HDFS Java API 操作
文章目录
- HDFS Java API操作
- 零、启动hadoop
- 一、HDFS常见类接口与方法
- 1、hdfs 常见类与接口
- 2、FileSystem 的常用方法
- 二、Java 创建Hadoop项目
- 1、创建文件夹
- 2、打开Java IDEA
- 1) 新建项目
- 2) 选择Maven
- 三、配置环境
- 1、添加相关依赖
- 2、创建日志属性文件
- 四、Java API操作
- 1、在HDFS上创建文件
- 2、在Java 上创建包
- 1) 编写`create1()`方法
- 2) 编写create2() 方法
- 3、在HDFS上写入文件
- 1) 将数据直接写入HDFS文件
- (1)编写write1() 方法
- 2) 将本地文件写入HDFS文件
- (1)、编写witer2() 方法
- (2)、编写write2_2() 方法
- 4、读取HDFS文件
- 1) 读取HDFS文件直接在控制台显示
- (1) 编写read1() 方法
- 2) 读取HDFS文件,保存为本地文件
- (1) 创建`read2()`方法
- 5、重命名目录或文件
- 1) 重命名目录
- (1) 编写`renameDir()` 方法
- 2) 重命名文件
- (1)编写renameFile() 方法
- 6、显示文件列表
- 1) 显示指定目录下文件全部信息
- (1)、编写list1() 方法
- 2) 显示指定目录下文件路径和长度信息
- (1) 编写list2() 方法
- 7、获取文件块信息
HDFS Java API操作
Hadoop是使用Java语言编写的,因此使用Java API操作Hadoop文件系统,HDFS Shell本质上就是对Java API的应用,通过编程的形式,操作HDFS,其核心是使用HDFS提供的Java API构造一个访问客户端对象,然后通过客户端对象对HDFS上的文件进行操作(增,删,改,查)
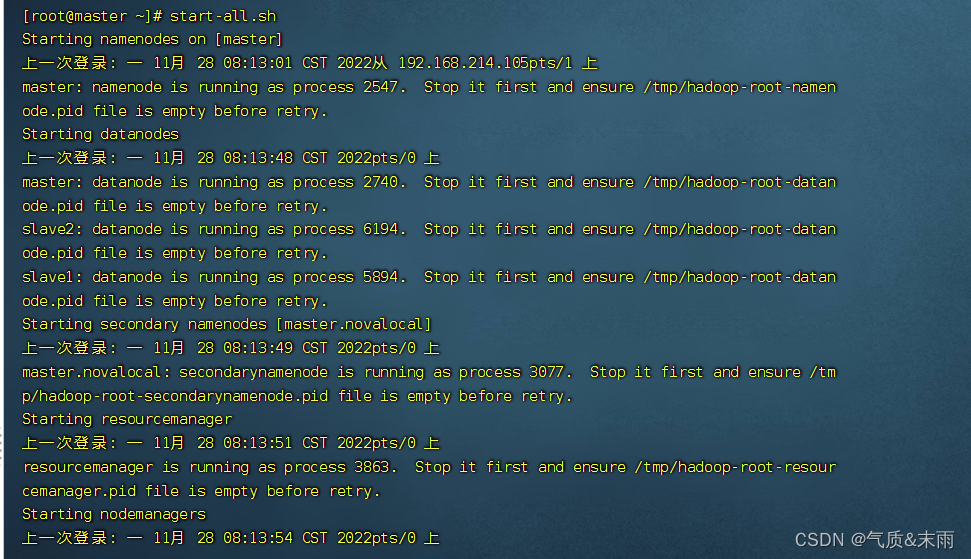
零、启动hadoop
一、HDFS常见类接口与方法
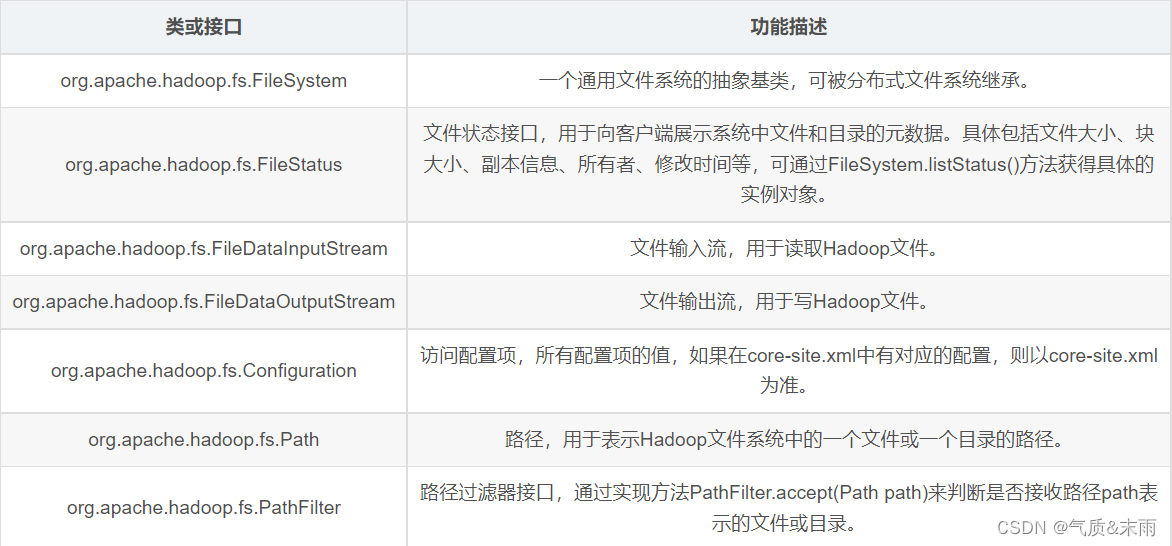
1、hdfs 常见类与接口
Hadoop 整合了众多文件系统,HDFS只是这个文件系统的一个实例
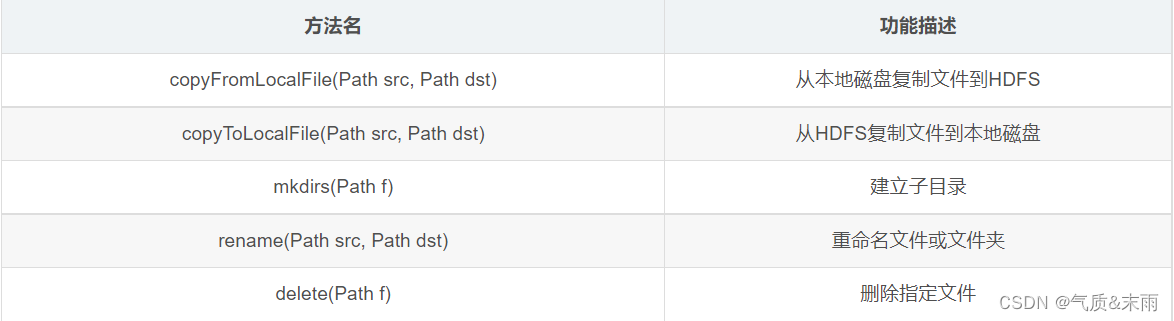
2、FileSystem 的常用方法
FileSystem 对象的一些方法可以对文件进行操作
二、Java 创建Hadoop项目
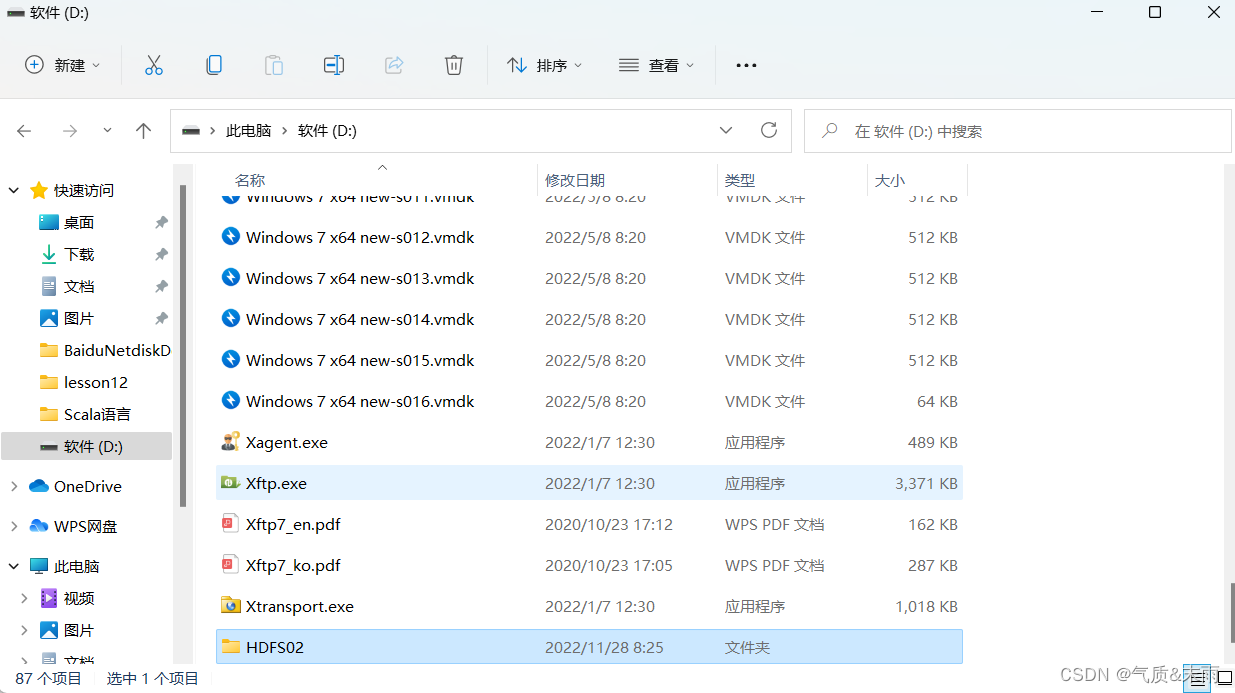
1、创建文件夹
现在D盘创建一个空的文件夹,HDFS02用来存放hadoop项目
2、打开Java IDEA
1) 新建项目
点击左上角,新建项目
2) 选择Maven
选择Maven包管理,记住一定是jdk1.8版本的,然后那个从archetype 不要选择

然后点击下一步,位置选择刚刚D盘创建的那个HDFS02文件夹,然后点击完成
三、配置环境
1、添加相关依赖
创建完成之后,进来是一个pom.xml文件
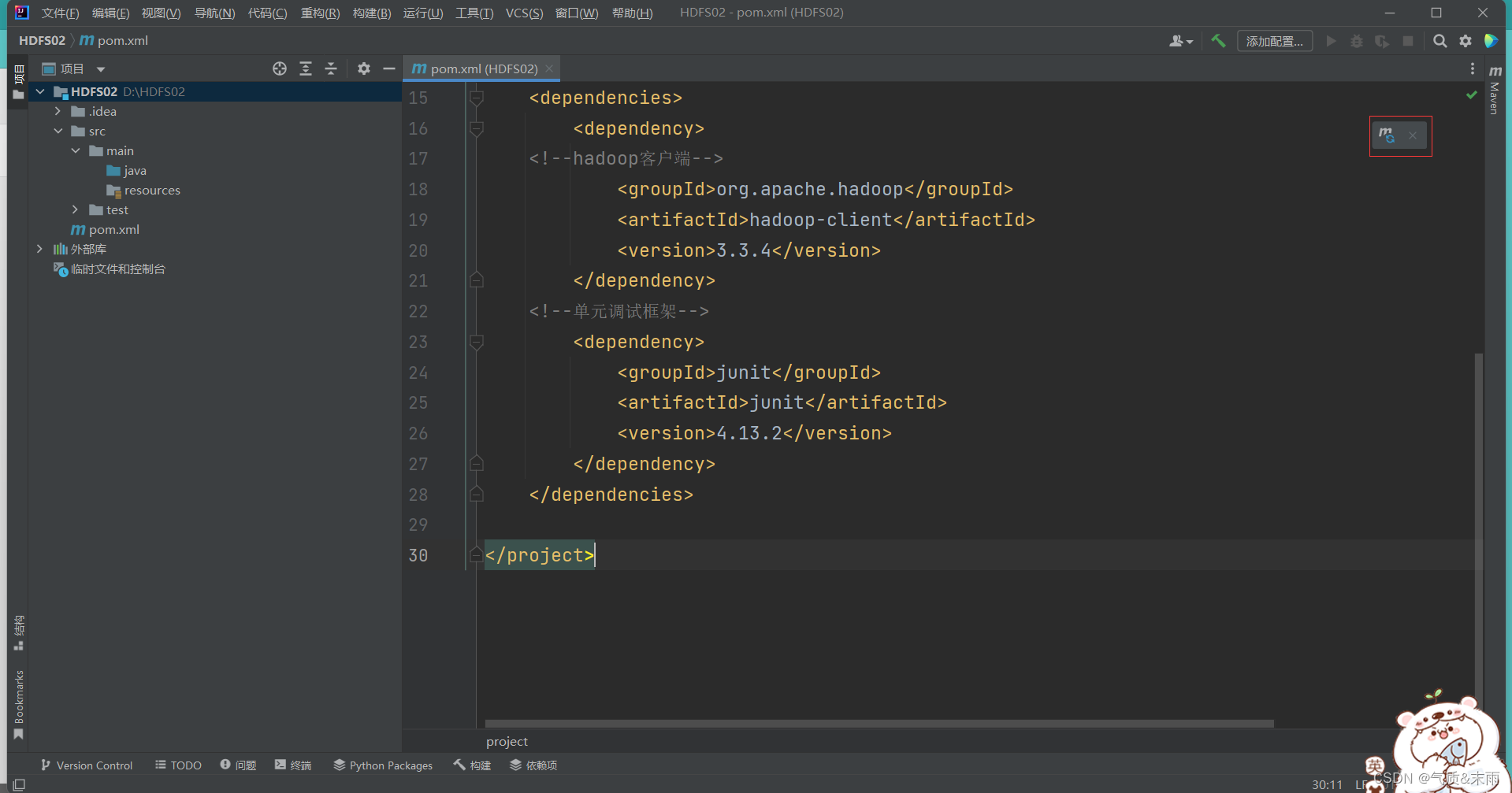
添加以下的相关的hadoop和junit依赖配置,其中大部分都是有的,主要是<dependencise></dependencise> 这个部分
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>HDFS02</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>18</maven.compiler.source><maven.compiler.target>18</maven.compiler.target></properties><dependencies><dependency><!--hadoop客户端--><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.4</version></dependency><!--单元调试框架--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version></dependency></dependencies></project>
然后右上角有一个m的图标,点击一下,加载配置文件,导入包,这个很关键,不然那些包都用不起
Manen Repository (Maven仓库) http://mvnrepository.com/
搜索 hadoop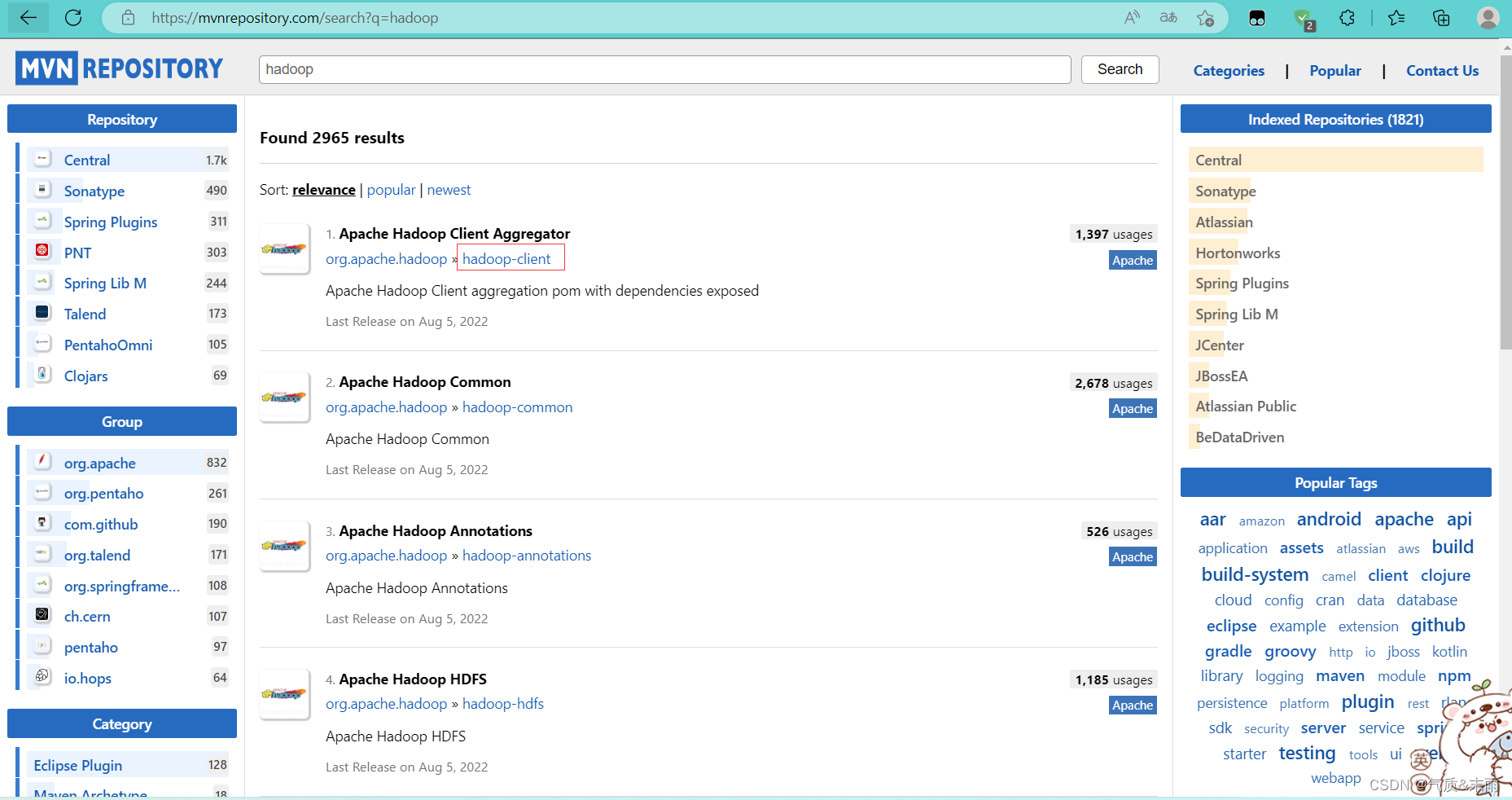
点击 hadoop-client 超链接,然后点击下面的3.3.4
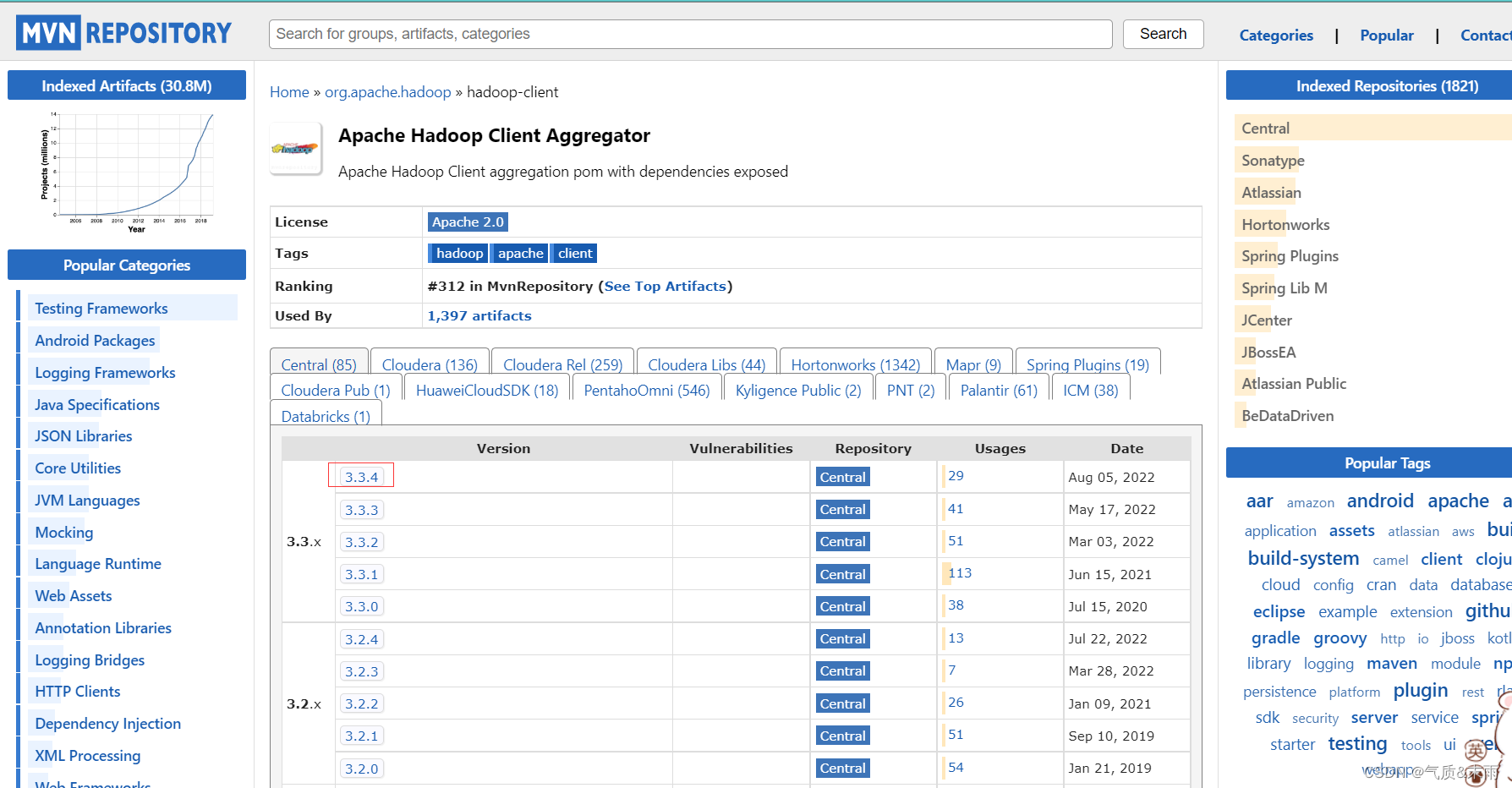
就可以看到上面在Java里面配置的hadoop的依赖就是这个地方的
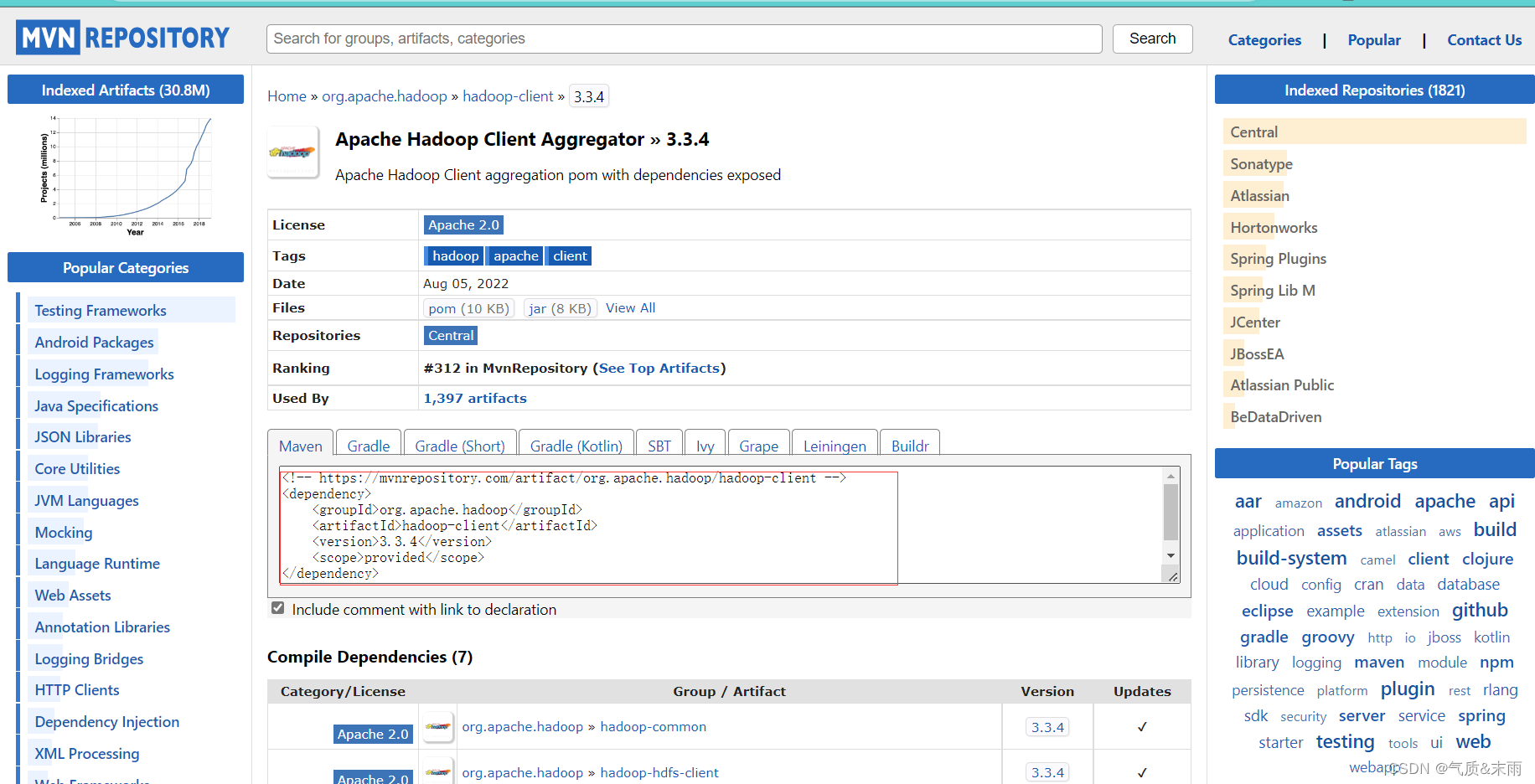
2、创建日志属性文件
在resources目录里创建log4j.properties文件
把下面的配置添加进去
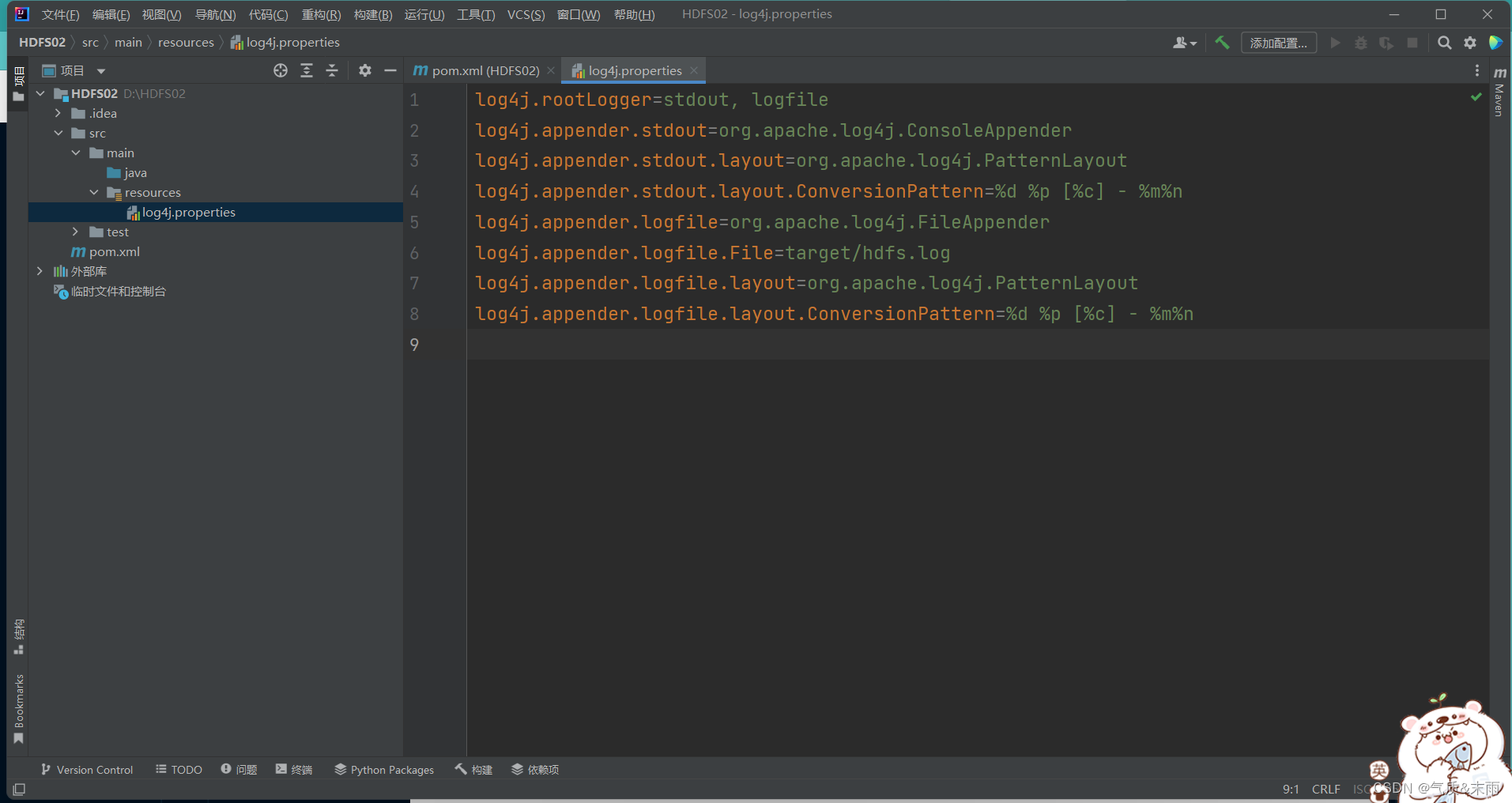
log4j.rootLogger=stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/hdfs.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
四、Java API操作
1、在HDFS上创建文件
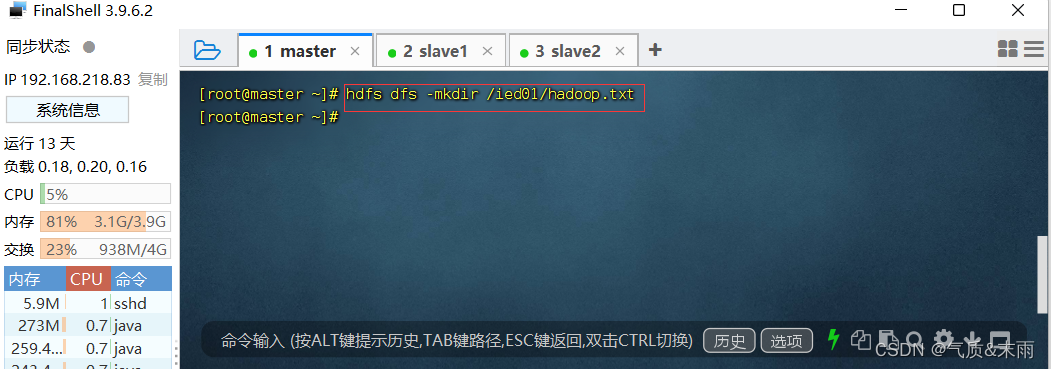
在 /ied01 目录里创建hadoop.txt 文件
输入命令:hdfs dfs -mkdir /ied01/hadoop.txt
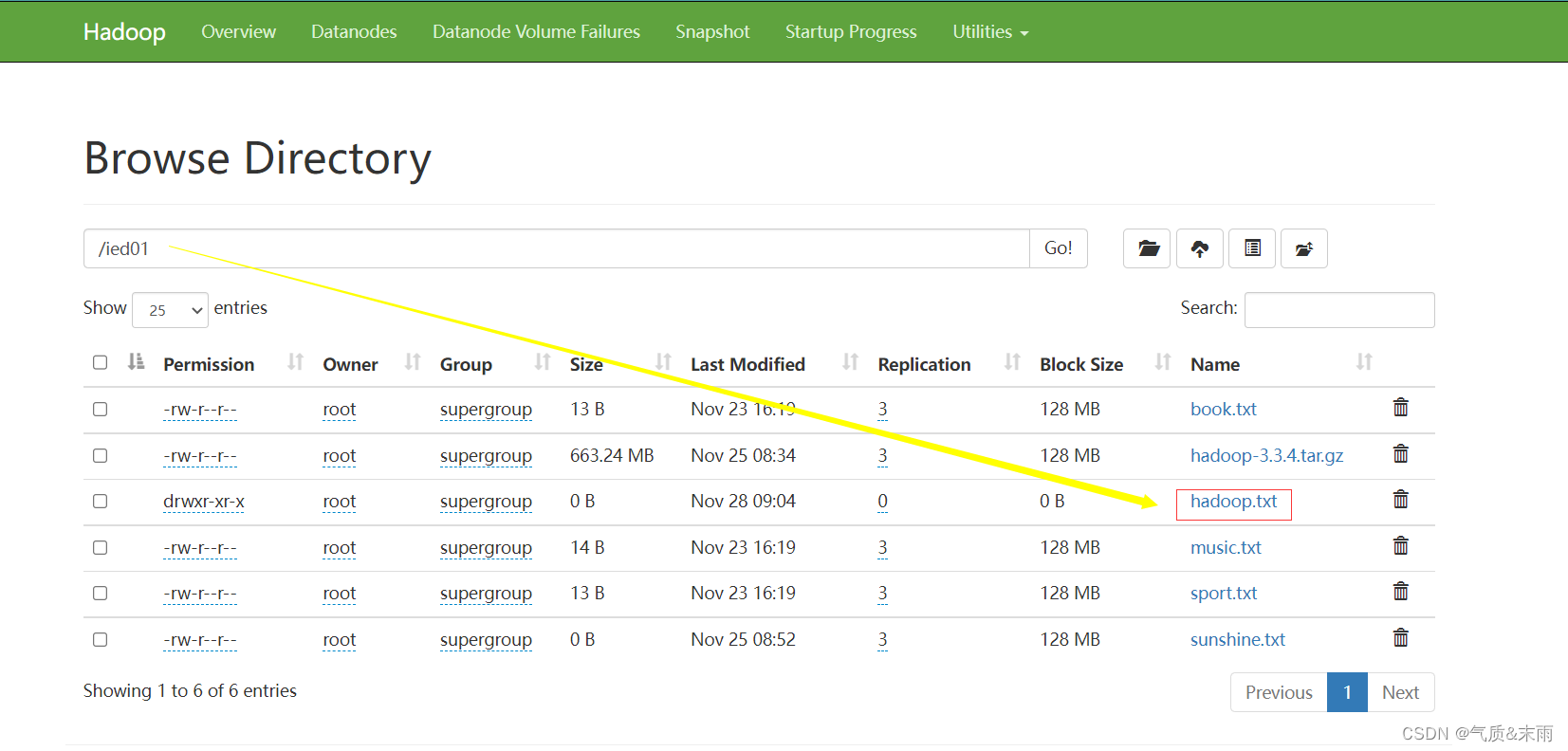
在webUI界面进行查看
2、在Java 上创建包
创建net.aex.hdfs包,在包里创建CreateFileOnHDFS类
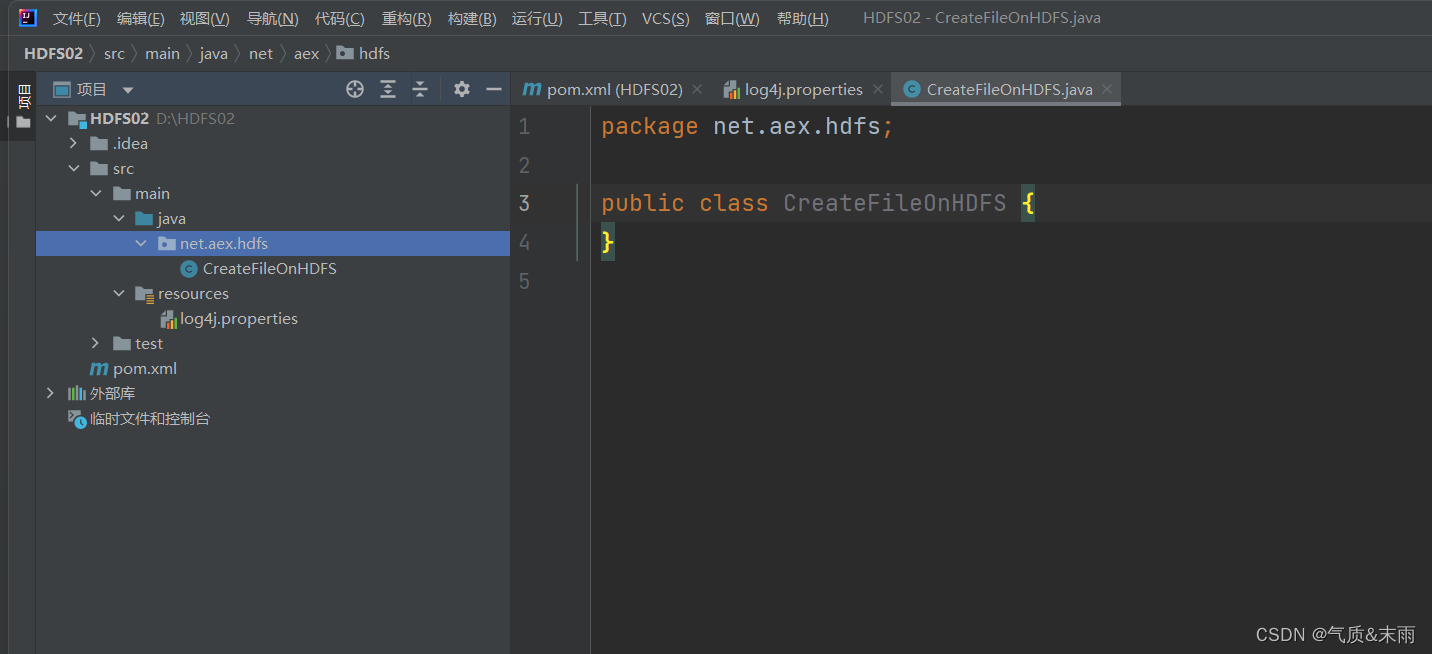
1) 编写create1()方法
注意导入包的时候一定不要导错了,有些很相似
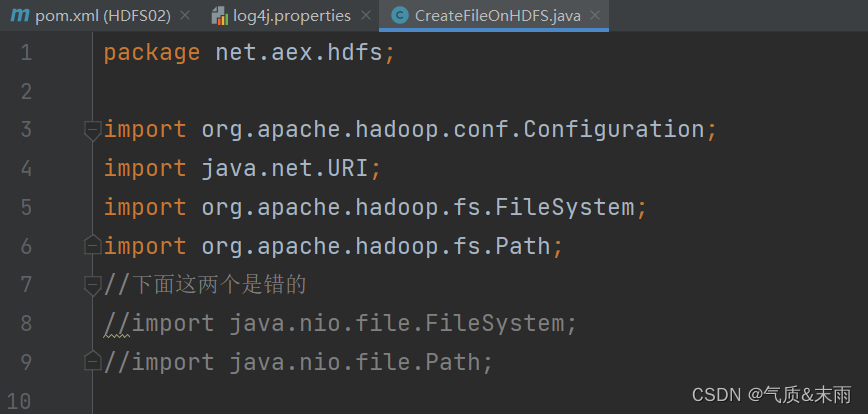
package net.aex.hdfs;import org.apache.hadoop.conf.Configuration;
import java.net.URI;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
//下面这两个是错的
//import java.nio.file.FileSystem;
//import java.nio.file.Path;public class CreateFileOnHDFS {public static void create1() throws Exception{//创建配置对象Configuration conf = new Configuration();//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf);//创建路径对象Path path = new Path(uri + "/ied01/hadoop.txt");//基于路径对象创建文件boolean result = fs.createNewFile(path);//根据返回值判断文件是否创建成功if(result){System.out.println("文件[" + path + "创建成功]");}else{System.out.println("文件[" + path + "创建失败]");}}public static void main(String[] args) throws Exception{create1();}
}
下面使用main方法 对CreateFileOnHDFS 函数方法进行调用

运行程序查看结果,创建失败,因为我们之前已经在linux本地 hdfs上创建了这个文件
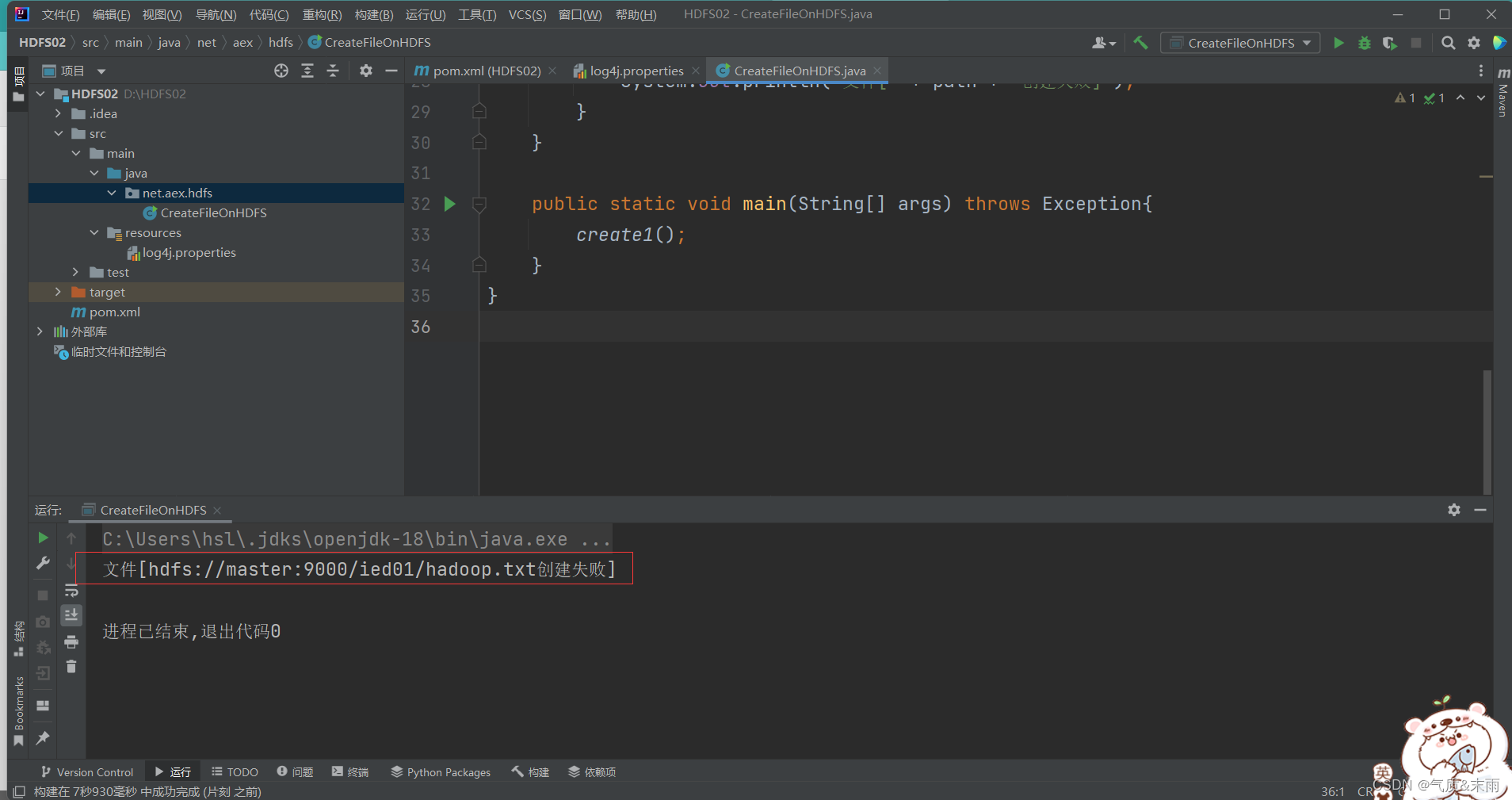
此时将这个创建的文件路径改为 /ied02/hadoop02.txt 就成功了
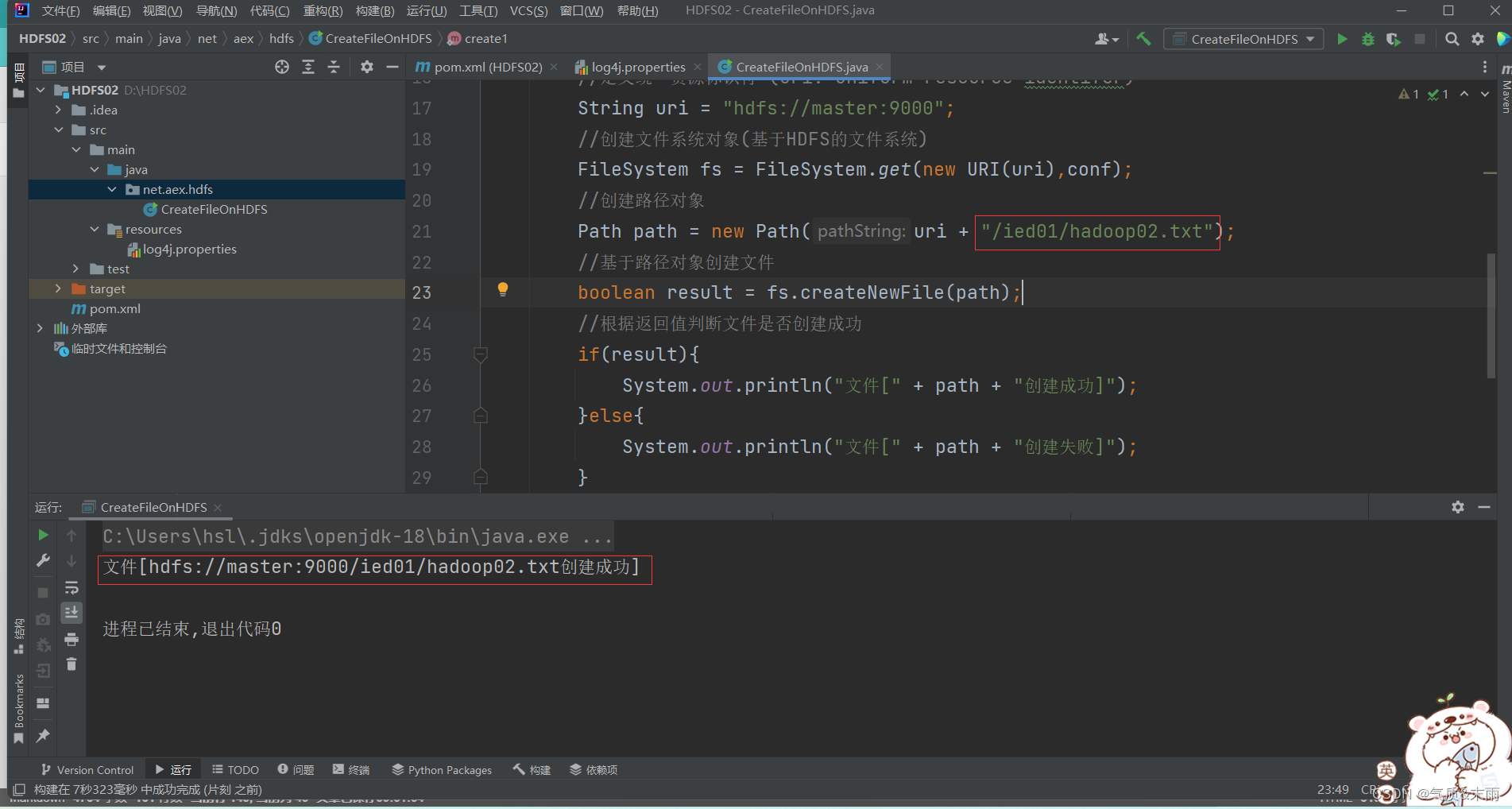
在webUI界面上进行查看
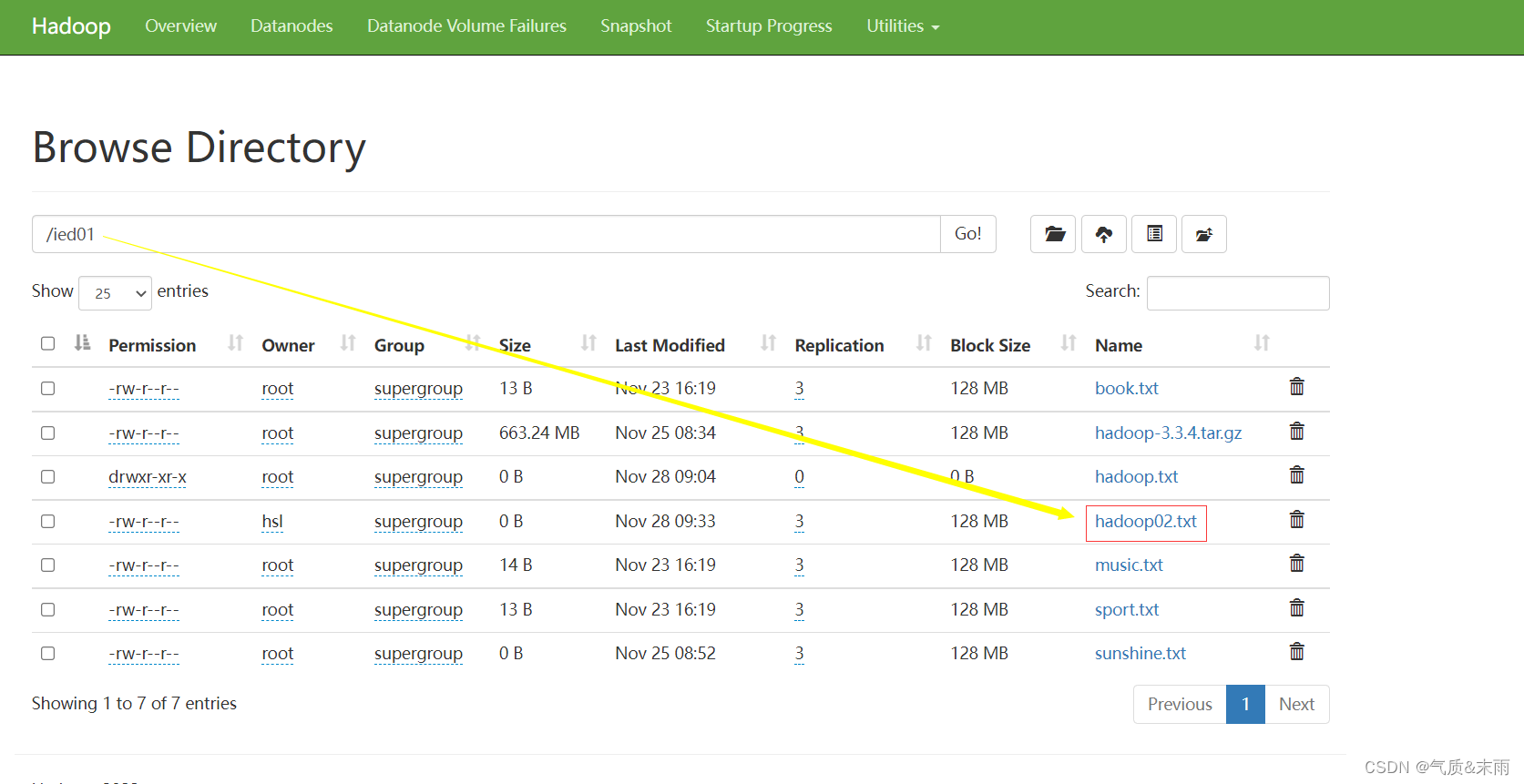
注意:在/ied01 目录里确实创建了一个0字节的hadoop02.txt文件,有点类似于Hadoop shell 里执行 hdfs dfs -touchz /ied01/hadoop02.txt 但是在linux上面重复执行不会失败,只是会不断改变这个文件的时间戳,但是在Java API里面操作,如果重复执行就会失败
2) 编写create2() 方法
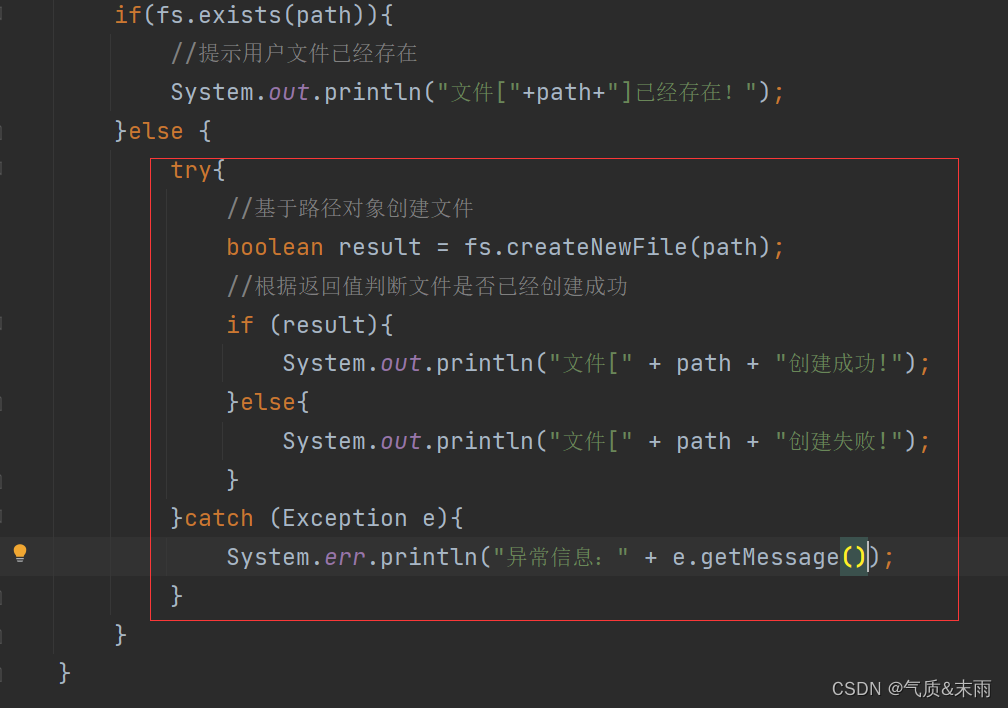
编写create2() 方法,事先判断文件是否已经存在
//create2public static void create2() throws Exception{//创建配置对象Configuration conf = new Configuration();//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf);//创建路径对象Path path = new Path(uri + "/ied01/hadoop.txt");//判断路径对象指定的文件是否已经存在if(fs.exists(path)){//提示用户文件已经存在System.out.println("文件["+path+"]已经存在!");}else {//基于路径对象创建文件boolean result = fs.createNewFile(path);//根据返回值判断文件是否已经创建成功if (result){System.out.println("文件[" + path + "创建成功!");}else{System.out.println("文件[" + path + "创建失败!");}}}
使用main方法调用create2() 函数方法,查看程序运行结果,提示文件已经存在

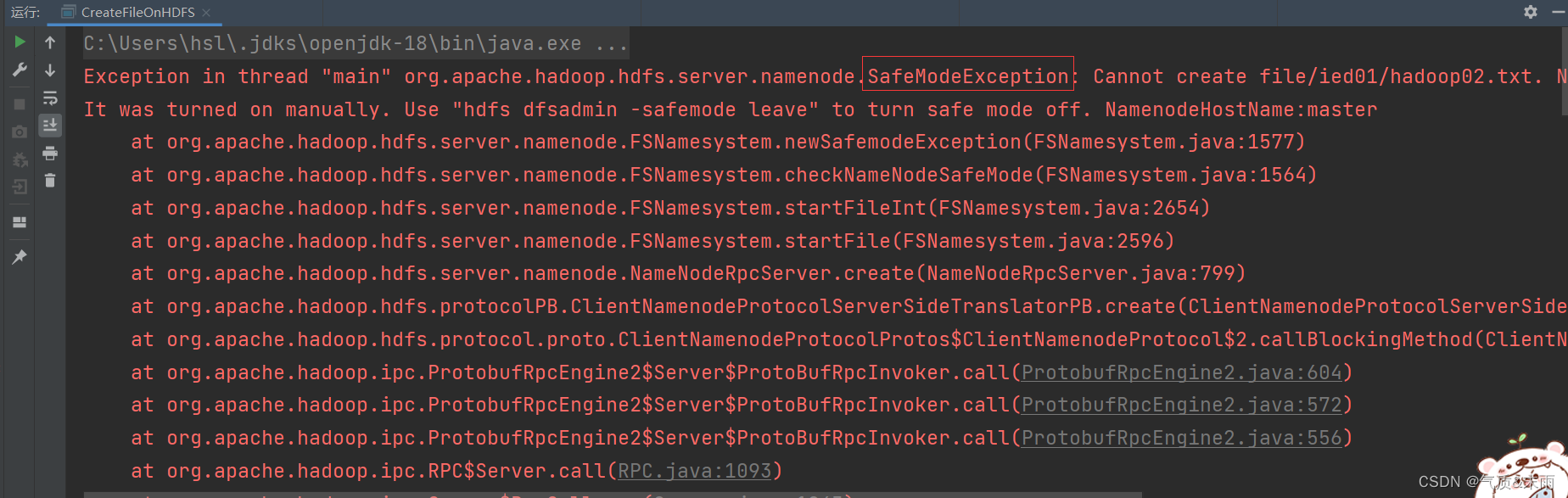
此时我们怎么才能出现文件创建失败的情况呢,我们故意让HDFS进入安全模式(只能读,不能写)
在linux上删除已经创建的/ied01/hadoop02.txt 文件
输入命令: hdfs dfs -rm /ied01/hadoop02.txt

输入命令:hdfs dfsadmin safemode enter 进入安全模式

此时,再运行程序,抛出SafeModelException 异常
修改程序,来处理这个可能会抛出的安全模式异常
使用try catch 来抛出捕获异常
运行程序,查看结果
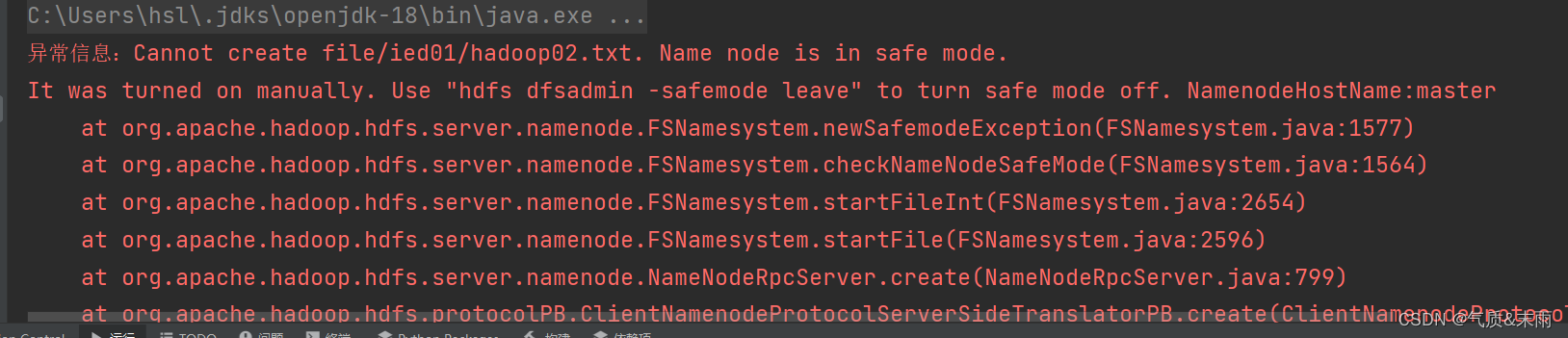
linux 输入命令:hdfs dfsadmin -safemode leave 关闭安全模式

再运行程序,查看结果 创建成功

3、在HDFS上写入文件
在net.aex.hdfs 包里创建WriteFileOnHDFS 类
1) 将数据直接写入HDFS文件
在linux本地 hdfs /ied01目录创建hello.txt文件

(1)编写write1() 方法
在Java 里创建 write1() 函数方法
package net.aex.hdfs;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;import java.net.URI;
import java.nio.charset.StandardCharsets;public class WriteFileOnHDFS {public static void write1() throws Exception{//创建配置对象Configuration conf = new Configuration();//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf);//创建路径对象Path path = new Path(uri + "/ied01/hello.txt");//创建文件系统数据字节输出流FSDataOutputStream out = fs.create(path);//通过字节输出流向文件写入数据out.write("Hello hadoop world".getBytes());//关闭输出流out.close();//关闭文件系统对象fs.close();}public static void main(String[] args) throws Exception{write1();}
}
运行程序,查看结果,报错,没有数据节点可以写入数据
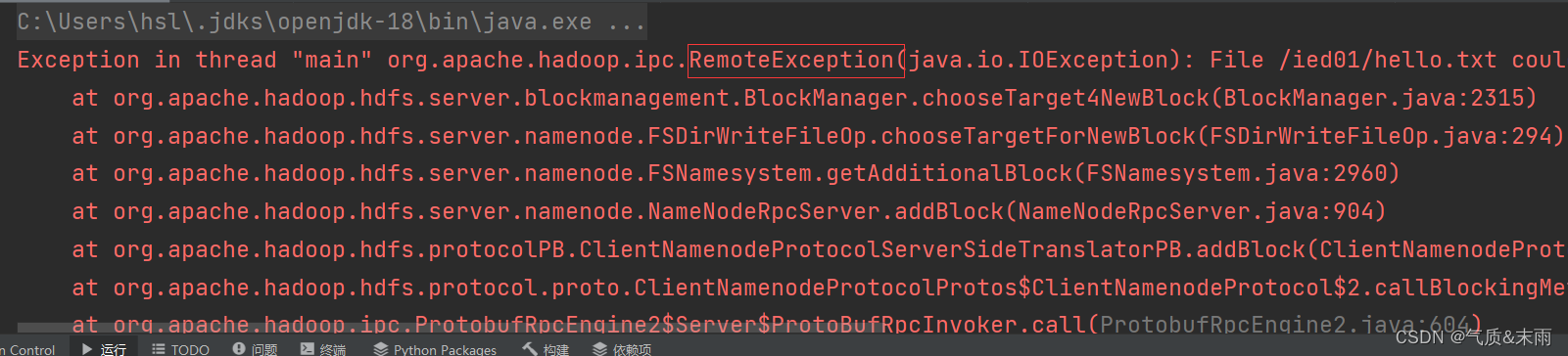
修改代码,添加一个 设置数据节点主机名属性
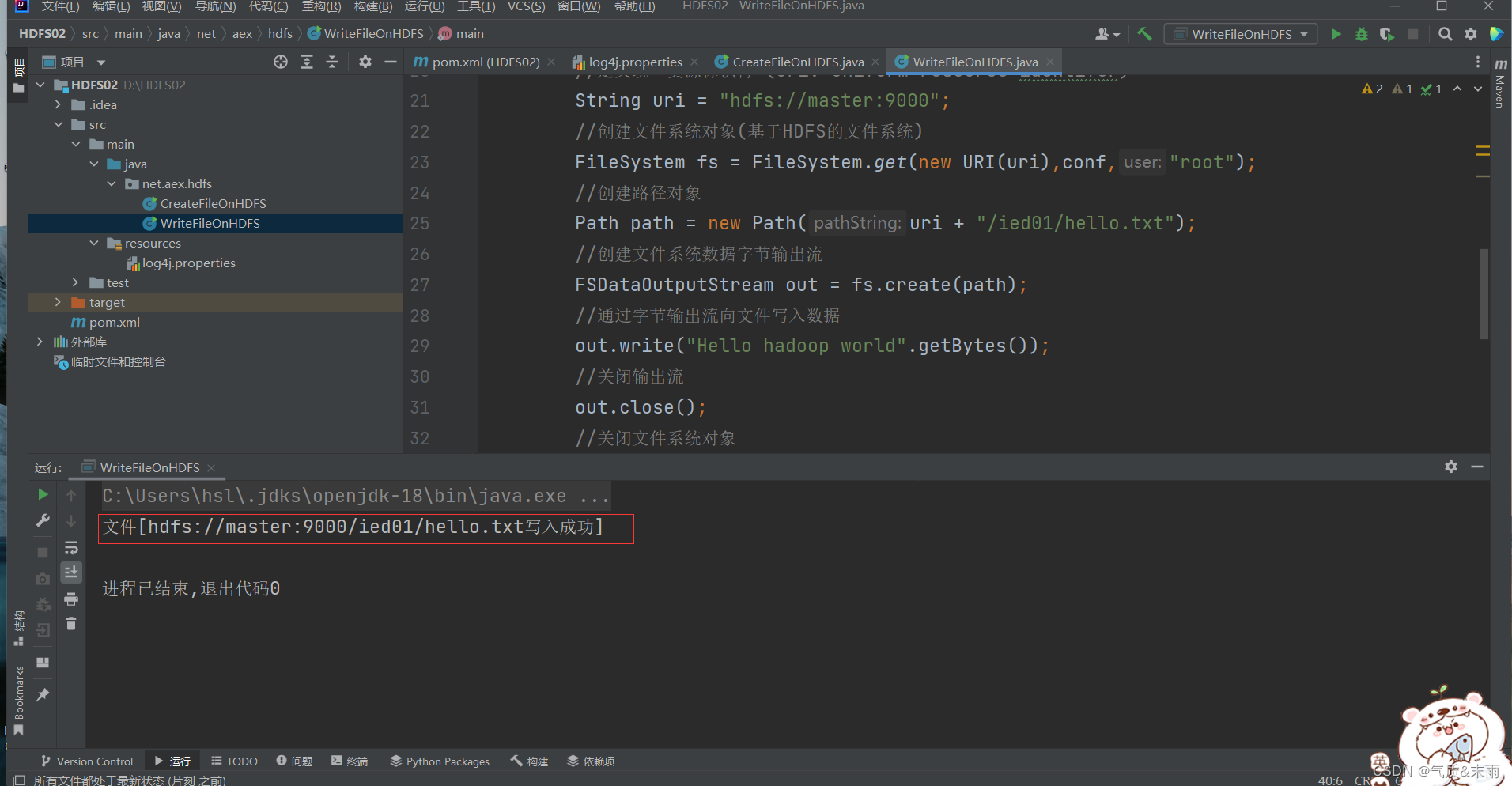
运行1程序,查看结果
在webUI界面上查看hello.txt 文件
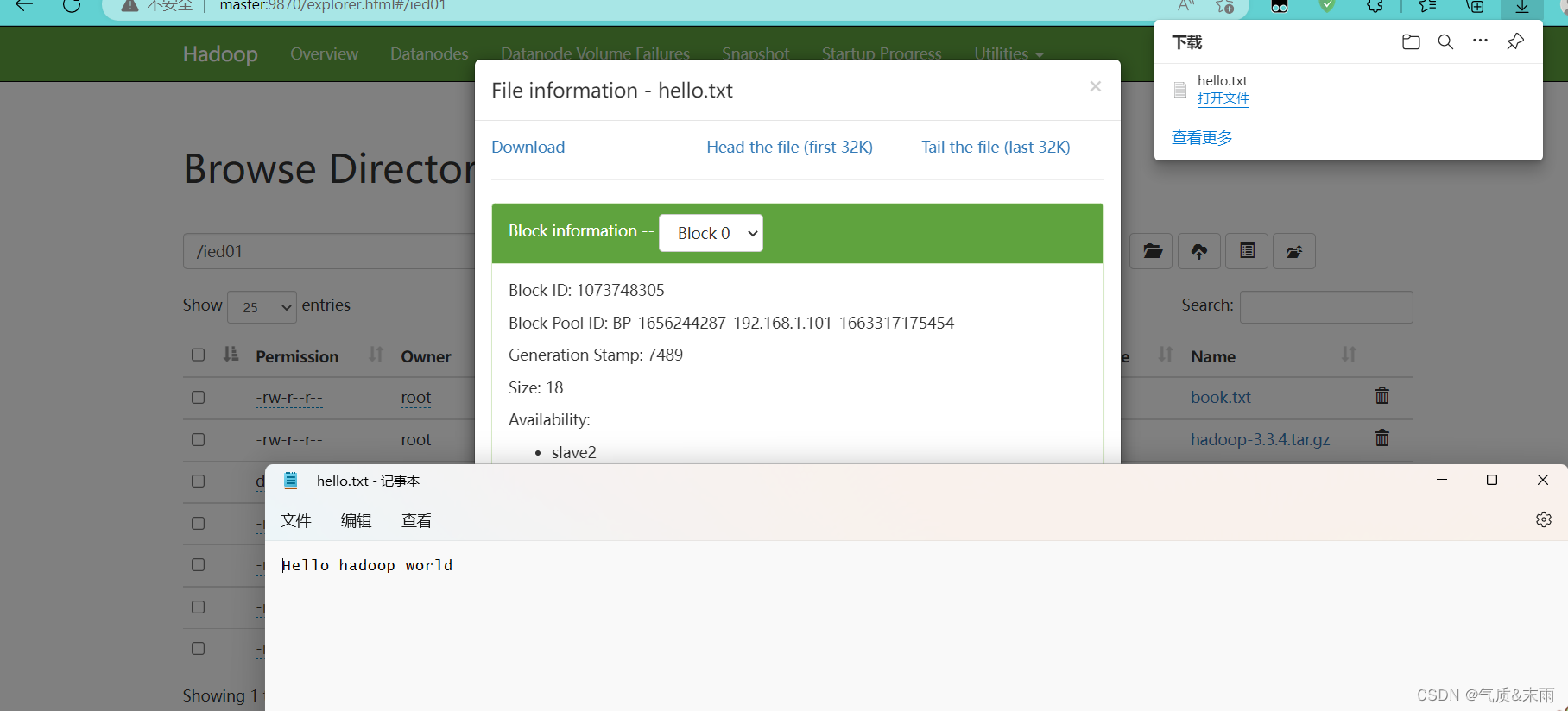
2) 将本地文件写入HDFS文件
在Java项目根目录创建一个文本文件test.txt
(1)、编写witer2() 方法
在Java WriteFileOnHDFS类里面创建 write2函数方法

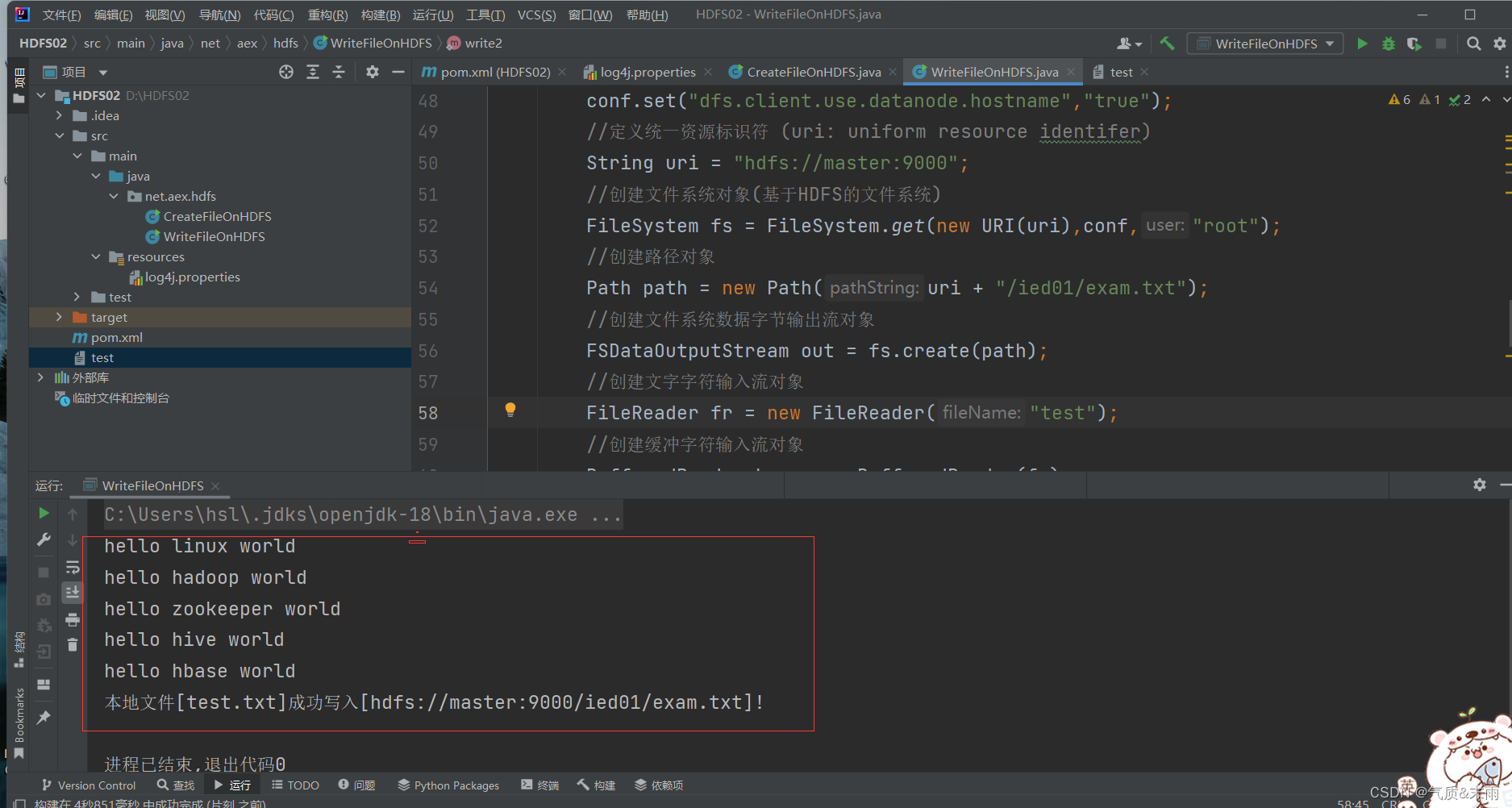
//write2public static void write2() throws Exception{//创建配置对象Configuration conf = new Configuration();//设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf,"root");//创建路径对象Path path = new Path(uri + "/ied01/exam.txt");//创建文件系统数据字节输出流对象FSDataOutputStream out = fs.create(path);//创建文字字符输入流对象FileReader fr = new FileReader("test.txt");//创建缓冲字符输入流对象BufferedReader br = new BufferedReader(fr);//定义行字符串String nextLine = "";//通过循环读取缓冲字符输入流while ((nextLine=br.readLine()) != null){//在控制台输出读取的行System.out.println(nextLine);//通过文件系统数据字节输出流对象写入指定文件out.write(nextLine.getBytes());}//关闭文件系统字节输出流out.close();//关闭缓冲字符输入流br.close();//关闭文件字符输入流fr.close();//提示用户写入文件成功System.out.println("本地文件[test.txt]成功写入[" + path + "]!");}
main函数调用write2() 方法,查看结果 写入成功
其实这个方法的功能就是将本地文件复制(上传)到HDFS,有更简单的处理方法,通过使用一个工具类IOUtils来完成文件的相关操作
(2)、编写write2_2() 方法
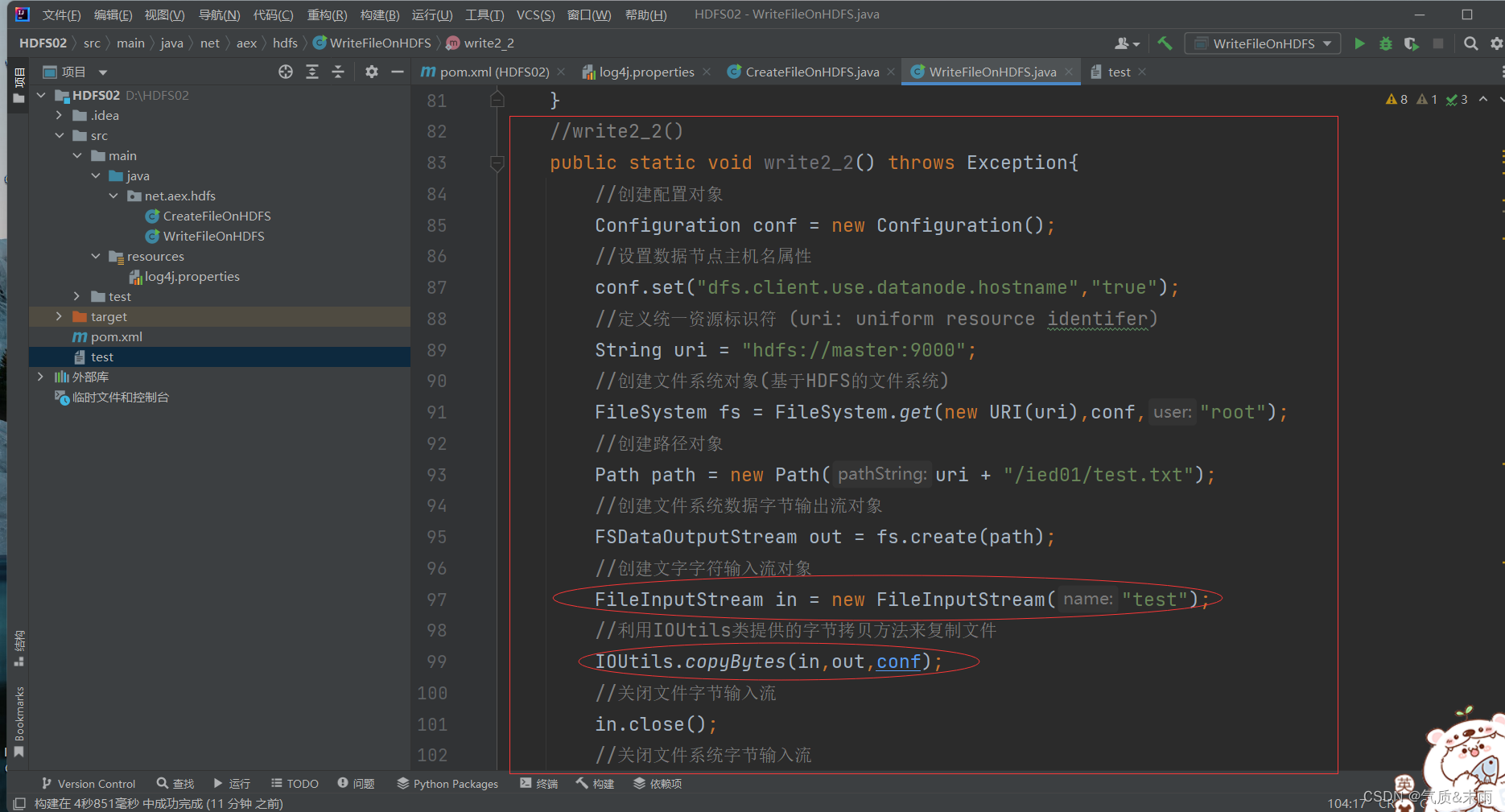
//write2_2()public static void write2_2() throws Exception{//创建配置对象Configuration conf = new Configuration();//设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf,"root");//创建路径对象Path path = new Path(uri + "/ied01/test.txt");//创建文件系统数据字节输出流对象FSDataOutputStream out = fs.create(path);//创建文字字符输入流对象FileInputStream in = new FileInputStream("test");//利用IOUtils类提供的字节拷贝方法来复制文件IOUtils.copyBytes(in,out,conf);//关闭文件字节输入流in.close();//关闭文件系统字节输入流out.close();//关闭文件系统fs.close();//提示用户写入文件成功System.out.println("本地文件[test.txt]成功写入[" + path + "]!");}
使用main方法,运行write2_2() 函数方法 查看结果 写入成功
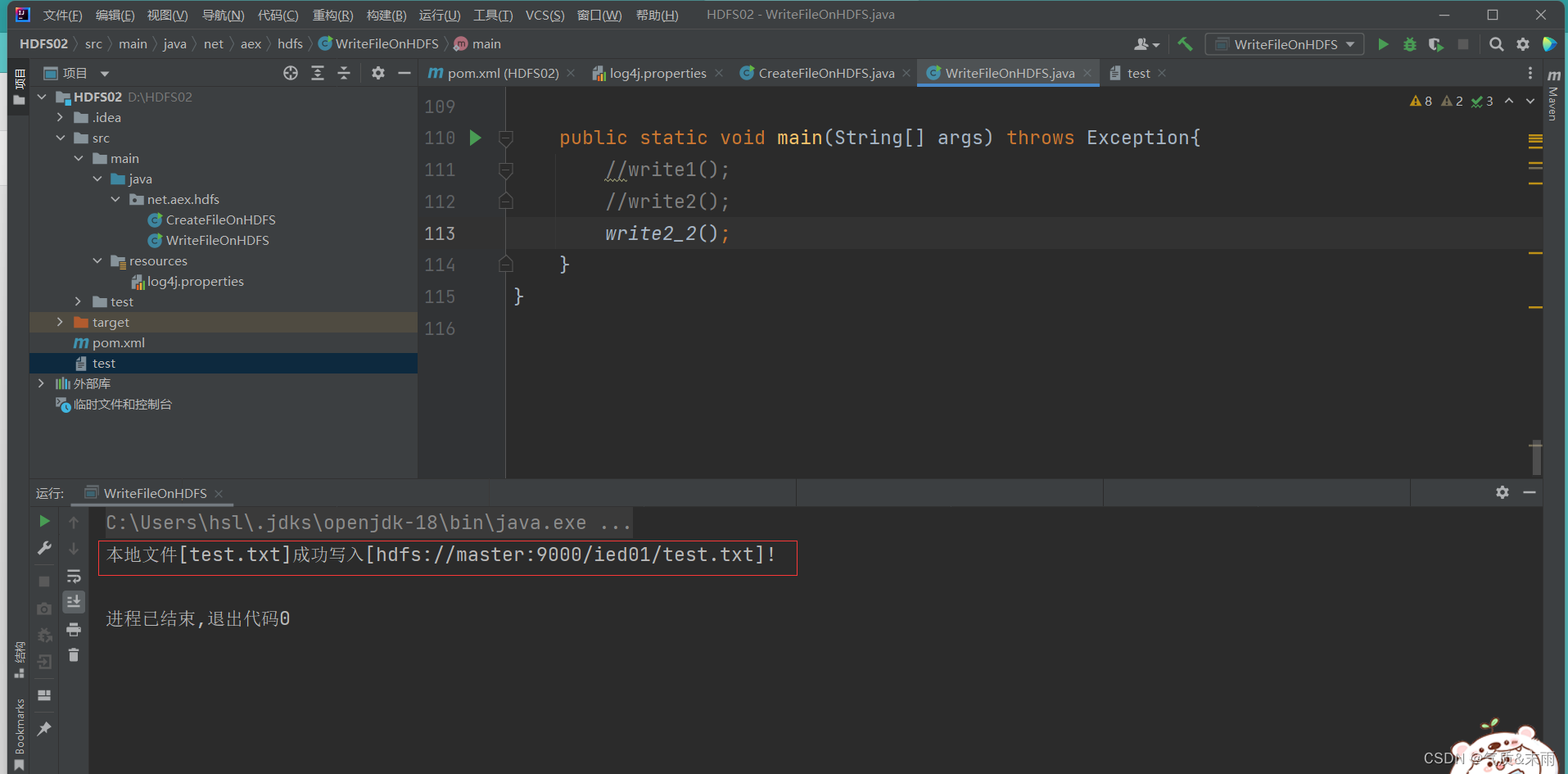
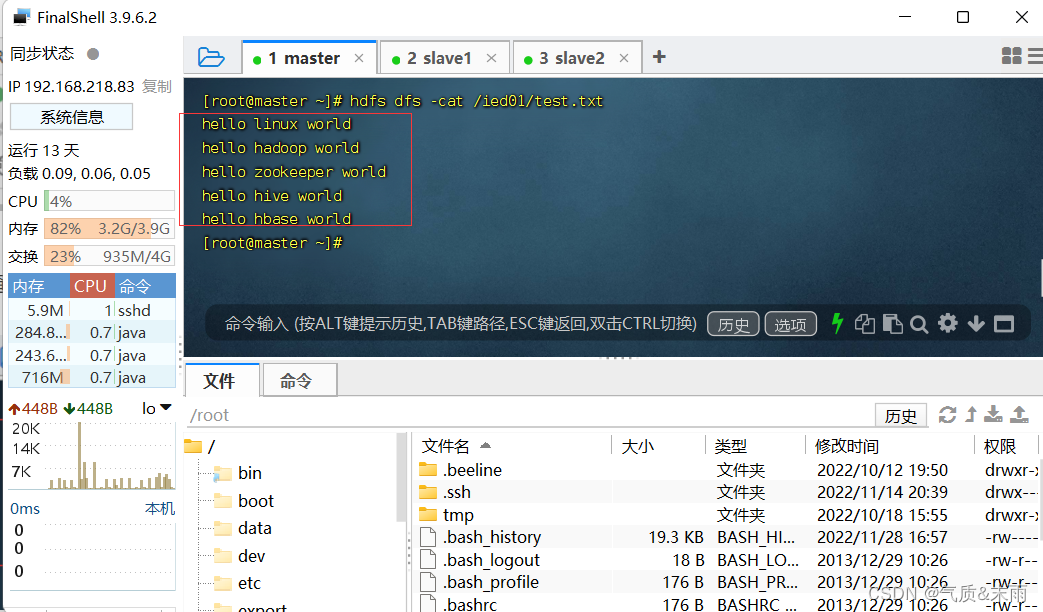
在linux查看hdfs 目录 /ied01/test.txt内容
4、读取HDFS文件
相当于Shell里的两个命令:hdfs dfs -cat 和 hdfs dfs -get
在net.aex.hdfs包里创建ReadFileOnHDFS类
1) 读取HDFS文件直接在控制台显示
准备读取 /ied01/test.txt 文件
(1) 编写read1() 方法
package net.aex.hdfs;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;import java.io.BufferedReader;
import java.io.FileReader;
import java.io.InputStreamReader;
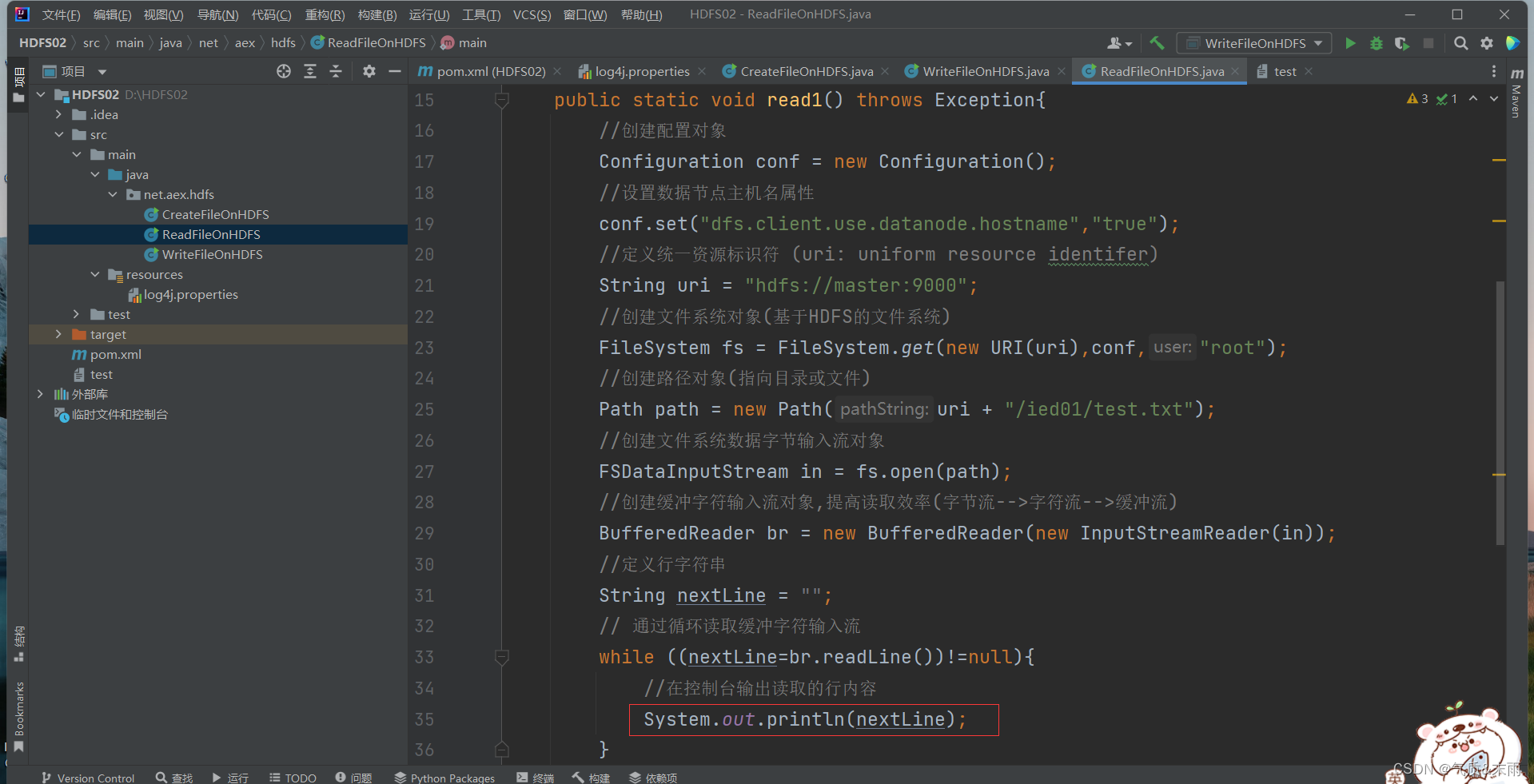
import java.net.URI;public class ReadFileOnHDFS {public static void read1() throws Exception{//创建配置对象Configuration conf = new Configuration();//设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf,"root");//创建路径对象(指向目录或文件)Path path = new Path(uri + "/ied01/test.txt");//创建文件系统数据字节输入流对象FSDataInputStream in = fs.open(path);//创建缓冲字符输入流对象,提高读取效率(字节流-->字符流-->缓冲流)BufferedReader br = new BufferedReader(new InputStreamReader(in));//定义行字符串String nextLine = "";// 通过循环读取缓冲字符输入流while ((nextLine=br.readLine())!=null){//在控制台输出读取的行内容System.out.println(nextLine);}//关闭缓冲字符输入流br.close();//关闭文件系统数据字节输入流in.close();//关闭文件系统fs.close();}public static void main(String[] args) throws Exception{read1();}
}
使用main方法调用 read1() 函数方法 查看结果 将/ied01/test.txt里的文件读取出来了
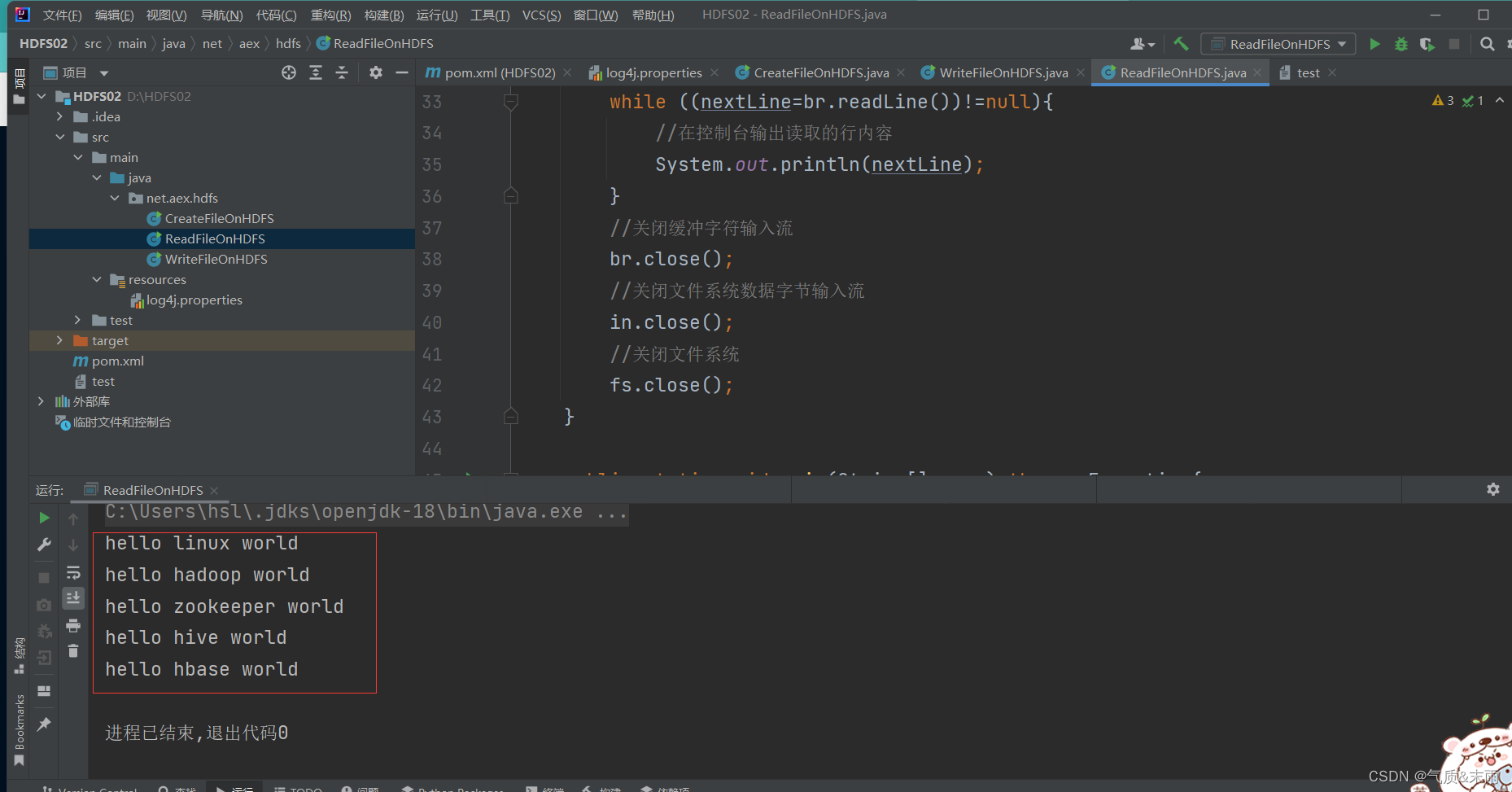
其实我们可以使用IOUtils类来简化代码,创建read_()函数方法
//read1_2()public static void read1_2() throws Exception{//创建配置对象Configuration conf = new Configuration();//设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf,"root");//创建路径对象(指向目录或文件)Path path = new Path(uri + "/ied01/test.txt");//创建文件系统数据字节输入流对象FSDataInputStream in = fs.open(path);//读取文件在控制台显示IOUtils.copyBytes(in,System.out,4096,false);//关闭文件系统数据字节输入流in.close();//关闭文件系统fs.close();}
使用main方法,调用read1_2() 函数方法 查看结果
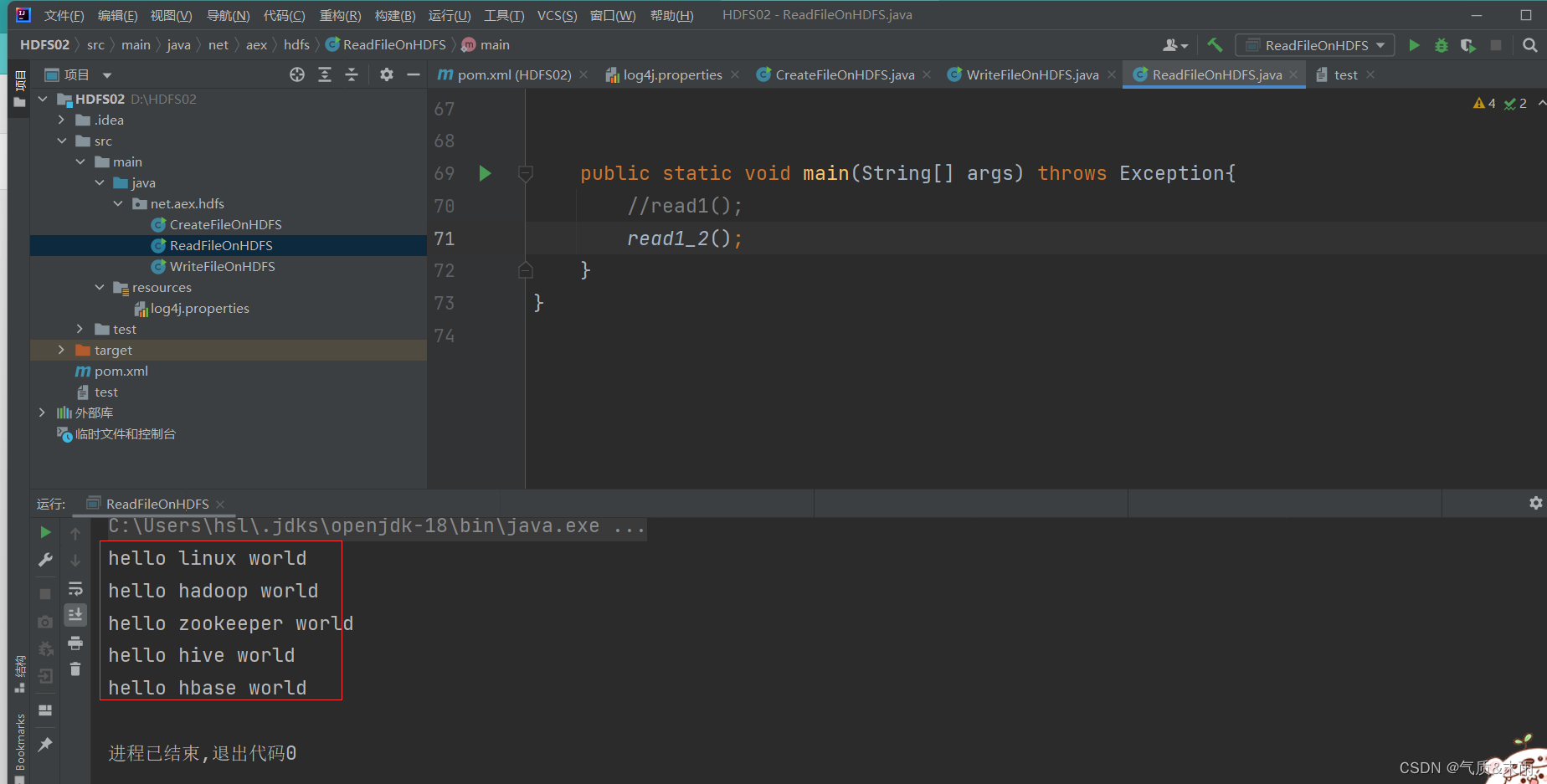
2) 读取HDFS文件,保存为本地文件
任务:将/ied01/test.txt 下载到项目下download目录里
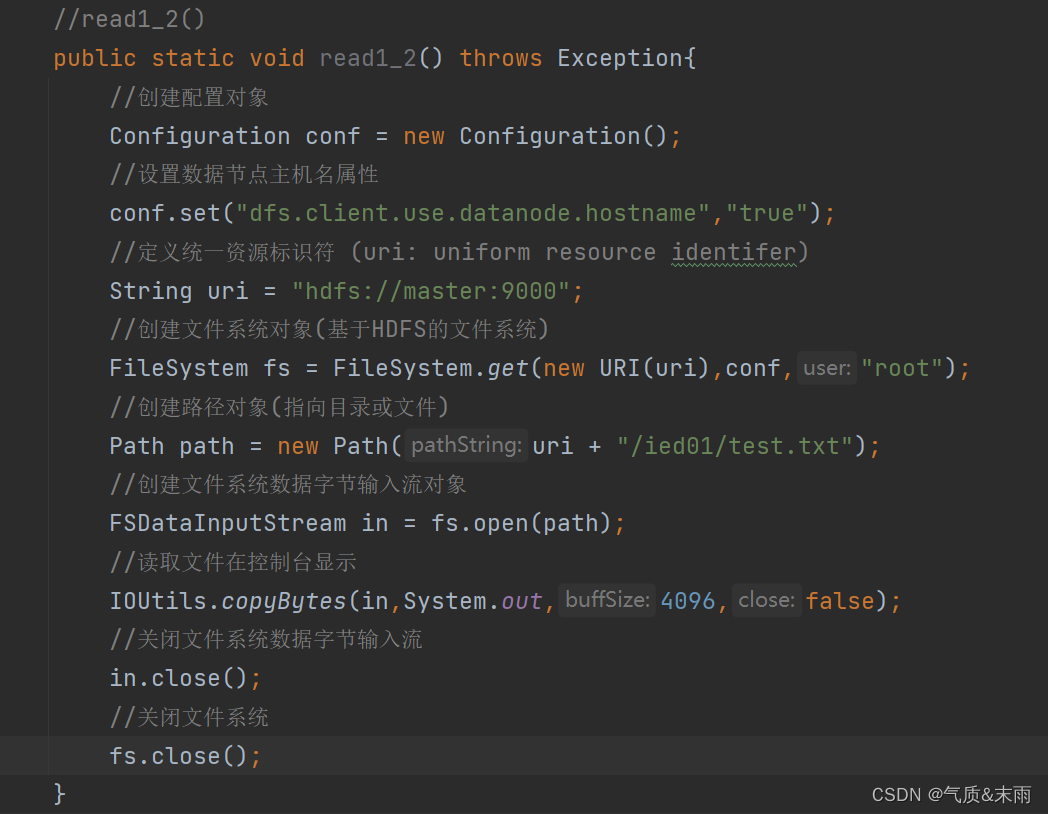
(1) 创建read2()方法
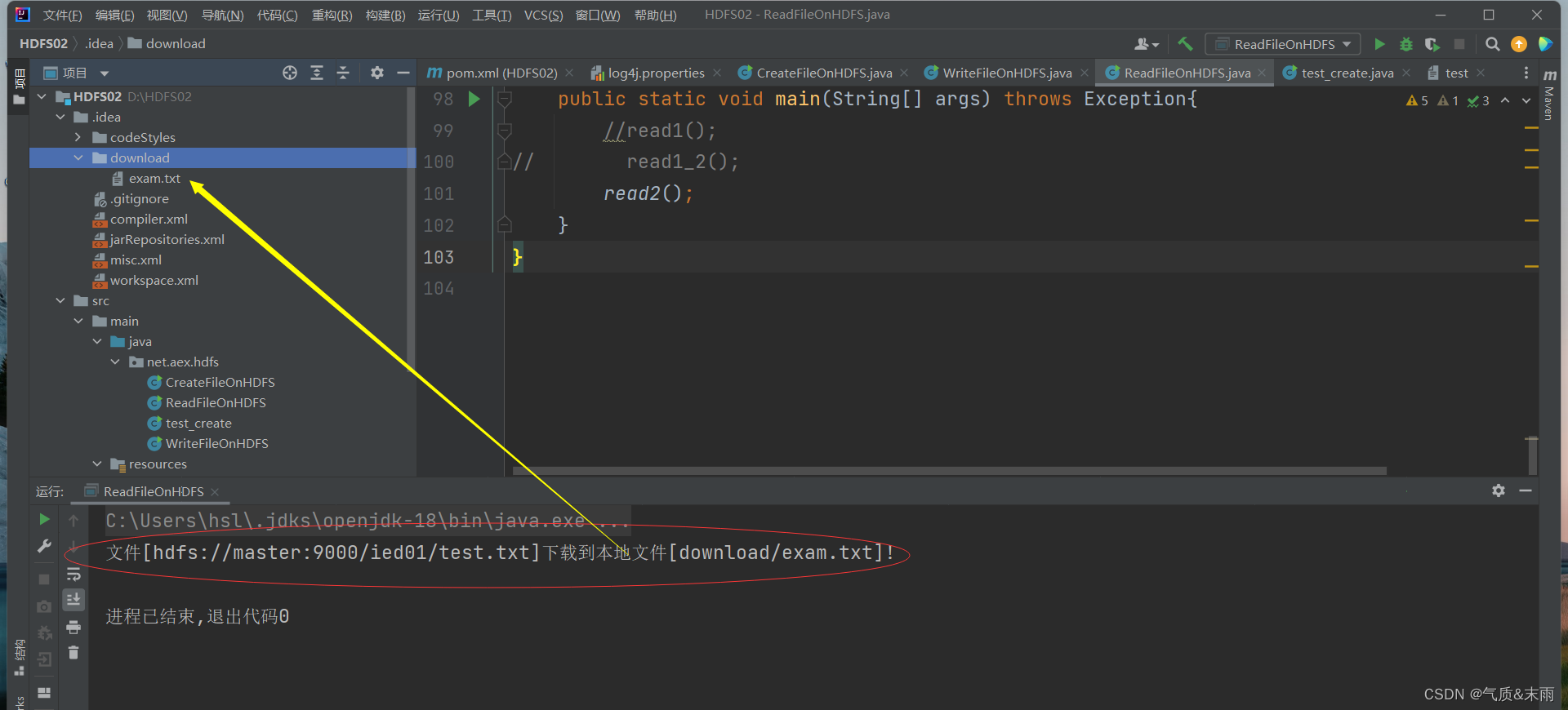
//read2()public static void read2() throws Exception{//创建配置对象Configuration conf = new Configuration();//设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf,"root");//创建路径对象(指向目录或文件)Path path = new Path(uri + "/ied01/test.txt");//创建文件系统数据字节输入流对象FSDataInputStream in = fs.open(path);//创建文件字节输出流FileOutputStream out = new FileOutputStream("D:\\HDFS02\\.idea\\download\\exam.txt");//读取HDFS文件(靠输入流),写入本地文件(靠输出流)IOUtils.copyBytes(in,out,conf);//关闭文件系统数据字节输入流in.close();//关闭文件字节输出流in.close();//关闭文件系统fs.close();//提示用户文件下载成功System.out.println("文件["+path+"]下载到本地文件[download/exam.txt]!");}
使用main方法,调用read2()函数,查看结果 exam.txt 文件已经下载到本地的download目录下了
5、重命名目录或文件
1) 重命名目录
任务:将/ied01 目录更名为 /lzy01
(1) 编写renameDir() 方法
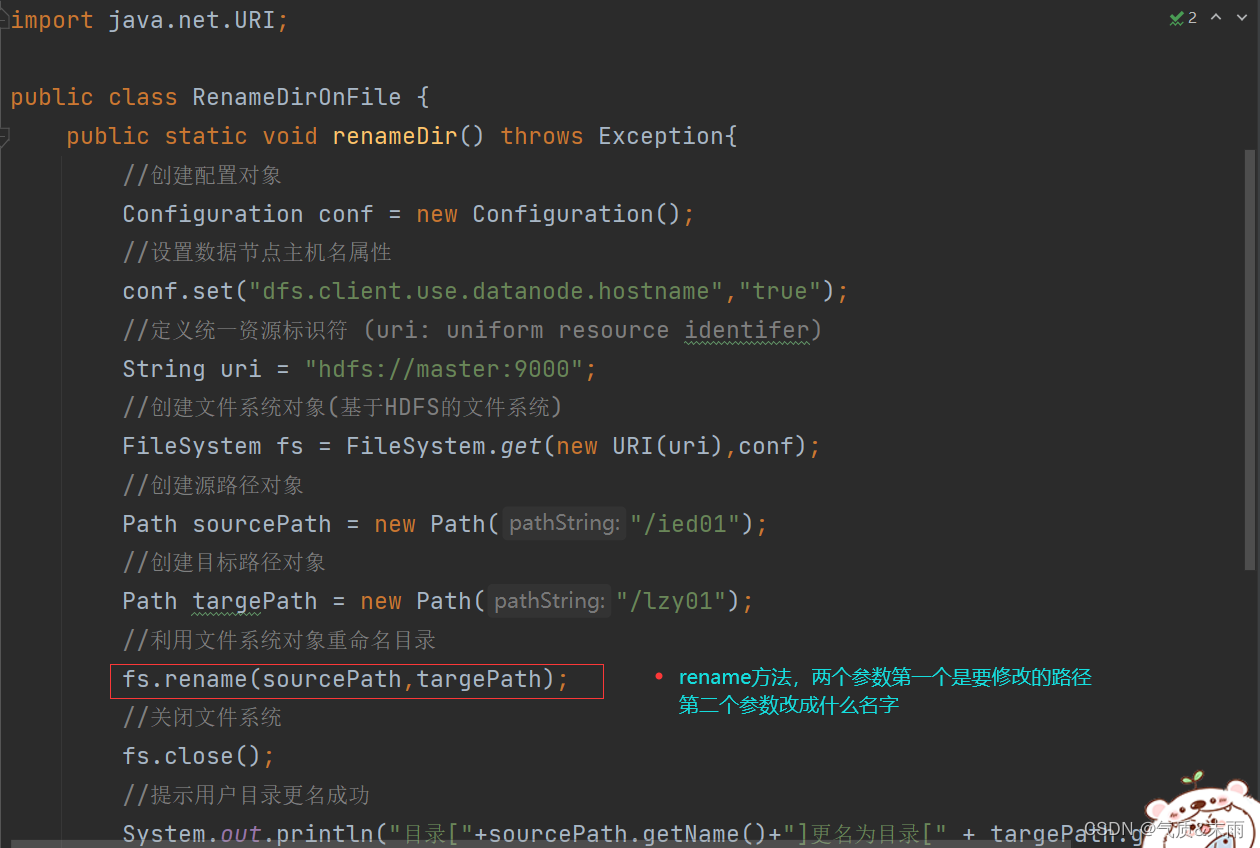
package net.aex.hdfs;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;import java.net.URI;public class RenameDirOnFile {public static void renameDir() throws Exception{//创建配置对象Configuration conf = new Configuration();//设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf);//创建源路径对象Path sourcePath = new Path("/ied01");//创建目标路径对象Path targePath = new Path("/lzy01");//利用文件系统对象重命名目录fs.rename(sourcePath,targePath);//关闭文件系统fs.close();//提示用户目录更名成功System.out.println("目录["+sourcePath.getName()+"]更名为目录[" + targePath.getName() + "]!");}public static void main(String[] args) throws Exception{renameDir();}
}
使用main方法调用renameDir()函数,查看结果 成功从/ied01 改为 lzy01
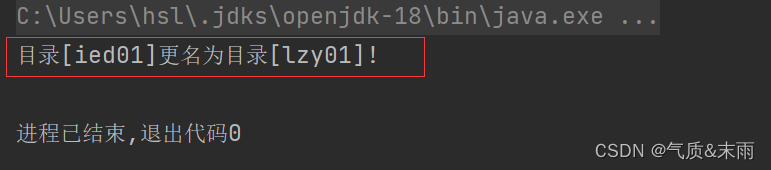
在webUI界面进行查看

2) 重命名文件
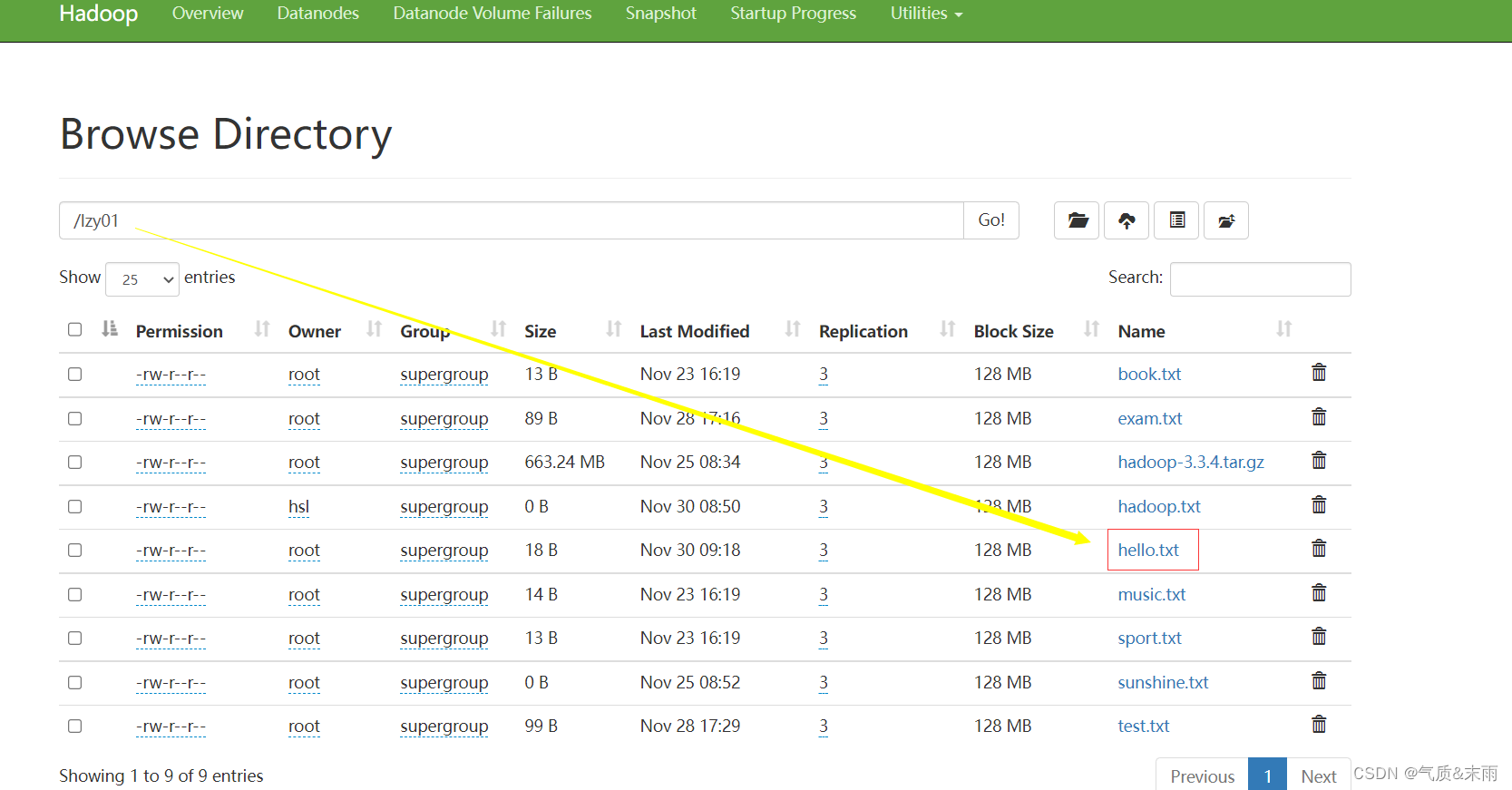
任务:将/lzy01目录下的hello.txt重名为hi.txt
(1)编写renameFile() 方法
主要需要两个对象的路径然后通过文件系统.rename()方法,把两个文件路径放进去进行更改
public static void renameFile() throws Exception{//创建配置对象Configuration conf = new Configuration();//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf);//创建源路径对象Path sourcePath = new Path("/lzy01/hello.txt");//目标对象//创建目标路径对象(指向文件)Path targePath = new Path("/lzy01/hi.txt");//利用文件系统重命名文件fs.rename(sourcePath,targePath);//关闭文件系统fs.close();//提示用户更更名成功System.out.println("文件[" + sourcePath.getName() + "]更名文件[" + targePath.getName() + "]!");}
使用main方法调用renameFile()方法,查看结果 更名成功

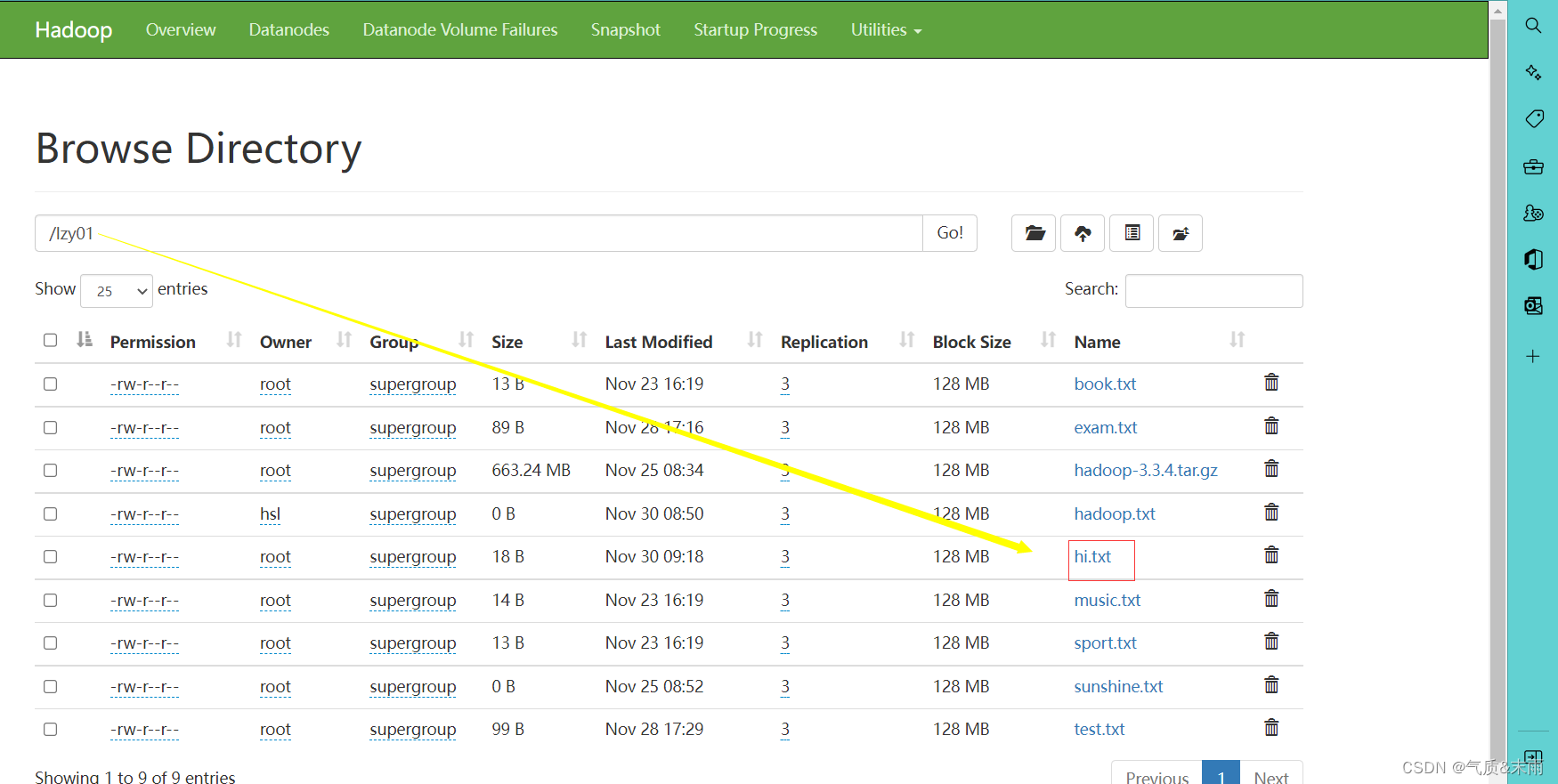
6、显示文件列表
在net.aex.hdfs 包里创建ListHDFSFiles类
1) 显示指定目录下文件全部信息
任务:显示/lzy01 目录下的文件列表
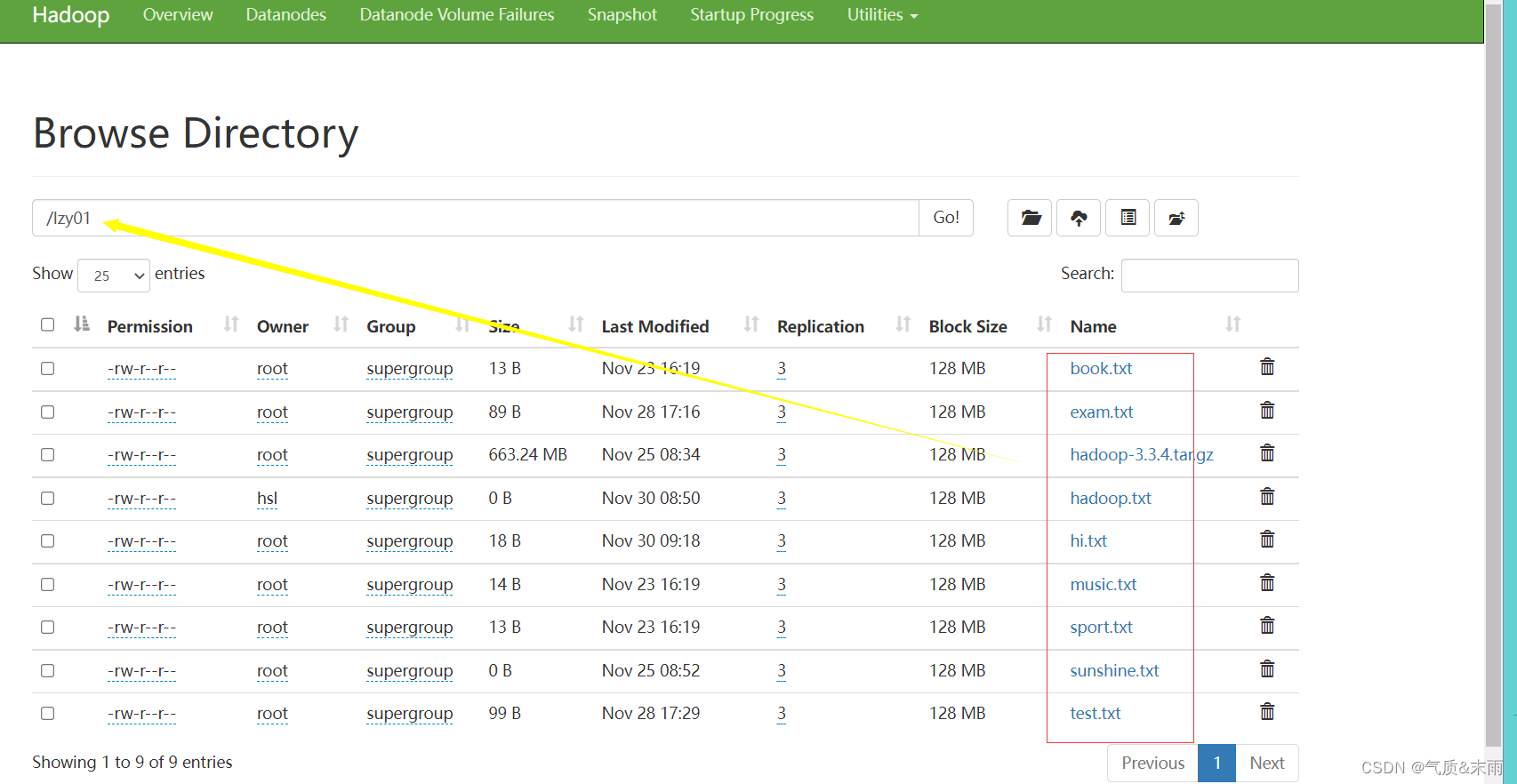
(1)、编写list1() 方法
package net.aex.hdfs;import jdk.jshell.execution.LoaderDelegate;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;import java.net.URI;public class ListHDFSFile {public static void list1() throws Exception{//设置配置对象Configuration conf = new Configuration();//设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri = "hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs = FileSystem.get(new URI(uri),conf,"root");//创建远程迭代器对象,泛型是位置文件状态类(相当于`hdfs dfs -ls -R /lzy01`)RemoteIterator<LocatedFileStatus> ri = fs.listFiles(new Path("/lzy01"),true);//遍历远程迭代器while (ri.hasNext()){System.out.println(ri.next());}}public static void main(String[] args) throws Exception{list1();}
}
使用main 方法,调用list1() 方法 查看结果 这些hdfs /lzy01 目录下的文件都读取出来了
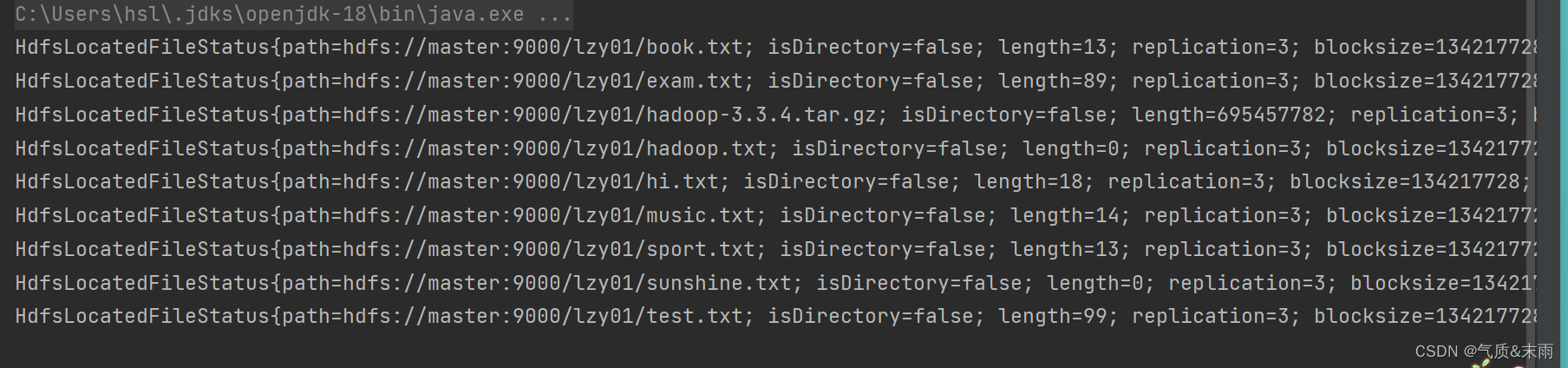 上述文件状态对象封装的有关信息,可以通过相应的方法来获取,比如getPath() 方法就可以获取路径信息,getLen()方法就可以获取文件长度信息
上述文件状态对象封装的有关信息,可以通过相应的方法来获取,比如getPath() 方法就可以获取路径信息,getLen()方法就可以获取文件长度信息
2) 显示指定目录下文件路径和长度信息
(1) 编写list2() 方法
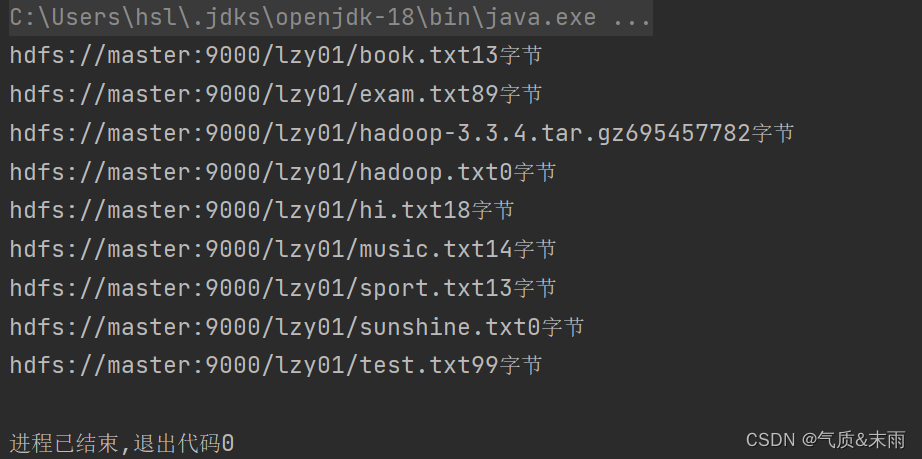
//list2()public static void list2() throws Exception{//创建配置对象Configuration conf = new Configuration();//设置数据节点主机名属性conf.set("dfs.client.use.datanode.hosename","true");//定义uri字符串String uri = "hdfs://master:9000";//创建文件系统对象FileSystem fs = FileSystem.get(new URI(uri),conf,"root");//创建远程迭代器对象,泛型是位置文件状态类(相当于`hdfs dfs -ls -R /lzy01`)RemoteIterator<LocatedFileStatus> ri = fs.listFiles(new Path("/lzy01"),true);//遍历远程迭代器while (ri.hasNext()){LocatedFileStatus lfs = ri.next();System.out.println(lfs.getPath() + "" + lfs.getLen() + "字节");}}
使用main方法调用list2() 方法,查看结果 /lzy01目录下的文件的字节都显示出来了
7、获取文件块信息
任务:获取/lzy01/hadoop-3.3.4.tar.gz文件块信息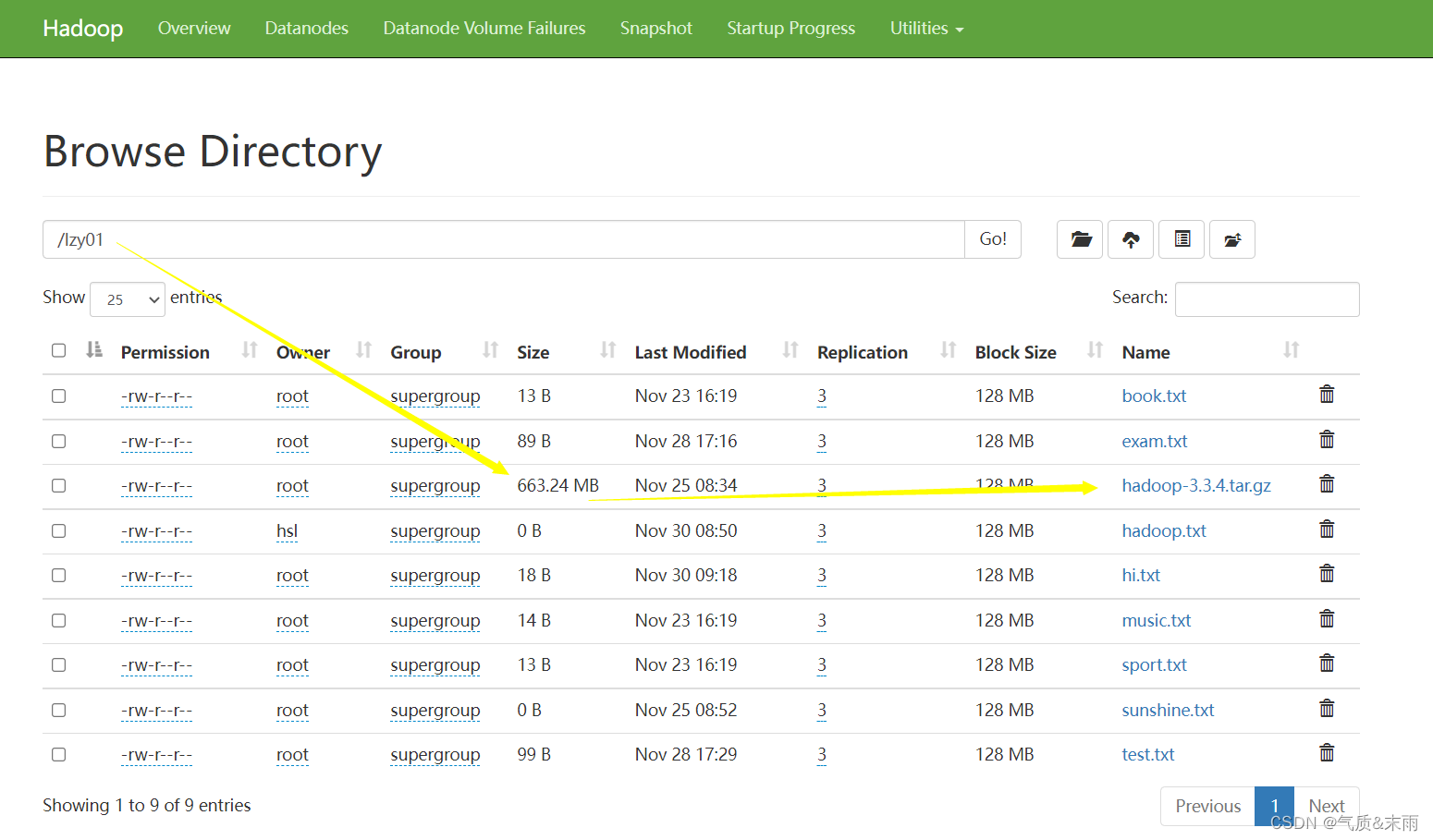
hadoop压缩包会分割成6个文件块
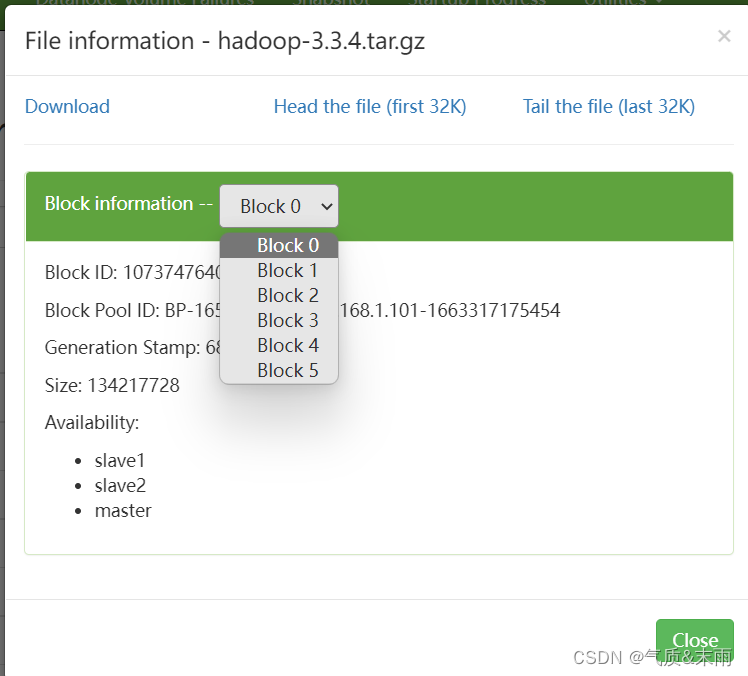
在net.aex.hdfs包里创建GetBlockLocations类
相关文章:
HDFS Java API 操作
文章目录 HDFS Java API操作零、启动hadoop一、HDFS常见类接口与方法1、hdfs 常见类与接口2、FileSystem 的常用方法 二、Java 创建Hadoop项目1、创建文件夹2、打开Java IDEA1) 新建项目2) 选择Maven 三、配置环境1、添加相关依赖2、创建日志属性文件 四、Java API操作1、在HDF…...
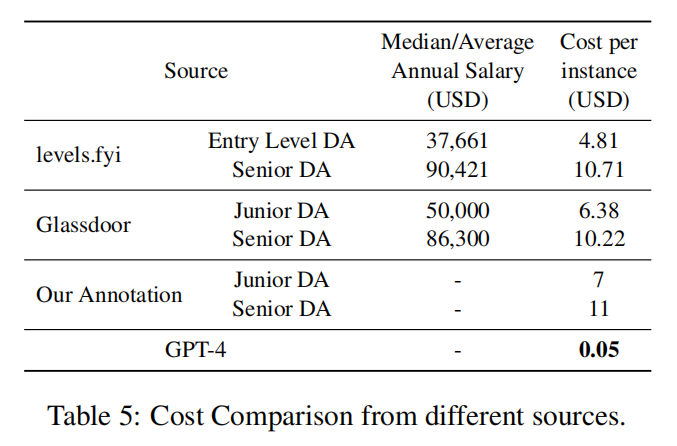
论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】
文章目录 论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】背景:数据分析师工作范围基于GPT-4的端到端数据分析框架将GPT-4作为数据分析师的框架的流程图 实验分析评估指标表1:GPT-4性能表现表2&…...
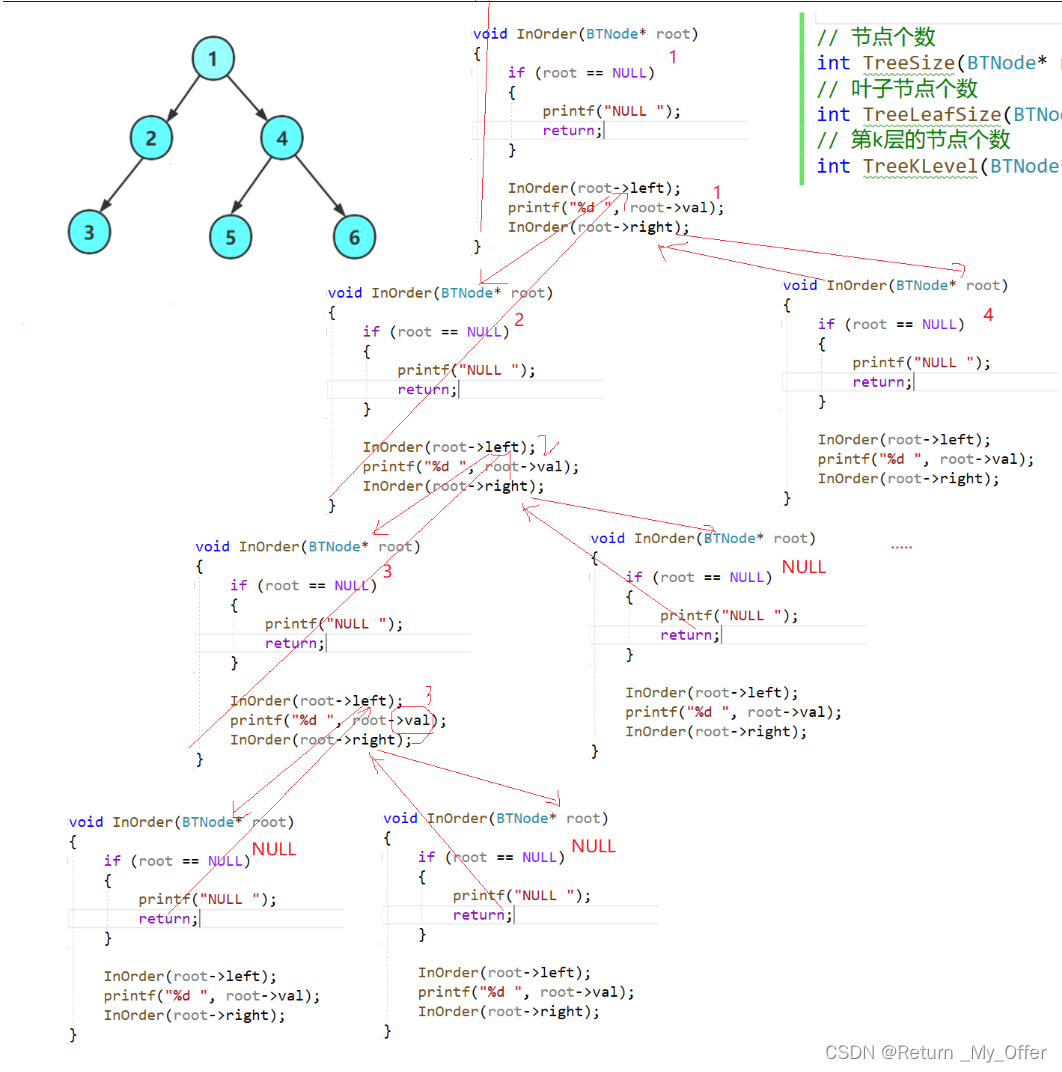
【数据结构】:二叉树与堆排序的实现
1.树概念及结构(了解) 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的有一个特殊的结点&#…...

纯css手写switch
CSS 手写switch 纯css手写switchcss变量 纯css手写switch 思路: switch需要的元素有:开关背景、开关按钮。点击按钮后,背景色变化,按钮颜色变化,呈现开关打开状态。 利用typecheckbox,来实现switch效果(修…...

PyTorch 深度学习之处理多维特征的输入Multiple Dimension Input(六)
1.Multiple Dimension Logistic Regression Model 1.1 Mini-Batch (N samples) 8D->1D 8D->2D 8D->6D 1.2 Neural Network 学习能力太好也不行(学习到的是数据集中的噪声),最好的是要泛化能力,超参数尝试 Example, Arti…...

LeetCode【438】找到字符串中所有字母异位词
题目: 注意:下面代码勉强通过,每次都对窗口内字符排序。然后比较字符串。 代码: public List<Integer> findAnagrams(String s, String p) {int start 0, end p.length() - 1;List<Integer> result new ArrayL…...
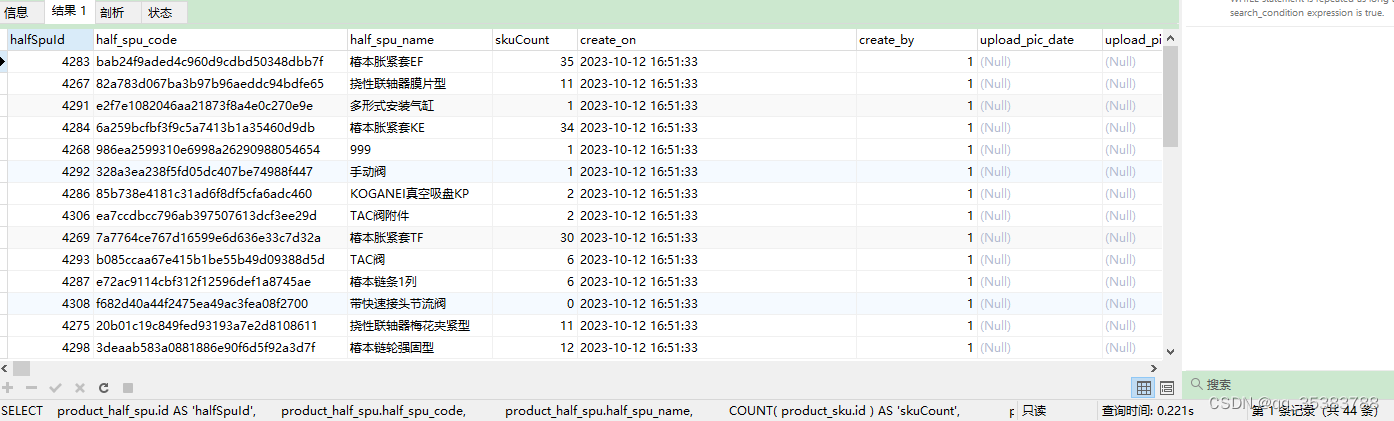
关于LEFT JOIN的一次理解
先看一段例子: SELECTproduct_half_spu.id AS halfSpuId,product_half_spu.half_spu_code,product_half_spu.half_spu_name,COUNT( product_sku.id ) AS skuCount,product_half_spu.create_on,product_half_spu.create_by,product_half_spu.upload_pic_date,produc…...

各报文段格式集合
数据链路层-- MAC帧 前导码8B:数据链路层将封装好的MAC帧交付给物理层进行发送,物理层在发送MAC帧前,还要在前面添加8字节的前导码(分为7字节的前同步码1字节的帧开始定界符)MAC地址长度6B数据长度46~1500B…...

【算法-动态规划】最长公共子序列
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kuan 的首页,持续学…...
区块链游戏的开发流程
链游(Blockchain Games)的开发流程与传统游戏开发有许多相似之处,但它涉及到区块链技术的集成和智能合约的开发。以下是链游的一般开发流程,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司&…...

目标检测网络系列——YOLO V2
文章目录 YOLO9000better,更准batch Normalization高分辨率的训练使用anchor锚框尺寸的选择——聚类锚框集成改进——直接预测bounding box细粒度的特征图——passthrough layer多尺度训练数据集比对实验VOC 2007VOC 2012COCOFaster,更快网络模型——Darknet19训练方法Strong…...
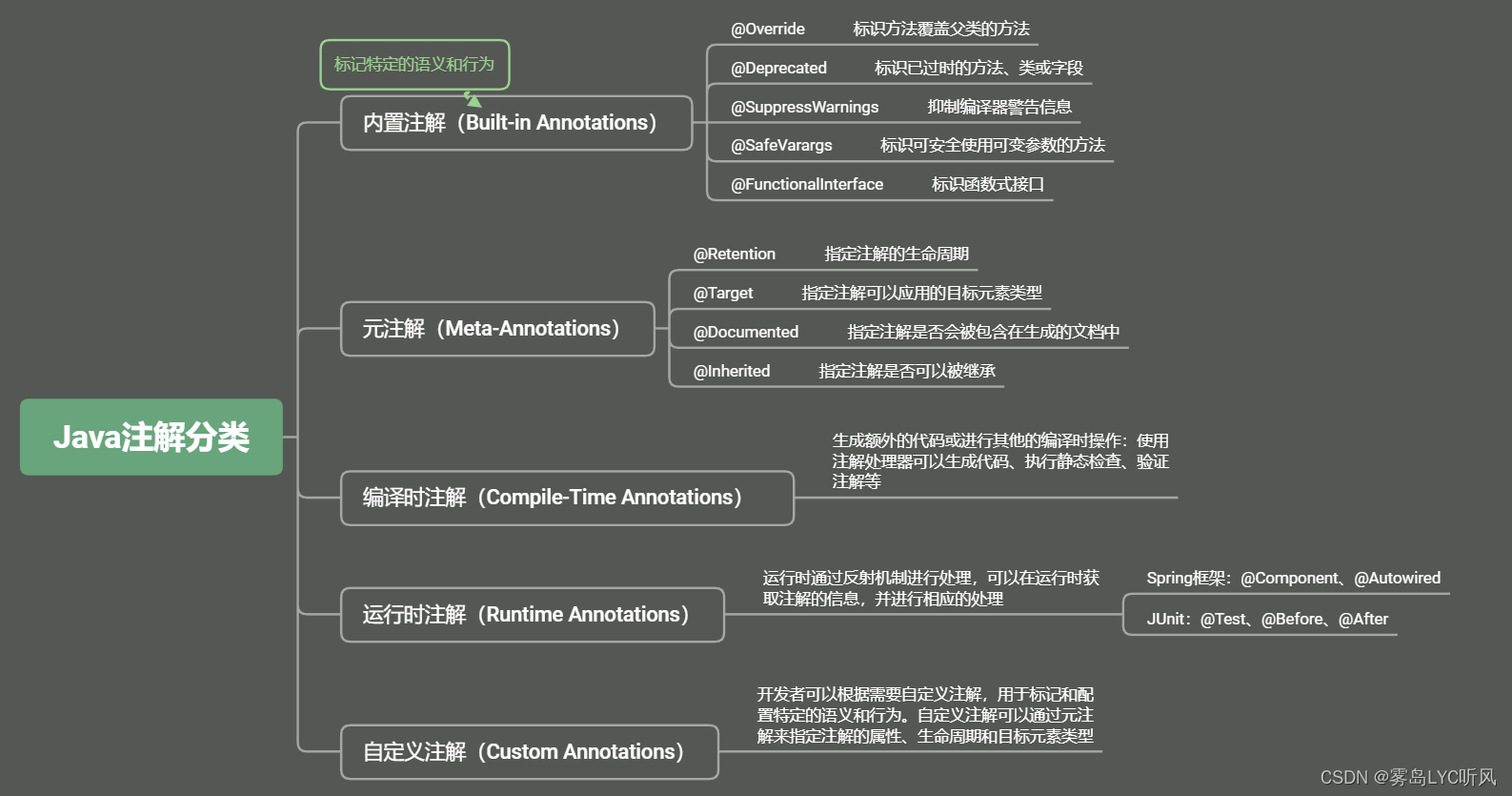
15. Java反射和注解
Java —— 反射和注解 1. 反射2. 注解 1. 反射 动态语言:变量的类型和属性可以在运行时动态确定,而不需要在编译时指定 常见动态语言:Python,JavaScript,Ruby,PHP,Perl;常见静态语言…...
pdf处理工具 Enfocus PitStop Pro 2022 中文 for mac
Enfocus PitStop Pro 2022是一款专业的PDF预检和编辑软件,旨在帮助用户提高生产效率、确保印刷品质量并减少错误。以下是该软件的一些特色功能: PDF预检。PitStop Pro可以自动检测和修复常见的PDF文件问题,如缺失字体、图像分辨率低、颜色空…...
微信小程序入门开发教程
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《微信小程序开发实战》。🎯Ἲ…...

php函数
1. strstr() 返回a在b中的第一个位置 2.substr() 截取字符串 3.PHP字符串函数parse_str(将字符串解析成多个变量)-CSDN博客 4.explode() 字符串分割为数组 5.trim() 1.去除字符串两边的 空白字符 2.去除指定字符 6.extract()函数从数组里…...

3.3 封装性
思维导图: 3.3.1 为什么要封装 ### 3.3.1 为什么要封装 **封装**,在Java的面向对象编程中,是一个核心的思想。它主要是为了保护对象的状态不被外部随意修改,确保数据的完整性和安全性。 #### **核心思想:** - 保护…...

Redis魔法:点燃分布式锁的奇妙实现
分布式锁是一种用于在分布式系统中控制对共享资源的访问的锁。它与传统的单机锁不同,因为它需要在多个节点之间协调以确保互斥访问。 本文将介绍什么是分布式锁,以及使用Redis实现分布式锁的几种方案。 一、前言 了解分布式锁之前,需要先了…...

iOS 项目避坑:多个分类中方法重复实现检测
#前言 在项目中,我们经常会使用分类 -> category。category在实际项目中一般有两个左右:1.给已有class增加方法,扩充起能力、2.将代码打散到多个文件中,避免因为一个类过于复杂而导致代码篇幅过长(应用于viewController中很好用) 但是 category 也有很多弊端~ **首…...
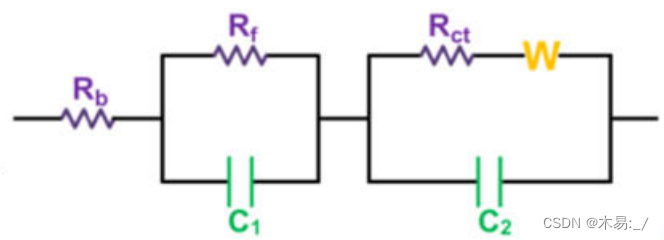
【003】EIS数据分析_#LIB
EIS数据分析 1. EIS测试及数据获取2. EIS数据分析2.1 EIS曲线划分 1. EIS测试及数据获取 点击查看往期介绍 2. EIS数据分析 2.1 EIS曲线划分 一般来说,实轴处的截获表示体电阻(Rb),它反映了电解质,隔膜和电极的电导率。高频区的半圆对应于…...
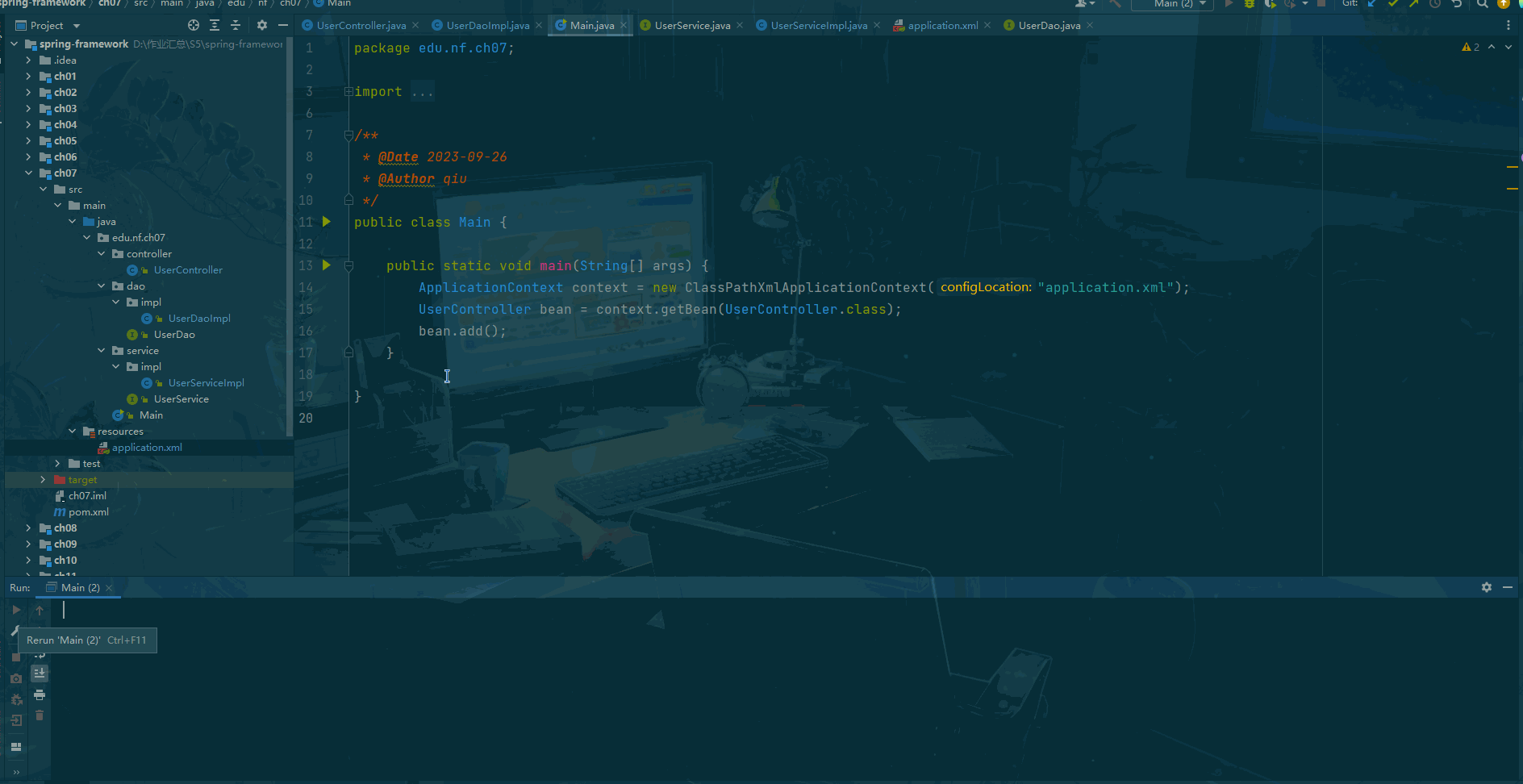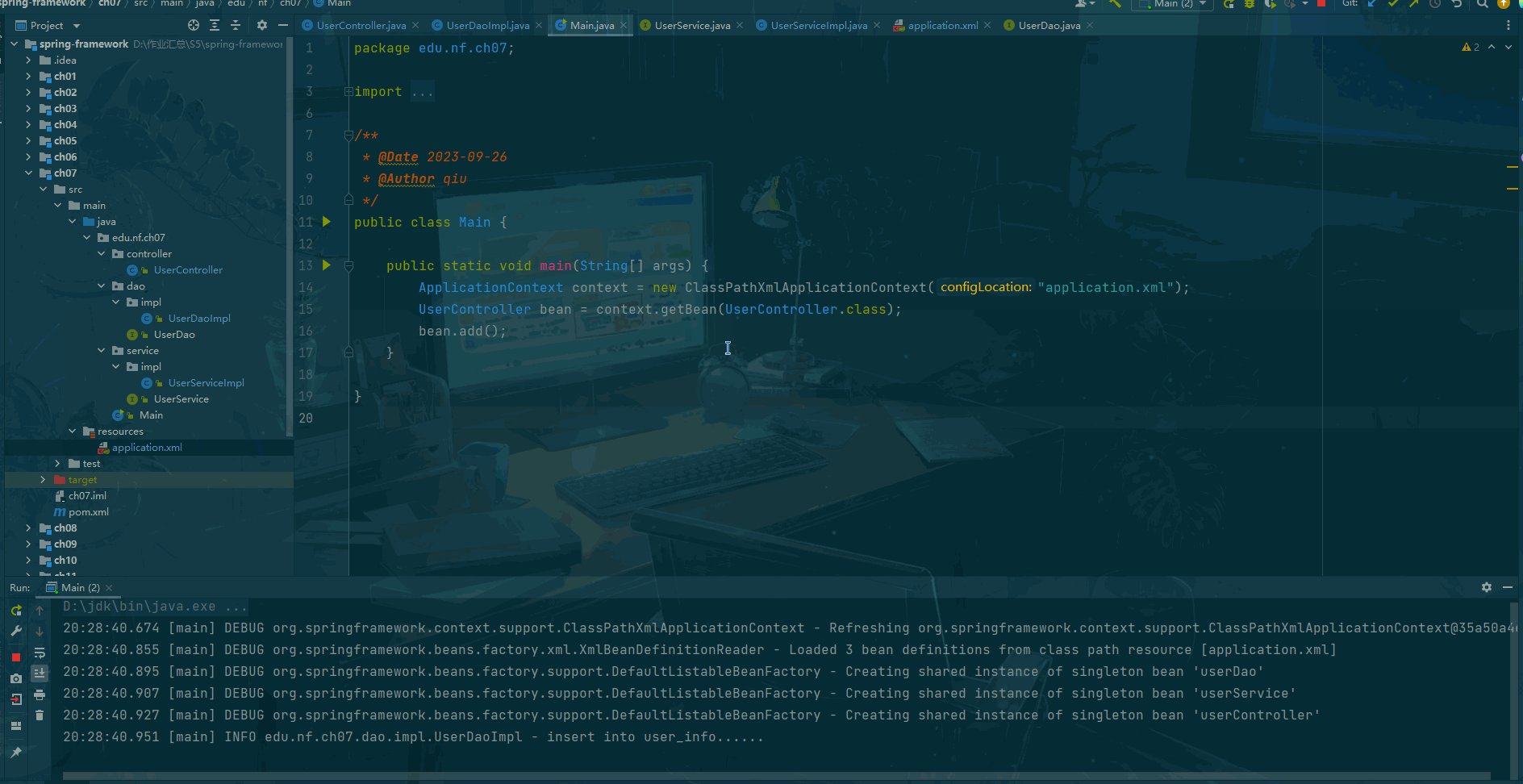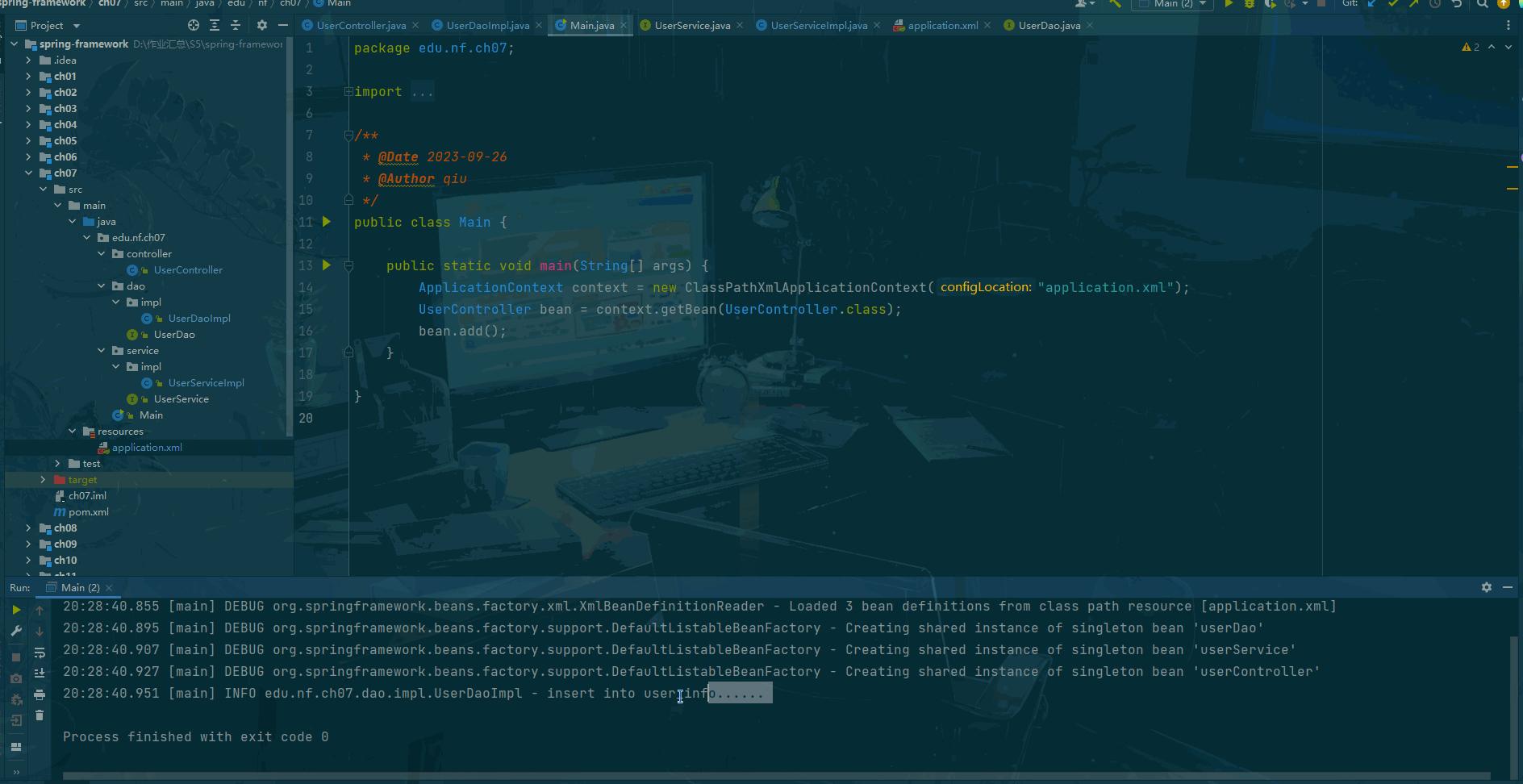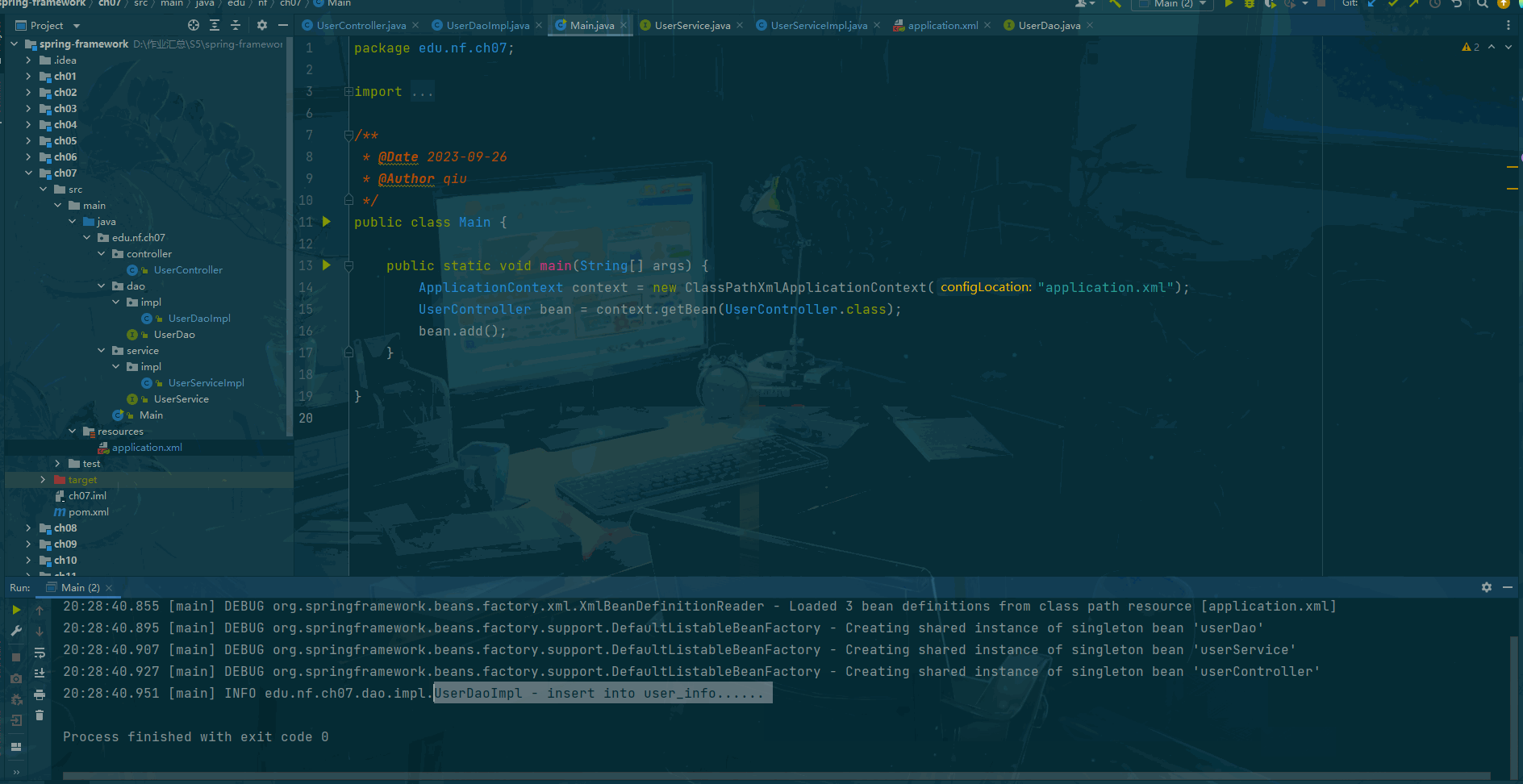
Sprint framework Day07:注解结合 xml 配置
前言 Spring注解结合XML配置是指在Spring应用中,使用注解和XML配置的方式来进行Bean的定义、依赖注入和其他配置。这种方式可以充分利用Spring框架的注解和XML配置两种不同的配置方式的特点。 在Spring框架中,我们可以使用注解来定义Bean,如…...

GD32F470驱动ST7735 TFT彩屏移植指南
1. 0.96英寸ST7735驱动TFT彩屏模块移植手册1.1 模块选型与硬件特性分析0.96英寸TFT液晶显示模块在嵌入式人机交互场景中具有体积小、功耗低、成本可控等显著优势。本项目采用的IPS面板型号为ST7735S驱动的80160 RGB分辨率显示屏,其核心价值在于在极小尺寸下实现良好…...
)
保姆级避坑指南:在Jetson Nano/Xavier上安装PyTorch 2.3和torchvision 0.18(JetPack 6.0)
从零到一:Jetson Nano/Xavier上PyTorch 2.3与torchvision 0.18完美安装手册 当你第一次拿到Jetson开发板时,那种想要立刻跑通第一个PyTorch模型的兴奋感,我完全理解。但现实往往会在安装环节给你当头一棒——ARM架构的特殊性、JetPack版本与…...
Xilinx FFT IP核仿真报错?手把手教你解决‘add_1 must be in range‘和‘inconsistent empty‘问题
Xilinx FFT IP核仿真报错?手把手教你解决add_1 must be in range和inconsistent empty问题 在FPGA开发中,Xilinx的FFT IP核因其高性能和易用性而广受欢迎。然而,即使是经验丰富的工程师,在Vivado仿真过程中也难免会遇到一些令人头…...

从Matlab到激光切割:手把手教你用DXFLib生成可用的工程图文件
从Matlab到激光切割:用DXFLib实现工程图自动化生成全流程 在工业设计和制造领域,数学建模与物理实现之间的桥梁往往是最容易被忽视的环节。许多工程师能够熟练使用Matlab进行复杂计算和仿真,却在将数字模型转化为实体产品时遇到瓶颈。本文将带…...

CYBER-VISION零号协议在网络安全领域的应用:威胁情报智能分析
CYBER-VISION零号协议在网络安全领域的应用:威胁情报智能分析 每天,安全运营中心(SOC)的告警大屏上,成千上万条日志像瀑布一样滚动。分析师小王紧盯着屏幕,试图从这些看似无关的“噪音”中,分辨…...

Z-Image-GGUF企业应用:跨境电商用Z-Image生成多语言商品场景图
Z-Image-GGUF企业应用:跨境电商用Z-Image生成多语言商品场景图 1. 快速开始:30秒上手Z-Image 你是不是也遇到过这样的烦恼?做跨境电商,每个商品都要配图,不同国家还要不同场景,找设计师太贵,自…...

在Java中如何验证环境是否配置成功
实现Java环境配置成功最直接的方法是实施Java -version命令并输出版本信息,同时确认JAVA_HOME指向JDK根目录,PATH包含其bin路径,并能正常运行javac -version和编译操作Hellon World程序。在Java开发中,验证环境配置成功最直接的方…...

Java锁升级深度解析:从偏向锁到重量级锁,一文读懂锁的“进化”之路
在Java并发编程中,synchronized关键字无疑是最基础、最常用的同步工具。很多新手对它的认知,可能还停留在“重量级锁”“性能一般”的层面,但实际上,JDK1.6之后,synchronized进行了重大优化,引入了偏向锁、…...

永磁同步电机三矢量MPC模型预测电流控制 参考文献:《永磁同步电机三矢量模型预测电流控制_徐艳...
永磁同步电机三矢量MPC模型预测电流控制 参考文献:《永磁同步电机三矢量模型预测电流控制_徐艳平》 (1)采用id0,速度环 PI 控制器的输出作为q轴电流的给定。 在核心模块 TV-MPCC 中,首先根据电流给定值和反馈值计算三个…...

计算机毕设 java基于微信小程序点餐系统的设计与实现 微信小程序智能点餐平台开发 基于 SpringBoot 的餐饮在线点餐系统设计
计算机毕设 java基于微信小程序点餐系统的设计与实现pmz399(配套有源码 程序 mysql 数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联 xi 可分享随着移动互联网的普及和微信小程序的广泛应用,“互联网 餐饮” 成为行业…...