【高级rabbitmq】
文章目录
- 1. 消息丢失问题
- 1.1 发送者消息丢失
- 1.2 MQ消息丢失
- 1.3 消费者消息丢失
- 1.3.1 消费失败重试机制
- 总结
- 2. 死信交换机
- 2.1 TTL
- 3. 惰性队列
- 3.1 总结:
- 4. MQ集群
消息队列在使用过程中,面临着很多实际问题需要思考:
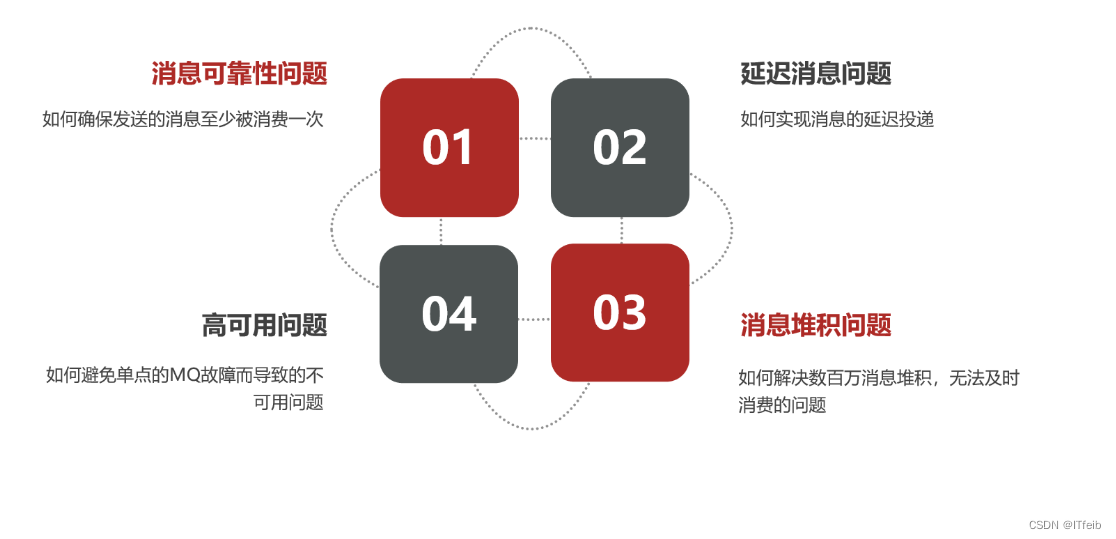
1. 消息丢失问题
1.1 发送者消息丢失
解决方式:生产者确认机制:
RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。这种机制必须给每个消息指定一个唯一ID。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。
返回结果有两种方式:
- publisher-confirm,发送者确认
- 消息成功投递到交换机,返回ack
- 消息未投递到交换机,返回nack
- publisher-return,发送者回执
- 消息投递到交换机了,但是没有路由到队列。返回ACK,及路由失败原因。

案例:
- 修改配置
首先,修改publisher服务中的application.yml文件,添加下面的内容:
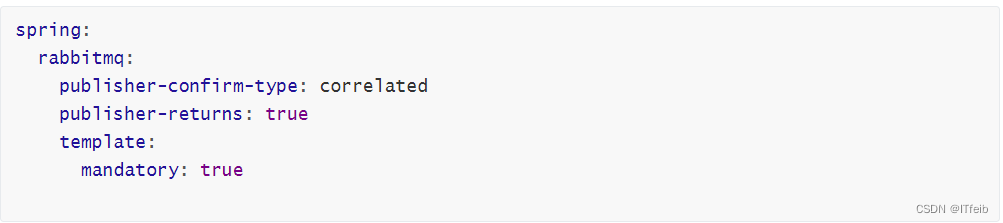
说明:
publish-confirm-type:开启publisher-confirm,这里支持两种类型:simple:同步等待confirm结果,直到超时correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback
publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallbacktemplate.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false:则直接丢弃消息
- 定义Return回调
每个RabbitTemplate只能配置一个ReturnCallback,因此需要在项目加载时配置:
修改publisher服务,添加一个:

- 定义ConfirmCallback
ConfirmCallback可以在发送消息时指定,因为每个业务处理confirm成功或失败的逻辑不一定相同。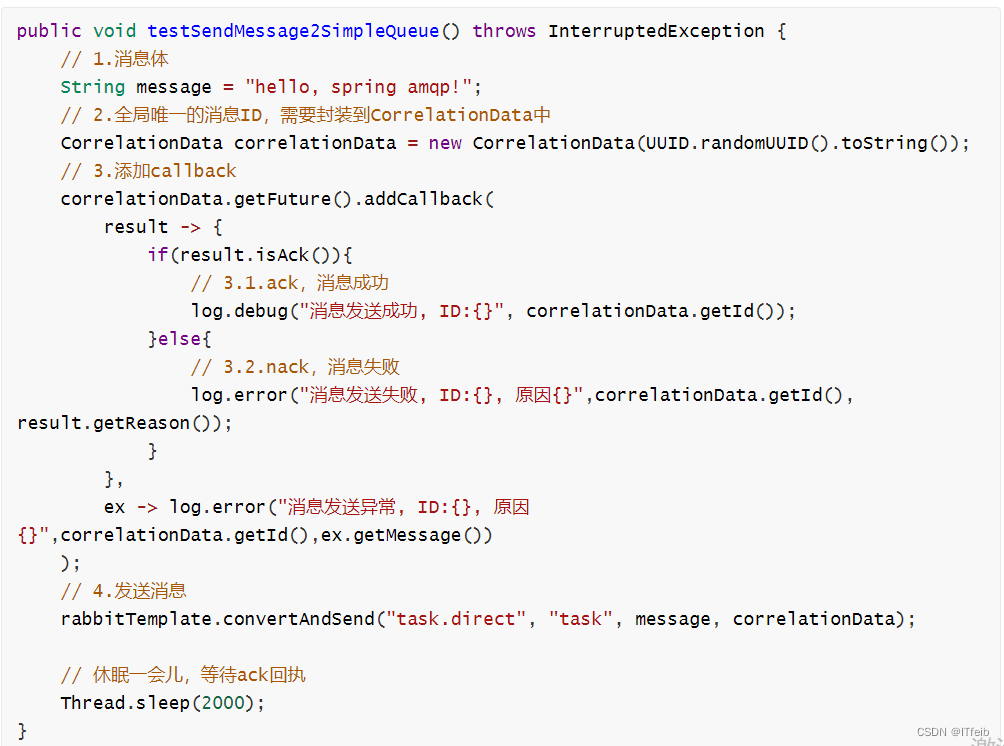
1.2 MQ消息丢失
解决方式: 交换机持久化、队列持久化、消息持久化
交换机持久化:RabbitMQ中交换机默认是非持久化的,mq重启后就丢失。SpringAMQP中可以通过代码指定交换机持久化:
事实上,默认情况下,由SpringAMQP声明的交换机都是持久化的。
队列持久化:RabbitMQ中队列默认是非持久化的,mq重启后就丢失。SpringAMQP中可以通过代码指定交换机持久化:
事实上,默认情况下,由SpringAMQP声明的队列都是持久化的。
消息持久化:利用SpringAMQP发送消息时,可以设置消息的属性(MessageProperties),指定delivery-mode: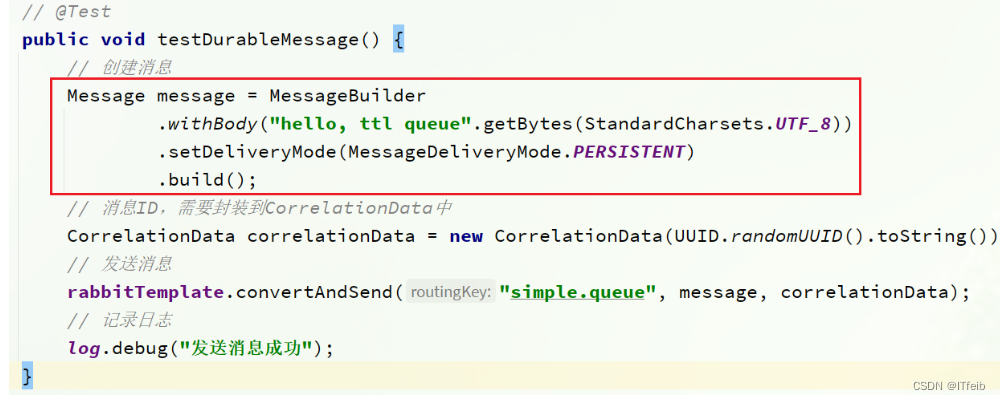
默认情况下,SpringAMQP发出的任何消息都是持久化的,不用特意指定。
1.3 消费者消息丢失
解决方式:消费者消息确认机制:消费者在成功处理了消息后告诉MQ成功处理
而SpringAMQP则允许配置三种确认模式:
-
manual:手动ack,需要在业务代码结束后,调用api发送ack。
-
auto:自动ack,由spring监测listener代码是否出现异常(aop),没有异常则返回ack;抛出异常则返回nack
-
none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
由此可知:
- none模式下,消息投递是不可靠的,可能丢失
- auto模式类似事务机制,出现异常时返回nack,消息回滚到mq;没有异常,返回ack
- manual:自己根据业务情况,判断什么时候该ack
一般,我们都是使用默认的auto即可。
案例:

1.3.1 消费失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升,带来不必要的压力:
解决办法:
本地重试:我们可以利用Spring的retry机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
修改consumer服务的application.yml文件,添加内容:
结论:
- 开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试
- 重试达到最大次数后,Spring会返回ack,消息会被丢弃
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecovery接口来处理,它包含三种不同的实现:
- RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
1)在consumer服务中定义处理失败消息的交换机和队列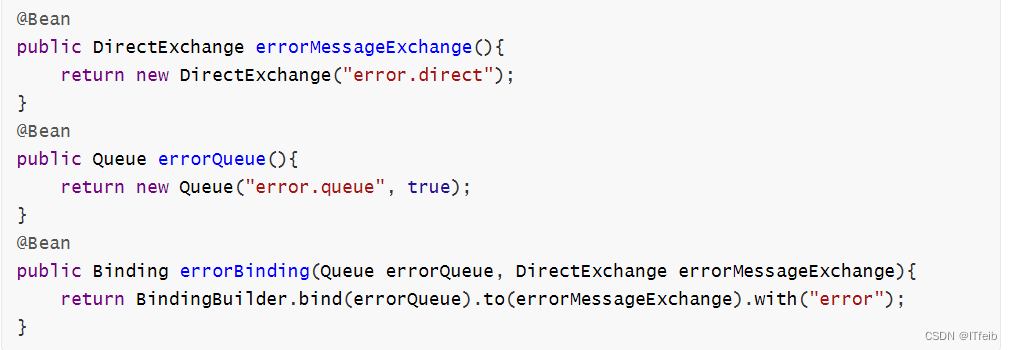
2)定义一个RepublishMessageRecoverer,关联队列和交换机自己定义的bean会覆盖原先默认的
总结
如何确保RabbitMQ消息的可靠性?
- 开启生产者确认机制,确保生产者的消息能到达队列
- 开启持久化功能,确保消息未消费前在队列中不会丢失
- 开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
- 开启消费者失败重试机制,并设置MessageRecoverer,多次重试失败后将消息投递到异常交换机,交由人工处理
2. 死信交换机
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
- 消费者使用basic.reject或 basic.nack声明消费失败,并且消息的requeue参数设置为false
- 消息是一个过期消息,超时无人消费
- 要投递的队列消息满了,无法投递
如果这个包含死信的队列配置了dead-letter-exchange属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换机(Dead Letter Exchange,检查DLX)。
在失败重试策略中,默认的RejectAndDontRequeueRecoverer会在本地重试次数耗尽后,发送reject给RabbitMQ,消息变成死信,被丢弃。
我们可以给simple.queue添加一个死信交换机,给死信交换机绑定一个队列。这样消息变成死信后也不会丢弃,而是最终投递到死信交换机,路由到与死信交换机绑定的队列。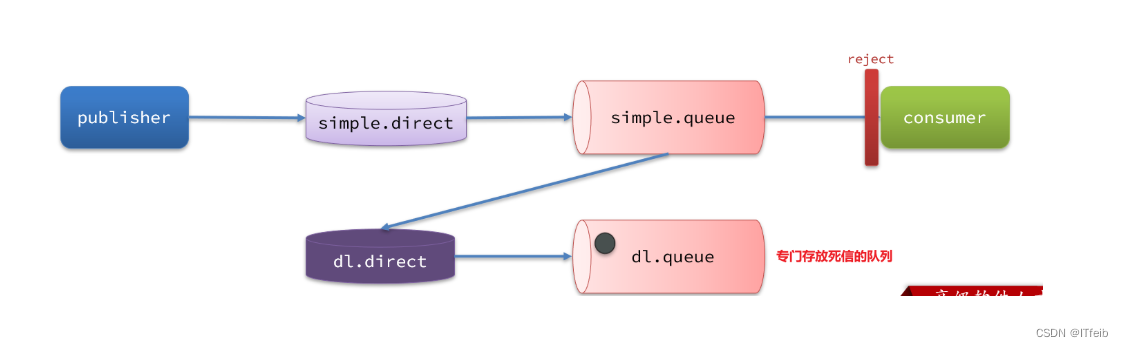
我们在consumer服务中,定义一组死信交换机、死信队列:
死信交换机的使用场景是什么?
- 如果队列绑定了死信交换机,死信会投递到死信交换机;
- 可以利用死信交换机收集所有消费者处理失败的消息(死信),交由人工处理,进一步提高消息队列的可靠性。
2.1 TTL
一个队列中的消息如果超时未消费,则会变为死信,超时分为两种情况:
- 消息所在的队列设置了超时时间
- 消息本身设置了超时时间
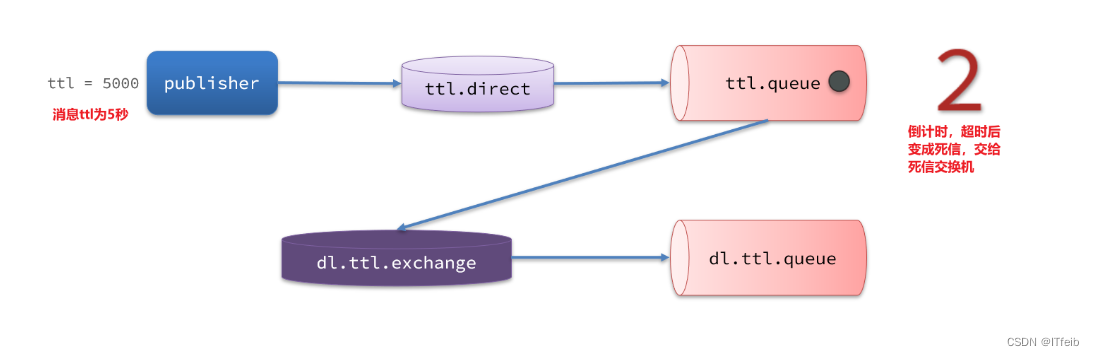
只需要在发消息中设置消息的超时时间,ttl.queue设置队列的超时时间。


总结:
消息超时的两种方式是?
- 给队列设置ttl属性,进入队列后超过ttl时间的消息变为死信
- 给消息设置ttl属性,队列接收到消息超过ttl时间后变为死信
如何实现发送一个消息20秒后消费者才收到消息?
- 给消息的目标队列指定死信交换机
- 将消费者监听的队列绑定到死信交换机
- 发送消息时给消息设置超时时间为20秒
延迟队列:
利用TTL结合死信交换机,我们实现了消息发出后,消费者延迟收到消息的效果。这种消息模式就称为延迟队列(Delay Queue)模式。
延迟队列的使用场景包括:
- 延迟发送短信
- 用户下单,如果用户在15 分钟内未支付,则自动取消
- 预约工作会议,20分钟后自动通知所有参会人员
因为延迟队列的需求非常多,所以RabbitMQ的官方也推出了一个插件,原生支持延迟队列效果。
这个插件就是DelayExchange插件。
DelayExchange需要将一个交换机声明为delayed类型。当我们发送消息到delayExchange时,流程如下:
- 接收消息
- 判断消息是否具备x-delay属性
- 如果有x-delay属性,说明是延迟消息,持久化到硬盘,读取x-delay值,作为延迟时间
- 返回routing not found结果给消息发送者
- x-delay时间到期后,重新投递消息到指定队列
使用DelayExchange:
插件的使用也非常简单:声明一个交换机,交换机的类型可以是任意类型,只需要设定delayed属性为true即可,然后声明队列与其绑定即可。


3. 惰性队列
消息堆积问题:当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。
解决消息堆积有三种思路:
- 增加更多消费者,提高消费速度。
- 在消费者内开启线程池加快出消息处理速度
- 扩大队列容积,提高堆积上限
惰性队列:扩大队列容积
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
基于@RabbitListener声明LazyQueue
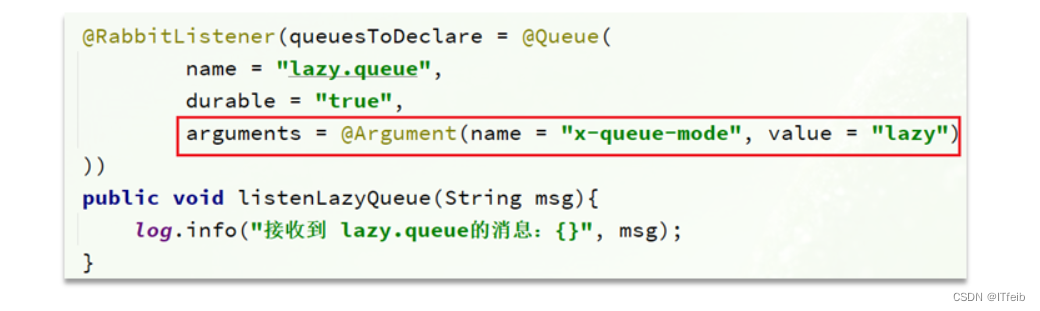
3.1 总结:
消息堆积问题的解决方案?
- 队列上绑定多个消费者,提高消费速度
- 使用惰性队列,可以在mq中保存更多消息
惰性队列的优点有哪些?
- 基于磁盘存储,消息上限高
- 没有间歇性的page-out,性能比较稳定
惰性队列的缺点有哪些?
- 基于磁盘存储,消息时效性会降低
- 性能受限于磁盘的IO
4. MQ集群
-
普通集群:是一种分布式集群,将队列分散到集群的各个节点,从而提高整个集群的并发能力。
-
镜像集群:是一种主从集群,普通集群的基础上,添加了主从备份功能,提高集群的数据可用性。
-
仲裁队列:镜像集群虽然支持主从,但主从同步并不是强一致的,某些情况下可能有数据丢失的风险。因此在RabbitMQ的3.8版本以后,推出了新的功能:仲裁队列来代替镜像集群,底层采用Raft协议确保主从的数据一致性。
Java代码创建仲裁队列:

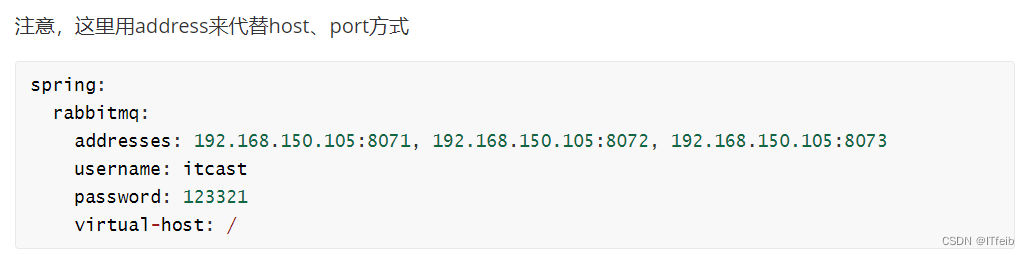
SpringAMQP连接MQ集群:
相关文章:
【高级rabbitmq】
文章目录 1. 消息丢失问题1.1 发送者消息丢失1.2 MQ消息丢失1.3 消费者消息丢失1.3.1 消费失败重试机制 总结 2. 死信交换机2.1 TTL 3. 惰性队列3.1 总结: 4. MQ集群 消息队列在使用过程中,面临着很多实际问题需要思考: 1. 消息丢失问题 1.1…...
数百个下载能够传播 Rootkit 的恶意 NPM 软件包
供应链安全公司 ReversingLabs 警告称,最近观察到的一次恶意活动依靠拼写错误来诱骗用户下载恶意 NPM 软件包,该软件包会通过 rootkit 感染他们的系统。 该恶意软件包名为“node-hide-console-windows”,旨在模仿 NPM 存储库上合法的“node-…...

SpringBoot的error用全局异常去处理
记录一下使用SpringBoot2.0.5的error用全局异常去处理 在使用springboot时,当访问的http地址或者说是请求地址输错后,会返回一个页面,如下: 这是因为请求的地址不存在,默认会显示error页面 但我们实际需要一个接口&a…...
MyBatisPlus(十一)包含查询:in
说明 包含查询,对应SQL语句中的 in 语句,查询参数包含在入参列表之内的数据。 in Testvoid inNonEmptyList() {// 非空列表,作为参数List<Integer> ages Stream.of(18, 20, 22).collect(Collectors.toList());in(ages);}Testvoid in…...

Linux命令定位与查找:which、whereis和find的用法详解
文章目录 Linux命令的定位与查找1. 简介Linux路径环境变量命令行和Shell 2. which命令which命令的作用使用which命令定位可执行文件多个可执行文件的定位which命令的选项及其使用 3. whereis命令whereis命令的作用使用whereis命令查找二进制文件查找源代码文件whereis命令的选项…...

LeetCode 面试题 17.10. Find Majority Element LCCI【摩尔投票法】简单
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

多校联测11 模板题
题目大意 给你四个整数 n , m , s e e d , w n,m,seed,w n,m,seed,w,其中 n , m n,m n,m为两个多项式 A ( x ) ∑ i 0 n a i x i A(x)\sum\limits_{i0}^na_ix^i A(x)i0∑naixi和 B ( x ) ∑ i 0 m b i x i B(x)\sum\limits_{i0}^mb_ix^i B(x)i0∑mbixi…...
Linux SSH连接远程服务器(免密登录、scp和sftp传输文件)
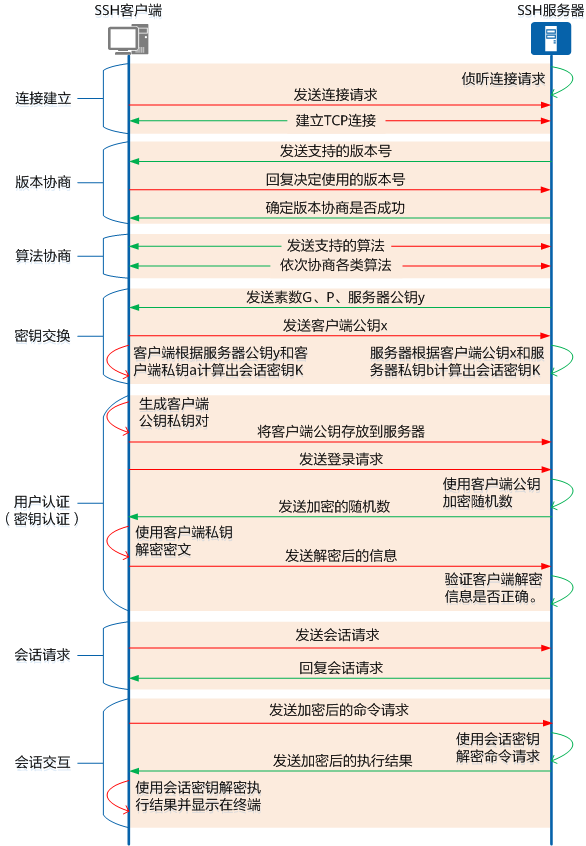
1 SSH简介 SSH(Secure Shell,安全外壳)是一种网络安全协议,通过加密和认证机制实现安全的访问和文件传输等业务。传统远程登录和文件传输方式,例如Telnet、FTP,使用明文传输数据,存在很多的安全…...
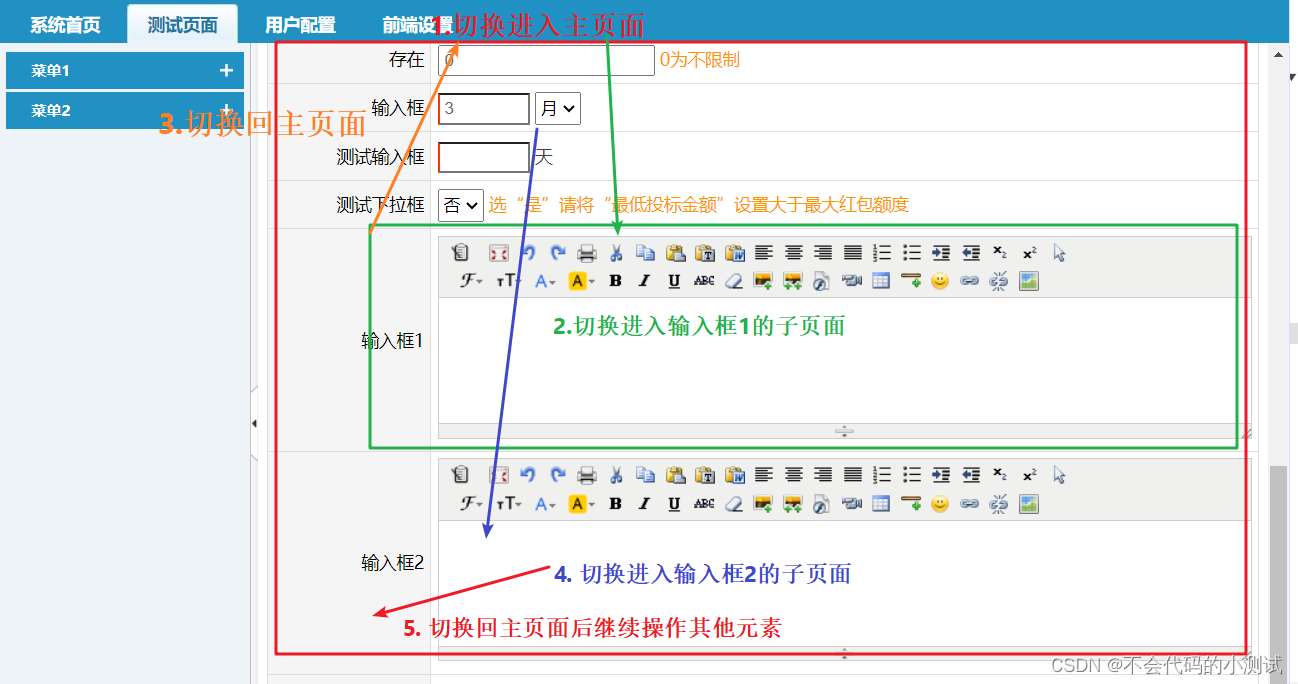
从0开始python学习-30.selenium frame子页面切换
目录 1. frame切换逻辑 2. 多层子页面情况进行切换 3. 多个子页面相互切换 1. frame切换逻辑 1.1. 子页面的类型一般分为两种 frame标签 iframe标签 1.2. 子页面里面的元素和主页面的元素是相互独立 子页面元素需要进去切换才能操作 如果已经进入子页面,那么…...
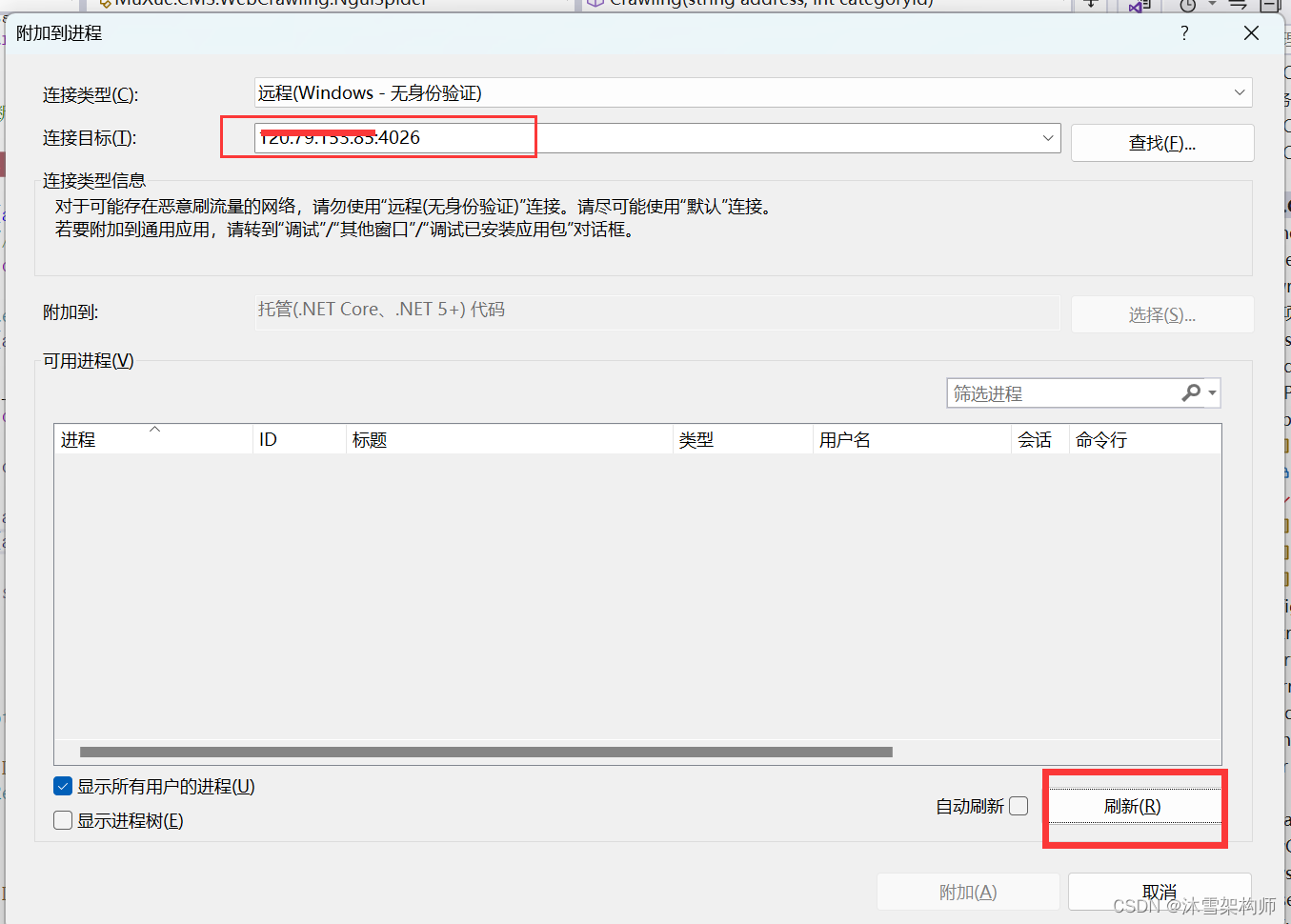
asp.net core 远程调试
大概说下过程: 1、站点发布使用Debug模式 2、拷贝到远程服务器,以及iis创建站点。 3、本地的VS2022的安装目录:C:\Program Files\Microsoft Visual Studio\2022\Professional\Common7\IDE下找Remote Debugger 你的服务器是64位就拷贝x64的目…...

Java spring boot 一次调用多个请求
Java Spring Boot是一种基于Java编程语言的开发框架,它提供了一种快速构建高效、可伸缩和易于维护的企业级应用程序的方式。在实际的应用开发中,我们常常需要调用多个独立的请求来完成某个业务功能。然而,传统的同步方式一次只能调用一个请求…...
)
DRM全解析 —— CRTC详解(4)
接前一篇文章:DRM全解析 —— CRTC详解(3) 本文继续对DRM中CRTC的核心结构struct drm_crtc的成员进行释义。 3. drm_crtc结构释义 (21)struct drm_object_properties properties /** properties: property tracking …...

六个为Rust构建的IDE
Rust语言的学习曲线适中,介于高级语言和低级语言之间。这门语言既能编写系统软件,将嵌入式设备编译为x86 ARM,也可以用于前端技术,这要归功于WebAssembly。 在日渐成熟的发展中,Rust开始拥有更好的工具来提高效率。最…...

25 Python的collections模块
概述 在上一节,我们介绍了Python的sqlite3模块,包括:sqlite3模块中一些常用的函数和类。在这一节,我们将介绍Python的collections模块。collections模块是Python中的内置模块,它实现了特殊的容器数据类型,提…...

JEPG Encoder IP verilog设计及实现
总体介绍: 采用通用的常规 Verilog 代码编写,可用于任何 FPGA。 该内核不依赖任何专有 IP 内核,而是用 Verilog 编写了实现 JPEG 编码器所需的所有功能,代码完全独立。 编码器内核的输入是一条 24 位数据总线,红色像素、绿色像素和蓝色像素各有 8 位。 信号 "data_i…...
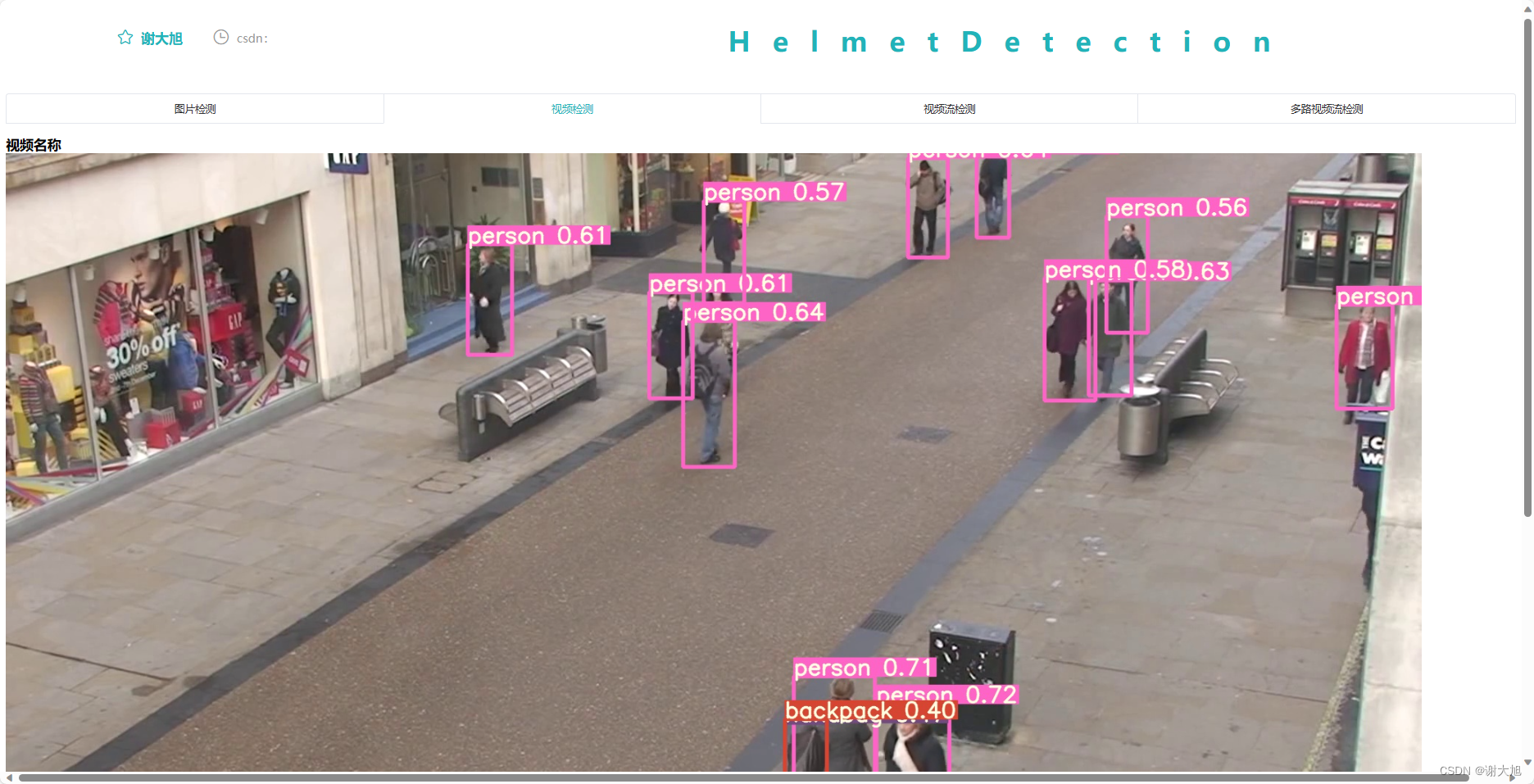
yolov5 web端部署进行图片和视频检测
目录 1、思路 2、代码结构 3、代码运行 4、api接口代码 5、web ui界面 6、参考资料 7、代码分享 1、思路 通过搭建flask微型服务器后端,以后通过vue搭建网页前端。flask是第一个第三方库。与其他模块一样,安装时可以直接使用python的pip命令实现…...
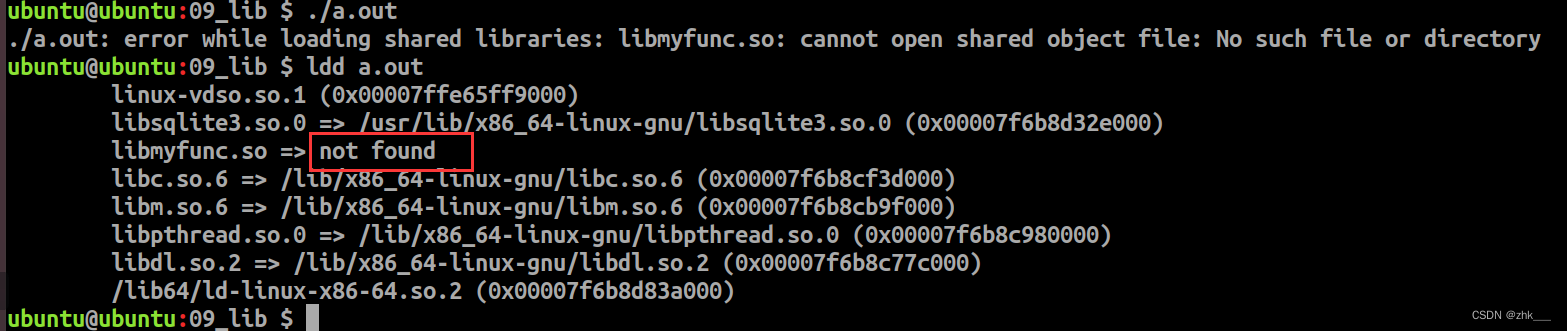
嵌入式养成计划-34--函数库
七十二、 函数库 1. 库的概念 库是一个二进制可执行文件,与二进制可执行程序比较,库是不能单独运行的。 库中存放的是功能函数,没有主函数(main函数) 库需要被载入到内存中使用 标准的基础库中存放了很多已经写好的…...

PM864AK01-eA 3BSE018161R2 工业人工智能供应链先驱
PM864AK01-eA 3BSE018161R2 工业人工智能供应链先驱 吞吐量和Macnica Networks的战略合作伙伴关系将使Macnica Networks的客户能够加速和量化智能工厂计划的投资回报(ROI)。高管、经理和运营负责人可以使用Macnica Networks领先的制造场所数据收集平台和ThroughPut基于约束理论…...

参与现场问题解决总结(Kafka、Hbase)
一. 背景 Kafka和Hbase在现场应用广泛,现场问题也较多,本季度通过对现场问题就行跟踪和总结,同时结合一些调研,尝试提高难点问题的解决效率,从而提高客户和现场满意度。非难点问题(历史遇到过问题…...
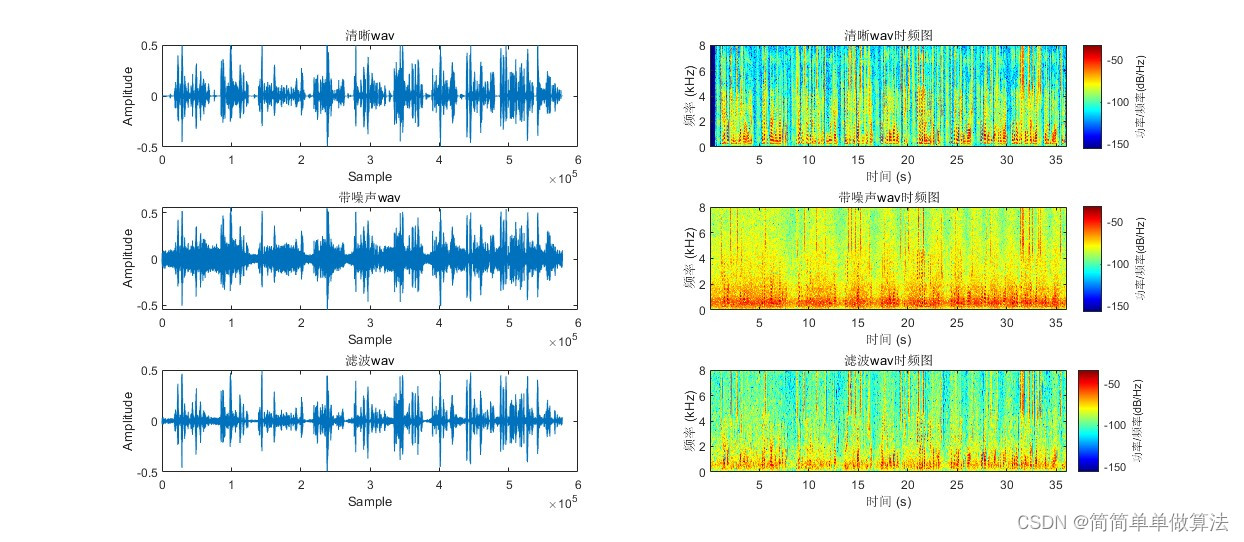
基于PSD-ML算法的语音增强算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 1.加窗处理: 2.分帧处理: 3.功率谱密度估计: 4.滤波处理: 5.逆变换处理: 6.合并处理: 5.算法完整程序工程 1.算法…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...