消息队列--Kafka
- Kafka简介
- 集群部署
- 配置Kafka
- 测试Kafka
1.Kafka简介
数据缓冲队列。同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
Kafka是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
特性:
高吞吐量:kafka每秒可以处理几十万条消息。
可扩展性:kafka集群支持热扩展- 持久性、
可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
它主要包括以下组件:
话题(Topic):是特定类型的消息流。(每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。)
生产者(Producer):是能够发布消息到话题的任何对象(发布消息到 kafka 集群的终端或服务).
消费者(Consumer):可以订阅一个或多个话题,从而消费这些已发布的消息。
服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。partition(区):每个 topic 包含一个或多个 partition。
replication:partition 的副本,保障 partition 的高可用。
leader:replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
follower:replica 中的一个角色,从 leader 中复制数据。
zookeeper:kafka 通过 zookeeper 来存储集群的信息。
Zookeeper:
ZooKeeper是一个分布式协调服务,它的主要作用是为分布式系统提供一致性服务,提供的功能包括:配置维护、分布式同步等。Kafka的运行依赖ZooKeeper。 也是java微服务里面使用的一个注册中心服务
ZooKeeper主要用来协调Kafka的各个broker,不仅可以实现broker的负载均衡,而且当增加了broker或者某个broker故障了,ZooKeeper将会通知生产者和消费者,这样可以保证整个系统正常运转。
在Kafka中,一个topic会被分成多个区并被分到多个broker上,分区的信息以及broker的分布情况与消费者当前消费的状态信息都会保存在ZooKeeper中。
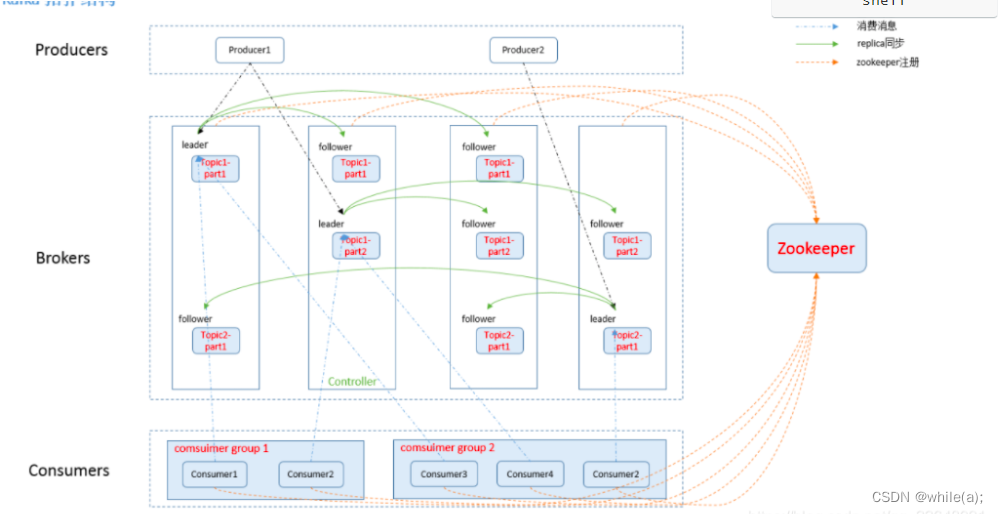
2.集群部署
2.1环境
系统:Centos-Stream7
节点:
192.168.26.166 es01
192.168.26.170 es02
192.168.26.171 es03
软件版本:kafka_2.12-3.0.2.tgz
2.2 安装配置jdk8
#yum install -y java-1.8.0-openjdk
2.3 安装配置zookeeper
在配置中要注意每个配置项后面不要有空格否则会导致zookeeper启动不起来!!!!
Kafka运行依赖ZK,Kafka官网提供的tar包中,已经包含了ZK,这里不再额外下载ZK程序。
配置相互解析---三台机器(在es集群上安装的kafka):
# vim /etc/hosts
192.168.26.166 es01
192.168.26.170 es02
192.168.26.171 es03
安装Kafka:
# wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.0.2/kafka_2.12-3.0.2.tgz
# tar xzvf kafka_2.12-2.8.0.tgz -C /usr/local/
# mv /usr/local/kafka_2.12-2.8.0/ /usr/local/kafka/
配置zookeeper:
在es01节点中:
# sed -i 's/^[^#]/#&/' /usr/local/kafka/config/zookeeper.properties
# vim /usr/local/kafka/config/zookeeper.properties #添加如下配置
dataDir=/opt/data/zookeeper/data # 需要创建,所有节点一致
dataLogDir=/opt/data/zookeeper/logs # 需要创建,所有节点一致
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10# 以下 IP 信息根据自己服务器的 IP 进行修改
server.1=192.168.19.20:2888:3888 //kafka集群IP:Port
server.2=192.168.19.21:2888:3888
server.3=192.168.19.22:2888:3888
#创建data、log目录# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件
# echo 1 > /opt/data/zookeeper/data/myid #myid号按顺序排
在es02节点中:
# sed -i 's/^[^#]/#&/' /usr/local/kafka/config/zookeeper.properties
# vim /usr/local/kafka/config/zookeeper.properties
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.19.20:2888:3888
server.2=192.168.19.21:2888:3888
server.3=192.168.19.22:2888:3888
#创建data、log目录# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件
# echo 2 > /opt/data/zookeeper/data/myid
在es03节点中:
# sed -i 's/^[^#]/#&/' /usr/local/kafka/config/zookeeper.properties
# vim /usr/local/kafka/config/zookeeper.properties
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.19.20:2888:3888
server.2=192.168.19.21:2888:3888
server.3=192.168.19.22:2888:3888
#创建data、log目录# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件
# echo 3 > /opt/data/zookeeper/data/myid
配置项含义:
dataDir ZK数据存放目录。
dataLogDir ZK日志存放目录。
clientPort 客户端连接ZK服务的端口。
tickTime ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
initLimit 允许follower连接并同步到Leader的初始化连接时间,当初始化连接时间超过该值,则表示连接失败。
syncLimit Leader与Follower之间发送消息时如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
server.1=192.168.19.20:2888:3888 2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。
3.配置Kafka
3.1 配置
# sed -i 's/^[^#]/#&/' /usr/local/kafka/config/server.properties
# vim /usr/local/kafka/config/server.properties #在最后添加
broker.id=1 #改
listeners=PLAINTEXT://192.168.19.20:9092 #改
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.19.20:2181,192.168.19.21:2181,192.168.19.22:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
[root@es01 ~]# mkdir -p /opt/data/kafka/logs
3.2 其他节点配置
只需把配置好的安装包直接分发到其他节点,修改 Kafka的broker.id和 listeners就可以了。
3.3 配置项含义
broker.id
每一个broker在集群中的唯一标识,要求是正数。在改变IP地址,不改变broker.id的时不会影响consumers
listeners=PLAINTEXT://192.168.19.22:9092
监听地址
num.network.threads
broker 处理消息的最大线程数,一般情况下不需要去修改
num.io.threads
broker处理磁盘IO 的线程数 ,数值应该大于你的硬盘数
socket.send.buffer.bytes
socket的发送缓冲区
socket.receive.buffer.bytes
socket的接收缓冲区
socket.request.max.bytes
socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
log.dirs 日志文件目录
num.partitions
num.recovery.threads.per.data.dir 每个数据目录(数据目录即指的是上述log.dirs配置的目录路径)用于日志恢复启动和关闭时的线程数量。
offsets.topic.replication.factortransaction state log replication factor 事务主题的复制因子(设置更高以确保可用性)。 内部主题创建将失败,直到群集大小满足此复制因素要求
log.cleanup.policy = delete
日志清理策略 选择有:delete和compact 主要针对过期数据的处理,或是日志文件达到限制的额度,会被 topic创建时的指定参数覆盖
log.cleanup.interval.mins=1
指定日志每隔多久检查看是否可以被删除,默认1分钟
log.retention.hours
数据存储的最大时间 超过这个时间 会根据log.cleanup.policy设置的策略处理数据,也就是消费端能够多久去消费数据。log.retention.bytes和log.retention.minutes或者log.retention.hours任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖log.segment.bytes
topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖
log.retention.check.interval.ms
文件大小检查的周期时间,是否触发 log.cleanup.policy中设置的策略
zookeeper.connect
ZK主机地址,如果zookeeper是集群则以逗号隔开。
zookeeper.connection.timeout.ms
连接到Zookeeper的超时时间。
4.测试Kafka
4.1 启动zookeeper集群
在三个节点依次执行:
# cd /usr/local/kafka
# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
查看端口:
# netstat -lntp | grep 2181

4.2 启动Kafka
在三个节点依次执行:
# cd /usr/local/kafka
# nohup bin/kafka-server-start.sh config/server.properties &
4.3 测验
验证 在192.168.26.166上创建topic:
# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
参数解释:
–zookeeper指定zookeeper的地址和端口,
–partitions指定partition的数量,
–replication-factor指定数据副本的数量在26.170上面查询192.168.26.166上的topic:
[root@es03 kafka]# bin/kafka-topics.sh --zookeeper 192.168.26.166:2181 --list
testtopic
(二)模拟消息生产和消费
发送消息到192.168.26.166:
[root@es01 kafka]# bin/kafka-console-producer.sh --broker-list 192.168.19.20:9092 --topic testtopic
>hello
>你好呀
>
从192.168.26.171接受消息:
[root@es02 kafka]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.21:9092 --topic testtopic --from-beginning

相关文章:

消息队列--Kafka
Kafka简介集群部署配置Kafka测试Kafka1.Kafka简介 数据缓冲队列。同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 Kafka是一个分布式、支持分区的(partition…...

外盘国际期货:我国当代年轻人结婚逐年下降
我国当代年轻人 结婚现状结婚少了 结婚晚了 2013年后结婚人数逐年下降 结婚少了 离婚多了 结婚年龄越来越迟 以30岁为界线,30岁之后结婚占比逐年增加 2018 20-24岁:435.6万人 25-29岁:736.2万人 30-34岁:314.7万人 35-3…...

Ubuntu 22.04.2 发布,可更新至 Linux Kernel 5.19
Ubuntu 22.04 LTS (Jammy Jellyfish) Ubuntu 22.04.2 发布,可更新至 Linux Kernel 5.19 请访问原文链接:Ubuntu 22.04 LTS (Jammy Jellyfish),查看最新版。原创作品,转载请保留出处。 作者主页:www.sysin.org 发行说…...

论文阅读笔记——《室内服务机器人的实时场景分割算法》
一、主要工作 通过深度可分离卷积、膨胀卷积和通道注意力机制设计轻量级的高准确度特征提取模块。融合浅层特征与深层语义特征获得更丰富的图像特征。在NYUDv2和CamVid数据集上的MIoU分别达到72.7%和59.9%,模型的计算力为4.2GFLOPs,参数量为8.3Mb。 二…...

Hive学习——自定义函数UDFUDTF
目录 一、添加依赖 二、编写自定义UDF函数 (一)自定义首字母大写函数 1.java代码 2.hive中运行 (二)自定义字符串全部小写的函数 1.java代码 2.hive运行 (三)创建解析JSON字符串的函数 1.java代码 三、自定义编写UDTF函数 1.java编写 2.hive运行 虽然Hive中内置了…...

自学前端,你必须要掌握的3种定时任务
当你看到这篇博客的时候,一定会和狗哥结下不解之缘,因为狗哥的博客里不仅仅有代码,还有很多代码之外的东西,如果你可以看到最底部,看到投票环节,我相信你一定感觉到了,狗哥的真诚,狗…...
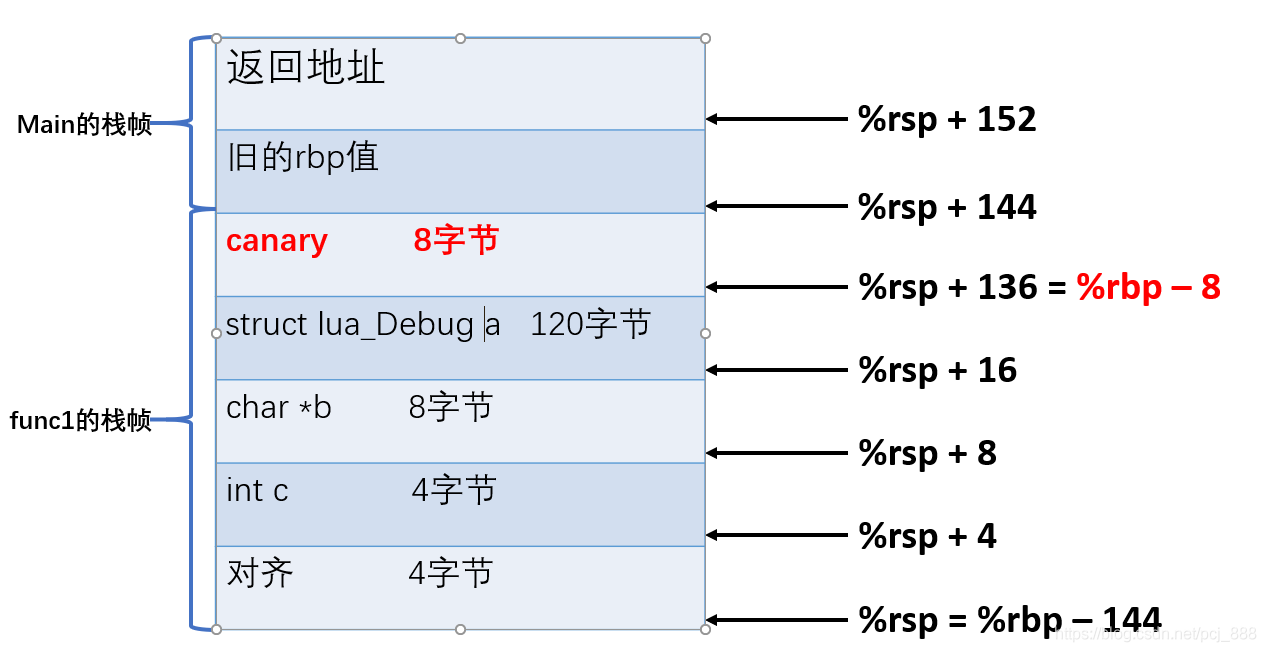
__stack_chk_fail问题分析
一、问题进程收到SIGABRT信号异常退出,异常调用栈显示__stack_chk_fail*** *** *** *** *** *** *** *** *** *** *** *** *** *** *** *** Build fingerprint: Pico/A7H10/PICOA7H10:10/5.5.0/smartcm.1676912090:userdebug/dev-keys Revision: 0 ABI: arm64 Times…...

linux 查看当前系统用户
1.查看当前登录账号(whoami) whoami ---------------------- root2.查看当前账号信息(id) id --------------------------- uid0(root) gid0(root) groups0(root)3.查看/etc/passwd文件 可以看到每行记录对应着一个用户信息,每条记录 共7段 用 冒号: 拼接…...

AI算法创新赛-人车目标检测竞赛总结05
队伍:AI0000043 1. 算法方案 由于赛题同时要求速度和精度,所以我们优先考虑小模型,在保证模型速度的同时通过模型调优稳 定提升模型精度。此外,由于图片分辨率比较大,且数据集中小目标占比高,我们计划使用…...

CSS 浮动【快速掌握知识点】
目录 前言 一、设置浮动属性 二、确定浮动元素的宽度 三、清除浮动 总结: 前言 CSS浮动是一种布局技术,它允许元素浮动到其父元素的左侧或右侧,从而腾出空间给其他元素。 一、设置浮动属性 使用CSS float属性将元素设置为浮动。例如&…...

在做自动化测试前需要知道的
什么是自动化测试? 做测试好几年了,真正学习和实践自动化测试一年,自我感觉这一个年中收获许多。一直想动笔写一篇文章分享自动化测试实践中的一些经验。终于决定花点时间来做这件事儿。 首先理清自动化测试的概念,广义上来讲&a…...

机器人学习的坚持与收获-2023
所有的机会都需要自己努力去争取,毕竟天会下雨下雪,但是不会掉馅饼。之前写过关于毕业生的一些博文。机器人工程ROS方向应用型本科毕业设计重点课题学生验收成果(暂缓通过)机器人工程ROS方向应用型本科毕业设计重点课题学生验收成…...

RSA签名加密解密
目录Java 接口RSAUtils.java示例中的依赖生成密钥对示例签名示例验证签名示例加密和解密示例Javascript 接口引入依赖生成密钥对示例签名示例验证签名示例加密和解密示例说在最后Java 接口 支持的密钥长度包括4种 RSA512、RSA1024、RSA2048、RSA4096支持的签名算法包括7种 MD2…...
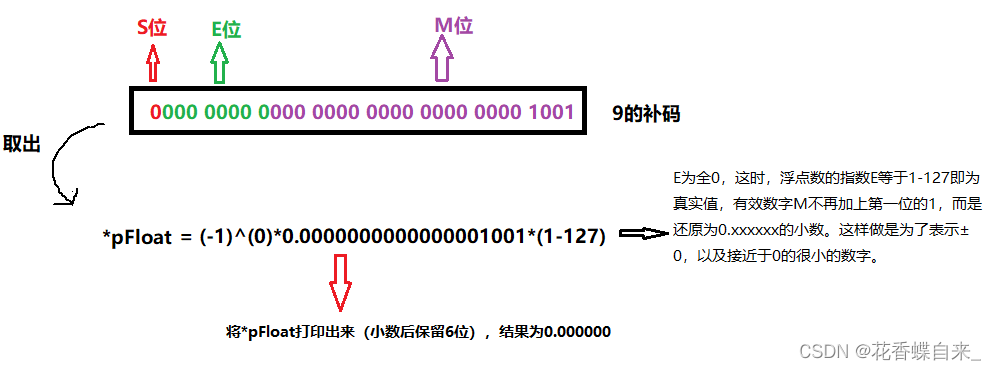
【C语言】数据的存储
☃️内容专栏:【C语言】进阶部分 ☃️本文概括: C语言中的数据类型及其存储方式。 ☃️本文作者:花香碟自来_ ☃️发布时间:2023.2.24 目录 一、数据类型详细介绍 1.1 基本的数据类型 1.2 整型家族 1.3 构造类型 1.4 指针类型…...
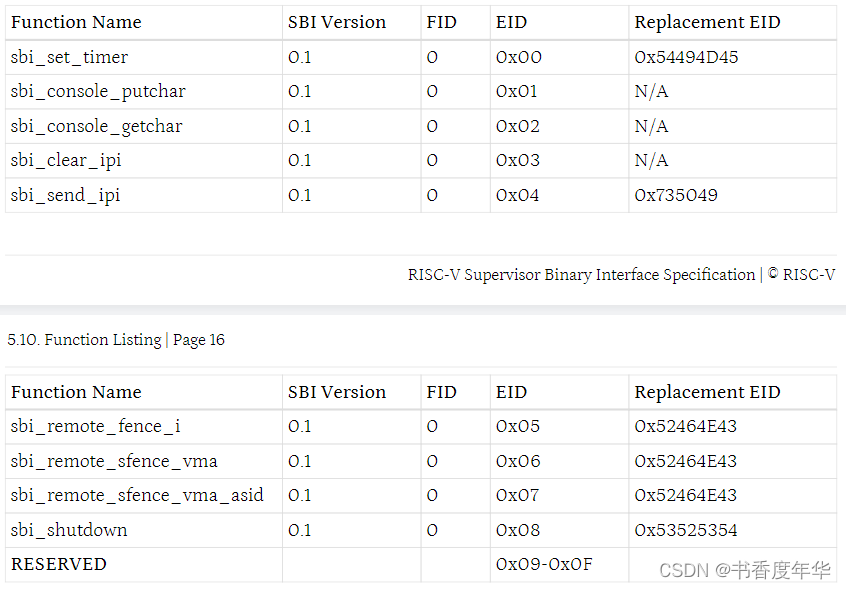
「RISC-V Arch」SBI 规范解读(上)
术语 SBI,Supervisor Binary Interface,管理二进制接口 U-Mode,User mode,用户模式 S-Mode,Supervisor mode,监督模式 VS-Mode,Virtualization Supervisor mode,虚拟机监督模式 …...

2023年全国最新二级建造师精选真题及答案5
百分百题库提供二级建造师考试试题、二建考试预测题、二级建造师考试真题、二建证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 51.下列国有资金占控股或者主导地位的依法必须进行招标的项目,可以采取邀请招标的…...

365智能云打印怎么样?365小票无线订单打印机好用吗?
365智能云打印怎么样?365智能云打印是有赞官方首推的订单小票打印机,荣获2016年有赞最佳硬件服务商。可以实现远程云打印,无需连接电脑,只需通过GPRS流量或者WIFI即可连接,不受地理位置和距离限制。365小票无线订单打印…...

细说react源码中的合成事件
最近在做一个功能,然后不小心踩到了 React 合成事件 的坑,好奇心的驱使,去看了 React 官网合成事件 的解释,这不看不知道,一看吓一跳… SyntheticEvent是个什么鬼?咋冒出来了个事件池? 我就一…...
【架构师】零基础到精通——架构演进
博客昵称:架构师Cool 最喜欢的座右铭:一以贯之的努力,不得懈怠的人生。 作者简介:一名Coder,软件设计师/鸿蒙高级工程师认证,在备战高级架构师/系统分析师,欢迎关注小弟! 博主小留言…...
Hadoop命令大全
HDFS分布式文件系统 , 将一个大的文件拆分成多个小文件存储在多台服务器中 文件系统: 目录结构(树状结构) "/" 树根, 目录结构在namenode中维护 目录 1.查看当前目录 2.创建多级目录 3.上传文件 4.查…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...