HTTP和HTTPS协议
HTTP协议
HTTP协议是一种应用层的协议,全称为超文本传输协议。
URL
URL值统一资源定位标志,也就是俗称的网址。

协议方案名
http://表示的就是协议方案名,常用的协议有HTTP协议、HTTPS协议、FTP协议等。HTTPS协议是以HTTP协议为基础,通过传输加密和身份认证保证了传输过程的安全性。
登录信息
user:pass表示登录认证信息。绝大多数情况下,该字段是被省略。一般通过登录窗口的方式让用户输入。比如gitee的登录窗口:
服务器地址
服务器地址也叫做域名。在进行网络访问时,网络地址通过DNS域名解析转换为标识唯一主机的IP地址。比如使用ping命令访问百度和京东的官网,最后会被转换为ip地址:
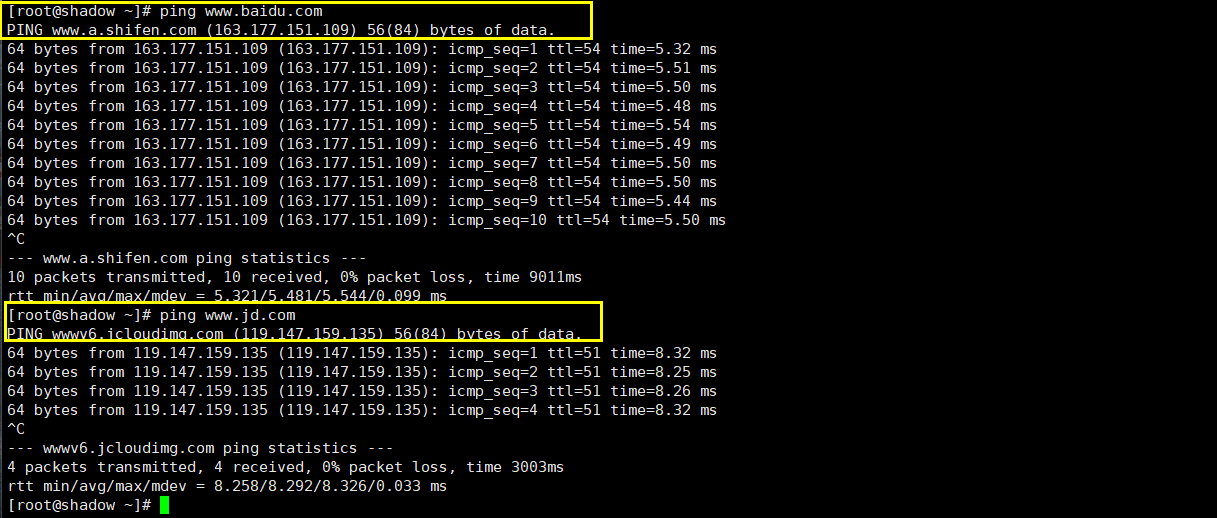
实际上,可以认为域名和IP地址是等价的;在计算机世界中使用的时候既可以使用域名,也可以使用IP地址。但URL呈现出来是可以让用户看到的,因此URL当中是以域名的形式表示服务器地址的。
服务器端口
一般0-1023号端口已经被一些特定的服务占有。比如HTTP协议默认的端口是80,HTTPS默认的端口是443。

带层次的文件路径
/dir/index.htm表示的是要访问的资源所在的路径。访问服务器的目的是获取服务器上的某种资源,通过前面的域名和端口已经能够找到对应的服务器进程了,此时要做的就是指明该资源所在的路径。
这里的’/'并不是指根目录,而是指web更目录。具体的信息将在后面解释。
查询字符串
uid=1表示的是请求时提供的额外的参数,这些参数是以键值对的形式,通过&符号分隔开的。
比如我们查询晓歌的灯如昼新皮肤的信息:
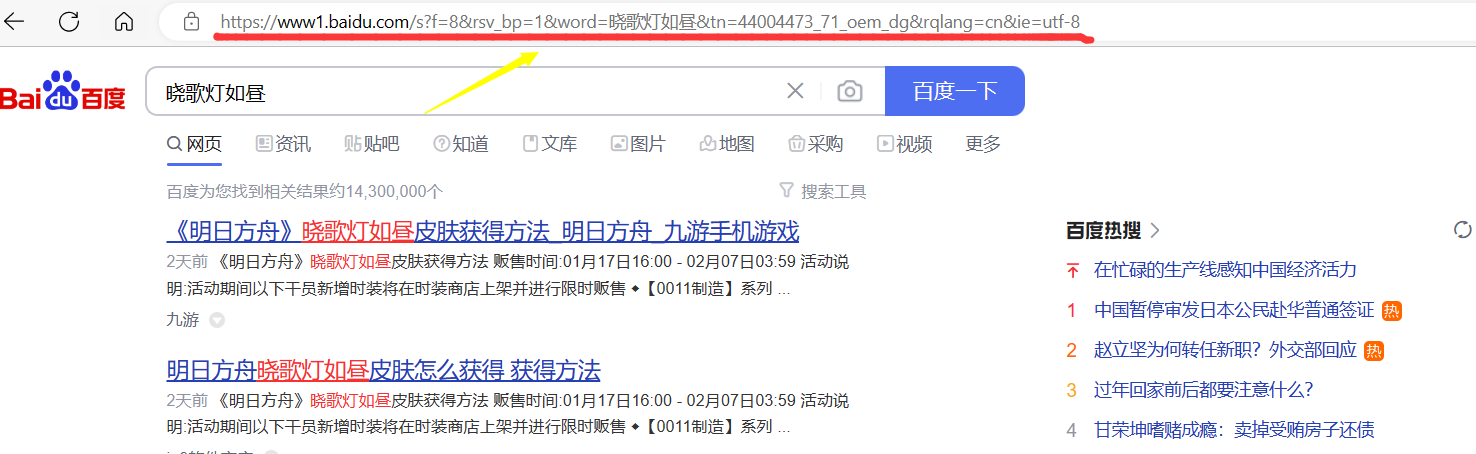
在上面的URL中,存在wd这个字段。这个字段也就是我们想要查询的关键字。
片段标识符
片段标识符是对资源的补充
urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现。
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义 。
比如我们搜索C++关键字:
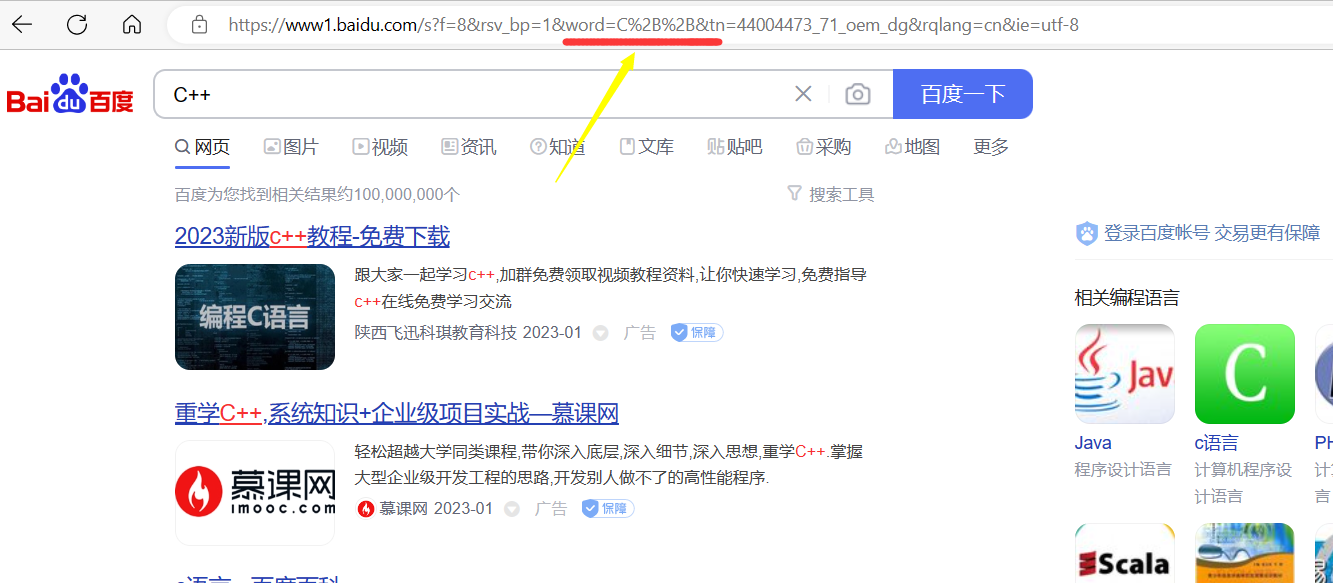
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
在线编码工具
市面上存在很多免费的在线编码工具:https://tool.chinaz.com/Tools/urlencode.aspx
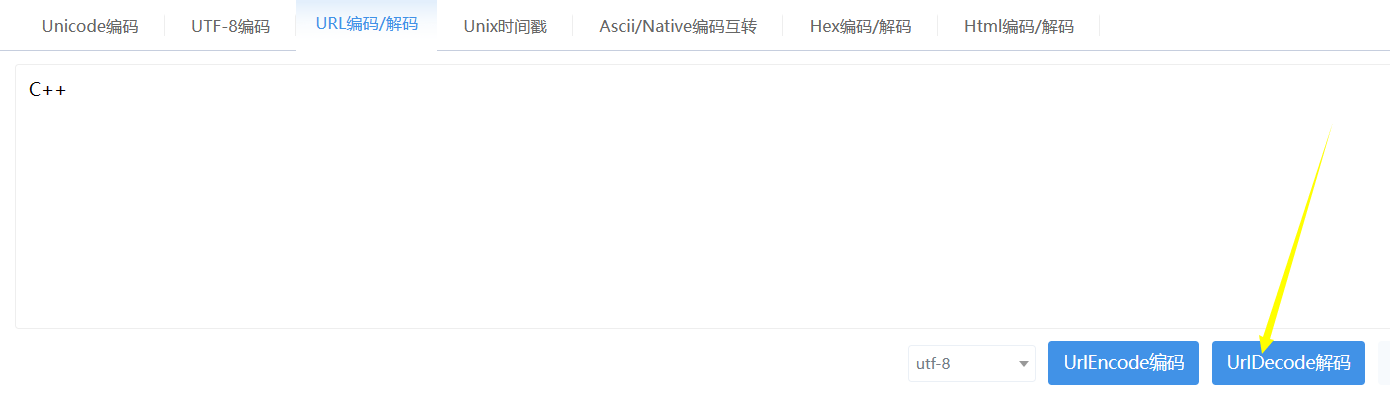
比如输入C++并进行编码,就可以得到C++对应的编码为C%2B%2B
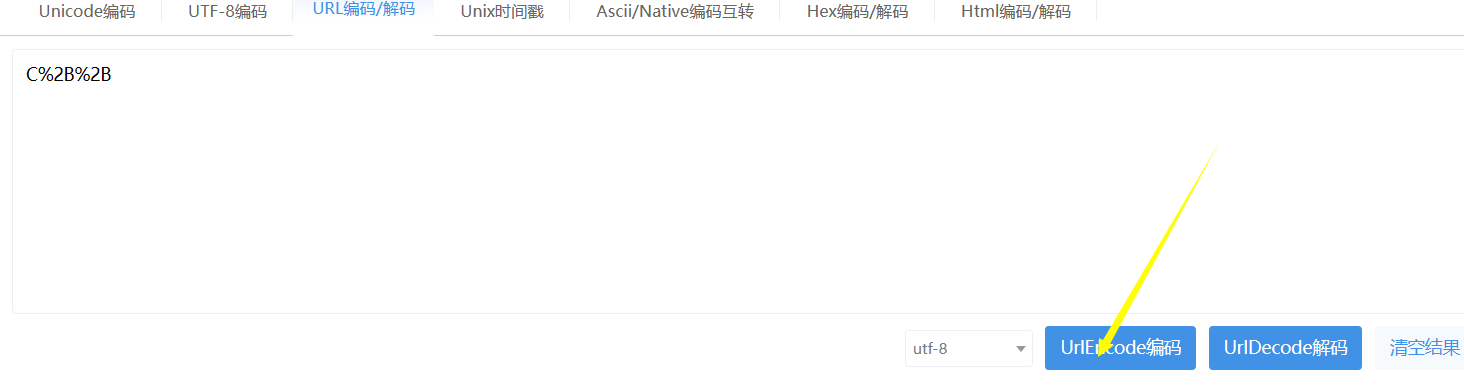
比如输入C%2B%2B进行解密,就可以得到对应的解码为C++
HTTP协议的格式
HTTP协议能够干什么?
HTTP协议是向特定的服务器申请特定的资源,并获取到本地的协议。
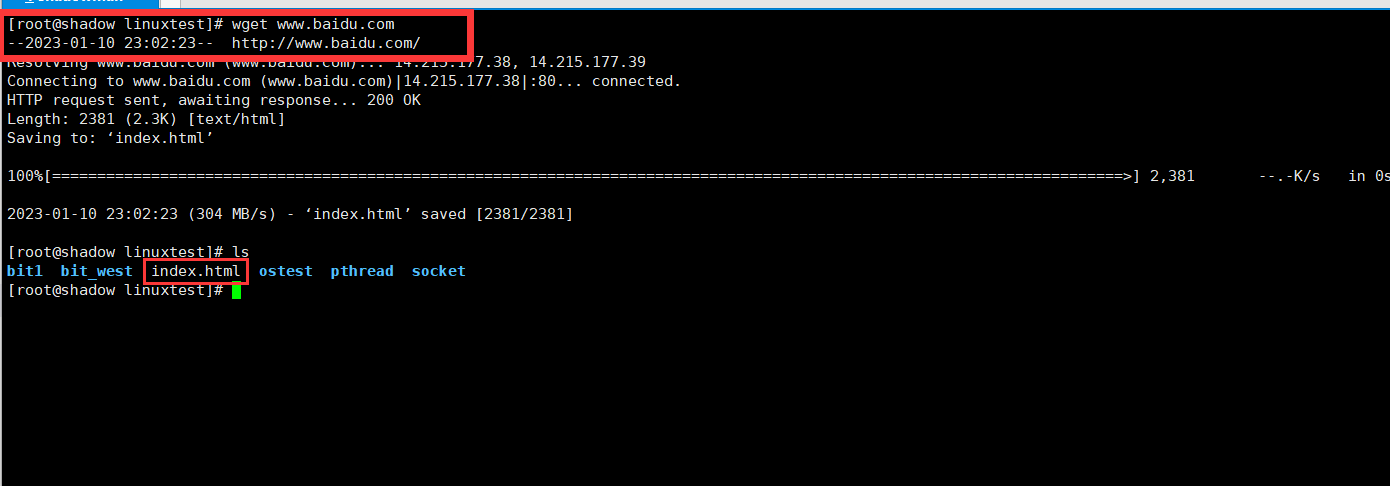
通过wget命令申请百度首页的资源。并得到一个html文件到本地。我们将html中的内容在浏览器中打开:
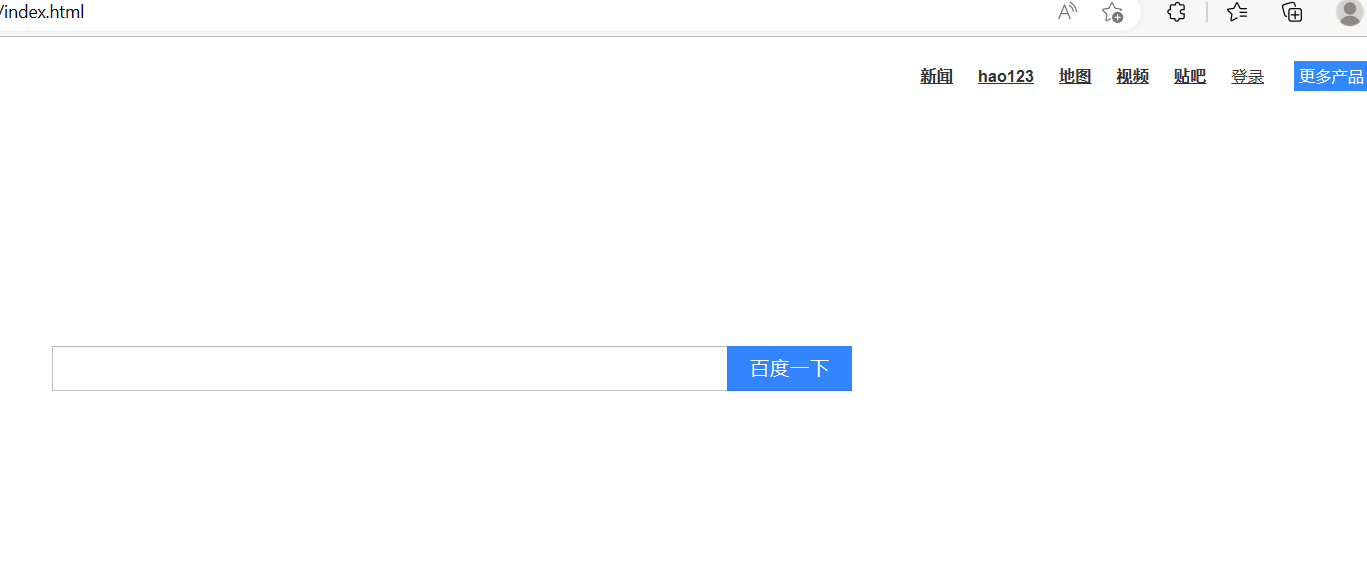
因此成功获取百度首页的静态资源。
HTTP协议的请求格式
HTTP请求格式可以分为四个部分,格式如下:
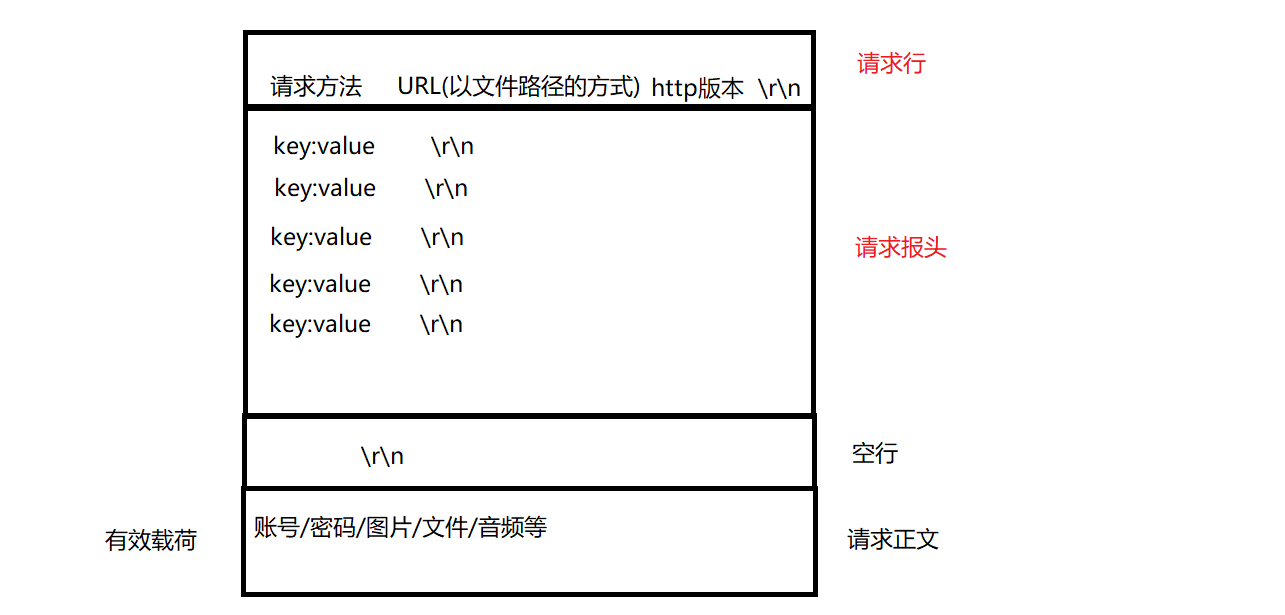
请求格式包含以下四个部分:
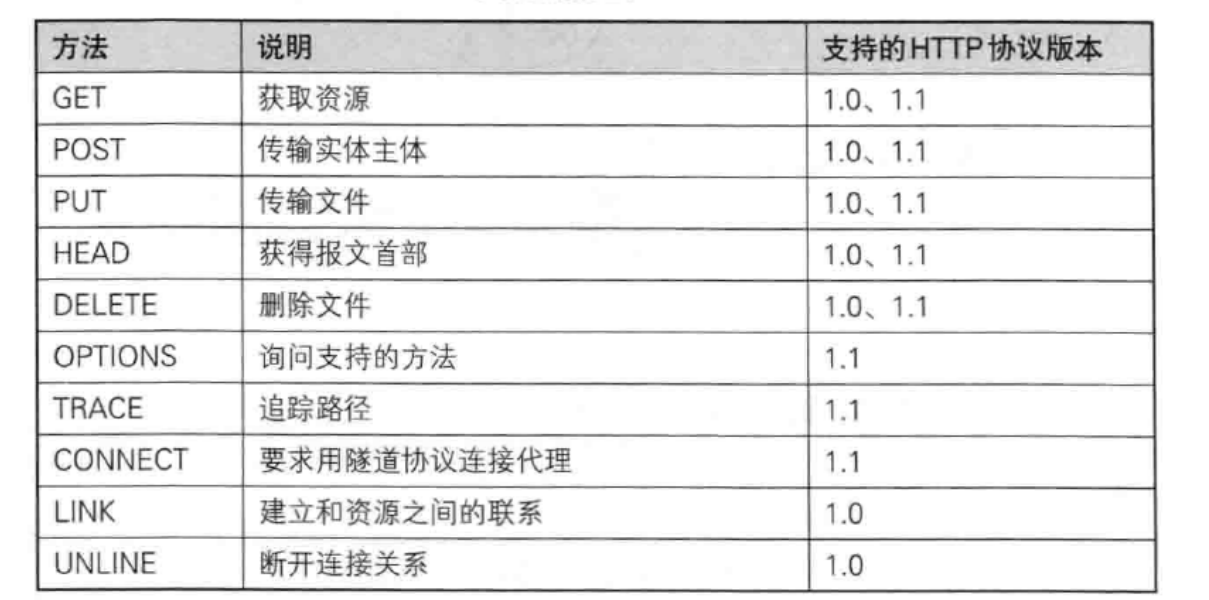
- 请求行:请求方法+url(文件路径格式)+http版本
- 请求报头:请求的属性,这些属性都是以
key: value的形式按行陈列的。 - 空行:作为请求报头和请求正文的的分割线
- 请求正文:请求正文允许为空字符串,如果请求正文存在,则在请求报头中会有一个Content-Length属性来标识请求正文的长度。
HTTP如何保证自己的报头和有效载荷全部被读取?
- 读取完整的报头:逐行读取,直到读取到空行。
- 读取完整的正文:在报头中一定存在一个关于key:value保存正文长度的属性。
获取HTTP请求
HTTP协议的底层通常使用的传输层协议是TCP协议,因此可以通过一个TCP服务器获取HTTP请求。
int main()
{//创建套接字int listen_sock = socket(AF_INET, SOCK_STREAM, 0);if (listen_sock < 0){cerr << "socket error!" << endl;return 1;}//绑定struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(8888);local.sin_addr.s_addr = htonl(INADDR_ANY);if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0){cerr << "bind error!" << endl;return 2;}//监听if (listen(listen_sock, 5) < 0){cerr << "listen error!" << endl;return 3;}//启动服务器struct sockaddr peer;memset(&peer, 0, sizeof(peer));socklen_t len = sizeof(peer);for (;;){int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){cerr << "accept error!" << endl;continue;}if (fork() == 0){ //爸爸进程close(listen_sock);if (fork() > 0){ //爸爸进程exit(0);}//孙子进程char buffer[1024];recv(sock, buffer, sizeof(buffer), 0); //读取HTTP请求cout << "--------------------------request begin--------------------------" << endl;cout << buffer << endl;cout << "---------------------------request end---------------------------" << endl;close(sock);exit(0);}//爷爷进程close(sock);waitpid(-1, nullptr, 0); //等待爸爸进程}return 0;
}
上面的服务器通过监听8888端口获取HTTP请求信息。
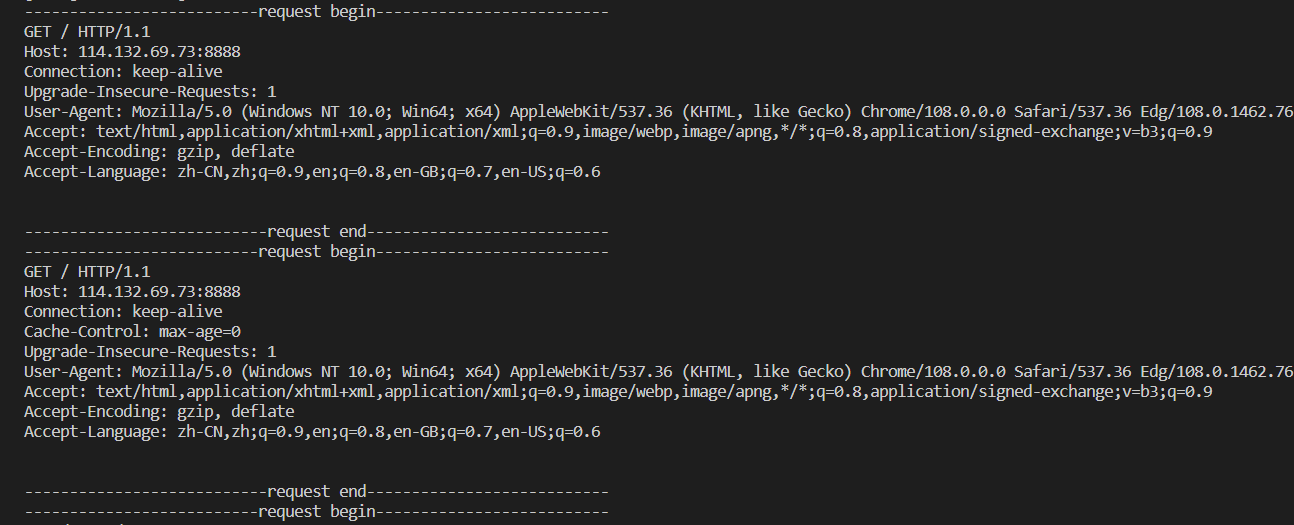
说明:
- 浏览器向服务器发起HTTP请求后,由于服务器没有对其进行响应,此时浏览器就会认为服务器没有收到请求,然后再不断发起新的HTTP请求。因此虽然我们只用浏览器访问了一次,但会受到多次HTTP请求。
- 由于浏览器发起请求时默认用的就是HTTP协议,因此我们在浏览器的url框当中输入网址时可以不用指明HTTP协议。
- 这里URL中的
/并不是指云服务器的根目录,而是web根目录。web根目录可以由自己指定。
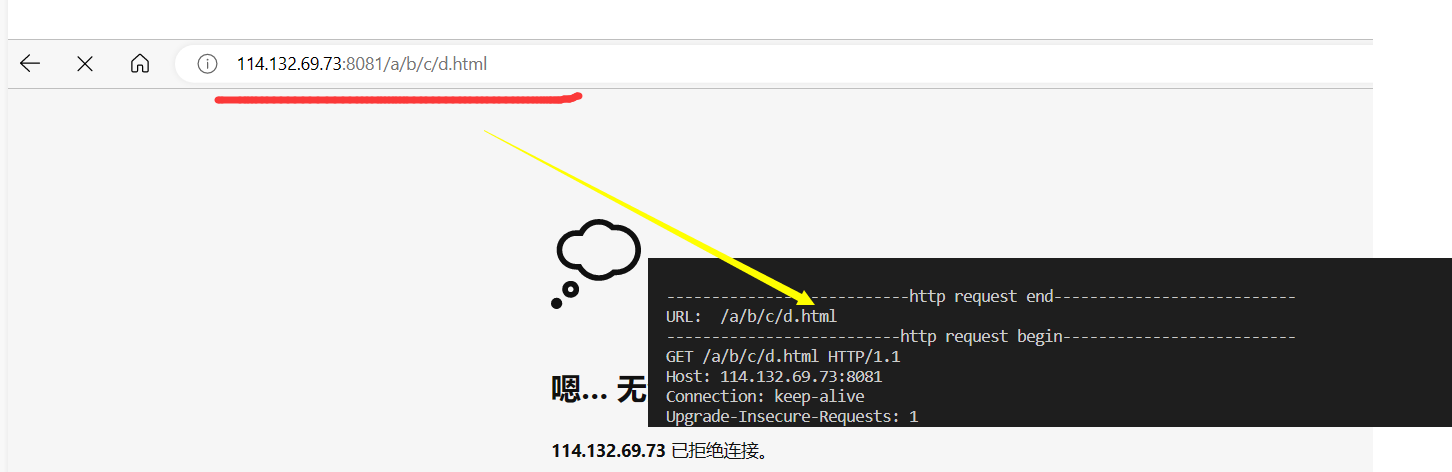
下面访问其他路径下的资源:
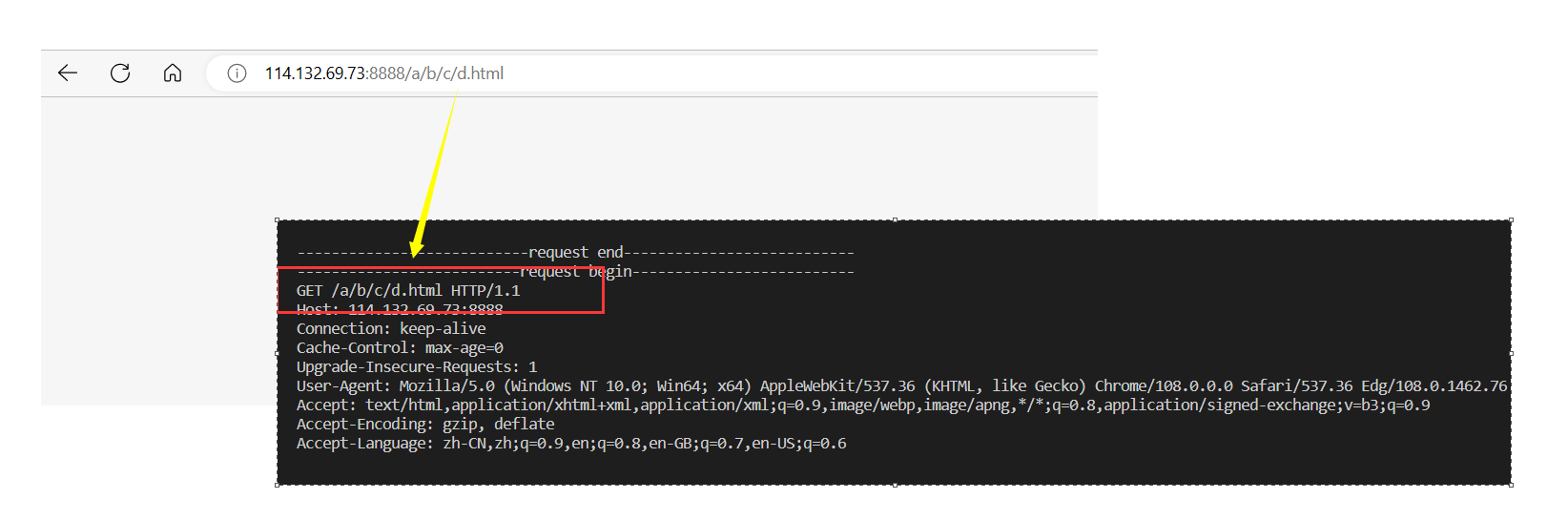
当访问的资源发生变化时,请求头中的URL也跟着改变。
HTTP的响应格式
HTTP响应格式可以分为四个部分,格式如下:

响应格式包含以下四个部分:
- 状态行:HTTP版本+状态码+状态码描述符
- 响应报头:响应的属性,以
key: value键值对的形式按行陈列的。 - 空行:响应报头和响应正文的分割线
- 响应正文:响应正文允许为空字符串,如果响应正文存在,则响应报头中会有一个Content-Length属性来标识响应正文的长度。
比如我们访问百度搜索晓歌的信息:
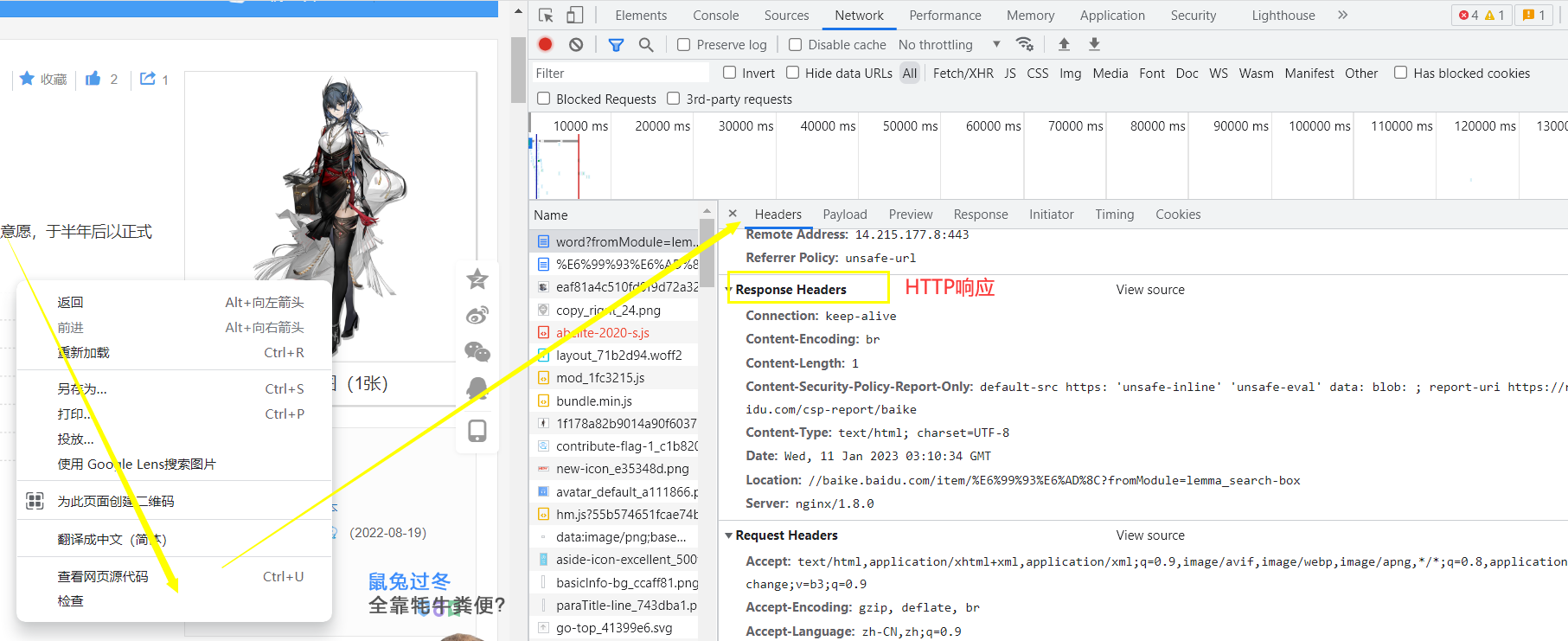
模拟HTTP的响应
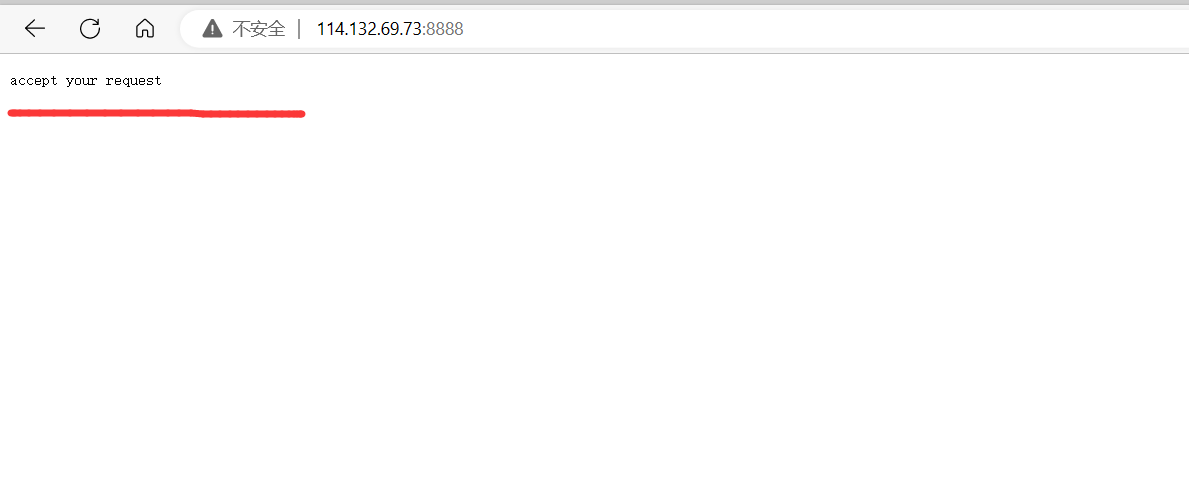
下面我们在服务器中构建HTTP响应:当浏览器发送请求时,在网页上显示accept your request。
int main()
{//创建套接字int listen_sock = socket(AF_INET, SOCK_STREAM, 0);if (listen_sock < 0){cerr << "socket error!" << endl;return 1;}//绑定struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(8888);local.sin_addr.s_addr = htonl(INADDR_ANY);if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0){cerr << "bind error!" << endl;return 2;}//监听if (listen(listen_sock, 5) < 0){cerr << "listen error!" << endl;return 3;}//启动服务器struct sockaddr peer;memset(&peer, 0, sizeof(peer));socklen_t len = sizeof(peer);for (;;){int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){cerr << "accept error!" << endl;continue;}if (fork() == 0){ //爸爸进程close(listen_sock);if (fork() > 0){ //爸爸进程exit(0);}//孙子进程char buffer[1024];recv(sock, buffer, sizeof(buffer), 0); //读取HTTP请求cout << "--------------------------request begin--------------------------" << endl;cout << buffer << endl;cout << "---------------------------request end---------------------------" << endl;//构建HTTP响应string response="http/1.1 200 ok\r\n";string world="accept your request";response+=("Content-Length: "+ to_string(world.size()) + "\r\n");response+="\r\n";response+=world;send(sock,response.c_str(),response.size(),0);close(sock);exit(0);}//爷爷进程close(sock);waitpid(-1, nullptr, 0); //等待爸爸进程}return 0;
}
在实际的使用中,难道每一个请求都需要程序员去构造响应正文?实际上,HTTP请求的请求行中存在URL,URL就是请求需要访问资源的存放地址。
响应正文存放在哪?
在URL中,存在一个带层次的文件路径:(比如) /dir/index.html。所以可以从请求行的第二个字段中获取资源路径。
GET /dir/index.html http/1.0
下面的函数实现了从请求行提取读取URL路径:
#define CRLF "\r\n"
#define SPACE " "
#define SPACELEN strlen(SPACE)
#define ROOT_PATH "wwwpath"
#define HOME_PAGE "index.html"
string readURL(string buffer){//读取第一行size_t pos=buffer.find(CRLF);if(pos==std::string::npos) return "";string firstline=buffer.substr(0,pos);size_t first=firstline.find(SPACE);if(first==std::string::npos) return "";size_t second=firstline.rfind(SPACE);if(second==std::string::npos) return "";string URL=buffer.substr(first+SPACELEN,second-SPACELEN-first);if(URL.size()==1&&URL[0]=='/'){URL+=HOME_PAGE;}return URL;
}
注意:
对于访问web根目录/,需要进行特殊处理。一般默认为web根目录下的index.html文件。
实验
当我们访问对应URL路径在资源时,便打开对应文件夹,并添加到HTTP响应正文并返回。
string readFile(const string& filepath)
{std::ifstream in(filepath,std::ifstream::binary);if(!in.is_open()) return "404";std::string content;std::string line;while (getline(in,line)){content+=line;}cout<<content<<endl;in.close();return content;
}
假设我们将当前目录设置为根目录,并创建一个index.html文件。
<html><head></head><body><h1>Hello webroot</h1></body>
</html>
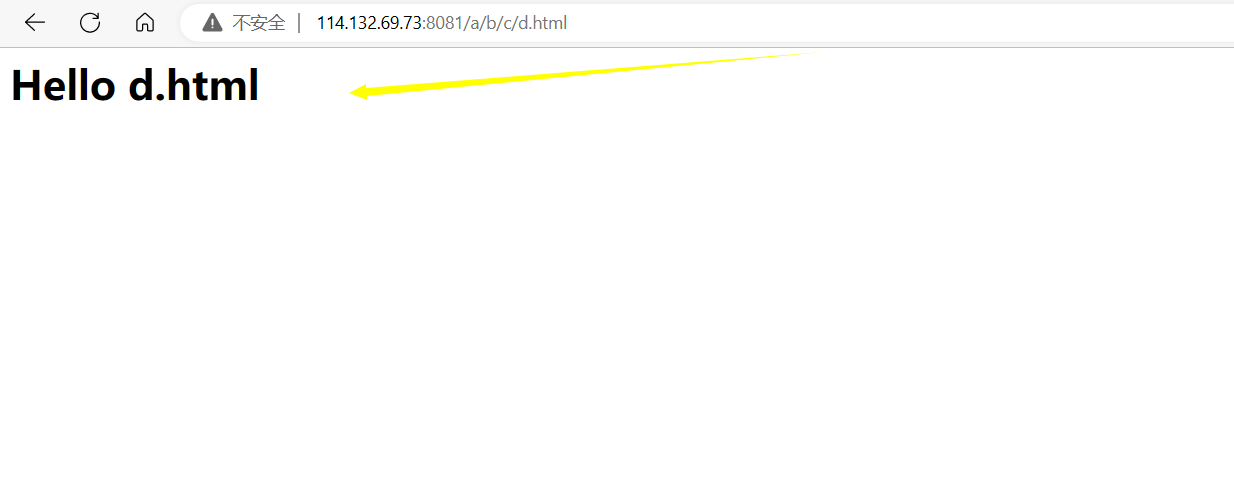
并创建文件夹a/b/c,在该文件夹下创建一个d.html文件
<html><head></head><body><h1>Hello d.html</h1></body>
</html>
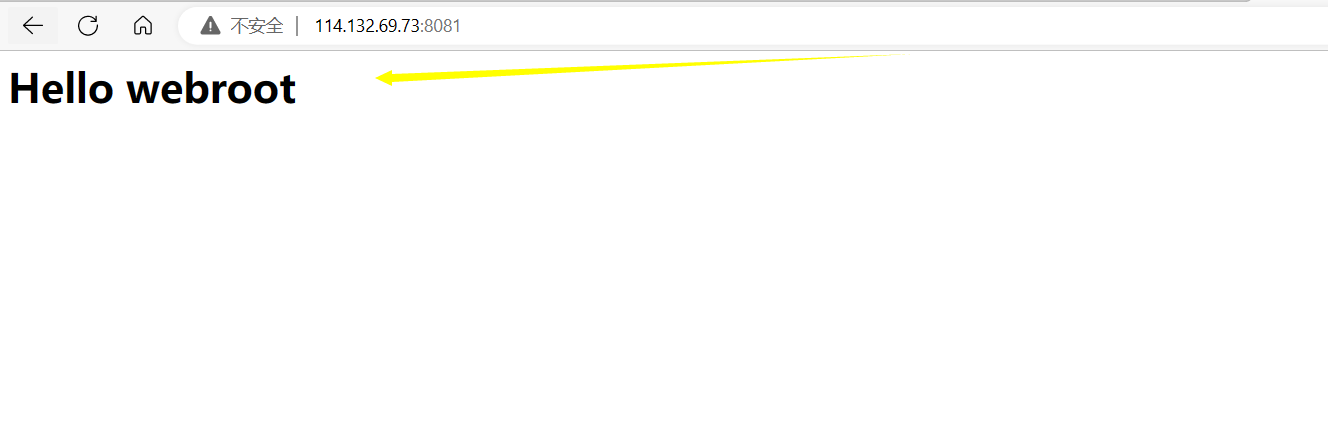
访问web根目录结果:
访问/a/b/c/d.html资源结果:
完整的主程序
int main()
{//创建套接字int listen_sock = socket(AF_INET, SOCK_STREAM, 0);if (listen_sock < 0){cerr << "socket error!" << endl;return 1;}//绑定struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(8081);local.sin_addr.s_addr = htonl(INADDR_ANY);if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0){cerr << "bind error!" << endl;return 2;}//监听if (listen(listen_sock, 5) < 0){cerr << "listen error!" << endl;return 3;}//启动服务器struct sockaddr peer;memset(&peer, 0, sizeof(peer));socklen_t len = sizeof(peer);for (;;){int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){cerr << "accept error!" << endl;continue;}if (fork() == 0){ //爸爸进程close(listen_sock);if (fork() > 0){ //爸爸进程exit(0);}//孙子进程char buffer[1024];recv(sock, buffer, sizeof(buffer), 0); //读取HTTP请求//读取URLstring URL=readURL(buffer);cout<<"URL:"<<URL<<endl;//拼接路径string filepath=ROOT_PATH+URL;cout<<filepath<<endl;//构建HTTP响应string response="http/1.1 200 ok\r\n";string world=readFile(filepath);response+=("Content-Length: "+ to_string(world.size()) + "\r\n");response+="\r\n";response+=world;send(sock,response.c_str(),response.size(),0);close(sock);exit(0);close(sock);exit(0);}//爷爷进程close(sock);waitpid(-1, nullptr, 0); //等待爸爸进程}return 0;
}
POST和GET方法
GET方法
网络行文无非有两种:
- 把远端的资源拿到本地:GET
- 将自己的属性提交到远端:POST或者GET方法。
我们在web根目录下的index.html文件中添加一个表单用于比较两者的区别:
<html><head></head><body><h1>Hello webroot</h1><form action="/a/b/c/d.html" method="get">Username: <input type="text" name="user"><br>Password: <input type="password" name="passwd"><br><input type="submit" value="Submit"> </form></body>
</html>
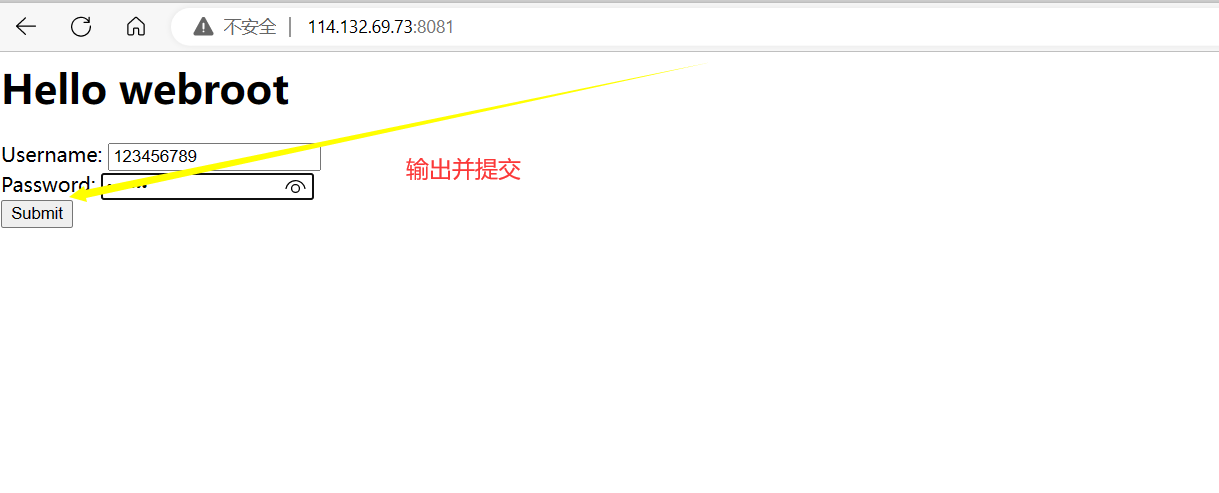
得到结果为:
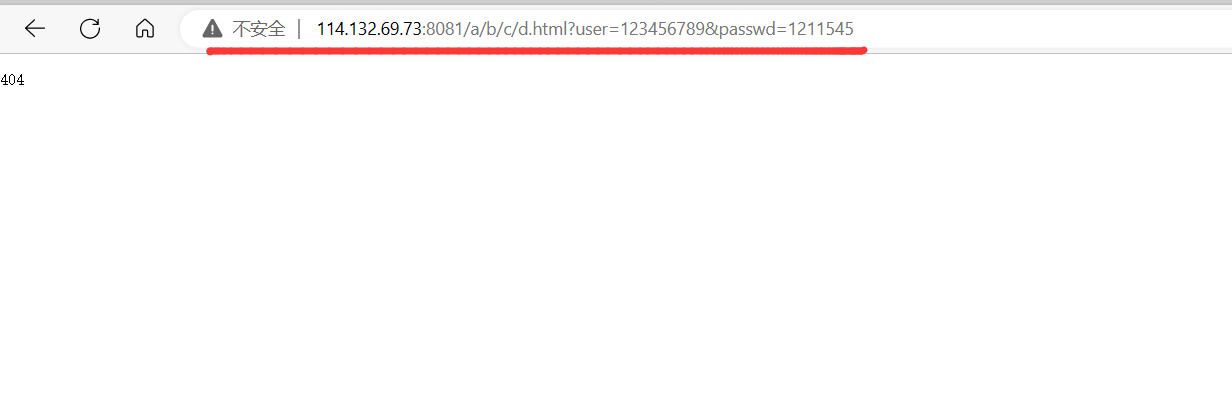
观察URL的变化。提交的user和passwd以明文的方式出现在URL中。
这也是GET方法的特点:把参数以明文的方式按照Key:value格式拼接到URL后面。
POST方法
将表单的方法修改为POST。
<html><head></head><body><h1>Hello webroot</h1><form action="/a/b/c/d.html" method="post">Username: <input type="text" name="user"><br>Password: <input type="password" name="passwd"><br><input type="submit" value="Submit"> </form></body>
</html>
再次访问并提交用户密码:
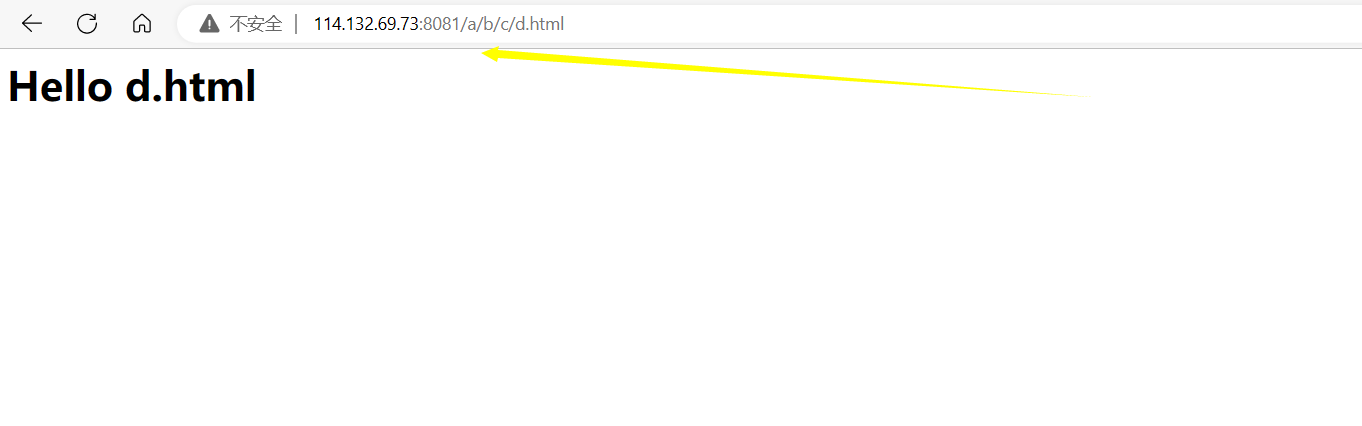
这次并没有将参数添加到URL中,观察HTTP请求,可以看到user和password参数都出现在HTTP请求正文中。
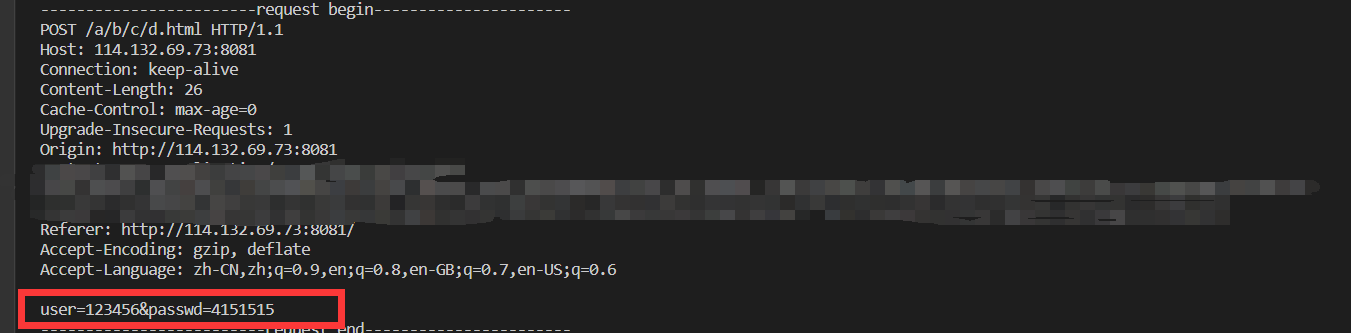
POST和GET方法的区别
-
GET方法以URL传参
-
POST通过HTTP请求正文传参
-
GET传参的方式不私密。
注意:一定不是不安全,因为GET方法和POST方法通过代理服务器或者抓包等方法都可以获取对应的参数,要想实现数据安全,就需要对传输的数据进行加密。比如HTTPS协议
-
GET通过URL传参,URL有长度的限制,所以数据量较大的参数都会通过POST方法传递。
-
URL是文本类,没有严格意义上的数据类型。而请求正文有。
HTTP其他的请求方法
HTTP状态码
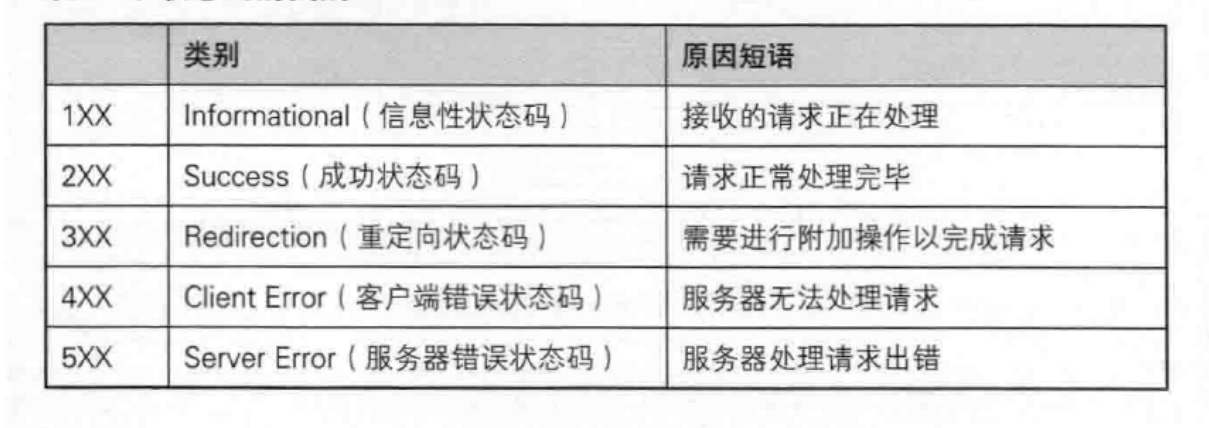
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
常见的状态码
重定向就是通过各种方法将各种网络请求重新定个方向转到其它位置,此时这个服务器相当于提供了一个引路的服务。
重定向又可分为临时重定向和永久重定向,其中状态码301表示的就是永久重定向,而状态码302和307表示的是临时重定向。

临时重定向实验
下面我们实现:访问我们的服务时,会跳转到B站的首页。
在实现的过程中,将HTTP的响应码设置为302,还需要在HTTP响应报头当中添加Location字段,这个Location后面跟的就是你需要重定向到的网页,比如我们这里将其设置为CSDN的首页。
int main()
{//创建套接字int listen_sock = socket(AF_INET, SOCK_STREAM, 0);if (listen_sock < 0){cerr << "socket error!" << endl;return 1;}//绑定struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(8081);local.sin_addr.s_addr = htonl(INADDR_ANY);if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0){cerr << "bind error!" << endl;return 2;}//监听if (listen(listen_sock, 5) < 0){cerr << "listen error!" << endl;return 3;}//启动服务器struct sockaddr peer;memset(&peer, 0, sizeof(peer));socklen_t len = sizeof(peer);for (;;){int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){cerr << "accept error!" << endl;continue;}if (fork() == 0){ //爸爸进程close(listen_sock);if (fork() > 0){ //爸爸进程exit(0);}//孙子进程char buffer[1024];recv(sock, buffer, sizeof(buffer), 0); //读取HTTP请求cout<<"------------------------request begin----------------------"<<endl;cout<<buffer<<endl;cout<<"-------------------------request end-----------------------"<<endl;string response="http/1.1 302 Temporary Redirect/\r\n";response+="Location: https://www.bilibili.com/\r\n";response+="\r\n";send(sock,response.c_str(),response.size(),0);close(sock);exit(0);close(sock);exit(0);}//爷爷进程close(sock);waitpid(-1, nullptr, 0); //等待爸爸进程}return 0;
}使用telnet命令只是接收到了服务器发送的HTTP响应,并没有实现重定向功能。实际上的重定向功能是由浏览器实现完成。
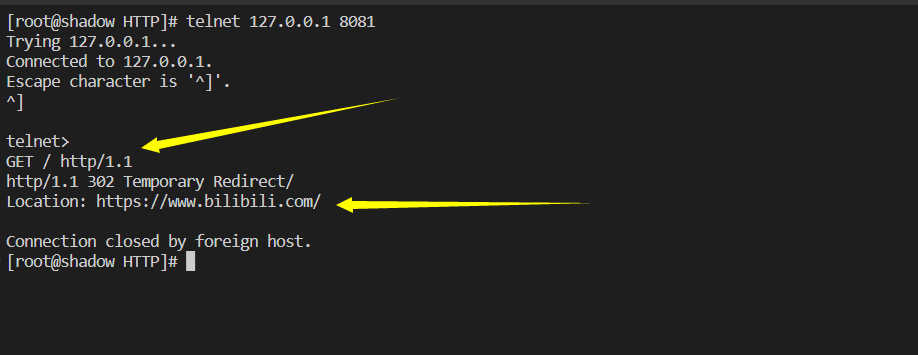
下面我们用浏览器访问该网址:
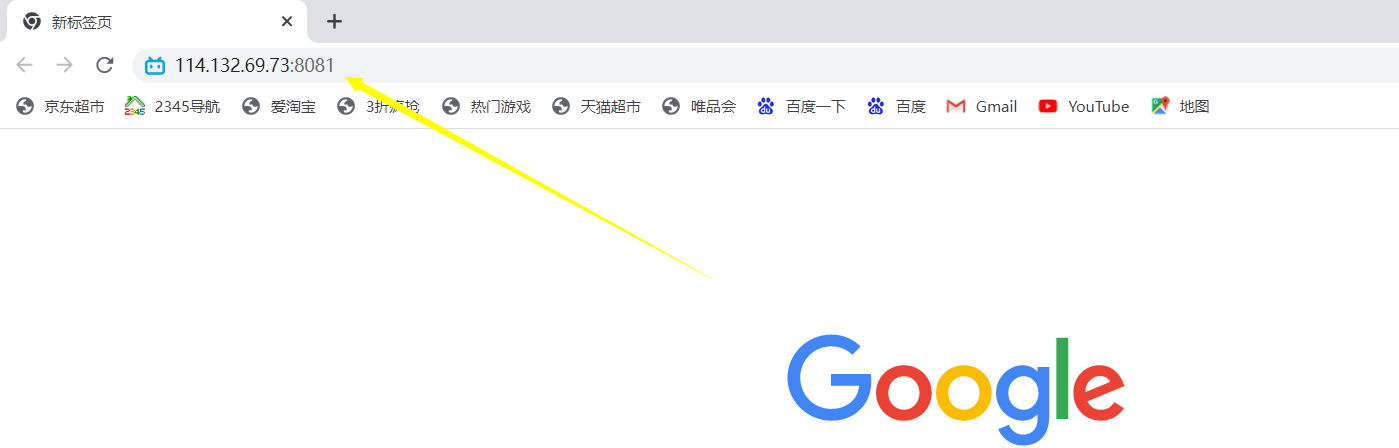
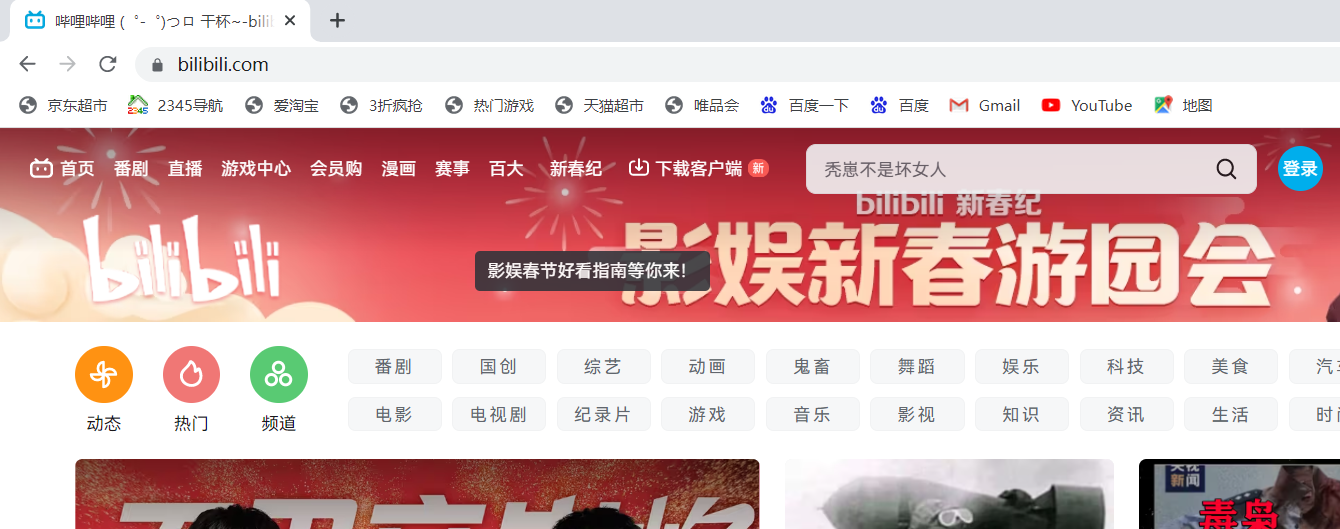
回车发送请求:重定向到B站官网
临时重定向和永久重定向的区别
- 两者的区别主要体现在用户体验方面
- 临时重定向主要用于网站维护、网站服务升级等。服务升级结束和维护成功后,原网址依然可以被使用。临时重定向不需要客户记住新的网址。
- 永久重定向,比如用于使用新的网址,原网址被废弃的情况。永久重定向需要用户记住新的网址。
HTTP常见的Header
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
Cookie
HTTP协议的特点之一:无状态。对于用户的状态,HTTP协议不会记录用户的信息和行为。
而Cookie是实现HTTP状态化的一种手段。比如实现网址的无登陆访问,VIP访问VIP资源。(回忆下面的场景:我们在使用B站时,第一次需要我们输入账号密码登录。后续再使用时,我们可以直接进入B站而不需要登录。这就是HTTP状态化的一种手段;
比如你是某个视频网站的VIP,这个网站里面的VIP视频有成百上千个,你每次点击一个视频都要重新进行VIP身份认证。而HTTP不支持记录用户状态,那么我们就需要有一种独立技术来帮我们支持,这种技术目前现在已经内置到HTTP协议当中了,叫做cookie。)
Cookie实验一
此时已经登录了账号。点击网址前面的小锁,可以看到网页的Cookie。
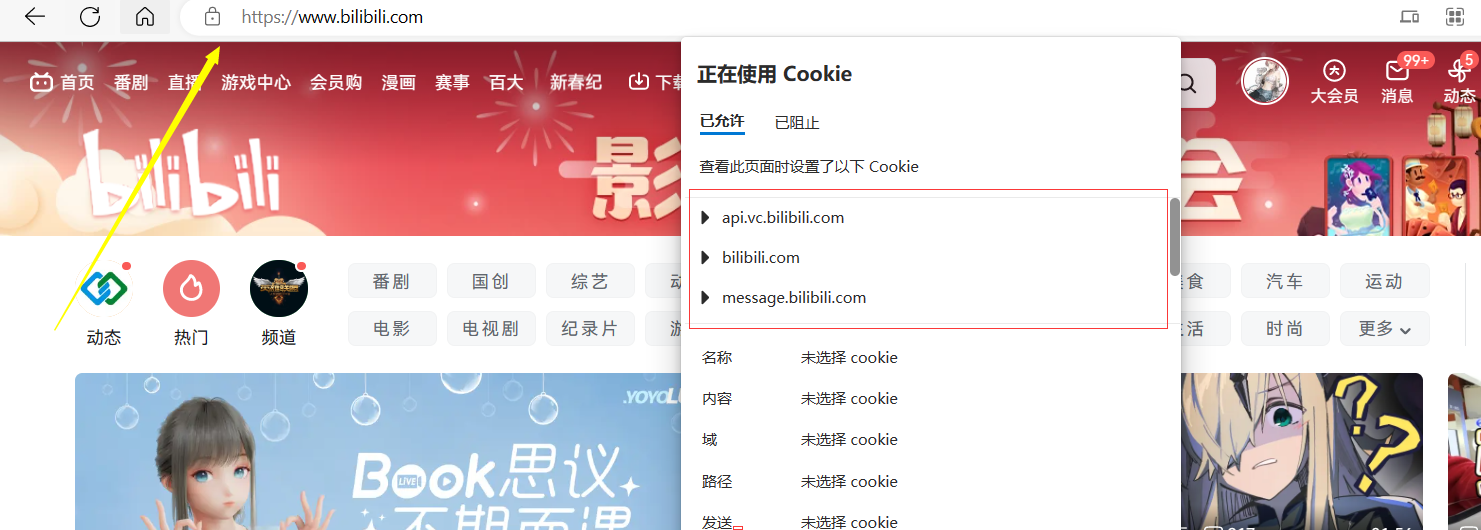
下面我们将关于B站的Cookie全部删除,再访问B站。
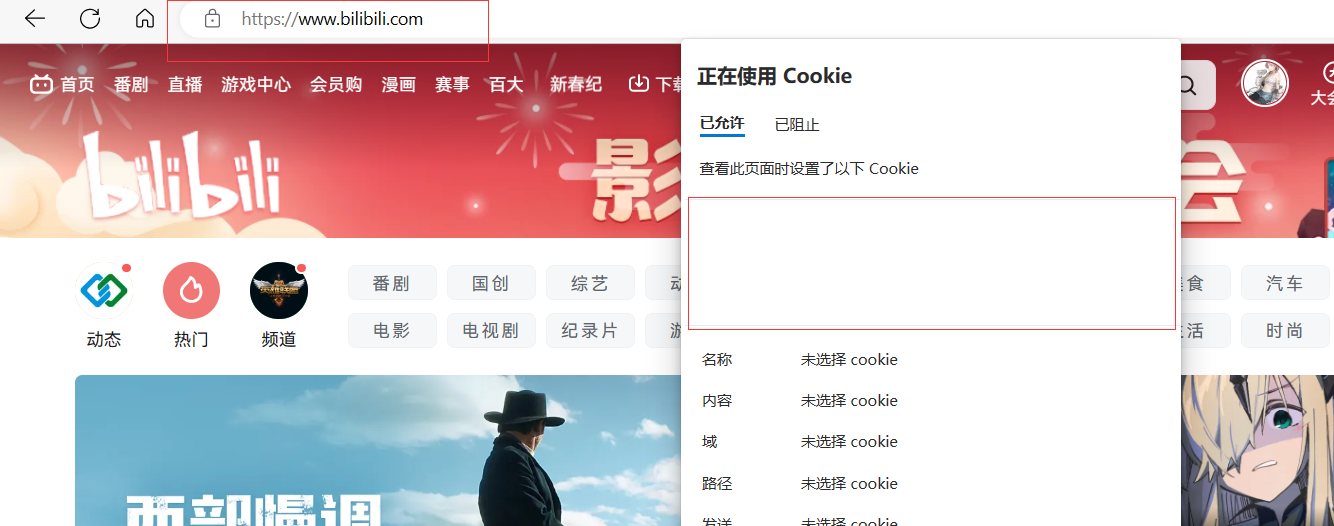
回车访问B站,可以看到需要我们重新登录。
Cookie的原理
在我们第一次登录输入账号和密码进行身份认证时,如果认证成功,服务端就会向客户端发送对应的响应,其中就包含Set-Cookie字段(Set-Cookie也是HTTP报头当中的一个字段)。该字段通知客户端设置Cookie。输入的账号和密码就保存在本地浏览器Cookie文件当中。
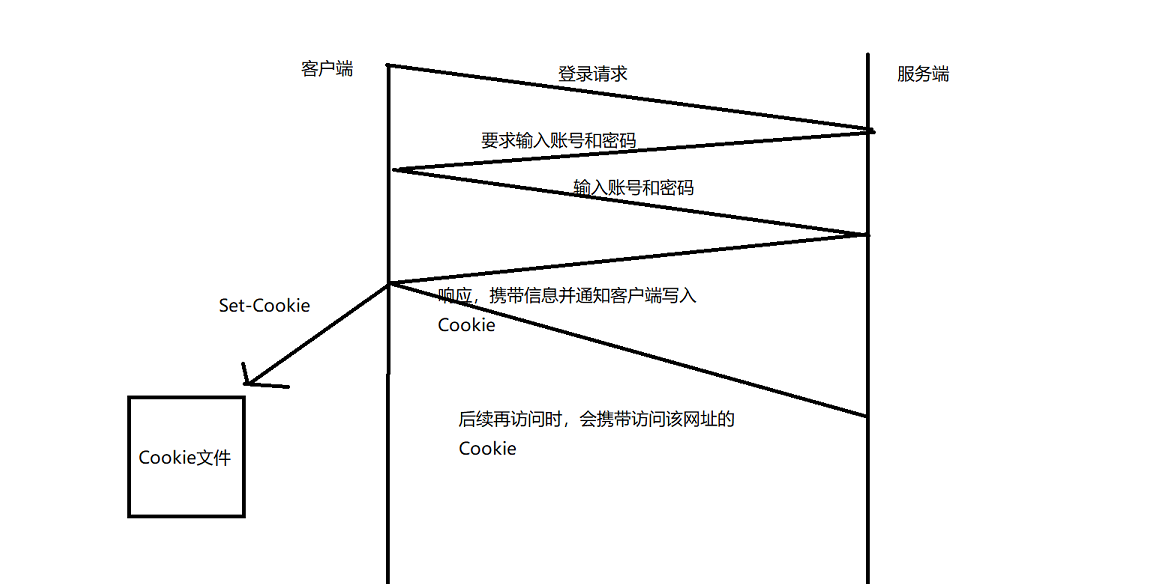
后续再次访问相同的网址时,浏览器发送的HTTP请求当中就会包含一个Cookie信息。服务端在需要认证时会提取Cookie当中账号和密码。
Cookie文件:内存级和磁盘级别
cookie就是在浏览器当中的一个小文件,文件里记录的就是用户的私有信息。cookie文件可以分为两种:一种是内存级别的cookie文件,另一种是磁盘文件级别的cookie文件。
- 浏览器关闭后再打开,访问之前的网站,需要输入账号和密码。此时浏览器保存的是内存级别的Cookie文件
- 浏览器关闭再打开,甚至重启电脑。访问之前的网站,不需要输入账号和密码。浏览器保存的是磁盘文件级别的Cookie文件。
设置Cookie
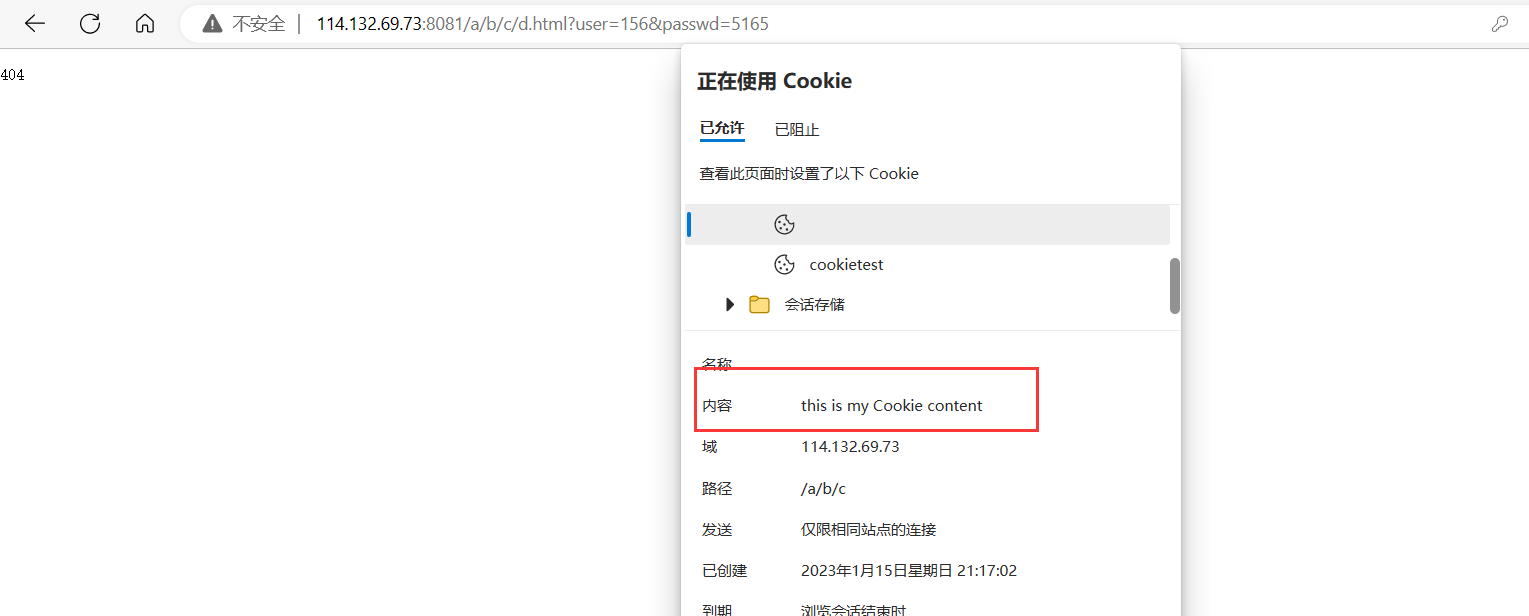
设置Cookie可以在HTTP响应中添加一个Set-Cookie字段。(Set-Cookie:Cookie信息)
设置Cookie实验
int main()
{//创建套接字int listen_sock = socket(AF_INET, SOCK_STREAM, 0);if (listen_sock < 0){cerr << "socket error!" << endl;return 1;}//绑定struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(8081);local.sin_addr.s_addr = htonl(INADDR_ANY);if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0){cerr << "bind error!" << endl;return 2;}//监听if (listen(listen_sock, 5) < 0){cerr << "listen error!" << endl;return 3;}//启动服务器struct sockaddr peer;memset(&peer, 0, sizeof(peer));socklen_t len = sizeof(peer);for (;;){int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){cerr << "accept error!" << endl;continue;}if (fork() == 0){ //爸爸进程close(listen_sock);if (fork() > 0){ //爸爸进程exit(0);}//孙子进程char buffer[1024];recv(sock, buffer, sizeof(buffer), 0); //读取HTTP请求cout<<"------------------------request begin----------------------"<<endl;cout<<buffer<<endl;cout<<"-------------------------request end-----------------------"<<endl;//读取URLstring URL=readURL(buffer);//拼接路径string filepath=ROOT_PATH+URL;//构建HTTP响应string response="http/1.1 200 ok/\r\n";response+="Set-Cookie:this is my Cookie content\r\n";string world=readFile(filepath);response+=("Content-Length: "+ to_string(world.size()) + "\r\n");response+="\r\n";response+=world;send(sock,response.c_str(),response.size(),0);close(sock);exit(0);close(sock);exit(0);}//爷爷进程close(sock);waitpid(-1, nullptr, 0); //等待爸爸进程}return 0;
}
Session
单纯的使用Cookie是不安全的。cookie文件当中就保存的是你的私密信息,一旦cookie文件泄漏你的隐私信息也就泄漏。
为了保证Cookie的安全性。后来又引入了Session的概念。当我们第一次登录某个网站输入账号和密码后,服务器认证成功后还会服务端生成一个对应的SessionID,这个SessionID与用户信息是不相关的。系统会将所有登录用户的SessionID值统一维护起来。
此时当认证通过后服务端在对浏览器进行HTTP响应时,就会将这个生成的SessionID值响应给浏览器。浏览器收到响应后会自动提取出SessionID的值,将其保存在浏览器的cookie文件当中。后续访问该服务器时,对应的HTTP请求当中就会自动携带上这个SessionID。
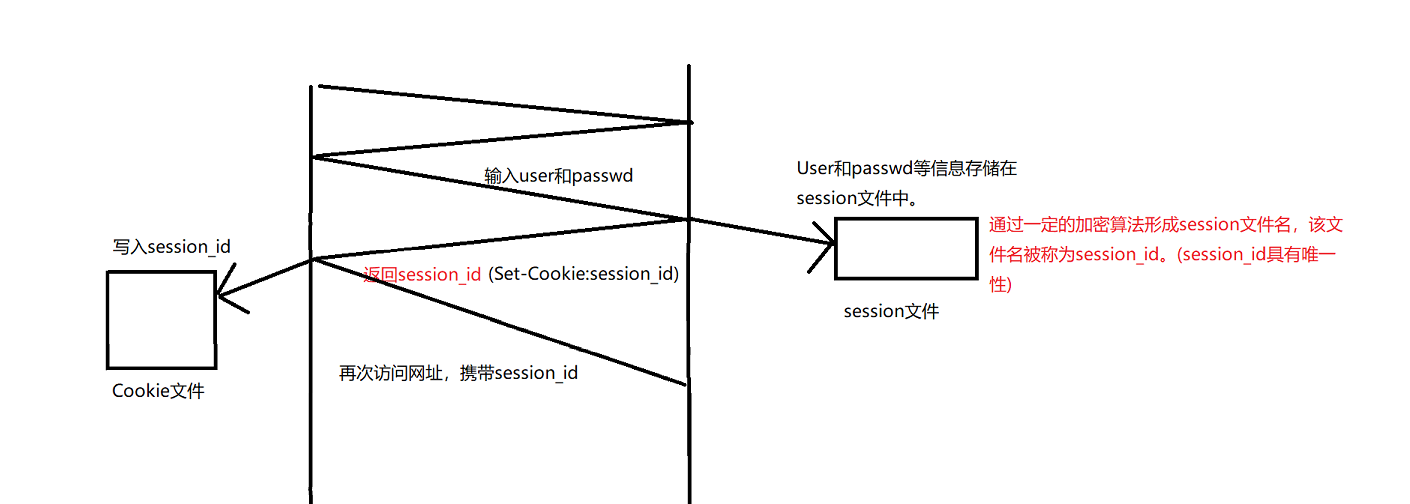
服务端会根据session_id找到对应的Session文件。再提取session文件中的私密信息。
Cookie+Session的安全保证:着手于Session_id的加密方式。比如用户的IP地址等。
Connection字段
HTTP有两种连接方式:长连接和短链接。
- Connection:keep_alive
- Connection:closed
HTTP的长连接和短链接本质上是TCP的长连接和短链接。
HTTP短连接
在HTTP/1.0中,默认使⽤的是短连接。也就是说,浏览器和服务器每进⾏⼀次HTTP操作,就建⽴⼀次连接,但任务结束就中断连接。
随着网页信息不断的增大,需要传输的数据量也不断增加。如果客户端访问的某个HTML或其他类型的web页中包含有其他的web资源,如JavaScript⽂件、图像⽂件、CSS⽂件等,当浏览器每遇到这样⼀个web资源,就会建⽴⼀个HTTP会话。如果建立多个HTTP短连接传输数据,**传输层会不断的进行三次握手和四次挥手,**过于浪费网络资源。
因此HTTP长连接诞生。
HTTP长连接
但从HTTP/1.1起,默认使⽤长连接,⽤以保持连接特性。使⽤长连接的HTTP协议,会在请求头和响应头加⼊这⾏代码。Connection: keep-alive。
在使⽤长连接的情况下,当⼀个⽹页打开完成后,客户端和服务器之间⽤于传输HTTP数据的TCP链接不会关闭,如果客户端再次访问这个服务器上的⽹页,会继续使⽤这⼀条已经建⽴的连接(HTTP长连接利⽤同⼀个TCP连接处理多个HTTP请求和响应)。
Keep-Alive不会永久保持连接,它有⼀个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接要客户端和服务端都⽀持长连接。长连接中关闭连接通过Connection:closed头部字段。如果请求或响应中的Connection被指定为closed,表⽰在当前请求或相应完成后将关闭TCP连接。
TCP的keep-alive是检查当前TCP连接是否活着;HTTP的Keep-Alive是要让⼀个TCP连接活久点。
长连接如何保证读取完整的信息?
HTTP报头中存在Conten-Length字段。通过控制读取的长度判断是否读取完整的信息。
如何保证长连接的响应顺序?
pipeline技术。
HTTP VS HTTPS
HTTPS协议也是⼀个应⽤层协议。是在HTTP协议的基础上引⼊了⼀个加密层。这场加密层也输入应用层,他会对用户传输的信息进行加密。
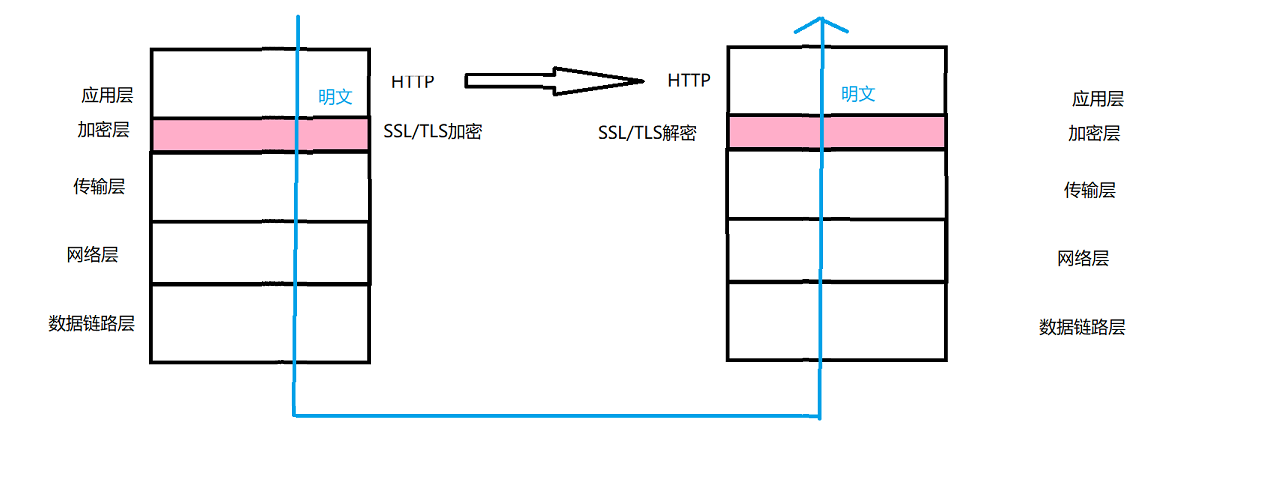
而在用户和服务端使用时,对应拿到的都是明文数据。
为什么要加密?
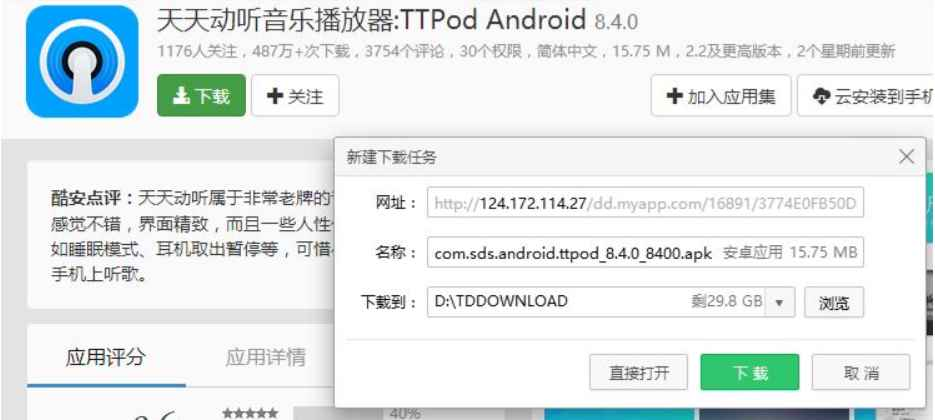
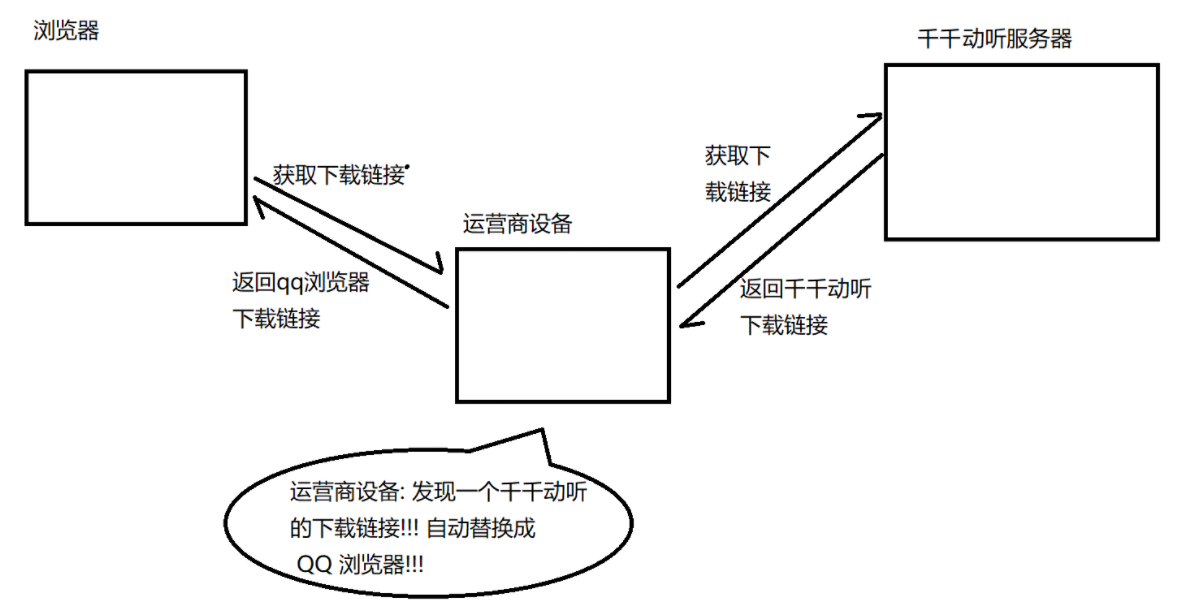
QQ浏览器的运营商劫持例子。
下载天天动听,在未被QQ浏览器劫持的情况:
已被劫持的效果,点击下载按钮,就会弹出QQ浏览器的下载链接:
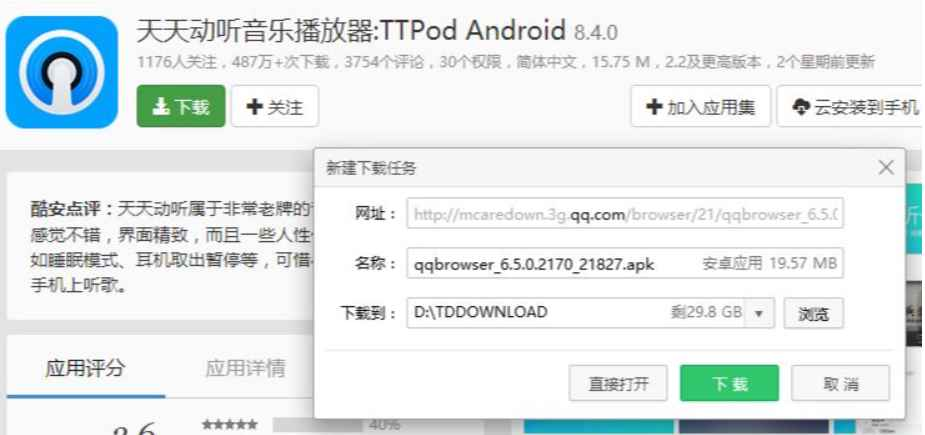
通过劫持天天动听的下载链接从而达到推广产品的目的。
http的内容是明⽂传输的,明⽂数据会经过路由器、wifi热点、通信服务运营商、代理服务
器等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传输的信息且不被双⽅察觉,这就是中间⼈攻击 ,所以我们才需要对信息进⾏加密。
对称加密和非对称加密
对称加密
- 采⽤单钥密码系统的加密⽅法,同⼀个密钥可以同时⽤作信息的加密和解密,这种加密⽅法称为对称加密,也称为单密钥加密,特征:加密和解密所⽤的密钥是相同的
- 常⻅对称加密算法:DES、3DES、AES、TDEA、Blowfish、RC2等
- 特点:算法公开、计算量⼩、加密速度快、加密效率⾼
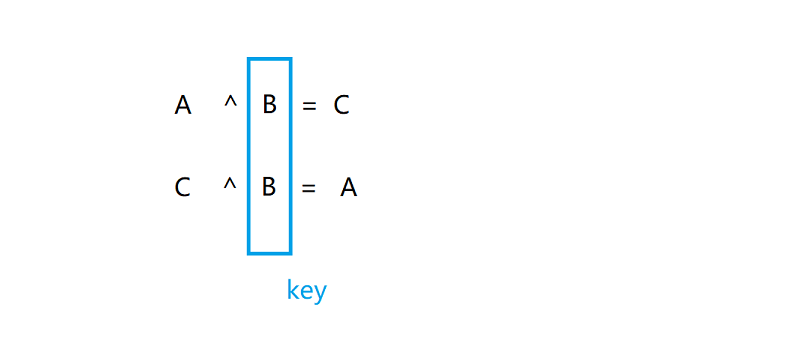
最简单的对称加密算法:异或加密
假设明⽂a=1234,密钥key=8888。则加密akey得到的密⽂b为9834。然后针对密⽂9834再次进⾏运算bkey,得到的就是原来的明⽂1234。
非对称加密
- 需要两个密钥来进⾏加密和解密,这两个密钥是公开密钥(publickey,简称公钥)和私有密钥(private key,简称私钥)。
- 常见非对称加密算法:RSA,DSA,ECDSA
- 特点:算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,⽽使得加密解密速度没有对称加密解密的速度快
非对称加密要⽤到两个密钥,⼀个叫做"公钥",⼀个叫做"私钥"。公钥和私钥是配对的。非对称加密最⼤的缺点就是运算速度⾮常慢,比对称加密要慢很多。
- 通过公钥对明⽂加密,变成密⽂
- 通过私钥对密⽂解密,变成明⽂
也可以反着⽤
• 通过私钥对明⽂加密,变成密⽂
• 通过公钥对密⽂解密,变成明⽂
对称加密和非对称加密联合使用
对称加密的效率更高,因此双方在进行正常通信时使用的是对称加密。
对称加密的过程
- 通信双方建立连接的时候,双方就可以把支持的加密算法作协商,协商之后在服务器端形成非对称加密时使用的公钥和私钥,在客户端形成对称加密时使用的密钥。
- 然后服务器将公钥交给客户端(这个公钥全世界都可以看到),然后客户端用这个公钥对客户端形成的密钥进行加密,将加密后的密钥发送给服务器,服务器拿到后再用它的私钥进行解密,最终服务器就拿到了客户端的密钥。
- 这时客户端和服务器都有了这个密钥,并且其他人是不知道的,此时客户端和服务器就可以进行对称加密通信了。
数据摘要和数据指纹
- 数字指纹(数据摘要),其**基本原理是利⽤单向散列函数(Hash函数)**对信息进⾏运算,⽣成⼀串固定⻓度的数字摘要。数字指纹并不是⼀种加密机制,但可以⽤来判断数据有没有被窜改。
- 摘要常⻅算法:有MD5、SHA1、SHA256、SHA512等。
- 摘要特征:和加密算法的区别是,摘要严格意义不是加密,因为没有解密,只不过从摘要很难反推原信息,通常⽤来进⾏数据对比(哈希函数是不可逆的,所以无法从数据摘要反推数据全文,因此数据摘要常用来数据的对比)。
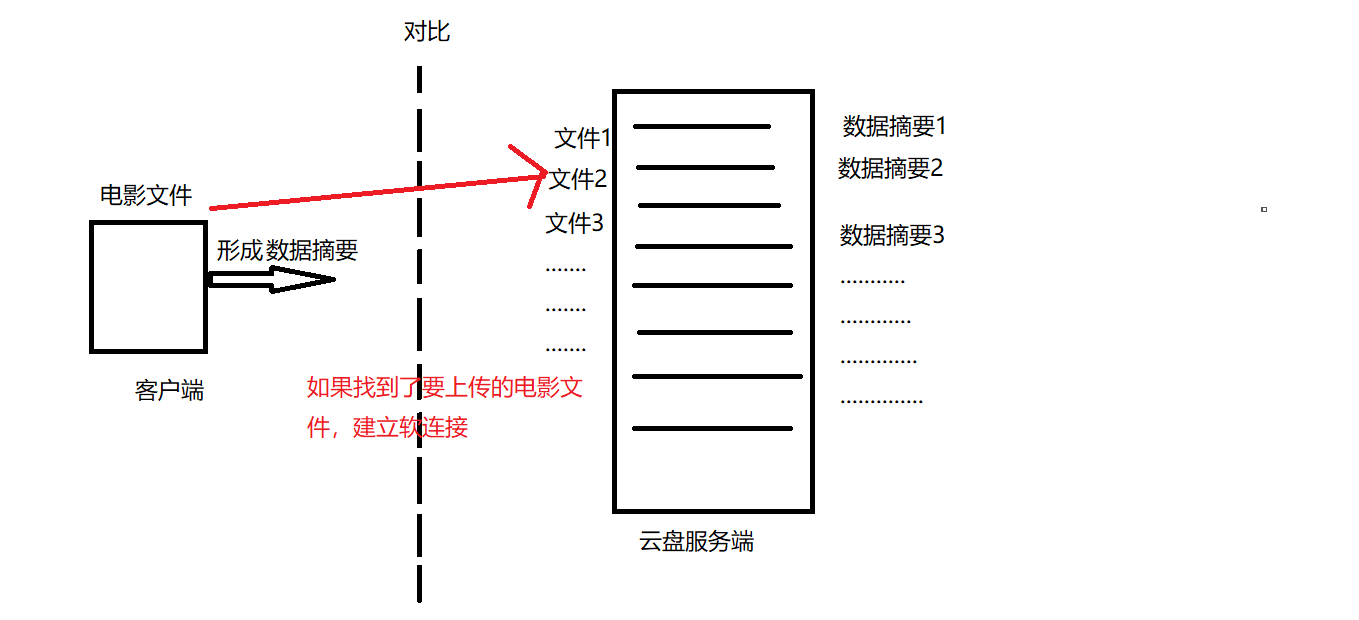
云盘的秒传功能
一些云盘实现了一秒上传文件的功能。其原理就使用了数据摘要。
比如用户要上传一部电影,云盘接收到请求后,先对电影数据进行数据摘要得到摘要信息。此时服务端会对该数据摘要和其他用户已经上传的文件的数据摘要进行对比。如果存在用户想要上传的文件,就建立软连接,指向原来用户上传好的相同文件。
HTTPS的工作过程加密
既然要保证数据安全,就需要进行加密。
方案一:只使用对称加密
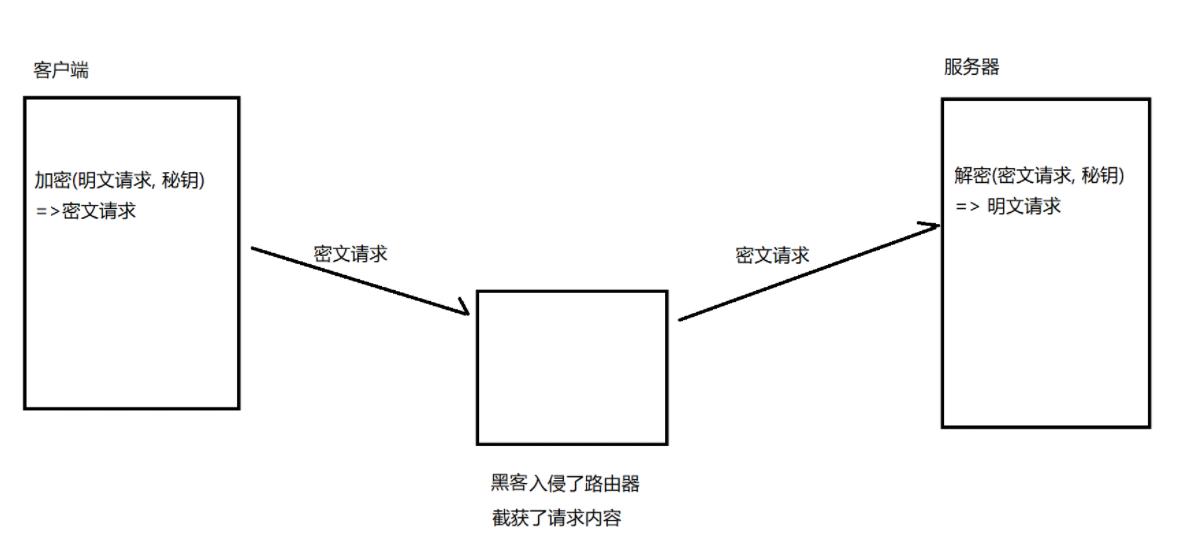
服务器同⼀时刻其实是给很多客户端提供服务的。每个客⼾端,每个⼈⽤的秘钥都必须是不同的(如果是相同那密钥,⿊客就也能拿到了)。因此服务器就需要维护每个客户端和每个密钥之间的关联关系 。
而同时维护多个密钥,服务端的压力就比较大。因此理想的做法是所有的客户端使用同一个密钥。
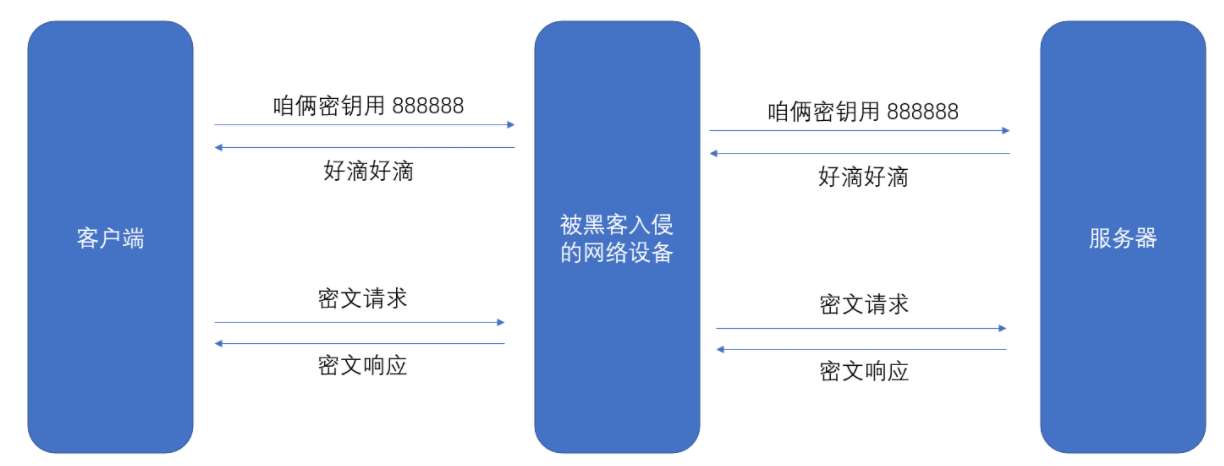
如果直接把密钥明⽂传输,那么⿊客也就能获得密钥了。因此就需要对密钥进行加密。但是要想对密钥进⾏对称加密,就仍然需要先协商确定⼀个"密钥的密钥"。这就成了"先有鸡还是先有蛋"的问题。
方案二:只使用非对称加密
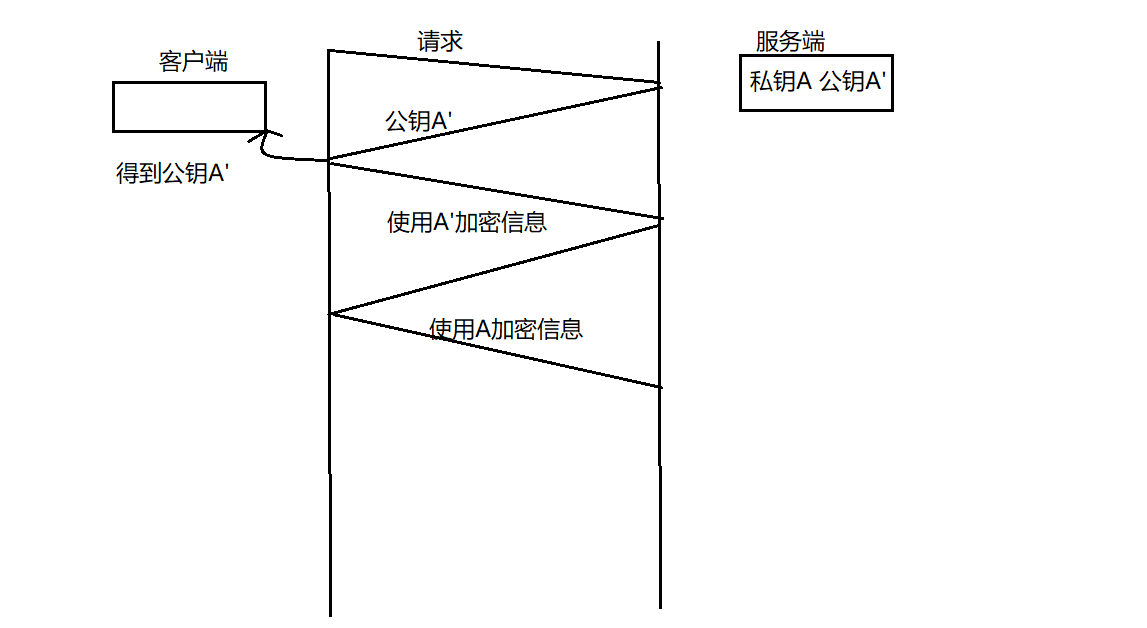
由于服务端在传输公钥时没有进行加密,因此所有人都可以得到公钥。因此服务端发送消息可能被中间人劫持。服务端到客户端的信息传输是不安全的。
方案三:双方都使用非对称加密
- 1.服务端拥有公钥S与对应的私钥S’,客户端拥有公钥C与对应的私钥C’
- 2.客户和服务端交换公钥
- 3.客⼾端给服务端发信息:先⽤S对数据加密,再发送,只能由服务器解密,因为只有服务器有私钥S’
- 4.服务端给客户端端发信息:先⽤C对数据加密,在发送,只能由客户端解密,因为只有客户端有私钥C’
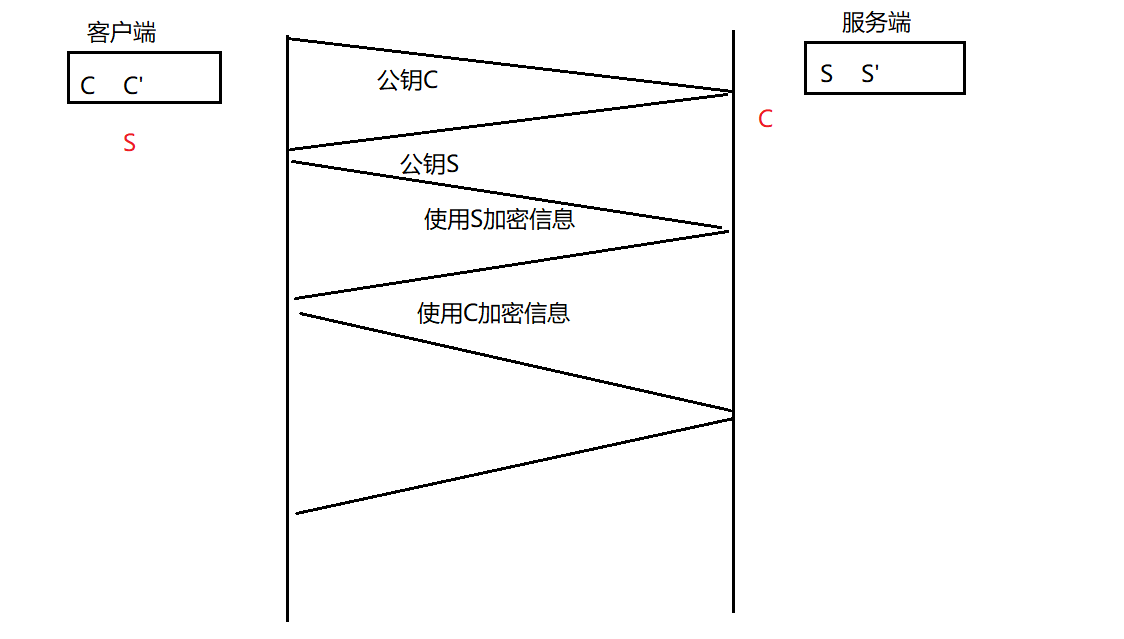
使用2对非对称密钥可以实现客户端和服务端的信息安全。缺点:效率太低并且依然有安全问题(存在中间人攻击)
方案四:使用对称加密+非对称加密
- 服务端具有⾮对称公钥S和私钥S’
- 客⼾端发起https请求,获取服务端公钥S
- 客⼾端在本地⽣成对称密钥C,通过公钥S加密,发送给服务器。
- 这样客户端和服务端都拥有密钥C,可以进行通信。
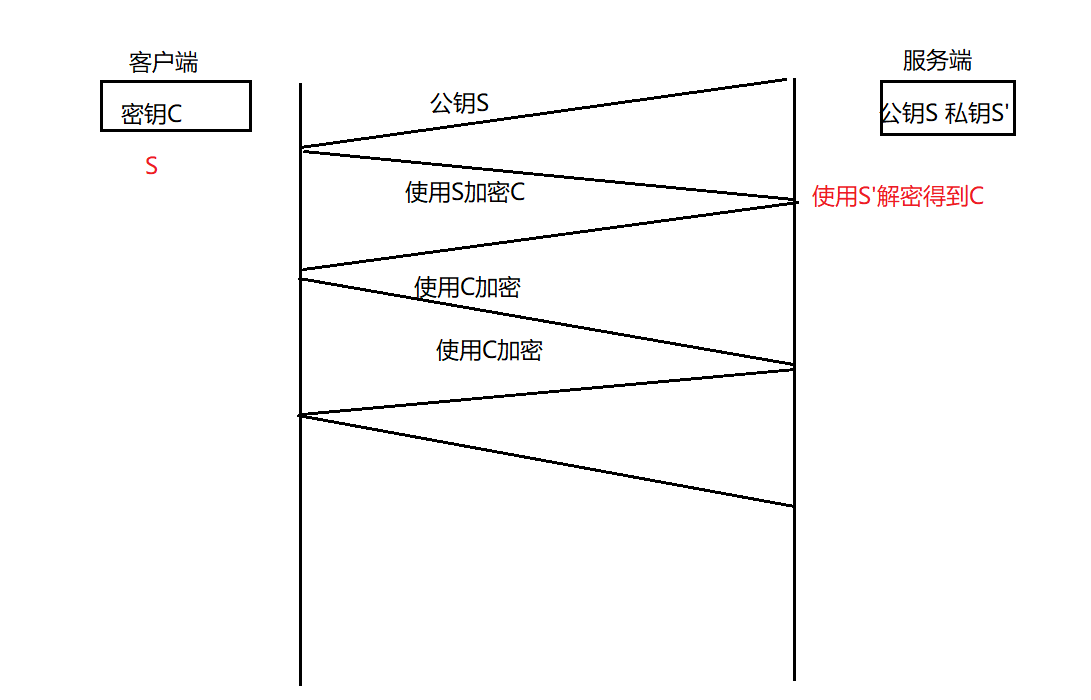
该方案相对于方案三解决了效率低的问题。但是依然存在安全问题:中间人攻击
中间人攻击
在⽅案2/3/4中,客⼾端获取到公钥S之后,对客⼾端形成的对称秘钥X⽤服务端给客⼾端的公钥
S进⾏加密,中间⼈即使窃取到了数据,此时中间⼈确实⽆法解出客⼾端形成的密钥X,因为只有服务器有私钥S’。但是中间⼈的攻击,如果在最开始握⼿协商的时候就进⾏了,就会发生安全问题。
以方案四为例
假设黑客一开始就成为了中间人。
- 服务器具有⾮对称加密算法的公钥S,私钥S’
- 中间⼈具有⾮对称加密算法的公钥M,私钥M’
- 客⼾端向服务器发起请求,服务器明⽂传送公钥S给客⼾端
- 中间⼈劫持数据报⽂,提取公钥S并保存好,然后将被劫持报⽂中的公钥S替换成为⾃⼰的公钥M,并将伪造报⽂发给客⼾端
- 客⼾端收到报⽂,提取公钥M(⾃⼰当然不知道公钥被更换过了),⾃⼰形成对称秘钥X,⽤公钥M加密X,形成报⽂发送给服务器
- 中间⼈劫持后,直接⽤⾃⼰的私钥M’进⾏解密,得到通信秘钥X,再⽤曾经保存的服务端公钥S加密后,将报⽂推送给服务器
- 服务器拿到报⽂,⽤⾃⼰的私钥S’解密,得到通信秘钥X
- 客户端和服务端双方开始采⽤X进⾏对称加密,进⾏通信。但⼀切都在中间⼈的掌握中,劫持数据,进⾏窃听甚⾄修改,都是可以的
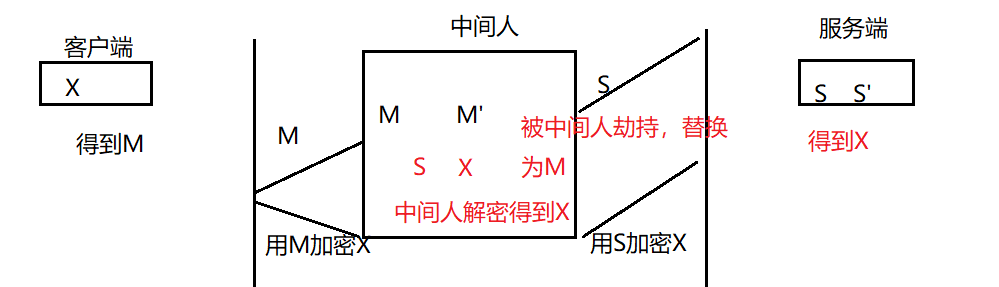
双方通信的密钥X被中间人掌握。
问题的本质是:客⼾端⽆法确定收到的含有公钥的数据报⽂,就是⽬标服务器发送过来的
证书
为了应对中间人攻击,网络通信又引入了证书。
CA证书
服务端在使⽤HTTPS前,需要向CA机构申领⼀份数字证书,数字证书⾥含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书⾥获取公钥就可。
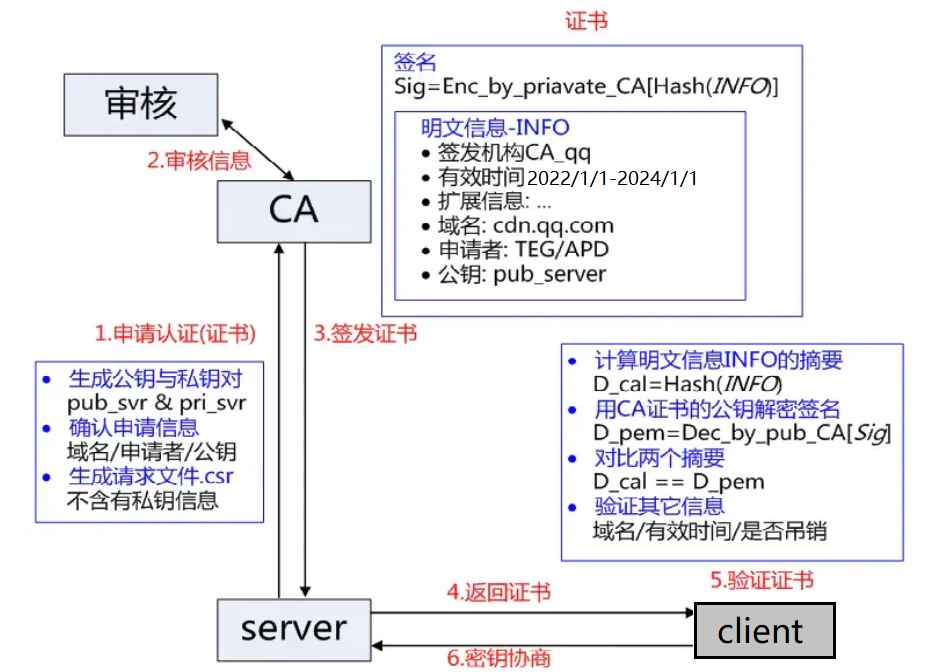
证书包含以下的信息(证书明文和数据签名):
- 证书颁发的机构
- 证书有效期
- 公钥B
- 证书持有者
- 数据签名
在申请证书时,需要在特定的权威平台生成,并且会产生一对公钥B和私钥B’。公钥会附加在证书上,私钥被CA机构和服务端保存。这对密钥在网络通信中进行明文加密和数字签名
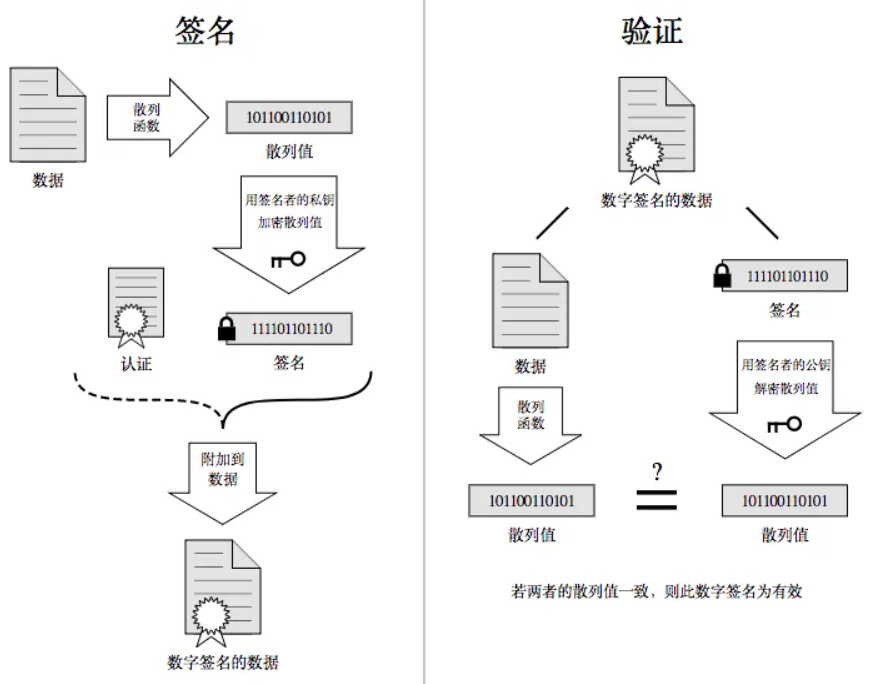
数据签名
签名的形成是基于⾮对称加密算法的。数据签名是由数据摘要通过私钥加密得到。
**证书包括证书明文和数据签名两个部分。**数据签名部分是由证书明文通过摘要算法形成数据摘要,数据摘要被再CA公司的私钥A加密得到。
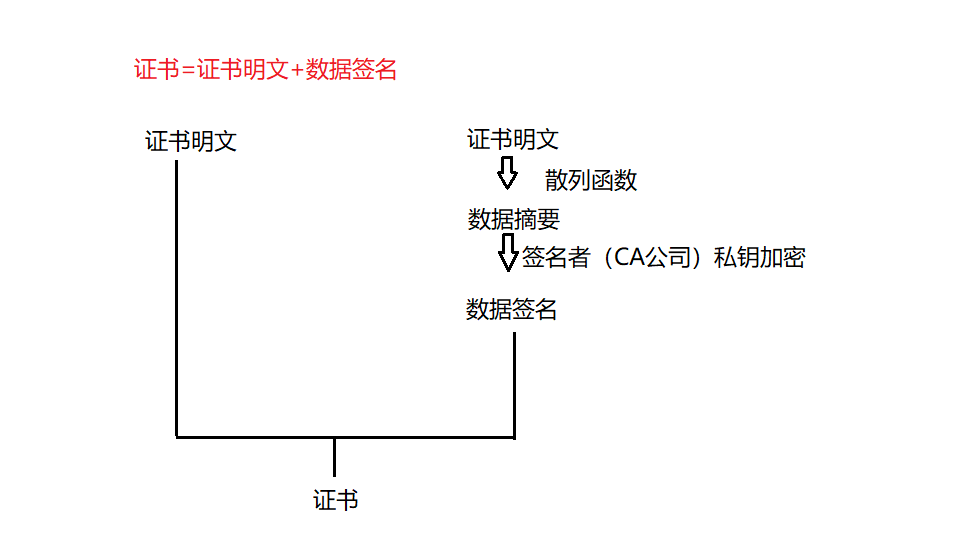
- CA机构拥有⾮对称加密的私钥A和公钥A’
- CA机构对服务端申请的证书明⽂数据进⾏hash,形成数据摘要
- 然后对数据摘要⽤CA私钥A’加密,得到数字签名S。
- 数据签名附加在证书明文上形成证书。
服务端申请的证书明⽂和数字签名S共同组成了数字证书,这样⼀份数字证书就可以颁发给服务端了。
注意:上述过程中一共出现了两对密钥。
一对是服务端申请的密钥,也就是CA证书上公钥B对应的密钥。这对密钥的作用是:在网络通信中对数据信息进行加密。且被服务端和CA公司都持有。
一对是CA公司持有的密钥,也就是对证书明文的数据摘要进行加密的私钥A’对应的密钥。该对密钥的作用是:形成数据签名并被用于检查证书的合法性。只被CA公司持有私钥,公钥被嵌入到操作系统中。
方案五:非对称加密+对称加密+证书
首先需要明确:CA公司的公钥被嵌入到了操作系统中。
在使用方案五时。证书上已经包含了服务端进行通信的公钥B。服务端与客户端要进行通信时,服务端先将证书发送给客户端,客户端检查证书的合法性(检查是否被篡改),并提取公钥B。
随后客户端使用B加密客户端形成的对称密钥X,发送给客户端。客户端使用私钥B’解密得到对称密钥X。
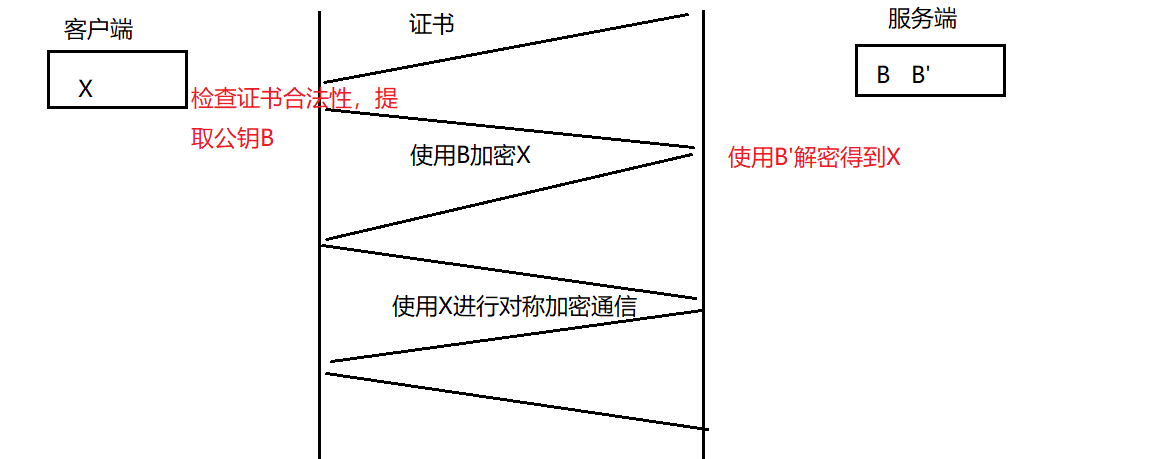
如何检查证书的合法性?
证书包含证书明文和数据签名两部分。数据签名被CA机构的密钥A’加密无法被更改。
如果有第三方修改了证书明文,比如证书上用于通信的公钥。客户端在拿到服务端发送的证书后,会使用被嵌入到操作系统的CA机构公钥A进行解密得到数据摘要。再将证书明文通过摘要算法形成数据摘要。
如果两个摘要相同,证书就合法。否则,证书被修改,不合法。
以证书明文数据为hello为例:
假设我们的证书只是⼀个简单的字符串hello,对这个字符串计算hash值(⽐如md5),结果为
BC4B2A76B9719D91
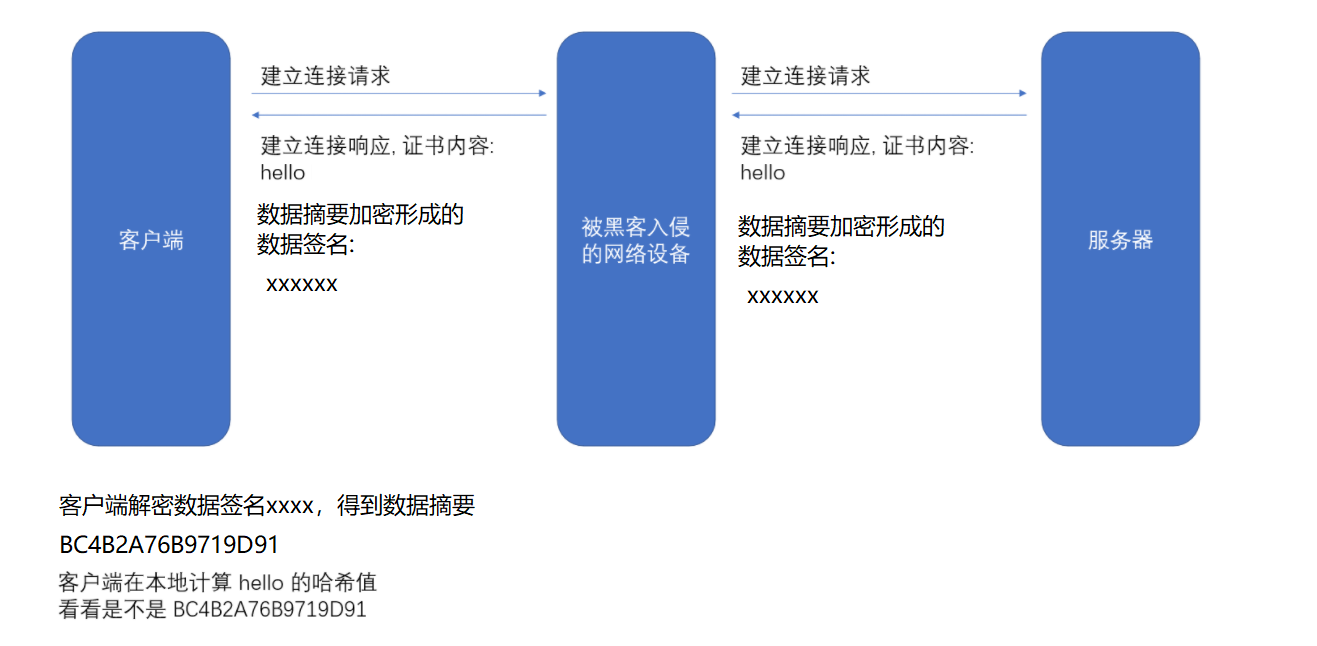
如果相同表示证书是合法的。
如果⿊客把hello篡改为了hella。
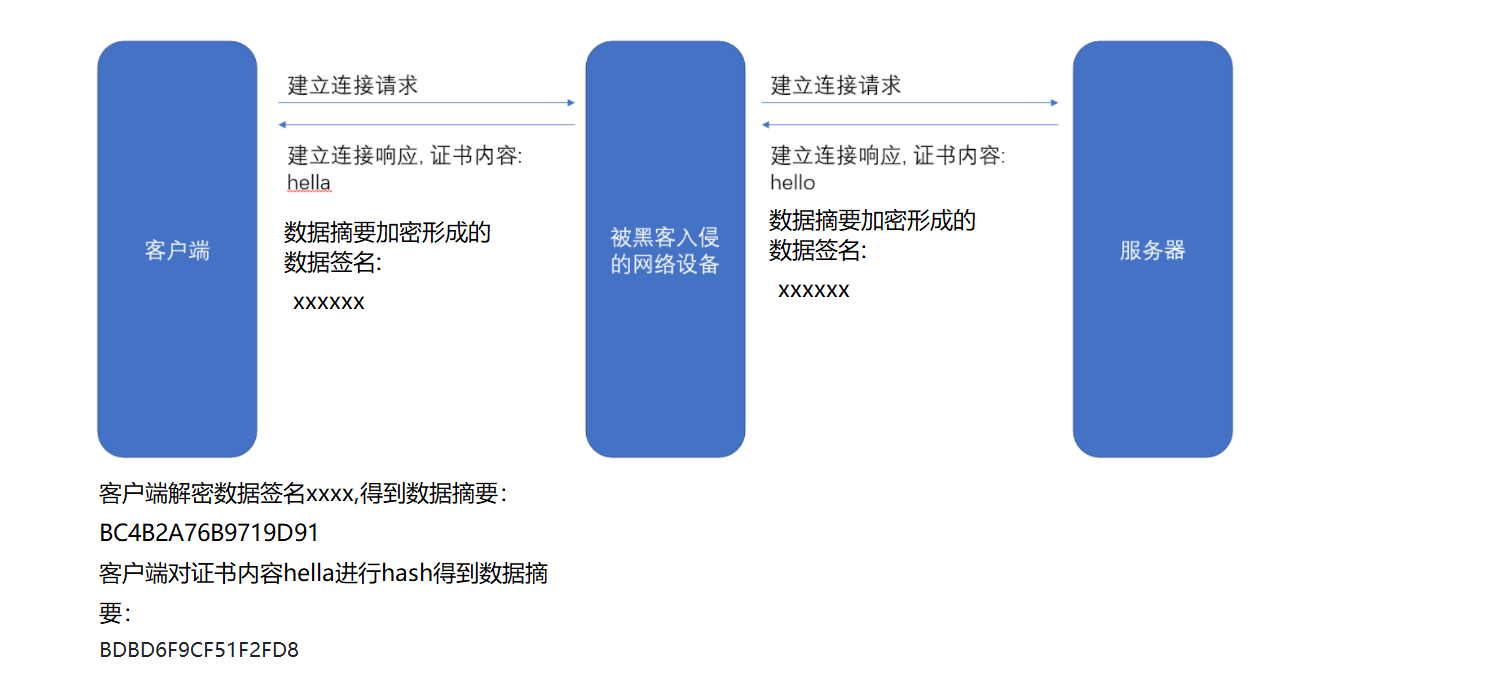
客户端通过比较两个数据摘要发现不同,说明证书内容被篡改,证书不合法。客户端停止对服务端发送消息。
查看浏览器的受信任证书发布机构
打开浏览器,点击右上⻆的设置
找到”隐私设置和安全性“里面的安全属性:
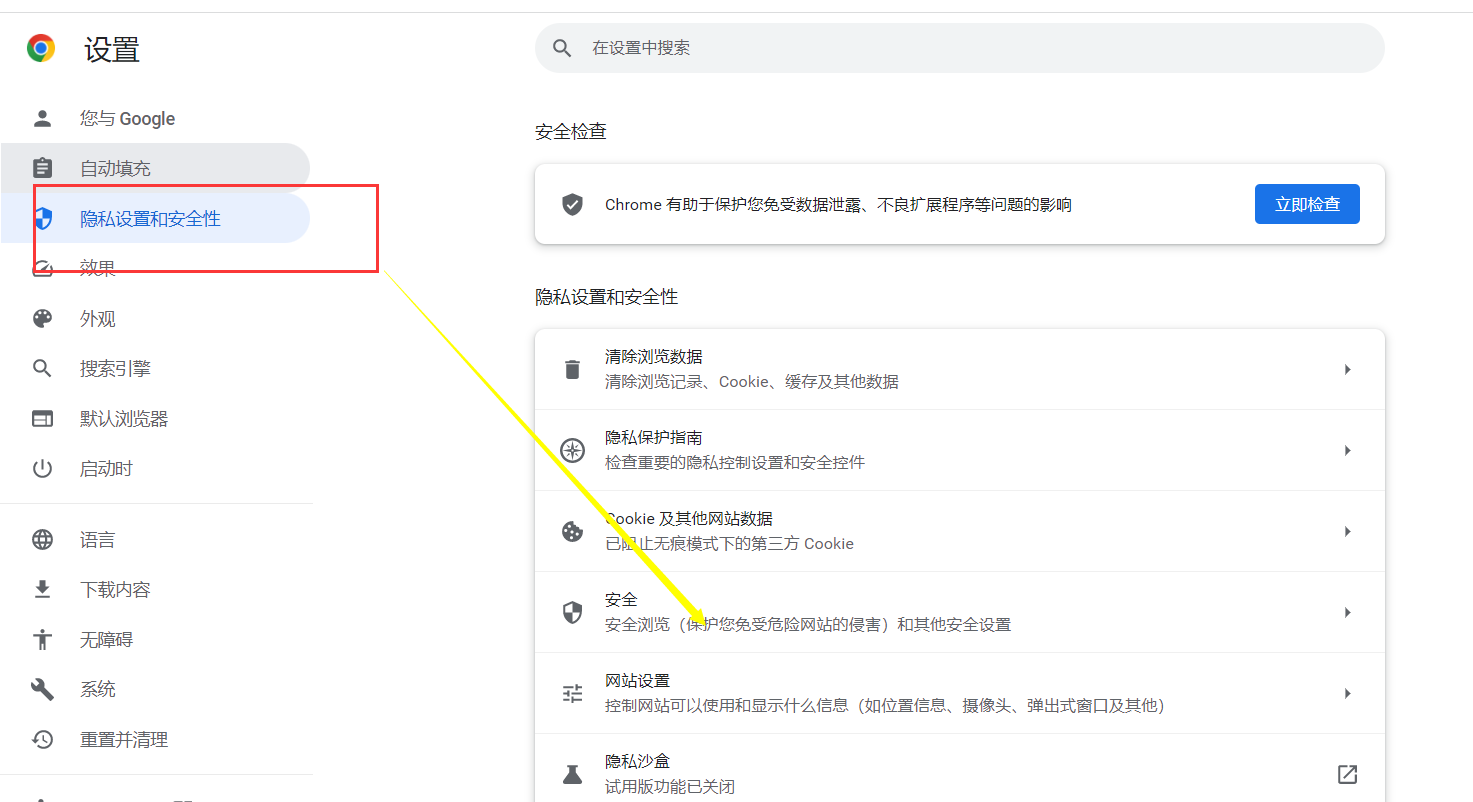
往下翻可以看到相关的字段:
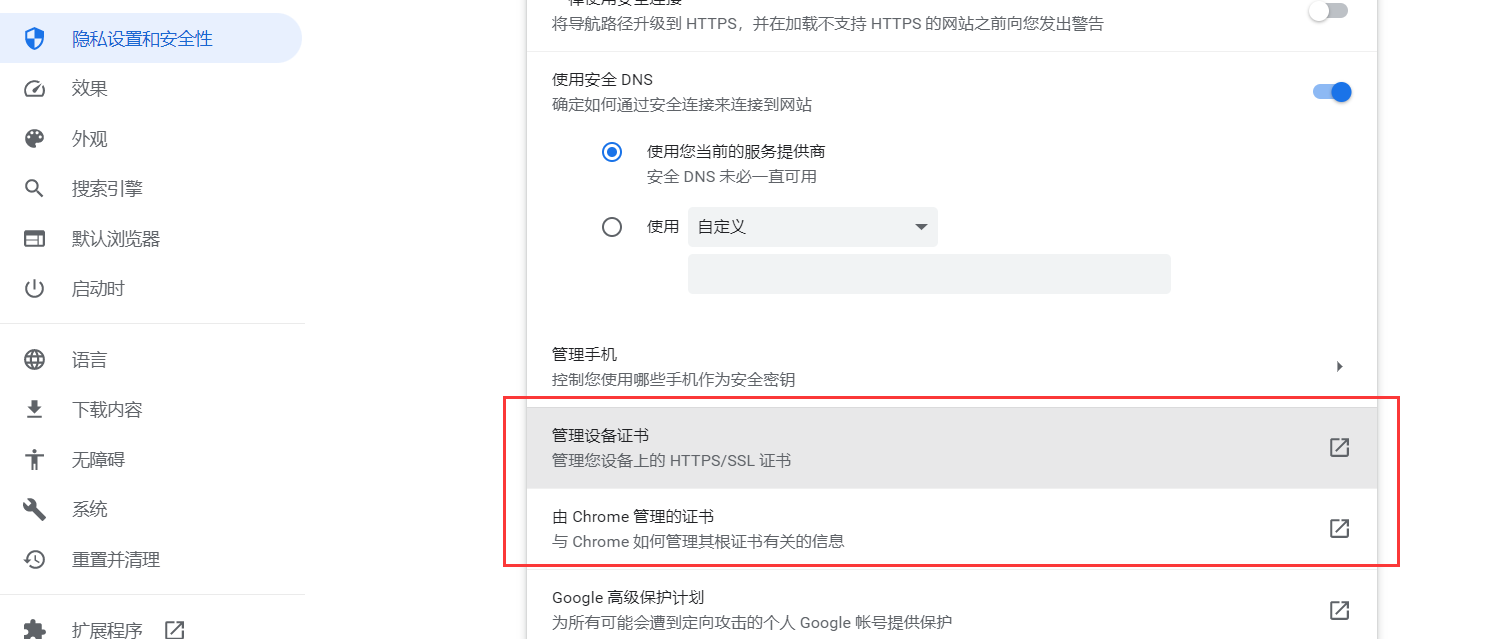
总结
下面是HTTPS通信的完整流程:
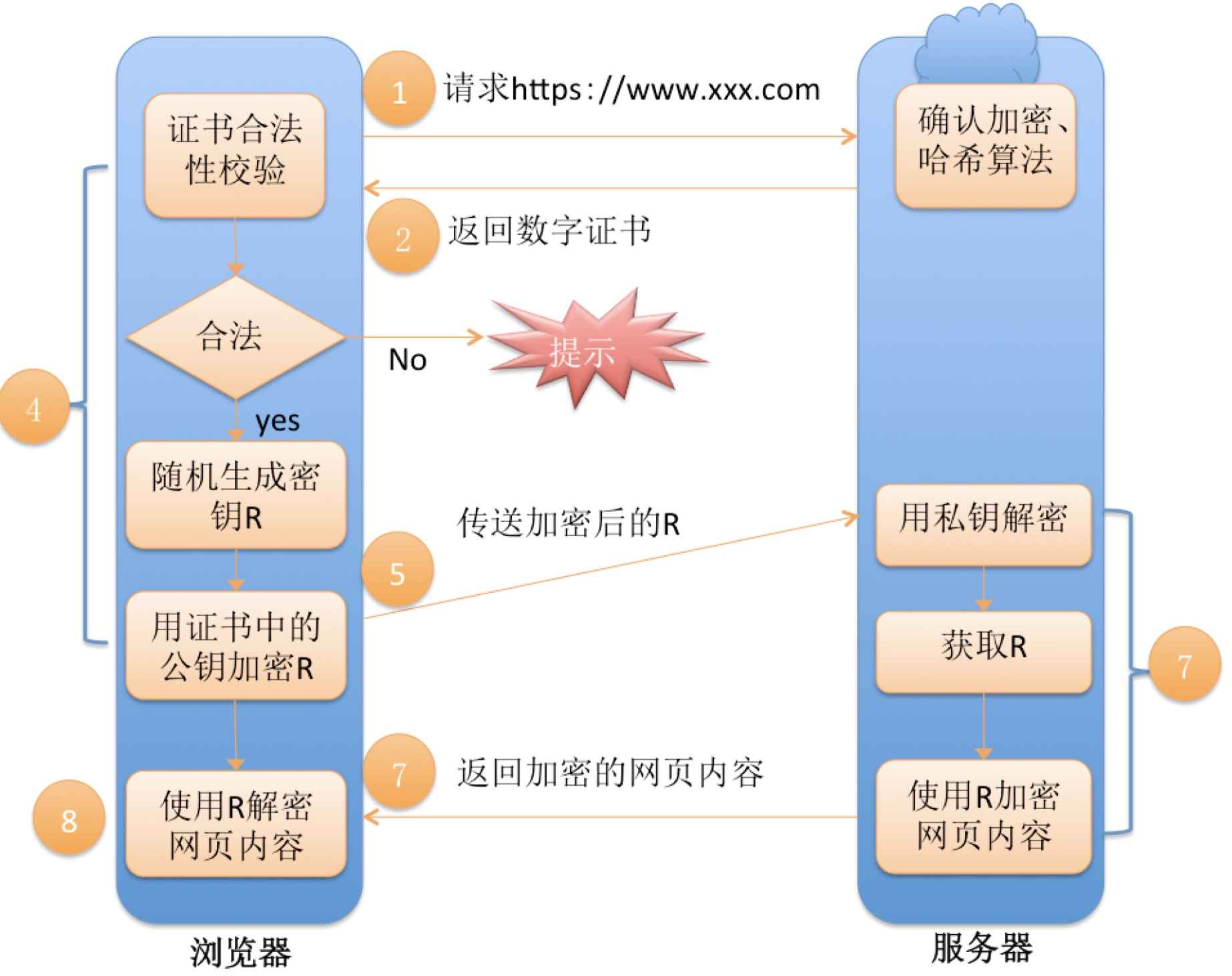
HTTPS工作流程一共包含三组密钥:
第一组(非对称加密):用于形成数据签名和校验证书是否被篡改。CA机构和服务端持有私钥,公钥被嵌入到操作系统中(操作系统包含了可信任的CA认证机构有哪些,同时持有对应的公钥) 。服务器在客⼾端请求时,返回携带签名的证书。客⼾端通过这个公钥进⾏证书验证,保证证书的合法性,进⼀步保证证书中携带的服务端公钥权威性。
第二组(非对称加密):用于客户端和服务端协商对称加密的密钥。服务端生成公钥和私钥。公钥被填写到CA证书上。客⼾端⽤收到的CA证书中的公钥(是可被信任的)给随机⽣成的对称加密的密钥加密,传输给服务器,服务器通过私钥解密获取到对称加密密钥。
第三组(对称加密):客户端生成。用于服务端和客户端进行加密通信。
相关文章:
HTTP和HTTPS协议
HTTP协议 HTTP协议是一种应用层的协议,全称为超文本传输协议。 URL URL值统一资源定位标志,也就是俗称的网址。 协议方案名 http://表示的就是协议方案名,常用的协议有HTTP协议、HTTPS协议、FTP协议等。HTTPS协议是以HTTP协议为基础&#…...
day3——有关java运算符的笔记
今天主要学习的内容有java的运算符 赋值运算符算数运算符关系运算符逻辑运算符位运算符(专门写一篇笔记)条件运算符运算符的优先级流程控制 赋值运算符 赋值运算符()主要用于给变量赋值,可以跟算数运算符相结合&…...
Git多人协同远程开发
1. 李四(项目负责人)操作步骤 在github中创建远程版本库testgit将基础代码上传⾄testgit远程库远程库中基于main分⽀创建dev分⽀将 githubleaflife/testgit 共享给组员李四继续在基础代码上添加⾃⼰负责的模块内容 2. 张三、王五(组员&…...

Chapter4:机器人仿真
ROS1{\rm ROS1}ROS1的基础及应用,基于古月的课,各位可以去看,基于hawkbot{\rm hawkbot}hawkbot机器人进行实际操作。 ROS{\rm ROS}ROS版本:ROS1{\rm ROS1}ROS1的Melodic{\rm Melodic}Melodic;实际机器人:Ha…...
python(14)--集合
前言 本篇文章学习的是 python 中集合的基础知识。 集合元素的内容是不可变的,常见的元素有整数、浮点数、字符串、元组等。至于可变内容列表、字典、集合等不可以是集合元素。虽然集合不可以是集合的元素,但是集合本身是可变的,可以去增加或…...

【Spark分布式内存计算框架——Spark Core】4. RDD函数(中)Transformation函数、Action函数
3.2 Transformation函数 在Spark中Transformation操作表示将一个RDD通过一系列操作变为另一个RDD的过程,这个操作可能是简单的加减操作,也可能是某个函数或某一系列函数。值得注意的是Transformation操作并不会触发真正的计算,只会建立RDD间…...
Mysql 数据类型
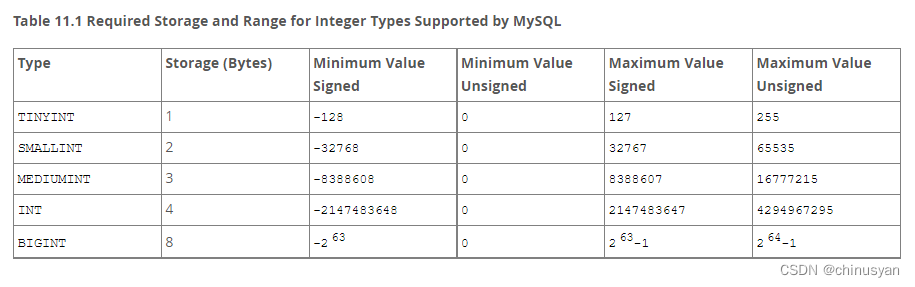
1、数值数据类型 1.1 整数类型(精确值) INTEGER, INT, SMALLINT, TINYINT, MEDIUMINT, BIGINT MySQL支持SQL标准的整数类型INTEGER (或INT)和SMALLINT。作为标准的扩展,MySQL还支持整数类型TINYINT、MEDIUMINT和BIGINT。下表显示了每种整数类型所需的存储和范围。…...

运行Whisper笔记(1)
最近chatGPT很火,就去逛了一下openai的github项目。发现了这个项目。 这个项目可以识别视频中的音频,转换出字幕。 带着一颗好奇的心就尝试自己去部署玩一玩 跟着这篇文章一步步来进行安装,并且跟着这篇文章解决途中遇到的问题。 途中还会遇…...
2023年最强大的12款数据可视化工具,值得收藏
做数据分析也有年头了,好的坏的工具都用过,推荐几个觉得很好用的,避坑必看! PS:一般比较成熟的公司里,数据分析工具不只是满足业务分析和报表制作,像我现在给我们公司选型BI工具,是做…...

LeetCode刷题系列 -- 523. 连续的子数组和
给你一个整数数组 nums 和一个整数 k ,编写一个函数来判断该数组是否含有同时满足下述条件的连续子数组:子数组大小 至少为 2 ,且子数组元素总和为 k 的倍数。如果存在,返回 true ;否则,返回 false 。如果存…...

LeetCode刷题系列 -- 525. 连续数组
给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度。示例 1:输入: nums [0,1]输出: 2说明: [0, 1] 是具有相同数量 0 和 1 的最长连续子数组。示例 2:输入: nums [0,1,0]输出: 2说明: [0, 1] (或 [1, 0]) 是具有相同数…...
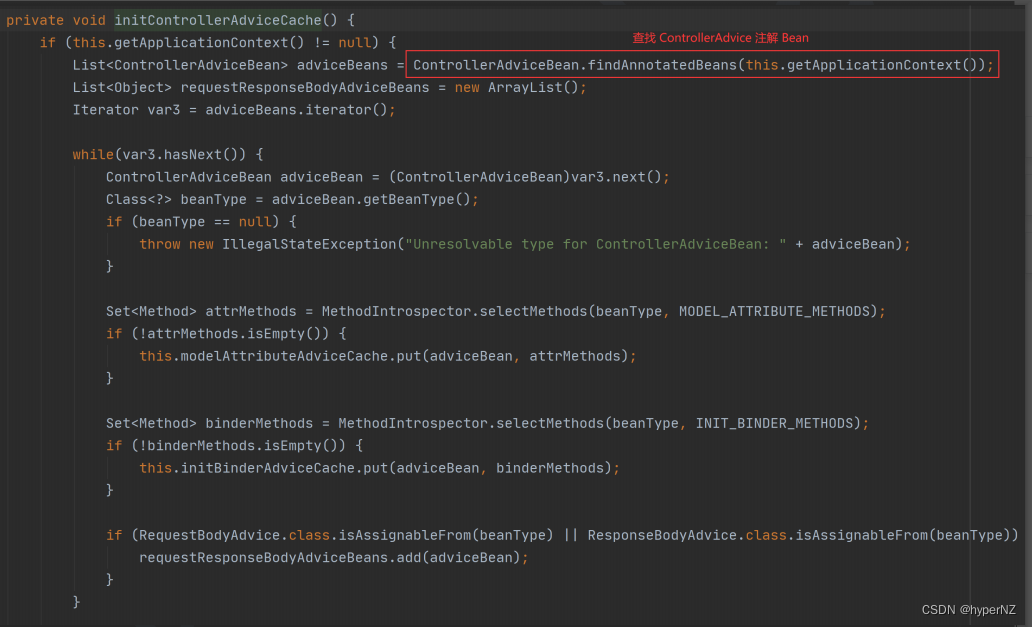
JavaEE15-Spring Boot统一功能处理
目录 1.统一用户登录权限效验 1.1.最初用户登录验证 1.2.Spring AOP用户统一登录验证的问题 1.3.Spring拦截器 1.3.1.创建自定义拦截器,实现 HandlerInterceptor 接口并重写 preHandle(执行具体方法之前的预处理)方法 1.3.2.将自定义拦…...
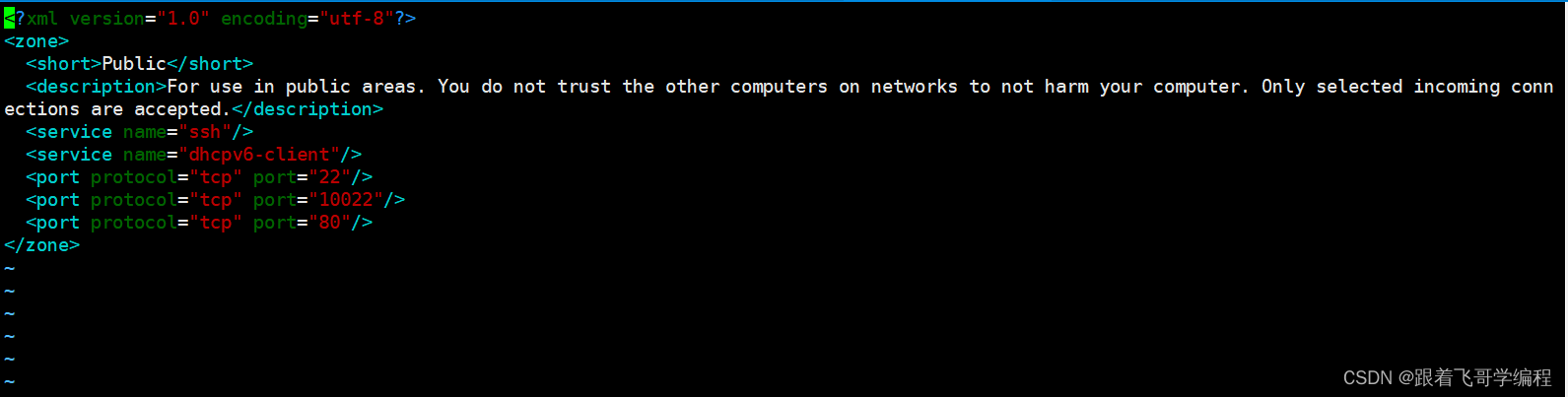
centos7.6 设置防火墙
1、查看系统版本 cat /etc/redhat-release2、查看防火墙运行状态 systemctl status firewalld这里可以看到当前是未运行状态(inactive)。 3、关闭开机自启动防火墙 systemctl disable firewalld.service4、启动防火墙并查看状态,系统默认 22 端口是开启的。 sy…...
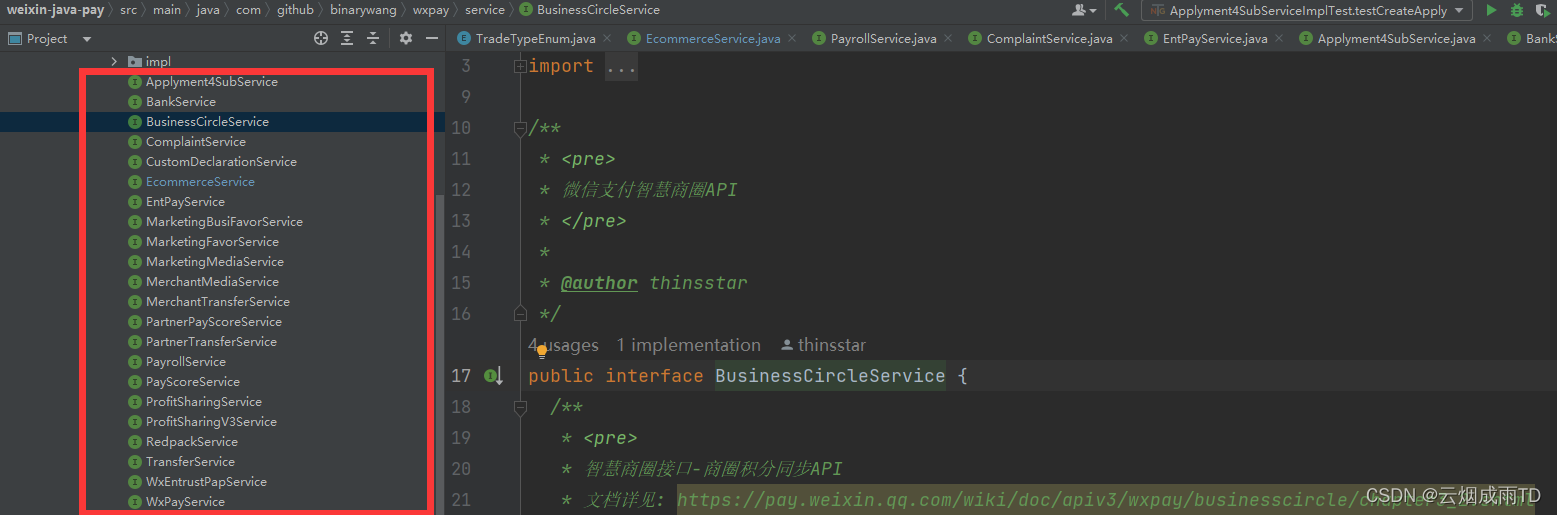
在线支付系列【22】微信支付实战篇之集成服务商API
有道无术,术尚可求,有术无道,止于术。 文章目录前言1. 环境搭建2. 特约商户进件3. 统一下单总结前言 在上篇文档中,我们做好了接入前准备工作,接下来使用开源框架集成服务商相关API。 一个简单的支付系统完成支付流程…...

3.2 埃尔米特转置
定义 对于复矩阵,转置又不一样,常见的操作是共轭转置,也叫埃尔米特转置Hermitian transpose。埃尔米特转置就是对矩阵先共轭,再转置,一般来说用三种符号表示埃尔米特转置: 第一种符号是AHA^HAH,…...
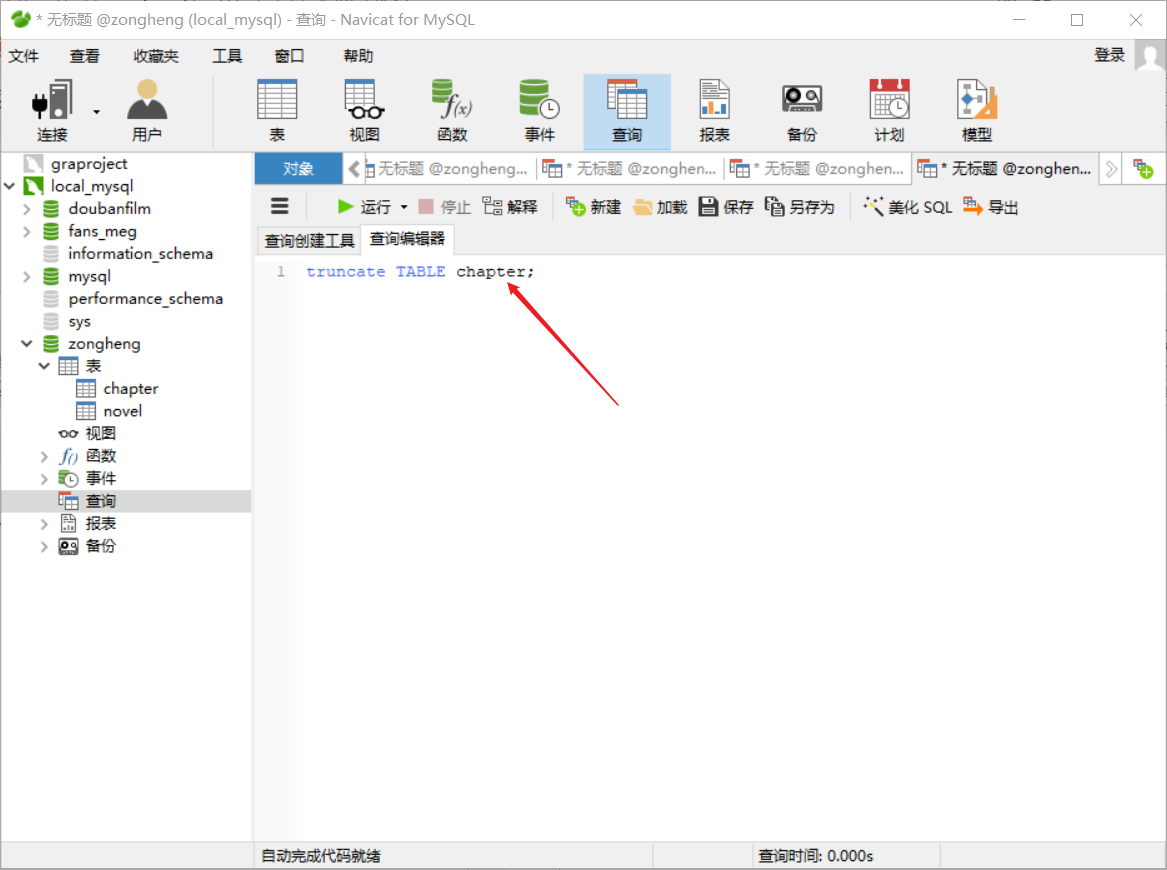
Python爬虫之Scrapy框架系列(13)——实战ZH小说爬取数据入MySql数据库
目录:1 数据持久化存储,写入Mysql数据库①定义结构化字段:②重新编写爬虫文件:③编写管道文件:④辅助配置(修改settings.py文件):⑤navicat创库建表:⑥ 效果如下…...
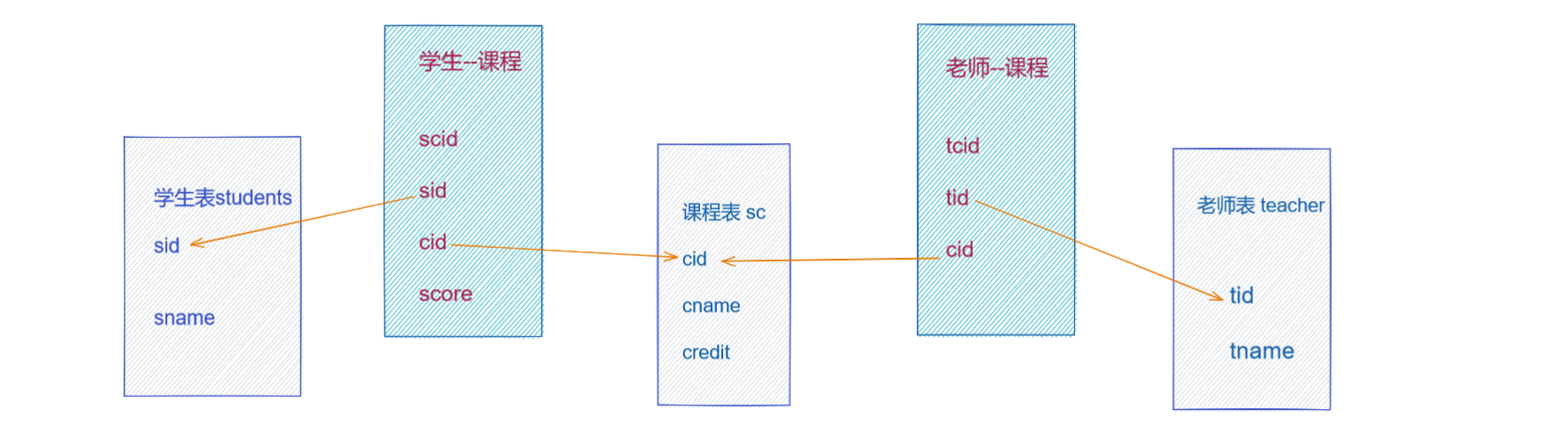
MySQL篇02-三大范式,多表查询
数据入库时,由于数据设计不合理,会存在数据重复、更新插入异常等情况, 故数据库中表的设计遵循的设计规范:三大范式1.第一范式(1NF)要求数据库的每一列都是不可分割的原子数据项,即原子性。强调的是列的原子性,即数据库中每一列的…...

vue-cli3创建Vue项目
文章目录前言一、使用vue-cli3创建项目1.检查当前vue的版本2.下载并安装Vue-cli33.使用命令行创建项目二、关于配置前言 本文讲解了如何使用vue-cli3创建属于自己的Vue项目,如果本文对你有所帮助请三连支持博主,你的支持是我更新的动力。 下面案例可供…...
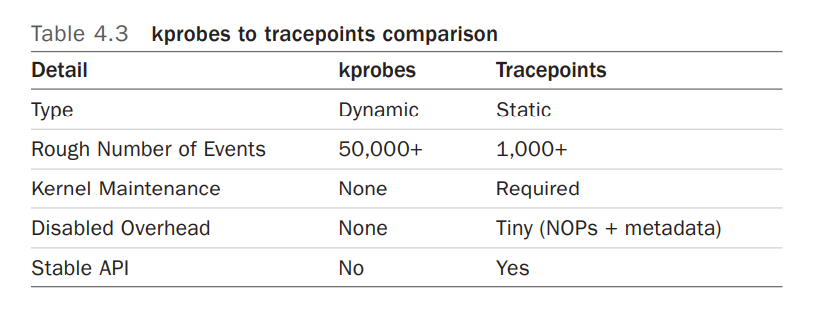
Linux perf probe 的使用(三)
文章目录前言一、Dynamic Tracing二、kprobes2.1 perf kprobe 的使用2.2 kprobe Arguments3.3 tcp_sendmsg()3.3.1 Kernel: tcp_sendmsg()3.3.2 Kernel: tcp_sendmsg() with size3.3.2 Kernel: tcp_sendmsg() line number and local variable三、uprobes的使用3.1 perf uprobe …...

python GUI编程 多窗口跳转
# 多窗口跳转例子from tkinter import *def main(): # 主窗体def goto(num):root.destroy() # 关闭主窗体if num 1:one() # 进入第1个窗体elif num 2:two() # 进入第2个窗体root Tk()root.geometry(300x150600200)root.title(登录窗口)but1 Button(root, text"进入…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...