常见排序算法详解
目录
排序的相关概念
排序:
稳定性:
内部排序:
外部排序:
常见的排序:
常见排序算法的实现
插入排序:
基本思想:
直接插入排序:
希尔排序(缩小增量排序):
选择排序:
基本思想:
直接选择排序:
堆排序:
交换排序:
基本思想:
冒泡排序:
快速排序:
Hoare版本:
挖坑法:
前后指针法:
快排递归优化:
Hoare版本(优化):
挖坑法(优化):
前后指针(优化):
非递归快排:
归并排序:
基本思想:
递归版本:
非递归版本:
计数排序:
基本思想:
总结
排序的相关概念
排序:
所谓排序,就是使用一定的方法使一段可排序的序列变得有一定的顺序(递增或递减)。
稳定性:
假定在待排序的序列中,存在多个具有相同的关键字的元素,若经过排序,这些元素的相对次
序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
内部排序:
数据元素全部放在内存中进行排序。
外部排序:
数据元素太多,无法同时全部放进内存中进行排序。因此,需要将待排序的数据存储在外存(磁盘)上,排序时再把数据一部分一部分地调入内存中进行排序,在排序过程中需要多次进行内存和外存之间地交换。这种排序方法就称作外部排序。
常见的排序:

常见排序算法的实现
插入排序:
基本思想:
把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。
日常生活中玩扑克牌拼牌时就用到了插入排序。

直接插入排序:
当插入第i(i>=1)个元素时,前面的i-1个元素已经排好序,此时用a[i]的值依次与a[i-1],a[i-2],…,a[0]的值进行比较,找到插入位置即将a[i]插入,原来位置上的元素顺序后移。
排序过程如下图所示:
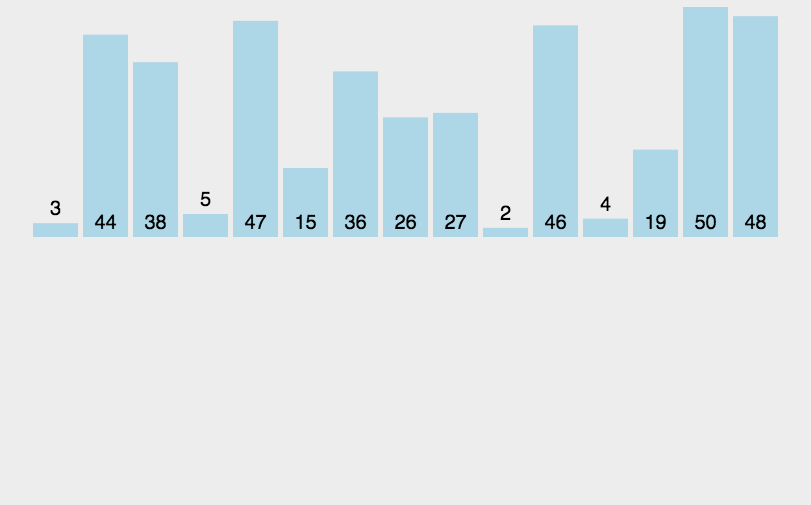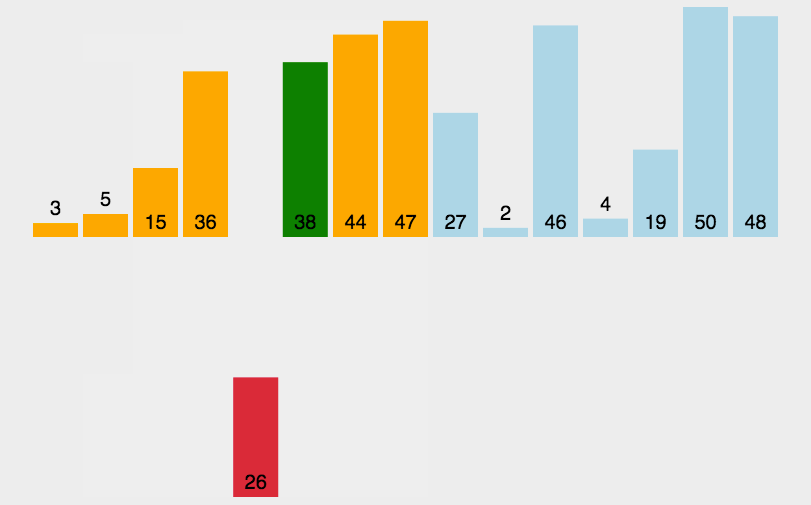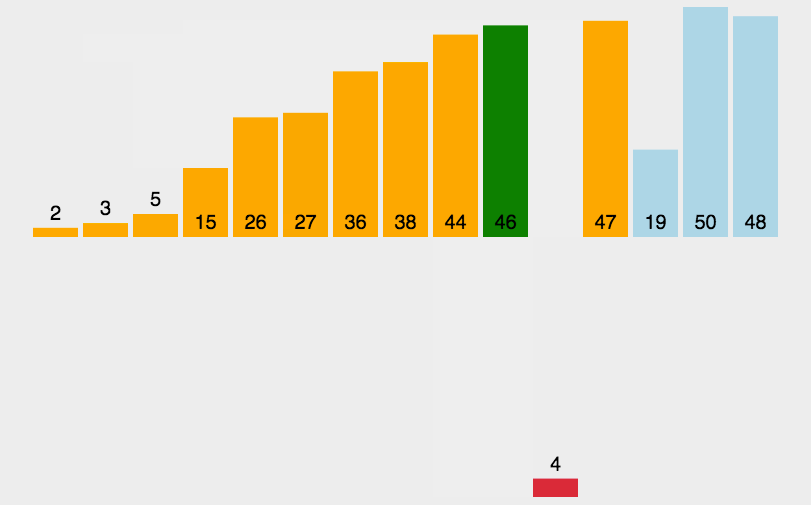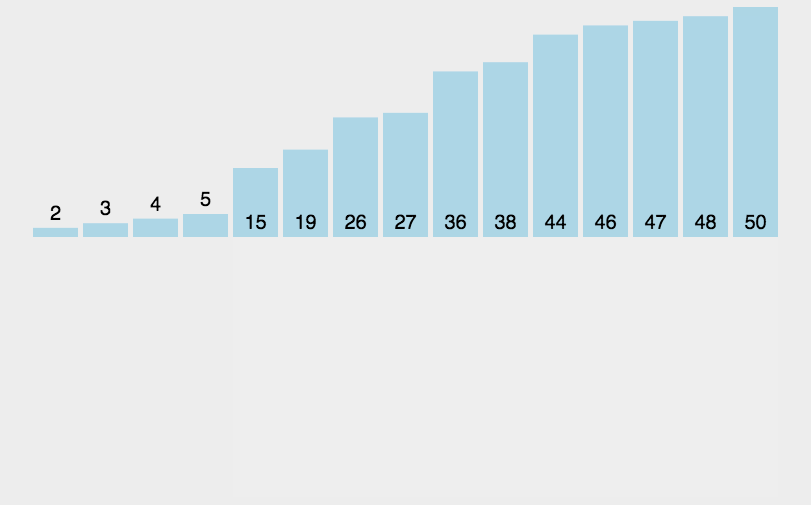
代码如下:
void InsertSort(int* a, int n)
{assert(a);int i = 0, j = 0;for (i = 1; i < n; i++)//从第二个元素开始,依次与前边的元素比较{int tem = a[i];j = i - 1;while (j >= 0){if (a[j] > tem){a[j + 1] = a[j];}else{break;}j--;}a[j + 1] = tem;}
}
特性总结:
1. 元素集合越接近有序,直接插入排序算法的时间效率越高
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:稳定
希尔排序(缩小增量排序):
先选定一个整数gap,把待排序数据分成gap个组,所有距离为gap的数据分在同一组内,并对每一组内的记录进行排序。然后,缩小gap重复上述分组和排序的工作。当到达gap=1时,所有数据在同一组内排好序。
排序过程如下:

代码如下:
void ShellSort(int* a, int n)
{assert(a);int gap = n;while (gap > 1){gap /= 2;//一组一组排序/*int i = 0;for (i = 0; i < gap; i++){int j = 0;for (j = i; j < n - gap; j += gap)//排一组{int front = j;int back = j + gap;int tem = a[back];//记录back位置原始数据while (front >= 0){if (tem < a[front]){a[back] = a[front];front -= gap;back -= gap;}else{break;}}a[front + gap] = tem;}}*///多组同时排序int j = 0;for (j = 0; j < n - gap; j ++)//多组同时排{int front = j;int back = j + gap;int tem = a[back];//记录back位置原始数据while (front >= 0){if (tem < a[front]){a[back] = a[front];front -= gap;back -= gap;}else{break;}}a[front + gap] = tem;}}}特性总结:
1. 希尔排序是对直接插入排序的优化。
2. 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap = 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。
3. 时间复杂度:希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,但有一个大致的范围O(N^1.3)~O(N^2)4.空间复杂度:O(1)
选择排序:
基本思想:
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置(或末尾位置),直到全部待排序的数据元素排完。
直接选择排序:
在元素集合a[i]--a[n-1]中选择最大(小)的数据元素,若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换,在剩余的a[i]--a[n-2](a[i+1]--a[n-1])集合中,重复上述步骤,直到集合剩余1个元素。
排序过程如下:

代码如下:
void swap(int* p1, int* p2)//交换函数
{int k = *p1;*p1 = *p2;*p2 = k;
}void SelectSort(int* a, int n)
{assert(a);//每次选最小的放前边//int i = 0, j = 0;//int mini = 0;//最小数的下标//for (j = 0; j < n; j++)//{// mini = j;// for (i = j + 1; i < n; i++)// {// if (a[i] < a[mini])// {// mini = i;// }// }// swap(&a[mini], &a[j]);//}//优化--一次选出区间中最大的和最小的,分别插入头部和尾部int begin = 0, end = n - 1;while (begin < end){int maxi = end, mini = begin;//最大最小值的下标int i = begin;for (; i <= end; i++){if (a[i] < a[mini]){mini = i;}if (a[i] > a[maxi]){maxi = i;}}swap(&a[begin], &a[mini]);if (maxi == begin)//防止原begin位置是最大值,被换到mini位置{maxi = mini;}swap(&a[end], &a[maxi]);begin++;end--;}
}特性总结:
1. 直接选择排序思考非常好理解,但是效率不是很好,实际中很少使用
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:不稳定
堆排序:
堆排序即利用堆的思想来进行排序,思路如下:
1. 建堆
升序:建大堆
降序:建小堆
2. 利用堆删除思想来进行排序
因为堆顶元素一定是最大值(或最小值)每次把堆顶元素与最后一个元素交换,然后把数组尾指针向前移动1,再对新的堆顶元素进行向下调整,重复上述操作,直至数组尾指针指向第一个元素,此时的数组中的数据就是一个有序的序列。
代码如下:
void swap(int* p1, int* p2)//交换函数
{int k = *p1;*p1 = *p2;*p2 = k;
}//向下调整(建大堆)
void HeapDown(int* a, int parent, int n)
{assert(a);int child = parent * 2 + 1;//左孩子while (child < n){if (child+1 < n && a[child] < a[child + 1])//找到大的{child += 1;}if (a[child] > a[parent])//大的孩子取代父亲{swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}//堆排序
void HeapSort(int* a, int n)
{assert(a);int parent = (n - 1 - 1) / 2;//建大堆for (parent; parent >= 0; parent--){HeapDown(a, parent, n);}//排序int end = n - 1;while (end >= 0){swap(&a[0], &a[end]);//把最大的放最后,从根向下调整HeapDown(a, 0, end);//从根向下调整end--;}}特性总结:
1. 堆排序使用堆来选数,效率就高了很多。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(1)
4. 稳定性:不稳定
交换排序:
基本思想:
根据序列中两个元素值的比较结果来决定是否交换这两个元素在序列中的位置,进而达到将值较大的元素向序列的尾部移动,值较小的元素向序列的前部移动的目的。
冒泡排序:
两两元素相比,前一个比后一个大就交换,直到将最大的元素交换到末尾位置,这是第一趟排序,第二趟找出第二大的语速放在倒数第二个位置……进行n-1趟排序后,全部数据就是有序的了。
排序动图如下:
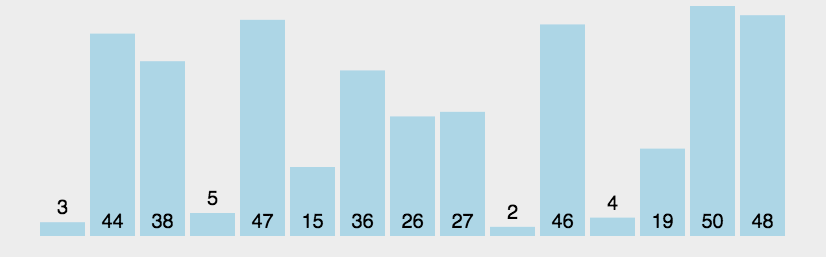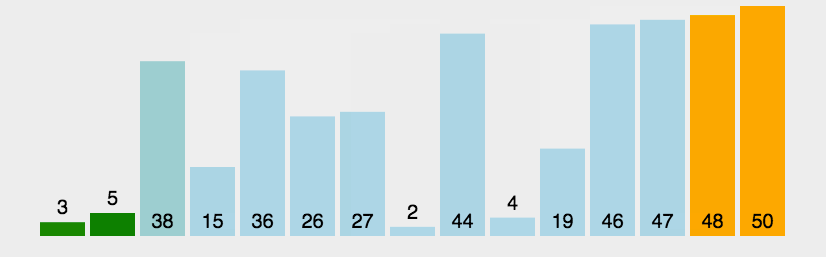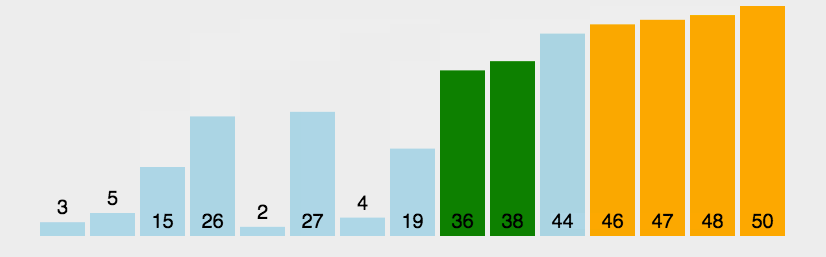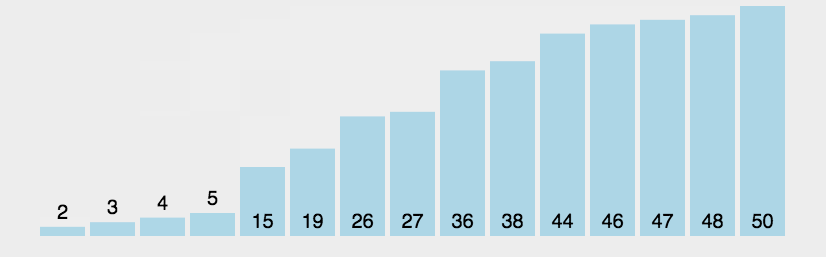
代码如下:
void swap(int* p1, int* p2)//交换函数
{int k = *p1;*p1 = *p2;*p2 = k;
}//冒泡排序
void BubbleSort(int* a, int n)
{assert(a);int i = 0, j = 0;for (i = 0; i < n - 1; i++){int flag = 0;//标记是否进行过交换for (j = 1; j < n - i; j++){if (a[j-1] > a[j])//每次相邻两个交换{/*int k = a[i];a[i] = a[j];a[j] = k;*/swap(&a[j-1], &a[j]);flag++;}}if (flag == 0){break;}}
}特性总结:
1. 冒泡排序是一种非常容易理解的排序
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:稳定
快速排序:
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
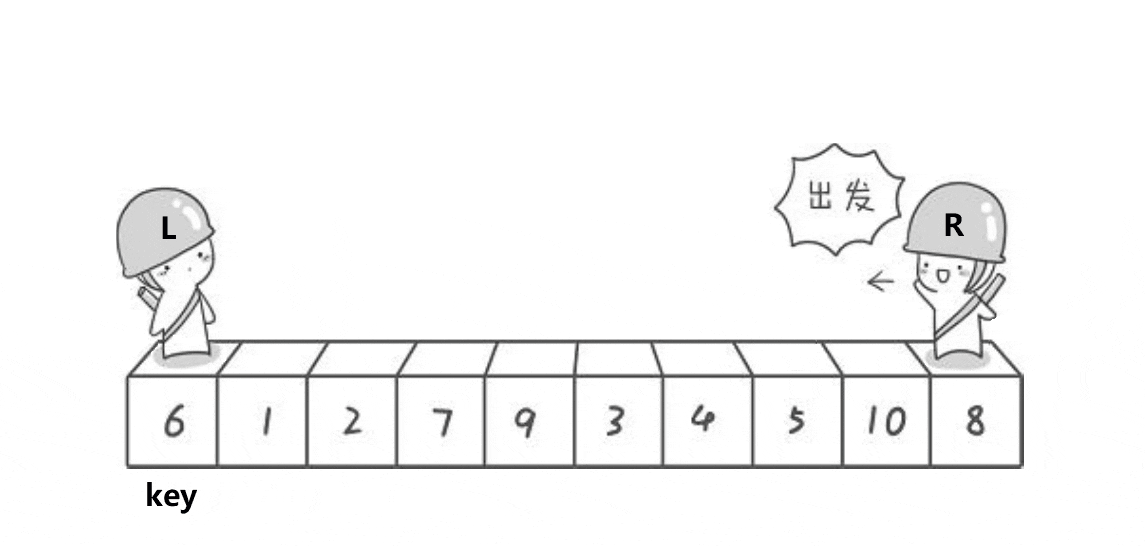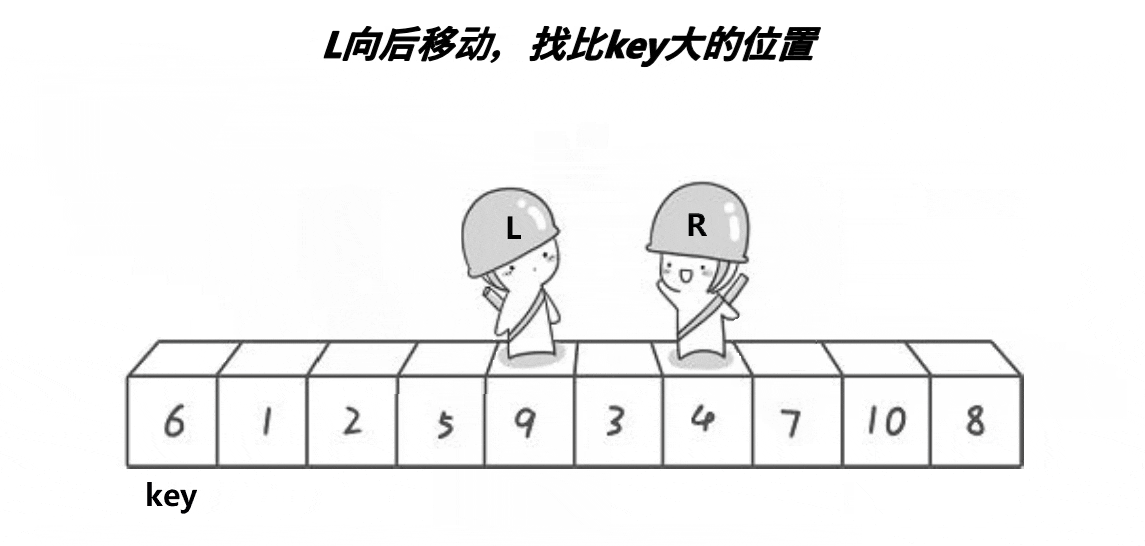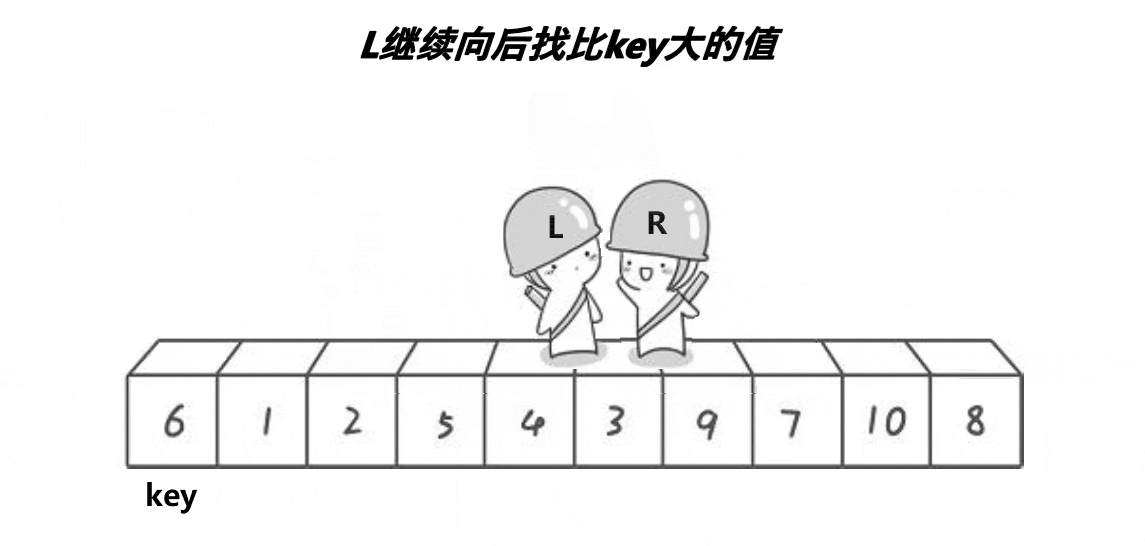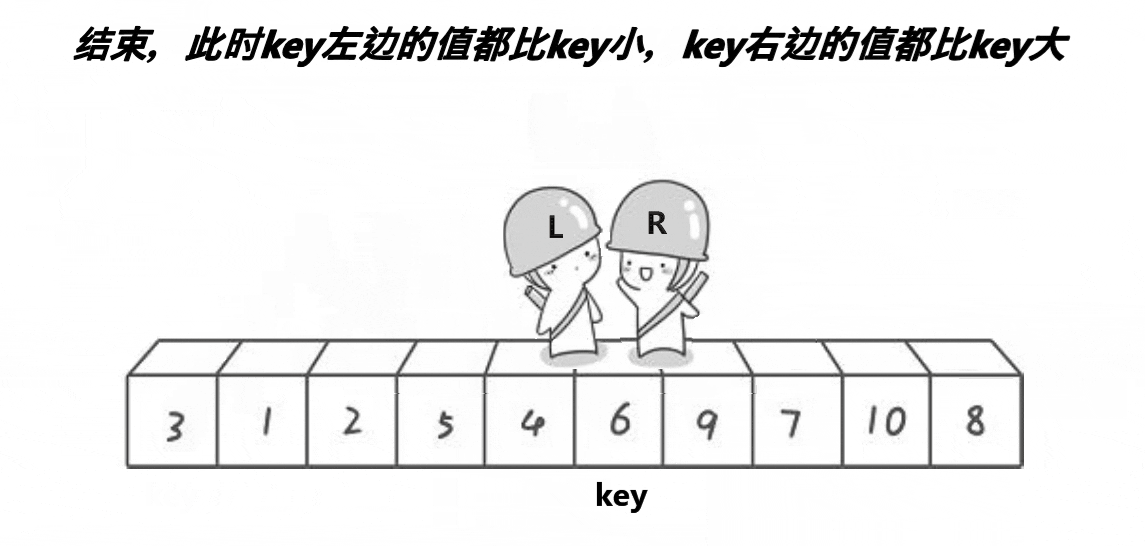
Hoare版本:
1、选最左边作key,右边先走找到比key小的值
2、左边后走找到大于key的值
3、然后交换left和right的值
4、一直循环重复上述1 2 3步
5、两者相遇时的位置,与最左边选定的key值交换(因为是让右边先走,保证了最后相遇时,该位置的值一定是小于key的)
排序过程如下:
代码如下:
void swap(int* p1, int* p2)//交换函数
{int k = *p1;*p1 = *p2;*p2 = k;
}//Hoare
int PartSort1(int* a, int left, int right)
{int keyi = left;while (left < right){while (left < right && a[right] >= a[keyi])//找小{right--;}while (left < right && a[left] <= a[keyi])//找大{left++;}swap(&a[left], &a[right]);}swap(&a[keyi], &a[left]);//因为是右边先开始循环,则当left=right时,a[left]一定小于a[keyi]return left;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int keyi = PartSort1(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}挖坑法:
创建变量key储存最左边值,以最左边为第一个坑位,不断填充坑位,并不断改变坑位的位置,直至左右指针相遇,此时为最后一个坑位,再把key填入。
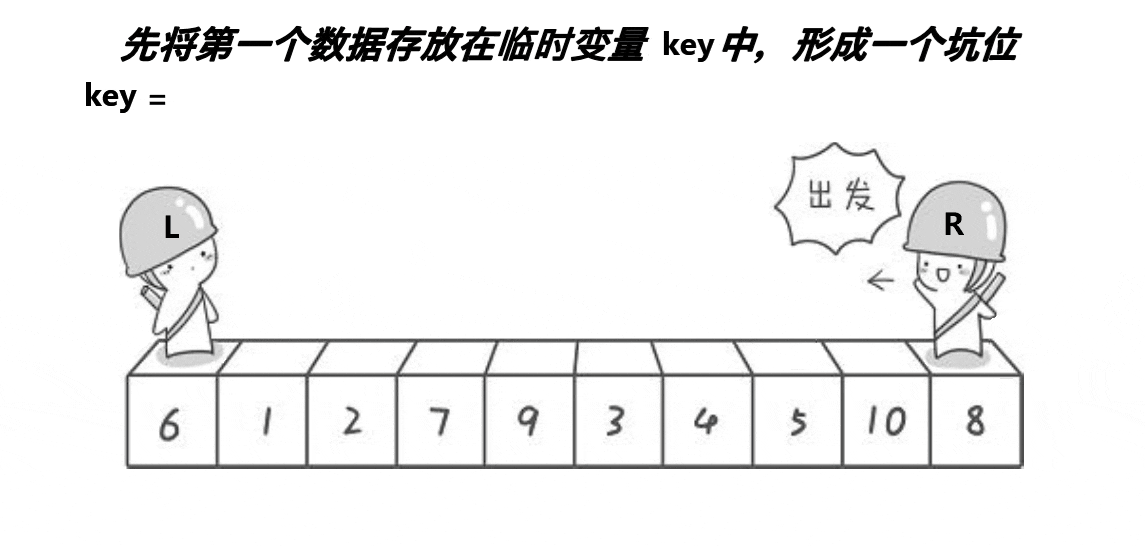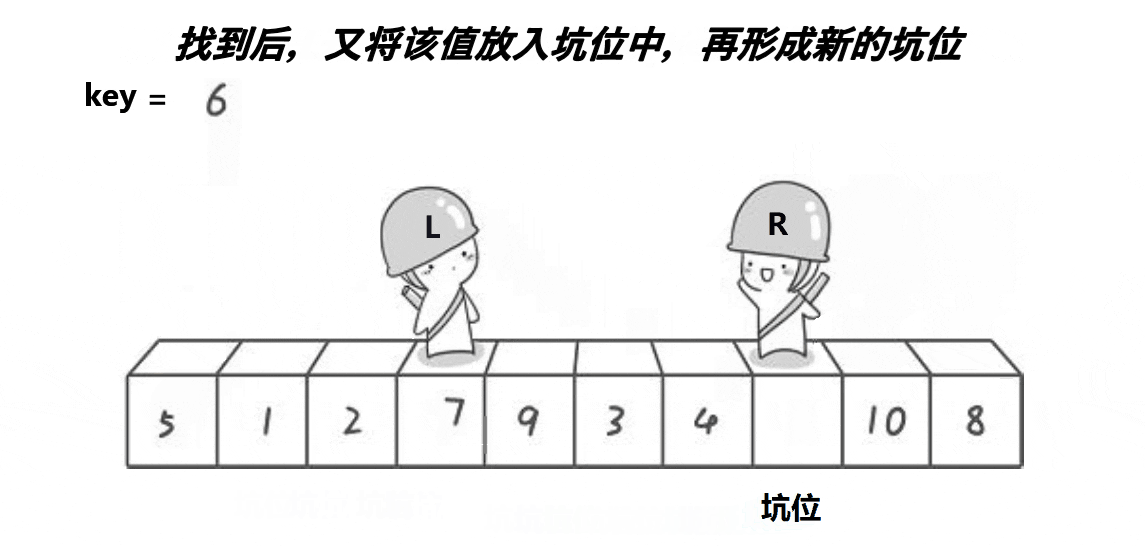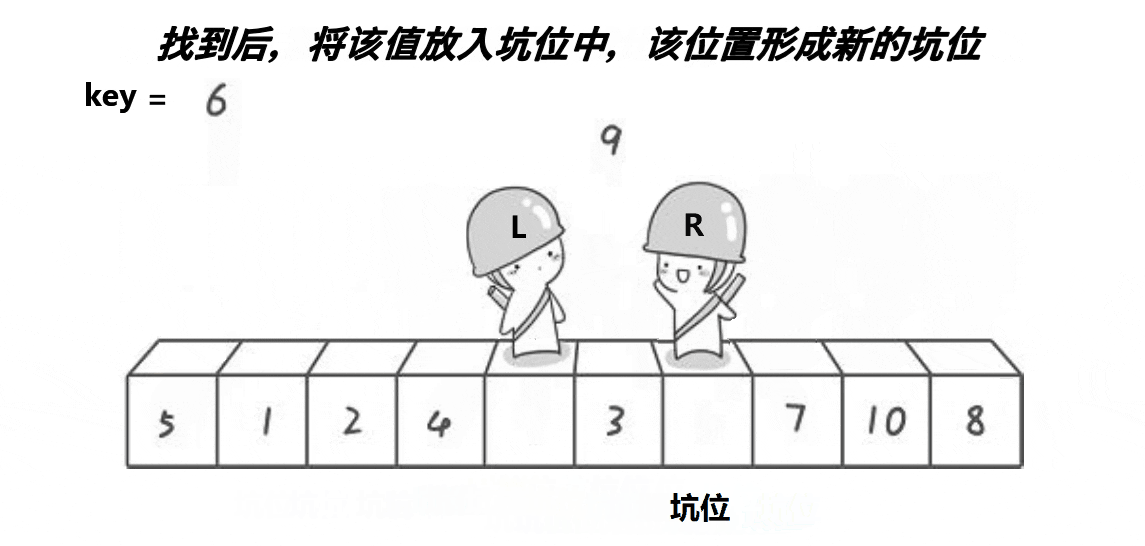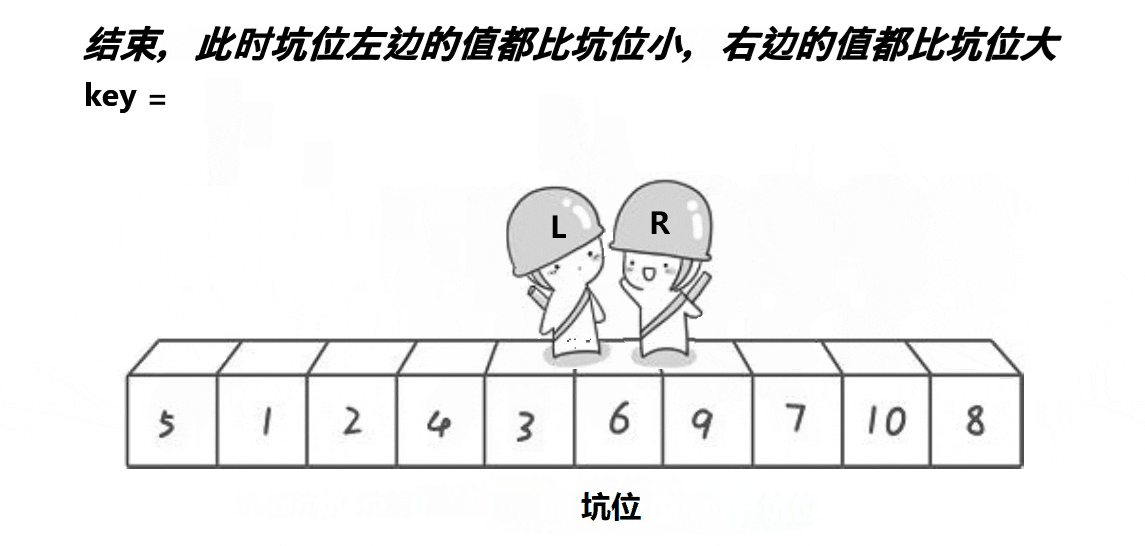
代码入下:
//挖坑法
int PartSort2(int* a, int left, int right)
{int key = a[left];int hold = left;//坑位while (left < right){while (left < right && a[right] >= key){right--;}a[hold] = a[right];hold = right;//更新坑位while (left < right && a[left] <= key){left++;}a[hold] = a[left];hold = left;//更新坑位}a[left] = key;return left;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int keyi = PartSort2(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}前后指针法:

代码入下:
void swap(int* p1, int* p2)//交换函数
{int k = *p1;*p1 = *p2;*p2 = k;
}//前后指针
int PartSort3(int* a, int left, int right)
{int keyi = left;int prev = left;int cur = left + 1;//cur找比a[keti]小的就和prev后一个交换位置while (cur <= right){if (a[cur] < a[keyi]){swap(&a[++prev], &a[cur]);}cur++;}swap(&a[prev], &a[keyi]);return prev;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int keyi = PartSort3(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}快排递归优化:
1.三数取中:
快速排序对于数据是敏感的,如果这个序列是非常无序,杂乱无章的,那么快速排序的效率是非常高的,可是如果数列有序,时间复杂度就会从O(N*logN)变为O(N^2),相当于冒泡排序了。若每趟排序所选的key都正好是该序列的中间值,即单趟排序结束后key位于序列正中间,那么快速排序的时间复杂度就是O(NlogN),但是这是理想情况,当我们面对一组极端情况下的序列,就是有序的数组,选择左边作为key值的话,那么就会退化为O(N^2)的复杂度,所以此时我们选择首位置,尾位置,中间位置的数分别作为三数,选出值大小在中间的数,放到最左边,这样选key还是从左边开始,这样优化后,就不会出现选到最大值或最小值的极端情况了。
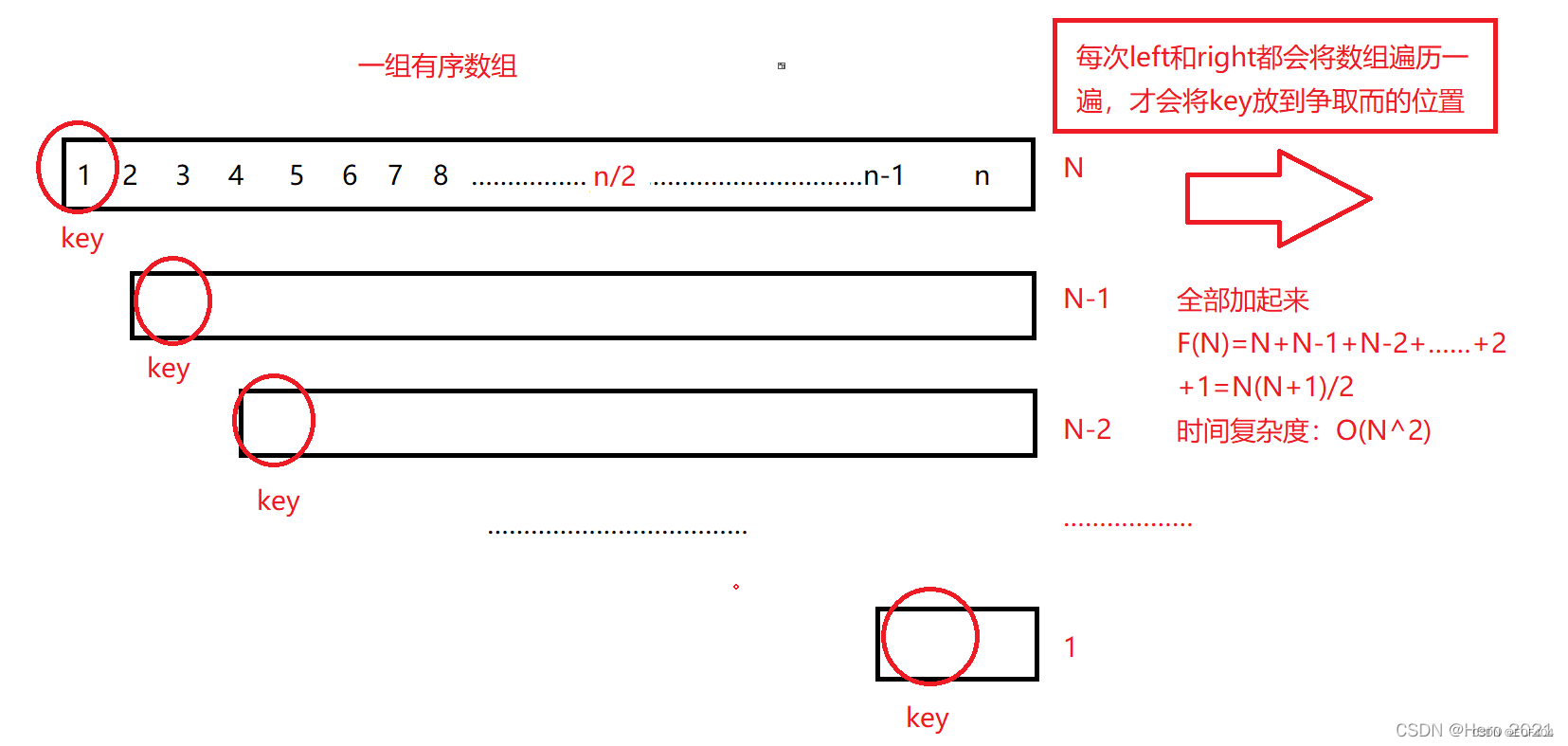
2.小区间优化:
随着递归深度的增加,递归次数以每层2倍的速度增加,这对效率有着很大的影响,当待排序序列的长度分割到一定大小后,继续分割的效率比插入排序要差,此时可以使用插排而不是快排。
我们可以当划分区间长度小于10的时候,用插入排序对剩下的数进行排序
Hoare版本(优化):
void swap(int* p1, int* p2)//交换函数
{int k = *p1;*p1 = *p2;*p2 = k;
}//三数取中
int GetMid(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] > a[mid]){if (a[mid] > a[right]){return mid;}else//a[mid]<a[right]{if (a[left] > a[right]){return right;}else{return left;}}}else//a[left]<a[mid] {if (a[left] > a[right]){return left;}else//a[left]<a[right]{if (a[mid] > a[right]){return right;}else{return mid;}}}
}int PartSort1(int* a, int left, int right)
{int mid = GetMid(a, left, right);//三数取中swap(&a[mid], &a[left]);int keyi = left;while (left < right){while (left < right && a[right] >= a[keyi])//找小{right--;}while (left < right && a[left] <= a[keyi])//找大{left++;}swap(&a[left], &a[right]);}swap(&a[keyi], &a[left]);//因为是右边先开始循环,则当left=right时,a[left]一定小于a[keyi]return left;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}if (end - begin + 1 > 10)//小区间优化{int keyi = PartSort1(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}else{InsertSort(a + begin, end - begin + 1);//调用直接插入排序}}
挖坑法(优化):
void swap(int* p1, int* p2)//交换函数
{int k = *p1;*p1 = *p2;*p2 = k;
}//三数取中
int GetMid(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] > a[mid]){if (a[mid] > a[right]){return mid;}else//a[mid]<a[right]{if (a[left] > a[right]){return right;}else{return left;}}}else//a[left]<a[mid] {if (a[left] > a[right]){return left;}else//a[left]<a[right]{if (a[mid] > a[right]){return right;}else{return mid;}}}
}//挖坑法
int PartSort2(int* a, int left, int right)
{int mid = GetMid(a, left, right);swap(&a[mid], &a[left]);int key = a[left];int hold = left;//坑位while (left < right){while (left < right && a[right] >= key){right--;}a[hold] = a[right];hold = right;//更新坑位while (left < right && a[left] <= key){left++;}a[hold] = a[left];hold = left;//更新坑位}a[left] = key;return left;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}if (end - begin + 1 > 10)//小区间优化{int keyi = PartSort2(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}else{InsertSort(a + begin, end - begin + 1);//调用直接插入排序}}
前后指针(优化):
void swap(int* p1, int* p2)//交换函数
{int k = *p1;*p1 = *p2;*p2 = k;
}int PartSort3(int* a, int left, int right)
{int keyi = left;int prev = left;int cur = left + 1;//cur找比a[keti]小的就和prev后一个交换位置while (cur <= right){if (a[cur] < a[keyi]){swap(&a[++prev], &a[cur]);}cur++;}swap(&a[prev], &a[keyi]);return prev;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}if (end - begin + 1 > 10)//小区间优化{int keyi = PartSort3(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}else{InsertSort(a + begin, end - begin + 1);//直接调用插入排序}}非递归快排:
当数据量较大时,一直递归调用就会一直开辟栈帧,增加栈的消耗,因此我们可以人工创建一个栈结构,代替递归调用开辟新的栈帧。
关于栈我在栈和队列详解中有详细介绍,在这里就不再过多介绍。
具体思路如下:
1. 申请一个栈,将整个数组的起始位置和终点位置入栈,起始位置先进栈。
2. 利用栈的特性(后进先出),末位置后进栈,所以末位置先出栈。 定义right、left接收的靠近栈顶的两个元素,作为排序序列的始末位置。
3. 对数组进行一次单趟排序,返回一个下标keyi。
4. 此时待排序列被分为[left,keyi-1],keyi,[keyi+1,right]三段,再把左右两边区间的始末位置入栈(若该区间合法),要求区间起始位置先进栈。
5. 重复2、3、4操作直至栈内为空。
代码如下:
//快速排序(非递归)
void QuickSortNonr(int* a, int n)
{ST st;STInit(&st);//栈储存[0,n-1]区间左右下标,先入右下标,后入左下标STPush(&st, n - 1);STPush(&st, 0);while (!STEmpty(&st)){int left = STTop(&st);STPop(&st);int right = STTop(&st);STPop(&st);int keyi = PartSort3(a, left, right);//[left,right]区间分为[left,keyi-1],keyi,[keyi+1,right]if (keyi + 1 < right)//入[keyi+1,right]区间下标{STPush(&st, right);STPush(&st, keyi + 1);}if (keyi - 1 > left)//入[left,keyi-1]区间下标{STPush(&st, keyi - 1);STPush(&st, left);}}STDestroy(&st);
}
特性总结:
1. 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(logN)
4. 稳定性:不稳定
归并排序:
基本思想:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列,即先使每个子序列有序,再合并子序列并保证其有序。若将两个有序表合并成一个有序表,称为二路归并。 归并排序核心步骤: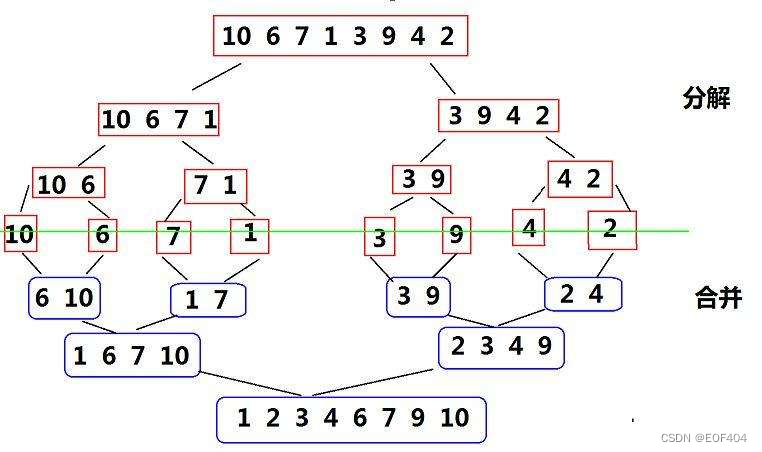

递归版本:
void MerSort(int* a, int* tem, int left, int right)
{if (left >= right){return;}//递归划分区间int mid = (left + right) / 2;MerSort(a, tem, left, mid);MerSort(a, tem, mid + 1, right);//归并到tem数组int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int index = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tem[index++] = a[begin1++];}else{tem[index++] = a[begin2++];}}while (begin1 <= end1){tem[index++] = a[begin1++];}while (begin2 <= end2){tem[index++] = a[begin2++];}//拷贝回原数组---因为每次都要从原数组中归并到tem数组中,因此每次归并完后都要拷贝回原数组memcpy(a + left, tem + left, sizeof(int) * (right - left + 1));
}
//归并排序
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");exit(-1);}MerSort(a, tmp, 0, n - 1);free(tmp);
}非递归版本:
与快排类似,当数据量较大时,一直递归调用会增加栈的消耗,因此我们可以考虑改非递归的方法实现。
归并改非递归时,可以定义一个gap作为每次归并的区间长度,一趟归并后再把gap乘以2,作为新的归并区间长度,继续归并,直至全部归并完成。其关键在于对边界的控制:

代码如下:
//归并排序(非递归)
void MergeSortNonr(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");exit(-1);}int gap = 1;//每次归并的长度while (gap < n){int i = 0;for (i = 0; i < n; i += gap * 2){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + gap + gap - 1;if (begin2 >= n || end1 >= n)//要归并的第二个区间不存在,直接退出{//memcpy(tmp + i, a + i, sizeof(int) * (n - i));//把不归并的数据提前拷贝进tmp数组,防止因为a数组没有全部进行归并,tmp数组中存在随机值,//进而导致后续把tmp数组数据拷贝进a数组时,拷贝随机数据进a数组break;}if (end2 >= n)//要归并的第二个区间,右边越界,重置右区间{end2 = n - 1;}//printf("[%d,%d][%d,%d]", begin1, end1, begin2, end2);//打印每次归并区间int index = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}while (begin1 <= end1){tmp[index++] = a[begin1++];}while (begin2 <= end2){tmp[index++] = a[begin2++];}memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));//每次归并完成后,把tmp中数据拷贝进a数组,防止丢失数据}//memcpy(a, tmp, sizeof(int) * n);//一趟归并后再把tmp数组的数据拷贝进a数gap *= 2;}free(tmp);
}特性总结:
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(N)
4. 稳定性:稳定
计数排序:
基本思想:
遍历数组,统计数组中每个元素的出现频率,再按顺序放回原数组。

需要注意的是,由于待排序列不一定是从0开始的且不知道要创建多大的数组进行计数,因此在遍历数组统计频率时,要同时找出最大最小值,每次计数时,用该位置数值减去最小值即为该数对应的下标,用最大值减去最小值再加1就是要创建的计数数组的大小。
代码如下:
// 计数排序
void CountSort(int* a, int n)
{int min = a[0];int max = a[0];for (int i = 0; i < n; i++)//找最大值和最小值{if (a[i] > max){max = a[i];}if (a[i] < min){min = a[i];}}int range = max - min + 1;//最小值到最大值有多少个数(闭区间)int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){perror("malloc fail");exit(-1);}memset(count, 0, sizeof(int) * range);//每个数减去min就是对应的下标for (int i = 0; i < n; i++){count[a[i] - min]++;}//重新写入原数组,下标+min就是原始值int i = 0;for (int j = 0; j < range; j++){while (count[j]--){a[i++] = j + min;}}free(count);
}
特性总结:
1. 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
2. 时间复杂度:O(MAX(N,范围))
3. 空间复杂度:O(范围)4. 稳定性:稳定
总结
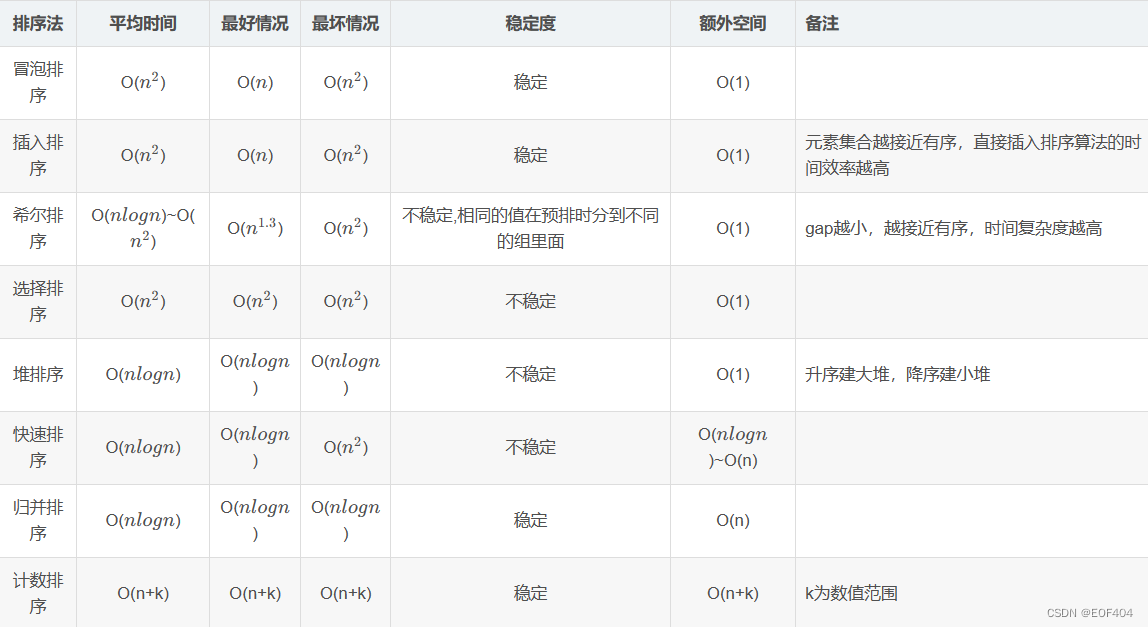
相关文章:
常见排序算法详解
目录 排序的相关概念 排序: 稳定性: 内部排序: 外部排序: 常见的排序: 常见排序算法的实现 插入排序: 基本思想: 直…...
监控搭建-Prometheus
监控搭建-Prometheus 1、背景2、目标3、选型4、Prometheus4.1、介绍4.2、架构4.3、构件4.4、运行机制4.5、环境介绍4.6、数据准备4.7、网络策略4.7.1、主机端口放行4.7.2、设备端口放行 4.8、部署4.9、验证4.10、配置 1、背景 随着项目信息化进程的推进,操作系统、…...

指纹浏览器开发指南-EasyBR
想开发一款指纹浏览器,指纹浏览器名字叫做EasyBR,大致构思了下开发的步骤。 EasyBR指纹浏览器开发指南: 后台技术、前端技术和指纹修改 简介: EasyBR指纹浏览器是一款旨在提供个性化服务和广告定位的浏览器,通过收…...

qml入门
window import QtQuick 2.15 import QtQuick.Window 2.15 import QtQuick.Controls 2.5Window { //root控件,父窗口是主界面width: 640height: 480visible: true//相对于父控件的偏移量x: 100y:100minimumWidth: 400 //最小宽度minimumHeight: 300 //最小高度ma…...

一文熟练使用python修改Excel中的数据
使用python修改Excel中的内容 1.初级修改 1.1 openpyxl库的功能: openpyxl模块是一个读写Excel 2010文档的Python库,如果要处理更早格式的Excel文档,需要用到额外的库,例如Xlwings。openpyxl是一个比较综合的工具,能…...
java Spring Boot在配置文件中关闭热部署
之前更大家一起搭建了一个热部署的开发环境 但是 大家要清楚一个情况 我们线上程序运行突然内部发生变化这是不可能的。 所以 他就只会对我们开发环境有效 是否开启 我们可以通过 application配置文件来完成 我这里是yml格式的 参考代码如下 spring:devtools:restart:enabled…...

【物联网】Arduino+ESP8266物联网开发(一):开发环境搭建 安装Arduino和驱动
ESP8266物联网开发 1.开发环境安装 开发软件下载地址: 链接: https://pan.baidu.com/s/1BaOY7kWTvh4Obobj64OHyA?pwd3qv8 提取码: 3qv8 1.1 安装驱动 将ESP8266连接到电脑上,安装ESP8266驱动CP210x 安装成功后,打开设备管理器,…...

自定义UI对象转流程节点
自定义UI对象转流程节点 实体自定义对象转bpmn activitiy学习 (动态加签,动态流程图,指定节点跳转,指定多人节点跳转) 前端页面仿的这个 提供一个思路 实体 ActivitiValueVo import io.swagger.annotations.ApiModel; import io.swagger.a…...

P1-P5_动手学深度学习-pytorch(李沐版,粗浅的笔记)
目录 预告 1.学习深度学习的关键是动手 2.什么是《动手学深度学习》 3.曾经推出的版本(含github链接) 一、课程安排 1.目标 2.内容 3.上课形式 4.你将学到什么 5.资源 二、深度学习的介绍 1.AI地图 2.深度学习在一些应用上…...
Android Studio修改模拟器AVD Manger目录
Android Studio修改虚拟机AVD Manger目录 1、在AS的设备管理器Device Manager中删除原来创建的所有虚拟机(Android Virtual Device); 2、新建一个自定义的AVD目录,例如:D:\Android\AndroidAVD 3、在高级系统设置中增加…...

STM32--MQ2烟雾传感器
本文主要介绍STM32F103C8T6和烟雾传感器模块的控制算法 简介 烟雾模块选用MQ-2气体传感器,根据传感器的电导率随空气中可燃气体浓度的增加而增大的特性检测空气中可燃气体,然后将电导率的变化转换成对应的电信号 MQ系列烟雾传感分类如下: 该…...
GitHub要求开启2FA,否则不让用了。
背景 其实大概在一个多月前,在 GitHub 网页端以及邮箱里都被提示:要求开启 2FA ,即双因子认证;但是当时由于拖延症和侥幸心理作祟,直接忽略了相关信息,毕竟“又不是不能用”。。 只到今天发现 GitHub 直接…...

Python 编程基础 | 第三章-数据类型 | 3.6、元组
一、元组 Python 的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。 1、创建元组 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可,例如: tup1 (physics, ch…...

2023/10/7 -- ARM
【程序状态寄存器读写指令】 1.指令码以及格式 mrs:读取CPSR寄存器的值 mrs 目标寄存器 CPSR:读取CPSR的数值保存到目标寄存器中msr:修改CPSR寄存器的数值msr CPSR,第一操作数:将第一操作数的数值保存到CPSR寄存器中//修改CPSR寄存器,也就表示程序的状…...

yolov5加关键点回归
文章目录 一、数据1)数据准备2)标注文件说明 二、基于yolov5-face 修改自己的yolov5加关键点回归1、dataloader,py2、augmentations.py3、loss.py4、yolo.py 一、数据 1)数据准备 1、手动创建文件夹: yolov5-face-master/data/widerface/tr…...
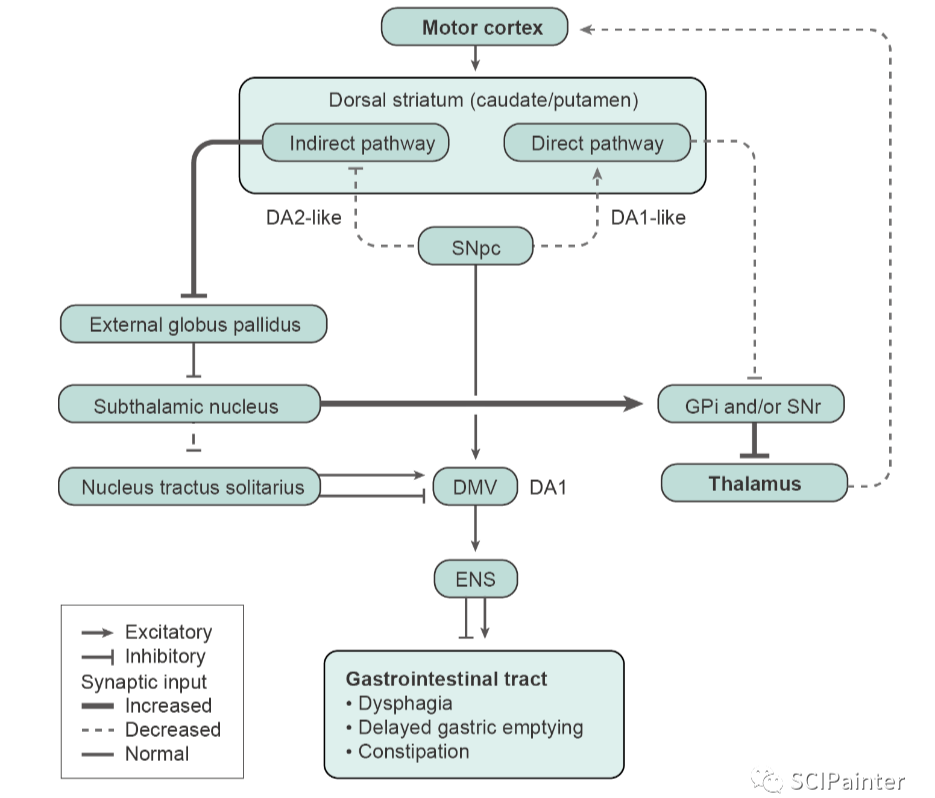
untitle
实用的科研图形美化处理教程分享 显微照片排版标记 除了统计图表之外,显微照片也是文章中必不可少的实验结果呈现方式。除了常规实验的各种组织切片照片,在空间转录组文章中显微照片更是常见。显微照片的呈现方式也是有讲究的,比如对照片…...

《论文阅读》监督对抗性对比学习在对话中的情绪识别 ACL2023
《论文阅读》监督对抗性对比学习在对话中的情绪识别 前言摘要相关知识最坏样本干扰监督对比学习生成式对抗网络纳什均衡琴森香农散度范式球模型架构监督对抗性对比学习模型结构图实验结果问题前言 你是否也对于理解论文存在困惑? 你是否也像我之前搜索论文解读,得到只是中文…...

2023-10-07 LeetCode每日一题(股票价格跨度)
2023-10-07每日一题 一、题目编号 901. 股票价格跨度二、题目链接 点击跳转到题目位置 三、题目描述 设计一个算法收集某些股票的每日报价,并返回该股票当日价格的 跨度 。 当日股票价格的 跨度 被定义为股票价格小于或等于今天价格的最大连续日数(…...
聊聊分布式架构04——RPC通信原理
目录 RPC通信的基本原理 RPC结构 手撸简陋版RPC 知识点梳理 1.Socket套接字通信机制 2.通信过程的序列化与反序列化 3.动态代理 4.反射 思维流程梳理 码起来 服务端时序图 服务端—Api与Provider模块 客户端时序图 RPC通信的基本原理 RPC(Remote Proc…...
维吉尼亚密码
维吉尼亚密码属于多表代换密码 其中A<–>0,B<–>1,…,Z<–>25,则每个密钥K相当于一个长度为m的字母串,称为密钥字。维吉尼亚密码一次加密m个明文字母。 示例:设m6,密钥字为…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...