[Machine Learning] Learning with Noisy Data
文章目录
- Probabilistic Perspective of Noise
- Bias and Variance
- Robustness among Surrogate Loss Functions
- NMF
Probabilistic Perspective of Noise
假设数据来源于一个确定的函数,叠加了高斯噪声。我们有:
y = h ( x ) + ϵ y = h(x) + \epsilon y=h(x)+ϵ
其中 ϵ ∼ N ( 0 , β − 1 ) \epsilon \sim \mathcal{N}(0, \beta^{-1}) ϵ∼N(0,β−1)
等价地,给定输入 x x x,以及函数 h h h 和噪声的精度 β \beta β, y y y 的条件分布可以写作:
p { y ∣ x , h , β } = N ( y ∣ h ( x ) , β − 1 ) p\{y|x, h, \beta\} = \mathcal{N}(y|h(x), \beta ^ {-1}) p{y∣x,h,β}=N(y∣h(x),β−1)
即 y y y 的条件分布是以 h ( x ) h(x) h(x) 为均值、以 β − 1 \beta^{-1} β−1 为方差的正态分布。
我们现在有一个由 n n n 个数据点组成的数据集 S = { ( x 1 , y 1 ) , … , ( x n , y n ) } S = \{(x_1,y_1), \ldots, (x_n,y_n)\} S={(x1,y1),…,(xn,yn)}。我们假设数据点是独立同分布的,即每个数据点的生成不依赖于其他数据点。因此,整个数据集 S S S 的似然是所有单个数据点似然的乘积:
p ( S ∣ X , h , β − 1 ) = ∏ i = 1 n p ( y i ∣ h ( x i ) , β − 1 ) p(S|X, h, \beta^{-1}) = \prod\limits_{i=1}^n p(y_i|h(x_i), \beta^{-1}) p(S∣X,h,β−1)=i=1∏np(yi∣h(xi),β−1)
这个似然模型告诉我们,对于给定的函数 h h h 和噪声精度 β \beta β,数据集 S S S 的"可能性"或"合理性"是多少。
假设我们的模型参数为 h h h,先验分布为 p ( h ) p(h) p(h),那么基于贝叶斯定理,参数 h h h 的后验分布为:
p ( h ∣ S ) = p ( S ∣ h ) p ( h ) p ( S ) p(h|S) = \frac{p(S|h) p(h)}{p(S)} p(h∣S)=p(S)p(S∣h)p(h)
其中, p ( S ∣ h ) p(S|h) p(S∣h) 是似然, p ( S ) p(S) p(S) 是边缘似然,与参数 h h h 无关。
MAP估计就是找到使后验分布 p ( h ∣ S ) p(h|S) p(h∣S) 最大的参数 h h h。由于分母 p ( S ) p(S) p(S) 与 h h h 无关,所以MAP估计等价于:
h MAP = arg max h p ( S ∣ h ) p ( h ) h_{\text{MAP}} = \argmax_{h} p(S|h) p(h) hMAP=hargmaxp(S∣h)p(h)
取负对数,问题可以转化为:
h MAP = arg min h { − ln p ( S ∣ h ) − ln p ( h ) } h_{\text{MAP}} = \argmin_{h} \{-\ln p(S|h) - \ln p(h)\} hMAP=hargmin{−lnp(S∣h)−lnp(h)}
为了解决这个优化问题,你通常需要的是:
- 一个关于似然的负对数的表达式
- 一个关于先验的负对数的表达式
回顾我们的似然模型:
p ( S ∣ X , h , β − 1 ) = ∏ i = 1 n N ( y i ∣ h ( x i ) , β − 1 ) p(S|X, h, \beta^{-1}) = \prod_{i=1}^n \mathcal{N}(y_i|h(x_i), \beta^{-1}) p(S∣X,h,β−1)=i=1∏nN(yi∣h(xi),β−1)
根据正态分布的定义:
N ( y ∣ h ( x ) , β − 1 ) = β 2 π exp ( − β ( y − h ( x ) ) 2 2 ) \mathcal{N}(y|h(x), \beta^{-1}) = \frac{\beta}{\sqrt{2\pi}} \exp\left(-\frac{\beta (y - h(x))^2}{2}\right) N(y∣h(x),β−1)=2πβexp(−2β(y−h(x))2)
因此,我们可以写出似然函数为:
p ( S ∣ X , h , β − 1 ) = ∏ i = 1 n β 2 π exp ( − β ( y i − h ( x i ) ) 2 2 ) p(S|X, h, \beta^{-1}) = \prod_{i=1}^n \frac{\beta}{\sqrt{2\pi}} \exp\left(-\frac{\beta (y_i - h(x_i))^2}{2}\right) p(S∣X,h,β−1)=i=1∏n2πβexp(−2β(yi−h(xi))2)
对似然函数取对数,我们得到:
ln p ( S ∣ X , h , β − 1 ) = ∑ i = 1 n ln β 2 π − β ( y i − h ( x i ) ) 2 2 \ln p(S|X, h, \beta^{-1}) = \sum_{i=1}^n \ln \frac{\beta}{\sqrt{2\pi}} - \frac{\beta (y_i - h(x_i))^2}{2} lnp(S∣X,h,β−1)=i=1∑nln2πβ−2β(yi−h(xi))2
将上述式子进一步拆分并合并相似的项,我们可以得到:
ln p ( S ∣ X , h , β − 1 ) = n ln β − n 2 ln ( 2 π ) − β 2 ∑ i = 1 n ( y i − h ( x i ) ) 2 \ln p(S|X, h, \beta^{-1}) = n \ln \beta - \frac{n}{2} \ln(2\pi) - \frac{\beta}{2} \sum_{i=1}^n (y_i - h(x_i))^2 lnp(S∣X,h,β−1)=nlnβ−2nln(2π)−2βi=1∑n(yi−h(xi))2
此时, − β 2 ∑ i = 1 n ( y i − h ( x i ) ) 2 -\frac{\beta}{2} \sum_{i=1}^n (y_i - h(x_i))^2 −2β∑i=1n(yi−h(xi))2就是我们定义的风险 R S ( h ) R_S(h) RS(h)的部分,它表示模型在训练数据上的平均误差。
因此,我们有:
− ln p ( S ∣ h ) = − n 2 ln β + n 2 ln ( 2 π ) + β 2 n R S ( h ) -\ln p(S|h) = -\frac{n}{2} \ln \beta + \frac{n}{2} \ln(2\pi) + \frac{\beta}{2} n R_S(h) −lnp(S∣h)=−2nlnβ+2nln(2π)+2βnRS(h)
这就是似然的负对数的表达式。
为了完整地解决优化问题,你还需要一个先验的负对数形式。比如,如果 h h h的先验是高斯分布,那么负对数先验的形式会是 h h h的二次函数。
结合似然和先验的负对数形式,你可以使用优化技巧(例如梯度下降)来求解 h MAP h_{\text{MAP}} hMAP。这样得到的 h MAP h_{\text{MAP}} hMAP既考虑了数据的似然,又考虑了先验知识,从而可能得到更好、更稳定的估计结果。
Bias and Variance
当 λ \lambda λ 很小或为0时:模型可能会过于复杂,拟合训练数据中的每一个细节,包括噪声。这会导致低偏差但高方差,即模型容易过拟合。
当 λ \lambda λ 很大时:模型会变得过于简单,参数值会被强烈地压缩,导致模型不能很好地捕获数据中的模式。这会导致高偏差但低方差,即模型容易欠拟合。
Robustness among Surrogate Loss Functions
在许多优化问题中,直接对目标函数进行操作可能会非常困难。可能是因为这个函数在数学上很复杂,或者它涉及到的计算量太大,导致直接优化不切实际。在这些情况下,转化或重参数化问题可以使其更容易处理。
在这里,考虑 g ( t ) = f ( t h ) g(t) = f(th) g(t)=f(th) 是一个这样的尝试。通过引入新的变量 t t t 并考虑如何改变 h h h 的长度(即通过 t t t 来缩放),我们试图在某种程度上简化问题。
当 t = 1 t=1 t=1 时,我们实际上是在查看原始函数 f f f 在点 h h h 的行为。如果 g ′ ( 1 ) = 0 g'(1) = 0 g′(1)=0,那么我们知道 f f f 在 h h h 这点取得极值(可能是最小值或最大值)。因此,这个技巧为我们提供了另一种方式来寻找 f ( h ) f(h) f(h) 的最小值点,而不是直接对 f f f 进行操作。
现在考虑四种损失函数及其对应的 g ′ ( 1 ) g'(1) g′(1):
-
最小二乘损失 (Least squares loss):
ℓ ( h ( x i ) , y i ) = ( y i − h ( x i ) ) 2 \ell(h(x_i), y_i) = (y_i - h(x_i))^2 ℓ(h(xi),yi)=(yi−h(xi))2
这意味着,
g ′ ( 1 ) = − 2 ∑ i = 1 n ( y i − h ( x i ) ) h ( x i ) g'(1) = -2 \sum_{i=1}^n (y_i - h(x_i)) h(x_i) g′(1)=−2i=1∑n(yi−h(xi))h(xi) -
绝对损失 (Absolute loss):
ℓ ( h ( x i ) , y i ) = ∣ y i − h ( x i ) ∣ \ell(h(x_i), y_i) = |y_i - h(x_i)| ℓ(h(xi),yi)=∣yi−h(xi)∣
这的导数与误差的符号有关。 -
Cauchy损失 (Cauchy loss):
ℓ ( h ( x i ) , y i ) = log ( 1 + ( y i − h ( x i ) ) 2 σ 2 ) \ell(h(x_i), y_i) = \log(1 + \frac{(y_i - h(x_i))^2}{\sigma^2}) ℓ(h(xi),yi)=log(1+σ2(yi−h(xi))2)
其中, σ \sigma σ是一个正的常数。 -
Correntropy损失 (Welsch loss):
ℓ ( h ( x i ) , y i ) = σ 2 2 ( 1 − exp ( − ( y i − h ( x i ) ) 2 σ 2 ) ) \ell(h(x_i), y_i) = \frac{\sigma^2}{2}(1 - \exp(-\frac{(y_i - h(x_i))^2}{\sigma^2})) ℓ(h(xi),yi)=2σ2(1−exp(−σ2(yi−h(xi))2))
对于每个损失函数, g ′ ( 1 ) g'(1) g′(1)都会有一个与 c i = ( y i − h ( x i ) ) ( − h ( x i ) ) c_i = (y_i - h(x_i))(- h(x_i)) ci=(yi−h(xi))(−h(xi))相关的项。这个项可以被看作是数据点 ( x i , y i ) (x_i, y_i) (xi,yi)对损失函数的贡献与 h ( x i ) h(x_i) h(xi)的关系。具体地说, c i c_i ci可以被看作为两部分的乘积:
-
( y i − h ( x i ) ) (y_i - h(x_i)) (yi−h(xi)):这是观测值 y i y_i yi与预测值 h ( x i ) h(x_i) h(xi)之间的误差。此误差项衡量了模型在特定数据点上的预测准确性。
-
− h ( x i ) - h(x_i) −h(xi):这是模型预测的负值,这种乘积形式通常是为了衡量模型的响应强度和误差之间的关系。在某些情境中,更强烈的模型响应(无论正负)可能与更大的误差相关。
整体来说, c i c_i ci是一个衡量在数据点 ( x i , y i ) (x_i, y_i) (xi,yi)上模型响应强度与模型误差之间关系的量。不同的损失函数会对这些项赋予不同的权重,当误差(或噪声)增大时,某些损失函数会对这些项赋予更小的权重,从而更"鲁棒"。
NMF
-
标准的NMF (Basic NMF):
使用欧氏距离或Frobenius范数来最小化重建误差。此方法对噪声敏感。
min W , H ∥ X − W H ∥ F 2 subject to W ≥ 0 , H ≥ 0 \min_{W,H} \|X - WH\|_F^2 \text{ subject to } W \geq 0, H \geq 0 W,Hmin∥X−WH∥F2 subject to W≥0,H≥0 -
L1-Norm Regularized Robust NMF:
在NMF的基础上加入L1正则化项,旨在捕获噪声和离群值。
min W , H , E ∥ X − W H − E ∥ F 2 + λ ∥ E ∥ 1 subject to W ≥ 0 , H ≥ 0 \min_{W,H,E} \|X - WH - E\|_F^2 + \lambda \|E\|_1 \text{ subject to } W \geq 0, H \geq 0 W,H,Emin∥X−WH−E∥F2+λ∥E∥1 subject to W≥0,H≥0 -
L1-Norm Based NMF:
使用L1范数来衡量重建误差,使得分解更加鲁棒,尤其是对噪声和离群值。L1范数倾向于产生稀疏的解。
min W , H ∥ X − W H ∥ 1 subject to W ≥ 0 , H ≥ 0 \min_{W,H} \|X - WH\|_1 \text{ subject to } W \geq 0, H \geq 0 W,Hmin∥X−WH∥1 subject to W≥0,H≥0 -
L2,1-Norm Based NMF:
使用L2,1范数来增强鲁棒性。L2,1范数可以鼓励列的稀疏性,使得某些特定的特征在所有样本上都为零,这有助于去除离群值带来的影响。
min W , H ∥ X − W H ∥ 2 , 1 subject to W ≥ 0 , H ≥ 0 \min_{W,H} \|X - WH\|_{2,1} \text{ subject to } W \geq 0, H \geq 0 W,Hmin∥X−WH∥2,1 subject to W≥0,H≥0 -
Truncated Cauchy NMF:
这种方法使用截断的Cauchy损失来增加鲁棒性。与L1和L2范数相比,Cauchy损失更能够容忍较大的离群值,因此这种方法在面对有很多噪声和离群值的数据时更为鲁棒。 -
Hypersurface Cost Based NMF:
通过在损失函数中加入超曲面成本项来增加鲁棒性。此方法试图找到描述数据变化的超曲面,从而更好地应对噪声和离群值。
相关文章:

[Machine Learning] Learning with Noisy Data
文章目录 Probabilistic Perspective of NoiseBias and VarianceRobustness among Surrogate Loss FunctionsNMF Probabilistic Perspective of Noise 假设数据来源于一个确定的函数,叠加了高斯噪声。我们有: y h ( x ) ϵ y h(x) \epsilon yh(x)ϵ…...

C++中有哪些常用的标准库?
C中有许多常用的标准库,这些库提供了丰富的功能和工具,方便开发人员进行各种任务。以下是一些常见的C标准库: iostream:用于输入和输出操作,包括cin、cout和cerr等类和函数。algorithm:提供了许多常用的算…...

软考-信息安全工程师概述
本文为作者学习文章,按作者习惯写成,如有错误或需要追加内容请留言(不喜勿喷) 本文为追加文章,后期慢慢追加 2023年10月 信息考试大纲 通过本考试的合格人员能够掌握网络信息安全的基础知识和技术原理,…...

2023-2024年华为ICT网络赛道模拟题库
2023-2024年网络赛道模拟题库上线啦,全面覆盖网络,安全,vlan考点,都是带有解析 参赛对象及要求: 参赛对象:现有华为ICT学院及未来有意愿成为华为ICT学院的本科及高职院校在校学生。 参赛要求:…...

英特尔参与 CentOS Stream 项目
导读红帽官方发布公告欢迎英特尔参与进 CentOS Stream 项目,并表示 “这一举措不仅进一步深化了我们长期的合作关系,也构建在英特尔已经在 Fedora 项目中积极贡献的基础之上。” 目前,CentOS Stream 共包括以下特别兴趣小组(SIG&a…...

Centos 服务器 MySQL 8.0 快速开启远程访问
环境: MySQL 8.0(低版本会有些不同), Rocky Linux 9.0(CentOS) 直接上干货,相信大家看到这个文章的时候都已经安装完了。 1. 先从服务器上使用 root 进行登录(刚安装完默认只能本地…...
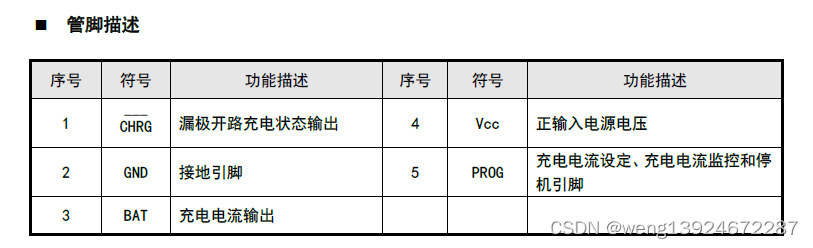
充电保护芯片TP4054国产替代完全兼容DP4054DP4054H 锂电充电芯片
■产品概述 DP4054H是-款完整的采用恒定电流/恒定电压单节锂离子电池充电管理芯片。其SOT小封装和较少的外部元件数目使其成为便携式应用的理想器件,DP4054H可 以适合USB电源和适配器电源工作。 由于采用了内部PMOSFET架构,加上防倒充电路,所以不需要外…...

Java Spring Boot中的爬虫防护机制
随着互联网的发展,爬虫技术也日益成熟和普及。然而,对于某些网站来说,爬虫可能会成为一个问题,导致资源浪费和安全隐患。本文将介绍如何使用Java Spring Boot框架来防止爬虫的入侵,并提供一些常用的防护机制。 引言&a…...

状态模式 行为型模式之六
1.定义 允许一个对象在其对象内部状态改变时改变它的行为。 2.组成结构 Context:定义客户感兴趣的接口;维护一个ConcreteState子类的实例,这个实例定义当前的状态。State:定义一个接口来封装Context的与特定状态相关的行为。Co…...
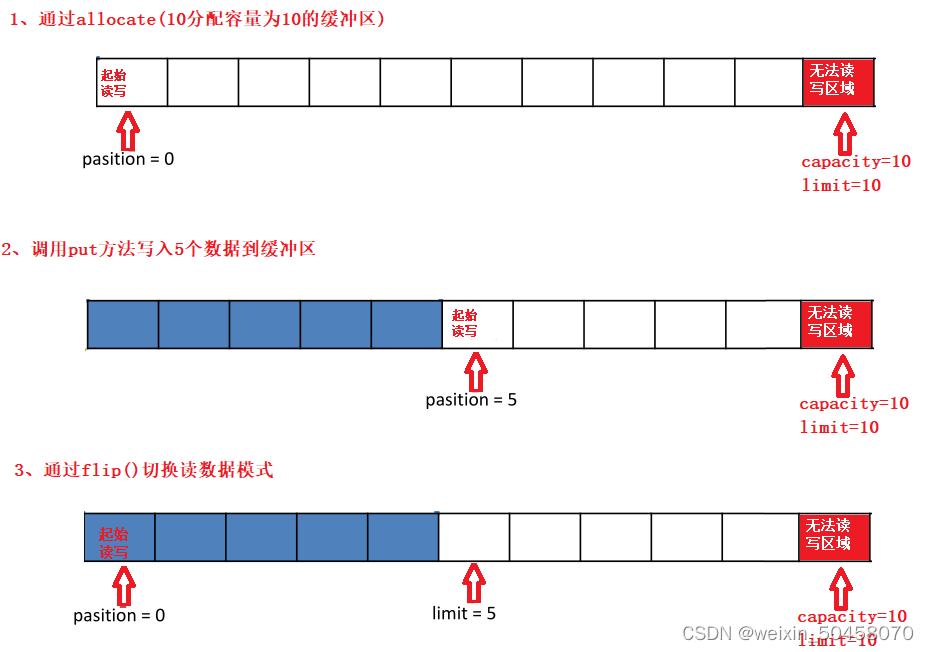
JAVA NIO深入剖析
4.1 Java NIO 基本介绍 Java NIO(New IO)也有人称之为 java non-blocking IO是从Java 1.4版本开始引入的一个新的IO API,可以替代标准的Java IO API。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的、基于通道的IO操作。NIO将以更加高效的方…...
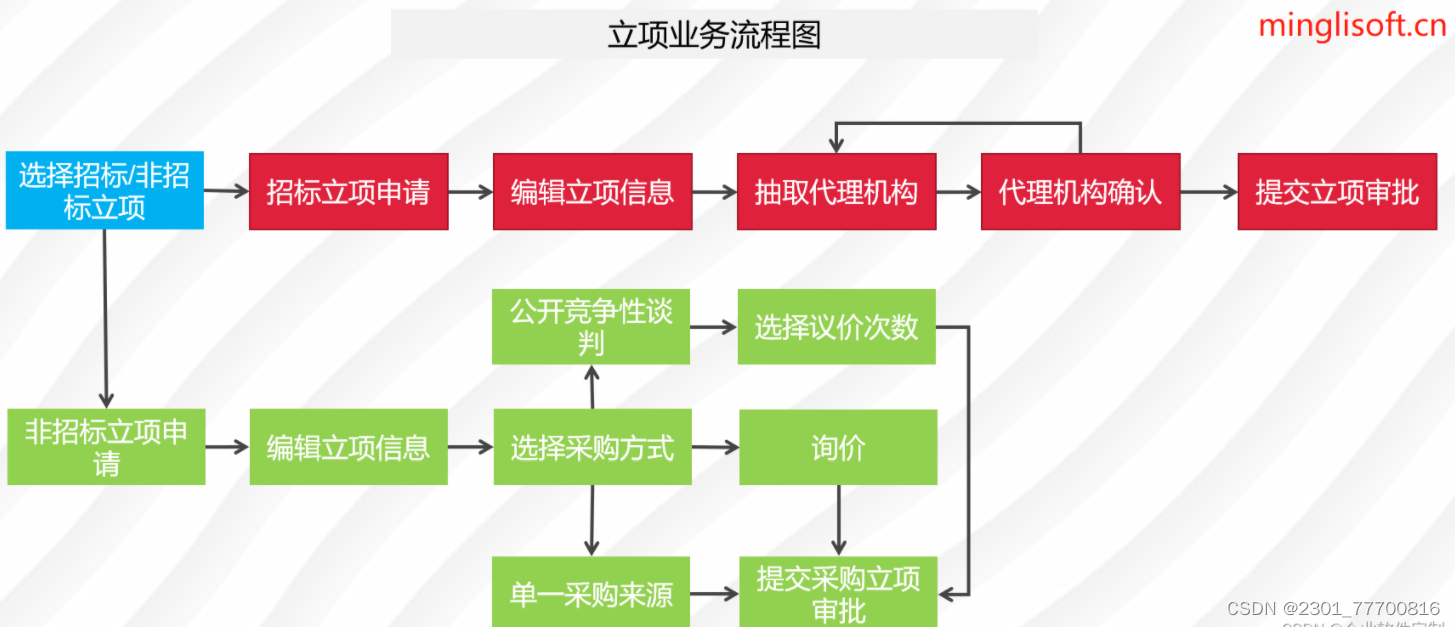
企业电子招投标系统源码之电子招投标系统建设的重点和未来趋势
功能描述 1、门户管理:所有用户可在门户页面查看所有的公告信息及相关的通知信息。主要板块包含:招标公告、非招标公告、系统通知、政策法规。 2、立项管理:企业用户可对需要采购的项目进行立项申请,并提交审批,查看所…...

基于正点原子alpha开发板的第三篇系统移植
系统移植的三大步骤如下: 系统uboot移植系统linux移植系统rootfs制作 一言难尽,踩了不少坑,当时只是想学习驱动开发,发现必须要将第三篇系统移植弄好才可以学习后面驱动,现将移植好的文件分享出来: 仓库&…...
数据结构与算法设计分析——贪心算法的应用
目录 一、贪心算法的定义二、贪心算法的基本步骤三、贪心算法的性质(一)最优子结构性质(二)贪心选择性质 四、贪心算法的应用(一)哈夫曼树——哈夫曼编码(二)图的应用——求最小生成…...

Leetcode 2895. Minimum Processing Time
Leetcode 2895. Minimum Processing Time 1. 解题思路2. 代码实现 题目链接:2895. Minimum Processing Time 1. 解题思路 这一题整体上来说其实没啥难度,就是一个greedy算法,只需要想明白耗时长的任务一定要优先执行,不存在某个…...

学信息系统项目管理师第4版系列21_范围管理
1. 产品范围 1.1. 某项产品、服务或成果所具有的特征和功能 1.2. 产品范围的完成情况是根据产品需求来衡量的 1.3. “需求”是指根据特定协议或其他强制性规范,产品、服务或成果必须具备的条件或能力 2. 项目范围 2.1. 包括产品范围,是为交付具有规…...

threejs 透明贴图,模型透明,白边
问题 使用Threejs加载模型时,模型出现了上面的问题。模型边缘部分白边,或者模型出现透明问题。 原因 出现这种问题是模型制作时使用了透明贴图。threejs无法直接处理贴图。 解决 场景一 模型有多个贴图时(一个透贴和其他贴图࿰…...

CCF CSP认证 历年题目自练Day21
题目一 试题编号: 201909-1 试题名称: 小明种苹果 时间限制: 2.0s 内存限制: 512.0MB 题目分析(个人理解) 先看输入,第一行输入苹果的棵树n和每一次掉的苹果数m还是先如何存的问题…...
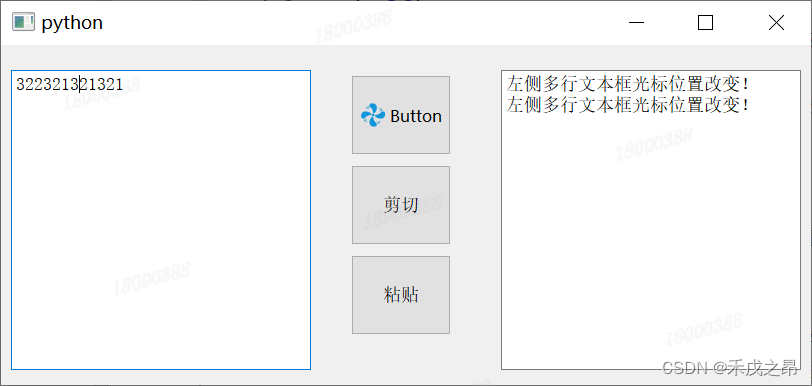
【Python_PySide2学习笔记(十六)】多行文本框QPlainTextEdit类的的基本用法
多行文本框QPlainTextEdit类的的基本用法 前言正文1、创建多行文本框2、多行文本框获取文本3、多行文本框获取选中文本4、多行文本框设置提示5、多行文本框设置文本6、多行文本框在末尾添加文本7、多行文本框在光标处插入文本8、多行文本框清空文本9、多行文本框拷贝文本到剪贴…...
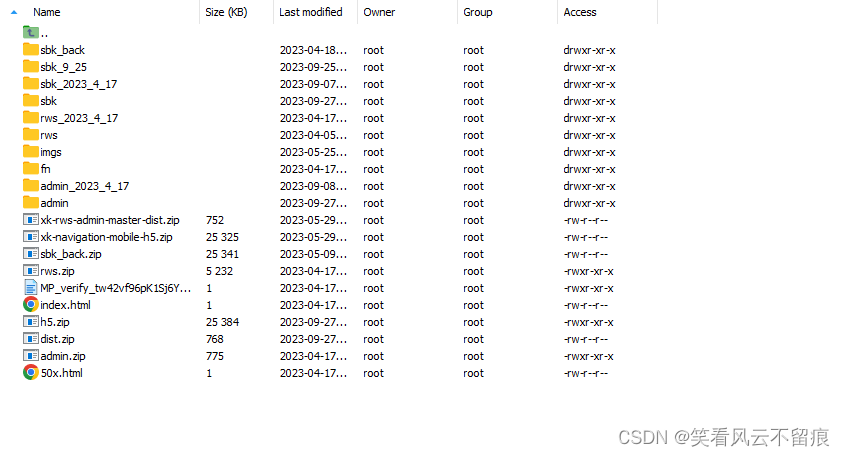
linux上negix部署静态页面
1.看配置文件 进入cndf.d 这里的是配置部署项目中的文件 进入一个查看下 上面的是服务的域名,服务是http://test.fun-med.cn/#/,后面加服务名(你的前端) 2.看下页面位置 和上面的路径要匹配...

41.说说Promise自身的静态方法
41.说说Promise自身的静态方法 Promise.all (有一个失败就失败,所有的都成功就成功)Promise.race (有一个成功就成功,有一个失败就失败)Promise.allSettled (所有的异步操作执行完毕之后&#…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...
CSS3相关知识点
CSS3相关知识点 CSS3私有前缀私有前缀私有前缀存在的意义常见浏览器的私有前缀 CSS3基本语法CSS3 新增长度单位CSS3 新增颜色设置方式CSS3 新增选择器CSS3 新增盒模型相关属性box-sizing 怪异盒模型resize调整盒子大小box-shadow 盒子阴影opacity 不透明度 CSS3 新增背景属性ba…...
)
2025.6.9总结(利与弊)
凡事都有两面性。在大厂上班也不例外。今天找开发定位问题,从一个接口人不断溯源到另一个 接口人。有时候,不知道是谁的责任填。将工作内容分的很细,每个人负责其中的一小块。我清楚的意识到,自己就是个可以随时替换的螺丝钉&…...
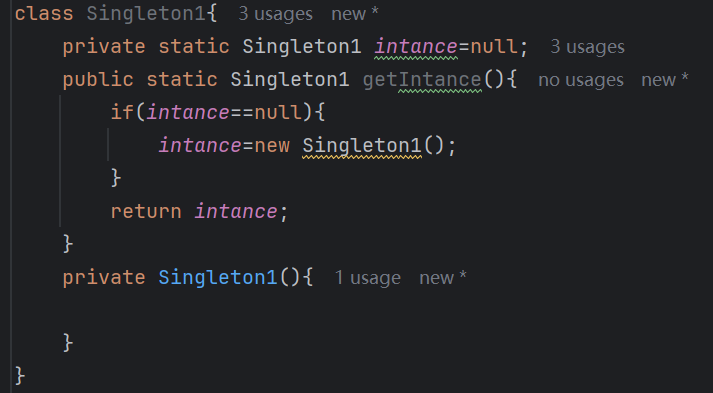
【Java多线程从青铜到王者】单例设计模式(八)
wait和sleep的区别 我们的wait也是提供了一个还有超时时间的版本,sleep也是可以指定时间的,也就是说时间一到就会解除阻塞,继续执行 wait和sleep都能被提前唤醒(虽然时间还没有到也可以提前唤醒),wait能被notify提前唤醒…...