使用Python创建faker实例生成csv大数据测试文件并导入Hive数仓
文章目录
- 一、Python生成数据
- 1.1 代码说明
- 1.2 代码参考
- 二、数据迁移
- 2.1 从本机上传至服务器
- 2.2 检查源数据格式
- 2.3 检查大小并上传至HDFS
- 三、beeline建表
- 3.1 创建测试表并导入测试数据
- 3.2 建表显示内容
- 四、csv文件首行列名的处理
- 4.1 创建新的表
- 4.2 将旧表过滤首行插入新表
一、Python生成数据
1.1 代码说明
这段Python代码用于生成模拟的个人信息数据,并将数据保存为CSV文件。
-
导入必要的模块:
csv:用于处理CSV文件的模块。random:用于生成随机数。faker:用于生成模拟数据的库。
-
定义生成数据所需的基本信息:
file_base_path:生成的CSV文件的基本路径。rows_per_file:每个CSV文件中包含的行数。num_rows:要生成的总行数。fake:创建faker.Faker()实例,用于生成模拟数据。
-
定义模拟数据的字典:
nationalities:包含国籍编码和对应的国家。regions:包含区域编码和对应的区域名称。source_codes:包含一组源代码。
-
使用计数器
row_counter来跟踪生成的行数。 -
使用循环生成多个CSV文件,每个文件包含
rows_per_file行数据。 -
在每个文件中,生成随机的个人信息数据,并将其写入CSV文件。
-
数据生成的过程中,每10000行数据打印一次进度。
-
所有数据生成后,打印生成的总行数。
这段代码使用Faker库生成模拟的个人信息数据,每个CSV文件包含一定数量的行数据,数据字段包括 Rowkey, Name, Age, Email, Address, IDNumber, PhoneNumber, Nationality, Region, SourceCode。
1.2 代码参考
import csv
import random
import faker# 文件基本路径
file_base_path = './output/personal_info_extended'
# 每个文件的行数
rows_per_file = 10000
# 总行数
num_rows = 10000000# 创建Faker实例
fake = faker.Faker()# 定义数据字典
nationalities = {1: 'US',2: 'CA',3: 'UK',4: 'AU',5: 'FR',6: 'DE',7: 'JP',
}regions = {1: 'North',2: 'South',3: 'East',4: 'West',5: 'Central',
}source_codes = ['A123', 'B456', 'C789', 'D101', 'E202']# 计数器用于跟踪生成的行数
row_counter = 0# 循环生成数据文件
for file_number in range(1, num_rows // rows_per_file + 1):file_path = f"{file_base_path}_{file_number}.csv"# 打开CSV文件以写入数据with open(file_path, 'w', newline='') as csvfile:csv_writer = csv.writer(csvfile)# 写入CSV文件的标题行if row_counter == 0:csv_writer.writerow(['Rowkey', 'Name', 'Age', 'Email', 'Address', 'IDNumber', 'PhoneNumber', 'Nationality', 'Region', 'SourceCode'])# 生成并写入指定行数的扩展的个人信息模拟数据for _ in range(rows_per_file):name = fake.name()age = random.randint(18, 99)email = fake.email()address = fake.address().replace('\n', ' ') // 替换掉地址中的换行,保持数据生成为一行id_number = fake.ssn()phone_number = fake.phone_number()nationality_code = random.randint(1, len(nationalities))nationality = nationalities[nationality_code]region_code = random.randint(1, len(regions))region = regions[region_code]source_code = random.choice(source_codes)data_row = [row_counter + 1, name, age, email, address, id_number, phone_number, nationality, region, source_code]csv_writer.writerow(data_row)row_counter += 1print(f'已生成 {row_counter} 行数据')print(f'{num_rows} 行扩展的个人信息模拟数据已生成')在这里插入图片描述
二、数据迁移
2.1 从本机上传至服务器
[root@hadoop10 personInfo]# pwd
/opt/data/personInfo
[root@hadoop10 personInfo]# ls -l| wc -l
215
[root@hadoop10 personInfo]# wc -l *
...10000 personal_info_extended_98.csv10000 personal_info_extended_99.csv10000 personal_info_extended_9.csv2131609 总用量
通过命令显示我们使用了生成的215个csv文件,现在已经上传到了/opt/data/personInfo目录下。
2.2 检查源数据格式
[root@hadoop10 personInfo]# head personal_info_extended_1.csv
Rowkey,Name,Age,Email,Address,IDNumber,PhoneNumber,Nationality,Region,SourceCode
1,Hayley Jimenez,58,garrisonalicia@harris.com,"92845 Davis Circles Apt. 198 East Jerryshire, NV 35424",657-35-2900,(141)053-9917,DE,North,C789
2,Amy Johnson,23,samuelrivera@hall.com,"119 Manning Rapids Suite 557 New Randyburgh, MN 58113",477-76-9570,+1-250-531-6115,UK,North,D101
3,Sara Harper,31,gsandoval@hotmail.com,"98447 Robinson Dale Garzatown, ME 35917",254-77-4980,7958192189,AU,East,A123
4,Alicia Wang,53,kellyreed@evans.com,"531 Lucas Vista New Laura, MO 62148",606-19-1971,001-295-093-9174x819,DE,West,C789
5,Lauren Rodriguez,71,rebeccasaunders@yahoo.com,"060 Gomez Ports Suite 355 Lake Aarontown, CO 38284",186-61-7463,8458236624,DE,East,E202
6,Juan Harris,98,davidsonjohn@hines.com,"50325 Alvarez Forge Apt. 800 New Ericchester, AL 16131",529-53-1492,+1-302-675-5810,CA,East,B456
7,Stephanie Price,90,sroberts@becker.com,"9668 Erik Inlet Port Joshua, MO 62524",303-11-9577,628.011.4670,UK,East,C789
8,Nicole Parker,61,tmcneil@rose-rodriguez.com,"485 Elliott Branch Scottshire, NJ 03885",473-55-5636,001-625-925-3712x952,FR,West,A123
9,Joel Young,54,john03@hotmail.com,"9413 Houston Flats Apt. 095 West Peggy, MD 56240",547-31-2815,920.606.0727x27740,JP,Central,E202
使用head命令查看文件的头,发现了首行字段,我们可以通过首行字段编写建表语句。
2.3 检查大小并上传至HDFS
[root@hadoop10 data]# du -h
282M ./personInfo
282M .
[root@hadoop10 data]# hdfs dfs -put /opt/data/personInfo /testdir/[root@hadoop10 data]# hdfs dfs -du -h /testdir/
281.4 M 281.4 M /testdir/personInfo
linux本地文件占用282M,上传至HDFS集群/testdir/目录后占用281.4M.
三、beeline建表
3.1 创建测试表并导入测试数据
CREATE TABLE personal_info (Rowkey STRING,Name STRING,Age STRING,Email STRING,Address STRING,IDNumber STRING,PhoneNumber STRING,Nationality STRING,Region STRING,SourceCode STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;LOAD DATA INPATH '/testdir/personInfo/*.csv' INTO TABLE personal_info;
如果csv文件的每一行都有同样的列名,需要在建表语句最后添加以下代码:TBLPROPERTIES ("skip.header.line.count"="1"),将首行跳过。
本案例由于使用python生成文件,只有第一个csv文件有列名,其余csv没有列名,我们稍后单独处理这一个首行。
3.2 建表显示内容
0: jdbc:hive2://hadoop10:10000> CREATE TABLE personal_info (
. . . . . . . . . . . . . . . > Rowkey STRING,
. . . . . . . . . . . . . . . > Name STRING,
. . . . . . . . . . . . . . . > Age STRING,
. . . . . . . . . . . . . . . > Email STRING,
. . . . . . . . . . . . . . . > Address STRING,
. . . . . . . . . . . . . . . > IDNumber STRING,
. . . . . . . . . . . . . . . > PhoneNumber STRING,
. . . . . . . . . . . . . . . > Nationality STRING,
. . . . . . . . . . . . . . . > Region STRING,
. . . . . . . . . . . . . . . > SourceCode STRING
. . . . . . . . . . . . . . . > )
. . . . . . . . . . . . . . . > ROW FORMAT DELIMITED
. . . . . . . . . . . . . . . > FIELDS TERMINATED BY ','
. . . . . . . . . . . . . . . > STORED AS TEXTFILE;
No rows affected (0.147 seconds)
0: jdbc:hive2://hadoop10:10000> LOAD DATA INPATH '/testdir/personInfo/*.csv' INTO TABLE personal_info;
No rows affected (2.053 seconds)
0: jdbc:hive2://hadoop10:10000> select * from personal_info limit 5;
+-----------------------+---------------------+--------------------+----------------------------+------------------------------------------------+-------------------------+----------------------------+----------------------------+-----------------------+---------------------------+
| personal_info.rowkey | personal_info.name | personal_info.age | personal_info.email | personal_info.address | personal_info.idnumber | personal_info.phonenumber | personal_info.nationality | personal_info.region | personal_info.sourcecode |
+-----------------------+---------------------+--------------------+----------------------------+------------------------------------------------+-------------------------+----------------------------+----------------------------+-----------------------+---------------------------+
| Rowkey | Name | Age | Email | Address | IDNumber | PhoneNumber | Nationality | Region | SourceCode |
| 1 | Hayley Jimenez | 58 | garrisonalicia@harris.com | "92845 Davis Circles Apt. 198 East Jerryshire | NV 35424" | 657-35-2900 | (141)053-9917 | DE | North |
| 2 | Amy Johnson | 23 | samuelrivera@hall.com | "119 Manning Rapids Suite 557 New Randyburgh | MN 58113" | 477-76-9570 | +1-250-531-6115 | UK | North |
| 3 | Sara Harper | 31 | gsandoval@hotmail.com | "98447 Robinson Dale Garzatown | ME 35917" | 254-77-4980 | 7958192189 | AU | East |
| 4 | Alicia Wang | 53 | kellyreed@evans.com | "531 Lucas Vista New Laura | MO 62148" | 606-19-1971 | 001-295-093-9174x819 | DE | West |
+-----------------------+---------------------+--------------------+----------------------------+------------------------------------------------+-------------------------+----------------------------+----------------------------+-----------------------+---------------------------+
5 rows selected (0.52 seconds)
四、csv文件首行列名的处理
4.1 创建新的表
解决思路是通过将整表的数据查询出,插入到另一个新表中,而后删除旧的表,该方法如果在生产环境中使用应考虑机器性能和存储情况。
CREATE TABLE pinfo (Rowkey STRING,Name STRING,Age STRING,Email STRING,Address STRING,IDNumber STRING,PhoneNumber STRING,Nationality STRING,Region STRING,SourceCode STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;查询旧表中的行数。
0: jdbc:hive2://hadoop10:10000> select count(*) from personal_info;
+----------+
| _c0 |
+----------+
| 2131609 |
+----------+
1 row selected (45.762 seconds)
4.2 将旧表过滤首行插入新表
INSERT OVERWRITE TABLE pinfo
SELECTt.Rowkey,t.Name,t.Age,t.Email,t.Address,t.IDNumber,t.PhoneNumber,t.Nationality,t.Region,t.SourceCode
FROM (SELECTRowkey,Name,Age,Email,Address,IDNumber,PhoneNumber,Nationality,Region,SourceCodeFROM personal_info
) t
WHERE t.Name != 'Name';
0: jdbc:hive2://hadoop10:10000> select * from pinfo limit 5;
+---------------+-------------------+------------+----------------------------+------------------------------------------------+-----------------+--------------------+-----------------------+---------------+-------------------+
| pinfo.rowkey | pinfo.name | pinfo.age | pinfo.email | pinfo.address | pinfo.idnumber | pinfo.phonenumber | pinfo.nationality | pinfo.region | pinfo.sourcecode |
+---------------+-------------------+------------+----------------------------+------------------------------------------------+-----------------+--------------------+-----------------------+---------------+-------------------+
| 1 | Hayley Jimenez | 58 | garrisonalicia@harris.com | "92845 Davis Circles Apt. 198 East Jerryshire | NV 35424" | 657-35-2900 | (141)053-9917 | DE | North |
| 2 | Amy Johnson | 23 | samuelrivera@hall.com | "119 Manning Rapids Suite 557 New Randyburgh | MN 58113" | 477-76-9570 | +1-250-531-6115 | UK | North |
| 3 | Sara Harper | 31 | gsandoval@hotmail.com | "98447 Robinson Dale Garzatown | ME 35917" | 254-77-4980 | 7958192189 | AU | East |
| 4 | Alicia Wang | 53 | kellyreed@evans.com | "531 Lucas Vista New Laura | MO 62148" | 606-19-1971 | 001-295-093-9174x819 | DE | West |
| 5 | Lauren Rodriguez | 71 | rebeccasaunders@yahoo.com | "060 Gomez Ports Suite 355 Lake Aarontown | CO 38284" | 186-61-7463 | 8458236624 | DE | East |
+---------------+-------------------+------------+----------------------------+------------------------------------------------+-----------------+--------------------+-----------------------+---------------+-------------------+
5 rows selected (0.365 seconds)
0: jdbc:hive2://hadoop10:10000>
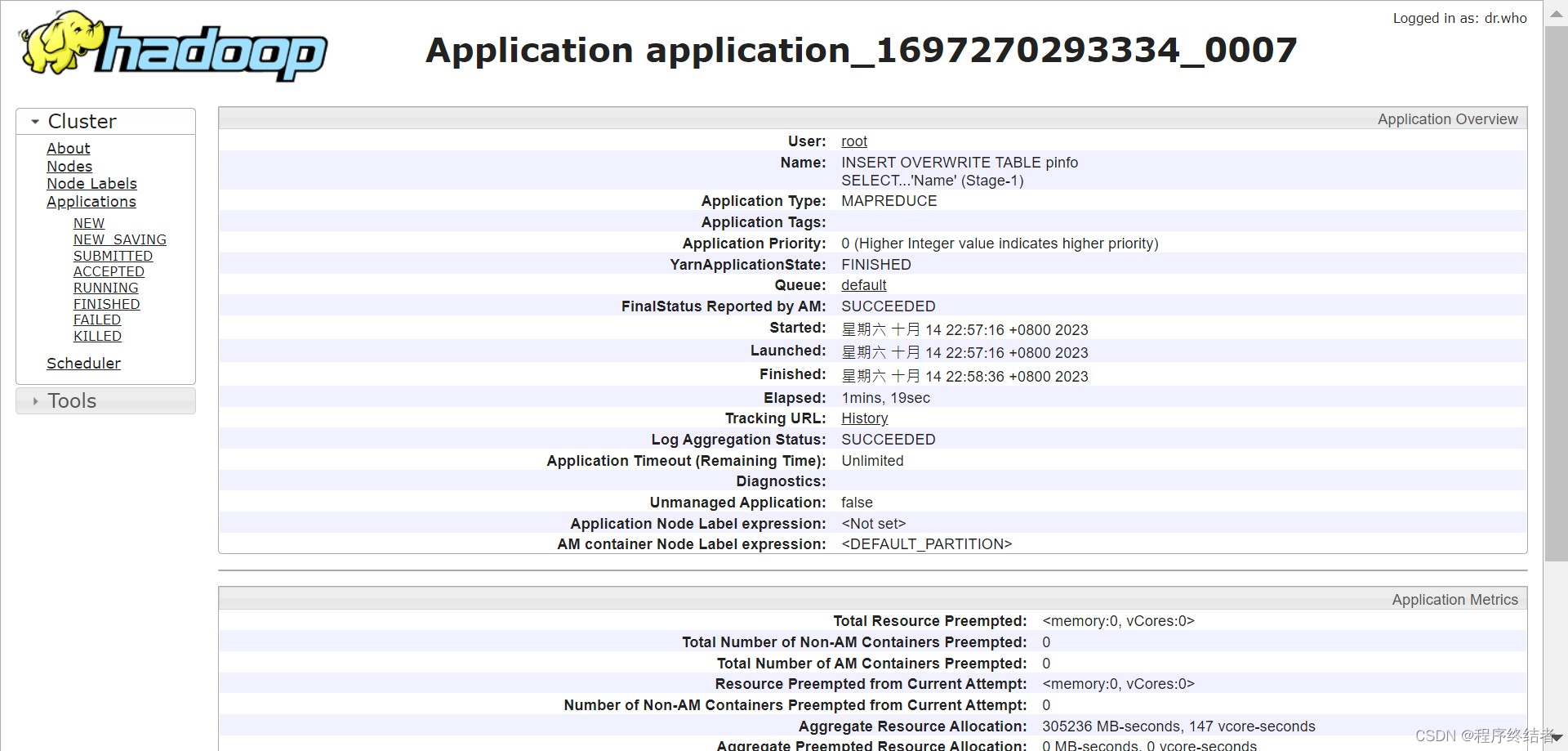
在yarn中查看新表插入的进度。
最后新表的查询结果显示比旧表少1行即为插入处理完成。
0: jdbc:hive2://hadoop10:10000> select count(*) from pinfo;
+----------+
| _c0 |
+----------+
| 2131608 |
+----------+
1 row selected (0.291 seconds)
相关文章:
使用Python创建faker实例生成csv大数据测试文件并导入Hive数仓
文章目录 一、Python生成数据1.1 代码说明1.2 代码参考 二、数据迁移2.1 从本机上传至服务器2.2 检查源数据格式2.3 检查大小并上传至HDFS 三、beeline建表3.1 创建测试表并导入测试数据3.2 建表显示内容 四、csv文件首行列名的处理4.1 创建新的表4.2 将旧表过滤首行插入新表 一…...

qml基础语法
文章目录 基础语法例子 属性例子 核心元素元素item RectangleText例子 Image例子 MouseArea例子Component(组件)例子简单变换例子 定位器ColumnRowGridFlowRepeater 布局InputKeys 基础语法 QML是一种用于描述对象如何相互关联的声明式语言。 QtQuick是…...
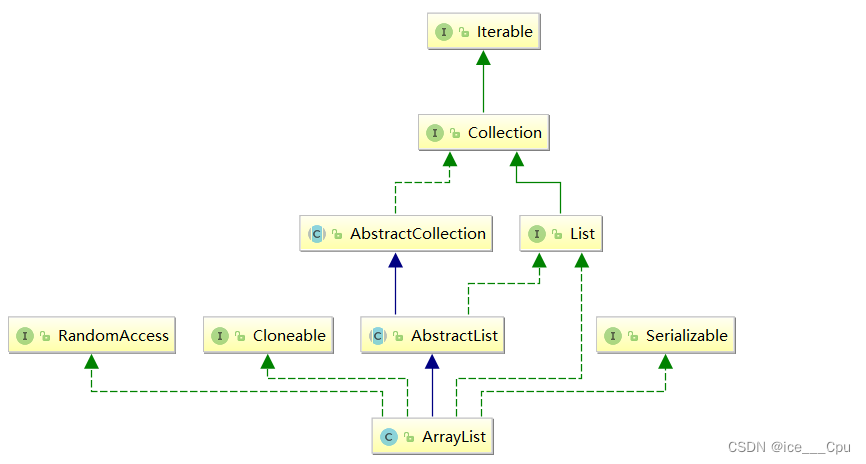
数据结构 - 2(顺序表10000字详解)
一:List 1.1 什么是List 在集合框架中,List是一个接口,继承自Collection。 Collection也是一个接口,该接口中规范了后序容器中常用的一些方法,具体如下所示: Iterable也是一个接口,Iterabl…...

05在IDEA中配置Maven的基本信息
配置Maven信息 配置Maven家目录 每次创建Project工程后都需要设置Maven家目录位置,否则IDEA将使用内置的Maven核心程序和使用默认的本地仓库位置 一般我们配置了Maven家目录后IDEA就会自动识别到conf/settings.xml配置文件和配置文件指定的本地仓库位置创建新的P…...
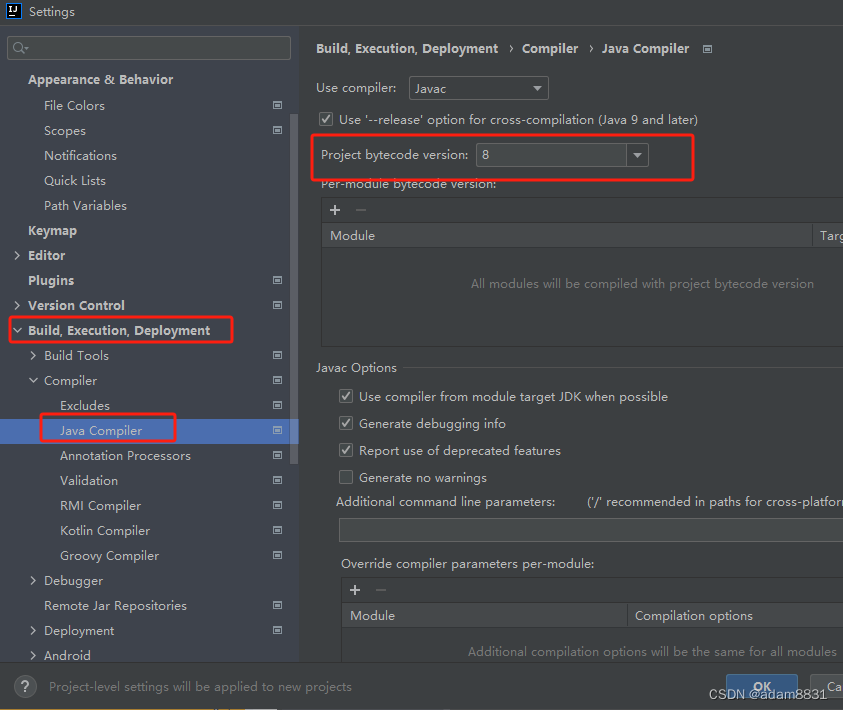
基于IDEA 配置Maven环境和JDK版本(全局)
1.首先启动IDEA,进去初始界面 选择 Customize 之后,选择 All settings 2. 选择下图中的列表配置 3. 找到Maven下的Runner, 配置JRE的版本,选择自己下载使用的jdk的版本即可 4.最后配置Compiler 下的 Java Compiler 选择自己的jdk版本号&am…...

mysql数据库 windows迁移至linux
1.打开navicat,选择一个数据库进行操作: 之后文件会保存为一个xxx.sql文件,之后打开xftp,把生成的sql放进一个文件夹中(/home/dell/linuxmysql): 之后登录mysql数据库,并创建一个新的数据库,然后…...

P4491 [HAOI2018] 染色
传送门:洛谷 解题思路: 写本题需要知道一个前置知识: 假设恰好选 k k k个条件的方案数为 f ( k ) f(k) f(k);先钦定选 k k k个条件,其他条件无所谓的方案数为 g ( k ) g(k) g(k) 那么存在这样的一个关系: g ( k ) ∑ i k n C i k f ( i ) g(k)\sum_{ik}^nC_{i}^kf(i) g(k)…...
)
12096 - The SetStack Computer (UVA)
题目链接如下: Online Judge 这道题我一开始的思路大方向其实是对的,但细节怎么实现set到int的哈希没能想清楚(没想到这都能用map)。用set<string>的做法来做,测试数据小的话答案是对的,但大数据时…...

Pygame中将鼠标形状设置为图片2-1
在Pygame中利用Sprite类的派生类将鼠标形状设置为图片,其原理就是将Sprite类的派生类对应图片的位置设置为鼠标的当前位置即可。其效果如图1所示。 图1 将鼠标设置为图片 从图1可以看出,鼠标的形状变为红色的,该红色的随着鼠标的移动而移动&…...

Vue3 + Nodejs 实战 ,文件上传项目--实现图片上传
目录 技术栈 1. 项目搭建前期工作(不算太详细) 前端 后端 2.配置基本的路由和静态页面 3.完成图片上传的页面(imageUp) 静态页面搭建 上传图片的接口 js逻辑 4.编写上传图片的接口 5.测试效果 结语 博客主页:専心_前端,javascript,mys…...
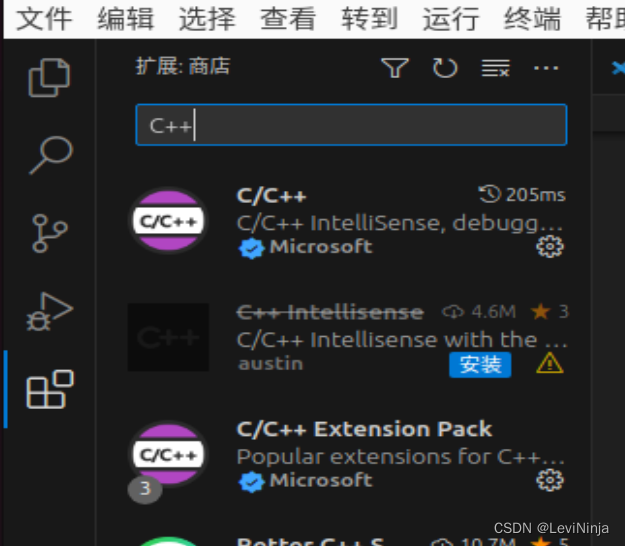
linux C++ vscode连接mysql
1.linux使用Ubuntu 2.Ubuntu安装vscode 2.1 安装的是snap版本,直接打开命令行执行 sudo snap install --classic code 3.vscode配置C 3.1 直接在扩展中搜索C安装即可 我安装了C, Chinese, code runner, 安装都是同理 4.安装mysql sudo apt update sudo apt install mysql-…...
[资源推荐]langchain、LLM相关
之前很多次逛github或者去B站看东西或者说各种浏览资讯的情况,都会先看两眼然后收藏然后就吃灰的情况,那既然这样,不如多看几眼,看看是否真的能用得上,能用在哪,然后用几句话总结出来,分享出来&…...

hdfs笔记
1.HDFS shell 1.0查看帮助 hadoop fs -help <cmd> 1.1上传 hadoop fs -put <linux上文件> <hdfs上的路径> 1.2查看文件内容 hadoop fs -cat <hdfs上的路径> 1.3查看文件列表 hadoop fs -ls / 1.4…...

java_方法引用和构造器引用
文章目录 一、方法引用1.1、方法引用的理解1.2、格式1.3、举例 二、构造器引用2.1、格式2.2、例子2.3、数组引用 一、方法引用 1.1、方法引用的理解 方法引用,可以看做是基于lambda表达式的进一步刻画当需要提供一个函数式接口的实例时,可以使用lambda…...

Flink Log4j 2.x使用Filter过滤日志类型
Flink Log4j 2.x使用Filter过滤日志类型(区别INFO、ERROR) 文章目录 Flink Log4j 2.x使用Filter过滤日志类型(区别INFO、ERROR)ThresholdFilterLevelMatchFilter 日志级别: ALL < TRACE < DEBUG < INFO < …...
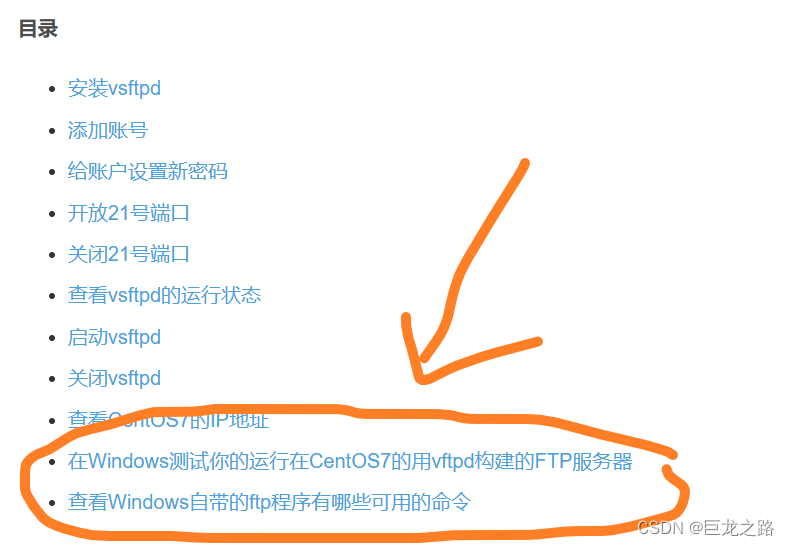
Ubuntu下怎么配置vsftpd
2023年10月12日,周四中午 目录 首先要添加一个系统用户然后设置这个系统用户的密码给新创建的系统用户创建主目录启动vsftpd服务查看vsftpd服务的状态打开外界访问vsftpd服务所需的端口获取服务器的IP地址大功告成 首先要添加一个系统用户 useradd 用户名然后设置…...

链表(7.27)
3.3 链表的实现 3.3.1头插 原理图: newnode为新创建的节点 实现: //头插 //让新节点指向原来的头指针(节点),即新节点位于开头 newnode->next plist; //再让头指针(节点)指向新节点&#…...
在 Elasticsearch 中实现自动完成功能 1:Prefix queries
自动完成与搜索功能不同 - 我们应该在用户键入下一个字符后立即更新自动完成选项,每秒都会访问数据库,过滤数百万条记录,而不会导致任何性能下降! Elasticsearch 是一种可以轻松实现此类功能的技术,它是一种基于 Apac…...

『PyQt5-Qt Designer篇』| 13 Qt Designer中如何给工具添加菜单和工具栏?
13 Qt Designer中如何给工具添加菜单和工具栏? 1 创建默认窗口2 添加菜单栏3 查看和调用1 创建默认窗口 当新创建一个窗口的时候,默认会显示有:菜单栏和状态栏,如下: 可以在菜单栏上右键-移除菜单栏: 可以在菜单栏上右键-移除状态栏: 2 添加菜单栏 在窗口上,右键-创建…...
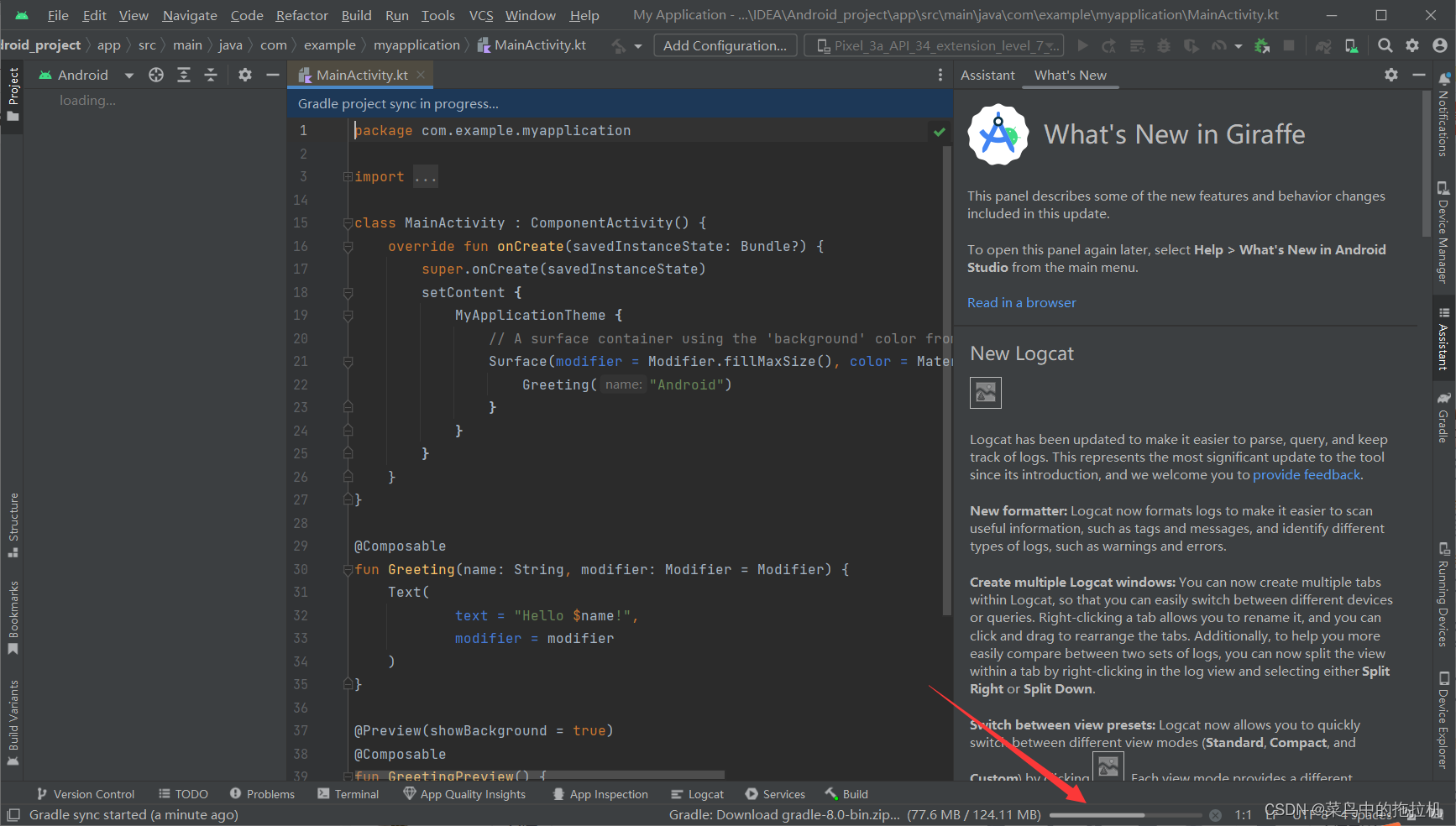
Android Studio新建项目教程
Android Studio新建项目教程 一、创建新项目 二、选择空白页项目类型 配置然后finish 等待项目完成初试化 等待初始化结束,创建完成...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...
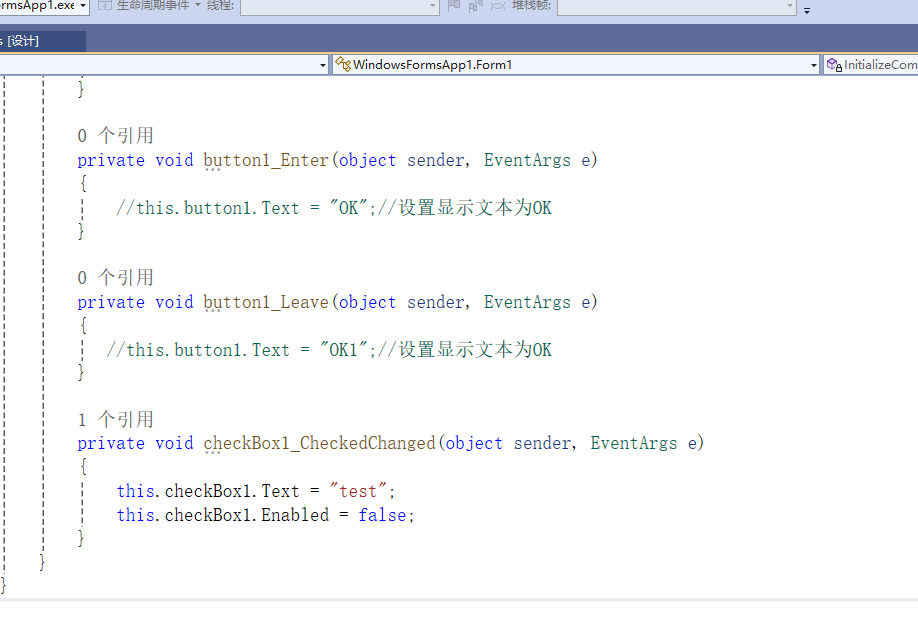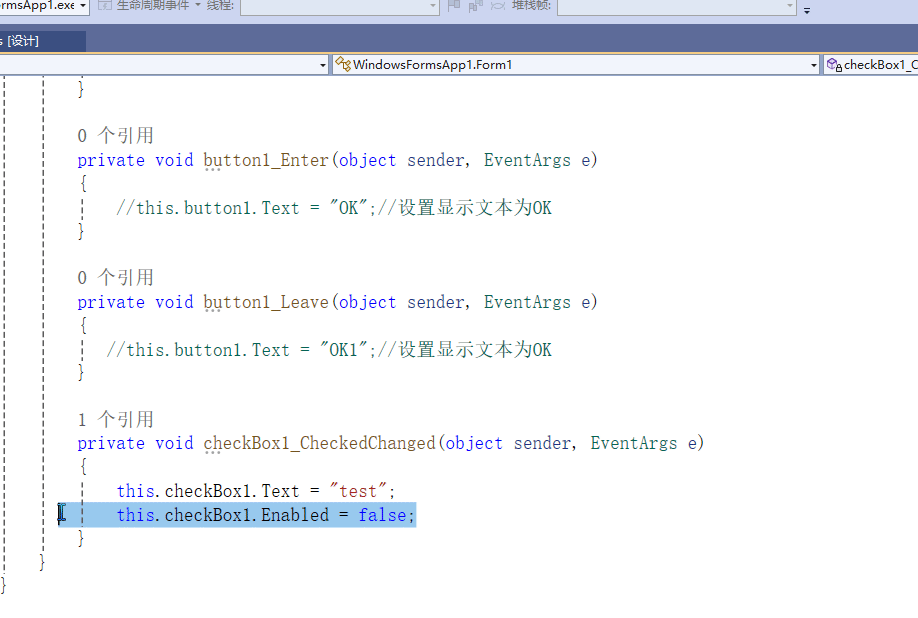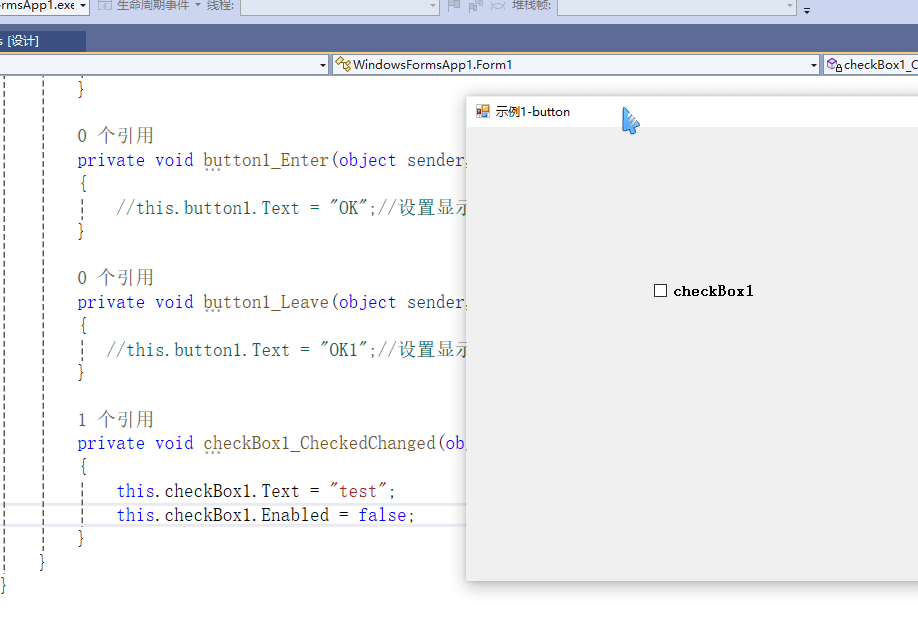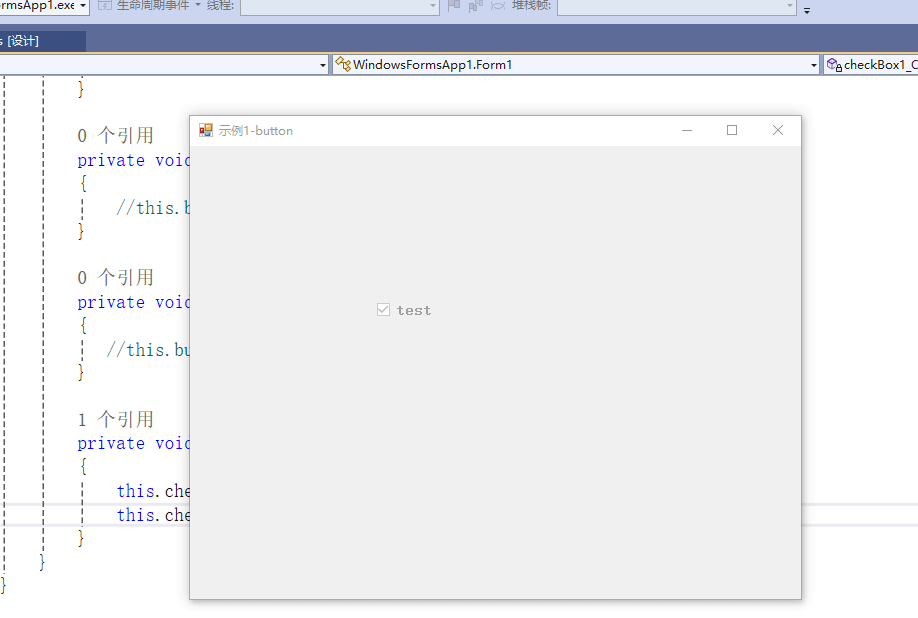
C# winform教程(二)----checkbox
一、作用 提供一个用户选择或者不选的状态,这是一个可以多选的控件。 二、属性 其实功能大差不差,除了特殊的几个外,与button基本相同,所有说几个独有的 checkbox属性 名称内容含义appearance控件外观可以变成按钮形状checkali…...