hadoop集群安装并配置
文章目录
- 1.安装JDK 环境
- 2.系统配置
- 2.1修改本地hosts文件
- 2.2创建hadoop 用户
- 2.2 设置ssh免密(使用hadoop 用户生成)
- 3.安装 hadoop 3.2.4
- 3.1 安装hadoop
- 3.1.1 配置Hadoop 环境变量
- 3.2配置 HDFS
- 3.2.1 配置 workers 文件
- 3.2.2 配置hadoop-env.sh
- 3.2.3 配置core-site.xml
- 3.2.3 配置 hdfs-site.xml
- 3.2.4 启动hdfs
- 3.3 配置MapReduce
- 3.3.1 配置 mapred-env.sh
- 3.3.2配置 mapred-site.xml
- 3.4配置yarn
- 3.4.1配置 yarn-env.sh
- 3.4.2 配置 yarn-site.xml
- 3.4.3启动yarn 集群
- 3.5hadoop集群启动
1.安装JDK 环境
JDK1.8下载链接
使用wget 下载到liunx 主机
#创建文件夹
mkdir /usr/app
# 进入文件夹
cd /usr/app
#下载java
wget https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz
#解压
tar -zvxf jdk-8u181-linux-x64.tar.gz
#修改名称
mv jdk-8u181-linux-x64 jdk.18
//配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/app/jdk1.8 # java解压的路径
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JRE_HOME=$JAVA_HOME/jre
//加载
source /etc/profile
每台节点都安装jdk
2.系统配置
2.1修改本地hosts文件
配置本地hosts文件,后面我们直接使用hostname 去连接主机 不再输入ip地址
每个节点都执行
#编辑host文件vi /etc/hosts
#文件末尾添加自己的主机和hostname
192.168.56.103 hadoop01
192.168.56.104 hadoop02
192.168.56.105 hadoop03
保存后ping hadoop02 网络正常
2.2创建hadoop 用户
每台机器都指向
#新增用户
useradd hadoop
#设置hadoop 用户密码为 123456
passwd hadoop 123456
#切换到hadoop 用户
su - hadoop
2.2 设置ssh免密(使用hadoop 用户生成)
由于hadoop 一般为集群,我们安装时 直接使用ssh 命令 复制安装 hadoop 效率会更高
我们一般使用ssh 命令时会遇到输入密码验证的问题 我们可以提前配置免密操作
全部节点 执行该命令生成密钥,执行后一直按Enter 即可
#生成密钥
ssh-keygen -t rsa -b 4096
将密钥拷贝到其他两个子节点,命令如下:
ssh-copy-id -i hadoop01
ssh-copy-id -i hadoop02
ssh-copy-id -i hadoop03
结果打印
3.安装 hadoop 3.2.4
国内下载地址 华为镜像
官网下载地址 官网链接
3.1 安装hadoop
在hadoop01 服务器下载hadoop安装包,如果不能连接外网请下载后上传到服务器
cd /usr/app
#下载
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
#解压
tar -zvxf hadoop-3.2.4.tar.gz
mv hadoop-3.2.4 hadoop
3.1.1 配置Hadoop 环境变量
在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/usr/app/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
从hadoop01 将hadoop安装文件夹远程复制到hadoop02、hadoop03
3.2配置 HDFS
配置HDFS集群,我们主要涉及到如下文件的修改
| 修改文件 | 作用 |
|---|---|
| workers | 配置从节点(DataNode)有哪些 |
| hadoop-env.sh | 配置Hadoop的相关环境变量 |
| core-site.xml | Hadoop核心配置文件 |
| hdfs-site.xml | HDFS核心配置文件 |
这些文件均存在与$HADOOP_HOME/etc/hadoop文件夹中。
ps:$HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即/app/hadoop
3.2.1 配置 workers 文件
# 进入配置文件目录
cd etc/hadoop
# 编辑workers文件
vim workers
# 填入如下内容
hadoop01
hadoop02
hadoop03
3.2.2 配置hadoop-env.sh
# 填入如下内容
#JAVA_HOME,指明JDK环境的位置在哪
export JAVA_HOME=/usr/jdk
#HADOOP_HOME,指明Hadoop安装位置
export HADOOP_HOME=/usr/hadoop
#HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#HADOOP_LOG_DIR,指明Hadoop运行日志目录位置
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
3.2.3 配置core-site.xml
<configuration>
<!--含义:HDFS文件系统的网络通讯路径
协议为hdfs:// namenode为hadoop01 namenode通讯端口为8020 --><property><name>fs.defaultFS</name><value>hdfs://hadoop01:8020</value></property>
<!--含义:io操作文件缓冲区大小值:131072 bit--><property><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>
3.2.3 配置 hdfs-site.xml
<configuration>
<!--hdfs文件系统,默认创建的文件权限设置 值:700,即:rwx--><property><name>dfs.datanode.data.dir.perm</name><value>700</value></property>
<!--NameNode元数据的存储位置 值:/data/nn,在hadoop01节点的/data/nn目录下 --><property><name>dfs.namenode.name.dir</name><value>/data/nn</value></property><!--NameNode允许哪几个节点的DataNode连接(即允许加入集群)hadoop01,hadoop02,hadoop03,这三台服务器被授权--><property><name>dfs.namenode.hosts</name><value>hadoop01,hadoop02,hadoop03</value></property><!--hdfs默认块大小 值:268435456(256MB) -->
<property><name>dfs.blocksize</name><value>268435456</value></property><!--namenode处理的并发线程数 以100个并行度处理文件系统的管理任务--><property><name>dfs.namenode.handler.count</name><value>100</value></property>
<!--NameNode元数据的存储位置 值:/data/nn,在所有节点的/data/nn目录下--><property><name>dfs.datanode.data.dir</name><value>/data/dn</value></property>
</configuration>目前,已经基本完成Hadoop的配置操作,可以从hadoop01 将hadoop安装文件夹远程复制到hadoop02、hadoop03
3.2.4 启动hdfs
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
3.3 配置MapReduce
3.3.1 配置 mapred-env.sh
# 设置JDK路径
export JAVA_HOME=/usr/app/jdk1.8
# 设置JobHistoryServer进程内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
#设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFORFA
3.3.2配置 mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description>MapReduce 的运行框架设置为YARN</description></property><property><name>mapreduce.jobhistory.address</name><value>hadoop01:10020</value><description> 历史服务器通讯地址设置为hadoop01:10020</description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop01:19888</value><description>历史服务器web端口为hadoop01:19888</description></property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/data/mr-history/tmp</value><description>历史信息在hdfs的记录临时路径</description></property><property><name>mapreduce.jobhistory.done-dir</name><value>/data/mr-history/done</value><description>历史信息在hdfs的记录路径</description></property>`在这里插入代码片`
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>设置环境变量地址</description>
</property>
<property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>设置环境变量地址</description>
</property>
<property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>设置环境变量地址</description>
</property>
</configuration>3.4配置yarn
3.4.1配置 yarn-env.sh
#设 置 JDK路径的环境变量
export JAVA_HOME=/usr/jdk1.8
#设置 HADOOP HOME的环境变量
export HADOOP_HOME=/export/server/hadoop
#设置配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs3.4.2 配置 yarn-site.xml
<configuration>
<property><name>yarn.log.server.url</name><value>http://hadoop01:19888/jobhistory/logs</value><description>历史服务器URL </description>
</property><property><name>yarn.web-proxy.address</name><value>hadoop01:8089</value><description> 代理服务器主机和端口</description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description> 开启聚合日志</description></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><descriptionn>程序日志HDFs的存储路径</description></property><property><name>yarn.resourcemanager.hostname</name><value>node1</value><description>>ResourceManager设置在hadoop01节点</description></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description>选择公平调度</description></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>NodeManger中间数据本地存储路径</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>NodeManagers数据日志本地存储路径</description></property><property><name>yarn.nodemanager.log.retain-seconds</name><value>10800</value><description>在NodeManager上保留日志文件的时间</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>为MapReduce 程序开启Shuffle服务</description></property>
</configuration>
3.4.3启动yarn 集群
- 一键启动YARN集群
$HADOOP_HOME/sbin/start-yarn.sh
会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager
会基于workers文件配置的主机启动NodeManager
- 一键停止YARN集群
$HADOOP_HOME/sbin/stop-yarn.sh
- 在当前机器,单独启动或停止进程
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserver
start和stop决定启动和停止 可控制resourcemanager、nodemanager、proxyserver三种进程
- 历史服务器启动和停止
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver
3.5hadoop集群启动
一键启动hadoop 集群:
$HADOOP_HOME/sbin/start-all.sh
一键停止hadoop 集群
$HADOOP_HOME/sbin/stop-all.sh
相关文章:
hadoop集群安装并配置
文章目录 1.安装JDK 环境2.系统配置2.1修改本地hosts文件2.2创建hadoop 用户2.2 设置ssh免密(使用hadoop 用户生成) 3.安装 hadoop 3.2.43.1 安装hadoop3.1.1 配置Hadoop 环境变量 3.2配置 HDFS3.2.1 配置 workers 文件3.2.2 配置hadoop-env.sh3.2.3 配置…...
Quarto 入门教程 (3):代码框、图形、数据框设置
简介 本文是《手把手教你使用 Quarto 构建文档》第三期,前两期分别介绍了: 第一期 介绍了Quarto 构建文档的原理;可创建的文档类型;对应的参考资源分享。 第二期 介绍了如何使用 Quarto,并编译出文档(PDF…...
虚拟机Ubuntu18.04安装对应ROS版本详细教程!(含错误提示解决)
参考链接: Ubuntu18.04安装Ros(最新最详细亲测)_向日葵骑士Faraday的博客-CSDN博客 1.4 ROS的安装与配置_哔哩哔哩_bilibili ROS官网:http://wiki.ros.org/melodic/Installation/Ubuntu 一、检查cmake 安装ROS时会自动安装旧版的Cmake3.10.2。所以在…...

#力扣:14. 最长公共前缀@FDDLC
14. 最长公共前缀 一、Java class Solution {public String longestCommonPrefix(String[] strs) {for (int l 0; ; l) {for (int i 0; i < strs.length; i) {if (l > strs[i].length() || strs[i].charAt(l) ! strs[0].charAt(l)) return strs[0].substring(0, l);}…...

Android 13.0 解锁状态下禁止下拉状态栏功能实现
1.前言 在13.0的系统定制化开发中,在关于一些systemui下拉状态栏的定制化功能开发中,对于关于systemui的下拉状态栏 是否可以下拉做了定制,用系统属性来判断是否可以在解锁的情况下可以下拉状态栏布局,虽然11.0 12.0和13.0的关于 下拉状态栏相关分析有区别,可以通过分析相…...

chromium线程模型(1)-普通线程实现(ui和io线程)
通过chromium 官方文档,线程和任务一节我们可以知道 ,chromium有两类线程,一类是普通线程,最典型的就是io线程和ui线程。 另一类是 线程池线程。 今天我们先分析普通线程的实现,下一篇文章分析线程池的实现。ÿ…...
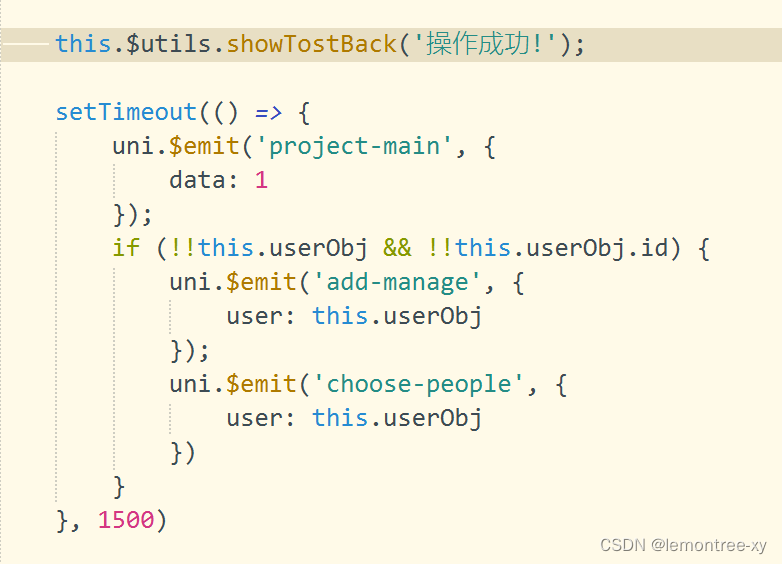
uniapp uni.showToast 一闪而过的问题
问题:在页面跳转uni.navigateBack()等操作的前或后,执行uni.showToast,即使代码中设置2000ms的显示时间,也会一闪而过。 解决:用setTimeout延后navigateBack的执行。...
)
代理模式介绍及具体实现(设计模式 三)
代理模式是一种结构型设计模式,它允许通过创建一个代理对象来控制对另一个对象的访问 实例介绍和实现过程 假设我们正在开发一个电子商务网站,其中有一个商品库存管理系统。我们希望在每次查询商品库存之前,先进行权限验证,以确…...

【18】c++设计模式——>适配器模式
c的适配器模式是一种结构型设计模式,他允许将一个类的接口转换成另一个客户端所期望的接口。适配器模式常用于已存在的,但不符合新需求或者规范的类的适配。 在c中实现适配器模式时,通常需要一下几个组件: 1.目标接口(…...
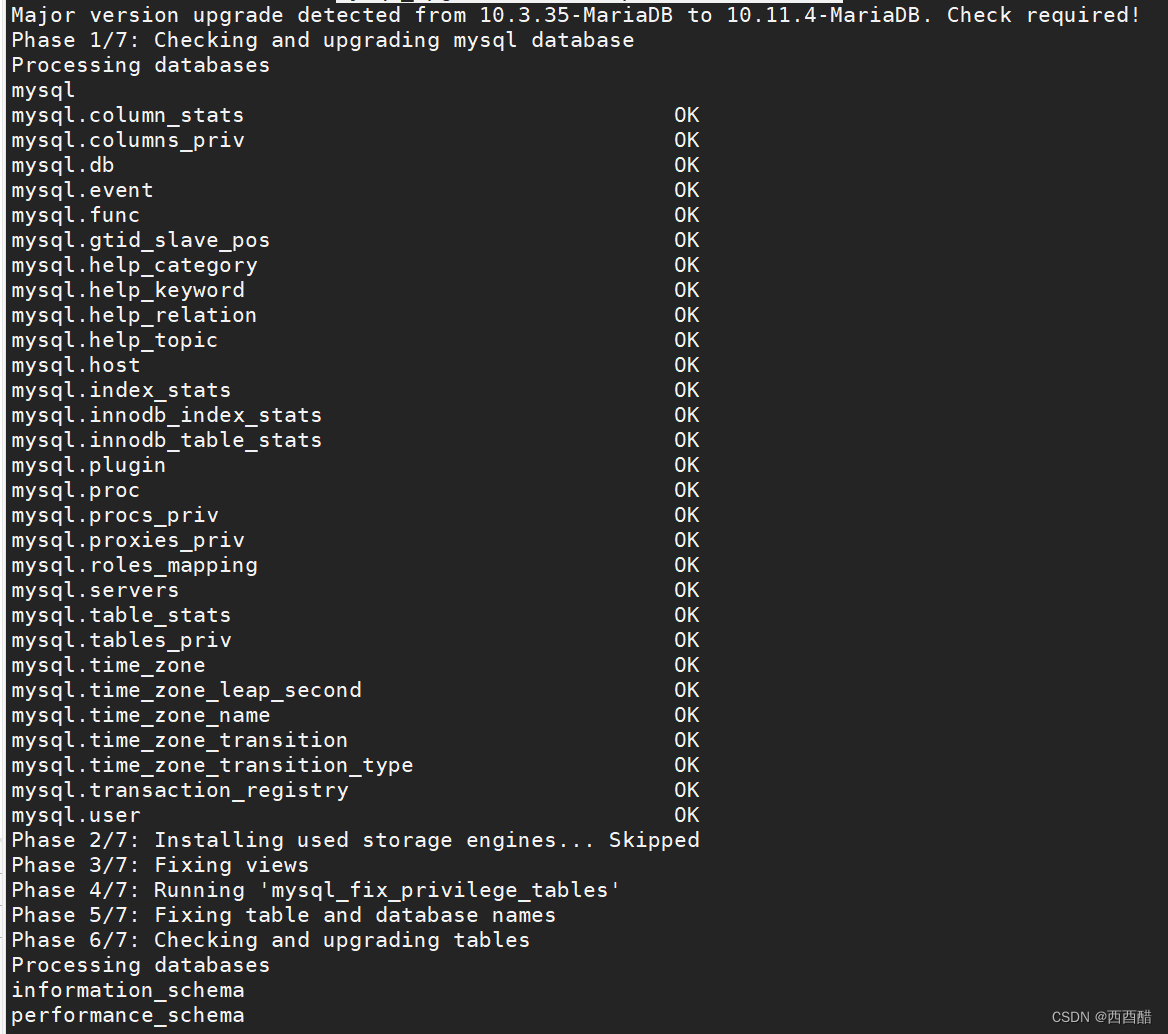
mariadb 错误日志中报错:Incorrect definition of table mysql.column_stats:
数据库错误日志出现此错误原因是因为系统表中字段类型或者数据结构有变动导致,一般是因为升级数据库版本后未同步升级系统表结构。 解决方法: 1.如果错误日志过大,直接删除。 2.执行 mysql_upgrade -u[用户名] -p[密码];,这一步…...

【SpringBoot】多环境配置和启动
环境分类,可以分为 本地环境、测试环境、生产环境等,通过对不同环境配置内容,来实现对不同环境做不同的事情。 SpringBoot 项目,通过 application-xxx.yml 添加不同的后缀来区分配置文件,启动时候通过后缀启动即可。 …...

跨qml通信
****Commet.qml //加载其他文件中的组件 不需要声明称Component //1.用loader.item.属性 访问属性 //2.loader.item.方法 访问方法 //3.用loader.item.方法.connect(槽)连接信号 Item { Loader{ id:loader; width: 200; …...
力扣-404.左叶子之和
Idea attention:先看清楚题目,题目说的是左叶子结点,不是左结点【泣不成声】 遇到像这种二叉树类型的题目呢,我们一般还是选择dfs,然后类似于前序遍历的方式加上判断条件即可 AC Code class Solution { public:void d…...
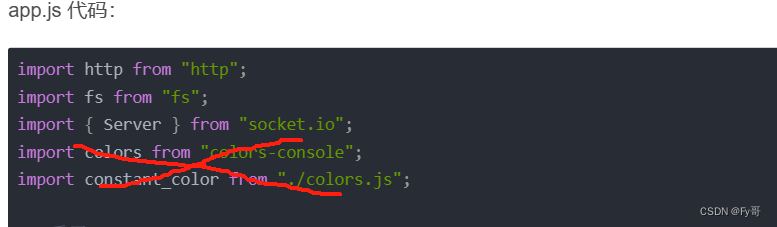
如何搭建一个 websocket
环境: NodeJssocket.io 4.7.2 安装依赖 yarn add socket.io创建服务器 引入文件 特别注意: 涉及到 colors 的代码,请采取 console.log() 打印 // 基础老三样 import http from "http"; import fs from "fs"; import { Server } from &quo…...
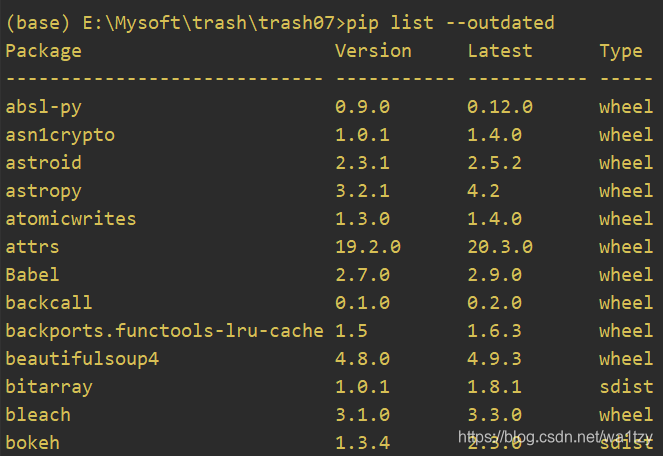
pip常用命令
TOC(pip常用命令) 1.pip 2.where pip 3.pip install --upgrade pip 4.安装 这里暂用flask库举例,安装flask库,默认安装最新版: pip install flask指定要安装flask库的版本: pip install flask版本号我们在安装第三方库时可…...
[QT编程系列-43]: Windows + QT软件内存泄露的检测方法
目录 一、如何查找Windows程序是否有内存泄露 二、如何定位Windows程序内存泄露的原因 二、Windows环境下内存监控工具的使用 2.1 内存监测工具 - Valgrind 2.2.1 Valgrind for Linux 2.2.2 Valgrind for Windows 2.2 内存监测工具 - Dr. Memory 2.2.1 特点 2.2.2 安装…...

【Java-LangChain:使用 ChatGPT API 搭建系统-5】处理输入-思维链推理
第五章,处理输入-思维链推理 在本章中,我们将专注于处理输入,即通过一系列步骤生成有用地输出。 有时,模型在回答特定问题之前需要进行详细地推理。如果您参加过我们之前的课程,您将看到许多这样的例子。有时…...
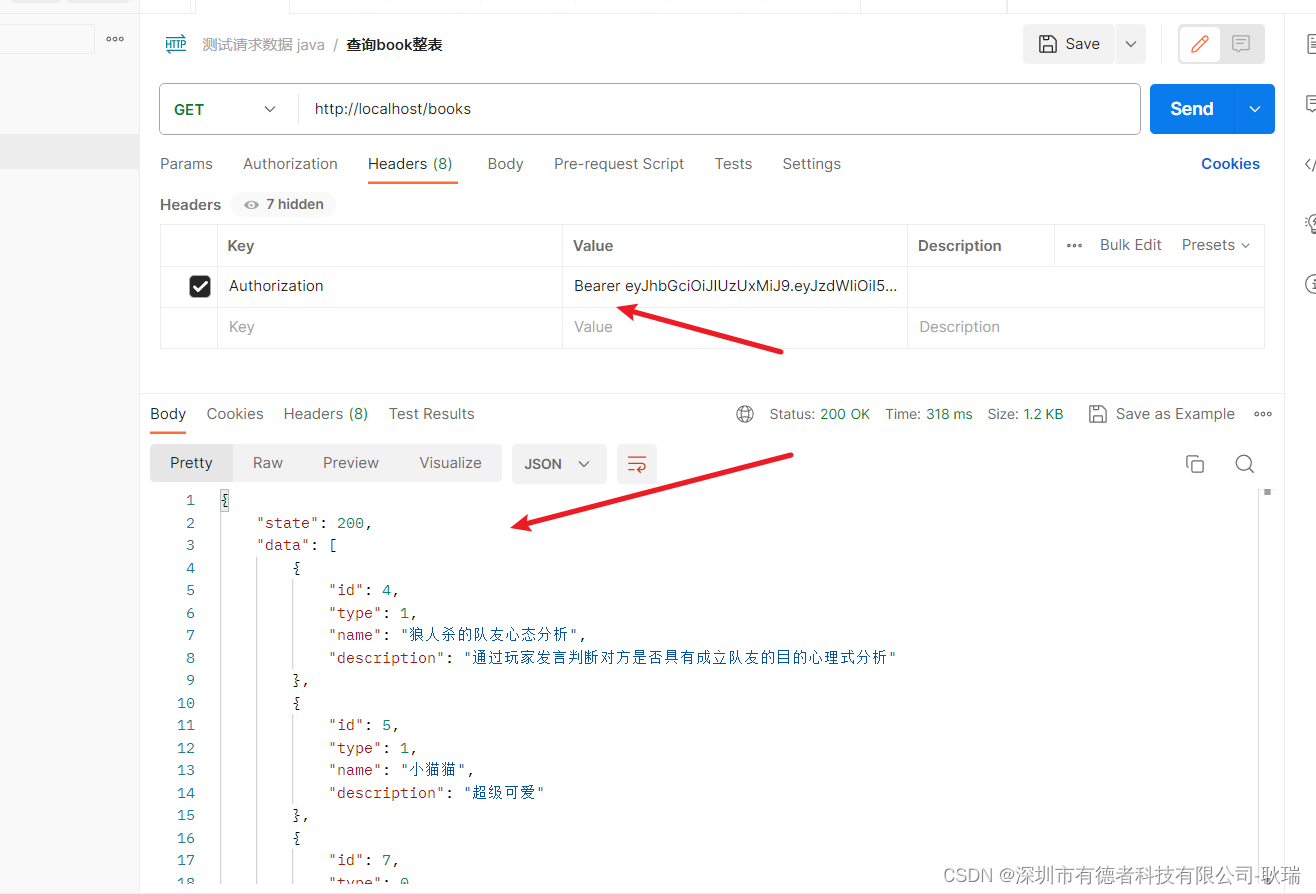
java Spring Boot RequestHeader设置请求头,当请求头中没有Authorization 直接400问题解决
我在接口中 写了一个接收请求头参数 Authorization 但是目前代理一个问题 那就是 当请求时 请求头中没有这个Authorization 就会直接因为参数不匹配 找不到指向 这里其实很简单 我们设置 value 为我们需要的字段内容 required 是否必填 我们设置为 false 就可以了 这样 没有也…...
[CISCN2019 华北赛区 Day1 Web5]CyberPunk 二次报错注入
buu上 做点 首先就是打开环境 开始信息收集 发现源代码中存在?file 提示我们多半是包含 我原本去试了试 ../../etc/passwd 失败了 直接伪协议上吧 php://filter/readconvert.base64-encode/resourceindex.phpconfirm.phpsearch.phpchange.phpdelete.php 我们通过伪协议全…...
双机并联逆变器自适应虚拟阻抗下垂控制(Droop)策略Simulink仿真模型
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...