13、Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
简介
主页:https://github. com/microsoft/Swin-Transformer.
Swin Transformer 是 2021 ICCV最佳论文,屠榜了各大CV任务,性能优于DeiT、ViT和EfficientNet等主干网络,已经替代经典的CNN架构,成为了计算机视觉领域通用的backbone。
Swin Transformer 基于了ViT模型的思想,创新性的引入了滑动窗口机制,让模型能够学习到跨窗口的信息,同时也。同时通过下采样层,使得模型能够处理超分辨率的图片,节省计算量以及能够关注全局和局部的信息
ViT 开启了transformer在视觉领域的征途,但是transformer从自然语言领域应用到计算机视觉领域还有两大挑战:
- 视觉实体的方差较大,例如同一个物体,拍摄角度不同,转化为二进制后的图片就会具有很大的差异。同时在不同场景下视觉 Transformer 性能未必很好。
- 图像分辨率高,像素点多,如果采用ViT模型,自注意力的计算量会与像素的平方成正比。
针对上述两个问题,论文中提出了一种基于滑动窗口机制,具有层级设计(下采样层) 的 Swin Transformer。
其中滑窗操作包括不重叠的 local window,和重叠的 cross-window。将注意力计算限制在一个窗口(window size固定)中,一方面能引入 CNN 卷积操作的局部性,另一方面能大幅度节省计算量,它只和窗口数量成线性关系。
通过下采样的层级设计,能够逐渐增大感受野,从而使得注意力机制也能够注意到全局的特征
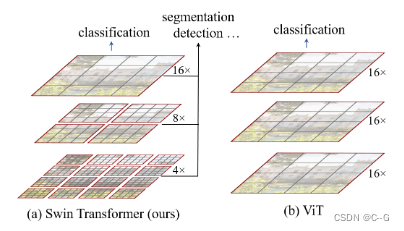
从上图可知,Swin Transformer 思想是实现 ViT 到类似卷积模式的转变,这样的结构模式能适用于各类视觉任务,真正成为视觉领域通用的backbone。
实现原理
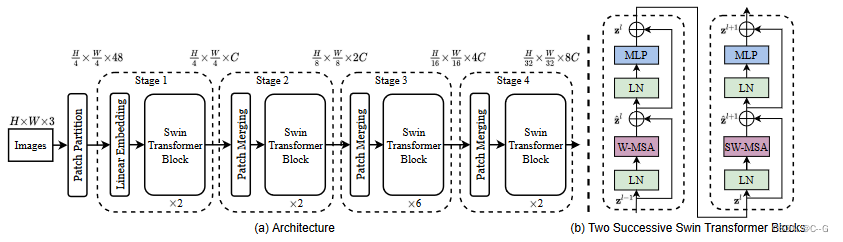
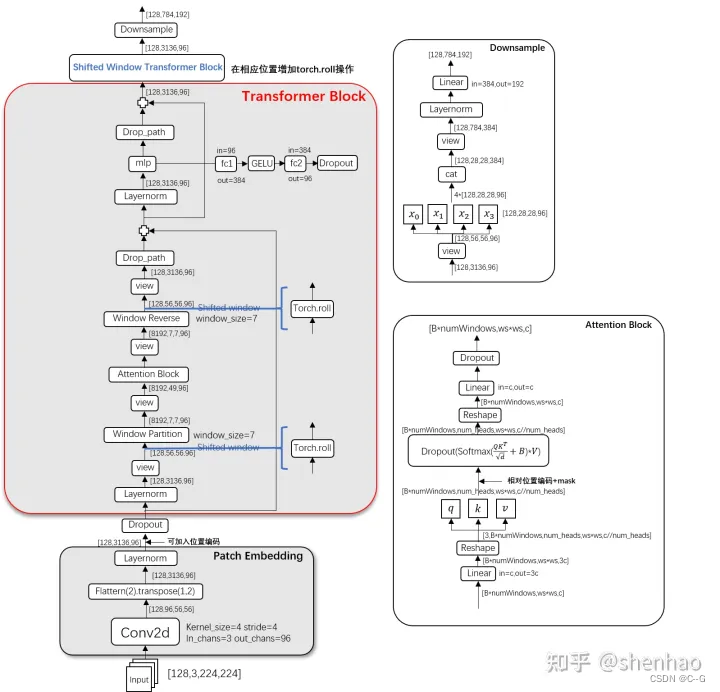
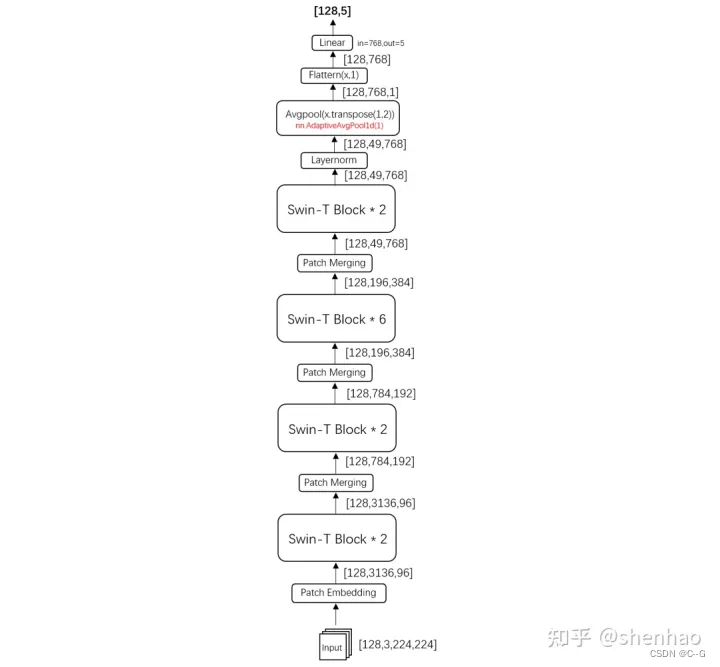
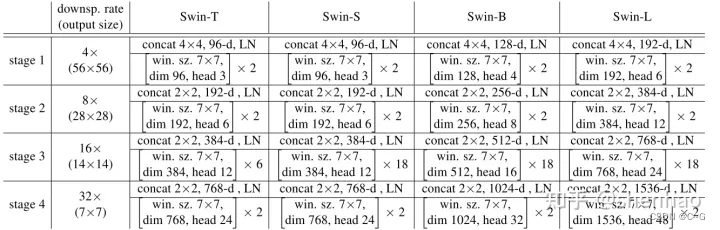
模型整体采取了层次化的设计
- 在输入开始的时候做了一个Patch Partition,即ViT中的Patch Embedding操作,通过Patch_size为4的卷积层将图片切成一个个Patch,并嵌入到Embedding,将embedding_size 转变为48(可以将 CV 中图片的通道数理解为NLP中token的词嵌入长度)
- 第一行Stage中通过Linear Embedding 调整通道数为 C
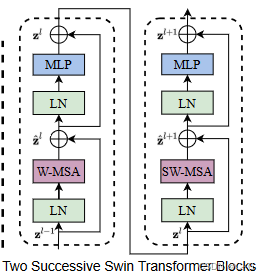
- 在后3个Stage均由Patch Merging 和 多个 Swin Transformer Block组成
- Patch Merging 模块主要在每个Stage一开始降低图片分辨率,进行下采样操作
- Swin Transformer Block如上图右边所示,主要是LayerNorm,Window Attention,Shifted Window Attention和MLP组成
Patch Merging 总是在两个Swin Transformer Block之间执行下采样,最后一个Stage不需要下采样操作,之间通过后续的全连接层与 target label 计算损失。
class SwinTransformer(nn.Module):r""" Swin TransformerA PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -https://arxiv.org/pdf/2103.14030Args:img_size (int | tuple(int)): Input image size. Default 224patch_size (int | tuple(int)): Patch size. Default: 4in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000embed_dim (int): Patch embedding dimension. Default: 96depths (tuple(int)): Depth of each Swin Transformer layer.num_heads (tuple(int)): Number of attention heads in different layers.window_size (int): Window size. Default: 7mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: Nonedrop_rate (float): Dropout rate. Default: 0attn_drop_rate (float): Attention dropout rate. Default: 0drop_path_rate (float): Stochastic depth rate. Default: 0.1norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.ape (bool): If True, add absolute position embedding to the patch embedding. Default: Falsepatch_norm (bool): If True, add normalization after patch embedding. Default: Trueuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: Falsefused_window_process (bool, optional): If True, use one kernel to fused window shift & window partition for acceleration, similar for the reversed part. Default: False"""def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,norm_layer=nn.LayerNorm, ape=False, patch_norm=True,use_checkpoint=False, fused_window_process=False, **kwargs):super().__init__()self.num_classes = num_classesself.num_layers = len(depths)self.embed_dim = embed_dimself.ape = apeself.patch_norm = patch_normself.num_features = int(embed_dim * 2 ** (self.num_layers - 1))self.mlp_ratio = mlp_ratio# split image into non-overlapping patchesself.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,norm_layer=norm_layer if self.patch_norm else None)num_patches = self.patch_embed.num_patchespatches_resolution = self.patch_embed.patches_resolutionself.patches_resolution = patches_resolution# absolute position embeddingif self.ape:self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))trunc_normal_(self.absolute_pos_embed, std=.02)self.pos_drop = nn.Dropout(p=drop_rate)# stochastic depthdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule# build layersself.layers = nn.ModuleList()for i_layer in range(self.num_layers):layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),input_resolution=(patches_resolution[0] // (2 ** i_layer),patches_resolution[1] // (2 ** i_layer)),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,mlp_ratio=self.mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,use_checkpoint=use_checkpoint,fused_window_process=fused_window_process)self.layers.append(layer)self.norm = norm_layer(self.num_features)self.avgpool = nn.AdaptiveAvgPool1d(1)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)def forward_features(self, x):x = self.patch_embed(x)if self.ape:x = x + self.absolute_pos_embedx = self.pos_drop(x)for layer in self.layers:x = layer(x)x = self.norm(x) # B L Cx = self.avgpool(x.transpose(1, 2)) # B C 1x = torch.flatten(x, 1)return xdef forward(self, x):x = self.forward_features(x)x = self.head(x)return xdef flops(self):flops = 0flops += self.patch_embed.flops()for i, layer in enumerate(self.layers):flops += layer.flops()flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)flops += self.num_features * self.num_classesreturn flops- ViT 在输入会给 embedding 进行位置编码。而 Swin-T 这里则是作为一个可选项(self.ape),Swin-T 是在计算 Attention 的时候做了一个相对位置编码,我认为这是这篇论文设计最巧妙的地方。
- ViT 会单独加上一个可学习参数,作为分类的 token。而 Swin-T 则是直接做平均(avgpool),输出分类,有点类似 CNN 最后的全局平均池化层。
Patch Embedding
在进入 Block 前,需要将图片切分成多个 patch,然后嵌入向量,具体做法是对原始图片裁成多个 window_size * window_size 的窗口大小,然后进行嵌入。即通过二维卷积层,设置 stride = kernel_size = window_size,设定输出通道来确定嵌入向量的大小。最后将 H,W 维度展开,并移动到第一维度。

class PatchEmbed(nn.Module):r""" Image to Patch EmbeddingArgs:img_size (int): Image size. Default: 224.patch_size (int): Patch token size. Default: 4.in_chans (int): Number of input image channels. Default: 3.embed_dim (int): Number of linear projection output channels. Default: 96.norm_layer (nn.Module, optional): Normalization layer. Default: None"""def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):super().__init__()img_size = to_2tuple(img_size)patch_size = to_2tuple(patch_size)patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]self.img_size = img_sizeself.patch_size = patch_sizeself.patches_resolution = patches_resolutionself.num_patches = patches_resolution[0] * patches_resolution[1]self.in_chans = in_chansself.embed_dim = embed_dimself.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)if norm_layer is not None:self.norm = norm_layer(embed_dim)else:self.norm = Nonedef forward(self, x):B, C, H, W = x.shape# FIXME look at relaxing size constraintsassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw Cif self.norm is not None:x = self.norm(x)return xdef flops(self):Ho, Wo = self.patches_resolutionflops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])if self.norm is not None:flops += Ho * Wo * self.embed_dimreturn flops
Patch Merging
在每个 Stage 开始前做降采样,用于缩小分辨率,调整通道数进而形成层次化的设计,同时也能节省一定运算量。
在 CNN 中,则是在每个 Stage 开始前用stride=2的卷积/池化层来降低分辨率。
每次降采样是两倍,因此在行方向和列方向上,间隔 2 选取元素。
然后拼接在一起作为一整个张量,最后展开。此时通道维度会变成原先的 4 倍(因为 H,W 各缩小 2 倍),此时再通过一个全连接层再调整通道维度为原来的两倍。

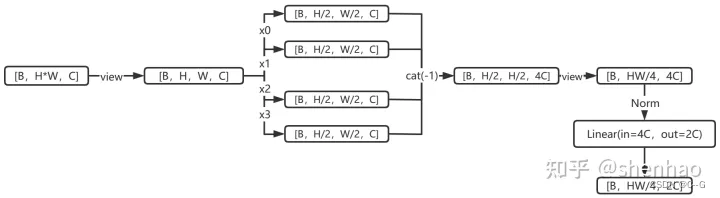
class PatchMerging(nn.Module):r""" Patch Merging Layer.Args:input_resolution (tuple[int]): Resolution of input feature.dim (int): Number of input channels.norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):super().__init__()self.input_resolution = input_resolutionself.dim = dimself.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)self.norm = norm_layer(4 * dim)def forward(self, x):"""x: B, H*W, C"""H, W = self.input_resolutionB, L, C = x.shapeassert L == H * W, "input feature has wrong size"assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."x = x.view(B, H, W, C)x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 Cx1 = x[:, 1::2, 0::2, :] # B H/2 W/2 Cx2 = x[:, 0::2, 1::2, :] # B H/2 W/2 Cx3 = x[:, 1::2, 1::2, :] # B H/2 W/2 Cx = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*Cx = x.view(B, -1, 4 * C) # B H/2*W/2 4*Cx = self.norm(x)x = self.reduction(x)return xdef extra_repr(self) -> str:return f"input_resolution={self.input_resolution}, dim={self.dim}"def flops(self):H, W = self.input_resolutionflops = H * W * self.dimflops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dimreturn flops
Window Partition/Reverse
window partition函数是用于对张量划分窗口,指定窗口大小。将原本的张量从 N H W C, 划分成 num_windowsB, window_size, window_size, C,其中 num_windows = HW / window_size*window_size,即窗口的个数。而window reverse函数则是对应的逆过程。这两个函数会在后面的Window Attention用到。
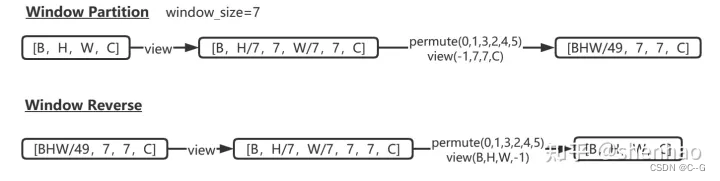
def window_partition(x, window_size):"""Args:x: (B, H, W, C)window_size (int): window sizeReturns:windows: (num_windows*B, window_size, window_size, C)"""B, H, W, C = x.shapex = x.view(B, H // window_size, window_size, W // window_size, window_size, C)windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size, H, W):"""Args:windows: (num_windows*B, window_size, window_size, C)window_size (int): Window sizeH (int): Height of imageW (int): Width of imageReturns:x: (B, H, W, C)"""B = int(windows.shape[0] / (H * W / window_size / window_size))x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return x
Window Attention
传统的 Transformer 都是基于全局来计算注意力的,因此计算复杂度十分高。而 Swin Transformer 则将注意力的计算限制在每个窗口内,进而减少了计算量。
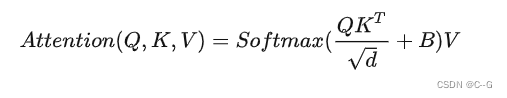
主要区别是在原始计算 Attention 的公式中的 Q,K 时加入了相对位置编码 B
class WindowAttention(nn.Module):r""" Window based multi-head self attention (W-MSA) module with relative position bias.It supports both of shifted and non-shifted window.Args:dim (int): Number of input channels.window_size (tuple[int]): The height and width of the window.num_heads (int): Number of attention heads.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if setattn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0proj_drop (float, optional): Dropout ratio of output. Default: 0.0"""def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # Wh, Wwself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5# define a parameter table of relative position biasself.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Wwcoords_flatten = torch.flatten(coords, 1) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Wwself.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)trunc_normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)
相关位置编码
Q,K,V.shape=[numWindwosB, num_heads, window_sizewindow_size, head_dim]
window_size*window_size 即 NLP 中token的个数
head_dim = Embeddingdimnumheads\frac{Embedding_dim}{num_heads}numheadsEmbeddingdim即 NLP 中token的词嵌入向量的维度
QKTQK^TQKT计算出来的Attention张量的形状为[numWindowsB, num_heads, Q_tokens, K_tokens],其中Q_tokens=K_tokens=window_sizewindow_size
以 window_size = 2 为例
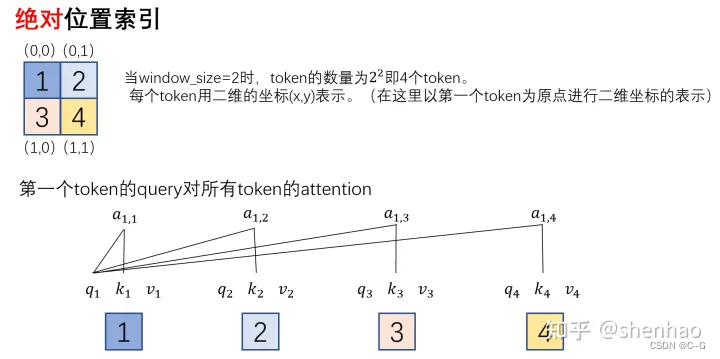
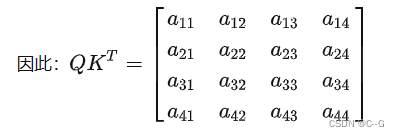
第 i 行表示第 i 个 token 的query对所有token的key的attention。
对于 Attention 张量来说,以不同元素为原点,其他元素的坐标也是不同的
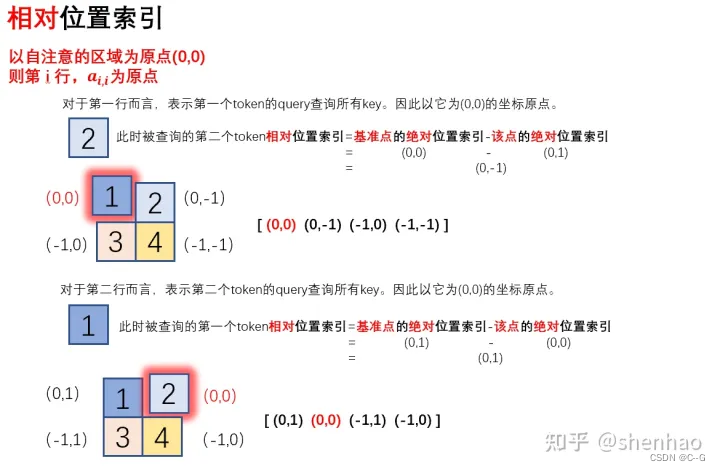
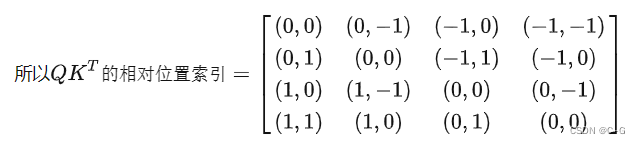
由于最终我们希望使用一维的位置坐标 x+y 代替二维的位置坐标(x,y),为了避免 (1,2) (2,1) 两个坐标转为一维时均为3,我们之后对相对位置索引进行了一些线性变换,使得能通过一维的位置坐标唯一映射到一个二维的位置坐标,详细可以通过代码部分进行理解。
利用torch.arange和torch.meshgrid函数生成对应的坐标
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2*(wh, ww)
"""(tensor([[0, 0],[1, 1]]), tensor([[0, 1],[0, 1]]))
"""
# 堆叠起来,展开为一个二维向量
coords = torch.stack(coords) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
"""
tensor([[0, 0, 1, 1],[0, 1, 0, 1]])
"""# 利用广播机制,分别在第一维,第二维,插入一个维度,进行广播相减,得到 2, wh*ww, wh*ww的张量
relative_coords_first = coords_flatten[:, :, None] # 2, wh*ww, 1
relative_coords_second = coords_flatten[:, None, :] # 2, 1, wh*ww
relative_coords = relative_coords_first - relative_coords_second # 最终得到 2, wh*ww, wh*ww 形状的张量
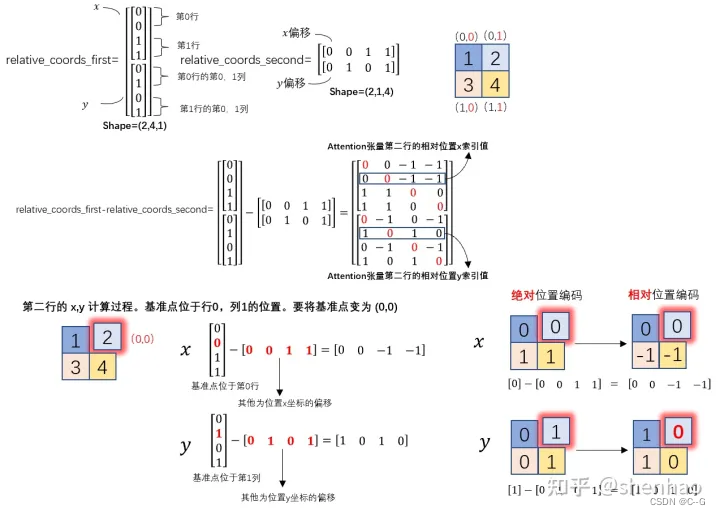
因为采取的是相减,所以得到的索引是从负数开始的,加上偏移量,让其从 0 开始。
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
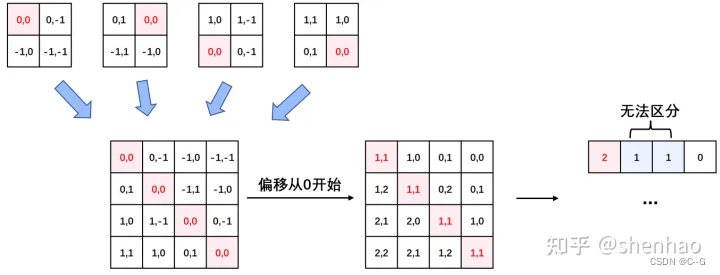
需要将其展开成一维偏移量。而对于 (1,2)和(2,1)这两个坐标。在二维上是不同的,但是通过将 x,y 坐标相加转换为一维偏移的时候,他的偏移量是相等的。
对其中做了个乘法操作,以进行区分
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1

然后再最后一维上进行求和,展开成一个一维坐标,并注册为一个不参与网络学习的变量
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
之前计算的是相对位置索引,并不是相对位置偏置参数。真正使用到的可训练参数β^\hat{\beta}β^是保存在 relative position bias table 表里的,这个表的长度是等于 (2M−1) × (2M−1) (在二维位置坐标中线性变化乘以2M-1导致)的。那么上述公式中的相对位置偏执参数 B是根据上面的相对位置索引表根据查relative position bias table表得到的。
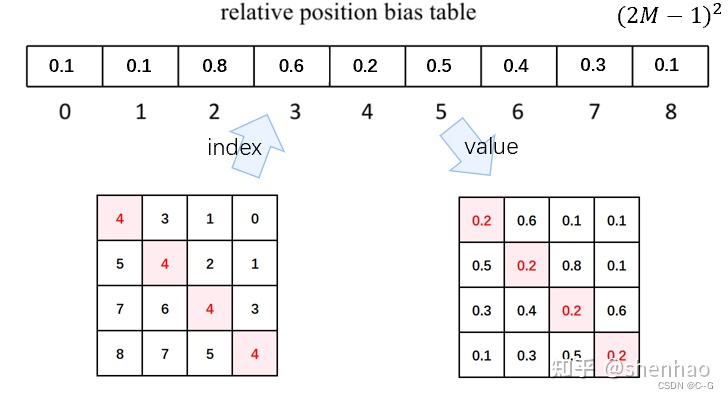
接着Window Attention代码
def forward(self, x, mask=None):"""Args:x: input features with shape of (num_windows*B, N, C)mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None"""B_, N, C = x.shapeqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)q = q * self.scaleattn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return xdef extra_repr(self) -> str:return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'def flops(self, N):# calculate flops for 1 window with token length of Nflops = 0# qkv = self.qkv(x)flops += N * self.dim * 3 * self.dim# attn = (q @ k.transpose(-2, -1))flops += self.num_heads * N * (self.dim // self.num_heads) * N# x = (attn @ v)flops += self.num_heads * N * N * (self.dim // self.num_heads)# x = self.proj(x)flops += N * self.dim * self.dimreturn flops- 首先输入张量形状为 [numWindows*B, window_size * window_size, C]
- 然后经过self.qkv这个全连接层后,进行 reshape,调整轴的顺序,得到形状为[3, numWindowsB, num_heads, window_sizewindow_size, c//num_heads],并分配给q,k,v
- 根据公式,我们对q乘以一个scale缩放系数,然后与k(为了满足矩阵乘要求,需要将最后两个维度调换)进行相乘。得到形状为[numWindowsB,num_heads, window_sizewindow_size, window_size*window_size]的attn张量
- 之前我们针对位置编码设置了个形状为(2window_size-12window_size-1,numHeads)的可学习变量。我们用计算得到的相对编码位置索引self.relative_position_index.vew(-1)选取,得到形状为(window_sizewindow_size,window_size*window_size, numHeads)的编码,再permute(2,0,1)后加到attn张量上
- 暂不考虑 mask 的情况,剩下就是跟 transformer 一样的 softmax,dropout,与V矩阵乘,再经过一层全连接层和dropout
Shifted Window Attention
Window Attention 是在每个窗口下计算注意力的,为了更好的和其他 window 进行信息交互,Swin Transformer 还引入了 shifted window 操作。
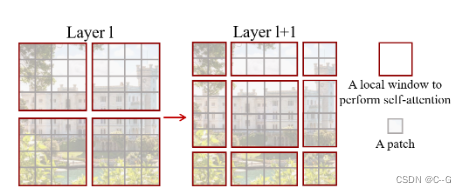
左边是没有重叠的 Window Attention,而右边则是将窗口进行移位的 Shift Window Attention。可以看到移位后的窗口包含了原本相邻窗口的元素。但这也引入了一个新问题,即 window 的个数翻倍了,由原本四个窗口变成了 9 个窗口。
在实际代码里,我们是通过对特征图移位,并给 Attention 设置 mask 来间接实现的。能在保持原有的 window 个数下,最后的计算结果等价。
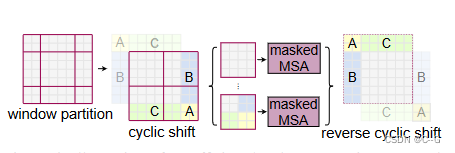
Shifted Window step
代码里对特征图移位是通过 torch.roll 来实现的
torch.roll(input, shifts, dims=None) → Tensor
shifts的值为正数相当于向下挤牙膏,挤出的牙膏又从顶部塞回牙膏里面;shifts的值为负数相当于向上挤牙膏,挤出的牙膏又从底部塞回牙膏里面
以 4x4 矩阵 a 为例
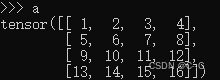
a 矩阵中的 ( 1 )代表 A 区域,( 2,3,4 ) 代表 C 区域,( 5,9,13 )代表 B区域,首先将第一行挤到最后一行,如下图矩阵 b
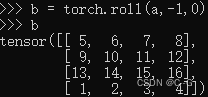
然后再将第一列挤到最后一列,如下图矩阵 b
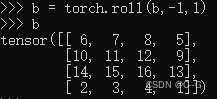
如果需要reverse cyclic shift的话只需把参数shifts设置为对应的正数值
Attention Mask
通过 roll 操作,我们确实把9块归为了4块,但是 cyclic shift 中,A 从左上角 移动到了 右下角,显然,直接对 cyclic shift 4块进行计算会破坏原有的语义信息,为此,这里使用了 mask 操作。
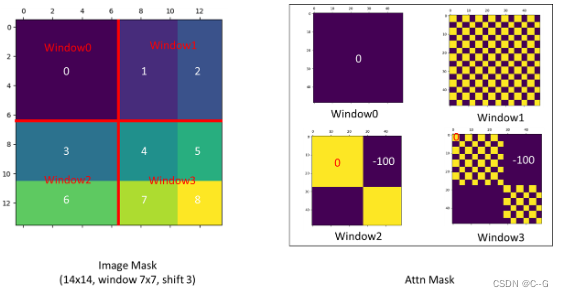
上图展示 cyclic shift 后 特征图,拿到 window后,执行 QKTQK^TQKT ,就是将Q KTK^TKT 分别展平然后对应元素相乘,根据这一过程,可以得到如上图所示不同 Windows 的 Mask,-100的紫色区域表示遮掩,紫色部分是不同块的运算结果,应该丢弃
具体代码在 SwinTransformerBlock中
if self.shift_size > 0:# calculate attention mask for SW-MSAH, W = self.input_resolutionimg_mask = torch.zeros((1, H, W, 1)) # 1 H W 1h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1mask_windows = mask_windows.view(-1, self.window_size * self.window_size)attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))else:attn_mask = None
从上图代码中,可以得到如下的Mask
tensor([[[[[ 0., 0., 0., 0.],[ 0., 0., 0., 0.],[ 0., 0., 0., 0.],[ 0., 0., 0., 0.]]],[[[ 0., -100., 0., -100.],[-100., 0., -100., 0.],[ 0., -100., 0., -100.],[-100., 0., -100., 0.]]],[[[ 0., 0., -100., -100.],[ 0., 0., -100., -100.],[-100., -100., 0., 0.],[-100., -100., 0., 0.]]],[[[ 0., -100., -100., -100.],[-100., 0., -100., -100.],[-100., -100., 0., -100.],[-100., -100., -100., 0.]]]]])
在上面的 window attention 模块的前向代码中,使用mask掩膜
if mask is not None:nW = mask.shape[0] # 一张图被分为多少个windows eg:[4,49,49]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0) # torch.Size([128, 4, 12, 49, 49]) torch.Size([1, 4, 1, 49, 49])attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)
else:attn = self.softmax(attn)
将 mask 加到 attention 的计算结果,并进行 softmax。mask 的值设置为 - 100,softmax 后就会忽略掉对应的值。
W-MSA和MSA的复杂度对比
在原论文中,作者提出的基于滑动窗口操作的 W-MSA 能大幅度减少计算量。那么两者的计算量和算法复杂度大概是如何的呢,论文中给出了一下两个公式进行对比。
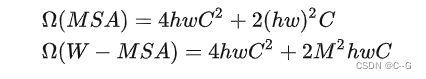
- h:feature map的高度
- w:feature map的宽度
- C:feature map的通道数(也可以称为embedding size的大小)
- M:window_size的大小
MSA模块的计算量
首先对于feature map中每一个token(一共有 h w 个token,通道数为C),记作Xhw×CX^{hw\times C}Xhw×C,需要通过三次线性变换 Vq,Wk,WvV_q,W_k,W_vVq,Wk,Wv ,产生对应的q,k,v向量,记作 Qhw×C,Khw×C,Vhw×CQ^{hw \times C},K^{hw \times C},V^{hw \times C}Qhw×C,Khw×C,Vhw×C(通道数为C)。
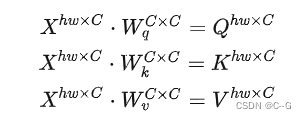
根据矩阵运算的计算量公式可以得到运算量为 3hwC23hwC^23hwC2
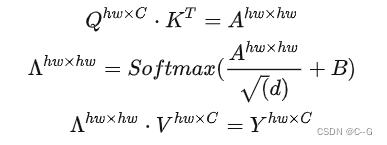
忽略除以 d\sqrt{d}d 以及softmax的计算量,根据根据矩阵运算的计算量公式可得 hwC×hw+hw2×ChwC \times hw + hw^2 \times ChwC×hw+hw2×C,即2(hw2)C2(hw^2)C2(hw2)C

最终再通过一个Linear层输出,计算量为 hwC2hwC^2hwC2。因此整体的计算量为 4hwC2+2(hw)2C4hwC^2+2(hw)^2C4hwC2+2(hw)2C
W-MSA模块的计算量
对于W-MSA模块,首先会将feature map根据window_size分成 hwM2\frac{hw}{M^2}M2hw的窗口,每个窗口的宽高均为 M,然后在每个窗口进行MSA的运算。因此,可以利用上面MSA的计算量公式,将 h = M, w = M 带入,可以得到一个窗口的计算量为 4M2C2+2M4C4M^2C^2 + 2M^4C4M2C2+2M4C,又因为有 hwM2\frac{hw}{M^2}M2hw个窗口
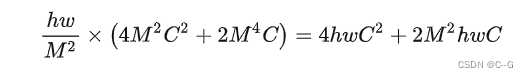
整体流程
文章来源:https://zhuanlan.zhihu.com/p/430047908
相关文章:
13、Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
简介 主页:https://github. com/microsoft/Swin-Transformer. Swin Transformer 是 2021 ICCV最佳论文,屠榜了各大CV任务,性能优于DeiT、ViT和EfficientNet等主干网络,已经替代经典的CNN架构,成为了计算机视觉领域通用…...

C++基础入门丨8. 结构体——还需要知道这些
Author:AXYZdong 硕士在读 工科男 有一点思考,有一点想法,有一点理性! 定个小小目标,努力成为习惯!在最美的年华遇见更好的自己! CSDNAXYZdong,CSDN首发,AXYZdong原创 唯…...
算法第十六期——动态规划(DP)之线性DP
【概述】 线性动态规划,是较常见的一类动态规划问题,其是在线性结构上进行状态转移,这类问题不像背包问题、区间DP等有固定的模板。 线性动态规划的目标函数为特定变量的线性函数,约束是这些变量的线性不等式或等式,目…...
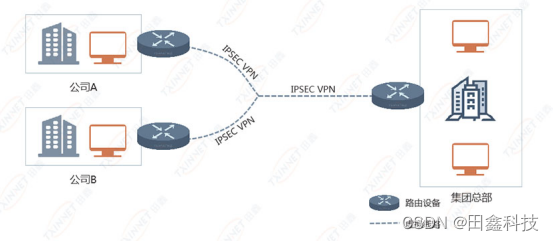
智慧新零售网络解决方案,助力新零售企业数智化转型
随着数字化时代的不断发展,新零售连锁业务模式“线上线下”融合发展,数据、设备在逐渐增加,门店数量也会随着企业规模的扩大而增加,但由于传统网络架构不稳定、延时、容量小影响服务质量(QoS)、分支设备数量…...

Go语言规范中的可赋值
了解可赋值规范的重要性当使用type关键字定义类型的时候,会遇到一些问题,如下:func main(){var i int 2pushInt(i) } type MyInt int //基于int定义MyInt func pushInt(i MyInt){}结果:调用函数pushInt报错 cannot use i (variab…...

外盘国际期货招商:原油市场热点话题
原油市场热点话题 问:目前美国原油库存如何? 答:EIA原油库存数据显示,由于美国炼油厂季节性检修,开工率继续下降,原油库存连续九周增长至2021年5月份以来最高水平,同期美国汽油库存减少而精炼…...
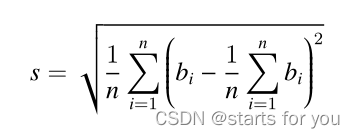
[蓝桥杯 2018 省 A] 付账问题 贪心题
几个人一起出去吃饭是常有的事。但在结帐的时候,常常会出现一些争执。现在有 n 个人出去吃饭,他们总共消费了 S 元。其中第 i 个人带了 ai 元。幸运的是,所有人带的钱的总数是足够付账的,但现在问题来了:每个人分别要出…...
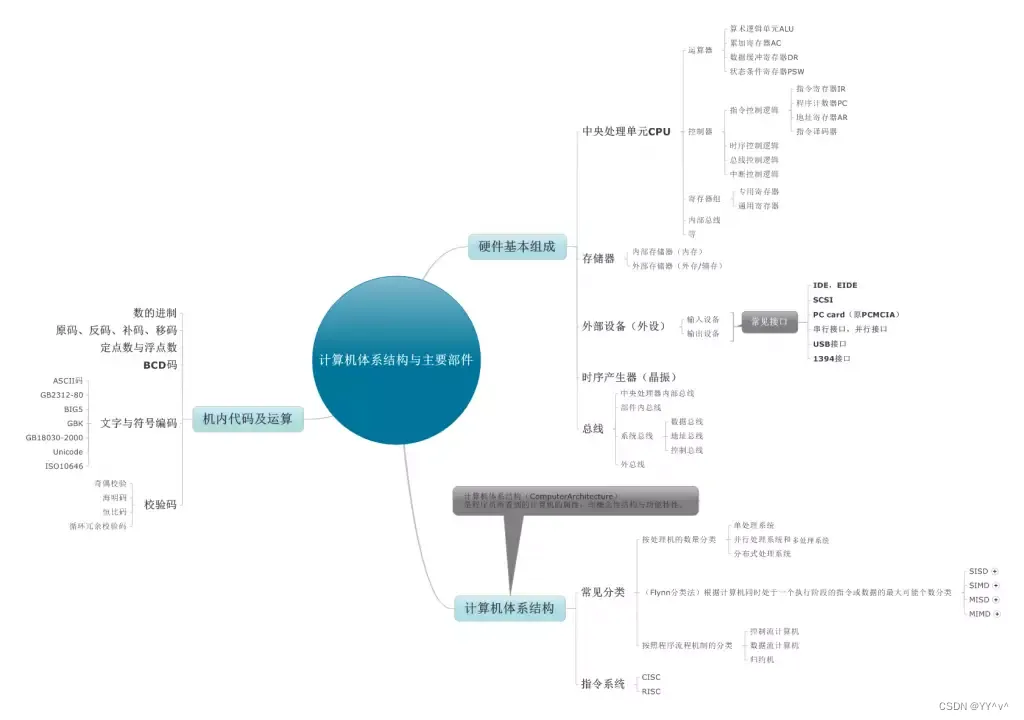
微机原理复习(周五),计算机组成原理图
1.计算机由运算器,控制器,存储器,输入设备,输出设备等5大基本部件组成。 2.冯诺依曼提出存储设计思想是:数字计算机的数制采用二进制,存储程序,程序控制。 3.计算机的基本组成框图:…...

用了10年Postman,意想不到它的Mock功能也如此强大
最近在做一些app,前后端分离的开发模式是必须的。一直用的python flask做后端的快速POC,python本身就是一门胶水语言,开发起来方便快捷,而flask又是一个极简的webserver框架(比Django简洁)。但在这里推荐的…...

项目重构,从零开始搭建一套新的后台管理系统
背景 应公司发展需求,我决定重构公司的后台管理系统,从提出需求建议到现在的实施,期间花了将近半个月的时间,决定把这些都记录下来。 之前的后台管理系统实在是为了实现功能而实现的,没有考虑到后期的扩展性…...

day20_Map
今日内容 上课同步视频:CuteN饕餮的个人空间_哔哩哔哩_bilibili 同步笔记沐沐霸的博客_CSDN博客-Java2301 零、 复习昨日 一、作业 二、比较器排序 三、Collections 四、Map 五、HashMap 六、TreeMap 零、 复习昨日 HashSet 不允许重复元素,无序 HashSet去重原理: 先比较hashco…...
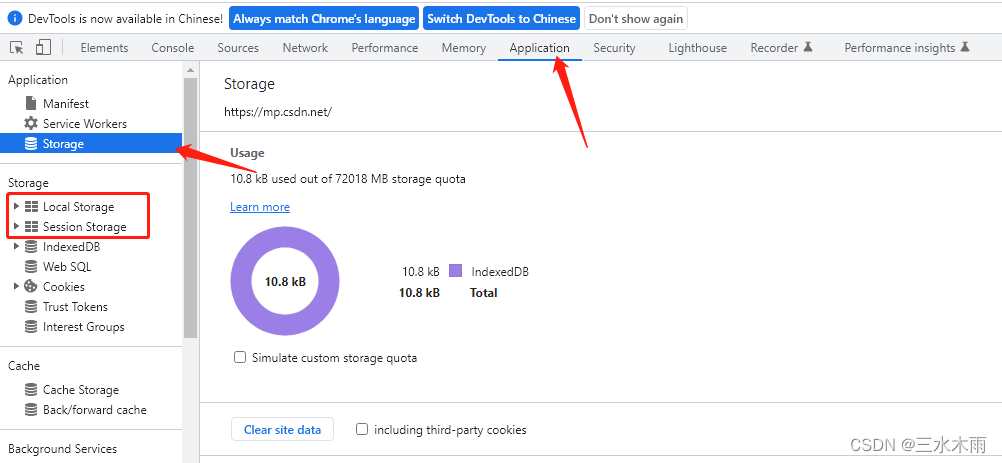
localStorage和sessionStorage
目录 一、localStorage和SessionStorage在哪里,是什么 二、localStorage和sessionStorage区别 三、localStorage常用方法 四、sessionStorage常用方法 一、localStorage和SessionStorage在哪里,是什么 【1】在浏览器开发者工具的Application栏目里&…...
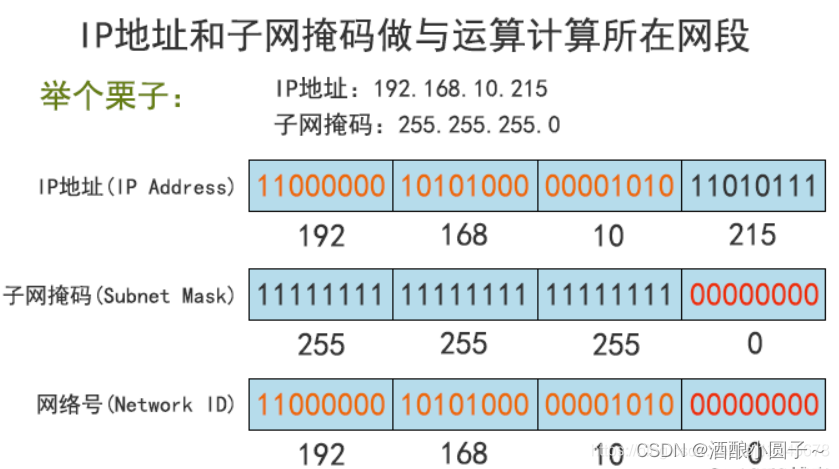
IP地址,子网掩码,网段 概念详解
文章目录1. 子网掩码1.1 子网掩码的概念及作用1.2 子网掩码的组成1.3 子网掩码的表示方法1.4 为什么要使用子网掩码?1.5 子网掩码的分类2. 子网掩码和IP地址的关系2.1 根据掩码确定网段IP地址是以 网络号和 主机号来标示网络上的主机的,我们把网络号相同…...

数影周报:动视暴雪疑似数据泄露,数据出境安全评估申报最新进展
本周看点:动视暴雪疑似员工敏感信息及游戏数据泄露;谷歌云计算部门:两名员工合用一个工位;数据出境安全评估申报最新进展;TikTok Shop东南亚商城在泰国和菲律宾公布;智己汽车获九大金融机构50亿元贷款签约.…...

Web安全最详细学习路线指南,从入门到入职(含书籍、工具包)
在这个圈子技术门类中,工作岗位主要有以下三个方向: 安全研发 安全研究:二进制方向 安全研究:网络渗透方向 下面逐一说明一下. 第一个方向:安全研发 你可以把网络安全理解成电商行业、教育行业等其他行业一样&#x…...

ChatGPT?听说Biying把它下架了
ChatGPT被玩疯了,开始放飞自我 ChatGPT版微软必应上线不到10天…就被网友玩坏了 先说这个词,放飞自我,什么东西才会放飞自我? 人放飞自我,人?你确定是人? 所以让我们来把上面的句子改写一下。…...
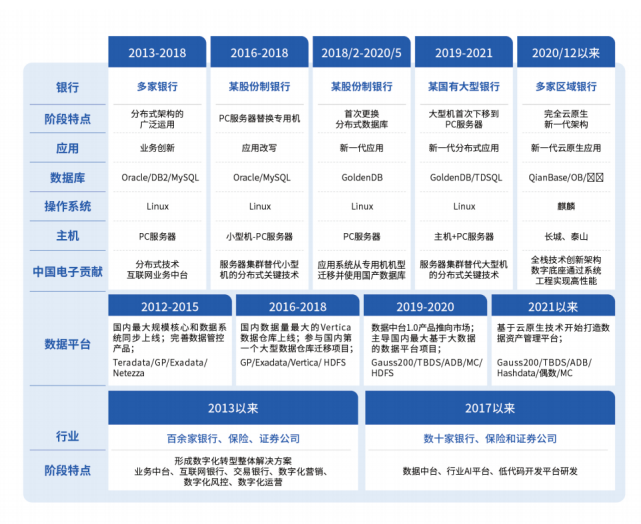
中电金信:金融数字化转型路在何方?这里有答案
近期,媒体大数网整合了业内10份研究报告,详解金融数字化转型的思路、方法与路径。其中「中国电子金融级数字底座“源启”白皮书」也被收录其中。让我们一同阅读文章,探究金融数字化转型相关问题的答案吧。 当前,金融科技正在回归…...

【Leedcode】数据结构中链表必备的面试题(第五期)
【Leedcode】数据结构中链表必备的面试题(第五期) 文章目录【Leedcode】数据结构中链表必备的面试题(第五期)1.题目2.思路图解(1)第一步:复制每一个结点,插入到原结点和下一个结点之…...

ECDH secp256k1 集成
在Android 原生api是不支持secp256k1算法的,所以要先集成以下库:implementation com.madgag.spongycastle:core:1.58.0.0compile com.madgag.spongycastle:prov:1.54.0.0compile com.madgag.spongycastle:pkix:1.54.0.0compile com.madgag.spongycastle:…...
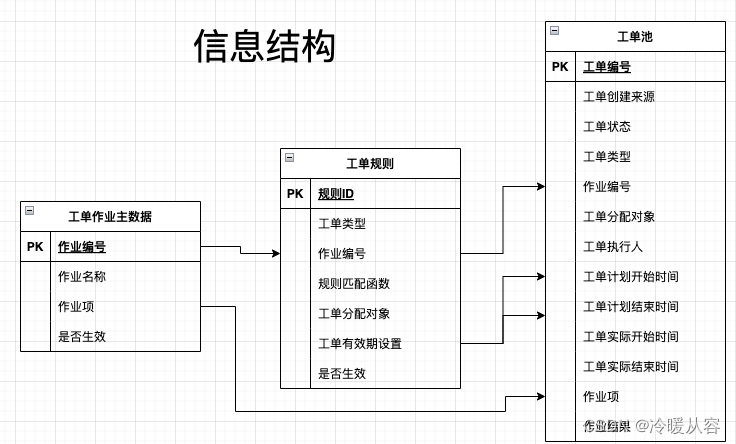
工单模型的理解与应用
工单(任务单)模型的定义 工单模型是一种分派任务的方法,可以用来跟踪、评估和报告任务的完成情况。它通常用于针对特定目标的重复性任务或项目,以确保任务能够按时完成并符合期望的标准。 工单模型的基本流程为:提…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...