【动手学深度学习-Pytorch版】BERT预测系列——用于预测的BERT数据集
本小节的主要任务即是将wiki数据集转成BERT输入序列,具体的任务包括:
- 读取wiki数据集
- 生成下一句预测任务的数据—>主要用于
_get_nsp_data_from_paragraph函数 - 从输入paragraph生成用于下一句预测的训练样本:
_get_nsp_data_from_paragraph - 生成遮蔽语言模型任务的数据—>将生成的tokens的一部分随机换成masked的tokens,用于
_get_mlm_data_from_tokens函数 - 得到掩蔽语言模型的数据:
_get_mlm_data_from_tokens函数 - 将输入信息附加
特殊词元< mask > - 下载并生成WikiText-2数据集,并从中生成预训练样本:
load_data_wiki函数 - 得到
train_iter与vocab
"""较小的语料库WikiText-2"""
import os
import random
import torch
from d2l import torch as d2l
#@save
d2l.DATA_HUB['wikitext-2'] = ('https://s3.amazonaws.com/research.metamind.io/wikitext/''wikitext-2-v1.zip', '3c914d17d80b1459be871a5039ac23e752a53cbe')
"""仅使用句号作为分隔符来拆分句子"""
#@save
def _read_wiki(data_dir):file_name = os.path.join(data_dir, 'wiki.train.tokens')with open(file_name, 'r',encoding='utf-8') as f:lines = f.readlines()# 大写字母转换为小写字母paragraphs = [line.strip().lower().split(' . ')for line in lines if len(line.split(' . ')) >= 2]random.shuffle(paragraphs)return paragraphs# 生成下一句预测任务的数据--->用于:_get_nsp_data_from_paragraph函数
#@save
def _get_next_sentence(sentence, next_sentence, paragraphs):if random.random() < 0.5:is_next = Trueelse:# paragraphs是三重列表的嵌套next_sentence = random.choice(random.choice(paragraphs))is_next = Falsereturn sentence, next_sentence, is_next"""
下面的函数通过调用_get_next_sentence函数从输入paragraph生成用于下一句预测的训练样本。
这里paragraph是句子列表,其中每个句子都是词元列表。自变量max_len指定预训练期间的BERT输入序列的最大长度。
"""
#@save
def _get_nsp_data_from_paragraph(paragraph, paragraphs, vocab, max_len):nsp_data_from_paragraph = []"""nsp_data_from_paragraph中的每一个元素都是(tokens,segments,is_next)(词元,句子属性,是否是下一个句子)"""for i in range(len(paragraph) - 1):tokens_a, tokens_b, is_next = _get_next_sentence(paragraph[i], paragraph[i + 1], paragraphs)# 考虑1个'<cls>'词元和2个'<sep>'词元if len(tokens_a) + len(tokens_b) + 3 > max_len:continuetokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)nsp_data_from_paragraph.append((tokens, segments, is_next))return nsp_data_from_paragraph# 生成遮蔽语言模型任务的数据---》将生成的tokens的一部分随机换成masked的tokens
# -》》用于_get_mlm_data_from_tokens函数
"""
输入:
1、tokens:表示BERT输入序列的词元的列表
2、candidate_pred_positions:不包括特殊词元的BERT输入序列的词元索引的列表(特殊词元在遮蔽语言模型任务中不被预测)
3、num_mlm_preds:指示预测的数量(选择15%要预测的随机词元)
"""
#@save
def _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds,vocab):# 为遮蔽语言模型的输入创建新的词元副本,其中输入可能包含替换的“<mask>”或随机词元mlm_input_tokens = [token for token in tokens]pred_positions_and_labels = []# 打乱后用于在遮蔽语言模型任务中获取15%的随机词元进行预测random.shuffle(candidate_pred_positions)for mlm_pred_position in candidate_pred_positions:# 如果生成的预测数量已经超过了最大的预测值 15% 就停止if len(pred_positions_and_labels) >= num_mlm_preds:breakmasked_token = None# 80%的时间:将词替换为“<mask>”词元if random.random() < 0.8:masked_token = '<mask>'else:# 10%的时间:保持词不变if random.random() < 0.5:masked_token = tokens[mlm_pred_position]# 10%的时间:用随机词替换该词else:masked_token = random.choice(vocab.idx_to_token)# 将masked的位置填入随机词元或保持不变或<mask>mlm_input_tokens[mlm_pred_position] = masked_tokenpred_positions_and_labels.append((mlm_pred_position, tokens[mlm_pred_position]))return mlm_input_tokens, pred_positions_and_labels"""
输入:BERT输入序列的tokens
输出:
1、输入词元的索引【词元已经被masked】
2、发生预测的词元索引
3、发生预测的标签索引
"""
"""当然,会有相关的词元会被masked"""
#@save
def _get_mlm_data_from_tokens(tokens, vocab):candidate_pred_positions = []# tokens是一个字符串列表for i, token in enumerate(tokens):# 在遮蔽语言模型任务中不会预测特殊词元if token in ['<cls>', '<sep>']:continuecandidate_pred_positions.append(i)# 遮蔽语言模型任务中预测15%的随机词元num_mlm_preds = max(1, round(len(tokens) * 0.15))mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds, vocab)pred_positions_and_labels = sorted(pred_positions_and_labels,key=lambda x: x[0])pred_positions = [v[0] for v in pred_positions_and_labels]mlm_pred_labels = [v[1] for v in pred_positions_and_labels]return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]"""
将特殊的“<mask>”词元附加到输入
"""
#@save
def _pad_bert_inputs(examples, max_len, vocab):max_num_mlm_preds = round(max_len * 0.15)all_token_ids, all_segments, valid_lens, = [], [], []all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], []nsp_labels = []for (token_ids, pred_positions, mlm_pred_label_ids, segments,is_next) in examples:# 如果长度不够会加入<pad>all_token_ids.append(torch.tensor(token_ids + [vocab['<pad>']] * (max_len - len(token_ids)), dtype=torch.long))# 而且所有的<pad>的segments都是0all_segments.append(torch.tensor(segments + [0] * (max_len - len(segments)), dtype=torch.long))# valid_lens不包括'<pad>'的计数 只是对token_ids计数,并不是对all_token_ids计数valid_lens.append(torch.tensor(len(token_ids), dtype=torch.float32))all_pred_positions.append(torch.tensor(pred_positions + [0] * (max_num_mlm_preds - len(pred_positions)), dtype=torch.long))# 填充词元的预测将通过乘以0权重在损失中过滤掉all_mlm_weights.append(torch.tensor([1.0] * len(mlm_pred_label_ids) + [0.0] * (max_num_mlm_preds - len(pred_positions)),dtype=torch.float32))all_mlm_labels.append(torch.tensor(mlm_pred_label_ids + [0] * (max_num_mlm_preds - len(mlm_pred_label_ids)), dtype=torch.long))nsp_labels.append(torch.tensor(is_next, dtype=torch.long))return (all_token_ids, all_segments, valid_lens, all_pred_positions,all_mlm_weights, all_mlm_labels, nsp_labels)#@save
class _WikiTextDataset(torch.utils.data.Dataset):def __init__(self, paragraphs, max_len):# 输入paragraphs[i]是代表段落的句子字符串列表;# 而输出paragraphs[i]是代表段落的句子列表,其中每个句子都是词元列表paragraphs = [d2l.tokenize(paragraph, token='word') for paragraph in paragraphs]sentences = [sentence for paragraph in paragraphsfor sentence in paragraph]self.vocab = d2l.Vocab(sentences, min_freq=5, reserved_tokens=['<pad>', '<mask>', '<cls>', '<sep>'])# 获取下一句子预测任务的数据examples = []for paragraph in paragraphs:examples.extend(_get_nsp_data_from_paragraph(paragraph, paragraphs, self.vocab, max_len))# 获取遮蔽语言模型任务的数据examples = [(_get_mlm_data_from_tokens(tokens, self.vocab)+ (segments, is_next))for tokens, segments, is_next in examples]# 填充输入(self.all_token_ids, self.all_segments, self.valid_lens,self.all_pred_positions, self.all_mlm_weights,self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs(examples, max_len, self.vocab)def __getitem__(self, idx):return (self.all_token_ids[idx], self.all_segments[idx],self.valid_lens[idx], self.all_pred_positions[idx],self.all_mlm_weights[idx], self.all_mlm_labels[idx],self.nsp_labels[idx])def __len__(self):return len(self.all_token_ids)"""下载并生成WikiText-2数据集,并从中生成预训练样本"""
#@save
def load_data_wiki(batch_size, max_len):"""加载WikiText-2数据集"""num_workers = d2l.get_dataloader_workers()data_dir = d2l.download_extract('wikitext-2', 'wikitext-2')paragraphs = _read_wiki(data_dir)train_set = _WikiTextDataset(paragraphs, max_len)train_iter = torch.utils.data.DataLoader(train_set, batch_size,shuffle=True, num_workers=num_workers)return train_iter, train_set.vocab
"""将批量大小设置为512,将BERT输入序列的最大长度设置为64,我们打印出小批量的BERT预训练样本的形状。"""
"""同时会有(64*0.15)的遮蔽语言模型需要预测的位置"""
batch_size, max_len = 512, 64
train_iter, vocab = load_data_wiki(batch_size, max_len)if __name__=='__main__':for (tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X,mlm_Y, nsp_y) in train_iter:print(tokens_X.shape, segments_X.shape, valid_lens_x.shape,pred_positions_X.shape, mlm_weights_X.shape, mlm_Y.shape,nsp_y.shape)break相关文章:

【动手学深度学习-Pytorch版】BERT预测系列——用于预测的BERT数据集
本小节的主要任务即是将wiki数据集转成BERT输入序列,具体的任务包括: 读取wiki数据集生成下一句预测任务的数据—>主要用于_get_nsp_data_from_paragraph函数从输入paragraph生成用于下一句预测的训练样本:_get_nsp_data_from_paragraph生…...

【数据结构-字符串 三】【栈的应用】字符串解码
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【字符串转换】,使用【字符串】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为&…...

Stm32_标准库_10_TIM_显示时间日期
利用TIM计数耗费1s,启动中断,秒表加一 时间显示代码: #include "stm32f10x.h" // Device header #include "Delay.h" #include "OLED.h"uint16_t num 0; TIM_TimeBaseInitTypeDef TIM_TimeBaseInitStructure; NVIC_I…...

10-SRCNN-使用CNN实现超分辨成像
文章目录 utils_dataset.pymodel.pytrain.pyuse.py主要文件 utils_dataset.py 工具文件,主要用来制作dataset,便于加入dataloader,用于实现数据集的加载和并行读取 model.py 主要写入网络(模型) train.py 主要用于训练 use.py 加载训练好的模型,用于测试或使用 utils_dat…...

cmd/bat 输出符,控制台日志输出到文件
前言 略 输出符 A > B将A执行结果覆盖写入B A >> B将A执行结果追加写入B 常用句柄 句柄句柄的数字代号描述STDIN0键盘输入STDOUT1输出到命令提示符窗口STDERR2错误输出到命令提示符窗口 控制台日志输出到文件 1.bat 1>d:\log.log将控制台日志输出到文件 d:…...

ODrive移植keil(七)—— 插值算法和偏置校准
目录 一、角度读取1.1、硬件接线1.2、程序演示1.3、代码说明 二、锁相环和插值算法2.1、锁相环2.2、插值2.3、角度补偿 三、偏置校准3.1、硬件接线3.2、官方代码操作3.3、移植后的代码操作3.4、代码说明3.5、SimpleFOC的偏置校准对比 ODrive、VESC和SimpleFOC 教程链接汇总&…...
【肌电信号】OpenSignals使用方法 --- 肌电信号采集及导入matlab
一、 多通道采集教学 1. 数据线连接 将PLUX设备通过USB或蓝牙与电脑连接,注意确认在几号通道接线。 2.实时数据采集可视化 进行设置。需要在软件中选择你的PLUX设备,并配置相关的参数,如采样率、分辨率、信号类型等 3 支持数据回放和…...

STM32 多功能按键中断
key1 开关实现led1亮灭,key2开关实现蜂鸣器开关,key3开关实现风扇开关 main.c #include "uart.h" #include "key_it.h" #include "led.h" int main() {char c;char *s;uart4_init();//串口初始化all_led_init();key_it_config();fengshan_init…...
Linux-文件管理命令
绝对路径:从根目录开始描述的路径 pwd输入即为绝对路径, 开头一定是“/”,因为一定是从根目录开始走 相对路径:从当前路径开始描述的路径,开头不一定是“/”,因为不一定是从根目录开始走的 .:是当前目录 。…...
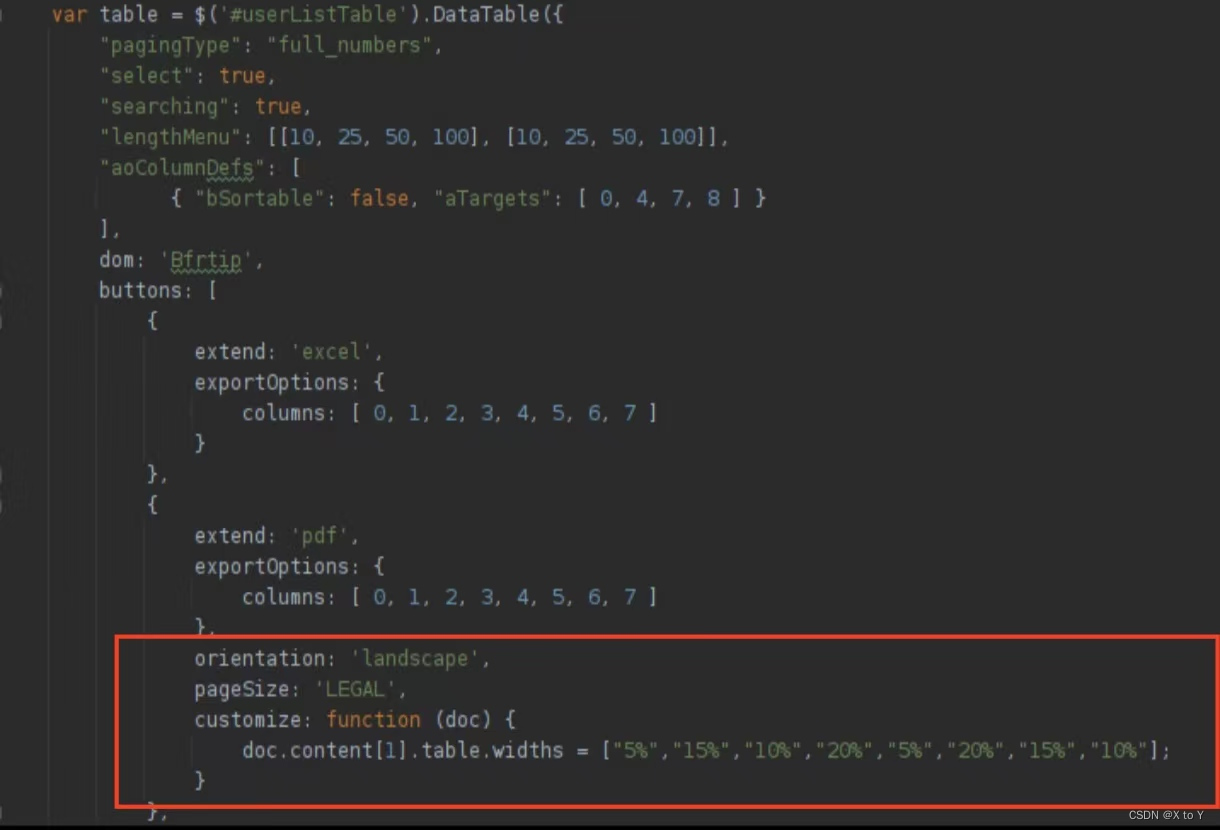
JS DataTable中导出PDF右侧列被截断的问题解决
JS DataTable中导出PDF右侧列被截断的问题解决 文章目录 JS DataTable中导出PDF右侧列被截断的问题解决一. 问题二. 解决办法三. 代码四. 参考资料 一. 问题 二. 解决办法 设置PDF大小和版型 orientation: landscape, pageSize: LEGAL,上述代码设置打印的PDF尺寸为LEGAL&…...
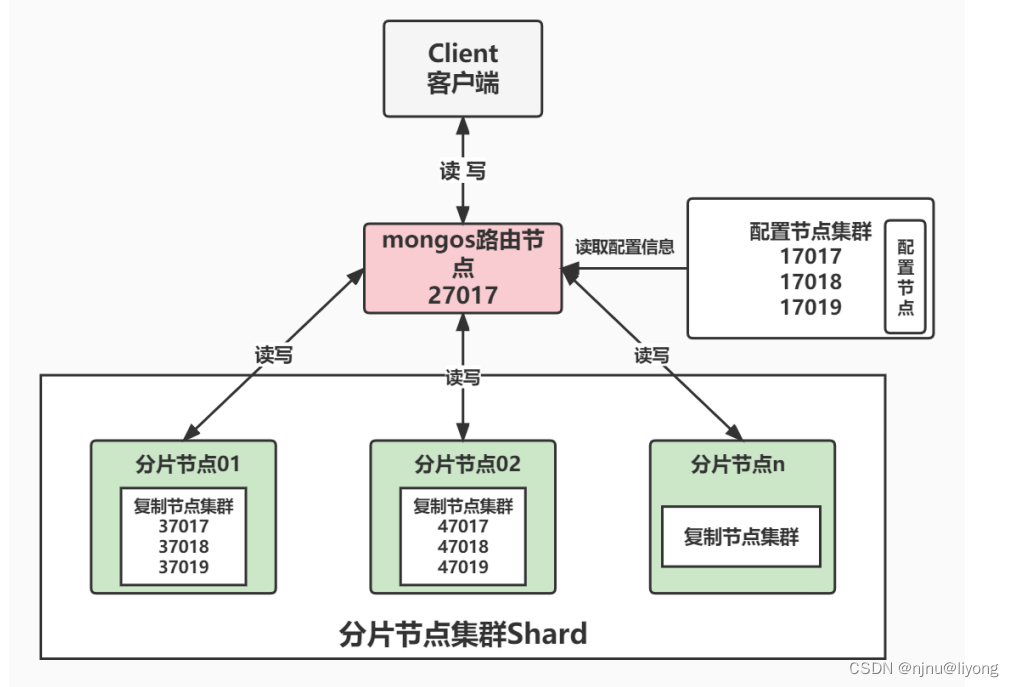
学习笔记-MongoDB(复制集,分片集集群搭建)
复制集群搭建 基本介绍 什么是复制集? 复制集是由一组拥有相同数据集的MongoDB实例做组成的集群。 复制集是一个集群,它是2台及2台以上的服务器组成,以及复制集成员包括Primary主节点,Secondary从节点和投票节点。 复制集提供了…...
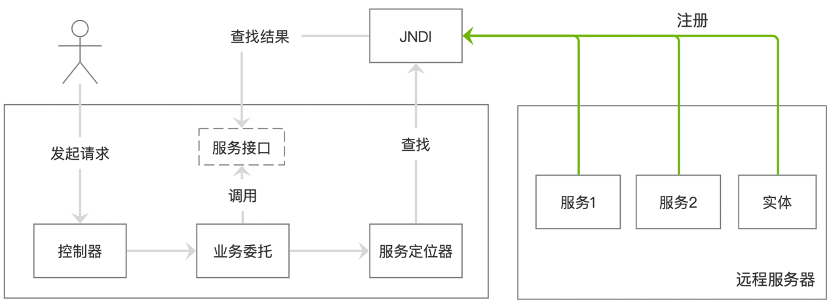
Servlet与设计模式
1 过滤器和包装器 过滤器可以拦截请求及控制响应,而servlet对此毫无感知。过滤器有如下作用: 1)请求过滤器:完成安全检查、重新格式化请求首部或体、建立请求审计日志。 2)响应过滤器:压缩响应流、追加或…...

Python学习基础笔记六十五——布尔值
布尔对象: Python中有一种对象类型称之为布尔对象(英文叫bool)。 布尔对象只有两种取值,True和False。对应的是真和假,或者说是和否。True对应的是,False对应的是否。 我觉得这句话是一个关键:…...
ChatGPT生产力|实用指令(prompt)
GPT已经成为一个不可或缺的科研生产力了,但是大多数人只知晓采用直接提问、持续追问以及细节展开的方式来查阅相关资料,本文侧重于探讨“限定场景限定角色限定主题”、“可持续追问细节展开”等多种方式来获取更多信息,帮人们解决更多问题。 …...
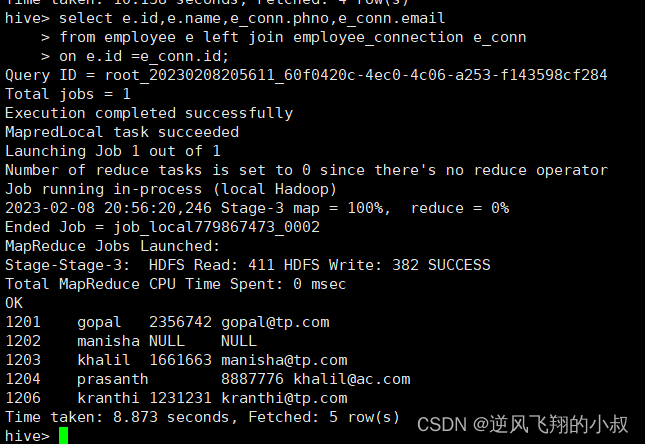
【大数据Hive】hive select 语法使用详解
目录 一、前言 二、Hive select 完整语法树 三、Hive select 操作演示 3.1 数据准备 3.1.1 创建一张表 3.1.2 将数据load加载到t_usa_covid19表 3.1.3 再创建一张分区表 3.1.4 使用动态分区插入数据 3.2 select 常用语法 3.2.1 查询所有字段或者指定字段 3.2.2 查询…...
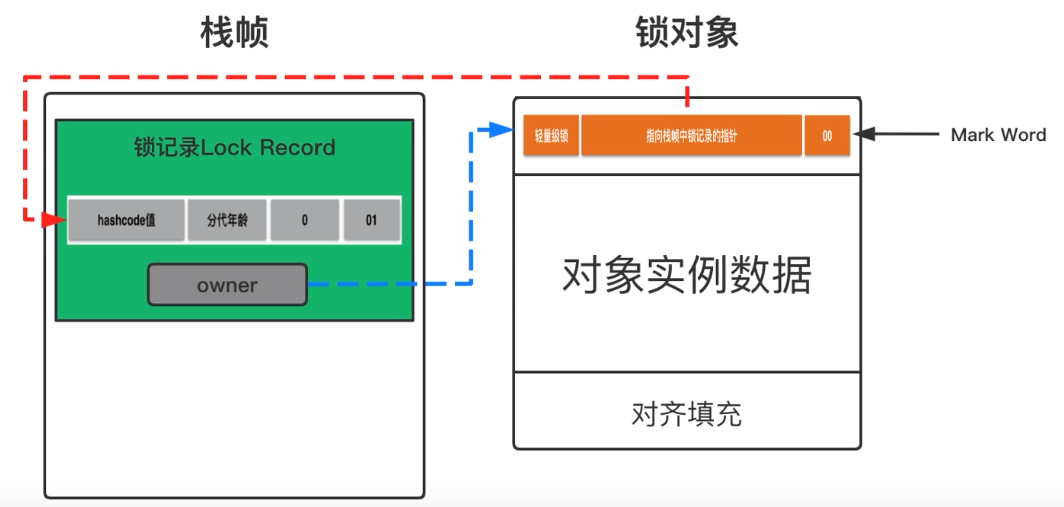
Android---java线程优化 偏向锁、轻量级锁和重量级锁
java 中的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统的帮忙,这就需要从用户态转换到核心态。状态转换需要花费很多时间,如下代码所示: private Object lock new Object();private int value;p…...

处理机调度
目录 处理机调度概述 处理机调度的层次 低级调度 中级调度 高级调度 进程调度 进程调度的时机 进程调度的方式 非抢占式调度方式 抢占式调度方式 调度算法的评价指标 调度算法 先来先服务调度算法(FCFS,First Come First Serve) …...
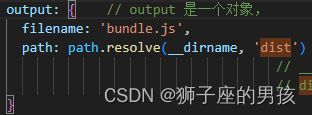
Webpack 解决:ReferenceError: dist is not defined 的问题
1、问题描述: 其一、报错为: ReferenceError: dist is not defined 中文为: ReferenceError:dist 未定义 其二、问题描述为: 想在 webpack 的配置中,创建一个 dist 文件夹来存放 npm run build 打包后…...

MySQL的index merge(索引合并)导致数据库死锁分析与解决方案 | 京东云技术团队
背景 在DBS-集群列表-更多-连接查询-死锁中,看到9月22日有数据库死锁日志,后排查发现是因为mysql的优化-index merge(索引合并)导致数据库死锁。 定义 index merge(索引合并):该数据库查询优化的一种技术࿰…...

第四章 网络层 | 计算机网络(谢希仁 第八版)
文章目录 第四章 网络层4.1 网络层提供的两种服务4.2 网际协议IP4.2.1 虚拟互连网络4.2.2 分类的IP地址4.2.3 IP地址与硬件地址4.2.4 地址解析协议ARP4.2.5 IP数据报的格式4.2.6 IP层转发分组的流程 4.3 划分子网和构造超网4.3.1 划分子网4.3.2 使用子网时分组的转发4.3.3 无分…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...

计算机系统结构复习-名词解释2
1.定向:在某条指令产生计算结果之前,其他指令并不真正立即需要该计算结果,如果能够将该计算结果从其产生的地方直接送到其他指令中需要它的地方,那么就可以避免停顿。 2.多级存储层次:由若干个采用不同实现技术的存储…...

CppCon 2015 学习:Simple, Extensible Pattern Matching in C++14
什么是 Pattern Matching(模式匹配) ❝ 模式匹配就是一种“描述式”的写法,不需要你手动判断、提取数据,而是直接描述你希望的数据结构是什么样子,系统自动判断并提取。❞ 你给的定义拆解: ✴ Instead of …...

CentOS 7.9安装Nginx1.24.0时报 checking for LuaJIT 2.x ... not found
Nginx1.24编译时,报LuaJIT2.x错误, configuring additional modules adding module in /www/server/nginx/src/ngx_devel_kit ngx_devel_kit was configured adding module in /www/server/nginx/src/lua_nginx_module checking for LuaJIT 2.x ... not…...

第6章:Neo4j数据导入与导出
在实际应用中,数据的导入与导出是使用Neo4j的重要环节。无论是初始数据加载、系统迁移还是数据备份,都需要高效可靠的数据传输机制。本章将详细介绍Neo4j中的各种数据导入与导出方法,帮助读者掌握不同场景下的最佳实践。 6.1 数据导入策略 …...