爬虫 | 基础模块了解
文章目录
- 📚http协议
- 📚requests模块
- 📚re模块
- 🐇 re.I 或 re.IGNORECASE
- 🐇re.M或 re.MULTILINE
- 🐇re.S 或 re.DOTALL
- 🐇 re.A 或 re.ASCII
- 🐇 re.X 或 re.VERBOSE
- 🐇特殊字符类
- 📚xpath模块
- 🐇节点的排序
- 🐇函数用法
- 🐇节点关系
- 🐇补充语法
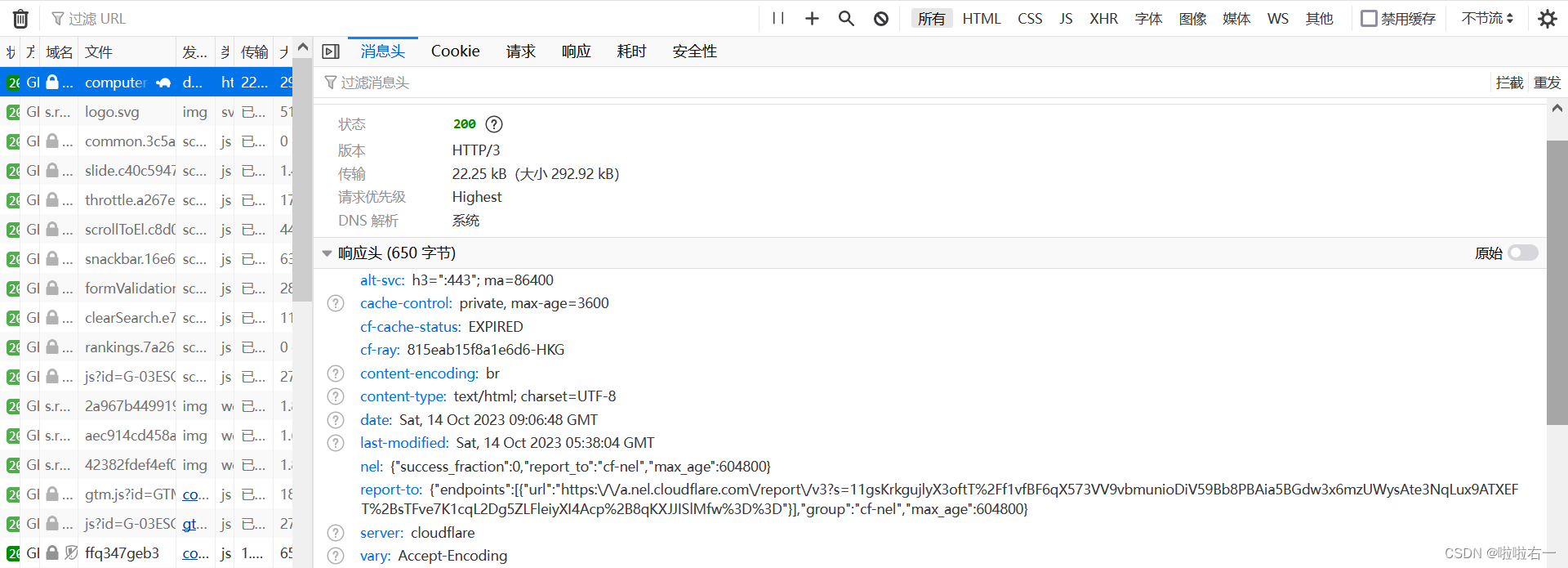
📚http协议
- 计算机网络|第二章:应用层
- Python爬虫教程(一):基础知识

- 请求行:请求方式(get/post)请求地址
- User-Agent:请求载体的身份标识(不同浏览器不同)
- cookie:本地字符串数据信息(用户登录信息)
- 请求体:放一些请求参数
📚requests模块
- 发送HTTP请求:通过调用requests库中的
get()、post()、put()、delete()等函数,可以发送不同类型的HTTP请求。 - 添加请求参数:可以通过传递参数给
get()或post()函数,向请求中添加查询字符串参数、请求头等信息。 - 处理响应:收到服务器的响应后,可以访问返回的响应状态码、头部信息和内容等,并根据需要进行处理。
- 管理会话:使用Session对象可以创建和管理会话,以便在多个请求之间保持一致的会话状态,如使用cookies和身份验证等。
- 处理异常:requests模块具有内置的异常处理机制,可以捕获和处理请求过程中可能出现的异常情况。
import requests# 发送HTTP GET请求,获取网页内容
url = "https://example.com"
response = requests.get(url)# 判断请求是否成功
if response.status_code == 200:# 输出网页内容print(response.text)
else:print("请求失败")
- 用requests库发送了一个HTTP GET请求,并指定了要请求的网址。然后,通过访问 response.status_code属性,判断请求是否成功(状态码为200表示成功)。如果请求成功,通过 response.text属性获取到网页内容,并将其打印出来。
import requests# 创建Session对象
session = requests.Session()# 发送登录请求,获取cookies
login_url = "https://example.com/login"
payload = {"username": "your_username", "password": "your_password"}
response = session.post(login_url, data=payload)# 判断登录是否成功
if response.status_code == 200:# 发送带有cookies的请求,获取其他页面内容profile_url = "https://example.com/profile"response = session.get(profile_url)# 判断请求是否成功if response.status_code == 200:# 输出页面内容print(response.text)
else:print("登录失败")
- 创建了一个Session对象。Session对象可以保持会话状态,并自动管理cookies。
- 发送一个登录请求(POST请求),传递用户名和密码等表单数据。登录成功后,会话中会自动保存返回的cookies信息。
- 通过使用相同的Session对象发送另一个请求(GET请求),这次访问一个需要登录后才能查看的页面。由于我们使用的是之前的会话,会携带之前登录成功后返回的cookies信息。
- 判断请求是否成功,并输出页面内容。
📚re模块
- 正则表达式匹配:使用re模块的
match()(从字符串的开头开始匹配)、search()(搜索第一个匹配)和findall()(返回所有匹配的结果)等函数,可以根据指定的正则表达式,在字符串中查找匹配的内容。 - 替换字符串:通过使用re模块的
sub()和subn()函数,可以将匹配到的内容替换为指定的字符串。sub()函数会替换所有匹配项,而subn()函数还会返回替换的次数。 - 分割字符串:re模块的
split()函数可以根据指定的正则表达式,将字符串分割为子字符串列表。 - 匹配对象的操作:re模块中的Match对象表示一个匹配项,可以从中获取匹配的内容、位置以及其他相关信息。
- 正则表达式修饰符:re模块提供了一些修饰符,用于控制正则表达式的匹配行为,如忽略大小写、多行匹配、全局匹配等。
🐇 re.I 或 re.IGNORECASE
- 忽略大小写匹配,不论目标字符串的字母是大写还是小写,都可以与正则表达式模式相匹配。
import re pattern = r"hello" text = "Hello, World!" result = re.search(pattern, text, re.I) print(result.group()) # 输出:Hello
🐇re.M或 re.MULTILINE
-
re.M或re.MULTILINE用于指定多行模式匹配。 -
正则表达式通常按照默认的单行模式进行匹配,也就是只将目标文本视为单个行。在这种模式下,
^表示字符串的开头,$表示字符串的结尾。 -
而使用
re.M标志可以将正则表达式切换到多行模式,即将目标文本视为多个行。在多行模式下,^和$分别表示行的开头和行的结尾,而不再仅限于字符串的开头和结尾。import re text = "Hello\nWorld\nHow are you?" pattern = re.compile("^H", re.M) matches = pattern.findall(text) print(matches) -
由于使用了多行模式,模式中的
^表示行的开头,因此只有以字母H开始的行会与模式进行匹配。所以最终的输出结果是['H', 'How'],分别对应于第一行和第三行匹配成功的结果。
🐇re.S 或 re.DOTALL
re.S或re.DOTALL单行匹配,用于指定点字符(.)匹配任意字符,包括换行符。- 在正则表达式中,
.通常表示匹配除了换行符之外的任意字符。默认情况下,它不匹配换行符,但是使用re.S标志可以使其匹配包括换行符在内的任意字符。import re pattern = r"hello.*world" text = "hello\nworld" # 匹配以 "hello" 开始,并以 "world" 结尾,中间可以有任意数量的任意字符。 result = re.search(pattern, text, re.S) print(result.group()) # 输出:hello\nworld
🐇 re.A 或 re.ASCII
- 限制模式中的字符匹配为ASCII字符集。
import re pattern = r"\w+" text = "你好, World!" result = re.findall(pattern, text, re.A) print(result) # 输出:['World']
🐇 re.X 或 re.VERBOSE
- 冗长模式,忽略正则表达式中的空白和注释。
import re pattern = r"""hello # 匹配 hello\s+ # 匹配一个或多个空格字符world # 匹配 world """ text = "hello world" result = re.search(pattern, text, re.X) print(result.group()) # 输出:hello world
🐇特殊字符类
\d:匹配任意数字。相当于[0-9]。\D:匹配任意非数字字符。相当于[^0-9]。\s:匹配任意空白字符,包括空格、制表符、换行符等。\S:匹配任意非空白字符。\w:匹配任意字母、数字和下划线字符。相当于[a-zA-Z0-9_]。\W:匹配任意非字母、数字和下划线字符。
-
这些特殊字符类可以在正则表达式中使用,以便更精确地匹配特定类型的字符。需要注意的是,大写形式的特殊字符类(例如
\D、\S、\W)表示相反的意义,即匹配对应类别之外的字符。 -
例如,使用
\d+可以匹配一个或多个连续的数字,而\D+则匹配一个或多个连续的非数字字符。
📚xpath模块
- XPath(XML Path Language)是一种用于在 XML 文档中定位和选择元素的语言。使用 XPath 模块,可以根据指定的 XPath 表达式从 XML 文档中定位和选择节点,提取所需的数据。
- XPath 模块提供了以下主要功能:
- 解析 XML 文档:使用
xml.etree.ElementTree.parse()函数加载 XML 文件,并返回一个表示整个 XML 文档的树结构 - 定位节点:使用 XPath 表达式
tree.xpath(xpath_expr)在 XML 树结构中定位满足条件的节点。XPath 表达式描述了节点的路径或属性等选择条件。 - 选择节点:使用
Element.xpath(xpath_expr)方法在当前节点下选择满足条件的子节点。 - 提取数据:使用
element.text获取节点的文本内容,使用element.attrib获取节点的属性信息。
from lxml import etree# 解析 XML 文档 tree = etree.parse("data.xml")# 使用 XPath 表达式定位和选择节点 # 从 XML 或 HTML 文档的根节点 catalog 中选取所有 book 元素下的 title 子元素,并提取它们的文本内容 title = tree.xpath("/catalog/book/title/text()") author = tree.xpath("/catalog/book/author/text()")# 获取节点的文本内容 title_text = title[0] author_text = author[0]# 打印结果 print("Title:", title_text) print("Author:", author_text)-
title = tree.xpath("/catalog/book/title/text()"):选择XML文档中所有 节点的文本内容。 .text()表示获取节点的文本内容,而不是节点本身。
- 解析 XML 文档:使用
🐇节点的排序
# 使用 [下标]来选择指定位置的节点,注意 XPath 下标从 1 开始计数
tree.xpath('//div[@class="root"]/div/p[2]/text()')# 获取当前层同级节点中的最后一个位置的节点
tree.xpath('//div[@class="root"]/div/p[last()]/text()')# 获取倒数第二个位置的节点
tree.xpath('//div[@class="root"]/div/p[last()-1]/text()')# 获取位置小于等于2的节点
tree.xpath('//div[@class="root"]/div/p[position() <= 2]/text()')
🐇函数用法
# 用于筛选嵌套文本长度大于5的嵌套文本
tree.xpath("//ul/li[string-length(text()) > 5]/text()")# 判断属性是否包含指定的子字符串
tree.xpath("//ul/li[contains(@class, 'price')]/text()")# 匹配以指定字符开头的节点
tree.xpath("//ul/li[starts-with(text(), '啦啦')]/text()")# 计算节点数量
tree.xpath("count(//ul/li)")
🐇节点关系
# self::代表当前节点自身
tree.xpath('//div/p/self::p/text()')# * 代替标签名称,匹配任何标签
tree.xpath('//div/p/self::*/text()')# following-sibling::选取当前节点之后的同级节点
tree.xpath("//div/p[text()='第三段']/following-sibling::*/text()")# preceding-sibling::选取当前节点之前的同级节点:
tree.xpath("//div/p[text()='第三段']/preceding-sibling::*/text()")# 父辈节点:parent::
tree.xpath('//div[@class="self"]/parent::*/@class')# 先辈节点:`ancestor::` 和 `ancestor-or-self::`
tree.xpath('//div[@class="self"]/ancestor::*/@class')
tree.xpath('//div[@class="self"]/ancestor-or-self::*/@class')# 后代关系:子节点 `child::`、所有后代节点 `descendant::` 和所有后代节点及自身 `descendant-or-self::`
tree.xpath("//div[@class='uncle']/child::*/@class")
tree.xpath("//div[@class='grandpa']/descendant::*/@class")
tree.xpath("//div[@class='grandpa']/descendant-or-self::*/@class")
🐇补充语法
- 使用
*通配符匹配任何满足条件的节点,不需要考虑父节点tree.xpath("//*[@class='price' or @class='price-item']/text()")
- 使用正则表达式模式匹配节点
tree.xpath("//ul/li[ns:match(text(), '哈哈$')]/text()", namespaces={"ns": "http://exslt.org/regular-expressions"})- 匹配带有以字母 “哈哈” 结尾的文本内容的 li 元素,并返回这些 li 元素的文本内容。同时使用 namespaces 参数来定义命名空间的映射。
参考博客:
- Python爬虫教程(一):基础知识
相关文章:
爬虫 | 基础模块了解
文章目录 📚http协议📚requests模块📚re模块🐇 re.I 或 re.IGNORECASE🐇re.M或 re.MULTILINE🐇re.S 或 re.DOTALL🐇 re.A 或 re.ASCII🐇 re.X 或 re.VERBOSE🐇特殊字符类…...
CSS复习笔记
CSS 文章目录 CSS1.概念2.CSS 引入方式3.选择器基础选择器:标签选择器类选择器id 选择器通配符选择器 复合选择器:**后代选择器****子代选择器****并集选择器****交集选择器-了解****伪类选择器** 结构伪类选择器:**:nth-child(公式)**伪元素…...

编译linux的设备树
使用make dtbs命令时 在arch/arm 的目录Makefile文件中有 boot : arch/arm/boot prepare 和scripts是空的 在文件scripts/Kbuild.include中 变量build : -f $(srctree)/scripts/Makefile.build obj build变量虽然没有在arch/arm 的目录Makefile文件中定义,但…...

⛳ MyBatis 中 Mapper 接口工作原理实例解析
🎍目录 ⛳ MyBatis 中 Mapper 接口工作原理实例解析🎨 一、Mapper 接口是怎么找到实现类的?🐾 二、从一段代码看起🚜 三、Mapper 接口🏭 四、Mapper 接口的动态代理类的生成🎁 五、总结 ⛳ MyBa…...

Android 音频可视化
Android音频可视化,指的是将音频的频率绘制到屏幕上,达到一种视觉效果,使播放或录制过程更加生动形象。 在Android进行视频可视化涉及的三个主要知识点,其中比较难以理解的傅里叶变换公式。 Android原生的Visualizer使用(获取频…...

刷机与救砖避坑指南
提示:快速进行刷机和救砖学习理解 文章目录 一、刷机1.什么是刷机,需要进行那些准备?2.刷机1.解开bl(bootloader)锁2.刷入TWRP和Magsik3.刷入第三方ROM 二、救砖(9008)1.手机售后一键线刷包&…...

软件建模知识点
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:…...
WSL 配置 Linux
WSL 配置 Linux Windows 启动 Linux 子系统 控制面板 -> 程序和功能, 将 适用于 Linux 的 Windows 子系统 勾选。 安装 Terminal 在 Microsoft Store 市场上搜索 Terminal 安装 Windows Terminal。 安装 编译工具链 sudo apt update # 更新软件包 sudo apt i…...
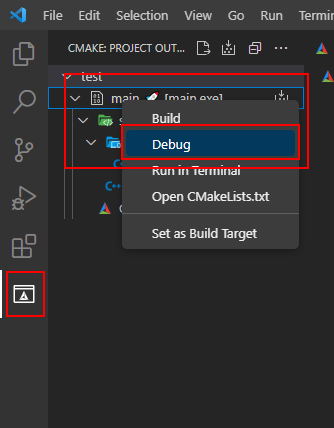
VS Code:CMake配置
概述 在VSCode和编译器MinGW安装完毕后,要更高效率的进行C/C开发,采用CMake。CMake是一个开源、跨平台的编译、测试和打包工具,它使用比较简单的语言描述编译,安装的过程,输出Makefile或者project文件,再去…...

Flex 词法分析实验实现(电子科技大学编译技术Icoding实验)
Flex 词法分析 此为电子科技大学编译技术 实验1:词法分析 将具体实现中的三个文件和自己的实验报告一起上传才能通过 根据词法分析实验中给定的文法,利用 flex 设计一词法分析器,该分析器从标准输入读入源代码后,输出单词的类别编…...

设计模式——20. 解释器模式
1. 说明 解释器模式(Interpreter Pattern)是一种行为型设计模式,它用于定义一门语言的语法解析,并为该语言创建解释器。该模式将一个问题或领域表达成一个语言,然后提供一个解释器来解释这种语言中的表达式,以执行特定操作。 要点和组成部分: 抽象表达式(Abstract Ex…...

多输入多输出 | MATLAB实现CNN-BiLSTM-Attention卷积神经网络-双向长短期记忆网络结合SE注意力机制的多输入多输出预测
MATLAB实现CNN-BiLSTM-Attention卷积神经网络-双向长短期记忆网络结合SE注意力机制的多输入多输出预测 目录 MATLAB实现CNN-BiLSTM-Attention卷积神经网络-双向长短期记忆网络结合SE注意力机制的多输入多输出预测预测效果基本介绍程序设计往期精彩参考资料 预测效果 基本介绍 C…...

一文让你玩转Linux多进程开发
Linux多进程开发 主要介绍多进程开发时的要点 进程状态转换 进程反应了进程执行的变化。 进程的状态分为三种 ,运行态,阻塞态,就绪态 在五态模型中分为以下几种,新建态,就绪态,运行态,阻塞态,终止态。 运行态:进程占用处理器正在运…...
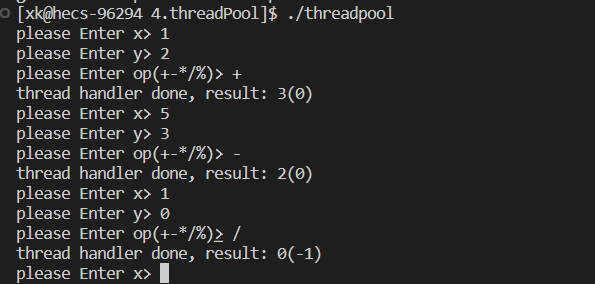
Linux线程同步实例
线程同步实例 1. 生产消费者模型基本概念2. 基于BlockingQueue的生产者消费者模型3. 基于环形队列的生产消费模型4. 线程池 1. 生产消费者模型基本概念 生产者消费者模型是一种常用的并发设计模式,它可以解决生产者和消费者之间的速度不匹配、解耦、异步等问题。生…...
-- iconv - iconv操作)
LuatOS-SOC接口文档(air780E)-- iconv - iconv操作
iconv.open(tocode, fromcode)# 打开相应字符编码转换函数 参数 传入值类型 解释 string 释义:目标编码格式 取值:gb2312/ucs2/ucs2be/utf8 string 释义:源编码格式 取值:gb2312/ucs2/ucs2be/utf8 返回值 返回值类型 解…...

matlab第三方硬件支持包下载和安装
1、在使用matlab内部的附加功能安装时,由于matlab会验证是否正版无法打开 2、在matlab官网直接找到对应的硬件支持包下载,但是是下图的安装程序 可以直接在matlab中跳转到该程序所在的文件夹双击安装,但是安装到最后出错了 3.根据出错时mala…...

docker compose和consul(服务注册与发现)
一、Docker-compose 简介 Docker-Compose项目是基于Python开发的Docker官方开源项目,负责实现对Docker容器集群的快速编排。 Docker-Compose将所管理的容器分为三层,分别是 工程(project),服务(service&a…...
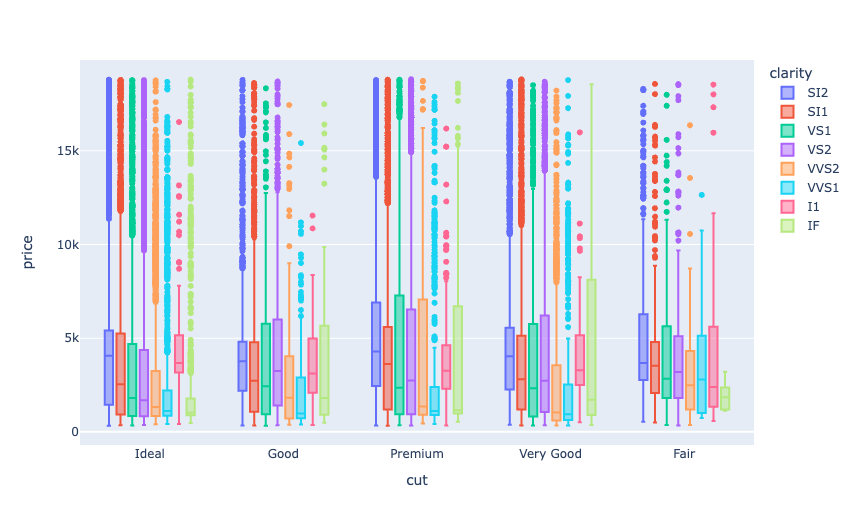
使用Python进行钻石价格分析
钻石是最昂贵的宝石之一。钻石的质量通常以其重量(克拉)、净度、颜色和切工来评估。重量越大、净度越高、色彩纯净、切工精细的钻石价格也越高。其中,4C标准是衡量钻石质量的国际标准,即克拉(Carat)、净度&…...

Java日期查询
本实例使用有关日期处理和日期格式化的类实现一个日期查询的功能,即查询指定日期所在周的周一日期、两个指定日期间相差的天数和指定日期为所在周的星期几的日期 3 个功能。 从功能上来看,本实例至少需要定义 3 个方法,分别完成:获…...
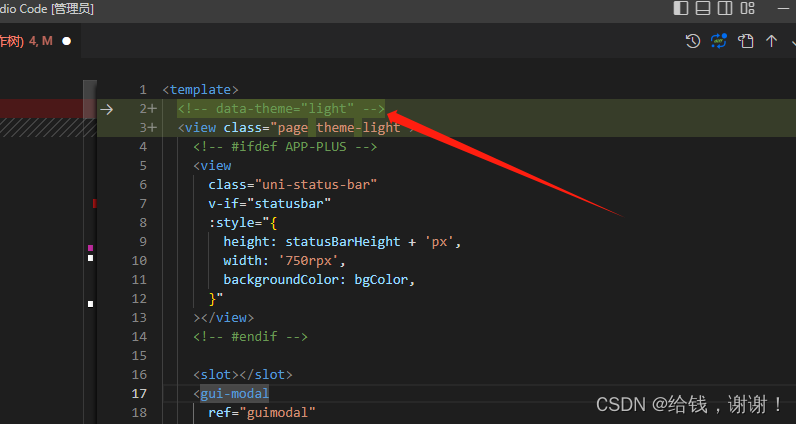
uniapp 运行到 app 报错 Cannot read property ‘nodeName‘ of null
uniapp 运行到某一个页面,报错,h5没有问题 Unhandled error during execution of scheduler flush. This is likely a Vue internals bug. Please open an issue at https://new-issue.vuejs.org/?repovuejs/coreat <GuiPagecustomHeadertruecustomF…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...
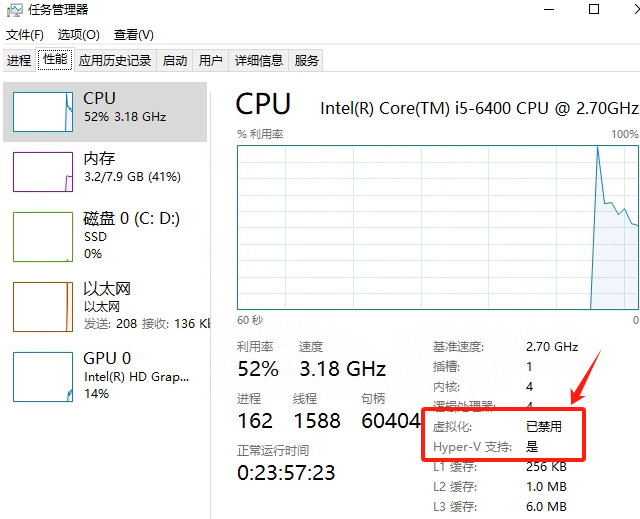
Windows电脑能装鸿蒙吗_Windows电脑体验鸿蒙电脑操作系统教程
鸿蒙电脑版操作系统来了,很多小伙伴想体验鸿蒙电脑版操作系统,可惜,鸿蒙系统并不支持你正在使用的传统的电脑来安装。不过可以通过可以使用华为官方提供的虚拟机,来体验大家心心念念的鸿蒙系统啦!注意:虚拟…...

深度解析:etcd 在 Milvus 向量数据库中的关键作用
目录 🚀 深度解析:etcd 在 Milvus 向量数据库中的关键作用 💡 什么是 etcd? 🧠 Milvus 架构简介 📦 etcd 在 Milvus 中的核心作用 🔧 实际工作流程示意 ⚠️ 如果 etcd 出现问题会怎样&am…...
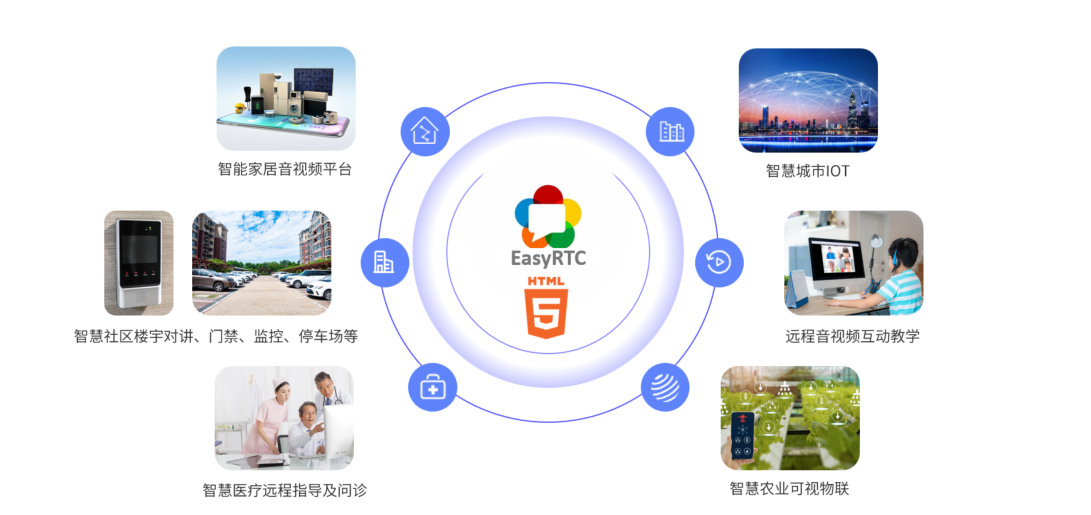
EasyRTC音视频实时通话功能在WebRTC与智能硬件整合中的应用与优势
一、WebRTC与智能硬件整合趋势 随着物联网和实时通信需求的爆发式增长,WebRTC作为开源实时通信技术,为浏览器与移动应用提供免插件的音视频通信能力,在智能硬件领域的融合应用已成必然趋势。智能硬件不再局限于单一功能,对实时…...