大模型应用疯狂加速,洗牌却在静悄悄进行了
 配图来自Canva可画
配图来自Canva可画
在被誉为“科技企业营销圣经”的《跨越鸿沟》一书中,杰弗里·摩尔写道:“高科技产品面世过程中,最危险、最关键的一点,就是由少数有远见者所主宰的早期市场,向实用主义者占支配地位的主流市场过渡。”此刻,狂飙突进已半年有余的国内生成式人工智能(AIGC)市场,正面临着这个关键的过渡。
截至8月底,首批8家AI大模型企业通过备案。与上半年“甚嚣尘上”的行业境况不同,具备实力且具备满腔“产业抱负”的实力型玩家,总是姗姗来迟,但却总是能够一鸣惊人,为产业的大规模应用创造机会。目前来看,随着未来不断有新的企业通过备案,“大模型+”的应用拐点正在到来。
“大模型+”应用拐点加速到来
8月份刚刚过去,9月初百度就迫不及待地对外公布了文心一言大模型开源。与此同时,“姗姗来迟”的腾讯混元大模型,一亮相便“秀”起了“肌肉”,科大讯飞与华为合作发布“星火一体机”,进一步把大模型端侧应用摆在了台面上。一波接一波的行业浪潮席卷而来,正推动整个“大模型+”应用时代加速到来。
首先,大模型从C端应用逐渐转向B端应用领域,以“实用”为导向的大模型日渐成为行业趋势。自从去年12月ChatGPT,在短短一个月之内实现月活破亿之后,围绕整个C端市场的AI大模型玩家如百度等,就开始大规模地涌入该领域,一时之间C端大模型应用迎来了外界的一致关注。但进入下半年以后,市面上越来越多的“面向B端”的应用开始出现,更加“实用”的行业大模型也在成群结队地出现,大大加速了生成式AI产业化的进程。比如,京东发布了言犀大模型、京医千询大模型,携程发布了携程问道大模型,网易有道发布了基于教育的子曰大模型,用友发布了用友GPT大模型等等。
相比通用大模型厂商而言,垂直大模型厂商在相关行业深耕已久,因而在寻找产业机会方面往往走得更加深入。以网易有道、京东两家为例,网易有道在教育领域深耕已久,它在长期深耕行业的过程中,不仅积累了庞大的用户和教育行业数据,还积累了相对应的高质量数据,这使其在做教育大模型过程中,拥有更多比较优势。无独有偶,京东在零售、大健康领域广有布局,这使其在构建产业大模型和京医大模型方面,拥有坚实根基;而携程则在文旅行业深耕已久,积累了广泛的文旅产业链数据和资源。
显然,相比通用大模型厂商而言,围绕垂直领域的行业大模型,不仅可以依靠专业数据让大模型更加“实用”,还可以在特定领域发挥独特作用,帮助行业尽快完成数字化转型。
其次,具备通用能力的大型云服务企业,正在加速与各路行业大模型企业展开合作,新的大模型生产机制正在成型。目前业内包括百度、腾讯、阿里、华为等主要云厂商,都纷纷依托自身的技术优势、团队优势和资金支持,在通用大模型领域实现抢跑。除此之外,各主要厂商还联合行业头部企业,推出行业大模型解决方案。
比如,腾讯云联合行业头部企业,已为文旅、政务、金融等10余个行业,提供了50多个大模型行业解决方案。华为旗下盘古大模型,更是可以提供5个基础大模型+N个行业大模型+X个场景模型的三层解耦架构,目前已经应用到了铁路、矿山、能源、气象、政务等诸多领域。阿里云更是对外开放了“通义千问”的全部能力,帮助企业结合自身的行业知识和应用场景,训练自己的企业大模型;加上目前已经开源的文心一言,由大的云平台提供包括云服务、算力、通用大模型工具支持等基础设施,各行业头部企业提供专业经验和数据训练的大模型生产机制已经基本成型。
志在必得的腾讯
对于大模型的发展,腾讯高层显然很早之前就已经定下了调子,但其推出的时间却在一众巨头中最晚。在上半年如火如荼的大模型混战中,腾讯的大模型在业内一直是“只闻其声、不见其名”的存在。但从9月其正式面世之后的外界反应来看,此前“默默无闻”的腾讯大模型,更多是在“厚积薄发”。
9月7日腾讯正式对外发布了腾讯混元大模型,据了解该模型拥有超千亿参数规模,预训练语料超过2万亿Tokens,并已接入腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档等50多个腾讯业务。而且在国家公布的首批大模型厂商中,腾讯混元大模型赫然在列。同时,腾讯混元大模型还宣布对外开放,千行百业的人都可以通过API调用混元,或者将其作为产业底座,为不同产业场景构建大模型应用,不难看出腾讯对大模型的“志在必得”。
首先,腾讯构建了“更强”的“探真”技术方法,这使其具备更强的信息可信度,极大增强了大模型自身的实用性。基于全网的数据检索和生成,是大模型的核心能力之一。值得一提的是,无论是基于GPT-3.5还是国内其他大模型,源于错误信息带来的错误答案,依然不可避免。但腾讯混元大模型却基于自身的技术能力,保证正确答案的输出。
与业界消除“幻觉”的通用做法不同,混元大模型并没有为大模型增加搜索或者知识图谱等外挂,而是从源头上解决问题。具体来说,混元大模型从第一行代码开始,就采用了预训练阶段优化目标函数的“探真”技术方法。据业内专业人士介绍,该方法与常见的开源大模型相比,能有效降低幻觉30%到50%。
除了“探真”能力优秀之外,腾讯混元的另一大超强能力在于其支持超长文本输出。尽管目前多模态正在成为主流大模型演进方向,但在文本输出方面,包括GPT-3.5和GPT-4在内的大模型,都很难支持1000字以上的文本输出,但腾讯混元通过位置编码优化提高了超长文的处理效果和性能,已经具备输出4000多字的完整答案的能力。
其次,腾讯构建了从软到硬的全流程基础设施,这让腾讯具备了更强的“全局优化”能力。从自研的星星海服务器,到新一代HCC高性能计算集群,再到自研的星脉高速网络,腾讯已经为自己打造了一整套面向AIGC的高性能智算网络。据腾讯内部负责人介绍,目前腾讯云已经可支持超过10万张卡并行计算的大规模训练集群,万亿参数大模型可以在四天之内完成。
目前,腾讯云已经建立起了围绕大模型的全套能力,包括高性能算力集群、云原生数据湖仓和向量数据库等数据处理引擎,以及模型安全、支持模型训练和精调的工具链等,企业和开发者都可以根据自己的需求,灵活选择产品,降低大模型的训练成本。
不甘落后的科大讯飞
除了腾讯大模型之外,在大模型上已经先行一步的科大讯飞也是不甘落后,不仅积极参与通用大模型的建设,还持续发力行业大模型的建设。目前科大讯飞的大模型已经具备7大能力,分别为:文本生成、语言理解、知识问答、逻辑推理、数学和多模态能力,并且这种能力还在不断提升。而基于大模型开发所需的巨大投入量,科大讯飞也做了多方面的准备。
一方面,科大讯飞积极展开与业内巨头的合作,强化星火大模型的技术实力。早在今年8月中旬,科大讯飞就与华为共同发布星火一体机,让所有企业都可以在国产自主创新平台上私有化部署大模型。一来,星火一体机基于星火认知大模型,针对污语料和幻觉问题,形成了“立体化”的内容安全机制。二来,星火一体机基于昇腾AI硬件、昇思AI开源框架,提供业界领先的大模型训练、推理能力,为大模型全流程创新提供坚实的自主创新算力底座。
具体来说,讯飞星火认知大模型基于训练推理一体化设计,实现大模型稀疏化、低精度量化的技术突破,能高效适配昇腾AI,加速大模型的行业落地应用和迭代;与此同时,以昇腾AI为核心,软硬件协同优化,构建算力集中、协同优化、供给稳定、数据安全的大模型训练集群,这些都可以强化星火大模型的自身实力。
另一方面,科大讯飞积极推动与自身业务场景的整合,加速大模型的场景落地。除了不断强化自己核心能力之外,科大讯飞还结合自身的业务场景,推动大模型在办公、政务、电力、教育、医疗、工业、司法、金融等行业的场景落地。星火一体机内已涵盖办公、代码、运维、客服、营销、采购等10多个场景包,支持对话开发、任务编排、插件执行、知识接入、提示工程等5种定制优化模式,并将持续拓展更多专业场景和模式优化,为客户快速定制企业专属大模型。
总的来看,科大讯飞在大模型上,外部合作和内部场景落地相结合的方式,很好地保证了其大模型产业化的加速落地。
大模型大洗牌正在加速到来
在众多头部巨头和行业巨头的共同努力之下,“百模大战”甚至“千模大战”的局面正在加速形成。而在这种的形势之下,围绕大模型的“行业大洗牌”或将提前到来。
首先,产品能力的比拼已经初见分晓。据知名厂商IDC依据算法模型、通用能力、创新能力、平台能力和安全可解释等五方面的要求,评估出了目前市面上在大模型方面综合评分最高的三家厂商,分别是百度、阿里巴巴、科大讯飞。不过由于这个数据排出的时间较早,未考虑到腾讯和华为的产品能力,所谓真实的综合技术实力方面,排名靠前的依旧会是BATH这些行业巨头。
但各家的能力并不相同,也各有侧重。具体来说,百度的能力在于其具有“芯片—框架—模型—应用”四层技术栈完整布局的独特优势:芯片层—昆仑芯、框架层—飞浆、模型层—文心大模型,以及各种AI的落地应用。阿里的能力也相近,其强大之处在于围绕云搭建起了一整个的大模型基础设施;华为的能力在于强大的基础技术能力,以及广泛的终端生态应用和B端应用能力。在BATH之外,其他大模型厂商依然排在第二梯队、第三梯队,产品层面的分化已经出现。
其次,是大模型生态服务能力的比拼已然拉开序幕。以阿里为例,阿里不仅推出了通义千问大模型,还推出了魔搭大模型社区,还有众多的生态合作伙伴;百度在这方面也不遑多让,不仅有基于大模型的技术能力,还有广泛的生态伙伴,推理能力和速度伴随着大模型的版本更新,也在日新月异;作为同级别大厂,华为、腾讯等厂商自然也具备类似能力。不难预见,未来各路厂商围绕预训练、逻辑推理等相关方面的技术服务,将成为行业竞争的常态。
当然,无论是产品维度还是服务能力,最终都要落地到产业实践上。从行业覆盖来看,从文心大模型出发,百度已经在能源、汽车、政务、交通、金融等重点领域布局11个行业大模型,将大模型融入到垂直领域,真正做到产业实践和商业落地。阿里、腾讯、华为等也覆盖电商零售、物流、社交、矿业等诸多行业,产业化落地也在快速提升。
而随着各大平台的大模型,在产品、生态服务和产业实践上的全面展开,大模型的大洗牌正在加速到来。
相关文章:
大模型应用疯狂加速,洗牌却在静悄悄进行了
配图来自Canva可画 在被誉为“科技企业营销圣经”的《跨越鸿沟》一书中,杰弗里摩尔写道:“高科技产品面世过程中,最危险、最关键的一点,就是由少数有远见者所主宰的早期市场,向实用主义者占支配地位的主流市场过渡。”…...

oracle后台进程详解#进程结构
一、oracle进程结构 oracle体系结构主要有实例数据库; 实例由内存结构(SGAPGA..)和进程结构(服务器进程后台进程..)组成;本文主要介绍进程结构 二、服务器进程 Oracle数据库创建服务器进程来处理连接到该实…...

解决DDP的参数未参与梯度计算
将find_unused_parameters改成False之后,如果出现模型有些参数未参与loss计算等错误。 可以用环境变量来debug查看log。 export TORCH_DISTRIBUTED_DEBUGDETAIL 代码上可以用以下方法查看。 # check parameters with no grad for n, p in model.named_parameters(…...

cpp primer笔记100-拷贝控制
如果拷贝构造函数如果传递的参数不是引用类型,则调用拷贝永远不成功,因为如果调用了拷贝构造函数,则必须拷贝它的实参,但是为了拷贝实参,我们又需要调用拷贝构造函数,如此循环。 如果想要删除默认构造函数…...
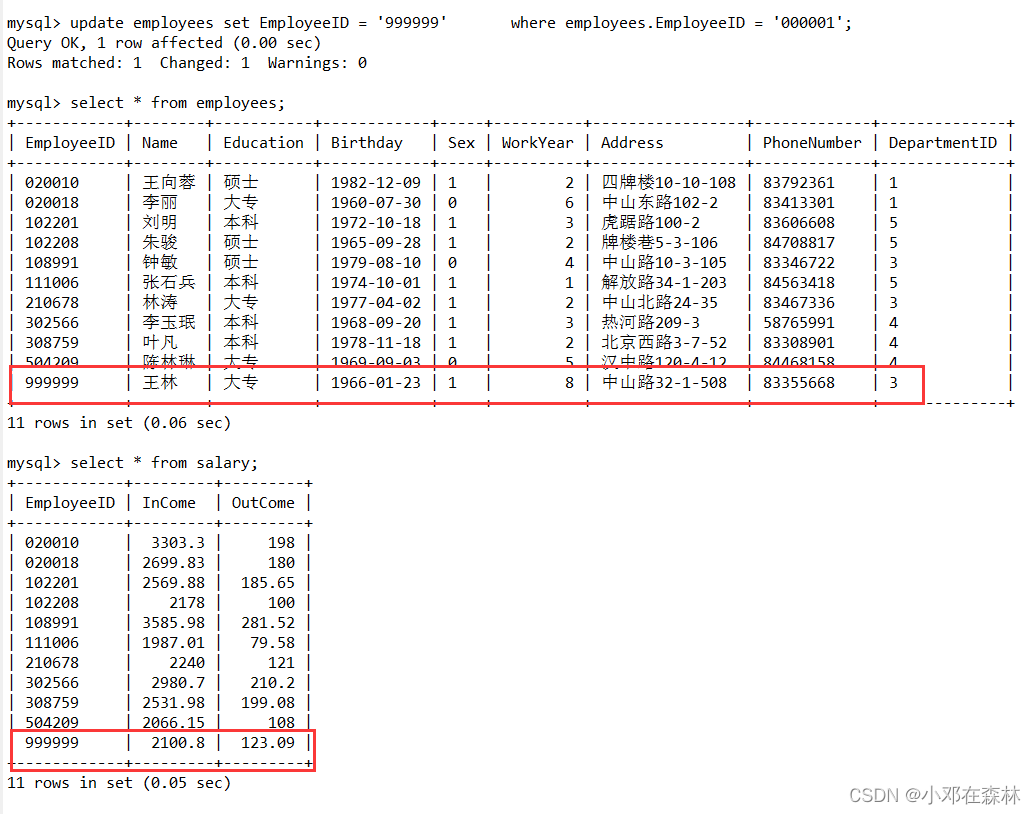
【数据库——MySQL】(16)游标和触发器习题及讲解
目录 1. 题目1.1 游标1.2 触发器 2. 解答2.1 游标2.2 触发器 1. 题目 1.1 游标 创建存储过程,利用游标依次显示某部门的所有员工的实际收入。(分别用使用 计数器 来循环和使用 标志变量 来控制循环两种方法实现) 创建存储过程,将某部门的员工工资按工作…...
toString的用法)
javascript二维数组(9)toString的用法
在JavaScript中,toString() 是一个内置方法,用于将特定的对象转化为字符串表示形式。 基本使用示例 以下是一些 toString() 方法的基本使用示例: 数字的 toString(): let num 123; console.log(num.toString()); // 输出: &…...

OpenAI重大更新!为ChatGPT推出语音和图像交互功能
原创 | 文 BFT机器人 OpenAI旗下的ChatGPT正在迎来一次重大更新,这个聊天机器人现在能够与用户进行语音对话,并且可以通过图像进行交互,将其功能推向与苹果的Siri等受欢迎的人工智能助手更接近的水平。这标志着生成式人工智能运动的一个显著…...

【开发篇】十六、SpringBoot整合JavaMail实现发邮件
文章目录 0、相关协议1、SpringBoot整合JavaMail2、发送简单邮件3、发送复杂邮件 0、相关协议 SMTP(Simple Mail Transfer Protocol):简单邮件传输协议,用于发送电子邮件的传输协议POP3(Post Office Protocol - Versi…...

如何在Ubuntu系统部署RabbitMQ服务器并公网访问【内网穿透】
文章目录 前言1.安装erlang 语言2.安装rabbitMQ3. 内网穿透3.1 安装cpolar内网穿透(支持一键自动安装脚本)3.2 创建HTTP隧道 4. 公网远程连接5.固定公网TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 前言 RabbitMQ是一个在 AMQP(高级消息队列协议)基…...
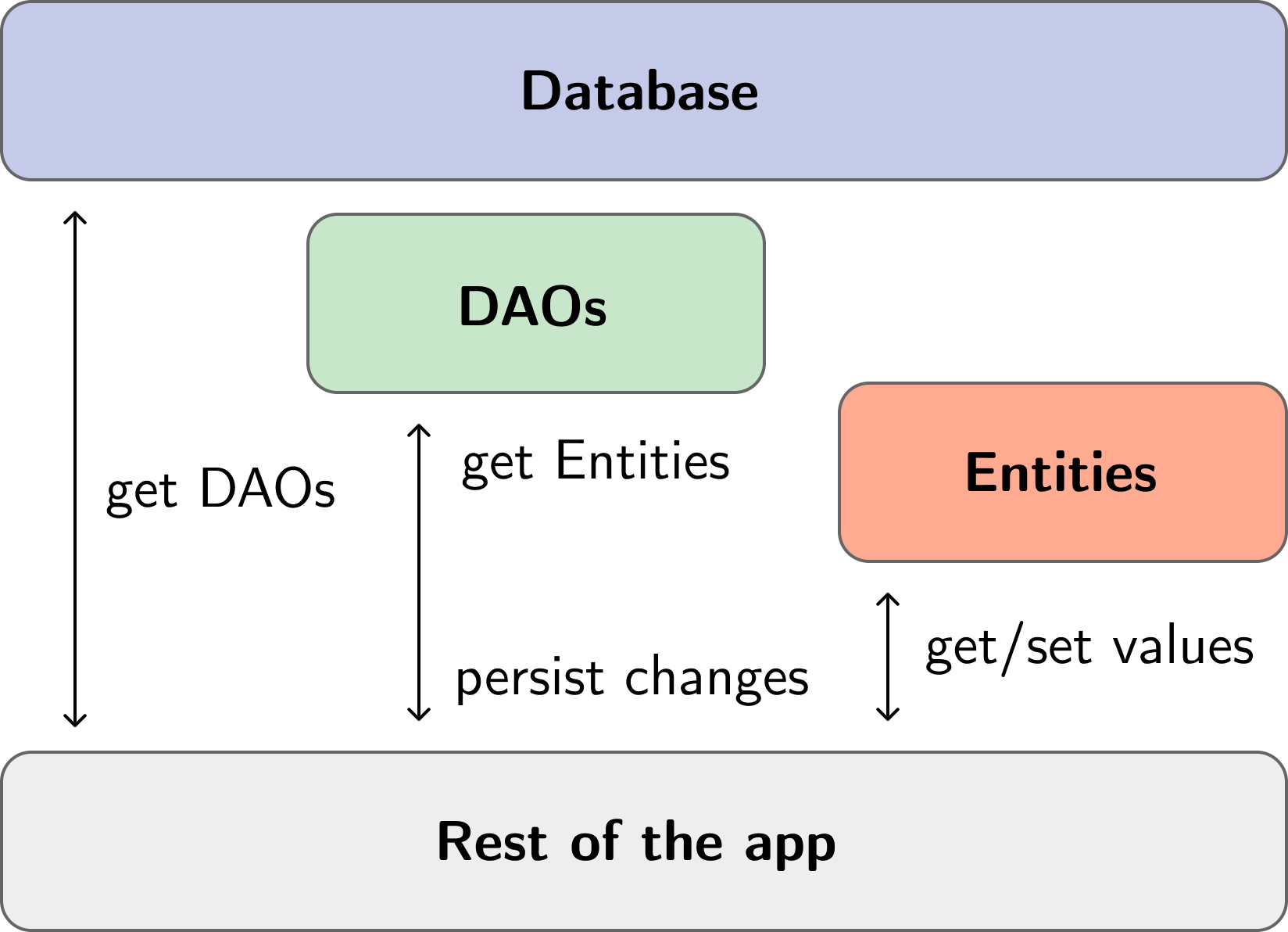
Flutter笔记:用于ORM的Floor框架简记
Flutter笔记 用于ORM的Floor框架简记 本文地址:https://blog.csdn.net/qq_28550263/article/details/133377191 floor 模块地址:https://pub.dev/packages/floor 【介绍】:最近想找用于Dart和Flutter的ORM框架,偶然间发现了Floor…...
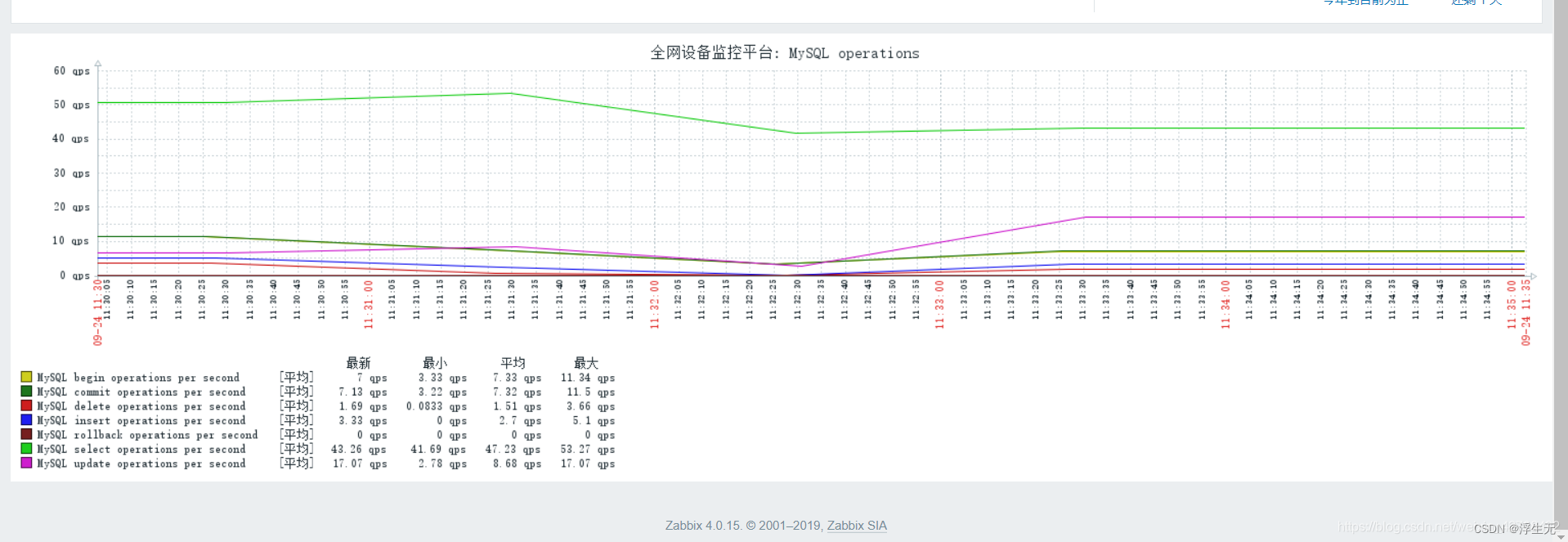
Zabbix自定义脚本监控MySQL数据库
一、MySQL数据库配置 1.1 创建Mysql数据库用户 [rootmysql ~]# mysql -uroot -p create user zabbix127.0.0.1 identified by 123456; flush privileges; 1.2 添加用户密码到mysql client的配置文件中 [rootmysql ~]# vim /etc/my.cnf.d/client.cnf [client] host127.0.0.1 u…...
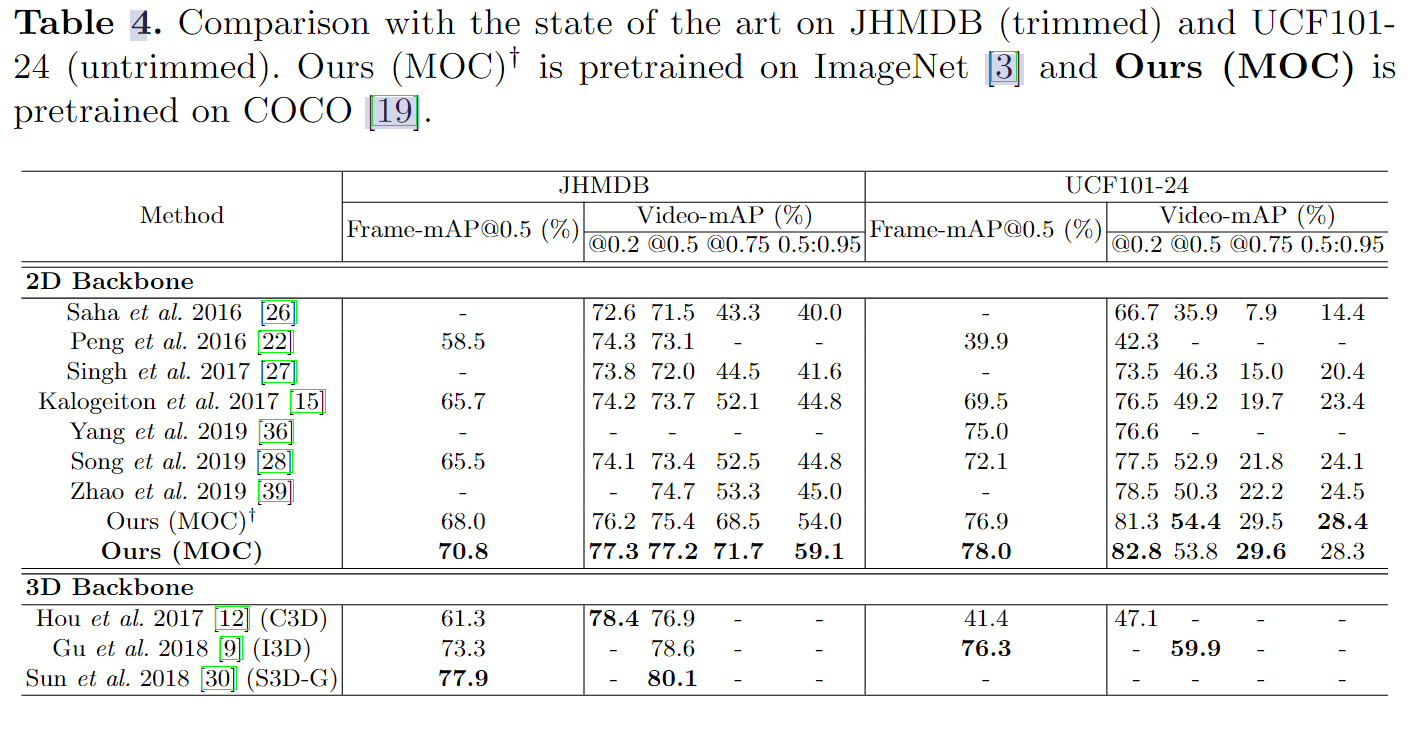
【Spatial-Temporal Action Localization(五)】论文阅读2020年
文章目录 1. Actions as Moving Points摘要和结论引言:针对痛点和贡献模型框架实验 1. Actions as Moving Points Actions as Moving Points (ECCV 2020) 摘要和结论 MovingCenter Detector (MOCdetector) 通过将动作实例视为移动点的轨迹。通过三个分支生成 tub…...

Linux基本指令(中)——“Linux”
各位CSDN的uu们好呀,今天,小雅兰的内容是Linux基本指令呀!!!下面,让我们进入Linux的世界吧!!! cp指令(重要) mv指令(重要)…...

OWASP Top 10漏洞解析(3)- A3:Injection 注入攻击
作者:gentle_zhou 原文链接:OWASP Top 10漏洞解析(3)- A3:Injection 注入攻击-云社区-华为云 Web应用程序安全一直是一个重要的话题,它不但关系到网络用户的隐私,财产,而且关系着用户对程序的新…...

Java自定义类加载器的详解与步骤
自定义类加载器的步骤 继承ClassLoader类:首先创建一个新的类,该类需要继承ClassLoader类。可以通过直接继承ClassLoader或是间接继承URLClassLoader等子类来实现。重写findClass()方法:在自定义类加载器中,最重要的是重写findCl…...
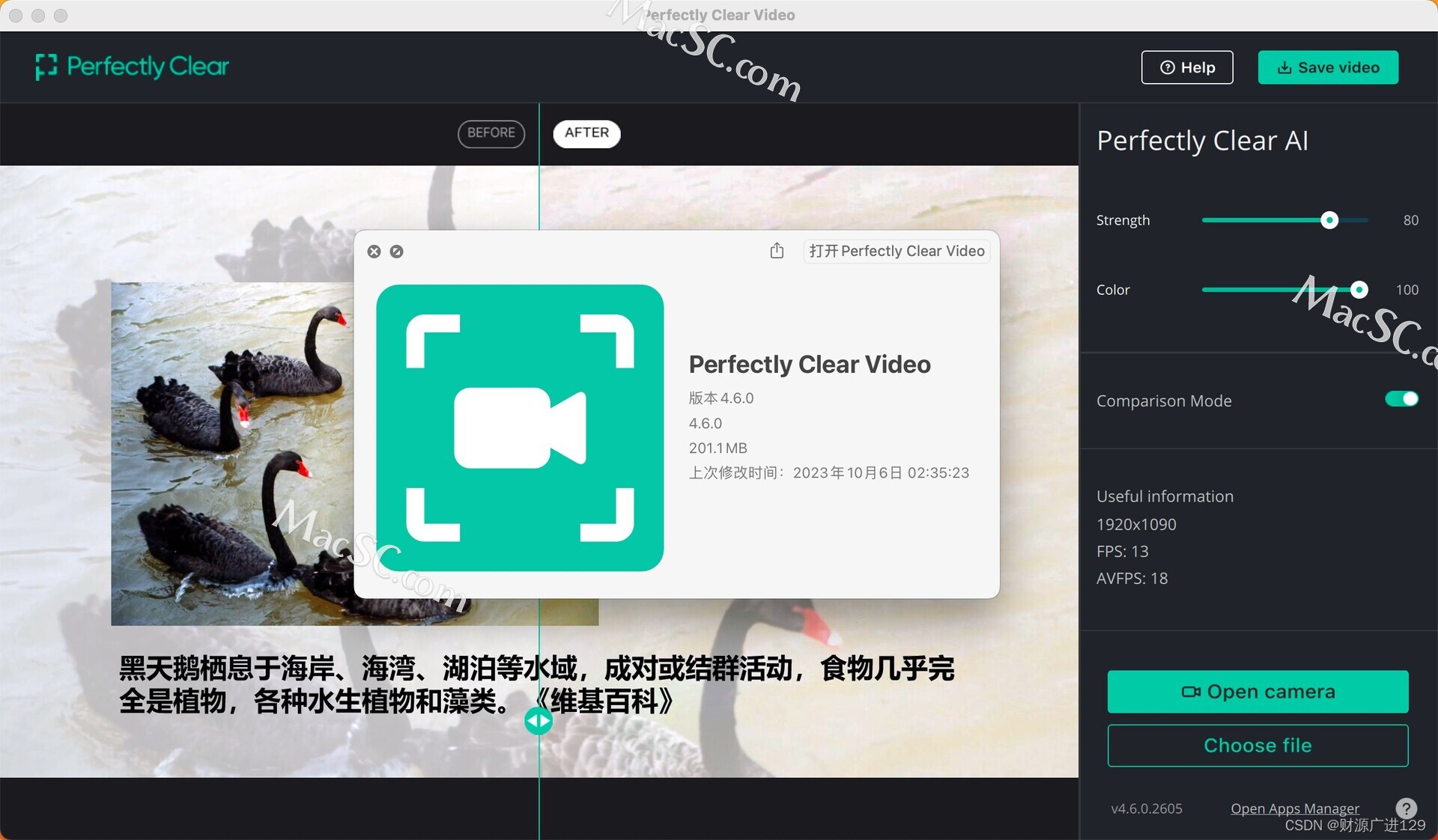
完美清晰,炫酷畅享——Perfectly Clear Video为你带来卓越的AI视频增强体验
在我们日常生活中,我们经常会拍摄和观看各种视频内容,无论是旅行记录、家庭聚会还是商务演示,我们都希望能够呈现出最清晰、最精彩的画面效果。而现在,有一个强大的工具可以帮助我们实现这一目标,那就是Perfectly Clea…...

如何让FileBeat支持http的output插件
目录 1 缘由2 编译filebeat3 配置虚拟机访问外网4 编译beats-output-http4.1 使用本地包4.2 发布在线包 5 测试6 beats-output-http的部分解释 1 缘由 官网的filebeat只有以下几种output插件: Elasticsearch ServiceElasticsearchLogstashKafkaRedisFileConsole …...

解密人工智能:决策树 | 随机森林 | 朴素贝叶斯
文章目录 一、机器学习算法简介1.1 机器学习算法包含的两个步骤1.2 机器学习算法的分类 二、决策树2.1 优点2.2 缺点 三、随机森林四、Naive Bayes(朴素贝叶斯)五、结语 一、机器学习算法简介 机器学习算法是一种基于数据和经验的算法,通过对…...
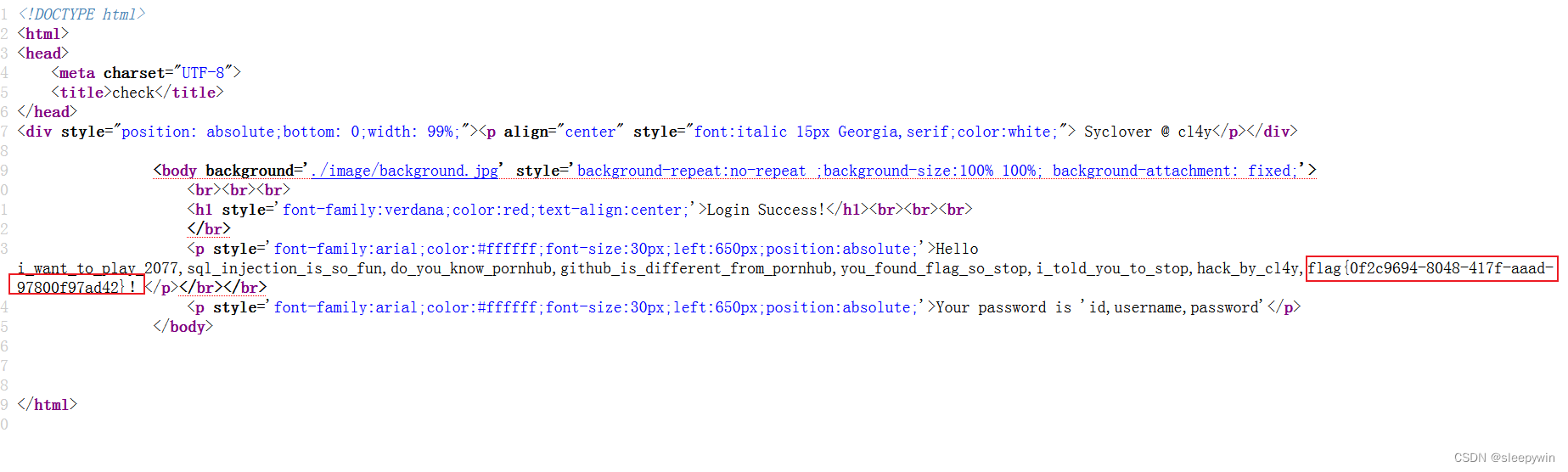
web:[极客大挑战 2019]BabySQL
题目 点进页面显示如下 查看源代码 先尝试一下万能密码 没用,or被过滤了 试着双写看看 回显一串,也不是flag 先查询列数尝试一下,把union select过滤了,使用双写 构造payload /check.php?usernameadmin&password1 %27 ununi…...
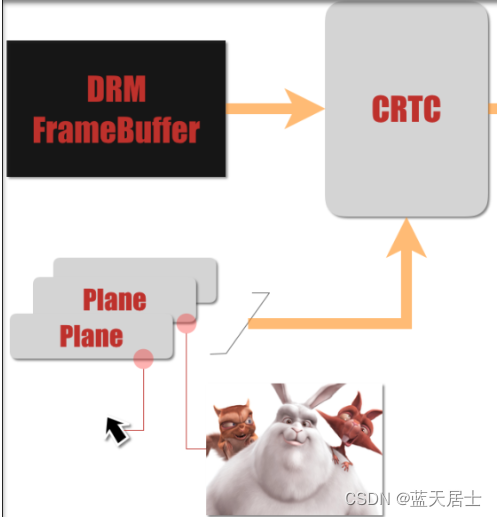
DRM全解析 —— plane详解(1)
本文参考以下博文: Linux内核4.14版本——drm框架分析(5)——plane分析 特此致谢! 1. 简介 一个plane代表一个image layer(硬件图层),最终的image由一个或者多个plane(s)组成。plane和 Framebuffer 一样是内存地址。…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...