一文搞懂pytorch hook机制
pytorch的hook机制允许我们在不修改模型class的情况下,去debug backward、查看forward的activations和修改梯度。hook是一个在forward和backward计算时可以被执行的函数。在pytorch中,可以对Tensor和nn.Module添加hook。hook有两种类型,forward hook和backward hook。
1. 对Tensors添加hook
对于Tensors来说,只有backward hook,没有forward hook。对于backward hook来说,其函数输入输出形式是 hook(grad) -> Tensor or None。其中,grad是pytorch执行backward之后,一个tensor的grad属性值。
例如:
import torch
a = torch.ones(5)
a.requires_grad = Trueb = 2*a
c = b.mean()
c.backward()print(f'a.grad = {a.grad}, b.grad = {b.grad}')
输出:
a.grad = tensor([0.4000, 0.4000, 0.4000, 0.4000, 0.4000]), b.grad = None
由于b不是叶子节点,因此在计算完梯度后,b的grad会被释放。因此,b.grad=None。这里,我们要显式的指定不释放掉非叶子节点的grad。代码改为下面这样:
import torch
a = torch.ones(5)
a.requires_grad = Trueb = 2*ab.retain_grad() # 让非叶子节点b的梯度保持
c = b.mean()
c.backward()print(f'a.grad = {a.grad}, b.grad = {b.grad}')
输出:
a.grad = tensor([0.4000, 0.4000, 0.4000, 0.4000, 0.4000]), b.grad = tensor([0.2000, 0.2000, 0.2000, 0.2000, 0.2000])
我们可以通过加print的方式来查看一个tensor的梯度值,也可以通过加hook的方式来实现这点。
import torcha = torch.ones(5)a.requires_grad = Trueb = 2*aa.register_hook(lambda x:print(f'a.grad = {x}'))
b.register_hook(lambda x: print(f'b.grad = {x}')) c = b.mean()c.backward()
输出:
b.grad = tensor([0.2000, 0.2000, 0.2000, 0.2000, 0.2000])
a.grad = tensor([0.4000, 0.4000, 0.4000, 0.4000, 0.4000])
使用hook的一个好处是:代码中的b.retain_grad() # 让非叶子节点b的梯度保持 这句可以删除掉,同样可以记录到非叶子节点的值。对于不方便修改源码的程序,可以通过对tensors添加hook查看梯度。同时,.retain_grad()操作会增加显存的使用。
另外一点对Tensors使用hook的好处是,可以对backward时的梯度进行修改。来看一个更加实际具体的例子:
import torch
import torch.nn as nnclass myNet(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(3,10,2, stride = 2)self.relu = nn.ReLU()self.flatten = lambda x: x.view(-1)self.fc1 = nn.Linear(160,5)def forward(self, x):x = self.relu(self.conv(x))# 修改反向传播时,conv输出的梯度不小于0x.register_hook(lambda grad : torch.clamp(grad, min = 0))# 打印确认是否有小于0的梯度x.register_hook(lambda grad: print("Gradients less than zero:", bool((grad < 0).any()))) return self.fc1(self.flatten(x))net = myNet()for name, param in net.named_parameters():# 使用named_parameters对fc和bias添加修改,使其梯度全部为0if "fc" in name and "bias" in name:param.register_hook(lambda grad: torch.zeros(grad.shape))out = net(torch.randn(1,3,8,8)) (1 - out).mean().backward()print("The biases are", net.fc1.bias.grad)
输出为:
Gradients less than zero: False
The biases are tensor([0., 0., 0., 0., 0.])
2. 对nn.Module添加hook
对nn.Module添加hook的函数输入输出形式为:
backward hook:hook(module, grad_input, grad_output) -> Tensor or None
forward hook:hook(module, input, output) -> None
对nn.Module添加backward hook,非常容易造成困扰。看下面的例子:
import torch
import torch.nn as nnclass myNet(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(3,10,2, stride = 2)self.relu = nn.ReLU()self.flatten = lambda x: x.view(-1)self.fc1 = nn.Linear(160,5)def forward(self, x):x = self.relu(self.conv(x))return self.fc1(self.flatten(x))net = myNet()def hook_fn(m, i, o):print(m)print("------------Input Grad------------")for grad in i:try:print(grad.shape)except AttributeError: print ("None found for Gradient")print("------------Output Grad------------")for grad in o: try:print(grad.shape)except AttributeError: print ("None found for Gradient")print("\n")net.conv.register_backward_hook(hook_fn)
net.fc1.register_backward_hook(hook_fn)
inp = torch.randn(1,3,8,8)
out = net(inp)(1 - out.mean()).backward()
输出为:
Linear(in_features=160, out_features=5, bias=True)
------------Input Grad------------
torch.Size([5])
torch.Size([5])
------------Output Grad------------
torch.Size([5])Conv2d(3, 10, kernel_size=(2, 2), stride=(2, 2))
------------Input Grad------------
None found for Gradient
torch.Size([10, 3, 2, 2])
torch.Size([10])
------------Output Grad------------
torch.Size([1, 10, 4, 4])
可以看到对nn.Module添加的backward hook,对于Input Grad和Output Grad,对于弄清其具体指代的梯度,是比较难以搞清楚的。
对nn.Module添加forward hook,对于我们查看每层的激活值(输出,activations)是非常方便的。
import torch
import torch.nn as nnclass myNet(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(3,10,2, stride = 2)self.relu = nn.ReLU()self.flatten = lambda x: x.view(-1)self.fc1 = nn.Linear(160,5)self.seq = nn.Sequential(nn.Linear(5,3), nn.Linear(3,2))def forward(self, x):x = self.relu(self.conv(x))x = self.fc1(self.flatten(x))x = self.seq(x)net = myNet()
visualisation = {}def hook_fn(m, i, o):visualisation[m] = o def get_all_layers(net):for name, layer in net._modules.items():#If it is a sequential, don't register a hook on it# but recursively register hook on all it's module childrenif isinstance(layer, nn.Sequential):get_all_layers(layer)else:# it's a non sequential. Register a hooklayer.register_forward_hook(hook_fn)get_all_layers(net)out = net(torch.randn(1,3,8,8))# Just to check whether we got all layers
print(visualisation.keys()) #output includes sequential layers
print(visualisation)
输出为:
dict_keys([Conv2d(3, 10, kernel_size=(2, 2), stride=(2, 2)), ReLU(), Linear(in_features=160, out_features=5, bias=True), Linear(in_features=5, out_features=3, bias=True), Linear(in_features=3, out_features=2, bias=True)]){Conv2d(3, 10, kernel_size=(2, 2), stride=(2, 2)): tensor([[[[ 0.8381, 0.3751, 0.0268, -0.1155],[-0.2221, 1.1316, 1.1800, -0.1370],[ 1.1750, -0.6800, -0.1855, 0.3174],[-0.3929, 0.1941, 0.8611, -0.4447]],[[ 0.2377, 0.5215, 1.2715, -0.1600],[-0.7852, -0.2954, -0.0898, 0.0045],[-0.6077, -0.0088, -0.0572, -0.4161],[-0.6604, 0.7242, -0.7878, 0.0525]],[[-0.7283, -0.2644, -1.0609, 0.4960],[ 0.7989, -1.2582, -0.4996, 0.4377],[ 0.0798, 1.3804, -0.2886, -0.1540],[ 1.4034, -0.6836, -0.0658, 0.5268]],[[-0.6073, -0.3875, -0.3015, 0.7174],[-1.2842, 0.7734, -0.6014, 0.4114],[-0.3582, -1.4564, -0.6590, -1.0223],[-0.7667, 0.6816, 0.0602, -0.2622]],[[-0.6175, -0.3179, -1.2208, -0.8645],[ 1.1918, -0.3578, -0.7223, -1.1834],[ 0.1654, -0.1522, 0.0066, 0.0934],[ 0.7423, -0.7827, 0.2465, 0.4299]],...[0.5625, 0.4753, 0.0000, 0.0000],[0.6904, 0.1533, 0.6416, 0.0000]]]], grad_fn=<ReluBackward0>),Linear(in_features=160, out_features=5, bias=True): tensor([-0.0816, -0.1588, -0.0201, -0.4695, 0.2911], grad_fn=<AddBackward0>),Linear(in_features=5, out_features=3, bias=True): tensor([-0.3199, 0.0220, -0.3564], grad_fn=<AddBackward0>),Linear(in_features=3, out_features=2, bias=True): tensor([ 0.5371, -0.5260], grad_fn=<AddBackward0>)}
下面通过一个例子来展示forward hook以及对hook出的activation进行可视化。
import torch
from torchvision.models import resnet34
from PIL import Image
from torchvision import transforms as T
import matplotlib.pyplot as pltdevice = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')model = resnet34(pretrained=True)
model = model.to(device)# 定义hook
class SaveOutput:def __init__(self):self.outputs = []def __call__(self, module, module_in, module_out):self.outputs.append(module_out)def clear(self):self.outputs = []# 对Conv2d注册hook
save_output = SaveOutput()
hook_handles = []
for layer in model.modules():if isinstance(layer, torch.nn.modules.conv.Conv2d):handle = layer.register_forward_hook(save_output)hook_handles.append(handle)image = Image.open('cat.jpg')
transform = T.Compose([T.Resize((224, 224)), T.ToTensor()])
X = transform(image).unsqueeze(dim=0).to(device)out = model(X)print(len(save_output.outputs)) # 输出应该是36def module_output_to_numpy(tensor):return tensor.detach().to('cpu').numpy() images = module_output_to_numpy(save_output.outputs[0])with plt.style.context("seaborn-white"):plt.figure(figsize=(20, 20), frameon=False)for idx in range(64): # 这里根据输出通道数,不止可以索引到64,可以通过打印images的channels来查看最大的输出通道数plt.subplot(8, 8, idx+1)plt.imshow(images[0, idx])plt.setp(plt.gcf().get_axes(), xticks=[], yticks=[]);
matplotlib画出第一层的activation为:

我们修改代码如下,来查看比较靠后层的activation:
images = module_output_to_numpy(save_output.outputs[30]) # 将此处的索引改为30,查看第30层的activationwith plt.style.context("seaborn-white"):plt.figure(figsize=(20, 20), frameon=False)for idx in range(64): # 这里根据输出通道数,不止可以索引到64,可以通过打印images的channels来查看最大的输出通道数plt.subplot(8, 8, idx+1)plt.imshow(images[0, idx])plt.setp(plt.gcf().get_axes(), xticks=[], yticks=[]);

我们同样查看中间层,例如第15层的activation。

可以看到随着网络层的加深,activation越来越抽象。
除了上述的对forward加hook查看activation、对backward加hook、对Tensors加hook进行梯度相关的操作外,还可以参考kaggle的文章进行一些更深层次的理解,比如对backward过程的详细解释以及配合backward hook使用GRAD-CAM来查看网络等方法。
相关文章:
一文搞懂pytorch hook机制
pytorch的hook机制允许我们在不修改模型class的情况下,去debug backward、查看forward的activations和修改梯度。hook是一个在forward和backward计算时可以被执行的函数。在pytorch中,可以对Tensor和nn.Module添加hook。hook有两种类型,forwa…...

文本挖掘入门
文本挖掘的基础步骤 文本挖掘是从文本数据中提取有用信息的过程,通常包括文本预处理、特征提取和建模等步骤。以下是文本挖掘的基础入门步骤: 数据收集:首先,收集包含文本数据的数据集或文本文档。这可以是任何文本数据ÿ…...

【C++ techniques】Smart Pointers智能指针
Smart Pointers智能指针 看起来、用起来、感觉起来像内置指针,但提供更多的机能。拥有以下各种指针行为的控制权: 构造和析构;复制和赋值;解引。 Smart Pointers的构造、赋值、析构 C的标准程序库提供的auto_ptr template: au…...
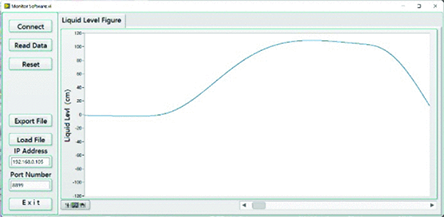
LabVIEW利用以太网开发智能液位检测仪
LabVIEW利用以太网开发智能液位检测仪 目前,工业以太网接口在国内外的发展已经达到了相当深入的程度,特别是在自动化控制和工业控制领域有着非常广泛的应用。在工业生产过程中,钢厂的连铸机是前后的连接环节,其中钢水从大钢包进入…...
 数组文字循环播放)
文字转语音:语音合成(Speech Synthesis) 数组文字循环播放
前言: HTML5中和Web Speech相关的API实际上有两类,一类是“语音识别(Speech Recognition)”,另外一个就是“语音合成(Speech Synthesis)”, 这两个名词实际上指的分别是“语音转文字”,和“文字变语音”。 speak() –…...
Spark基础
一、spark基础 1、为什么使用Spark Ⅰ、MapReduce编程模型的局限性 (1) 繁杂 只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码 (2) 处理效率低 Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据 任务调度与启动开销大 (…...
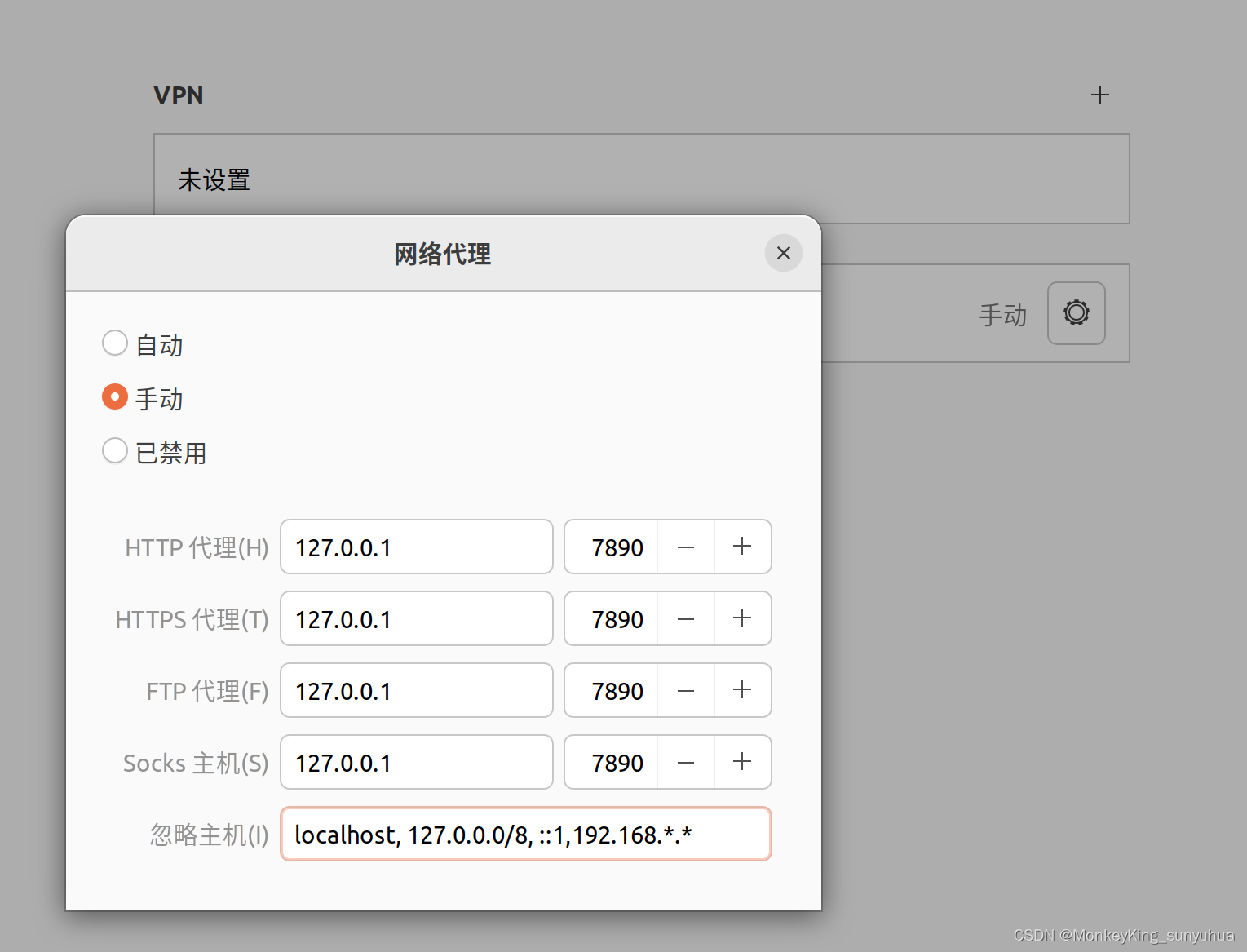
localhost和127.0.0.1都可以访问项目,但是本地的外网IP不能访问
使用localhost和127.0.0.1都可以访问接口,比如: http://localhost:8080/zhgl/login/login-fy-list或者 http://127.0.0.1:8080/zhgl/login/login-fy-list返回json {"_code":10000,"_msg":"Success","_data":…...
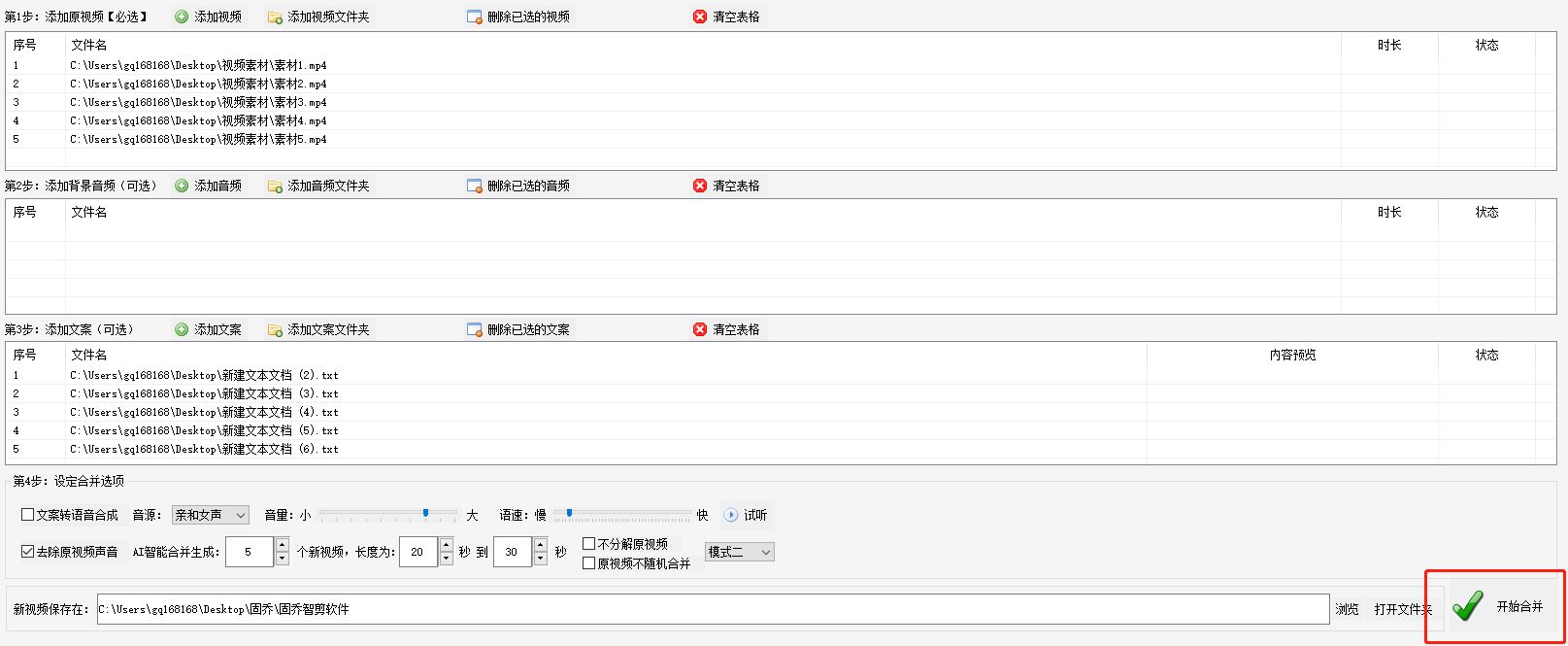
快速掌握批量合并视频
在日常的工作和生活中,我们经常需要对视频进行编辑和处理,而合并视频、添加文案和音频是其中常见的操作。如何快速而简便地完成这些任务呢?今天我们介绍一款强大的视频编辑软件——“固乔智剪软件”,它可以帮助我们轻松实现批量合…...
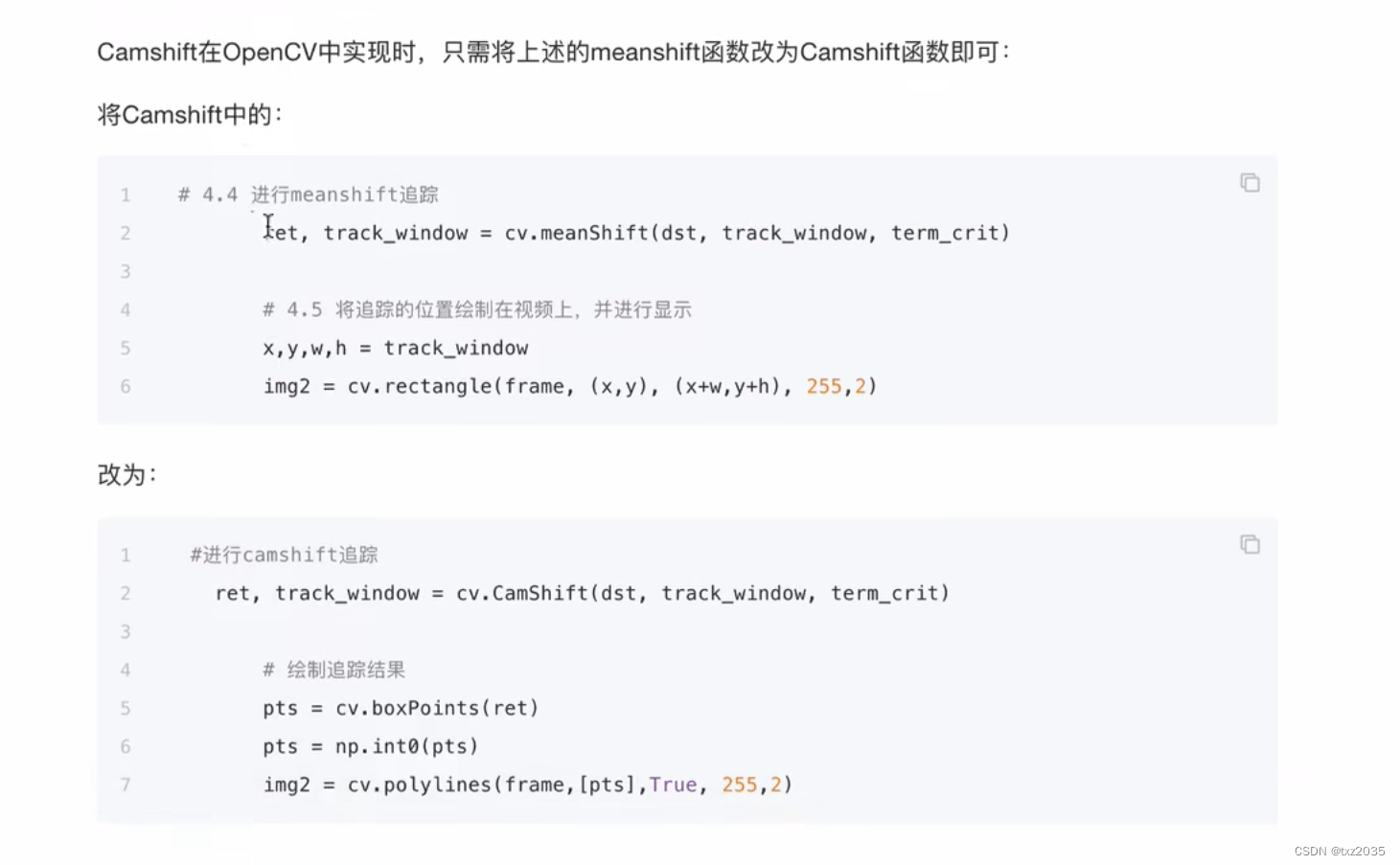
OpenCV利用Camshift实现目标追踪
目录 原理 做法 代码实现 结果展示 原理 做法 代码实现 import numpy as np import cv2 as cv# 读取视频 cap cv.VideoCapture(video.mp4)# 检查视频是否成功打开 if not cap.isOpened():print("Error: Cannot open video file.")exit()# 获取第一帧图像&#x…...

使用pywin32读取doc文档的方法及run输出乱码 \r\x07
想写一个读取doc文档中表格数据,来对文档进行重命名。经查资料,py-docx无法读取doc文档,原因是这种是旧格式。所以,采用pywin32来进行读取。 import win32com.client as win32word win32.gencache.EnsureDispatch(Word.Applicati…...

一天一八股——TCP保活keepalive和HTTP的Keep-Alive
TCP属于传输层,关于TCP的设置在内核态完成 HTTP属于用户层的协议,主要用于web服务器和浏览器之间的 http的Keep-Alive都是为了减少多次建立tcp连接采用的保持长连接的机制,而tcp的keepalive是为了保证已经建立的tcp连接依旧可用(双端依旧可以…...

头部品牌停业整顿,鲜花电商的中场战事迎来拐点?
鲜花电商行业再次迎来标志性事件,曾经4年接连斩获6轮融资的明星品牌花加,正式宣布停业整顿。 梳理来看,2015年是鲜花电商赛道的发展爆发期,彼时花加等品牌相继成立,并掀起一波投资热潮,据媒体统计…...
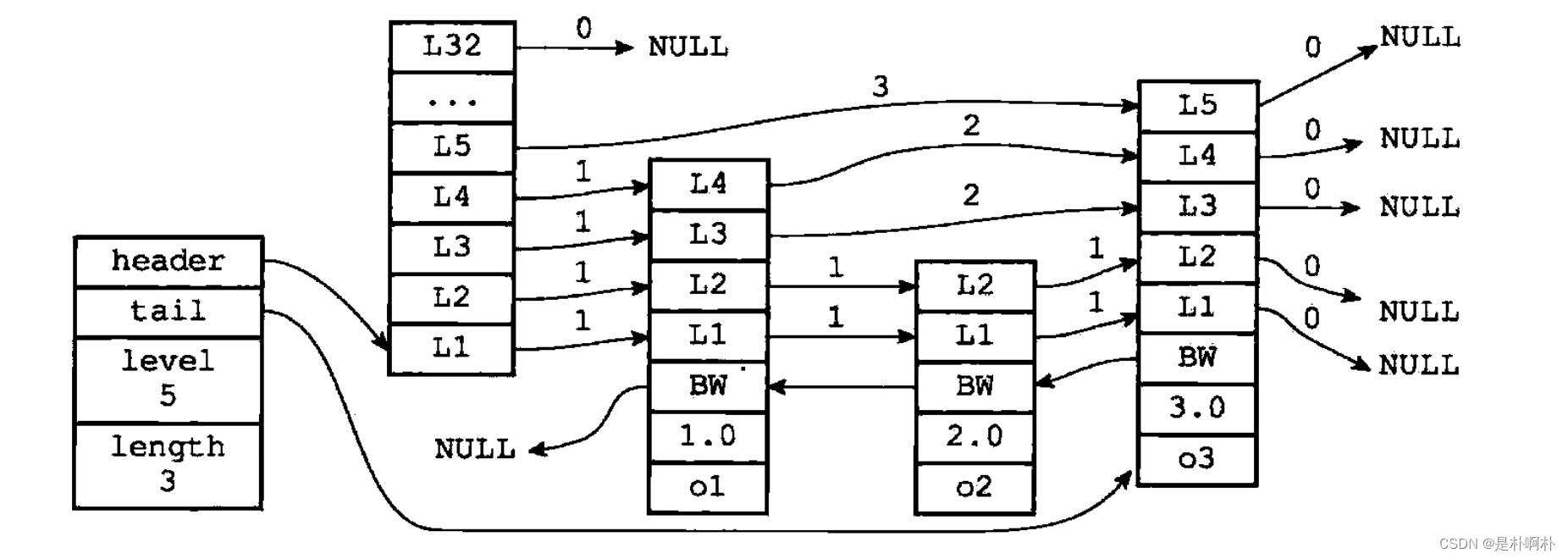
深入解读redis的zset和跳表【源码分析】
1.基本指令 部分指令,涉及到第4章的api,没有具体看实现,但是逻辑应该差不多。 zadd <key><score1><value1><score2><value2>... 将一个或多个member元素及其score值加入到有序集key当中。根据zslInsert zran…...
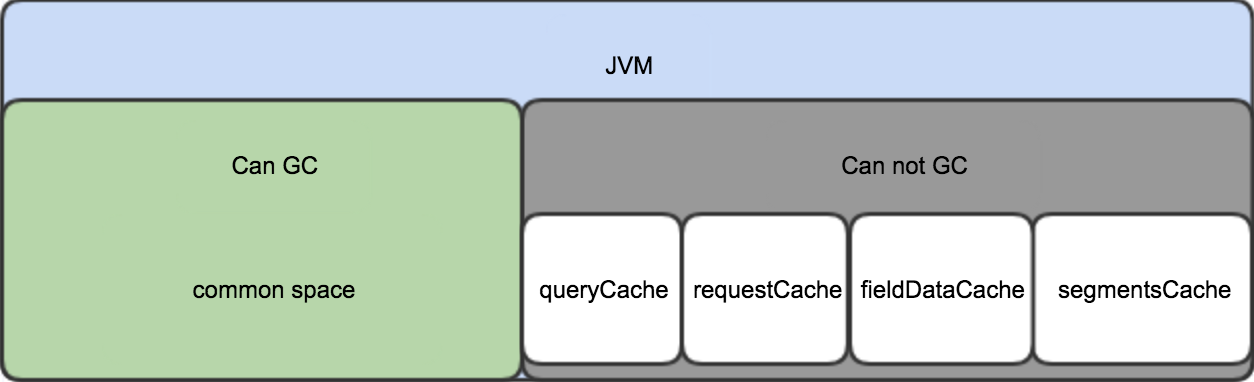
elasticsearch内存占用详细分析
内存占用 ES的JVM heap按使用场景分为可GC部分和常驻部分。 可GC部分内存会随着GC操作而被回收; 常驻部分不会被GC,通常使用LRU策略来进行淘汰; 内存占用情况如下图: common space 包括了indexing buffer和其他ES运行需要的clas…...

【研究生学术英语读写教程翻译 中国科学院大学Unit3】
研究生学术英语读写教程翻译 中国科学院大学Unit1-Unit5 Unit3 Theorists,experimentalists and the bias in popular physics理论家,实验家和大众物理学的偏见由于csdn专栏机制修改,请想获取资料的同学移步b站工房,感谢大家支持!研究生学术英语读写教程翻译 中国科学院大学…...
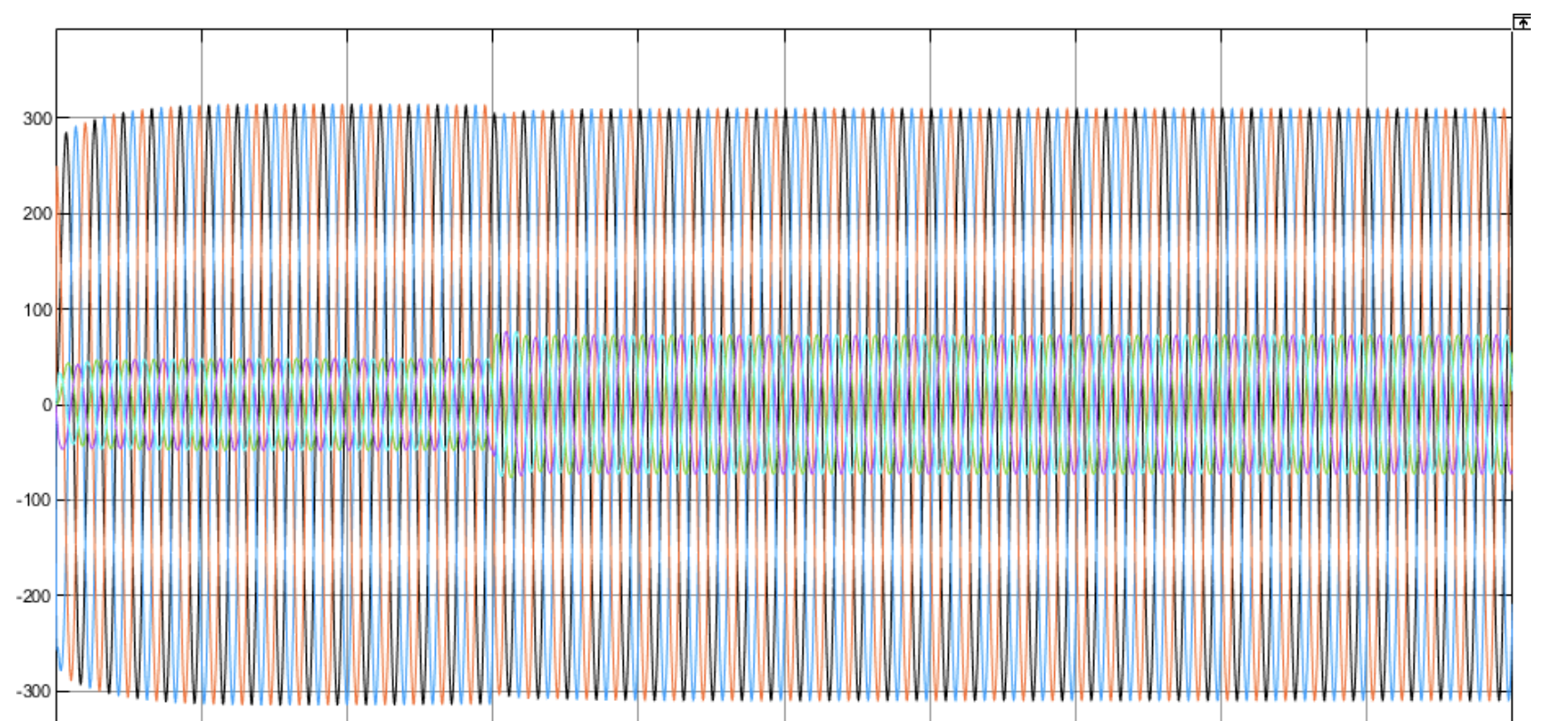
基于虚拟同步发电机控制的双机并联Simulink仿真模型
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

微信小程序开发——自定义堆叠图
先看效果图 点击第一张图片实现折叠,再次点击实现展开 思路 图片容器绑定点击事件获取当前图片索引,触发onTap函数,根据索引判断当前点击的图片是否为第一张,并根据当前的折叠状态来更新每张图片的位置,注意图片向上…...

国庆day5
QT实现TCP服务器客户端搭建的代码 ser.h #ifndef SER_H #define SER_H#include <QWidget> #include<QTcpServer> #include<QTcpSocket> #include<QMessageBox> #include<QList> QT_BEGIN_NAMESPACE namespace Ui { class …...

经典算法----迷宫问题(找出所有路径)
目录 前言 问题描述 算法思路 定义方向 回溯算法 代码实现 前言 前面我发布了一篇关于迷宫问题的解决方法,是通过栈的方式来解决这个问题的(链接:经典算法-----迷宫问题(栈的应用)-CSDN博客)ÿ…...

macOS下 /etc/hosts 文件权限问题修复方案
文章目录 前言解决方案权限验证 macOS下 etc/hosts 文件权限问题修复 前言 当在 macOS 上使用 vi编辑 /etc/hosts 文件时发现出现 Permission Denied 的提示,就算在前面加上 sudo 也照样出现一样的提示,解决方案如下; 解决方案 可以尝试使用如下命令尝试解除锁定; sudo chf…...

埃夫特机器人仿真软件ER_Factory_Trail:从零搭建工作站全流程解析
1. 初识埃夫特机器人仿真软件ER_Factory_Trail 第一次打开ER_Factory_Trail时,我被它简洁的界面设计惊艳到了。作为一款工业机器人仿真软件,它没有想象中那么复杂难懂。主界面分为四个核心区域:左上角的项目资源管理器用来管理所有模型和组件…...

GTE-Base-ZH在ComfyUI中的应用:为AI绘画工作流添加语义搜索节点
GTE-Base-ZH在ComfyUI中的应用:为AI绘画工作流添加语义搜索节点 如果你经常用ComfyUI画图,可能遇到过这样的烦恼:随着收集的LoRA模型、风格模板越来越多,每次创作时,想找到最贴合当前想法的那一个,就像大海…...
与性能瓶颈定位方法)
Phi-3 Mini 128K部署教程:GPU监控(nvidia-smi)与性能瓶颈定位方法
Phi-3 Mini 128K部署教程:GPU监控(nvidia-smi)与性能瓶颈定位方法 1. 为什么部署后还要关心GPU? 你可能已经成功部署了Phi-3 Forest Laboratory,看着它流畅地回答问题,感觉一切都很完美。但当你开始处理更…...

Cosmos-Reason1-7B效果展示:手术室视频中器械摆放是否符合无菌区物理规则
Cosmos-Reason1-7B效果展示:手术室视频中器械摆放是否符合无菌区物理规则 1. 模型能力概览 Cosmos-Reason1-7B是NVIDIA开源的一款7B参数量的多模态视觉语言模型,专注于物理理解与思维链推理能力。作为Cosmos世界基础模型平台的核心组件,它能…...

2026年人事系统多少钱一套?
2026年人事系统多少钱一套?4类方案价格拆解选型攻略,帮你省30%预算做HR的小夏最近找我吐槽:“看了5家人事系统,价格从3000元/年到30万元不等,到底差在哪?难道贵的就一定好?”其实,人…...

408考研必备:置换-选择排序在外部排序中的实战应用与优化策略
1. 从一道真题说起:为什么置换-选择排序是408的“必考题”? 我记得第一次在408真题里碰到置换-选择排序的时候,心里也犯嘀咕:这算法名字听着就拗口,什么“置换”又“选择”的,感觉特别复杂。但后来我花了点…...

prompttools实验结果可视化:如何用图表分析LLM性能
prompttools实验结果可视化:如何用图表分析LLM性能 【免费下载链接】prompttools Open-source tools for prompt testing and experimentation, with support for both LLMs (e.g. OpenAI, LLaMA) and vector databases (e.g. Chroma, Weaviate, LanceDB). 项目地…...

打造个性化编辑器:vim-moonfly-colors主题自定义高亮颜色的完整教程
打造个性化编辑器:vim-moonfly-colors主题自定义高亮颜色的完整教程 【免费下载链接】vim-moonfly-colors A dark charcoal theme for modern Neovim & classic Vim 项目地址: https://gitcode.com/gh_mirrors/vi/vim-moonfly-colors vim-moonfly-colors…...

C#实现基于硬件信息的软件授权加密系统实战
1. 为什么你需要一个硬件绑定的授权系统? 做软件的朋友们,尤其是做ToB或者独立软件的朋友,肯定都遇到过这个头疼的问题:辛辛苦苦开发出来的软件,怎么防止被用户无限复制、随意分发?传统的用户名密码授权太容…...

StructBERT孪生网络教程:如何微调StructBERT适配垂直领域语料
StructBERT孪生网络教程:如何微调StructBERT适配垂直领域语料 1. 项目概述 StructBERT中文语义智能匹配系统是一个基于孪生网络架构的专业文本处理工具,专门解决中文文本相似度计算和特征提取需求。这个系统彻底解决了传统方法中无关文本相似度虚高的问…...