关联规则挖掘(下):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
🐴作者:秋无之地🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、留言💬、关注🤝,关注必回关
上一篇文章已经跟大家介绍过《关联规则挖掘(上):数据分析 | 数据挖掘 | 十大算法之一》,相信大家对关联规则挖掘(上)都有一个基本的认识。下面我讲一下,关联规则挖掘(下):数据分析 | 数据挖掘 | 十大算法之一
今天我来带你用 Apriori 算法做一个项目实战。你需要掌握的是以下几点:
- 熟悉几个重要概念:支持度、置信度和提升度;
- 熟悉与掌握 Apriori 工具包的使用;
- 在实际问题中,灵活运用。包括数据集的准备等。
一、如何使用 Apriori 工具包
Apriori 虽然是十大算法之一,不过在 sklearn 工具包中并没有它,也没有 FP-Growth 算法。这里教你个方法,来选择 Python 中可以使用的工具包,你可以通过https://pypi.org/搜索工具包。

这个网站提供的工具包都是 Python 语言的,你能找到 8 个 Python 语言的 Apriori 工具包,具体选择哪个呢?建议你使用第二个工具包,即 efficient-apriori。后面我会讲到为什么推荐这个工具包。
首先你需要通过 pip install efficient-apriori 安装这个工具包。
然后看下如何使用它,核心的代码就是这一行:
itemsets, rules = apriori(data, min_support, min_confidence)其中 data 是我们要提供的数据集,它是一个 list 数组类型。min_support 参数为最小支持度,在 efficient-apriori 工具包中用 0 到 1 的数值代表百分比,比如 0.5 代表最小支持度为 50%。min_confidence 是最小置信度,数值也代表百分比,比如 1 代表 100%。
关于支持度、置信度和提升度,我们再来简单回忆下。
支持度指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的概率越大。
置信度是一个条件概念,就是在 A 发生的情况下,B 发生的概率是多少。
提升度代表的是“商品 A 的出现,对商品 B 的出现概率提升了多少”。
接下来我们用这个工具包,跑一下上节课中讲到的超市购物的例子。下面是客户购买的商品列表:

具体实现的代码如下:
from efficient_apriori import apriori
# 设置数据集
data = [('牛奶','面包','尿布'),('可乐','面包', '尿布', '啤酒'),('牛奶','尿布', '啤酒', '鸡蛋'),('面包', '牛奶', '尿布', '啤酒'),('面包', '牛奶', '尿布', '可乐')]
# 挖掘频繁项集和频繁规则
itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)
print(itemsets)
print(rules)
运行结果:
{1: {('啤酒',): 3, ('尿布',): 5, ('牛奶',): 4, ('面包',): 4}, 2: {('啤酒', '尿布'): 3, ('尿布', '牛奶'): 4, ('尿布', '面包'): 4, ('牛奶', '面包'): 3}, 3: {('尿布', '牛奶', '面包'): 3}}
[{啤酒} -> {尿布}, {牛奶} -> {尿布}, {面包} -> {尿布}, {牛奶, 面包} -> {尿布}]你能从代码中看出来,data 是个 List 数组类型,其中每个值都可以是一个集合。实际上你也可以把 data 数组中的每个值设置为 List 数组类型,比如:
data = [['牛奶','面包','尿布'],['可乐','面包', '尿布', '啤酒'],['牛奶','尿布', '啤酒', '鸡蛋'],['面包', '牛奶', '尿布', '啤酒'],['面包', '牛奶', '尿布', '可乐']]两者的运行结果是一样的,efficient-apriori 工具包把每一条数据集里的项式都放到了一个集合中进行运算,并没有考虑它们之间的先后顺序。因为实际情况下,同一个购物篮中的物品也不需要考虑购买的先后顺序。
而其他的 Apriori 算法可能会因为考虑了先后顺序,出现计算频繁项集结果不对的情况。所以这里采用的是 efficient-apriori 这个工具包。
二、挖掘导演是如何选择演员的
在实际工作中,数据集是需要自己来准备的,比如今天我们要挖掘导演是如何选择演员的数据情况,但是并没有公开的数据集可以直接使用。因此我们需要使用之前讲到的 Python 爬虫进行数据采集。
不同导演选择演员的规则是不同的,因此我们需要先指定导演。数据源我们选用豆瓣电影。
先来梳理下采集的工作流程。
首先我们先在https://movie.douban.com搜索框中输入导演姓名,比如“宁浩”。

页面会呈现出来导演之前的所有电影,然后对页面进行观察,你能观察到以下几个现象:
- 页面默认是 15 条数据反馈,第一页会返回 16 条。因为第一条数据实际上这个导演的概览,你可以理解为是一条广告的插入,下面才是真正的返回结果。
- 每条数据的最后一行是电影的演出人员的信息,第一个人员是导演,其余为演员姓名。姓名之间用“/”分割。
有了这些观察之后,我们就可以编写抓取程序了。在代码讲解中你能看出这两点观察的作用。抓取程序的目的是为了生成宁浩导演(你也可以抓取其他导演)的数据集,结果会保存在 csv 文件中。完整的抓取代码如下:
# -*- coding: utf-8 -*-
# 下载某个导演的电影数据集
from efficient_apriori import apriori
from lxml import etree
import time
from selenium import webdriver
import csv
driver = webdriver.Chrome()
# 设置想要下载的导演 数据集
director = u'宁浩'
# 写CSV文件
file_name = './' + director + '.csv'
base_url = 'https://movie.douban.com/subject_search?search_text='+director+'&cat=1002&start='
out = open(file_name,'w', newline='', encoding='utf-8-sig')
csv_write = csv.writer(out, dialect='excel')
flags=[]
# 下载指定页面的数据
def download(request_url):driver.get(request_url)time.sleep(1)html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")html = etree.HTML(html)# 设置电影名称,导演演员 的XPATHmovie_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='title']/a[@class='title-text']")name_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='meta abstract_2']")# 获取返回的数据个数num = len(movie_lists)if num > 15: #第一页会有16条数据# 默认第一个不是,所以需要去掉movie_lists = movie_lists[1:]name_lists = name_lists[1:]for (movie, name_list) in zip(movie_lists, name_lists):# 会存在数据为空的情况if name_list.text is None: continue# 显示下演员名称print(name_list.text)names = name_list.text.split('/')# 判断导演是否为指定的directorif names[0].strip() == director and movie.text not in flags:# 将第一个字段设置为电影名称names[0] = movie.textflags.append(movie.text)csv_write.writerow(names)print('OK') # 代表这页数据下载成功print(num)if num >= 14: #有可能一页会有14个电影# 继续下一页return Trueelse:# 没有下一页return False# 开始的ID为0,每页增加15
start = 0
while start<10000: #最多抽取1万部电影request_url = base_url + str(start)# 下载数据,并返回是否有下一页flag = download(request_url)if flag:start = start + 15else:break
out.close()
print('finished')代码中涉及到了几个模块,我简单讲解下这几个模块。
在引用包这一段,我们使用 csv 工具包读写 CSV 文件,用 efficient_apriori 完成 Apriori 算法,用 lxml 进行 XPath 解析,time 工具包可以让我们在模拟后有个适当停留,代码中我设置为 1 秒钟,等 HTML 数据完全返回后再进行 HTML 内容的获取。使用 selenium 的 webdriver 来模拟浏览器的行为。
在读写文件这一块,我们需要事先告诉 python 的 open 函数,文件的编码是 utf-8-sig(对应代码:encoding=‘utf-8-sig’),这是因为我们会用到中文,为了避免编码混乱。
编写 download 函数,参数传入我们要采集的页面地址(request_url)。针对返回的 HTML,我们需要用到之前讲到的 Chrome 浏览器的 XPath Helper 工具,来获取电影名称以及演出人员的 XPath。我用页面返回的数据个数来判断当前所处的页面序号。如果数据个数 >15,也就是第一页,第一页的第一条数据是广告,我们需要忽略。如果数据个数 =15,代表是中间页,需要点击“下一页”,也就是翻页。如果数据个数 <15,代表最后一页,没有下一页。
在程序主体部分,我们设置 start 代表抓取的 ID,从 0 开始最多抓取 1 万部电影的数据(一个导演不会超过 1 万部电影),每次翻页 start 自动增加 15,直到 flag=False 为止,也就是不存在下一页的情况。
你可以模拟下抓取的流程,获得指定导演的数据,比如我上面抓取的宁浩的数据。这里需要注意的是,豆瓣的电影数据可能是不全的,但基本上够我们用。

有了数据之后,我们就可以用 Apriori 算法来挖掘频繁项集和关联规则,代码如下:
# -*- coding: utf-8 -*-
from efficient_apriori import apriori
import csv
director = u'宁浩'
file_name = './'+director+'.csv'
lists = csv.reader(open(file_name, 'r', encoding='utf-8-sig'))
# 数据加载
data = []
for names in lists:name_new = []for name in names:# 去掉演员数据中的空格name_new.append(name.strip())data.append(name_new[1:])
# 挖掘频繁项集和关联规则
itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)
print(itemsets)
print(rules)代码中使用的 apriori 方法和开头中用 Apriori 获取购物篮规律的方法类似,比如代码中都设定了最小支持度和最小置信系数,这样我们可以找到支持度大于 50%,置信系数为 1 的频繁项集和关联规则。
这是最后的运行结果:
{1: {('徐峥',): 5, ('黄渤',): 6}, 2: {('徐峥', '黄渤'): 5}}
[{徐峥} -> {黄渤}]你能看出来,宁浩导演喜欢用徐峥和黄渤,并且有徐峥的情况下,一般都会用黄渤。你也可以用上面的代码来挖掘下其他导演选择演员的规律。
三、总结
Apriori 算法的核心就是理解频繁项集和关联规则。在算法运算的过程中,还要重点掌握对支持度、置信度和提升度的理解。在工具使用上,你可以使用 efficient-apriori 这个工具包,它会把每一条数据中的项(item)放到一个集合(篮子)里来处理,不考虑项(item)之间的先后顺序。
在实际运用中你还需要灵活处理,比如导演如何选择演员这个案例,虽然工具的使用会很方便,但重要的还是数据挖掘前的准备过程,也就是获取某个导演的电影数据集。
版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。
相关文章:
关联规则挖掘(下):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

8、【Qlib】【主要组件】预测模型:模型训练和预测
8、【主要组件】预测模型:模型训练和预测 简介基本类Example简介 预测模型(Forecast Model)旨在对股票做出预测评分。用户可以通过 qrun 在自动化工作流中使用预测模型。 由于 Qlib 中的组件设计成了松耦合方式,预测模型也可以作为一个独立模块使用。 基本类 Qlib 提供了…...

kettle安装
kettle安装 安装java环境 mkdir /data/java ln -s /data/java/ /opt/ cd /opt/javatar zxvf jdk-8u171-linux-x64.tar.gz#java export JAVA_HOME/opt/java/jdk1.8.0_171 export JRE_HOME$JAVA_HOME/jre export CLASSPATH$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH$J…...

基于生物地理学优化的BP神经网络(分类应用) - 附代码
基于生物地理学优化的BP神经网络(分类应用) - 附代码 文章目录 基于生物地理学优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.生物地理学优化BP神经网络3.1 BP神经网络参数设置3.2 生物地理学算法应用 4…...
第二证券:买基金1w一个月能赚多少?
跟着经济的开展和出资观念的改动,越来越多的人开始出资基金,购买基金已成为普遍且盛行的出资方式之一。在这个商场中,人们最重视的问题莫过于“买基金1w一个月能赚多少?”本文将从多个角度分析这一问题,协助出资者更全…...

蓝桥杯每日一题2023.10.7
跑步锻炼 - 蓝桥云课 (lanqiao.cn) 题目描述 题目分析 简单枚举,对于2的情况特判即可 #include<bits/stdc.h> using namespace std; int num, ans, flag; int m[13] {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}; bool is_ren(int n) {if((n %…...
Linux 系统为何产生大量的 core 文件?
Author:rab 目录 一、问题分析二、解决方案扩展 一、问题分析 上一篇刚讲到《Docker 配置基础优化》,这里再补充一下。就在中秋国庆这段小长假里,接收到了线上服务器磁盘告警通知,线上服务器架构是一个 Docker Swarm 集群&#x…...
Web_python_template_injection SSTI printer方法
这题挺简单的 就是记录一下不同方法的rce python_template_injection ssti了 {{.__class__.__mro__[2].__subclasses__()}} 然后用脚本跑可以知道是 71 {{.__class__.__mro__[2].__subclasses__()[71]}} 然后直接 init {{.__class__.__mro__[2].__subclasses__()[71].__i…...
)
TCP/IP网络江湖——江湖导航(网络层上篇)
目录 一、引言 二、IP地址与路由 三、IP协议与数据包转发 3.1 IP协议:网络江湖的规矩...
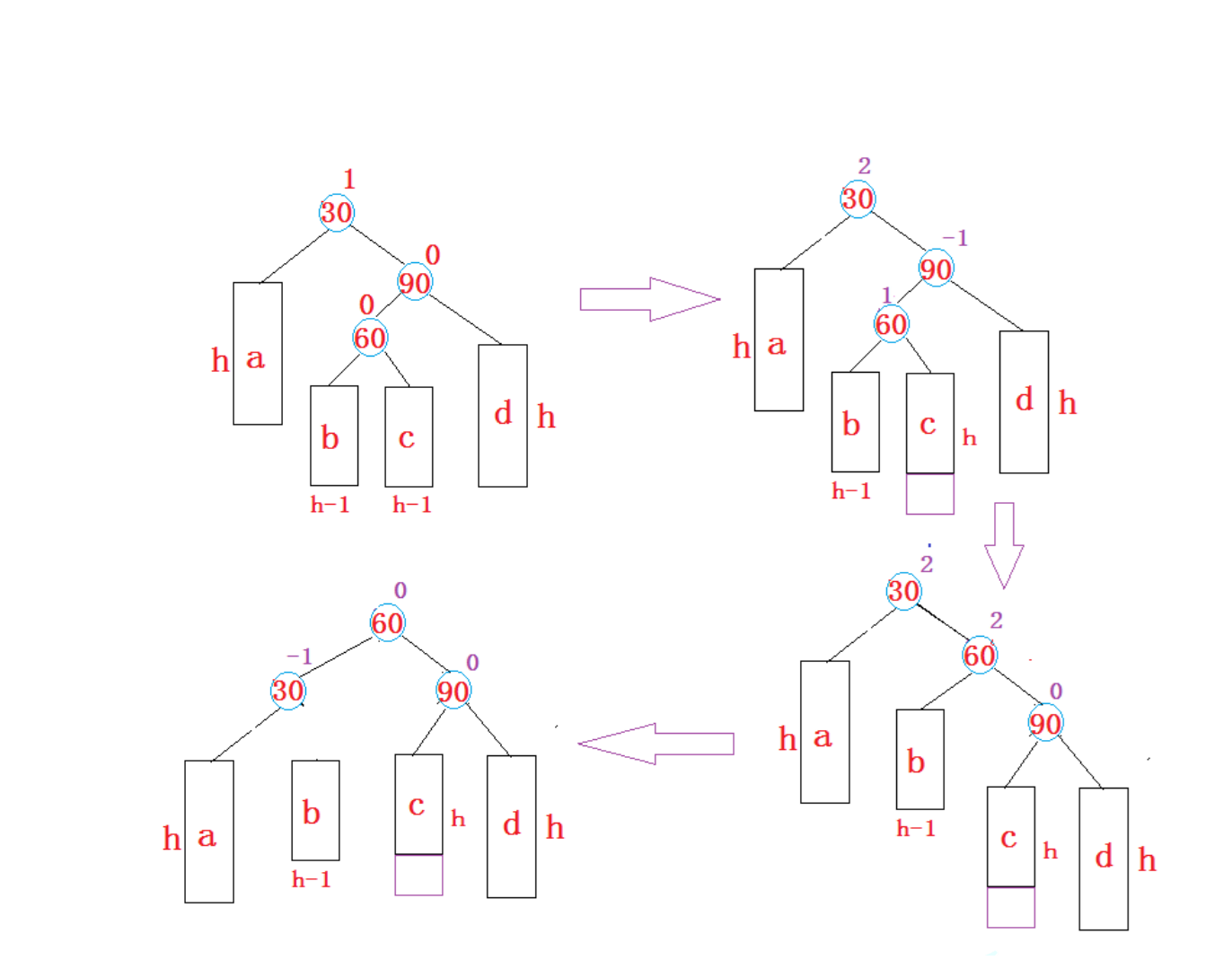
数据结构——AVL树(详解 + C++模拟实现)
文章目录 前言AVL树的概念AVL树节点的定义AVL树类框架AVL树的插入AVL树的旋转新节点插入较高子树的左侧 —— 左左: 右单旋新节点插入较高右子树的右侧——右右: 左单旋新节点插入较高左子树的右侧 —— 左右: 先左单旋然后再有单旋新节点插入较高右子树的左侧&…...

redis 雪崩,穿透,击穿及解决方案
一、缓存雪崩: 1. 原因: 缓存雪崩是指在我们设置缓存时大量采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。 2. 解决方案: 将失效时间分散,通过生成随机数使得key的过期时间…...
Flutter环境搭建及新建项目
一、下载安装压缩包 https://storage.flutter-io.cn/flutter_infra_release/releases/stable/windows/flutter_windows_3.10.6-stable.zip 二、解压缩 解压之后,将里面的flutter整体拿出来 三、配置环境变量 将flutter/bin全路径配置到系统环境变量里面 四、运行…...

【面试题精讲】深拷贝和浅拷贝区别了解吗?什么是引用拷贝?
“ 有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top ” 首发博客地址[1] 面试题手册[2] 系列文章地址[3] 深拷贝和浅拷贝的区别: 深拷贝(Deep Copy)和浅拷贝&#…...

CentOS7.9中使用packstack安装train版本
这里写目录标题 材料准备为什么选择packstack安装静态ip系统配置使用阿里云yum源安装packstack部署openstack 材料准备 ecs云服务器8核心16g内存一台,系统盘100GB,系统CentOS7.9vpc网段:192.168.0.1/24eip一个,带宽5M以上 为什么…...

mfw git泄露构造闭合
这题也挺有想法 第一次确实没有想到 首先我们可以扫出 git 然后 我们githack 泄露一下 然后我们看index.php代码 <?phpif (isset($_GET[page])) {$page $_GET[page]; } else {$page "home"; }$file "templates/" . $page . ".php";/…...
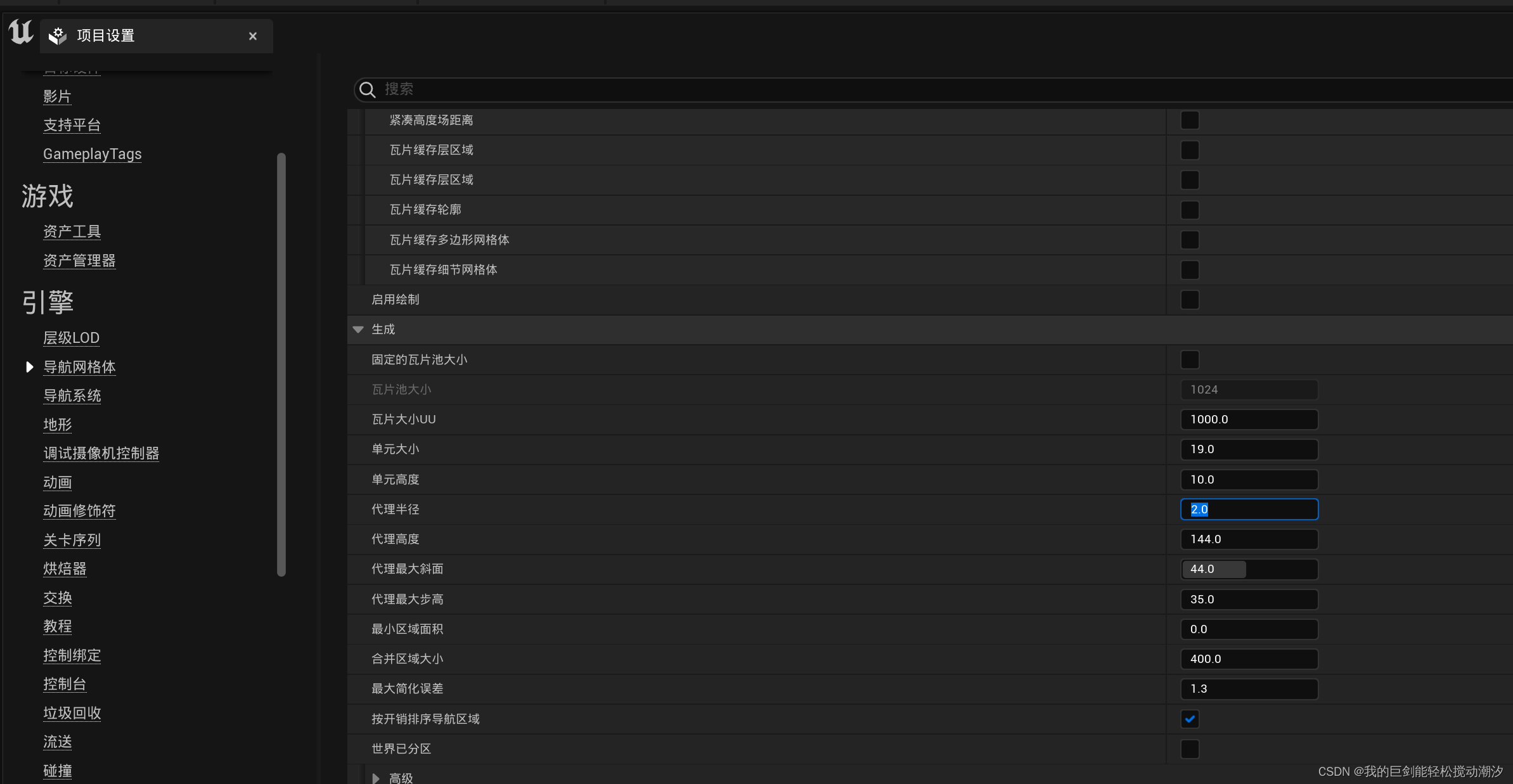
UE5修改导航网格的参数
Unreal Engine 4 - Recast NavMesh Size, how to Change Agent Radius / Tutorial - YouTubehttps://www.youtube.com/watch?vf3hF6xdmCTk 修改当前的 代理半径就是一般贴边的长度 修改编辑器的...
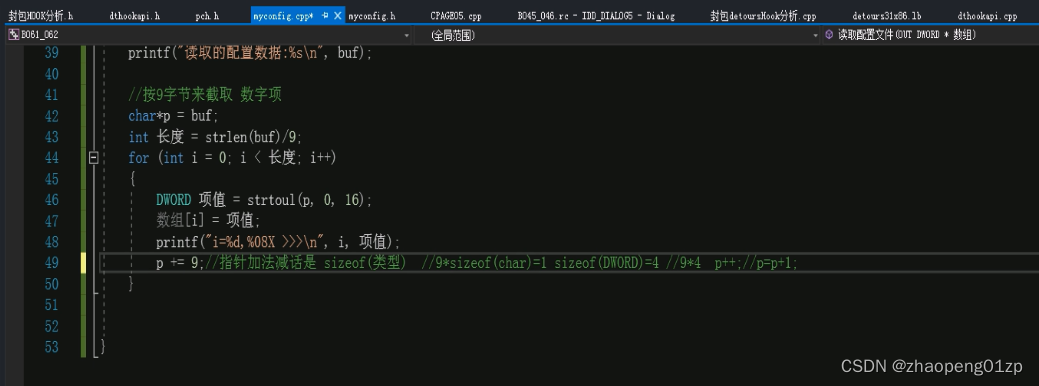
郁金香2021年游戏辅助技术中级班(七)
郁金香2021年游戏辅助技术中级班(七) 058-C,C写代码HOOK分析封包数据格式A059-C,C写代码HOOK分析封包数据格式B-detours劫持060-C,C写代码HOOK分析封包数据格式C-过滤和格式化061-C,C写代码HOOK分析封包数据格式D-写入配置文件062-C,C写代码HOOK分析封包…...
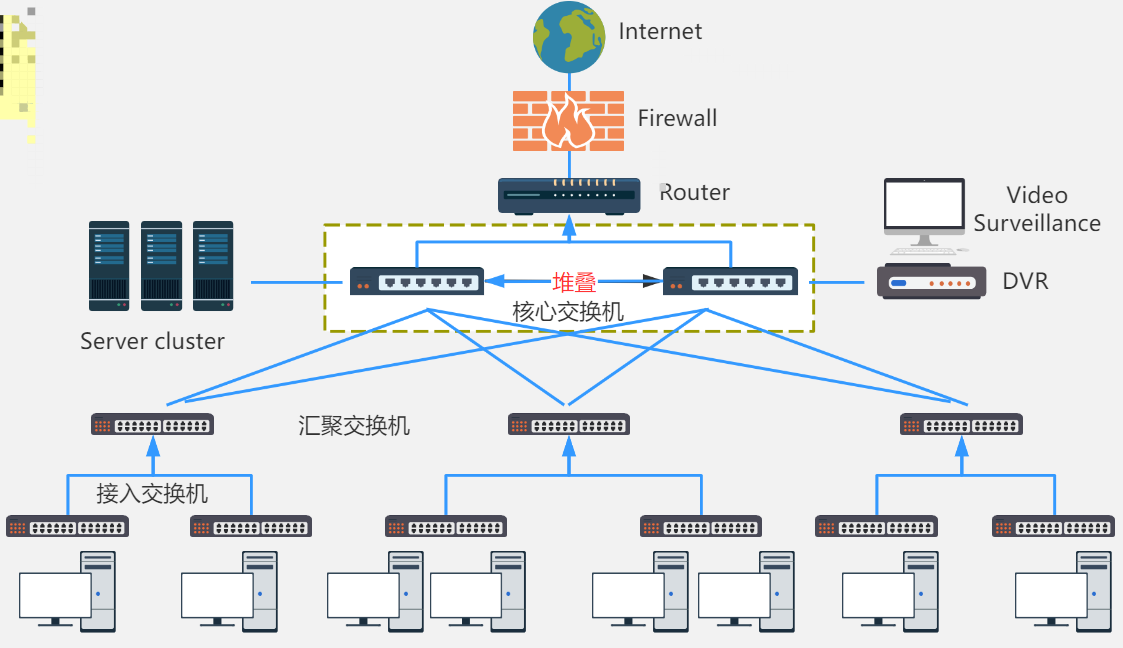
【网络】路由器和交换机的区别
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁 🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁 🪁🍁 希望本文能够给您带来一定的帮助…...
 函数、COALESCE()函数、DATEDIFF()函数)
SQL的CASE WHEN函数、CAST函数、CONVERT() 函数、COALESCE()函数、DATEDIFF()函数
一、CASE WHEN简单使用 SELECT CASE WHEN age > 18 AND age < 25 THEN 18-25WHEN age > 25 AND age < 35 THEN 25-35WHEN age > 35 AND age < 45 THEN 36-45ELSE 45END AS age_groupFROM peopleGROUP BY age_group;二、CASE WHEN语句与聚合函数一起使用 SE…...
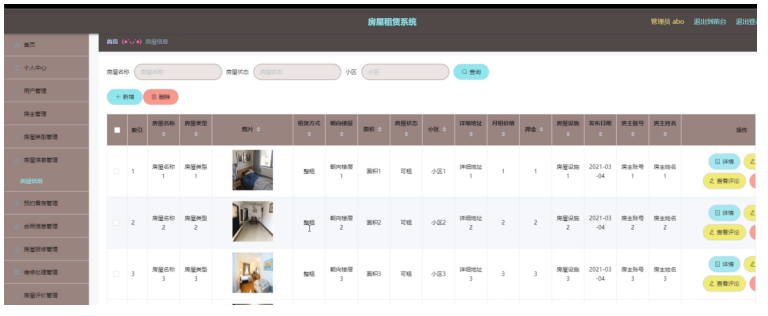
前后端分离计算机毕设项目之基于springboot+vue的房屋租赁系统《内含源码+文档+部署教程》
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ 🍅由于篇幅限制,想要获取完整文章或者源码,或者代做&am…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...