ChatGLM2-6B的通透解析:从FlashAttention、Multi-Query Attention到GLM2的微调、源码解读
前言
本文最初和第一代ChatGLM-6B的内容汇总在一块,但为了阐述清楚FlashAttention、Multi-Query Attention等相关的原理,以及GLM2的微调、源码解读等内容,导致之前那篇文章越写越长,故特把ChatGLM2相关的内容独立抽取出来成本文
第一部分 相比第一代的改进点:FlashAttention与Multi-Query Attention
ChatGLM2-6B(GitHub项目地址、HuggingFace地址)是开源中英双语对话模型 ChatGLM-6B 的第二代版本,相比第一代,第二点引入了如下新特性:
- 数据集上
经过了 1.4T 中英标识符的预训练与人类偏好对齐训练 - 更长的上下文
基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话
(当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,会在后续迭代升级中着重进行优化) - 更高效的推理
基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K - 模型架构上变成了decoder only的架构
chatglm还是encoder架构,但是到了chatglm2 变成了decoder only的架构(这点很少有资料会提及到),何以见得呢?
如七月黄老师所说,chatglm2仓库的modeling用了新版pytorch的这个函数:context_layer
context_layer 这个函数实现了attention机制的计算,入参 is_causal=True 表示遮后看前的mask(这种类型的注意力通常用在transformer的decoder部分,以确保当前位置只能关注到之前的位置,俗称“看不见未来”,从而使模型可以进行自回归预测 )

- 允许商业使用
- 准确性不足
尽管模型在训练的各个阶段都尽力确保数据的合规性和准确性,但由于 ChatGLM2-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确性,且模型易被误导
第二部分 FlashAttention:减少内存访问提升计算速度——更长上下文的关键
FlashAttention是斯坦福联合纽约州立大学在22年6月份提出的一种具有 IO 感知,且兼具快速、内存高效的新型注意力算法「对应论文为:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,这是其GitHub地址,这是其解读之一,该解读也是本第二部分的重要参考」
2.1 FlashAttention相关的背景知识
2.1.1 transformer模型的计算复杂度和空间复杂度
它要解决一个什么样的问题呢?
首先,GPT3、LLaMA、ChatGLM、BLOOM等大语言模型输入输出的最大序列长度只有2048或4096,扩展到更长序列的难度在哪里呢?本质原因是,transformer模型的计算复杂度和空间复杂度都是 的,其中
为序列长度
具体地,当输入批次大小为 ,序列长度为
时
层transformer模型的计算量为
,
是隐藏层维度通常等于词向量维度,可能不少同学都会疑问这个计算量是怎么一步一步计算得来的,下面详细拆解下这个计算过程
- 首先,我们知道,transformer模型由
个相同的层组成,每个层分为两部分:self-attention块和MLP块
self-attention块的模型参数有两部分,一部分是、
、
的权重矩阵
、
、
和偏置,另一部分是输出权重矩阵
和偏置
故第一步就是计算
即
该矩阵乘法的输入和输出形状为
计算量为:
- 计算
该部分的输入和输出形状为
计算量为:
- 计算在
该部分矩阵乘法的输入和输出形状为
计算量为: - attention后的线性映射,矩阵乘法的输入和输出形状为
计算量为
最终自注意力层的输出结果为
- 接下来计算MLP层,MLP块由2个线性层组成,一般地,第一个线性层是,第二个线性层再将维度从
映射到
第一个线性层的权重矩阵 的形状为
,相当于先将维度从
,计算量为
第二个线性层的权重矩阵 的形状为
,相当于再将维度从
,计算量为
- 将上述所有表粗所示的计算量相加,得到每个transformer层的计算量大约为
- 此外,另一个计算量的大头是logits的计算(毕竟词嵌入矩阵的参数量也较多),将隐藏向量映射为词表大小,说白了,词向量维度通常等于隐藏层维度
,最后的输出层的权重矩阵通常与词嵌入矩阵是参数共享的「解释一下,如七月杜老师所说,这个是transformer中一个重要的点,参数共享可以减小参数量,词嵌入矩阵是[vocab_size,hidden_size],输出层矩阵是 [hidden_size,vocab_size],是可以共享的」
其矩阵乘法的输入和输出形状为,计算量为
- 因此,对于一个
的情况下,一次训练迭代的计算量为
中间激活的显存大小为
,其中
为注意力头数「至于这个结果的具体推导过程见此文《分析transformer模型的参数量、计算量、中间激活、KV cache》」
可以看到,transformer模型的计算量和储存复杂度随着序列长度 呈二次方增长。这限制了大语言模型的最大序列长度
的大小
其次,GPT4将最大序列长度 扩大到了32K,Claude更是将最大序列长度
扩大到了100K,这些工作一定采用了一些优化方法来降低原生transformer的复杂度,那具体怎么优化呢?
我们知道,每个transformer层分为两部分:self-attention块和MLP块。上面计算量中的 项和中间激活中的
项都是self-attention块产生的,与MLP块无关
如此,FlashAttention提出了一种加速计算、节省显存和IO感知的精确注意力,可以有效地缓解上述问题
Meta推出的开源大模型LLaMA,阿联酋推出的开源大模型Falcon都使用了Flash Attention来加速计算和节省显存。目前,Flash Attention已经集成到了pytorch2.0中,另外triton、xformer等开源框架也进行了整合实现
2.1.2 分析GPU的内存分析图:计算的瓶颈是显存访问
通过上文可知,transformer的核心组件self-attention块的计算复杂度和空间复杂度是序列长度 的二次方
- 对于self-attention块,除了大矩阵乘法是计算受限的,其他操作(计算softmax、dropout、mask)都是内存受限的。
尽管已经有许多近似注意力的方法尝试减少attention的计算和内存要求。例如,稀疏近似和低秩近似的方法,将计算复杂度降低到了序列长度的线性或亚线性 - 但这些近似注意力方法方法并没有得到广泛应用。因为这些方法过于关注FLOPs(浮点数计算次数)的减少,而忽略了IO读写的内存访问开销,导致这并没有效减少运行时间(wall-clock time)
总之,在现代GPU中,计算速度已经远超过了显存访问速度,transformer中的大部分计算操作的瓶颈是显存访问。对于显存受限的操作,IO感知是非常重要的,因为显存读写占用了大部分的运行时间 - 而Flash Attention则是IO感知的,通过减少内存访问,来计算精确注意力,从而减少运行时间,实现计算加速
GPU的内存由多个不同大小和不同读写速度的内存组成。内存越小,读写速度越快。对于A100-40GB来说,内存分级图如下所示
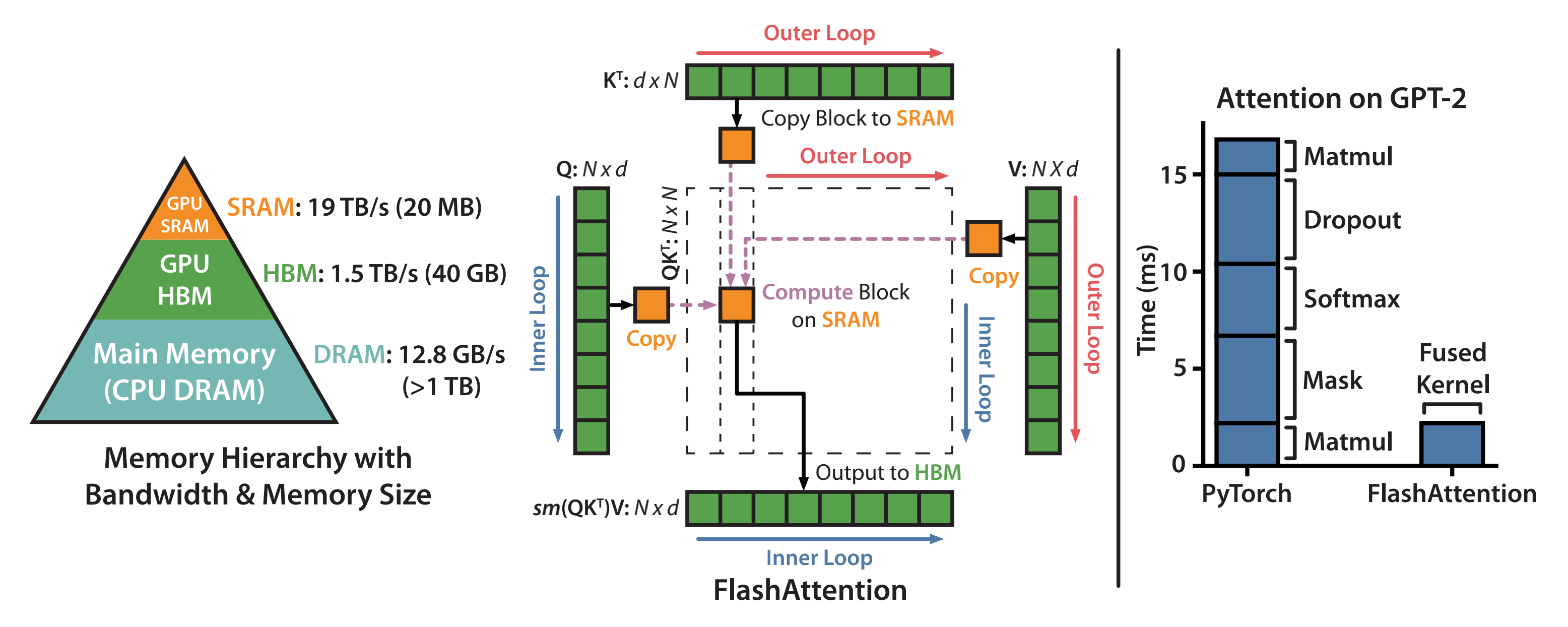
- SRAM内存分布在108个流式多处理器上,每个处理器的大小为192K。合计为
- 高带宽内存HBM(High Bandwidth Memory),也就是我们常说的显存,大小为40GB。SRAM的读写速度为19TB/s,而HBM的读写速度只有1.5TB/s,不到SRAM的1/10
所以,上面讲到计算注意力的主要瓶颈是显存访问,因此减少对HBM的读写次数,有效利用更高速的SRAM来进行计算是非常重要的,而GPU有大量的线程来执行某个操作,称为kernel。GPU执行操作的典型方式分为三步:
- 每个kernel将输入数据从低速的HBM中加载到高速的SRAM中
- 在SRAM中,进行计算
- 计算完毕后,将计算结果从SRAM中写入到HBM中
而对于性能受限于内存带宽的操作,进行加速的常用方式就是kernel融合。kernel融合的基本思想是:避免反复执行“从HBM中读取输入数据,SRAM执行计算,最后将计算结果写入到HBM中”,将多个操作融合成一个操作,减少读写HBM的次数(需要注意的是,模型训练通常会影响到算子融合的效果,因为为了后向传递计算梯度,通常需要将某些中间结果写入到HBM中)
2.1.3 safe softmax与Standard Attention
继续行文之前,先补充两个背景知识,一个是safe softmax,一个是Standard Attention
对于第一个背景知识:safe softmax而言
- 考虑到向量
,原生softmax的计算过程如下:
- 在实际硬件中,浮点数表示的范围是有限的
对于float32和bfloat16来说,当 时,
就会变成inf,发生数据上溢的问题
故为了避免发生数值溢出的问题,保证数值稳定性,计算时通常会“减去最大值”,称为“safe softmax”
即现在所有的深度学习框架中都采用了“safe softmax”这种计算方式 - 在训练语言模型时,通常会采用交叉熵损失函数。交叉熵损失函数等价于先执行log_softmax函数,再计算负对数似然函数
且在计算log_softmax时,同样会执行“减去最大值”,这不仅可以避免数值溢出,提高数值稳定性,还可以加快计算速度
对于第二个背景知识:Standard Attention
- 首先,transformer中注意力机制的计算过程为:
其中,,其中
是序列长度,
是每个注意力头的维度,输出可以记为
- 上面的式子可以拆解为:
在标准注意力实现中, 都要写回到HBM中,占用了
的内存,通常
例如,对于GPT2,,
;对于GPT3,
,
总之,注意力矩阵 需要的内存
所需要的内存
相当于,self-attention中,大部分操作都是内存受限的逐点运算,例如,对 的mask操作、
的dropout操作,这些逐点操作的性能是受限于内存带宽的,会减慢运行时间
- 下图展示了标准注意力的实现过程

标准注意力实现存在两个问题:
1. 显存占用多,过程中由于实例化了完整的注意力矩阵 ,导致了
2. HBM读写次数多,减慢了运行时间(wall- clock time)
// 待更..
第三部分 多查询注意力(Muti Query Attention):各自Query矩阵,但共享Key 和 Value 矩阵
多查询注意力(Muti Query Attention)是 19 年Google一研究者提出的一种新的 Attention 机制(对应论文为:Fast Transformer Decoding: One Write-Head is All You Need、这是其解读之一),其能够在保证模型效果的同时加快 decoder 生成 token 的速度
那其与17年 Google提出的transformer中多头注意力机制(简称MHA)有啥本质区别呢?有意思的是,区别在于:

- 我们知道MHA的每个头都各自有一份不同的Key、Query、Value矩阵
- 而MQA 让所有的头之间 共享 同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量
总之,MQA 实际上是将 head 中的 key 和 value 矩阵抽出来单独存为一份共享参数,而 query 则是依旧保留在原来的 head 中,每个 head 有一份自己独有的 query 参数
下图对比了多头注意力(Multi-Head Attention)、LLaMA2中分组查询注意力(Grouped-Query Attention)、多查询注意力(Muti Query Attention)的差别
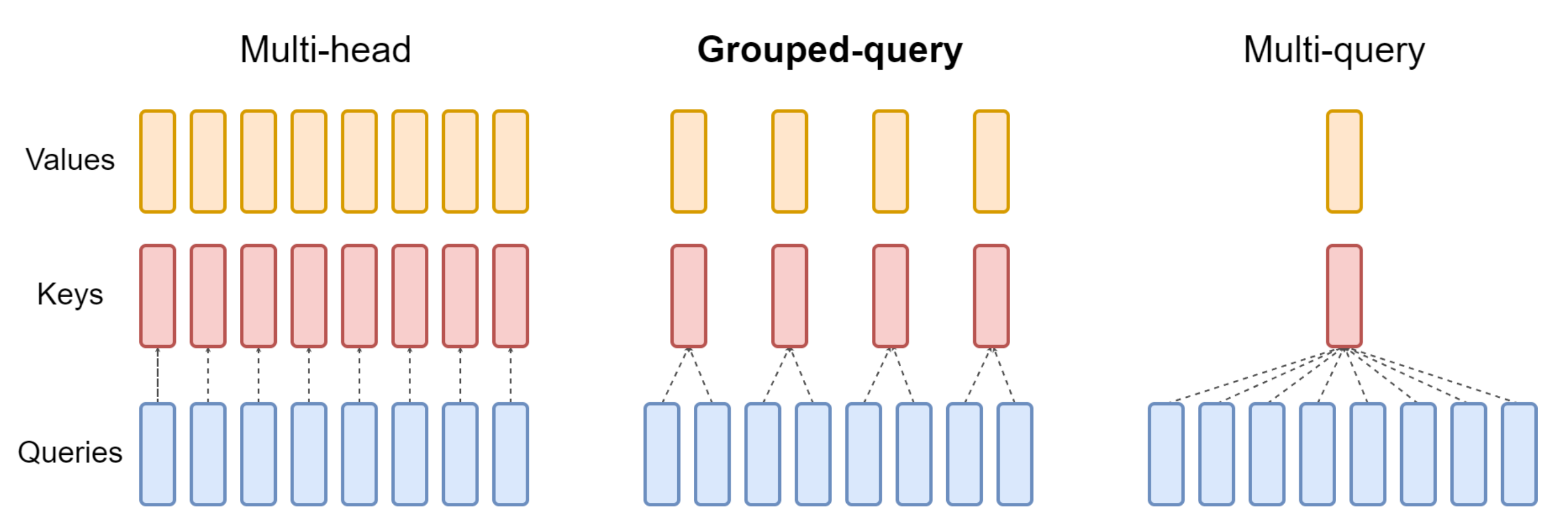
总之,MHA 和 MQA 之间的区别只在于建立 Wqkv Layer 上
# Multi Head Attention
self.Wqkv = nn.Linear( # 【关键】Multi-Head Attention 的创建方法self.d_model, 3 * self.d_model, # 有 query, key, value 3 个矩阵, 所以是 3 * d_modeldevice=device
)query, key, value = qkv.chunk( # 【关键】每个 tensor 都是 (1, 512, 768)3, dim=2
)# Multi Query Attention
self.Wqkv = nn.Linear( # 【关键】Multi-Query Attention 的创建方法d_model,d_model + 2 * self.head_dim, # 只创建 query 的 head 向量,所以只有 1 个 d_modeldevice=device, # 而 key 和 value 不再具备单独的头向量
)query, key, value = qkv.split( # query -> (1, 512, 768)[self.d_model, self.head_dim, self.head_dim], # key -> (1, 512, 96)dim=2 # value -> (1, 512, 96)
)对比上面的代码,你可以发现
- 在 MHA 中,query, key, value 每个向量均有 768 维度
- 而在 MQA 中,只有 query 是 768 维,而 key 和 value 均只剩下 96 维了,恰好是 1 个 head_dim 的维度
因此,可以确认:在 MQA 中,除了 query 向量还保存着 8 个头,key 和 value 向量都只剩 1 个「公共头」了,这也正好印证了论文中所说的「所有 head 之间共享一份 key 和 value 的参数」
剩下的问题就是如何将这 1 份参数同时让 8 个头都使用,代码里使用矩阵乘法 matmul 来广播,使得每个头都乘以这同一个 tensor,以此来实现参数共享:
def scaled_multihead_dot_product_attention(query,key,value,n_heads,multiquery=False,):q = rearrange(query, 'b s (h d) -> b h s d', h=n_heads) # (1, 512, 768) -> (1, 8, 512, 96)kv_n_heads = 1 if multiquery else n_headsk = rearrange(key, 'b s (h d) -> b h d s', h=kv_n_heads) # (1, 512, 768) -> (1, 8, 96, 512) if not multiquery # (1, 512, 96) -> (1, 1, 96, 512) if multiqueryv = rearrange(value, 'b s (h d) -> b h s d', h=kv_n_heads) # (1, 512, 768) -> (1, 8, 512, 96) if not multiquery # (1, 512, 96) -> (1, 1, 512, 96) if multiqueryattn_weight = q.matmul(k) * softmax_scale # (1, 8, 512, 512)attn_weight = torch.softmax(attn_weight, dim=-1) # (1, 8, 512, 512)out = attn_weight.matmul(v) # (1, 8, 512, 512) * (1, 1, 512, 96) = (1, 8, 512, 96)out = rearrange(out, 'b h s d -> b s (h d)') # (1, 512, 768)return out, attn_weight, past_key_value第四部分 模型的使用/部署、微调
4.1 模型的使用/部署
- 首先需要下载本仓库:
git clone https://github.com/THUDM/ChatGLM2-6B cd ChatGLM2-6B - 然后使用 pip 安装依赖: 其中 transformers 库版本推荐为
pip install -r requirements.txt4.30.2,torch推荐使用 2.0 及以上的版本,以获得最佳的推理性能 - 代码调用
可以通过如下代码调用 ChatGLM2-6B 模型来生成对话:你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。>>> from transformers import AutoTokenizer, AutoModel >>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True) >>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda') >>> model = model.eval() >>> response, history = model.chat(tokenizer, "你好", history=[]) >>> print(response)晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history) >>> print(response)
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议
从本地加载模型
以上代码会由 transformers 自动下载模型实现和参数
完整的模型实现在 Hugging Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
从 Hugging Face Hub 下载模型需要先安装Git LFS,然后运行
git clone https://huggingface.co/THUDM/chatglm2-6b如果你从 Hugging Face Hub 上下载 checkpoint 的速度较慢,可以只下载模型实现
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b
然后从这里手动下载模型参数文件,并将下载的文件替换到本地的
chatglm2-6b目录下将模型下载到本地之后,将以上代码中的
THUDM/chatglm2-6b替换为你本地的chatglm2-6b文件夹的路径,即可从本地加载模型。模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以在
from_pretrained的调用中增加revision="v1.0"参数。v1.0是当前最新的版本号,完整的版本列表参见 Change Log
最后,可以通过以下命令启动基于 Gradio 的网页版 demo:
python web_demo.py
4.2 基于 P-Tuning v2 的微调(官方)
P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行(当然,我司杜老师也会在七月类ChatGPT微调实战课上录一个ChatGLM2-6B的微调视频)
- 环境配置
在原chatglm-6b的环境中安装以下依赖
pip install rouge_chinese nltk jieba datasets - 微调数据准备
ADGEN 数据集任务为根据输入(content)生成一段广告词(summary)从 Google Drive 或者 Tsinghua Cloud 下载处理好的 ADGEN 数据集,将解压后的 AdvertiseGen 目录放到本 ptuning 目录下即可{ “content”: “类型#上衣版型#宽松版型#显瘦图案#线条衣样式#衬衫衣袖型#泡泡袖衣款式#抽绳”, “summary”: “这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。” } - 微调
修改train.sh文件
去掉最后的 --quantization_bit 4( 去掉后为FP16 精度加载)
修改模型路径,THUDM/chatglm-6b修改为/data/sim_chatgpt/chatglm2-6b
目前专业级GPU Tesla P100也不支持INT4或8量化
执行train.sh文件如遇报错:bash train.sh
wandb.errors.UsageError: api_key not configured (no-tty). call wandb.login(k…
解决方法:
在main.py文件中加入下面两行,禁用wandb即可 - import os
os.environ["WANDB_DISABLED"] = "true"
其中,train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。
微调过程显存使用情况如下:
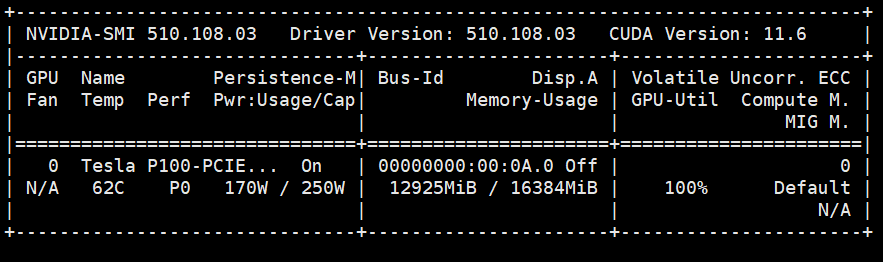
微调完成后,在./output/adgen-chatglm2-6b-pt-128-2e-2 下回生成微调好的模型文件。
我们可以对比下微调前后的效果
以命令行 Demo为例,只需修改ptuning路径下web_demo.sh中的模型路径为/data/sim_chatgpt/chatglm2-6b,运行 web_demo.py即可:
bash web_demo.shInput:
类型#上衣材质#牛仔布颜色#白色风格#简约图案#刺绣衣样式#外套衣款式#破洞
Label:
简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。
Output[微调前]:
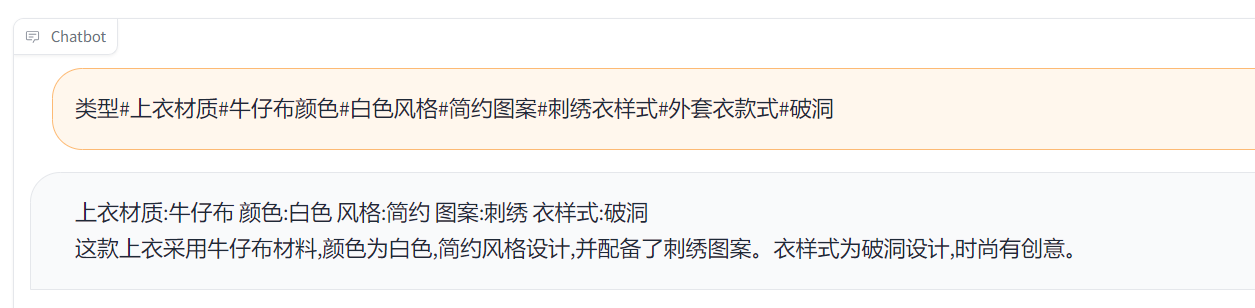
Output[微调后]:
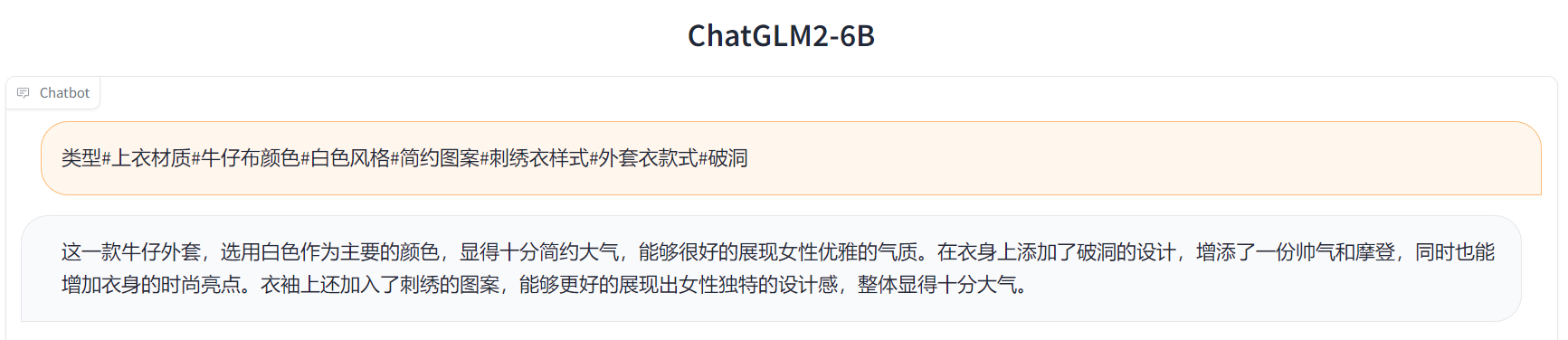
// 待更
相关文章:
ChatGLM2-6B的通透解析:从FlashAttention、Multi-Query Attention到GLM2的微调、源码解读
前言 本文最初和第一代ChatGLM-6B的内容汇总在一块,但为了阐述清楚FlashAttention、Multi-Query Attention等相关的原理,以及GLM2的微调、源码解读等内容,导致之前那篇文章越写越长,故特把ChatGLM2相关的内容独立抽取出来成本文 …...
3D人脸生成的论文
一、TECA 1、论文信息 2、开源情况:comming soon TECA: Text-Guided Generation and Editing of Compositional 3D AvatarsGiven a text description, our method produces a compositional 3D avatar consisting of a mesh-based face and body and NeRF-based ha…...

解决问题:可以用什么方式实现自动化部署
自动化部署可以使用多种工具来实现: 脚本编写:可以使用 Bash、Python 等编写脚本来实现自动化部署。例如,可以使用 Bash 脚本来自动安装、配置和启动应用程序。 配置管理工具:像 Ansible、Puppet、Chef、Salt 等配置管理工具可以…...

【数据结构】链表栈
目录: 链表栈 1. 链式栈的实现2. 链表栈的创建3. 压栈4. 弹栈 链表栈 栈的主要表示方式有两种,一种是顺序表示,另一种是链式表示。本文主要介绍链式表示的栈。 链栈实际上和单链表差别不大,唯一区别就在于只需要对链表限定从头…...

Android笔记:Android 组件化方案探索与思考
组件化项目,通过gradle脚本,实现module在编译期隔离,运行期按需加载,实现组件间解耦,高效单独调试。 先来一张效果图 组件化初衷 APP版本不断的迭代,新功能的不断增加,业务也会变的越来越复杂…...
MeterSphere v2.10.X-lts 双节点HA部署方案
一、MeterSphere高可用部署架构及服务器配置 1.1 服务器信息 序号应用名称操作系统要求配置要求描述1负载均衡器CentOS 7.X /RedHat 7.X2C,4G,200GB部署Nginx,实现负载路由。 部署NFS服务器。2MeterSphere应用节点1CentOS 7.X /RedHat 7.X8C,16GB,200G…...
Java进阶篇--网络编程
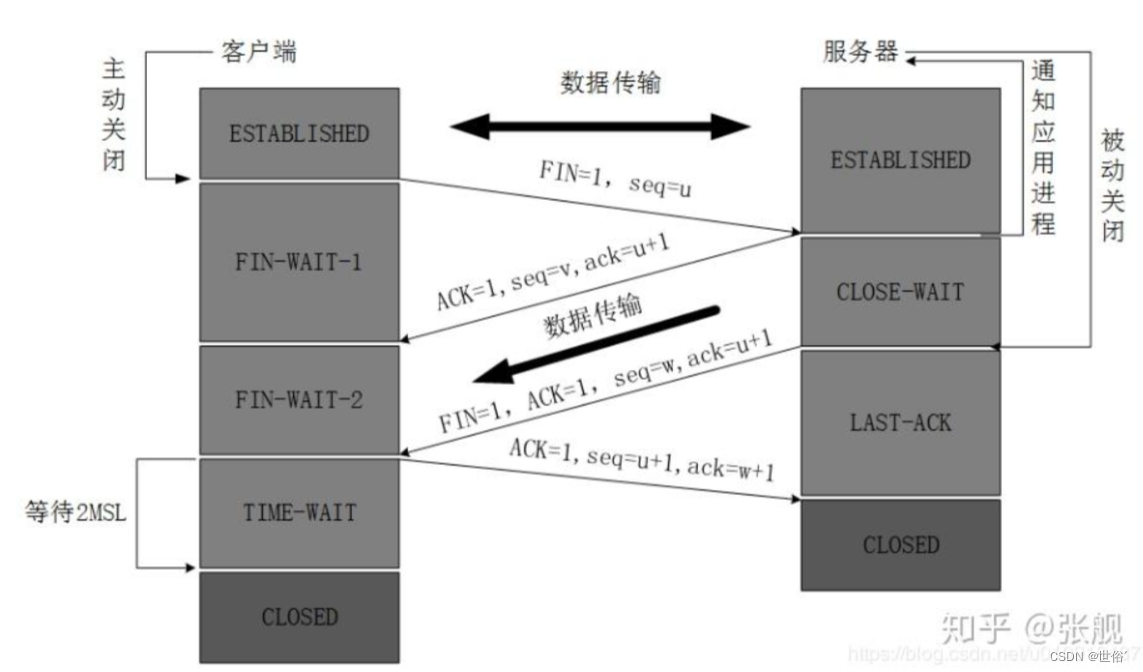
目录 计算机网络体系结构 什么是网络协议? 为什么要对网络协议分层? 网络通信协议 TCP/IP 协议族 应用层 运输层 网络层 数据链路层 物理层 TCP/IP 协议族 TCP的三次握手四次挥手 TCP报文的头部结构 三次握手 四次挥手 …...

PyTorch入门之【CNN】
参考:https://www.bilibili.com/video/BV1114y1d79e/?spm_id_from333.999.0.0&vd_source98d31d5c9db8c0021988f2c2c25a9620 书接上回的MLP故本章就不详细解释了 目录 traintest train import torch from torchvision.transforms import ToTensor from torchvi…...

马斯洛需求层次模型之安全需求之云安全浅谈
在互联网云服务领域,安全需求是用户首要考虑的因素之一。用户希望在将数据和信息托付给云服务提供商时,这些数据和信息能够得到充分的保护,避免遭受未经授权的访问、泄露或破坏。这种安全需求的满足,对于用户来说是至关重要的&…...
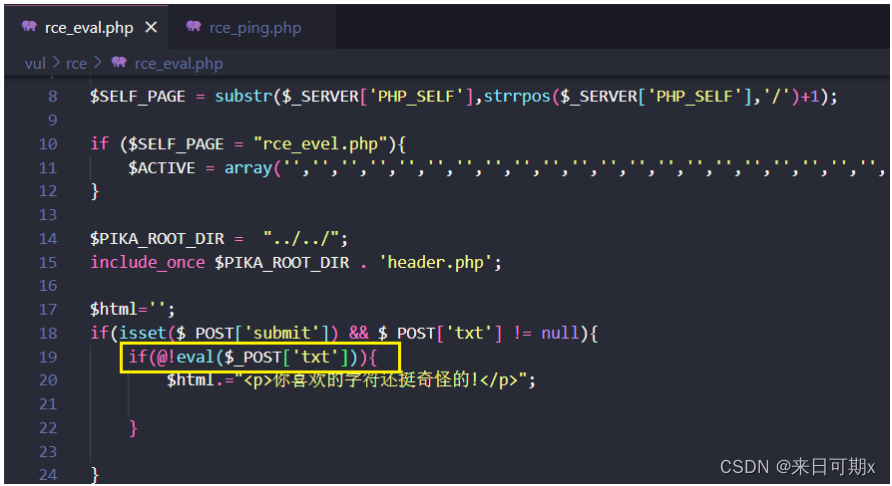
Pikachu靶场——远程命令执行漏洞(RCE)
文章目录 1. RCE1.1 exec "ping"1.1.1 源代码分析1.1.2 漏洞防御 1.2 exec "eval"1.2.1 源代码分析1.2.2 漏洞防御 1.3 RCE 漏洞防御 1. RCE RCE(remote command/code execute)概述: RCE漏洞,可以让攻击者直接向后台服务器远程注入…...
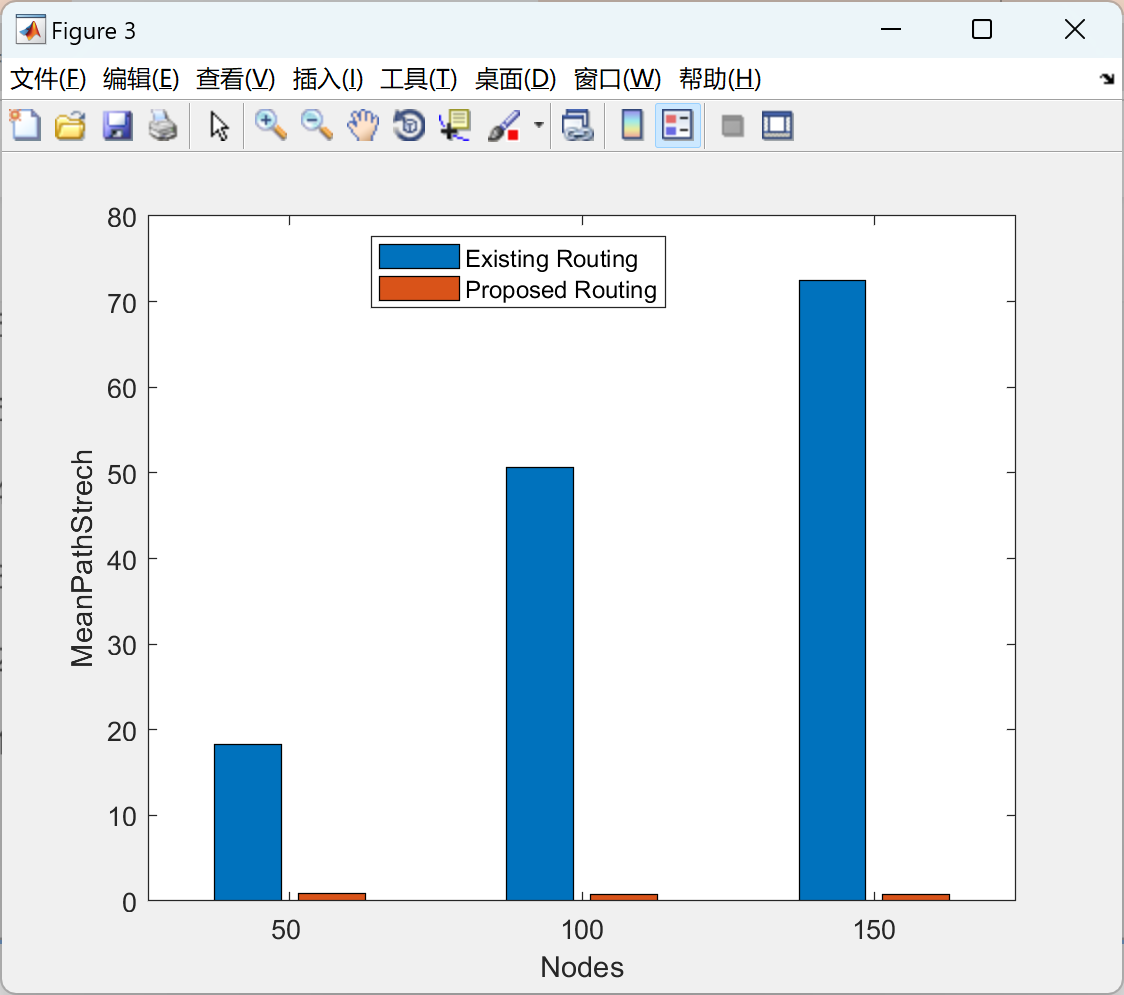
【WSN】无线传感器网络 X-Y 坐标到图形视图和位字符串前缀嵌入方法研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Linux定时任务
文章目录 前言设置定时任务流程定时规则例子 终止定时任务列出当前的定时任务重启任务调度 前言 在Linux系统中有时侯需要周期性的自动执行一些命令,这时候Linux定时任务就派上用场了 设置定时任务流程 进入定时任务的编辑模式 crontab -e编辑定时任务ÿ…...
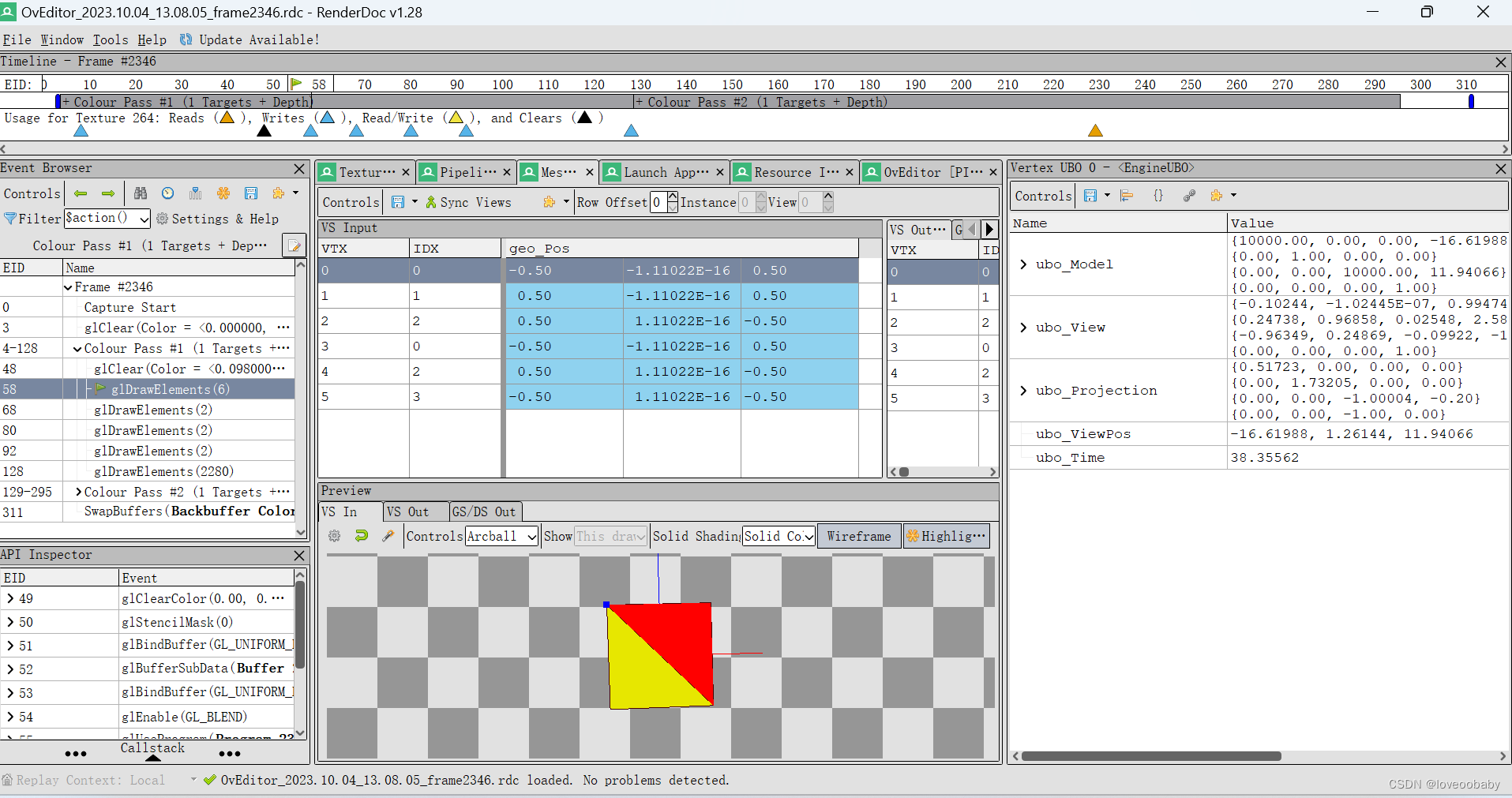
【Overload游戏引擎分析】画场景网格的Shader
Overload引擎地址: GitHub - adriengivry/Overload: 3D Game engine with editor 一、栅格绘制基本原理 Overload Editor启动之后,场景视图中有栅格线,这个在很多软件中都有。刚开始我猜测它应该是通过绘制线实现的。阅读代码发现࿰…...

【JavaEE】多线程进阶(一)饿汉模式和懒汉模式
多线程进阶(一) 文章目录 多线程进阶(一)单例模式饿汉模式懒汉模式 本篇主要引入多线程进阶的单例模式,为后面的大冰山做铺垫 代码案例介绍 单例模式 非常经典的设计模式 啥是设计模式 设计模式好比象棋中的 “棋谱”…...
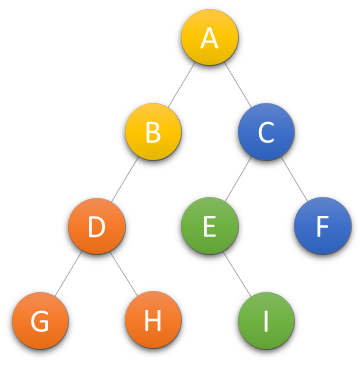
C++树详解
树 树的定义 树(Tree)是n(n≥0)个结点的有限集。n0时称为空树。在任意一颗非空树中:①有且仅有一个特定的称为根(Root)的结点;②当n>1时,其余结点可分为m(…...

支付环境安全漏洞介绍
1、平台支付逻辑全流程分析 2、平台支付漏洞如何利用?买东西还送钱? 3、BURP抓包分析修改支付金额,伪造交易状态? 4、修改购物车参数实现底价购买商品 5、SRC、CTF、HW项目月入10W副业之路 6、如何构建最适合自己的网安学习路线 1…...
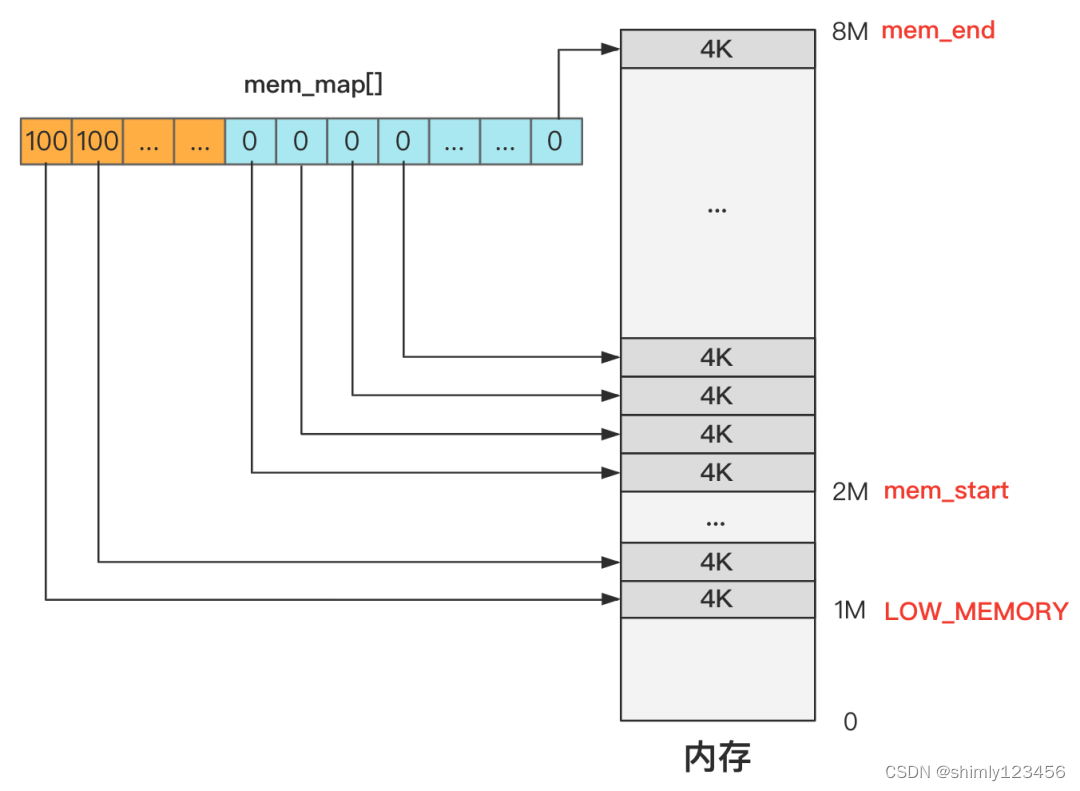
抄写Linux源码(Day16:内存管理)
回忆我们需要做的事情: 为了支持 shell 程序的执行,我们需要提供: 1.缺页中断(不理解为什么要这个东西,只是闪客说需要,后边再说) 2.硬盘驱动、文件系统 (shell程序一开始是存放在磁盘里的,所以需要这两个东…...

Cookie和Session详解以及结合生成登录效果
目录 引言 1.Cookie中的数据从哪来数据长啥样? 2.Cookie有什么作用? 3.cookie与session的工作关联? 4.Cookie到哪去? 5.Cookie如何存? 6.Session 7.Cookie与Session的关联与区别 8.通过代码理解 8.1 相关代码 8.2…...
Spring基础以及核心概念(IoC和DIQ)
1.Spring是什么 Spring是包含了众多工具方法的IoC容器 2.loC(Inversion of Control )是什么 IoC:控制反转,Spring是一个控制反转容器(控制反转对象的生命周期) Spring是一个loC容器,我们之前学过的List/Map就是数据存储的容器,to…...

《C和指针》笔记32:多维数组初始化
文章目录 使用括号进行初始化初始化省略维度 使用括号进行初始化 我们可以给数组赋值一个长长的列表: int matrix[2][3] { 100, 101, 102, 110, 111, 112 };它等价于 matrix[0][0]100; matrix[0][1]101; matrix[0][2]102; matrix[1][0]110; matrix[1][1]111; ma…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...