竞赛选题 深度学习 opencv python 实现中国交通标志识别_1
文章目录
- 0 前言
- 1 yolov5实现中国交通标志检测
- 2.算法原理
- 2.1 算法简介
- 2.2网络架构
- 2.3 关键代码
- 3 数据集处理
- 3.1 VOC格式介绍
- 3.2 将中国交通标志检测数据集CCTSDB数据转换成VOC数据格式
- 3.3 手动标注数据集
- 4 模型训练
- 5 实现效果
- 5.1 视频效果
- 6 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于深度学习的中国交通标志识别算法研究与实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 yolov5实现中国交通标志检测
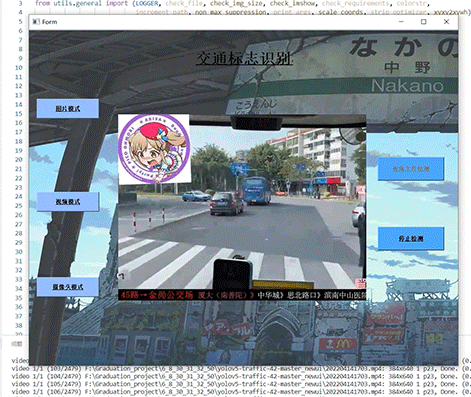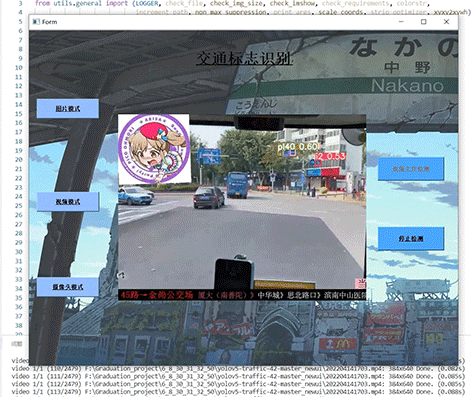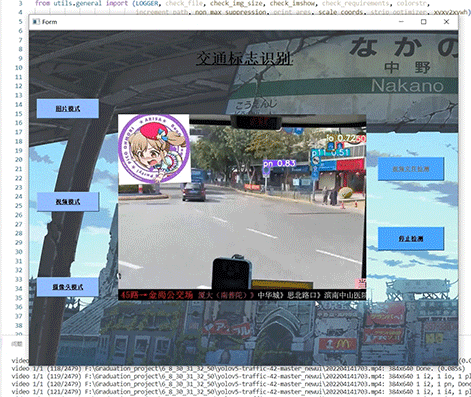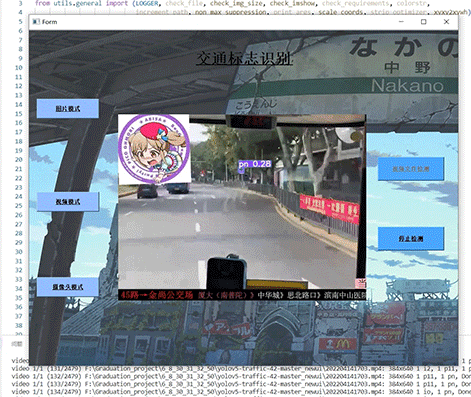
整个互联网基本没有国内交通标志识别的开源项目(都是国外的),今天学长分享一个中国版本的实时交通标志识别项目,非常适合作为竞赛项目~
2.算法原理
2.1 算法简介
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
2.2网络架构
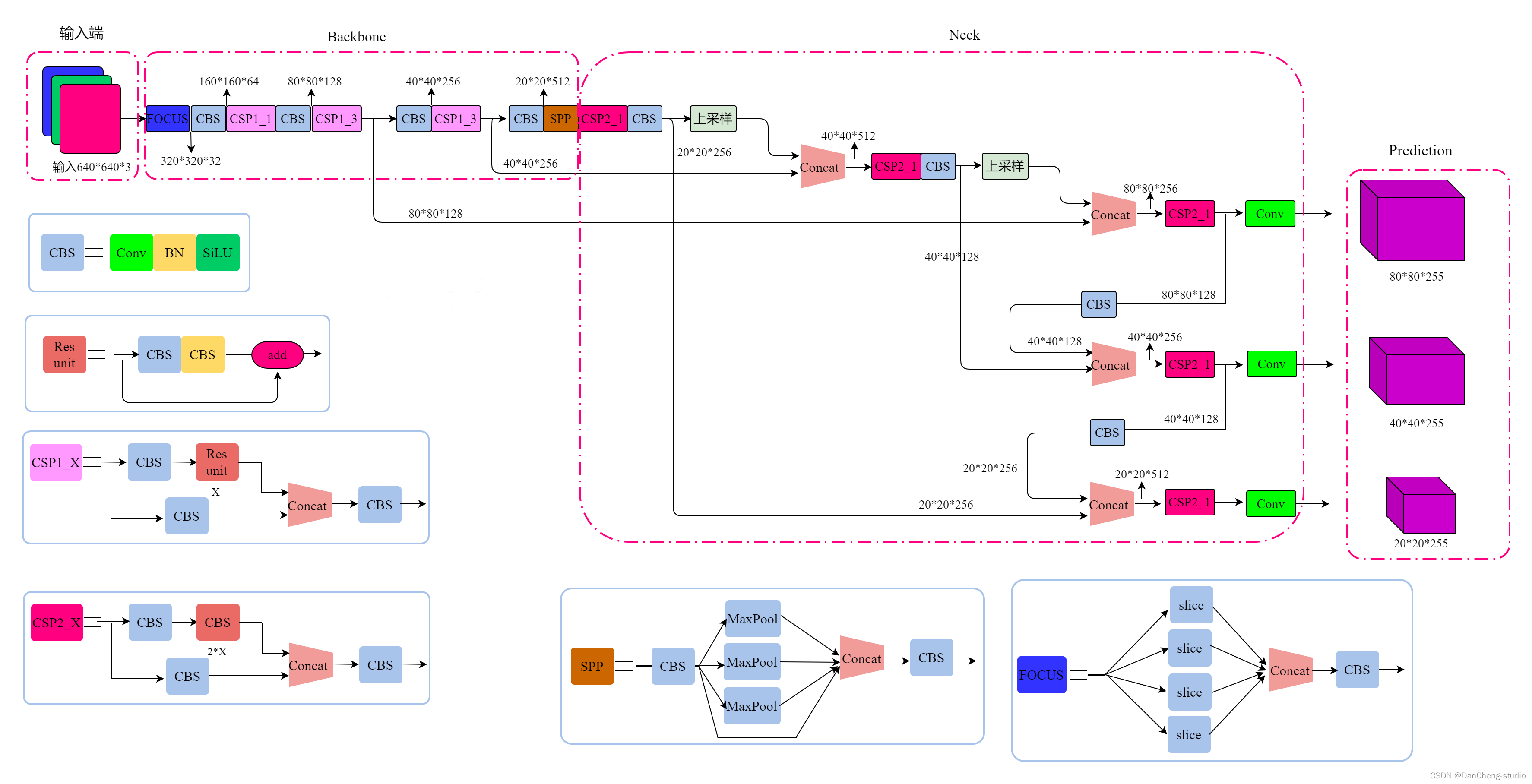
上图展示了YOLOv5目标检测算法的整体框图。对于一个目标检测算法而言,我们通常可以将其划分为4个通用的模块,具体包括:输入端、基准网络、Neck网络与Head输出端,对应于上图中的4个红色模块。YOLOv5算法具有4个版本,具体包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四种,本文重点讲解YOLOv5s,其它的版本都在该版本的基础上对网络进行加深与加宽。
- 输入端-输入端表示输入的图片。该网络的输入图像大小为608*608,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
- 基准网络-基准网络通常是一些性能优异的分类器种的网络,该模块用来提取一些通用的特征表示。YOLOv5中不仅使用了CSPDarknet53结构,而且使用了Focus结构作为基准网络。
- Neck网络-Neck网络通常位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。虽然YOLOv5同样用到了SPP模块、FPN+PAN模块,但是实现的细节有些不同。
- Head输出端-Head用来完成目标检测结果的输出。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。YOLOv4利用GIOU_Loss来代替Smooth L1 Loss函数,从而进一步提升算法的检测精度。
2.3 关键代码
class Detect(nn.Module):stride = None # strides computed during buildonnx_dynamic = False # ONNX export parameterdef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nl # init gridself.anchor_grid = [torch.zeros(1)] * self.nl # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.inplace = inplace # use in-place ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)y = x[i].sigmoid()if self.inplace:y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xywh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, y[..., 4:]), -1)z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].deviceif check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilityyv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')else:yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()anchor_grid = (self.anchors[i].clone() * self.stride[i]) \.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()return grid, anchor_gridclass Model(nn.Module):def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classessuper().__init__()if isinstance(cfg, dict):self.yaml = cfg # model dictelse: # is *.yamlimport yaml # for torch hubself.yaml_file = Path(cfg).namewith open(cfg, encoding='ascii', errors='ignore') as f:self.yaml = yaml.safe_load(f) # model dict# Define modelch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channelsif nc and nc != self.yaml['nc']:LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")self.yaml['nc'] = nc # override yaml valueif anchors:LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')self.yaml['anchors'] = round(anchors) # override yaml valueself.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelistself.names = [str(i) for i in range(self.yaml['nc'])] # default namesself.inplace = self.yaml.get('inplace', True)# Build strides, anchorsm = self.model[-1] # Detect()if isinstance(m, Detect):s = 256 # 2x min stridem.inplace = self.inplacem.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forwardm.anchors /= m.stride.view(-1, 1, 1)check_anchor_order(m)self.stride = m.strideself._initialize_biases() # only run once# Init weights, biasesinitialize_weights(self)self.info()LOGGER.info('')def forward(self, x, augment=False, profile=False, visualize=False):if augment:return self._forward_augment(x) # augmented inference, Nonereturn self._forward_once(x, profile, visualize) # single-scale inference, traindef _forward_augment(self, x):img_size = x.shape[-2:] # height, widths = [1, 0.83, 0.67] # scalesf = [None, 3, None] # flips (2-ud, 3-lr)y = [] # outputsfor si, fi in zip(s, f):xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))yi = self._forward_once(xi)[0] # forward# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # saveyi = self._descale_pred(yi, fi, si, img_size)y.append(yi)y = self._clip_augmented(y) # clip augmented tailsreturn torch.cat(y, 1), None # augmented inference, traindef _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return xdef _descale_pred(self, p, flips, scale, img_size):# de-scale predictions following augmented inference (inverse operation)if self.inplace:p[..., :4] /= scale # de-scaleif flips == 2:p[..., 1] = img_size[0] - p[..., 1] # de-flip udelif flips == 3:p[..., 0] = img_size[1] - p[..., 0] # de-flip lrelse:x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scaleif flips == 2:y = img_size[0] - y # de-flip udelif flips == 3:x = img_size[1] - x # de-flip lrp = torch.cat((x, y, wh, p[..., 4:]), -1)return pdef _clip_augmented(self, y):# Clip YOLOv5 augmented inference tailsnl = self.model[-1].nl # number of detection layers (P3-P5)g = sum(4 ** x for x in range(nl)) # grid pointse = 1 # exclude layer counti = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indicesy[0] = y[0][:, :-i] # largei = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indicesy[-1] = y[-1][:, i:] # smallreturn ydef _profile_one_layer(self, m, x, dt):c = isinstance(m, Detect) # is final layer, copy input as inplace fixo = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPst = time_sync()for _ in range(10):m(x.copy() if c else x)dt.append((time_sync() - t) * 100)if m == self.model[0]:LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')if c:LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency# https://arxiv.org/abs/1708.02002 section 3.3# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.m = self.model[-1] # Detect() modulefor mi, s in zip(m.m, m.stride): # fromb = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)b.data[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # clsmi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)def _print_biases(self):m = self.model[-1] # Detect() modulefor mi in m.m: # fromb = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)LOGGER.info(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))# def _print_weights(self):# for m in self.model.modules():# if type(m) is Bottleneck:# LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weightsdef fuse(self): # fuse model Conv2d() + BatchNorm2d() layersLOGGER.info('Fusing layers... ')for m in self.model.modules():if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):m.conv = fuse_conv_and_bn(m.conv, m.bn) # update convdelattr(m, 'bn') # remove batchnormm.forward = m.forward_fuse # update forwardself.info()return selfdef autoshape(self): # add AutoShape moduleLOGGER.info('Adding AutoShape... ')m = AutoShape(self) # wrap modelcopy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributesreturn mdef info(self, verbose=False, img_size=640): # print model informationmodel_info(self, verbose, img_size)def _apply(self, fn):# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffersself = super()._apply(fn)m = self.model[-1] # Detect()if isinstance(m, Detect):m.stride = fn(m.stride)m.grid = list(map(fn, m.grid))if isinstance(m.anchor_grid, list):m.anchor_grid = list(map(fn, m.anchor_grid))return selfdef parse_model(d, ch): # model_dict, input_channels(3)LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)layers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argsm = eval(m) if isinstance(m, str) else m # eval stringsfor j, a in enumerate(args):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept NameError:passn = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in [BottleneckCSP, C3, C3TR, C3Ghost]:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)elif m is Detect:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2else:c2 = ch[f]m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []ch.append(c2)return nn.Sequential(*layers), sorted(save)3 数据集处理
中国交通标志检测数据集CCTSDB,由长沙理工大学提供,包括上万张有标注的图片
推荐只使用前4000张照片,因为后面有很多张图片没有标注,需要一张一张的删除,太过于麻烦,所以尽量用前4000张图
3.1 VOC格式介绍
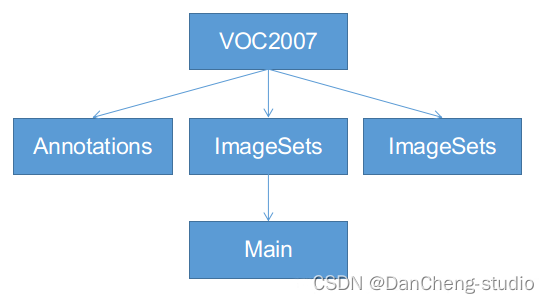
VOC格式主要包含三个文件夹Annotations,ImageSets,JPEGImages,主要适用于faster-
rcnn等模型的训练,ImageSets下面有一个Main的文件夹,如下图,一定按照这个名字和格式建好文件夹:
-
Annotations:这里是存放你对所有数据图片做的标注,每张照片的标注信息必须是xml格式。
-
JPEGImages:用来保存你的数据图片,一定要对图片进行编号,一般按照voc数据集格式,采用六位数字编码,如000001.jpg、000002.jpg等。
-
ImageSets:该文件下有一个main文件,main文件下有四个txt文件,分别是train.txt、test.txt、trainval.txt、val.txt,里面都是存放的图片号码。
3.2 将中国交通标志检测数据集CCTSDB数据转换成VOC数据格式
将标注的数据提取出来并且排序,并将里面每一行分割成一个文件

3.3 手动标注数据集
如果为了更深入的学习也可自己标注,但过程相对比较繁琐,麻烦。
以下简单介绍数据标注的相关方法,数据标注这里推荐的软件是labelimg,通过pip指令即可安装,相关教程可网上搜索
pip install labelimg
4 模型训练
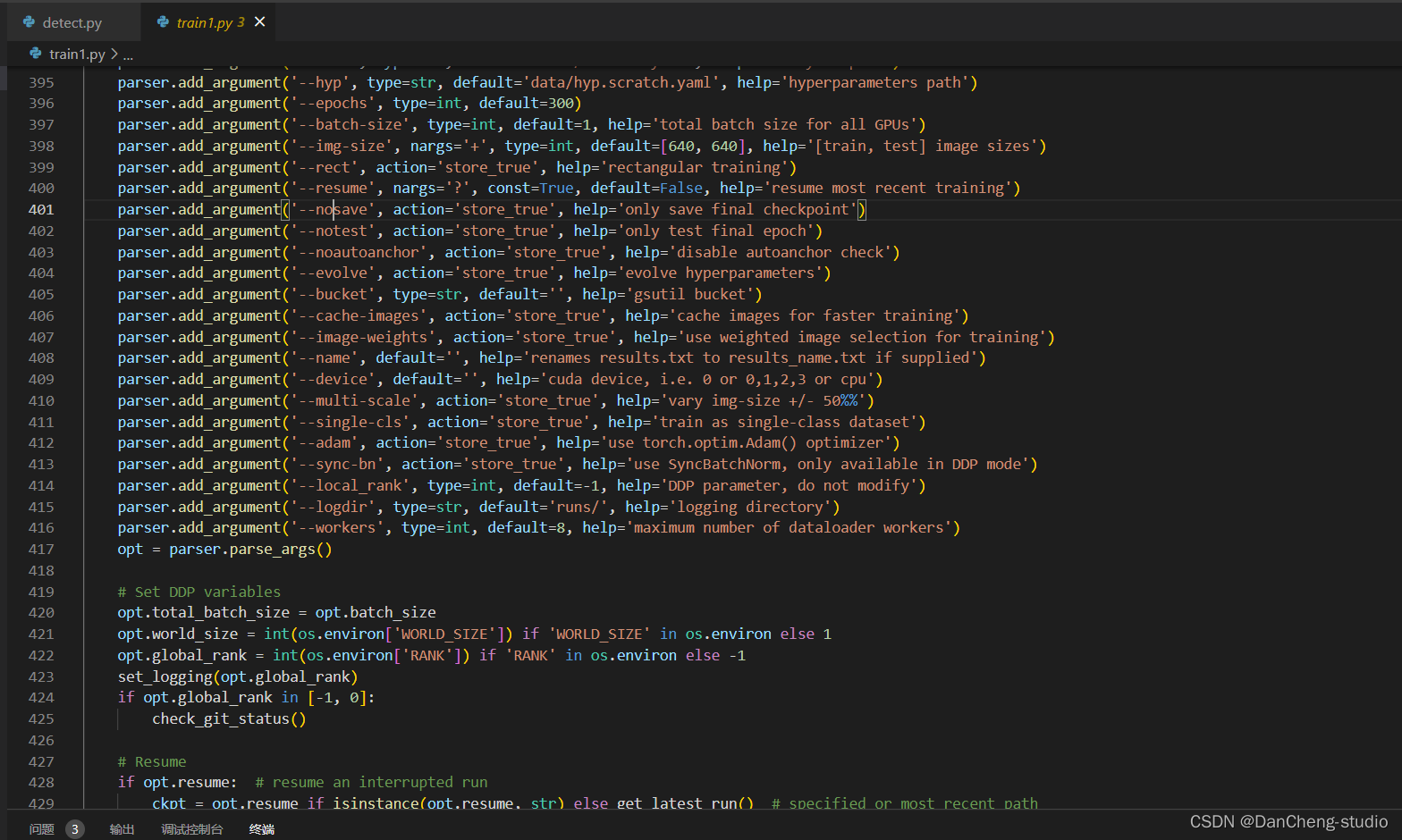
修改train.py中的weights、cfg、data、epochs、batch_size、imgsz、device、workers等参数
训练代码成功执行之后会在命令行中输出下列信息,接下来就是安心等待模型训练结束即可。

5 实现效果
5.1 视频效果
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛选题 深度学习 opencv python 实现中国交通标志识别_1
文章目录 0 前言1 yolov5实现中国交通标志检测2.算法原理2.1 算法简介2.2网络架构2.3 关键代码 3 数据集处理3.1 VOC格式介绍3.2 将中国交通标志检测数据集CCTSDB数据转换成VOC数据格式3.3 手动标注数据集 4 模型训练5 实现效果5.1 视频效果 6 最后 0 前言 🔥 优质…...
Qt 关于mouseTracking鼠标追踪和tabletTracking平板追踪的几点官方说明
mouseTracking属性用于保存是否启用鼠标跟踪,缺省情况是不启用的。 没启用的情况下,对应部件只接收在鼠标移动同时至少一个鼠标按键按下时的鼠标移动事件。 启用鼠标跟踪的情况下,任何鼠标移动事件部件都会接收。 部件方法hasMouseTrackin…...
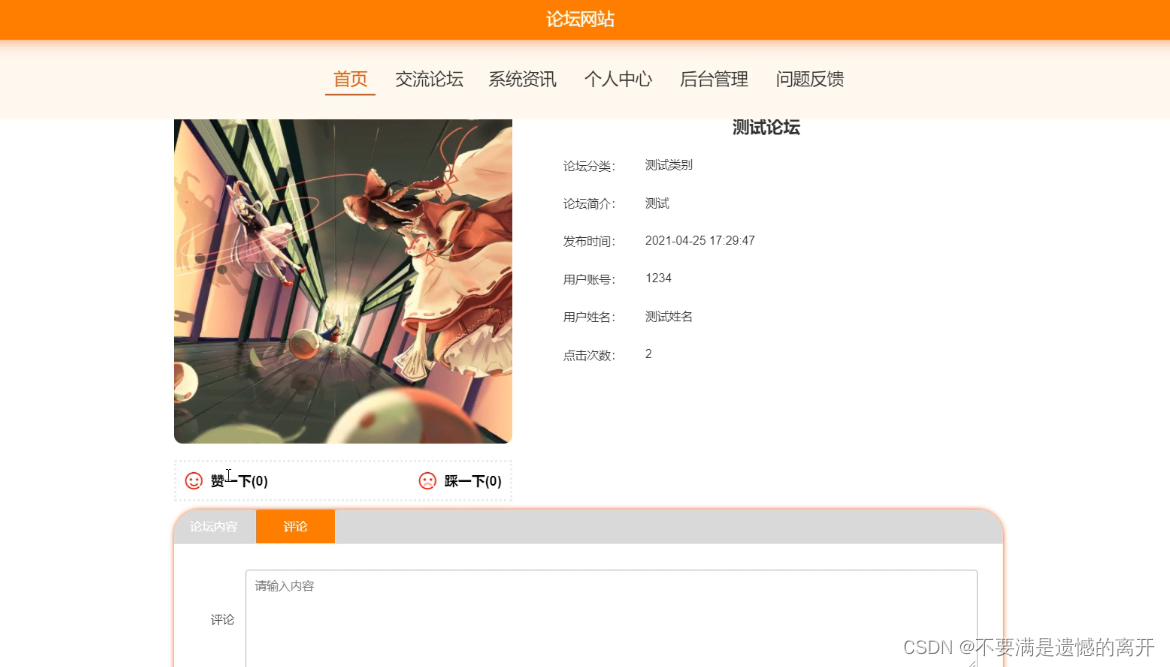
基于springboot的论坛网站
目录 前言 一、技术栈 二、系统功能介绍 用户信息管理 普通管理员管理 交流论坛 交流论坛评论 三、核心代码 1、登录模块 2、文件上传模块 3、代码封装 前言 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了…...
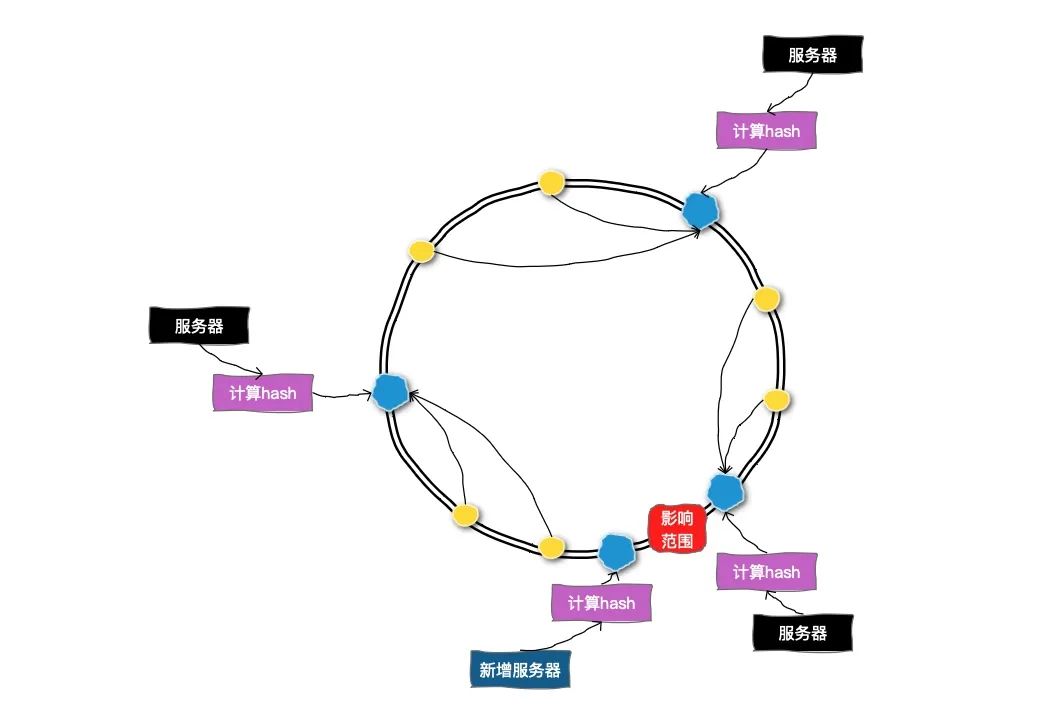
分库分表理论总结
一、概述 分库分表是在面对高并发、海量数量时常见的数据库层面的解决方案。通过把数据分散到不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。比如:将电商数据库拆分为若干独立的数据…...

RK3568平台开发系列讲解(外设篇)AP3216C 三合一环境传感器驱动
🚀返回专栏总目录 文章目录 一、AP3216C 简介二、AP3216C驱动程序2.1、设备树修改2.2、驱动程序沉淀、分享、成长,让自己和他人都能有所收获!😄 📢在本篇将介绍AP3216C 三合一环境传感器的驱动。 一、AP3216C 简介 AP3216C 是由敦南科技推出的一款传感器,其支持环境光…...
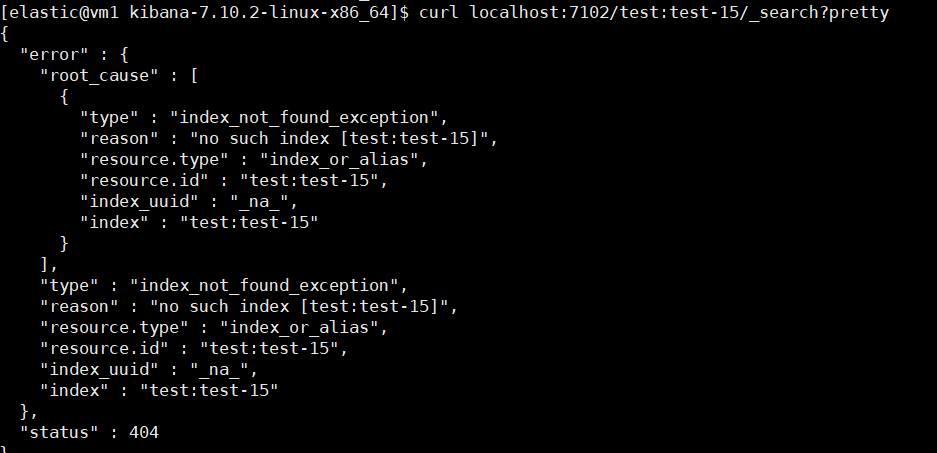
ES 关于 remote_cluster 的一记小坑
最近有小伙伴找到我们说 Kibana 上添加不了 Remote Cluster,填完信息点 Save 直接跳回原界面了。具体页面,就和没添加前一样。 我们和小伙伴虽然隔着网线但还是进行了深入、详细的交流,梳理出来了如下信息: 两个集群:…...
)
第五章:最新版零基础学习 PYTHON 教程—Python 字符串操作指南(第四节 - Python 中的字符串反转6种不同的方式方法)
Python 字符串库不支持内置的“ reverse() ”,就像其他 python 容器(如 list)所做的那样,因此了解其他反转字符串的方法可能会很有用。本文讨论了在Python中实现它的几种方法。 目录 Python 中使用循环反转字符串 在Python中使用递归反转字符串...
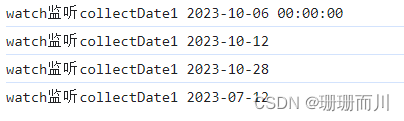
el-date-picker增加默认值 修改样式
预期效果 默认是这样的 但希望是直接有一个默认的当天日期,并且字体颜色啥的样式也要修改(在这里假设今天是2023/10/6 功能实现 踩了坑挺多坑的,特此记录 官方文档 按照官方的说明,给v-model绑定一个字符串就可以了 在j…...

Hive中生成自增序列的常用方法
在日常业务开发过程中,通常遇到需要hive数据表中生成一列唯一ID,当然连续递增的更好。 最近在结算业务中,需要在hive表中生成一列连续且唯一的账单ID,于是就了解生成唯一ID的方法 1. 利用row_number函数 语法:row_n…...

4.MySql安装配置(更新版)
MySql安装配置 无论计算机是否有安装其他mysql,都不要卸载。 只要确定大版本是8即可,8.0.33 8.0.34 差别不大即可。 MySql下载安装适合电脑配置属性有关,一次性安装成功当然是非常好的,因为卸载步骤是非常麻烦的 如果第一次安装…...

使用opencv及FFmpeg编辑视频
使用opencv及FFmpeg编辑视频 1.融合两个视频2.为视频添加声音2.1 安装ffmpy Python包2.2 下载ffmpeg2.3 代码实现 3.效果参考文献 帮朋友做了一个小作业,具体实现分为几个过程: 将两个mp4格式视频融合到一起为新视频添加声音 1.融合两个视频 其中一个…...

Python3 Selenium4 chromedriver Pycharm闪退的问题
Python3版本:3.11.5 Pycharm版本:2023.2.1 Chrome版本:117.0.5938.150(正式版本) 在使用最新版的Selenium4版本时,chromedriver可以驱动Chrome但是闪退,Selenium目前最新版本是4.13.0&#…...

019 基于Spring Boot的教务管理系统、学生管理系统、课表查询系统
基于Spring Boot的教务管理系统、学生管理系统、课表查询系统 一、系统介绍 本作品主要实现了一个课表查询系统,采用了SSM(Spring SpringMVC MyBatis)的基础架构。 二、使用技术 spring-bootspring-MVCthymeleafmybatis-plusdruidLombo…...

包装类?为什么需要包装类?
包装类是一种用于将基本数据类型(如整数、浮点数、字符等)封装成对象的类。在Java和许多其他编程语言中,基本数据类型是不具备面向对象特性的,它们不是对象,不能进行方法调用或参与泛型化。为了弥补这一不足,Java引入了包装类,允许基本数据类型被当作对象来处理。 Java…...
)
Java中的TCP通信(网络编程 二)
简介 TCP(传输控制协议)是一种在计算机网络中常用的协议,它提供了可靠的、面向连接的通信(协议信息链接:TCP协议)。在Java中,我们可以使用Socket和ServerSocket类来实现TCP通信。 Java TCP通信…...
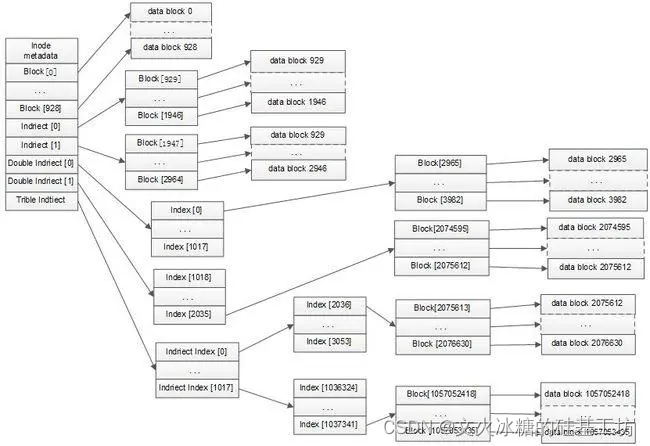
[架构之路-232]:目标系统 - 纵向分层 - 操作系统 - 数据存储:文件系统存储方法汇总
目录 前言: 一、文件系统存储方法基本原理和常见应用案例: 二、Windows FAT文件系统 2.1 概述 三、Linux EXT文件系统 3.1 基本原理 3.2 索引节点表(Inode Table) 3.2.1 索引节点表层次结构 3.2.2 间接索引表的大小和表项…...

【立体视觉(五)】之立体匹配与SGM算法
【立体视觉(五)】之立体匹配与SGM算法 一、立体匹配一)基本步骤二)局部立体匹配三)全局立体匹配四)评价标准1. 均方误差(RMS)2. 错误匹配率百分比(PBM) 二、半全局(SGM)立体匹配一)代价计算二&a…...
苹果系统_安装matplotlib__pygame,以pycharm导入模块
为了更便捷、连贯的进行python编程学习,尽量在开始安装python软件时,将编辑器、模块一并安装好,这样能避免以后版本冲突的问题。小白在开始安装pycharm、pip、matplotlib往往会遇到一些问题,文中列示其中部分bug,供大家…...

常用颜色的英文和十六进制
以下颜色都是按照下面格式所写 # size:文字大小(1~7);color:文字颜色 <font size5 colorred>红 red #ff0000</font>红 red #ff0000 橙 orange #ffa500 黄 yellow #ffff00 草绿 springgreen #00FF7F 绿…...

计算机网络第二章思考题
1. 调制与编码分别有何作用? 调制(Modulation)和编码(Coding)是通信系统中的两个关键概念,它们分别具有不同的作用和功能: 调制(Modulation): 作用ÿ…...

使用 Taotoken 的模型广场在 Ubuntu 开发中快速选型与切换 AI 模型
使用 Taotoken 的模型广场在 Ubuntu 开发中快速选型与切换 AI 模型 1. 模型广场的核心功能 Taotoken 模型广场是开发者进行模型选型的一站式信息中心。通过访问控制台中的模型广场页面,开发者可以查看平台当前支持的所有模型及其关键属性。每个模型条目会展示模型…...

DesignPatternsPHP:PHP开发者必备的设计模式百科全书
DesignPatternsPHP:PHP开发者必备的设计模式百科全书 【免费下载链接】DesignPatternsPHP Sample code for several design patterns in PHP 8.x 项目地址: https://gitcode.com/gh_mirrors/de/DesignPatternsPHP DesignPatternsPHP 是一个专注于PHP 8.x设计…...

深度学习优化核心:梯度下降与网络训练全解析
深度学习优化核心:梯度下降与网络训练全解析一、核心基石:权重更新公式与梯度下降的困境二、必备符号:深度学习数学符号正确读法三、学习率:模型训练的「油门与刹车」四、训练三剑客:Epoch / Batch / Iteration批次数快…...

FF14智能钓鱼计时器终极指南:渔人的直感完整使用教程
FF14智能钓鱼计时器终极指南:渔人的直感完整使用教程 【免费下载链接】Fishers-Intuition 渔人的直感,最终幻想14钓鱼计时器 项目地址: https://gitcode.com/gh_mirrors/fi/Fishers-Intuition 渔人的直感是专为《最终幻想14》玩家打造的智能钓鱼计…...

具身智能课程整体总结
具身智能课程1. CS188(快速过渡期)2. 承上启下的基础设施:CS231N 与 CS2293. 跨越鸿沟的关键点:CS285(强化学习)4. 终极挑战:底层物理与灵巧手操作(最底层)一、课程体系总…...

Rust跨平台应用开发:relic框架架构解析与实战指南
1. 项目概述:一个面向未来的跨平台应用构建方案最近在折腾一个个人项目,需要把同一个应用逻辑部署到桌面端、Web端,甚至未来可能还要上移动端。一开始想着用Electron,毕竟生态成熟,但一想到那动辄上百兆的安装包和不算…...

如何快速实现本地千万级图片秒级搜索:面向新手的完整指南
如何快速实现本地千万级图片秒级搜索:面向新手的完整指南 【免费下载链接】ImageSearch 基于.NET10的本地硬盘千万级图库以图搜图案例Demo和图片exif信息移除小工具分享 项目地址: https://gitcode.com/gh_mirrors/im/ImageSearch 你是否曾在海量图片库中迷失…...

STM32G0B1 FDCAN实战:从CubeMX配置到代码调试,手把手搞定CANFD通信
STM32G0B1 FDCAN实战指南:从零搭建高效CANFD通信系统 开篇:为什么选择STM32G0B1的FDCAN模块? 在工业控制、汽车电子和物联网领域,CAN总线因其高可靠性和实时性成为不可替代的通信协议。而CANFD作为CAN的升级版本,在保…...

用PyTorch手搓DDPG算法:从Actor-Critic到目标网络,一步步搞定连续控制
用PyTorch手搓DDPG算法:从Actor-Critic到目标网络,一步步搞定连续控制 在强化学习领域,连续控制问题一直是极具挑战性的研究方向。想象一下训练机器人完成精细操作,或者让自动驾驶车辆在复杂环境中平稳行驶——这些场景都需要算法…...

免费Mac工具QMCDecode:三步完成QQ音乐加密格式转换终极指南
免费Mac工具QMCDecode:三步完成QQ音乐加密格式转换终极指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,…...