第五课 树与图
文章目录
- 第五课 树与图
- lc94.二叉树的中序遍历--简单
- 题目描述
- 代码展示
- lc589.N叉树的层序遍历--中等
- 题目描述
- 代码展示
- lc297.二叉树的序列化和反序列化--困难
- 题目描述
- 代码展示
- lc105.从前序与中序遍历序列构造二叉树--中等
- 题目描述
- 代码展示
- lc106.从中序与后序遍历序列构造二叉树--中等
- 题目描述
- 代码展示
- lc236.二叉树的最近公共祖先(LCA)--中等
- 题目描述
- 代码展示
- lc207.课程表--中等
- 题目描述
- 代码展示
- lc210.课程表II--中等
- 题目描述
- 代码展示
- lc684.冗余连接--中等
- 题目描述
- 代码展示
第五课 树与图
lc94.二叉树的中序遍历–简单
题目描述
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
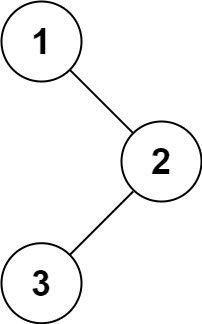
输入:root = [1,null,2,3]
输出:[1,3,2]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
代码展示
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:void inorder(TreeNode* root, vector<int>& res) {if (!root) {return;}inorder(root->left, res);res.push_back(root->val);inorder(root->right, res);}vector<int> inorderTraversal(TreeNode* root) {vector<int> res;inorder(root, res);return res;}
};
lc589.N叉树的层序遍历–中等
题目描述
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
示例 1:
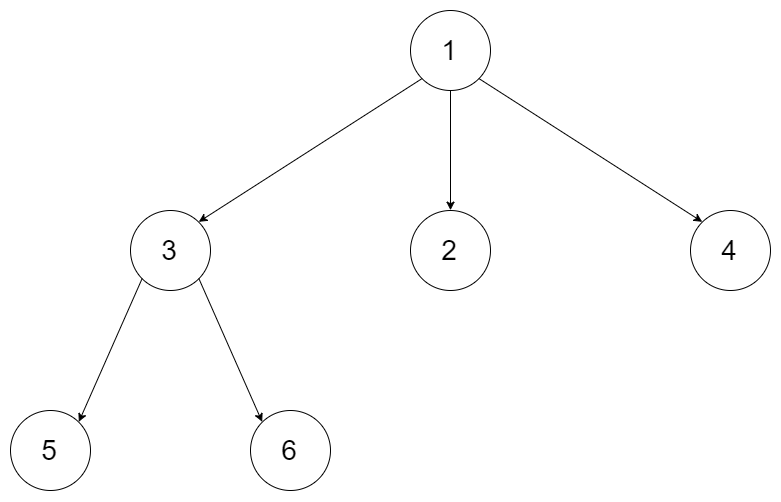
输入:root = [1,null,3,2,4,null,5,6]
输出:[[1],[3,2,4],[5,6]]
示例 2:
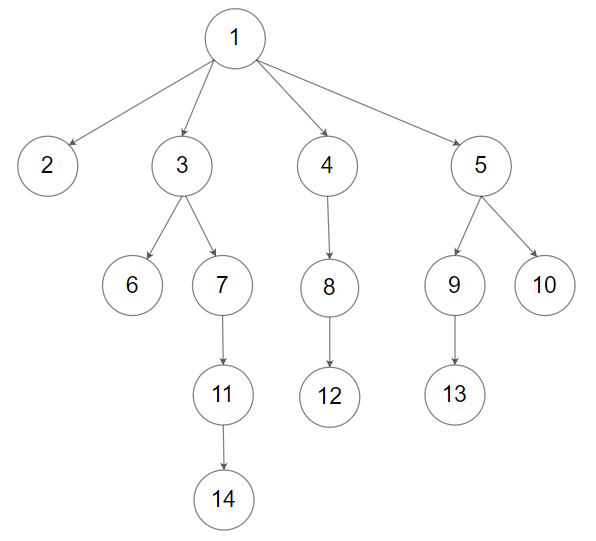
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
提示:
- 树的高度不会超过
1000 - 树的节点总数在
[0, 10^4]之间
代码展示
/*
// Definition for a Node.
class Node {
public:int val;vector<Node*> children;Node() {}Node(int _val) {val = _val;}Node(int _val, vector<Node*> _children) {val = _val;children = _children;}
};
*/class Solution {
public: //广度优先搜索vector<vector<int>> levelOrder(Node* root) {if (!root) {return {};}vector<vector<int>> ans;queue<Node*> q;q.push(root);while (!q.empty()) {int cnt = q.size();vector<int> level;for (int i = 0; i < cnt; ++i) {Node* cur = q.front();q.pop();level.push_back(cur->val);for (Node* child: cur->children) {q.push(child);}}ans.push_back(move(level));}return ans;}
};
lc297.二叉树的序列化和反序列化–困难
题目描述
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
示例 1:
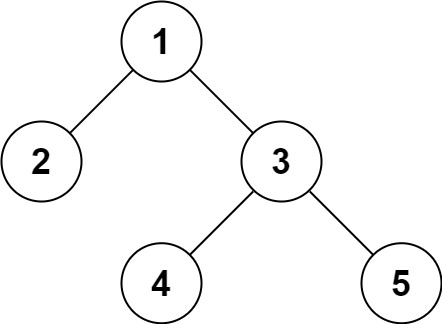
输入:root = [1,2,3,null,null,4,5]
输出:[1,2,3,null,null,4,5]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
示例 4:
输入:root = [1,2]
输出:[1,2]
提示:
- 树中结点数在范围
[0, 104]内 -1000 <= Node.val <= 1000
代码展示
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) : val(x), left(NULL), right(NULL) {}* };*/
class Codec {
public:void rserialize(TreeNode* root, string& str) {if (root == nullptr) {str += "None,";} else {str += to_string(root->val) + ",";rserialize(root->left, str);rserialize(root->right, str);}}string serialize(TreeNode* root) {string ret;rserialize(root, ret);return ret;}TreeNode* rdeserialize(list<string>& dataArray) {if (dataArray.front() == "None") {dataArray.erase(dataArray.begin());return nullptr;}TreeNode* root = new TreeNode(stoi(dataArray.front()));dataArray.erase(dataArray.begin());root->left = rdeserialize(dataArray);root->right = rdeserialize(dataArray);return root;}TreeNode* deserialize(string data) {list<string> dataArray;string str;for (auto& ch : data) {if (ch == ',') {dataArray.push_back(str);str.clear();} else {str.push_back(ch);}}if (!str.empty()) {dataArray.push_back(str);str.clear();}return rdeserialize(dataArray);}
};// Your Codec object will be instantiated and called as such:
// Codec ser, deser;
// TreeNode* ans = deser.deserialize(ser.serialize(root));
lc105.从前序与中序遍历序列构造二叉树–中等
题目描述
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:
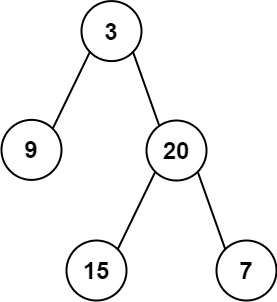
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
代码展示
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
private: unordered_map<int, int> index;public: //递归TreeNode* myBuildTree(const vector<int>& preorder, const vector<int>& inorder, int preorder_left, int preorder_right, int inorder_left, int inorder_right) {if (preorder_left > preorder_right) {return nullptr;}// 前序遍历中的第一个节点就是根节点int preorder_root = preorder_left;// 在中序遍历中定位根节点int inorder_root = index[preorder[preorder_root]];// 先把根节点建立出来TreeNode* root = new TreeNode(preorder[preorder_root]);// 得到左子树中的节点数目int size_left_subtree = inorder_root - inorder_left;// 递归地构造左子树,并连接到根节点// 先序遍历中「从 左边界+1 开始的 size_left_subtree」个元素就对应了中序遍历中「从 左边界 开始到 根节点定位-1」的元素root->left = myBuildTree(preorder, inorder, preorder_left + 1, preorder_left + size_left_subtree, inorder_left, inorder_root - 1);// 递归地构造右子树,并连接到根节点// 先序遍历中「从 左边界+1+左子树节点数目 开始到 右边界」的元素就对应了中序遍历中「从 根节点定位+1 到 右边界」的元素root->right = myBuildTree(preorder, inorder, preorder_left + size_left_subtree + 1, preorder_right, inorder_root + 1, inorder_right);return root;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {int n = preorder.size();// 构造哈希映射,帮助我们快速定位根节点for (int i = 0; i < n; ++i) {index[inorder[i]] = i;}return myBuildTree(preorder, inorder, 0, n - 1, 0, n - 1);}
};
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public: //迭代TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {if (!preorder.size()) {return nullptr;}TreeNode* root = new TreeNode(preorder[0]);stack<TreeNode*> stk;stk.push(root);int inorderIndex = 0;for (int i = 1; i < preorder.size(); ++i) {int preorderVal = preorder[i];TreeNode* node = stk.top();if (node->val != inorder[inorderIndex]) {node->left = new TreeNode(preorderVal);stk.push(node->left);}else {while (!stk.empty() && stk.top()->val == inorder[inorderIndex]) {node = stk.top();stk.pop();++inorderIndex;}node->right = new TreeNode(preorderVal);stk.push(node->right);}}return root;}
};
lc106.从中序与后序遍历序列构造二叉树–中等
题目描述
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
代码展示
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {int post_idx;unordered_map<int, int> idx_map;
public: //递归TreeNode* helper(int in_left, int in_right, vector<int>& inorder, vector<int>& postorder){// 如果这里没有节点构造二叉树了,就结束if (in_left > in_right) {return nullptr;}// 选择 post_idx 位置的元素作为当前子树根节点int root_val = postorder[post_idx];TreeNode* root = new TreeNode(root_val);// 根据 root 所在位置分成左右两棵子树int index = idx_map[root_val];// 下标减一post_idx--;// 构造右子树root->right = helper(index + 1, in_right, inorder, postorder);// 构造左子树root->left = helper(in_left, index - 1, inorder, postorder);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {// 从后序遍历的最后一个元素开始post_idx = (int)postorder.size() - 1;// 建立(元素,下标)键值对的哈希表int idx = 0;for (auto& val : inorder) {idx_map[val] = idx++;}return helper(0, (int)inorder.size() - 1, inorder, postorder);}
};
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public: //迭代TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {if (postorder.size() == 0) {return nullptr;}auto root = new TreeNode(postorder[postorder.size() - 1]);auto s = stack<TreeNode*>();s.push(root);int inorderIndex = inorder.size() - 1;for (int i = int(postorder.size()) - 2; i >= 0; i--) {int postorderVal = postorder[i];auto node = s.top();if (node->val != inorder[inorderIndex]) {node->right = new TreeNode(postorderVal);s.push(node->right);} else {while (!s.empty() && s.top()->val == inorder[inorderIndex]) {node = s.top();s.pop();inorderIndex--;}node->left = new TreeNode(postorderVal);s.push(node->left);}}return root;}
};
lc236.二叉树的最近公共祖先(LCA)–中等
题目描述
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:
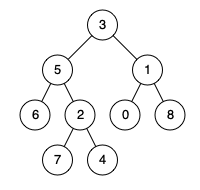
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
示例 2:
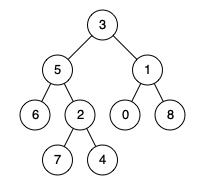
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
示例 3:
输入:root = [1,2], p = 1, q = 2
输出:1
提示:
- 树中节点数目在范围
[2, 105]内。 -109 <= Node.val <= 109- 所有
Node.val互不相同。 p != qp和q均存在于给定的二叉树中。
代码展示
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) : val(x), left(NULL), right(NULL) {}* };*/
class Solution {
public: //递归TreeNode* ans;bool dfs(TreeNode* root, TreeNode* p, TreeNode* q) {if (root == nullptr) return false;bool lson = dfs(root->left, p, q);bool rson = dfs(root->right, p, q);if ((lson && rson) || ((root->val == p->val || root->val == q->val) && (lson || rson))) {ans = root;} return lson || rson || (root->val == p->val || root->val == q->val);}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {dfs(root, p, q);return ans;}
};
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) : val(x), left(NULL), right(NULL) {}* };*/
class Solution {
public: //存储父节点unordered_map<int, TreeNode*> fa;unordered_map<int, bool> vis;void dfs(TreeNode* root){if (root->left != nullptr) {fa[root->left->val] = root;dfs(root->left);}if (root->right != nullptr) {fa[root->right->val] = root;dfs(root->right);}}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {fa[root->val] = nullptr;dfs(root);while (p != nullptr) {vis[p->val] = true;p = fa[p->val];}while (q != nullptr) {if (vis[q->val]) return q;q = fa[q->val];}return nullptr;}
};

lc207.课程表–中等
题目描述
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
代码展示
class Solution {
private:vector<vector<int>> edges;vector<int> visited;bool valid = true;public: //深度优先搜索void dfs(int u) {visited[u] = 1;for (int v: edges[u]) {if (visited[v] == 0) {dfs(v);if (!valid) {return;}}else if (visited[v] == 1) {valid = false;return;}}visited[u] = 2;}bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {edges.resize(numCourses);visited.resize(numCourses);for (const auto& info: prerequisites) {edges[info[1]].push_back(info[0]);}for (int i = 0; i < numCourses && valid; ++i) {if (!visited[i]) {dfs(i);}}return valid;}
};
class Solution {
private:vector<vector<int>> edges;vector<int> indeg;public: //广度优先搜索bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {edges.resize(numCourses);indeg.resize(numCourses);for (const auto& info: prerequisites) {edges[info[1]].push_back(info[0]);++indeg[info[0]];}queue<int> q;for (int i = 0; i < numCourses; ++i) {if (indeg[i] == 0) {q.push(i);}}int visited = 0;while (!q.empty()) {++visited;int u = q.front();q.pop();for (int v: edges[u]) {--indeg[v];if (indeg[v] == 0) {q.push(v);}}}return visited == numCourses;}
};
lc210.课程表II–中等
题目描述
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
- 例如,想要学习课程
0,你需要先完成课程1,我们用一个匹配来表示:[0,1]。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:[0,1]
解释:总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 [0,1] 。
示例 2:
输入:numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]]
输出:[0,2,1,3]
解释:总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。
因此,一个正确的课程顺序是 [0,1,2,3] 。另一个正确的排序是 [0,2,1,3] 。
示例 3:
输入:numCourses = 1, prerequisites = []
输出:[0]
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= numCourses * (numCourses - 1)prerequisites[i].length == 20 <= ai, bi < numCoursesai != bi- 所有
[ai, bi]互不相同
代码展示
class Solution {
private:// 存储有向图vector<vector<int>> edges;// 标记每个节点的状态:0=未搜索,1=搜索中,2=已完成vector<int> visited;// 用数组来模拟栈,下标 0 为栈底,n-1 为栈顶vector<int> result;// 判断有向图中是否有环bool valid = true;public: //深度优先搜索void dfs(int u) {// 将节点标记为「搜索中」visited[u] = 1;// 搜索其相邻节点// 只要发现有环,立刻停止搜索for (int v: edges[u]) {// 如果「未搜索」那么搜索相邻节点if (visited[v] == 0) {dfs(v);if (!valid) {return;}}// 如果「搜索中」说明找到了环else if (visited[v] == 1) {valid = false;return;}}// 将节点标记为「已完成」visited[u] = 2;// 将节点入栈result.push_back(u);}vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {edges.resize(numCourses);visited.resize(numCourses);for (const auto& info: prerequisites) {edges[info[1]].push_back(info[0]);}// 每次挑选一个「未搜索」的节点,开始进行深度优先搜索for (int i = 0; i < numCourses && valid; ++i) {if (!visited[i]) {dfs(i);}}if (!valid) {return {};}// 如果没有环,那么就有拓扑排序// 注意下标 0 为栈底,因此需要将数组反序输出reverse(result.begin(), result.end());return result;}
};
class Solution {
private:// 存储有向图vector<vector<int>> edges;// 存储每个节点的入度vector<int> indeg;// 存储答案vector<int> result;public: //广度优先搜索vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {edges.resize(numCourses);indeg.resize(numCourses);for (const auto& info: prerequisites) {edges[info[1]].push_back(info[0]);++indeg[info[0]];}queue<int> q;// 将所有入度为 0 的节点放入队列中for (int i = 0; i < numCourses; ++i) {if (indeg[i] == 0) {q.push(i);}}while (!q.empty()) {// 从队首取出一个节点int u = q.front();q.pop();// 放入答案中result.push_back(u);for (int v: edges[u]) {--indeg[v];// 如果相邻节点 v 的入度为 0,就可以选 v 对应的课程了if (indeg[v] == 0) {q.push(v);}}}if (result.size() != numCourses) {return {};}return result;}
};
lc684.冗余连接–中等
题目描述
树可以看成是一个连通且 无环 的 无向 图。
给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的那个。
示例 1:
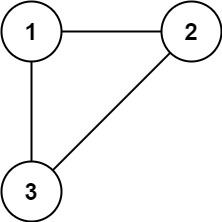
输入: edges = [[1,2], [1,3], [2,3]]
输出: [2,3]
示例 2:
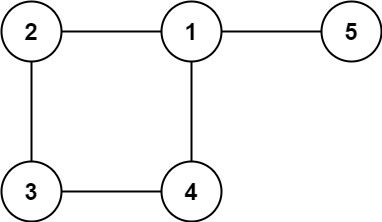
输入: edges = [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
提示:
n == edges.length3 <= n <= 1000edges[i].length == 21 <= ai < bi <= edges.lengthai != biedges中无重复元素- 给定的图是连通的
代码展示
class Solution {
public: //并查集int Find(vector<int>& parent, int index) {if (parent[index] != index) {parent[index] = Find(parent, parent[index]);}return parent[index];}void Union(vector<int>& parent, int index1, int index2) {parent[Find(parent, index1)] = Find(parent, index2);}vector<int> findRedundantConnection(vector<vector<int>>& edges) {int n = edges.size();vector<int> parent(n + 1);for (int i = 1; i <= n; ++i) {parent[i] = i;}for (auto& edge: edges) {int node1 = edge[0], node2 = edge[1];if (Find(parent, node1) != Find(parent, node2)) {Union(parent, node1, node2);} else {return edge;}}return vector<int>{};}
};
相关文章:
第五课 树与图
文章目录 第五课 树与图lc94.二叉树的中序遍历--简单题目描述代码展示 lc589.N叉树的层序遍历--中等题目描述代码展示 lc297.二叉树的序列化和反序列化--困难题目描述代码展示 lc105.从前序与中序遍历序列构造二叉树--中等题目描述代码展示 lc106.从中序与后序遍历序列构造二叉…...

2023-10-07 事业-代号z-副业-CQ私服-调研与分析
摘要: CQ作为一款运营了20年的游戏, 流传出的私服可以说是层出不穷, 到了现在我其实对这款游戏的长线运营的前景很悲观. 但是作为商业的一部分, 对其做谨慎的分析还是很有必要的. 传奇调研的来源: 一. 各种售卖私服的网站 传奇服务端版本库-传奇手游源码「免费下载」传奇GM论…...
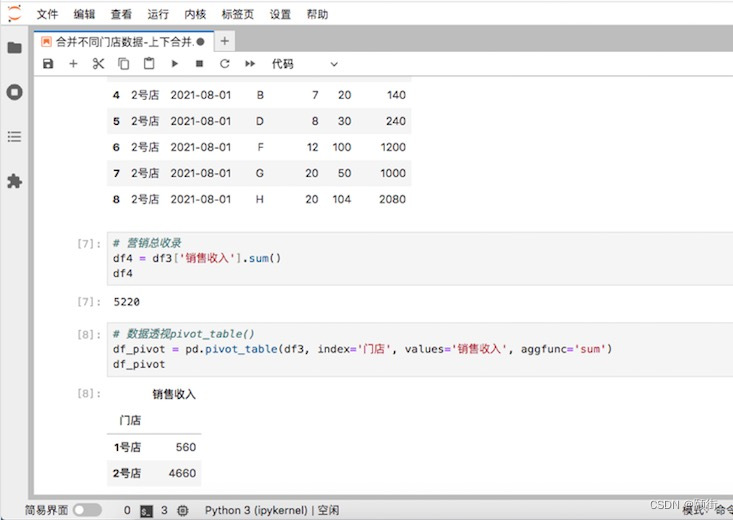
合并不同门店数据-上下合并
项目背景:线下超市分店,统计产品的销售数量和销售额,并用透视表计算求和 merge()函数可以根据链接键横向连接两张不同表,concat()函数可以上下合并和左右合并2种不同的合并方式。merge()函数只能横向连接两张表,而con…...

学习记忆——数学篇——案例——算术——整除特点
理解记忆法 对于数的整除特征大家都比较熟悉:比如4看后两位(因为100是4的倍数),8看后三位(因为1000是8的倍数),5末尾是0或5,3与9看各位数字和等等,今天重点研究一下3,9,…...

PHP8中的魔术方法-PHP8知识详解
在PHP 8中,魔术方法是一种特殊的方法,它们以两个下划线(__)开头。魔术方法允许您定义类的行为,例如创建对象、调用其他方法或访问和修改类的属性。以下是一些常见的魔术方法: __construct(): 类的构造函数…...

[图论]哈尔滨工业大学(哈工大 HIT)学习笔记23-31
视频来源:4.1.1 背景_哔哩哔哩_bilibili 目录 1. 哈密顿图 1.1. 背景 1.2. 哈氏图 2. 邻接矩阵/邻接表 3. 关联矩阵 3.1. 定义 4. 带权图 1. 哈密顿图 1.1. 背景 (1)以地球为建模,从一个大城市开始遍历其他大城市并且返回…...

Nginx+Keepalived实现服务高可用
Nginx 和 Keepalived 是常用于构建高可用性(High Availability)架构的工具。Nginx 是一款高性能的Web服务器和反向代理服务器,而Keepalived则提供了对Nginx服务的健康状态监测和故障切换功能。 下载Nginx 在服务器1和服务器2分别下载nginx …...
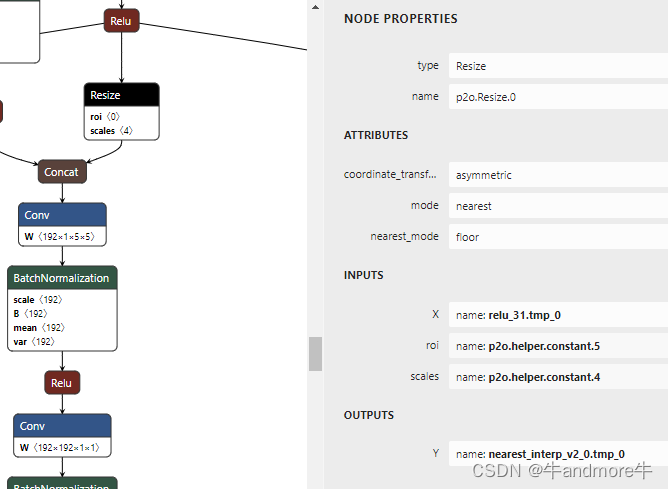
picodet onnx转其它芯片支持格式时遇到
文章目录 报错信息解决方法两模型精度对比 报错信息 报错信息为: Upsample(resize) Resize_0 not support attribute coordinate_transformation_mode:half_pixel. 解决方法 整个模型转换过程是:paddle 动态模型转成静态,再用paddle2onnx…...

【学习笔记】CF704B Ant Man
智商不够啊,咋想到贪心的😅 非常经典的贪心模型🤔 首先,从小到大将每个 i i i插入到排列中,用 D P DP DP记录还有多少个位置可以插入,可以通过钦定新插入的位置左右两边是否继续插入数来提前计算贡献。注…...

SQLines数据迁移工具
Data and Analytics Platform Migration - SQLines Tools SQLines提供的工具可以帮助您在不同的数据库平台之间传输数据、转换数据库模式(DDL)、视图、存储过程、包、用户定义函数(udf)、触发器、SQL查询和SQL脚本。 SQLines SQL Converter OverviewCommand LineConfigurati…...
)
pkl文件与打开(使用numpy和pickle)
文章目录 1. 什么是pkl文件2. 如何打开?Reference 1. 什么是pkl文件 1)python中有一种存储方式,可以存储为.pkl文件。 2)该存储方式,可以将python项目过程中用到的一些暂时变量、或者需要提取、暂存的字符串、列表、…...

3d渲染农场全面升级,好用的渲染平台值得了解
什么是渲染农场? 渲染农场是专门从事 3D 渲染的大型机器集合,称为渲染节点,这些机器组合在一起执行一项任务(渲染 3D 帧和动画)。通过将渲染工作分配给数百台机器,可以显着减少渲染时间,从而使…...

1.5 JAVA程序运行的机制
**1.5 Java程序的运行机制** --- **简介:** Java程序的运行涉及两个主要步骤:编译和运行。这种机制确保了Java的跨平台特性。 **主要内容:** 1. **Java程序的执行过程**: - **编译**:首先,扩展名为.jav…...

基于FPGA的拔河游戏设计
基于FPGA的拔河游戏机 设计内容: (1)拔河游戏机需要11个发光二极管排成一行,开机 后只有中间一个亮点,作为拔河的中间线。 游戏双方 各持一个按键,迅速且不断地按动产生脉冲,哪方按 得快,亮点就向哪方移动, 每按一次,亮点移动一次。 移到任一方二极管的终端,该方就…...
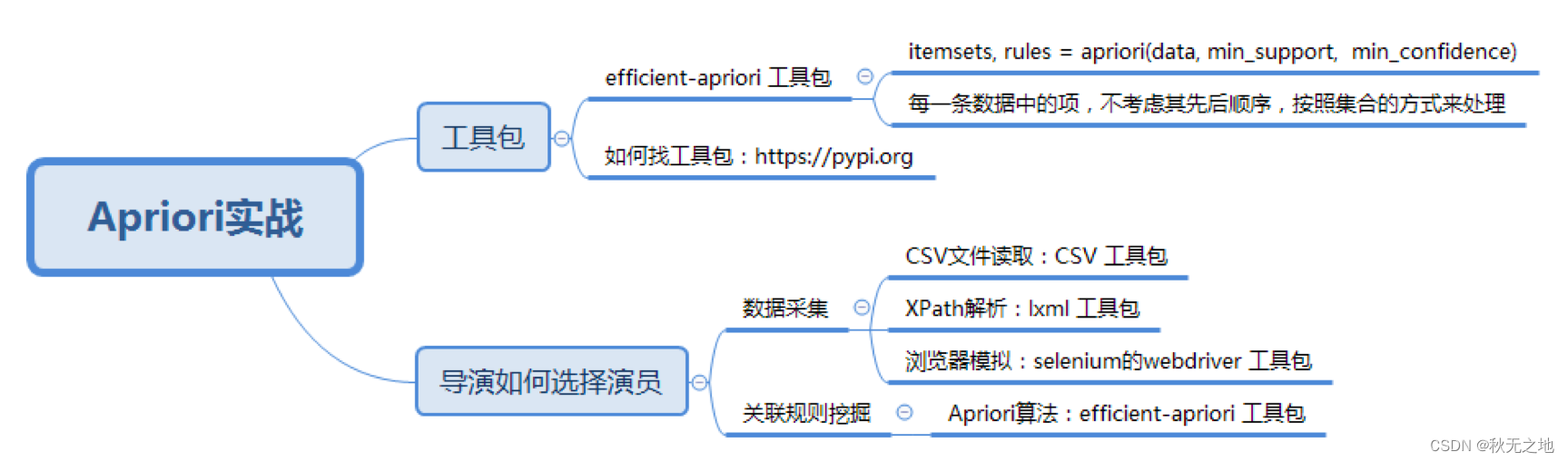
关联规则挖掘(下):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

8、【Qlib】【主要组件】预测模型:模型训练和预测
8、【主要组件】预测模型:模型训练和预测 简介基本类Example简介 预测模型(Forecast Model)旨在对股票做出预测评分。用户可以通过 qrun 在自动化工作流中使用预测模型。 由于 Qlib 中的组件设计成了松耦合方式,预测模型也可以作为一个独立模块使用。 基本类 Qlib 提供了…...

kettle安装
kettle安装 安装java环境 mkdir /data/java ln -s /data/java/ /opt/ cd /opt/javatar zxvf jdk-8u171-linux-x64.tar.gz#java export JAVA_HOME/opt/java/jdk1.8.0_171 export JRE_HOME$JAVA_HOME/jre export CLASSPATH$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH$J…...

基于生物地理学优化的BP神经网络(分类应用) - 附代码
基于生物地理学优化的BP神经网络(分类应用) - 附代码 文章目录 基于生物地理学优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.生物地理学优化BP神经网络3.1 BP神经网络参数设置3.2 生物地理学算法应用 4…...
第二证券:买基金1w一个月能赚多少?
跟着经济的开展和出资观念的改动,越来越多的人开始出资基金,购买基金已成为普遍且盛行的出资方式之一。在这个商场中,人们最重视的问题莫过于“买基金1w一个月能赚多少?”本文将从多个角度分析这一问题,协助出资者更全…...

蓝桥杯每日一题2023.10.7
跑步锻炼 - 蓝桥云课 (lanqiao.cn) 题目描述 题目分析 简单枚举,对于2的情况特判即可 #include<bits/stdc.h> using namespace std; int num, ans, flag; int m[13] {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}; bool is_ren(int n) {if((n %…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...

rm视觉学习1-自瞄部分
首先先感谢中南大学的开源,提供了很全面的思路,减少了很多基础性的开发研究 我看的阅读的是中南大学FYT战队开源视觉代码 链接:https://github.com/CSU-FYT-Vision/FYT2024_vision.git 1.框架: 代码框架结构:readme有…...

DeepSeek越强,Kimi越慌?
被DeepSeek吊打的Kimi,还有多少人在用? 去年,月之暗面创始人杨植麟别提有多风光了。90后清华学霸,国产大模型六小虎之一,手握十几亿美金的融资。旗下的AI助手Kimi烧钱如流水,单月光是投流就花费2个亿。 疯…...
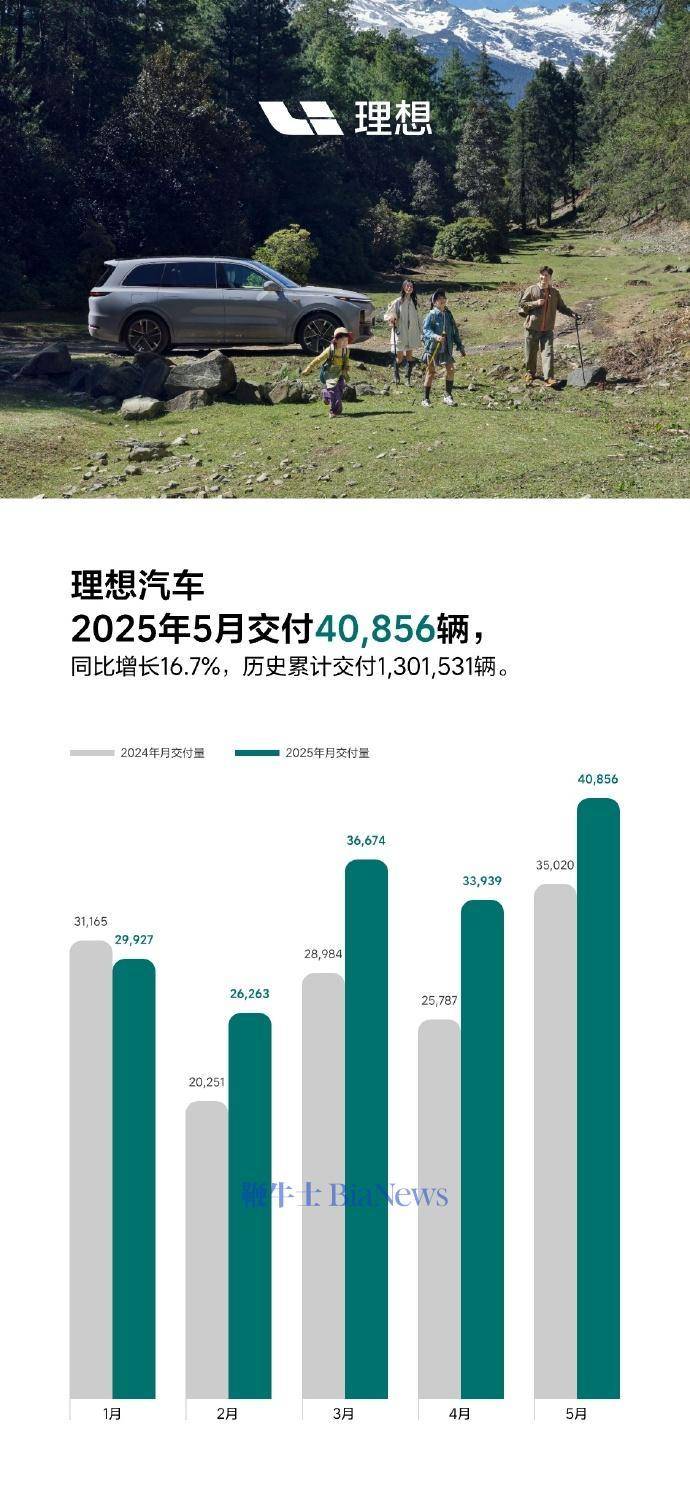
理想汽车5月交付40856辆,同比增长16.7%
6月1日,理想汽车官方宣布,5月交付新车40856辆,同比增长16.7%。截至2025年5月31日,理想汽车历史累计交付量为1301531辆。 官方表示,理想L系列智能焕新版在5月正式发布,全系产品力有显著的提升,每…...