Elasticsearch实现检索词自动补全(检索词补全,自动纠错,拼音补全,繁简转换) 包含demo
Elasticsearch实现检索词自动补全
- 自动补全
- 定义映射字段
- 建立索引
- 测试自动补全
- 自动纠错
- 查询语句
- 查询结果
- 拼音补全与繁简转换
- 安装 elasticsearch-analysis-pinyin 插件
- 定义索引与映射
- 建立拼音自动补全索引
- 测试拼音自动补全
- 测试繁简转换自动补全
- 代码实现
- demo结构
- demo获取
- 自动补全-官方文档
- 映射(Mapping)
- 索引(Indexing)
- 查询(Querying)
- 跳过重复建议
- 模糊查询(自动纠错)
- 正则表达式查询
自动补全
定义映射字段
下面的请求定义了一个名为 “book” 的 Elasticsearch 索引,其中包含一个 具有 “text” 数据类型和 “standard” 分析器且名为 “title” 的字段。此字段用于处理书籍标题的文本数据。定义了名为 “suggest” 的 “completion” 子字段,用于支持实时搜索建议的自动补全功能。
PUT /book
{"mappings": {"properties": {"title": {"type": "text","analyzer": "standard","fields": {"suggest": {"type": "completion"}}}}}
}
建立索引
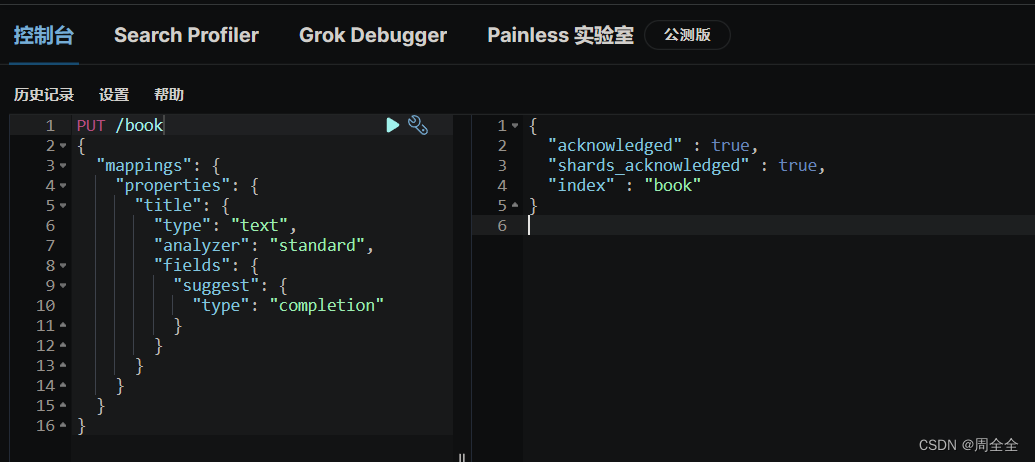
增加测试数据
PUT /book/_doc/1
{"title":"散文精选"
}PUT /book/_doc/2
{"title":"三国演义"
}PUT /book/_doc/3
{"title":"三体二:黑暗森林"
}测试自动补全
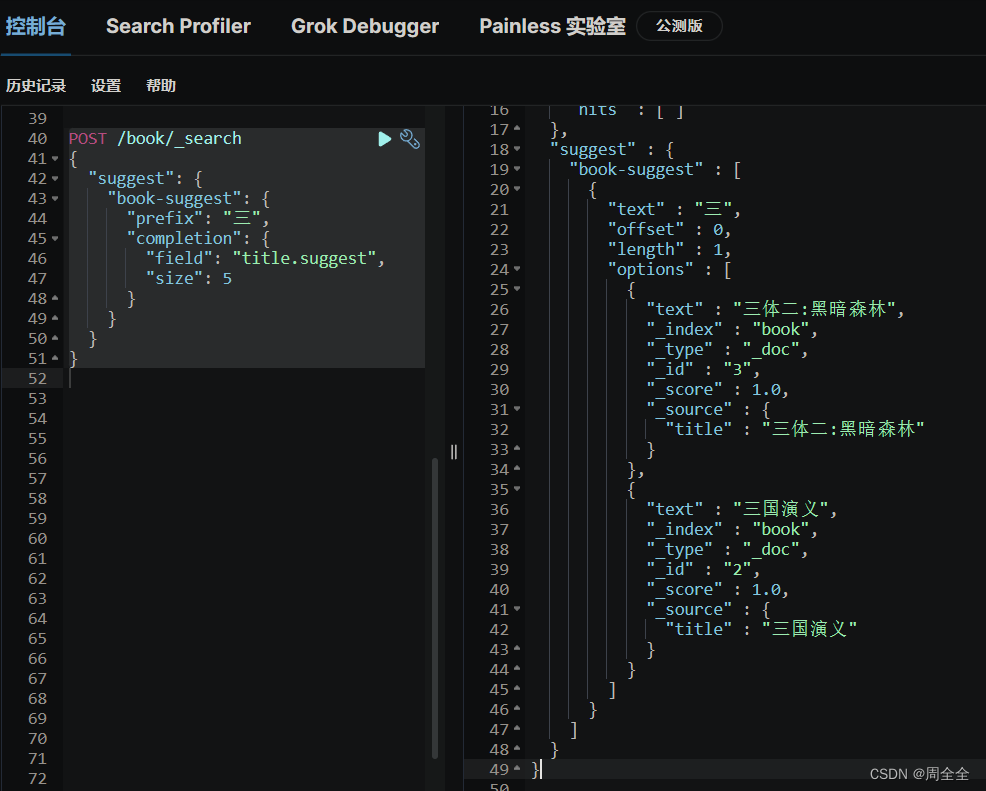
POST /book/_search
{"suggest": {"book-suggest": {"prefix": "三","completion": {"field": "title.suggest","size": 5}}}
}
查询结果如下:
自动纠错
查询语句
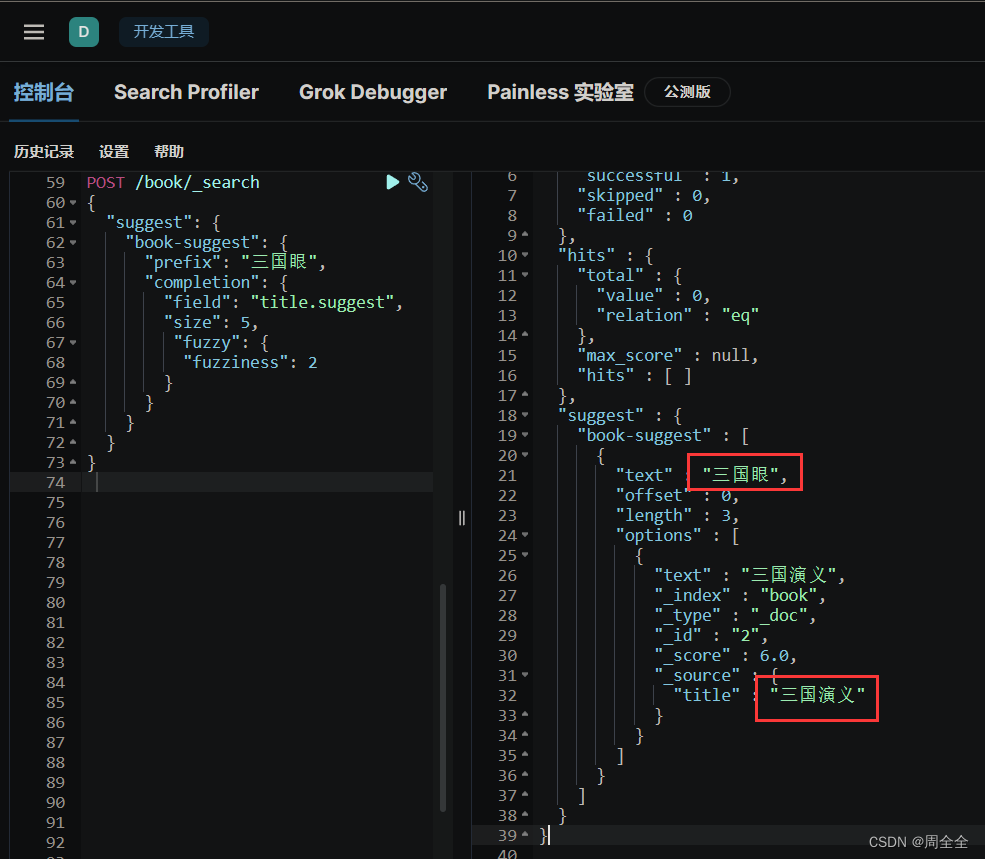
使用 “fuzzy” 参数来实现模糊匹配,即允许在查询中包含一定数量的拼写错误。可以根据需要调整 “fuzziness” 的值,以容忍更多或更少的拼写错误
POST /book/_search
{"suggest": {"book-suggest": {"prefix": "三国眼","completion": {"field": "title.suggest","size": 5,"fuzzy": {"fuzziness": 2}}}}
}
查询结果
拼音补全与繁简转换
拼音分词器(pinyin analyzer)通常需要自行引入,因为它不是 Elasticsearch 的默认分词器。可以使用 Elasticsearch 的插件来引入 pinyin 分词器,以便在索引中使用它。
安装 elasticsearch-analysis-pinyin 插件
选择与自己版本一致的版本,插件地址:
https://github.com/medcl/elasticsearch-analysis-pinyin/releases
elasticsearch-analysis-pinyin分词器目前没有下载即可使用的安装包,需要自己下载源码进行编译。可以在项目目录elasticsearch-analysis-pinyin\target\releases看到编译后的结果elasticsearch-analysis-pinyin-7.17.11.zip
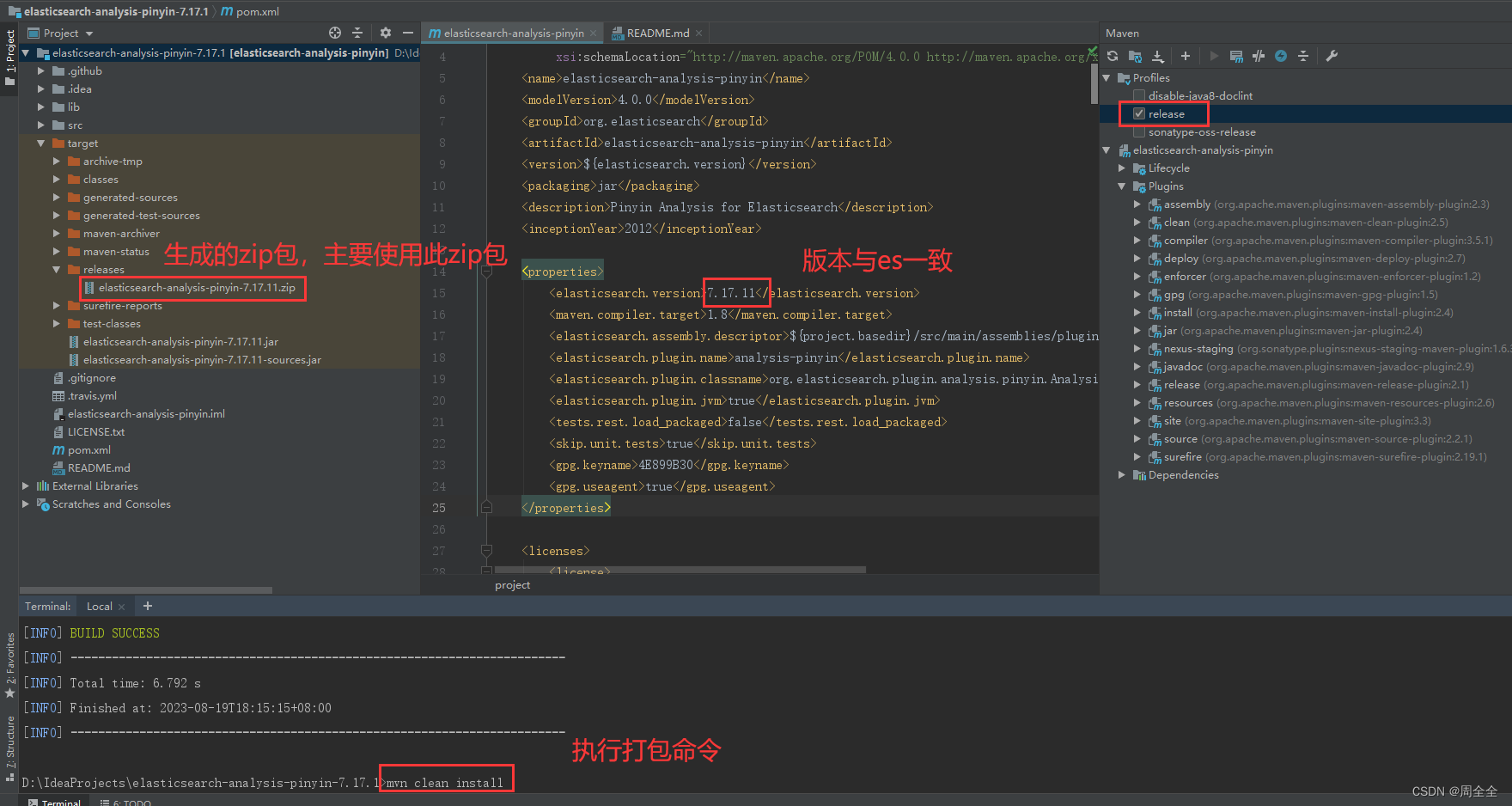
然后在es的安装目录下plugins目录下新建pinyin目录,并将解压后的文件复制到该目录下

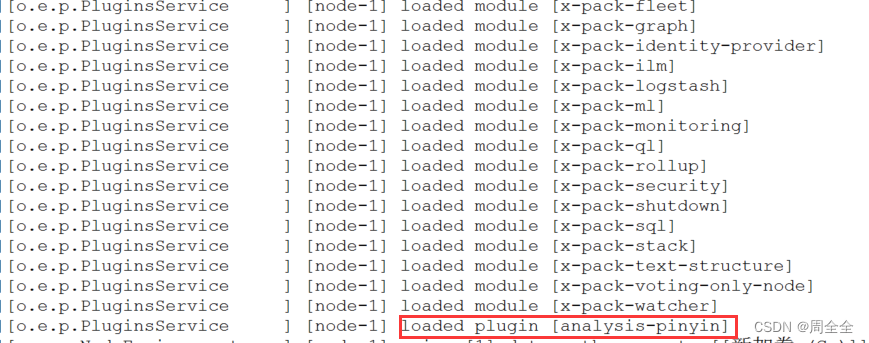
重启es,启动日志中已经加载了拼音插件
定义索引与映射
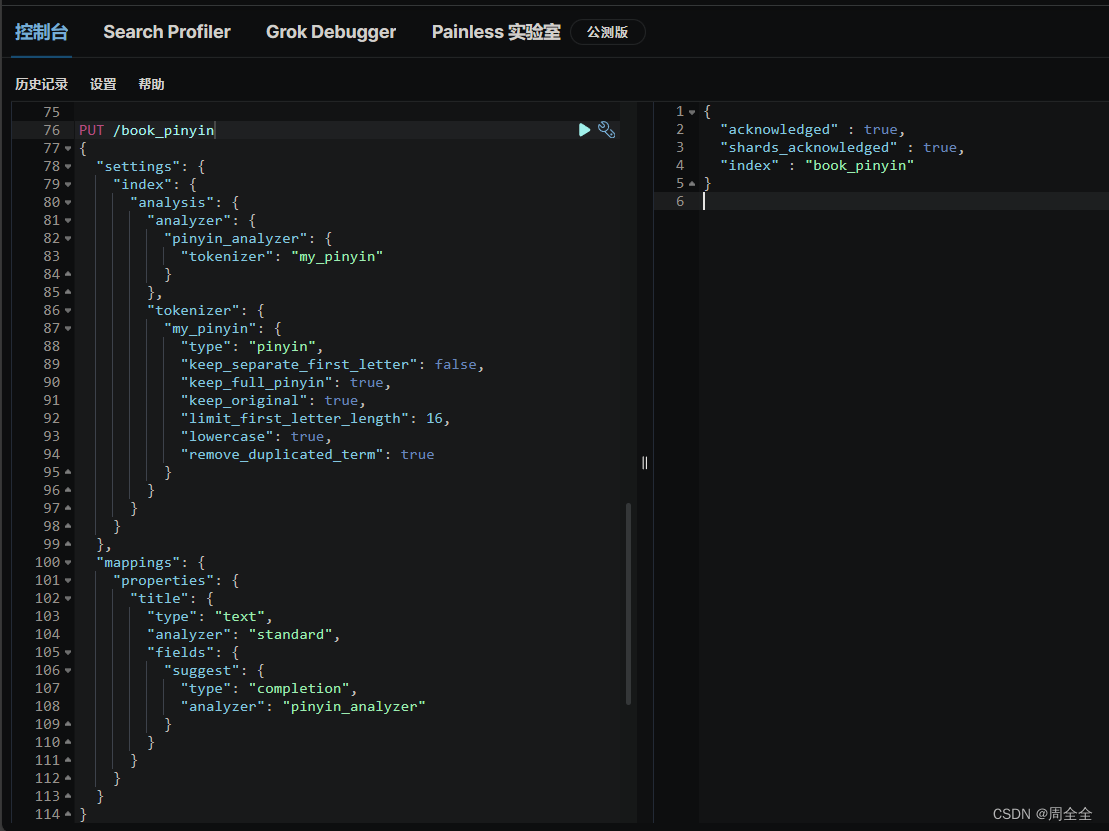
PUT /book_pinyin
{"settings": {"index": {"analysis": {"analyzer": {"pinyin_analyzer": {"tokenizer": "my_pinyin"}},"tokenizer": {"my_pinyin": {"type": "pinyin","keep_separate_first_letter": false,"keep_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"lowercase": true,"remove_duplicated_term": true}}}}},"mappings": {"properties": {"title": {"type": "text","analyzer": "standard","fields": {"suggest": {"type": "completion","analyzer": "pinyin_analyzer"}}}}}
}
建立拼音自动补全索引
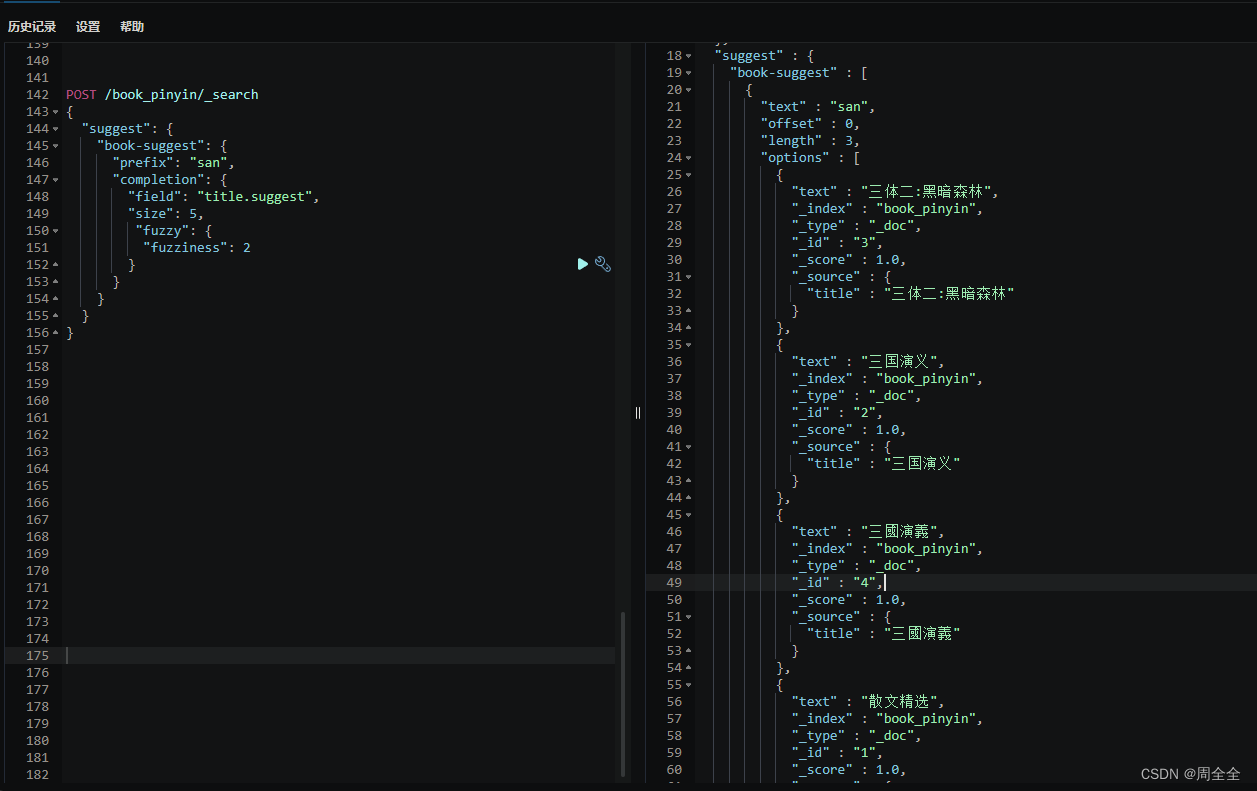
测试拼音自动补全
- 增加测试数据
PUT /book_pinyin/_doc/1 {"title":"散文精选" }PUT /book_pinyin/_doc/2 {"title":"三国演义" }PUT /book_pinyin/_doc/3 {"title":"三体二:黑暗森林" }PUT /book_pinyin/_doc/4 {"title":"三國演義" } - 执行检索
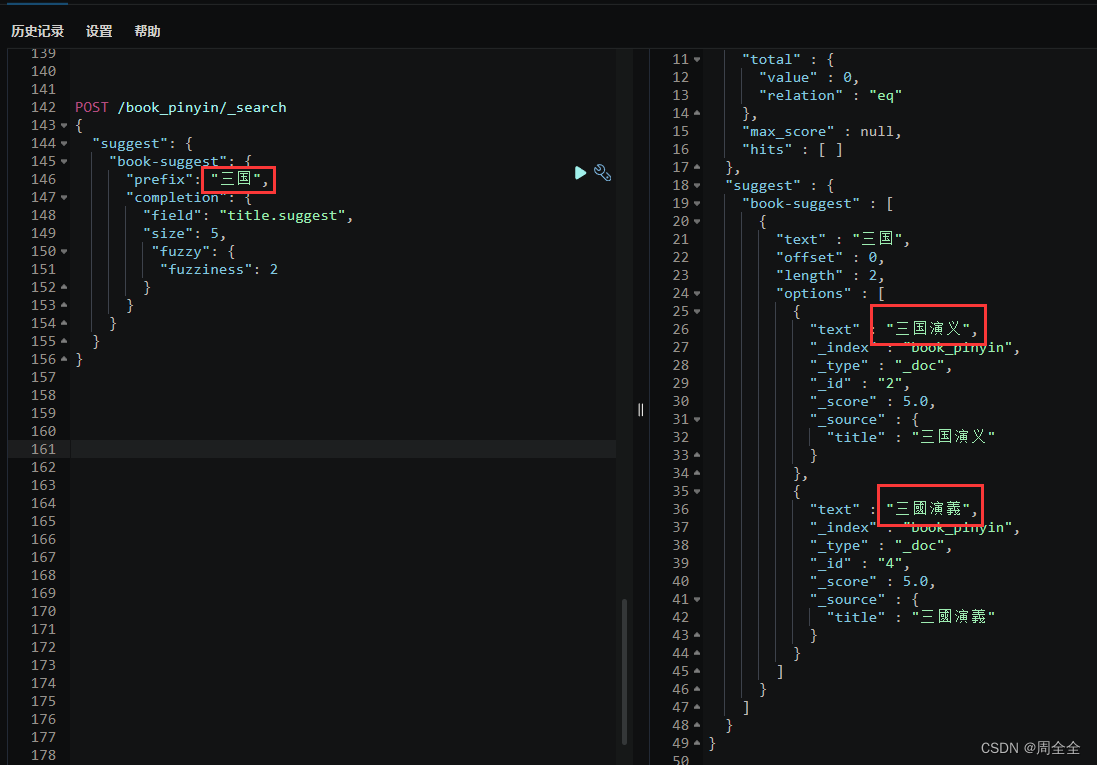
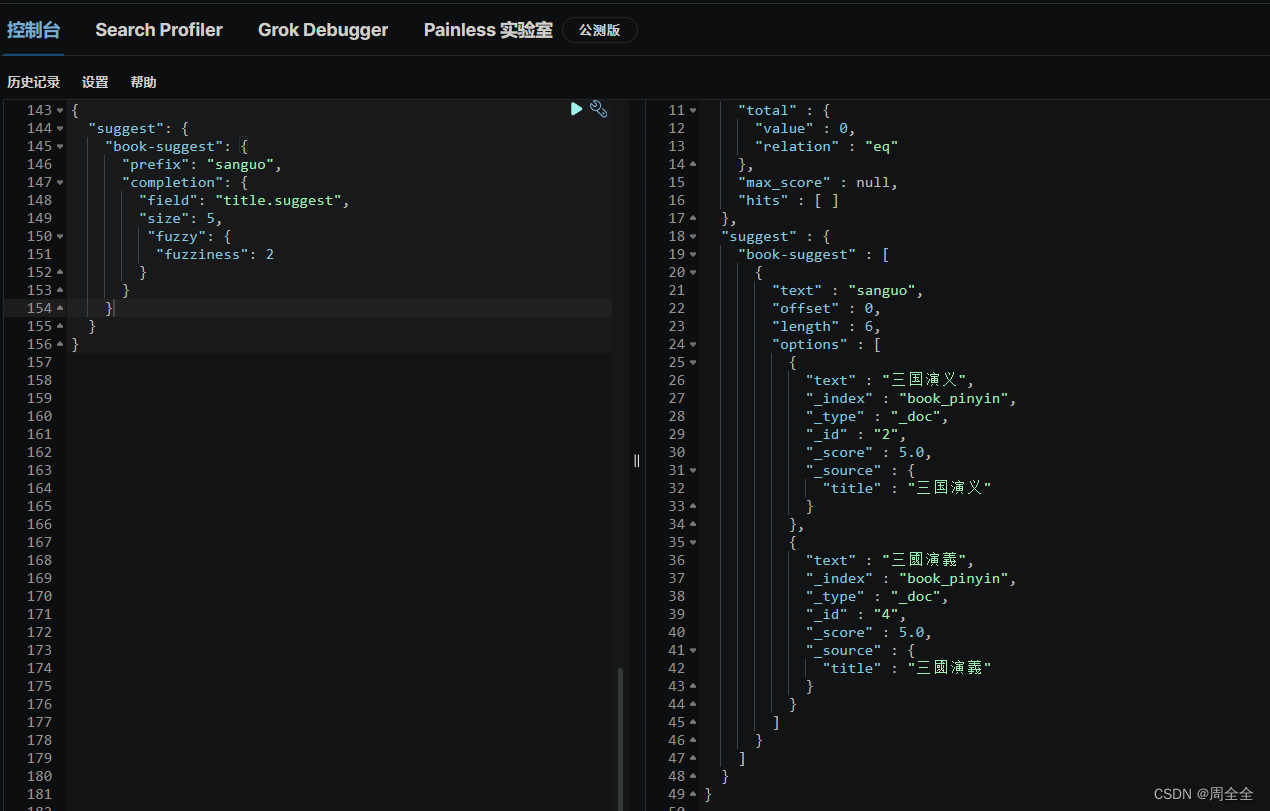
POST /book_pinyin/_search
{"suggest": {"book-suggest": {"prefix": "san","completion": {"field": "title.suggest","size": 5,"fuzzy": {"fuzziness": 2}}}}
}
测试繁简转换自动补全
我们这里实现了拼音转换后已经实现了繁简转换
代码实现
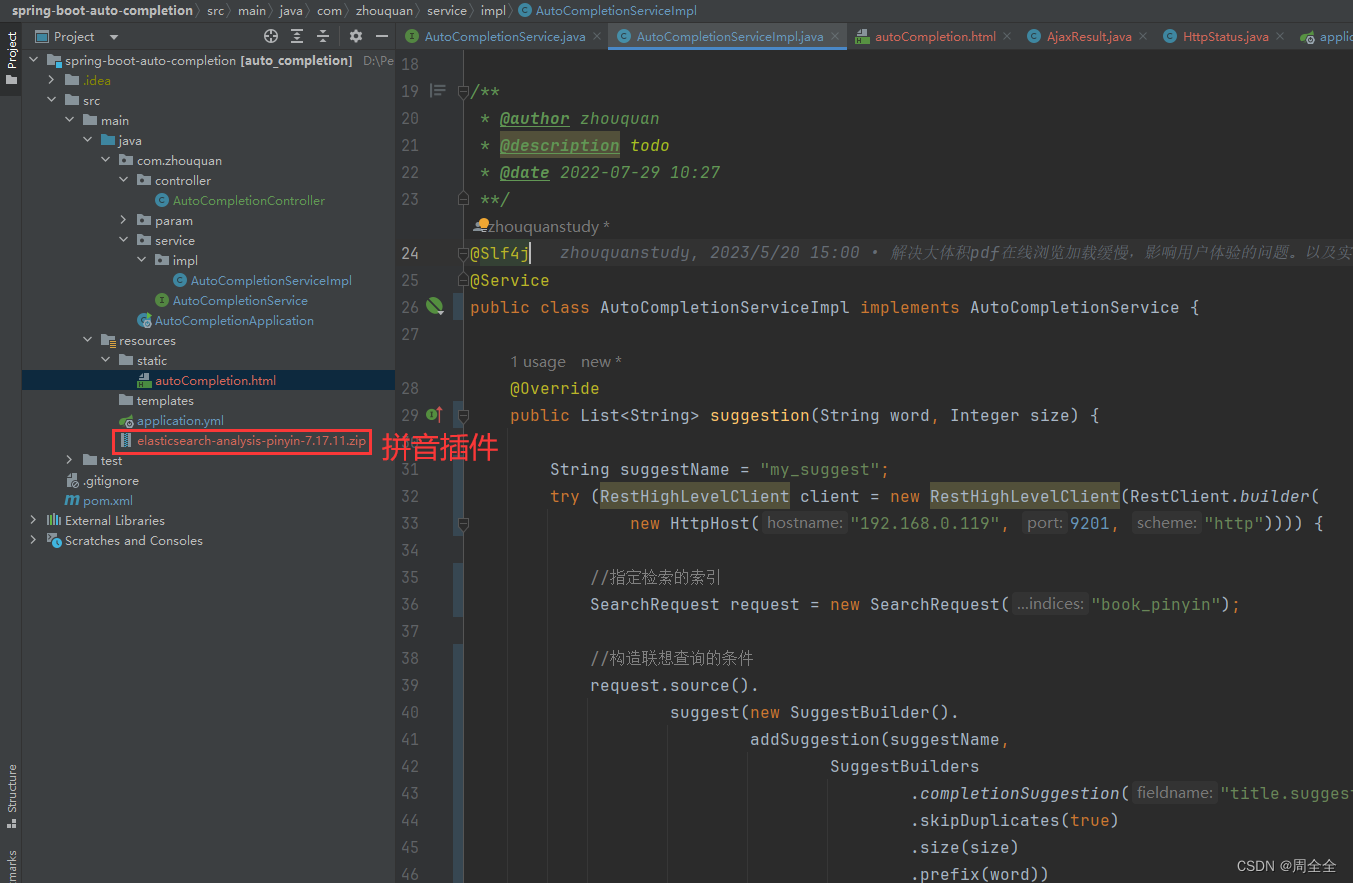
demo结构
简单创建一个springboot项目,使用html实现了一个简单的demo
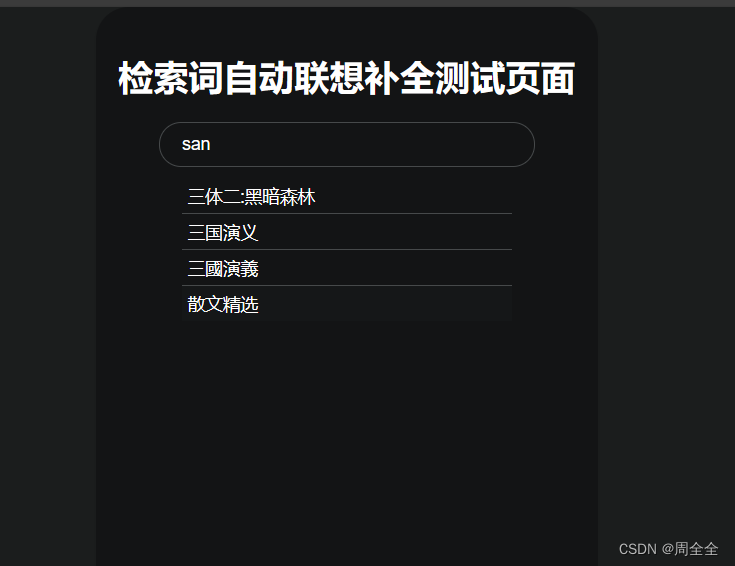
实现效果如下:
demo获取
自动补全-官方文档
Completion Suggester 是 Elasticsearch 提供的自动补全和搜索即时提示的功能。这是一种导航功能,可引导用户在键入时找到相关结果,从而提高搜索准确性。请注意,它不适用于拼写校正或类似 term 或 phrase suggesters 的“您是不是要这样说”功能。
理想情况下,自动补全功能应该与用户输入同步,以提供与用户已经键入的内容相关的即时反馈。因此,Completion Suggester 针对速度进行了优化。该建议器使用数据结构来实现快速查找,但构建和存储这些数据结构是昂贵的,并且存储在内存中。
映射(Mapping)
要使用此功能,需要为字段指定一个特殊的映射,以便为快速补全建议索引字段值。
PUT music
{"mappings": {"properties": {"suggest": {"type": "completion"},"title": {"type": "keyword"}}}
}
映射支持以下参数:
- analyzer:用于索引的分析器,默认为 simple。
- search_analyzer:用于搜索的分析器,默认为与 “analyzer” 相同。
- preserve_separators:保留分隔符,默认为 true。如果禁用,您可能会找到以 “Foo Fighters” 开头的字段,如果建议输入为 “foof”。
- preserve_position_increments:启用位置增量,默认为 true。如果禁用并使用停用词分析器,建议输入 “b” 时,您可能会得到以 “The Beatles” 开头的字段。请注意:如果能够丰富数据,也可以通过索引两个输入 “Beatles” 和 “The Beatles” 来实现,无需更改简单分析器。
- max_input_length:限制单个输入的长度,默认为 50 个 UTF-16 代码点。此限制仅在索引时使用,以减少每个输入字符串的字符总数,以防止底层数据结构膨胀。在大多数情况下,默认值不会对使用产生影响,因为前缀建议很少会增长到比一小撮字符长的前缀。
索引(Indexing)
索引建议与索引其他字段的数据相似。建议由输入和可选的权重属性组成。输入是建议查询中预期匹配的文本,而权重确定建议的评分。索引建议的示例如下:
PUT music/_doc/1?refresh
{"suggest" : {"input": [ "Nevermind", "Nirvana" ],"weight" : 34}
}
支持以下参数:
- input:要存储的输入,可以是字符串数组或仅为字符串。此字段是必需的。该值不能包含以下 UTF-16 控制字符:\u0000(null)、\u001f(信息分隔符一)、\u001e(信息分隔符二)。
- weight:正整数或包含正整数的字符串,用于定义权重,可用于排列建议。此字段是可选的。
您还可以使用以下简化形式,但请注意,在简化形式中不能为建议指定权重。
PUT music/_doc/1?refresh
{"suggest" : [ "Nevermind", "Nirvana" ]
}
查询(Querying)
建议查询与通常查询相似,不同之处在于您必须将建议类型指定为 “completion”。建议是近实时的,这意味着通过 “refresh” 可以立即显示新建议,已删除的文档永远不会被显示。
下面是一个查询的示例:
POST music/_search?pretty
{"suggest": {"song-suggest": {"prefix": "nir","completion": {"field": "suggest"}}}
}
在查询结果中,Elasticsearch 将返回与用户输入前缀匹配的建议。您可以使用这些建议为用户提供搜索建议。
自动补全建议还支持模糊查询和正则表达式查询,以处理用户输入中的拼写错误或其他变化。这些查询可以通过 "fuzzy" 和 "regex" 参数进行配置。
请注意,默认情况下,“_source” 元数据字段是启用的,以便返回建议的源数据。建议的权重通过 “_score” 返回。默认情况下,建议返回完整文档的 “_source”。如果 _source 大小会影响性能,可以使用源过滤来减小 _source 大小。
以上是使用 Completion Suggester 的基本概述。根据需求,您可以进一步配置和定制自动补全建议。 Completion Suggester 可以考虑索引中的所有文档。对于如何查询文档子集的详细信息,请查看上下文建议(Context Suggester)。
如果一个建议查询跨越多个分片,建议会在两个阶段执行,最后一个阶段从分片中获取相关文档,这意味着当建议跨多个分片时,在单个分片上执行建议请求会更有效,因为建议涵盖多个分片时需要执行文档提取开销。为了获得最佳的自动补全性能,建议将自动补全索引到单个分片索引中。如果由于分片大小而导致堆内存使用过高,仍建议将索引分成多个分片,而不是为了优化自动补全性能。
跳过重复建议
查询可能会返回来自不同文档的重复建议。通过将 "skip_duplicates" 设置为 true,可以修改此行为。设置为 true 时,此选项会减慢搜索,因为需要访问更多的建议以查找前 N 个。
模糊查询(自动纠错)
Completion Suggester 还支持模糊查询,这意味着您可以在搜索中出现拼写错误,仍然可以获得结果。
例如,以下是一个使用模糊查询的查询示例:
POST music/_search?pretty
{"suggest": {"song-suggest": {"prefix": "nor","completion": {"field": "suggest","fuzzy": {"fuzziness": 2}}}}
}
模糊查询会根据查询前缀与建议前缀的最长匹配来对建议进行评分。模糊查询支持各种参数,如 “fuzziness”、“transpositions”、“min_length”、“prefix_length” 和 “unicode_aware”,可以用于调整匹配的宽松程度和性能。
正则表达式查询
Completion Suggester 还支持正则表达式查询,这意味着您可以使用正则表达式来表示前缀。
例如,以下是一个使用正则表达式查询的示例:
POST music/_search?pretty
{"suggest": {"song-suggest": {"regex": "n[ever|i]r","completion": {"field": "suggest"}}}
}
正则表达式查询可以包含各种参数,如 “flags” 和 “max_determinized_states”,以用于调整匹配的方式和性能。
相关文章:
Elasticsearch实现检索词自动补全(检索词补全,自动纠错,拼音补全,繁简转换) 包含demo
Elasticsearch实现检索词自动补全 自动补全定义映射字段建立索引测试自动补全 自动纠错查询语句查询结果 拼音补全与繁简转换安装 elasticsearch-analysis-pinyin 插件定义索引与映射建立拼音自动补全索引测试拼音自动补全测试繁简转换自动补全 代码实现demo结构demo获取 自动补…...
LaunchView/启动页 的实现
1. 创建启动画板,LaunchScreen.storyboard 添加组件如图: 2. 项目中设置只支持竖屏,添加启动画板,如图: 3. 创建启动画面动画视图,LaunchView.swift import SwiftUI/// 启动视图 struct LaunchView: View {/// 字符串转换为字符串…...

windows安装npm教程
在安装和使用NPM之前,我们需要先了解一下,NPM 是什么,能干啥? 一、NPM介绍 NPM(Node Package Manager)是一个用于管理和共享JavaScript代码包的工具。它是Node.js生态系统的一部分,广泛用于构…...

网络端口验证
网络端口连通性验证 1、背景2、目标3、环境4、部署4.1、准备工作4.2、安装4.3、场景测试 1、背景 在日常运维过程中经常会遇到以下两种场景: 1、程序业务端口的开具及验证 2、业务程序访问异常网络排障 2、目标 1、验证端口的正确开具 2、网络策略的连通性 3、环…...

MongoDB 索引和常用命令
一、基本常用命令 1.1 案例需求 存放文章评论的数据存放到 MongoDB 中,数据结构参考如下,其中数据库为 articledb, 专栏文章评论 comment 字段名称 字段含义 字段类型 备注 _id ID ObjectId或String Mongo的主键的字段 articlei…...
【超详细】win10安装docker
win10安装docker 因为要在win10复现一个CVE漏洞,需要用到docker所以特地自己亲自安装了一下,其实在win10上安装docker与在Linux上面的原理一致,都是将docker安装在虚拟机里,不同的是win10是安装在Hyper-V虚拟机上的,需…...
)
JVM调优(一)
什么时候会有内存泄漏,怎么排查? 答: 首先内存泄漏是堆中的一些对象不会再被使用了,但是无法被垃圾收集器回收,如果不进行处理,最终会导致抛出 java.lang.OutOfMemoryError 异常。 内存泄露: …...
Parallels Desktop 19中文-- PD19最新安装
Parallels Desktop 19可以让我们在Mac电脑上运行Windows和其他操作系统,而无需重启计算机。这款软件的稳定性较高,能够在Mac上同时运行多个操作系统,如Windows、Linux等,而无需重启电脑。它可以让用户无缝地在不同操作系统之间切换…...

【c++】向webrtc学比较1:AheadOf、IsNewerTimestamp
webrtc源码分析-rtp序列号新旧比较 大神文章分析的非常到位。大神分析:AheadOrAt(a, b)是判断a是否比b新的核心,其原理是这样的:rfc1982规定了序列号递增间隔不能超过取值范围的1/2(这是自己理解的),那么要判断a是否比b新,只要判断b到a的递增是否在1/2即可,递增超过1/2,…...
华为云云耀云服务器L实例评测|企业项目最佳实践之docker部署及应用(七)
华为云云耀云服务器L实例评测|企业项目最佳实践系列: 华为云云耀云服务器L实例评测|企业项目最佳实践之云服务器介绍(一) 华为云云耀云服务器L实例评测|企业项目最佳实践之华为云介绍(二) 华为云云耀云服务器L实例评测࿵…...
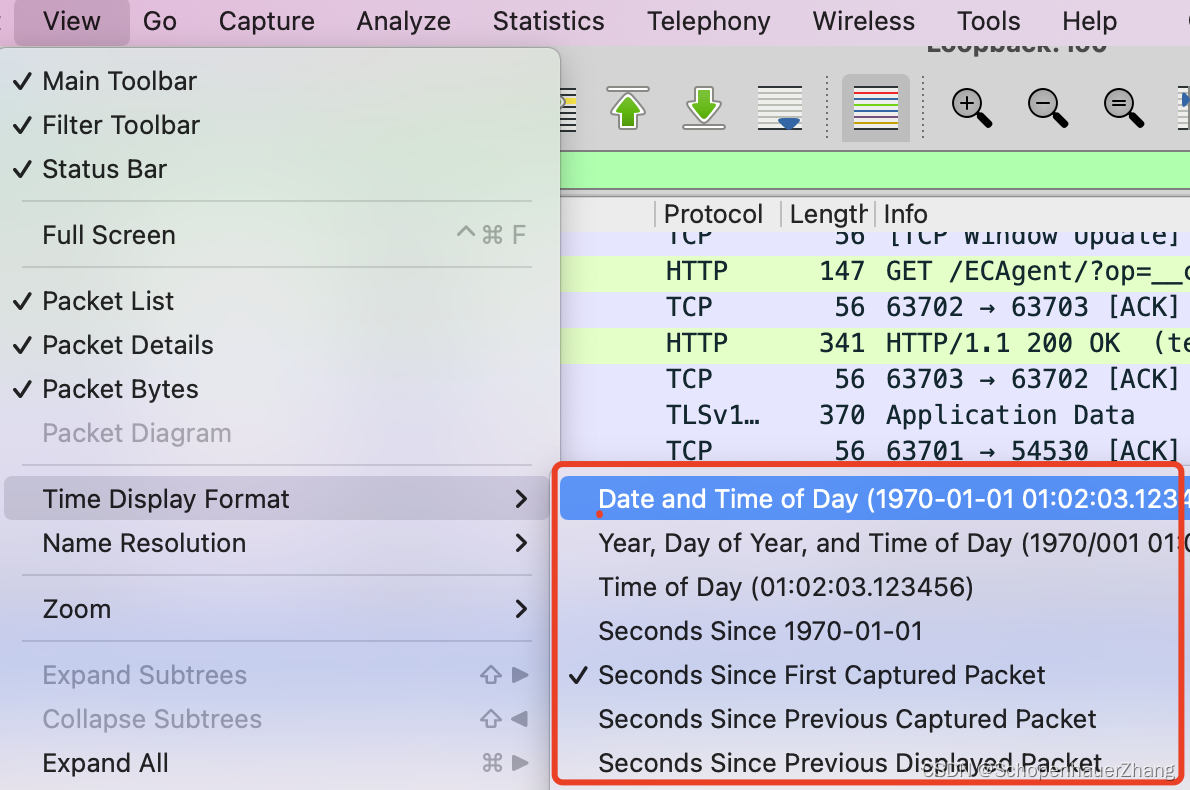
MAC上使用Wireshark常见问题
文章目录 介绍正文启动异常-Permission denied解决方法 过滤协议和地址指定源地址和目的地址调整 time format 介绍 简单记录Wireshark在日常使用过程中的遇到的小case。 正文 Wireshark相较于tcpdump使用较为简单,交互也更为友好。 点击Start即可启动抓包 启动…...

在C++中++a和a++有什么区别?
2023年10月16日,周一中午 a和a在语义上的区别 a是先进行运算(增加1),然后返回新值。 a是先返回原值,然后进行运算(增加1)。 a和a在效率上的区别 a直接返回新值,不需要临时变量保存原值。 而a需要先返回原值,然后再进行增加1的操作。这需要使用一个临时变量来保存…...
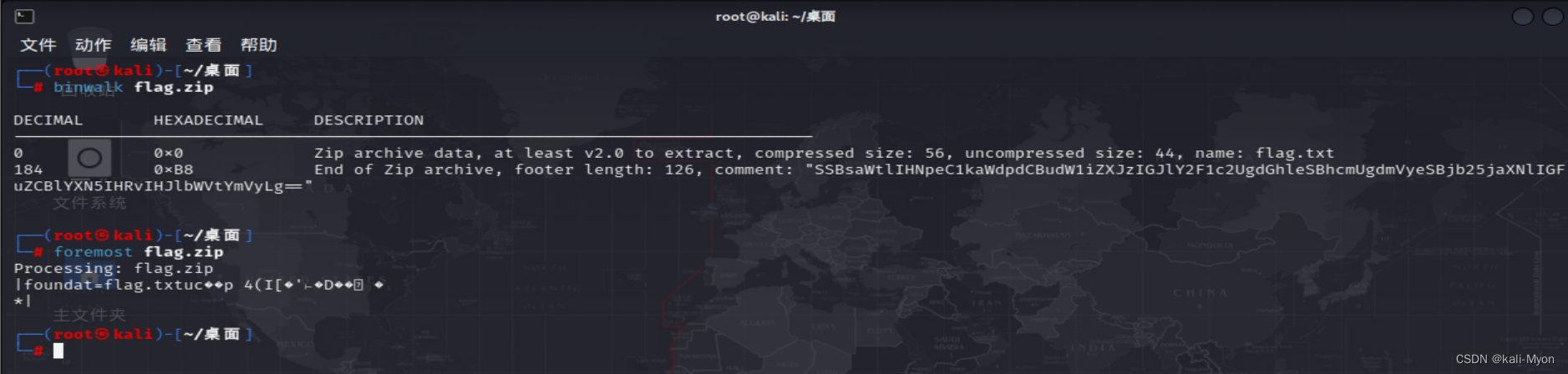
NewStarCTF2023公开赛道-压缩包们
题目提示是压缩包 用010editor打开,不见PK头,补上50 4B 03 04 14 00 00 00 将文件改成.zip后缀,打开,解压出flag.zip 尝试解压,报错 发现一串base64编码 SSBsaWtlIHNpeC1kaWdpdCBudW1iZXJzIGJlY2F1c2UgdGhleSBhcmUgd…...

oracle数据库增加表空间数据文件
查询数据文件:select * from dba_data_files order by file_name; 增加:alter tablespace 数据库名 add datafile data size 34359721984;...
)
【08】基础知识:React中收集表单数据(非受控组件和受控组件)
一、概念 非受控组件: 页面中所有输入类的 DOM,现用现取。 给组件绑定 ref 属性,在需要时通过 ref 获取相应值。 受控组件: 页面中所有输入类的 DOM,随着输入,将内容维护到状态 state中,当…...
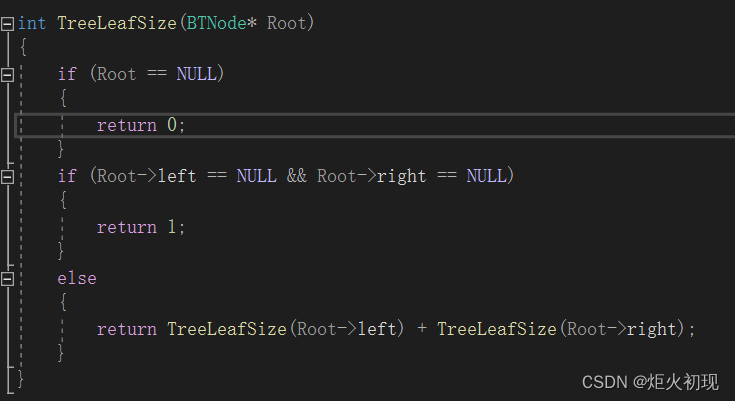
数据结构之堆排序和前,中,后,层序遍历,链式二叉树
首先我们要知道升序我们要建小堆,降序建大堆,这与我们的大多人直觉相违背。 因为我们大多数人认为应该将堆顶的数据输出,但如果这样就会导致堆顶出堆以后,堆结构会被破坏,显然我们不能这样。 所有我们反其道而行&…...
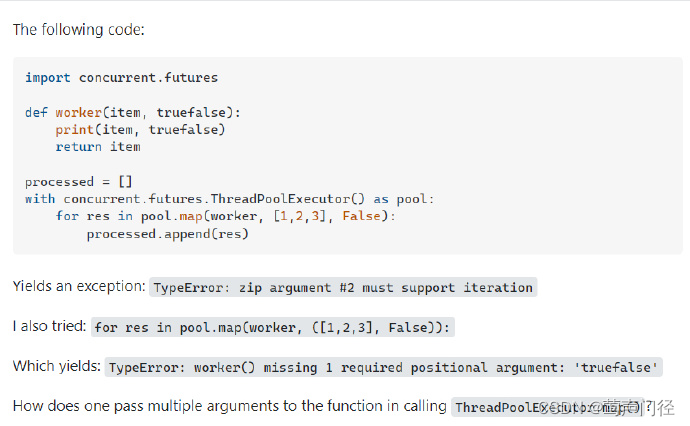
多线程中ThreadPoolExecutor.map()中传递多个参数
with concurrent.futures.ThreadPoolExecutor(max_threads) as executor:results executor.map(get_captcha_image, ip_addrs, [img_url] * len(ip_addrs)) #要传入多个参数时,每个参数都得是固定相同长度的可迭代对象# 收集结果for result in results:print(resul…...

linux centos7 环境下 no such file or directory
目录 1.问题描述2.主要原因2.1修改后代码2.2修改前代码 总结参考 1.问题描述 预览excel文件时无法找到对应的html文件 2.主要原因 异常原因:代码获取的是系统的tmp文件,但是linux环境环境中心tmp目录是没有权限的,所以不能获取系统的根目录…...

Nginx 反向代理 SSL 证书绑定域名
配置 Nginx 反向代理和 SSL 泛域名证书绑定域名 Nginx 是一个功能强大的 Web 服务器和反向代理服务器,可以用于将客户端请求转发到后端服务器,并提供安全的 HTTPS 连接。本文将介绍如何配置 Nginx 反向代理,并使用 SSL 泛域名证书绑定域名&a…...

SpringBoot 集成 JMS 与 IBMMQ 代码示例教程
文章目录 前言一、集成 JMS 与 IBMMQ1、pom 依赖2、yml 配置3、Properties 配置类4、Factory 连接工厂类5、配置连接认证6、配置缓存连接工厂7、配置事务管理器8、配置JMS模板9、消息发送与接收 总结 前言 SpringBoot 集成 IBMMQ,实现两个服务间的消息通信。 一、集…...

86745238
86745238...

C++中的策略模式实战
1、非修改序列算法这些算法不会改变它们所操作的容器中的元素。1.1 find 和 find_iffind(begin, end, value):查找第一个等于 value 的元素,返回迭代器(未找到返回 end)。find_if(begin, end, predicate):查找第一个满…...

Maven工具的下载,安装与使用
Maven的下载,安装配置与使用 文章目录Maven的下载,安装配置与使用前言一、Maven简介1.什么是 Maven?2.Maven的核心概念二、Maven 安装与配置(以Windows为例,Linux/macOS类似)1.下载Maven2. 安装 Maven3. 验…...

generatedata vs 传统测试工具:为什么它是开发者的终极选择?
generatedata vs 传统测试工具:为什么它是开发者的终极选择? 【免费下载链接】generatedata A powerful, feature-rich, random test data generator. 项目地址: https://gitcode.com/gh_mirrors/ge/generatedata 在软件开发过程中,测…...

文脉定序多场景落地:法律、医疗、教育领域语义重排序应用案例集
文脉定序多场景落地:法律、医疗、教育领域语义重排序应用案例集 1. 引言:当搜索不再“精准”,我们如何找到真正需要的答案? 你有没有过这样的经历?在搜索引擎里输入一个问题,它确实返回了一大堆结果&…...
AudioSeal Pixel Studio效果展示:同一段语音嵌入10种不同16位水印的并行检测结果
AudioSeal Pixel Studio效果展示:同一段语音嵌入10种不同16位水印的并行检测结果 1. 专业级音频水印技术解析 AudioSeal Pixel Studio是基于Meta研究院开源的AudioSeal算法构建的音频保护工具。这项技术的核心价值在于,它能在保持原始音频质量几乎不变…...
、 257. 二叉树的所有路径 (优先掌握递归)、 404.左叶子之和 (优先掌握递归)、 222.完全二叉树的节点个数(优先掌握)
代码随想录算法训练营day15| 110.平衡二叉树 (优先掌握递归)、 257. 二叉树的所有路径 (优先掌握递归)、 404.左叶子之和 (优先掌握递归)、 222.完全二叉树的节点个数(优先掌握
一、110.平衡二叉树 (优先掌握递归) 题目链接/文章讲解/视频讲解:https://programmercarl.com/0110.%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91.html 初见思路: 学习代码随想录之后:平衡二叉树:左右子…...
 产品的开发流程参考)
【AI】大语言模型 (LLM) 产品的开发流程参考
🔥小龙报:个人主页 🎬作者简介:C研发,嵌入式,机器人等方向学习者 ❄️个人专栏:《AI》 ✨ 永远相信美好的事情即将发生 文章目录前言一、个人开发者的大语言模型 (LLM) 产品的开发流程参考1.1 准…...

Git分支管理:Merge与Rebase的实战抉择
1. Git分支管理的核心痛点 每次看到团队仓库里那些错综复杂的分支线,我就想起刚入行时被Git历史图支配的恐惧。上周帮新人排查bug时,发现他为了把feature分支合入develop,竟然生成了7个merge commit——这简直是把版本历史变成了毛线团。相信…...

手慢无,阿里2026最新SpringBoot进阶笔记首次公开!
相信从事Java开发的朋友都听说过SSM框架,老点的甚至经历过SSH,说起来有点恐怖,比如我就是经历过SSH那个时代未流。当然无论是SSM还是SSH都不是今天的重点,今天要说的是Spring Boot,一个令人眼前一亮的框架,…...