Pytorch从零开始训练模型【识别数字模型】并测试
1 准备数据集
import torch
import torchvision
# 去网上下载CIFAR10数据集【此数据集为经典的图像数字识别数据集】
# train = True 代表取其中得训练数据集;
# transform 参数代表将图像转换为Tensor形式
# download 为True时会去网上下载数据集到指定路径【root】中,若本地已有此数据集则直接使用
train_data=torchvision.datasets.CIFAR10(root='./dataset',train=True,transform=torchvision.transforms.ToTensor(),download=True)
# 测试数据集
test_data=torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 查看数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print('训练数据集长度为:{}'.format(train_data_size))
print('测试数据集长度为:{}'.format(test_data_size))
2 加载数据集
from torch.utils.data import DataLoader
# 将数据集加载,每64张作为一组
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
3 搭建神经网络
3.1 原理演示

Pytorch图像输入输出格式图像变换官方文档
此处仅举一个例子,即输入图像为3@32×323@32\times 323@32×32【3通道,高为32,宽为32】以通过5×55\times55×5卷积核进行卷积操作时需要填写哪些参数,使其变成32@32×3232@32\times 3232@32×32【32通道,高为32,宽为32】的图像
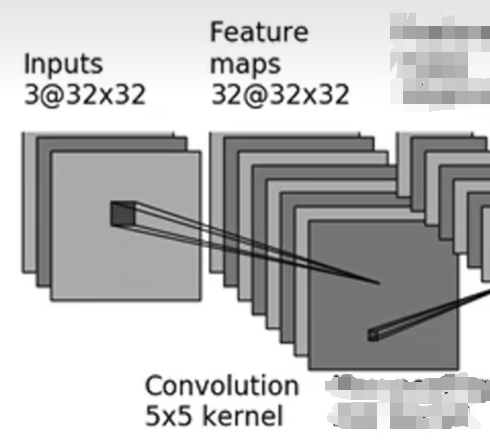
不知道卷积是啥意思的可以参考如下👇视频
B站土堆说卷积操作
官方文档中关于二维图像的卷积函数中的参数是这样解释的【此处仅对需要用到的部分进行注释】
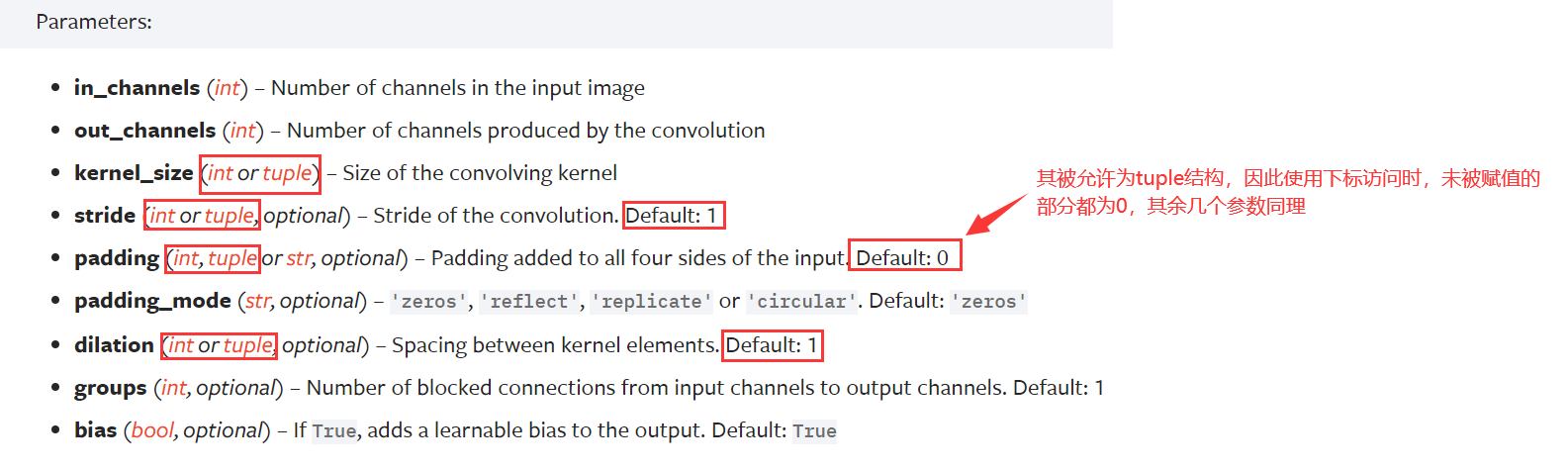
输入图像与输出图像的对应数学关系如下👇

图上没有采用空洞卷积,dilation参数默认是1,假设stride通常都是1,先尝试
Hout=⌊Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1stride[0]+1⌋32=⌊32+2×padding[0]−1×(5−1)−11+1⌋padding[0]=2Wout=⌊Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1stride[1]+1⌋∴同理可得,padding[1]也为2H_{out}=\left \lfloor \dfrac{H_{in}+2\times padding[0]-dilation[0]\times(kernel\_size[0]-1)-1}{stride[0]}+1 \right \rfloor \\ 32=\left \lfloor \dfrac{32+2\times padding[0] - 1\times (5-1)-1}{1}+1 \right \rfloor \\ padding[0]=2\\ \\ W_{out}=\left \lfloor \dfrac{W_{in}+2\times padding[1]-dilation[1]\times(kernel\_size[1]-1)-1}{stride[1]}+1 \right \rfloor \\ \therefore 同理可得,padding[1]也为2 Hout=⌊stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1⌋32=⌊132+2×padding[0]−1×(5−1)−1+1⌋padding[0]=2Wout=⌊stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1⌋∴同理可得,padding[1]也为2
padding直接传入参数2即可,默认会将padding这个tuple都赋为2
# 因此进行如上变换需要传参如下
self.conv1 = Conv2d(in_channels=3, out_channels=32,kernel_size=5, stride=1, padding=2)
3.2 代码实现
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear
# 神经网络模型
class TrainModule(nn.Module):def __init__(self):super().__init__()# 按照上边参考图对数据依次进行如下处理,最后得到的就是关于当前图像的分类概率预测self.model = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32,kernel_size=5, stride=1, padding=(2, 2)),# 最大池化操作nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),# 扁平化nn.Flatten(),# 线性处理nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return xnet = TrainModule()
# 以下部分均为测试神经网络功能
# 模拟输入数据:64张图片。每个图的格式为3*32*32
input = torch.ones((64, 3, 32, 32))
# 调用神经网络类时会调用forward方法
output = net(input)
# 输出结果为torch.Size([64, 10]),说明返回结果是64张图片再十个数字类别中的概率
print(output.shape)
4 损失函数
我们通过比对预测值和真实值的差距从而得知模型的训练优劣,损失函数将这个指标数据化,损失函数越小,说明模型训练得越好
import tensorboard
from torch.utils.tensorboard import SummaryWriter
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器,SGD为随机梯度下降法
# 传入需要梯度下降的参数以及学习率,1e-2等价于0.01
optimizer = torch.optim.SGD(net.parameters(), lr=1e-2)# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 训练轮数【电脑性能有限,只打个样例】
epoch = 2
writer = SummaryWriter('./logs')
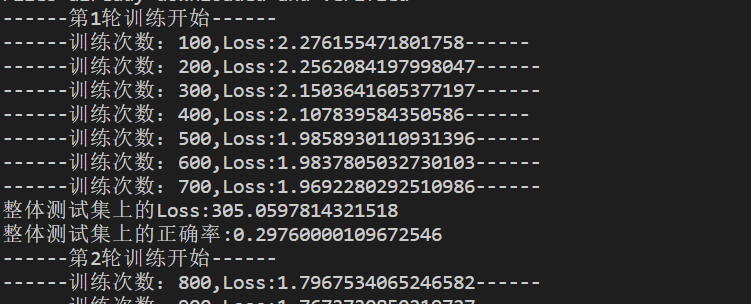
for i in range(epoch):print('------第{}轮训练开始------'.format(i+1))# 训练步骤开始for data in train_dataloader:imgs, targets = data# 将图片传入神经网络后得到输出结果outputs = net(imgs)# 将输出结果与原标签进行比对,计算损失函数loss = loss_fn(outputs, targets)# 在应用层面可以简单理解梯度清零,反向传播,优化器优化为三个固定步骤# 梯度清零optimizer.zero_grad()# 反向传播,更新权重loss.backward()# 对得到的参数进行优化optimizer.step()total_train_step += 1# 为避免打印太多,训练100次才打印1次if total_train_step % 100 == 0:# loss.item()作用是把tensor转为一个数字print('------训练次数:{},Loss:{}------'.format(total_train_step, loss.item()))writer.add_scalar('train_loss', loss.item(), total_train_step)# 测试步骤开始total_test_loss = 0total_accuracy = 0# with的这段语句可以简单理解为提升运行效率with torch.no_grad():# 拿测试集中的数据来验证模型for data in test_dataloader:imgs, targets = dataoutputs = net(imgs)loss = loss_fn(outputs, targets)total_test_loss += loss.item()# agrmax(1)是将tensor对象按行看最大值下标进行存储,此处是数字图像,因此最大值下标实则就是我们的预测值# 此处是拿标签进行验证,统计预测正确的概率,方便后边计算正确率accuracy = (outputs.argmax(1) == targets).sum()total_accuracy += accuracyprint('整体测试集上的Loss:{}'.format(total_test_loss))print('整体测试集上的正确率:{}'.format(total_accuracy/test_data_size))writer.add_scalar('test_loss', total_test_loss, total_test_step)total_test_step += 1# 将每轮训练的模型都进行保存,方便以后直接调用训练完毕的模型torch.save(net, 'tarin_{}.pth'.format(total_test_step))writer.close()
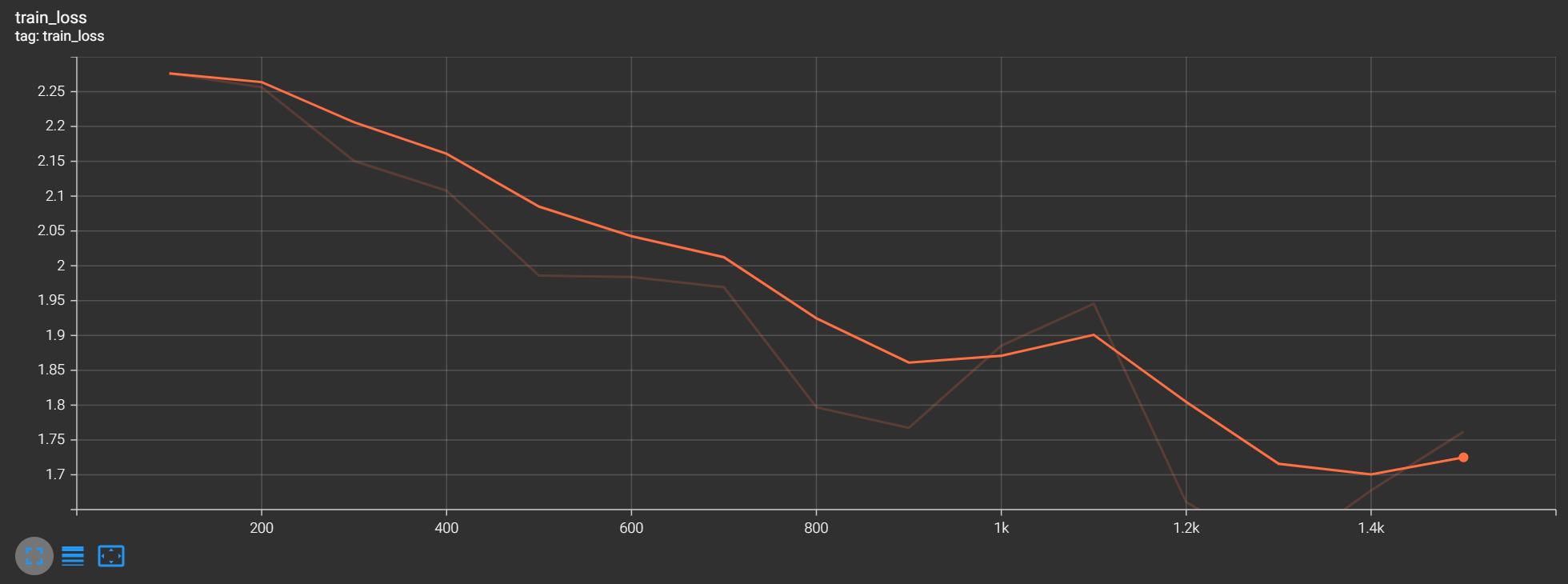
5. 利用GPU训练【优化训练速度】
如何电脑有
GPU的话,优先 利用GPU进行训练速度会快很多
# 在有cuda方法的部分都加上
if torch.cuda.is_available():# 把数据交给GPU处理imgs = imgs.cuda()targets = targets.cuda()
如下方法也可以【常用】
# 指定device指向设备的第一张显卡
device = torch.device('cuda:0')
# 优先使用这张显卡处理
imgs = imgs.to(device)# 也可以这样指定防止出错
device = torch.device( "cuda" if torch.cuda.is_available() else "cpu")
相关文章:
Pytorch从零开始训练模型【识别数字模型】并测试
1 准备数据集 import torch import torchvision # 去网上下载CIFAR10数据集【此数据集为经典的图像数字识别数据集】 # train True 代表取其中得训练数据集; # transform 参数代表将图像转换为Tensor形式 # download 为True时会去网上下载数据集到指定路径【root】…...

Leetcode DAY 44: 完全背包 and 零钱兑换 II and 组合总和 Ⅳ
完全背包518. 零钱兑换 II!!!程序未通过原因: 1、dp数组的初始化没考虑清楚 2、组合问题 dp数组的更新没考虑清楚 修改后: class Solution { public:int change(int amount, vector<int>& coins) {// dp[j…...

谷歌搜索留痕的技术公式【2023年新版】
本文主要分享谷歌搜索留痕的技术公式,让你更简单的去学习谷歌留痕的技术原理 本文由光算创作,有可能会被修改和剽窃,我们佛系对待这样的行为吧。 谷歌搜索留痕的技术公式是什么? 答案是:需要做排名的关键词海量能搜…...

2023财年Q4业绩继续下滑,ChatGPT能驱动英伟达重回巅峰吗?
近年来,全球科创风口不断变换,虚拟货币、元宇宙等轮番登场,不少企业匆忙上台又很快谢幕,但在此期间,有些企业扮演淘金潮中“卖水人”的角色,却也能够见证历史且屹立不倒。不过,这并不意味着其可…...
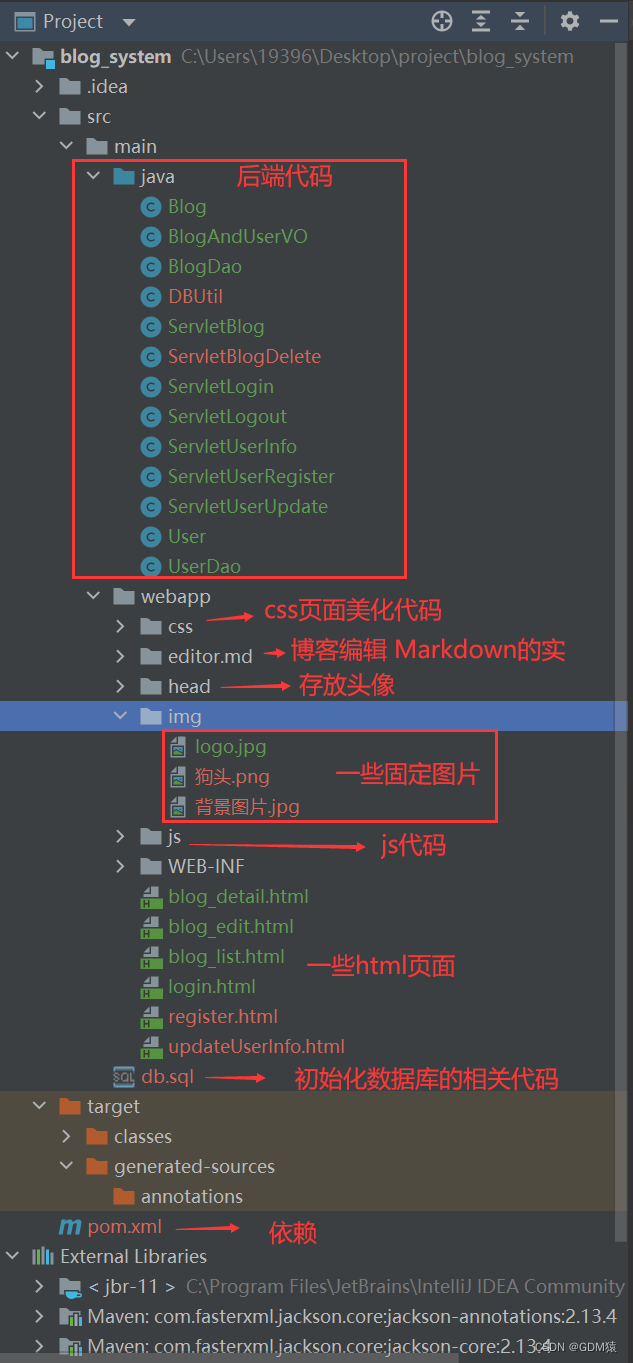
博客管理系统--项目说明
项目体验地址(账号:123,密码:123)http://120.53.20.213:8080/blog_system/login.html项目码云Gitee地址:https://gitee.com/GoodManSS/project/tree/master/blog_system(一)准备工作…...
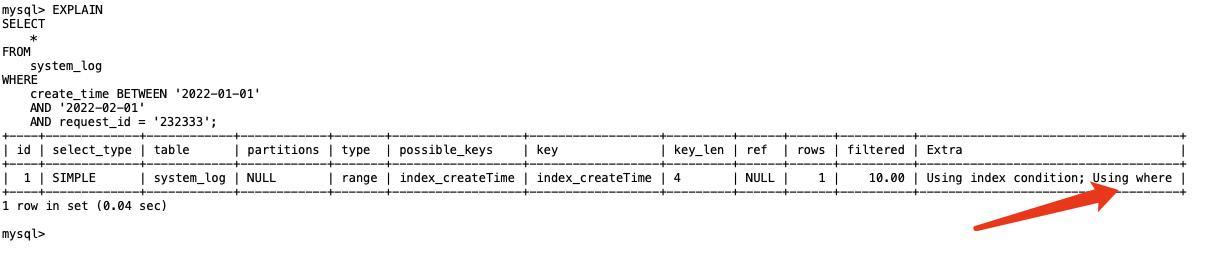
一文带你了解MySQL的Server层和引擎层是如何交互的?
对于很多开发小伙伴来说,每天写SQL是必不可少的一项工作。 那不知道大家有没有深入了解过,当我们的一条SQL命令被执行时,MySQL是如何把数据从硬盘/内存中查出来并展示到用户面前的呢? 其实,MySQL也没有大家想象的那么…...

CVNLP 常用数据集语料库资源汇总
深度学习常用数据集汇总CVClassificationNLPSentiment AnalysisText ClassificationDialogue Generation其他AudioMulti-ModalClassificationSearch & MatchingImage CaptioningVisualQATri-Modal其他CV ghcnclimate_sphereModelNet40Shrec17 data labelcosmo Spherica…...

lisp 表达式求值规则
lisp 表达式求值规则 一个要求值的 lisp 对象被称为lisp表达式(form)。 lisp 表达式分三种 1. 自求值表达式。前面说过数字、字符串、向量都是自求值表达式。还有两个特殊的符号 t 和 nil 也可以看成是自求值表达式。 2. 符号表达式。符号的求值…...

Sophos Firewall OS (SFOS) 19.5 MR1 - 同步下一代防火墙
Sophos Firewall OS (SFOS) 19.5 MR1 - 同步下一代防火墙 请访问原文链接:https://sysin.org/blog/sfos-19-5/,查看最新版。原创作品,转载请保留出处。 作者主页:www.sysin.org Sophos Firewall v19.5 现已推出 Sophos Firewall…...

为什么很多人转行IT考虑后端开发Java?
顺应互联网时代发展的选择 在计算机广泛运用于社会的各个角落的今天,选择学习一门计算机语言真的很不错,它会让你的生活从此与众不同。软件渗透到组织的运营和管理的后台之中,形成了组织运营支撑平台。这种形态是传统软件的重要应用场景。在…...

WebDAV之π-Disk派盘+Cloud Player
Cloud Player 支持WebDAV方式连接π-Disk派盘。 推荐一款云媒体播放器是存储在常见云平台中的内容的通用播放器。 Cloud Player云媒体播放器是存储在常见云平台中的内容的通用播放器,无需将其下载到设备。支持以下云平台:Google Drive、DropBox、One Drive、WebDav等。此外,…...
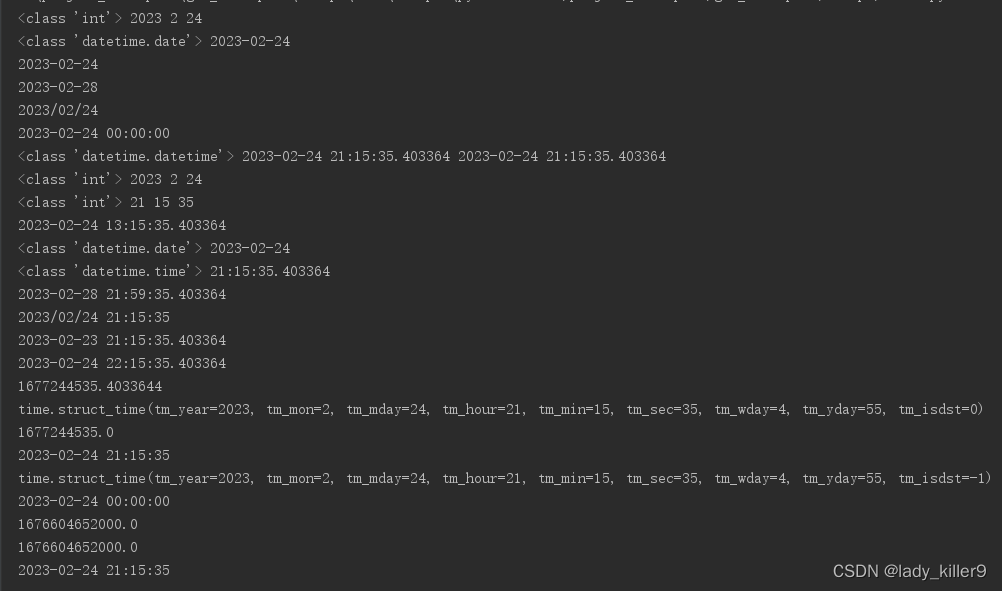
Python-datetime、time包常用功能汇总
目录基础知识时间格式有哪些?Python中的时间格式化时间戳datetimedatedatetimetimedeltatime常用获取今天凌晨字符串?将一个时间格式的字符串转为时间戳将一个时间戳转为指定格式的字符串全部代码参考基础知识 时间格式有哪些? 「格林威治标…...
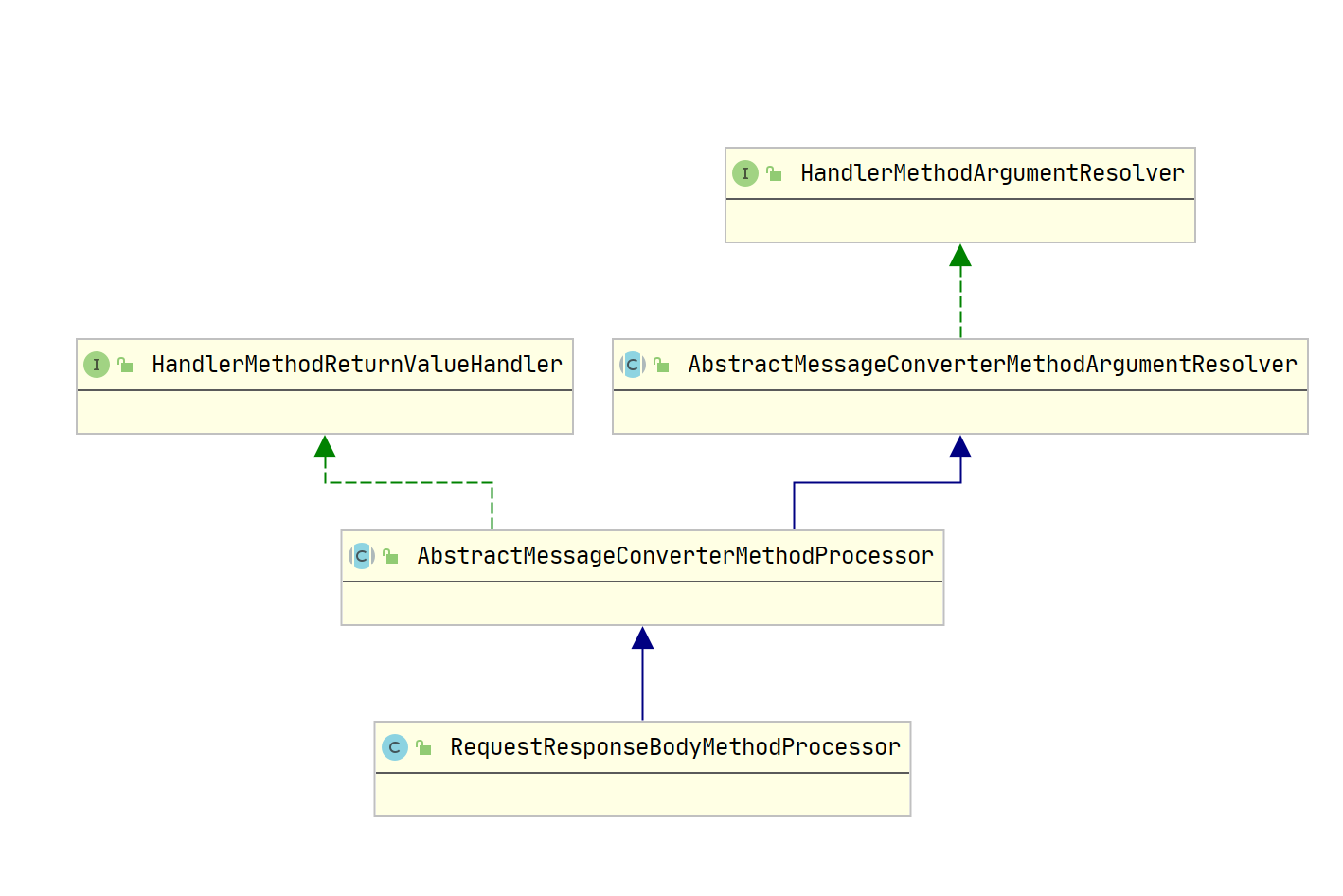
Spring MVC 源码- HandlerAdapter 组件(四)之 HandlerMethodReturnValueHandler
HandlerAdapter 组件HandlerAdapter 组件,处理器的适配器。因为处理器 handler 的类型是 Object 类型,需要有一个调用者来实现 handler 是怎么被执行。Spring 中的处理器的实现多变,比如用户的处理器可以实现 Controller 接口或者 HttpReques…...

2023面试必备:web自动化测试POM设计模式详解
1.背景 为UI页面写自动化测试用例时(如:web自动化、app自动化),使用普通的线性代码,测试用例中会存在大量的元素定位及操作细节,当UI界面变化时,测试用例也要跟着变化,在自动化测试…...

【人工智能 AI】Robotic Process Automation (RPA) 机器人流程自动化 (RPA)
目录 ROBOTIC PROCESS AUTOMATION SERVICES机器人流程自动化服务 What is RPA? 什么是机器人流程自动化?...
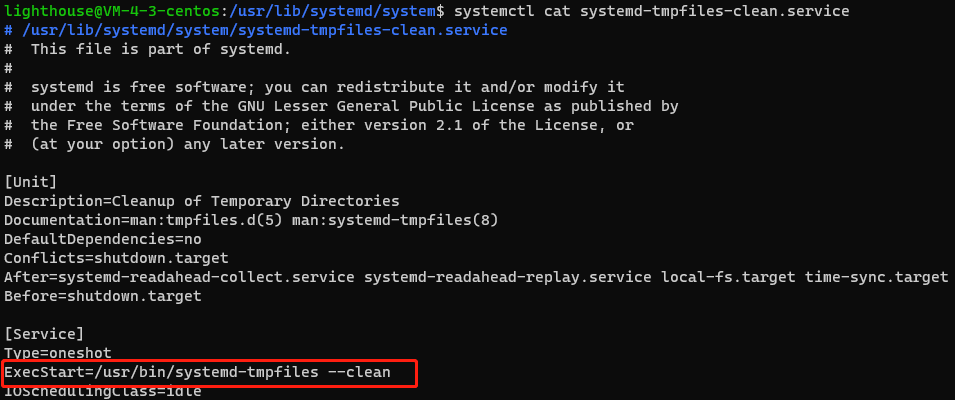
ubuntu/linux系统知识(37)systemd管理临时文件的方法systemd-tmpfiles
1、systemd-tmpfiles Linux产生大量的临时文件和目录,例如/tmp、/run 。systemd提供了一个结构化的可配置方法来管理临时文件和目录,即systemd-tmpfiles工具和配套的几个服务,以实现创建、删除和管理临时文件。 systemd创建了几个调用syste…...

云计算专业和计算机专业哪个好就业?
云计算专业其实也是属于计算机类专业呢,他包括了计算机硬件设备、计算机网络、磁盘柜、操作系统、中间件、数据库、服务器/虚拟机、应用软件开发等技术内容,云计算技术是以IT服务的形式面向用户的;所以云计算不是一门技术,而是众多…...

electron sha512 checksum mismatch
sha512 checksum mismatch错误 此错误常常发生在electron检查更新时,导致检查更新失败。 自动更新使用的模块 electron-updater or electron-differential-updater win下electron-builder打包 使用electron-builder打包之后,进行版本增量更新遇到的…...
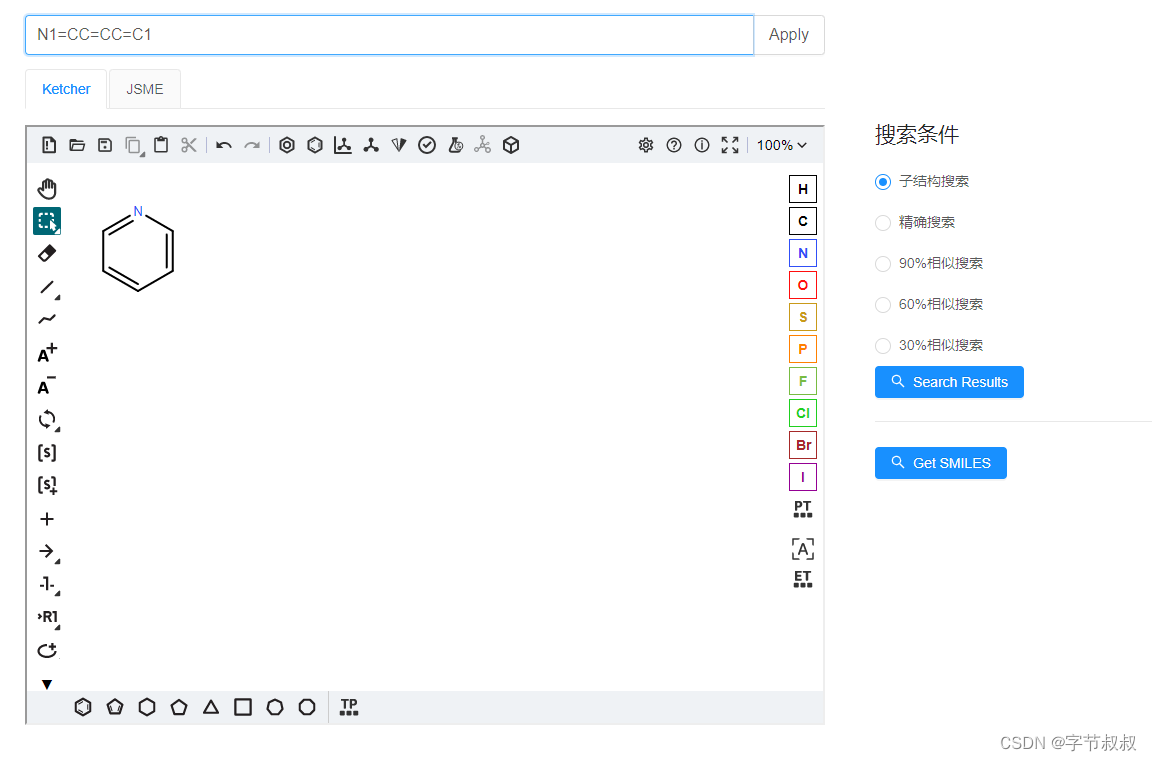
使用Chemistry Development Kit (CDK) 来进行化学SMILES子结构匹配
摘要 SMILES是一种用于描述化合物结构的字符串表示法,其中子结构搜索是在大规模化合物数据库中查找特定的结构。然而,这种搜索方法存在一个误解,即将化合物的子结构视为一个独立的实体进行搜索,而忽略了它们在更大的化合物中的上…...

CMake模块的使用和自定义模块
CMake模块的使用和自定义模块一、前言二、使用Find模块2.1、准备工作2.2、添加头文件路径和库文件2.3、< name >_FOUND 来控制工程特性三、编写自定义的Find模块3.1、 准备工作3.2、cmake 模块3.3、使用自定义的FindHELLO 模块构建工程3.4、如果没有找到hello library四、…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...
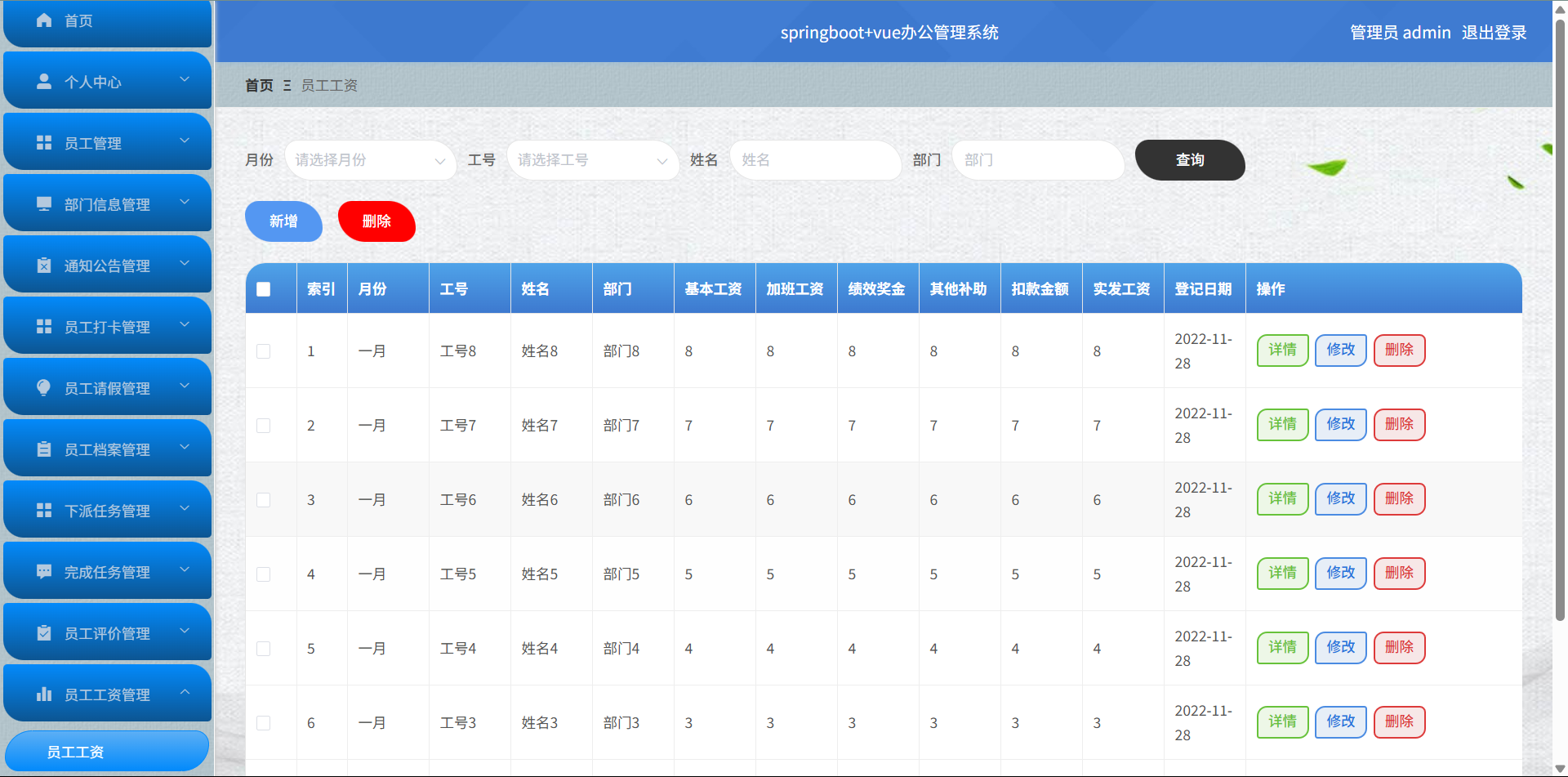
基于Springboot+Vue的办公管理系统
角色: 管理员、员工 技术: 后端: SpringBoot, Vue2, MySQL, Mybatis-Plus 前端: Vue2, Element-UI, Axios, Echarts, Vue-Router 核心功能: 该办公管理系统是一个综合性的企业内部管理平台,旨在提升企业运营效率和员工管理水…...