ChatGLM2-6B微调实践
ChatGLM2-6B微调实践
- 环境准备
- 安装部署
- 1、安装 Anaconda
- 2、安装CUDA
- 3、安装PyTorch
- 4、安装 ChatGLM2-6B
- 微调实践
- 1、准备数据集
- 2、安装python依赖
- 3、微调并训练新模型
- 4、微调后模型的推理与评估
- 5、验证与使用微调后的模型
- 微调过程中遇到的问题
环境准备
申请阿里云GPU服务器:
- CentOS 7.6 64
- Anaconda3-2023.07-1-Linux-x86_64
- Python 3.11.5
- GPU NVIDIA A10(显存24 G/1 core)
- CPU 8 vCore/30G

安装部署
1、安装 Anaconda
wget https://repo.anaconda.com/archive/Anaconda3-2023.07-1-Linux-x86_64.sh
sh Anaconda3-2023.07-1-Linux-x86_64.sh
根据提示一路安装即可。
2、安装CUDA
wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run
sh cuda_11.2.0_460.27.04_linux.run
根据提示安装即可
3、安装PyTorch
conda install pytorch torchvision pytorch-cuda=11.8 -c pytorch -c nvidia
如提示找不到conda命令,需配置Anaconda环境变量。
4、安装 ChatGLM2-6B
mkdir ChatGLM
cd ChatGLM
git clone https://github.com/THUDM/ChatGLM2-6B.git
cd ChatGLM2-6B
pip install -r requirements.txt
加载模型,需要从网上下载模型的7个分片文件,总共大约10几个G大小,可提前下载。
模型下载地址:https://huggingface.co/THUDM/chatglm2-6b/tree/main
微调实践
1、准备数据集
准备我们自己的数据集,分别生成训练文件和测试文件这两个文件,放在目录 ChatGLM2-6B/ptuning/myDataset/ 下面。
训练集文件: train_file.json
测试集文件: val_file.json
2、安装python依赖
后面微调训练,需要依赖一些 Python 模块,提前安装一下:
conda install rouge_chinese nltk jieba datasets
3、微调并训练新模型
修改 train.sh 脚本文件,根据自己实际情况配置即可,修改后的配置为:
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \--do_train \--train_file myDataset/train_file.json \--validation_file myDataset/val_file.json \--preprocessing_num_workers 6 \--prompt_column content \--response_column summary \--overwrite_cache \--model_name_or_path /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b \--output_dir output/zhbr-chatglm2-6b-checkpoint \--overwrite_output_dir \--max_source_length 64 \--max_target_length 128 \--per_device_train_batch_size 6 \--per_device_eval_batch_size 6 \--gradient_accumulation_steps 16 \--predict_with_generate \--max_steps 20 \--logging_steps 5 \--save_steps 5 \--learning_rate $LR \--pre_seq_len $PRE_SEQ_LEN \--quantization_bit 4
修改完即可进行微调:
cd /root/ChatGLM/ChatGLM2-6B/ptuning/
sh train.sh
运行结果如下:
(base) [root@iZbp178u8rw9n9ko94ubbyZ ptuning]# sh train.sh
[2023-10-08 13:09:12,312] torch.distributed.run: [WARNING] master_addr is only used for static rdzv_backend and when rdzv_endpoint is not specified.
10/08/2023 13:09:15 - WARNING - __main__ - Process rank: 0, device: cuda:0, n_gpu: 1distributed training: True, 16-bits training: False
10/08/2023 13:09:15 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=False,
do_predict=False,
do_train=True,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=IntervalStrategy.NO,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
generation_config=None,
generation_max_length=None,
generation_num_beams=None,
gradient_accumulation_steps=16,
gradient_checkpointing=False,
greater_is_better=None,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=HubStrategy.EVERY_SAVE,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=0.02,
length_column_name=length,
load_best_model_at_end=False,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=output/zhbr-chatglm2-6b-checkpoint/runs/Oct08_13-09-15_iZbp178u8rw9n9ko94ubbyZ,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=5,
logging_strategy=IntervalStrategy.STEPS,
lr_scheduler_type=SchedulerType.LINEAR,
max_grad_norm=1.0,
max_steps=20,
metric_for_best_model=None,
mp_parameters=,
no_cuda=False,
num_train_epochs=3.0,
optim=OptimizerNames.ADAMW_TORCH,
optim_args=None,
output_dir=output/zhbr-chatglm2-6b-checkpoint,
overwrite_output_dir=True,
past_index=-1,
per_device_eval_batch_size=6,
per_device_train_batch_size=6,
predict_with_generate=True,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=[],
resume_from_checkpoint=None,
run_name=output/zhbr-chatglm2-6b-checkpoint,
save_on_each_node=False,
save_safetensors=False,
save_steps=5,
save_strategy=IntervalStrategy.STEPS,
save_total_limit=None,
seed=42,
sharded_ddp=[],
skip_memory_metrics=True,
sortish_sampler=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
)
10/08/2023 13:09:16 - WARNING - datasets.builder - Found cached dataset json (/root/.cache/huggingface/datasets/json/default-8e52c57dfec9ef61/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 1379.71it/s]
[INFO|configuration_utils.py:713] 2023-10-08 13:09:16,749 >> loading configuration file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/config.json
[INFO|configuration_utils.py:713] 2023-10-08 13:09:16,751 >> loading configuration file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/config.json
[INFO|configuration_utils.py:775] 2023-10-08 13:09:16,751 >> Model config ChatGLMConfig {"_name_or_path": "/root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b","add_bias_linear": false,"add_qkv_bias": true,"apply_query_key_layer_scaling": true,"apply_residual_connection_post_layernorm": false,"architectures": ["ChatGLMModel"],"attention_dropout": 0.0,"attention_softmax_in_fp32": true,"auto_map": {"AutoConfig": "configuration_chatglm.ChatGLMConfig","AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration","AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration","AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration","AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"},"bias_dropout_fusion": true,"classifier_dropout": null,"eos_token_id": 2,"ffn_hidden_size": 13696,"fp32_residual_connection": false,"hidden_dropout": 0.0,"hidden_size": 4096,"kv_channels": 128,"layernorm_epsilon": 1e-05,"model_type": "chatglm","multi_query_attention": true,"multi_query_group_num": 2,"num_attention_heads": 32,"num_layers": 28,"original_rope": true,"pad_token_id": 0,"padded_vocab_size": 65024,"post_layer_norm": true,"pre_seq_len": null,"prefix_projection": false,"quantization_bit": 0,"rmsnorm": true,"seq_length": 32768,"tie_word_embeddings": false,"torch_dtype": "float16","transformers_version": "4.32.1","use_cache": true,"vocab_size": 65024
}[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:09:16,752 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:09:16,752 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:09:16,752 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:09:16,753 >> loading file tokenizer_config.json
[INFO|modeling_utils.py:2776] 2023-10-08 13:09:16,832 >> loading weights file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/pytorch_model.bin.index.json
[INFO|configuration_utils.py:768] 2023-10-08 13:09:16,833 >> Generate config GenerationConfig {"_from_model_config": true,"eos_token_id": 2,"pad_token_id": 0,"transformers_version": "4.32.1"
}Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:05<00:00, 1.39it/s]
[INFO|modeling_utils.py:3551] 2023-10-08 13:09:21,906 >> All model checkpoint weights were used when initializing ChatGLMForConditionalGeneration.[WARNING|modeling_utils.py:3553] 2023-10-08 13:09:21,906 >> Some weights of ChatGLMForConditionalGeneration were not initialized from the model checkpoint at /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b and are newly initialized: ['transformer.prefix_encoder.embedding.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
[INFO|modeling_utils.py:3136] 2023-10-08 13:09:21,908 >> Generation config file not found, using a generation config created from the model config.
Quantized to 4 bit
input_ids [64790, 64792, 790, 30951, 517, 30910, 30939, 30996, 13, 13, 54761, 31211, 55046, 54766, 36989, 38724, 54643, 31962, 13, 13, 55437, 31211, 30910, 30939, 31201, 54675, 54592, 33933, 31211, 31779, 32804, 51962, 31201, 39510, 57517, 56689, 31201, 48981, 57486, 55014, 31201, 55568, 56528, 55082, 54831, 54609, 54659, 30943, 31201, 35066, 54642, 36989, 31211, 31779, 35066, 54642, 56042, 55662, 31201, 54539, 56827, 31201, 55422, 54639, 55534, 31201, 33576, 57062, 54848, 31201, 55662, 55816, 41670, 39305, 33760, 36989, 54659, 30966, 31201, 32531, 31838, 54643, 31668, 31687, 31211, 31779, 32531, 31838, 33853, 31201, 32077, 43641, 31201, 54933, 55194, 32366, 32531, 49729, 39305, 33760, 36989, 54659, 30972, 31201, 31641, 48655, 31211, 31779, 36293, 54535, 32155, 31201, 45561, 54585, 31940, 54535, 32155, 31201, 54962, 55478, 54535, 32155, 54609, 31641, 31746, 31639, 31123, 32023, 54603, 36989, 55045, 58286, 49539, 31639, 31123, 36128, 33423, 32077, 36989, 31155, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
inputs [Round 1]问:配网故障类别及原因答: 1、外力破坏:包括车辆撞击、树木刮擦、风筝坠落、倒杆断线等;2、季节性故障:包括季节性覆冰、大雾、雨加雪、温度骤变、冰灾等因素导致的线路故障;3、施工质量及技术方面:包括施工质量不良、设备老化、未按规范施工等原因导致的线路故障;4、管理不到位:包括巡视不及时、发现问题后处理不及时、消缺不及时等管理上的问题,导致小故障积攒成大问题,进而引发设备故障。
label_ids [-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 30910, 30939, 31201, 54675, 54592, 33933, 31211, 31779, 32804, 51962, 31201, 39510, 57517, 56689, 31201, 48981, 57486, 55014, 31201, 55568, 56528, 55082, 54831, 54609, 54659, 30943, 31201, 35066, 54642, 36989, 31211, 31779, 35066, 54642, 56042, 55662, 31201, 54539, 56827, 31201, 55422, 54639, 55534, 31201, 33576, 57062, 54848, 31201, 55662, 55816, 41670, 39305, 33760, 36989, 54659, 30966, 31201, 32531, 31838, 54643, 31668, 31687, 31211, 31779, 32531, 31838, 33853, 31201, 32077, 43641, 31201, 54933, 55194, 32366, 32531, 49729, 39305, 33760, 36989, 54659, 30972, 31201, 31641, 48655, 31211, 31779, 36293, 54535, 32155, 31201, 45561, 54585, 31940, 54535, 32155, 31201, 54962, 55478, 54535, 32155, 54609, 31641, 31746, 31639, 31123, 32023, 54603, 36989, 55045, 58286, 49539, 31639, 31123, 36128, 33423, 32077, 36989, 31155, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100]
labels 1、外力破坏:包括车辆撞击、树木刮擦、风筝坠落、倒杆断线等;2、季节性故障:包括季节性覆冰、大雾、雨加雪、温度骤变、冰灾等因素导致的线路故障;3、施工质量及技术方面:包括施工质量不良、设备老化、未按规范施工等原因导致的线路故障;4、管理不到位:包括巡视不及时、发现问题后处理不及时、消缺不及时等管理上的问题,导致小故障积攒成大问题,进而引发设备故障。
[INFO|trainer.py:565] 2023-10-08 13:09:26,290 >> max_steps is given, it will override any value given in num_train_epochs
[INFO|trainer.py:1714] 2023-10-08 13:09:26,460 >> ***** Running training *****
[INFO|trainer.py:1715] 2023-10-08 13:09:26,460 >> Num examples = 17
[INFO|trainer.py:1716] 2023-10-08 13:09:26,460 >> Num Epochs = 20
[INFO|trainer.py:1717] 2023-10-08 13:09:26,460 >> Instantaneous batch size per device = 6
[INFO|trainer.py:1720] 2023-10-08 13:09:26,460 >> Total train batch size (w. parallel, distributed & accumulation) = 96
[INFO|trainer.py:1721] 2023-10-08 13:09:26,460 >> Gradient Accumulation steps = 16
[INFO|trainer.py:1722] 2023-10-08 13:09:26,460 >> Total optimization steps = 20
[INFO|trainer.py:1723] 2023-10-08 13:09:26,460 >> Number of trainable parameters = 1,835,0080%| | 0/20 [00:00<?, ?it/s]10/08/2023 13:09:26 - WARNING - transformers_modules.chatglm2-6b.modeling_chatglm - `use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.warnings.warn(
{'loss': 0.5058, 'learning_rate': 0.015, 'epoch': 5.0} 25%|██████████████████████████████████████████████▎ | 5/20 [00:21<00:56, 3.77s/it]Saving PrefixEncoder
[INFO|configuration_utils.py:460] 2023-10-08 13:09:47,797 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/config.json
[INFO|configuration_utils.py:544] 2023-10-08 13:09:47,797 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/generation_config.json
[INFO|modeling_utils.py:1953] 2023-10-08 13:09:47,805 >> Model weights saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/pytorch_model.bin
[INFO|tokenization_utils_base.py:2235] 2023-10-08 13:09:47,805 >> tokenizer config file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/tokenizer_config.json
[INFO|tokenization_utils_base.py:2242] 2023-10-08 13:09:47,807 >> Special tokens file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/special_tokens_map.json
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.warnings.warn(
{'loss': 0.2925, 'learning_rate': 0.01, 'epoch': 9.0} 50%|████████████████████████████████████████████████████████████████████████████████████████████ | 10/20 [00:34<00:31, 3.17s/it]Saving PrefixEncoder
[INFO|configuration_utils.py:460] 2023-10-08 13:10:01,413 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/config.json
[INFO|configuration_utils.py:544] 2023-10-08 13:10:01,413 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/generation_config.json
[INFO|modeling_utils.py:1953] 2023-10-08 13:10:01,419 >> Model weights saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/pytorch_model.bin
[INFO|tokenization_utils_base.py:2235] 2023-10-08 13:10:01,420 >> tokenizer config file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/tokenizer_config.json
[INFO|tokenization_utils_base.py:2242] 2023-10-08 13:10:01,420 >> Special tokens file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/special_tokens_map.json
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.warnings.warn(
{'loss': 0.2593, 'learning_rate': 0.005, 'epoch': 13.0} 75%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 15/20 [00:48<00:14, 2.93s/it]Saving PrefixEncoder
[INFO|configuration_utils.py:460] 2023-10-08 13:10:15,139 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/config.json
[INFO|configuration_utils.py:544] 2023-10-08 13:10:15,139 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/generation_config.json
[INFO|modeling_utils.py:1953] 2023-10-08 13:10:15,146 >> Model weights saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/pytorch_model.bin
[INFO|tokenization_utils_base.py:2235] 2023-10-08 13:10:15,146 >> tokenizer config file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/tokenizer_config.json
[INFO|tokenization_utils_base.py:2242] 2023-10-08 13:10:15,146 >> Special tokens file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/special_tokens_map.json
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.warnings.warn(
{'loss': 0.3026, 'learning_rate': 0.0, 'epoch': 18.0}
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [01:05<00:00, 3.35s/it]Saving PrefixEncoder
[INFO|configuration_utils.py:460] 2023-10-08 13:10:32,333 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/config.json
[INFO|configuration_utils.py:544] 2023-10-08 13:10:32,333 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/generation_config.json
[INFO|modeling_utils.py:1953] 2023-10-08 13:10:32,340 >> Model weights saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/pytorch_model.bin
[INFO|tokenization_utils_base.py:2235] 2023-10-08 13:10:32,340 >> tokenizer config file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/tokenizer_config.json
[INFO|tokenization_utils_base.py:2242] 2023-10-08 13:10:32,340 >> Special tokens file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/special_tokens_map.json
[INFO|trainer.py:1962] 2023-10-08 13:10:32,354 >> Training completed. Do not forget to share your model on huggingface.co/models =){'train_runtime': 65.8941, 'train_samples_per_second': 29.138, 'train_steps_per_second': 0.304, 'train_loss': 0.3400604248046875, 'epoch': 18.0}
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [01:05<00:00, 3.29s/it]
***** train metrics *****epoch = 18.0train_loss = 0.3401train_runtime = 0:01:05.89train_samples = 17train_samples_per_second = 29.138train_steps_per_second = 0.304
4、微调后模型的推理与评估
对微调后的模型进行评估验证,修改 evaluate.sh 脚本中的 checkpoint 目录:
PRE_SEQ_LEN=128
CHECKPOINT=zhbr-chatglm2-6b-checkpoint
STEP=20
NUM_GPUS=1torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \--do_predict \--validation_file myDataset/train_file.json \--test_file myDataset/val_file.json \--overwrite_cache \--prompt_column content \--response_column summary \--model_name_or_path /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b \--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \--output_dir ./output/$CHECKPOINT \--overwrite_output_dir \--max_source_length 64 \--max_target_length 64 \--per_device_eval_batch_size 1 \--predict_with_generate \--pre_seq_len $PRE_SEQ_LEN \--quantization_bit 4
对微调后的模型进行推理和评估:
/root/ChatGLM/ChatGLM2-6B/ptuning/
sh evaluate.sh
运行结果如下:
(base) [root@iZbp178u8rw9n9ko94ubbyZ ptuning]# sh evaluate.sh
[2023-10-08 13:19:53,448] torch.distributed.run: [WARNING] master_addr is only used for static rdzv_backend and when rdzv_endpoint is not specified.
10/08/2023 13:19:56 - WARNING - __main__ - Process rank: 0, device: cuda:0, n_gpu: 1distributed training: True, 16-bits training: False
10/08/2023 13:19:56 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=False,
do_predict=True,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=IntervalStrategy.NO,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
generation_config=None,
generation_max_length=None,
generation_num_beams=None,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
greater_is_better=None,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=HubStrategy.EVERY_SAVE,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=5e-05,
length_column_name=length,
load_best_model_at_end=False,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=./output/zhbr-chatglm2-6b-checkpoint/runs/Oct08_13-19-56_iZbp178u8rw9n9ko94ubbyZ,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=500,
logging_strategy=IntervalStrategy.STEPS,
lr_scheduler_type=SchedulerType.LINEAR,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=None,
mp_parameters=,
no_cuda=False,
num_train_epochs=3.0,
optim=OptimizerNames.ADAMW_TORCH,
optim_args=None,
output_dir=./output/zhbr-chatglm2-6b-checkpoint,
overwrite_output_dir=True,
past_index=-1,
per_device_eval_batch_size=1,
per_device_train_batch_size=8,
predict_with_generate=True,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=[],
resume_from_checkpoint=None,
run_name=./output/zhbr-chatglm2-6b-checkpoint,
save_on_each_node=False,
save_safetensors=False,
save_steps=500,
save_strategy=IntervalStrategy.STEPS,
save_total_limit=None,
seed=42,
sharded_ddp=[],
skip_memory_metrics=True,
sortish_sampler=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
)
Downloading and preparing dataset json/default to /root/.cache/huggingface/datasets/json/default-98f5c44ca2dd481e/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4...
Downloading data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 17623.13it/s]
Extracting data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 3012.07it/s]
Dataset json downloaded and prepared to /root/.cache/huggingface/datasets/json/default-98f5c44ca2dd481e/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4. Subsequent calls will reuse this data.
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 1488.66it/s]
[INFO|configuration_utils.py:713] 2023-10-08 13:19:57,908 >> loading configuration file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/config.json
[INFO|configuration_utils.py:713] 2023-10-08 13:19:57,909 >> loading configuration file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/config.json
[INFO|configuration_utils.py:775] 2023-10-08 13:19:57,910 >> Model config ChatGLMConfig {"_name_or_path": "/root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b","add_bias_linear": false,"add_qkv_bias": true,"apply_query_key_layer_scaling": true,"apply_residual_connection_post_layernorm": false,"architectures": ["ChatGLMModel"],"attention_dropout": 0.0,"attention_softmax_in_fp32": true,"auto_map": {"AutoConfig": "configuration_chatglm.ChatGLMConfig","AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration","AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration","AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration","AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"},"bias_dropout_fusion": true,"classifier_dropout": null,"eos_token_id": 2,"ffn_hidden_size": 13696,"fp32_residual_connection": false,"hidden_dropout": 0.0,"hidden_size": 4096,"kv_channels": 128,"layernorm_epsilon": 1e-05,"model_type": "chatglm","multi_query_attention": true,"multi_query_group_num": 2,"num_attention_heads": 32,"num_layers": 28,"original_rope": true,"pad_token_id": 0,"padded_vocab_size": 65024,"post_layer_norm": true,"pre_seq_len": null,"prefix_projection": false,"quantization_bit": 0,"rmsnorm": true,"seq_length": 32768,"tie_word_embeddings": false,"torch_dtype": "float16","transformers_version": "4.32.1","use_cache": true,"vocab_size": 65024
}[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:19:57,911 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:19:57,911 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:19:57,911 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:19:57,911 >> loading file tokenizer_config.json
[INFO|modeling_utils.py:2776] 2023-10-08 13:19:57,988 >> loading weights file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/pytorch_model.bin.index.json
[INFO|configuration_utils.py:768] 2023-10-08 13:19:57,989 >> Generate config GenerationConfig {"_from_model_config": true,"eos_token_id": 2,"pad_token_id": 0,"transformers_version": "4.32.1"
}Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.41it/s]
[INFO|modeling_utils.py:3551] 2023-10-08 13:20:02,988 >> All model checkpoint weights were used when initializing ChatGLMForConditionalGeneration.[WARNING|modeling_utils.py:3553] 2023-10-08 13:20:02,988 >> Some weights of ChatGLMForConditionalGeneration were not initialized from the model checkpoint at /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b and are newly initialized: ['transformer.prefix_encoder.embedding.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
[INFO|modeling_utils.py:3136] 2023-10-08 13:20:02,989 >> Generation config file not found, using a generation config created from the model config.
Quantized to 4 bit
input_ids [64790, 64792, 790, 30951, 517, 30910, 30939, 30996, 13, 13, 54761, 31211, 55046, 54848, 55623, 55279, 36989, 13, 13, 55437, 31211]
inputs [Round 1]问:配变雷击故障答:
label_ids [64790, 64792, 30910, 55623, 54710, 31921, 55279, 54538, 55046, 38754, 33760, 54746, 32077, 31123, 32023, 33760, 41711, 31201, 32077, 55870, 56544, 35978, 31155]
labels 雷电直接击中配电网线路或设备,导致线路损坏、设备烧毁等问题。
10/08/2023 13:20:06 - INFO - __main__ - *** Predict ***
[INFO|trainer.py:3119] 2023-10-08 13:20:06,946 >> ***** Running Prediction *****
[INFO|trainer.py:3121] 2023-10-08 13:20:06,946 >> Num examples = 2
[INFO|trainer.py:3124] 2023-10-08 13:20:06,946 >> Batch size = 1
[INFO|configuration_utils.py:768] 2023-10-08 13:20:06,949 >> Generate config GenerationConfig {"_from_model_config": true,"eos_token_id": 2,"pad_token_id": 0,"transformers_version": "4.32.1"
}0%| | 0/2 [00:00<?, ?it/s][INFO|configuration_utils.py:768] 2023-10-08 13:20:11,223 >> Generate config GenerationConfig {"_from_model_config": true,"eos_token_id": 2,"pad_token_id": 0,"transformers_version": "4.32.1"
}100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:01<00:00, 1.09it/s]Building prefix dict from the default dictionary ...
10/08/2023 13:20:13 - DEBUG - jieba - Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
10/08/2023 13:20:13 - DEBUG - jieba - Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.440 seconds.
10/08/2023 13:20:13 - DEBUG - jieba - Loading model cost 0.440 seconds.
Prefix dict has been built successfully.
10/08/2023 13:20:13 - DEBUG - jieba - Prefix dict has been built successfully.
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.14s/it]
***** predict metrics *****predict_bleu-4 = 10.9723predict_rouge-1 = 44.0621predict_rouge-2 = 11.9047predict_rouge-l = 33.5968predict_runtime = 0:00:06.56predict_samples = 2predict_samples_per_second = 0.305predict_steps_per_second = 0.305
5、验证与使用微调后的模型
方法一:
编写python脚本,加载微调训练后生成的 Checkpoint 路径:
from transformers import AutoConfig, AutoModel, AutoTokenizer
import os
import torch
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
config = AutoConfig.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join("./output/zhbr-chatglm2-6b-checkpoint/checkpoint-20", "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():if k.startswith("transformer.prefix_encoder."):new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)# Comment out the following line if you don't use quantization
model = model.quantize(4) #或者8
model = model.half().cuda()
model.transformer.prefix_encoder.float()
model = model.eval()response, history = model.chat(tokenizer, "配网线路故障有哪些", history=[])
print(response)
方法二:
修改ptuning中的web_demo.sh,根据自己实际情况配置:
PRE_SEQ_LEN=128CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \--model_name_or_path /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b \--ptuning_checkpoint output/zhbr-chatglm2-6b-checkpoint/checkpoint-20 \--pre_seq_len $PRE_SEQ_LEN
执行web_demo.sh,访问http://xxx.xxx.xxx.xxx:7860。
(base) [root@iZbp178u8rw9n9ko94ubbyZ ptuning]# sh web_demo.sh
/root/ChatGLM/ChatGLM2-6B-main/ptuning/web_demo.py:101: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(
Loading prefix_encoder weight from output/zhbr-chatglm2-6b-checkpoint/checkpoint-20
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.47it/s]
Some weights of ChatGLMForConditionalGeneration were not initialized from the model checkpoint at /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b and are newly initialized: ['transformer.prefix_encoder.embedding.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Running on local URL: http://127.0.0.1:7860To create a public link, set `share=True` in `launch()`.
微调过程中遇到的问题
报错信息如下:
dataclasses.FrozenInstanceError: cannot assign to field generation_max_length
和
dataclasses.FrozenInstanceError: cannot assign to field generation_num_beams
解决方法:
在main.py文件中注释掉以下代码。

相关文章:
ChatGLM2-6B微调实践
ChatGLM2-6B微调实践 环境准备安装部署1、安装 Anaconda2、安装CUDA3、安装PyTorch4、安装 ChatGLM2-6B 微调实践1、准备数据集2、安装python依赖3、微调并训练新模型4、微调后模型的推理与评估5、验证与使用微调后的模型 微调过程中遇到的问题 环境准备 申请阿里云GPU服务器&…...

YOLOv7独家改进FPN系列:结合新颖的 GhostSlimPAN 范式网络结构,进一步提升检测器性能
💡本篇内容:YOLOv7改进FPN系列:结合新颖的 GhostSlimFPN 范式网络结构,进一步提升检测器性能 重点:🔥🔥🔥YOLOv7 使用这个 核心创新点 在数据集改进做实验:即插即用: 当 Slim 遇到 YOLO 系列 💡🚀🚀🚀本博客 YOLO系列 + 改进源代码改进 适用于 YOLOv7…...
12. Java异常及异常处理处理
Java —— 异常及处理 1. 异常2. 异常体系3. 常见Exception4. 异常处理4.1 try finally catch关键字4.2 throws和throw 自定义异常4.3 finally,final,finalize三者的区别 1. 异常 异常:在程序执行过程中发生的意外状况,可能导致程…...

自定义hooks函数
体会1 1、js文件中定义useXX函数 export function usetestY() {const count ref(10);const doubleCount computed(() > count.value * 2);return {count,doubleCount,}; } 2、在vue文件中使用useXX函数 import { usetestY } from ./data;const { count, doubleCount } …...
Linux系统及Docker安装RabbitMq
目录 一、linux系统安装 1、上传文件 2、在线安装依赖环境 3、安装Erlang 4、安装RabbitMQ 5、开启管理界面及配置 6、启动 7、删除mq 二、docker安装 1、上传mq.tar包或使用命令拉取镜像 2、启动并运行 3、访问mq 一、linux系统安装 1、上传文件 2、在线安装依赖环…...

山东省赛二阶段第一部分解题思路
提交攻击者的IP地址 192.168.1.7 这个直接awk过滤一下ip次数,这个ip多得离谱,在日志里面也发现了它的恶意行为,后门,反弹shell 识别攻击者使用的操作系统 Linux 找出攻击者资产收集所使用的平台 shodan 提交攻击者目…...
WebGoat 靶场 JWT tokens 四 五 七关通关教程
文章目录 webGoat靶场第 四 关 修改投票数第五关第七关 你购买书,让Tom用户付钱 webGoat靶场 越权漏洞 将webgoat-server-8.1.0.jar复制到kali虚拟机中 sudo java -jar webgoat-server-8.1.0.jar --server.port8888解释: java:这是用于执行…...

【单元测试】如何使用 JUnit5 框架?
JUnit5 单元测试框架使用教程 一、Junit5 是什么? Junit5是一个用于在Java平台上进行单元测试的框架。JUnit 5 框架主要由三部分组成:JUnit Platform、JUnit Jupiter 和 JUnit Vintage。 JUnit Platform:定义了测试引擎的 API,是…...

C#封装、继承和多态的用法详解
大家好,今天我们将来详细探讨一下C#中封装、继承和多态的用法。作为C#的三大面向对象的特性,这些概念对于程序员来说非常重要,因此我们将对每个特性进行详细的说明,并提供相应的示例代码。 目录 1. 封装(Encapsulati…...

数据结构与算法(持续更新)
线性表 单链表 单链表的定义 由于顺序表的插入删除操作需要移动大量的元素,影响了运行效率,因此引入了线性表的链式存储——单链表。单链表通过一组任意的存储单元来存储线性表中的数据元素,不需要使用地址连续的存储单元,因此它…...
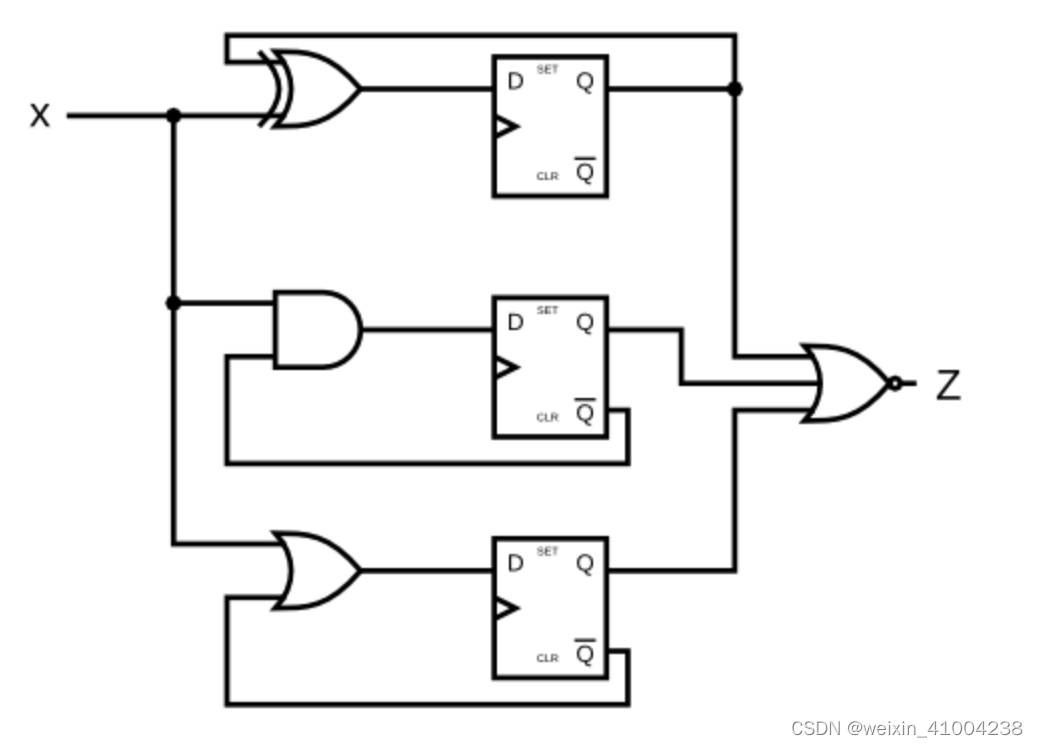
HDLbits: ece241 2014 q4
module top_module (input clk,input x,output z ); reg [2:0] Q;always(posedge clk)beginQ[0] < Q[0] ^ x;Q[1] < (~Q[1]) & x;Q[2] < (~Q[2]) | x;z < ~(| Q[2:0]); //错误!!!!endendmodule 正确答案…...
-- gmssl - 国密算法)
LuatOS-SOC接口文档(air780E)-- gmssl - 国密算法
sm.sm2encrypt(pkx,pky,data)# sm2算法加密 参数 传入值类型 解释 string 公钥x,必选 string 公钥y,必选 string 待计算的数据,必选,最长255字节 返回值 返回值类型 解释 string 加密后的字符串, 原样输出,未经HEX转换 例子 local originStr "encryptio…...

【线性代数及其应用 —— 第一章 线性代数中的线性方程组】-1.线性方程组
所有笔记请看: 博客学习目录_Howe_xixi的博客-CSDN博客https://blog.csdn.net/weixin_44362628/article/details/126020573?spm1001.2014.3001.5502思维导图如下: 内容笔记如下:...
vue实现拖拽排序
在业务中列表拖拽排序是比较常见的需求,常见的JS拖拽库有Sortable.js,Vue.Draggable等,大多数同学遇到这种需求也是更多的求助于这些JS库,其实,使用HTML原生的拖放事件来实现拖拽排序并不复杂,结合Vue的tra…...
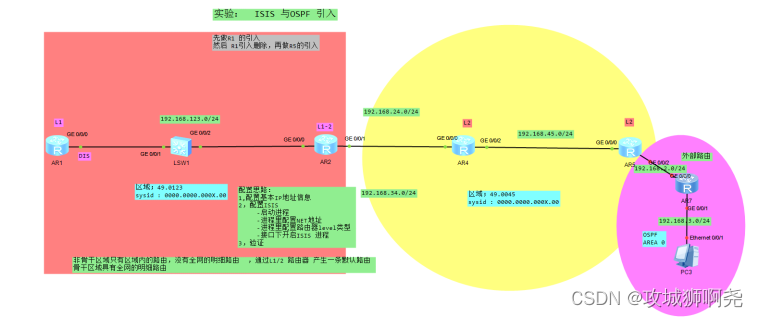
IS-IS
二、IS-IS中的DIS与OSPF中的DR Level-1和Level-2的DIS是分别选举的,用户可以为不同级别的DIS选举设置不同的优先级。DIS的选举规则如下:DIS优先级数值最大的被选为DIS。如果优先级数值最大的路由器有多台,则其中MAC地址最大的路由器会成为DI…...
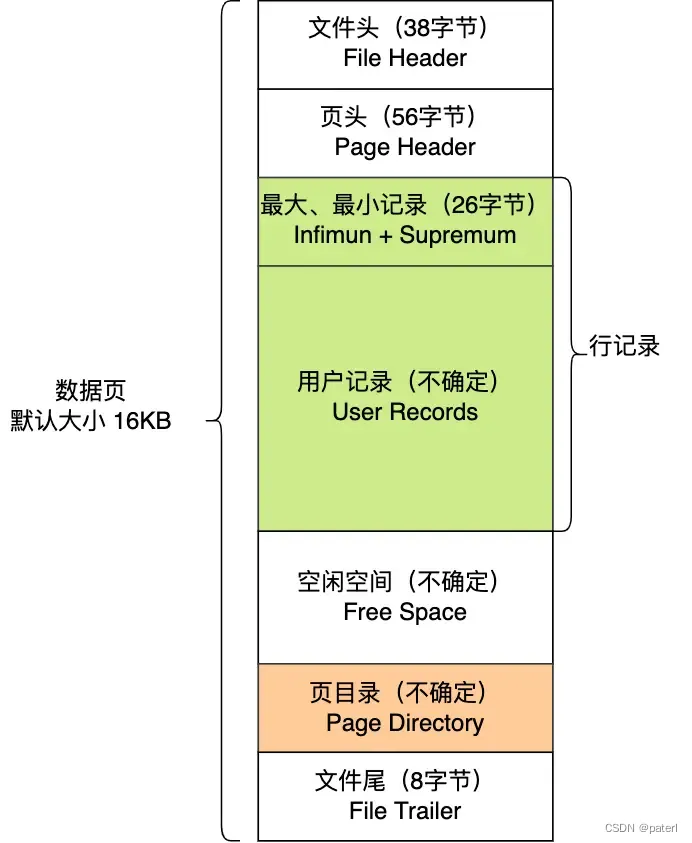
【MySQL】为什么使用B+树做索引
MySQL的innoDB引擎使用的是B树的结构来存储索引的,那么为什么会使用B树呢?为什么不使用其他的结构?本篇我们深入MySQL底层来了解B树。本文中说到的MySQL都是InnoDB引擎的 在这之前,先了解一下InnoDB是如何存储数据的 MySQL是根据数据页的方式…...
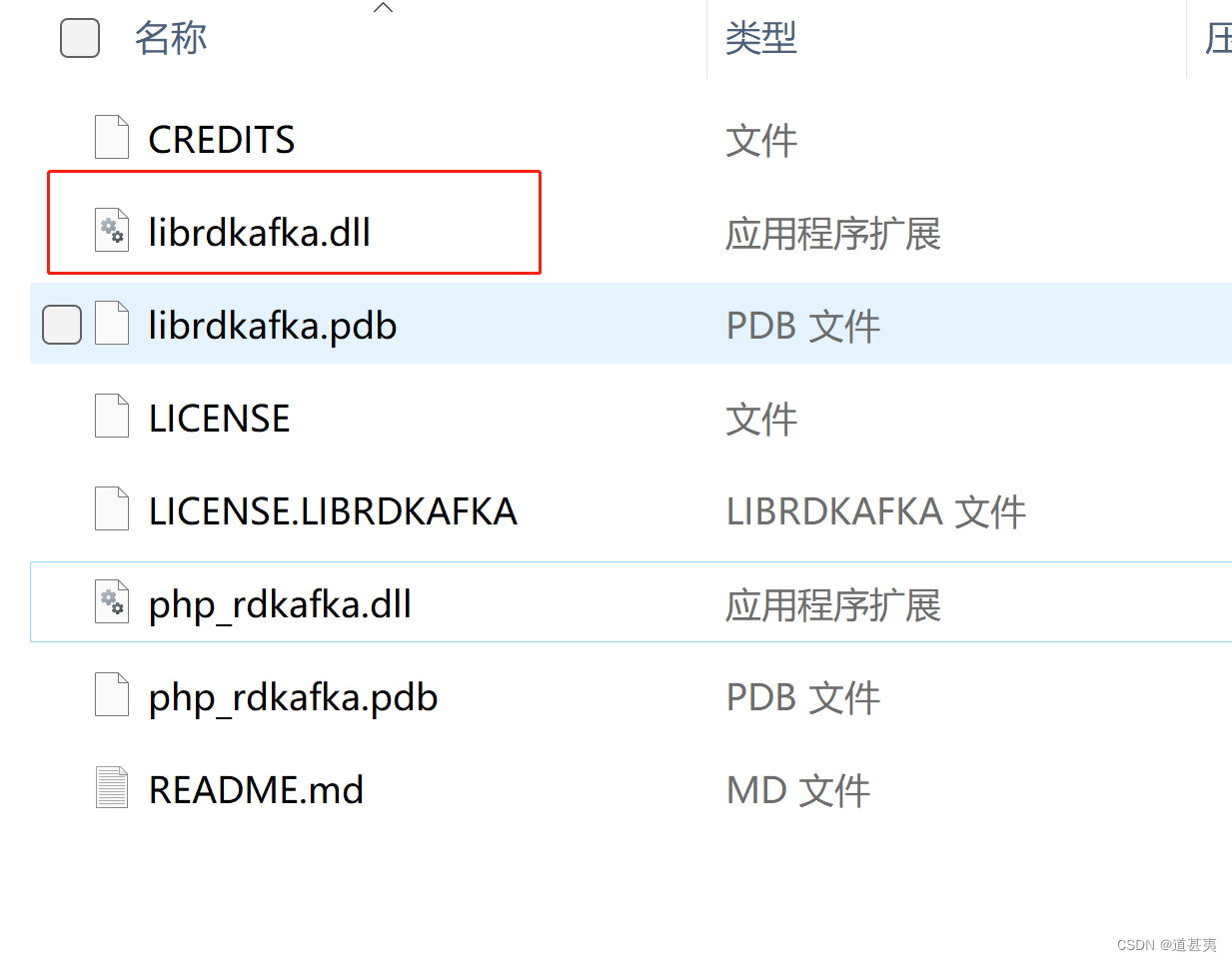
php 安装mongodb扩展模块,rdkafka模块
mongodb mongodb扩展下载 选择php版本,根据报错提示,选择扩展对应的版本选择非安全进程将php_mongodb.dll放到php/ext目录下修改php.ini配置,添加extensionphp_mongodb.dll开启php_mongodb扩展,重启服务php -m 查看是否开启成功…...

【数据结构】初探时间与空间复杂度:算法评估与优化的基础
🚩纸上得来终觉浅, 绝知此事要躬行。 🌟主页:June-Frost 🚀专栏:数据结构 🔥该文章主要了解算法的时间复杂度与空间复杂度等相关知识。 目录: 🌏 时间复杂度🔭…...

SpringCloud Alibaba - Sentinel 限流规则(案例 + JMeter 测试分析)
目录 一、Sentinel 限流规则 1.1、簇点链路 1.2、流控模式 1.2.1、直接流控模式 1.2.2、关联流控模式 a)在 OrderController 中新建两个端点. b)在 Sentinel 控制台中对订单查询端点进行流控 c)使用 JMeter 进行测试 d)分…...

uniapp 条件编译 APP 、 H5 、 小程序
一、#ifdef、#ifndef、 #endif三者的区别、 标识作用#ifdef仅在某个平台上使用#ifndef在除了这个平台的其他平台上使用(非此平台使用)#endif结束条件编译 二、平台标识 标识平台APP-PLUS5AppMP微信小程序/支付宝小程序/百度小程序/头条小程序/QQ小程序MP-WEIXIN微…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...