CSS 全称为层叠样式表(Cascading Style Sheet),用来定义 HTML 文件最终显示的外观。
为了理解 CSS 的加载与解析,需要对 CSS 样式表的组成,尤其是 CSS Selector 有所了解,相关部分可以参看这里。
HTML 文件里面引入 CSS 样式表有 3 种方式:
1 外部样式表
2 内部样式表
3 行内样式
不同的引入方式,CSS 加载与解析不一样。
CSS 样式表的引入方式可以参看这里。
1 外部样式表
1.1 相关类图
外部样式表加载与解析相关的类图如下所示:
1.2 加载
对于外部样式表,需要将样式表从服务器下载回来才能进行解析。
当构建 DOM 树解析到 <link> 标签的 href 属性时,就会发起下载样式表的请求,发起请求的调用栈如下:
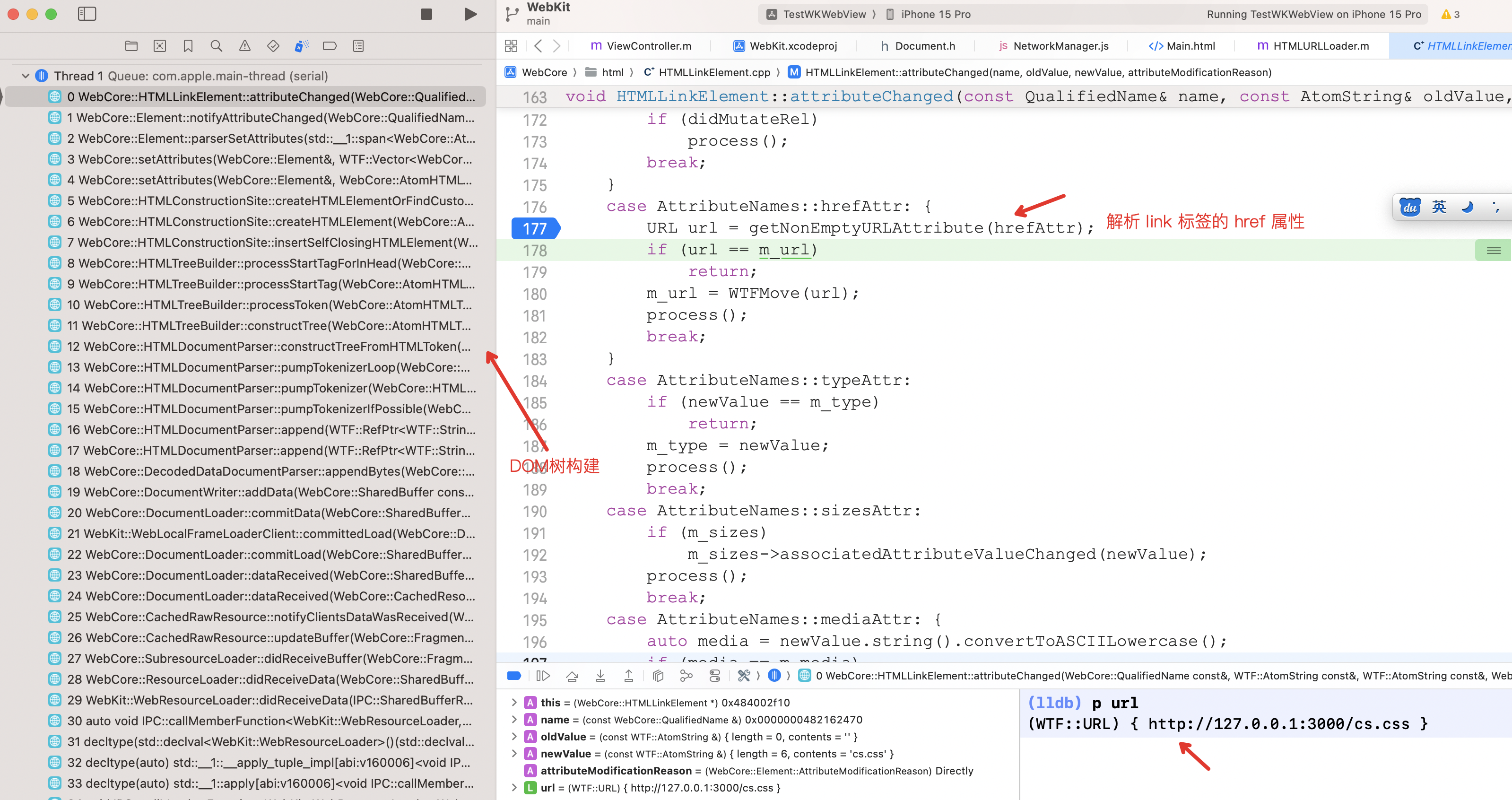
下载外部样式表的请求会从渲染进程传递到网络进程,由网络进程进行下载。
下载的过程中,DOM 树会继续构建,CSS 下载请求并不会阻塞 DOM 树的构建。
1.3 解析
当网络进程下载完样式表数据之后,会将数据传递回渲染进程,由 HTMLLinkElement 对象进行处理,处理的入口函数调用栈如下:

从网络下载回的样式表数据存储在 cachedStyleSheet 对象中,然后在 setCSSStyleSheet 方法中创建 CSSStyleSheet 对象和 StyleSheetContents 对象,最后调用 StyleSheetContents 对象的 parseAuthorStyleSheet 方法开始对 CSS 样式表进行解析,相关代码如下:
1 void HTMLLinkElement::setCSSStyleSheet(const String& href, const URL& baseURL, const String& charset, const CachedCSSStyleSheet* cachedStyleSheet)2 {3 ...4 CSSParserContext parserContext(document(), baseURL, charset);5 ...6 // 1. 创建 StyleSheetContents 对象7 auto styleSheet = StyleSheetContents::create(href, parserContext);8 // 2. 创建 CSSStyleSheet 对象9 initializeStyleSheet(styleSheet.copyRef(), *cachedStyleSheet, MediaQueryParserContext(document()));
10
11 // FIXME: Set the visibility option based on m_sheet being clean or not.
12 // Best approach might be to set it on the style sheet content itself or its context parser otherwise.
13 // 3. 在 if 语句这里开始进行 CSS 样式表解析
14 if (!styleSheet.get().parseAuthorStyleSheet(cachedStyleSheet, &document().securityOrigin())) {
15 ...
16 return;
17 }
18 ...
19 }
StyleSheetContents::parseAuthorStyleSheet 方法内部调用 CSSParser::parseSheet 方法, CSSParser::parseSheet 方法接收样式表内容字符串进行解析,代码如下所示:
1 bool StyleSheetContents::parseAuthorStyleSheet(const CachedCSSStyleSheet* cachedStyleSheet, const SecurityOrigin* securityOrigin)2 {3 ...4 // 1. 获取从网上下载回来的样式表内容字符串5 String sheetText = cachedStyleSheet->sheetText(mimeTypeCheckHint, &hasValidMIMEType);6 ...7 // 2. 解析样式表字符串8 CSSParser(parserContext()).parseSheet(*this, sheetText);9 return true;
10 1 }
上面代码注释 1 处 cachedStyleSheet 对象中获取样式表字符串。
注释2 处开始对样式表字符串进行解析。
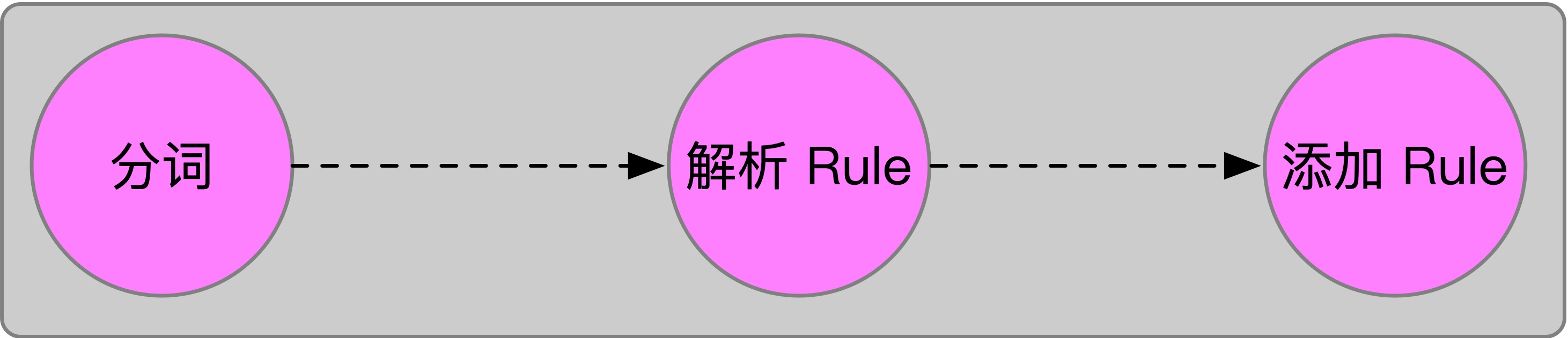
样式表字符串的解析分成 3 个步骤:
1 分词
2 解析样式表 Rule
3 添加样式表 Rule
具体流程如下图所示:
相关代码如下图所示:
1 void CSSParserImpl::parseStyleSheet(const String& string, const CSSParserContext& context, StyleSheetContents& styleSheet)2 {3 // 1. CSSParserImpl 内部持有 CSSTokenizer 对象,再 CSSParserImpl 对象构建的时对样式表字符串进行分词4 CSSParserImpl parser(context, string, &styleSheet, nullptr);5 // 2. parser.consumeRuleList 解析样式表的 rule6 bool firstRuleValid = parser.consumeRuleList(parser.tokenizer()->tokenRange(), TopLevelRuleList, [&](Ref<StyleRuleBase> rule) {7 ...8 // 3. 将解析好的 rule 添加到 StyleSheetContents 对象中,StyleSheetContents 使用 Vector 存储 rule9 styleSheet.parserAppendRule(WTFMove(rule));
10 });
11 }
上面代码注释 1 处进行分词操作。
注释 2 处对 CSS Rule 进行解析。
注释 3 处 将解析好的 CSS Rule 添加到 StyleSheetContents , StyleSheetContents 对象内部有 Vector 用来存储解析出来的 CSS Rule。
CSSParserImpl 内部持有 CSSTokenizer 对象,该对象负责对样式表字符串进行分词。
上面代码注释 1 创建 CSSParserImpl 对象时,就会同时创建 CSSTokenizer 对象,分词过程在 CSSTokenizer 对象内部完成。
分词的结果就是产生一个个 CSSParserToken 对象,存储到 CSSTokenizer 对象内部的数组中:
1 class CSSTokenizer {
2 ...
3 // 1. 存储分词结果
4 Vector<CSSParserToken, 32> m_tokens;
5 };
所谓分词就是根据 CSS 语法,顺序遍历整个样式表字符串的每个字符,将相关字符组成一个个 CSSParserToken 对象。
比如有如下样式表字符串:
div,p {background-color: red;font-size: 24px;
}div.item {margin-top: 2px;
}#content.item {padding-top: 2px;
}div+p {border-width: 2px;
}
CSSTokenizer 发现第一个字符为 'd' ,而字母在 CSS 语法里面属于标识符,因此扫描继续。
下一个字符为 'i',也属于标识符,扫描继续,直到碰到字符 ','。
字符 ',' 在 CSS 语法里是 Selector List 的分割符,因此第一个 Token 扫描结束。 CSSTokenizer 创建一个 CSSParserToken 用来存储 div,同时也会创建另一个 CSSParserToken 用来存储字符 ','。
整个分词流程结束之后,就会产生如下的 CSSParserToken 数组(忽略换行符):

为了解析出整个样式表的 Rule List,需要遍历整个 CSSParserToken 数组,遍历的的时候使用 CSSParserTokenRange 对象。
CSSParserTokenRange 内部有两个指针, m_first 指向第一个 CSSParserToken , m_last 指向最后一个 CSSParserToken 。同时,CSSParserTokenRange 还有 2 个方法:
peek 方法返回 m_first 指针指向的 CSSParserToken 对象;
comsume 方法向后移动 m_first 指针。

遍历整个 CSSParserToken 数组的方法如下:
1 // 参数 Range 指向整个 CSSParserToken 数组2 template<typename T>3 bool CSSParserImpl::consumeRuleList(CSSParserTokenRange range, RuleListType ruleListType, const T callback)4 {5 // 1. 遍历整个 CSSParserToken 数组6 while (!range.atEnd()) {7 ...8 // 2. 解析 at-rule9 case AtKeywordToken:
10 rule = consumeAtRule(range, allowedRules);
11 break;
12 ...
13 default:
14 // 3. 解析 Qualified Rule
15 rule = consumeQualifiedRule(range, allowedRules);
16 break;
17 }
18 ...
19 if (rule) {
20 // 4. callback 函数将解析出来的 Rule 天健到 SytleSheetContents 对象
21 callback(Ref { *rule });
22 }
23 }
24
25 return firstRuleValid;
26 }
上面代码注释 1 处遍历整个 CSSParserToken 数组。
代码注释 2 处解析样式表中的 At-Rule .
代码注释 3 处解析样式表中的 Qualified Rule 。从 CSS 样式表的组成可以知道,组成样式表的 Rule 是 At-Rule 和 Style Rule ,而 Style Rule 是一种特殊的 Qualified Rule 。因此 注释 2 和 注释 3 可以解析出 CSS 样式表中的所有 Rule。
代码注释 4 处调用回调函数 callback ,这个回调函数将解析出来的 CSS Rule 添加到 StyleSheetContents 对象中。
1.3.1 解析 Style Rule
如果 Qualified Rule 的 prelude 是 Selector List ,那么 Qualified Rule 就是 Style Rule 。因此,解析 Style Rule 分为 2 步:
1 解析 Style Rule 中的 Selector List 。
2 解析 Style Rule 中的 声明块 。
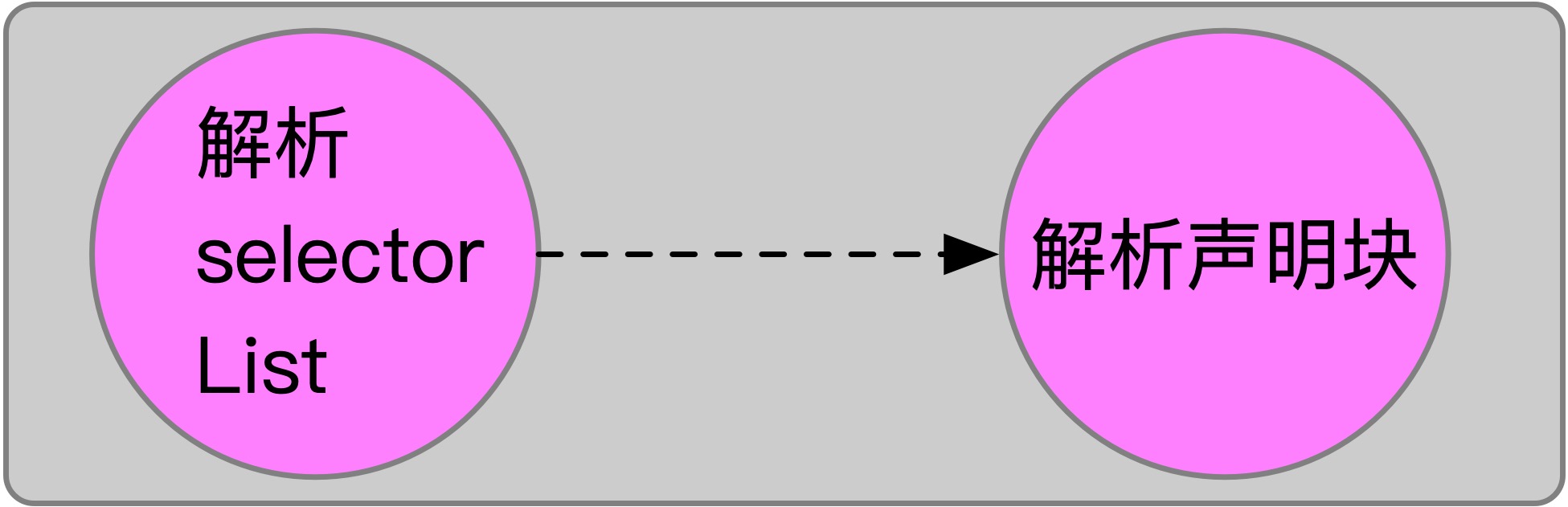
相关代码如下:
1 RefPtr<StyleRuleBase> CSSParserImpl::consumeQualifiedRule(CSSParserTokenRange& range, AllowedRulesType allowedRules)2 {3 ...4 // 1. prelude 变量表示 Qualified Rule 的 Prelude 范围5 CSSParserTokenRange prelude = range.makeSubRange(preludeStart, &range.peek());6 // 2. block 变量表示 Qualified Rule 的声明块范围7 CSSParserTokenRange block = range.consumeBlockCheckingForEditability(m_styleSheet.get());8 9 if (allowedRules <= RegularRules)
10 // 3. 1
11 return consumeStyleRule(prelude, block);
12
13 ...
14 return nullptr;
15 }
上面代码注释 1 处首先找到当前 Qualified Rule 的 Prelude ,如果是 Style Rule , Prelude 就是 Selector List 。
注释 2 处获取 Qualifed Rule 声明块的范围。
注释 3 处 开始解析 Style Rule 。

解析 Style Rule 的代码如下所示:
1 RefPtr<StyleRuleBase> CSSParserImpl::consumeStyleRule(CSSParserTokenRange prelude, CSSParserTokenRange block)2 {3 // 1. 解析 Selector List4 auto selectorList = parseCSSSelector(prelude, m_context, m_styleSheet.get(), isNestedContext() ? 5 ...6 RefPtr<StyleRuleBase> styleRule;7 runInNewNestingContext([&] {8 {9 // 2. 解析声明块
10 consumeStyleBlock(block, StyleRuleType::Style);
11 }
12 ...
13 // 3. 注释 2 解析声明块的值存储在 m_parsedProperties 变量中,
14 // 此处使用 m_parsedProperties 变量创建 ImmutableStyleProperties 对象,
15 // ImmutableStyleProperties 对象存储 Style Rule 声明块的值
16 auto properties = createStyleProperties(topContext().m_parsedProperties, m_context.mode);
17
18 // We save memory by creating a simple StyleRule instead of a heavier StyleRuleWithNesting when we don't need the CSS Nesting features.
19 if (nestedRules.isEmpty() && !selectorList->hasExplicitNestingParent() && !isNestedContext())
20 // 4. 使用解析出来的 elector List 和声明块值创建一个 Style Rule 对象
21 styleRule = StyleRule::create(WTFMove(properties), m_context.hasDocumentSecurityOrigin, WTFMove(*selectorList));
22 else {
23 ...
24 }
25 });
26
27 return styleRule;
28 }
上面代码注释 1 处解析出 Style Rule 的 Selector List 。
注释 2 处解析 Style Rule 的声明块,解析出来的值存储在 m_parsedProperties 变量中。
注释 3 处根据解析出来的声明块的值创建 ImmutableStyleProperties 对象,该对象最终存储声明块的值。
注释 4 处是有那个解析出来的 Selector List 和声明块的值,创建了 Style Rule 对象。
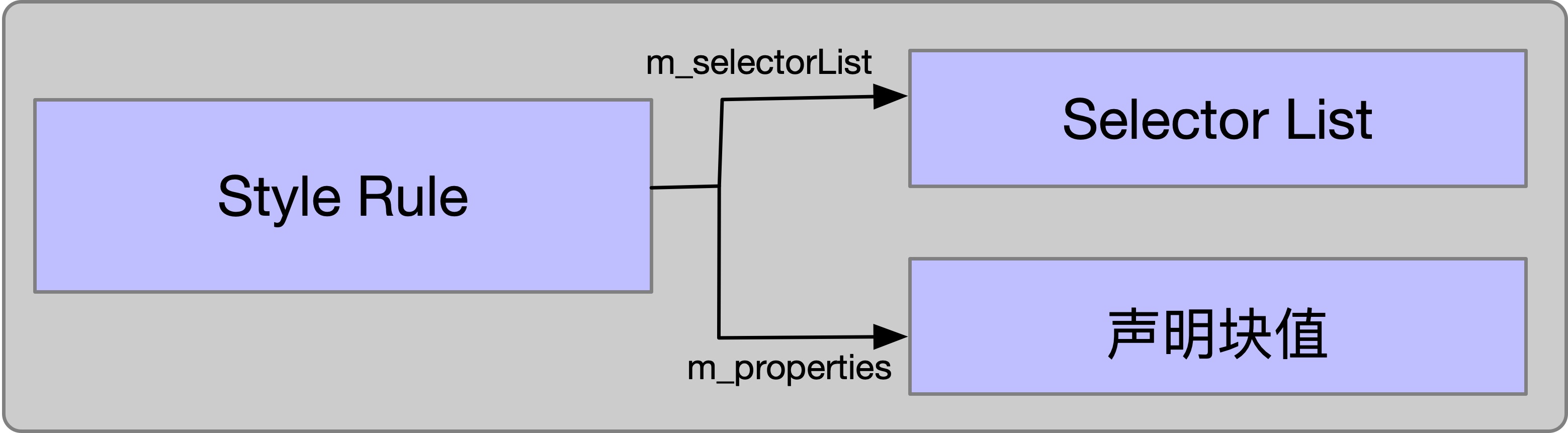
上面的函数 CSSParserImpl::consumeStyleRule 内部调用 parseCSSSelector 函数解析 Style Rule 的 Selector List 。
从 CSS 样式表的组成可以知道,CSS 的 Selector 分为 4 类:
1 简单 Selector (Simple Selector)
2 复合 Selector (Compound Selector)
3 组合 Selector (Complex Selector)
4 Selector List
Selector List 由前面 3 类 Selector 任意组合,通过逗号 ',' 连接而来,比如下面就是 2 种类型的 Selector List :
div /* 简单 Selector */, div + p/*组合 Selector */, p#item/*复合 Selector */div/* 简单 Selector */, p/* 简单 Selector */
而复合 Selector 和组合 Selector 由简单 Selector 构成,因此为了理解函数 parseCSSSelector 的过程,首先需要理解简单 Selector 的解析过程。
1.3.2 解析简单 Selector
简单 Selector 有 6 种:
1 类型 Selector (Type Selector),比如: div 。
2 通用 Selector (Universal Selector),比如: * 。
3 属性 Selector (Attribute Selector),比如: [attr=val] 。
4 类 Selector (Class Selector),比如: .item 。
5 ID Selector,比如: #item 。
6 伪类 Selector (Pseudo-Class Selector),比如: :hover 。
和伪类 Selector 类似的,还有伪元素 Selector (Pseudo-Element Selector),比如: ::first-letter 。
解析出来的简单 Selector 由类 CSSParserSelector 和 CSSSelector 表示,其中 CSSParserSelector 内部通过 m_selector 属性持有 CSSSelector 。
CSSSelector 类有一个属性 Match m_match ,代表这个简单 Selector 使用何种方式进行匹配。
Match 的定义如下:
// 定义在 CSSSelector.h 文件
enum class Match : uint8_t {Unknown = 0, // 初始化值Tag, // 类型 Selector,比如 divId, // ID Selector,比如 #itemClass, // 类 Selector,比如 .itemExact, // 属性 Selector 中的 [attr=val]Set, // 属性 Selector 中的 [attr]List, // 属性 Selector 中的 [atr~=val]Hyphen, // 属性 Selector 中的 [attr|=val]PseudoClass, // 伪类 Selector,比如 :hoverPseudoElement, // 伪类 Selector,比如 ::first-letterContain, // 属性 Selector 中的 [attr*=val]Begin, // 属性 Selector 中的 [attr^=val]End, // 属性 Selector 中的 [attr$=val]PagePseudoClass, // 与 @page Rule 相关NestingParent, // 与嵌套 CSS Rule 相关ForgivingUnknown, // 与伪类函数,比如 :is() 相关ForgivingUnknownNestContaining // 与伪类函数,比如 :is() 相关
};
解析简单 Selector 的代码如下所示:
1 std::unique_ptr<CSSParserSelector> CSSSelectorParser::consumeSimpleSelector(CSSParserTokenRange& range)2 {3 const CSSParserToken& token = range.peek();4 // 1. 返回值是 CSSParserSelector 对象5 std::unique_ptr<CSSParserSelector> selector;6 if (token.type() == HashToken)7 // 2. ID Selector8 selector = consumeId(range);9 else if (token.type() == DelimiterToken && token.delimiter() == '.')
10 // 3. 类 Selector
11 selector = consumeClass(range);
12 else if (token.type() == DelimiterToken && token.delimiter() == '&' && m_context.cssNestingEnabled)
13 // 4. 嵌套 CSS Rule 标识符也在这里解析,嵌套 CSS 后面介绍
14 selector = consumeNesting(range);
15 else if (token.type() == LeftBracketToken)
16 // 5. 属性 Selector
17 selector = consumeAttribute(range);
18 else if (token.type() == ColonToken)
19 // 6. 伪类或者伪元素 Selector
20 // consumePseudo 内部判断如果只有一个 ':' 就解析成伪类 Selector,
21 // 如果连着 2 个 ':' 就解析成伪元素 Selector.
22 selector = consumePseudo(range);
23 else
24 return nullptr;
25 ...
26 return selector;
27 }
从代码注释 1 处看到,解析后的简单 Selector 是一个 CSSParserSelector 对象。
注释 2-6 分别解析了 4 种简单 Selector 和嵌套 CSS Rule 表示符 '&' 。类型 Selector 和通用 Selector 在代码实现上并没有在这里进行解析,而是放到了别的地方。
嵌套 CSS Rule 后文有介绍。
由于类型 Selector 和通用 Selector 可以结合命名空间使用,它们的解析放在了 CSSSelectorParser::consumeName 函数中:
1 // 参数 name 是一个引用,它用来存储解析出来的类型 Selector 标签名或者通用 Selector 名 "*"2 bool CSSSelectorParser::consumeName(CSSParserTokenRange& range, AtomString& name, AtomString& namespacePrefix)3 {4 ...5 const CSSParserToken& firstToken = range.peek();6 if (firstToken.type() == IdentToken) {7 // 1. 解析类型 Selector 名8 name = firstToken.value().toAtomString();9 range.consume();
10 } else if (firstToken.type() == DelimiterToken && firstToken.delimiter() == '*') {
11 // 2. 解析通用 Selector 名
12 name = starAtom();
13 range.consume();
14 }
15 ...
16 return true;
17 }
上面代码参数 name 是一个引用,用来存储解析出来的名字: 要么是类型 Selector 的 HTML 标签名,要么是通用 Selector 名 "*" 。
代码注释 1 解析类型 Selector HTML 标签名。
代码注释 2 解析通用 Selector 名 "*" 。
由于本质上说,通用 Selector 是一种特殊的类型 Selector,因此通用 Selector 的 m_match 属性也是 Match::Tag 。
1.3.3 解析复合 Selector
复合 Selector 由一个或者多个简单 Selector 连接而成,这些简单 Selector 之间不能有其他字符,包括空格。
比如 div#item 就是一个复合 Selector,而 div #item 不是一个复合 Selector,而是一个组合 Selector。
解析复合 Selector 的代码如下:
std::unique_ptr<CSSParserSelector> CSSSelectorParser::consumeCompoundSelector(CSSParserTokenRange& range)
{...// 1. elementName 存储类型 Selector 对应的 HTML 标签名,或者通用 Selector 名 "*"AtomString elementName;// 2. 解析类型 Selector 名或者通用 Selector 名const bool hasName = consumeName(range, elementName, namespacePrefix);if (!hasName) {// 3. 对于 #item.news 这样的复合 Selector,并没有类型 Selector 和通用 Selector,// 因此 hasName = false,这里解析出第一个 ID Selector #itemcompoundSelector = consumeSimpleSelector(range);...}// 4. 循环解析后续的简单 Selector,因为一个复合 Selector 可能包含许多个简单 Selector,比如 div#item.newswhile (auto simpleSelector = consumeSimpleSelector(range)) {...if (compoundSelector)// 5. CSSParserSelector 是一个链表结构,这里将复合 Selector 里面解析出来的简单 Selector 串成一个链表compoundSelector->appendTagHistory(CSSSelector::RelationType::Subselector, WTFMove(simpleSelector));elsecompoundSelector = WTFMove(simpleSelector);}...if (!compoundSelector) {// 6. 如果复合 Selector 只有类型 Seledtor 或者通用 Selector,比如 div 或者 *,那么就直接返回这个 Selectorreturn makeUnique<CSSParserSelector>(QualifiedName(namespacePrefix, elementName, namespaceURI));}// 7. 如果复合 Selector 是 div#item.news 这种以类型 Selector 开头, 或者 *#item.news 这种以通用 Selector 开头,// 那么根据 CSS 语法,类型 Selector 和通用 Selector 应该位于复合 Selector 的最前面,// 因此这个方法会根据 elementName 创建一个 CSSParserSelector,并添加到复合 Selector 链最前面。// 如果注释 2 处没有解析出 elementName,也就是 #item.news 这种形式的复合 Selector,这个函数什么也不做prependTypeSelectorIfNeeded(namespacePrefix, elementName, *compoundSelector);// 8. 这个函数大部分场景会直接返回上面解析出来的复合 Selector 链, 只会在一些特殊场景下重新排列复合 Selector 链,然后返回.return splitCompoundAtImplicitShadowCrossingCombinator(WTFMove(compoundSelector), m_context);
}
上面代码注释 1 处的变量 elementName 就是用来存储 consumeName 方法解析出来的类型 Selector 对应的 HTML 标签名,或者通用 Selector 名 '*' 。
代码注释 2 处是在解析类型 Selector 对应的 HTML 标签名或者通用 Selector 名。
如果复合 Selector 里面没有类型 Selector 或者通用 Selector,比如 #item.news ,那么就会运行到注释 3 处,解析出 ID Selector #item 。
代码注释 4 处遍历复合 Selector 的其他简单 Selector。
代码注释 5 将从复合 Selector 里面解析出来的简单 Selector 串起来。类 CSSParserSelector 里面有一个属性 m_tagHistory ,它的类型是一个 CSSParserSelector * ,这样 CSSParserSelector 就是一个链表。比如复合 Selector
div#item.news 解析完成之后,就会形成 div -> #item -> .news 这样的链表结构:

注释 5 在构成复合 Selector 链表时,还为构成复合 Selector 的简单 Selector 之间设置了 Relation : CSSSelector::RelationType::Subselector 。构成复合 Selector 的简单 Selector 之间的 Relation 都是 CSSSelector::RelationType::Subselector ,其他类型的 Relation 在解析组合 Selector 可以看到。
如果复合 Selector 本身只是一个类型 Selector,比如 div 或者 是一个通用 Selector '*' ,那么注释 6 处就直接返回这个 CSSParserSelector 。
根据 CSS 语法,如果复合 Selector 里面的简单 Selector 有类型 Selector 或者通用 Selector,那么它们需要在复合 Selector 的最前面,注释 7 正是处理这种情况。
代码注释 8 正常情形下会直接返回解析出来的复合 Selector 对象,只有在一些特殊情况会调整复合 Selector 链表的顺序。特殊情形在 splitCompoundAtImplicitShadowCrossingCombinator 方法内部的注释里面有解释:
// The tagHistory is a linked list that stores combinator separated compound selectors// from right-to-left. Yet, within a single compound selector, stores the simple selectors// from left-to-right.//// ".a.b > div#id" is stored in a tagHistory as [div, #id, .a, .b], each element in the// list stored with an associated relation (combinator or Subselector).//// ::cue, ::shadow, and custom pseudo elements have an implicit ShadowPseudo combinator// to their left, which really makes for a new compound selector, yet it's consumed by// the selector parser as a single compound selector.//// Example: input#x::-webkit-inner-spin-button -> [ ::-webkit-inner-spin-button, input, #x ]//
1.3.4 解析组合 Selector
组合 Selector 由 Combinator 连接复合 Selector 组成,根据 CSS 语法 Combinator 有 4 种:
1 空格 : div p
2 > : div > p
3 + : div + p
4 ~ : div ~ p
解析组合 Selector 的相关代码如下:
1 std::unique_ptr<CSSParserSelector> CSSSelectorParser::consumeComplexSelector(CSSParserTokenRange& range)2 {3 // 1. 从组合 Selector 里面解析出一个复合 Selector4 auto selector = consumeCompoundSelector(range);5 if (!selector)6 return nullptr;7 ...8 while (true) {9 // 2. 解析 Combinator
10 auto combinator = consumeCombinator(range);
11 // 3. 如果 CSS Rule 是 div{background-color: red;},那么 consumeCombinator 方法
12 // 返回 CSSSelector::RelationType::Subselector
13 if (combinator == CSSSelector::RelationType::Subselector)
14 // 4. 在注释 3 这种情形下,直接跳出循环,返回 Selector div
15 break;
16
17 // 5. 代码运行到这里可能碰到两种 CSS Rule 情形:
18 // Case 1: div {background-color: red;}
19 // Case 2: div + p {background-color: red;}
20 // 在 Case 2 下,可以解析到下一个 Selector p,此时 Combinator 是 '+',
21 // 在 Case 1 下,Combinator 是空格,但是确没有下一个 Selector
22 auto nextSelector = consumeCompoundSelector(range);
23 if (!nextSelector)
24 // 6. 如果是 Case 1,则直接返回 Selector div
25 return isDescendantCombinator(combinator) ? WTFMove(selector) : nullptr;
26 ...
27 CSSParserSelector* end = nextSelector.get();
28 ...
29 // 7. 如果能解析到下一个复合 Selector,由于复合 Selector 是一个链表结构,这里遍历链表到末尾,
30 // 遍历结束,end 是 nextSelector 的末尾
31 while (end->tagHistory()) {
32 end = end->tagHistory();
33 ...
34 }
35 // 8. 根据 Combinator 设置 Selector 之间的关系
36 end->setRelation(combinator);
37 ...
38 // 9. 组合 Selector 之间也构成了链表关系
39 end->setTagHistory(WTFMove(selector));
40 selector = WTFMove(nextSelector);
41 }
42
43 return selector;
44 }
上面代码注释 1 首先解析出一个复合 Selector。
注释 2 处尝试解析 Combinator 。 Combinator 表示的是 Selector 之间的关系,在代码实现上将 Subselector 也当成了 Combinator 的一种,如注释 3 所示。
如果解析的 CSS Rule 为 div{background-color: red;} ,注意 div 和 { 之间没有空格。此时方法 consumeCombinator 解析出来的 Combinator 为 CSSSelector::RelationType::Subselector ,那么就会进入到注释 4 处跳出循环,直接返回 Selector div 。
如果不是上面注释 3 的情形,则如注释 5所示,CSS Rule 又有两种 Case:
Case 1: div {background-color: red;} , 注意 div 和 { 之间有空格。
Case 2: div + p { background-color: red;} 。
在 Case 1 下,由于解析不到后续的 Selector,将进入注释 6,注释 6 会直接返回 Selector div 。
在 Case 2 下, Combinator 解析为 + ,而且可以解析出下一个 Selector p ,因此代码运行到注释 7 处。
由于 Selector 本身是一个链表结构,注释 7 遍历这个链表,并且将链表最后一个 Selector 存入变量 end 。
注释 8 根据 Combinator 设置 Selector 之间的关系,由于 Combinator 有 4 种,对应的关系也有 4种:
1 // 定义在 CSSSelector.h
2 enum class RelationType : uint8_t {
3 Subselector = 0, // 复合 Selector 使用
4 DescendantSpace, // 空格
5 Child, // >
6 DirectAdjacent, // +
7 IndirectAdjacent, // ~
8 ...
9 };
注释 9 和复合 Selecto 一样,也将解析出来的 Selector 构造成一个列表。
不一样的是,复合 Selector 链表顺序就是简单 Selector 的排列顺序,比如复合 Selector div#item.news 解析出来的链表结构为 div -> #item -> .news 。而对于组合 Selector,链表顺序和 复合Selector 顺序是相反的,比如组合 Selector p#content + div#item.news ,解析出来的链表结构为 div -> #item -> .news -> p -> #content。
1.3.5 解析 Selector List
有了上面的介绍,下面来看解析 Selector List 的代码。解析 Selector List 的代码位于函数 parseCSSSelector :
1 std::optional<CSSSelectorList> parseCSSSelector(CSSParserTokenRange range, const CSSSelectorParserContext& context, StyleSheetContents* styleSheet, CSSParserEnum::IsNestedContext isNestedContext)2 {3 // 1. 创建 Selector 解析器4 CSSSelectorParser parser(context, styleSheet, isNestedContext);5 range.consumeWhitespace();6 auto consume = [&] {7 ...8 // 2. 解析组合 Selector List9 return parser.consumeComplexSelectorList(range);
10 };
11 CSSSelectorList result = consume();
12 ...
13 return result;
14 }
上面代码注释 1 创建 CSS Selector 解析器。
上面代码注释 2 解析组合 Selector List,相关代码如下:
CSSSelectorList CSSSelectorParser::consumeComplexSelectorList(CSSParserTokenRange& range)
{return consumeSelectorList(range, [&] (CSSParserTokenRange& range) {// 1. 解析组合 Selectorreturn consumeComplexSelector(range);});
}template <typename ConsumeSelector>
CSSSelectorList CSSSelectorParser::consumeSelectorList(CSSParserTokenRange& range, ConsumeSelector&& consumeSelector)
{// 2. 存储解析出来的 Selector ListVector<std::unique_ptr<CSSParserSelector>> selectorList;// 3. consumeSelector 是一个回调函数,就是上面代码注释 1 中的 consumeComplexSelectorauto selector = consumeSelector(range);if (!selector)return { };// 4. 将解析出来的 Selector 添加到数组中selectorList.append(WTFMove(selector));// 5. 遍历 CSS Selector Tokens,如果遇到逗号 CommaToken,说明还有下一个 Selector 需要解析while (!range.atEnd() && range.peek().type() == CommaToken) {range.consumeIncludingWhitespace();// 6. 解析逗号后面的下一个 Selector,也就是调用函数 consumeComplexSelectorselector = consumeSelector(range);if (!selector)return { };// 7. 继续添加解析出来的 Selector 到数组中selectorList.append(WTFMove(selector));}...return CSSSelectorList { WTFMove(selectorList) };
}
上面代码注释 2 的 变量 selectorList 存储所有解析出来的 CSS Selector。
代码注释 3 调用了一个回调函数,回调函数就是注释 1 的 consumeComplexSelector ,用来解析组合 Selector。
注释 4 将解析出来的组合 Selector 添加到数组中。
注释 5 遍历 CSS Selector Tokens,如果遇到了逗号 , 说明还有下一个 Selector 需要解析,那么就会运行到注释 6 调用 consumeComplexSelector 继续解析。
注释 7 继续添加解析出来的 Selector。
综合整个 Selector List 的解析过程,函数调用栈如下:

1.3.6 解析声明块
解析声明块的函数是 CSSParserImpl::consumeStyleBlock ,这个函数内部调用 CSSParserImpl::consumeBlockContent 函数,这个函数内部解析声明块:
1 void CSSParserImpl::consumeBlockContent(CSSParserTokenRange range, StyleRuleType ruleType, OnlyDeclarations onlyDeclarations, ParsingStyleDeclarationsInRuleList isParsingStyleDeclarationsInRuleList)2 {3 ...4 // 1. 声明块里面会有多个声明,这里进行遍历5 while (!range.atEnd()) {6 ...7 case IdentToken: {8 const auto declarationStart = &range.peek();9 ...
10 // 2. 获取一条声明的范围
11 const auto declarationRange = range.makeSubRange(declarationStart, &range.peek());
12 // 3. 解析一条声明
13 auto isValidDeclaration = consumeDeclaration(declarationRange, ruleType);
14 ...
15 break;
16 }
17 ..
18 }
19 ...
20 }
由于声明块中会有多条声明,上面代码注释 1 处就是循环遍历所有声明。
注释 2 获取一条声明的 Token 范围。
注释 3 对这条声明进行解析,函数 consumeDeclaration 相关代码如下所示:
1 bool CSSParserImpl::consumeDeclaration(CSSParserTokenRange range, StyleRuleType ruleType)2 {3 ...4 // 1. 获取属性名 Token5 auto& token = range.consumeIncludingWhitespace();6 // 2. 获取属性名对应的属性 ID7 auto propertyID = token.parseAsCSSPropertyID();8 ...9 if (propertyID != CSSPropertyInvalid)
10 // 3. 解析属性值
11 consumeDeclarationValue(range.makeSubRange(&range.peek(), declarationValueEnd), propertyID, important, ruleType);
12 ...
13 return didParseNewProperties();
14 }
上面代码注释 1 获取声明中属性名 Token。
属性名解析出来并不是直接存储属性名字符串,而是存储其对应的属性 ID,如注释 2 所示。 CSSPropertyID 定义在 CSSPropertyNames.h 文件中,下面截取部分定义:
// 定义在 CSSPropertyNames.h
enum CSSPropertyID : uint16_t {CSSPropertyInvalid = 0,CSSPropertyCustom = 1,CSSPropertyColorScheme = 2,CSSPropertyWritingMode = 3,CSSPropertyWebkitRubyPosition = 4,CSSPropertyColor = 5,CSSPropertyDirection = 6,CSSPropertyDisplay = 7,CSSPropertyFontFamily = 8,...
}
需要注释的是 CSSPropertyNames.h 头文件是 WebKit 工程使用 Python 脚本动态生成,需要运行 WebKit 工程才可以看到。
上面代码注释 3 解析属性的值,解析出来的属性值存储在 CSSValue 对象中,相关代码如下:
1 void CSSParserImpl::consumeDeclarationValue(CSSParserTokenRange range, CSSPropertyID propertyID, bool important, StyleRuleType ruleType)2 {3 // 1. 调用 CSSPropertyParser 类方法解析属性值4 CSSPropertyParser::parseValue(propertyID, important, range, m_context, topContext().m_parsedProperties, ruleType);5 }6 7 bool CSSPropertyParser::parseValue(CSSPropertyID propertyID, bool important, const CSSParserTokenRange& range, const CSSParserContext& context, ParsedPropertyVector& parsedProperties, StyleRuleType ruleType)8 {9 ...
10 // 2. 创建属性解析器
11 CSSPropertyParser parser(range, context, &parsedProperties);
12 bool parseSuccess;
13 if (ruleType == StyleRuleType::FontFace)
14 ...
15 else
16 // 3. 解析属性值为 CSSValue 对象,然后使用 propertyID 和 CSSValue 对象创建 CSSProperty 对象,
17 // CSSProperty 对象会被存储在 m_parsedProperties 中
18 parseSuccess = parser.parseValueStart(propertyID, important);
19 ...
20 return parseSuccess;
21 }
上面代码注释 1 调用 CSSPropertyParser 类方法 parseValue 解析属性值。
注释 2 创建 CSSPropertyParser 。
注释 3 将属性值解析为 CSSValue 对象,然后使用 propertyID 和 CSSValue 对象创建 CSSProperty 对象,这个 CSSProperty 对象存储到数组 m_parsedProperties 中。

1.3.7 解析 At-Rule
CSSParserImpl::consumeRuleList 方法中解析 At-Rule,At-Rule 的解析和 Qualifed Rule 的解析类似,也是先解析 Prelude ,然后解析声明块。
不同的 At-Rule 语法上有所差异,比如有些 At-Rule 只有 Prelude 部分,没有声明块,比如:
@charset "UTF-8";
有些 At-Rule 有声明块但是没有 Prelude ,比如:
@font-face {font-family: "Trickster";
}
而有些 At-Rule 既有 Prelude 也有声明块,比如:
@media screen, print {body {line-height: 1.2;}
}
无论何种形式,解析 At-Rule 的 Prelude 和声明块原理,与解析 Qualified Rule 类似。
相关代码如下:
1 RefPtr<StyleRuleBase> CSSParserImpl::consumeAtRule(CSSParserTokenRange& range, AllowedRulesType allowedRules)2 {3 4 ...5 // 1. 获取 prelude 范围6 CSSParserTokenRange prelude = range.makeSubRange(preludeStart, &range.peek());7 // 2. 根据 @ 符号后面的 name,获取对应的 ID 值,8 // 比如对于 @charset,cssAtRuleID 方法根据 "charset" 字符串,返回 CSSAtRuleCharset9 CSSAtRuleID id = cssAtRuleID(name);
10
11 // 3. 有些 At-Rule 没有 block,比如 @charset "UTF-8; 因此直接解析 prelude 生成对应的 Rule 对象
12 if (range.atEnd() || range.peek().type() == SemicolonToken) {
13 range.consume();
14 if (allowedRules == AllowCharsetRules && id == CSSAtRuleCharset)
15 // 4. 解析 @charset At-Rule,返回对应的 Rule 对象
16 return consumeCharsetRule(prelude);
17 ...
18 }
19
20 // 5. 获取声明块范围
21 CSSParserTokenRange block = range.consumeBlock();
22 ...
23 // 6. 根据对应的 CSSAtRuleID,解析相应的 At-Rule
24 switch (id) {
25 ...
26 case CSSAtRuleFontFace:
27 // 7. 解析生成 @font-face At-Rule,返回对应的 Rule 对象
28 return consumeFontFaceRule(prelude, block);
29 ...
30 }
上面代码注释 1 处先获取 prelude 范围。
注释 2 根据 '@' 符号后面的 name,获取对应的 ID。
比如 @charset 的 name 是 "charset" 字符串,调用函数 cssAtRuleID 返回值 CSSAtRuleIDCharset 。
enum CSSAtRuleID 定义在 CSSAtRuleID.h 头文件中,截取部分代码如下:
// 定义在 CSSAtRuleID.h
enum CSSAtRuleID {CSSAtRuleInvalid = 0,CSSAtRuleCharset,CSSAtRuleFontFace,CSSAtRuleImport,CSSAtRuleKeyframes,CSSAtRuleMedia,...
}
因为 At-Rule 分为 Statement At-Rule 和 块式 At-Rule 。比如 @charset "UTF-8"; 就是 Statement At-Rule ,而 @font-face {font-family: "Trickster";} 就是一个 块式 At-Rule 。
由于 Statement At-Rule 没有声明块,所以注释 3 处就是专门解析这些 Statement At-Rule 。
如果是 块式 At-Rule ,那么在注释 5 处会获取声明块的范围。
注释 6 处根据 CSSAtRuleID 调用对应的函数,解析出对应的 At-Rule 对象。
1.3.8 解析嵌套 CSS Rule
CSS Style Rule 支持嵌套,比如:
.foo {color: red;/* 嵌套的 CSS Rule */a {color: blue;}
}
这种嵌套的 CSS Rule 等价于 2 条 CSS Rule:
.foo {color: red;
}.foo a {color: blue;
}
与嵌套 CSS Rule 相关的一个 Selector 是 Nesting Selector ,就是之前解析简单 Selector 遇到的 '&' 符号, '&' 符号代表父 Rule 的 Selector List 。
相关例子如下:
.foo {color: red;/* & 符号 */&:hover { color: blue; }
}
上面这条嵌套 Rule 等价于下面 2 条 Rule:
.foo {color: red;
}.foo:hover {color: blue;
}
这里只是简单介绍了嵌套 Rule 的规则,更详细的介绍可以参看这里。
在代码实现上,如果一条 CSS Rule 包含嵌套 Rule,那么解析这条 Rule 返回的对象就不再是 StyleRule ,而是 StyleRuleWithNesting 。 StyleRuleWithNesting 继承自 StyleRule ,它内部有一个数组属性 m_nestedRules 存储所有的嵌套子 Rule。
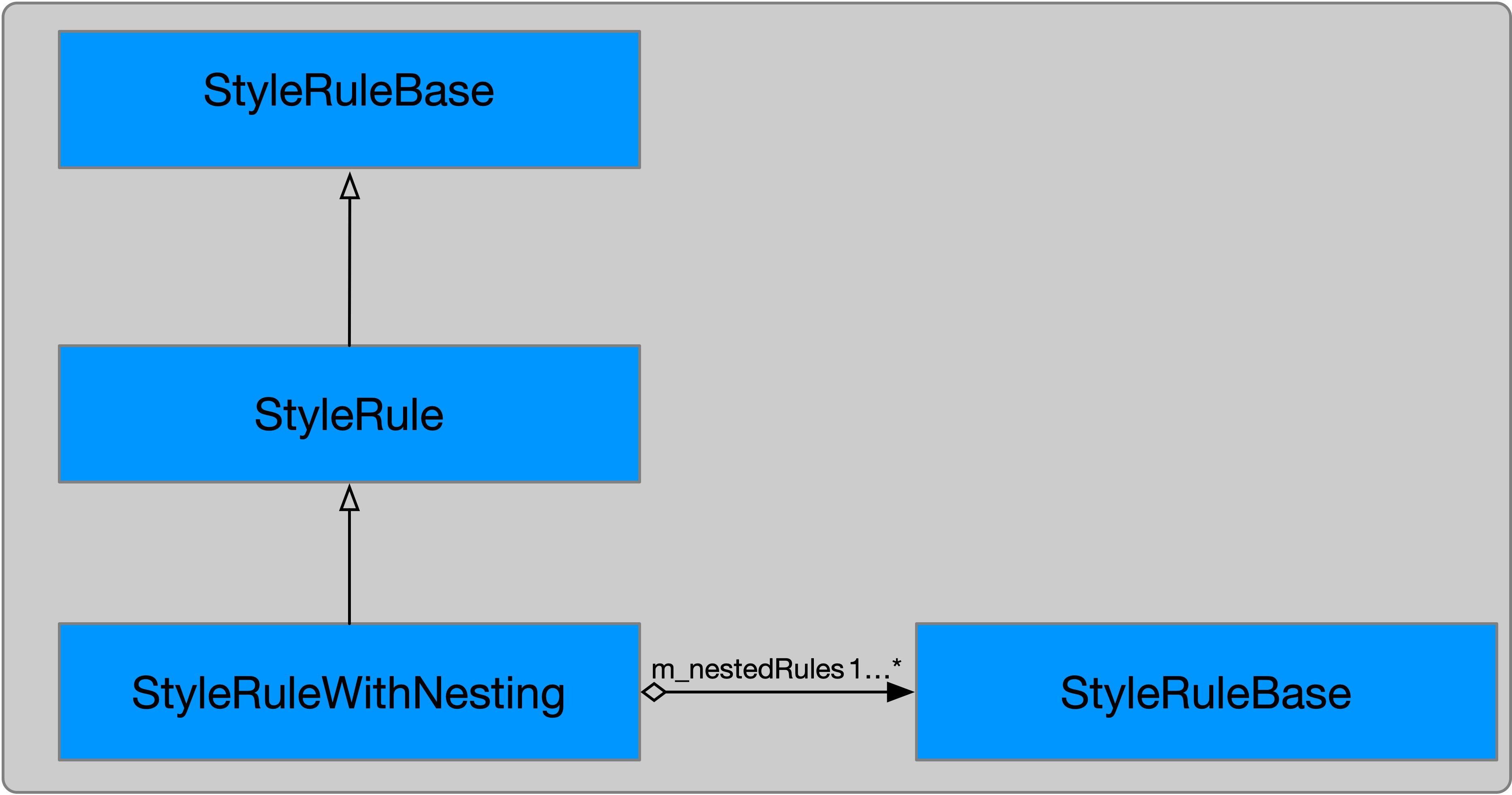
相关代码如下:
1 RefPtr<StyleRuleBase> CSSParserImpl::consumeStyleRule(CSSParserTokenRange prelude, CSSParserTokenRange block)2 {3 ...4 RefPtr<StyleRuleBase> styleRule;5 6 runInNewNestingContext([&] {7 ...8 if (nestedRules.isEmpty() && !selectorList->hasExplicitNestingParent() && !isNestedContext())9 // 1. 创建非嵌套的 Style Rule
10 styleRule = StyleRule::create(WTFMove(properties), m_context.hasDocumentSecurityOrigin, WTFMove(*selectorList));
11 else {
12 // 2. 创建嵌套的 Style Rule
13 styleRule = StyleRuleWithNesting::create(WTFMove(properties), m_context.hasDocumentSecurityOrigin, WTFMove(*selectorList), WTFMove(nestedRules));
14 m_styleSheet->setHasNestingRules();
15 }
16 });
17
18 return styleRule;
19 }
上面代码注释 1 创建非嵌套 Style Rule 。
代码注释 2 创建嵌套 StyleRuleWithNesting 。
2 内部样式表
内部样式表直接写在 HTML 文件的 <style> 中,当 WebKit 解析完 </style> 标签,就会解析 <style> 标签包围的样式表字符串。
2.1 相关类图
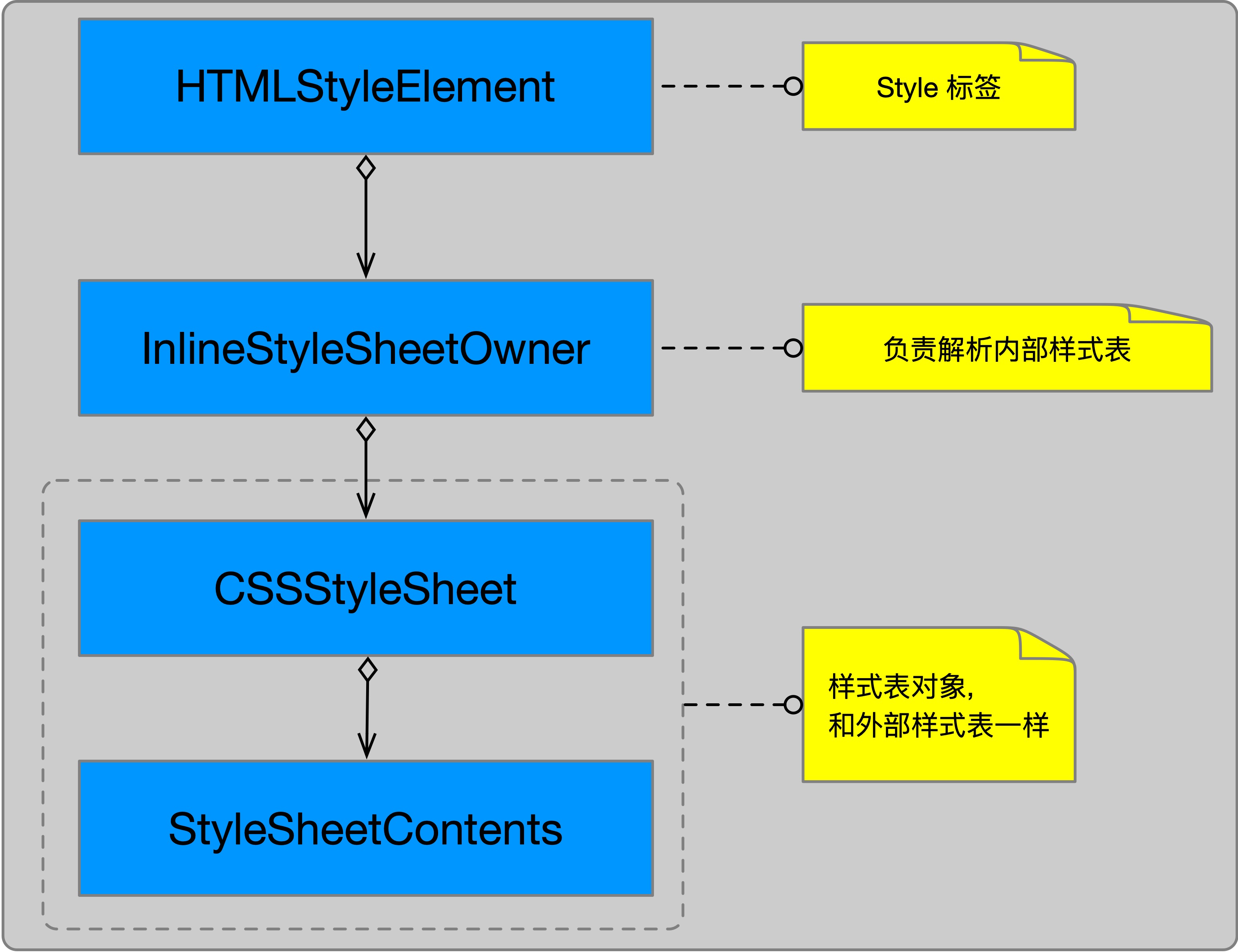
2.2 解析
inlineStyleSheetOwner 解析内部样式表与外部样式表一样,首先创建 CSSStyleSheet 对象和 StyleSheetContents 对象,然后由 StyleSheetContents 发起解析流程。
相关代码如下:
1 // 参数 text 就是 <style> 标签包围的样式表字符串2 void InlineStyleSheetOwner::createSheet(Element& element, const String& text)3 {4 ...5 // 1. 创建 StyleSheetContents6 auto contents = StyleSheetContents::create(String(), parserContextForElement(element));7 // 2. 创建 CSSStyleSheet8 m_sheet = CSSStyleSheet::createInline(contents.get(), element, m_startTextPosition);9 ...
10 // 3. 由 StyleSheetContents 对象发起解析
11 contents->parseString(text);
12 ...
13 }
上面代码的 text 参数就是 <style> 标签包围的样式表字符串。
代码注释 1 创建 StyleSheetContents 对象。
代码注释 2 创建 CSSStyleSheet 对象。
代码注释 3 调用 StyleSheetContents::parseString 方法开始解析,其代码如下:
1 bool StyleSheetContents::parseString(const String& sheetText)
2 {
3 CSSParser p(parserContext());
4 // 1. 创建解析器,并调用了和外部样式表一样的方法开始解析内部样式表
5 p.parseSheet(*this, sheetText);
6 return true;
7 }
上面代码注释 1 调用了和解析外部样式表一样的方法,来解析内部样式表,因此,两者的解析流程一样。
3 行内样式
行内样式位于 HTML 标签的 style 属性中,当 WebKit 在构建 DOM 树解析到某个 HTML 标签的 style 属性时,就会将 style 属性的值进行解析。
由于 style 属性值只是一系列声明,因此只需要进行声明的解析。解析的结果存储在这个 HTML 元素上。
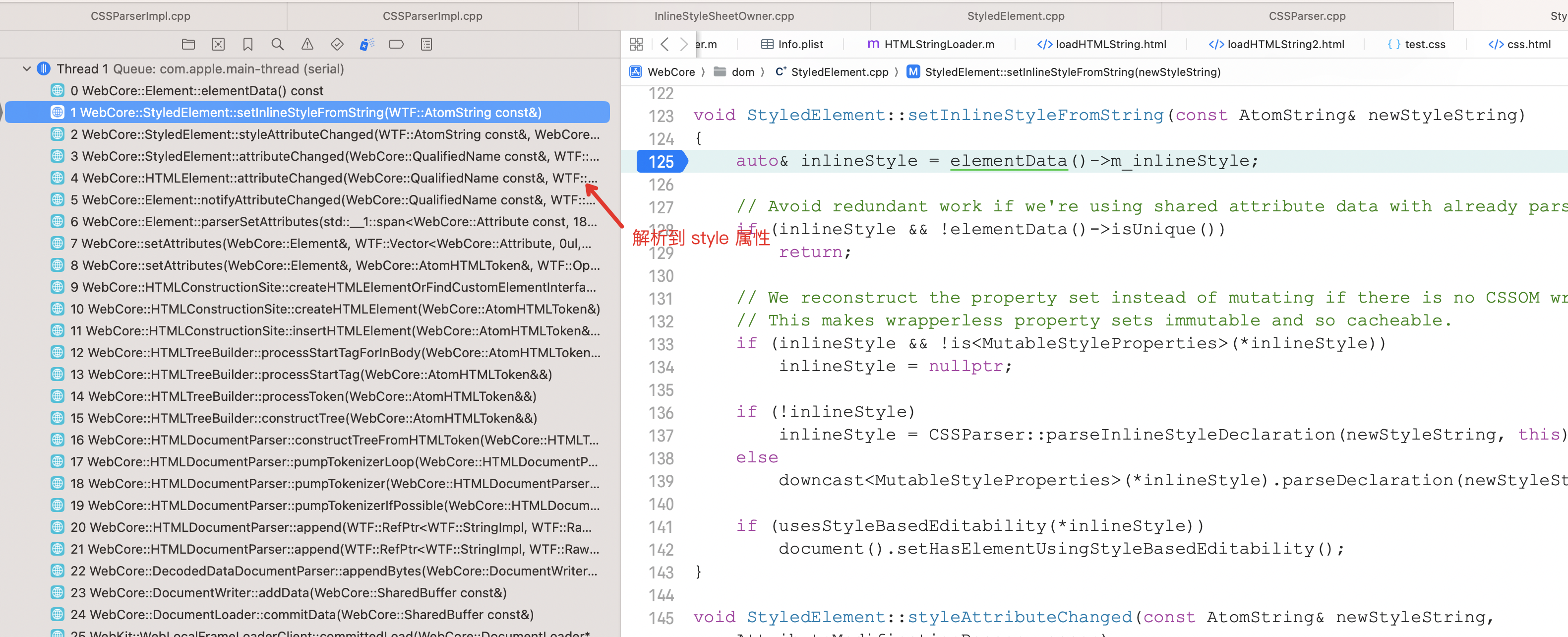
3. 1 相关类图
类图以 <div> 标签为例

3.2 解析
行内样式的解析比较简单。
因为行内样式只有属性 List,所以只需要解析对应的属性即可,相关代码如下:
1 // 参数 newStyleString 就是 style 属性对应的值2 void StyledElement::setInlineStyleFromString(const AtomString& newStyleString)3 {4 // inlineStyle 是一个引用类型,最后解析出来的属性值存储在这里5 auto& inlineStyle = elementData()->m_inlineStyle;6 ...7 if (!inlineStyle)8 // 2. 调用 CSSParser:parserInlineStyleDeclaration 开始解析9 inlineStyle = CSSParser::parseInlineStyleDeclaration(newStyleString, this);
10 ...
11 }
上面代码参数 newStyleString 就是 style 属性对应的值。
代码注释 1 变量 inlineStyle 是一个引用类型,存储解析出来的属性值。
代码注释 2 处的方法解析声明 List,其代码如下:
1 Ref<ImmutableStyleProperties> CSSParser::parseInlineStyleDeclaration(const String& string, const Element* element)2 {3 // 1. CSSParser 调用 CSSParserImpl 的对应方法进行解析4 return CSSParserImpl::parseInlineStyleDeclaration(string, element);5 }6 7 Ref<ImmutableStyleProperties> CSSParserImpl::parseInlineStyleDeclaration(const String& string, const Element* element)8 {9 CSSParserContext context(element->document());
10 ...
11 CSSParserImpl parser(context, string);
12 // 2. 解析声明 List
13 parser.consumeDeclarationList(parser.tokenizer()->tokenRange(), StyleRuleType::Style);
14 // 3. 创建返回值
15 return createStyleProperties(parser.topContext().m_parsedProperties, context.mode);
16 }
上面代码注释 2 就是解析声明 List 的地方。
代码注释 3 将解析出来的值返回。
参考资料
CSS Nesting Model












)








