分布式主键算法
目录
- 一、引言
- 二、常见算法介绍
- 雪花算法(Snowflake Algorithm)
- 特性
- 详解
- 优势
- 劣势
- UUID(Universally Unique Identifier)
- 特性
- 详解
- 优势
- 劣势
- 数据库自增主键
- 特性
- 详解
- 优势
- 劣势
- 分布式数据库的序列(Sequence)
- 特性
- 详解
- 优势
- 劣势
- 基于数据库的分布式唯一ID生成服务
- 特性
- 详解
- 优势
- 劣势
- 三、重点算法总结
- 1.雪花算法详解
- 2. 雪花算法的结构
- 3. 雪花算法的工作原理
- 4. 优点和限制
- 5. 示例
- 6. 总结
一、引言
分布式主键算法的产生背景主要在于分布式系统的需求。在分布式系统中,由于多个节点同时进行操作,需要有一种机制来确保全局唯一性,避免发生冲突。这种机制就是分布式主键算法。
在互联网行业中,新开的项目基本都需要进行分库分表,这就需要在不同的表或库中生成的ID都是全局唯一的。此外,对于大型互联网应用来说,除了数据库表的分片外,还需要考虑如何设计能支持高并发、高可用性的分布式系统。
在这种情况下,分布式主键算法就变得非常重要。它们可以生成全局唯一的ID,这些ID不仅可以在多个表或库之间进行区分,还可以用于构建分布式系统的唯一标识符。
二、常见算法介绍
雪花算法(Snowflake Algorithm)
特性
简单高效:雪花算法是一种相对简单且高效的算法,易于实现。
全局唯一:生成的ID在分布式环境中是全局唯一的。
有序性:ID的生成是有序的,有助于提高数据库索引性能。
详解
雪花算法将一个64位的整数ID分为三个部分:时间戳、机器ID和序列号。其中,时间戳占用了41位,机器ID占用了10位,序列号占用了12位。算法的工作原理如下:
时间戳部分记录了生成ID的时间,通常是从系统启动时开始计算的毫秒数。这意味着雪花算法可以在69年内生成不重复的ID。
机器ID标识了不同的分布式节点,最多可以有1024个不同的节点。
序列号部分用于确保在同一毫秒内生成的ID不会重复。如果在同一毫秒内生成多个ID,序列号部分会自增。
这三个部分的组合确保了雪花算法生成的ID在分布式环境中是唯一且有序的。
优势
高性能:雪花算法生成ID的性能很高,适用于高吞吐量的系统。
相对简单:算法本身相对简单,不需要依赖外部服务。
劣势
时钟同步性要求:算法依赖于时钟同步,如果系统时钟回退可能导致ID重复。
有限的机器ID数:机器ID的位数限制了可分配的机器数量。
UUID(Universally Unique Identifier)
特性
全球唯一:UUID是全球唯一的,不同系统生成的UUID也不会冲突。
分散性:UUID的生成不需要中心化控制,各个节点可以独立生成。
详解
UUID是128位的全局唯一标识符,通常表示为36个字符的字符串。它的生成不依赖于中心化控制,可以在不同的系统中生成。UUID的生成通常基于随机数或基于MAC地址和时间戳等信息。由于其全局唯一性,UUID在跨系统集成和数据交换中很有用。
优势
全局唯一性:UUID在全球范围内保持唯一。
无需中心化服务:不需要依赖中心化的ID生成服务。
劣势
较大的存储空间:UUID通常是128位的,相比于64位的雪花ID,占用更多的存储空间。
不适合按时间排序:UUID的生成不依赖于时间戳,因此不适合按时间排序的场景。
数据库自增主键
特性
数据库依赖:生成主键依赖于数据库的自增主键机制。
顺序性:生成的主键是有序递增的,有助于提高数据库性能。
详解
在关系型数据库中,可以使用自增主键列来生成唯一标识符。这种方法需要确保分布式系统中不同节点使用不同的数据库,并且需要数据库引擎的支持。数据库自增主键通常是整数或长整数,它们在插入新数据时会自动递增,保证了唯一性和顺序性。
优势
可靠性:数据库自增主键是数据库引擎控制的,保证了唯一性。
易于维护:不需要额外的分布式算法,易于维护和管理。
劣势
数据库压力:高并发情况下,数据库可能成为性能瓶颈。
不适用于多数据库:在多个数据库实例上生成唯一ID可能需要复杂的配置。
分布式数据库的序列(Sequence)
特性
数据库依赖:依赖于支持序列对象的分布式数据库。
顺序性:生成的序列号是有序的。
详解
一些分布式数据库(如Oracle)支持序列对象,可以用来生成全局唯一的序列号。这种方法需要数据库的支持,并且需要确保分布式系统中的不同节点都能访问到同一数据库实例。序列号是由数据库引擎控制的,保证了唯一性和有序性。
优势
可靠性:分布式数据库控制序列的生成,保证唯一性。
适用于多数据库:可以在多个分布式数据库实例上使用。
劣势
数据库依赖性:需要依赖特定类型的分布式数据库。
配置复杂:配置和管理分布式数据库可能较为复杂。
基于数据库的分布式唯一ID生成服务
特性
高可用性:这些服务通常具有高可用性和容错性。
可配置性:可以根据需求配置不同的ID生成规则。
详解
一些公司使用分布式的ID生成服务,例如Twitter的Snowflake服务或美团点评的Leaf服务。这些服务提供了高性能和高可用性的分布式ID生成,通常基于自定义的算法。
优势
高可用性:这些服务通常具有高可用性,不易发生单点故障。
高性能:专门优化的服务通常具有出色的性能。
劣势
引入外部依赖:需要依赖外部服务,增加了系统的复杂性。
配置和维护成本:需要配置和维护分布式ID生成服务。
三、重点算法总结
1.雪花算法详解
雪花算法(Snowflake Algorithm)是一种用于分布式系统中生成唯一标识符的算法,由Twitter开发。它通过将一个64位的整数ID分为不同的部分,确保在分布式环境中生成的ID不会重复。本文将详细介绍雪花算法的工作原理和结构。
2. 雪花算法的结构
雪花算法的生成的64位整数ID被分为三个部分,每一部分表示不同的信息,如下所示:
sql| 时间戳 (41位) | 机器ID (10位) | 序列号 (12位) |
以下是各个部分的详细解释:
- 时间戳 (41位):时间戳占据了ID的高41位,通常是从系统启动开始计算的毫秒数。这意味着雪花算法可以在69年内生成不重复的ID(2^41毫秒约等于69年)。
- 机器ID (10位):机器ID用于标识不同的分布式机器。每台机器都必须有一个唯一的机器ID,通常在部署前分配。这意味着最多可以有1024个不同的机器。
- 序列号 (12位):序列号用于确保在同一毫秒内生成的ID不会重复。如果在同一毫秒内生成多个ID,序列号部分会自增,从0开始,最大可达4095。
3. 雪花算法的工作原理
雪花算法的工作原理如下:
- 当一个新的ID被生成时,算法会记录当前的时间戳(以毫秒为单位)。
- 如果当前时间与上次生成ID的时间相同,会在序列号部分自增。
- 如果序列号达到了最大值(4095),则会等待下一毫秒,以确保不会生成重复的ID。
- 如果当前时间与上次生成ID的时间不同,序列号重置为0。
- 然后,将各部分的值组合起来,生成一个64位的唯一ID。
4. 优点和限制
优点:
- 全局唯一性:雪花算法生成的ID在分布式环境中是全局唯一的,不会发生重复。
- 有序性:生成的ID具有有序性,有助于提高数据库检索性能。
- 高性能:算法的实现相对简单,生成ID的性能很高。
限制:
- 时钟同步性要求:雪花算法依赖于时钟同步,如果系统时钟回退可能会导致ID重复。
- 有限的机器ID数:机器ID的位数限制了可分配的机器数量,最多只能有1024个不同的机器。
- 时间戳回退限制:由于时间戳占据了41位,所以算法可以在2^41毫秒(约69年)内生成不重复的ID。如果系统运行时间超过了这个限制,可能需要额外的处理来防止时间戳回退问题。
5. 示例
以下是一个示例雪花ID的结构:
| 00011001010111011011001000101010011011111 | 0010101010 |110110000101 || 时间戳 (41位) | 机器ID (10位) | 序列号 (12位) |
在示例中,时间戳部分占据了前41位,机器ID占据了接下来的10位,序列号占据了最后的12位。这三个部分共同组成了一个唯一的雪花ID。
以下是一个简单的Java实现雪花算法的例子:
public class SnowflakeIdGenerator {private final long epoch = 1629331200000L; // 2021-08-20 00:00:00private final int dataCenterIdBits = 5;private final int workerIdBits = 5;private final int sequenceBits = 12;private final int maxDataCenterId = ~(-1 << dataCenterIdBits);private final int maxWorkerId = ~(-1 << workerIdBits);private final int workerIdShift = sequenceBits;private final int dataCenterIdShift = sequenceBits + workerIdBits;private final int timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;private final int sequenceMask = ~(-1 << sequenceBits);private final long dataCenterId;private final long workerId;private long sequence = 0L;private long lastTimestamp = -1L;public SnowflakeIdGenerator(long dataCenterId, long workerId) {if (dataCenterId > maxDataCenterId || dataCenterId < 0) {throw new IllegalArgumentException("Data center ID can't be greater than " + maxDataCenterId + " or less than 0");}if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException("Worker ID can't be greater than " + maxWorkerId + " or less than 0");}this.dataCenterId = dataCenterId;this.workerId = workerId;}public synchronized long nextId() {long timestamp = System.currentTimeMillis();if (timestamp < lastTimestamp) {throw new RuntimeException("Clock moved backwards. Refusing to generate id for " + (lastTimestamp - timestamp) + " milliseconds.");}if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0L;}lastTimestamp = timestamp;return ((timestamp - epoch) << timestampLeftShift) | (dataCenterId << dataCenterIdShift) | (workerId << workerIdShift) | sequence;}private long tilNextMillis(long lastTimestamp) {long timestamp = System.currentTimeMillis();while (timestamp <= lastTimestamp) {timestamp = System.currentTimeMillis();}return timestamp;}
}
在这个例子中,我们定义了一个
SnowflakeIdGenerator类,该类具有nextId()方法,用于生成雪花ID。在构造函数中,我们需要传入数据中心ID和工作节点ID,它们是用来唯一标识每个雪花ID的。在nextId()方法中,我们首先获取当前时间戳,并检查它是否比上次生成ID的时间戳更大。如果是,则将序列号重置为0,并更新上次生成ID的时间戳。否则,我们将序列号递增,并检查是否超过了最大序列号。如果超过了最大序列号,则我们将时间戳递增到下一个毫秒。最后,我们将时间戳、数据中心ID、工作节点ID和序列号合并起来,得到最终的雪花ID。
6. 总结
雪花算法是一种可靠且高效的分布式主键生成算法,已在实际生产中得到广泛应用。通过将时间戳、机器ID和序列号组合在一起,它确保了生成的ID在分布式环境中不会重复。雪花算法的全局唯一性和有序性使其成为分布式系统中的理想选择之一,特别适用于需要生成唯一标识符的场景。
点赞收藏,富婆包养✋✋
相关文章:

分布式主键算法
目录 一、引言二、常见算法介绍雪花算法(Snowflake Algorithm)特性详解优势劣势 UUID(Universally Unique Identifier)特性详解优势劣势 数据库自增主键特性详解优势劣势 分布式数据库的序列(Sequence)特性…...
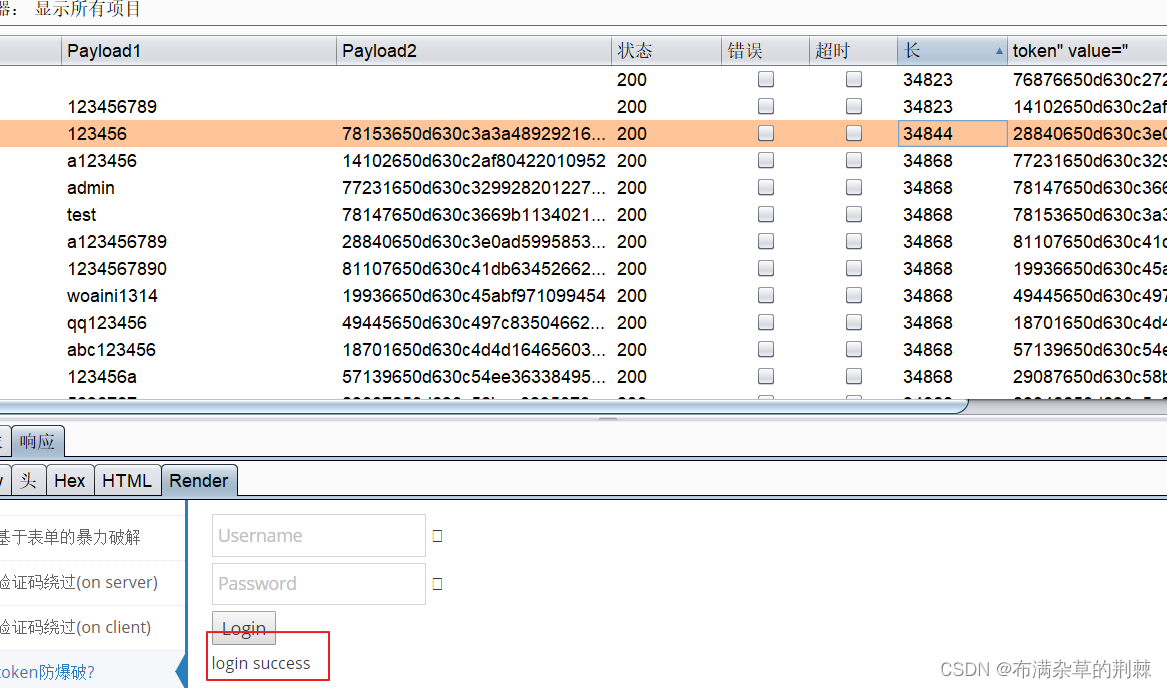
暴力破解及验证码安全
1.暴力破解注意事项 1、破解前一定要有一个有郊的字典(Top100 TOP2000 csdn QQ 163等密码) https://www.bugku.com/mima/ 密码生成器 2、判断用户是否设置了复杂的密码 在注册页面注册一个,用简单密码看是否可以注册成功 3、网站是…...

程序无法启动,提示“找不到msvcp140.dll”或“msvcp140.dll缺失报错”解决方法
大家好!今天我来给大家分享一下msvcp140.dll丢失的解决方法。我们都知道,在运行一些软件或游戏时,经常会遇到“找不到msvcp140.dll”的错误提示,这会让我们非常苦恼。那么,这个问题该怎么解决呢?下面我将为…...
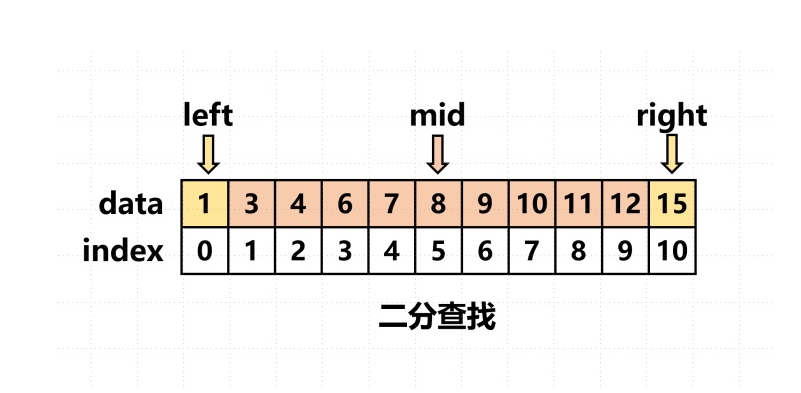
【Python查找算法】二分查找、线性查找、哈希查找
目录 1 二分查找算法 2 线性查找算法 3 哈希查找算法 1 二分查找算法 二分查找(Binary Search)是一种用于在有序数据集合中查找特定元素的高效算法。它的工作原理基于将数据集合分成两半,然后逐步缩小搜索范围,直到找到目标元素…...
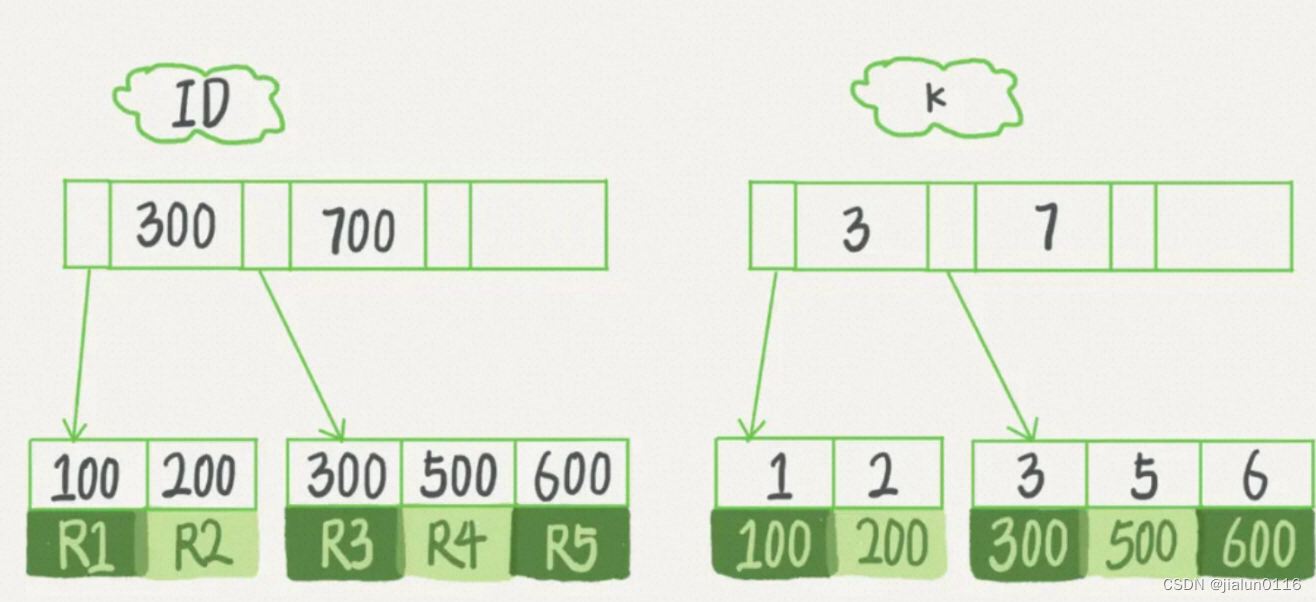
【MySQL实战45讲-基础篇】
基础篇 基础架构 MySQL的基本架构示意图:MySQL可以分为Server层和存储引擎层两部分。 Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函…...

asp.net core中间件预防防止xss攻击
using System; using System.Text.Json; using System.Text.Json.Serialization;namespace CommonUtils {/// <summary>/// newtonsoft的转化器/// 防止xss攻击/// </summary>public class AntiXssNewtonsoftConverter : Newtonsoft.Json.JsonConverter<string&…...

jvm概述
1、JVM体系结构 2、JVM运行时数据区 3、JVM内存模型 JVM运行时内存 共享内存区 线程内存区 3.1、共享内存区 共享内存区 持久带(方法区 其他) 堆(Old Space Young Space(den S0 S1)) 持久代: JVM用持久带(Permanent Space)实现方法…...
C++简单上手helloworld 以及 vscode找不到文件的可能性原因
helloworld #include <iostream>int main() {std::cout << "hello world!" << std::endl;return 0; }输入输出小功能 #include <iostream> using namespace std; /* *主函数 *输出一条语句 */int main() {// 输出一条语句cout << &q…...

掌动智能:性能压力测试的重要性
采用性能压力测试可以帮助企业预估系统容量、提升用户体验以及降低风险和成本。在软件开发过程中,将性能压力测试纳入测试策略的重要一环,将为企业的成功和用户满意度打下坚实的基础。 性能压力测试的重要性: 一、发现性能瓶颈 性能压力测试能…...
kafka日志文件详解及生产常见问题总结
一、kafka的log日志梳理 日志文件是kafka根目录下的config/server.properties文件,配置log.dirs/usr/local/kafka/kafka-logs,kafka一部分数据包含当前Broker节点的消息数据(在Kafka中称为Log日志),称为无状态数据,另外一部分存在…...

Linux-Centos中配置docker
1.安装yum工具 yum install -y yum-utils 2.配置yam源头 yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo 3.安装docker yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin 4. 查看d…...
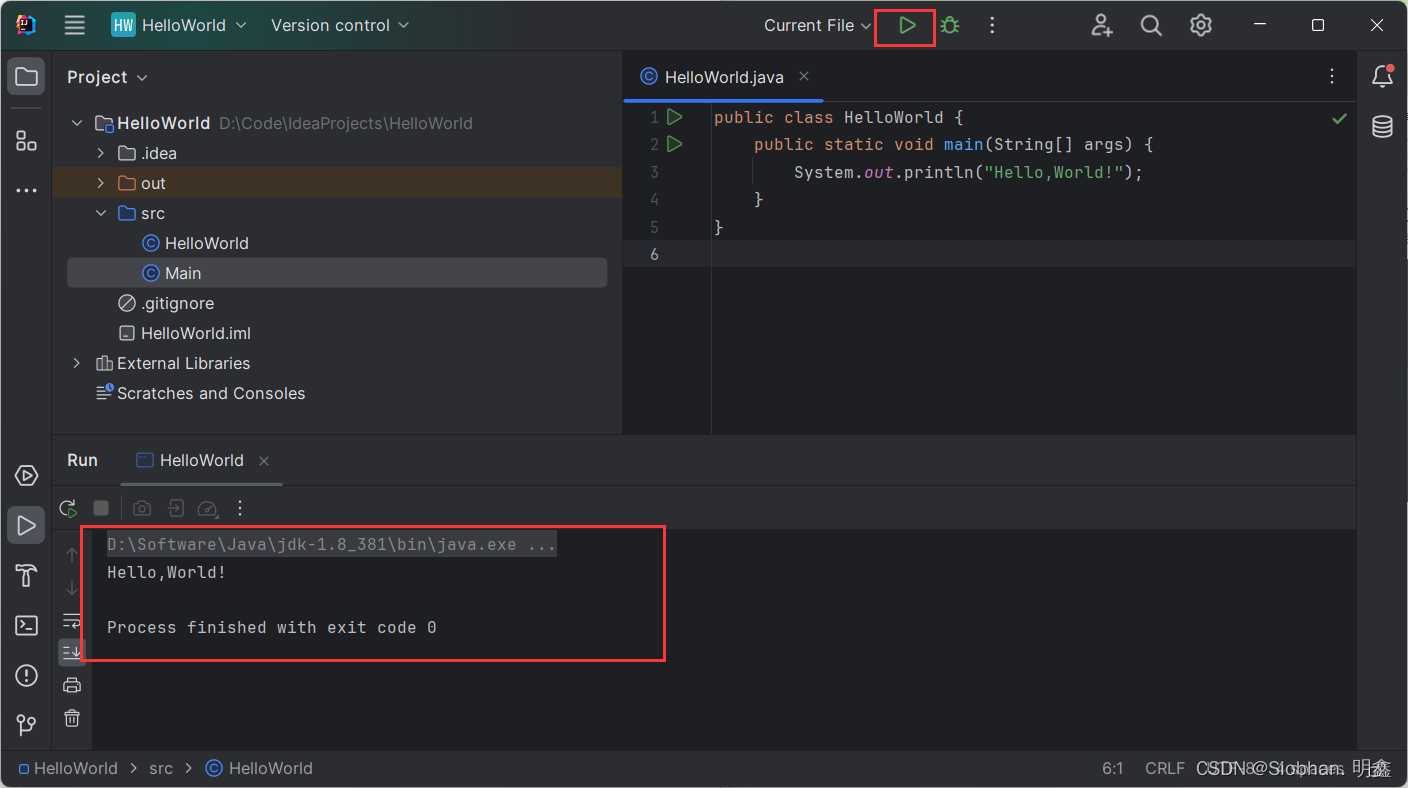
IDEA-2023-jdk8 HelloWorld的实现
目录 1 新建Project - Class 2 编写代码 3 运行 1 新建Project - Class 选择"New Project": 指名工程名、使用的JDK版本等信息。如下所示: 接着创建Java类: 2 编写代码 public class HelloWorld {public static void main(S…...
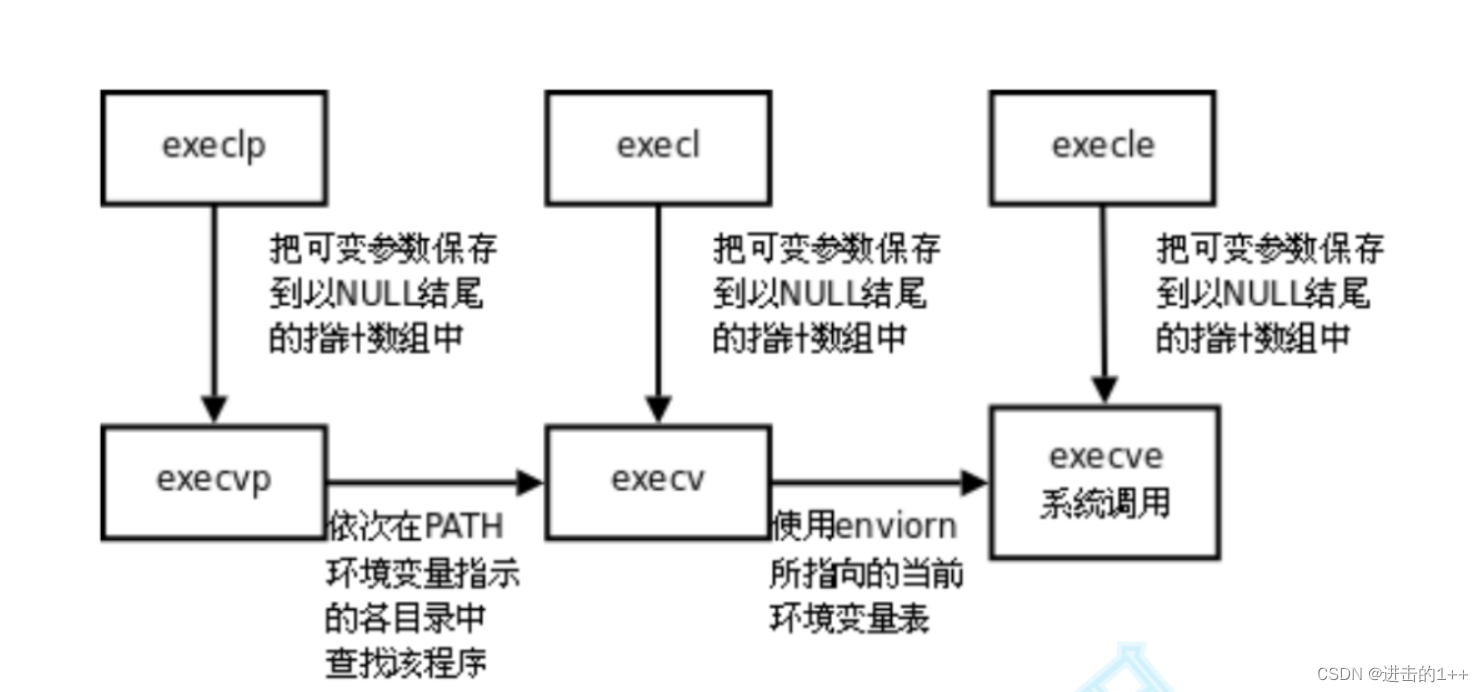
【1++的Linux】之进程(五)
👍作者主页:进击的1 🤩 专栏链接:【1的Linux】 文章目录 一,什么是进程替换二,替换函数三,实现我们自己的shell 一,什么是进程替换 我们创建出来进程是要其做事情的,它可…...

用url类来访问服务器上的文件
场景一: package com.guonian.miaosha;import java.io.BufferedReader; import java.io.File; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL;…...
【重拾C语言】六、批量数据组织(二)线性表——分类与检索(主元排序、冒泡排序、插入排序、顺序检索、对半检索)
目录 前言 六、批量数据组织——数组 6.1~3 数组基础知识 6.4 线性表——分类与检索 6.4.1 主元排序 6.4.2 冒泡排序 6.4.3 插入排序 6.4.4 顺序检索(线性搜索) 6.4.5 对半检索(二分查找) 算法比较 前言 线性表是一种常…...

24 Python的sqlite3模块
概述 在上一节,我们介绍了Python的shutil模块,包括:shutil模块中一些常用的函数。在这一节,我们将介绍Python的sqlite3模块。sqlite3模块是Python中的内置模块,用于与SQLite数据库交互。SQLite是一个轻量级的磁盘数据库…...

ARM-流水灯
.text .global _start _start: 1、设置GPIOE寄存器的时钟使能 RCC_MP_AHB$ENSETR[4]->1 0x50000a28LDR R0,0X50000A28 LDR R1,[R0] 从R0起始地址的4字节数据取出放在R1 ORR R1,R1,#(0X3<<4) 第4位设置为1 STR R1,[R0] 写回2、设置PE10、PE8、PF10管脚为输出模式 …...

【虚拟机】NAT 模式下访问外网
目录 一、NAT 模式的作用原理 二、配置 NAT 模式实现外网访问 1、配置NAT模式的网段 2、虚拟机选择 VMnet8 网卡 3、IP地址设为自动分配 一、NAT 模式的作用原理 NAT模式下,虚拟机的系统会把宿主机当作一个大路由器,发送的网络请求和数据都是先发给…...
React 入门笔记
前言 国庆值班把假期拆了个稀碎, 正好不用去看人潮人海, 趁机会赶个晚集入门一下都火这么久的 React 前端技术. 话说其实 n 年前也了解过一丢丢来着, 当时看到一上来就用 JS 写 DOM 的套路直接就给吓退了, 扭头还去看 Vue 了🤣, 现在从市场份额 社区活度来看, 确实…...
Ubuntu MySQL
在安装前,首先看你之前是否安装过,如果安装过,但是没成功,就要先卸载。 一、卸载 1.查看安装 dpkg --list | grep mysql 有东西,就说明您之前安装过mysql。 2.卸载 先停掉server sudo systemctl stop mysql.servic…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...
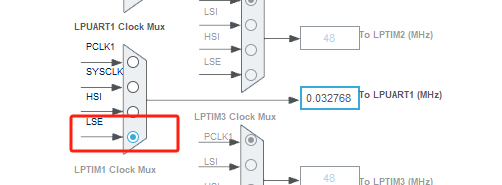
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...

写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里
写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里 脚本1 #!/bin/bash #定义变量 ip10.1.1 #循环去ping主机的IP for ((i1;i<10;i)) doping -c1 $ip.$i &>/dev/null[ $? -eq 0 ] &&am…...