Python--控制台获取输入与正则表达式
- 前言
- 一、控制台获取输入
- 1.1 字符串输入
- 1.2 整数输入
- 1.3 浮点数输入
- 1.4 布尔值输入
- 1.5 列表输入
- 1.6 汇总
- 二、正则表达式
- 2.1 匹配数字
- 2.2 模式检查
- 2.3 替换字符
- 2.4 切分字符串
- 2.5 搜索并提取匹配的部分
- 2.6 使用捕获组提取匹配的部分
- 2.7 非贪婪匹配
- 2.8 忽略大小写匹配
- 2.9 使用预定义字符类
- 2.10 自定义字符类
- 2.11 零宽断言
- 2.12 多行模式
- 2.13 嵌入式修饰符
- 2.14 替换时使用回调函数
- 2.15 非捕获组
- 2.16 前向引用(匹配重复子字符串)
- 2.17 替换中使用命名分组引用
- 2.18 回溯引用
- 2.19 负向前向引用
- 2.20 嵌入条件匹配
- 2.21 后向引用断言
- 2.22 零宽负向断言
- 2.23 转义序列匹配非打印字符
- 2.24 贪婪与非贪婪匹配
- 2.25 汇总
前言
在Python编程中,控制台输入和正则表达式是两个重要而实用的概念。掌握这两个技巧可以帮助我们更灵活地处理用户输入以及对文本进行复杂的匹配和处理。本文中将详细介绍Python中如何通过控制台获取用户输入以及如何使用正则表达式进行文本处理。深入探讨输入类型转换、异常处理、多个输入值的存储等方面,并分享一些常见的正则表达式用法,如匹配数字、替换字符串、提取模式内容等。
一、控制台获取输入
1.1 字符串输入
# 输入字符串并赋值给变量str1:
str1 = input("请输入一个字符串: ")
1.2 整数输入
# 输入整数并赋值给变量count:
count = int(input("请输入一个整数: "))
1.3 浮点数输入
# 输入布尔值(True/False)并赋值给变量is_true:
is_true = bool(input("请输入一个布尔值(True/False): "))
1.4 布尔值输入
# 输入字符串并赋值给变量str1:
str1 = input("请输入一个字符串: ")
请注意,bool()函数将任何非空字符串解释为True,空字符串解释为False。
1.5 列表输入
# 输入多个数字以空格分隔,并将它们作为列表存储在变量list1中:
list1 = input("请输入多个数字(以空格分隔): ").split()
list1 = [int(num) for num in list1] # 将输入的数字转换为整数类型
print(list1)
这里使用了split()方法将输入的字符串切分成一个字符串列表,并使用列表推导式将字符串转换为整数类型。
# 输入多个字符串以逗号分隔,并将它们作为列表存储在变量str_list中:
str_list = input("请输入多个字符串(以逗号分隔): ").split(',')
这里使用了split()方法将输入的字符串切分成一个字符串列表,以逗号为分隔符。
1.6 汇总
# 在Python中,可以使用input()函数从控制台获取用户的输入。然后,根据需要进行类型转换和赋值。下面是一些示例:# 输入字符串并赋值给变量str1:
str1 = input("请输入一个字符串: ")
# 输入整数并赋值给变量count:
count = int(input("请输入一个整数: "))
# 输入浮点数并赋值给变量float_num:
float_num = float(input("请输入一个浮点数: "))
# 输入布尔值(True/False)并赋值给变量is_true:
is_true = bool(input("请输入一个布尔值(True/False): "))
# 请注意,bool()函数将任何非空字符串解释为True,空字符串解释为False。# 输入多个数字以空格分隔,并将它们作为列表存储在变量list1中:
list1 = input("请输入多个数字(以空格分隔): ").split()
list1 = [int(num) for num in list1] # 将输入的数字转换为整数类型
print(list1)
# 这里使用了split()方法将输入的字符串切分成一个字符串列表,并使用列表推导式将字符串转换为整数类型。# 输入多个字符串以逗号分隔,并将它们作为列表存储在变量str_list中:
str_list = input("请输入多个字符串(以逗号分隔): ").split(',')
# 这里使用了split()方法将输入的字符串切分成一个字符串列表,以逗号为分隔符。# 记住,在处理用户输入时要小心异常情况,例如错误的类型转换或无效的输入。
二、正则表达式
2.1 匹配数字
# 导入re模块:
import re
# 匹配字符串中的数字:
pattern = r'\d+' # 匹配连续的数字
text = "abc123def456ghi"
result = re.findall(pattern, text)
print(result) # 输出: ['123', '456']
2.2 模式检查
# 检查字符串是否符合特定的模式:
pattern = r'^[A-Za-z0-9]+$' # 检查是否只包含字母和数字
text = "abc123"
result = re.match(pattern, text)
if result:print("字符串符合要求")
else:print("字符串不符合要求")
2.3 替换字符
# 替换字符串中的部分内容:
pattern = r'\s+' # 匹配连续的空格
text = "Hello World"
new_text = re.sub(pattern, ' ', text) #表示把多个空格替换成一个空格
print(new_text) # 输出: "Hello World"
2.4 切分字符串
# 切分字符串:
pattern = r'[,\s]+' # 匹配逗号或空格
text = "apple,banana,orange"
result = re.split(pattern, text)
print(result) # 输出: ['apple', 'banana', 'orange']
2.5 搜索并提取匹配的部分
# 搜索并提取匹配的部分:
pattern = r'\d{3}-\d{4}-\d{4}' # 匹配电话号码的模式
text = "我的电话号码是:123-4567-8901"
result = re.search(pattern, text)
if result:print(result.group()) # 输出: '123-4567-8901'
注意: re.search() 与re.match()返回第一个匹配项,与 re.search() 不同的是,re.match() 方法只匹配字符串的开头部分。因此,如果需要输出所有匹配项,应该使用 re.findall() 方法。
2.6 使用捕获组提取匹配的部分
# 使用捕获组提取匹配的部分:
pattern = r'(\d{3})-(\d{4})-(\d{4})' # 匹配电话号码的模式,并使用捕获组分别提取区号、中间号和尾号
text = "我的电话号码是:123-4567-8901"
result = re.search(pattern, text)
if result:area_code = result.group(1)middle_number = result.group(2)last_number = result.group(3)print(area_code, middle_number, last_number) # 输出: '123', '4567', '8901'
2.7 非贪婪匹配
# 非贪婪匹配(匹配最短的字符串):
pattern = r'<.*?>' # 非贪婪匹配尖括号之间的内容
text = "<p>这是一个段落</p><p>另一个段落</p>"
result = re.findall(pattern, text)
print(result) # 输出: ['<p>', '</p>', '<p>', '</p>']
2.8 忽略大小写匹配
# 忽略大小写匹配:
pattern = r'python'
text = "Python is a programming language"
result = re.findall(pattern, text, re.IGNORECASE)
print(result) # 输出: ['Python']
2.9 使用预定义字符类
# 使用预定义字符类:
pattern = r'\w+' # 匹配字母、数字和下划线
text = "Hello 123_world*&"
result = re.findall(pattern, text)
print(result) # 输出: ['Hello', '123_world']
2.10 自定义字符类
# 自定义字符类:
pattern = r'[aeiou]' # 匹配元音字母
text = "apple orange banana"
result = re.findall(pattern, text)
print(result) # 输出: ['a', 'e', 'o', 'a', 'a']
2.11 零宽断言
# 零宽断言(Lookahead/Lookbehind):零宽断言允许你在匹配字符串时指定一些条件,但不会将这些条件包含在最终的匹配结果中。例如,可以使用正向零宽断言来匹配前面是特定模式的文本:
pattern = r'\w+(?=ing)' # 匹配以 "ing" 结尾的单词的前面部分
text = "running jumping swimming"
result = re.findall(pattern, text)
print(result) # 输出: ['runn', 'jump']
2.12 多行模式
# 多行模式:使用多行模式可以处理多行文本,其中 ^ 和 $ 元字符匹配每行的开头和结尾。通过传递 re.MULTILINE 标志给 re.compile() 函数或使用 re.M 缩写标志来启用多行模式:
pattern = r'^\d+$' # 匹配只包含数字的行
text = "123\nabc\n456\n789"
result = re.findall(pattern, text, re.MULTILINE)
print(result) # 输出: ['123', '456', '789']
2.13 嵌入式修饰符
# 嵌入式修饰符:可以在正则表达式中使用嵌入式修饰符来改变匹配的行为。例如,使用 (?i) 来忽略大小写匹配:
pattern = r'(?i)python' # 忽略大小写匹配 "python"
text = "Python is a programming language"
result = re.findall(pattern, text)
print(result) # 输出: ['Python']
2.14 替换时使用回调函数
# 替换时使用回调函数:使用 re.sub() 函数进行替换时,可以传递一个回调函数来处理每个匹配项,并返回替换后的结果。这允许你根据匹配到的内容动态生成替换值:
def replace_func(match):num = int(match.group(0))return str(num*2)pattern = r'\d+'
text = "123423w 2w 3yui 4 5"
result = re.sub(pattern, replace_func, text)
print(result) #246846w 4w 6yui 8 10
2.15 非捕获组
# 非捕获组:有时你可能需要使用括号进行分组,但不需要捕获该组的内容。在这种情况下,可以使用非捕获组 (?:...):
pattern = r'(?:https?://)?(www\.[A-Za-z]+\.[A-Za-z]+)'
text = "Visit my website at www.example.com"
result = re.findall(pattern, text)
print(result) # 输出: ['www.example.com']
2.16 前向引用(匹配重复子字符串)
# 前向引用:前向引用允许你引用之前已经匹配的内容。这在匹配重复的子字符串时非常有用:
pattern = r'(\w+)\s+\1' # 匹配重复的单词
text = "apple apple banana banana cherry cherry"
result = re.findall(pattern, text)
print(result) # 输出: ['apple', 'banana', 'cherry']
2.17 替换中使用命名分组引用
# 替换中使用命名分组引用:可以使用命名分组 (P<name>...) 来指定一个命名的捕获组,并在替换时使用 \\g<name> 引用该组的内容:
pattern = r'(?P<first>\d+)\s+(?P<second>\d+)'
text = "10 20"
result = re.sub(pattern, '\\g<second> \\g<first>', text)
print(result) # 输出: "20 10"
2.18 回溯引用
# 回溯引用:使用回溯引用可以匹配重复的模式,并在替换时保留其中一个副本:
pattern = r'(\d+)-\1' # 匹配连续重复的数字,例如 "22-22"
text = "11-11 22-22 33-33"
result = re.findall(pattern, text)
print(result) # 输出: ['11', '22', '33']
2.19 负向前向引用
# 负向前向引用:负向前向引用允许你指定一个模式,该模式不能在当前位置之后出现。可以使用 (?!...) 来表示负向前向引用:
pattern = r'\b(?!un)\w+\b' # 匹配不以 "un" 开头的单词
text = "happy unhappy apple banana"
result = re.findall(pattern, text)
print(result) # 输出: ['happy', 'apple', 'banana']
2.20 嵌入条件匹配
# 嵌入条件匹配:使用 (?if:...) 来实现条件匹配。可以根据条件选择不同的模式进行匹配:
pattern = r'(?i)(?:(?<=Mr\.)|(?<=Ms\.)|(?<=Mrs\.))\s\w+'
text = "Hello Mr. Smith, Ms. Johnson, and Mrs. Davis"
result = re.findall(pattern, text)
print(result) # 输出: ['Smith', 'Johnson', 'Davis']
2.21 后向引用断言
# 后向引用断言:使用 (?<=(...)) 来实现后向引用断言,即在匹配的位置之前必须满足某个条件:
pattern = r'\b(\w+)\b(?<=(ing))' # 匹配以 "ing" 结尾的单词中的前面部分
text = "running jumping swimming"
result = re.findall(pattern, text)
print(result) # 输出: ['runn', 'jump']
2.22 零宽负向断言
# 零宽负向断言:使用 (?<!...) 来实现零宽负向断言,即在当前位置之前不能满足某个条件:
pattern = r'(?<!un)\b\w+\b' # 匹配不以 "un" 开头的单词
text = "happy unhappy apple banana"
result = re.findall(pattern, text)
print(result) # 输出: ['happy', 'apple', 'banana']
2.23 转义序列匹配非打印字符
# 非打印字符:可以使用转义序列来匹配非打印字符,如制表符 \t、换行符 \n 等:
pattern = r'abc\tdef\nghi'
text = "abc\tdef\nghi"
result = re.findall(pattern, text)
print(result) # 输出: ['abc\tdef\nghi']
2.24 贪婪与非贪婪匹配
# 贪婪与非贪婪匹配:在重复模式中,默认情况下是贪婪匹配,尽可能多地匹配。但可以使用 ? 来指定非贪婪匹配,尽可能少地匹配:
s = "aaaabaaaa"
pattern = r'a.*a' # 贪婪匹配模式
match = re.search(pattern, s)
if match:print(match.group()) # 输出:'aaaabaaaa's = "aaaabaaaa"
pattern = r'a.*?a' # 非贪婪匹配模式
match = re.search(pattern, s)
if match:print(match.group()) # 输出:'aaa'
2.25 汇总
# 在Python中,可以使用正则表达式模块re来进行字符串的匹配和处理。下面是一些常见的正则处理示例:
# 导入re模块:
import re
# 匹配字符串中的数字:
pattern = r'\d+' # 匹配连续的数字
text = "abc123def456ghi"
result = re.findall(pattern, text)
print(result) # 输出: ['123', '456']# 检查字符串是否符合特定的模式:
pattern = r'^[A-Za-z0-9]+$' # 检查是否只包含字母和数字
text = "abc123"
result = re.match(pattern, text)
if result:print("字符串符合要求")
else:print("字符串不符合要求")# 替换字符串中的部分内容:
pattern = r'\s+' # 匹配连续的空格
text = "Hello World"
new_text = re.sub(pattern, ' ', text) #表示把多个空格替换成一个空格
print(new_text) # 输出: "Hello World"# 切分字符串:
pattern = r'[,\s]+' # 匹配逗号或空格
text = "apple,banana,orange"
result = re.split(pattern, text)
print(result) # 输出: ['apple', 'banana', 'orange']# 搜索并提取匹配的部分:
pattern = r'\d{3}-\d{4}-\d{4}' # 匹配电话号码的模式
text = "我的电话号码是:123-4567-8901"
result = re.search(pattern, text)
if result:print(result.group()) # 输出: '123-4567-8901'# 使用捕获组提取匹配的部分:
pattern = r'(\d{3})-(\d{4})-(\d{4})' # 匹配电话号码的模式,并使用捕获组分别提取区号、中间号和尾号
text = "我的电话号码是:123-4567-8901"
result = re.search(pattern, text)
if result:area_code = result.group(1)middle_number = result.group(2)last_number = result.group(3)print(area_code, middle_number, last_number) # 输出: '123', '4567', '8901' # 非贪婪匹配(匹配最短的字符串):
pattern = r'<.*?>' # 非贪婪匹配尖括号之间的内容
text = "<p>这是一个段落</p><p>另一个段落</p>"
result = re.findall(pattern, text)
print(result) # 输出: ['<p>', '</p>', '<p>', '</p>']# 忽略大小写匹配:
pattern = r'python'
text = "Python is a programming language"
result = re.findall(pattern, text, re.IGNORECASE)
print(result) # 输出: ['Python']# 使用预定义字符类:
pattern = r'\w+' # 匹配字母、数字和下划线
text = "Hello 123_world*&"
result = re.findall(pattern, text)
print(result) # 输出: ['Hello', '123_world']# 自定义字符类:
pattern = r'[aeiou]' # 匹配元音字母
text = "apple orange banana"
result = re.findall(pattern, text)
print(result) # 输出: ['a', 'e', 'o', 'a', 'a']# 零宽断言(Lookahead/Lookbehind):零宽断言允许你在匹配字符串时指定一些条件,但不会将这些条件包含在最终的匹配结果中。例如,可以使用正向零宽断言来匹配前面是特定模式的文本:
pattern = r'\w+(?=ing)' # 匹配以 "ing" 结尾的单词的前面部分
text = "running jumping swimming"
result = re.findall(pattern, text)
print(result) # 输出: ['runn', 'jump']# 多行模式:使用多行模式可以处理多行文本,其中 ^ 和 $ 元字符匹配每行的开头和结尾。通过传递 re.MULTILINE 标志给 re.compile() 函数或使用 re.M 缩写标志来启用多行模式:
pattern = r'^\d+$' # 匹配只包含数字的行
text = "123\nabc\n456\n789"
result = re.findall(pattern, text, re.MULTILINE)
print(result) # 输出: ['123', '456', '789']# 嵌入式修饰符:可以在正则表达式中使用嵌入式修饰符来改变匹配的行为。例如,使用 (?i) 来忽略大小写匹配:
pattern = r'(?i)python' # 忽略大小写匹配 "python"
text = "Python is a programming language"
result = re.findall(pattern, text)
print(result) # 输出: ['Python']# 替换时使用回调函数:使用 re.sub() 函数进行替换时,可以传递一个回调函数来处理每个匹配项,并返回替换后的结果。这允许你根据匹配到的内容动态生成替换值:
def replace_func(match):num = int(match.group(0))return str(num*2)pattern = r'\d+'
text = "123423w 2w 3yui 4 5"
result = re.sub(pattern, replace_func, text)
print(result) #246846w 4w 6yui 8 10# 非捕获组:有时你可能需要使用括号进行分组,但不需要捕获该组的内容。在这种情况下,可以使用非捕获组 (?:...):
pattern = r'(?:https?://)?(www\.[A-Za-z]+\.[A-Za-z]+)'
text = "Visit my website at www.example.com"
result = re.findall(pattern, text)
print(result) # 输出: ['www.example.com']# 前向引用:前向引用允许你引用之前已经匹配的内容。这在匹配重复的子字符串时非常有用:
pattern = r'(\w+)\s+\1' # 匹配重复的单词
text = "apple apple banana banana cherry cherry"
result = re.findall(pattern, text)
print(result) # 输出: ['apple', 'banana', 'cherry']# 替换中使用命名分组引用:可以使用命名分组 (P<name>...) 来指定一个命名的捕获组,并在替换时使用 \\g<name> 引用该组的内容:
pattern = r'(?P<first>\d+)\s+(?P<second>\d+)'
text = "10 20"
result = re.sub(pattern, '\\g<second> \\g<first>', text)
print(result) # 输出: "20 10"# 回溯引用:使用回溯引用可以匹配重复的模式,并在替换时保留其中一个副本:
pattern = r'(\d+)-\1' # 匹配连续重复的数字,例如 "22-22"
text = "11-11 22-22 33-33"
result = re.findall(pattern, text)
print(result) # 输出: ['11', '22', '33']# 负向前向引用:负向前向引用允许你指定一个模式,该模式不能在当前位置之后出现。可以使用 (?!...) 来表示负向前向引用:
pattern = r'\b(?!un)\w+\b' # 匹配不以 "un" 开头的单词
text = "happy unhappy apple banana"
result = re.findall(pattern, text)
print(result) # 输出: ['happy', 'apple', 'banana']# 嵌入条件匹配:使用 (?if:...) 来实现条件匹配。可以根据条件选择不同的模式进行匹配:
pattern = r'(?i)(?:(?<=Mr\.)|(?<=Ms\.)|(?<=Mrs\.))\s\w+'
text = "Hello Mr. Smith, Ms. Johnson, and Mrs. Davis"
result = re.findall(pattern, text)
print(result) # 输出: ['Smith', 'Johnson', 'Davis']# 后向引用断言:使用 (?<=(...)) 来实现后向引用断言,即在匹配的位置之前必须满足某个条件:
pattern = r'\b(\w+)\b(?<=(ing))' # 匹配以 "ing" 结尾的单词中的前面部分
text = "running jumping swimming"
result = re.findall(pattern, text)
print(result) # 输出: ['runn', 'jump']# 零宽负向断言:使用 (?<!...) 来实现零宽负向断言,即在当前位置之前不能满足某个条件:
pattern = r'(?<!un)\b\w+\b' # 匹配不以 "un" 开头的单词
text = "happy unhappy apple banana"
result = re.findall(pattern, text)
print(result) # 输出: ['happy', 'apple', 'banana']# 非打印字符:可以使用转义序列来匹配非打印字符,如制表符 \t、换行符 \n 等:
pattern = r'abc\tdef\nghi'
text = "abc\tdef\nghi"
result = re.findall(pattern, text)
print(result) # 输出: ['abc\tdef\nghi']# 贪婪与非贪婪匹配:在重复模式中,默认情况下是贪婪匹配,尽可能多地匹配。但可以使用 ? 来指定非贪婪匹配,尽可能少地匹配:
s = "aaaabaaaa"
pattern = r'a.*a' # 贪婪匹配模式
match = re.search(pattern, s)
if match:print(match.group()) # 输出:'aaaabaaaa's = "aaaabaaaa"
pattern = r'a.*?a' # 非贪婪匹配模式
match = re.search(pattern, s)
if match:print(match.group()) # 输出:'aaa'
相关文章:

Python--控制台获取输入与正则表达式
前言一、控制台获取输入1.1 字符串输入1.2 整数输入1.3 浮点数输入1.4 布尔值输入1.5 列表输入1.6 汇总 二、正则表达式2.1 匹配数字2.2 模式检查2.3 替换字符2.4 切分字符串2.5 搜索并提取匹配的部分2.6 使用捕获组提取匹配的部分2.7 非贪婪匹配2.8 忽略大小写匹配2.9 使用预定…...
网络基础知识面试题1
VC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)...

JavaScript系列从入门到精通系列第十五篇:JavaScript中函数的实参介绍返回值介绍以及函数的立即执行
文章目录 一:函数的参数 1:形参如何定义 2:形参的使用规则 二:函数的返回值 1:函数返回值如何定义 2:函数返回值种类 三:实参的任意性 1:方法可以作为实参 2:将匿…...
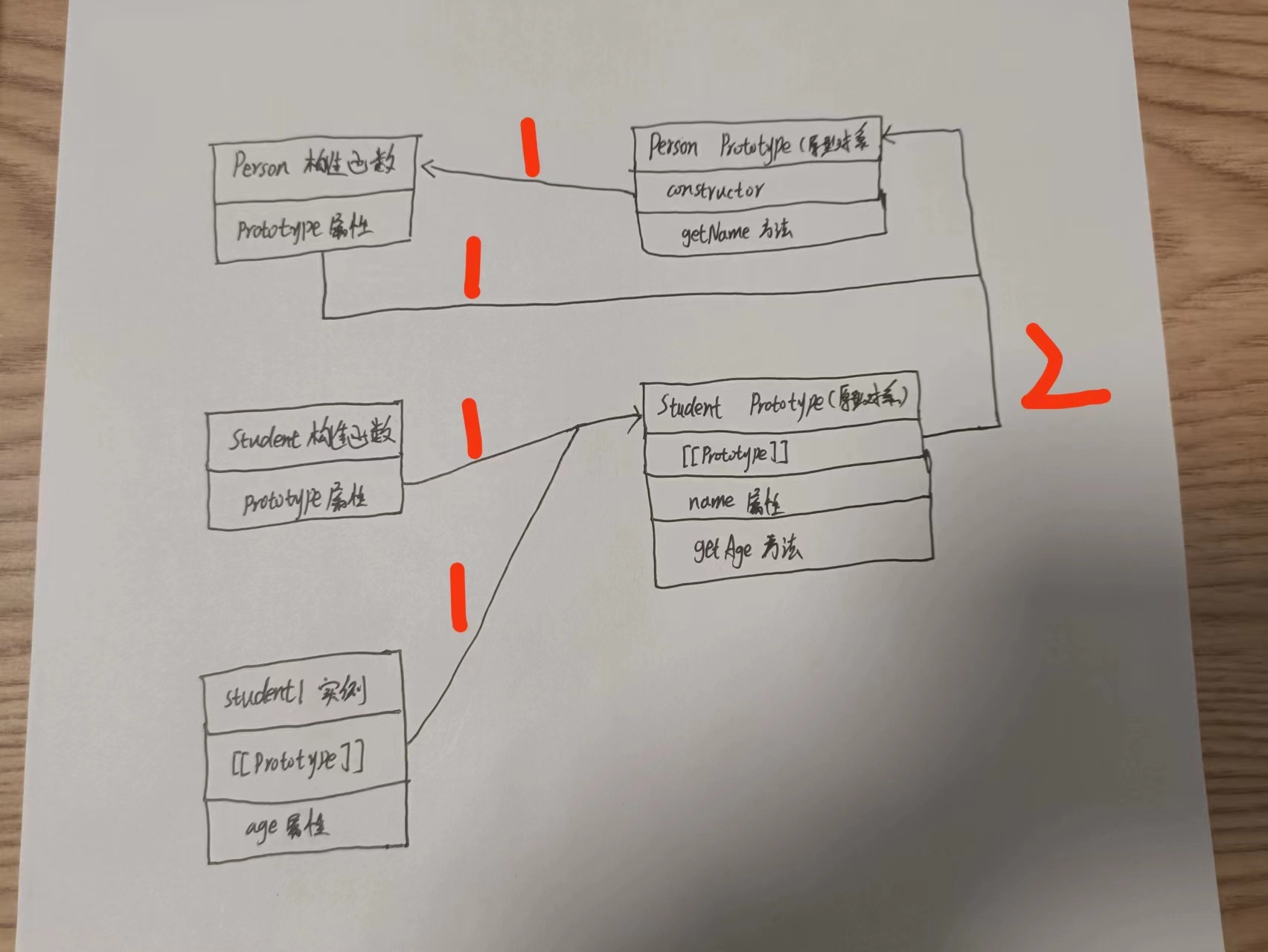
js中的原型链
编写思路: 简单介绍构造函数介绍原型对象原型对象、实例的关系,从而引出原型链的基本概念 原型链基本思想是利用原型让一个引用类型继承另一个引用类型的属性和方法。 1. 什么是构造函数 构造函数本身跟普通函数一样,也不存在定义构造函数…...
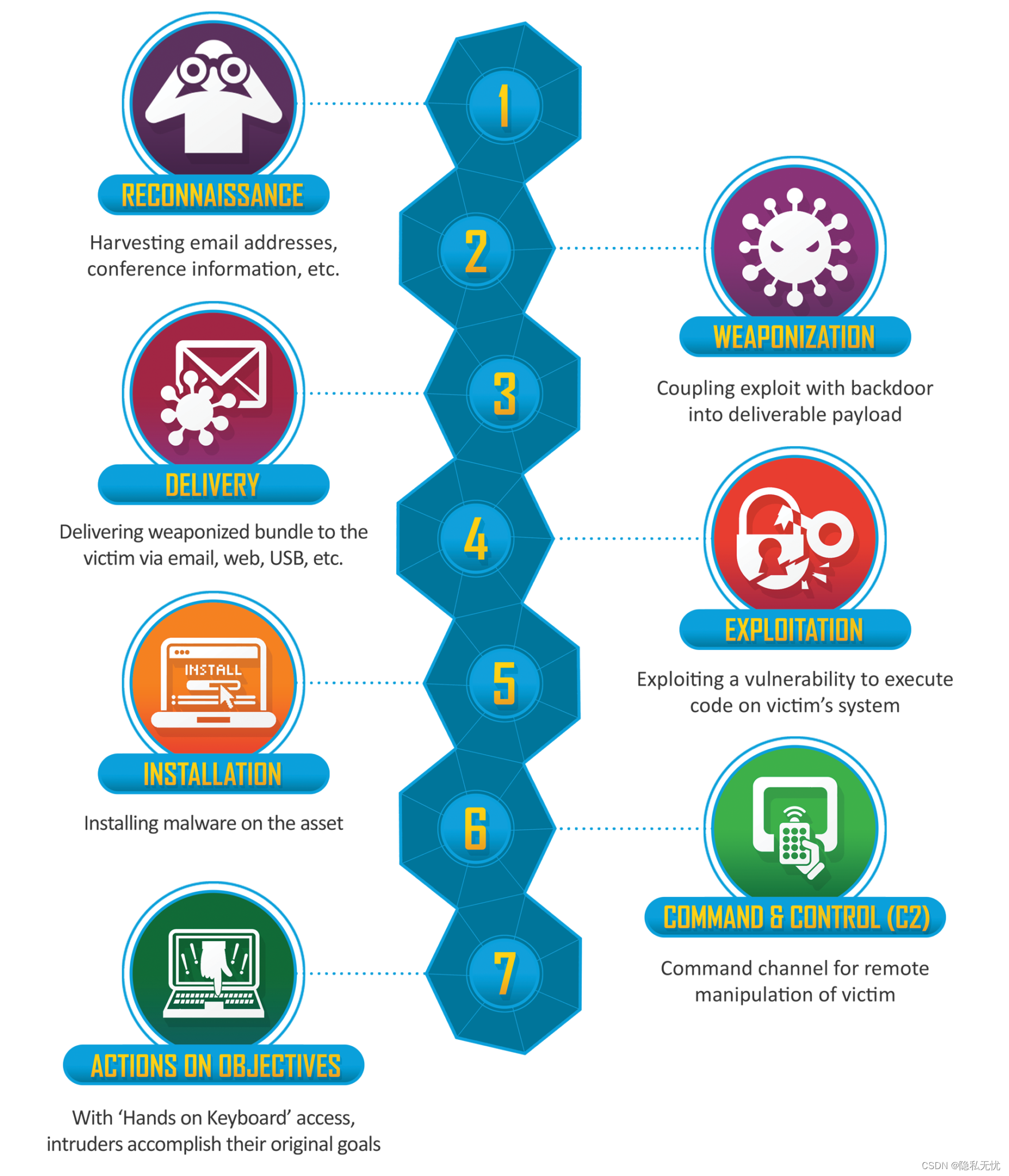
一文搞懂APT攻击
APT攻击 1. 基本概念2. APT的攻击阶段3. APT的典型案例参考 1. 基本概念 高级持续性威胁(APT,Advanced Persistent Threat),又叫高级长期威胁,是一种复杂的、持续的网络攻击,包含高级、长期、威胁三个要素…...

在pandas中通过一列数据映射出另一列的几种思路和方法
如果一句话中出现某个品牌的关键词,那么就将该品牌进行提取,开始我的做法是写了很多elif,如下: def brand_describe(x):if TRUM in x.upper():return "通快"elif BYSTRONIC in x.upper():return "百超"elif …...
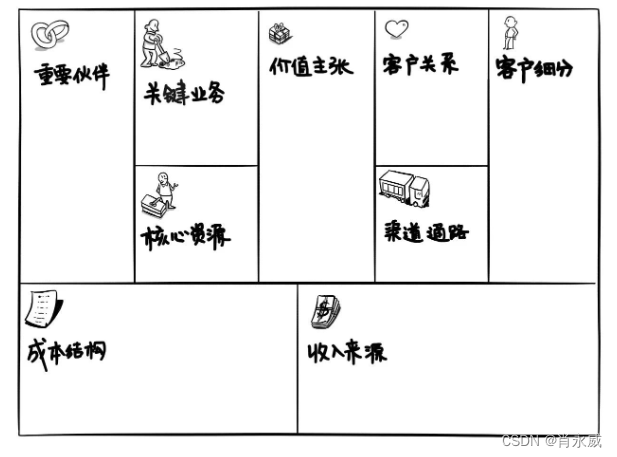
数据分析视角中的商业分析学习笔记
数据分析一大堆,结果却是大家早就知道的结论?是工具和方法出问题了吗?真正原因可能是你的思维有误区。 为什么分析的这么辛苦,得出的结论大家早知道,谁谁都不满意?核心原因有3个: 分析之前&am…...
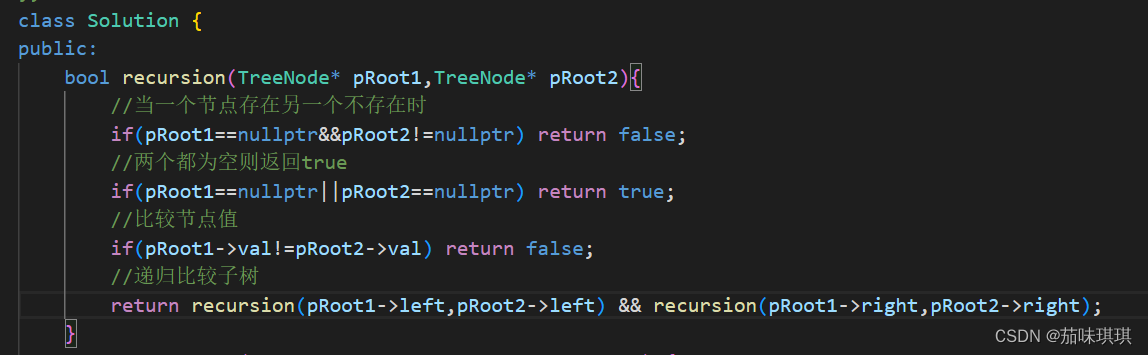
剑指offer——JZ26 树的子结构 解题思路与具体代码【C++】
一、题目描述与要求 树的子结构_牛客题霸_牛客网 (nowcoder.com) 题目描述 输入两棵二叉树A,B,判断B是不是A的子结构。(我们约定空树不是任意一个树的子结构) 假如给定A为{8,8,7,9,2,#,#,#,#,4,7},B为{8,9,2}&…...

NEFU数字图像处理(1)绪论
一、简介 1.1什么是数字图像 图像是三维场景在二维平面上的影像。根据其存储方式和表现形式,可以将图像分为模拟图像和数字图像两大类 图像处理方法:光学方法、电子学方法 模拟图像:连续的图像数字图像:通过对时间上和数值上连续…...
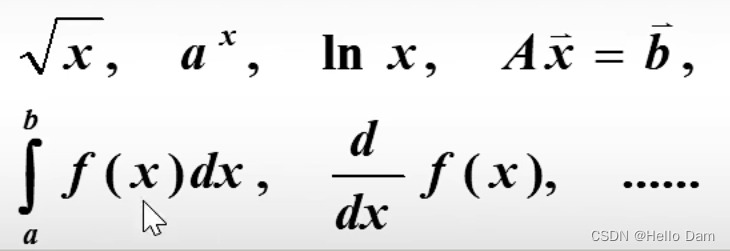
数值分析学习笔记——绪论【华科B站教程版本】
绪论 数值分析概念 用计算机求解数学问题的数值方法和理论 三大科学研究方法 实验理论分析科学计算(用计算机去辅助研究):数值方法计算机 解析解和近似解 解析解:使用数学方法求出或推导出的结果,往往可以求解出…...

节日灯饰灯串灯出口欧洲CE认证办理
灯串(灯带),这个产品的形状就象一根带子一样,再加上产品的主要原件就是LED,因此叫做灯串或者灯带。2022年,我国灯具及相关配件产品出口总额超过460亿美元。其中北美是最大的出口市场。其次是欧洲市场&#…...
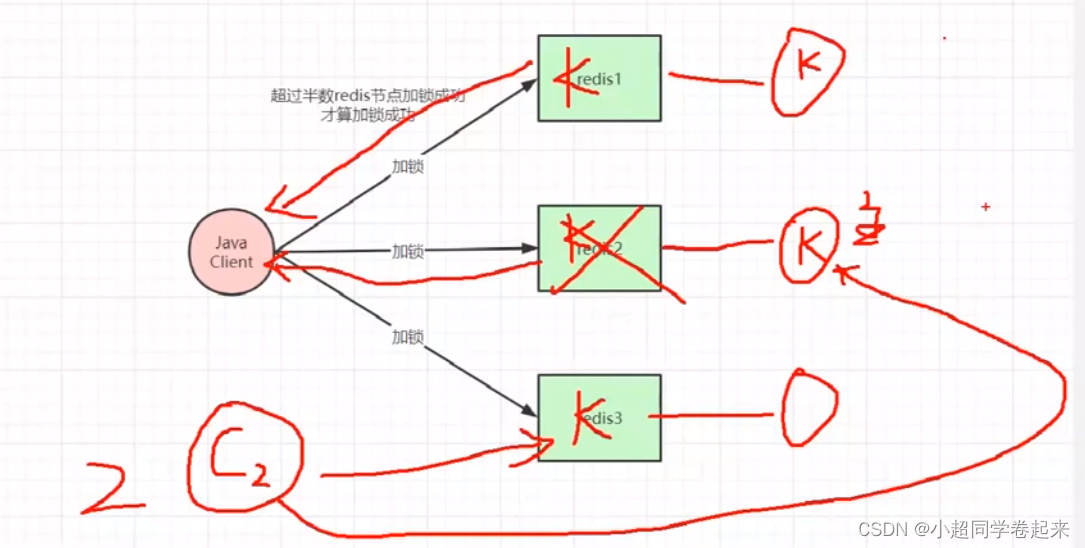
一线大厂Redis高并发缓存架构实战与性能优化
文章目录 一、redis主从架构锁失效问题分析二、从CAP角度剖析redis与zookeeper分布式锁区别三、redlock分布式锁原理与存在的问题分析四、大促场景如何将分布式锁性能提升100倍五、高并发redis架构代码实战 一、redis主从架构锁失效问题分析 我们都知道,一般的互联…...

PHP 行事准则:allow_url_fopen 与 allow_url_include
文章目录 参考环境allow_url_fopenallow_url_fopen 配置项操作远程文件file 协议 allow_url_includeallow_url_include 配置项 allow_url_include 与 allow_url_fopen区别联系默认配置配置项关闭所导致异常运行时配置ini_set()限制 参考 项目描述搜索引擎Bing、GoogleAI 大模型…...
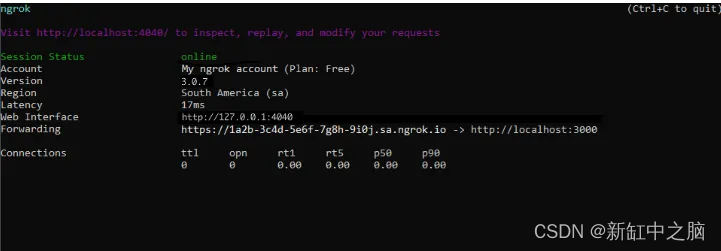
Replicate + ngrok云端大模型API实现教程
ChatGPT 的诞生预示着人工智能和机器学习领域的新时代。 日新月异,Hugging Face 不断推出突破性的语言模型,重新定义人机交互的界限。欢迎来到未来! 当然,有很多选项可以对它们进行推断。在本文中,我将告诉大家如何使…...

蓝桥等考Python组别十四级005
蓝桥等考Python组别十四级 第一部分:选择题 1、Python L14 (15分) 运行下面程序,输出的结果是( )。 d = {1 : one, 2 : two, 3 : three, 4 : four} print(d[2]) onetwothreefour正确答案:B...
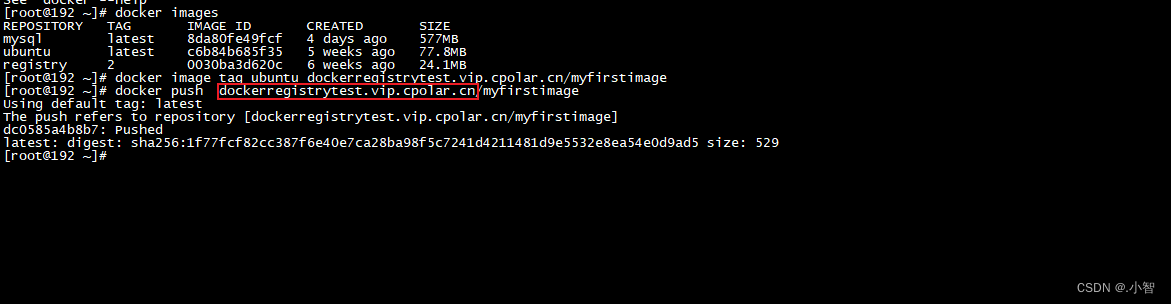
Linux 本地 Docker Registry本地镜像仓库远程连接
Linux 本地 Docker Registry本地镜像仓库远程连接 Docker Registry 本地镜像仓库,简单几步结合cpolar内网穿透工具实现远程pull or push (拉取和推送)镜像,不受本地局域网限制! 1. 部署Docker Registry 使用官网安装方式,docker命令一键启动,该命令启动一个regis…...
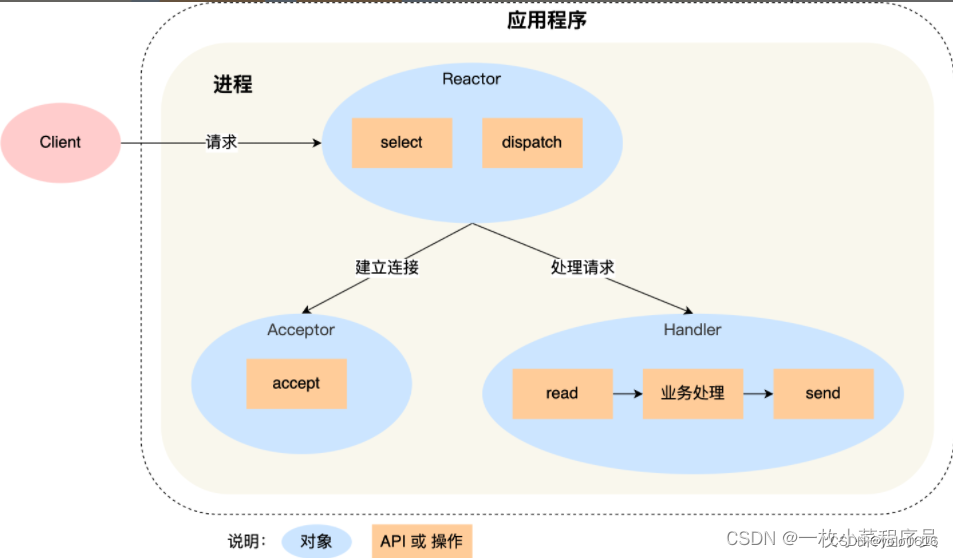
二十九、高级IO与多路转接之epollreactor(收官!)
文章目录 一、Poll(一)定义(二)实现原理(三)优点(四)缺点 二、I/O多路转接之epoll(一)从网卡接收数据说起(二)如何知道接收了数据&…...

vite dev开发模式下支持外部模块引用
web工程中经常需要使用外部的cdn资源,比如lodash、three.js等: <script type"importmap">{"imports": {"lodash": "https://unpkg.com/lodash-es4.17.21/lodash.js"}} </script> vite build通过r…...

Chrome出现STATUS_STACK_BUFFER_OVERRUN解决方法之一
Chrome出现STATUS_STACK_BUFFER_OVERRUN错误代码,setting都无法打开 解决方法1:兼容性设置为win7 解决方法2: 1,开始菜单搜索Exploit Protection 2,添加程序进行自定义,点号,按程序名称添加 …...
【JavaEE】JavaScript
JavaScript 文章目录 JavaScript组成书写方式行内式内嵌式外部式(推荐写法) 输入输出变量创建动态类型基本数据类型数字类型特殊数字值 String转义字符求长度字符串拼接布尔类型undefined未定义数据类型null 运算符条件语句if语句三元表达式switch 循环语…...

MLX90632红外温度传感器Arduino驱动库详解
1. ProtoCentral MLX90632 非接触式红外温度传感器库深度解析1.1 项目定位与工程价值ProtoCentral MLX90632 库是专为 Melexis MLX90632 红外非接触温度传感器设计的 Arduino 兼容驱动库,面向嵌入式系统工程师、硬件开发者及电子爱好者提供开箱即用的高精度测温能力…...

YAYI 2训练故障恢复终极指南:断点续训最佳实践
YAYI 2训练故障恢复终极指南:断点续训最佳实践 【免费下载链接】YAYI2 YAYI 2 是中科闻歌研发的新一代开源大语言模型,采用了超过 2 万亿 Tokens 的高质量、多语言语料进行预训练。(Repo for YaYi 2 Chinese LLMs) 项目地址: https://gitcode.com/gh_m…...

RMBG-2.0在SpringBoot项目中的集成实践:Java开发指南
RMBG-2.0在SpringBoot项目中的集成实践:Java开发指南 1. 开篇:为什么选择RMBG-2.0做智能抠图 如果你正在开发需要图像处理功能的Java应用,特别是需要智能抠图、背景去除的场景,那么RMBG-2.0绝对值得你关注。这个由BRIA AI团队开…...

Whisper-large-v3企业级部署教程:Nginx反向代理+HTTPS安全访问完整配置
Whisper-large-v3企业级部署教程:Nginx反向代理HTTPS安全访问完整配置 1. 引言 如果你已经成功在本地跑通了Whisper-large-v3语音识别服务,那么恭喜你,你已经迈出了第一步。但要让这个服务真正能被团队或客户使用,本地访问是远远…...
的3个常见坑:First()/Dequeue()实战避雷指南)
避开Unity队列(Queue)的3个常见坑:First()/Dequeue()实战避雷指南
Unity队列(Queue)实战避坑指南:从First()到Dequeue()的深度解析 在Unity开发中,队列(Queue)作为一种基础但强大的数据结构,经常被用于处理需要先进先出(FIFO)逻辑的场景。然而,许多开发者在实际使用Queue时,往往会陷入…...

MAX7219四合一点阵驱动原理与同步显示设计
1. 项目概述MAX7219四合一点阵显示模块是一种面向嵌入式系统设计的高集成度LED驱动解决方案,其核心目标是通过极简的硬件接口和确定性的时序控制,实现多片88点阵的稳定、无闪烁显示。该模块并非通用显示终端,而是专为需要紧凑空间部署、低资源…...

告别经纬度模糊聚合!用Uber H3 Java库实现六边形地理网格的5个实战场景
告别经纬度模糊聚合!用Uber H3 Java库实现六边形地理网格的5个实战场景 当我们需要分析城市热力图或规划物流配送区域时,传统基于圆形或矩形的聚合方法常面临边界模糊、计算量大等问题。Uber开源的H3六边形网格系统,通过将地球表面划分为数百…...

实测有效:ERNIE-4.5-0.3B镜像部署,Chainlit界面聊天体验分享
实测有效:ERNIE-4.5-0.3B镜像部署,Chainlit界面聊天体验分享 1. 开箱即用的ERNIE-4.5体验 最近在测试各种开源大语言模型时,发现百度ERNIE-4.5系列中的0.3B版本特别适合快速部署和体验。这个轻量级模型虽然参数规模不大,但在文本…...

手把手教你用LingBot-Depth:RGB-D数据融合的5步完整流程
手把手教你用LingBot-Depth:RGB-D数据融合的5步完整流程 1. 环境准备与快速部署 LingBot-Depth是一个基于DINOv2 ViT-L/14编码器的深度估计与补全模型,能够将RGB图像与稀疏深度数据融合生成高质量的完整深度图。在开始使用前,我们需要先完成…...

Qwen3-ForcedAligner-0.6B部署案例:医疗问诊录音术语时间锚点提取系统
Qwen3-ForcedAligner-0.6B部署案例:医疗问诊录音术语时间锚点提取系统 1. 引言:当医生的话变成数据 想象一下这个场景:一位医生正在问诊,他对着录音设备说:“患者主诉右上腹持续性钝痛三天,伴恶心、呕吐&…...