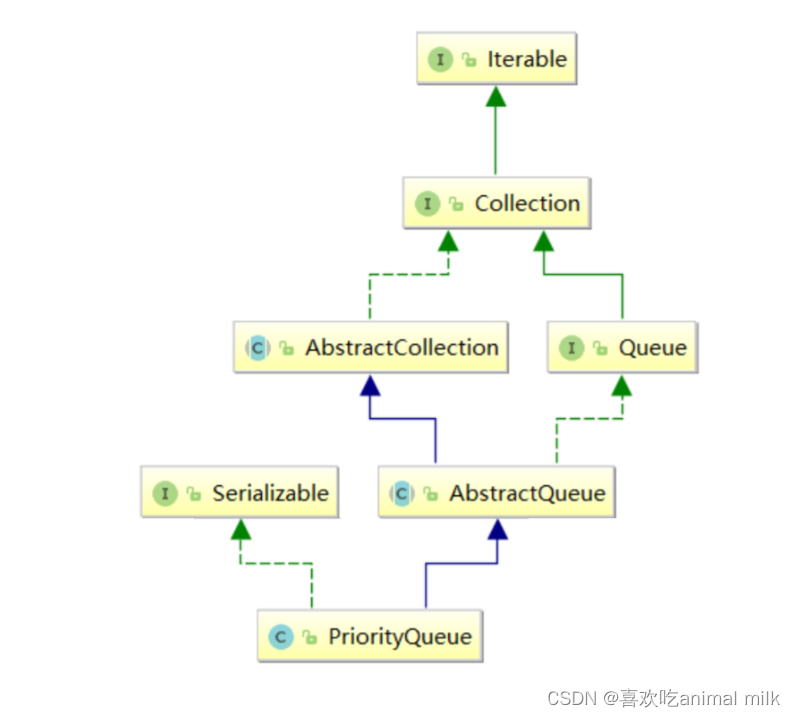
数据结构-优先级队列(堆)
文章目录 目录 文章目录 前言 一 . 堆 二 . 堆的创建(以大根堆为例) 堆的向下调整(重难点) 堆的创建 堆的删除 向上调整 堆的插入 三 . 优先级队列 总结 前言 大家好,今天给大家讲解一下堆这个数据结构和它的实现 - 优先级队列 一 . 堆 堆(Heap࿰…...
C++11新特性(语法糖,新容器)
距离C11版本发布已经过去那么多年了,为什么还称为新特性呢?因为笔者前面探讨的内容,除了auto,范围for这些常用的,基本上是用着C98的内容,虽说C11已经发布很多年,却是目前被使用最广泛的版本。因…...
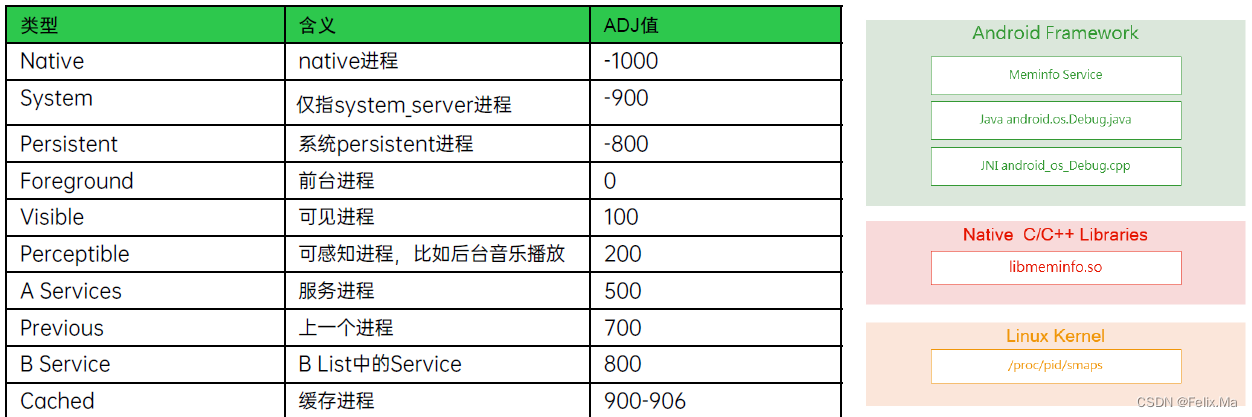
开机可用内存分析Tip
一、开机内存简介 开机内存指的是开机一段时间稳定后的可用内存。一般项目都会挑选同平台其他优秀竞品内存数据,这个也是衡量性能的一个重要标准。所以要进行开机内存检测,同时优化非法内存进程占用。 二、测试前期核查任务 开机内存测试前要进行测试机…...

【Python基础】4. 基本语句
文章目录 注释(Comment)解释伴随行文本编码问题 输入输出语句(Input & Output)输出语句普通输出格式化输出(3种)format 格式总结 输入语句 基本语句if 语句match 语句(Python3.10 新增&…...

兼顾友好与安全,隐私协议 Unijoin 助推新一轮 Web3 浪潮
区块链本身不仅崇尚去中心化,同时也崇尚公开透明,虽然这正在让 DAO 治理等变得更加公平,但它同时也是一把双刃剑,个人交易者尤其是一些巨鲸交易者的所以链上交易都被公之于众,这似乎并不是他们想要的结果。 所以从加密…...
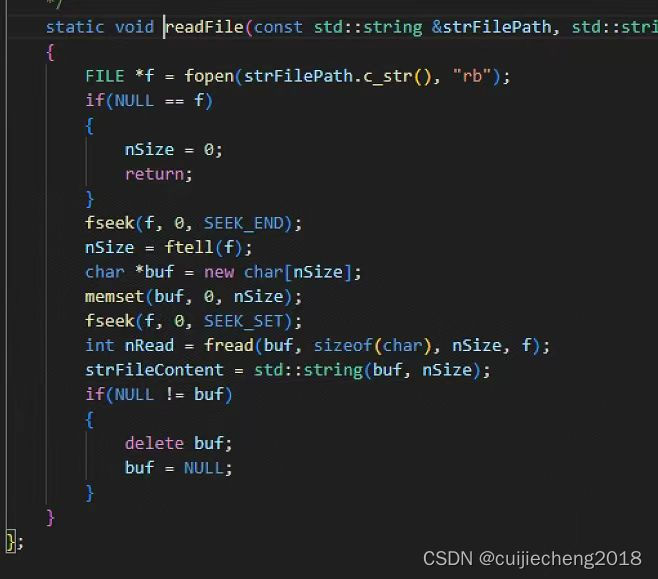
TCP端口崩溃,msg:socket(): Too many open files
一、现象 linux系统中运行了一个TCP服务器,该服务器监听的TCP端口为10000。但是长时间运行时发现该端口会崩溃,TCP客户端连接该端口会失败: 可以看到进行三次握手时,TCP客户端向该TCP服务器的10000端口发送了SYN报文,…...

Pearcleaner:macOS深度清理终极指南,让磁盘空间翻倍
Pearcleaner:macOS深度清理终极指南,让磁盘空间翻倍 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经卸载了macOS应用&…...
)
PyAutoGUI图像识别踩坑实录:如何让游戏自动化脚本更稳定?(附避坑指南)
PyAutoGUI图像识别稳定性优化实战:从原理到避坑指南游戏自动化脚本开发中,图像识别是最容易翻车的环节。上周我的《原神》自动采集脚本在好友电脑上运行时,连续三次误点了传送锚点而非目标采集物——这让我意识到不同设备环境对locateOnScree…...

揭秘CuCl超低热导率:四声子散射与温度重正化的关键作用
1. 项目概述:为何要深挖CuCl的热导率?在材料科学和凝聚态物理的交叉领域,热输运性质的研究从来都不是一个孤立的课题。它直接关系到热电材料的转换效率、电子器件的散热能力,以及热障涂层的服役寿命。传统上,我们倾向于…...
的使用场景)
Python运算符:成员运算符(in/not in)的使用场景
Python运算符:成员运算符(in/not in)的使用场景📚 本章学习目标:深入理解成员运算符(in/not in)的使用场景的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最…...

CVE-2026-35397深度解析:Jupyter Server路径遍历漏洞,CVSS 8.8高危威胁数据科学全生态
一、引言:数据科学基础设施的"心脏出血" Jupyter生态是全球数据科学与AI开发领域的事实标准,据Stack Overflow 2026年开发者调查显示,超过87%的数据科学家和AI工程师日常使用Jupyter Notebook/Lab进行代码开发、数据分析和模型训练…...

D3KeyHelper终极指南:5分钟掌握暗黑3技能自动化
D3KeyHelper终极指南:5分钟掌握暗黑3技能自动化 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为《暗黑破坏神3》玩…...

如何让旧电脑联网?安卓手机以太网共享来帮忙!
通过安卓手机以太网共享让旧电脑联网2026 年 5 月 21 日,阅读时长 3 分钟。有人喜欢摆弄 90 年代和 21 世纪初的旧电脑和软件,比如童年时的 Amiga 500 电脑至今仍被保留且让人爱不释手。不过,Windows 9x/XP 时代的计算机使用经历最让人怀念&a…...

机器学习算子零样本超分辨率为何失败?多分辨率训练方案解析
1. 项目概述与核心问题在科学计算和科学机器学习领域,我们常常面临一个根本性的挑战:如何用离散的数据和模型去理解和预测连续世界的物理现象。无论是模拟流体湍流、预测天气变化,还是设计新材料,其背后的物理规律通常由偏微分方程…...

在Ubuntu 20.04上从源码编译Spconv 1.2.1:一份给点云感知开发者的避坑指南
在Ubuntu 20.04上从源码编译Spconv 1.2.1:一份给点云感知开发者的避坑指南 对于从事3D点云感知研究的开发者来说,Spconv库的安装往往是搭建开发环境时遇到的第一个"拦路虎"。这个专为稀疏卷积优化的库,虽然在性能上表现出色&#…...

Keil µVision中实现函数级编译时间戳追踪方案
1. 在Vision调试器中追踪函数编写时间的完整方案作为一名嵌入式开发老手,我经常需要回溯某个关键函数的最后修改时间。特别是在团队协作或维护遗留代码时,准确掌握函数级别的版本信息能大幅提升调试效率。今天要分享的正是如何在Keil Vision调试环境中实…...