小样本学习——匹配网络
目录
匹配网络
(1)简单介绍:
(2)专业术语
(3)主要思想
(4)训练过程
问题
回答
MANN
匹配网络
(1)简单介绍:
Matching networks(匹配网络)的架构主要受到注意力模型(attention model)和基于记忆的网络(memory-based networks)的启发。在所有这些模型中,都定义了神经注意机制来访问存储有解决当前任务所需信息的记忆矩阵。首先,我们需要了解一些与匹配网络相关的术语。
-
Attention Model(注意力模型):是一种模拟人类注意力机制的计算模型,用于确定模型在处理输入时应该关注哪些部分。它可以根据输入的重要性权重来动态地选择性地聚焦于不同的输入部分。
-
Memory-based Networks(基于记忆的网络):是一类模型,其设计灵感来源于人类记忆系统。这些网络通过使用外部存储器(通常是一个矩阵或向量)来存储和检索信息,并通过读取和写入操作来更新存储器中的内容。
-
Neural Attention Mechanism(神经注意机制):是一种可以学习对不同输入部分赋予不同权重的机制。它通过计算每个输入部分与当前任务的相关度,为不同输入部分分配注意力权重。这种机制可以使模型更加关注与当前任务相关的信息。
综上所述,匹配网络结合了注意力模型和基于记忆的网络的思想,通过神经注意机制来访问存储有关键信息的记忆矩阵,以解决特定任务。
(2)专业术语
这些专业术语与元学习(meta-learning)有关,主要用于描述一种称为N-way k-shot学习的训练方法。
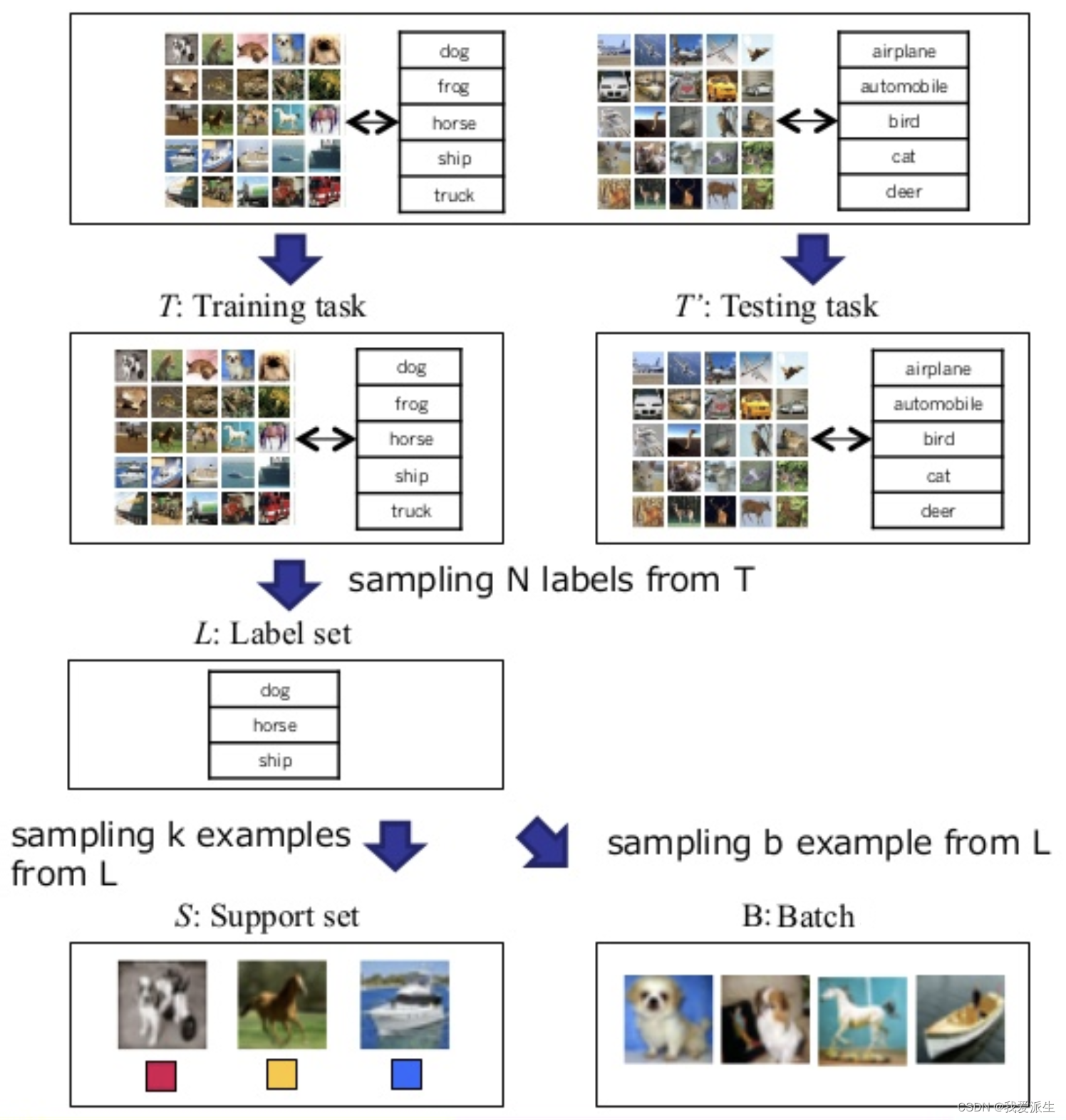
标签集(Label set):指包含所有可能类别的样本集合。例如,如果我们使用ImageNet数据集,它包含数千个类别(如猫、狗和鸟),但在标签集中,我们只使用其中五个类别。
支持集(Support set):是从标签集中抽取的输入数据点(例如图像),用于训练模型。支持集是训练过程中所使用的样本。
批次(Batch):类似于支持集,批次也是一个由标签集中的输入数据点组成的样本集合。在训练过程中,通常会将批次作为模型的输入。
N-way k-shot 方法:这是一种元学习方法,其中N表示支持集的大小,也可以理解为训练集中可能类别的数量。
例如,在下面的图示中,我们有四种不同品种的狗,并且计划使用5-shot学习方法,即每个类别至少有五个样本。这将使我们的匹配网络架构使用4-way 5-shot学习,如下图所示: 这种方法的目标是通过少量样本来训练一个模型,使其能够在面对新类别时进行准确分类。通过在训练过程中使用不同的支持集和批次,模型可以学习到泛化能力更强的特征表示,从而提高在未见过的类别上的分类能力。
(3)主要思想
Matching networks是一种模型,其核心思想是将图像映射到一个嵌入空间(embeddings space),该空间不仅包含了标签分布信息,还可以使用不同的架构将测试图像投影到相同的嵌入空间中。然后,我们使用余弦相似度来衡量相似度度量。
具体而言,Matching networks通过使用一个编码器网络(encoder network)来将图像转换为嵌入向量(embedding vector)。这个嵌入向量捕捉了图像的特征和语义信息。在训练过程中,Matching networks会根据任务需求,将图像的嵌入向量与对应的标签进行匹配,并学习到一个映射函数,使得相同类别的图像在嵌入空间中更加接近。
在测试阶段,Matching networks使用一个不同的架构,将测试图像投影到相同的嵌入空间中。这样,我们可以通过计算测试图像与训练图像之间的嵌入向量之间的余弦相似度,来度量它们之间的相似度。余弦相似度值越高,表示两个图像在特征和语义上越相似。
总的来说,Matching networks通过将图像映射到嵌入空间并使用余弦相似度来度量相似度,实现了图像匹配的任务。这种方法可以在许多视觉和语义相关的任务中得到应用,例如图像分类、目标检测等。
(4)训练过程
在训练体系结构中,匹配网络遵循一种特定的技术:它们试图在训练阶段复制测试条件。简单来说,正如我们在前面的部分中学到的那样,匹配网络从训练数据中采样标签集,然后从同一个标签集生成支持集(support set)和批量集(batch set)。经过数据预处理后,匹配网络通过将支持集作为训练集、批量集作为测试集来训练模型以最小化误差,从而学习其参数。这种将支持集作为训练集、批量集作为测试集的训练过程使得匹配网络能够复制测试条件。
接下来我们将学习匹配网络的网络架构和算法,并且学会如何使用这个在模型训练阶段用来测试的批量集(batch set)。
(5)建模水平 - 匹配网络架构
匹配网络将支持集(k 个示例)S= 映射到分类器。基本上,匹配网络将映射(mapping)定义为参数化神经网络(parametrized neural network)。如果我们谈论最简单的形式,它将是支持集标签的线性组合形式:
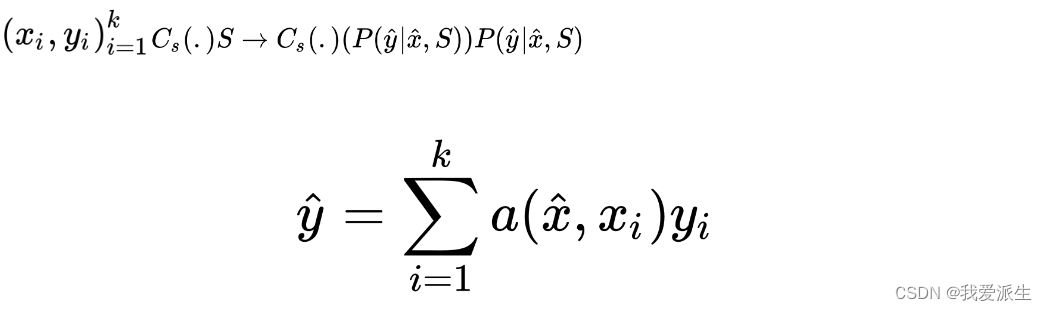
从逻辑角度看,softmax函数在非参数意义上被正确计算。这是因为:
从逻辑角度来看,"softmax函数在非参数意义上被正确计算"的意思是,在使用softmax函数时,根据其定义和计算方式的正确性,可以确保计算结果符合预期并满足所需的要求。
具体来说,softmax函数被广泛用于多分类问题中,用于将一组实数转换为表示概率分布的向量。它的计算公式为:
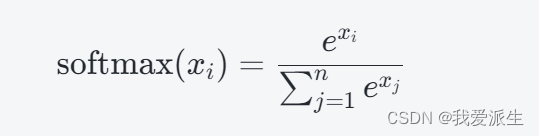
其中,xi表示输入向量中的第i个元素,n表示向量的长度。通过该公式,softmax函数将每个元素的指数函数值除以所有元素的指数函数值之和,得到归一化的概率值。
从逻辑角度来看,softmax函数的计算是基于每个元素的指数函数值和总和的比例,因此可以确保输出的概率值在0到1之间,并且所有概率值的总和为1,符合概率分布的要求。因此,可以说softmax函数在非参数意义上被正确计算。
For example, if we have 2 classes, 0 and 1, 2 examples (k=2) are as follows:
举个例子,如果我们有两个类(我们设置为0,1),两个样本( k = 2)如下:

将文本转换为one-hot编码向量,可以得到以下结果:

它们各自的核心价值如下:

通过引入变量a和y的值,我们可以得到以下方程:

解决之后,我们将得到以下方程。

总的来说,我们可以看到如何将成为决定测试输入属于哪个类别的概率线性组合。为了将任何形式的函数转换为概率空间,深度学习社区最常选择的方法是使用softmax函数,使得如下:
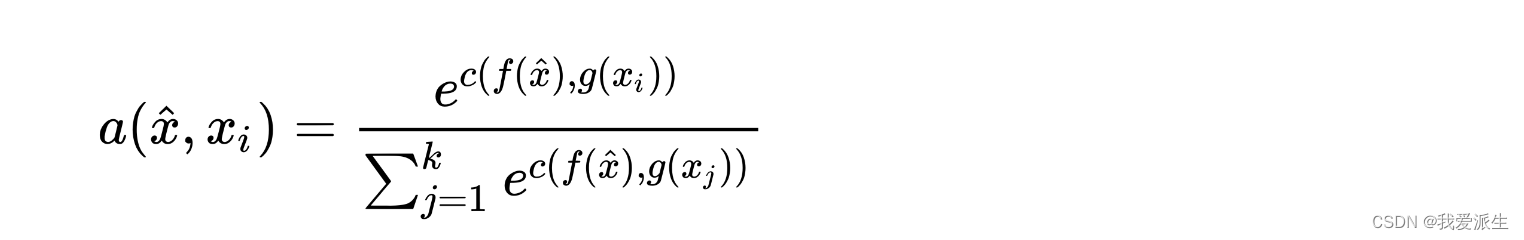
其中,c是训练集和测试数据点之间的余弦相似度函数。
现在,问题是如何从测试集和训练集中提取嵌入向量。任何形式的神经网络都可以使用。对于图像,著名的VGG16或Inception Net将通过使用迁移学习为测试和训练图像提供适当的嵌入向量;基本上,这就是过去大多数基于度量的方法所做的,但无法获得人类水平的认知结果。
VGG16和Inception Net是深度学习架构,它们在ImageNet数据集上取得了最先进的结果。它们通常用于对任何图像进行初始特征提取,因为这将为我们的架构提供适当的初始化训练过程。 匹配网络指出了前面简单的非参数方法存在两个问题:
问题1:训练集图像的嵌入是相互独立的,没有考虑它们作为支持集的一部分,尽管分类策略取决于支持集。
解决方案:匹配网络使用双向长短期记忆(LSTM)来使每个数据点在整个支持集的上下文中进行编码。LSTM通常用于理解数据序列,因为它们能够使用细胞内的门控机制在数据中保持上下文。类似地,双向LSTM用于更好地理解数据序列。匹配网络使用双向LSTM以确保支持集中一个图像的嵌入将具有所有其他图像嵌入的一些上下文。
注:
在传统的训练集中,图像的嵌入通常是相互独立的,没有考虑它们作为支持集的一部分,即没有利用到它们在分类策略中的关系。
为了解决这个问题,提出了使用双向长短期记忆(LSTM)来编码每个数据点。LSTM是一种适用于理解数据序列的神经网络模型,它通过细胞内的门控机制来保持数据的上下文信息。而双向LSTM则更好地理解数据序列,通过同时考虑前向和后向的上下文信息。
在匹配网络中使用双向LSTM的目的是确保支持集中的一个图像嵌入能够捕获到其他所有图像嵌入的一些上下文信息,从而更好地进行分类策略的决策。换句话说,通过使用双向LSTM,每个图像的嵌入可以更好地反映其在整个支持集中的位置和关系,从而提高分类的准确性。
问题2:如果我们想计算两个数据点之间的相似度,我们首先需要将它们带入相同的嵌入空间。因此,支持集S需要能够对提取测试图像嵌入做出贡献。
解决方案:匹配网络使用LSTM与对支持集S的读取注意力机制。
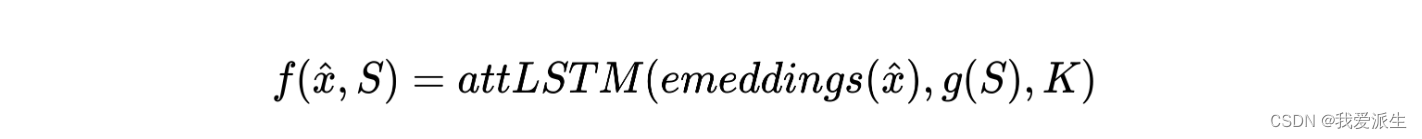
其中,K代表展开步骤的数量,X是通过VGG16/Inception网络获得的测试图像嵌入,而Y是将测试图像嵌入带入相同空间的样本集贡献。
注:
匹配网络是一种用于计算两个数据点之间相似度的模型。在这种情况下,我们想要计算测试图像与支持集S中图像之间的相似度。
为了实现这一目标,匹配网络使用了LSTM(长短期记忆)和读取注意力机制。LSTM是一种递归神经网络结构,能够处理序列数据并捕捉其上下文信息。通过使用LSTM,匹配网络可以对输入图像进行编码,并提取其特征表示。
读取注意力机制是一种注意力机制的变体,它允许网络在处理支持集S时选择性地关注其中的不同部分。这种机制使得网络能够根据输入的内容动态调整其注意力,从而更好地捕捉相关信息。
综合使用LSTM和读取注意力机制,匹配网络能够将测试图像和支持集S中的图像映射到相同的嵌入空间,并计算它们之间的相似度。这样,我们就可以通过比较它们的嵌入表示来评估它们之间的相似程度。
匹配网络结构图如下:
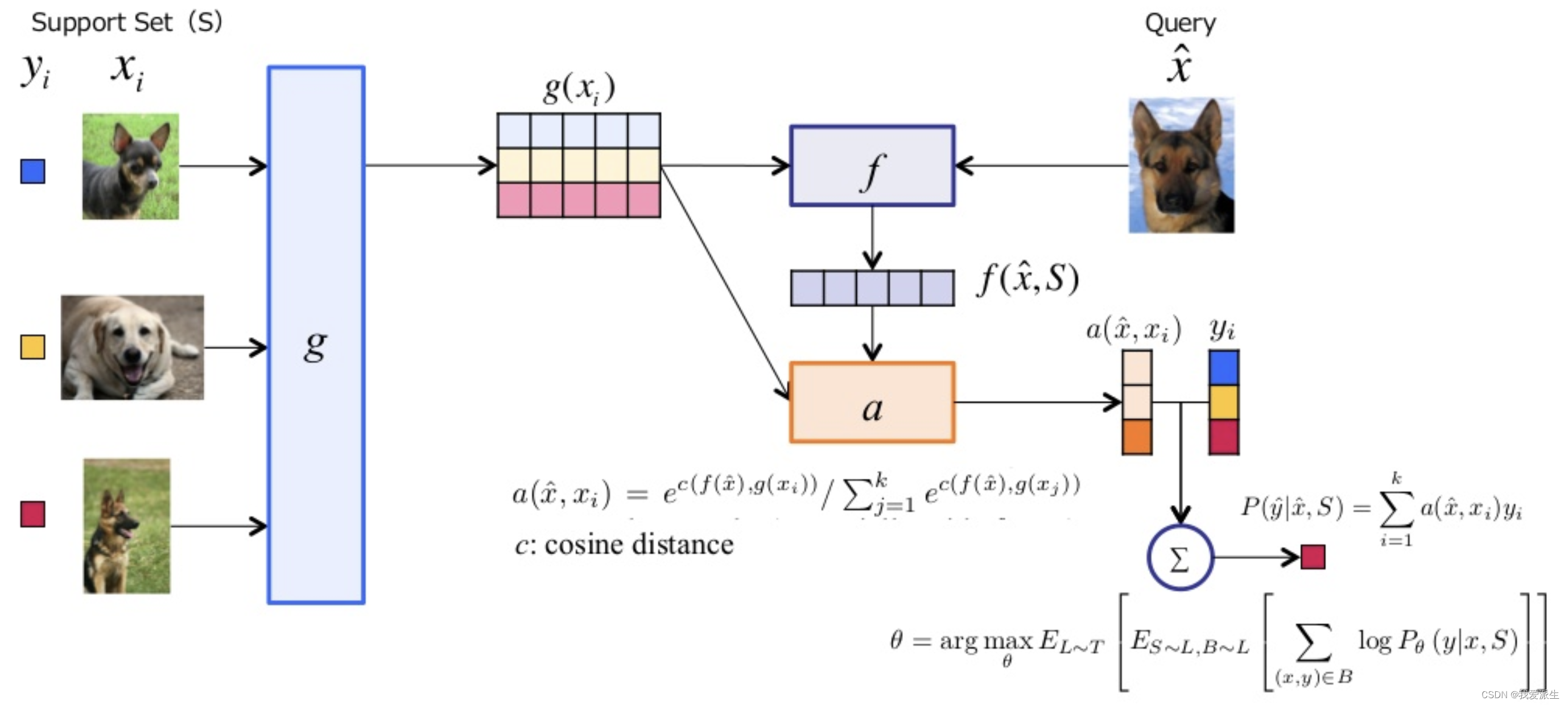
匹配网络的架构使用端到端的框架来解决one shot learning的问题,以在训练模型时复制测试条件,正如在训练过程部分所讨论的那样。匹配网络的架构中包含许多子部分。为了简化和更清晰地理解它,我们将从左到右逐个介绍每个过程。
- 作为数据预处理的一部分,将创建一个支持集合S,其中包含k个示例。
- 在获得支持集之后,它通过标准特征提取层(如VGG或Inception)进行处理。
- 首先,支持集中的嵌入(g层的输出)被提取出来,并输入到一个双向LSTM架构中。通过这个架构,模型可以学习到支持集中存在的标签的概率分布。与训练集类似,对于查询图像(即测试图像),完整的上下文嵌入也会经过一个组合的双向LSTM架构进行提取(也会经过g层)。同时,它还会从支持集中获取贡献信息,以便在相同的嵌入空间中进行映射。这样,模型就可以将查询图像与支持集中的标签进行匹配和比较,从而得出相应的结果或预测。
- 在获得两个架构的输出之后,将它们通过softmax层(也称为注意力核步骤)传递。
- 从中获取的输出然后用于检查查询图像属于哪个类别。
 在上面等式中,是支持集中标签的加权和。
在上面等式中,是支持集中标签的加权和。
在这里,注意力核是一个softmax函数,其值为g(xi)和f'(x)之间的余弦距离。要训练模型,我们可以使用任何基于分类的损失函数,比如交叉熵损失函数。
交叉熵损失函数是一种常用的分类损失函数,常用于多分类问题。它通过比较模型的预测概率分布与真实标签之间的差异来评估模型的性能。
在这种情况下,模型的预测概率分布是通过对注意力核进行softmax转换得到的。注意力核中的余弦距离反映了输入特征向量g(xi)和目标特征向量f'(x)之间的相似度。通过将余弦距离转换为概率分布,模型可以更好地区分不同类别之间的关系。
因此,使用交叉熵损失函数可以帮助我们最大化模型对正确类别的预测概率,并最小化与错误类别的预测概率之间的差异。通过反向传播算法和梯度优化方法,我们可以更新模型的参数,使其逐渐优化并提高分类性能。
注:匹配网络中的注意力机制通常基于点积注意力(Dot Product Attention)。点积注意力是一种用于计算两个向量之间的相似度的方法。在匹配网络中,通常会使用点积注意力来计算待匹配的两个句子或序列之间的关联程度。具体而言,对于给定的查询向量和键向量,点积注意力会通过计算两者之间的点积来得到一个相似度分数,然后将这个分数进行归一化处理,得到注意力权重,用于加权求和查询向量对应的值向量。这样,通过注意力机制可以捕捉到查询和键之间的相关性,并在匹配任务中起到重要作用。
匹配网络的关键思想是创建一种体系结构,可以在训练数据中没有的类别(即支持集)上表现良好。匹配网络是一种用于one shot learning的众所周知的方法,其创新的训练程序和完全上下文嵌入。如果我们试图以人类学习的角度理解匹配网络的方法,它与儿童教学程序非常相似。为了学习一个新任务,他们被呈现一系列少量的示例,然后是一小组测试集,这个过程反复进行。利用人脑的上下文记忆保留能力,儿童学会了新的任务。
问题
- What are similarity metrics? Why does cosine similarity work best?
- Why do matching networks use the LSTM architecture to obtain embeddings?
- What are the disadvantages associated with the contrastive loss function, and how does the triplet loss function assist in solving it?
- What is the curse of dimensionality? How can we deal with it?
回答
- 相似度度量是衡量两个向量或数据点之间相似程度的方法。常用的相似度度量包括欧氏距离、余弦相似度和皮尔逊相关系数等。其中,余弦相似度在某些情况下效果最好。余弦相似度是通过计算两个向量之间的夹角来度量它们之间的相似程度。由于余弦相似度不受向量的绝对大小和位移的影响,更适合用于比较文本、图像和其他高维数据的相似性。此外,余弦相似度可以通过将向量归一化为单位向量来减少计算复杂性。
- 匹配网络使用LSTM(长短期记忆)架构来获取嵌入是因为LSTM能够处理序列数据并捕捉其长期依赖关系。在匹配任务中,输入通常是两个序列,例如句子或文档,LSTM可以学习到输入序列之间的交互模式,并生成表示这些序列的固定长度嵌入。这些嵌入可以用于度量两个序列之间的相似度或进行后续的匹配任务。
- 对比损失函数的缺点是它要求正例和负例之间的差异足够大,这在训练数据不平衡或难以分类的情况下可能很困难。此外,对比损失函数只利用了负例样本中最相似的样本作为参考,忽略了其他可能有用的信息。三元组损失函数通过引入一个中间样本(锚点)来解决对比损失函数的缺点。它要求锚点与正例之间的距离小于锚点与负例之间的距离,这可以更好地约束嵌入空间中的样本分布,提高模型的鲁棒性和泛化能力。通过使用三元组损失函数,模型可以更好地学习到样本之间的相对距离关系。
- 维度诅咒是指在高维空间中,样本之间的距离变得非常稀疏和不可靠,导致传统的距离度量方法失效。在高维空间中,数据点之间的距离会变得非常相似,使得相似度度量变得困难和不准确。应对维度诅咒的方法包括特征选择、降维和局部敏感哈希等。特征选择通过选择最相关的特征来减少数据的维度,降维通过使用主成分分析(PCA)等方法将数据映射到低维空间,局部敏感哈希通过将相似的数据映射到相邻的桶中来加速相似度搜索。这些方法可以减少维度诅咒对数据建模和相似度计算的影响。
MANN
第一个问题可以通过循环神经网络(RNN)来解决,RNN在各种任务上已经取得了最先进的性能。
第二个问题可以通过研究神经图灵机(NTM)来解决。在本节中,我们将讨论NTM的整体架构,这对于理解增强记忆的神经网络(MANN)以及将其修改为一次学习任务非常重要。
参考文章:Jadon S. An overview of deep learning architectures in few-shot learning domain[J]. arXiv preprint arXiv:2008.06365, 2020.
相关文章:
小样本学习——匹配网络
目录 匹配网络 (1)简单介绍: (2)专业术语 (3)主要思想 (4)训练过程 问题 回答 MANN 匹配网络 (1)简单介绍: Matching netwo…...

CSS 常用样式 之字体属性
font-weight(字体粗细) 字体粗细用于设置文本的粗细程度,可以使用如下的值: normal:正常字体(默认)bold:加粗字体bolder:更加加粗lighter:更加细 代码实例…...
nodejs+vue游戏测评交流系统elementui
可以实现首页、发布招募、公司资讯、我的等,另一方面来说也可以提高在游戏测评交流方面的效率给相关管理人员的工作带来一定的便利。在我的页面可以对游戏攻略、我的收藏管理、实际上如今信息化成为一个未来的趋势或者可以说在当前现代化的城市典范中,发布招募等功能…...

1.2.OpenCV技能树--第一单元--OpenCV安装
目录 1.文章内容来源 2.OpenCV安装 3.课后习题代码复现 4.易错点总结与反思 1.文章内容来源 1.题目来源:https://edu.csdn.net/skill/opencv/opencv-662dbd65c89d4ddb9e392f44ffe16e1a?category657 2.资料来源:https://edu.csdn.net/skill/opencv/opencv-662dbd65c89d4ddb…...
全志ARM926 Melis2.0系统的开发指引⑥
全志ARM926 Melis2.0系统的开发指引⑥ 编写目的9. 系统启动流程9.1. Shell 部分9.2.Orange 和 desktop 部分9.3. app_root 加载部分9.4. home 加载部分 10. 显示相关知识概述10.1. 总体结构10.2. 显示过程10.3. 显示宽高参数关系 -. 全志相关工具和资源-.1 全志固件镜像修改工具…...

Junit单元测试为什么不能有返回值?
这个问题的产生来源于我们老师上节课说的我们班一个男生问他的想法,刚开始听到这个还觉得挺有意思,我之前使用单元测试好像下意识的就将它的返回值写为void,一般都是进行简单的测试,也从没思考过在某个单元测试中调用另一个单元测试ÿ…...
【成像光敏描记图提取和处理】成像-光电容积描记-提取-脉搏率-估计(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
Ubuntu无法引导启动的修复
TLDR:使用Boot-Repair工具。 Boot-Repair Boot-Repair是一个简单的工具,用于修复您在Ubuntu中可能遇到的常见启动问题,例如在安装Windows或其他Linux发行版后无法启动Ubuntu时,或者在安装Ubuntu后无法启动Windows时,…...

Windows电脑上的多开软件是否安全?
在Windows电脑上使用多开软件可以让使用者同时运行多个相同或不同的程序,这对于某些需要同时操作多个账号或实例的用户来说非常有用。但是很多人担心使用多开软件是否安全。 多开软件的安全问题主要在于它们可能会破坏操作系统的稳定性和安全性,导致系统…...

U盘支持启动区+文件存储区的分区方法
准备新U盘 启动diskgenius ,先建立一个主分区(7G),剩余空间建立为第二分区,然后设定第二分区激活。 diskgenius格式化 用diskgenius格式化,在格式化的过程中有一个 写入dos系统的选项,在格式…...
JavaEE-线程进阶
模拟实现一个定时器 运行结果如下: 上述模拟定时器的全部代码: import java.util.PriorityQueue;//创建一个类,用来描述定时器中的一个任务 class MyTimerTask implements Comparable<MyTimerTask> {//任务执行时间private long …...

【开发篇】十五、Spring Task实现定时任务
文章目录 1、使用示例2、相关配置3、Scheduled注解4、Spring Task单线程下的阻塞坑5、Spring Task阻塞问题的处理思路6、Spring Task在分布式环境中 上一篇用Quartz来实现了定时任务,但相对来说,这个框架还是比较繁琐。Spring Boot默认在无任何第三方依赖…...

Python常用功能的标准代码
后台运行并保存log 1 2 3 4 5 6 7 8 9 nohup python -u test.py > test.log 2>&1 & #最后的&表示后台运行 #2 输出错误信息到提示符窗口 #1 表示输出信息到提示符窗口, 1前面的&注意添加, 否则还会创建一个名为1的文件 #最后会把日志文件输出到test.log文…...
Electron.js入门-构建第一个聊天应用程序
什么是electron 电子是一个开源框架,用于使用web技术构建跨平台桌面应用程序;即: HTML、CSS和JavaScript;被集成为节点模块,我们可以为我们的应用程序使用节点的所有功能;组件,如数据库、Api休…...

ubuntu 22.04 更新NVIDIA显卡驱动,重启后无网络图标等系统奇奇怪怪问题
环境 win10, ubuntu 22.04双系统 笔记本电脑,4060显卡 解决思路 具体的过程当时没有记录下来,然后因为在解决系统的问题,也没有截图啥的,只有一些大概记忆,供未来的自己参考吧。 首先是更新显卡驱动 我是直接在soft…...

Python综合案例:学生管理系统
目录 需求说明: 功能: 创建入口函数: 实现菜单函数: 实现增删查操作: 1. 新增学生 2. 展示学生 3. 查找学生 4. 删除学生 加入存档读档: 1. 约定存档格式 2. 实现存档函数 3. 实现读档函数 打…...
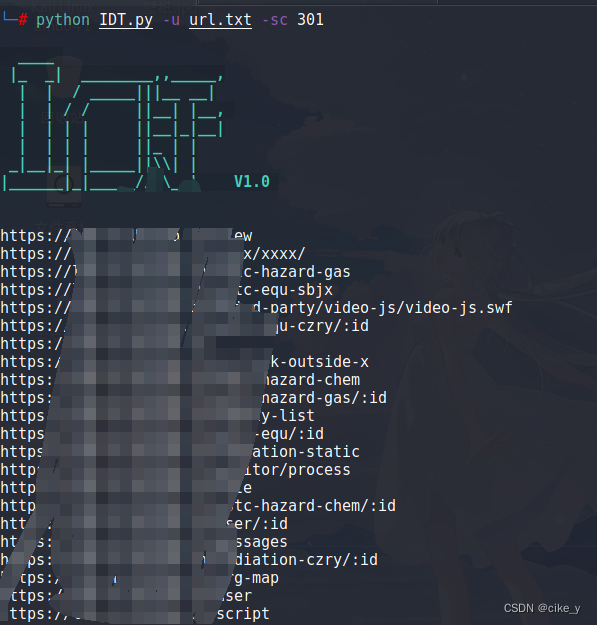
IDT 一款自动化挖掘未授权访问漏洞的信息收集工具
IDT v1.0 IDT 意为 Interface detection(接口探测) 项目地址: https://github.com/cikeroot/IDT/该工具主要的功能是对批量url或者接口进行存活探测,支持浏览器自动打开指定的url,避免手动重复打开网址。只需输入存在批量的url文件即可。 …...
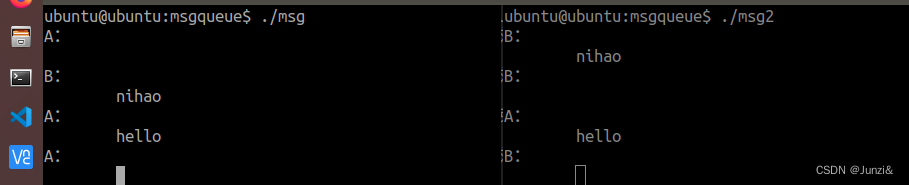
复习 --- 消息队列
进程间通信机制(IPC) 简述 IPC:Inter Process Communication 进程和进程之间的用户空间相互独立,但是4G内核空间共享,进程间的通信就是通过这4G的内核空间 分类 传统的进程间通信机制 无名管道(pipe) 有名管道&…...

AcWing 288. 休息时间,《算法竞赛进阶指南》
288. 休息时间 - AcWing题库 在某个星球上,一天由 N 个小时构成,我们称 0 点到 1 点为第 1 个小时、1 点到 2 点为第 2 个小时,以此类推。 在第 i 个小时睡觉能够恢复 Ui 点体力。 在这个星球上住着一头牛,它每天要休息 B 个小…...

ES6中字符串的扩展
字符串的遍历器接口 使用for…of for(let x of foo) {console.log(x); } // f; o; oat() ES5中的charAt()方法,返回字符串给定位置的字符。但是不能识别码点大于0xFFFF的字符,at方法可以 includes()、startsWith()、endsWith() 用来确定一个字符串是…...

Midscene.js与Playwright融合:企业级自动化测试效率提升88%的智能架构实践
Midscene.js与Playwright融合:企业级自动化测试效率提升88%的智能架构实践 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 副标题:从传统…...
搞定VS项目的中英文翻译)
别再乱码了!手把手教你用Qt Linguist(Qt语言家)搞定VS项目的中英文翻译
彻底解决Qt多语言乱码:VS项目国际化全流程实战指南 在跨语言桌面应用开发中,乱码问题堪称开发者噩梦。当你的中文界面在Qt Linguist中显示为"烫烫烫",或者翻译后的文字变成问号方块时,这种挫败感足以让任何开发者抓狂。…...

自愈代码代理:基于LLM与感知-决策-执行闭环的智能缺陷修复实践
1. 项目概述与核心价值最近在开源社区里,一个名为ProblematicToucan/self-healing-code-agent的项目引起了我的注意。这个名字本身就很有意思——“有问题的巨嘴鸟”开发的“自愈代码代理”。作为一个在软件开发一线摸爬滚打了十多年的老码农,我深知“代…...

文本到图像生成中的人类反馈数据集构建与实践
1. 文本到图像生成中的人类反馈数据集构建实践 在大型语言模型(LLMs)领域,基于人类偏好的学习方法取得了显著成功,这启发了我们在文本到图像生成领域采用类似的方法论。传统的图像偏好标注(即从两张图像中选择更好的一张)虽然有用,但存在信息…...

Windows系统优化终极指南:5个高效清理技巧与智能资源管理实战
Windows系统优化终极指南:5个高效清理技巧与智能资源管理实战 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设…...

多模态数据提取:微调与少样本提示
这是一篇偏实践向的记录,主要整理我在「用多模态大模型做发票数据结构化提取」过程中踩过的坑、验证过的方案,以及一些比较稳妥的落地思路。整体目标只有一个:让模型稳定输出可直接用的 JSON,而不是“看起来很聪明”的一大段解释。 背景与目标 实际业务里,我们经常会遇到…...

周大福一物一码吗:企业判断一物一码公司,别只看能不能做
周大福一物一码吗?别只看有没有做,要看能不能做深“周大福一物一码吗”这个问题,表面是在问某个品牌有没有上系统,实际是在问一物一码有没有业务价值。真正有参考意义的,不是品牌做没做,而是一物一码能不能…...

07.基于Ultralytics的完整工程实践
YOLO(You Only Look Once)系列目标检测算法自2015年提出以来,已迭代至YOLOv8、YOLOv9、YOLOv10等多个版本,成为工业界部署最广泛的目标检测框架。 本文面向具备Python基础、希望系统掌握YOLO实战的开发者,从算法核心原理出发,围绕数据准备、模型训练、评估优化、部署推理…...

DyCAST:动态字符对齐的语音分词技术解析与实践
1. 项目背景与核心价值在语音处理领域,如何将连续的语音信号准确切分成有意义的语言单元一直是个技术难点。传统基于固定窗口的语音分词方法在面对不同语速、口音和语境时表现不稳定,而DyCAST(Dynamic Character Alignment Speech Tokenizer&…...

全球困于孤岛与慢仿真,中国镜像视界以可执行元神实现代差领跑
全球困于孤岛与慢仿真,中国镜像视界以可执行元神实现代差领跑当前全球数字孪生产业普遍陷入两大瓶颈:数据孤岛林立、多系统无法互通,以及仿真滞后、虚实不同步、只能展示不能执行,绝大多数方案仍停留在 “可视化孪生” 的初级阶段…...