深度学习-房价预测案例
1. 实现几个函数方便下载数据
import hashlib
import os
import tarfile
import zipfile
import requests#@save
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'def download(name, cache_dir=os.path.join('..', 'data')): #@save"""下载一个DATA_HUB中的文件,返回本地文件名"""assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"# 判断变量name是否存在于DATA_HUB中,不在则抛出异常url, sha1_hash = DATA_HUB[name]os.makedirs(cache_dir, exist_ok=True)# cache_dir目录不存在,则创建该目录,如果目录已经存在,则什么都不做fname = os.path.join(cache_dir, url.split('/')[-1])# 拼接成一个完整的路径if os.path.exists(fname): # 路径存在sha1 = hashlib.sha1() # 创建了一个哈希对象with open(fname, 'rb') as f:while True:data = f.read(1048576)if not data:breaksha1.update(data)if sha1.hexdigest() == sha1_hash:return fname # 命中缓存print(f'正在从{url}下载{fname}...')r = requests.get(url, stream=True, verify=True)with open(fname, 'wb') as f:f.write(r.content)return fnamedef download_extract(name, folder=None): #@save"""下载并解压zip/tar文件"""fname = download(name)base_dir = os.path.dirname(fname)data_dir, ext = os.path.splitext(fname)if ext == '.zip':fp = zipfile.ZipFile(fname, 'r')elif ext in ('.tar', '.gz'):fp = tarfile.open(fname, 'r')else:assert False, '只有zip/tar文件可以被解压缩'fp.extractall(base_dir)return os.path.join(base_dir, folder) if folder else data_dirdef download_all(): #@save"""下载DATA_HUB中的所有文件"""for name in DATA_HUB:download(name)
2. 使用pandas读入并处理数据
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2lDATA_HUB['kaggle_house_train'] = ( # 将数据集的名称kaggle_house_train作为字典DATA_HUB的键DATA_URL + 'kaggle_house_pred_train.csv', # 数据集的下载链接'585e9cc93e70b39160e7921475f9bcd7d31219ce') # 哈希值用于验证数据的完整性DATA_HUB['kaggle_house_test'] = ( DATA_URL + 'kaggle_house_pred_test.csv','fa19780a7b011d9b009e8bff8e99922a8ee2eb90')# 从指定的数据源下载名为'kaggle_house_train'的CSV文件,
# 并使用pd.read_csv()函数将其读取为一个DataFrame对象,并将该对象赋值
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))print(train_data.shape)
print(test_data.shape)

观察特征
打印出前4行,前4列和最后3列打印出来
【使用iloc属性对train_data这个DataFrame对象进行切片操作,选取了指定行和列的数据子集】
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])

在每个样本中,第一个特征ID不能参与训练,所以要将其删除
saleprice作为标签在训练数据中要进行删除
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))# 将train_data去除第一列ID和最后一列标签,和去除id的test_data进行合并
将所有缺失的值替换为相应特征的平均值,通过将特征重新缩放到零均值和单位方差来标准化数据
【.fillna(0)对选择的数值型特征进行了填充操作,将缺失值(NaN值)填充为0。fillna()是一个DataFrame对象的方法,用于填充缺失值】
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index # all_features.dtypes != 'object'-》数值型数据
"""-》将数值特征均值设为0,方差设为1"""
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std())) # 将(数值特征 - 均值)/方差 all_features[numeric_features] = all_features[numeric_features].fillna(0) # 对选择的数值型特征进行了填充操作,将缺失值(NaN值)填充为0
处理离散值,用一次独热编码替换它们
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape

从pandas格式中提取NumPy格式,并将其转化为张量表示
【.values将该列数据转换为一个Numpy数组。
.reshape(-1, 1)改变数组的形状,将其变为一个列向量(具有一列)。】
n_train = train_data.shape[0]
all_features = all_features.astype(float) # 进行强制类型转化否则会报错
train_features = torch.tensor(all_features[:n_train].values, # 之前将train_data和 test_data结合,现在进行下标分开dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1, 1),# SalePrice列数据提取出来,并将其转换为一个列向量(具有一列)dtype=torch.float32)
训练
loss = nn.MSELoss()
in_features = train_features.shape[1]def get_net():net = nn.Sequential(nn.Linear(in_features, 1)) # 使用单层线性回归,输入特征数:in_features,输出特征数:1return net
为解决误差的影响,可以使用相对误差 (真实房价-预测房价/真实房价),其中一种方法是用价格预测的对数来衡量差异
【torch.clamp()函数会将输出结果中小于下界的值替换为下界,将大于上界的值替换为上界,因此它可以用来对输出结果进行范围限制】
def log_rmse(net, features, labels): # log可以将除法转化为减法clipped_preds = torch.clamp(net(features), 1, float('inf'))# 对输出进行截断,将小于1的值设置为1,大于float('inf')的值保持不变rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels))) # 对预测和实际标签进行log,然后传入损失函数后取根号return rmse.item()# 返回 张量rmse中的值提取为一个标量
训练函数将借助Adam优化器
def train(net, train_features, train_labels, test_features, test_labels,num_epochs, learning_rate, weight_decay, batch_size):train_ls, test_ls = [], []train_iter = d2l.load_array((train_features, train_labels), batch_size)optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate,# 使用Adam【对学习率不太敏感】进行优化weight_decay=weight_decay) # 权重衰减(weight decay)参数【lamdb】,用于控制模型参数的正则化"""训练"""for epoch in range(num_epochs):for X, y in train_iter:optimizer.zero_grad() # 优化器梯度清0l = loss(net(X), y) # 计算损失l.backward() # 反向传播计算梯度optimizer.step() # 更新优化器参数train_ls.append(log_rmse(net, train_features, train_labels)) # 更新数据if test_labels is not None:test_ls.append(log_rmse(net, test_features, test_labels))return train_ls, test_ls
K则交叉验证
def get_k_fold_data(k, i, X, y):assert k > 1fold_size = X.shape[0] // k # 每一折的大小是样本数/kX_train, y_train = None, Nonefor j in range(k):idx = slice(j * fold_size, (j + 1) * fold_size) # 计算每个切片的起始和终止位置,根据切片索引idx取出相应位置上的数。X_part, y_part = X[idx, :], y[idx] # 取出相应位置if j == i: # 如果此时j==i,当前迭代的fold为验证集,则将切片X_part和y_part赋值给X_valid和y_valid。X_valid, y_valid = X_part, y_partelif X_train is None: # 如果训练集为空,则将切片X_part和y_part赋值给X_train和y_trainX_train, y_train = X_part, y_partelse: # 否则,将切片X_part和y_part与之前的训练集进行拼接,使用torch.cat()函数进行行拼接,将结果重新赋值给X_train和y_train。X_train = torch.cat([X_train, X_part], 0)y_train = torch.cat([y_train, y_part], 0)# 返回训练集和验证集return X_train, y_train, X_valid, y_valid
返回训练和验证误差的平均值
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,batch_size):train_l_sum, valid_l_sum = 0, 0for i in range(k): # 做k次交叉验证data = get_k_fold_data(k, i, X_train, y_train)net = get_net()train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,weight_decay, batch_size)train_l_sum += train_ls[-1]valid_l_sum += valid_ls[-1]if i == 0:d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],legend=['train', 'valid'], yscale='log')print(f'fold {i + 1}, train log rmse {float(train_ls[-1]):f}, 'f'valid log rmse {float(valid_ls[-1]):f}')return train_l_sum / k, valid_l_sum / k # 返回平均测试集和验证集的损失
模型选择
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, 'f'平均验证log rmse: {float(valid_l):f}')

需要关注valid验证集的损失,需要不断的调整参数实现最小的损失
提交Kaggle预测
def train_and_pred(train_features, test_feature, train_labels, test_data,num_epochs, lr, weight_decay, batch_size):net = get_net()train_ls, _ = train(net, train_features, train_labels, None, None,num_epochs, lr, weight_decay, batch_size) # 返回训练过程中的训练误差列表train_ls和验证误差列表valid_ls,但在这个函数调用中用下划线 _ 代替了后者# 绘制并显示训练误差的变化情况d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',ylabel='log rmse', xlim=[1, num_epochs], yscale='log')print(f'train log rmse {float(train_ls[-1]):f}')# 使用训练好的模型net对测试特征进行预测,得到预测结果predspreds = net(test_features).detach().numpy()# 预测结果转换为Numpy数组,并将其赋值给测试数据集test_data的'SalePrice'列。test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])# 将预测结果和对应的'Id'列组合成一个DataFrame submissionsubmission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)# 将submission保存为CSV文件submission.csvsubmission.to_csv('submission.csv', index=False)
# 调用了train_and_pred()函数,传入相应的参数,执行整个训练和预测的过程
train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size)

相关文章:
深度学习-房价预测案例
1. 实现几个函数方便下载数据 import hashlib import os import tarfile import zipfile import requests#save DATA_HUB dict() DATA_URL http://d2l-data.s3-accelerate.amazonaws.com/def download(name, cache_diros.path.join(.., data)): #save"""下载…...

【26】c++设计模式——>命令模式
c命令模式 C的命令模式是一种行为模式,通过将请求封装成对象,以实现请求发送者和接受者的解耦。 在命令模式中,命令被封装成一个包含特定操作的对象,这个对象包含的执行该操作的方法,以及一些必要的参数。命令对象可以…...
)
ElasticSearch容器化从0到1实践(一)
背景 通过kubernetes集群聚合多个Elasticsearch集群碎片资源,提高运维效率。 介绍 Kubernetes Operator 是一种特定的应用控制器,通过 CRD(Custom Resource Definitions,自定义资源定义)扩展 Kubernetes API 的功能…...
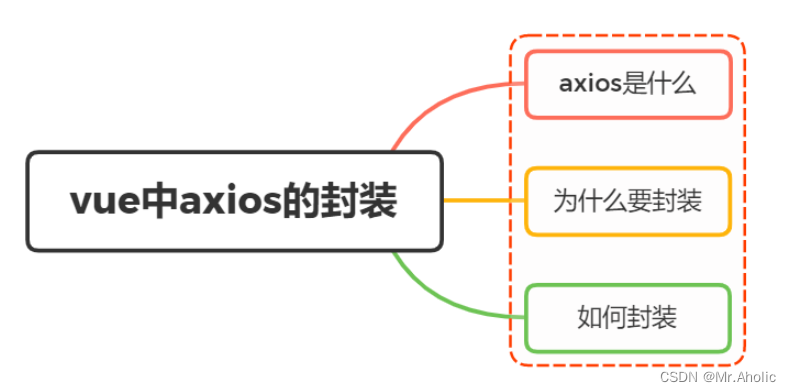
【Vue面试题二十四】、Vue项目中有封装过axios吗?主要是封装哪方面的?
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官:Vue项目中有封装过axios…...
旅游票务商城小程序的作用是什么
随着环境放开,旅游行业恢复了以往的规模,本地游、外地游成为众多用户选择,而在旅游时,不少人会报名旅行团前往各风景热点游玩,对旅游票务经营者而言,市场高需求的同时也面临一些难题。 对旅游票务经营商家…...
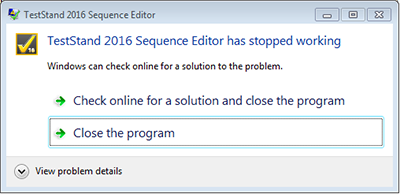
LabVIEW在安装了其它的NI软件之后崩溃了
LabVIEW在安装了其它的NI软件之后崩溃了 在安装了其它的NI软件之后,一些原本安装好的或者新安装的软件由于缺少必要的DLL而崩溃掉了。例如,在这种情况下,Teststand可能会报下面的错误: RetrievingCOM class factory for compone…...

基于Java的个人健康管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...

nginx https的配置方法
文章目录 安装证书工具安装根证书生成域名证书配置转发 ssl的请求到http请求 安装证书工具 curl ‘http://pan.itshine.cn:5080/?explorer/share/fileOut&shareID64h6PiQQ&path%7BshareItemLink%3A64h6PiQQ%7D%2F%E5%B7%A5%E5%85%B7%2Fmkcert’ > ‘./mkcert’ c…...

使用WebDriver采样器将JMeter与Selenium集成
目录 第一步:在JMeter中添加Selenium / WebDriver插件 第二步:创建一条测试计划--添加线程组 第三步:下载 chromedriver.exe 第四步:在Web Driver 采样器中添加测试脚本 第五步:运行并且验证 注意: 第…...

flink教程
文章目录 来自于尚硅谷教程1. Flink概述1.1 特点1.2 与SparkStreaming对比 2. Flink部署2.1 集群角色2.2 部署模式2.3 Standalone运行模式2.3.1 本地会话模式部署2.3.2 应用模式 2.4 YARN运行模式2.4.1 会话模式部署2.4.2 应用模式部署 2.5 历史服务 3. 系统架构3.1 并行度3.2 …...
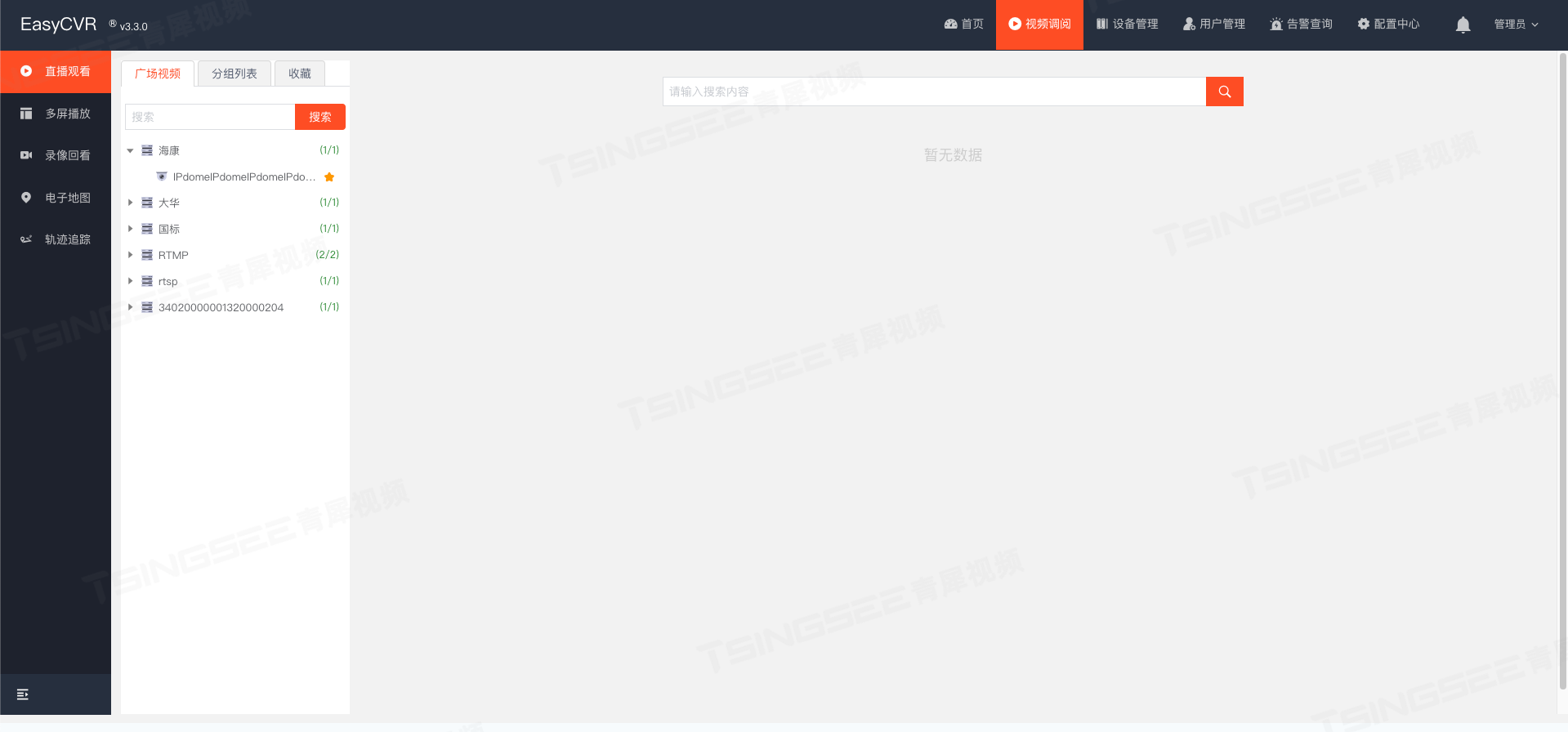
视频监控系统/安防视频平台EasyCVR广场视频细节优化
安防视频监控系统/视频云存储/安防监控EasyCVR视频汇聚平台基于云边端智能协同,支持海量视频的轻量化接入与汇聚、转码与处理、全网智能分发、视频集中存储等。安防视频汇聚平台EasyCVR拓展性强,视频能力丰富,可实现视频监控直播、视频轮播、…...
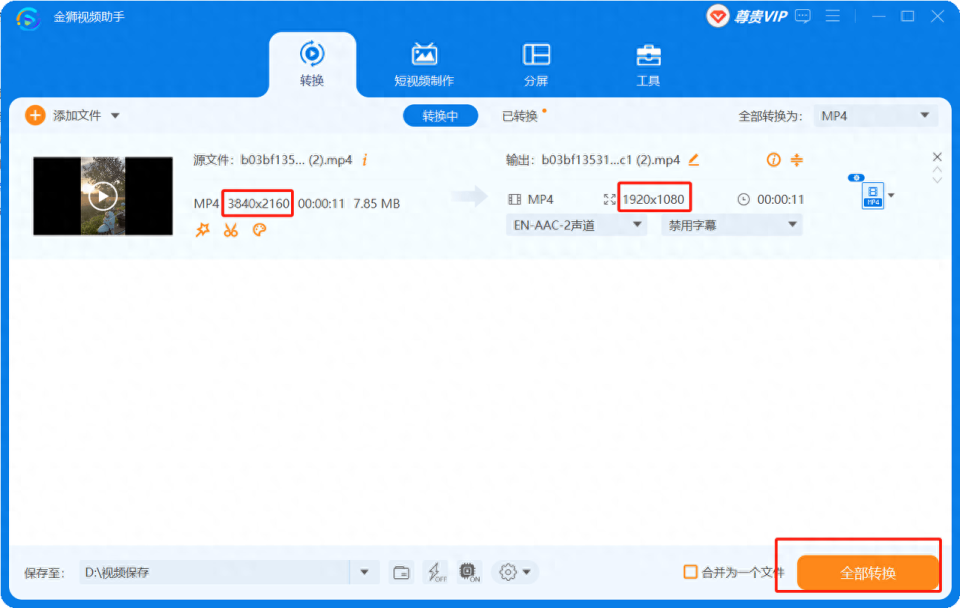
电脑上播放4K视频需要具备哪些条件?
在电视上播放 4K( 4096 2160 像素)视频是很简单的,但在电脑设备上播放 4K 视频并不容易。相反,它们有自己必须满足的硬件要求。 如果不满足要求,在电脑上打开 4K 分辨率文件或大型视频文件会导致卡顿、音频滞后以及更…...

测试除了点点点,还有哪些内容呢?
今天和一个网友讨论了一下关于互联网行业中测试的情况,希望能够了解现在的互联网行业主要的测试工作内容。小编根据以往的工作经历和经验情况,来做一个总结和整理。 1、岗位分类 现在的岗位划分主要是分为两大类:测试工程师 和 测试开发工程…...

HTTP的本质理解
HTTP是超文本传输协议,从协议、传输和超文本三个关键词进行进行分解。 协议关键词讲解 1.协议的第一个词是协,这个就表明需要至少两方参与到其中。 2.协议的第二个词是议,表明HTTP是规范和约定,需要大家共同遵守,也包…...

微信小程序获取公众号的文章
背景:我有一个《砂舞指南》的小程序,主要是分享砂舞最新动态等 最近做了一个小程序,想要一些固定的文章展示在小程序里面,比如《什么是砂舞》《玩砂舞注意点》等普及砂舞知识的文章 开发流程: 1、刚开始测试了 素材…...

【算法|动态规划No.20】leetcode416. 分割等和子集
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【手撕算法系列专栏】【LeetCode】 🍔本专栏旨在提高自己算法能力的同时,记录一下自己的学习过程,希望…...

深入解析C语言中的strstr函数
目录 一,strstr函数简介 二,strstr函数实现原理 三,strstr函数的用法 四,strstr函数的注意事项 五,strstr函数的模拟实现 一,strstr函数简介 strstr函数是在一个字符串中查找另一个字符串的第一次出现&…...
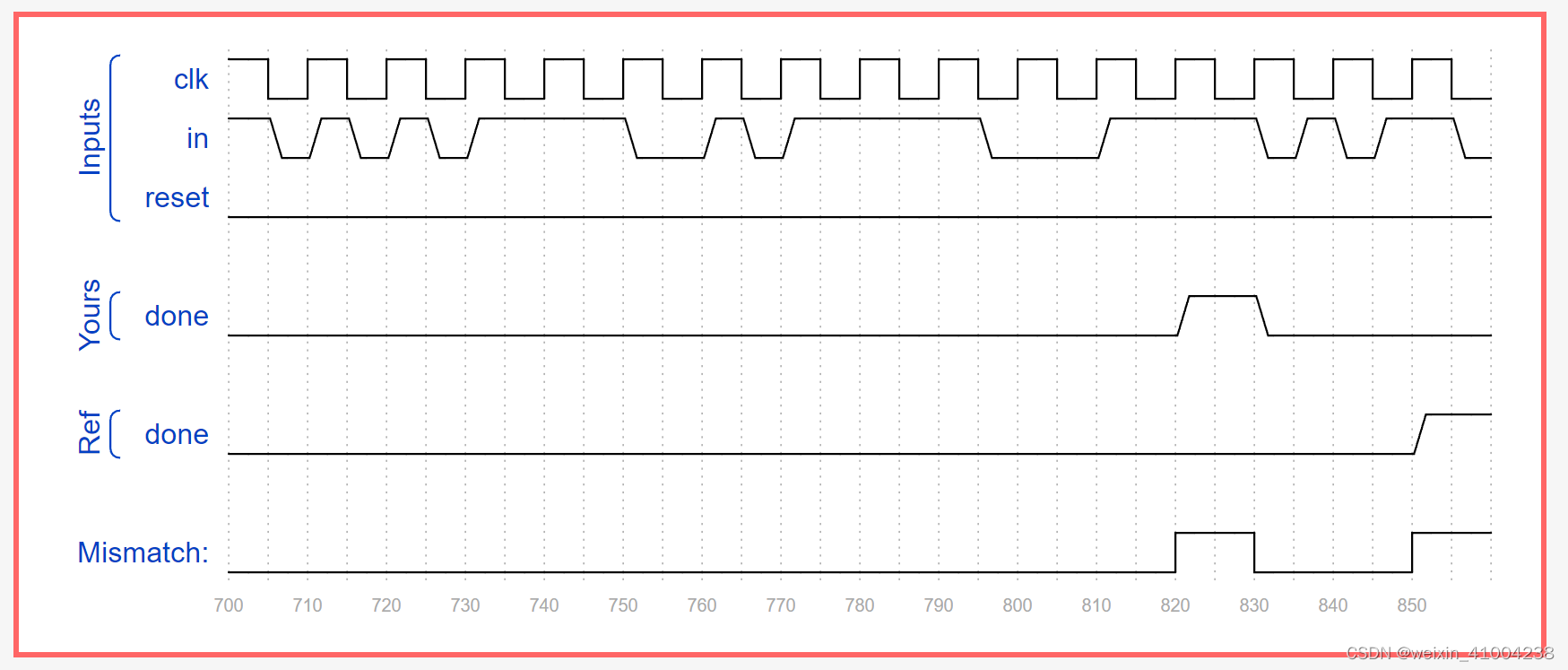
HDLbits: Fsm serial
根据题意设计了四个状态,写出代码如下: module top_module(input clk,input in,input reset, // Synchronous resetoutput done ); parameter IDLE 3b000, START 3b001, DATA 3b010, STOP 3b100, bit_counter_end 4d7;reg [2:0] state,next_sta…...
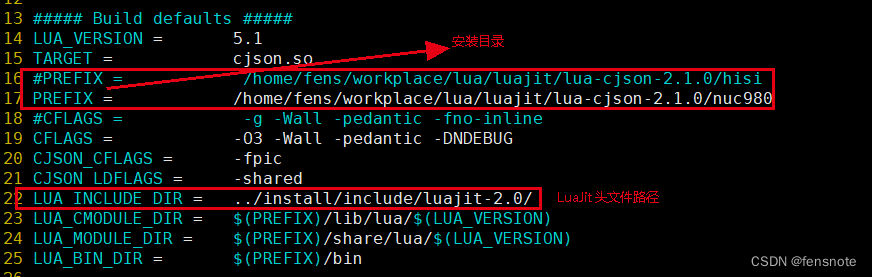
LuaJit交叉编译移植到ARM Linux
简述 Lua与LuaJit的主要区别在于LuaJIT是基于JIT(Just-In-Time)技术开发的,可以实现动态编译和执行代码,从而提高了程序的运行效率。而Lua是基于解释器技术开发的,不能像LuaJIT那样进行代码的即时编译和执行。因此&…...
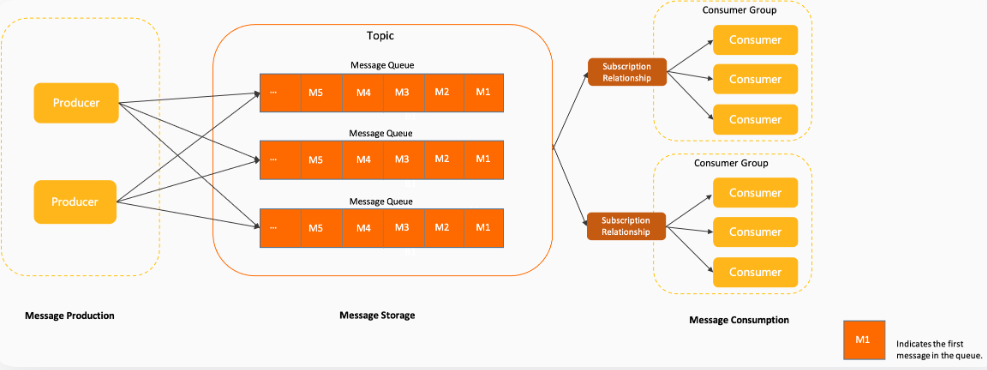
【RocketMQ系列一】初识RocketMQ
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。 💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...
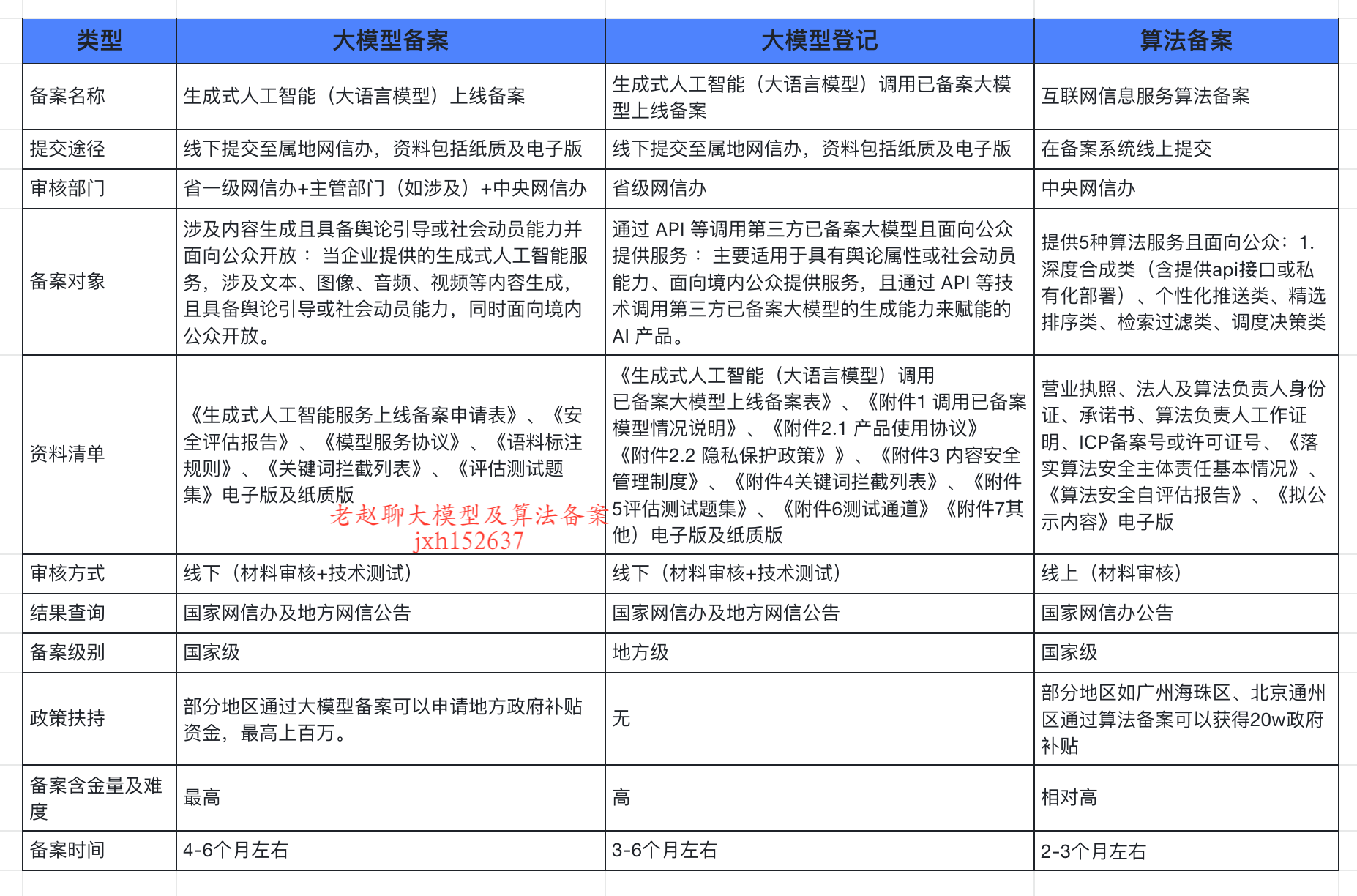
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...