UniAD 论文学习
一、解决了什么问题?
当前的自动驾驶方案大致由感知(检测、跟踪、建图)、预测(motion、occupancy)和规划三个模块构成。

为了实现各种功能,智驾方案大致包括两种路线。一种是针对每个任务都部署一个模型,该范式能降低各团队间的研发困难度,但由于各个优化目标是孤立的,会引发模块之间信息丢失、错误累加和特征不对齐的问题。另一种是多任务的设计路线,多个任务 heads 共享一个特征提取器,该范式能节省边缘计算平台的资源消耗,并且扩展性强,但会带来“负迁移”的问题。
端到端运动规划
自从 Pomerleau 提出使用一个网络直接预测控制信号,端到端运动规划受到越来越多的关注。后续研究通过闭环仿真、多模态输入、多任务学习、强化学习以及专家模型蒸馏的方式,取得了长足进展。但是,考虑到鲁棒性和安全性,这些方法直接从传感器数据输出控制信号、从合成场景迁移到实际应用仍有问题。因此,学者们试图显式地构造出一个网络的中间表征,预测场景是如何变化的。
二、提出了什么方法?
本文认为应该围绕着规划这一最终的目标来设计整体架构,于是提出了 UniAD。UniAD 在一个网络中包括了全栈的自动驾驶任务,它能充分利用各模块的优势,从全局的角度为各 agents 之间的交流提供互补的特征抽象,并且它以统一的 query 接口来连接所有的模块,推动各模块向规划这一目标对齐。
UniAD 遵循一切为规划服务的原则,核心构成就是 query-based 的接口设计,连接各个模块。与经典的边框表征相比,queries 得益于更大的感受野,能减轻上游任务预测所带来的复合错误的影响,而且能灵活地编码和建模 agents 之间的交流。
任务定义
检测和跟踪
检测和跟踪是自动驾驶领域两个重要的任务,在 3D 空间对它们做表征以支持下游任务。3D 检测负责定位每个时刻周围的物体(坐标、长宽高、偏航角等);跟踪目的是找到不同时刻物体之间的对应关系,在时域内将它们串联起来。本文使用多目标跟踪来表示检测和跟踪的过程。最终输出是每帧内的一组 3D 框,它们对应的特征 Q A Q_A QA 会输入运动模块。此外,有一个特殊的自车 query 用于下游任务,在预测框和 ground-truth 框的匹配过程中不会包括自车 query。
在线建图
地图体现了环境的几何和语义信息。在线建图是利用车载传感器数据,分割出有价值的道路元素,以替代离线标注的高精地图。在 UniAD,在线地图建模了四种元素:车道线、可行驶区域、间隔物、人行横道。在 BEV 视角下对它们做分割。运动预测模块使用 map queries Q M Q_M QM 来建模 agent-map 关系。
运动预测
运动预测将感知和规划连接起来,在整个自动驾驶系统扮演重要角色,确保最终的安全。通常,运动预测是一个独立模块,利用高精地图和检测到的边框来预测 agent 未来的轨迹。现有的运动数据集,边框都是 ground-truth 标注,这在车载场景不现实。本文,运动预测模块将之前编码的稀疏 queries( Q A Q_A QA和 Q M Q_M QM)和密集 BEV 特征 B B B 作为输入,预测各 agent 在未来 T T T 时刻的 K \mathcal{K} K 个可能轨迹,这些预测的轨迹是各 agent 的相对当前位置的偏移。Agent 特征编码了过去和未来的信息,会输入占用模块来理解未来的场景。
自车 query 预测未来时刻自车的运动,它实际上是比较粗糙的规划估计,planner 会利用该特征来生成最终的目标路径点。
占用预测
占用网格图是离散化的 BEV 表征,每个网格表示它是否被占用的置信度。占用预测任务用于发现网格图在未来 T o T_o To 时刻是如何变化的。运动预测依赖于稀疏的 agents,占用预测则是全场景密集表征的。为了研究场景和稀疏 agents 是如何变化的,占用模块的输入是 BEV 特征 B B B 和 agent 特征 G t G^t Gt。完成多步骤 agent-scene 交流后,对占用特征和密集场景特征做矩阵乘,得到实例级的概率图 O ^ A t ∈ R N a × H × W \hat{O}_A^t \in \mathbb{R}^{N_a\times H\times W} O^At∈RNa×H×W。然后使用逐像素的 arg max \argmax argmax 操作,将各时刻的概率图融合,得到保留了 agent ID 的全场景占用 O ^ t ∈ R H × W \hat{O}^t \in \mathbb{R}^{H\times W} O^t∈RH×W。
规划
规划模块是最终的目的,输入是上述模块的输出。传统的规划方法都是 rule-based,由各种 if-else 状态机组成,用检测和预测的结果来描述各类场景。而本文提出的 learning-based 模型则以上游的自车 query、密集的 BEV 特征 B B B 作为输入,预测全部 T p T_p Tp 时刻的轨迹 τ ^ \hat{\tau} τ^。然后,用上游预测的未来占用 O ^ \hat{O} O^ 来优化预测轨迹 τ ^ \hat{\tau} τ^,以防发生碰撞,确保安全。
概览
UniAD 包括四个基于 transformer decoder 的感知与预测模块,以及一个 planner。Queries Q Q Q 将整个流程串联起来,建模驾驶场景中各实例间的不同关系。下图展示了 UniAD 的流程,设计上非常精妙,遵循规划导向的思想。作者探索了感知和预测各模块的作用,充分发挥节点协同优化的优势。

-
首先,将多相机图像输入特征提取器,通过 BEVFormer 的 BEV 编码器将透视视角的特征变换为 BEV 特征 B B B。
-
然后在 TrackFormer 中,track queries 从 B B B 中查询各 agents 的信息,进行检测和跟踪。
-
在 MapFormer 中,map queries 作为道路元素(车道线、间隔物)的语义抽象,并进行 maps 的全景分割。
-
MotionFormer 获取各 agents 和 maps 之间的关系,预测每个 agent 未来的轨迹。在场景里面,各 agent 的行为会彼此影响,所以 MotionFormer 对所有的 agents 做联合预测。
-
OccFormer 以 BEV 特征 B B B 作为 queries,将 agent 的信息作为 keys 和 values,预测未来多步的占用网格图(保留 agents 的 IDs)。
-
最终,Planner 利用 MotionFormer 给出的自车 query 来预测出规划结果,并让自车远离 OccFormer 预测的被占用区域,以防碰撞发生。
1. 感知:跟踪和建图
1.1 TrackFormer
它协同完成检测和多目标跟踪任务,没有不可微的后处理操作。除了目标检测任务用到的检测 queries,它还包含了跟踪用的 track queries。在每一时刻,新初始化的检测 queries 负责检测首次被感知到的 agents,而 track queries 则对之前帧检测到的 agents 持续建模。检测 queries 和 track queies 都是通过关注 BEV 特征 B B B 来获取各 agents 的信息。随着场景的变化,当前时刻的 track queries 通过一个自注意力模块与之前时刻的 queries 进行交流,聚合时域信息,直到相应的 agents 完全消失在画面中。TrackFormer 包括 N N N 层,最终的输出 Q A Q_A QA 提供 N a N_a Na 个有效 agents 的信息,供下游任务使用。除了编码自车周围 agents 的 queries,作者还增加了一个自车 query,显式地建模自车本身,规划模块会用到。
1.2 MapFormer
作者基于 2D 全景分割方法 Panoptic SegFormer 设计 MapFormer。将道路元素稀疏地表征为 map queries,编码了位置和结构信息,从而帮助下游的运动预测。本文将车道线、间隔物和人行横道设为 things,将可行驶区域设为 stuff。MapFormer 也有 N N N 层,最后一层的 queries Q M Q_M QM 会输入 MotionFormer 做 agent-map 交流。
2. 预测:运动预测
有了 TrackFormer 和 MapFormer 分别提供的动态 agents 的 queries Q A Q_A QA 和静态图 Q M Q_M QM,MotionFormer 就可以预测所有 agents 未来的多模态运动了,即 top-k 个可能的轨迹。同时,作者将 TrackFormer 中的自车 query 传入 MotionFormer,让自车和其它 agents 产生交流。输出的运动状态表示为 { x ^ i , k ∈ R T × 2 ∣ i = 1 , . . . , N a ; k = 1 , . . . , K } \{\hat{\mathbf{x}}_{i,k} \in \mathbb{R}^{T\times 2}| i=1,...,N_a; k=1,..., \mathcal{K}\} {x^i,k∈RT×2∣i=1,...,Na;k=1,...,K},其中 i i i 表示 agent 的索引, k k k 表示轨迹模态的索引, T T T 是预测的长度。
2.1 MotionFormer
包括 N N N 层,每层都获取到三种交互关系:agent-agent, agent-map, agent-goal point。对于每个 motion query Q i , k Q_{i,k} Qi,k,它和其它 agents Q A Q_A QA 或地图元素 Q M Q_M QM 的关系可以表示如下:
Q a / m = MHCA ( MHSA ( Q ) , Q A / Q M ) Q_{a/m}=\text{MHCA}(\text{MHSA}(Q), Q_A/Q_M) Qa/m=MHCA(MHSA(Q),QA/QM)
上面的 MHCA \text{MHCA} MHCA 和 MHSA \text{MHSA} MHSA 表示多头跨注意力和多头自注意力。同时,我们也要关注目标点(goal point),优化预测轨迹,本文基于可变形注意力设计了一个 agent-goal point 注意力:
Q g = DeformAttn ( Q , x ^ T l − 1 , B ) Q_g = \text{DeformAttn}(Q, \hat{\mathbf{x}}_T^{l-1}, B) Qg=DeformAttn(Q,x^Tl−1,B)
其中 x ^ T l − 1 \hat{\mathbf{x}}_T^{l-1} x^Tl−1 是上一层预测轨迹的路径点。 DeformAttn ( q , r , x ) \text{DeformAttn}(q,r,x) DeformAttn(q,r,x) 是可变形注意力,输入为 query q q q、参考点 r r r 和空间特征 x x x。它对参考点周围的空间特征应用稀疏注意力。这样,预测轨迹能进一步感知到路径点周围的环境。
这三种交互关系的建模是同时进行的,然后将生成的 Q a , Q m , Q g Q_a, Q_m, Q_g Qa,Qm,Qg concat 到一起,输入一个 MLP,得到 query context Q c t x Q_{ctx} Qctx。然后将 Q c t x Q_{ctx} Qctx 输入后续的层做优化,或者在最后一层就解码为预测结果。
2.2 Motion queries
MotionFormer 每一层的输入 queries 记作 motion queries,包括两个部分:前一层输出的 query context Q c t x Q_{ctx} Qctx 和 query position Q p o s Q_{pos} Qpos。 Q p o s Q_{pos} Qpos 整合了四重的位置信息:
- 场景级 anchor I s I^s Is 的位置;
- agent 级 anchor I a I^a Ia 的位置;
- 第 i i i 个 agent 的当前位置;
- 预测的 goal point。
Q p o s = MLP ( PE ( I s ) ) + MLP ( PE ( I a ) ) + MLP ( PE ( x ^ 0 ) ) + MLP ( PE ( x ^ T l − 1 ) ) Q_{pos}=\text{MLP}(\text{PE}(I^s)) + \text{MLP}(\text{PE}(I^a)) + \text{MLP}(\text{PE}(\hat{\mathbf{x}}_0)) + \text{MLP}(\text{PE}(\hat{\mathbf{x}}_T^{l-1})) Qpos=MLP(PE(Is))+MLP(PE(Ia))+MLP(PE(x^0))+MLP(PE(x^Tl−1))
这里的正弦位置编码 P E ( ⋅ ) PE(\cdot) PE(⋅) 后跟着一个 MLP 用于编码位置点,第一层的 I s I^s Is 设为 x ^ T 0 \hat{\mathbf{x}}_T^0 x^T0。场景级 anchor 代表了全局视角下之前时刻的运动统计,agent 级 anchor 则在局部坐标捕捉可能的意图。它们都通过 k-means 算法对 ground-truth 轨迹的路径点做聚类,从而缩小预测结果的搜索空间。起始点提供每个 agent 的位置编码,而预测出的路径点则作为动态 anchor,逐层不断地优化。
2.3 非线性优化
直接从一个不准确的检测位置或偏航角回归 ground-truth 的路径点会产生不真实的轨迹预测,曲率和加速度可能会非常大。于是作者采用了一个非线性平滑方法,来调节目标的轨迹,使它们更加合理。该过程如下:
x ~ ∗ = arg min x c ( x , x ~ ) \tilde{\mathbf{x}}^\ast = \argmin_{\mathbf{x}}{c(\mathbf{x}, \tilde{\mathbf{x}})} x~∗=xargminc(x,x~)
其中 x ~ \tilde{\mathbf{x}} x~ 和 x ~ ∗ \tilde{\mathbf{x}}^\ast x~∗ 表示 ground-truth 和平滑后的轨迹, x \mathbf{x} x 通过 multiple-shooting 产生,代价函数为:
c ( x , x ~ ) = λ x y ∥ x , x ~ ∥ 2 + λ g o a l ∥ x T , x ~ T ∥ 2 + ∑ ϕ ∈ Φ ϕ ( x ) c(\mathbf{x}, \tilde{\mathbf{x}})=\lambda_{xy}\left\| \mathbf{x}, \tilde{\mathbf{x}} \right\|_2 + \lambda_{goal} \left\| \mathbf{x}_T, \tilde{\mathbf{x}}_T \right\|_2 + \sum_{\phi\in \Phi}{\phi(\mathbf{x})} c(x,x~)=λxy∥x,x~∥2+λgoal∥xT,x~T∥2+ϕ∈Φ∑ϕ(x)
其中, λ x y \lambda_{xy} λxy 和 λ g o a l \lambda_{goal} λgoal 是超参数,动力学函数集合 Φ \Phi Φ 有五项,包括 jerk, curvature, curvature rate, acceleration, lateral acceleration。这个代价函数对目标轨迹起到正则的作用,使其遵守动力学约束条件。目标轨迹优化只在训练时进行,不影响推理。
3. 预测:占用预测
占用网格图是离散化的 BEV 表征,每个格子都有一个置信度,表示该格子是否被占用。占用预测任务用于预测网格图在未来是如何变化的。OccFormer 从两个方面融合了场景级和 agent 级的语义信息:
- 通过一个精心设计的注意力模块,从密集场景特征学到 agent 级的特征;
- 对 agent 级特征和密集场景特征做矩阵乘法,输出实例占用。
OccFormer 由 T o T_o To 个序列模块组成, T o T_o To 表示预测的长度。由于占用网格图过于密集,这里的 T o T_o To 通常要小于运动任务中的预测长度 T T T。每个模块的输入包括丰富的 agent 特征 G t G^t Gt 和前一层的状态(密集特征) F t − 1 F^{t-1} Ft−1,然后输出 t t t 时刻的状态 F t F^t Ft。为了得到 agent 特征 G t G^t Gt,我们在模态维度对 MotionFormer 的 motion queries 做最大池化,记作 Q X ∈ R N a × D Q_X \in \mathbb{R}^{N_a\times D} QX∈RNa×D, D D D 是特征维度。然后通过一个时域 MLP 将它与上游的 track query Q A Q_A QA 及当前位置编码 P A P_A PA 融合:
G t = MLP ( [ Q A , P A , Q X ] ) , t = 1 , . . . , T o G^t = \text{MLP}([Q_A, P_A, Q_X]), t=1,..., T_o Gt=MLP([QA,PA,QX]),t=1,...,To
[ ⋅ ] [\cdot] [⋅] 表示 concat 操作。对于场景级信息,出于计算效率考虑,BEV 特征 B B B 会缩小到 1 / 4 1/4 1/4 分辨率,作为第一个模块的输入 F 0 F^0 F0。为了进一步节约训练时内存占用,每个模块都遵循下采样-上采样的方式,在中间有一个注意力模块,在 1 / 8 1/8 1/8 大小的特征(记作 F d s t F_{ds}^t Fdst)上进行 pixel-agent 交流。
3.1 Pixel-agent 交流
在预测未来占用网格图时,Pixel-agent 交流用于统一对场景和 agents 的理解。将密集特征 F d s t F_{ds}^t Fdst 作为 queries,实例级特征作为 keys 和 values 不断更新密集特征。 F d s t F_{ds}^t Fdst 输入一个自注意力层,建模网格间的响应,然后用一个跨注意力层建模 agent 特征 G t G^t Gt 和各网格的特征之间的关系。为了对齐 pixel-agent 的对应关系,作者用一个注意力 mask 来约束跨注意力,每个像素只关注于 t t t 时刻占据它的 agent。密集特征的更新过程如下:
D d s t = MHCA ( MHSA ( F d s t ) , G t , attn_mask = O m t ) D_{ds}^t = \text{MHCA}(\text{MHSA}(F_{ds}^t), G^t, \text{attn\_mask}=O_m^t) Ddst=MHCA(MHSA(Fdst),Gt,attn_mask=Omt)
注意力 mask O m t O^t_m Omt 语义上类似于占用网格图,用一个额外的 agent 级特征和密集特征 F d s t F_{ds}^t Fdst 相乘得到,我们将这个 agent 级特征叫做 mask 特征 M t = MLP ( G t ) M^t = \text{MLP}(G^t) Mt=MLP(Gt)。经过上述交流过程, D d s t D_{ds}^t Ddst 就上采样到了 B B B 的 1 / 4 1/4 1/4 大小。我们将 D d s t D_{ds}^t Ddst 通过残差连接加到模块输入 F t − 1 F^{t-1} Ft−1 上,得到的结果 F t F^t Ft 再输入进下一模块。
3.2 实例级占用
它表示的是保留了每个 agent ID 的占用网格图。它可以通过简单的矩阵乘法提取。为了得到 BEV 特征 B (原始大小为 H × W H\times W H×W )的预测占用,场景级特征 F t F^t Ft 通过一个卷积解码器上采样为 F d e c t ∈ R C × H × W F_{dec}^t \in \mathbb{R}^{C\times H\times W} Fdect∈RC×H×W,其中 C C C 是通道维度。
对于 agent 级特征,我们通过另一个 MLP 进一步将粗糙的 mask 特征 M t M^t Mt 更新为占用特征 U t ∈ R N a × C U^t \in \mathbb{R}^{N_a\times C} Ut∈RNa×C。实验表明, U t U^t Ut 要比 G t G^t Gt 带来更优的表现。最终 t t t 时刻的实例级占用表示为:
O ^ A t = U t ⋅ F d e c t \hat{O}_A^t = U^t \cdot F_{dec}^t O^At=Ut⋅Fdect
4. 规划
不带高精地图的规划一般需要高层级的指令来表示往哪个方向走。作者将原始的导航信号(左转、右转、保持前进)转换为三个可学习的 embeddings,叫做 command embeddings。由于 MotionFormer 的自车 query 已经表达了多模态意图,作者用 command embeddings 补充它,得到 plan query。然后将 plan query 关注到 BEV 特征 B B B,使它感知周围环境,然后将其解码,得到未来的路径点 τ ^ \hat{\tau} τ^。
为了避免碰撞,只在推理时基于牛顿法来优化 τ ^ \hat{\tau} τ^:
τ ∗ = arg min τ f ( τ , τ ^ , O ^ ) \tau^\ast = \argmin_{\tau}{f(\tau, \hat{\tau}, \hat{O})} τ∗=τargminf(τ,τ^,O^)
其中, τ ^ \hat{\tau} τ^ 是原始的规划预测, τ ∗ \tau^\ast τ∗ 表示优化后的规划,最小化代价函数 f ( ⋅ ) f(\cdot) f(⋅) 得到。 O ^ \hat{O} O^ 是经典的二值占用网格图,从 OccFormer 的实例占用预测融合得到。代价函数如下:
f ( τ , τ ^ , O ^ ) = λ c o o r d ∥ τ , τ ^ ∥ 2 + λ o b s ∑ t D ( τ t , O ^ t ) f(\tau, \hat{\tau}, \hat{O}) = \lambda_{coord}\left\| \tau, \hat{\tau} \right\|_2 + \lambda_{obs}\sum_t \mathcal{D}(\tau_t, \hat{O}^t) f(τ,τ^,O^)=λcoord∥τ,τ^∥2+λobst∑D(τt,O^t)
D ( τ t , O ^ t ) = ∑ ( x , y ) ∈ S 1 σ 2 π exp ( − ∥ τ t − ( x , y ) ∥ 2 2 2 σ 2 ) \mathcal{D}(\tau_t, \hat{O}^t)=\sum_{(x,y)\in \mathcal{S}} \frac{1}{\sigma \sqrt{2\pi}}\exp(-\frac{\left\| \tau_t - (x,y) \right\|_2^2}{2\sigma^2}) D(τt,O^t)=(x,y)∈S∑σ2π1exp(−2σ2∥τt−(x,y)∥22)
这里, λ c o o r d , λ o b s \lambda_{coord}, \lambda_{obs} λcoord,λobs 和 σ \sigma σ 是超参数, t t t 是未来时刻的索引。考虑到周围的位置受到 S = { ( x , y ) ∣ ∥ ( x , y ) − τ t ∥ 2 < d , O ^ x , y t = 1 } \mathcal{S}=\left\{ (x,y) | \left\| (x,y)-\tau_t \right\|_2 < d, \hat{O}_{x,y}^t=1 \right\} S={(x,y)∣∥(x,y)−τt∥2<d,O^x,yt=1} 的限制, l 2 l_2 l2 代价函数将轨迹拉向原来预测的位置,而碰撞项 D \mathcal{D} D 则将其推离开被占用的网格。
5. 学习
UniAD 训练包括两个阶段。首先协同训练感知部分,即跟踪和建图模块,训练 6 6 6 个 epochs。然后端到端训练感知、预测和规划模块共 20 20 20 个 epochs。
5.1 共享匹配
UniAD 包括实例建模,所以在感知和预测任务上,需要将预测结果和 ground-truths 配对。与 DETR 相似,在跟踪和在线建图阶段它使用了二分匹配算法。至于跟踪,检测 queries 的候选框会和新出现的 ground-truth 物体做配对,track queries 的预测则会继承之前帧的配对结果。跟踪模块的匹配结果会在运动和占用节点复用,从而持续地对历史跟踪的 agents 和未来的运动之间做建模。
6. 实现细节
6.1 检测和跟踪
继承了 BEVFormer 的大多数检测设计,通过一个 BEV 编码器将图像特征变换为 BEV 特征 B B B,再使用一个可变形 DETR 头对 B B B 做检测。为了避免繁琐的匹配后处理,作者引入了一组 track queries,持续地跟踪之前检出的实例。跟踪过程细节如下:
6.1.1 训练阶段
训练开始时,所有的 queries 默认为检测 queries,预测新出现的目标,这和 BEVFormer 一样。通过匈牙利算法将检测 queries 和 ground-truths 匹配起来。将它们保存起来,在下一时刻通过 query interaction 模块(QIM)更新为 track queries。在下一时刻,track queries 会根据对应的 track ID 直接匹配到部分的 ground-truth 目标,而检测 queries 会匹配到其余的 ground-truths(新出现的目标)。为了让训练稳定,采用 3D IOU 来过滤匹配到的 queries。只保存和更新那些与 ground-truth 框的 3D IOU 大于一定阈值的预测框。
6.1.2 推理阶段
推理时,序列帧按顺序送入网络,track queries 存在的时间可能要长于训练时的。另一区别就是 query 更新,推理时使用分类得分来过滤 queries,而非 3D IOU(因为没有 ground-truths 了)。此外,为了避免由遮挡引发的短时间轨迹中断的情况,在推理阶段使用了生命周期机制。对于每个 track query,若它的分类得分低连续在 2 s 2s 2s 内于 0.35 0.35 0.35,它就被认为完全消失,则被移除。
6.2 在线建图
Map queries 被分为 thing queries 和 stuff queries。Thing queries 建模实例级的地图元素(即车道线、边界、人行横道),通过二分匹配来关联到 ground-truths,stuff queries 只负责语义元素(即可行驶区域),通过固定类别分配来处理。Thing queries 个数为 300 300 300,stuff query 个数为 1 1 1。堆叠了 6 6 6 个位置解码层和 4 4 4 个 mask 解码层。选取位置解码器后的 thing queries 作为 map queries Q M Q_M QM 供下游任务用。
6.3 运动预测

MotionFormer 用 I T a , I T s , x ^ 0 , x ^ T l − 1 ∈ R K × 2 I_T^a, I_T^s, \hat{x}_0, \hat{x}_T^{l-1}\in \mathbb{R}^{\mathcal{K}\times 2} ITa,ITs,x^0,x^Tl−1∈RK×2 来编码 query 位置,用 Q c t x l − 1 Q_{ctx}^{l-1} Qctxl−1 作为 query context。通过 k-means 算法对训练数据中所有的 agents 做聚类,得到 anchors, K = 6 \mathcal{K}=6 K=6 与输出模态个数一样。为了编码场景先验,根据各 agent 的当前位置和偏航角,将 anchor I T a I_T^a ITa 旋转和平移到世界坐标系下,记作 I T s I_T^s ITs:
I i , T s = R i I T a + T i I^s_{i,T} = R_i I_T^a + T_i Ii,Ts=RiITa+Ti
其中 i i i 是 agent 的索引。作者也使用了前一层预测的 goal point x ^ T l − 1 \hat{x}_T^{l-1} x^Tl−1,使得更加准确。同时,将 agent 当前的位置广播到其它模态,记作 x ^ 0 \hat{x}_0 x^0。然后,对每个先验位置信息应用 MLP 和正弦位置编码,记作 query position Q p o s ∈ R K × D Q_{pos}\in\mathbb{R}^{\mathcal{K}\times \mathcal{D}} Qpos∈RK×D,形状与 Q c t x Q_{ctx} Qctx 一样。 Q c t x Q_{ctx} Qctx 和 Q p o s Q_{pos} Qpos 一起构建了 motion query。在 MotionFormer 中, D = 256 \mathcal{D}=256 D=256。
MotionFormer 有三个 transformer 模块,agent-agent, agent-map, agent-goal point 关系模块。Agent-agent 和 agent-map 模块用标准的 transformer 解码层构建,包括一个多头自注意力层、一个多头跨注意力层和一个前馈网络,内部还有多个归一化层和残差连接。作者也在 Q A Q_A QA 和 Q M Q_M QM 中加入了正弦位置编码,然后跟着 MLPs 层。Agent-goal 模块用可变形跨注意力层构建,将之前预测轨迹的 goal point ( R i x ^ i , T l − 1 + T i R_i\hat{x}_{i,T}^{l-1} + T_i Rix^i,Tl−1+Ti)作为参考点使用,如下图所示。每条轨迹的采样点点个数为 4 4 4,每个 agent 有 6 6 6 条轨迹。将每个关系模块的输出特征 concat 到一起,用 MLP 层映射成维度 D = 256 \mathcal{D}=256 D=256。然后,使用高斯混合模型构建每个 agent 的轨迹,其中 x ^ l ∈ R K × T × 5 \hat{x}_l\in\mathcal{R}^{\mathcal{K}\times \mathcal{T}\times 5} x^l∈RK×T×5。预测时长 T = 12 T=12 T=12,约 6 6 6 秒。最终输出轨迹是最后一个维度的前两个值,即 x , y x, y x,y。此外,也要预测每个模态的得分, s c o r e ( x ^ l ) ∈ R K score(\hat{x}_l)\in \mathcal{R}^\mathcal{K} score(x^l)∈RK。将该模块堆叠 N = 3 N=3 N=3 次。

6.4 占用预测
给定 BEV 特征,首先用卷积层将其下采样 ( / 4 /4 /4),然后输入 OccFormer。OccFormer 由 T o T_o To 个序列模块组成,如下图所示。 T o = 5 T_o=5 To=5 是时间长度(包括当前和未来帧),每个模块负责生成一帧的占用。该方法融合了密集场景特征和稀疏的 agent 特征。密集场景特征来自于最后一个模块的输出,用卷积层进一步下采样( / 8 /8 /8),降低 pixel-agent 的计算量。将 track query Q A Q_A QA, agent positions P A P_A PA 和 motion query Q X Q_X QX concat 到一起,输入一个时域 MLP。计算像素级的自注意力,对剧烈变化的场景所需的长期依赖关系做建模;然后将每个像素点关注到对应的 agent,做 scene-agent 融合。为了增强 agents 和像素之间的位置对齐,用一个注意力 mask 来约束跨注意力,该注意力 mask 通过计算 mask 特征和下采样后的场景特征的矩阵乘得到,用一个 MLP 来编码 agent 特征以得到 mask 特征。然后,将密集特征上采样到与输入 F t − 1 F^{t-1} Ft−1 相同的分辨率( / 4 /4 /4),用残差连接将它和 F t − 1 F^{t-1} Ft−1 相加。得到的特征 F t F^t Ft 输入下一模块和卷积解码器,以预测占用。复用 mask 特征,输入另一个 MLP,得到占用特征。对占用特征和解码的密集特征 F d e c t F_{dec}^t Fdect 做矩阵乘,得到实例级的占用。注意,在所有的 T o T_o To 模块中,共享 mask 特征的 MLP 层、占用特征的 MLP 层和卷积解码器,其它的组件则是独立的。在 OccFormer 中,所有的密集特征和 agent 特征的维度都是 256 256 256。
相关文章:
UniAD 论文学习
一、解决了什么问题? 当前的自动驾驶方案大致由感知(检测、跟踪、建图)、预测(motion、occupancy)和规划三个模块构成。 为了实现各种功能,智驾方案大致包括两种路线。一种是针对每个任务都部署一个模型&a…...
用冒泡排序模拟实现qsort()函数交换整数)
(c语言)用冒泡排序模拟实现qsort()函数交换整数
#include<stdio.h> int cmp(const void* x1, const void* x2) { return (*(int*)x1 - *(int*)x2); } void Swap(char* x, char* y, int width) //将两个数改为char*类型,每次只交换一个字节,直到将int*的四个字节全部交换一遍 { int i 0; f…...

【Java-LangChain:使用 ChatGPT API 搭建系统-11】用 ChatGPT API 构建系统 总结篇
第十一章,用 ChatGPT API 构建系统 总结篇 本课程详细介绍了 LLM 工作原理,包括分词器(tokenizer)的细节、评估用户输入的质量和安全性的方法、使用思维链作为 Prompt、通过链式 Prompt 分割任务以及返回用户前检查输出等。 本课…...

3D 生成重建004-DreamFusion and SJC :TEXT-TO-3D USING 2D DIFFUSION
3D 生成重建004-DreamFusion and SJC :TEXT-TO-3D USING 2D DIFFUSION 文章目录 0 论文工作1 论文方法1.1论文方法1.2 CFG1.3影响1.4 SJC 2 效果 0 论文工作 对于生成任务,我们是需要有一个数据样本,让模型去学习数据分布 p ( x ) p(x) p(x…...

机械臂抓取的产业落地进展与思考
工业机械臂是一种能够模拟人类手臂动作的机械装置,具有高精度、高速度和高灵活性的特点。近年来,随着人工智能和机器人技术的快速发展,机械臂在工业生产、物流仓储、医疗护理等领域得到了广泛应用。机械臂抓取技术作为机械臂的核心功能之一&a…...
分析)
【RuoYi-Cloud项目研究】【ruoyi-auth模块】登录请求(/login)分析
文章目录 0. 网关如何处理登录请求1. Controller1.1. 获取用户信息1.2. 创建用户的token 2. Service2.1. FeignClient远程查询用户信息2.2. 验证密码 3. 何时刷新 token,如何刷新【本文重点】 本文主要是分析登录请求 /login 的过程。 调用过程是:ruoyi-…...
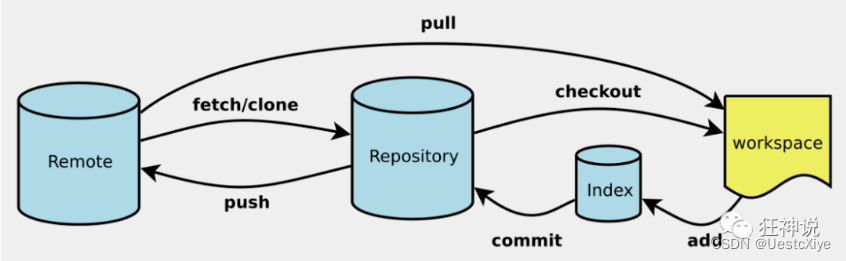
Git 学习笔记 | Git 项目创建及克隆
Git 学习笔记 | Git 项目创建及克隆 Git 学习笔记 | Git 项目创建及克隆创建工作目录与常用指令本地仓库搭建克隆远程仓库 Git 学习笔记 | Git 项目创建及克隆 创建工作目录与常用指令 工作目录(WorkSpace)一般就是你希望Git帮助你管理的文件夹,可以是…...

C++默认参数(实参)
在本文中,您将学习什么是默认参数,如何使用它们以及使用它的必要声明。在C 编程中,您可以提供函数参数的默认值。默认参数背后的想法很简单。如果通过传递参数调用函数,则这些参数将由函数使用。但是,如果在调用函数时…...

Datax数据同步支持SqlServer 主键自增
允许写入的SQL SET IDENTITY_INSERT table_name ON;-- 插入数据,指定主键值 INSERT INTO table_name (id, column1, column2, ...) VALUES (new_id_value, value1, value2, ...);SET IDENTITY_INSERT table_name OFF; 写入插件处理 核心类:com.alibab…...

C++开发学习笔记3
C 中枚举的使用 在C中,枚举常量(Enumeration Constants)是一种定义命名常量的方式。枚举类型允许我们为一组相关的常量赋予有意义的名称,并将它们作为一个独立的类型来使用。 以下是定义和使用枚举常量的示例: enum…...

计算机中常说的SDK是什么意思?
SDK是Software Development Kit的英文缩写,意思是软件开发包。 软件开发包中往往包含有多种辅助进行软件开发的内容,包括一些软件开发工具、文档说明、库和示例代码。这些内容能够帮助使用SDK进行软件开发的人员更好地开发程序。 SDK的作用就是简化软件…...
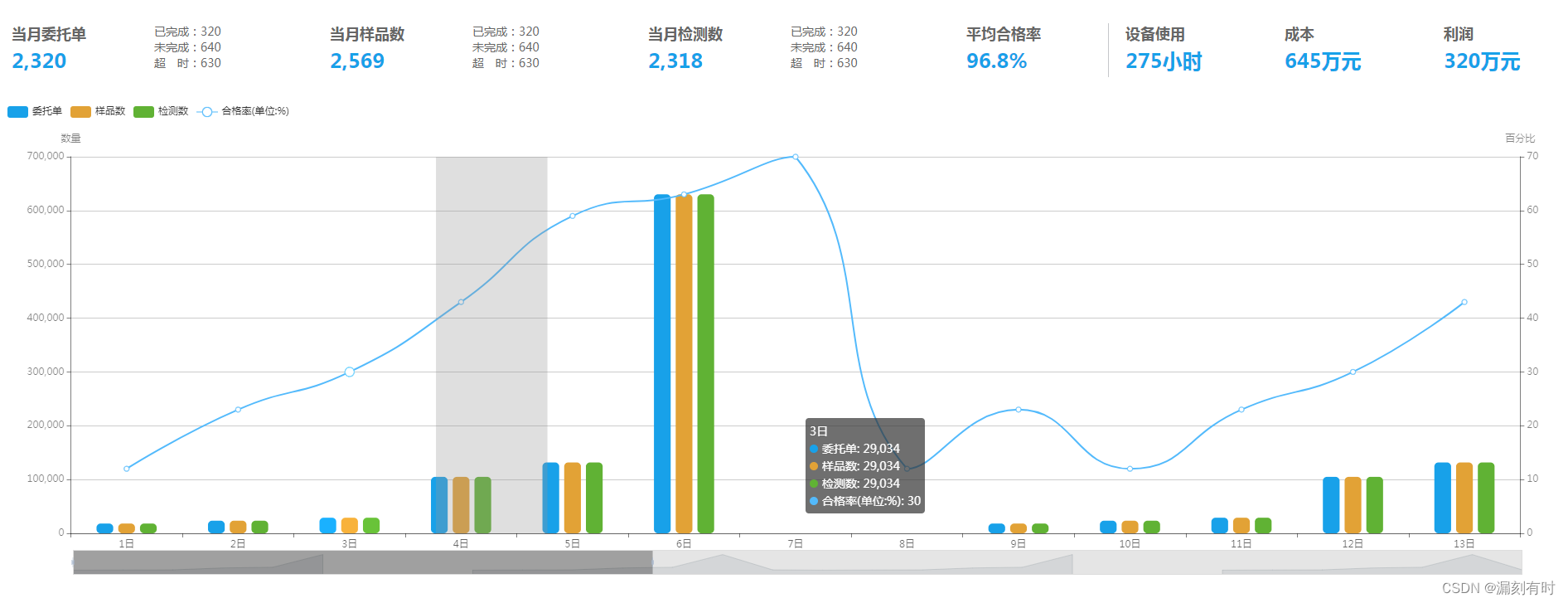
漏刻有时数据可视化大屏(16)数据指标KPI和柱图折线图混排
CSS样式表 /*面板*/ .pannel {width: 100%;margin-top: 30px;clear: both; }.item_l {float: left;width: 20%; /*3格60%*/margin: 0; }.item_r {float: left;width: 10%; /*4格40%*/margin: 0; }.item_child {float: left;width: 50%; }.item_child_b {float: left;width: 10…...
基于Stable Diffusion的图像合成数据集
当前从文本输入生成合成图像的模型不仅能够生成非常逼真的照片,而且还能够处理大量不同的对象。 在论文“评估使用稳定扩散生成的合成图像数据集”中,我们使用“稳定扩散”模型来研究哪些对象和类型表现得如此逼真,以便后续图像分类正确地分配…...

云计算:常用运维软件工具
目录 一、理论 1.云管理工具 2.虚拟化工具 3.容器管理工具 4.运维自动化工具 5.版本控制工具 6.配置管理工具 7.编辑器工具 8.代码质量工具 9.网络管理工具 10.数据库管理工具 11.数据中心设备管理工具 12.数据可视化工具 13.服务器管理工具 14.应用性能管理工具…...
多测师肖sir_高级金牌讲师_python的安装002
一、python安装 1、python包(我们目前学习的版本是3.7) python-3.7.3 版本 2、Python下载的官网:https://www.python.org/downloads/ 最新包:3.12 3、下载好python安装包,在新建一个python文件件,我们要…...

gin实现event stream
event stream是属于http的一种通信方式,可以实现服务器主动推送。原理于客户端请求服务器之后一直保持链接,服务端持续返回结果给客户端。相比较于websocket有如下区别: 基于http的通信方式,在各类框架的加持下不需要开发人员自己…...
pytorch中transform库中常用的函数有哪些及其用法?
在PyTorch的torchvision.transforms库中,有许多常用的图像变换函数可用于数据增强和预处理。下面列举了一些常用的函数及其用法: Resize(size): 调整图像大小为给定的尺寸。 transform transforms.Resize((256, 256))RandomCrop(size, paddingNone): 随…...
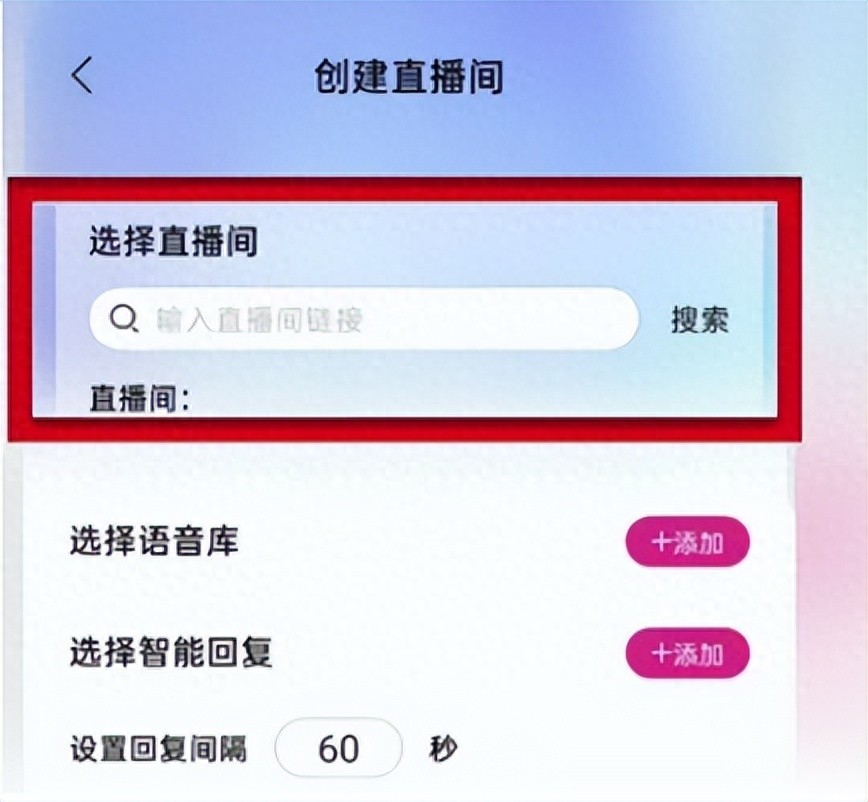
抖音手机实景无人直播间怎么搭建?
手机无人直播已成为用户直播和商家直播带货的一项热门技术趋势,为消费者提供了全新的观看体验。无人直播,顾名思义,即通过无人直播软件或数字人来进行无人直播。这一技术的广泛应用,不仅为短视频渠道带来了更丰富的玩法࿰…...

【新书推荐】当 Python 遇到 ChatGPT —— 自动化办公落地
文章目录 当 Python 遇到 ChatGPT:一种强大的组合1. 文本生成2. 自动翻译3. 对话生成4. 情感分析 新书推荐《Python自动化办公应用大全(ChatGPT版):从零开始教编程小白一键搞定烦琐工作(上下册)》前言内容简…...
RSA攻击:Smooth攻击
目录 前言:缘起 P-1光滑攻击 P1光滑攻击 前缀知识 Lucas-Subsquence(卢卡斯序列) 编码实现与理解 小试牛刀 [NCTF 2019]childRSA 引用 前言:缘起 Smooth攻击(光滑攻击),在最近刷题的时候总是能偶尔蹦跶到我的脑子里面。不是天天遇见它&am…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...