milvus和相似度检索
流程
milvus的使用流程是 创建collection -> 创建partition -> 创建索引(如果需要检索) -> 插入数据 -> 检索
这里以Python为例, 使用的milvus版本为2.3.x
首先按照库, python3 -m pip install pymilvus
Connect
from pymilvus import connections
connections.connect(alias="default",user='username',password='password',host='localhost',port='19530'
)connections.list_connections()
connections.get_connection_addr('default')connections.disconnect("default")
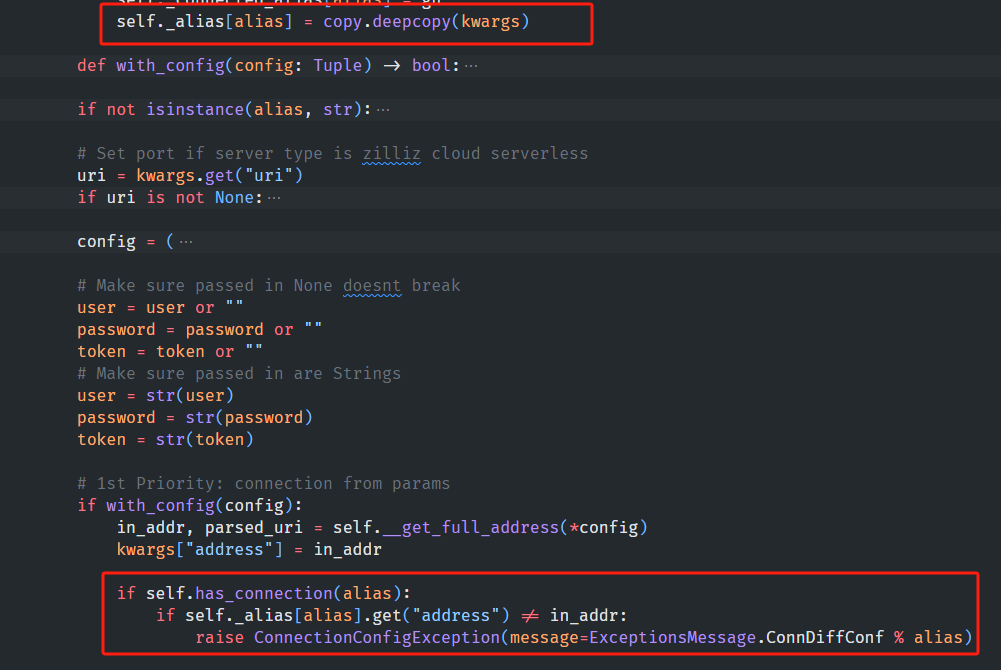
以上是源码,可以看出alias只是一个字典的映射的key
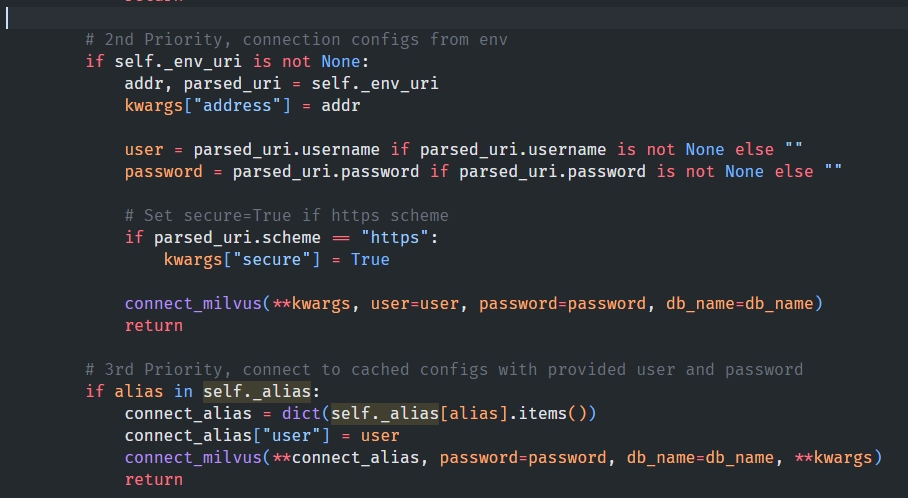
通过源码可以看到,还有两种连接方式:
- 在.env文件中添加参数,
MILVUS_URI=milvus://<Your_Host>:<Your_Port>,之后可以使用connections.connect()连接 - 在一次连接成功后,将连接配置数据保存在内存,下次近执行
connections.connect()即可连接,可以通过connections.remove_connection删除连接配置数据
Database
from pymilvus import connections, dbconn = connections.connect(host="127.0.0.1", port=19530)database = db.create_database("book")db.using_database("book") # 切换数据库
db.list_database()
db.drop_database("book")
Collection
和一些非关系型数据库(MongoDB)类似,Collection就是表
# collection
from pymilvus import Collection, CollectionSchema, FieldSchema, DataType, utility## 需要提前创建列的名称、类型等数据,并且必须添加一个主键
book_id = FieldSchema(name="book_id",dtype=DataType.INT64,is_primary=True,
)
book_name = FieldSchema(name="book_name",dtype=DataType.VARCHAR,max_length=200,# The default value will be used if this field is left empty during data inserts or upserts.# The data type of `default_value` must be the same as that specified in `dtype`.default_value="Unknown"
)
word_count = FieldSchema(name="word_count",dtype=DataType.INT64,# The default value will be used if this field is left empty during data inserts or upserts.# The data type of `default_value` must be the same as that specified in `dtype`.default_value=9999
)
book_intro = FieldSchema(name="book_intro",dtype=DataType.FLOAT_VECTOR,dim=2
)
# dim=2是向量的维度schema = CollectionSchema(fields=[book_id, book_name, word_count, book_intro],description="Test book search",enable_dynamic_field=True
)collection_name = "book"collection = Collection(name=collection_name,schema=schema,using='default',shards_num=2)utility.rename_collection("book", "lights4")
utility.has_collection("lights1")
utility.list_collections()
# utility.drop_collection("lights")collection = Collection("lights3")
collection.load(replica_number=2)
# reduce memory usage
collection.release()
Partition
# Create a Partitioncollection = Collection("book") # Get an existing collection.
collection.create_partition("novel")
Index
milvus的索引决定了搜索所用的算法,必须设置好所引才能进行搜索。
# Index
index_params = {"metric_type":"L2","index_type":"IVF_FLAT","params":{"nlist":1024}
}collection.create_index(field_name="book_intro", index_params=index_params
)## metric_type是相似性计算算法,可选的有以下
## For floating point vectors:
## L2 (Euclidean distance)
## IP (Inner product)
## COSINE (Cosine similarity)
## For binary vectors:
## JACCARD (Jaccard distance)
## HAMMING (Hamming distance)
utility.index_building_progress("<Your_Collection>")
Data
数据可以从dataFrame来,也可以从其他方式获得,只要列名对上,即可。
import pandas as pd
import numpy as npinsert_data = pd.read_csv("<Your_File>")
mr = collection.insert(insert_data)
Search
# search
search_params = {"metric_type": "L2", "offset": 5, "ignore_growing": False, "params": {"nprobe": 10}
}results = collection.search(data=[[0.1, 0.2]], anns_field="book_intro", # the sum of `offset` in `param` and `limit` # should be less than 16384.param=search_params,limit=10,expr=None,# 这里需要将想看的列名列举出来output_fields=['title'],consistency_level="Strong"
)# get the IDs of all returned hits
results[0].ids# get the distances to the query vector from all returned hits
results[0].distances# get the value of an output field specified in the search request.
hit = results[0][0]
hit.entity.get('title')
具体的代码在我的github。希望对你有所帮助!
相关文章:
milvus和相似度检索
流程 milvus的使用流程是 创建collection -> 创建partition -> 创建索引(如果需要检索) -> 插入数据 -> 检索 这里以Python为例, 使用的milvus版本为2.3.x 首先按照库, python3 -m pip install pymilvus Connect from pymilvus import connections c…...
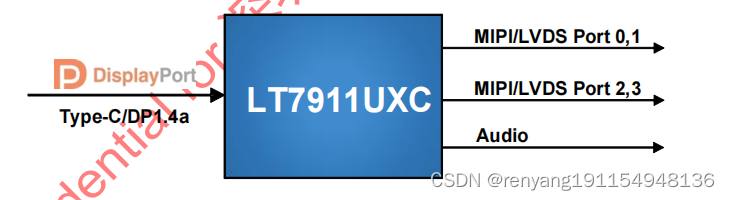
龙迅LT7911UXC 是一款高性能TYPE-C/DP/EDP转换四端口MIPI/LVDS的芯片,还支持图像处理
龙迅LT7911UXC 1.描述: LT7911UXC是一款用于VR/显示应用的高性能Type-C/DP1.4a到MIPI或LVDS芯片。HDCP RX作为 HDCP中继器的上游端,可以与其他芯片的HDCP TX协同工作,实现中继器的功能。对于DP1.4a 输入,LT7911UXC可以配置为1…...
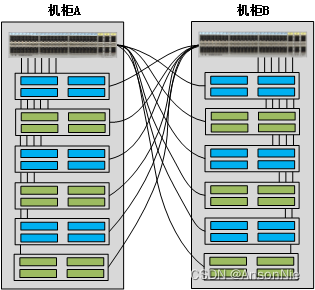
TOR(Top of Rack)
TOR TOR(Top of Rack)指的是在每个服务器机柜上部署1~2台交换机,服务器直接接入到本机柜的交换机上,实现服务器与交换机在机柜内的互联。虽然从字面上看,Top of Rack指的是“机柜顶部”,但实际T…...
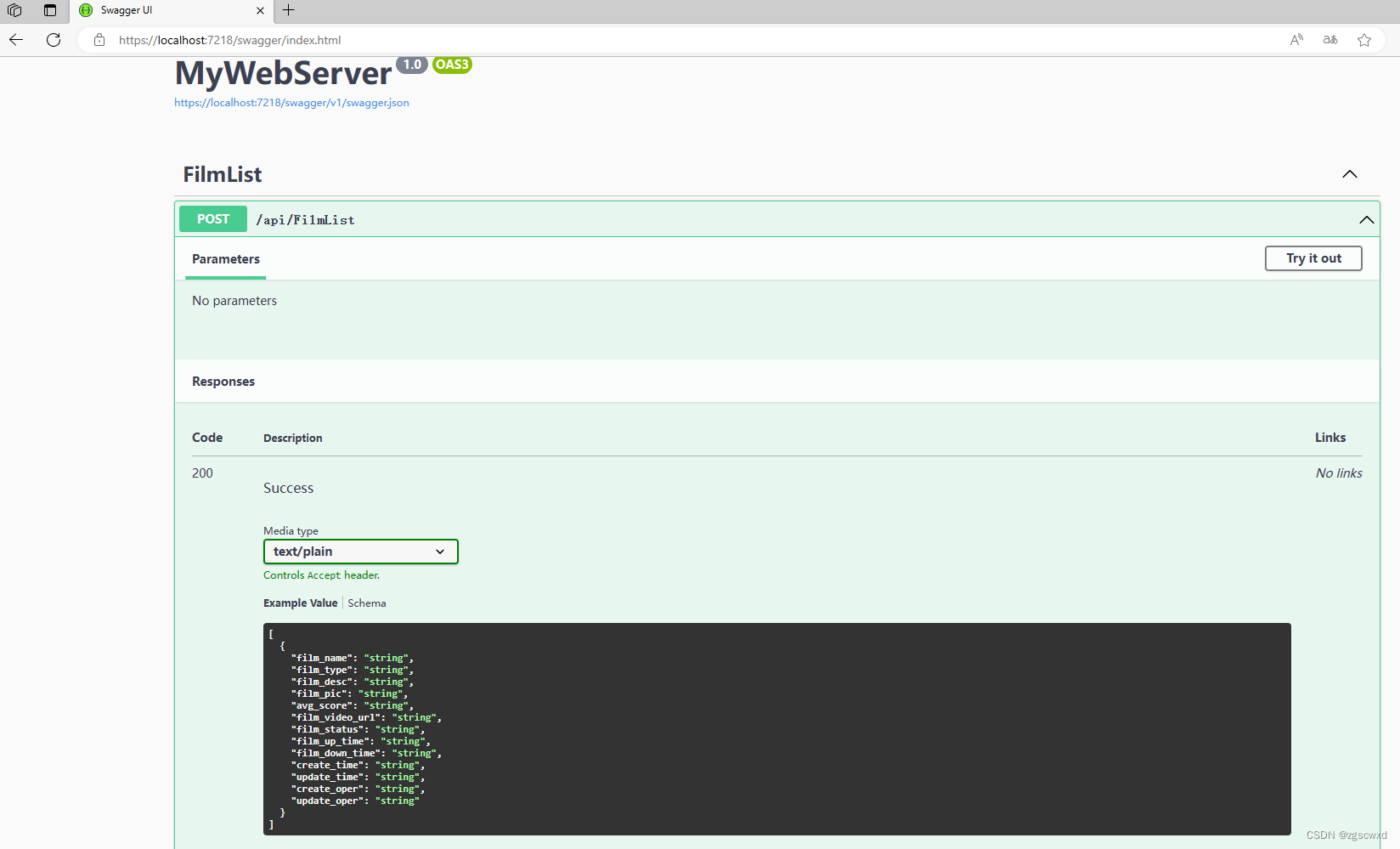
使用asp.net core web api创建web后台,并连接和使用Sql Server数据库
前言:因为要写一个安卓端app,实现从服务器中获取电影数据,所以需要搭建服务端代码,之前学过C#,所以想用C#实现服务器段代码用于测试,本文使用C#语言,使用asp.net core web api组件搭建服务器端&…...
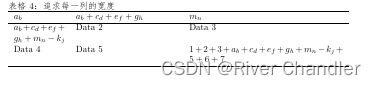
LaTeX 公式与表格绘制技巧
LaTeX 公式与绘图技巧公式基本可以分为 单一公式单一编号单一公式按行编号单一公式多个子编号单一公式部分子编号分段公式现在给出各自的代码单一公式单一编号 公式1:equationaligned\begin{equation}\begin{aligned}a&bc\\b&a2\\c&b-3\end{aligned}\en…...
Spring Cloud--Nacos+@RefreshScope实现配置的动态更新
原文网址:Spring Cloud--NacosRefreshScope实现配置的动态更新_IT利刃出鞘的博客-CSDN博客 简介 说明 本文介绍SpringCloud整合Nacos使用RefreshScope实现动态更新配置。 官网 Nacos Spring Cloud 快速开始 动态更新的介绍 动态更新的含义:修改应…...
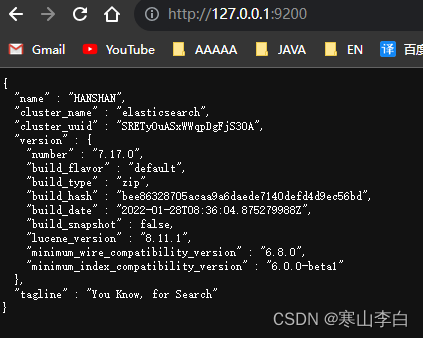
Elasticsearch安装
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

【JavaSE API 】生成随机数的2种方法:Random类和Math类的Random方法
生成随机数的两种方法 Random类和Math类的random方法都可以用来生成随机数 而Math类的random方法则是基于系统时间的伪随机数生成器,大于等于0.0小于1.0的随机double值范围[0,1)。例如: double num1 Math.random() * 5 4;//范围[4,9) Random类是基于种…...

微软和OpenAI正在开发AI芯片, 并计划下个月发布
今年初,Chat**引起了无数网友关注,一度成为了热门话题。这是由人工智能研究实验室OpenAI开发的一款聊天机器人模型,也称为一种人工智能(AI)技术驱动的自然语言处理工具。能够通过学习和理解人类的语言来进行对话&#…...
记一次Hbase2.1.x历史数据数据迁移方案
查看待迁移的表 list_namespace_tables vaas_dwm2. 制作待迁移表“DWM_TRIP_PART”的快照 snapshot vaas_dwm:DWM_TRIP_PART,dwm_trip_part_snapshot3. 统计待迁移表数据总数 hbase org.apache.hadoop.hbase.mapreduce.RowCounter vaas_dwm:DWM_TRIP_PART...

luajit简介
LuaJIT是一种高效的Lua解释器,其通过即时编译技术将Lua代码转换为机器代码,从而提供了非常快速的执行速度。在本文中,我们将介绍LuaJIT的原理、使用方法以及在嵌入式Linux系统中的应用示例。 LuaJIT的原理 LuaJIT基于Lua 5.1实现࿰…...

1.2 switch实现两个数的四则运算
注意: 1、每一个case后面要有break 2、/运算的时候注意分母不能为0 int a, b;char c;cin>>a>>b>>c;switch (c){case :cout << a << << b << << a b << endl;break;case -:cout << a << - …...

mysql面试题47:MySQL中Innodb的事务实现原理
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:Innodb的事务实现原理 InnoDB是MySQL中一种常用的存储引擎,它支持事务和行级锁等特性。以下是InnoDB事务实现的简要原理: 事务定义: 事务是指一…...

Google云平台构建数据ETL任务的最佳实践
在数据处理中,我们经常需要构建ETL的任务,对数据进行加载,转换处理后再写入到数据存储中。Google的云平台提供了多种方案来构建ETL任务,我也研究了一下这些方案,比较方案之间的优缺点,从而找到一个最适合我…...
)
【更新】囚生CYの备忘录(202331014~)
文章目录 20221014 20221014 本以为下午怡宝的比赛至少是能跑到前三,结果连前五都没混到,赛前都知道路线不可能有5km,因为即便是绕着主校区最外沿跑一圈也才4km出头,我估摸着大概是2500米,结果实际上只有1700米&#x…...
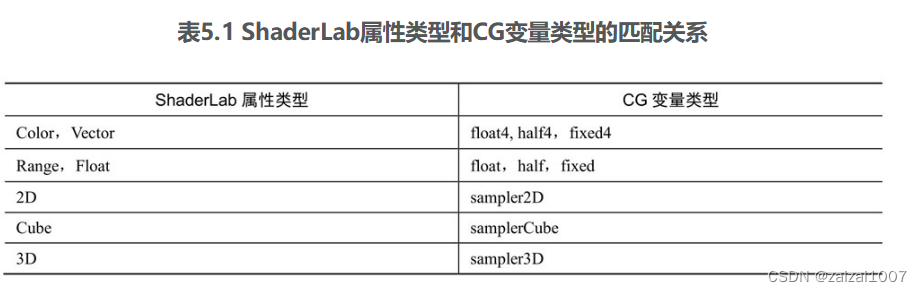
《UnityShader入门精要》学习4
一个最简单的顶点/片元着色器 一个最简单的顶点/片元着色器 Unity Shader的基本结构。它包含了Shader、Properties、SubShader、Fallback等语义块。顶点/片元着色器的结构与之大体类似 Shader "MyShaderName" {Properties {// 属性}SubShader {// 针对显卡A的S…...
kaggle新赛:写作质量预测大赛【数据挖掘】
赛题名称:Linking Writing Processes to Writing Quality 赛题链接:https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality 赛题背景 写作过程中存在复杂的行为动作和认知活动,不同作者可能采用不同的计划修…...

导入导出Excel
Springboot Easyexcel导入导出excel EasyExcel 的导出导入支持两种方式进行处理*easyexcel 导出不用监听器,导入需要写监听器* 一、导入:简单实现1. 导入依赖,阿里的easyexcel插件2. 程序2-1. 实体类:2-2. 定义一个 监听类&#…...

C# Thread.Sleep(0)有什么用?
一、理论分析 回答这个要先从线程时间精度(时间片)开始说起。很多参考书说,默认情况下,时间片为15ms 左右,但是这是已经过时的知识。在老的 Windows 操作系统里,应用程序模式时时间片 15ms 左右࿰…...

二十四、【参考素描三大面和五大调】
文章目录 三种色面(黑白灰)五种色调 这个可以参考素描对物体受光的理解:素描调子的基本规律与素描三大面五大调物体的明暗规律 三种色面(黑白灰) 如下图所示,我们可以看到光源是从亮面所对应的方向射过来的,所以我们去分析图形的时候,首先要…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...
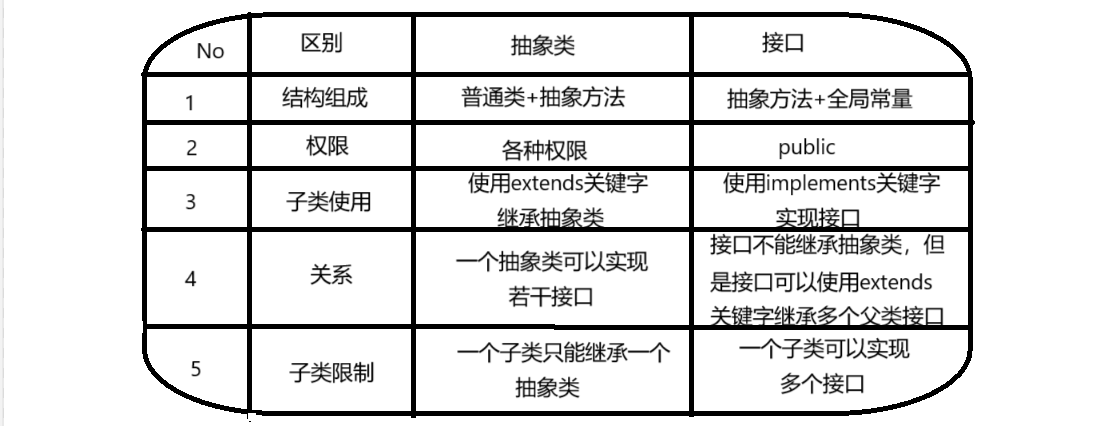
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...
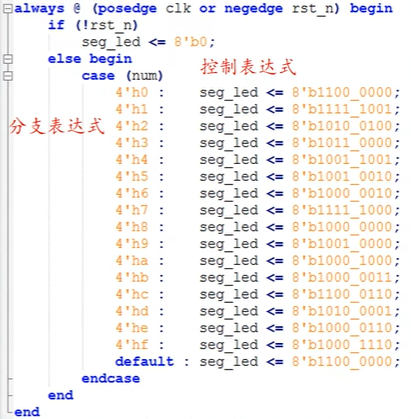
ZYNQ学习记录FPGA(二)Verilog语言
一、Verilog简介 1.1 HDL(Hardware Description language) 在解释HDL之前,先来了解一下数字系统设计的流程:逻辑设计 -> 电路实现 -> 系统验证。 逻辑设计又称前端,在这个过程中就需要用到HDL,正文…...

npm安装electron下载太慢,导致报错
npm安装electron下载太慢,导致报错 背景 想学习electron框架做个桌面应用,卡在了安装依赖(无语了)。。。一开始以为node版本或者npm版本太低问题,调整版本后还是报错。偶尔执行install命令后,可以开始下载…...
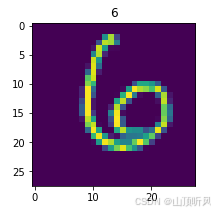
MLP实战二:MLP 实现图像数字多分类
任务 实战(二):MLP 实现图像多分类 基于 mnist 数据集,建立 mlp 模型,实现 0-9 数字的十分类 task: 1、实现 mnist 数据载入,可视化图形数字; 2、完成数据预处理:图像数据维度转换与…...