Text to image论文精读ALR-GAN:文本到图像合成的自适应布局优化
ALR-GAN是北京工业大学学者提出的一种自适应布局优化生成对抗网络,其可以在没有任何辅助信息的情况下自适应地优化合成图像的布局。
文章发表于2023年,IEEE Transactions on Multimedia(TMM)期刊(CCF B,JCR1区),是一篇值得一读的文章。
文章链接:https://ieeexplore.ieee.org/document/10023990
一、原文摘要
文章提出了一种新的文本到图像生成网络——自适应布局优化生成对抗网络(ALR-GAN),其能够在没有任何辅助信息的情况下自适应地优化合成图像的布局。ALR-GAN包括一个自适应布局优化(ALR)模块和一个布局视觉优化(LVR)丢失。ALR模块将合成图像的布局结构(指物体和背景的位置)与相应的真实图像对齐。在ALR模块中,我们提出了一种自适应布局优化(Adaptive Layout refine, ALR)损失来平衡难特征和易特征的匹配,以实现更高效的布局结构匹配。LVR损失在细化布局结构的基础上,进一步细化布局区域内的视觉表示。在两个广泛使用的数据集上的实验结果表明,ALR-GAN在文本到图像生成任务中具有竞争力。
二、为什么提出ALR-GAN?
文本到图像生成(T2I)旨在从文本描述中合成逼真的图像。为了实现这一具有挑战性的跨模态生成任务,研究者们主要通过:①促进高分辨率图像合成;②细化图像细节;③增强图像语义这些方面来进行改进。
但它们往往专注于单一物体的合成,如鸟、花或狗。对于复杂的图像合成任务,合成的对象很容易被放置在图像的各种不合理的位置上,即布局结构很容易混乱。
在之前的一些工作中,一些方法使用辅助信息如:对象边框object bounding box, 对象形状object shape, 和场景图scene graph来辅助生成,但是①这种辅助信息的获取一般价格昂贵,不利于任务的推广应用;②这些方法通常忽略了布局区域内的视觉质量。
ALR-GAN的目标就是在没有辅助信息的情况下改进合成图像的布局。
ALR-GAN提出了一种自适应布局优化生成对抗网络来改善合成图像的布局,包括一个自适应布局优化(ALR)模块和布局视觉优化(LVR)损失。ALR模块和提出的自适应布局细化(ALR)损失的作用是自适应地将合成图像的布局结构与其对应的真实图像的视觉表示对齐。
三、ALR-GAN模型
3.1、模型框架

上图显示了所提出的ALR- GAN的架构,可以看到其是一种类似StackGAN++、AttnGAN、MirrorGAN、DM-GAN的多阶段模型,由文本编码器、三个生成器和三个鉴别器组成,另外框架还包含几个新组件:初始特征转换模块(IFTM)、自适应布局优化(ALR)模块、布局视觉优化(LVR)损耗。
ALR模块配备了所提出的自适应布局细化(LVR)损失以自适应地细化合成图像的布局结构,辅助其对应的真实图像。
LVR损失旨在增强布局区域内的纹理感知和风格信息。
主要流程:文本编码器将输入的文本描述(单个句子)转换为句子特征s0和单词特征W,IFTM将文本嵌入s和噪声z∼N(0,1)转换为图像特征H0,ALR模块在训练过程中对生成器合成图像的布局结构进行自适应细化(后两层次),三个鉴别器对三个阶段的生成器分别鉴别优化,帮助生成器更好的训练。
3.2、自适应布局优化(ALR)模块

可以看到ALR模块包括一个语义相似矩阵(semantic Similarity Matrix, SSM)和一个文本视觉矩阵(Text-vision Matrix ,TVM)
1️⃣、布局结构构建
SSM语义相似矩阵θ\thetaθ(semantic Similarity Matrix) SSM矩阵用于计算单词W和图像子区域Hi−1H_{i−1}Hi−1之间的语义匹配,计算方法与AttnGAN大致相同:θk,j=exp(Sk,j′)∑k=1Texp(Sk,j′),Sk,j′=(hi−1k)Twj\theta_{k, j}=\frac{\exp \left(S_{k, j}^{\prime}\right)}{\sum_{k=1}^{T} \exp \left(S_{k, j}^{\prime}\right)}, \quad S_{k,j}^{\prime}=\left(h_{i-1}^{k}\right)^{T} w_{j}θk,j=∑k=1Texp(Sk,j′)exp(Sk,j′),Sk,j′=(hi−1k)Twj,其中θk,jθ_{k,j}θk,j为第j个单词wiw_iwi与第k个图像子区域hi−1kh^k_{i−1}hi−1k之间的语义相似度权值。
由于生成器对文本语义的理解不正确或不充分,合成图像的布局结构往往是混乱的。因此,我们希望合成图像的θ\thetaθ与真实图像的θ∗\theta*θ∗对齐。

通俗来讲,要保证合成图像的θ\thetaθ与真实图像的θ\thetaθ对齐,即要使合成图像SSM语义相似矩阵与真实图像的SSM语义相似矩阵一致,作者引入了真实图像的重建,如图所示:Ii∗I_i^*Ii∗为真实图像,首先设计一个Encoder(包含一系列卷积块)提取图像特征Hi∗H_i^*Hi∗,为了保证这个提取过程能够保证质量,作者将生成器设置为Decoder,并引入重构损失:LiREC=∥Ii∗−Ii∗∗∥1\mathcal{L}_{i}^{R E C}=\left\|I_{i}^{*}-I_{i}^{**}\right\|_{1}LiREC=∥Ii∗−Ii∗∗∥1
2️⃣、自适应布局优化(ALR)损失
θ\thetaθ和θ∗\theta^*θ∗中的一些元素很容易匹配,而有些则很难匹配。硬区域是导致布局优化过程中的主要问题。因此,在训练过程中,模型应该更加注意硬区域的匹配。作者提出了自适应布局优化(ALR)损失来解决这个问题。它的构造有四个步骤:
- 计算绝对残差张量:R =Abs.(Θ∗ − Θ)
- 将R中的元素分为硬元素和软元素。我们设定一个阈值γ,ri,j < γ易于匹配则为软元素,元素ri,j≥γ难以匹配则为硬元素。
- 设计了一种自适应的特征级权重自适应机制,以调整Θ和Θ *中软和硬匹配元素的损失权重。自适应权重自适应机制的构建分为4个步骤(如3a~3d所示)
3a.保持小于γ的软元素,其余的设为0,记为R‘easyR^`easyR‘easy
3b.R‘easyR^`easyR‘easy通过填充零,映射到与H *相同的潜空间,称为ReasyR_{easy}Reasy,以便后续与H *进行运算
3c.将ReasyR_{easy}Reasy与H∗ 做矩阵元素相乘(哈达玛乘积)得到:Reasy ⊙H∗R_{\text {easy }} \odot H^{*}Reasy ⊙H∗
3d.然后将其做一系列卷积和激活操作φα(·),得到α=ϕα(Reasy ⊙H∗)\alpha=\phi_{\alpha}\left(R_{\text {easy }} \odot H^{*}\right)α=ϕα(Reasy ⊙H∗),硬元素采用类似的的方法得到β=ϕβ(Rhard ⊙H∗)\beta=\phi_{\beta}\left(R_{\text {hard }} \odot H^{*}\right)β=ϕβ(Rhard ⊙H∗)- 在培训过程中,更应该把重点放在最难的部分,因此,权重β应大于α。为此,我们在LALR中设计了softplus(max(α)−min(β))的正则化项来满足它。这里,y = softplus(x) = ln(1 + ex)是一个单调递增函数,通过避免负损失值来帮助数值优化。
根据步骤1-4,ALR损失定义为:LiALR=1N⋅D(∥αi⊙Reasy i∥F+∥βi⊙Rhard i∥F+∥softplus(max(αi)−min(βi))∥F)\begin{array}{l} L_{i}^{A L R}=\frac{1}{N \cdot D}\left(\left\|\alpha_{i} \odot R_{\text {easy }_{i}}\right\|_{F}+\left\|\beta_{i} \odot R_{\text {hard }_{i}}\right\|_{F}\right. \left.+\left\|\operatorname{softplus}\left(\max \left(\alpha_{i}\right)-\min \left(\beta_{i}\right)\right)\right\|_{F}\right) \end{array}LiALR=N⋅D1(αi⊙Reasy iF+∥βi⊙Rhard i∥F+∥softplus(max(αi)−min(βi))∥F)
其中,下标F代表矩阵的F-范数
3️⃣、构建文本视觉矩阵(TVM)
基于修正后的SSM语义相似矩阵,对于第K个图像子区域,词动态表示为:hi−1k,qi−1k=∑j=1Tθj,kwjh_{i-1}^{k} \text ,q_{i-1}^{k}=\sum_{j=1}^{T} \theta_{j, k} w_{j}hi−1k,qi−1k=∑j=1Tθj,kwj,因此,用于词嵌入W和图像特征Hi−1的文本-视觉矩阵(TVM)表示为Qi−1Q_{i−1}Qi−1
最后将文本视觉矩阵TVM的矩阵Qi−1Q_{i−1}Qi−1与图像特征Hi−1H_{i−1}Hi−1进行拼接,送入ResBlocks和Upsampling模块输出图像特征HiH_iHi
3.3、布局视觉细化(LVR)损失
在精细化布局结构的基础上,进一步增强布局区域内的视觉表现力。为此,我们提出了布局视觉细化(LVR)损失来增强布局中的纹理感知和风格信息。
LVR损失包括感知细化(PR)损失和风格细化(SR)损失。
感知细化(PR)损失:LiPR=1N⋅D∥MaskΘi⊙Hi−MaskΘi∗⊙Hi∗∥FL_{i}^{P R}=\frac{1}{N \cdot D}\left\|M a s k_{\Theta_{i}} \odot H_{i}-\operatorname{Mask}_{\Theta_{i}^{*}} \odot H_{i}^{*}\right\|_{F}LiPR=N⋅D1MaskΘi⊙Hi−MaskΘi∗⊙Hi∗F
风格细化(SR)损失:LiSR=1N⋅D∥G(Mask Θi⊙Hi)−G(MaskΘi∗⊙Hi∗)∥FL_{i}^{S R}=\frac{1}{N \cdot D} \| \mathcal{G}\left(\text { Mask }_{\Theta_{i}} \odot H_{i}\right)-\mathcal{G}\left(\operatorname{Mask}_{\Theta_{i}^{*}} \odot H_{i}^{*}\right) \|_{F}LiSR=N⋅D1∥G( Mask Θi⊙Hi)−G(MaskΘi∗⊙Hi∗)∥F
四、ALR-GAN的总体损失
结合上述模块,在ALR-GAN的第i阶段,生成损失LGiL_{G_i}LGi定义为LGi=−12EI^i∼PGi[logDi(I^i)]⏟unconditional loss −12EI^i∼PGi[logDi(I^i,s)]⏟conditional loss ,L_{G_{i}}=\underbrace{-\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log D_{i}\left(\hat{I}_{i}\right)\right]}_{\text {unconditional loss }}-\underbrace{\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log D_{i}\left(\hat{I}_{i}, s\right)\right]}_{\text {conditional loss }},LGi=unconditional loss −21EI^i∼PGi[logDi(I^i)]−conditional loss 21EI^i∼PGi[logDi(I^i,s)],
其中,无条件损失推动合成图像更真实,以欺骗鉴别器,而条件损失驱动合成图像更好地匹配相应的文本描述。判别损失定义为:
LDi=−12EIi∗∼Pdata i[logDi(Ii∗)]−12EI^i∼PGi[log(1−Di(I^i)]⏟unconditional loss +−12EIi∗∼Pdatai[logDi(Ii∗,s)]−12EI^i∼PGi[log(1−Di(I^i,s)]⏟conditional loss ,\begin{aligned} L_{D_{i}}= & \underbrace{-\frac{1}{2} \mathbb{E}_{I_{i}^{*} \sim P_{\text {data }_{i}}}\left[\log D_{i}\left(I_{i}^{*}\right)\right]-\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log \left(1-D_{i}\left(\hat{I}_{i}\right)\right]\right.}_{\text {unconditional loss }}+ \\ & \underbrace{-\frac{1}{2} \mathbb{E}_{I_{i}^{*} \sim P_{d a t a_{i}}}\left[\log D_{i}\left(I_{i}^{*}, s\right)\right]-\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log \left(1-D_{i}\left(\hat{I}_{i}, s\right)\right]\right.}_{\text {conditional loss }}, \end{aligned}LDi=unconditional loss −21EIi∗∼Pdata i[logDi(Ii∗)]−21EI^i∼PGi[log(1−Di(I^i)]+conditional loss −21EIi∗∼Pdatai[logDi(Ii∗,s)]−21EI^i∼PGi[log(1−Di(I^i,s)],
其中II∗I^*_III∗和I^i\hat{I}_{i}I^i是第i个尺度图像,判别损失LDiL_{Di}LDi从真实图像分布或合成图像分布中对输入图像采样进行分类。
生成网络最终目标函数定义为:LG=∑i=0m−1LGi+∑i=1m−1[LiALR+λ1LiREC+LiLVR]+λ2LDAMSML_{G}=\sum_{i=0}^{m-1} L_{G_{i}}+\sum_{i=1}^{m-1}\left[L_{i}^{A L R}+\lambda_{1} L_{i}^{R E C}+L_{i}^{L V R}\right]+\lambda_{2} L_{D A M S M}LG=∑i=0m−1LGi+∑i=1m−1[LiALR+λ1LiREC+LiLVR]+λ2LDAMSM,
判别网络的最终目标函数定义为:LD=∑i=0m−1LDiL_{D}=\sum_{i=0}^{m-1} L_{D_{i}}LD=∑i=0m−1LDi
五、实验
5.1、实验设置
数据集:CUB-Bird、MS-COCO
Baseline: AttnGAN
评价指标:作者一共选用了四个度量指标即:Inception Score (IS↑)、Fréchet Inception Distance (FID↓)、Semantic Object Accuracy (SOA↑)、R-precision↑
5.2、实验结果
1️⃣、定量实验:

训练时间、训练周期、模型大小和测试时间:

2️⃣、视觉效果


3️⃣、细微改变后的布局变化

ALR-GAN在MS-COCO测试集上捕捉文本描述细微变化(红色短语或单词)的能力,并以合理的布局合成不同的图像。
4️⃣、消融实验




六、总结
说实话这篇文章我暂时也没看很懂,原理部分还有待仔细研习,但值得一提的是,本文的实验做的非常充分,特别是消融实验,做的很严谨,建议看原文学习一下。而且在单阶段GAN大流行的情况下,这篇多阶段GAN仍然有很大的学习和借鉴价值。
这篇论文提出了一个文本到图像的生成模型:ALR-GAN,以改进合成图像的布局。ALR- GAN包括ALR模块和LVR损耗。
ALR模块结合所提出的ALR损失自适应地细化了合成图像的布局结构。LVR损失在细化布局的基础上,进一步细化布局区域内的视觉表现。实验结果和分析证明了这些方案的有效性,ALR模块和LVR损耗提高了其他基于gan的T2I方法的性能。
💡 最后
我们已经建立了🏤T2I研学社群,如果你还有其他疑问或者对🎓文本生成图像很感兴趣,可以私信我加入社群。
📝 加入社群 抱团学习:中杯可乐多加冰-深度学习T2I研习群
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
相关文章:
Text to image论文精读ALR-GAN:文本到图像合成的自适应布局优化
ALR-GAN是北京工业大学学者提出的一种自适应布局优化生成对抗网络,其可以在没有任何辅助信息的情况下自适应地优化合成图像的布局。 文章发表于2023年,IEEE Transactions on Multimedia(TMM)期刊(CCF B,JCR…...
windows版 redis在同一局域网下互联
项目场景: 同一局域网下各个主机互相连接同一个redis 问题描述 无法连接 原因分析: 没有放行对方的地址 解决方案: 修改配置文件 最重要的一步如下 然后把 redis.windows.conf的文件也照上面的修改一下保持一致 然后安装一下redis服务这…...

Near-Optimal Bayesian Online Assortment of Reusable Resources
摘要 受租赁服务在电子商务中的应用的激励,我们考虑为不同类型的到达消费者提供可重复使用资源的在线分类的收入最大化。我们针对贝叶斯环境中的最优在线策略设计了具有竞争力的在线算法,其中类型随时间独立于已知的异构分布绘制。在初始库存最小值cmin…...

数据库复习2
一. 简答题(共1题,100分) 1. (简答题) 存在数据库test,数据库中有如下表: 1.学生表 Student(Sno,Sname,Sage,Ssex) --Sno 学号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别 主键Sno 2.教师表 Teacher(Tno,Tname) --T…...

公众号运营之竞品分析,教你拆解公众号
知己知彼,百战不殆,公众号运营亦是如此。 当运营者只关注自己账号的时候,很容易陷入某个误区中出不来。这个时候就要拓宽我们的视野,多去看看“外面的世界”,不要只局限于自己的一片小天地中。 看看同领域优秀公众号…...

python常见问题详解
Python python 没有多态,而是鸭子类型 多继承,没有接口,可通过语法糖实现接口的作用 lambda中只能有一句 "/"表示之前的参数是必须是位置参数,”**“表示是后面的必须是关键字参数 Python多进程 Python 多线程是伪多线…...
MyBatis-常用SQL操作
一、动态SQL 1.概述】 1.1动态SQL: 是 MyBatis 的强大特性之一,解决拼接动态SQL时候的难题,提高开发效 1.2分类: if choose(when,otherwise) trim(where,set) foreach 2.if 2.1 做 where 语句后面条件查询的,if 语句是可以…...
DSPE-PEG-TCO;磷脂-聚乙二醇-反式环辛烯科研用化学试剂简介
中文名称 磷脂-聚乙二醇-反式环辛烯 英文名称 DSPE-PEG-TCO 外观:粉末或半固体,取决于分子量。 溶剂:溶于大部分有机溶剂,如:DCM、DMF、DMSO、THF等等。在水中有很好的溶解性 稳定性:冷藏保存ÿ…...
)
华为OD机试真题Java实现【最小施肥机能效】真题+解题思路+代码(20222023)
最小施肥机能效 某农场主管理了一大片果园,fields[i]表示不同果林的面积,单位:( m 2 m^2 m2),现在要为所有的果林施肥且必须在 n 天之内完成,否则影响收成。 小布是果林的工作人员,他每次选择一片果林进行施肥,且一片果林施肥完后当天不再进行施肥作业。 假设施肥机的…...

【问题记录】【排查问题的方法总结】vue3中数据失去响应式?为什么数据变了,视图只更新了一次就不再更新了?
一、问题概述: 持续请求的数据变动之后,控制台输出绑定的响应式变量 mapObj 的确变了,但是视图上只更新了一次,后续就不再更新了。 二、排查过程: PC上用定时器setInterval模拟数据(全是小于0的数据)更新࿰…...

基于遗传算法的柔性生产调度研究(Matlab代码实现)
👨🎓个人主页:研学社的博客💥💥💞💞欢迎来到本博客❤️❤️💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密…...

Heroku的12条准则
I. Codebase One codebase tracked in revision control, many deploys 要有代码仓库,多版本控制,如使用git来管理代码仓库。 II. Dependencies Explicitly declare and isolate dependencies 明确声明依赖,隔离依赖。强依赖往往会导致连…...
Qt图片定时滚动
目录参考结构PicturePlay.promain.cpppictureplay.hpictureplay.cpppictureplay.ui效果参考 Qt图片浏览器 QT制作一个图片播放器 Qt中自适应的labelpixmap充满窗口后,无法缩小只能放大 可以显示jpg、jpeg、png、bmp。可以从电脑上拖动图到窗口并显示出来或者打开文件…...
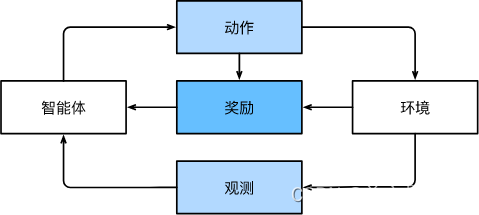
深度学习引言
动手学深度学习pytorch版-笔记原文链接日常生活中的机器学习机器学习中的关键组件数据模型目标函数优化算法各种机器学习问题监督学习回归分类标记问题搜索推荐系统序列学习无监督学习与环境互动强化学习特点小结原文链接 动手学深度学习pytorch中文版 日常生活中的机器学习 …...

ESP32 WIFI使用介绍
ESP32 WIFI 概述 WIFI 库支持配置及监控 ESP32 WIFI 连网功能。支持配置 station 模式(即 STA 模式或 WIFI 客户端模式),此时 ESP32 连接到接入点(AP)。AP 模式(即 soft-AP 模式或接入点模式)&…...

JavaEE简单实例——MyBatis的一对一映射的嵌套查询的简单介绍和基础配置
简单介绍: 在前一章我们介绍了关于MyBatis的多表查询的时候的对应关系,其中有三种对应关系,分别是一对一,一对多,多对多的关系。如果忘记了这三种方式的对应形式可以去前面看看,一定要记住这三种映射关系的…...
(1))
详解指针(进阶版)(1)
前言:总篇章分为(1)和(2),本篇内容包括:指针数组,数组指针,&数组名与数组名的区分 数组传参 ,函数指针,函数指针数组 part 1:指…...

【OJ】盐荒子孙
📚Description: 盐体图 盐是对人类生存具有重要意义的物质之一。当中国古人从肉食为主转向谷食为主的时候,吃盐的需求就发生了,因为动物血肉里面包含有足够人体所需的盐分,而谷 物本身不包含盐分。在长达几十万年的旧石器时代&…...

Java数据结构 —— 手写线性结构(稀疏数组、栈、队列、链表)
目录 稀疏数组 顺序表 链表 单向顺序链表 双向链表 双向循环链表求解约瑟夫环(Joseph) 栈 顺序栈 队列 顺序队列 顺序循环队列 稀疏数组 当一个数组中大部分值为0,或者相同时,可以采用稀疏数组的方式来保存,从而节约存储…...
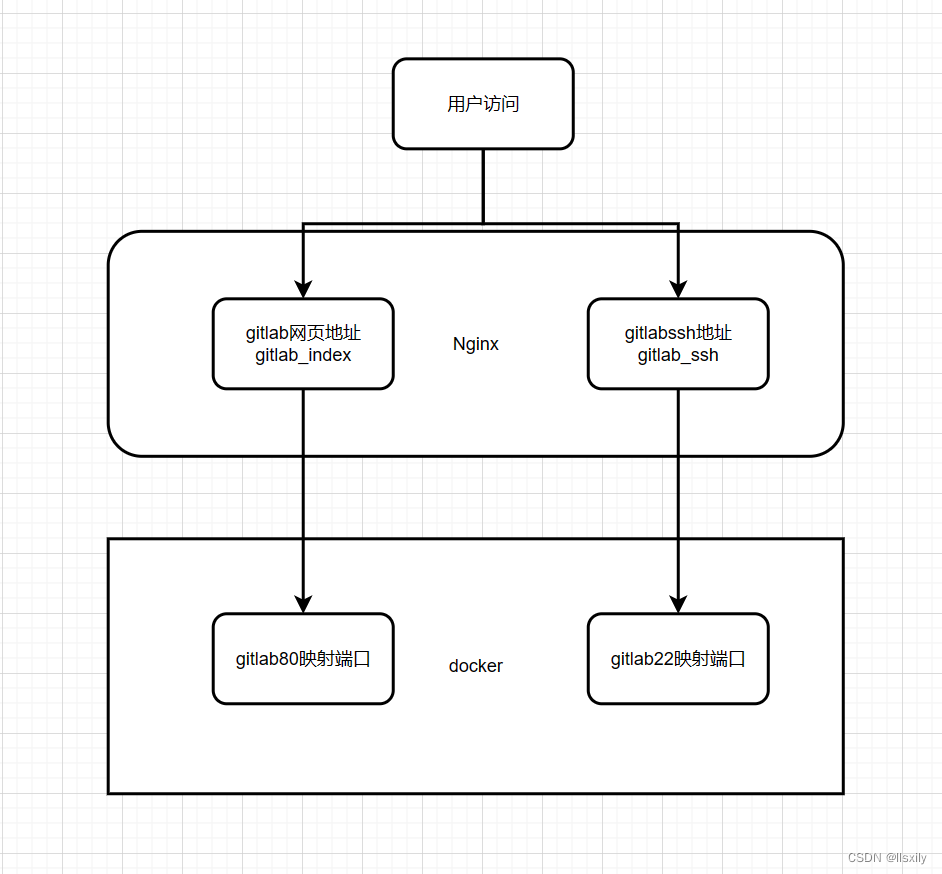
docker部署gitlab过程中遇到的一些问题记录
文章目录用nginx代理docker部署的gitlab服务密码重置docker0网卡异常离线安装apt的包用nginx代理docker部署的gitlab服务 一般咱们不会去暴露很多端口给外面,所以部署完gitlab后,我希望能够用nginx来代理我们的gitlab服务。 gitlab的docker部署参考这个…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...