DPDK系列之三十三DPDK并行机制的底层支持
一、背景介绍
在前面介绍了DPDK中的上层对并行的支持,特别是对多核的支持。但是,大家都知道,再怎么好的设计和架构,再优秀的编码,最终都要落到硬件和固件对整个上层应用的支持。单纯的硬件好处理,一个核不够多个核,在可能的情况下把CPU的频率增加,加大缓存等等。在现有水平的范围内,这些都是可以比较容易做到的。
但是另外一个,就是在CPU上如何最终运行指令(也可以叫做固件设计),这个就需要设计人员动脑子了。一般来说,IPC(Instruction Per Clock,一个时钟周期内执行的指令数量,可不要看成进程间通信)的数量越高,CPU运行性能越高(频率和核数相同)。
现代CPU基本使用了越标量(superscalar)体系结构,通过以空间换时间的方式实行了指令级并行运算。不同的架构的处理器,可能在硬件设计本身有所不同,但在追求并行度上,原理基本相同。
在前面的多核编程中,介绍过几种指令,目前常用的基本以SIMD(单指令流多数据流)和MIMD(多指令流多数据流)为主。后者一般是多核和多CPU(当然更高层次的多计算机也算),但在分析本文中更倾向的是SIMD,毕竟一个核心能处理多少更能体现性能和效率。
SIMD其实很容易理解,可以认为是一种并行的批处理。原来只能一次取一条指令处理一条数据,这次可以一条指令处理多条数据。举个最简单的例子,加指令,需要有两次读操作数,而如果使用SIMD,则一次就可以都读进来。其后的处理周期也是如此,那么效率至少增加了一倍。
而这些指令设计和处理会形成一个指令集,它的发展也有一个过程,intel的SIMD指令集主要有MMX, SSE, AVX, AVX-512,主流就是SSE/AVX。AMD的比较复杂,有兴趣可以查找看一下。
二、DPDK中的应用
在DPDK中对SIMD的应用体现在数据的处理上,DPDK提供了一个化化的拷贝memcpy函数,它充分利用了SIMD指令集:
static __rte_always_inline void *
rte_memcpy(void *dst, const void *src, size_t n)
{if (!(((uintptr_t)dst | (uintptr_t)src) & ALIGNMENT_MASK))return rte_memcpy_aligned(dst, src, n);elsereturn rte_memcpy_generic(dst, src, n);
}
static __rte_always_inline void *
rte_memcpy_aligned(void *dst, const void *src, size_t n)
{void *ret = dst;/* Copy size < 16 bytes */if (n < 16) {return rte_mov15_or_less(dst, src, n);}/* Copy 16 <= size <= 32 bytes */if (n <= 32) {rte_mov16((uint8_t *)dst, (const uint8_t *)src);rte_mov16((uint8_t *)dst - 16 + n,(const uint8_t *)src - 16 + n);return ret;}/* Copy 32 < size <= 64 bytes */if (n <= 64) {rte_mov32((uint8_t *)dst, (const uint8_t *)src);rte_mov32((uint8_t *)dst - 32 + n,(const uint8_t *)src - 32 + n);return ret;}/* Copy 64 bytes blocks */for (; n >= 64; n -= 64) {rte_mov64((uint8_t *)dst, (const uint8_t *)src);dst = (uint8_t *)dst + 64;src = (const uint8_t *)src + 64;}/* Copy whatever left */rte_mov64((uint8_t *)dst - 64 + n,(const uint8_t *)src - 64 + n);return ret;
}
static __rte_always_inline void *
rte_memcpy_generic(void *dst, const void *src, size_t n)
{__m128i xmm0, xmm1, xmm2, xmm3, xmm4, xmm5, xmm6, xmm7, xmm8;void *ret = dst;size_t dstofss;size_t srcofs;/*** Copy less than 16 bytes*/if (n < 16) {return rte_mov15_or_less(dst, src, n);}/*** Fast way when copy size doesn't exceed 512 bytes*/if (n <= 32) {rte_mov16((uint8_t *)dst, (const uint8_t *)src);rte_mov16((uint8_t *)dst - 16 + n, (const uint8_t *)src - 16 + n);return ret;}if (n <= 48) {rte_mov32((uint8_t *)dst, (const uint8_t *)src);rte_mov16((uint8_t *)dst - 16 + n, (const uint8_t *)src - 16 + n);return ret;}if (n <= 64) {rte_mov32((uint8_t *)dst, (const uint8_t *)src);rte_mov16((uint8_t *)dst + 32, (const uint8_t *)src + 32);rte_mov16((uint8_t *)dst - 16 + n, (const uint8_t *)src - 16 + n);return ret;}if (n <= 128) {goto COPY_BLOCK_128_BACK15;}if (n <= 512) {if (n >= 256) {n -= 256;rte_mov128((uint8_t *)dst, (const uint8_t *)src);rte_mov128((uint8_t *)dst + 128, (const uint8_t *)src + 128);src = (const uint8_t *)src + 256;dst = (uint8_t *)dst + 256;}
COPY_BLOCK_255_BACK15:if (n >= 128) {n -= 128;rte_mov128((uint8_t *)dst, (const uint8_t *)src);src = (const uint8_t *)src + 128;dst = (uint8_t *)dst + 128;}
COPY_BLOCK_128_BACK15:if (n >= 64) {n -= 64;rte_mov64((uint8_t *)dst, (const uint8_t *)src);src = (const uint8_t *)src + 64;dst = (uint8_t *)dst + 64;}
COPY_BLOCK_64_BACK15:if (n >= 32) {n -= 32;rte_mov32((uint8_t *)dst, (const uint8_t *)src);src = (const uint8_t *)src + 32;dst = (uint8_t *)dst + 32;}if (n > 16) {rte_mov16((uint8_t *)dst, (const uint8_t *)src);rte_mov16((uint8_t *)dst - 16 + n, (const uint8_t *)src - 16 + n);return ret;}if (n > 0) {rte_mov16((uint8_t *)dst - 16 + n, (const uint8_t *)src - 16 + n);}return ret;}/*** Make store aligned when copy size exceeds 512 bytes,* and make sure the first 15 bytes are copied, because* unaligned copy functions require up to 15 bytes* backwards access.*/dstofss = (uintptr_t)dst & 0x0F;if (dstofss > 0) {dstofss = 16 - dstofss + 16;n -= dstofss;rte_mov32((uint8_t *)dst, (const uint8_t *)src);src = (const uint8_t *)src + dstofss;dst = (uint8_t *)dst + dstofss;}srcofs = ((uintptr_t)src & 0x0F);/*** For aligned copy*/if (srcofs == 0) {/*** Copy 256-byte blocks*/for (; n >= 256; n -= 256) {rte_mov256((uint8_t *)dst, (const uint8_t *)src);dst = (uint8_t *)dst + 256;src = (const uint8_t *)src + 256;}/*** Copy whatever left*/goto COPY_BLOCK_255_BACK15;}/*** For copy with unaligned load*/MOVEUNALIGNED_LEFT47(dst, src, n, srcofs);/*** Copy whatever left*/goto COPY_BLOCK_64_BACK15;
}
更多相关的代码在rte_memcpy.h和rte_memcpy.c中,注意,它包含不同CPU架构平台的多个版本,不要搞混。
从上面的代码可以看到,影响拷贝速度的有以下几点:
1、字节对齐和数据的加载存储。
这个大家都明白,除了字节对齐速度加快外,而且DPDK中还对不同的字节对齐以及长度进行了控制,充分发挥SIMD的优势(说直白一点就是在条件允许的情况下,一次拷贝数量多【16字节:128位】,这个和平台支持有关)
2、函数和库调用开销,库函数需要调用过程,这个也浪费时间。这个库调用过程在编译选择优化的过程中,优化难度也比较大,不如在DPDK中直接调用,特别是使用
static __rte_always_inline(静态内联)时,这在网上有很多优化的比较,自己也可以试一试。
3、整体上来说,数据量越大,上面的优化越优势越大;否则优势则不明显。
上述的比较是针对库glibc以及DPDK相比而言的,至于个人优化过的则不在此范畴之内。另外,随着技术的进步,如果用高版本的glibc并开启优化后,可能效果差别也不大,这个没有进行比较。
有兴趣可以看看rte_mov256等几个函数。
需要说明的是,对于某一类函数,没有普遍最优之说。只有场景条件限制下的最合适。也就是说,DPDK的拷贝函数不代表此函数比glibc中的拷贝函数优秀,只是说明此函数在DPDK的应用场景下更合适。
最后总结一下,针对内存拷贝的优化点:
1、减少拷贝过程中的附加处理如字节对齐
2、在平台允许情况下使用最大带宽(拷贝最大数量)
3、使用平坦顺序内存并使用分支预测(减少分支跳转,如是否有范围重叠等)
4、有可能的情况下使用non-temporal访存执令
5、使用加速拷贝的一些指令(string操作指令等)。
6、处理大内存(M以上)和小内存(K以下)的不同场景(这个在一些常用框架中都会处理)
三、总结
性能和效率的提升,是一个系统工程。它可能会从一个点开始,然后不断的影响别的点,然后这些点又互相影响,最后蔓延到整个系统,形成一个量变到质变的过程。计算机应用也不外乎这样。
DPDK中通过Linux内核的一些设计(如大页),通过一种工程优化的手段来提高网络通信的效率,但反过来,内核也会借鉴DPDK的一些特点来吸收到内核中去。同样,DPDK的出现对硬件本身的设计也提出了虚拟化的相关等要求。硬件水平的提高又可以提高DPDK的性能。
国内的缺少的不是后面的一系列动作,缺少的恰恰是开始那个点,那个用于爆发的创新点。
相关文章:

DPDK系列之三十三DPDK并行机制的底层支持
一、背景介绍 在前面介绍了DPDK中的上层对并行的支持,特别是对多核的支持。但是,大家都知道,再怎么好的设计和架构,再优秀的编码,最终都要落到硬件和固件对整个上层应用的支持。单纯的硬件好处理,一个核不…...
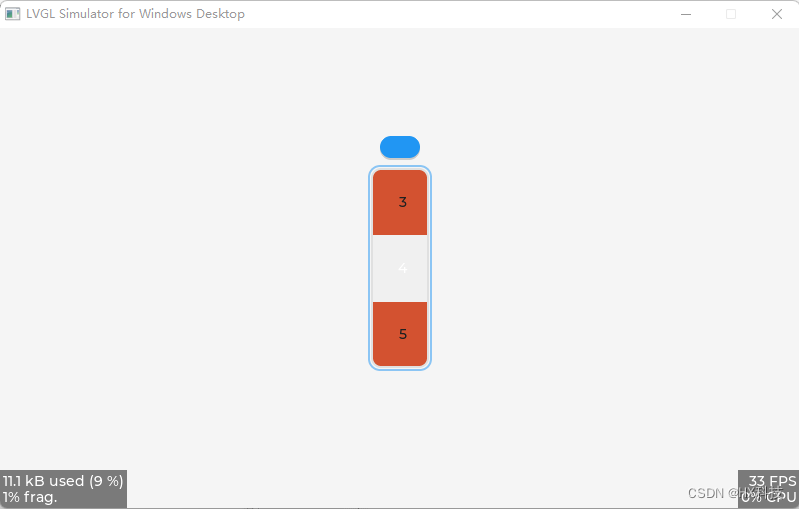
LVGL_基础控件滚轮roller
LVGL_基础控件滚轮roller 1、创建滚轮roller控件 /* 创建一个 lv_roller 部件(对象) */ lv_obj_t * roller lv_roller_create(lv_scr_act()); // 创建一个 lv_roller 部件(对象),他的父对象是活动屏幕对象// 将部件(对象)添加到组,如果设置了默认组,…...
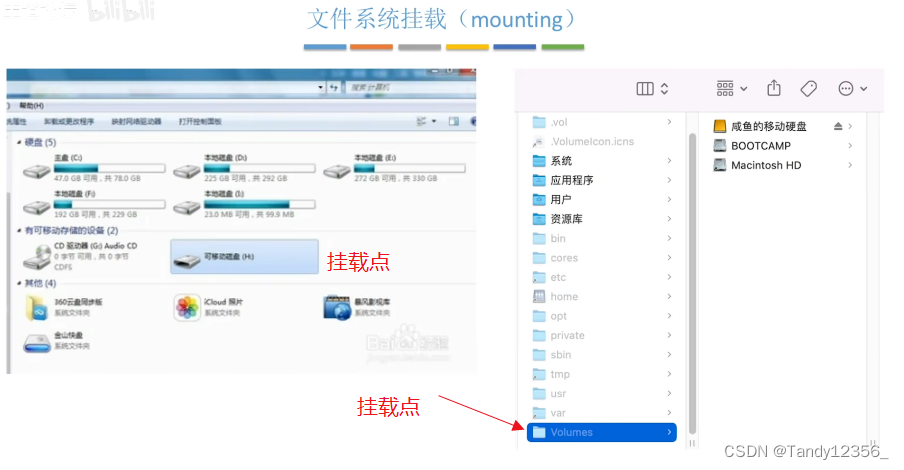
王道考研操作系统——文件管理
磁盘的基础知识 .txt用记事本这个应用程序打开,文件最重要的属性就是文件名了 保护信息:操作系统对系统当中的各个用户进行了分组,不同分组的用户对文件的操作权限是不一样的 文件的逻辑结构就是文件内部的数据/记录应该被怎么组织起来&…...
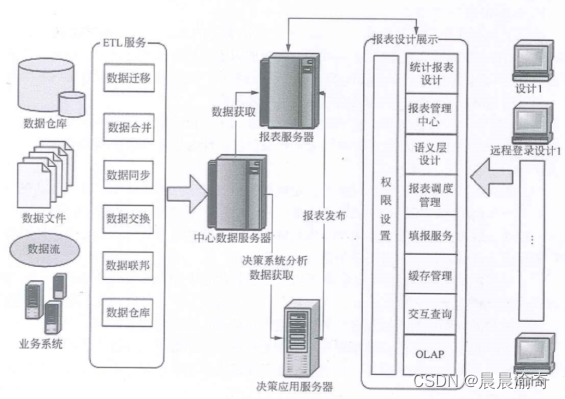
商业智能系统的主要功能包括数据仓库、数据ETL、数据统计输出、分析功能
ETL服务内容包含: 数据迁移数据合并数据同步数据交换数据联邦数据仓库...

基于帝国主义竞争优化的BP神经网络(分类应用) - 附代码
基于帝国主义竞争优化的BP神经网络(分类应用) - 附代码 文章目录 基于帝国主义竞争优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.帝国主义竞争优化BP神经网络3.1 BP神经网络参数设置3.2 帝国主义竞争算…...

将python项目部署在一台服务器上
将python项目部署在一台服务器上 1.服务器2.部署方法2.1 手动部署2.2 容器化技术部署2.3 服务器less技术部署 1.服务器 服务器一般为:物理服务器和云服务器。 我的是物理服务器:这是将服务器硬件直接放置在您自己的数据中心或机房的传统方法。这种方法需…...
【C语言】善于利用指针(二)
💗个人主页💗 ⭐个人专栏——C语言初步学习⭐ 💫点击关注🤩一起学习C语言💯💫 目录 导读:1. 字符指针1.1 字符串的引用方式1.2 有趣的面试题 2. 数组指针2.1 一维数组指针的定义2.2 一维数组…...

Python调用C++
https://www.cnblogs.com/renfanzi/p/10276997.html Linux使用Python调用C/C接口(一) - 代码先锋网 linux系统上使用Python调用C生成的.so动态链接库opencv_linux 下python 编译为so ,给c使用_比赛学习者的博客-CSDN博客 https://www.cnblogs.com/shuimuqingyang/p/13618105…...
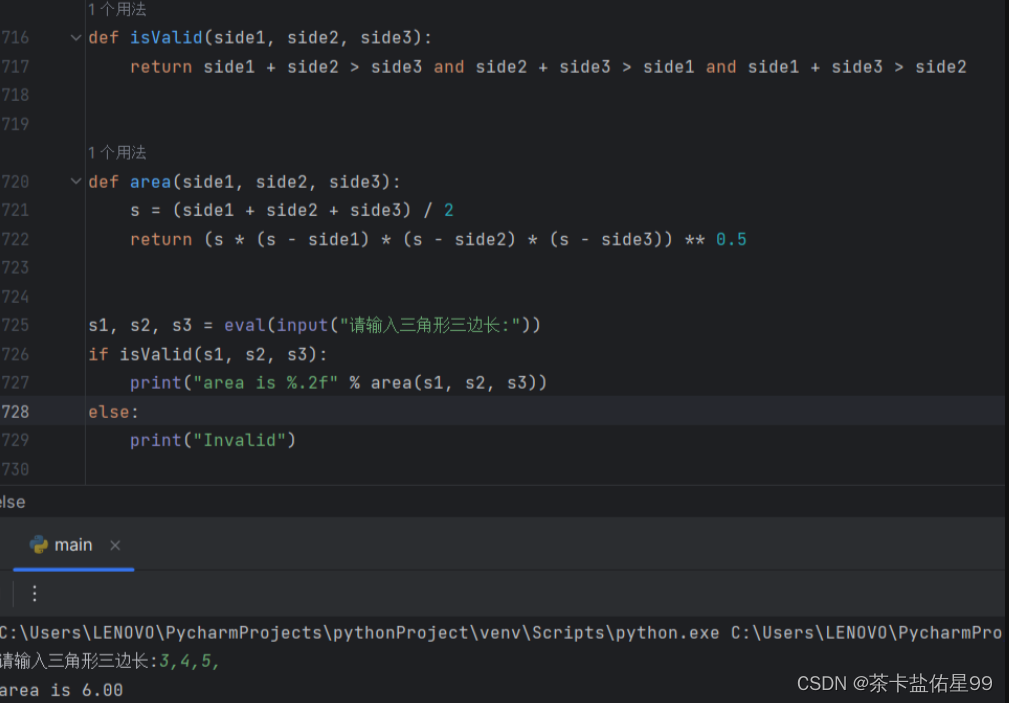
自己实现扫描全盘文件的函数。
1.自己实现扫描全盘的函数 def scan_disk(dir): global count,dir_count if os.path.isdir(dir): files os.listdir(dir) for file in files: print(file) dir_count 1 if os.path.isdir(dir os.sep file): …...

JSON文件读写
1、依赖文件 #include <QFile> #include <QJsonDocument> #include <QJsonObject> #include <QDebug> #include <QStringList>2、头文件 bool ReadJsonFile(const QString& filePath""); bool WriteJsonFile(const QString&…...
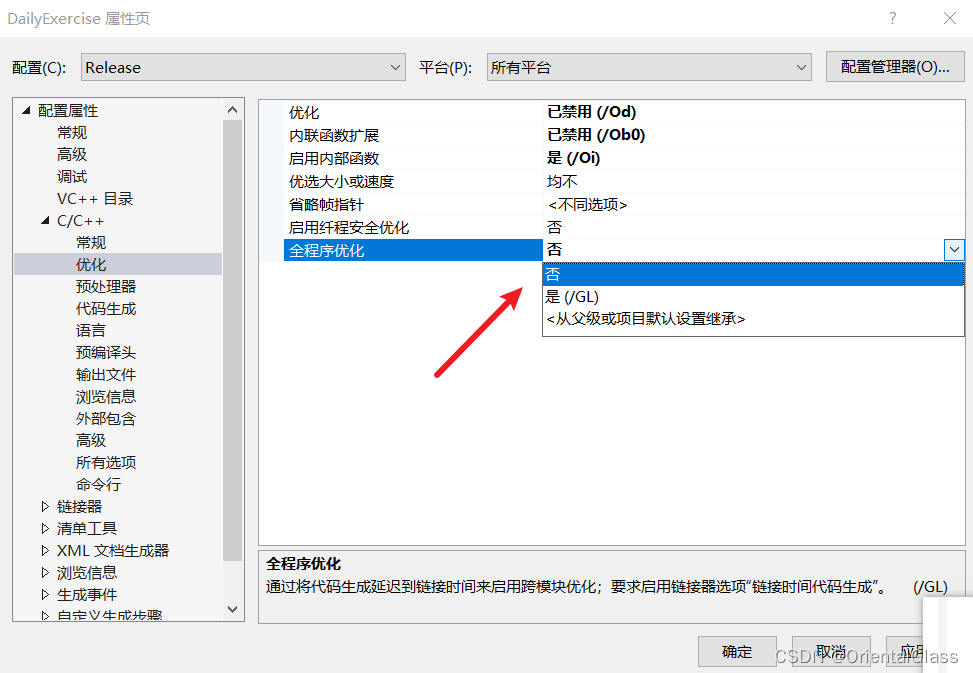
VisualStudio2022环境下Release模式编译dll无法使用TLS函数问题
Debug x86环境下正常使用TLS回调函数 切换到Release发现程序没有使用tls 到C/C > 优化中将全程序优化关闭即可...
ChatGPT基础使用总结
文章目录 一、ChatGPT基础概念大型语言模型LLMs---一种能够以类似人类语言的方式“说话”的软件ChatGPT定义---OpenAI 研发的一款聊天机器人程序(2022年GPT-3.5,属于大型语言模型)ChatGPT4.0---OpenAI推出了GPT系列的最新模型ChatGPT典型使用…...
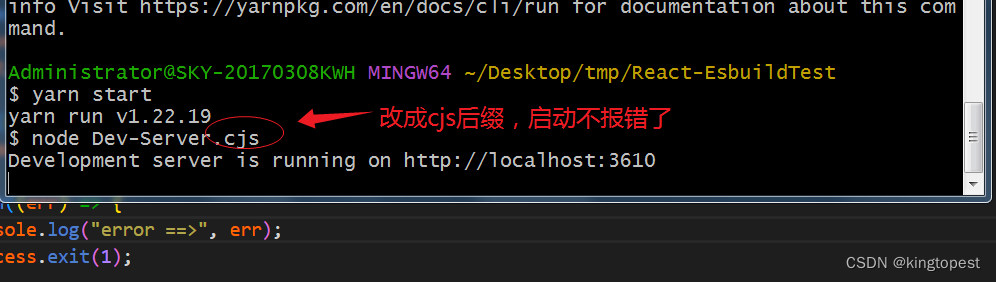
解决报错: require is not defined in ES module scope
用node启动mjs文件报错:require is not defined in ES module scope 现象如下: 原因: 文件后缀是mjs, 被识别为es模块,但是node默认是commonjs格式,不支持也不能识别es模块。 解决办法:把文件后缀从.mjs改…...
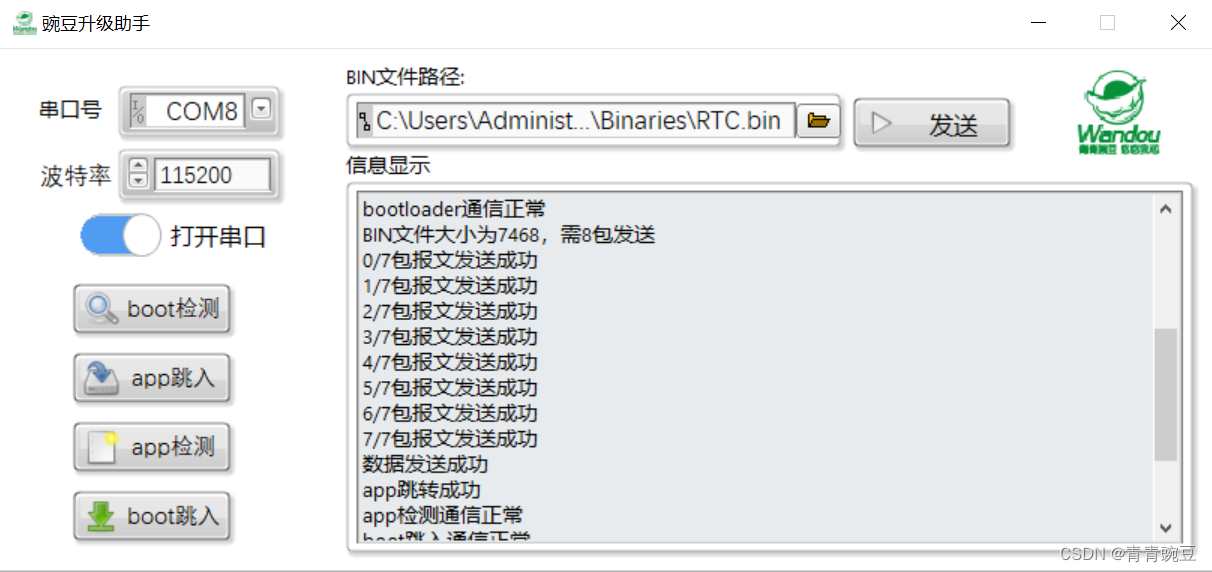
STM32 10个工程篇:1.IAP远程升级(六)
在IAP远程升级的最后一篇博客里,笔者想概括性地梳理总结IAP程序设计中值得注意的问题,诚然市面上或者工作后存在不同版本的IAP下位机和上位机软件,也存在不同定义的报文格式,甚至对于相似的知识点不同教程又有着完全不同的解读&am…...

【智能家居项目】裸机版本——字体子系统 | 显示子系统
🐱作者:一只大喵咪1201 🐱专栏:《智能家居项目》 🔥格言:你只管努力,剩下的交给时间! 今天实现上图整个项目系统中的字体子系统和显示子系统。 目录 🀄设计思路…...

PDF中跳转到参考文献后,如何回到原文
在PDF中,点击了参考文献的超链接可以直接跳至参考文献的位置。 如果想从当前参考文献在回到正文中对应位置时,可以通过 Alt \red{\text{Alt}} Alt ← \red{\leftarrow} ← 实现。...
了解基于Elasticsearch 的站内搜索,及其替代方案
对于一家公司而言,数据量越来越多,如果快速去查找这些信息是一个很难的问题,在计算机领域有一个专门的领域IR(Information Retrival)研究如何获取信息,做信息检索。在国内的如百度这样的搜索引擎也属于这个…...

【多模态融合】TransFusion学习笔记(2)
接上篇【多模态融合】TransFusion学习笔记(1)。 从TransFusion-L到TransFusion ok,终于可以给出论文中那个完整的框架图了,我第一眼看到这个图有几个疑问: Q:Image Guidance这条虚线引出的Query Initialization是什么意思? Q:图像分支中的…...

Pyhon-每日一练(1)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...
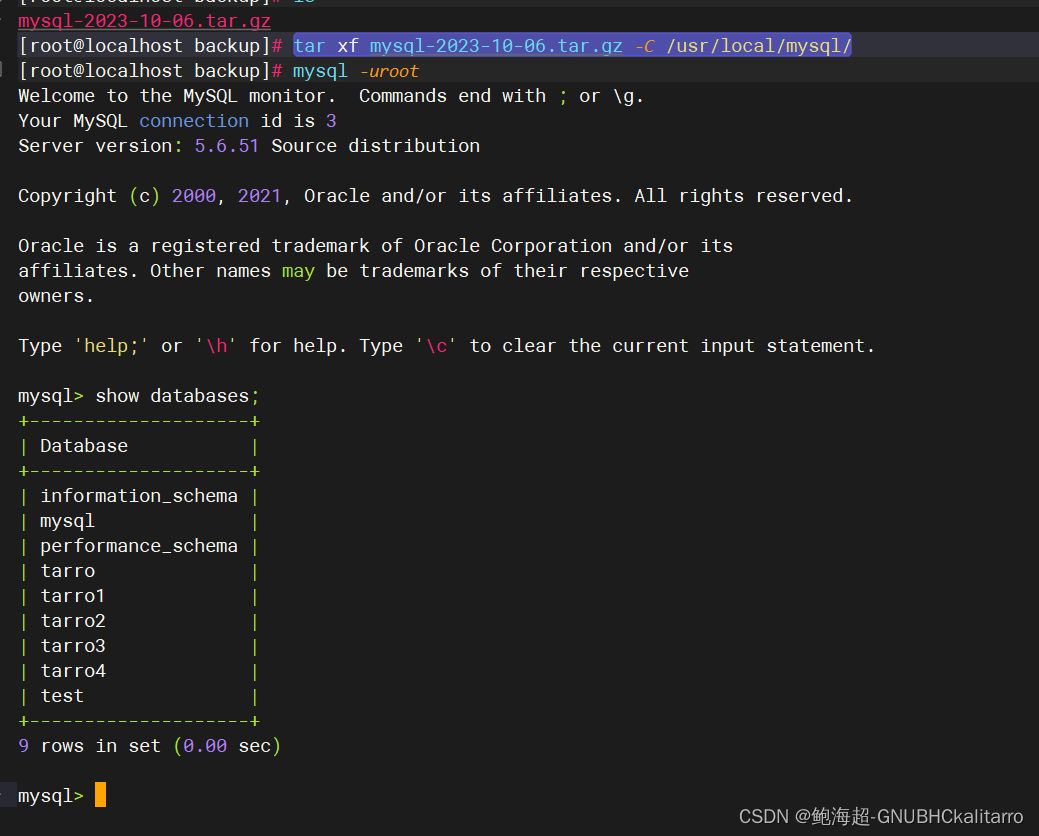
MySQL:数据库的物理备份和恢复-冷备份(3)
介绍 物理备份: 直接复制数据文件进行的备份 优点:不需要其他的工具,直接复制就好,恢复直接复制备份文件即可 缺点:与存储引擎有关,跨平台能力较弱 逻辑备份: 从数据库中导出数据另存而进行的备…...

Ubuntu 上安装 ping 和 nslookup 命令
Ubuntu 上安装 ping 和 nslookup 命令 在使用 Ubuntu 系统时,ping 和 nslookup 是我们最常用的网络诊断工具。然而,有时当你尝试运行它们时,系统却提示“command not found”。这通常发生在 Ubuntu Server 最小化安装或 Docker 容器环境中。本…...

IndexTTS 2.0快速上手:3步完成音色克隆,小白也能做出专业级配音
IndexTTS 2.0快速上手:3步完成音色克隆,小白也能做出专业级配音 1. 为什么你需要IndexTTS 2.0? 想象一下这样的场景:你刚完成了一段精彩的视频剪辑,画面流畅、节奏紧凑,但当你尝试配上语音时,…...

【无人机路径规划】基于改进A星算法
研究课题:基于改进A星算法的无人机路径规划关键词:无人机; 路径规划; A星算法改进方向:自适应权重系数优化启发函数课题说明:研究标准A star算法的基本原理和三维地图路径规划求解方法,结合参考…...

预告 线性代数:入门与全领域展开
【底层数学四部曲第四部重磅预告】 线性代数:入门与全领域展开 ——构筑高维世界的底层结构与系统思维 在《微积分:入门与全领域展开》《第一性原理:入门与全领域展开》《概率与统计:入门与全领域展开》相继完成之后,我将开启本系列的第四部、也是底层知识体系中最后一…...

从零到一:使用EJML的SimpleMatrix进行Java矩阵编程实战
1. 为什么是EJML?一个Java开发者的矩阵运算救星 如果你用Java写过算法,尤其是涉及到机器学习、图像处理或者科学计算,那你肯定对矩阵运算的“痛”深有体会。用原生的二维数组?光是写个矩阵乘法就得三层嵌套循环,代码又…...
)
【2026年最新600套毕设项目分享】springboot“校园淘”二手交易平台(14127)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

什么是 OpenClaw
OpenClaw(曾用名 Clawdbot、Moltbot)是一款开源的个人 AI 助手平台,于 2026 年初在GitHub 上迅速走红,成为近年来增长最快的开源项目之一。它能够在用户自己的设备上本地运行,通过 WhatsApp、Telegram、Discord、飞书、…...

Flutter 三方库 hotp 的鸿蒙适配指南 - 实现 RFC 4226 标准双因素认证、在 OpenHarmony 上打造极致安全的动态令牌实战
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net Flutter 三方库 hotp 的鸿蒙适配指南 - 实现 RFC 4226 标准双因素认证、在 OpenHarmony 上打造极致安全的动态令牌实战 前言 在鸿蒙(OpenHarmony)生态的金融管理、…...

Gorilla技术播客系列:与AI先驱探讨函数调用的未来
Gorilla技术播客系列:与AI先驱探讨函数调用的未来 【免费下载链接】gorilla Gorilla: An API store for LLMs 项目地址: https://gitcode.com/gh_mirrors/go/gorilla Gorilla作为LLM的API商店,正在引领函数调用技术的革新。本播客系列邀请AI领域先…...

如何让Flashlight插件完美支持不同macOS版本:完整兼容性指南
如何让Flashlight插件完美支持不同macOS版本:完整兼容性指南 【免费下载链接】Flashlight The missing Spotlight plugin system 项目地址: https://gitcode.com/gh_mirrors/fl/Flashlight Flashlight作为macOS系统上强大的Spotlight增强工具,让用…...