Spring的创建和使用
目录
创建Spring项目
步骤
1)使用Maven的方式创建Spring项目
2)添加Spring依赖
3)创建启动类
存Bean对象
1.创建Bean对象
2.将Bean注册到Spring中
取Bean对象并使用
步骤
1.先得到Spring上下文对象
2.从Spring中获取Bean对象
3.使用Bean
ApplicationContext VS BeanFactory
存储Bean对象(更简单)
1.前置工作
2.使用注解存储对象
使用类注解
方法注解@Bean
获取Bean对象(对象装配)
1.属性注入
优点
缺点
2.setter注入
优点
缺点
3.构造方法注入
优点
@Resource注解
注意事项
这篇博客我将介绍Spring项目的创建和Bean对象的注入和使用
创建Spring项目
步骤
我来详细介绍创建过程
1)使用Maven的方式创建Spring项目
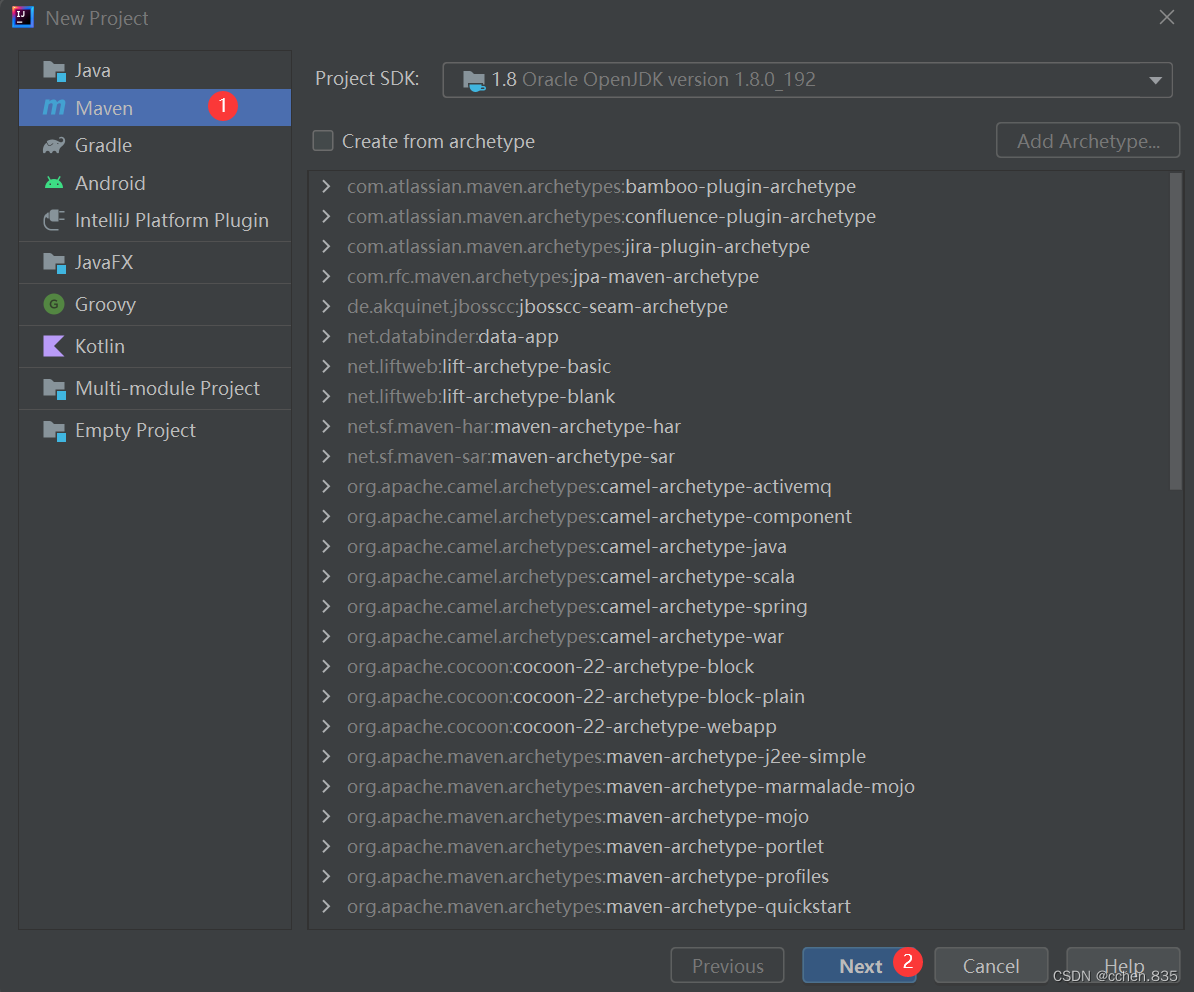

2)添加Spring依赖
在pom.xml中添加依赖(spring-context/spring-beans)
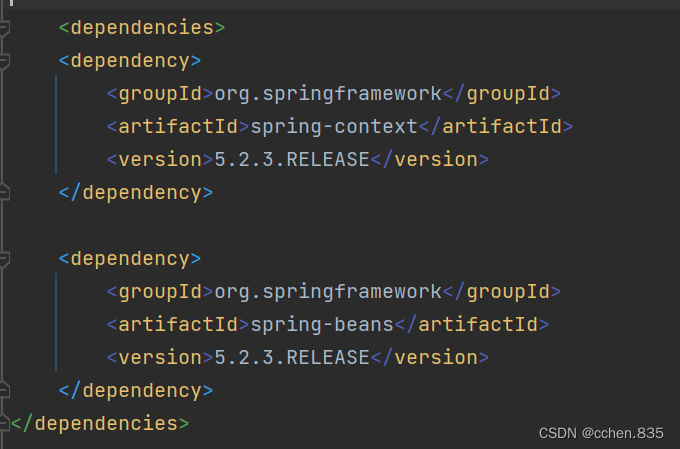
3)创建启动类
在java文件夹中创建启动类包含main方法即可
存Bean对象
我们创建完Spring项目就可以开始存Bean对象了,Bean就是Java中普通的对象
1.创建Bean对象
public class User {//Bean对象public void fun() {System.out.println("hello world");}
}2.将Bean注册到Spring中
在resources中创建Spring-config.xml配置并使用

Spring配置文件内容固定只需要添加要注册的Bean,具体操作是在<Beans>中添加如下配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><!-- 注册一个对象到spring中 --><bean class="com.User" id="user"></bean>
</beans>在上面代码中可以看到我已经注册一个对象到Spring中了,其中有两个参数 class表示要注册对象的位置(包名+类名),id表示标识(一般为类名小驼峰)作为取对象使用
取Bean对象并使用
步骤
1.先得到Spring上下文对象
ApplicationContext context = new ClassPathXmlApplicationContext("spring-config.xml");注意:参数中的内容要和创建的xml名称一一对应
2.从Spring中获取Bean对象
User user = (User) context.getBean("user");context.getBean()的方法重载有很多这里先介绍最简单的根据Sting [bean id]获取Bean,通过之前在xml中注册的id作为getBean的参数来从Spring中获取bean对象
根据Class参数获取Bean [根据类型]
User user1= context.getBean(User.class);根据String [bean id]和Class获取bean
User user2=context.getBean("user",User.class);3.使用Bean
user.fun();//使用Bean对象ApplicationContext VS BeanFactory
ApplicationContext context = new ClassPathXmlApplicationContext("spring-config.xml");
BeanFactory context= new XmlBeanFactory(new ClassPathResource("spring-config.xml"));共同点:都是用来获取Spring上下文对象
不同点:
1.继承关系和功能:ApplicationContext属于BeanFactory子类,ApplicationContext拥有独特的特性, 还添加了对国际化支持、资源访问支持、以及事件传播等方面的支持
2.性能方面来说:ApplicationContext 是⼀次性加载并初始化所有的 Bean 对象,而BeanFactory 是需要那个才去加载那个,因此更加轻量
在上面的博客内容中我们已经可以实现Spring的读取和存储对象的功能了,但是感觉并不高效,所以接下来我将介绍Spring更简单的读取和存储对象就是通过使用注解
存储Bean对象(更简单)
1.前置工作
在存储Bean对象前我们先需要在xml中配置⼀下存储对象的扫描包路径,只有被配置的包下的所有类,添加了注解才能被正确的识别并保存到 Spring 中

2.使用注解存储对象
要将对象存储到Spring中有两种注解类型可以实现
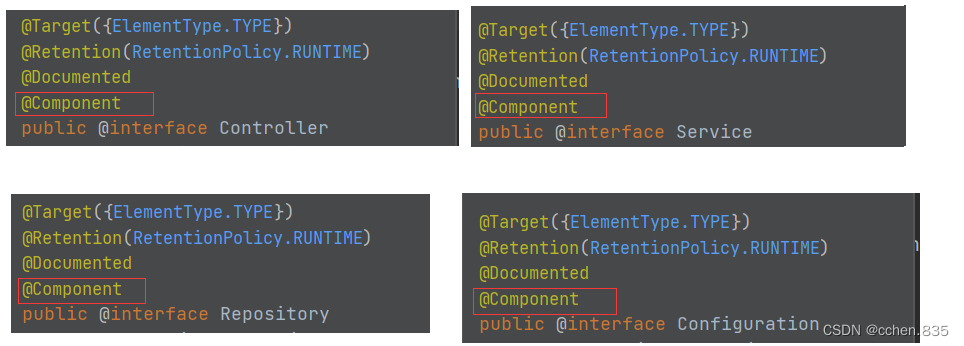
使用类注解
1.@Controller 控制器 验证前端传递的参数
2.@Service 服务层 服务调用的编排和汇总
3.@Repository 仓库(数据仓库) 直接操作数据库
4.@Componet 组件 通用化的工具类
5.@Configuration 配置 项目的所有配置
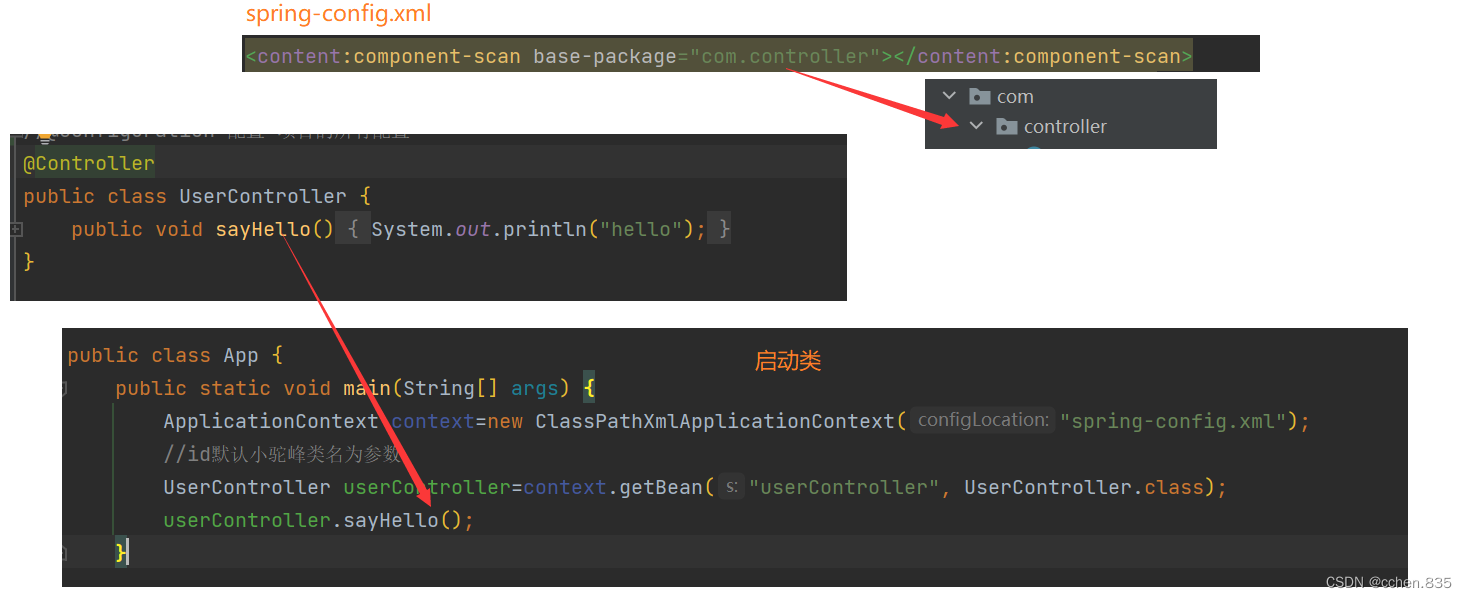
在上面的代码片段中我们会发现几个问题,注解都能完成相同的任务为什么要有这么多的类注解,它们之间的关系怎样的,读取bean为什么使用小驼峰,接下来我会一一介绍
1)为什么这么多的类注解
这么多的类注解就是让程序员在看到类注解之后能够知道当前类的用途,进而提高代码的可读性和可阅读性
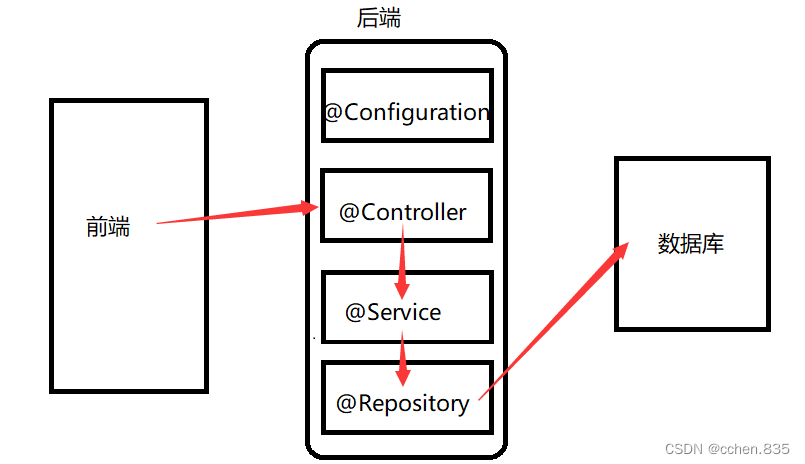
2)类注解之间的关系
我们可以通过源码来看看 @Controller / @Service / @Repository / @Configuration 等注解都是基于@Component,它们的作用是将Bean对象存储到Spring中
3)Bean的命名规范
默认情况:我们通常命名Bean是使用大驼峰命名,但是在读取Bean时又要将首字母小写来获取

特殊情况:但是在有开头两个字母大写的时候,在读取时却要使用定义的类名才能找到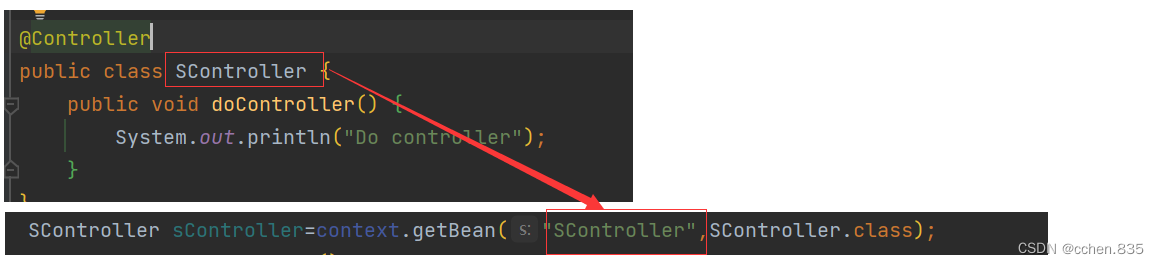
原因是什么呢?我们就需要了解一下Bean的命名规则了

方法注解@Bean
使用方法注解将Bean存储到Spring中,在使用类注解时我们是将类注解添加到类上的,使用方法注解则是需要将@Bean添加到方法上并配合五大类注解使用,本质是为了提升效率
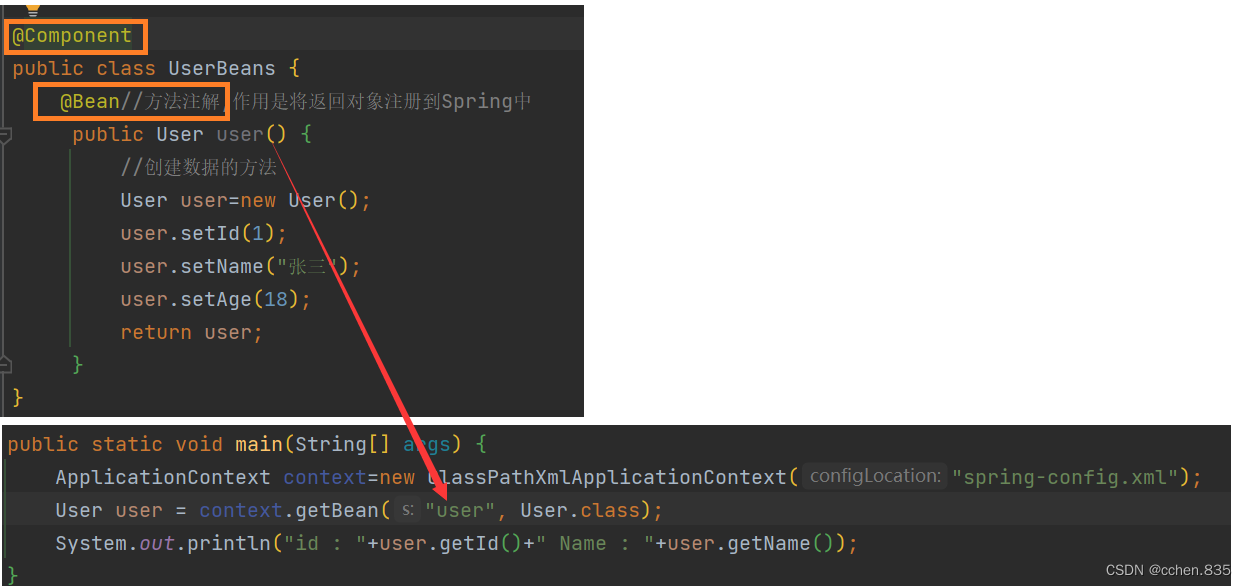
@Bean注解方法名(命名规则)
在上面的代码中我们可以看到在getBean中我们使用方法名来获取Bean对象,和五大类注解的命名方式并不相同,因为在相同类中可能有多个返回相同类型的方法,所以选择使用方法名是更好的选择,但是在不同类中也会出现同名的方法这就会造成使用的麻烦,所以就需要重命名Bean
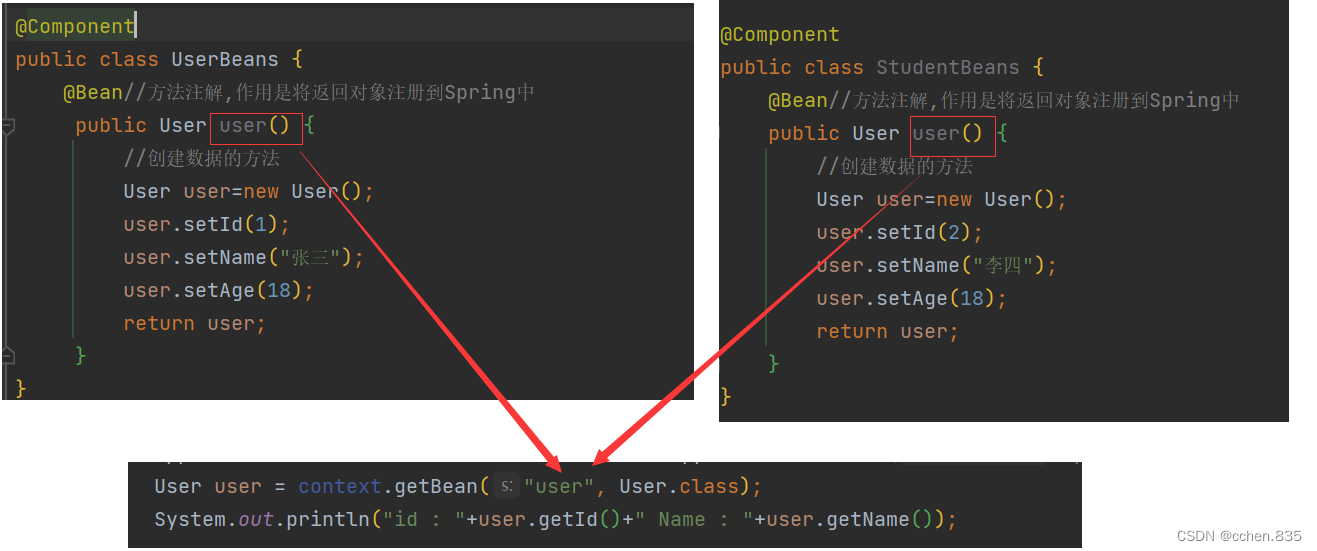
此时只能获取到唯一的结果,我们就可以使用重命名Bean来获取所需要的Bean了
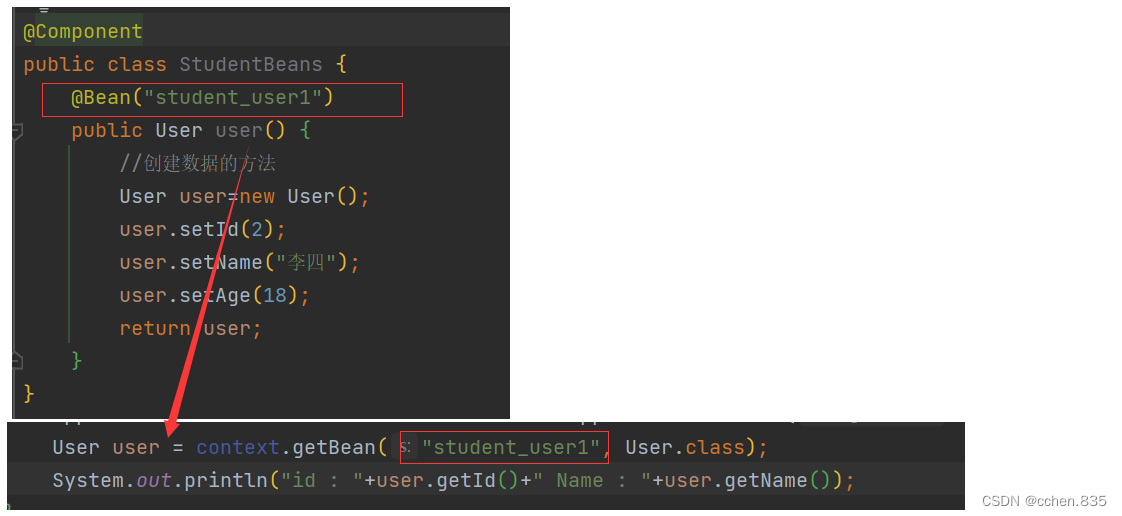
@Bean重命名的格式
@Bean("student_user1")@Bean(name = "stu_user1")@Bean(value = "stu_user2")@Bean(name={"student_user1","stu_user1"})注意事项
1.@Bean必须配合五大类注解一起使用(不然注入不进去)
2.@Bean方法注解只能使用在无参的方法上(Spring 初始化存储时,没法提供相应的参数)
3@Bean重命名之后使用方法名就不能获取Bean对象了
获取Bean对象(对象装配)
获取Bean对象也叫做对象装配,是将对象取出来放到某个类中有时候也叫对象注入
1.属性注入
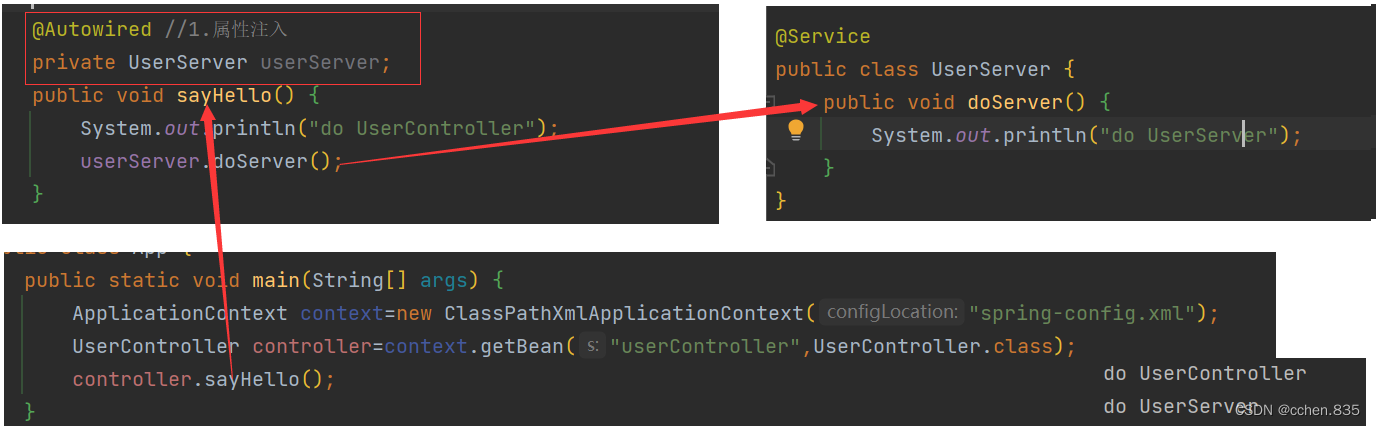
优点
属性注入实现简单,使用简单,只需要给变量上添加一个注解@Autowired就可以在不new对象的情况下,直接获得注入对象了
缺点
①不能注入final修饰的变量
②通用性弱只适用IoC框架(容器)
③更容易违背单一设计原则
④idea不建议使用
2.setter注入
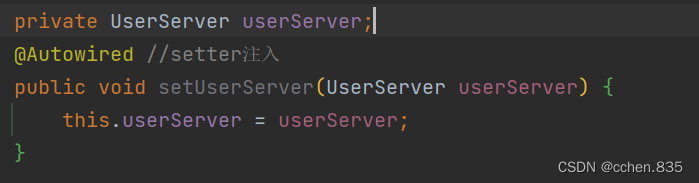
在设置 set 方法的时候需要加上 @Autowired 注解
优点
①符合单一设计原则(一个setter只针对一个对象)
缺点
①不能注入final修饰的变量
②注入对象可能被改变(setter方法可能被多次调用,存在篡改的风险)
3.构造方法注入
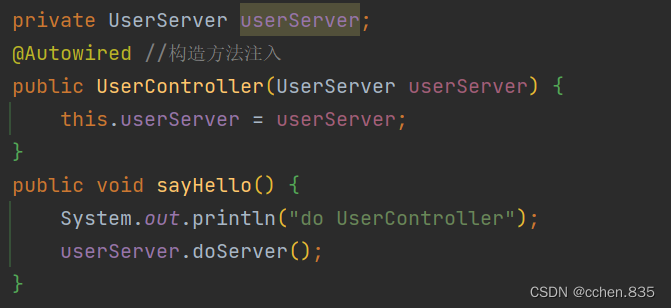
当当前类只有一个构造方法时此时@Autowrired注解可以省略,言外之意多个构造方法必须使用@Autowired注解指定构造方法
优点
①可以注入不可变对象(final修饰的对象)
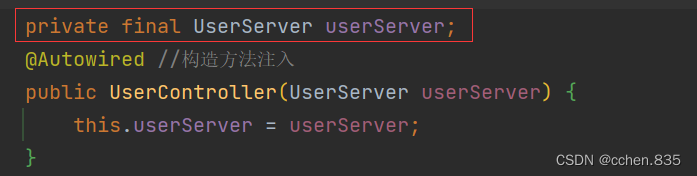
为什么构造方法注入就可以解决呢,这里是遵循了Java的规范也就是final的用法:①创建时直接赋值②在构造方法中进行赋值,构造方法注入就符合②的方式了而前两种注入方式无法满足
②注入对象不会被修改
构造方法在对象创建时只会执行一次因此注入的对象不存在被随意修改的情况
③依赖的对象在使用前一定会完全初始化
因为依赖的类是在构造方法中执行的,而构造方法是在类创建之初就会执行的方法
④通用性更好
因为构造方法是Java(JDK)支持的,所以更换任何框架都是适用的
@Resource注解
我们除了可以使用@Autowired进行注入还可以使用@Resource进行对象注入
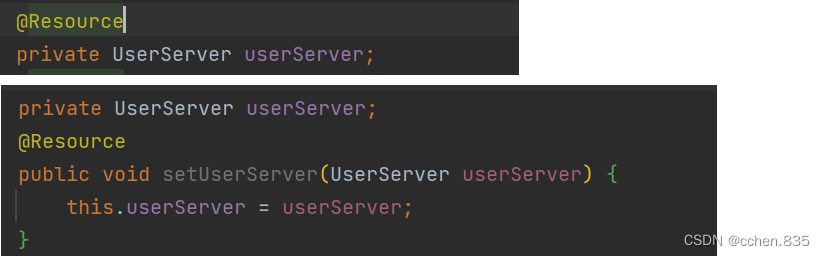
注意事项
@Resource注解在属性注入和stetter注入是支持的但是构造方法注入不支持
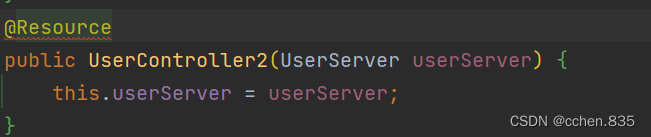
@Resource注解有更多的方法,在特殊情况下有更好的效果
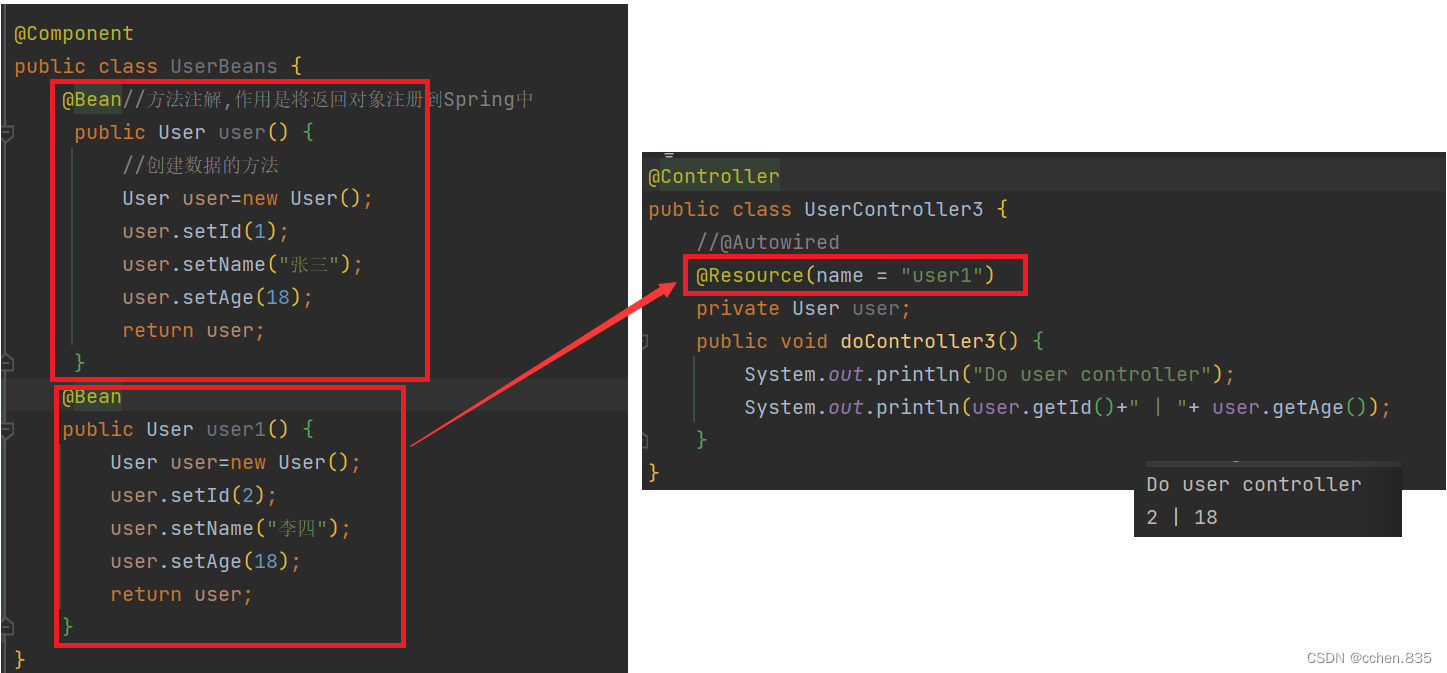
在上面的代码片段中我们看到可以修改@Resource的name方法来获取指定的Bean对象,@Autowired就没有相同方式获取Bean对象了,但是可以通过@Qualifier注解处理同一类型多个Bean对象获取问题
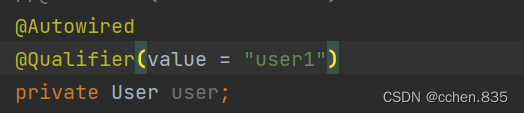
通过@AutoWired+@Qualifier的value方法就可以解决了
相关文章:
Spring的创建和使用
目录 创建Spring项目 步骤 1)使用Maven的方式创建Spring项目 2)添加Spring依赖 3)创建启动类 存Bean对象 1.创建Bean对象 2.将Bean注册到Spring中 取Bean对象并使用 步骤 1.先得到Spring上下文对象 2.从Spring中获取Bean对象 3.使用Bean ApplicationContext VS Bea…...
如何实现外网跨网远程控制内网计算机?快解析来解决
远程控制,是指管理人员在异地通过计算机网络异地拨号或双方都接入Internet等手段,连通需被控制的计算机,将被控计算机的桌面环境显示到自己的计算机上,通过本地计算机对远方计算机进行配置、软件安装程序、修改等工作。通俗来讲&a…...

【跟着ChatGPT学深度学习】ChatGPT教我文本分类
【跟着ChatGPT学深度学习】ChatGPT教我文本分类 ChatGPT既然无所不能,我为啥不干脆拜他为师,直接向他学习,岂不是妙哉。说干就干,我马上就让ChatGPT给我生成了一段文本分类的代码,不看不知道,一看吓一跳&am…...

IM即时通讯架构技术:可靠性、有序性、弱网优化等
消息的可靠性是IM系统的典型技术指标,对于用户来说,消息能不能被可靠送达(不丢消息),是使用这套IM的信任前提。 换句话说,如果这套IM系统不能保证不丢消息,那相当于发送的每一条消息都有被丢失的…...

【算法】三道算法题两道难度中等一道困难
算法目录只出现一次的数字(中等难度)java解答参考二叉树的层序遍历(难度中等)java 解答参考给表达式添加运算符(比较困难)java解答参考大家好,我是小冷。 上一篇是算法题目 接下来继续看下算法题…...
正交实验与极差分析
正交试验极差分析流程如下图: 正交试验说明 正交试验是研究多因素试验的设计方法。对于多因素、多水平的实验要求,如果每个因素的每个水平都要进行试验,这样就会耗费大量的人力和时间,正交试验可以选择出具有代表性的少数试验进行…...
DEXTUpload .NET增强的上传速度和可靠性
DEXTUpload .NET增强的上传速度和可靠性 DEXTUpload.NET Pro托管在Windows操作系统上的Internet Information Server(IIS)上,服务器端组件基于HTTP协议,支持从web浏览器到web服务器的文件上载。它也可以在ASP.NET服务器应用程序平台开发的任何网站上使用…...
)
SkyWalking 将方法加入追踪链路(@Trace)
SkyWalking8 自定义链路追踪@Trace 自定义链路,需要依赖skywalking官方提供的apm-toolkit-trace包.在pom.xml的dependencies中添加如下依赖: <dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-trace</artifactId>&…...
MySQL Administrator定时备份MySQL数据库
1、下载并安装软件mysql-gui-tools-5.0-r17-win32.exe 2、将汉化包zh_CN文件夹拷贝到软件安装目录 3、菜单中打开MySql Adminstrator,见下图,初次打开无服务实例。 点击已存储连接右侧按钮①,打开下图对话框。点击“新连接”按钮ÿ…...

Kubernetes入门教程 --- 使用二进制安装
Kubernetes入门教程 --- 使用二进制安装1. Introduction1.1 架构图1.2 关键字介绍1.3 简述2. 使用Kubeadm Install2.1 申请三个虚拟环境2.2 准备安装环境2.3 配置yum源2.4 安装Docker2.4.1 配置docker加速器并修改成k8s驱动2.5 时间同步2.6 安装组件3. 基础知识3.1 Pod3.2 控制…...

深度学习模型压缩方法概述
一,模型压缩技术概述 1.1,模型压缩问题定义 因为嵌入式设备的算力和内存有限,因此深度学习模型需要经过模型压缩后,方才能部署到嵌入式设备上。 模型压缩问题的定义可以从 3 角度出发: 模型压缩的收益: 计算: 减少浮点运算量(FLOPs),降低延迟(Latency)存储: 减少内…...

《NFL橄榄球》:坦帕湾海盗·橄榄1号位
坦帕湾海盗(英语:Tampa Bay Buccaneers)是一支位于佛罗里达州的坦帕湾职业美式橄榄球球队。他们是全国橄榄球联盟的南区其中一支球队。在1976年,与西雅图海鹰成为NFL的球队。球队在最初的两个球季连败26场,在二十世纪七…...
Xmake v2.7.7 发布,支持 Haiku 平台,改进 API 检测和 C++ Modules 支持
layout: post.cn title: “Xmake v2.7.7 发布,支持 Haiku 平台,改进 API 检测和 C Modules 支持” tags: xmake lua C/C package modules haiku cmodules categories: xmake Xmake 是一个基于 Lua 的轻量级跨平台构建工具。 它非常的轻量,没…...

苹果ios签名证书的生成方法
在使用hbuilderx打包uniapp或html5应用的时候,假如是打包ios应用,是需要ios签名证书,和证书profile文件的,这个证书要求是p12格式的证书,profile文件又叫描述文件。 这两个文件,需要在苹果开发者中心生成&…...

c++开发配置常用网站记录
1.ubuntu 镜像源: (1) 清华源:https://mirror.tuna.tsinghua.edu.cn/help/ubuntu/ (2) 阿里源:https://developer.aliyun.com/mirror/ubuntu?spma2c6h.13651102.0.0.3e221b11VuM27s 包含了ubuntu各个版本的source源 2.ubuntu iso镜像下载…...
DC-1 靶场学习
以前写过了,有一些忘了,快速的重温一遍。 DC一共九个靶场,目标一天一个。 文章目录环境配置:信息搜集:漏洞复现:FLAG获取环境配置: 最简单的办法莫过于将kali和DC-1同属为一个nat的网络下。 信…...

oracle 不使用索引深入解析
首先,我们要确定数据库运行在何种优化模式下,相应的参数是:optimizer_mode。缺省的设置应是"choose",即如果对已分析的表查询的话选择CBO,否则选择RBO。如果该参数设为“rule”,则不论表是否分析…...

什么是自助式BI工具,有没有推荐
为什么需要自助式BI? 传统的BI采用的是“业务提报表需求,IT进行开发”的模式。决策管理者和业务人员提出用报表等来展示经营管理数据的需求;接着IT响应需求,进行需求沟通、数据处理加工、报表开发等主体工作;最后决策管…...

如何高效管理自己的时间,可以从这几个方向着手
如果你是上班族,天选打工人,你的绝大多数时间都属于老板,能够自己支配的时间其实并不多,所以你可能察觉不到时间管理的重要性。但如果你是自由职业者或者创业者,想要做出点成绩,那你就需要做好时间管理&…...
)
【PAT甲级题解记录】1014 Waiting in Line (30 分)
【PAT甲级题解记录】1014 Waiting in Line (30 分) 前言 Problem:1014 Waiting in Line (30 分) Tags:模拟 双端队列 Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1014 Waiting in Line (30 分) 问题描述 银行有N个…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...