Hadoop3.3.1完全分布式部署
Hadoop目录
- Hadoop3.3.1完全分布式部署(一)
- 1、HDFS
- 一、安装
- 1、基础安装
- 1.1、配置JDK-18
- 1.2、下载并解压hadoop安装包
- 本地运行模式测试 eg:
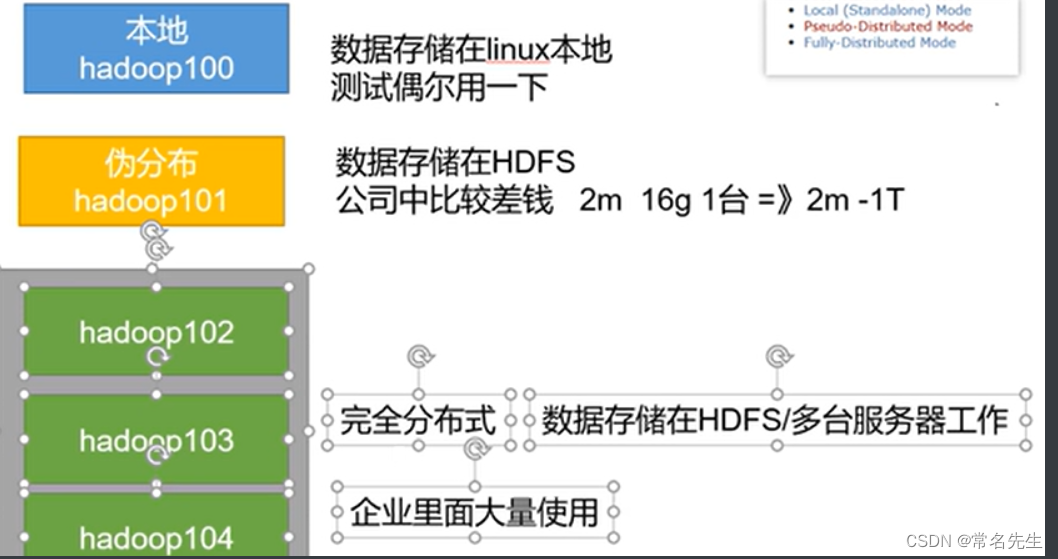
- 2、完全分布式运行模式
- 1、概要:
- 2、编写集群分发脚本,把1~4步安装的同步到其他服务器:
- 2.1、创建脚本`vim /var/opt/hadoopSoftware/hadoopScript/bin/xsync`,添加执行权限
- 2.2、开始同步JDK、Hdoop、环境变量
- 3、配置ssh免密
- 4、配置xml
- 4.1、集群部署规划如下:
- 4.2、所需配置文件
- 4.3、配置集群
- 1)核心配置文件
- 2)HDFS配置文件
- 3)YARN配置文件
- 4)MapReduce配置文件
- 5、启动整个集群
- 5.1、配置workers
- 5.2、启动集群
- 5.3、页面地址:
- 6、集群测试
- 6.1、上传文件到集群测试
- 6.2、上传大文件测试
- 6.3、hadoop集群测试
- 7、集群崩溃处理
- 1)先停止集群
- 2)删除每个集群上的
- 3)格式化集群
- 4)启动集群
- 8、配置历史服务器
- 8.1、配置mapred-site.xml
- 8.2、同步配置
- 8.3、在hadoop1上启动历史服务器
- 8.4、查看历史服务器是否启动
- 8.5、查看JobHistory
- 9、配置日志聚合功能
- 1)配置yarn-site.xml
- 2)同步配置
- 3)关闭重启NodeManager、ResourceManager、HistoryServer
- 10、集群启停总结:
- 1、整体启动停止(推荐)
- 1)整体启动、停止HDFS
- 2)整体启动体制YARN
- 3)启停historyserver
- 2、各个服务组件分别启/停
- 1)启/停HDFS组件
- 2)启/停YARN组件
- 3)启停historyserver
- 11、编写Hadoop集群常用脚本
- 1)批量启停`hadoop`服务
- 2)查看所有服务器Java进程脚本:jpsall
- 12、常用端口号
- 参考网站
Hadoop3.3.1完全分布式部署(一)
Hadoop 是一种分析和处理大数据的软件平台,是一个用 Java 语言实现的 Apache 的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。
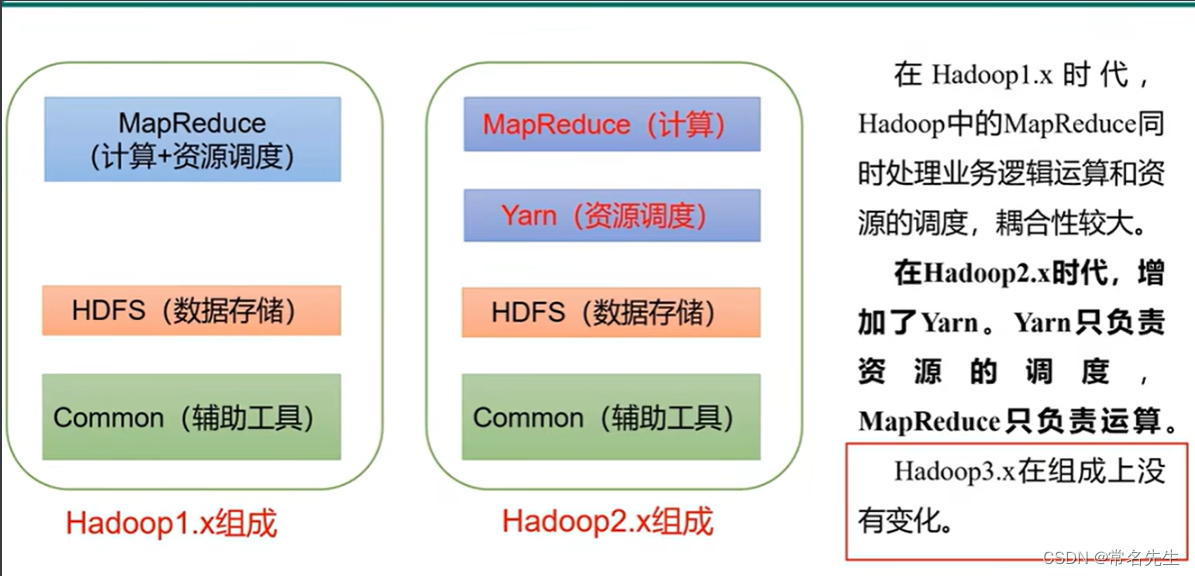
结构框架
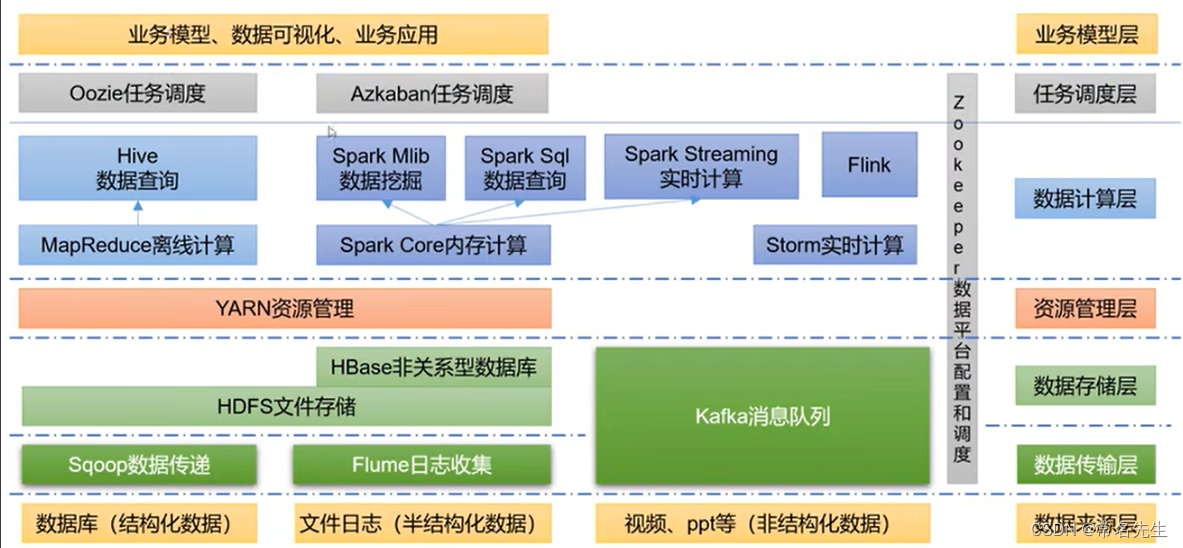
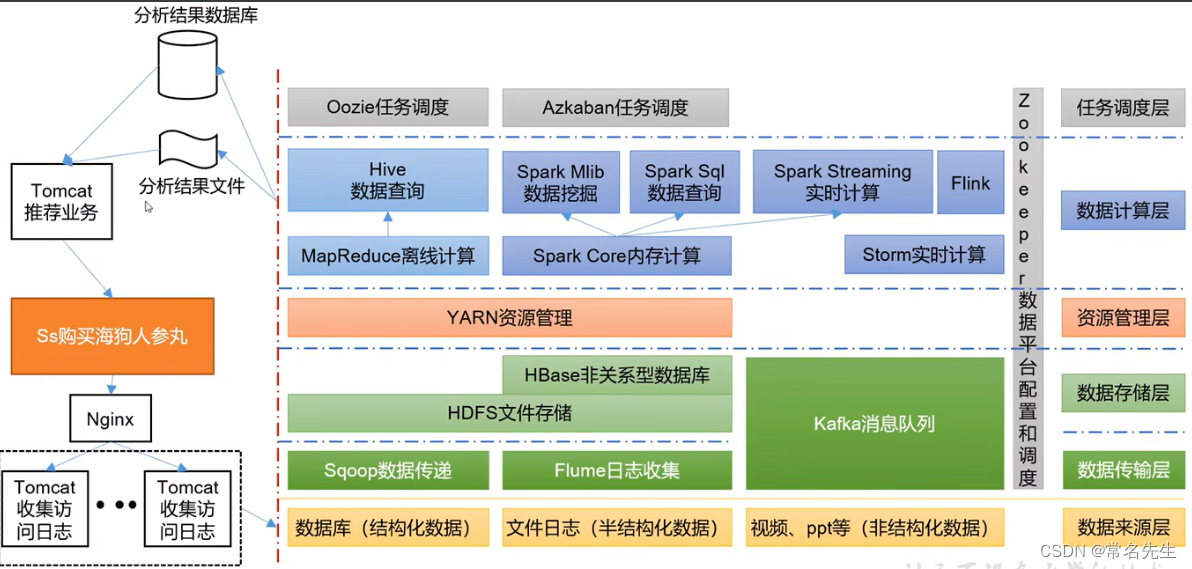
推荐架构
1、HDFS
一个提供高可用的获取应用数据的分布式文件系统。
从字面上来看,SecondaryNameNode 很容易被当作是 NameNode 的备份节点,其实不然。可以通过下图看 HDFS 中 SecondaryNameNode 的作用。
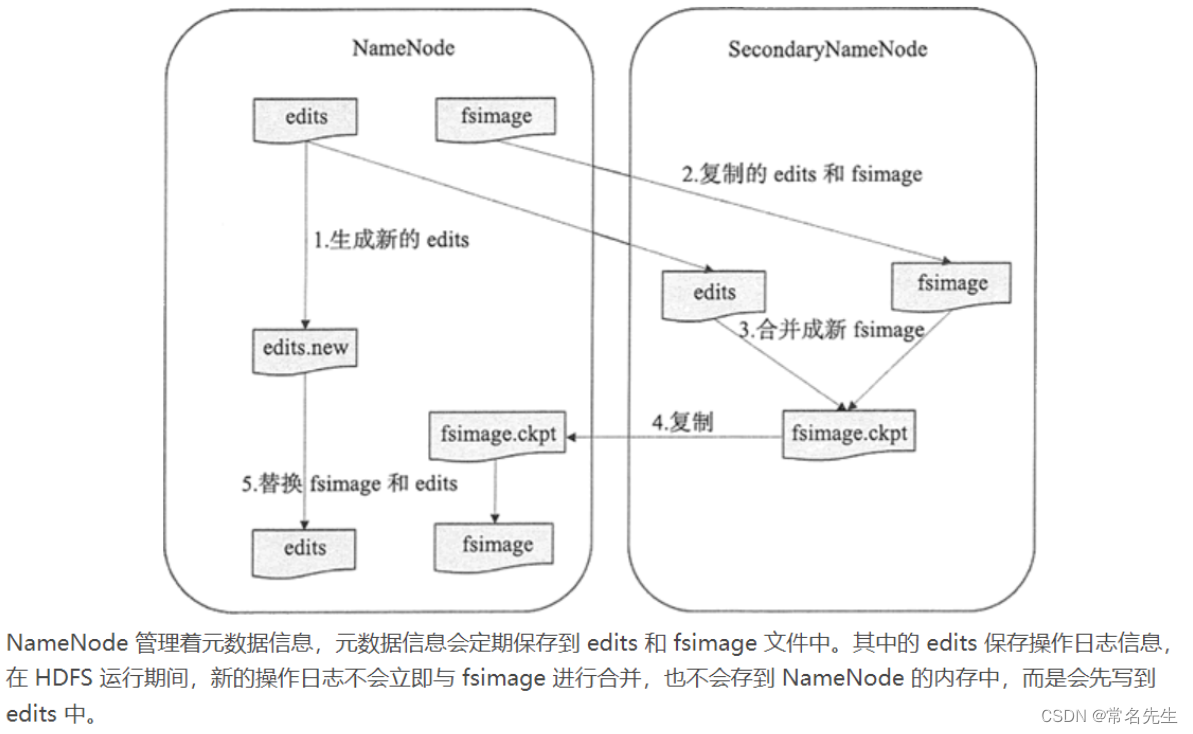
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
fsimage - 它是在NameNode启动时对整个文件系统的快照
edit logs - 它是在NameNode启动后,对文件系统的改动序列
Secondary NameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
- 它定时到NameNode去获取edit logs,并更新到自己的fsimage上。
- 一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
- NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
一、安装
1、基础安装
$ yum install -y gcc vim wget
$ sudo yum install ssh
$ sudo yum install pdsh -y
1.1、配置JDK-18
JDK地址
安装参考
# JDK17
#wget https://download.oracle.com/java/17/archive/jdk-17_linux-x64_bin.tar.gz -P /var/opt/hadoopSoftware
# JDK19
#wget https://download.oracle.com/java/19/latest/jdk-19_linux-x64_bin.tar.gz -P /var/opt/hadoopSoftware# JDK18(本文所选,但是需要ORACLE账号才可以下载)
tar -zxvf /var/opt/hadoopSoftware/jdk-8u361-linux-x64.tar.gz -C /var/opt/hadoopSoftware
配置环境变量,在profile.d下创建hadoop所需的环境变量
cat >> /etc/profile.d/my_env.sh <<Leo
# JAVA_HOME
export JAVA_HOME=/var/opt/software/jdk1.8.0_361
export PATH=\$PATH:\$JAVA_HOME/bin
Leo
使配置生效
source /etc/profile
1.2、下载并解压hadoop安装包
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz -P /var/opt/hadoopSoftware
tar -zvxf /var/opt/hadoopSoftware/hadoop-3.3.1.tar.gz -C /var/opt/hadoopSoftware
配置环境变量
cat >> /etc/profile.d/my_env.sh <<Leo
# HADOOP_HOME
export HADOOP_HOME=/var/opt/hadoopSoftware/hadoop-3.3.1
export PATH=\$PATH:\$HADOOP_HOME/bin
export PATH=\$PATH:\$HADOOP_HOME/sbin
# Hadoop run need add
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
Leo
生效
source /etc/profile
- 查看配置的全局环境变量
echo $PATH
hadoop目录介绍
bin:和hdfs yarn mapred
sbin:启动停止相关的命令
share:一些参考
(Hadoop参考)
官网
本地运行模式测试 eg:
mkdir -p /var/opt/hadoopSoftware/hadoop-3.3.1/tinput
cat >> /var/opt/hadoopSoftware/hadoop-3.3.1/tinput/word.txt <<Leo
aa
bb
cc
cc
Leo
测试计算每个单词出现的次数(输入路径:tinput/ 输出路径:./timport)
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount tinput/ ./toutputtoutput]# cat part-r-00000
aa 1
bb 1
cc 2
2、完全分布式运行模式
1、概要:
前提:
1、准备三台server(关闭防火墙、静态ip、主机名)
2、安装JDK
3、安装Hadoop
4、配置环境变量
所需其他配置:
5、配置集群
6、单点启动
7、配置ssh
8、测试集群
2、编写集群分发脚本,把1~4步安装的同步到其他服务器:
mkdir -p /var/opt/hadoopSoftware/hadoopScript/bin
mkdir -p /var/opt/hadoopSoftware/hadoopScript/config
创建需要同步的服务器地址
cat /var/opt/hadoopSoftware/hadoopScript/config/hadoop_hosts
hadoop2
hadoop3
2.1、创建脚本vim /var/opt/hadoopSoftware/hadoopScript/bin/xsync,添加执行权限
#!/bin/bash# 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Argument!exit;
fi# 遍历所有的服务器
#for host in hadoop1 hadoop2 hadoop3
for host in `cat /var/opt/hadoopSoftware/hadoopScript/config/hadoop_hosts`
doecho =======================$host=======================# 遍历所有目录for file in $@do# 判断文件是否存在if [ -e $file ]then# 获取父目录名,例如有软连接他会cd到真正的数据目录pdir=$(cd -P $(dirname $file); pwd)# 获取当前文件名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file dose not exists!fidone
done
目前xsync只能同步当前目录下的文件,用法xsync bin/,如果同步根目录需要写xsync脚本的绝对路径/var/opt/hadoopSoftware/hadoopScript/bin/xsync
2.2、开始同步JDK、Hdoop、环境变量
2.2.1、开始同步(选用):
# 全局调用使用绝对路径
sudo /var/opt/hadoopSoftware/hadoopScript/bin/xsync /var/opt/hadoopSoftware
sudo /var/opt/hadoopSoftware/hadoopScript/bin/xsync /etc/profile.d/my_env.sh
- 注:每台服务器都需要重新刷新环境变量
source /etc/profile(根据自身需求,后期可以使用ansible-playbook)
2.2.2、配置环境变量同步(本文选用如下方法):
或:如果想要应用这个脚本到全局可以进行如下环境变量设置(根据自身情况进行设置,仅参考):
cat >> /etc/profile.d/my_env.sh <<Leo
# hadoopScript_home
export HSCRIPT_HOME=/var/opt/hadoopSoftware/hadoopScript
export PATH=$PATH:$HSCRIPT_HOME/bin
Leo
同步开始:
xsync /var/opt/hadoopSoftware
xsync /etc/profile.d/my_env.sh
3、配置ssh免密
参考配置
配置hadoop1和hadoop2免密登录hadoop[1,2,3]
4、配置xml
官网参考:[Apache Hadoop 3.3.4 – Hadoop Cluster Setup]
4.1、集群部署规划如下:
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | NodeManager ResourceManager | NodeManager |
注:NameNode、 NodeManager、 SecondaryNameNode最好放在不同的服务器上。
4.2、所需配置文件
1)默认配置文件:
| 默认文件名 | 文件存放路径(cd $HADOOP_HOME) |
|---|---|
| core-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-common/core-default.xml |
| hdfs-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml |
| yarn-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-yarn/hadoop-yarn-common/yarn-default.xml |
| mapred-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml |
2)自定义配置文件:
文件位置$HADOOP_HOME/etc/hadoop
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
4.3、配置集群
1)核心配置文件
cat $HADOOP_HOME/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定NameNode地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop1:8082</value></property><!-- 指定hadoop数据存储目录 --><property><name>hadoop.tmp.dir</name><value>/var/opt/hadoopSoftware/hadoop-3.3.1/data</value></property><!-- 配置hadoop网页登录使用的静态用户为leojiang --><property><name>hadoop.http.staticuser.user</name><value>root</value></property>
</configuration>2)HDFS配置文件
cat $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. --><configuration><!-- nn web 端访问地址 --><property><name>dfs.namenode.http-address</name><value>hadoop1:9870</value></property><!-- 2nn web 端访问地址 --><property><name>dfs.namenode.secondary.http-address</name><value>hadoop3</value></property><property><name>dfs.datanode.http.address</name><value>0.0.0.0:9864</value><description>The datanode http server address and port.</description></property><!-- 如果为true(默认值),则namenode要求连接datanode的地址必须解析为主机名。如有必要,将执行反向DNS查找。所有从不可解析地址注册datanode的尝试都将被拒绝。建议保留该设置,以防止在DNS中断期间意外注册由excluded文件中hostname列出的datanode。只有在没有基础设施支持反向DNS查找的环境中,才将此设置为false。--><!--<property><name>dfs.namenode.datanode.registration.ip-hostname-check</name><value>false</value></property>--></configuration>
3)YARN配置文件
cat $HADOOP_HOME/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MR走shutffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop2</value></property><!-- 环境变量的继承 3.1.3需要配置HADOOP_MAPRED_HOME。3.2以上修复了就不用配置了--><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,HADOOP_MAPRED_HOME</value></property></configuration>
4)MapReduce配置文件
cat $HADOOP_HOME/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
修改完成后同步到所有服务器
xsync $HADOOP_HOME/etc/hadoop
5、启动整个集群
5.1、配置workers
# 注意: 不允许有任何空格、空行
vim $HADOOP_HOME/etc/hadoop/workers
hadoop1
hadoop2
hadoop3
同步文件到所有服务器
xsync $HADOOP_HOME/etc/hadoop/workers
5.2、启动集群
前提添加写权限否则会出现namenode无法启动的状况
chmod -R a+w $HADOOP_HOME
1、初始化文件系统(第一次运行,格式化集群)
hadoop1 $ hdfs namenode -format
可以查看下生成的版本号
cat $HADOOP_HOME/data/dfs/name/current/VERSION
2、启动集群NameNode和DataNode守护进程:
启动:
hadoop1 $ $HADOOP_HOME/sbin/start-dfs.sh
查看启动的服务jps
3、启动ResourceManager (注意要在ResourceManager 的服务器上启动)
hadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
5.3、页面地址:
# hdfs的NameNode
http://hadoop1:9870# YARN的ResourceManager
http://hadoop2:8088
6、集群测试
6.1、上传文件到集群测试
# 先在hadoop上创建目录
hadoop fs -mkdir /tinput# 上传…….txt文件
hadoop fs -put tinput/word.txt /tinput
6.2、上传大文件测试
hadoop fs -put ../jdk-8u361-linux-x64.tar.gz /tinput
数据在datanode下存储
# 查看datanode存储的数据可以使用如下方式还原,每一台服务器存储的都一样
cd data/dfs/data/current/BP-12……/current/finalized/subdir0/subdir0/blk……/……# word.txt
cat blk_1073741825# 还原 jdk-8u361-linux-x64.tar.gz
cat blk_1073741826 >>tmp.tar.gz
cat blk_1073741827 >>tmp.tar.gz
# 解压后可以发现这个就是我们之前导入的jdk压缩包
tar -zxvf tmp.tar.gz
6.3、hadoop集群测试
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /tinput /toutput
7、集群崩溃处理
1)先停止集群
hadoop2 $ $HADOOP_HOME/sbin/stop-yarn.sh
hadoop1 $ $HADOOP_HOME/sbin/stop-dfs.sh
2)删除每个集群上的
rm -rf $HADOOP_HOME/data/ $HADOOP_HOME/logs/
3)格式化集群
hadoop1 $ hdfs namenode -format
4)启动集群
hadoop1 $ $HADOOP_HOME/sbin/start-dfs.sh
hadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
8、配置历史服务器
8.1、配置mapred-site.xml
文件中添加如下配置
hadoop1$ vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration><!-- 配置历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>hadoop1:10020</value></property><!-- 配置历史服务web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop1:10888</value></property>
</configuration>
8.2、同步配置
hadoop1 $ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
8.3、在hadoop1上启动历史服务器
如果yarn启动需要关闭重启yarn
hadoop2 $ $HADOOP_HOME/sbin/stop-yarn.sh
hadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
启动历史服务器
hadoop1 $ mapred --daemon start historyserver
8.4、查看历史服务器是否启动
hadoop1 $ jps
8.5、查看JobHistory
# 先在hadoop上创建目录
hadoop fs -mkdir /tinput# 上传…….txt文件
hadoop fs -put tinput/word.txt /tinputhadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /tinput /toutput2
9、配置日志聚合功能
功能:将程序运行日志信息上传到HDFS系统上
- 注:开启日志聚合功能,需要重启NodeManager、ResourceManager、HistoryServer。
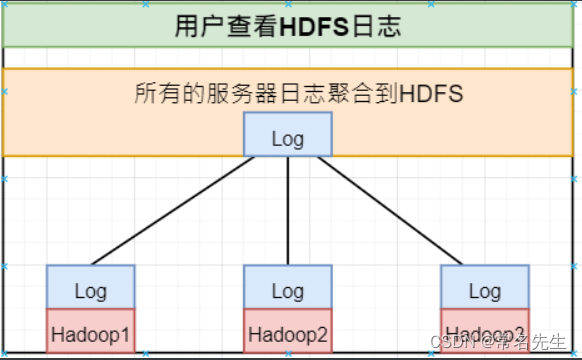
1)配置yarn-site.xml
hadoop1 $ vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration><!-- 开启日志聚合功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志聚合服务器地址 --><property><name>yarn.log.server.url</name><value>http://hadoop1:19888/jobhistory/logs</value></property><!-- 设置日志保留时间为7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
</configuration>
2)同步配置
hadoop1 $ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
3)关闭重启NodeManager、ResourceManager、HistoryServer
关闭
hadoop1 $ mapred --daemon stop historyserver
hadoop2 $ $HADOOP_HOME/sbin/stop-yarn.sh
重启
hadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
hadoop1 $ mapred --daemon start historyserver
10、集群启停总结:
1、整体启动停止(推荐)
1)整体启动、停止HDFS
hadoop1 $ $HADOOP_HOME/sbin/stop-dfs.shhadoop1 $ $HADOOP_HOME/sbin/start-dfs.sh
2)整体启动体制YARN
hadoop2 $ $HADOOP_HOME/sbin/stop-yarn.shhadoop2 $ $HADOOP_HOME/sbin/start-yarn.sh
3)启停historyserver
hadoop1 $ $HADOOP_HOME/bin/mapred --daemon stop historyserverhadoop1 $ mapred --daemon start historyserver
2、各个服务组件分别启/停
1)启/停HDFS组件
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon stop namenode
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon stop datanode[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start datanode
2)启/停YARN组件
[yarn]$ $HADOOP_HOME/bin/yarn --daemon stop resourcemanager
[yarn]$ $HADOOP_HOME/bin/yarn --daemon stop nodemanager[yarn]$ $HADOOP_HOME/bin/yarn --daemon start resourcemanager
[yarn]$ $HADOOP_HOME/bin/yarn --daemon start nodemanager
3)启停historyserver
[mapred]$ $HADOOP_HOME/bin/mapred --daemon stop historyserver[mapred]$ $HADOOP_HOME/bin/mapred --daemon start historyserver
11、编写Hadoop集群常用脚本
1)批量启停hadoop服务
hadoop1 $ vim $HSCRIPT_HOME/bin/myhadoop
cat myhadoop
#!/bin/bashif [ $# -lt 1 ]
thenecho "No Args Input..."exit ;ficase $1 in
"start")echo "=============== 启动 hadoop 集群 ==============="echo "--------------- 启动 hdfs ---------------"ssh hadoop1 "$HADOOP_HOME/sbin/start-dfs.sh"echo "--------------- 启动 yarn ---------------"ssh hadoop2 "$HADOOP_HOME/sbin/start-yarn.sh"echo "--------------- 启动 historyserver ---------------"ssh hadoop1 "$HADOOP_HOME/bin/mapred --daemon start historyserver"
;;
"stop")echo "=============== Shutdown hadoop 集群 ==============="echo "--------------- 停止 historyserver ---------------"ssh hadoop1 "$HADOOP_HOME/bin/mapred --daemon stop historyserver" echo "--------------- 停止 yarn ---------------"ssh hadoop2 "$HADOOP_HOME/sbin/stop-yarn.sh"echo "--------------- 停止 hdfs ---------------"ssh hadoop1 "$HADOOP_HOME/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error.."
;;
esac
使用:
# 赋权
hadoop1 $ chmod +x $HSCRIPT_HOME/bin/myhadoop# 启动
hadoop1 $ myhadoop start
# 停止
hadoop1 $ myhadoop stop
2)查看所有服务器Java进程脚本:jpsall
hadoop1 $ vim $HSCRIPT_HOME/bin/jpsall
创建所需查看服务器的host地址
cat /var/opt/hadoopSoftware/hadoopScript/config/all_hadoop_hosts
hadoop1
hadoop2
hadoop3
cat jpsall
#!/bin/bashfor host in `cat /var/opt/hadoopSoftware/hadoopScript/config/all_hadoop_hosts`
doecho ======== $host ========ssh $host jpsecho -e "\n"
done
运行:
# 赋权
hadoop1 $ chmod +x $HSCRIPT_HOME/bin/jpsall# 执行检查
hadoop1 $ jpsall
12、常用端口号
| 端口名称 | Hadoop3.x |
|---|---|
| NameNode 内部通信端口 | 8020、9000、9820 |
| NameNode HTTP UI | 9870 |
| MapReduce 查看执行任务端口 | 8088 |
| 历史服务器通信端口 | 19888 |
参考网站
Hadoop官网:http://hadoop.apache.org/
Hadoop下载:https://www.apache.org/dyn/closer.cgi/hadoop/common/
Hadoop历史版本下载:http://archive.apache.org/dist/hadoop/core/
Hadoop文档:http://hadoop.apache.org/docs/
Hive官网:http://hive.apache.org/
Hive下载:http://mirror.bit.edu.cn/apache/hive/
Hive历史版本下载:http://archive.apache.org/dist/hive/
Hive文档:https://cwiki.apache.org/confluence/display/Hive
HBase官网:http://hbase.apache.org/
HBase下载:http://mirrors.sonic.net/apache/hbase/
HBase历史版本下载:http://archive.apache.org/dist/hbase/
HBase文档:http://hbase.apache.org/book.html
HBase中文文档:http://abloz.com/hbase/book.html
Spark官网:http://spark.apache.org/
Spark下载:http://spark.apache.org/downloads.html
Spark文档:http://spark.apache.org/docs/latest/
Zookeeper官网:http://zookeeper.apache.org/
Zookeeper下载:http://zookeeper.apache.org/releases.html#download
Flume官网:http://flume.apache.org/
Flume下载:http://flume.apache.org/download.html
Flume文档:http://flume.apache.org/documentation.html
Mahout官网:http://mahout.apache.org/
Mahout下载:http://mahout.apache.org/general/downloads.html
Tez官网:http://tez.apache.org/
cdh5版本:
下载地址:http://archive.cloudera.com/cdh5/cdh/5/
文档地址:http://archive.cloudera.com/cdh5/cdh/5/
相关文章:
Hadoop3.3.1完全分布式部署
Hadoop目录Hadoop3.3.1完全分布式部署(一)1、HDFS一、安装1、基础安装1.1、配置JDK-181.2、下载并解压hadoop安装包本地运行模式测试 eg:2、完全分布式运行模式1、概要:2、编写集群分发脚本,把1~4步安装的同步到其他服务器:2.1、创建脚本vim …...

SpringMVC中的注解
SpringMVC中的注解 文章目录SpringMVC中的注解RequestMapping注解RequestMapping中的value属性RequestMapping中的method属性派生类PathVariable注解RequestParam注解RequestMapping注解 RequestMapping中的value属性 RequestMapping:既可以标识在方法上也可以标识…...
python+Vue学生作业系统 django课程在线学习网站系统
系统分为学生,教师,管理员三个角色: 学生功能: 1.学生注册登录系统 2.学生查看个人信息,修改个人信息 3.学生查看主页综合评价,查看今日值班信息 4.学生在线申请请假信息,查看请假的审核结果和请…...
CSS 美化网页元素【快速掌握知识点】
目录 一、为什么使用CSS 二、字体样式 三、文本样式 color属性 四、排版文本段落 五、文本修饰和垂直对齐 1、文本装饰 2、垂直对齐方式 六、文本阴影 七、超链接伪类 1、语法 2、示例 3、访问时,蓝色;访问后,紫色; …...
Tableau连接openGauss实践
目录 一、摘要 二、什么是Tableau? 三、安装Tableau 四、安装ODBC驱动 1、openGauss数据库 2、连接前置条件 3、Tableau连接openGauss方式一 4、Tableau连接openGauss方式二 一、摘要 Tableau可以连接到多种数据库,包括关系型数据库࿰…...

RabbitMQ 实现延迟队列
业务场景:1.生成订单30分钟未支付,则自动取消,我们该怎么实现呢?2.生成订单60秒后,给用户发短信1 安装rabbitMqwindows安装ubuntu中安装2 添加maven依赖<!-- https://mvnrepository.com/artifact/org.springframework.boot/spr…...
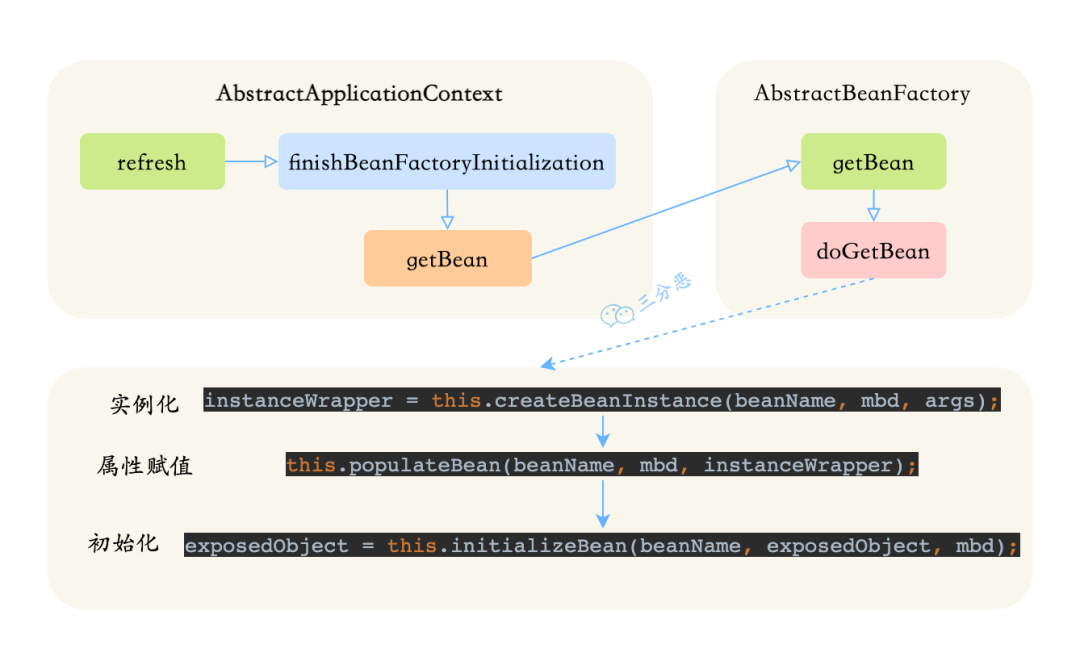
Spring Bean 生命周期,好像人的一生
简单说说IoC和Bean IoC,控制反转,想必大家都知道,所谓的控制反转,就是把new对象的权利交给容器,所有的对象都被容器控制,这就叫所谓的控制反转。 控制反转 Bean,也不是什么新鲜玩意儿…...

C++算法基础课 05 —— 数据结构1_单链表/双链表/栈/单调栈/队列/单调队列/KMP
文章目录 1. 单链表(用数组模拟链表)1.1 模板1.1.1 插入操作1.1.2 删除操作1.2 习题1 —— 826.单链表2. 双链表2.1 模板2.1.1 插入操作2.1.2 删除操作2.2 习题1 —— 827.双链表3. 栈(用数组模拟栈)3.1 模板3.2 习题1 —— 828.模拟栈4. 单调栈4.1 模板4.2 习题1 —— 830.单调…...

小型水库大坝安全监测的主要对象
一、监测背景 大坝监测的目的分成两个大的方面,一方面是为了验证设计、指导施工、为科研提供必要的资料;另一方面,也可以说是更重要的方面,就是为了长期监视大坝的安全运行。因此,一个成功的监测设计者不仅要能充分领会…...
版本介绍)
常见软件开源(alpha,beta等)版本介绍
一、开发期Alpha:是内部测试版,一般不向外部发布,会有很多Bug.一般只有测试人员使用。Beta:也是测试版,这个阶段的版本会一直加入新的功能。在Alpha版之后推出。-RC(ReleaseCandidate):最终测试版本;可能成为最终产品的…...
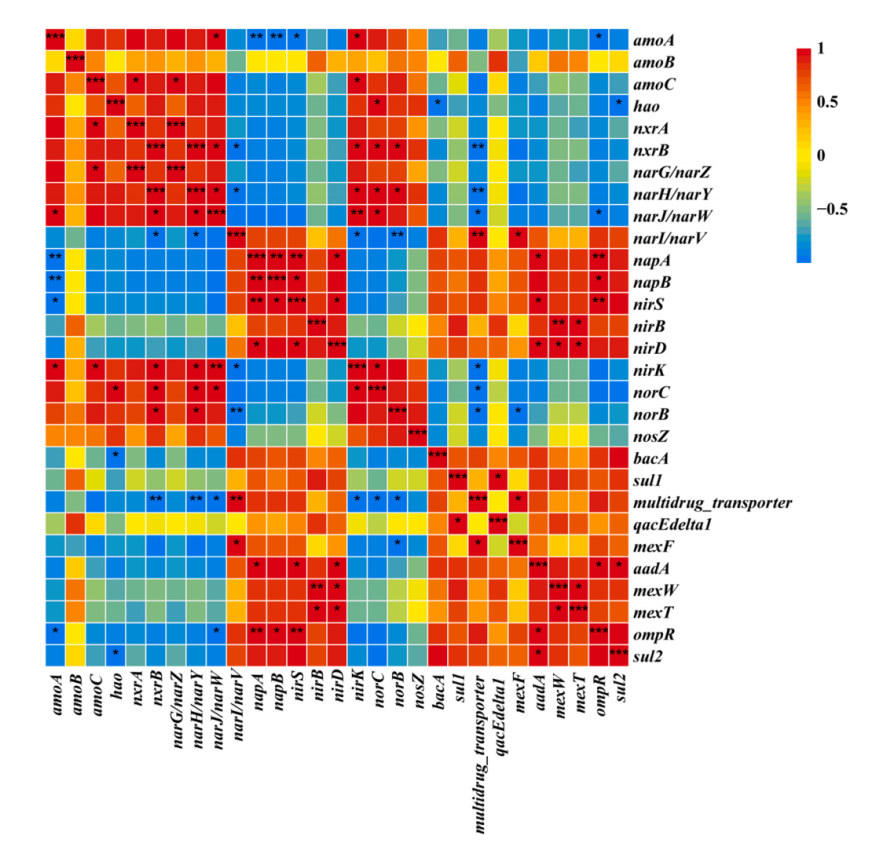
凌恩生物资讯|抗性宏基因组又一力作|抗性基因+可移动元件研究新成果!
凌恩生物合作客户:合肥工业大学崔康平老师团队利用凌恩生物宏基因组抗性基因研究解决方案,对污水处理厂活性污泥中的钆(Gd(III))和抗生素磺胺甲噁唑(SMX)的联合污染情况进行了调查&a…...
(二))
常见前端基础面试题(HTML,CSS,JS)(二)
ES6 新增哪些东西 箭头函数字符串模板支持模块化(import、export)类(class、constructor、extends)let、const 关键字新增一些数组、字符串等内置构造函数方法,例如 Array.from、Array.of 、Math.sign、Math.trunc 等…...

按关键词搜索,商品详情采集,API接口
公共参数 名称类型必须描述keyString是 调用key(必须以GET方式拼接在URL中) 注册Key和secret测试: https://o0b.cn/anzexi secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_g…...

C++的纯虚函数使用与接口实现
虚函数主要是为了父类指针访问子类同名成员方法而引入的,即通过重写了父类的方法,从而实现多态。 01 为何引入纯虚函数 对于普通虚函数,如果子类没有重写相应的虚函数,那么父类指针就只能调用父类函数实现,然而父类有…...

Exception has occurred: ModuleNotFoundErrorNo module named ‘urllib3‘【已解决】
问题描述 实际上只是想要测试一下torch是否安装成功,输出相应版本。谁知道就报错了。 Exception has occurred: ModuleNotFoundError No module named urllib3 解决方案 (1)使用pip或者conda卸载urllib3 pip uninstall urllib3conda unin…...

CSS 盒子模型【快速掌握知识点】
目录 一、什么是盒子模型 二、边框border-color 三、边框粗细border-width 四、边框样式border-style 五、外边距margin 六、内边距padding 七、圆角边框 八、圆形 九、盒子阴影 一、什么是盒子模型 css盒子模型又称为框模型,盒子的最内部是元素的实际内容…...
公网远程连接Oracle数据库【内网穿透】
文章目录1. 数据库搭建2. 内网穿透2.1 安装cpolar内网穿透2.2 创建隧道映射3. 公网远程访问4. 配置固定TCP端口地址4.1 保留一个固定的公网TCP端口地址4.2 配置固定公网TCP端口地址4.3 测试使用固定TCP端口地址远程OracleOracle,是甲骨文公司的一款关系数据库管理系…...

国内售价仅10元的鸭子滑梯玩具TK卖到20美元,相关视频获400万+播放!
在TikTok上玩具一直是增速极快的一个类目,不同于很多其他品类在疫情期间取得了巨大增长但在疫情后销售大幅下降的现象不同,全球玩具市场继续表现并保持稳定的较高的销售水平。美国市场研究机构NPD的统计,2021年,全球玩具市场的销售…...

直播平台的视频美颜sdk是什么?
直播平台的视频美颜sdk是什么,可以做什么?简而言之,直播美颜sdk是将直播平台的视频美颜效果做成一个sdk,给用户提供美颜效果选择,同时提供不同的视频分辨率,可以让用户在观看直播时有更好的体验。那么具体有…...

实现Vue组件库
实现Vue组件库 如何实现一个Vue组件库 Vue组件库是一种常见的前端工具,可以提供可复用的UI组件来简化应用程序的开发和维护。本文将介绍如何实现一个基本的Vue组件库。 步骤一:创建Vue项目 首先,我们需要使用Vue CLI创建一个Vue项目。打开…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...