一文教你玩转 Apache Doris 分区分桶新功能
数据分片(Sharding)是分布式数据库分而治之 (Divide And Conquer) 这一设计思想的体现。过去的单机数据库在大数据量下往往面临存储和 IO 的限制,而分布式数据库则通过数据划分的规则,将数据打散分布至不同的机器或节点上,形成分布式存储,因此突破了单机存储空间和 IO 的瓶颈、使库表数据量可以无限拓展。
数据分片主要有范围分片或哈希分片这两种方式,而在实际数据库的实现中,往往呈现为分区和分桶两种形式。分区一般是按照时间或其他连续值对数据进行划分,在执行查询操作时可以通过分区裁剪过滤不必要的范围扫描,提升执行效率,同时也使得对分区数据的增删改等管理操作更为便捷。而分桶则是按照某个关键字执行哈希运算,将相同哈希值的数据放到一起,这样可以有效定位数据、避免数据倾斜。
在 Apache Doris 中,同样也遵从一定的数据分布规则。数据以关系表(Table)的形式进行呈现,会依次按照先分区(Partition)、再分桶(Bucket)的方式划分,最终在同一个分桶中的数据会形成数据分片(Tablet)。Tablet 是 Apache Doris 中多副本高可用、集群间数据调度与均衡的最小物理存储单位。
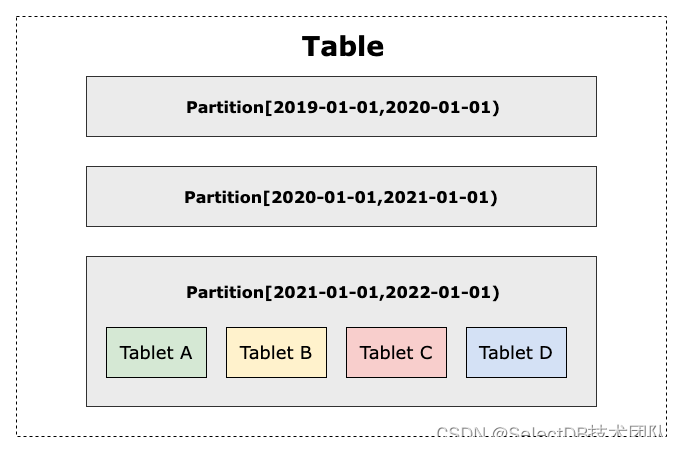
图1:Table-Partition-Tablet 之间的关系
# 现状与问题
在 Doris 中,分区与分桶是如何创建的?我们以一个网站站点的建表实例说明分区与分桶的创建方式,该网站的站点建表语句如下:
-- 该表记录了某个时间点,在某个站点上各个用户的pv数据
CREATE TABLE demo.test_tbl(sdate DATETIME, -- 日期site INT, -- 站点idcity VARCHAR(64), -- 城市user VARCHAR(32) DEFAULT '', -- 用户名pv BIGINT -- pv量
) ENGINE=olap DUPLICATE KEY(sdate, site, city)
[PARTITION_DESC]
[BUCKET_DESC]
PROPERTIES ("replication_num" = "1");其中 [PARTITION_DESC] 表示创建分区的详细语句,[BUCKET_DESC] 表示创建分桶的语句。
创建分区
Apache Doris 支持两种分区形式,List Partition 与 Range Partition。
List Partition
List Partition 相当于对分区的列值进行枚举,因此选择的分区列最好是有区分度的可枚举值,例如本例中的 city。根据 city 列的枚举值创建多个 List Partition,则 PARTITION_DESC可以写为:
-- 以city作为分区列,创建华北、东北、华中、西南等分区
PARTITION BY LIST(city)
(PARTITION `p_huabei` VALUES IN ("beijing", "tianjin", "shijiazhuang"),PARTITION `p_dongbei` VALUES IN ("shenyang", "dalian"),PARTITION `p_huazhong` VALUES IN ("wuhan", "changsha")PARTITION `p_xinan` VALUES IN ("chengdu", "chongqing")
)Range Partition
创建 Range partition 一般使用时间列,Range Partition 又可以分为静态和动态两种方式:
- 静态 Range Partition
此类 Partition 的创建会生成一个左闭右开的区间,定义一个分区只需要指定右边界,该分区的左边界由上一个分区的右边界确定,PARTITION_DESC可以写为:
-- 以sdate这个时间列作为分区列,
-- 日期处于[min, 2023-01-01)的数据,都放到名为p2022的分区下;
-- 日期处于[2023-01-01, 2023-01-02)的数据,都放到名为p20230101的分区下;
-- 日期处于[2023-01-02, 9999-12-31)的数据,都放到名为pmax的分区下;
PARTITION BY RANGE(sdate)
(PARTITION `p2022` VALUES LESS THAN ("2023-01-01"),PARTITION `p20230101` VALUES LESS THAN ("2023-01-02"),PARTITION `pmax` VALUES LESS THAN ("9999-12-31")
)可以看出,p20230101 这个分区的左边界由 p2022 分区的右边界确定,而 pmax 的左边界由 p20230101 的右边界确定。需注意的是,此处为了举例说明动态分区,使用了一个很大的边"9999-12-31",实际业务中很少会直接创建从 2023-01-02 到 9999-12-31 的分区。
- 动态 Range Partition
上述静态的分区需要手动指定边界,分区个数太多使用起来也不方便。动态 Range Partition 帮助我们解决了这个问题,只需指定一些分区的参数即可动态创建,PARTITION_DESC 相对更简单,只需指定哪个列作为分区列即可:
PARTITION BY RANGE(sdate)()剩余参数需要在PARTITION进行配置:
PROPERTIES ("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-30","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.create_history_partition"="true","replication_num" = "1"
);动态分区参数说明如下:
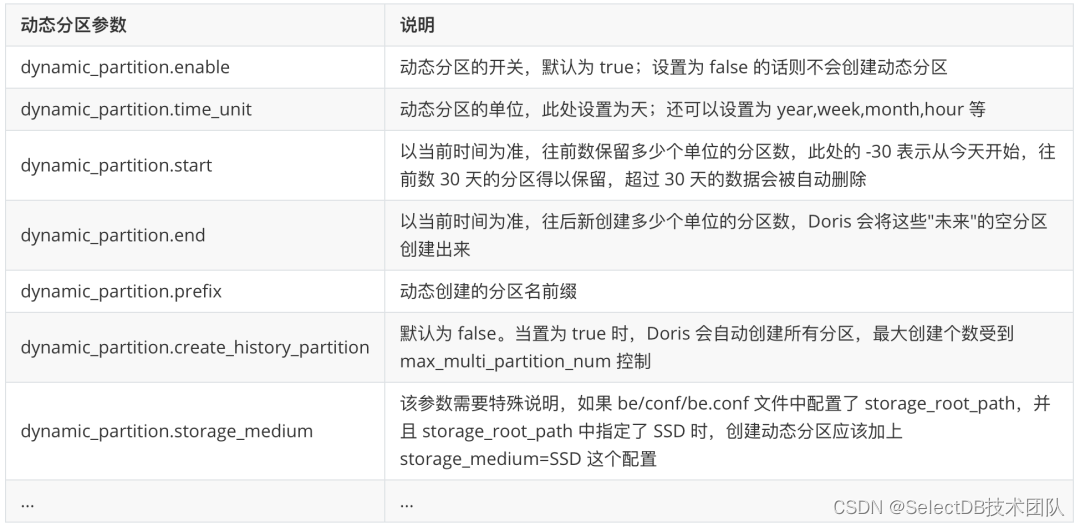
创建分桶
分桶在物理层面即数据分片(Tablet)。在数据表完成分区后,指定部分列作为分桶列,将这些列数据中相同哈希值的数据合到一起,形成了 Tablet。一个表中 Tablet 总数量 = 分区数(Partition num)x 分桶数(Bucket num)x 数据副本数(Replication_num) 。
[BUCKET_DESC] 语句非常简单,只需要一句:
DISTRIBUTED BY HASH(site) BUCKETS 20此时指定以 site 列的哈希值作为分桶,并且分桶个数设置为 20 个,需要注意的是这里的 20 仅作为示例,合适的分桶个数需要根据分区大小来确定。实际上单个分桶即 Tablet 的数据量理论上没有上下界,但建议在 1GB - 10GB 的范围内,即假设分区大小为 20GB,那么分桶个数设置为 10-20 个是合适的。
不足与思考
从以上对分区分桶的介绍,相信有不少用户和读者仍能发现其中一些不足之处:
分区数量过多的情况下,使用 List Partition 或者静态 Range Partition 会使得 SQL 较为繁琐,编写起来费时费力;
若是使用动态 Range Partition,则需要掌握多个参数,使用方式不友好且学习成本较高;而当存在大量历史冷数据来说,动态 Range Partition 只能指定单一粒度,无法灵活组合不同的分区粒度;
分桶个数的设置十分依赖用户对 Apache Doris 数据分布机制和业务数据本身的理解,使用门槛较高。不合理的分桶设置将对系统性能和稳定性造成一定程度冲击:分桶数太多将导致单个 Tablet 的数据量过小,数据聚合效果不佳、查询性能不能得到有效发挥,并且元数据管理压力大;个数太少则单个 Tablet 包含的数据量过大,不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价。
# 批量分区与Auto Bucket的设计与实现
克服数据库的复杂性是 Apache Doris 一直追求的目标之一,针对以上分区分桶存在的易用性问题,在 Apache Doris 最新的版本中已经得到解决。在 Apache Doris 1.2.1 版本中,我们新增了批量创建分区功能,简洁的语法和灵活的使用方式让批量创建历史分区更加得心应手;而针对分桶设置带来的学习成本,Apache Doris 在即将发布的 1.2.2 版本中新增了 Auto Bucket 自动分桶推算功能,分桶个数不再依赖于人工设置,通过规则的智能计算即可保证合理的数据划分,降低用户学习成本的同时还可以最大化提升用户开发效率。
批量创建分区
批量创建分区功能在前期充分调研了用户的需求,本着简洁、强大、易用的设计目标,将设计核心锁定在几个要素中:
时间区间范围(会考虑开闭问题)
时间跨度(即每个分区的时间维度的大小)
时间单位(年、月、日、时、周等)
结合前面提到的网站站点模型,假设其数据包含从几年前直到现在的全量信息,想要将十年内的数据按每一天一个分区进行创建。在批量分区功能中,PARTITION_DESC只需要一句,并且不用在PARTITION中设置分区相关参数:
-- 当然,分区创建个数受到max_multi_partition_num参数控制,该值默认为4096,有需求可以修改
PARTITION BY RANGE(sdate)
(FROM ("2013-01-01") TO ("2023-01-01") INTERVAL 1 DAY
)从这个 case 来看,批量分区功能的语法更为简洁,但该功能的易用性和灵活性远不止于此。从这个 case 来看,批量分区功能的语法更为简洁,但该功能的易用性和灵活性远不止于此。
假设有另一批数据:公司前几年的数据量较大且为冷数据,故可以将一年的数据合到一个分区里面;而后来因为业务迅速发展,需要将每一月的数据作为一个分区;随着公司业务进一步发展,按月分区已经不能满足快速增长的数据需求,需要按周进行分区;……;时至今日,公司每天产生海量数据,可能需要按小时分区才能符合需求。根据这个场景,不难写出批量分区创建的 PARTITION_DESC:
-- 此处需要注意,如果要使用小时级别的分区,则分区列必须是datetime类型
-- 同样的,分区创建个数也受到max_multi_partition_num参数控制
PARTITION BY RANGE(sdate)
(FROM ("2000-01-01") TO ("2021-01-01") INTERVAL 1 YEAR,FROM ("2021-01-01") TO ("2022-01-01") INTERVAL 1 MONTH,FROM ("2022-01-01") TO ("2023-01-01") INTERVAL 1 WEEK,FROM ("2023-01-01") TO ("2023-02-01") INTERVAL 1 DAY,FROM ("2023-02-01 00") TO ("2099-12-31 23") INTERVAL 1 HOUR
)除了上述不同时间粒度的分区可以灵活组合外,还可以将静态 Range Partition 和批量分区功能结合起来。例如需要将该公司 2022-01-01 到 2023-01-01 的数据按天创建分区,2022-01-01 之前的数据归到一个名为"pold"分区中,我们可以将静态分区和批量分区组合起来,PARTITION_DESC如下:
PARTITION BY RANGE(sdate)
(PARTITION pold VALUES LESS THAN ("2022-01-01"),FROM ("2022-01-01") TO ("2023-01-01") INTERVAL 1 DAY
)批量分区创建功能支持不同时间粒度,其语法简洁有力,且各种类型分区可以灵活组合,在面对大量历史分区和部分特殊分区的需求时,该功能显得游刃有余,可以极大提高开发效率。 批量分区功能 PR:*https://github.com/apache/doris/pull/13772*****
Auto Bucket 自动分桶推算
以往创建分桶时需要手动设定分桶数,而自动分桶推算功能是 Apache Doris 可以动态地推算分桶个数,使得分桶数始终保持在一个合适范围内,让用户不再操心桶数的细枝末节。首先说明一点,为了方便阐述该功能,该部分会将桶拆分为两个时期的桶,即初始分桶以及后续分桶。 (这里的初始和后续只是本文为了描述清楚该功能而采用的术语,Apache Doris 分桶本身没有初始和后续之分) 从上文中创建分桶一节我们知道,BUCKET_DESC非常简单,但是需要指定分桶个数;而在自动分桶推算功能上,BUCKET_DESC的语法直接将分桶数改成"Auto",并新增一个 Properties 配置即可:
-- 旧版本指定分桶个数的创建语法
DISTRIBUTED BY HASH(site) BUCKETS 20-- 新版本使用自动分桶推算的创建语法
DISTRIBUTED BY HASH(site) BUCKETS AUTO
properties("estimate_partition_size" = "100G")新增的配置参数estimate_partition_size表示一个单分区的数据量。该参数是可选的,如果没有给出则 Doris 会将 estimate_partition_size 的默认值取为 10GB。从上文中已经得知,一个分桶在物理层面就是一个Tablet,为了获得最好的性能,建议 Tablet 的大小在 1GB - 10GB 的范围内。那么自动分桶推算是如何保证 Tablet 大小处于这个范围内的呢?总结起来不外乎几个原则:
若是整体数据量较小,则分桶数不要设置过多
若是整体数据量较大,则应使桶数跟总的磁盘块数相关,充分利用每台 BE 机器和每块磁盘的能力
初始分桶推算
从原则出发,理解自动分桶推算功能的详细逻辑就变得简单了:首先来看初始分桶:
先根据数据量得出一个桶数 N。首先使用 estimate_partition_size 的值除以 5(按文本格式存入 Doris 中有 5 比 1 的数据压缩比计算),得到的结果为:
< 100MB,则取 N=1
< 1GB,则取 N=2
= 1GB,则每一个 GB 一个分桶
根据 BE 节点数以及每个 BE 节点的磁盘容量,计算出桶数 M。其中每个 BE 节点算 1,每 50G 的磁盘容量算 1,那么 M 的计算规则为:*M = BE 节点数 ( 一块磁盘块大小 / 50GB) * 磁盘块数, 例如有 3 台 BE,每台 BE 都有 4 块 500GB 的磁盘,那么 M = 3 * (500GB / 50GB) * 4 = 1203. 得到最终的分桶个数计算逻辑:
先计算一个中间值 x = min(M, N, 128),
如果 x < N并且x < BE节点个数,则最终分桶为 y 即 BE 节点个数;否则最终分桶数为 x
上述过程伪代码表现形式为:
int N = 计算N值;
int M = 计算M值;int y = BE节点个数;
int x = min(M, N, 128);if (x < N && x < y) {return y;
}
return x;有了上述算法,咱们再引入一些例子来更好地理解这部分逻辑:
case 1:
数据量 100 MB,10 台 BE 机器,2TB * 3 块盘
数据量 N = 1
BE 磁盘 M = 10 * (2TB/50GB) * 3 = 1230
x = min(M, N, 128) = 1
最终: 1
case 2:
数据量 1GB, 3 台 BE 机器,500GB * 2 块盘
数据量 N = 2
BE 磁盘 M = 3 * (500GB/50GB) * 2 = 60
x = min(M, N, 128) = 2
最终: 2
case 3:
数据量 100GB,3 台 BE 机器,500GB * 2 块盘
数据量 N = 20
BE 磁盘 M = 3 * (500GB/50GB) * 2 = 60
x = min(M, N, 128) = 20 *
最终: 20*
case 4:
数据量 500GB,3 台 BE 机器,1TB * 1 块盘
数据量 N = 100
BE 磁盘 M = 3 * (1TB /50GB) * 1 = 60
x = min(M, N, 128) = 63
最终: 63
case 5:
数据量 500GB,10 台 BE 机器,2TB * 3 块盘
数据量 N = 100
BE 磁盘 M = 10 * (2TB / 50GB) * 3 = 1230
x = min(M, N, 128) = 100
最终: 100
case 6:
数据量 1TB,10 台 BE 机器,2TB * 3 块盘
数据量 N = 205
BE 磁盘 M = 10 * (2TB / 50GB) * 3 = 1230
x = min(M, N, 128) = 128
最终: 128
case 7:
数据量 500GB,1 台 BE 机器,100TB * 1 块盘
数据量 N = 100
BE 磁盘 M = 1 * (100TB / 50GB) * 1 = 2048
x = min(M, N, 128) = 100
最终: 100
case 8:
数据量 1TB, 200 台 BE 机器,4TB * 7 块盘
数据量 N = 205
BE 磁盘 M = 200 * (4TB / 50GB) * 7 = 114800
x = min(M, N, 128) = 128
最终: 200
可以看到,详细逻辑与原则是匹配的。
后续分桶推算
上述是关于初始分桶的计算逻辑,后续分桶数因为已经有了一定的分区数据,可以根据已有的分区数据量来进行评估。后续分桶数会根据最多前 7 个分区数据量的 EMA[1](短期指数移动平均线)值,作为estimate_partition_size 进行评估。此时计算分桶有两种计算方式,假设以天来分区,往前数第一天分区大小为 S7,往前数第二天分区大小为 S6,依次类推到 S1;
如果 7 天内的分区数据每日严格递增,则此时会取趋势值
有6个delta值,分别是S7 - S6 = delta1,S6 - S5 = delta2,...S2 - S1 = delta6由此得到平均的delta值:avg_delta = (delta1 + delta2 + ... + delta6) / 6 = (S7 - S1) / 6那么,今天的estimate_partition_size = S7 + avg_delta
非第一种的情况,此时直接取前几天的 EMA 平均值
今天的 estimate_partition_size = EMA(S1, ..., S7)
根据上述算法,初始分桶个数以及后续分桶个数都能被计算出来。跟之前只能指定固定分桶数不同,由于业务数据的变化,有可能前面分区的分桶数和后面分区的分桶数不一样,这对用户是透明的,用户无需关心每一分区具体的分桶数是多少,而这一自动推算的功能会让分桶数更加合理。
自动分桶推算功能 PR:https://github.com/apache/doris/pull/15250
效果
当我们有了合适的分区分桶时,导入数据导到 Doris 后,数据会依照建表语句中的分区分桶列进行存储。上述网站站点数据的存储示例如图示:
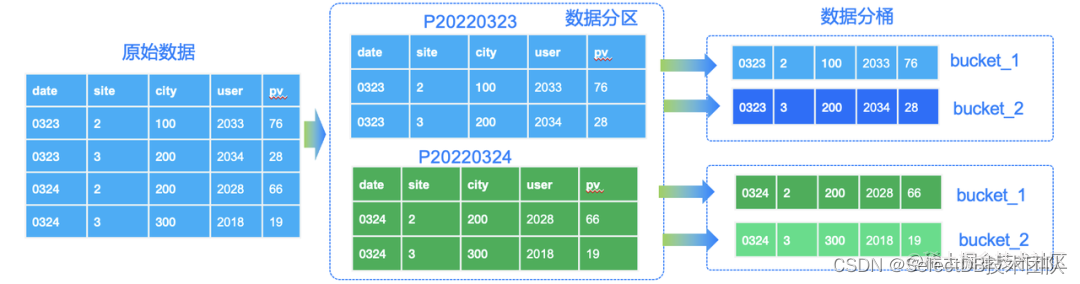
图2:Doris 分区分桶后的数据存储
此时如果执行 SQL 查询:
select * from test_tbl where sdate = "2020-03-23" and site = 1根据谓词 sdate = "2020-03-23" 可以定位到分区 p20200323,谓词 site = 1 能定位到该分区下的 bucket_1。假设有 30 天数据,自动分桶推算得到的分桶个数为 20 个。则经过明确的分区分桶谓词下推,则可以将数据全表扫描量变为原来的 1/600(30 天*20 个桶 = 600),极大减少了数据的扫描范围、提高了查询的效率。
# 总结
整体来看,批量创建分区功能语法简洁有力,解决了用户针对大量历史数据分区创建的难题,既避免了手动创建大量分区的低效语法,又避免了动态分区大量参数的学习使用成本,且方式灵活多变、随意搭配组合各种类型的分区,大大提升了 Doris 在建表过程中的易用性。自动分桶推断功能智能高效,用户不需再关心分桶的细枝末节,系统自动帮助用户扩缩不同分区的分桶数,真正做到桶随业务变,降低学习成本的同时更是提升了查询效率。在与社区用户持续沟通中,我们也不断收获着许多新的需求,例如分区列为非时间列等,因此后续我们仍将继续完善对其他分区列的支持,例如数字分区列的批量创建等。最后,我们期待倾听更多用户的声音,在不断回馈用户以极简易用的使用体验的同时,也期待有更多人参与到 Apache Doris 的建设中来,欢迎你的加入!
本文引用
[1] https://zhuanlan.zhihu.com/p/587187198
作者介绍:
许瑞亮,SelectDB 存储研发工程师
胡得潮,SelectDB 生态研发工程师
李仕杨,SelectDB 生态研发工程师
相关文章:
一文教你玩转 Apache Doris 分区分桶新功能
数据分片(Sharding)是分布式数据库分而治之 (Divide And Conquer) 这一设计思想的体现。过去的单机数据库在大数据量下往往面临存储和 IO 的限制,而分布式数据库则通过数据划分的规则,将数据打散分布至不同的机器或节点上…...

Spring JdbcTemplate 和 事务
JdbcTemplate概述 JdbcTemplate是spring框架中提供的一个对象,是对原始繁琐的Jdbc API对象的简单封装。spring框架为我们提供了很多的操作模板类。例如:操作关系型数据的JdbcTemplate和,操作nosql数据库的RedisTemplate,操作消息…...
C/C++:程序环境和预处理/宏
程序的翻译环境和执行环境 在ANSI C的任何一种实现中,存在两个不同的环境。第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。第2种是执行环境,它用于实际执行代码。 编译和链接 一份源代码(比如test.c)需要通过编译…...

什么是死锁?死锁产生的四个必要条件是啥?如何避免和预防死锁的产生?
点个关注,必回关 文章目录什么是死锁死锁产生的原因:1、系统资源的竞争2、进程运行推进顺序不当引起死锁产生死锁的四个必要条件:死锁的避免与预防什么是死锁 死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此…...

工程管理系统源码-物料管理-工程项目管理系统-建筑施工管理软件
如今建筑行业竞争激烈,内卷严重,发展趋势呈现两极分化,中小微企业的生存空间被逐步压缩,利润逐年减少。事实证明,工地上粗放式的人管人管理模式已经落于时代,劳动力纠纷和物料浪费现象尤其普遍,…...
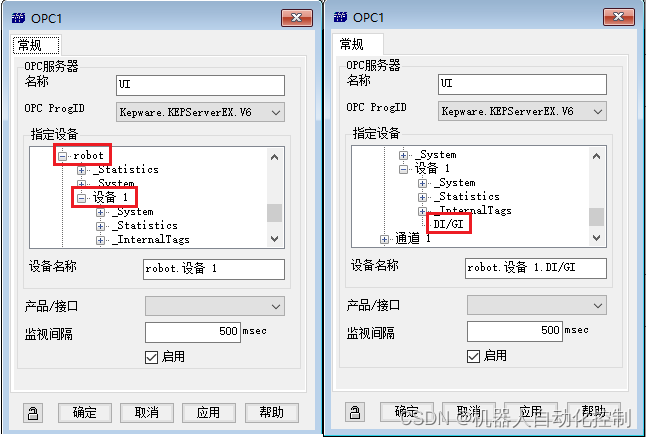
Roboguide与TIA V16通讯
软件需求:1. roboguide;2. TIA V16;3. KEPServer; 在之前的文章中介绍过KEPServer与TIA V16的通讯,此处不再介绍。接下来,介绍roboguide与KEPServer的仿真通讯。 创建一个roboguide项目。选择【外部设备】➡【添加外部设备】 选择【OPC Server】➡【OK】 OPC服务器名称命…...

利用PyTorch深度学习框架进行多元回归
目录前言数据加载数据转换模型定义模型训练模型评估模型保存与加载完整代码讨论参考文献前言 大多数数据科学家以往经常常是利用传统的机器学习框架sklearn搭建多元回归模型,随着深度学习和强化学习越来越普及,很多数据科学家尝试使用深度学习框架来进行…...

EBS常用接口开发
整理了一些工作中常用的Oracle EBS接口和API,最早是看着大神黄建华文档起来的,格式内容参考他的文档,加上一些自己开发的程序和经历而已。 PO PO接收、检验、入库、退货-InterfaceAPI_刘文钊1的博客-CSDN博客 基础数据 EBS物料、bom、工艺导入…...

【完整】UR机械臂逆运动学求解过程及c++代码实现
有任何问题请在评论区留言,我尽可能的回复大家 一. 逆运动学的求解需要以下数学运算 利用DH参数得到每个关节的变换矩阵;利用变换矩阵求出机械臂整个链的变换矩阵;求出末端位姿;利用已知末端位姿和整个链的变换矩阵,…...

68. Python的相对路径
68. Python的相对路径 文章目录68. Python的相对路径1. 知识回顾2. 什么是相对路径3. 相对路径的语法4. 查看相对路径的方法5. 写出所有txt文件的相对路径5.1 同目录5.2 上级目录6. 用相对路径读取txt文件6.1 读取旅游.txt6.2 读取旅游经费.txt6.3 读取笔记.txt和new.txt6.4 读…...
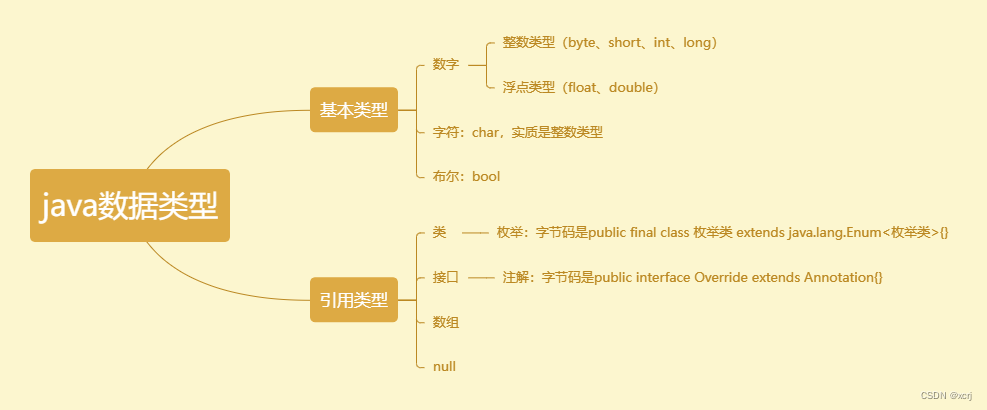
java数据类型
数据类型 类型分类,存储范围,字面量,默认值,类型转换 类型分类 存储范围 数据类型字节数表示范围byte1-128~127short2-32768~32767,正负3万左右int4-2147483648~2147483647,正负21亿左右long8-922337203…...

Kotlin 替换非空断言的几种方式
Kotlin 出现断言的两种情形 IDE java 与 kotlin 自动转换时,自动添加非空断言的代码Smart Cast 失效 代码展示: class JavaConvertExample {private var name: String? nullfun init() {name ""}fun foo() {name null;}fun test() {if (…...
2023年了,来试试前端格式化工具
在大前端时代,前端的各种工具链穷出不断,有eslint, prettier, husky, commitlint 等, 东西太多有的时候也是trouble😂😂😂,怎么正确的使用这个是每一个前端开发者都需要掌握的内容,请上车🚗&…...

spring cloud 企业工程项目管理系统源码+项目模块功能清单
工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和查看用户角色 4、菜单管理:实现对系统菜单的增删改查操…...

TCP分片解析
本文目录什么是IP分片为什么会产生IP分片为什么要避免IP分片如何避免IP分片什么是IP分片 IP协议栈将TCP/UDP传输层要求它发送的,但长度大于发送端口MTU的一个数据包,分割成多个IP报文后分多次发送。这些分成多次发送的多个IP报文就是IP分片。 为什么会…...
开发了一款基于 Flask 框架的在线电影网站系统(附 Python 源码)
文章目录前言项目介绍源码获取运行环境安装依赖库项目截图首页展示图视频展示页视频播放页后台管理页整体架构设计图项目目录结构图前台功能模块图后台功能模块图本地运行图前言 今天我给大家分享的是基于 Python 的 Flask 框架开发的在线电影网站系统,大家平时需要…...

如何获得CSM--敏捷教练证书
1、什么是CSM?CSM即Certified Scrum Master,Scrum Master负责确保所有人都能正确地理解并实施Scrum,确保Scrum团队遵循Scrum的理论、实践和规则。Scrum Master是Scrum团队中的服务型领导,帮助Scrum团队外的人员了解他们如何与Scrum团队交互是…...
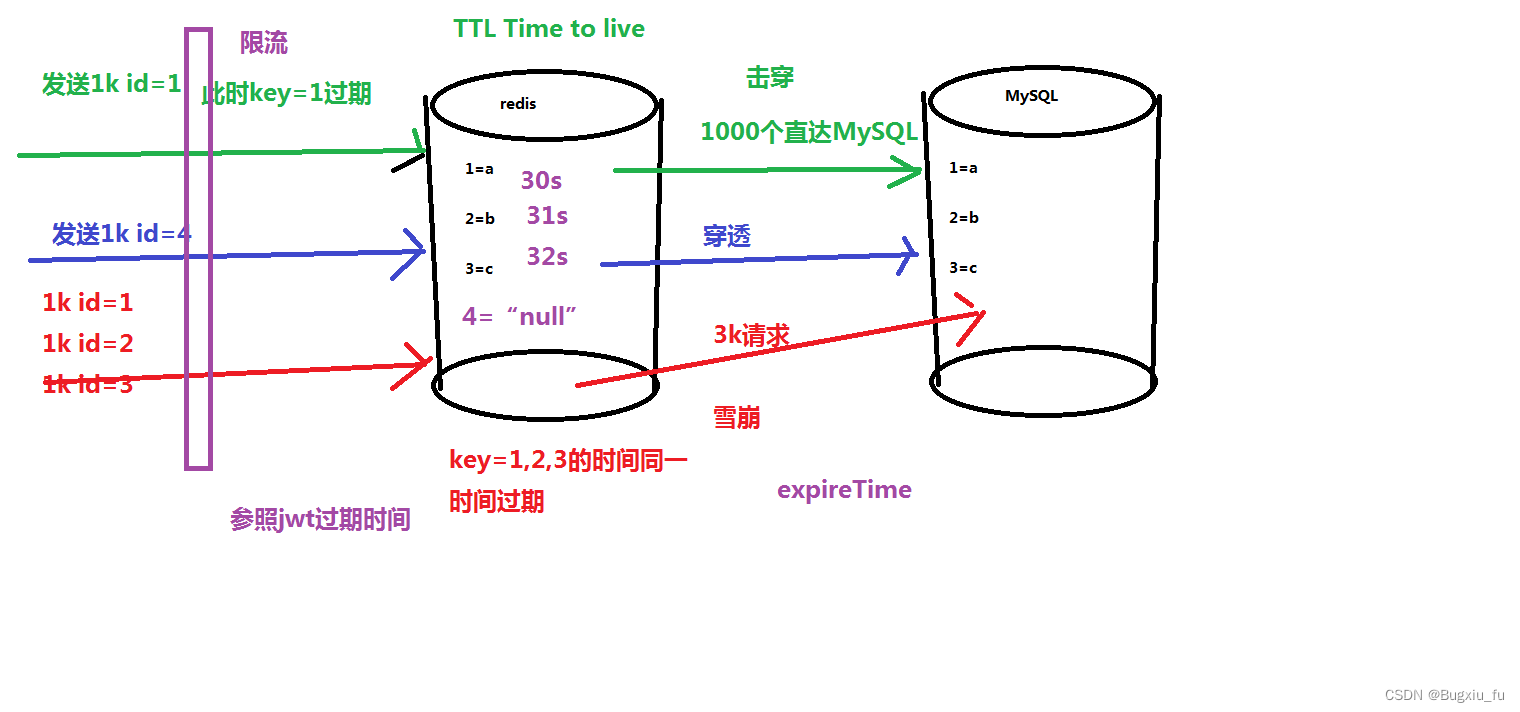
Java面试数据库
目录 一、关系型数据库 数据库权限 表设计及创建 表数据相关 数据库架构优化 二、非关系型数据库 redis 今天给大家稍微整理了一下,内容有数据表设计的三大范式原则、sql查询如何优化、redis数据的击穿、穿透、雪崩等...,以及相关的面试题࿰…...

关于进行vue-cli过程中的解决错误的问题
好久没发文章了,直到今天终于开始更新了,最近想进军全端,准备学习下vue,但是这东西真的太难了,我用了一天的时间来解决在配置中遇到的问题!主要问题:cnpm文件夹和vue-cli文件夹的位置不对并且vu…...

Rockchip Linux USB Gadget
一:概述 USB Gadget 是运行在 USB Peripheral 上配置 USB 功能的子系统,正常可被枚举的 USB 设备至少有 3 层逻辑层,有些功能还会在用户空间多跑一层逻辑代码。Gadget API 就是具体功能和硬件底层交互的中间层。从上到下,逻辑层分布为: USB Controller: USB上最底层的软…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...

es6+和css3新增的特性有哪些
一:ECMAScript 新特性(ES6) ES6 (2015) - 革命性更新 1,记住的方法,从一个方法里面用到了哪些技术 1,let /const块级作用域声明2,**默认参数**:函数参数可以设置默认值。3&#x…...