Hadoop3教程(一):Hadoop的定义、组成及全生态概览
文章目录
- (1)定义
- 1.1 发展历史
- 1.2 三大发行版本
- 1.3 Hadoop的优势
- 1.4 Hadoop的组成
- (13)HDFS概述
- (14)Yarn架构
- (15)MapReduce概述
- (16) HDFS、YARN、MapReduce三者关系
- (17)大数据技术生态体系
- 参考文献
(1)定义
Hadoop是一个由Apache基金会开发的一个分布式系统基础架构。
分布式,指多台机器共同来完成一项任务。
用途:解决海量数据的存储和分析计算问题
广义上来讲,Hadoop通常是指一个更广泛的概念:Hadoop生态圈。包含了很多基于Hadoop架构衍生发展出来的其他的东西,如HBASE等
1.1 发展历史
创始人Doug Cutting,他最初的目的是为了实现与Google类似的全文搜索功能,于是他在Lucene框架的基础上进行优化升级,查询引擎和索引引擎。
2001年底,Lucene框架称为Apache基金会的一个子项目。
对于海量数据的场景,Lucene同样遇到了跟Google一样的困难:海量数据存储难、海量的检索速度慢。
Doug 模仿Google,提出了一个微型版Nutch来解决这个问题。他基于谷歌提出的三篇论文,分别提出了HDFS、MR、HBase,因为可以认为Google是Hadoop的思想之源。
2006.03,MR和Nutch Distributed File System(NDFS)分别被纳入到了Hadoop项目中,Hadoop正式诞生。
Hadoop这个名字和logo来源于Doug儿子的玩具大象。
1.2 三大发行版本
Hadoop有三大发型版本:Apache、Cloudera、Hortonworks。
Apache版本,最原始且最基础的版本,非常适用于入门学习,开源,2006年正式提出。
Cloudera版本,在原始版本基础上集成了大量的大数据框架,2008年推出,对应商用产品CDH。
Hortonworks版本,也封装了自己的一套,2011年推出,对应产品HDP。
目前,Hortonworks已经被Cloudera公司收购,推出新的品牌CDP。
后两个版本都是商业收费的。
Cloudera,08年成立,是最早将Hadoop商用的公司,为合作伙伴提供商业解决方案。09年,Hadoop的创始人cutting也加入了该公司。
Hortonworks,2011年成立,主体是雅虎

1.3 Hadoop的优势
- 高可靠性。每份数据都会分布式维护多个副本,即使某台存储服务器出问题,也不会导致数据的丢失。
- 高扩展性。可以动态扩展计算节点以支持更庞大的计算需求,而不需要影响现有任务。
- 高效性。在MR的指导思想下,Hadoop是并行工作的。以加快任务处理速度。
- 高容错性。能够自动的将失败的任务重新分配。比如说某个子任务崩了,这时候会自动将这一计算任务迁移到其他节点重新计算,不影响整体计算。
1.4 Hadoop的组成
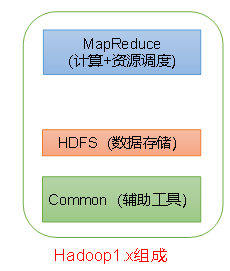
Hadoop1.x的组成:
- common(辅助工具)
- HDFS(数据存储)
- MapReduce(计算 + 资源调度):还负责调度计算内存资源等功能。
MR耦合性较大。
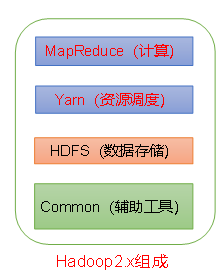
Hadoop2.x的组成:
- common(辅助工具)
- HDFS(数据存储)
- Yarn(资源调度)
- MapReduce(计算)
可以看到,资源调度和计算已经分离了。
Hadoop3.x跟2.x相比,在组成上没有区别。
(13)HDFS概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
负责海量数据的存储。
NameNode:存储文件的元数据,如文件名、文件目录结构、文件属性、每个文件的块列表以及每个块所在的DataNode,简称叫做nn;
DataNode:是具体存储数据的位置,也负责块数据的校验和。
2NN:辅助NameNode的工作。每隔一段时间对NameNode元数据备份。
(14)Yarn架构
Yet Another Resource Negotiator,简称YARN,是一种资源协调者,是Hadoop的资源管理器。
YARN的两个核心组成组件:
- Resource Manager:整个集群的资源的管理者,管理着一个及以上数量的NodeManager;
- NodeManager:单节点资源的管理者,可能是管理着单台服务器的资源。
NodeManager中,单个任务会被放在一个container中来执行,待执行完成后,就直接释放掉整个container。
客户端提交job到ResourceManager,由ResourceManager负责协调指挥NodeManager们的工作。
客户端可以有多个;集群上可以运行多个ApplicationMaster;每个NodeManager可以有多个Container。
一个contrainer容器分配的内存,是1G~8G,最少一个CPU。
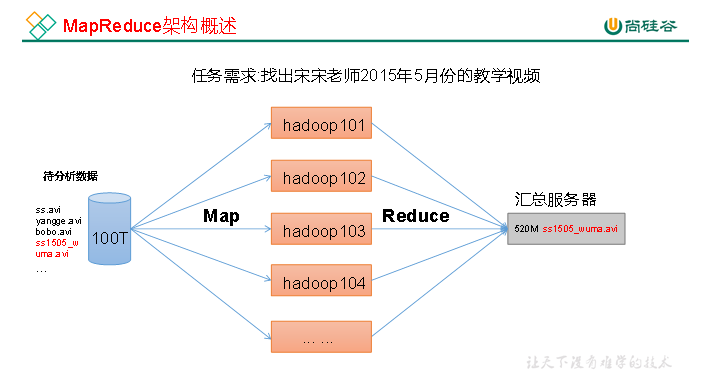
(15)MapReduce概述
负责计算。
将计算过程分成两部分:
- Map:将大任务分割成一个个小任务,以作并行处理;
- Reduce:将一个个小任务的运行结果合并作为大任务的运行结果,即对Map的结果进行汇总。
举例说明:
假设我有一万篇笔记,我想找到其中一篇,
如果我自己找的话,需要一个人看完这1w篇笔记;
但是我可以找100个人帮我一起找,把这1w篇笔记分成100组,给那100个人,然后每个人看100篇文档。(这就是Map的过程)
最后每个人再把查的结果反馈给我,我做下汇总,就可以知道我想要找的那篇在哪儿了。这个过程就是Reduce。
(16) HDFS、YARN、MapReduce三者关系
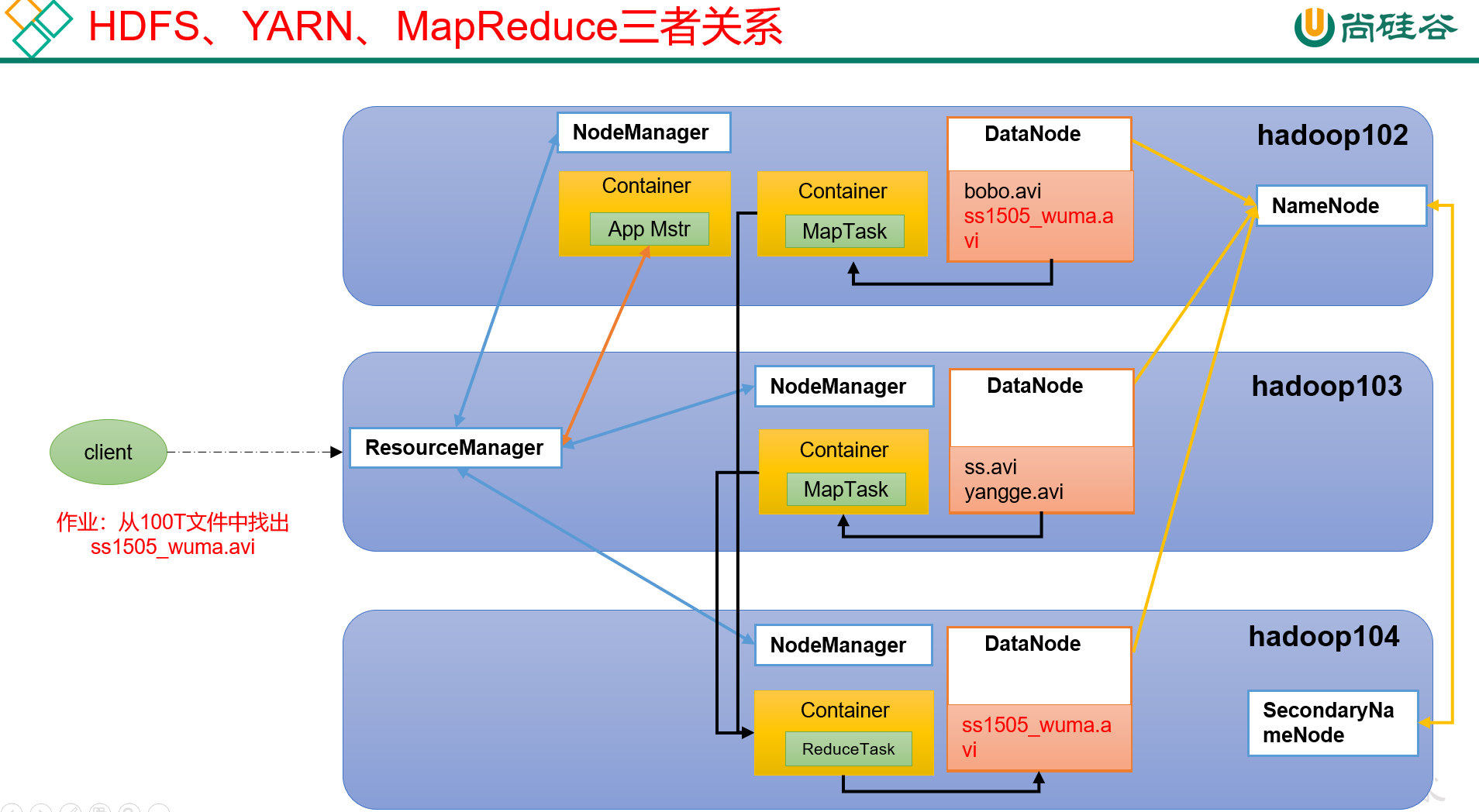
觉得需要注意的一点是,client提交任务到YARN的ResourceManager之后,ResourceManager会在任一节点启动一个Container,运行一个App Mstr,这个App Mstr比较重要。
接下来的流程,按我的理解是这样的:
首先App Mstr会计算当前任务运行所需的资源等,并向ResourceManager发出资源申请,告诉它,我需要xx个节点来运行我的任务;
其次当ResourceManager按照App Mstr的要求,为它分配了xx个节点之后,App Mstr会在这些节点上分别启动MapTask进行计算。
最后会在某个节点上启动一个ReduceTask,来汇总各个MapTask的结果。
再最后,ReduceTask的执行结果,可能会写入HDFS的DataNode,做持久化保存。
(17)大数据技术生态体系
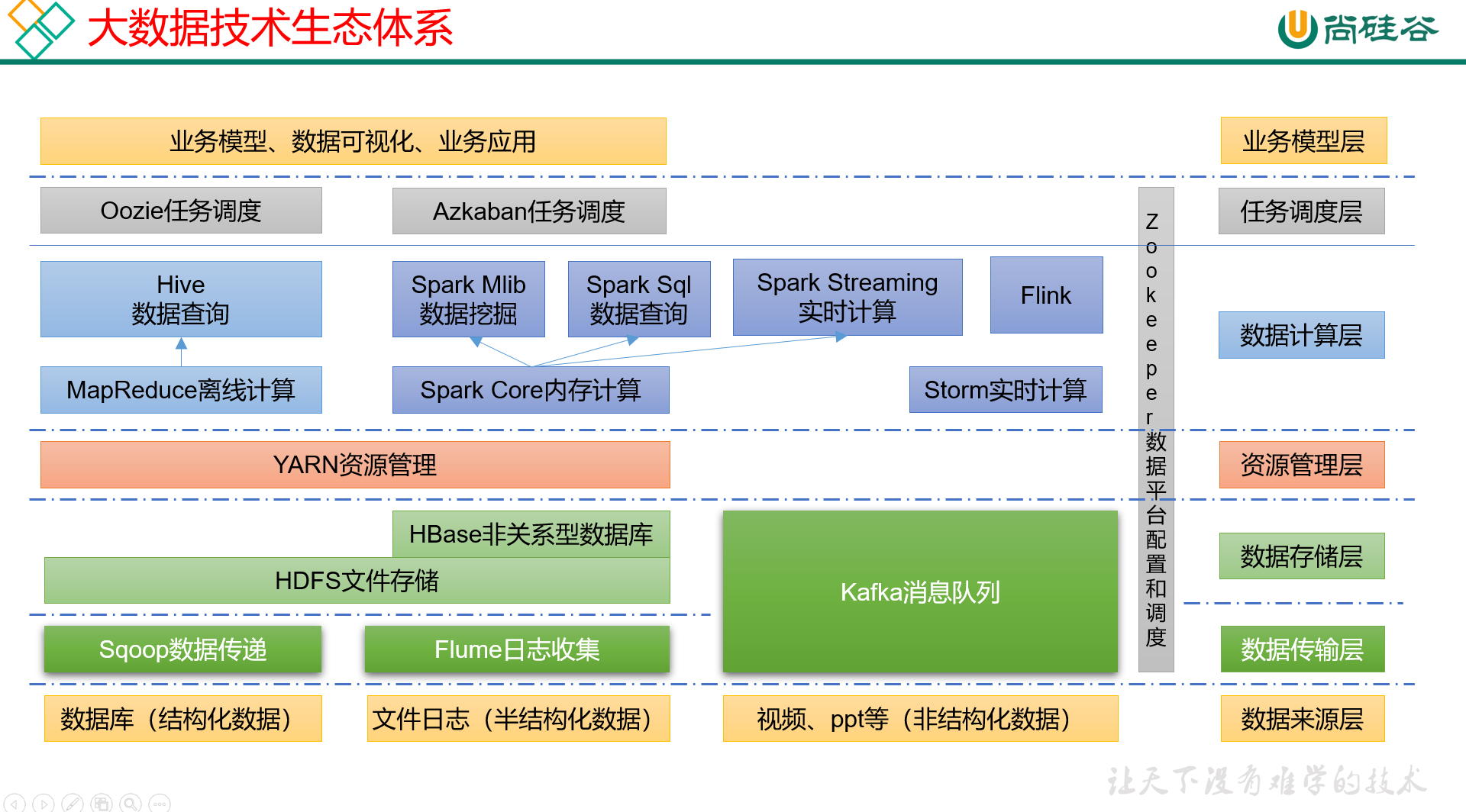
上图举例了一个经典的大数据技术生态体系,从图上来看,
数据来源层,分这么三大类:
- 结构化数据,如数据库,有行+有列;
- 半结构化数据,如文件日志,有行+分隔符间隔的列;
- 非结构化数据,如视频和ppt等。
数据传输层,即分别使用什么方式,来采集不同来源的数据:
- 结构化数据 -> Sqoop数据传递;
- 半结构化数据 -> Flume日志收集;
- 非结构化数据 -> Kafka消息队列(处理结构化和半结构化其实都可以)
数据存储层,
- Sqoop数据传递 + Flume日志收集 -> HDFS文件存储;
- Flume日志收集 -> HBase非关系型数据库
- Kafka消息队列,自带文件存储。
资源管理层:
- YARN
数据计算层:
- MapReduce离线计算 -> hive数据查询;
- Spark Core 内存计算 -> Spark Mlib数据挖掘(基于代码) + Spark SQL数据查询
- 实时计算 -> Storm实时计算(基本认为是过气了) + Spark Streaming实时计算 + Flink;
任务调度层:
- Oozie任务调度
- Azkaban任务调度
贯穿各层的,负责数据平台配置和调度的:
- zookeeper
业务模型层:
- 业务模型、数据可视化、业务应用
图中涉及到的技术名词进行解释:
- sqoop:sqoop是一款开源工具,主要用于hadoop、hive与传统的数据库(如MySQL)间进行数据传递。可以将关系型数据库中的数据导进Hadoop的HDFS里,也可以将HDFS中的数据通过sqoop导入关系型数据库里;
- Flume:分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
- Kafka:分布式分布订阅消息系统;
- Spark:当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的数据进行计算;
- Flink:当前最流行的开源大数据内存计算框架。主要用于实时计算场景;
- Oozie:是一个管理Hadoop作业的工作流程调度管理系统;
- Hbase:分布式的、面向列的开源数据库。不同于一般的关系型数据库,Hbase是一个适合于非结构化数据存储的数据库;
- Hive:基于Hadoop体系的一个数据仓库工具,
- 可以将结构化的数据文件映射为一张数据库表,如此更加直观的展现HDFS上存储的数据;
- 提供了简单的SQL查询功能,不需要再直接编写MapReduce任务了,直接使用SQL查询即可,hive会自动将SQL查询转换成对应的MR任务在后台执行,从而大大降低了学习成本,不需要再手写MR代码了,只要学会SQL就可以。十分的适合数据仓库的统计分析。
- ZooKeeper:是一个针对大型分布式系统的可靠的协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
教程讲到这里还给了一个推荐系统的框架图,以简单的实例来讲解,大数据这些框架是如何结合在一起来解决实际问题的。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(一):Hadoop的定义、组成及全生态概览
文章目录 (1)定义1.1 发展历史1.2 三大发行版本1.3 Hadoop的优势1.4 Hadoop的组成 (13)HDFS概述(14)Yarn架构(15)MapReduce概述(16) HDFS、YARN、MapReduce三…...
成为数据分析师要具备什么能力——功法篇(上)
这篇文章适合做了一段时间数据分析工作,开始思考怎么继续提升自己的分析师、运营或者是实习了一段时间的同学,这时的你也许会想几个问题: 为什么我做出来的分析总觉得没有别人的那么高级? 老板为什么总说我的分析“太浅了”&#…...

【MySQL】Java的JDBC编程
目录 ♫什么是JDBC ♫JDBC常用接口和类 ♪Connection接口 ♪Statement对象 ♪ResultSet对象 ♫JDBC的使用 ♪添加“驱动包” ♪创建数据源,描述数据库服务器在哪 ♪和数据库服务器建立连接 ♪构建SQL语句 ♪执行SQL语句 ♪释放资源 ♫什么是JDBC 我们前面操…...
最简安装教程)
windows OpenCV(包含cuda)最简安装教程
windows OpenCV(包含cuda)最简安装教程 1. 在Windows下安装vcpkg vcpkg是一个开源的C包管理器,它能帮助我们轻松地安装和管理C库和工具。要在Windows上安装vcpkg,可以按照以下步骤进行: 克隆vcpkg仓库: 首…...
Vue3 + Nodejs 实战 ,文件上传项目--实现文件批量上传(显示实时上传进度)
目录 技术栈 1.后端接口实现 2.前端实现 2.1 实现静态结构 2.2 整合上传文件的数据 2.3 实现一键上传文件 2.4 取消上传 博客主页:専心_前端,javascript,mysql-CSDN博客 系列专栏:vue3nodejs 实战--文件上传 前端代码仓库:jiangjunjie…...

狂砸40亿美元,亚马逊向OpenAI竞争对手Anthropic投资
9 月 25 日下午,亚马逊在公司官网发布,向大模型公司 Anthropic 投资 40 亿美元, Anthropic以拥有对标 ChatGPT 的谈天机器人 Claude 而出名。 这项新的战略合作将结合双方在更安全的生成式AI领域的技术和专业知识,加速Anthropic未…...

目标检测YOLO实战应用案例100讲-基于YOLOv5_tiny算法的路面裂缝智能检测
目录 前言 国内外研究现状 公路路面裂缝检测方法现状 基于深度学习检测算法现状...

P5682 [CSP-J2019 江西] 次大值% 运算 set 去重的一道好题
#include <bits/stdc.h> using namespace std; int n, x, len, a[100010], ans; set<int> s; set<int>::iterator asd; int main() {/*a[n-1] 是最大的a[n-2] 可能是次大的a[n]%a[n-1]<a[n-1] 不可能是最大的,可能是次大的a[n-1]%a[n-2]<…...
vue3后台管理框架之API接口统一管理
在开发项目的时候,接口可能很多需要统一管理。在src目录下去创建api文件夹去统一管理项目的接口; 参数请参考mock中的模拟接口 //统一管理咱们项目用户相关的接口import request from @/utils/requestimport type { loginForm, loginResponseData, userInfoReponseData } fro…...

线性表的插入、删除和查询操作
线性表的插入、删除和查询操作 1、定义线性表 定义一个线性结构,有列表默认长度设置为50,列表数量 #include <stdio.h> #define MaxSize 50typedef int Element; typedef struct{Element data[MaxSize];int length; }SqList;2、顺序表插入 插入…...

基于深度学习网络的疲劳驾驶检测算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1疲劳检测理论概述 4.2 本课题说明 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 In_layer_Size [227 227 3]; img_size [224,…...

【文件系统】Linux文件系统的基本存储机制
Linux文件系统是Linux操作系统的重要组成部分,它负责管理计算机存储设备上的文件和目录。Linux文件系统采用类Unix的设计,具有强大的性能和可扩展性,支持多种文件系统类型,如ext4、XFS、Btrfs等。在项目存储架构的设计中ÿ…...
Outlook导入导出功能灰色,怎么解决
下载安装 Outlook 软件后,登陆账号,然后选择“文件” - “导出”,结果发现“导出”按钮是灰色的,根本无法导出。根据官方说法:由于配置没有完成或者office产品没有正确激活。outlook导出键为灰色原因由于配置没有完成或…...
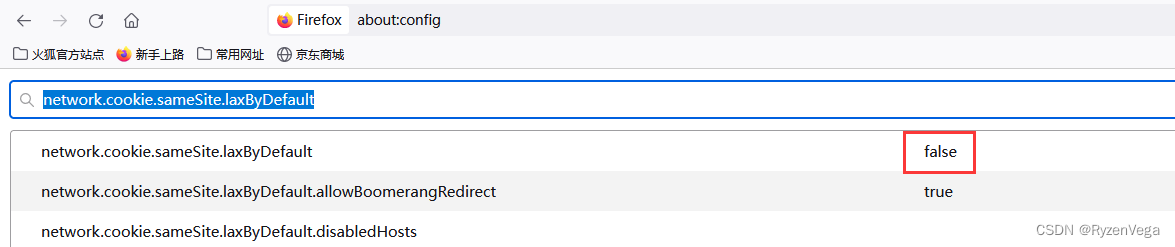
Chrome 同站策略(SameSite)问题
问题产生 问题复现: A项目页面使用 iframe 引用了B项目 B项目登录页面输入账号密码后点击登录 无法跳转 尝试解决: 在B项目修改了跳转方式 但无论是 this.$router.push 还是 window.herf 都无法实现跳转在iframe中使用 sandbox 沙箱属性 同样无法实现跳…...

docker搭建nginx+php-fpm
docker run --name nginx -p 8898:80 -d nginx:1.20.2-alpine# 将容器nginx.conf文件复制到宿主机 docker cp nginx:/etc/nginx/nginx.conf /usr/local/nginx/conf/nginx.conf# 将容器conf.d文件夹下内容复制到宿主机 docker cp nginx:/etc/nginx/conf.d /usr/local/nginx/conf…...

数据结构与算法---单调栈结构
数据结构与算法---单调栈结构 1 滑动窗口问题 1 滑动窗口问题 1 滑动窗口问题 由一个代表题目,引出一种结构 【题目】 有一个整型数组 arr 和一个大小为 w 的窗口从数组的最左边滑到最右边,窗口每次向右边滑一个位置。 例如,数组为[4,3,…...
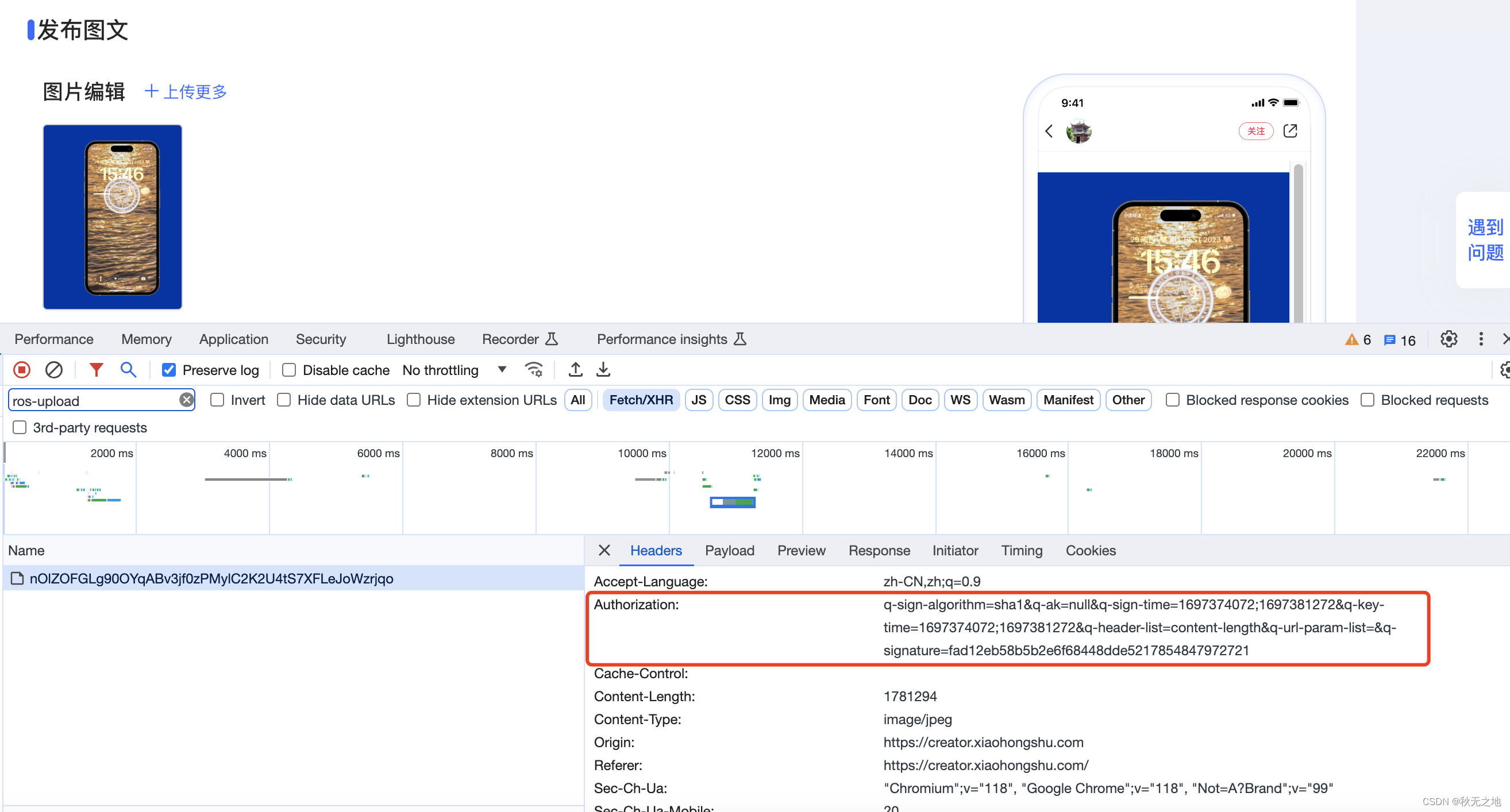
Python爬虫:某书平台的Authorization参数js逆向
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...
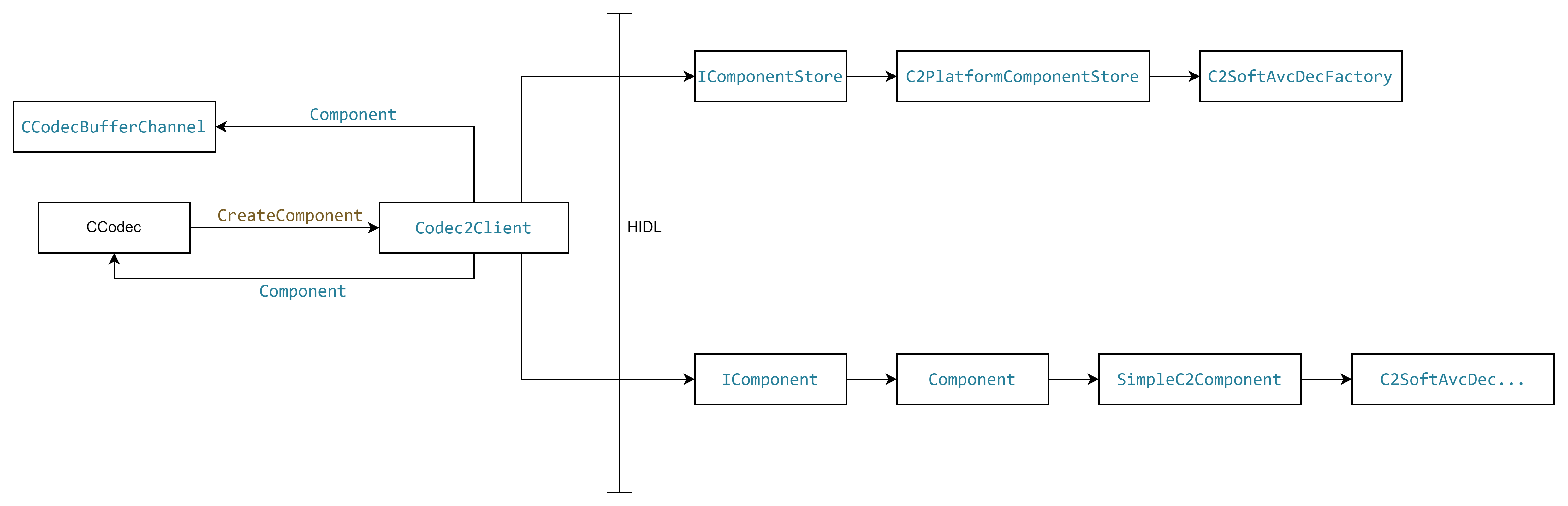
Android MediaCodec 框架 基于codec2
系列文章的目的是什么? 粗略: 解码需要哪些基础的服务?标准解码的调用流程?各个流程的作用是什么?解码框架的层次?各个层次的作用? 细化: 解码参数的配置?解码输入数…...
【RocketMQ 系列三】RocketMQ集群搭建(2m-2s-sync)
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。 💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精…...

Go TLS服务端绑定证书的几种方式
随着互联网的发展,网站提供的服务类型和规模不断扩大,同时也对Web服务的安全性提出了更高的要求。TLS(Transport Layer Security)[1]已然成为Web服务最重要的安全基础设施之一。默认情况下,一个TLS服务器通常只绑定一个证书[2],但…...

手把手教你调试Linux下的lt8619c.c驱动:从设备树解析到V4L2控件初始化
手把手教你调试Linux下的lt8619c.c驱动:从设备树解析到V4L2控件初始化 在嵌入式Linux开发中,显示接口驱动调试往往是项目推进的关键环节。LT8619C作为一款高性能HDMI接收芯片,其驱动开发涉及设备树配置、V4L2框架集成、中断处理等多个技术要点…...

OLED菜单开发避坑指南:从结构体设计到按键消抖的完整方案
OLED菜单开发避坑指南:从结构体设计到按键消抖的完整方案 在嵌入式设备开发中,OLED屏幕因其高对比度、低功耗和快速响应等特性,成为人机交互界面的首选。然而,开发一个稳定、易用的多级菜单系统却常常让开发者踩坑无数——从混乱的…...

电力场景绝缘子破损自爆检测数据集VOC+YOLO格式702张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):702标注数量(xml文件个数):702标注数量(txt文件个数):702标注类别数&…...
)
TSMaster MBD模块实战:如何用Simulink模型快速搭建汽车电子测试环境(附完整配置流程)
TSMaster MBD模块实战:Simulink模型快速构建汽车电子测试环境的完整指南 在汽车电子开发领域,从算法设计到实车验证往往存在巨大的鸿沟。传统开发流程中,工程师需要将Simulink模型手动转换为代码,再部署到目标硬件进行测试&#x…...

股票系统前端路由守卫终极指南:权限控制与页面跳转拦截
股票系统前端路由守卫终极指南:权限控制与页面跳转拦截 【免费下载链接】stock stock,股票系统。使用python进行开发。 项目地址: https://gitcode.com/gh_mirrors/st/stock 在股票系统开发中,前端路由守卫是保障系统安全和用户体验的…...

DSPy框架实战:如何用声明式编程重构你的AI工作流
1. 为什么你的AI项目需要DSPy框架? 如果你曾经用过大语言模型开发应用,肯定经历过这样的痛苦:花80%时间反复调整提示词,却只换来20%的性能提升。每次模型升级都要重写所有提示,团队协作时提示版本混乱不堪,…...

聚势启新程|固驰亚太区运营中心正式揭幕
2026年1月30日,"啟天元,致千里——美国RTC暨固驰品牌亚太中心新址揭幕仪式"在南京圆满举行。品牌高层、核心合作伙伴、行业媒体及特邀嘉宾齐聚现场,共同见证固驰亚太运营中心全面启用。这标志着固驰在亚太市场的战略布局迈入全新阶…...

Metpy实战:从数据到洞察——湿位涡剖面分析与暴雨预报
1. 湿位涡:暴雨预报中的"全能选手" 第一次听说湿位涡这个概念时,我正盯着气象台的暴雨预报图发愁。那天的预报结论写着"湿位涡异常区与强降水落区高度吻合",但作为刚入行的气象分析员,我完全不明白这个拗口的…...
)
收藏!小白程序员必看:轻松入门大模型(训练、微调与推理全解析)
本文系统梳理了大模型从训练、微调到推理的全过程,解析了Transformer架构、RLHF、RAG及推理加速等关键技术。通过介绍模型训练如何赋予知识、微调如何塑造专长、以及推理如何运用知识解决问题,帮助读者理解大模型的运作机制。同时,详细解释了…...
)
UE5 + AirSim + ROS联合开发:如何在WSL2中实现无缝通信(保姆级教程)
UE5 AirSim ROS联合开发:WSL2环境下的高效通信实战指南 机器人仿真与自动驾驶研究正迎来技术融合的新阶段。当虚幻引擎5(UE5)的高保真渲染能力遇上AirSim的物理仿真特性,再结合ROS的机器人控制框架,开发者能够构建出…...